


Financial Time Series Forecasting: A Data Stream Mining-Based System


Abstract
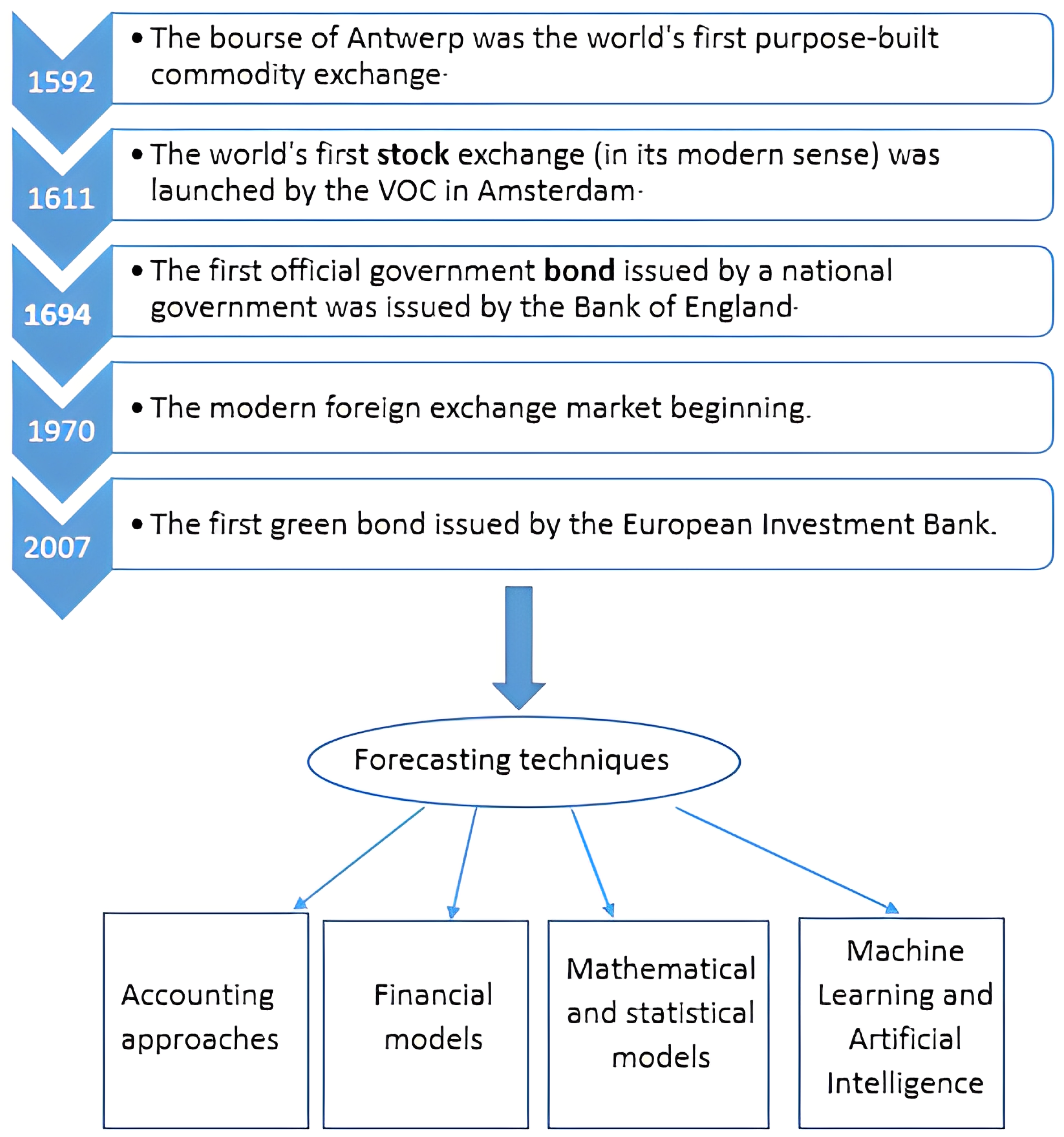
:1. Introduction
2. Literature Review
2.1. Machine Learning Application to Financial Forecasting
2.1.1. Overview
2.1.2. Optimization Techniques
2.2. Data Stream Mining Application to Financial Forecasting
2.2.1. Data Stream Mining
2.2.2. Online Learning
2.2.3. Incremental Learning
2.2.4. Adaptive Learning
2.2.5. Implications of Econometric Methods
2.2.6. Data Stream Mining Application to Financial Forecasting
3. Preliminaries
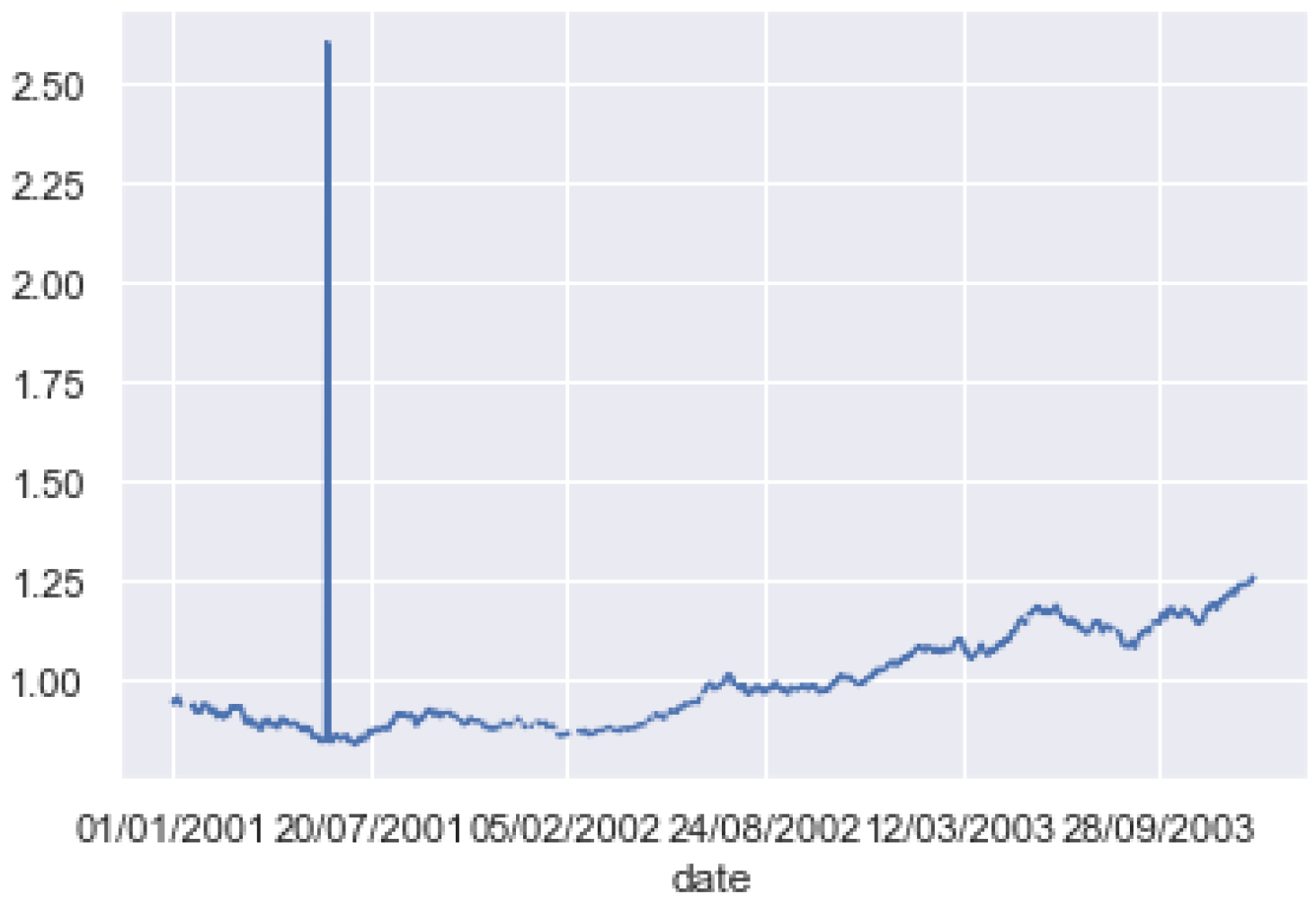
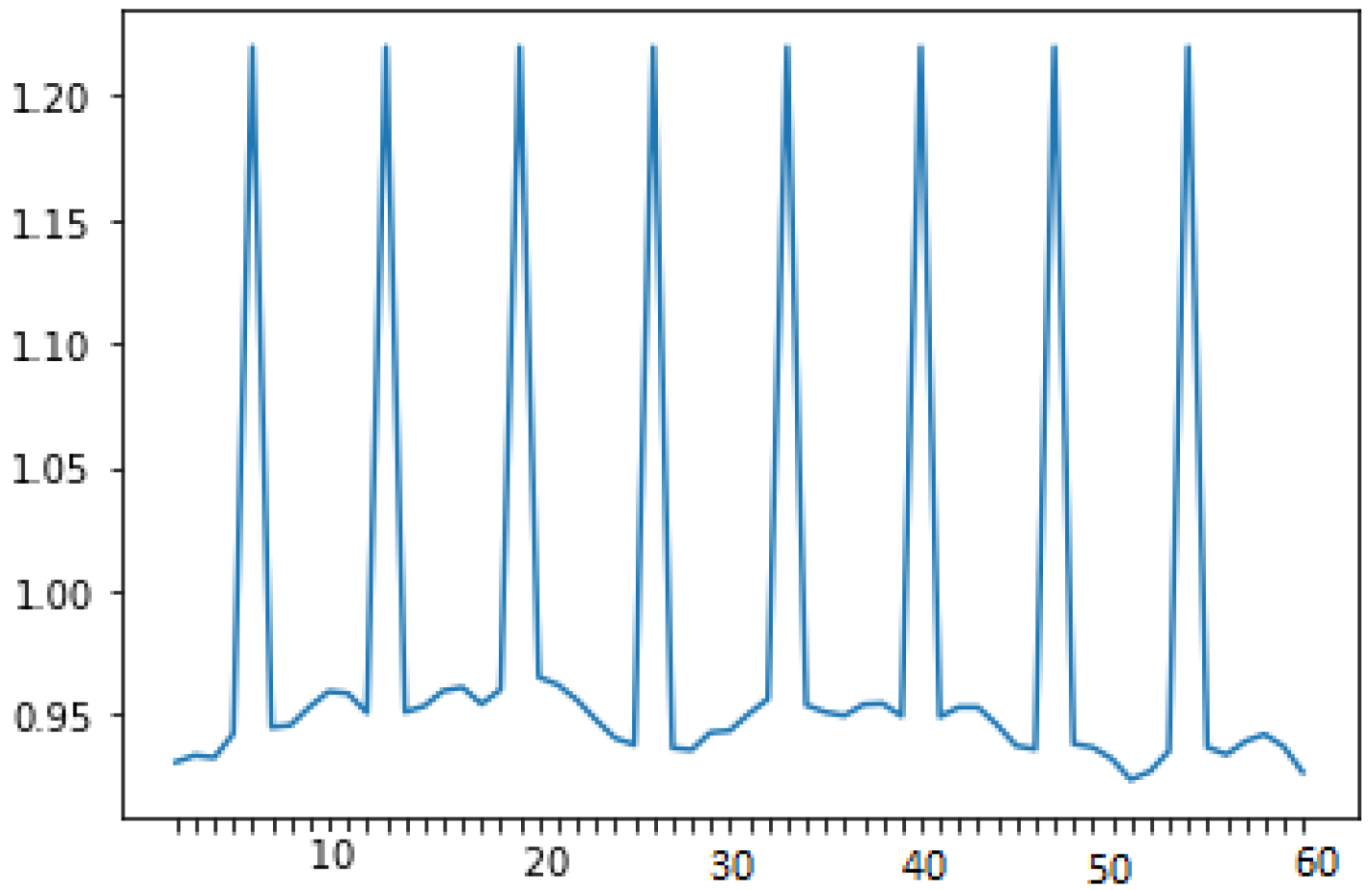
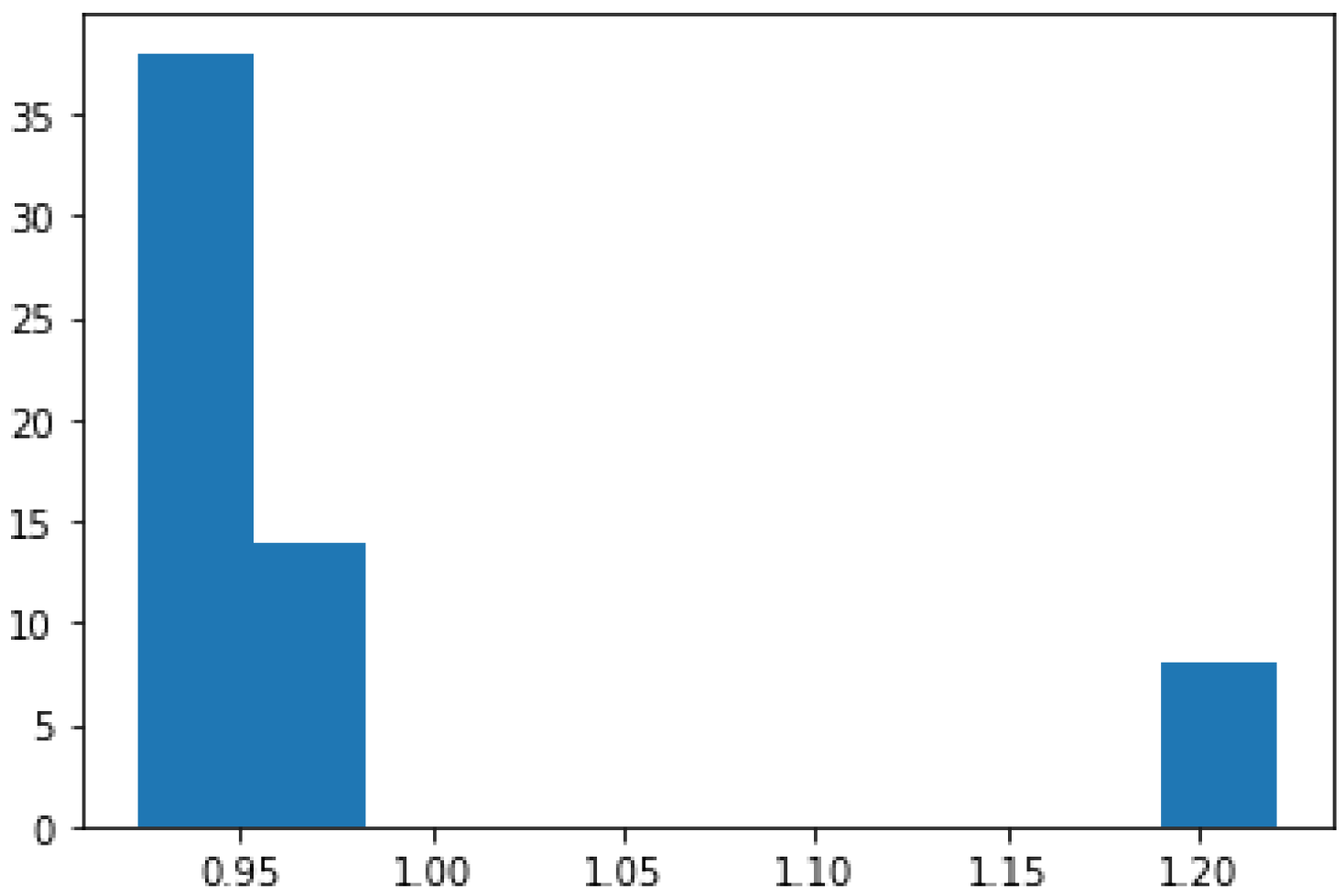
3.1. Dataset Description
3.2. Dataset Preprocessing
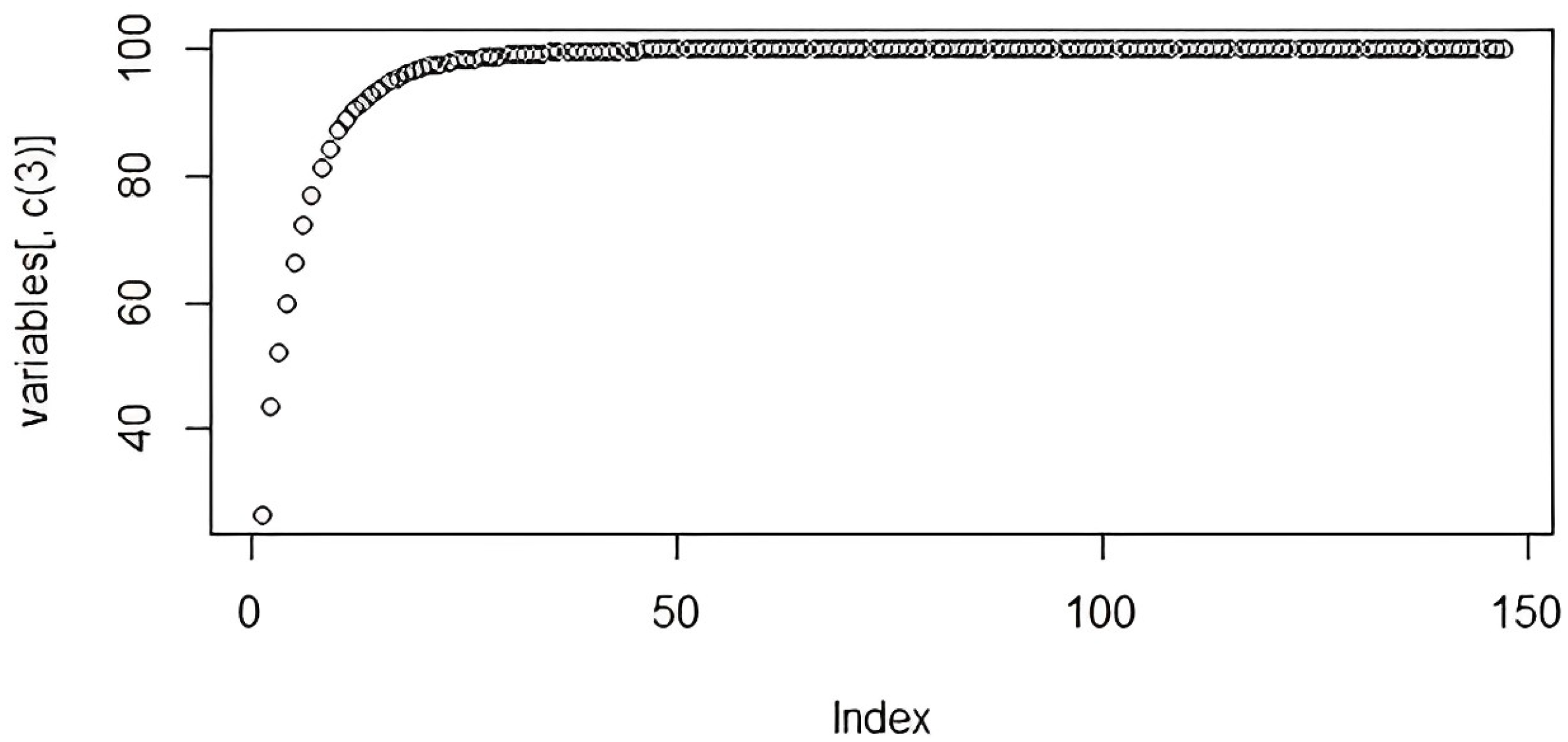
3.3. The Dataset Analysis and the Input Selection
3.4. Methodologies Adopted
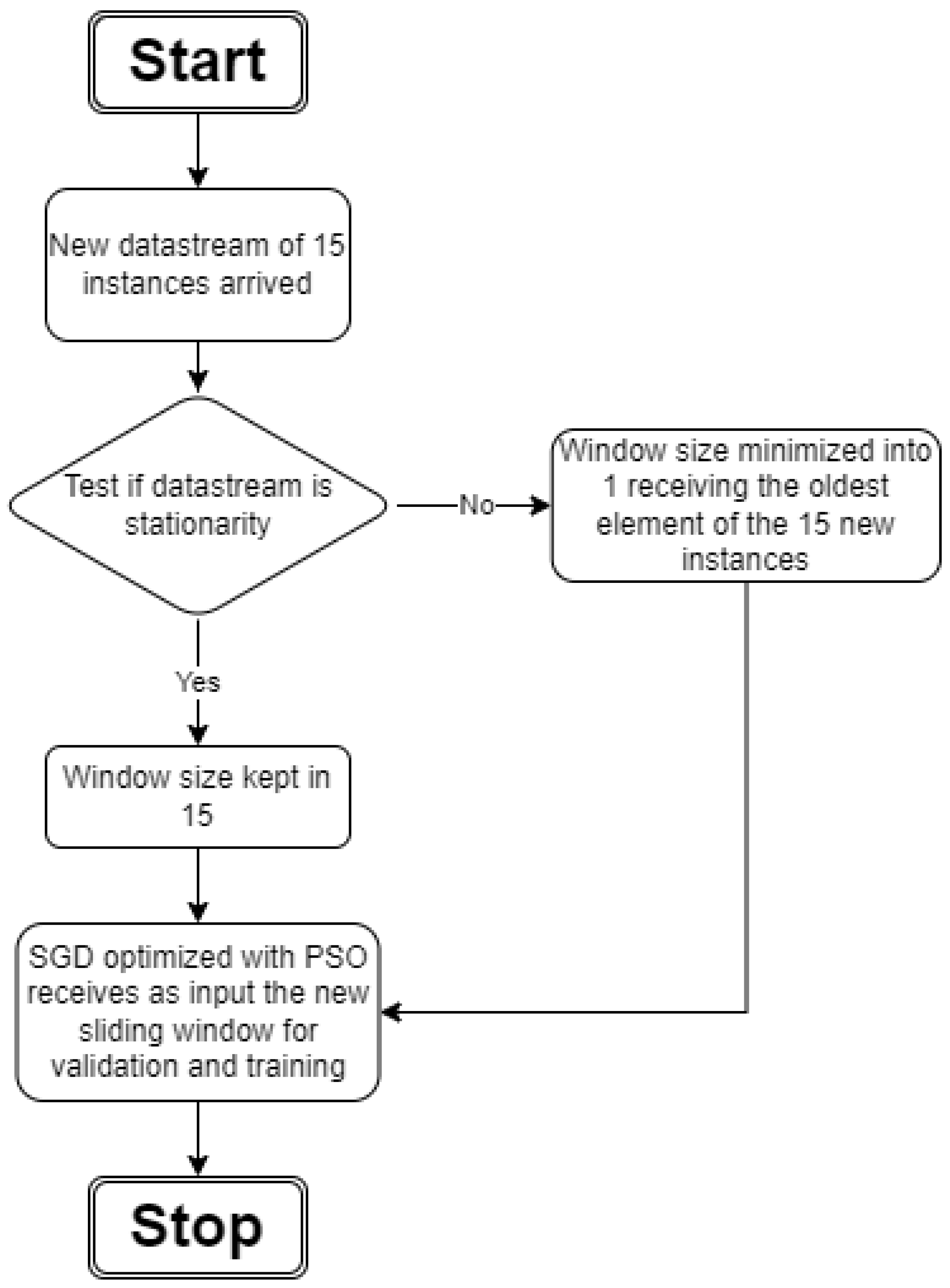
3.4.1. The Stationary Process
3.4.2. Stochastic Gradient Descent
3.4.3. PSO Metaheuristic Optimization Technique
4. Experimental Setup and Analysis
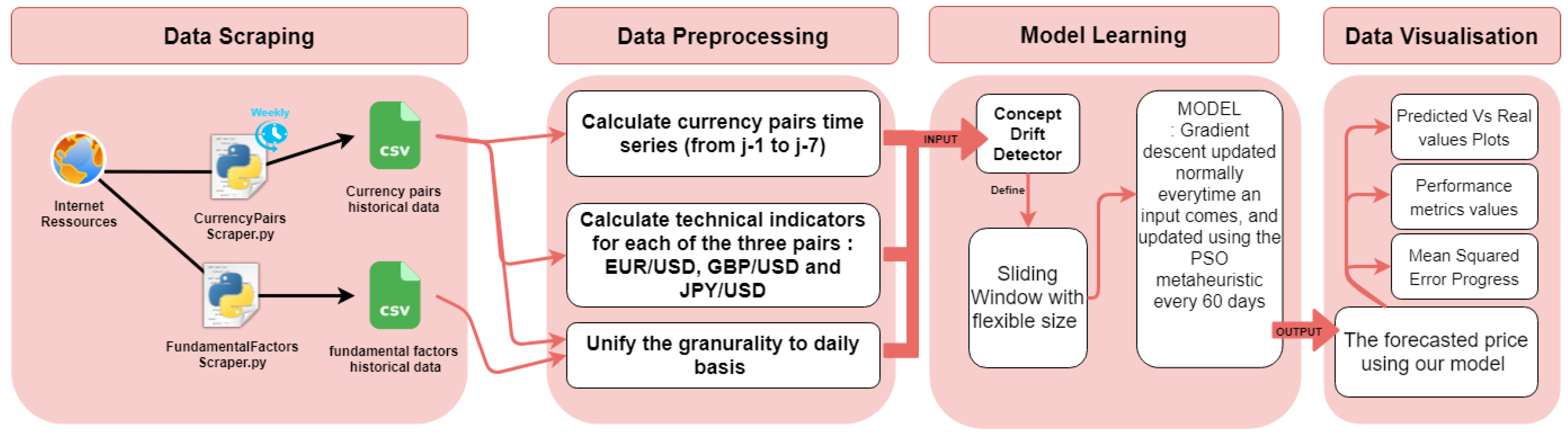
4.1. The Proposed Architecture
4.2. The Experiment Environment
4.3. The Parameters’ Description
4.4. The Proposed Search Algorithm
| Algorithm 1: The SGD algorithm optimized using the PSO metaheuristic with an adaptive sliding window |
 |
| Algorithm 2: Gradient algorithm descent optimized with Particle Swarm Optimization |
 |
4.5. The Performance Evaluation Metrics
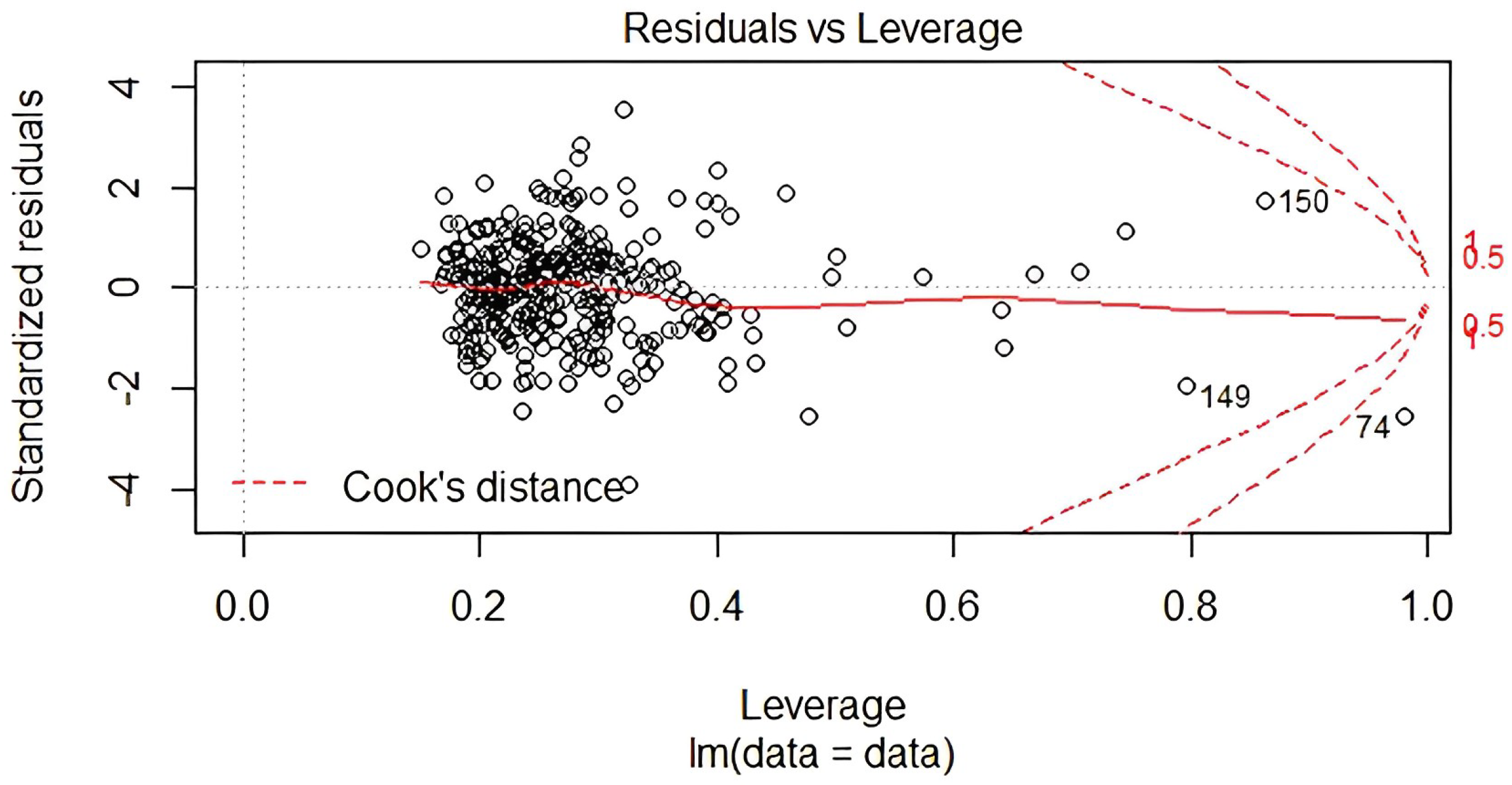
