
LiDAR Point Cloud Object Recognition Method via Intensity Image Compensation


Abstract
:1. Introduction
2. Methods
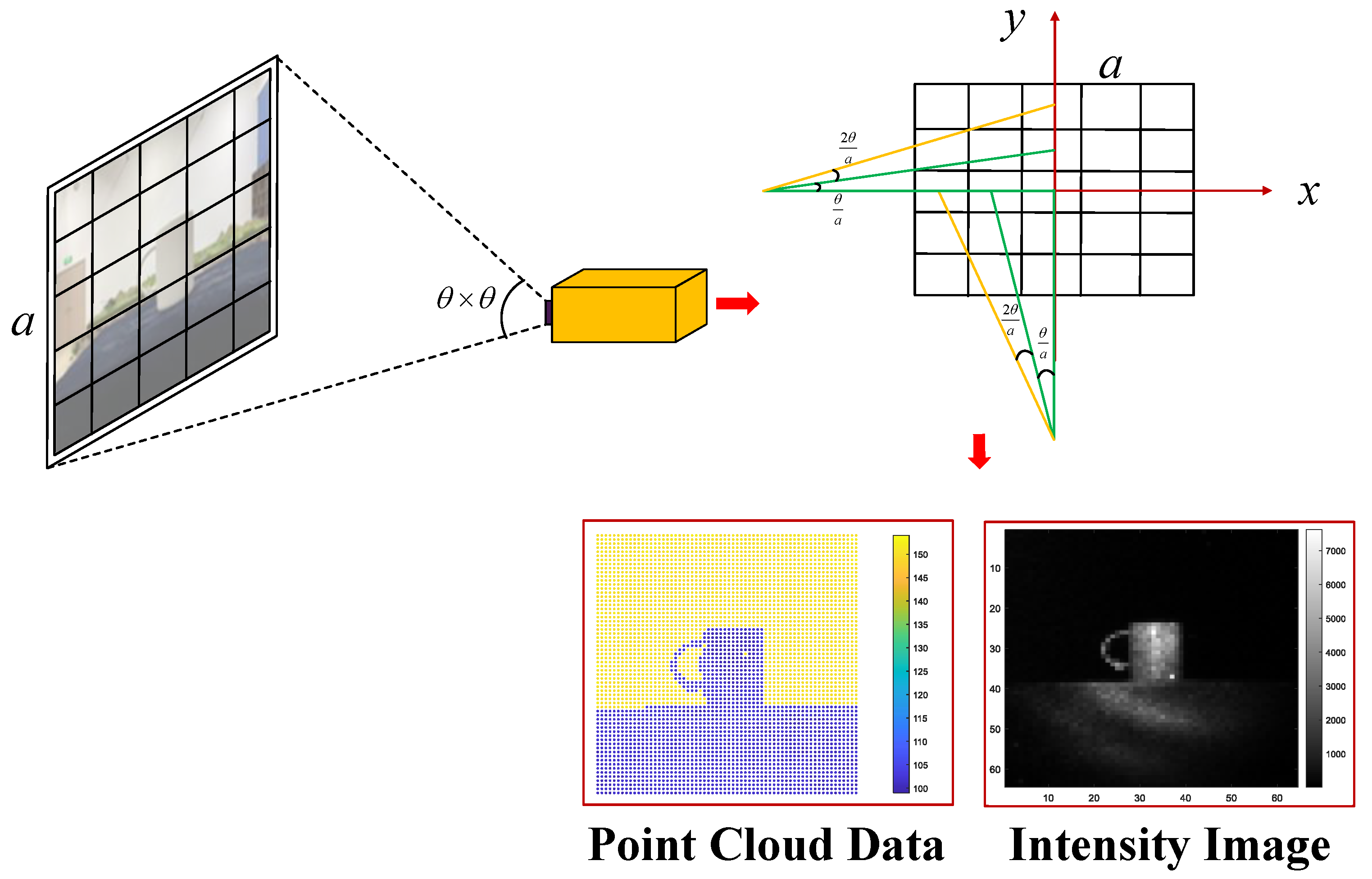
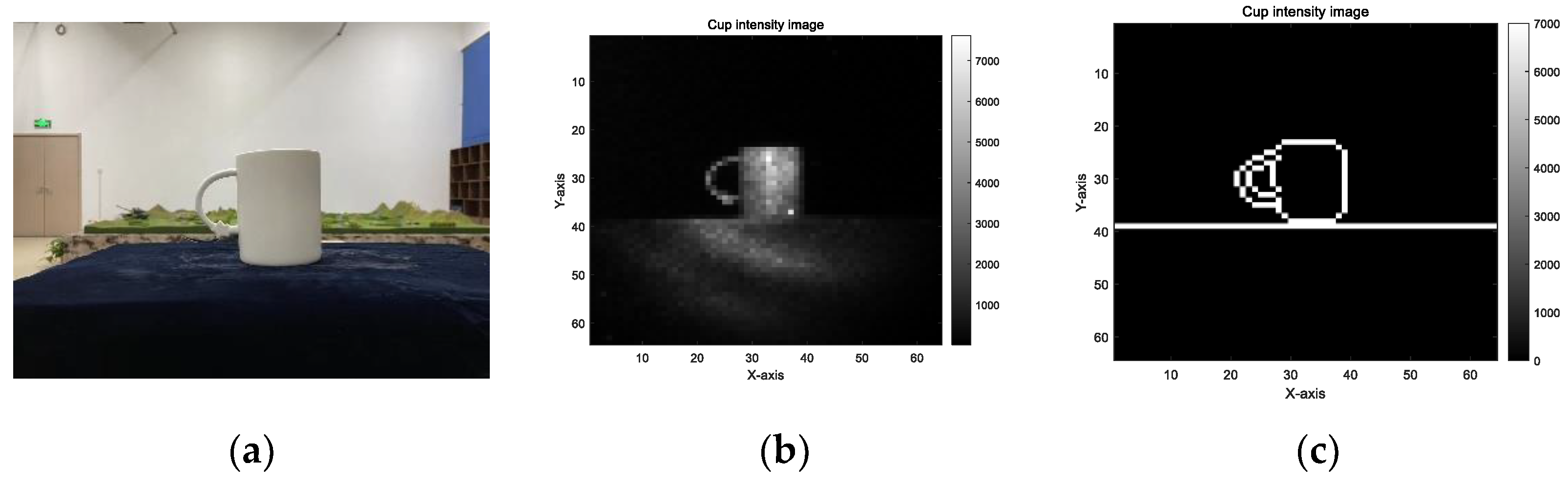
2.1. Acquisition Methods for Point Cloud and Intensity Images
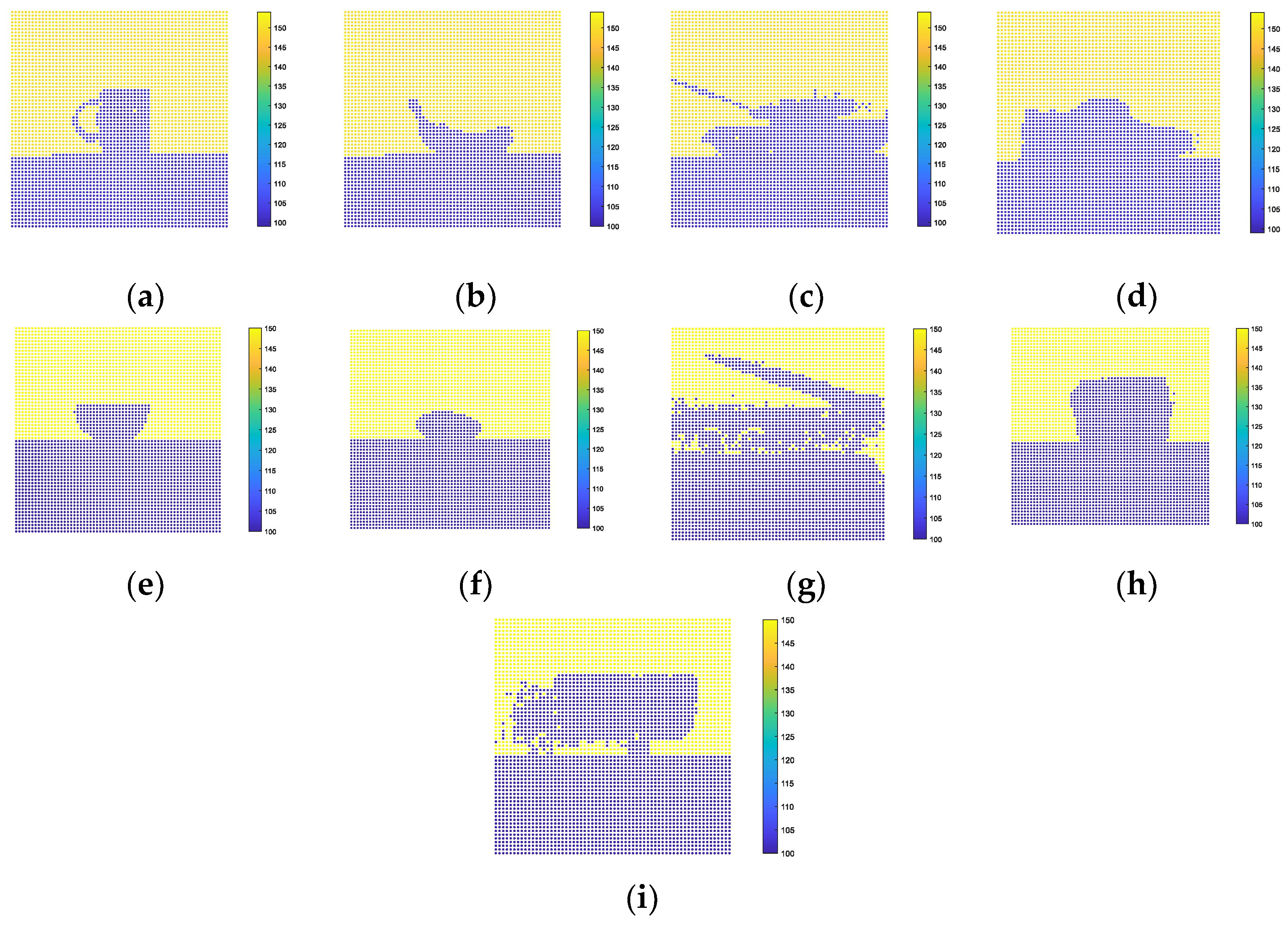
2.2. Deviation Angle Feature of Normal Vector
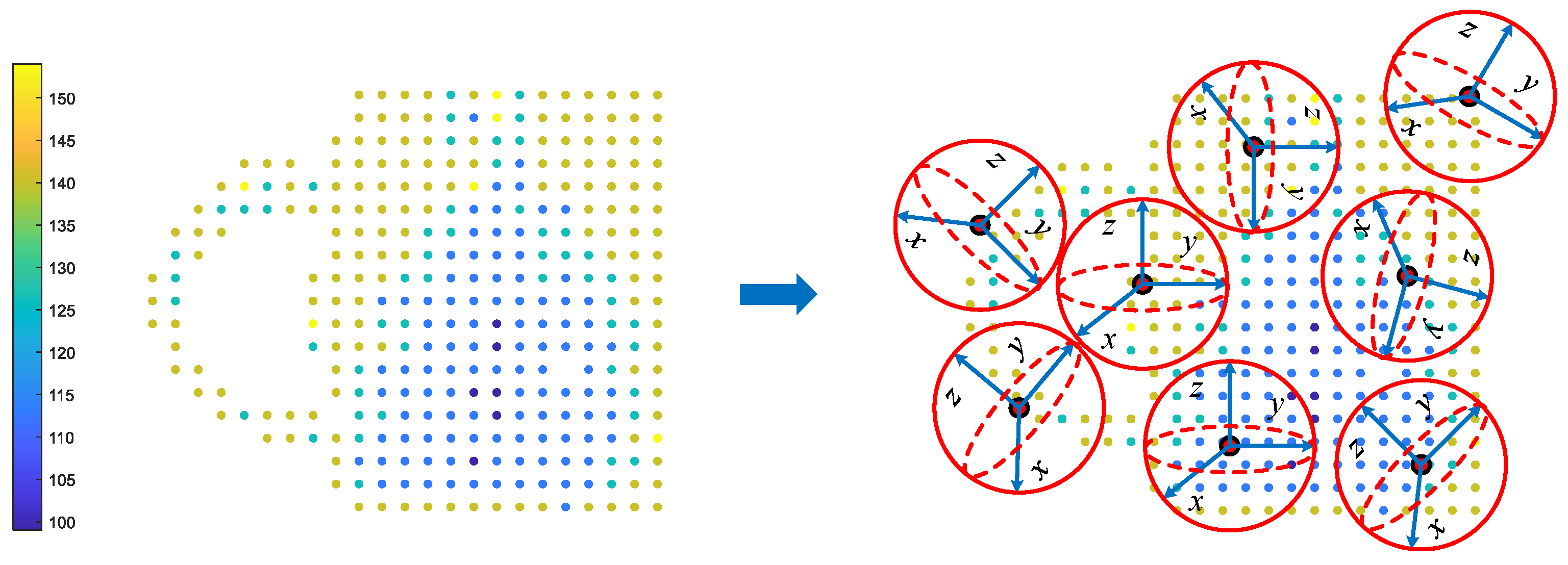
2.2.1. Construction of the LRF
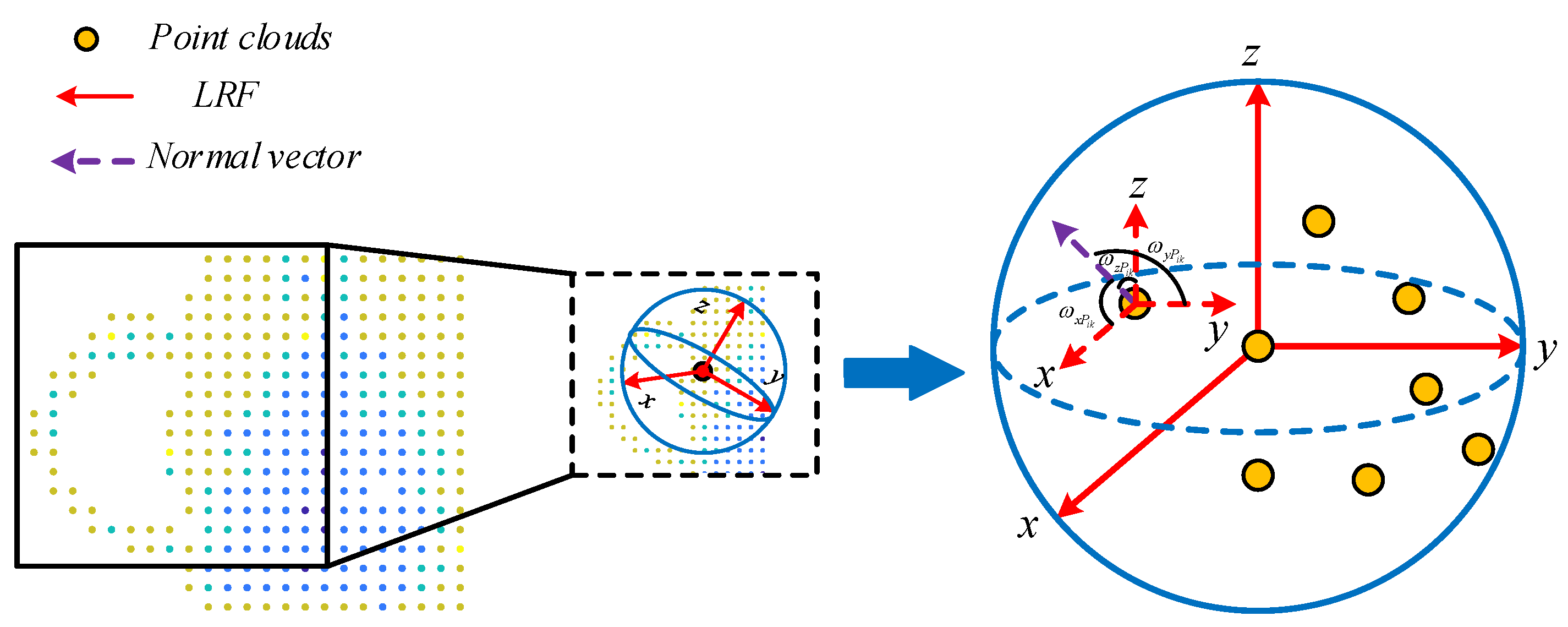
2.2.2. Feature of Normal Vectors Deviation Angle
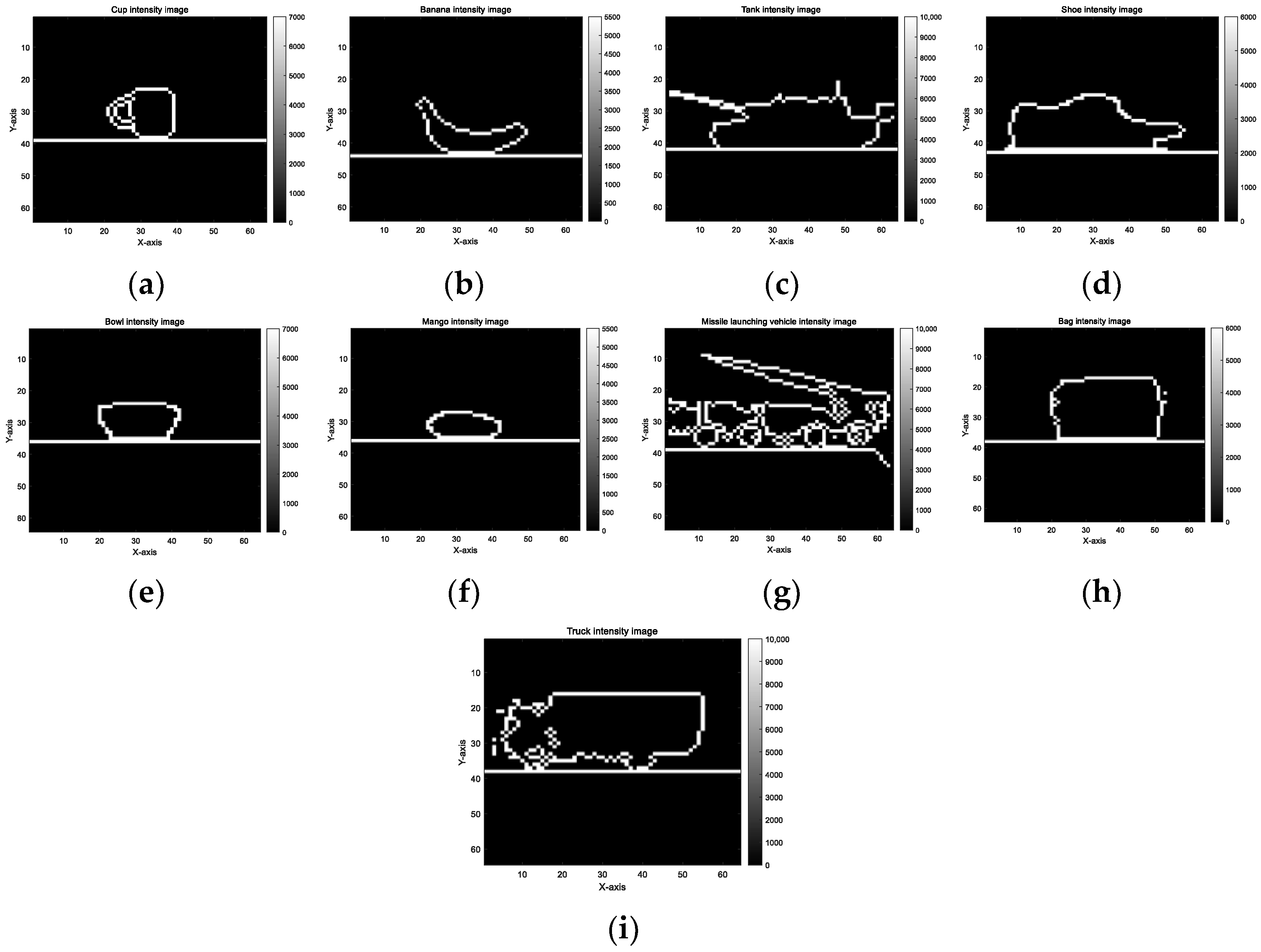
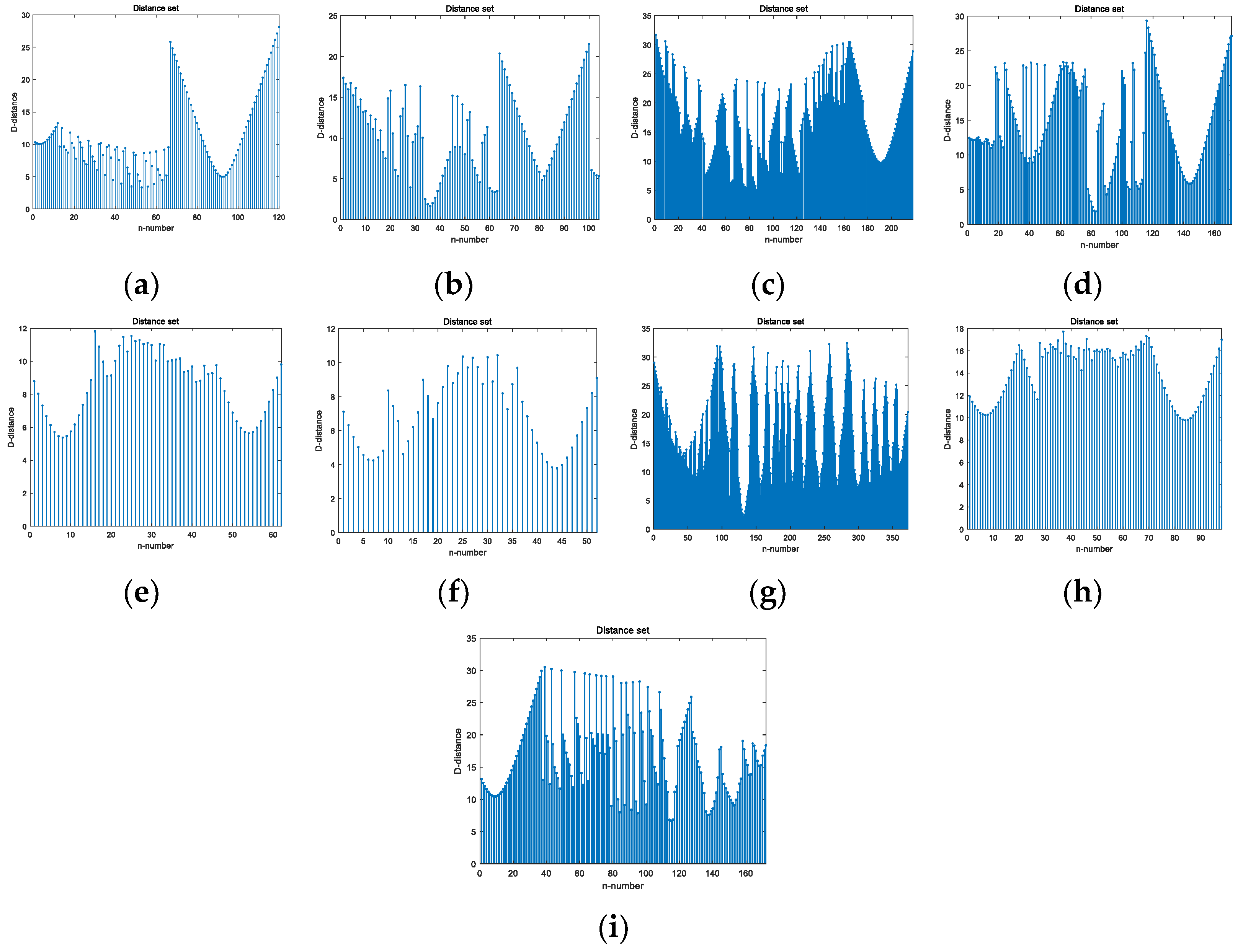
2.3. Contour Fourier Feature of the Intensity Image
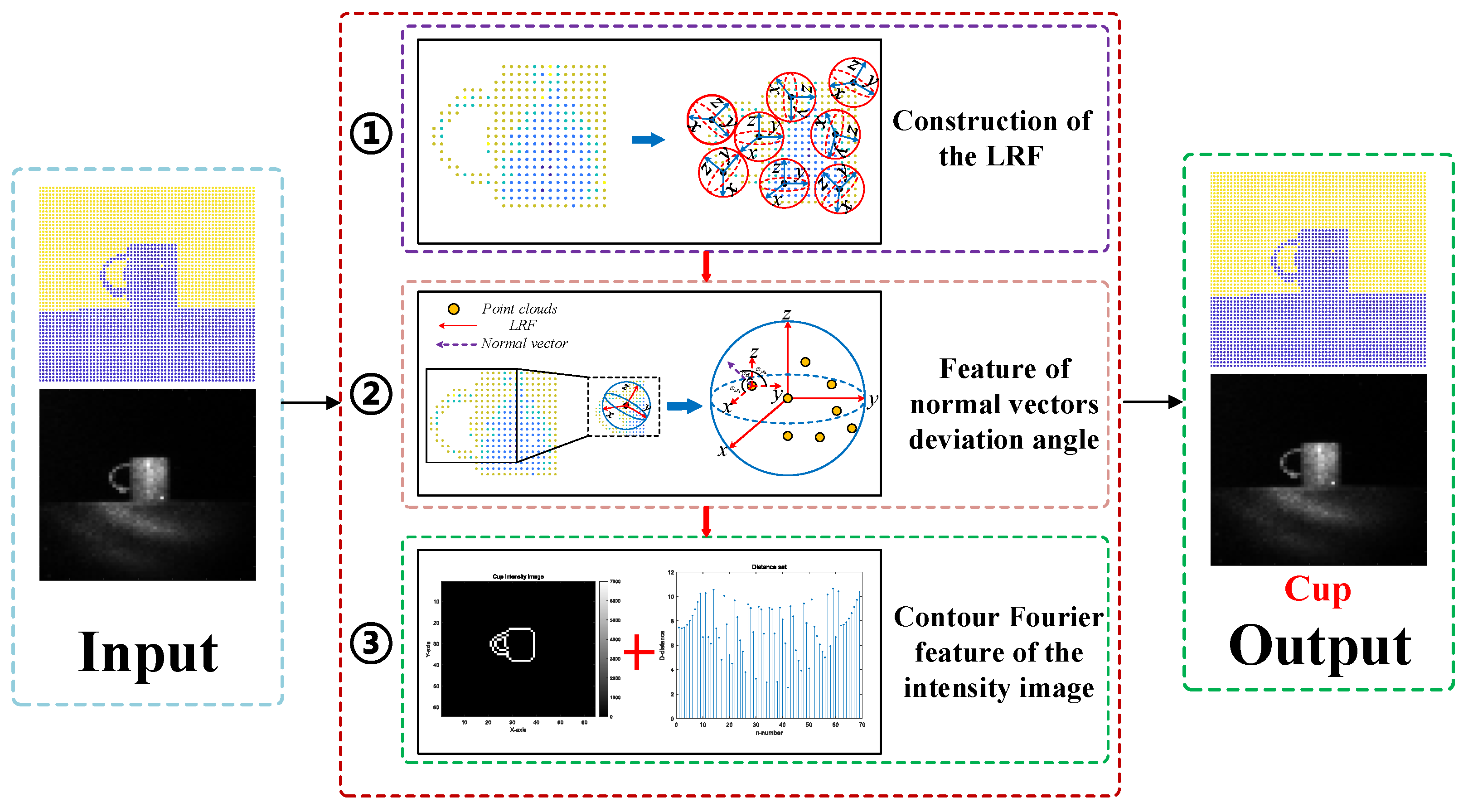
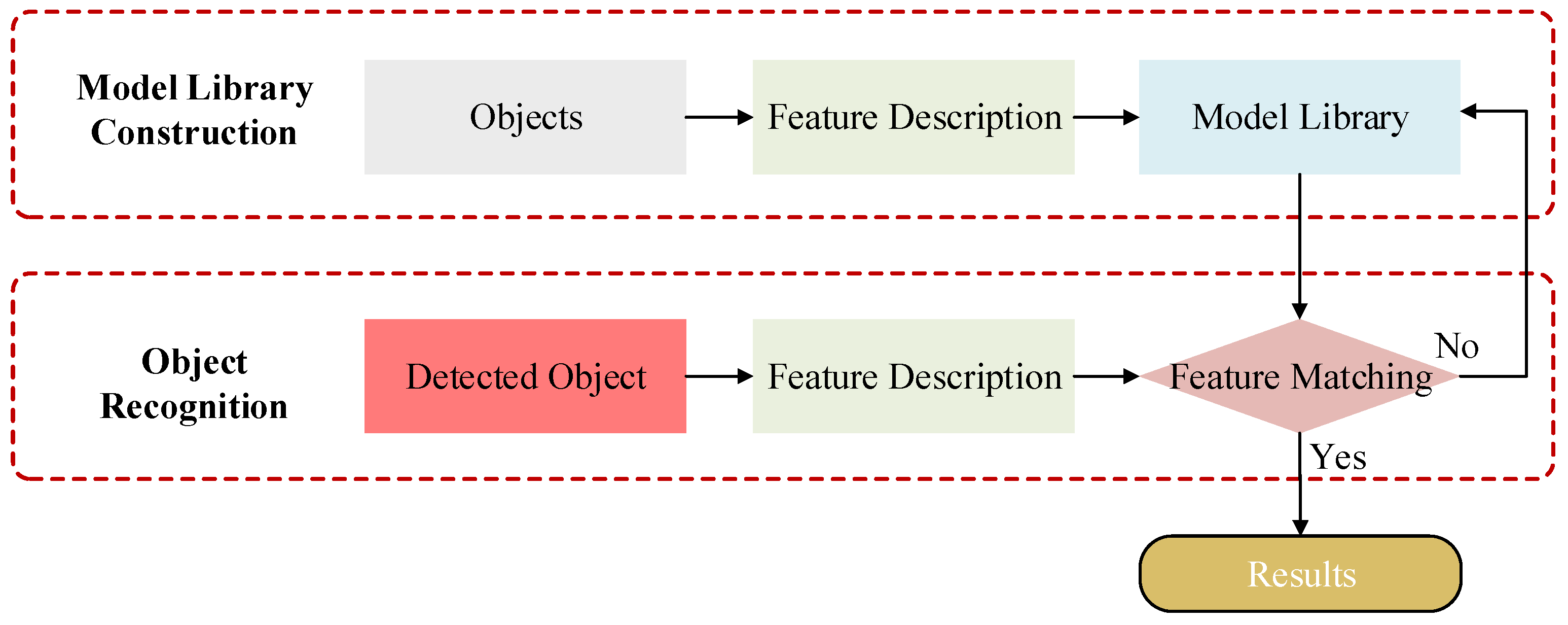
2.4. Object Recognition Process
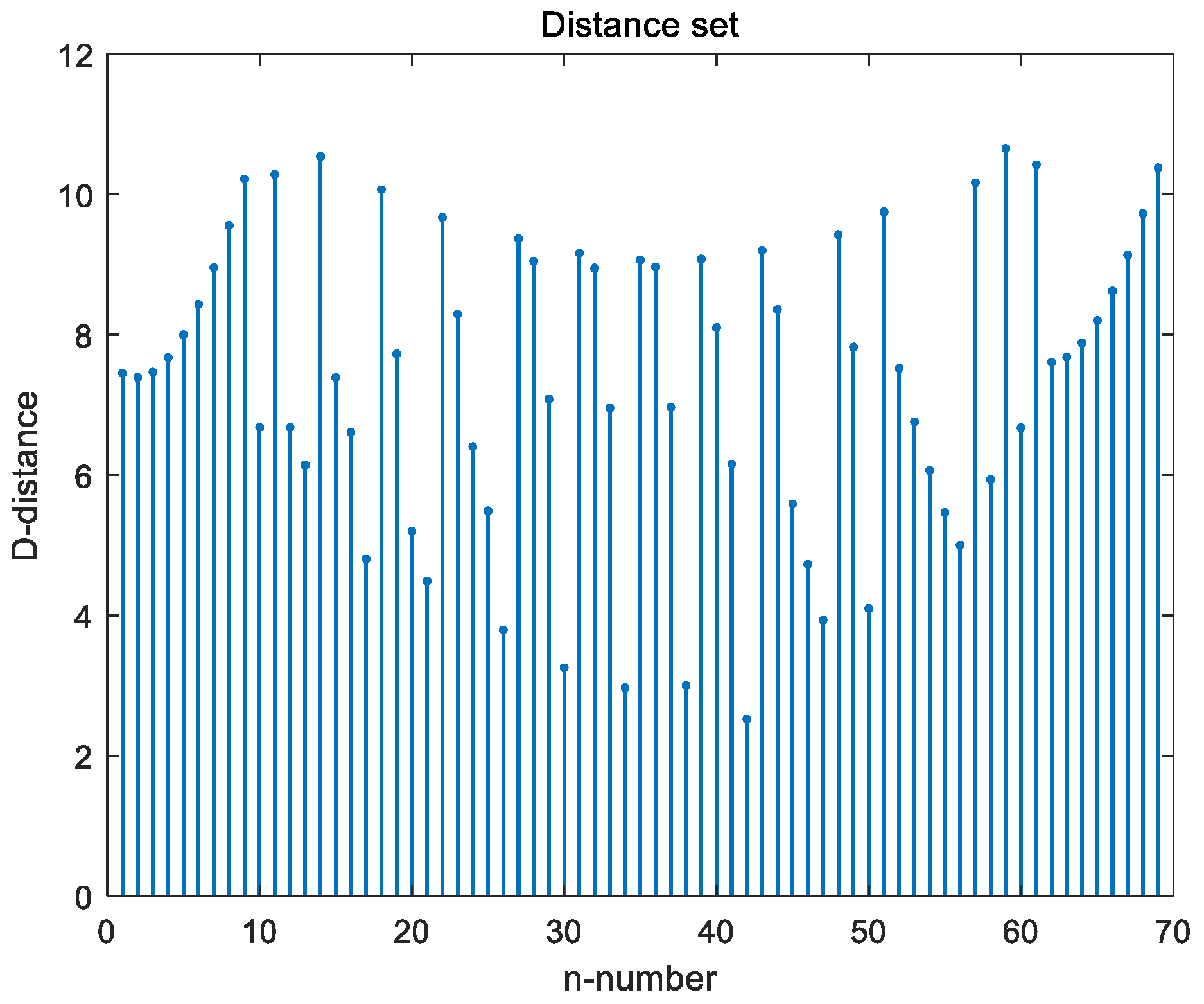
