



Distributed File System to Leverage Data Locality for Large-File Processing

Abstract
:1. Introduction
1.1. POSIX and Data Locality
1.2. Our Contributions
2. Related Works
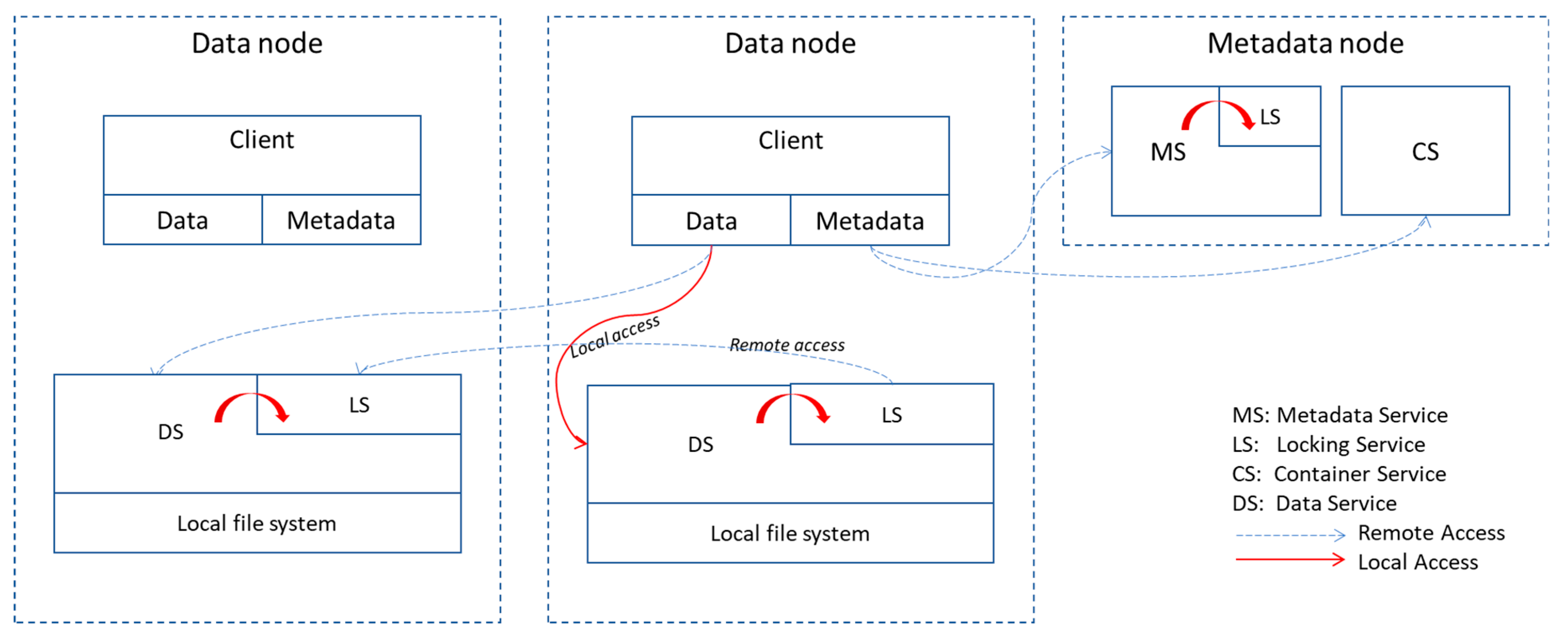
3. AwareFS Architecture
3.1. Data Placement
3.2. Architecture Overview
- DS: Data Service, responsible for storing and controlling access to both chunks and inodes organized in different containers. It is the DS’s responsibility to answer concurrent I/O requests in a consistent manner;
- LS: Locking Service, the AwareFS service that manages the locking requests required to guarantee consistent read and write operations. Every DS has an associated LS instance, controlling lock requests to I/O operations on the stored chunks and inodes;
- MS: Metadata Service, will control the access point of each file, maintaining a lookup table from file path names to its inodes;
- CS: Container Service, is responsible for maintaining the container list and organizing the creation of new containers by the available DSs;
- Client: The AwareFS client is responsible for managing the interface between user requests and other AwareFS components like the DS and MS.