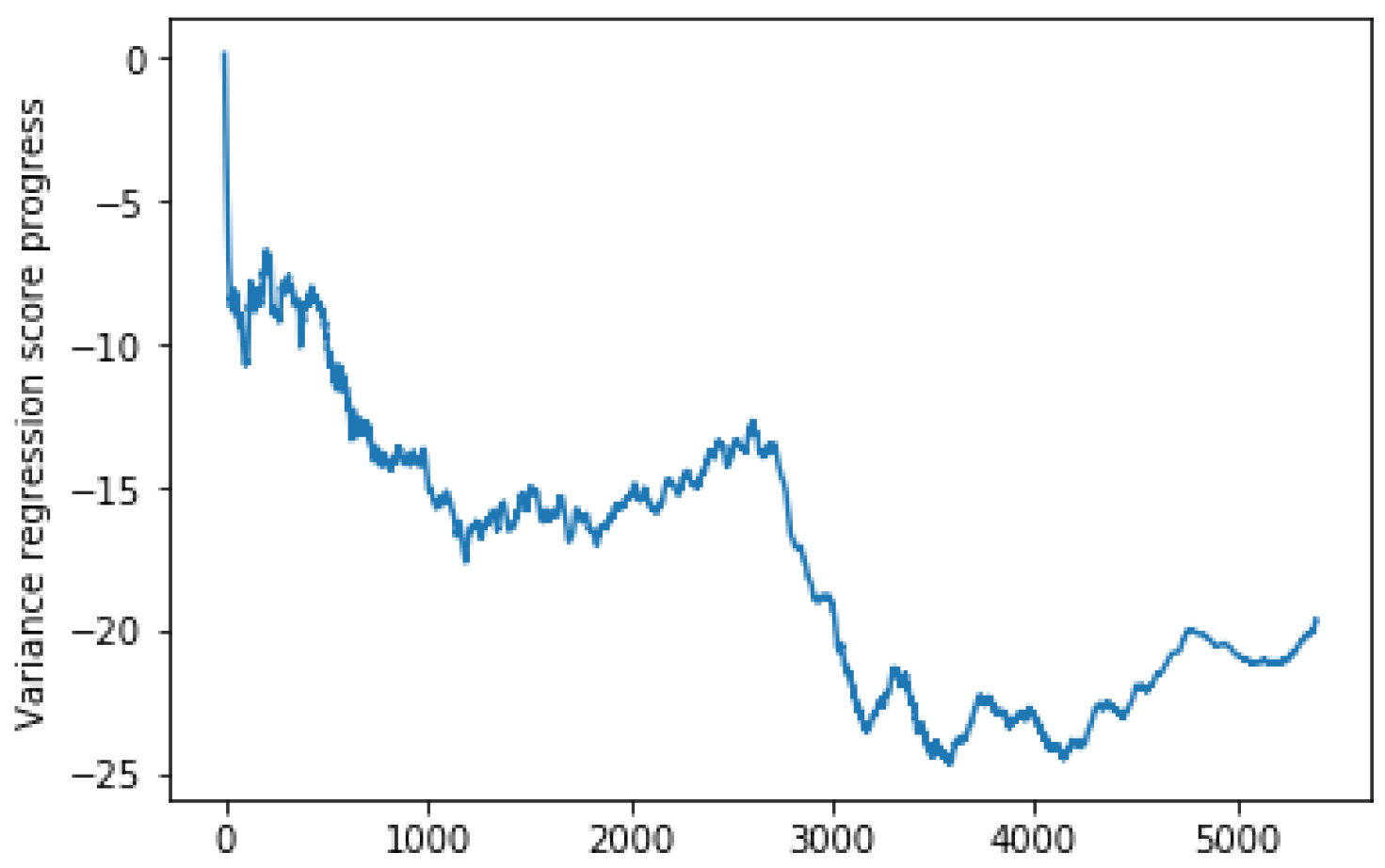
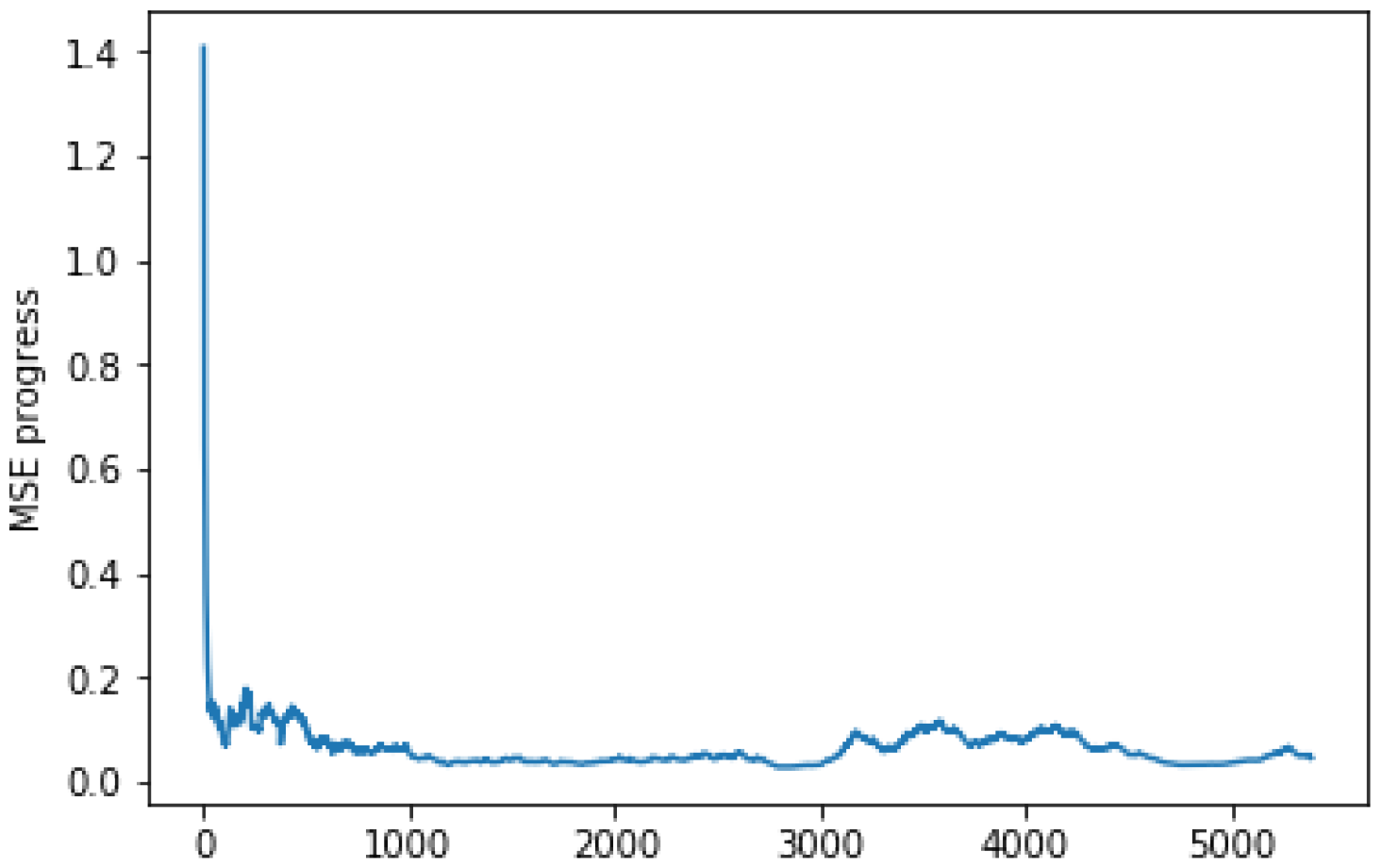
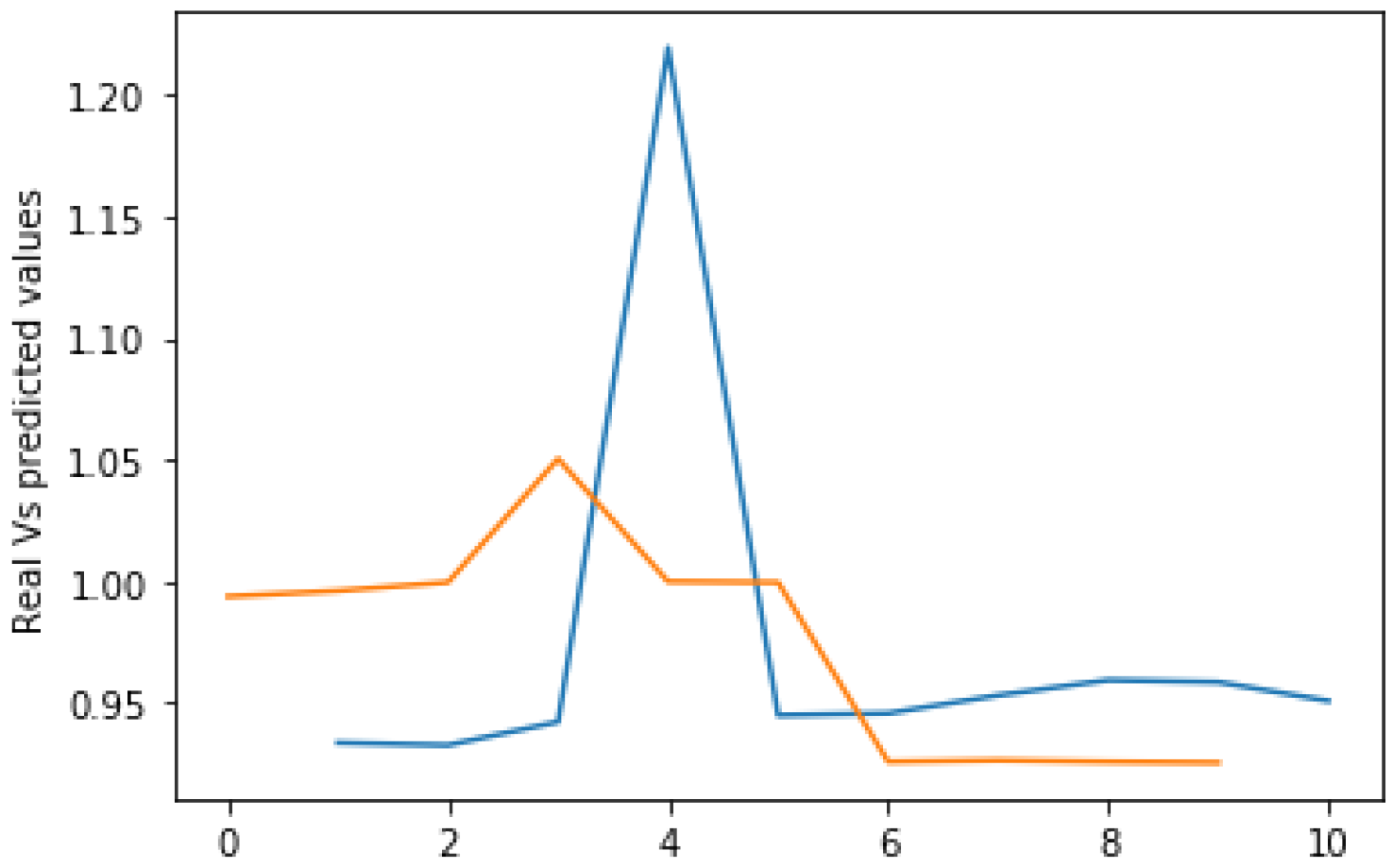
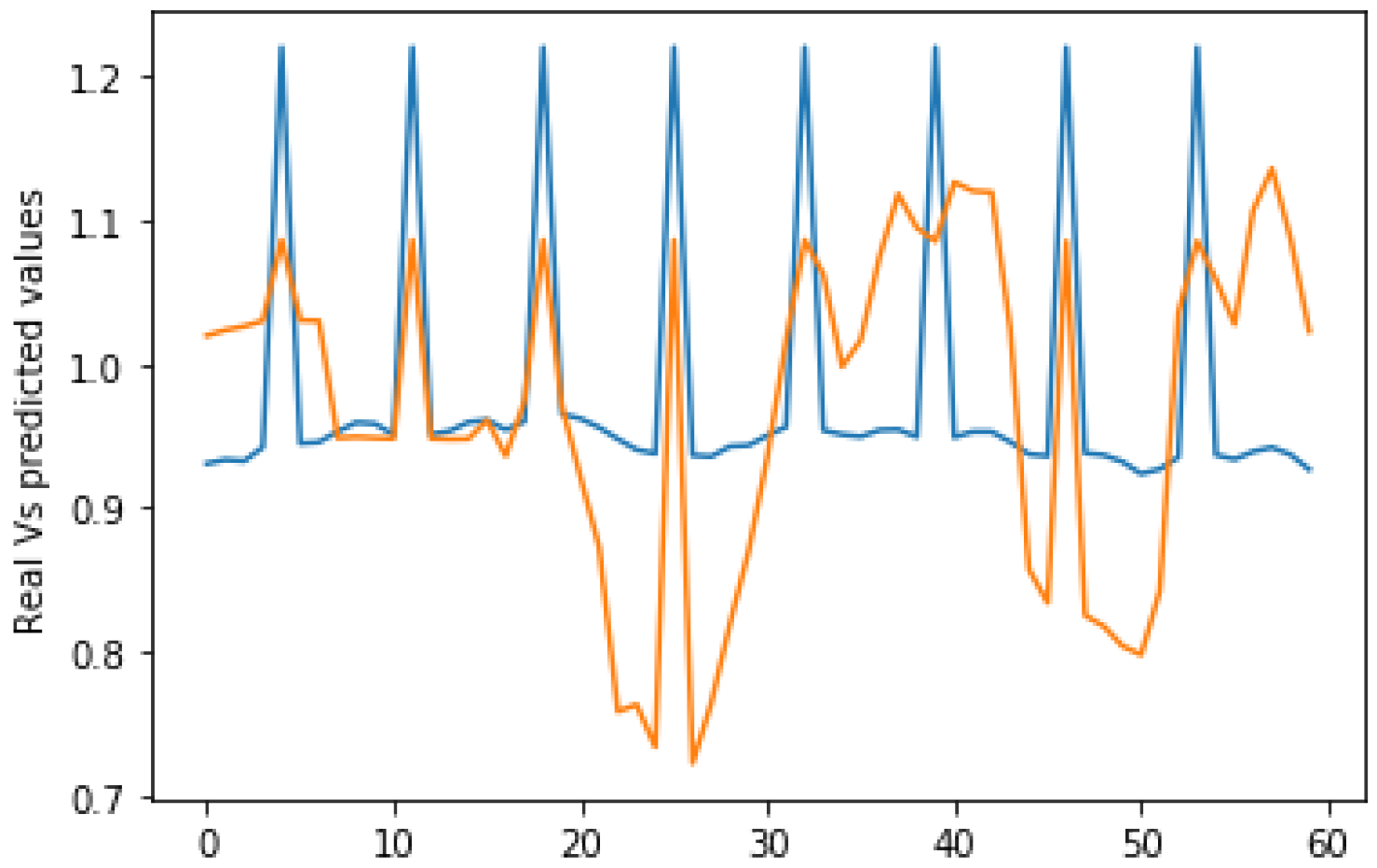
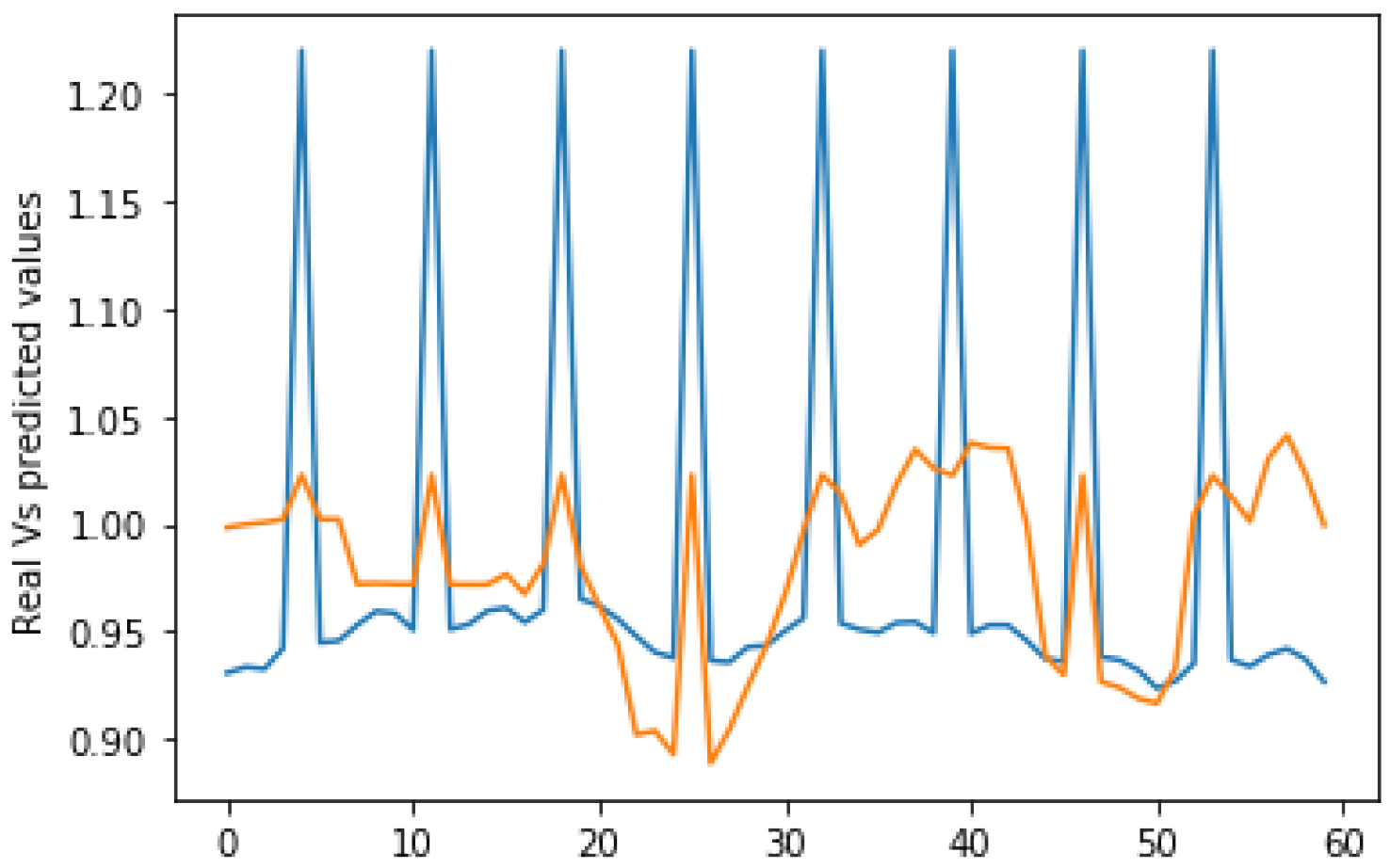
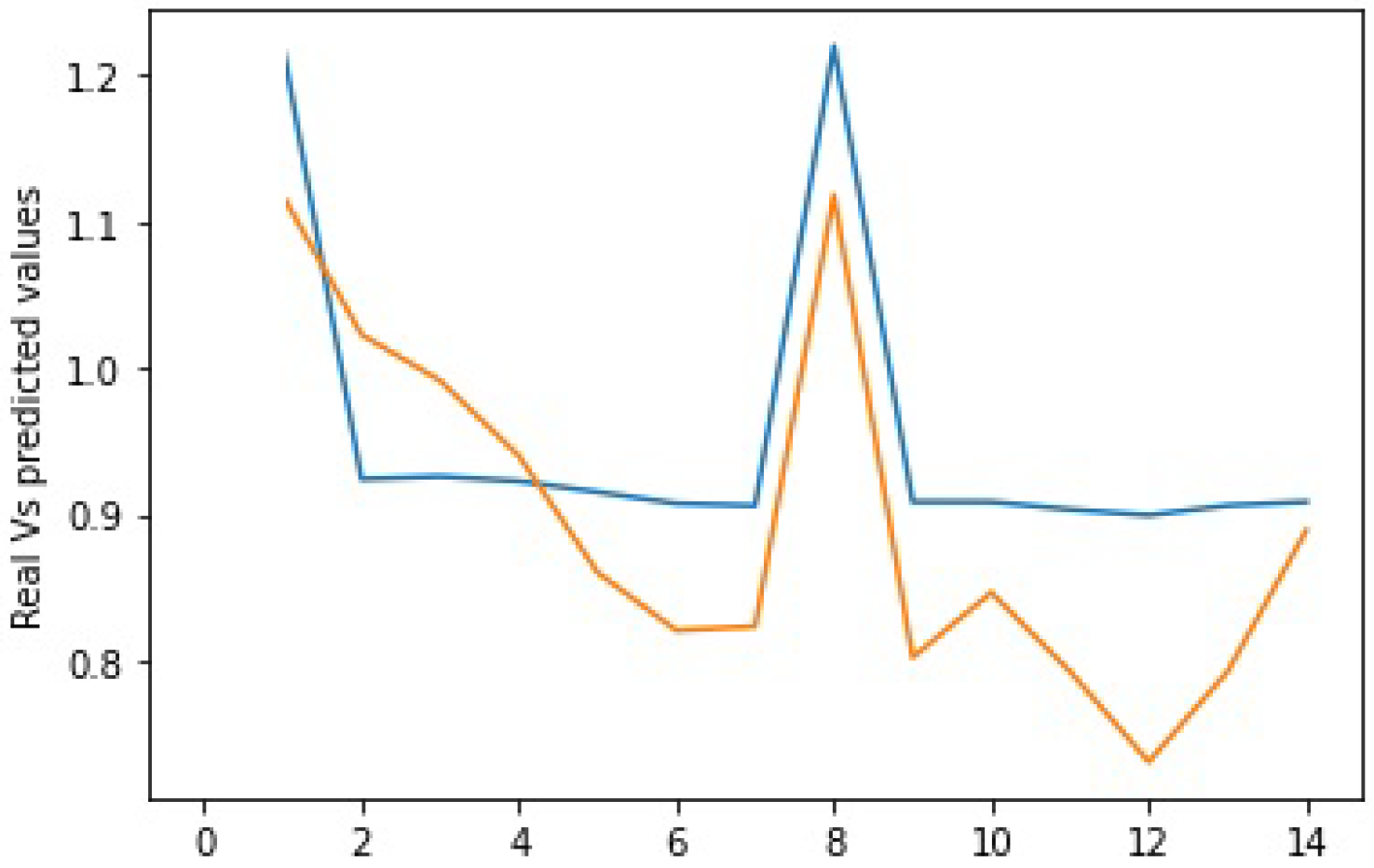
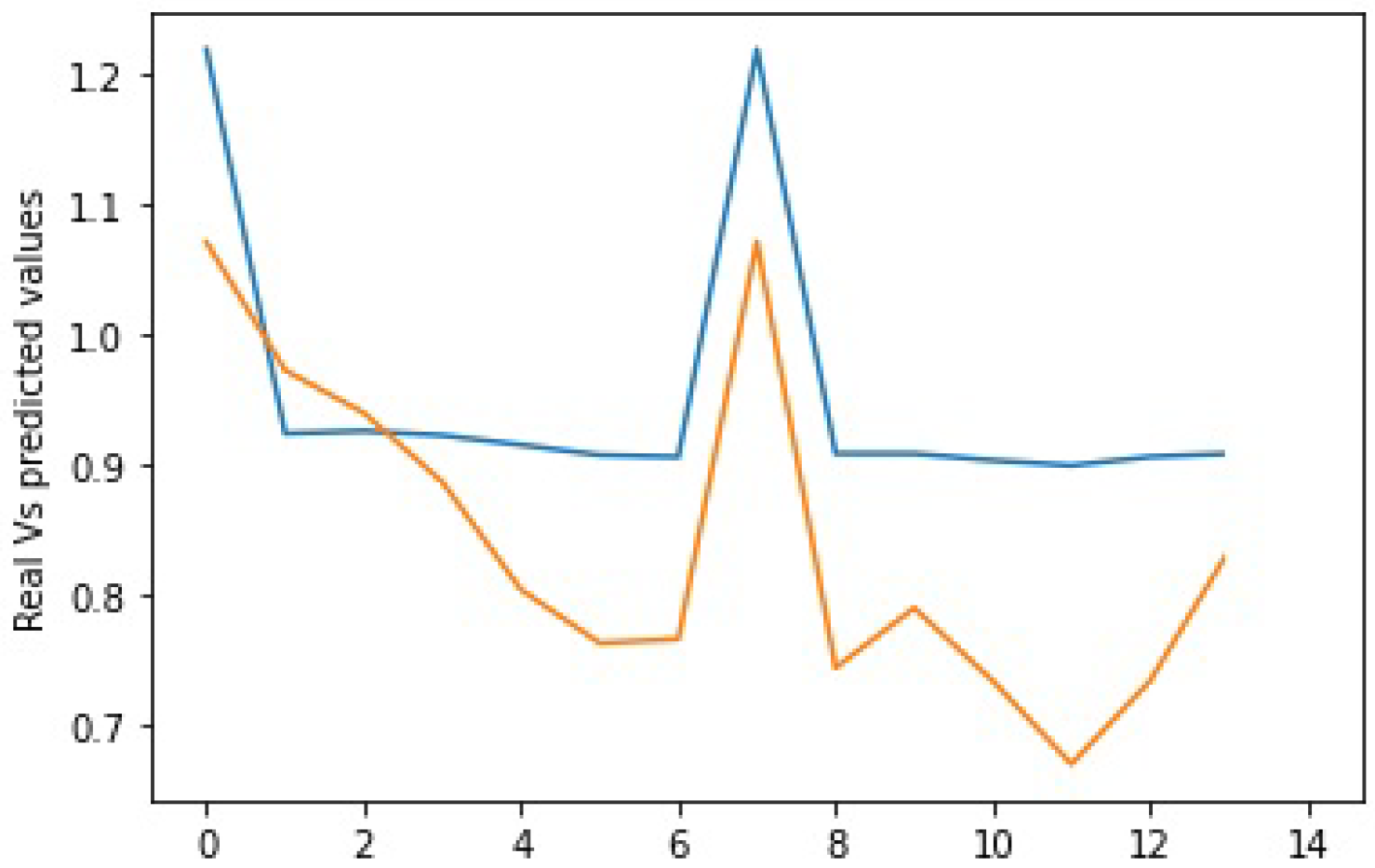
4.6. Analysis of Results
4.7. Discussions
5. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DSM | Data Stream Mining |
| FTSERF | Financial Time Series Exchange Rate Forecasting |
| PSO | Particle Swarm Optimization Metaheuristic |
| SGD | Stochastic Gradient Descent |
References
- Gerlein, E.A.; McGinnity, M.; Belatreche, A.; Coleman, S. Evaluating machine learning classification for financial trading: An empirical approach. Expert Syst. Appl. 2016, 54, 193–207. [Google Scholar] [CrossRef] [Green Version]
- Bousbaa, Z.; Bencharef, O.; Nabaji, A. Stock Market Speculation System Development Based on Technico Temporal Indicators and Data Mining Tools. In Heuristics for Optimization and Learning; Springer: Berlin/Heidelberg, Germany, 2021; pp. 239–251. [Google Scholar]
- Stitini, O.; Kaloun, S.; Bencharef, O. An Improved Recommender System Solution to Mitigate the Over-Specialization Problem Using Genetic Algorithms. Electronics 2022, 11, 242. [Google Scholar] [CrossRef]
- Jamali, H.; Chihab, Y.; García-Magariño, I.; Bencharef, O. Hybrid Forex prediction model using multiple regression, simulated annealing, reinforcement learning and technical analysis. Int. J. Artif. Intell. ISSN 2023, 2252, 8938. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Kranen, P.; Kremer, H.; Jansen, T.; Seidl, T. Moa: Massive online analysis, a framework for stream classification and clustering. In Proceedings of the First Workshop on Applications of Pattern Analysis, PMLR, Windsor, UK, 1–3 September 2010; pp. 44–50. [Google Scholar]
- Bifet, A. Adaptive Stream Mining: Pattern Learning and Mining from Evolving Data Streams; Ios Press: Amsterdam, The Netherlands, 2010; Volume 207. [Google Scholar]
- Thornbury, W.; Walford, E. Old and New London: A Narrative of Its History, Its People and Its Places; Cassell publisher: London, UK, 1878; Volume 6. [Google Scholar]
- Cummans, J. A Brief History of Bond Investing. 2014. Available online: http://bondfunds.com/ (accessed on 24 February 2018).
- BIS Site Development Project. Triennial central bank survey: Foreign exchange turnover in April 2016. Bank Int. Settl. 2016. Available online: https://www.bis.org/publ/rpfx16.htm (accessed on 24 February 2018).
- Lange, G.M.; Wodon, Q.; Carey, K. The Changing Wealth of Nations 2018: Building a Sustainable Future; Copyright: International Bank for Reconstruction and Development, The World Bank 2018, License type: CC BY, Access Rights Type: Open, Post date: 19 March 2018; World Bank Publications: Washington, DC, USA, 2018; ISBN 978-1-4648-1047-3. [Google Scholar]
- Makridakis, S.; Hibon, M. ARMA models and the Box–Jenkins methodology. J. Forecast. 1997, 16, 147–163. [Google Scholar] [CrossRef]
