
UFCC: A Unified Forensic Approach to Locating Tampered Areas in Still Images and Detecting Deepfake Videos by Evaluating Content Consistency


Abstract
:1. Introduction
- The camera-type classification models are improved and extended to apply to digital image forensics and Deepfake detection.
- A suitable dataset is formed for classifying camera types.
- A unified method is proposed for effectively evaluating image and video content consistency.
- A unified method is developed to deal with various Deepfake approaches.
2. Related Work
2.1. Digital Image Forensics
2.2. Deepfake
- Identity swapping
- 2.
- Expression reenactment
- 3.
- Face synthesis
- 4.
- Facial attribute manipulation
- 5.
- Hybrid approaches
2.3. Deepfake Detection
- Frame-level detection
- 2.
- Video-level detection
3. Proposed Scheme
3.1. System Architecture
3.2. Feature Extractor
3.3. Similarity Network
3.4. Similarity Network
3.5. Image Forgery Detection
Selecting Target Patches
- Randomly select a patch as the initial target patch.
- Execute a scanning-based detection on the entire image using the target patch.
- Select candidate patches that exhibit similarity to the target patch with relatively low SSIM values.
- From the candidate patches, randomly pick one as the new target patch for the next iteration.
- Repeat Steps 2 to 4 until the preset number of iterations is achieved.
3.6. Deepfake Video Detection
- Select the detection target frames and reference frames for similarity comparison.
- Locate facial regions and extract associated patches.
- Employ the similarity network to compare the region similarity of blocks.
- Average all the detection results to determine the video’s authenticity.
4. Experimental Results
4.1. Experiment Settings
4.2. Training Data
4.3. Forgery Image Detection Results
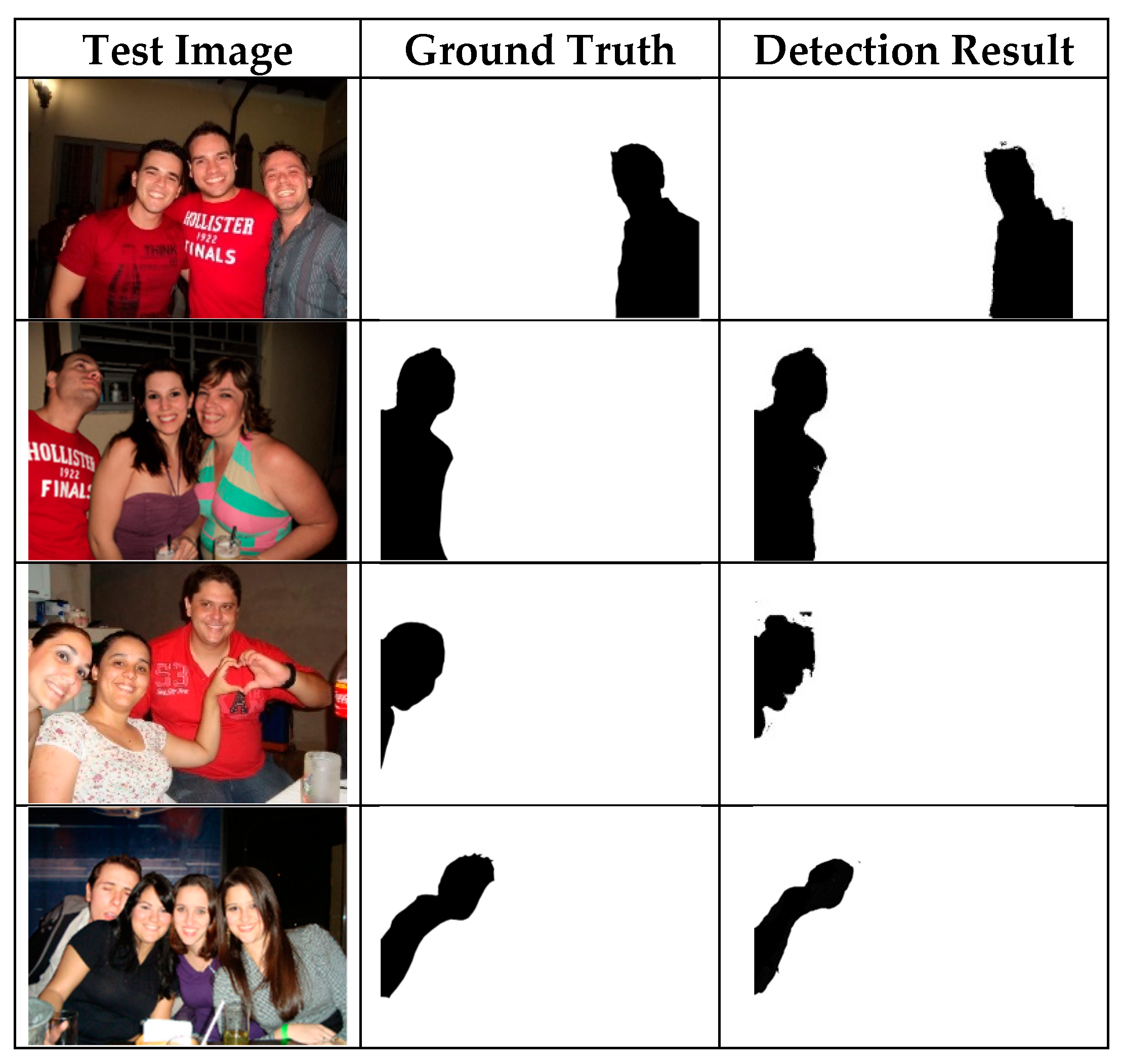
4.3.1. Visual Evaluation
4.3.2. Evaluation Metrics
- mAP (mean Average Precision)
- F1-measure
- MCC (Matthews Correlation Coefficient)
- cIoU
4.3.3. Performance Comparison
4.3.4. Ablation Tests
4.4. Detecting Deepfake Videos
4.4.1. Performance Comparison
4.4.2. Reference Frame Selection
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kuo, T.Y.; Lo, Y.C.; Huang, S.N. Image forgery detection for region duplication tampering. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo, San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Muhammad, G.; Hussain, M.; Bebis, G. Passive copy move image forgery detection using undecimated dyadic wavelet transform. Digit. Investig. 2012, 9, 49–57. [Google Scholar] [CrossRef]
- Kirchner, M.; Gloe, T. Forensic camera model identification. In Handbook of Digital Forensics of Multimedia Data and Devices; Wiley: Hoboken, NJ, USA, 2015; pp. 329–374. [Google Scholar]
- Swaminathan, A.; Wu, M.; Liu, K.R. Nonintrusive component forensics of visual sensors using output images. IEEE Trans. Inf. Forensics Secur. 2007, 2, 91–106. [Google Scholar] [CrossRef]
- Filler, T.; Fridrich, J.; Goljan, M. Using sensor pattern noise for camera model identification. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; IEEE: New York, NY, USA, 2008; pp. 1296–1299. [Google Scholar]
- Xu, G.; Shi, Y.Q. Camera model identification using local binary patterns. In Proceedings of the IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; IEEE: New York, NY, USA, 2012; pp. 392–397. [Google Scholar]
- Thai, T.H.; Cogranne, R.; Retraint, F. Camera model identification based on the heteroscedastic noise model. IEEE Trans. Image Process. 2013, 23, 250–263. [Google Scholar] [CrossRef] [PubMed]
- Van, L.T.; Emmanuel, S.; Kankanhalli, M.S. Identifying source cell phone using chromatic aberration. In Proceedings of the IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; IEEE: New York, NY, USA, 2007; pp. 883–886. [Google Scholar]
- Farid, H. Image forgery detection. IEEE Signal Process. Mag. 2009, 26, 16–25. [Google Scholar] [CrossRef]
- Wang, H.-T.; Su, P.-C. Deep-learning-based block similarity evaluation for image forensics. In Proceedings of the IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taoyuan, Taiwan, 28–30 September 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Dirik, A.E.; Memon, N. Image tamper detection based on demosaicing artifacts. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; IEEE: New York, NY, USA, 2009; pp. 1497–1500. [Google Scholar]
- Bondi, L.; Lameri, S.; Guera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. Tampering detection and localization through clustering of camera-based CNN features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1855–1864. [Google Scholar]
- Mayer, O.; Stamm, M.C. Learned forensic source similarity for unknown camera models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: New York, NY, USA, 2018; pp. 2012–2016. [Google Scholar]
- Deepfakes. Available online: https://github.com/deepfakes/faceswap (accessed on 21 November 2021).
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3677–3685. [Google Scholar]
- Zakharov, E.; Shysheya, A.; Burkov, E.; Lempitsky, V. Few-shot adversarial learning of realistic neural talking head models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9459–9468. [Google Scholar]
- Zhu, Y.; Li, Q.; Wang, J.; Xu, C.-Z.; Sun, Z. One shot face swapping on megapixels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4834–4844. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of styleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8110–8119. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of RGB videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Kim, H.; Garrido, P.; Xu, W.; Thies, J.; Nießner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Fried, O.; Tewari, A.; Zollhöfer, M.; Finkelstein, A.; Shechtman, E.; Goldman, D.B.; Genova, K.; Jin, Z.; Theobalt, C.; Agrawala, M. Text-based editing of talking-head video. ACM Trans. Graph. 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Nguyen, T.; Tran, A.T.; Hoai, M. Lipstick ain’t enough: Beyond color matching for in-the-wild makeup transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13305–13314. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. FSGAN: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Qu, Z.; Meng, Y.; Muhammad, G.; Tiwari, P. QMFND: A quantum multimodal fusion-based fake news detection model for social media. Inf. Fusion 2024, 104, 102172. [Google Scholar] [CrossRef]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1831–1839. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. MesoNet: A compact facial video forgery detection network. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 10–13 December 2018; IEEE: New York, NY, USA; pp. 1–7. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 2307–2311. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Li, J.; Xie, H.; Li, J.; Wang, Z.; Zhang, Y. Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6458–6467. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 772–781. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. In Proceedings of the IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Li, Y.; Chang, M.-C.; Lyu, S. In ictu oculi: Exposing AI created fake videos by detecting eye blinking. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 8261–8265. [Google Scholar]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting fake news: Image splice detection via learned self-consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a Siamese time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6, 737–744. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with Siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Neculoiu, P.; Versteegh, M.; Rotaru, M. Learning text similarity with Siamese recurrent networks. In Proceedings of the 1st Workshop on Representation Learning for NLP, Berlin, Germany, 11 August 2016; pp. 148–157. [Google Scholar]
- Hadsell, R. Dimensionality reduction by learning an invariant mapping. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: New York, NY, USA, 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Forte, M.; Pitié, F. $ F $, $ B $, Alpha Matting. arXiv 2020, arXiv:2003.07711. [Google Scholar]
- Shullani, D.; Fontani, M.; Iuliani, M.; Shaya, O.A.; Piva, A. Vision: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 1–16. [Google Scholar] [CrossRef]
- Stamm, M.; Bestagini, P.; Marcenaro, L.; Campisi, P. Forensic camera model identification: Highlights from the IEEE Signal Processing Cup 2018 Student Competition. IEEE Signal Process. Mag. 2018, 35, 168–174. [Google Scholar] [CrossRef]
- Gloe, T.; Böhme, R. The Dresden image database for benchmarking digital image forensics. In Proceedings of the ACM Symposium on Applied Computing, Sierre, Switzerland, 21–26 March 2010; pp. 1584–1590. [Google Scholar]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Van Rijsbergen, C.J.; Retrieval, I. Information Retrieval; Butterworth-Heinemann: Oxford, UK, 1979. [Google Scholar]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Et Biophys. Acta (BBA)-Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceeding of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Gu, A.-R.; Nam, J.-H.; Lee, S.-C. FBI-Net: Frequency-based image forgery localization via multitask learning With self-attention. IEEE Access 2022, 10, 62751–62762. [Google Scholar] [CrossRef]
- Ferrara, P.; Bianchi, T.; De Rosa, A.; Piva, A. Image forgery localization via fine-grained analysis of CFA artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1566–1577. [Google Scholar] [CrossRef]
- Ye, S.; Sun, Q.; Chang, E.-C. Detecting digital image forgeries by measuring inconsistencies of blocking artifact. In Proceedings of the IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; IEEE: New York, NY, USA, 2007; pp. 12–15. [Google Scholar]
- Mahdian, B.; Saic, S. Using noise inconsistencies for blind image forensics. Image Vis. