

Instance Segmentation of Irregular Deformable Objects for Power Operation Monitoring Based on Multi-Instance Relation Weighting Module


Abstract
:1. Introduction
- To solve the problem of introducing redundant background information when using the horizontal rectangular box detector, we perform instance segmentation in the electric power operation for irregular deformable objects. Using instance segmentation can not only locate and classify each object in the image but also achieve pixel-level segmentation of the object, achieving more precise detection.
- Adding a multi-instance relation weighting module to the instance segmentation network. First, the appearance and geometric features of objects are extracted through deep convolutional neural networks. Then, the features of the mutual relation among all the objects are learned through the multi-instance relationship weighting module in an end-to-end approach, improving the segmentation accuracy of deformable objects.
- Due to the lack of a detection dataset for various irregular deformable objects in power operation scenes, we built a dataset of irregular deformable objects for the electric power operation scenes, including three types of annotations: safety belts, safety seines and construction personnel. We performed data augmentation on the dataset and used it to train and test the method proposed in this paper. The experimental results show that the proposed method can achieve a high detection accuracy, effectively improving the safety monitoring efficiency for construction personnel.
- In order to further verify the generalization performance and practicability of the proposed instance segmentation method, we design an intelligent monitoring system for the electric power operation based on the proposed method to detect the protective equipment, avoid safety accidents and achieve the practical deployment of the algorithm.
2. Related Work
2.1. Instance Segmentation
2.2. Irregular Deformable Object Detection
2.3. Object Relation
2.4. Electric Power Field Monitoring System
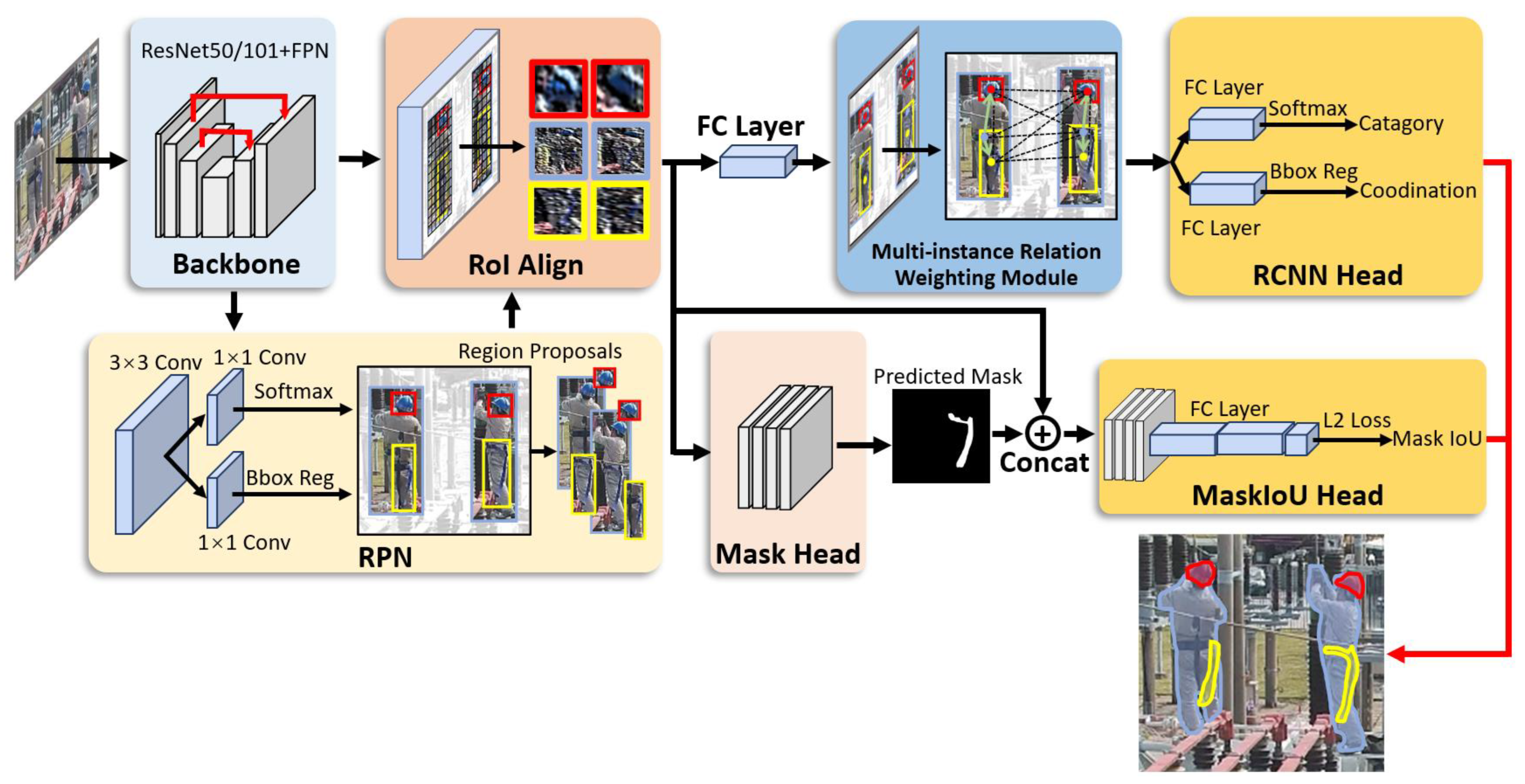
3. Methods
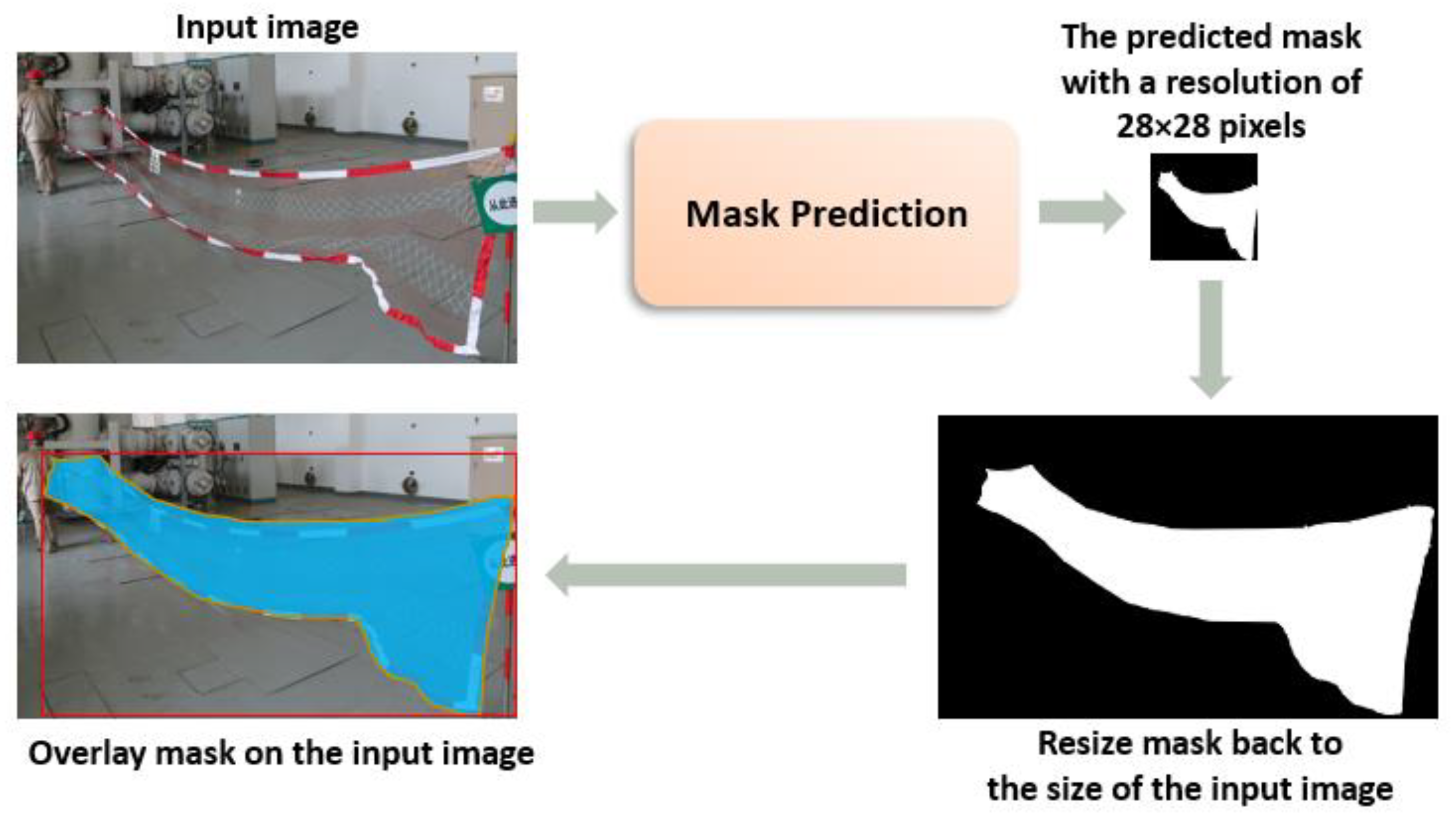
3.1. Mask Scoring-RCNN
3.2. Multi-Instance Relation Weighting Module
3.3. Model Loss Function
4. Experimental Results and Discussion
4.1. Dataset
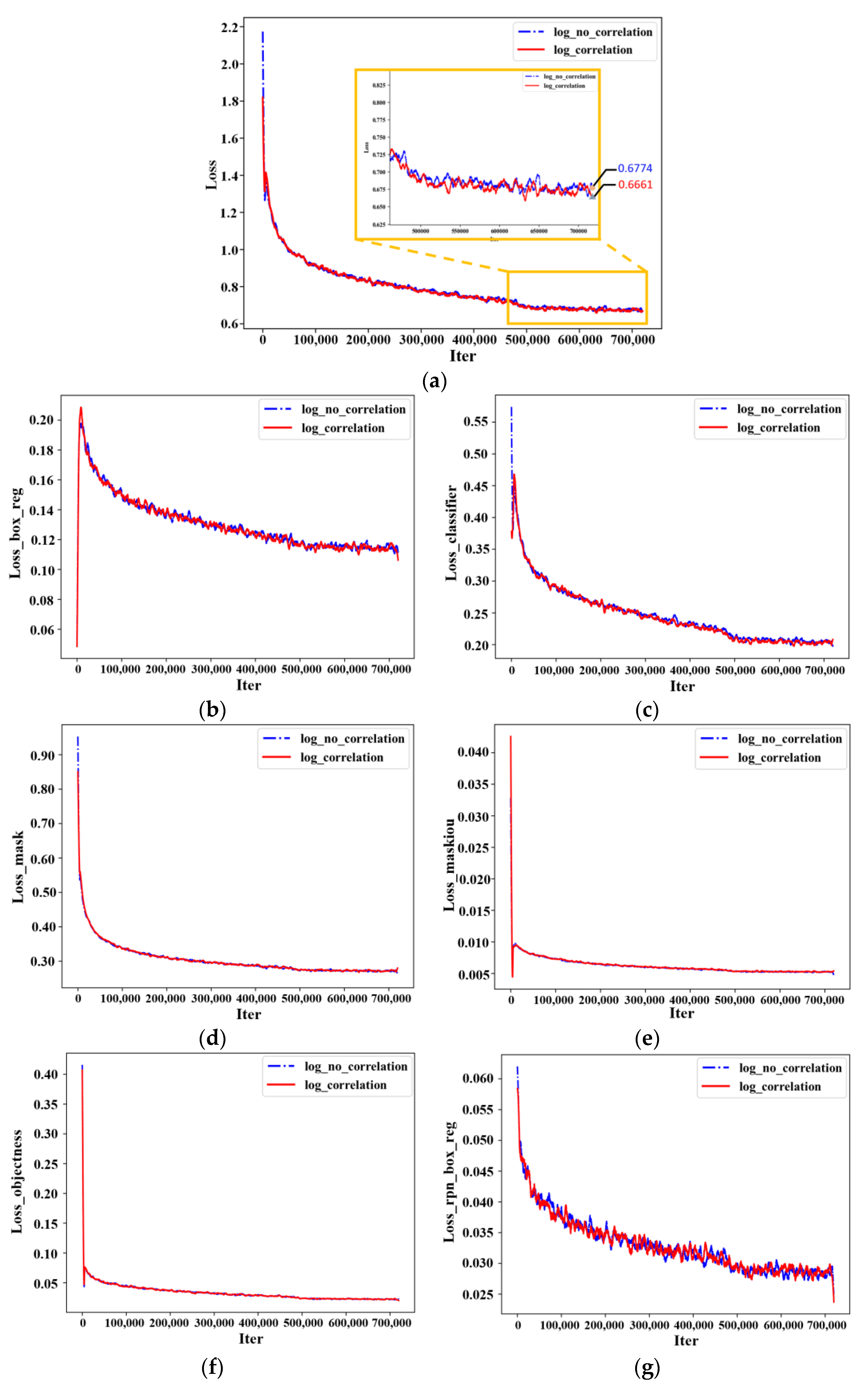
4.2. Training Details
4.3. Evaluation Metrics
4.4. Experimental Results and Analysis
4.4.1. Experiments on the Self-Built Dataset for Irregular Deformable Objects
4.4.2. Experiments on the COCO Dataset
5. Intelligent Monitoring System for Power Operation Scenes
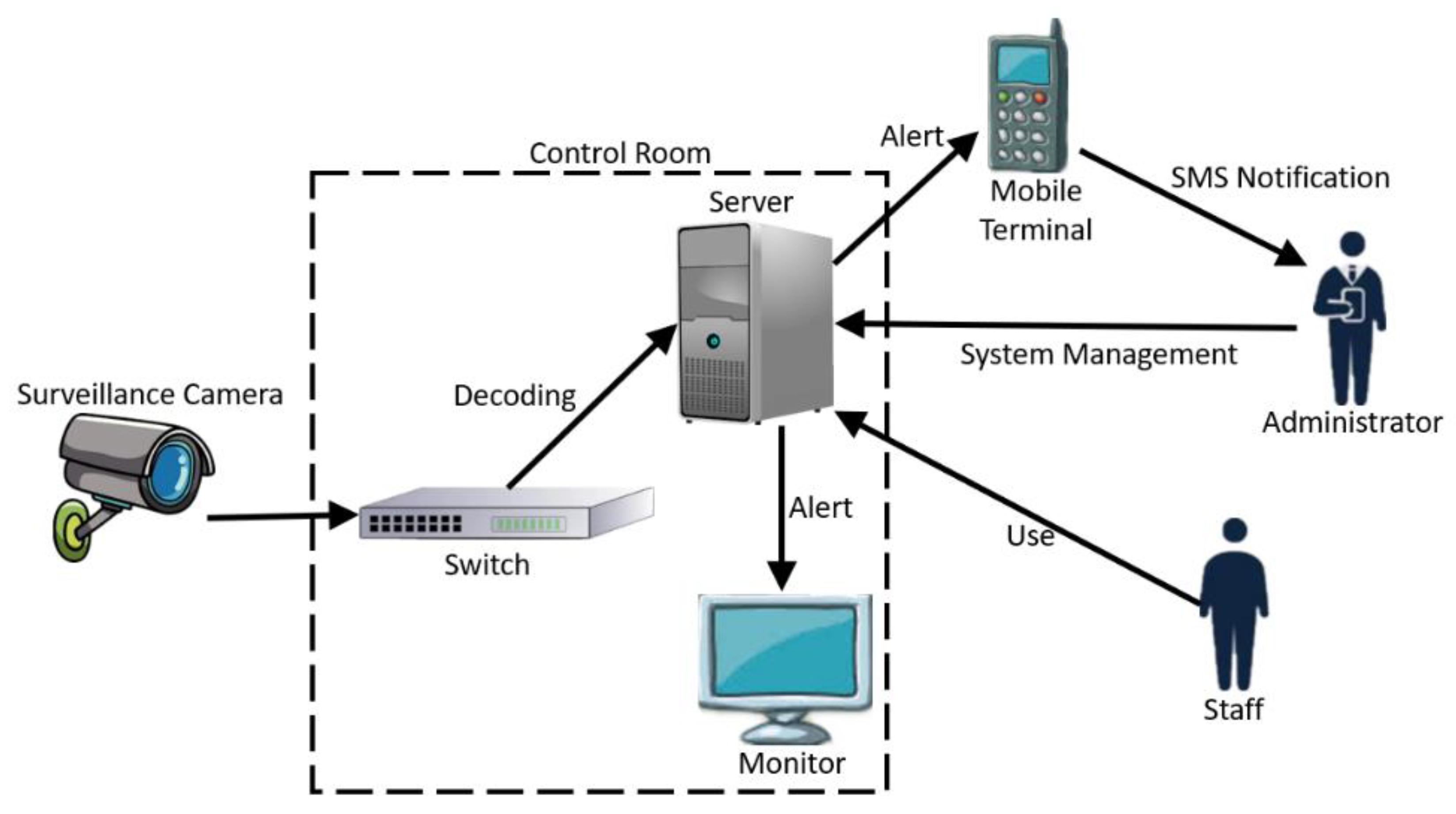
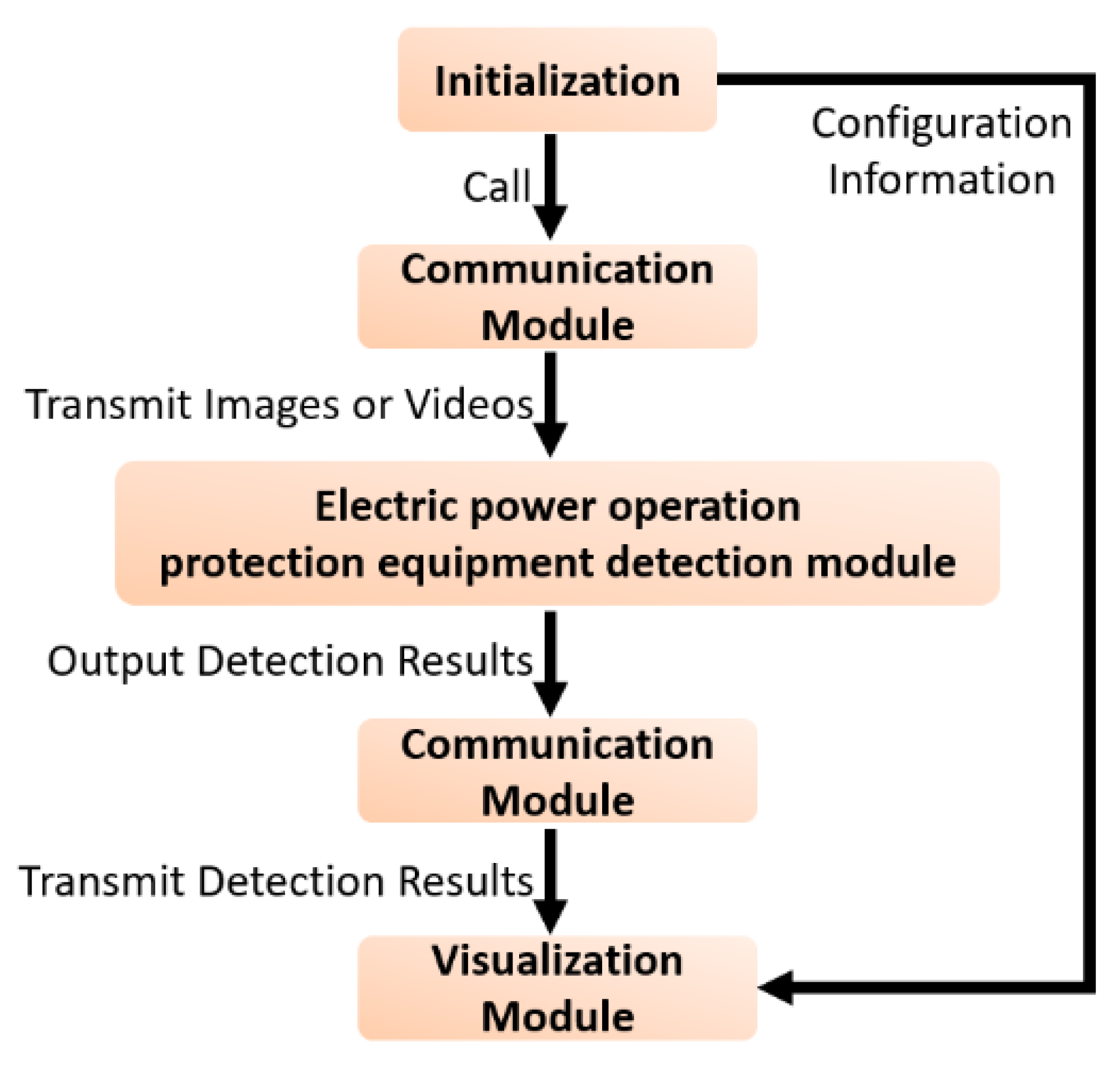
5.1. System Framework and Modular Design
5.1.1. Electric Power Operation Protection Equipment Detection Module
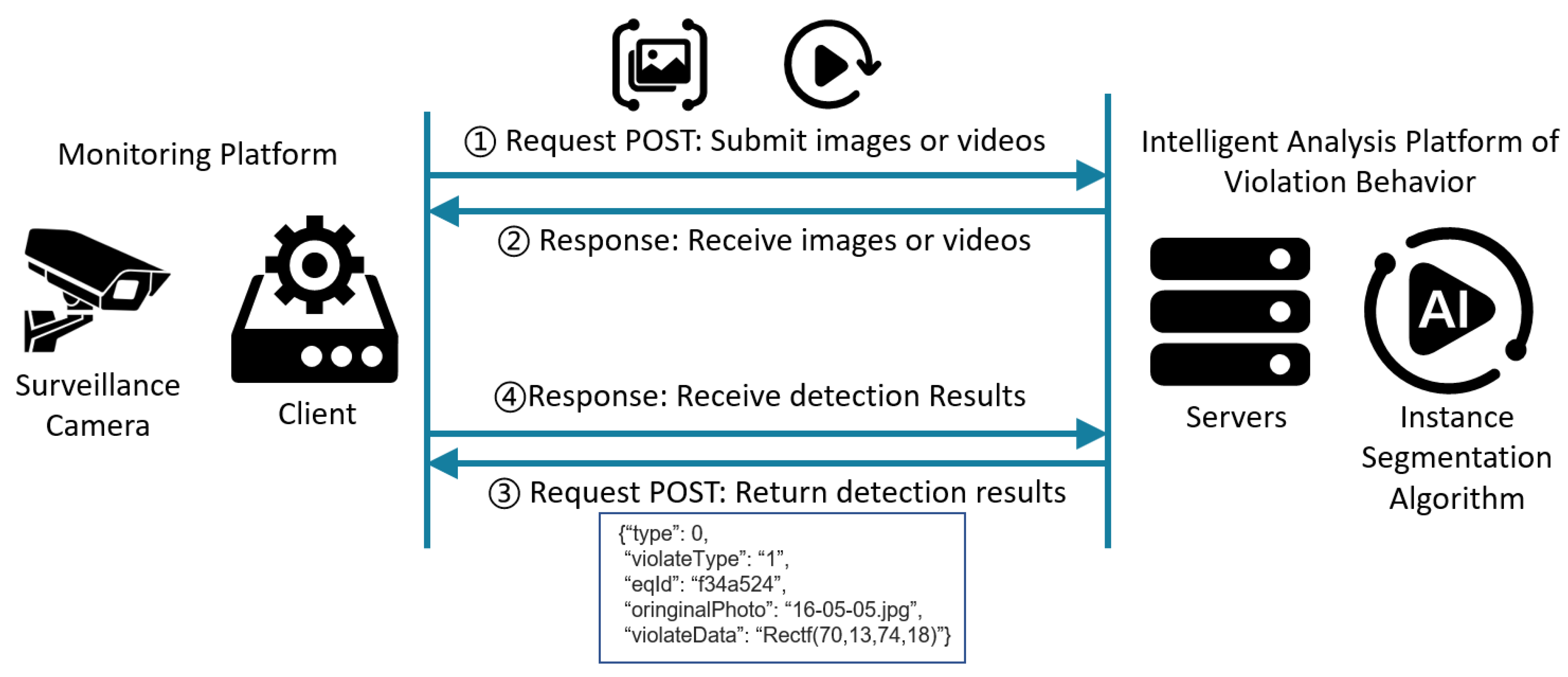
5.1.2. Communication Module
5.1.3. Visualization Module
5.2. System Function Realization and Test
5.2.1. Detection from Different Perspectives
5.2.2. Detection for Indoor and Outdoor Scenes
5.2.3. Detection for Different Working Height
5.2.4. Detection for Different Light and Weather
5.2.5. The Real-Time Detection
5.2.6. System Problems and Solutions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ali, S.S.; Choi, B.J. State-of-the-Art Artificial Intelligence Techniques for Distributed Smart Grids: A Review. Electronics 2020, 9, 1030. [Google Scholar] [CrossRef]