- Tinbergen, J. Statistical testing of business cycle theories: Part i: A method and its application to investment activity. In Statistical Testing of Business Cycle Theories; Agaton Press: New York, NY, USA, 1939; pp. 34–89. [Google Scholar]
- Xing, F.Z.; Cambria, E.; Welsch, R.E. Natural language based financial forecasting: A survey. Artif. Intell. Rev. 2018, 50, 49–73. [Google Scholar] [CrossRef] [Green Version]
- Cheung, Y.W.; Chinn, M.D.; Pascual, A.G. Empirical exchange rate models of the nineties: Are any fit to survive? J. Int. Money Financ. 2005, 24, 1150–1175. [Google Scholar] [CrossRef] [Green Version]
- Clifton, C., Jr.; Frazier, L.; Connine, C. Lexical expectations in sentence comprehension. J. Verbal Learn. Verbal Behav. 1984, 23, 696–708. [Google Scholar] [CrossRef]
- Brachman, R.J.; Khabaza, T.; Kloesgen, W.; Piatetsky-Shapiro, G.; Simoudis, E. Mining business databases. Commun. ACM 1996, 39, 42–48. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Ali, T.; Omar, B.; Soulaimane, K. Analyzing tourism reviews using an LDA topic-based sentiment analysis approach. MethodsX 2022, 9, 101894. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Rather, A.M.; Sastry, V.; Agarwal, A. Stock market prediction and Portfolio selection models: A survey. Opsearch 2017, 54, 558–579. [Google Scholar] [CrossRef]
- Cavalcante, R.C.; Brasileiro, R.C.; Souza, V.L.; Nobrega, J.P.; Oliveira, A.L. Computational intelligence and financial markets: A survey and future directions. Expert Syst. Appl. 2016, 55, 194–211. [Google Scholar] [CrossRef]