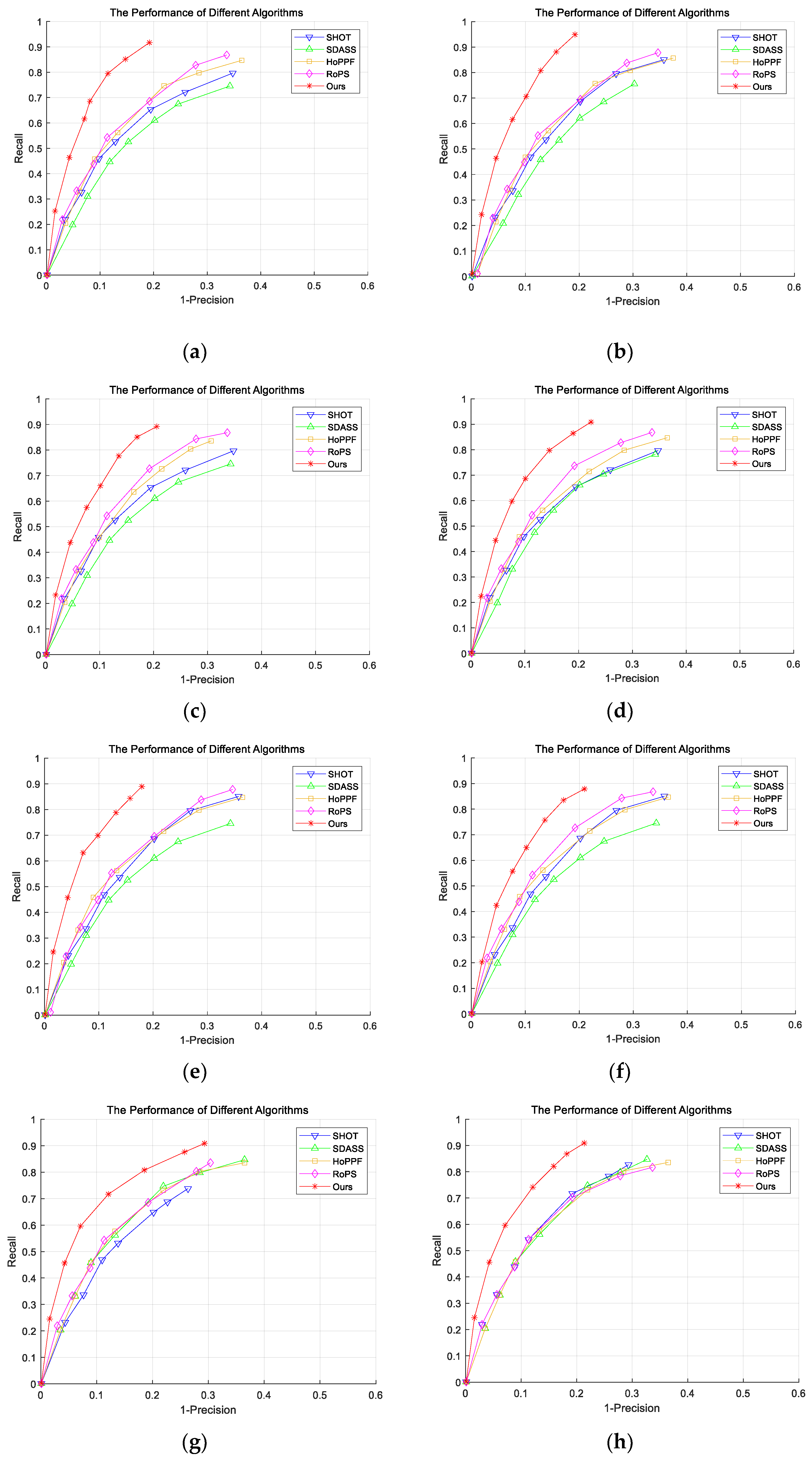
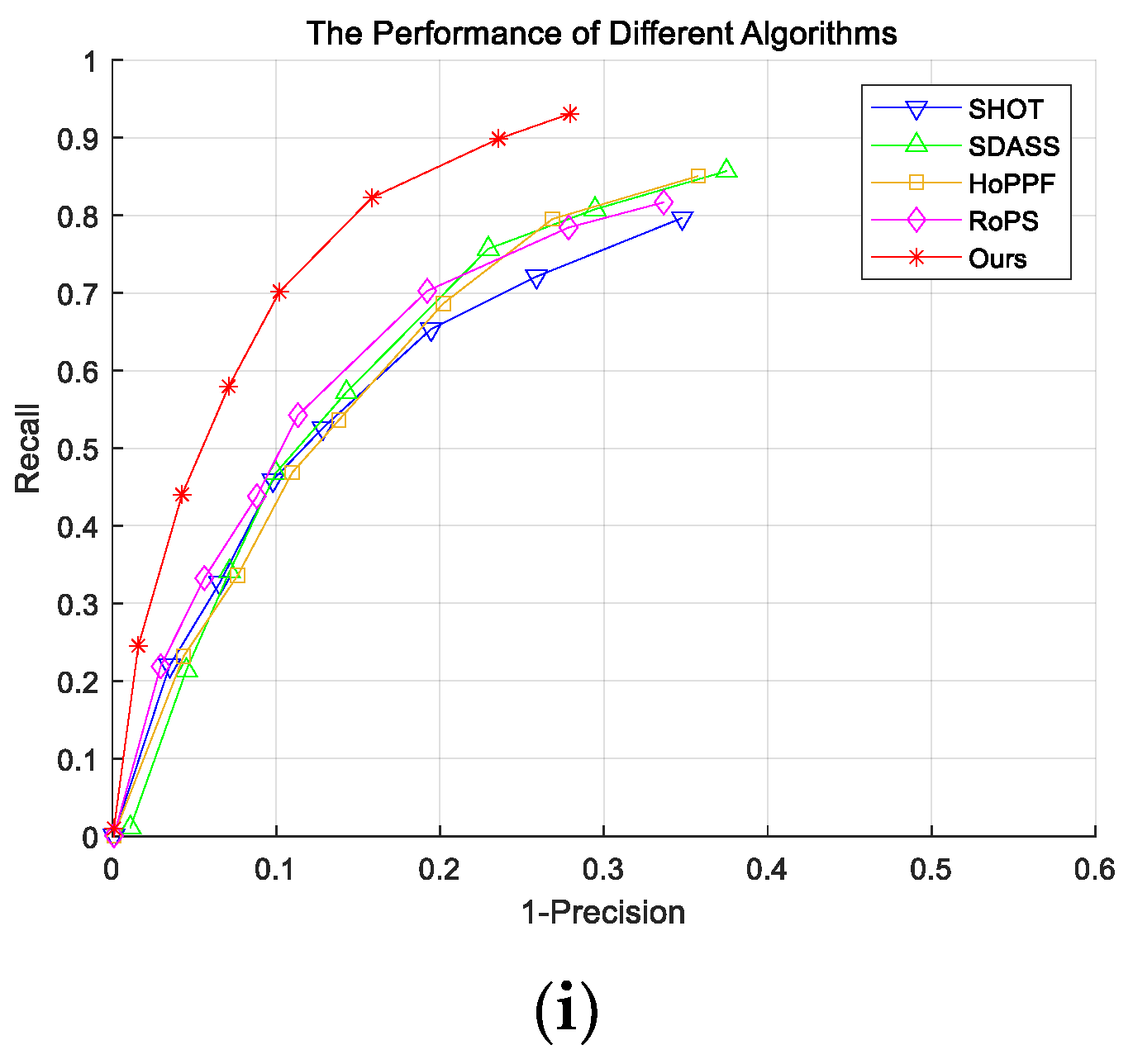
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tan, H.; Peng, J.Y.; Xiong, Z.W.; Liu, D.; Huang, X.; Li, Z.P.; Hong, Y.; Xu, F.H. Deep Learning Based Single–Photon 3D Imaging with Multiple Returns. In Proceedings of the International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020. [Google Scholar] [CrossRef]
- Nguyen, C.V.; Izadi, S.; Lovell, D. Modeling kinect sensor noise for improved 3D reconstruction and tracking. In Proceedings of the IEEE Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012. [Google Scholar] [CrossRef]
- Broggi, A.; Buzzoni, M.; Debattisti, S.; Grisleri, P.; Laghi, M.C.; Medici, P.; Versari, P. Extensive Tests of Autonomous Driving Technologies. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1403–1415. [Google Scholar] [CrossRef]