- Hu, Q.; Bai, Y.; He, L.; Huang, J.; Wang, H.; Cheng, G. Workers’ Unsafe Actions When Working at Heights: Detecting from Images. Sustainability 2022, 14, 6126. [Google Scholar] [CrossRef]
- Oliveira, B.A.S.; Neto, A.P.D.F.; Fernandino, R.M.A.; Carvalho, R.F.; Fernandes, A.L.; Guimaraes, F.G. Automated Monitoring of Construction Sites of Electric Power Substations Using Deep Learning. IEEE Access 2021, 9, 19195–19207. [Google Scholar] [CrossRef]
- Chen, S.; Tang, W.; Ji, T.; Zhu, H.; Ouyang, Y.; Wang, W. Detection of Safety Helmet Wearing Based on Improved Faster R-CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Chen, B.; Wang, X.; Bao, Q.; Jia, B.; Li, X.; Wang, Y. An Unsafe Behavior Detection Method Based on Improved YOLO Framework. Electronics 2022, 11, 1912. [Google Scholar] [CrossRef]
- Sharma, A.; Sharma, V.; Jaiswal, M.; Wang, H.C.; Jayakody, D.N.K.; Basnayaka, C.M.W.; Muthanna, A. Recent Trends in AI-Based Intelligent Sensing. Electronics 2022, 11, 1661. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time Video Fire/Smoke Detection Based on CNN in Antifire Surveillance Systems. J. Real Time Image Process. 2021, 18, 889–900. [Google Scholar] [CrossRef]
- Mazhar, T.; Irfan, H.M.; Haq, I.; Ullah, I.; Ashraf, M.; Shloul, T.A.; Ghadi, Y.Y.; Elkamchouchi, D.H. Analysis of Challenges and Solutions of IoT in Smart Grids Using AI and Machine Learning Techniques: A Review. Electronics 2023, 12, 242. [Google Scholar] [CrossRef]