- Gadre-Patwardhan, S.; Katdare, V.V.; Joshi, M.R. A Review of Artificially Intelligent Applications in the Financial Domain. In Artificial Intelligence in Financial Markets; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–44. [Google Scholar]
- Curry, H.B. The method of steepest descent for non-linear minimization problems. Q. Appl. Math. 1944, 2, 258–261. [Google Scholar] [CrossRef] [Green Version]
- Shao, H.; Li, W.; Cai, B.; Wan, J.; Xiao, Y.; Yan, S. Dual-Threshold Attention-Guided Gan and Limited Infrared Thermal Images for Rotating Machinery Fault Diagnosis Under Speed Fluctuation. IEEE Trans. Ind. Inform. 2023, 1–10. [Google Scholar] [CrossRef]
- Lv, L.; Zhang, J. Adaptive Gradient Descent Algorithm for Networked Control Systems Using Redundant Rule. IEEE Access 2021, 9, 41669–41675. [Google Scholar] [CrossRef]
- Sirignano, J.; Spiliopoulos, K. Stochastic gradient descent in continuous time. Siam J. Financ. Math. 2017, 8, 933–961. [Google Scholar] [CrossRef] [Green Version]
- Audrino, F.; Trojani, F. Accurate short-term yield curve forecasting using functional gradient descent. J. Financ. Econ. 2007, 5, 591–623. [Google Scholar]
- Bonyadi, M.R.; Michalewicz, Z. Particle swarm optimization for single objective continuous space problems: A review. Evol. Comput. 2017, 25, 1–54. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360), Anchorage, AK, USA, 4–9 May 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 69–73. [Google Scholar]
- Jha, G.K.; Thulasiraman, P.; Thulasiram, R.K. PSO based neural network for time series forecasting. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1422–1427. [Google Scholar]
- Wang, K.; Chang, M.; Wang, W.; Wang, G.; Pan, W. Predictions models of Taiwan dollar to US dollar and RMB exchange rate based on modified PSO and GRNN. Clust. Comput. 2019, 22, 10993–11004. [Google Scholar] [CrossRef]
- Junyou, B. Stock Price forecasting using PSO-trained neural networks. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 2879–2885. [Google Scholar]
- Yang, F.; Chen, J.; Liu, Y. Improved and optimized recurrent neural network based on PSO and its application in stock price prediction. Soft Comput. 2021, 27, 3461–3476. [Google Scholar] [CrossRef]
- Huang, C.; Zhou, X.; Ran, X.; Liu, Y.; Deng, W.; Deng, W. Co-evolutionary competitive swarm optimizer with three-phase for large-scale complex optimization problem. Inf. Sci. 2023, 619, 2–18. [Google Scholar] [CrossRef]
- Auer, P. Online Learning. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2016; pp. 1–9. [Google Scholar]
- Benczúr, A.A.; Kocsis, L.; Pálovics, R. Online machine learning algorithms over data streams. J. Encycl. Big Data Technol. 2018, 1207–1218. [Google Scholar]
- Julie, A.; McCann, C.Z. Adaptive Machine Learning for Changing Environments. 2018. Available online: https://www.turing.ac.uk/research/research-projects/adaptive-machine-learning-changing-environments (accessed on 1 September 2018).
- Grootendorst, M. Validating your Machine Learning Model. 2019. Available online: https://towardsdatascience.com/validating-your-machine-learning-model-25b4c8643fb7 (accessed on 26 September 2018).
- Gepperth, A.; Hammer, B. Incremental learning algorithms and applications. In European Symposium on Artificial Neural Networks (ESANN); HAL: Bruges, Belgium, 2016. [Google Scholar]
- Li, S.Z. Encyclopedia of Biometrics: I-Z; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Vishal Nigam, M.J. Advantages of Adaptive AI Over Traditional Machine Learning Models. 2019. Available online: https://insidebigdata.com/2019/12/15/advantages-of-adaptive-ai-over-traditional-machine-learning-models/ (accessed on 15 December 2018).
- Santos, J.D.D. Understanding and Handling Data and Concept Drift. 2020. Available online: https://www.explorium.ai/blog/understanding-and-handling-data-and-concept-drift/ (accessed on 24 February 2018).
- Brownlee, J. A Gentle Introduction to Concept Drift in Machine Learning. 2020. Available online: https://machinelearningmastery.com/gentle-introduction-concept-drift-machine-learning/ (accessed on 10 December 2018).
- Das, S. Best Practices for Dealing With Concept Drift. 2021. Available online: https://neptune.ai/blog/concept-drift-best-practices (accessed on 8 November 2018).
- Brzezinski, D.; Stefanowski, J. Prequential AUC for classifier evaluation and drift detection in evolving data streams. In Proceedings of the International Workshop on New Frontiers in Mining Complex Patterns; Springer: Berlin/Heidelberg, Germany, 2014; pp. 87–101. [Google Scholar]
- Dodge, Y. The Concise Encyclopedia of Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Chan, J.; Choy, S. Analysis of covariance structures in time series. J. Data Sci. 2008, 6, 573–589. [Google Scholar] [CrossRef]
- Ruppert, D.; Matteson, D.S. Statistics and Data Analysis for Financial Engineering; Springer: Berlin/Heidelberg, Germany, 2011; Volume 13. [Google Scholar]
- Zhang, C.; Zhang, Y.; Cucuringu, M.; Qian, Z. Volatility forecasting with machine learning and intraday commonality. arXiv 2022, arXiv:2202.08962. [Google Scholar] [CrossRef]
- Hsu, M.W.; Lessmann, S.; Sung, M.C.; Ma, T.; Johnson, J.E. Bridging the divide in financial market forecasting: Machine learners vs. financial economists. Expert Syst. Appl. 2016, 61, 215–234. [Google Scholar] [CrossRef] [Green Version]
- Demirel, U.; Handan, Ç.; Ramazan, Ü. Predicting stock prices using machine learning methods and deep learning algorithms: The sample of the Istanbul Stock Exchange. Gazi Univ. J. Sci. 2021, 34, 63–82. [Google Scholar] [CrossRef]
- Guerra, P.; Castelli, M.; Côrte-Real, N. Machine learning for liquidity risk modelling: A supervisory perspective. Econ. Anal. Policy 2022, 74, 175–187. [Google Scholar] [CrossRef]
- Kou, G.; Chao, X.; Peng, Y.; Alsaadi, F.E.; Herrera-Viedma, E. Machine learning methods for systemic risk analysis in financial sectors. Technol. Econ. Dev. Econ. 2019, 25, 716–742. [Google Scholar] [CrossRef]
- Leippold, M.; Wang, Q.; Zhou, W. Machine learning in the Chinese stock market. J. Financ. Econ. 2022, 145, 64–82. [Google Scholar] [CrossRef]
- Shivarova, A.; Matthew, F. Dixon, Igor Halperin, and Paul Bilokon: Machine learning in Finance from Theory to Practice. 2021. Available online: https://rdcu.be/daRTw (accessed on 8 November 2018).
- Das, S.R.; Mishra, D.; Rout, M. A hybridized ELM-Jaya forecasting model for currency exchange prediction. J. King Saud-Univ.-Comput. Inf. Sci. 2020, 32, 345–366. [Google Scholar] [CrossRef]
- Nayak, S.C. Development and performance evaluation of adaptive hybrid higher order neural networks for exchange rate prediction. Int. J. Intell. Syst. Appl. 2017, 9, 71. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Wang, S.; Lai, K.K. An Online BP Learning Algorithm with Adaptive Forgetting Factors for Foreign Exchange Rates Forecasting. In Foreign-Exchange-Rate Forecasting with Artificial Neural Networks; Springer: Boston, MA, USA, 2007; pp. 87–100. [Google Scholar] [CrossRef]
- Soares, S.G.; Araújo, R. An on-line weighted ensemble of regressor models to handle concept drifts. Eng. Appl. Artif. Intell. 2015, 37, 392–406. [Google Scholar] [CrossRef]
- Carmona, J.; Gavalda, R. Online techniques for dealing with concept drift in process mining. In Proceedings of the International Symposium on Intelligent Data Analysis; Springer: Berlin/Heidelberg, Germany, 2012; pp. 90–102. [Google Scholar]
- Yan, H.; Ouyang, H. Financial time series prediction based on deep learning. Wirel. Pers. Commun. 2018, 102, 683–700. [Google Scholar] [CrossRef]
- Barddal, J.P.; Gomes, H.M.; Enembreck, F. Advances on concept drift detection in regression tasks using social networks theory. Int. J. Nat. Comput. Res. (IJNCR) 2015, 5, 26–41. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.F.; Chen, W.L.; Huang, C.P.; Huang, S.H.; Chen, A.P. Financial time-series data analysis using deep convolutional neural networks. In Proceedings of the 2016 7th International Conference on Cloud Computing and Big Data (CCBD), Macau, China, 16–18 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 87–92. [Google Scholar]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Kumar Chandar, S. Fusion model of wavelet transform and adaptive neuro fuzzy inference system for stock market prediction. J. Ambient. Intell. Humaniz. Comput. 2019, 1–9. [Google Scholar] [CrossRef]
- Pradeepkumar, D.; Ravi, V. Forex rate prediction: A hybrid approach using chaos theory and multivariate adaptive regression splines. In Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 219–227. [Google Scholar]
- Wang, L.Y.; Park, C.; Yeon, K.; Choi, H. Tracking concept drift using a constrained penalized regression combiner. Comput. Stat. Data Anal. 2017, 108, 52–69. [Google Scholar] [CrossRef] [Green Version]
- Baier, L.; Hofmann, M.; Kühl, N.; Mohr, M.; Satzger, G. Handling Concept Drifts in Regression Problems–the Error Intersection Approach. arXiv 2020, arXiv:2004.00438. [Google Scholar]
- Maneesilp, K.; Kruatrachue, B.; Sooraksa, P. Adaptive parameter forecasting for forex automatic trading system using fuzzy time series. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guilin, China, 10–13 July 2011; IEEE: Piscataway, NJ, USA, 2011; Volume 1, pp. 189–194. [Google Scholar]
- Yu, L.; Wang, S.; Lai, K.K. An online learning algorithm with adaptive forgetting factors for feedforward neural networks in financial time series forecasting. Nonlinear Dyn. Syst. Theory 2007, 7, 51–66. [Google Scholar]
- Ilieva, G. Fuzzy Supervised Multi-Period Time Series Forecasting; Sciendo: Warszawa, Poland, 2019. [Google Scholar]
- Bahrepour, M.; Akbarzadeh-T, M.R.; Yaghoobi, M.; Naghibi-S, M.B. An adaptive ordered fuzzy time series with application to FOREX. Expert Syst. Appl. 2011, 38, 475–485. [Google Scholar] [CrossRef]
- Martín, C.; Quintana, D.; Isasi, P. Grammatical Evolution-based ensembles for algorithmic trading. Appl. Soft Comput. 2019, 84, 105713. [Google Scholar] [CrossRef]
- Hoan, M.V.; Mai, L.C.; Hui, D.T. Pattern discovery in the financial time series based on local trend. In Proceedings of the International Conference on Advances in Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2016; pp. 442–451. [Google Scholar]
- Yu, L.; Wang, S.; Lai, K.K. Forecasting Foreign Exchange Rates Using an Adaptive Back-Propagation Algorithm with Optimal Learning Rates and Momentum Factors. In Foreign-Exchange-Rate Forecasting with Artificial Neural Networks; Springer: Boston, MA, USA, 2007; pp. 65–85. [Google Scholar]
- Castillo, G.; Gama, J. An adaptive prequential learning framework for Bayesian network classifiers. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2006; pp. 67–78. [Google Scholar]
- Ramírez-Gallego, S.; Krawczyk, B.; García, S.; Woźniak, M.; Herrera, F. A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing 2017, 239, 39–57. [Google Scholar] [CrossRef]
- Husson, F.; Lê, S.; Pagès, J. Analyse de Données avec R; Presses universitaires de Rennes: Rennes, France, 2016. [Google Scholar]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Binder, M.D.; Hirokawa, N.; Windhorst, U. Encyclopedia of Neuroscience; Springer: Berlin/Heidelberg, Germany, 2009; Volume 3166. [Google Scholar]
- Pandey, P. Understanding the Mathematics behind Gradient Descent. 2019. Available online: https://towardsdatascience.com/understanding-the-mathematics-behind-gradient-descent-dde5dc9be06e (accessed on 18 March 2019).
- Clerc, M.; Siarry, P. Une nouvelle métaheuristique pour l’optimisation difficile: La méthode des essaims particulaires. J3eA 2004, 3, 007. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | 0.9819729708789546 |
| Variance | 0.008933902258522159 |
| ADF Statistic | −1.535025 |
| p-value | 0.516119 |
| Critical Values | 1%: −3.563; 5%: −2.919; 10%: −2.597 |
| Data | 1st 30 Days | 2nd 30 Days |
| Mean | 0.984582 | 0.979364 |
| Variance | 0.008592 | 0.008965 |
| ADF Statistic | −1.084344 | −1.193593 |
| p-value | 0.721275 | 0.676346 |
| Critical Values | 1%: −3.770; 5%: −3.005; 10%: −2.643 | 1%: −3.809; 5%: −3.022; 10%: −2.651 |
| Data | 1st 15days | 2nd 15days | 3rd 15days | 4th 15days |
| Mean | 0.983657 | 0.985506 | 0.986441 | 0.972288 |
| Variance | 0.008653 | 0.008529 | 0.008389 | 0.009440 |
| ADF Statistic | −4.419853 | −3.628841 | −17.540606 | −16.313688 |
| p-value | 0.000274 | 0.005233 | 0.0 | 0.0 |
| Critical Values | 1%: −4.473 5%: −3.290 10%: −2.772 | 1%: −4.473 5%: −3.290 10%: −2.772 | 1%: −4.473 5%: −3.290 10%: −2.772 | 1%: −4.473 5%: −3.290 10%: −2.772 |
| Flexible Window Size | Fixed Window Size | ||||||
|---|---|---|---|---|---|---|---|
| Range | MSE | ARV | Accuracy | Range | MSE | ARV | Accuracy |
| [0:15] | 0.0027 | 0.0519 | 66.6 | [0:15] | 0.002902 | 0.0538 | 66.6 |
| [1:16] | 0.002534 | 0.0503 | 66.6 | [15:30] | 0.00528 | 0.0726 | 80.0 |
| [2:17] | 0.00237 | 0.0486 | 73.3 | ||||
| [3:18] | 0.00217 | 0.0465 | 73.3 | ||||
| [4:19] | 0.0028 | 0.0529 | 73.3 | ||||
| [5:20] | 0.002 | 0.0447 | 73.3 | ||||
| [6:21] | 0.00192 | 0.0438 | 80.0 | ||||
| [7:22] | 0.00201 | 0.0448 | 86.6 | ||||
| [8:23] | 0.0031 | 0.0556 | 86.6 | ||||
| [9:24] | 0.00404 | 0.0635 | 80.0 | ||||
| [10:25] | 0.00528 | 0.0726 | 80.0 | ||||
| [11:26] | 0.00608 | 0.0779 | 80.0 | ||||
| [26:41] | 0.00727 | 0.0852 | 66.6 | [30:45] | 0.01416 | 0.1189 | 66.6 |
| [27:42] | 0.00658 | 0.0811 | 66.6 | ||||
| [28:43] | 0.00586 | 0.0765 | 66.6 | ||||
| [29:44] | 0.00495 | 0.0703 | 66.6 | ||||
| [30:45] | 0.00494 | 0.0702 | 66.6 | ||||
| [31:46] | 0.00546 | 0.0738 | 66.6 | [45:60] | 0.00607 | 0.0779 | 93.3 |
| [32:47] | 0.00686 | 0.0828 | 66.6 | ||||
| [33:48] | 0.00623 | 0.0789 | 66.6 | ||||
| [34:49] | 0.00699 | 0.0836 | 66.6 | ||||
| [35:50] | 0.00788 | 0.0887 | 73.3 | ||||
| [36:51] | 0.00874 | 0.0934 | 73.3 | ||||
| [37:52] | 0.00917 | 0.0957 | 73.3 | ||||
| [38:53] | 0.00895 | 0.0946 | 73.3 | ||||
| [39:54] | 0.01016 | 0.1007 | 80.0 | ||||
| [40:55] | 0.00887 | 0.0941 | 86.6 | ||||
| [41:56] | 0.00856 | 0.0925 | 93.3 | ||||
| [42:57] | 0.00857 | 0.0925 | 93.3 | ||||
| [43:58] | 0.00874 | 0.0934 | 93.3 | ||||
| [44:59] | 0.00895 | 0.0946 | 93.3 | ||||
| [45:60] | 0.00849 | 0.0921 | 93.3 | ||||
| [46:61] | 0.00922 | 0.096 | 93.3 | [60:75] | 0.00936 | 0.0967 | 73.3 |
| [47:62] | 0.00782 | 0.0884 | 93.3 | ||||
| [48:63] | 0.0071 | 0.0842 | 86.6 | ||||
| [49:64] | 0.00649 | 0.0805 | 86.6 | ||||
| [50:65] | 0.00635 | 0.0796 | 86.6 | ||||
| [51:66] | 0.00657 | 0.081 | 86.6 | ||||
| [52:67] | 0.00709 | 0.0842 | 80.0 | ||||
| [53:68] | 0.00843 | 0.0918 | 80.0 | ||||
| [54:69] | 0.00836 | 0.0914 | 80.0 | ||||
| [55:70] | 0.00908 | 0.0952 | 73.3 | ||||
| [56:71] | 0.01043 | 0.1021 | 73.3 | ||||
| [57:72] | 0.01237 | 0.1112 | 73.3 | ||||
| [58:73] | 0.00573 | 0.0756 | 73.3 | ||||
| [59:74] | 0.00464 | 0.0681 | 73.3 | ||||
| [74:89] | 0.00688 | 0.0829 | 80.0 | [75:90] | 0.0047 | 0.0685 | 80.0 |
| [75:90] | 0.00781 | 0.0883 | 80.0 | ||||
| [76:91] | 0.00917 | 0.0957 | 80.0 | [90:105] | 0.00672 | 0.0819 | 60.0 |
| [77:92] | 0.01095 | 0.1046 | 80.0 | ||||
| [78:93] | 0.0127 | 0.1126 | 86.6 | ||||
| [79:94] | 0.01469 | 0.1212 | 80.0 | ||||
| [80:95] | 0.01651 | 0.1284 | 73.3 | ||||
| [81:96] | 0.01672 | 0.1293 | 73.3 | ||||
| [82:97] | 0.01695 | 0.1301 | 73.3 | ||||
| [83:98] | 0.01727 | 0.1314 | 66.6 | ||||
| [84:99] | 0.01819 | 0.1348 | 66.6 | ||||
| [85:100] | 0.01864 | 0.4317 | 66.6 | ||||
| [86:101] | 0.0186 | 0.1363 | 66.6 | ||||
| [87:102] | 0.01881 | 0.1371 | 66.6 | ||||
| [88:103] | 0.01814 | 0.1346 | 66.6 | ||||
| [89:104] | 0.01837 | 0.1355 | 66.6 | ||||
| [90:105] | 0.01754 | 0.1324 | 60.0 | ||||
| [91:106] | 0.01636 | 0.1279 | 60.0 | [105:120] | 0.03948 | 0.1986 | 53.3 |
| [92:107] | 0.01427 | 0.1194 | 60.0 | ||||
| [93:108] | 0.01176 | 0.1084 | 66.6 | ||||
| [94:109] | 0.00956 | 0.0977 | 73.3 | ||||
| [95:110] | 0.00766 | 0.0875 | 73.3 | ||||
| [96:111] | 0.0074 | 0.086 | 73.3 | ||||
| [97:112] | 0.00712 | 0.0843 | 73.3 | ||||
| [98:113] | 0.00684 | 0.0827 | 66.6 | ||||
| [99:114] | 0.00586 | 0.0765 | 60.0 | ||||
| [100:115] | 0.00486 | 0.0697 | 60.0 | ||||
| [101:116] | 0.00624 | 0.0789 | 66.6 | ||||
| [102:117] | 0.00562 | 0.0749 | 60.0 | ||||
| [103:118] | 0.00836 | 0.0914 | 53.3 | ||||
| [104:119] | 0.01005 | 0.1002 | 60.0 | ||||
| [105:120] | 0.01068 | 0.1033 | 53.3 | ||||
| [120:135] | 0.01108 | 0.10526 | 60.0 | [120:135] | 0.00885 | 0.094 | 60.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bousbaa, Z.; Sanchez-Medina, J.; Bencharef, O. Financial Time Series Forecasting: A Data Stream Mining-Based System. Electronics 2023, 12, 2039. https://doi.org/10.3390/electronics12092039
Bousbaa Z, Sanchez-Medina J, Bencharef O. Financial Time Series Forecasting: A Data Stream Mining-Based System. Electronics. 2023; 12(9):2039. https://doi.org/10.3390/electronics12092039
Chicago/Turabian StyleBousbaa, Zineb, Javier Sanchez-Medina, and Omar Bencharef. 2023. "Financial Time Series Forecasting: A Data Stream Mining-Based System" Electronics 12, no. 9: 2039. https://doi.org/10.3390/electronics12092039
APA StyleBousbaa, Z., Sanchez-Medina, J., & Bencharef, O. (2023). Financial Time Series Forecasting: A Data Stream Mining-Based System. Electronics, 12(9), 2039. https://doi.org/10.3390/electronics12092039