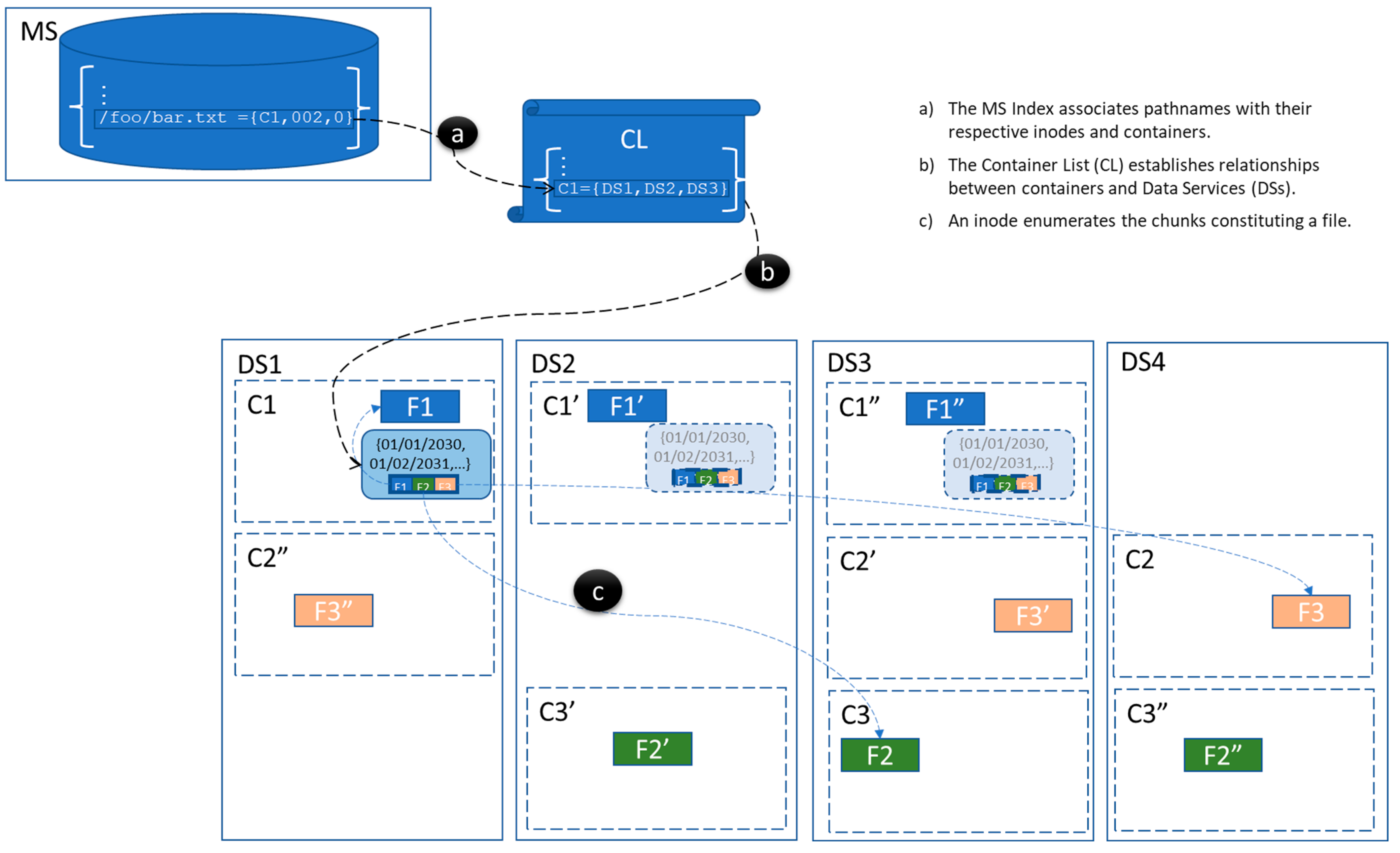
3.3. Metadata Management
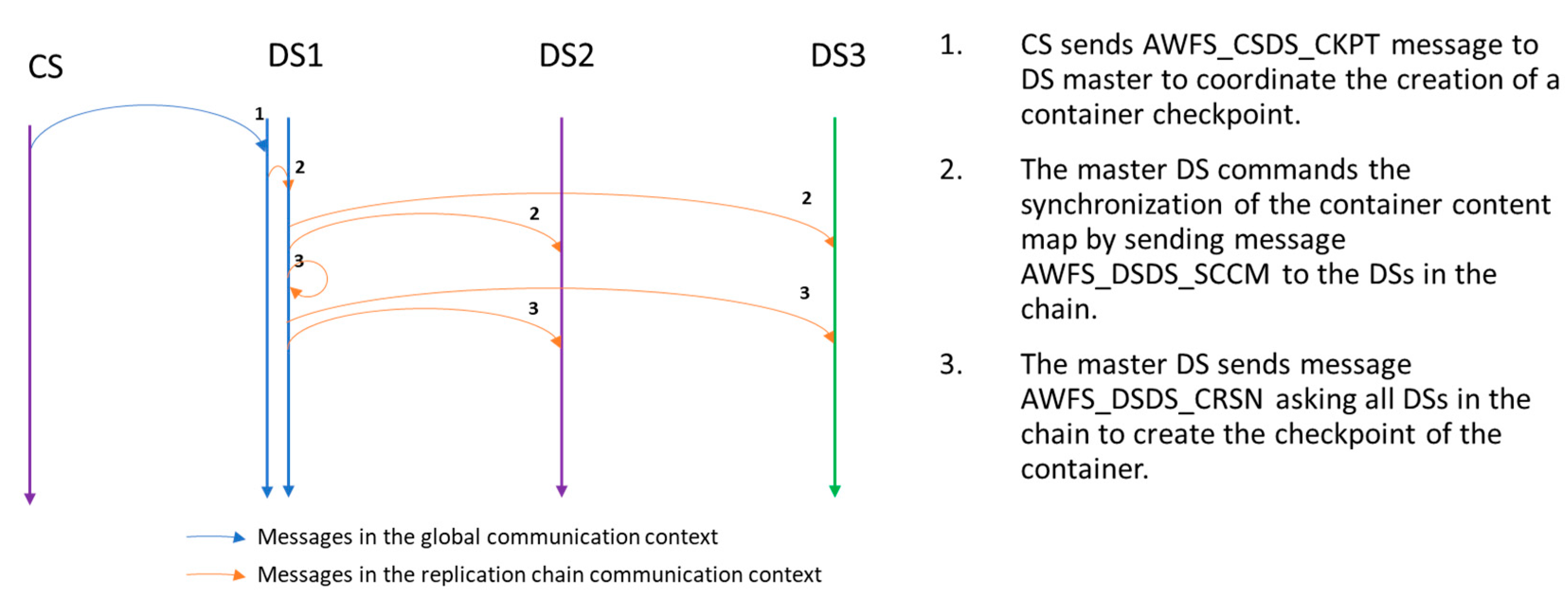
3.4. Replication and Checkpoints
Checkpoints
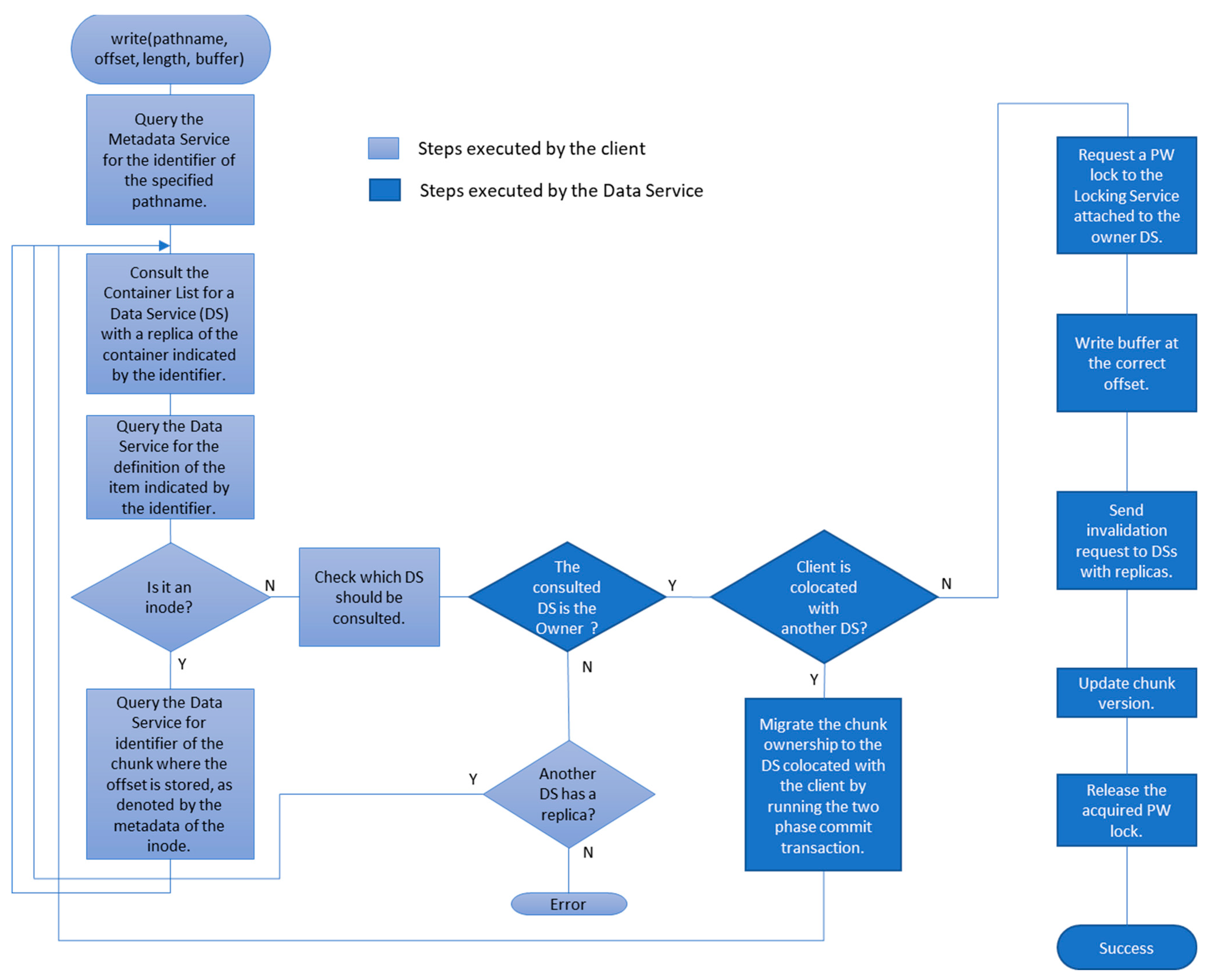
3.5. The Data Service and the Primary Copy Ownership Management
4. Distributed Locking Management
5. Implementation Details
5.1. Easy Deployment with Configuration Files
5.2. Fuse Client
6. Results and Discussion
6.1. I/O Evaluation
6.2. Comparing the Local-Write Protocol with a Commercial File System Remote-Write Protocol
- Remote-write protocols: the write operation is forwarded to the node with the primary copy;
- Local-write protocols: the primary copy migrates to the node that initiated the write operation.