- Seo, Y.W.; Lee, J.; Zhang, W.; Werrergreen, D. Recognition of highway work zones for reliable autonomous driving. IEEE Trans. Intell. Transp. Syst. 2015, 16, 708–718. [Google Scholar] [CrossRef]
- Chen, X.Z.; Ma, H.M.; Wan, J.; Li, B.; Xia, T. Multi–view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Tombari, F.; Salti, S.; Stefano, L.D. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, 5–11 September 2010. [Google Scholar] [CrossRef]
- Zhao, B.; Le, X.Y.; Xi, J.T. A novel SDASS descriptor for fully encoding the information of a 3D local surface. Inf. Sci. 2019, 483, 363–382. [Google Scholar] [CrossRef]
- Zhao, H.; Tang, M.J.; Ding, H. HoPPF: A novel local surface descriptor for 3D object recognition. Pattern Recognit. 2020, 103, 107272. [Google Scholar] [CrossRef]
- Guo, Y.L.; Sohel, F.; Bennamoun, M.; Lu, M.; Wan, J.W. Rotational projection statistics for 3D local surface description and object recognition. Int. J. Comput. Vis. 2013, 105, 63–86. [Google Scholar] [CrossRef]
- Guo, Y.L.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J.; Kwok, N.M. A comprehensive performance evaluation of 3D local feature descriptors. Int. J. Comput. Vis. 2016, 116, 66–89. [Google Scholar] [CrossRef]
- Ge, Z.X.; Shen, X.L.; Gao, Q.Q.; Sun, H.Y.; Tang, X.A.; Cai, Q.Y. A Fast Point Cloud Recognition Algorithm Based on Keypoint Pair Feature. Sensors 2022, 22, 6289. [Google Scholar] [CrossRef] [PubMed]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Qi, C.R.; Li, Y.; Hao, S.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real–time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar] [CrossRef]
- Liu, D.R.; Chen, C.C.; Xu, C.Q.; Cai, Q.; Chu, L.; Wen, F.; Qiu, R. A Robust and Reliable Point Cloud Recognition Network Under Rigid Transformation. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Jin, S.; Wu, Z.; Zhao, C.; Zhang, J.; Peng, G.; Wang, D. SectionKey: 3–D Semantic Point Cloud Descriptor for Place Recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022. [Google Scholar] [CrossRef]
- Zhao, H.S.; Jiang, L.; Jia, J.Y.; Torr, P.; Koltun, V. Point Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Qian, R.; Lai, X.; Li, X. BADet: Boundary–Aware 3D Object Detection from Point Clouds. Pattern Recognit. 2022, 125, 108524. [Google Scholar] [CrossRef]
- Yang, J.Q.; Zhang, Q.; Xiao, Y.; Cao, Z.G. TOLDI: An effective and robust approach for 3d local shape description. Pattern Recognit. 2017, 65, 175–187. [Google Scholar] [CrossRef]
- Mitra, N.J.; Nguyen, A.; Guibas, L. Estimating surface normals in noisy point cloud data. Int. J. Comput. Geom. Appl. 2004, 14, 261–276. [Google Scholar] [CrossRef]
- Rong, W.; Li, Z.; Zhang, W.; Sun, L. An improved Canny edge detection algorithm. In Proceedings of the IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 3–6 August 2014. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Support Radius/ Mesh Resolution (mr) | Dimensionality | Length | |
|---|---|---|---|
| Ours | 15 | 8 × 4 × 4 × 8 | 350 |
| SHOT | 15 | 8 × 2 × 2 × 10 | 340 |
| SDASS | 15 | 15 × 5 × 5 | 335 |
| HoPPF | 15 | 8 × 3 × 5 × 5 | 600 |
| RoPS | 15 | 3 × 3 × 3 × 5 | 135 |
| Times/s | SHOT | SDASS | HoPPF | RoPS | Ours |
|---|---|---|---|---|---|
| Cup | 0.092 | 0.067 | 0.052 | 0.061 | 0.049 |
| Banana | 0.081 | 0.056 | 0.044 | 0.052 | 0.037 |
| Tank | 0.188 | 0.109 | 0.088 | 0.096 | 0.088 |
| Shoe | 0.142 | 0.087 | 0.069 | 0.085 | 0.080 |
| Bowl | 0.087 | 0.060 | 0.048 | 0.054 | 0.045 |
| Mango | 0.079 | 0.052 | 0.041 | 0.050 | 0.038 |
| Missile-launching vehicle | 0.258 | 0.149 | 0.138 | 0.143 | 0.121 |
| Bag | 0.124 | 0.095 | 0.083 | 0.088 | 0.072 |
| Truck | 0.182 | 0.123 | 0.106 | 0.109 | 0.099 |
| Average computing times | 0.1370 | 0.0887 | 0.0743 | 0.0820 | 0.0699 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Wang, C.; Sun, S.; Liu, X.; Xi, G.; Ding, Y. LiDAR Point Cloud Object Recognition Method via Intensity Image Compensation. Electronics 2023, 12, 2087. https://doi.org/10.3390/electronics12092087
Shi C, Wang C, Sun S, Liu X, Xi G, Ding Y. LiDAR Point Cloud Object Recognition Method via Intensity Image Compensation. Electronics. 2023; 12(9):2087. https://doi.org/10.3390/electronics12092087
Chicago/Turabian StyleShi, Chunhao, Chunyang Wang, Shaoyu Sun, Xuelian Liu, Guan Xi, and Yueyang Ding. 2023. "LiDAR Point Cloud Object Recognition Method via Intensity Image Compensation" Electronics 12, no. 9: 2087. https://doi.org/10.3390/electronics12092087
APA StyleShi, C., Wang, C., Sun, S., Liu, X., Xi, G., & Ding, Y. (2023). LiDAR Point Cloud Object Recognition Method via Intensity Image Compensation. Electronics, 12(9), 2087. https://doi.org/10.3390/electronics12092087