- Wan, Z.; Chen, Y.; Deng, S.; Chen, K.; Yao, C.; Luo, J. Slender Object Detection: Diagnoses and Improvements. arXiv 2020, arXiv:2011.08529. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Wang, J.; Song, L.; Li, Z.; Sun, H.; Sun, J.; Zheng, N. End-to-End Object Detection with Fully Convolutional Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15849–15858. [Google Scholar]
- Shakya, S. Analysis of Artificial Intelligence Based Image Classification techniques. J. Innov. Image Process. 2020, 2, 44–54. [Google Scholar] [CrossRef]
- Gu, W.; Bai, S.; Kong, L. A Review on 2D Instance Segmentation Based on Deep Neural Networks. Image Vis. Comput. 2022, 120, 104401. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 29–31 October 2019; pp. 9157–9166. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. PolarMask: Single Shot Instance Segmentation with Polar Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12193–12202. [Google Scholar]
- Cai, J.; Li, Y. Realtime Single-Stage Instance Segmentation Network Based on Anchors. Comput. Electr. Eng. 2021, 95, 107464. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-Preserving Mask R-CNN. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference (ECCV), Glasgow, UK, 23–28 August 2020; pp. 660–676. [Google Scholar]
- Shen, X.; Yang, J.; Wei, C.; Deng, B.; Huang, J.; Hua, X.S.; Cheng, X.; Liang, K. Dct-mask: Discrete Cosine Transform Mask Representation for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8720–8729. [Google Scholar]
- Yu, J.; Yao, J.; Zhang, J.; Yu, Z.; Tao, D. SPRNet: Single-Pixel Reconstruction for One-Stage Instance Segmentation. IEEE Trans. Cybern. 2020, 51, 1731–1742. [Google Scholar] [CrossRef]
- Cao, D.; Chen, Z.; Gao, L. An Improved Object Detection Algorithm Based on Multi-Scaled and Deformable Convolutional Neural Networks. Hum. Cent. Comput. Inf. Sci. 2020, 10, 14. [Google Scholar] [CrossRef]
- Bhattacharjee, S.D.; Mittal, A. Part-Based Deformable Object Detection with a Single Sketch. Comput. Vis. Image Underst. 2015, 139, 73–87. [Google Scholar] [CrossRef]
- Keipour, A.; Bandari, M.; Schaal, S. Deformable One-Dimensional Object Detection for Routing and Manipulation. arXiv 2022, arXiv:2201.06775. [Google Scholar] [CrossRef]
- Shi, P.; Chen, X.; Qi, H.; Zhang, C.; Liu, Z. Object Detection Based on Swin Deformable Transformer-BiPAFPN-YOLOX. Comput. Intell. Neurosci. 2023, 2023, 18. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Fu, X.; Yuan, Z.; Yu, T.; Ge, Y. DA-FPN: Deformable Convolution and Feature Alignment for Object Detection. Electronics 2023, 12, 1354. [Google Scholar] [CrossRef]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-Up Object Detection by Grouping Extreme and Center Points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 850–859. [Google Scholar]
- Wang, X.; Jiang, Y.; Luo, Z.; Liu, C.L.; Choi, H.; Kim, S. Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 6449–6458. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15819–15829. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning Modulated Loss for Rotated Object Detection. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), Virtual Conference, 2–9 February 2021; pp. 2458–2466. [Google Scholar]
- Foysal, M.; Hossain, A.B.M.; Yassine, A.; Hossain, M.S. Detection of COVID-19 Case from Chest CT Images Using Deformable Deep Convolutional Neural Network. J. Healthc. Eng. 2023, 2023, 4301745. [Google Scholar] [CrossRef]
- Fang, W.; Ding, L.; Luo, H.; Love, P.E. Falls from Heights: A Computer Vision-Based Approach for Safety Harness Detection. Autom. Constr. 2018, 91, 53–61. [Google Scholar] [CrossRef]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Oliva, A.; Torralba, A. The role of context in object recognition. Trends Cogn. Sci. 2007, 11, 520–527. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Li, H.; Yang, S.; Wang, Z.; Loy, C.C.; et al. DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2403–2412. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- He, C.H.; Lai, S.C.; Lam, K.M. Improving Object Detection with Relation Graph Inference. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2537–2541. [Google Scholar]
- Chen, S.; Li, Z.; Tang, Z. Relation r-cnn: A Graph Based Relation-Aware Network for Object Detection. IEEE Signal Process. Lett. 2020, 27, 1680–1684. [Google Scholar] [CrossRef]
- Chai, D.; Bouzerdoum, A. A Bayesian Approach to Skin Color Classification in YCbCr Color Space. In Proceedings of the 2000 TENCON Proceedings, Kuala Lumpur, Malaysia, 24–27 September 2000; Intelligent Systems and Technologies for the New Millennium (Cat. No. 00CH37119). IEEE: New York, NY, USA, 2000; Volume 2, pp. 421–424. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Ku, B.; Kim, K.; Jeong, J. Real-Time ISR-YOLOv4 Based Small Object Detection for Safe Shop Floor in Smart Factories. Electronics 2022, 11, 2348. [Google Scholar] [CrossRef]
- Arabi, S.; Haghighat, A.; Sharma, A. A Deep Learning Based Solution for Construction Equipment Detection: From Development to Deployment. arXiv 2019, arXiv:1904.09021. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 6409–6418. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 3 May 2023).
- Chen, X.; Chen, W.; Su, L.; Li, T. Slender Flexible Object Segmentation Based on Object Correlation Module and Loss Function Optimization. IEEE Access 2023, 11, 29684–29697. [Google Scholar] [CrossRef]
- Hao, Y.; Liu, Y.; Chen, Y.; Han, L.; Peng, J.; Tang, S.; Chen, G.; Wu, Z.; Chen, Z.; Lai, B. EISeg: An Efficient Interactive Segmentation Annotation Tool Based on PaddlePaddle. arXiv 2022, arXiv:2210.08788. [Google Scholar]
- Dadboud, F.; Patel, V.; Mehta, V.; Bolic, M.; Mantegh, I. Single-Stage UVA Detection and Classification with YOLOv5: Mosaic Data Augmentation and Panet. In Proceedings of the 2021 17th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Washington, DC, USA, 16–19 November 2021; pp. 1–8. [Google Scholar]
- Wang, Y.; Xu, Z.; Shen, H.; Cheng, B.; Yang, L. Centermask: Single Shot Instance Segmentation with Point Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9313–9321. [Google Scholar]
- Chen, L.C.; Hermans, A.; Papandreou, G.; Schroff, F.; Wang, P.; Adam, H. Masklab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4013–4022. [Google Scholar]
- Zhang, R.; Tian, Z.; Shen, C.; You, M.; Yan, Y. Mask Encoding for Single Shot Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10226–10235. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollár, P. Tensormask: A Foundation for Dense Object Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 29–31 October 2019; pp. 2061–2069. [Google Scholar]
- Zhao, H.; Li, D.; Liu, Y.; Wang, Z.; Zhou, B.; Ji, H.; Shen, D. Research on the Solution of Safety Management System in Power Construction Project. In Proceedings of the 2022 IEEE 2nd International Conference on Power, Electronics and Computer Applications (ICPECA), Shengyang, China, 21–23 January 2022; pp. 229–232. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training Set | Training Set (DA) | Validation Set | Testing Set | Sum | Sum (DA) |
|---|---|---|---|---|---|---|
| Number of images | 1896 | 17,064 | 449 | 23 | 2368 | 17,536 |
| Number of annotations for “Human” | 1636 | 14,982 | 378 | 18 | 2032 | 15,378 |
| Number of annotations for “Safety belt” | 557 | 5102 | 144 | 6 | 707 | 5252 |
| Number of annotations for “Seine” | 1005 | 8975 | 233 | 14 | 1252 | 9222 |
| Confidence Score | MaskIoU | Practical Implications | Sample Categories |
|---|---|---|---|
| Mask | The object exists and is detected | TP | |
| The object does not exist but is detected | FP | ||
| / | The object exists but is not detected | FN |
| Methods | mAP (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|
| Mask R-CNN | 35.3 | 67.5 | 35.1 | 1.7 | 26.5 | 35.8 |
| MS R-CNN | 37.0 | 67.6 | 37.2 | 2.2 | 27.3 | 37.3 |
| MS R-CNN + MiRWM (WDA) | 33.9 | 65.7 | 33.5 | 1.3 | 25.0 | 33.5 |
| MS R-CNN + MiRWM | 38.2 | 68.1 | 40.6 | 2.8 | 28.3 | 37.0 |
| Methods | mAP (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|
| Mask R-CNN | 35.9 | 59.9 | 40.9 | 0.2 | 15.8 | 38.6 |
| MS R-CNN | 37.3 | 60.4 | 43.4 | 0.2 | 16.9 | 40.7 |
| MS R-CNN + MiRWM (WDA) | 33.5 | 56.3 | 38.6 | 0.2 | 14.5 | 36.2 |
| MS R-CNN + MiRWM | 37.5 | 60.0 | 41.5 | 0.4 | 18.0 | 39.5 |
| Methods | 1st Fold (%) | 2nd Fold (%) | 3rd Fold (%) | 4th Fold (%) | 5th Fold (%) | Average mAP (%) | Standard Deviation |
|---|---|---|---|---|---|---|---|
| Mask R-CNN | 35.6 | 33.5 | 33.1 | 36.1 | 35.9 | 34.8 | 1.3 |
| MS R-CNN | 38.1 | 36.9 | 36.4 | 37.5 | 37.9 | 37.4 | 0.6 |
| MS R-CNN + MiRWM | 39.2 | 37.8 | 36.9 | 38.6 | 38.9 | 38.3 | 0.8 |
| Methods | 1st Fold (%) | 2nd Fold (%) | 3rd Fold (%) | 4th Fold (%) | 5th Fold (%) | Average mAP (%) | Standard Deviation |
|---|---|---|---|---|---|---|---|
| Mask R-CNN | 36.3 | 34.5 | 34.1 | 35.9 | 36.1 | 35.4 | 0.9 |
| MS R-CNN | 38.5 | 36.4 | 37.9 | 38.1 | 37.5 | 37.7 | 0.7 |
| MS R-CNN + MiRWM | 38.9 | 37.8 | 38.0 | 38.5 | 37.4 | 38.1 | 0.5 |
| Methods | Training Rounds | mAP (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|
| MS R-CNN + MiRWM | 100,000 | 38.2 | 68.1 | 40.6 | 2.8 | 28.3 | 37.0 |
| MS R-CNN + MiRWM | 720,000 | 44.3 | 70.9 | 36.6 | 4.4 | 36.5 | 40.4 |
| Methods | Training Rounds | mAP (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|
| MS R-CNN + MiRWM | 100,000 | 37.5 | 60.0 | 41.5 | 0.4 | 18.0 | 39.5 |
| MS R-CNN + MiRWM | 720,000 | 44.8 | 66.1 | 48.8 | 1.5 | 26.5 | 48.8 |
| Methods | Backbone | mAP (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|
| MS R-CNN | ResNet50-FPN | 30.5 | 52.9 | 31.6 | 16.6 | 33.5 | 39.5 |
| MS R-CNN + MiRWM | ResNet50-FPN | 30.6 | 53.3 | 31.4 | 17.3 | 34.0 | 39.1 |
| MS R-CNN | ResNet101-FPN | 40.1 | 61.8 | 43.9 | 23.4 | 43.4 | 52.5 |
| MS R-CNN + MiRWM | ResNet101-FPN | 40.1 | 61.7 | 43.9 | 23.6 | 43.3 | 52.4 |
| Methods | Backbone | mAP (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|
| MS R-CNN | ResNet50-FPN | 29.1 | 49.1 | 30.3 | 12.2 | 31.2 | 43.0 |
| MS R-CNN + MiRWM | ResNet50-FPN | 29.2 | 49.4 | 30.3 | 12.3 | 31.7 | 42.5 |
| CenterMask [56] | Hourglass-104 | 34.5 | 56.1 | 36.3 | 16.3 | 37.4 | 48.4 |
| MaskLab [57] | ResNet101-FPN | 35.4 | 57.4 | 37.4 | 16.9 | 38.3 | 49.2 |
| YOLACT | ResNet101-FPN | 31.2 | 50.6 | 32.8 | 12.1 | 33.3 | 47.1 |
| MEInst [58] | ResNet101-FPN | 33.9 | 56.2 | 35.4 | 19.8 | 36.1 | 42.3 |
| PolarMask | ResNet101-FPN | 32.1 | 53.7 | 33.1 | 14.7 | 33.8 | 45.3 |
| TensorMask [59] | ResNet101-FPN | 37.1 | 59.3 | 39.4 | 17.4 | 39.1 | 51.6 |
| MS R-CNN | ResNet101-FPN | 37.4 | 58.2 | 40.4 | 17.4 | 40.1 | 54.3 |
| MS R-CNN + MiRWM | ResNet101-FPN | 37.5 | 58.5 | 40.2 | 17.7 | 40.2 | 54.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Su, L.; Lin, Z.; Chen, X.; Li, T. Instance Segmentation of Irregular Deformable Objects for Power Operation Monitoring Based on Multi-Instance Relation Weighting Module. Electronics 2023, 12, 2126. https://doi.org/10.3390/electronics12092126
Chen W, Su L, Lin Z, Chen X, Li T. Instance Segmentation of Irregular Deformable Objects for Power Operation Monitoring Based on Multi-Instance Relation Weighting Module. Electronics. 2023; 12(9):2126. https://doi.org/10.3390/electronics12092126
Chicago/Turabian StyleChen, Weihao, Lumei Su, Zhiwei Lin, Xinqiang Chen, and Tianyou Li. 2023. "Instance Segmentation of Irregular Deformable Objects for Power Operation Monitoring Based on Multi-Instance Relation Weighting Module" Electronics 12, no. 9: 2126. https://doi.org/10.3390/electronics12092126
APA StyleChen, W., Su, L., Lin, Z., Chen, X., & Li, T. (2023). Instance Segmentation of Irregular Deformable Objects for Power Operation Monitoring Based on Multi-Instance Relation Weighting Module. Electronics, 12(9), 2126. https://doi.org/10.3390/electronics12092126