6.2.1. The Experimental Setup
- Compression was disabled for MapR-FS directories;
- Since AwareFS writes to regular Linux files, MapR-FS was installed using block-based storage on top of Linux regular files;
- The client writeback cache was disabled to make AwareFS and MapR-FS acknowledge write requests only after a date is written to storage servers;
- Chunk size was configured to 64 MB for both AwareFS and MapR-FS.
6.2.2. About the Tests
- Concentrated write: All six files were created and rewritten using just one node of the cluster, with chunk replicas being sent to different nodes in the cluster. The purpose was to show sequential write performance when using a single node as the gateway for the cluster.
- Distributed write: All six files previously created on the concentrated write test were rewritten by different nodes (i.e., DS1 writes the file F1, DS2 writes F2, …, DS6 writes F6). Since primary copies were all stored in DS1, this time, write requests were all initiated in parallel in different nodes, many of them storing secondary copies of the modified chunks. In the case of using a remote-write protocol, every write request causes data to be sent to DS1, while write requests are attended to locally whenever possible when using a local-write protocol. The goal here was to demonstrate how beneficial writing directly to the local copies can be, as it avoids the need to send data through the network.
6.2.3. Test Results
6.3. Random I/O and Scalability Evaluation
6.3.1. The Effects of Page Cache
6.3.2. The Experimental Setup
- OMP_NUM_THREADS = 39
- OMP_PROC_BIND = spread
- OMP_PLACES = cores(39)
- GOMP_CPU_AFFINITY = 1–39
- GOMP_DEBUG = 1
6.3.3. Sequential I/O Leveraging Data Locality
6.3.4. Random Reads and Mixed Random Reads and Writes
6.3.5. Strategy for Evaluating the Local-Write Protocol with Random Operations
- Move disabled: Chunks created on a neighbor node are randomly written after disabling the primary copy ownership migration capability;
- Move enabled: After reenabling primary copy ownership migration, chunks created on a neighbor node are written randomly;
- Move enabled—2nd round: Chunks created on a neighbor node are randomly written, and the ownership of the primary copy may have been migrated to the local node during the previous test.
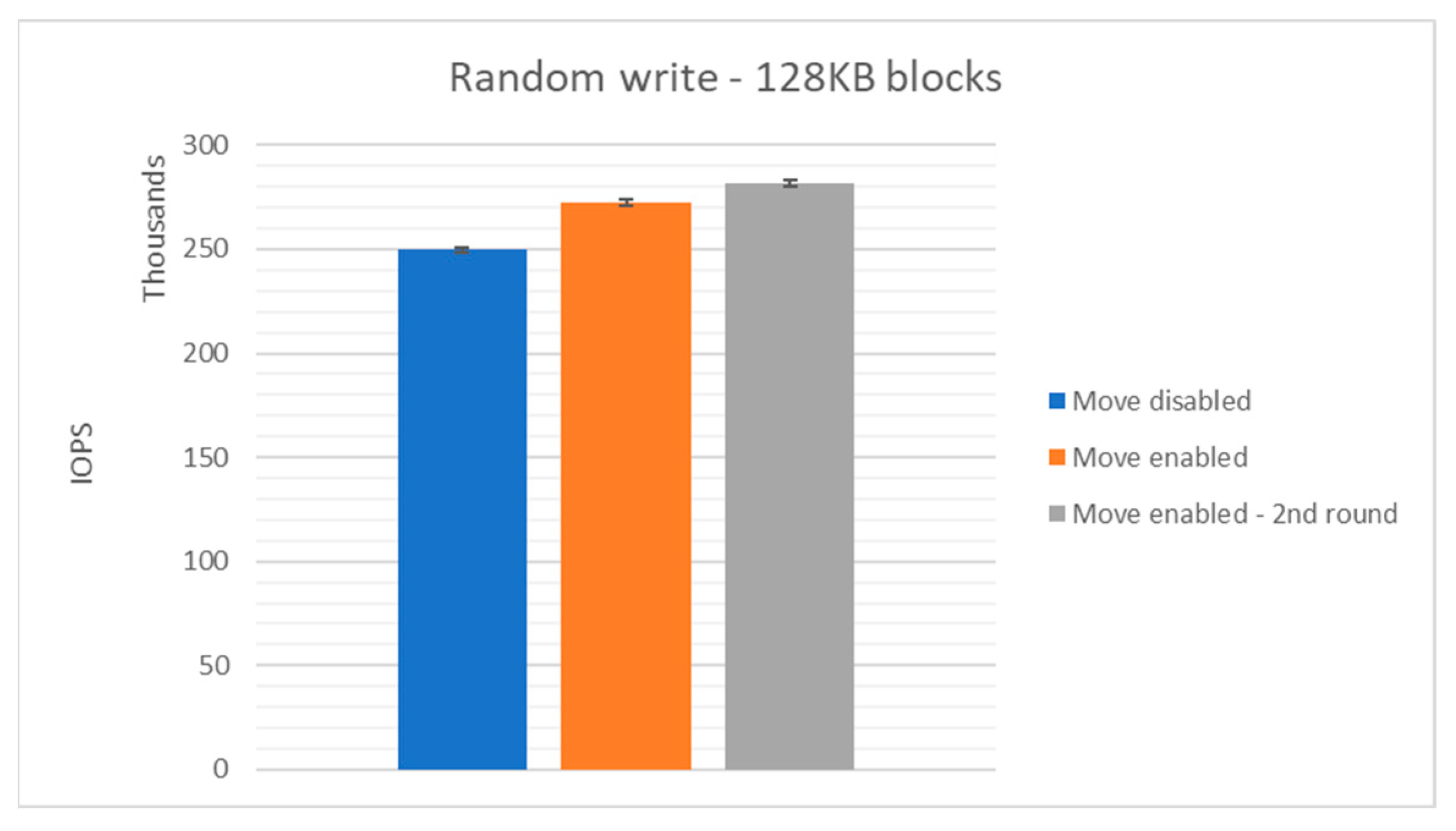
6.3.6. Random Write Performance with 128 KB Blocks
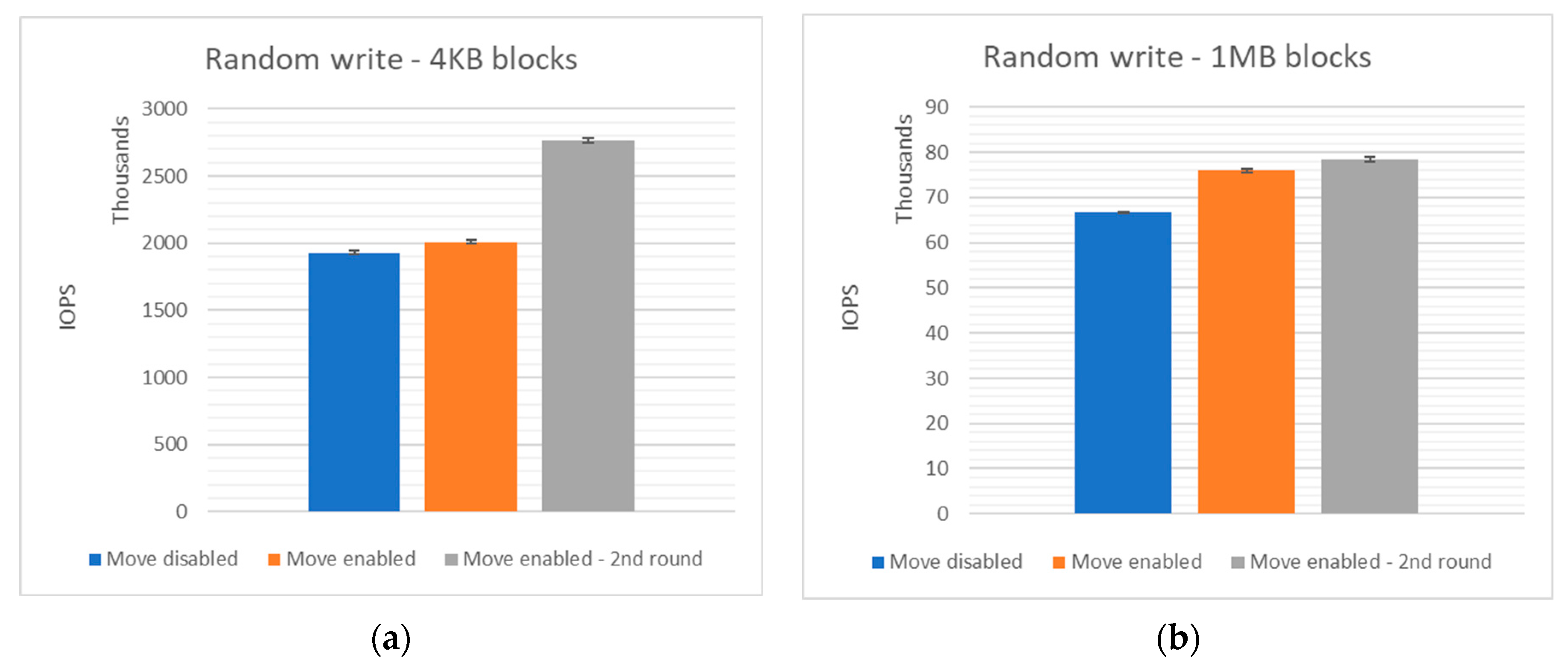
6.3.7. Random Write Performance with Different Block Sizes
6.3.8. Random Write Performance with Different Cluster Sizes
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bandi, A.; Adapa, P.V.S.R.; Kuchi, Y.E.V.P.K. The Power of Generative Ai: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges. Future Internet 2023, 15, 260. [Google Scholar] [CrossRef]
- Baig, M.I.; Shuib, L.; Yadegaridehkordi, E. Big Data Adoption: State of the Art and Research Challenges. Inf. Process. Manag. 2019, 56, 102095. [Google Scholar] [CrossRef]
- Rydning, D.R.-J.G.-J.; Reinsel, J.; Gantz, J. The Digitization of the World from Edge to Core. Fram. Int. Data Corp. 2018, 16, 1–28. [Google Scholar]
- Blomer, J. A Survey on Distributed File System Technology. J. Phys. Conf. Ser. 2015, 608, 012039. [Google Scholar] [CrossRef]
- Patgiri, R.; Ahmed, A. Big Data: The V’s of the Game Changer Paradigm. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications; IEEE 14th International Conference on Smart City; IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Sydney, NSW, Australia, 12–14 December 2016. [Google Scholar] [CrossRef]
- Thanh, T.D.; Mohan, S.; Choi, E.; Kim, S.; Kim, P. A Taxonomy and Survey on Distributed File Systems. In Proceedings of the 2008 Fourth International Conference on Networked Computing and Advanced Information Management, Gyeongju, Republic of Korea, 2–4 September 2008; Volume 1, pp. 144–149. [Google Scholar] [CrossRef]
- Lee, S.; Jo, J.-Y.; Kim, Y. Hadoop Performance Analysis Model with Deep Data Locality. Information 2019, 10, 222. [Google Scholar] [CrossRef]
- Wang, J.; Han, D.; Yin, J.; Zhou, X.; Jiang, C. ODDS: Optimizing Data-Locality Access for Scientific Data Analysis. IEEE Trans. Cloud Comput. 2020, 8, 220–231. [Google Scholar] [CrossRef]
- Wang, F.; Oral, H.S.; Shipman, G.M.; Drokin, O.; Wang, D.; Huang, H. Understanding Lustre Internals; Oak Ridge National Lab. (ORNL): Oak Ridge, TN, USA, 2009.
- Carns, P.; Lang, S.; Ross, R.; Vilayannur, M.; Kunkel, J.; Ludwig, T. Small-File Access in Parallel File Systems. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–11. [Google Scholar]
- Zou, J.; Iyengar, A.; Jermaine, C. Architecture of a Distributed Storage That Combines File System, Memory and Computation in a Single Layer. VLDB J. 2020, 29, 1049–1073. [Google Scholar] [CrossRef]
- Rao, T.R.; Mitra, P.; Bhatt, R.; Goswami, A. The Big Data System, Components, Tools, and Technologies: A Survey. Knowl. Inf. Syst. 2019, 60, 1165–1245. [Google Scholar] [CrossRef]
- Da Silva, E.C.; Sato, L.M.; Midorikawa, E.T. Distributed File System for Rewriting Big Data Files Using a Local-Write Protocol. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 3646–3655. [Google Scholar]
- White, T. Hadoop: The Definitive Guide; O’Reilly: Springfield, MO, USA, 2015; ISBN 978-1-4919-0163-2. [Google Scholar]
- Wang, K.; Zhou, X.; Li, T.; Zhao, D.; Lang, M.; Raicu, I. Optimizing Load Balancing and Data-Locality with Data-Aware Scheduling. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 119–128. [Google Scholar]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Long, D.D.E.; Maltzahn, C. Ceph: A Scalable, High-Performance Distributed File System; USENIX Association: Berkeley, CA, USA, 2006; pp. 307–320. [Google Scholar]
- Usman, S.; Mehmood, R.; Katib, I.; Albeshri, A. Data Locality in High Performance Computing, Big Data, and Converged Systems: An Analysis of the Cutting Edge and a Future System Architecture. Electronics 2022, 12, 53. [Google Scholar] [CrossRef]
- Chowdhury, F.; Zhu, Y.; Heer, T.; Paredes, S.; Moody, A.; Goldstone, R.; Mohror, K.; Yu, W. I/O Characterization and Performance Evaluation of BeeGFS for Deep Learning. In Proceedings of the 48th International Conference on Parallel Processing, Kyoto, Japan, 5–8 August 2019; p. 10, ISBN 978-1-4503-6295-5. [Google Scholar]
- Chandakanna, V. REHDFS: A Random Read/Write Enhanced HDFS. J. Netw. Comput. Appl. 2017, 103, 85–100. [Google Scholar] [CrossRef]
- Sharma, A.; Singh, G. A Review on Data Locality in Hadoop MapReduce. In Proceedings of the 2018 Fifth International Conference on Parallel, Distributed and Grid Computing (PDGC), Solan, India, 20–22 December 2018; pp. 723–728. [Google Scholar] [CrossRef]
- George, L. HBase—The Definitive Guide: Random Access to Your Planet-Size Data. 2011. Available online: https://learning.oreilly.com/library/view/hbase-the-definitive/9781449314682/ (accessed on 21 December 2023).
- Yadav, V. Working with HBase. In Processing Big Data with Azure HDInsight; Apress: Berkeley, CA, USA, 2017; pp. 123–142. [Google Scholar]
- Lee, J.-Y.; Kim, M.-H.; Raza Shah, S.A.; Ahn, S.-U.; Yoon, H.; Noh, S.-Y. Performance Evaluations of Distributed File Systems for Scientific Big Data in FUSE Environment. Electronics 2021, 10, 1471. [Google Scholar] [CrossRef]
- Srivas, M.C.; Ravindra, P.; Saradhi, U.; Pande, A.; Sanapala, C.; Renu, L.; Kavacheri, S.; Hadke, A.; Vellanki, V. Map-Reduce Ready Distributed File System. U.S. Patent 20110313973A1, 22 December 2011. [Google Scholar]
- Tanenbaum, A.S.; van Steen, M. Distributed Systems: Principles and Paradigms; Pearson Prentice Hall: Hoboken, NJ, USA, 2007; ISBN 978-0-13-613553-1. [Google Scholar]
- Pate, S.; Van Den Bosch, F. UNIX Filesystems: Evolution, Design and Impemenation; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003; ISBN 978-0-471-16483-8. [Google Scholar]
- Abernethy, R. Programmer’s Guide to Apache Thrift. 2019. Available online: https://learning.oreilly.com/library/view/programmers-guide-to/9781617296161/ (accessed on 21 December 2023).
- Gabriel, E.; Fagg, G.E.; Bosilca, G.; Angskun, T.; Dongarra, J.J.; Squyres, J.M.; Sahay, V.; Kambadur, P.; Barrett, B.; Lumsdaine, A.; et al. Open MPI: Goals, Concept, and Design of a Next Generation MPI Implemen Tation. In Proceedings of the Recent Advances in Parallel Virtual Machine and Message Passing Interface: 11th European PVM/MPI Users’ Group Meeting, Budapest, Hungary, 19–22 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 97–104. [Google Scholar]
- OpenMP Architecture Review Board. OpenMP Application Programming Interface Specification, Version 5.0. 2019. Available online: https://www.openmp.org/wp-content/uploads/OpenMP-API-Specification-5.0.pdf (accessed on 21 December 2023).
- Meyers, S. Effective Modern C++; O’Reilly Media: Sebastopol, CA, USA, 2014; ISBN 978-1-4919-0399-5. [Google Scholar]
- Bijlani, A.; Ramachandran, U. Extension Framework for File Systems in User Space; USENIX Association: Berkeley, CA, USA, 2019; pp. 121–134. [Google Scholar]
- Vangoor, B.K.R.; Agarwal, P.; Mathew, M.; Ramachandran, A.; Sivaraman, S.; Tarasov, V.; Zadok, E. Performance and Resource Utilization of FUSE User-Space File Systems. ACM Trans. Storage 2019, 15, 15. [Google Scholar] [CrossRef]
- Shan, H.; Shalf, J. Using IOR to Analyze the I/O Performance for HPC Platforms; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2007.
- Axboe, J. Fio-Flexible Io Tester. 2014. Available online: https://github.com/axboe/fio (accessed on 21 December 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CR | CW | PR | PW | EX | |
|---|---|---|---|---|---|
| CR | 1 | 1 | 1 | 1 | 0 |
| CW | 1 | 1 | 0 | 0 | 0 |
| PR | 1 | 0 | 1 | 0 | 0 |
| PW | 1 | 0 | 0 | 0 | 0 |
| EX | 0 | 0 | 0 | 0 | 0 |
| Component | Hardware Characteristics | Software Characteristics |
|---|---|---|
| Physical Hosts | vxRail P570 nodes with 1×Intel Xeon Silver 4110 @2.10 GHz, 8 cores (16 logical processors), 127.62 GB RAM, 4× 1.09TB HDD SAS Disks, and 2× 10GbE network interfaces | VMware ESXi version 7.0.3. Vmware vSphere vSAN 7.0.3 storage system |
| Switches | Cisco Nexus 3000 with 48× 10GbE | NX-OS version 6.0(2)U3(1) |
| Virtual Machines | 6 vCPUs, 32 GB RAM, 1 vNIC and 300 GB virtual disks | CentOS 7.7.1908 using XFS |
| Source | Target | Data Transferred (GB) | Transfer Rate (Gbps) |
|---|---|---|---|
| Virtual Node 5 | Virtual Node 3 | 2.74 | 4.71 |
| Virtual Node 5 | Virtual Node 4 | 5.49 | 9.43 |
| Virtual Node 5 | Virtual Node 2 | 15.50 | 26.70 |
| Virtual Node 4 | Virtual Node 3 | 5.49 | 9.44 |
| Virtual Node 4 | Virtual Node 2 | 5.49 | 9.43 |
| Virtual Node 3 | Virtual Node 2 | 5.49 | 9.43 |
| Virtual Node 6 | Virtual Node 2 | 5.18 | 8.89 |
| Virtual Node 6 | Virtual Node 4 | 5.48 | 9.42 |
| Virtual Node 6 | Virtual Node 3 | 15.10 | 25.90 |
| Virtual Node 6 | Virtual Node 1 | 5.48 | 9.42 |
| Virtual Node 6 | Virtual Node 5 | 5.48 | 9.41 |
| Virtual Node 1 | Virtual Node 4 | 15.10 | 26.00 |
| Virtual Node 1 | Virtual Node 3 | 5.49 | 9.43 |
| Virtual Node 1 | Virtual Node 5 | 5.49 | 9.43 |
| Virtual Node 2 | Virtual Node 1 | 3.03 | 5.28 |
| Test | Write Protocol | Transfer Rate (MB/s) | Std. Dev. | Conf. Int. |
|---|---|---|---|---|
| Concentrated | Remote-write | 238.978586 | 10.16399 | [236.9865: 240.9707] |
| Concentrated | Local-write | 431.830808 | 7.730645 | [430.3156: 433.3460] |
| Distributed | Remote-write | 195.54899 | 2.975474 | [194.9658: 196.1322] |
| Distributed | Local-write | 465.216869 | 20.08817 | [461.2797: 469.1541] |
| Component | Hardware Characteristics | Software Characteristics |
|---|---|---|
| Physical Hosts | Dell Technologies PowerEdge C6620 servers with 2× Intel Xeon Platinum 8480+ processors of 2.0 GHz, 56 cores per socket (8 NUMA regions), 512 GB RAM at 4800 MHz, 1× 1GbE network card, NVMe disks. | RedHat Linux 8.6 operating system with 407 GB XFS file system |
| Aggregation Switch | Dell Technologies Z9100-ON with 32× 10GbE | OS9 operating System |
| Top of Rack (TOR) Switches | Dell Technologies S3048-ON with 48× 1GbE | OS9 operating System |
| Observation Step | Block Size | IOPS Average | Samples | Standard Deviation | 95% Confidence Interval (Normal Distribution) |
|---|---|---|---|---|---|
| Move disabled | 4 KB | 1,929,046 | 6537 | 605,447.00 | [1,914,369.078:1,943,722.922] |
| Move enabled | 4 KB | 2,005,977 | 6970 | 571,088.00 | [1,992,569.903:2,019,384.097] |
| Move enabled 2nd round | 4 KB | 2,762,293 | 7399 | 732,518.00 | [2,745,602.095:2,778,983.905] |
| Move disabled | 128 KB | 249,789 | 5942 | 51,390.00 | [248,482.347:251,095.653] |
| Move enabled | 128 KB | 272,589 | 5932 | 58,474.00 | [271,100.975:274,077.025] |
| Move enabled 2nd round | 128 KB | 281,622 | 5989 | 63,949.00 | [280,002.411:283,241.589] |
| Move disabled | 1 MB | 66,678 | 5505 | 8913.00 | [66,442.553:66,913.447] |
| Move enabled | 1 MB | 75,944 | 5377 | 15,512.00 | [75,529.384:76,358.616] |
| Move enabled 2nd round | 1 MB | 78,316 | 5473 | 19,774.00 | [77,792.122:78,839.878] |
| Cluster Size | Test Duration (s) | Total Chunks | Changed Owner | Change Rate |
|---|---|---|---|---|
| 8 | 60 | 512 | 87 | 17.0% |
| 12 | 90 | 768 | 104 | 13.5% |
| 16 | 120 | 1024 | 113 | 11.0% |
| 20 | 150 | 1280 | 80 | 6.3% |
| 24 | 180 | 1536 | 76 | 4.9% |
| 28 | 210 | 1792 | 69 | 3.9% |
| 32 | 240 | 2048 | 54 | 2.6% |
| 36 | 270 | 2304 | 49 | 2.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
da Silva, E.C.; Sato, L.M.; Midorikawa, E.T. Distributed File System to Leverage Data Locality for Large-File Processing. Electronics 2024, 13, 106. https://doi.org/10.3390/electronics13010106
da Silva EC, Sato LM, Midorikawa ET. Distributed File System to Leverage Data Locality for Large-File Processing. Electronics. 2024; 13(1):106. https://doi.org/10.3390/electronics13010106
Chicago/Turabian Styleda Silva, Erico Correia, Liria Matsumoto Sato, and Edson Toshimi Midorikawa. 2024. "Distributed File System to Leverage Data Locality for Large-File Processing" Electronics 13, no. 1: 106. https://doi.org/10.3390/electronics13010106
APA Styleda Silva, E. C., Sato, L. M., & Midorikawa, E. T. (2024). Distributed File System to Leverage Data Locality for Large-File Processing. Electronics, 13(1), 106. https://doi.org/10.3390/electronics13010106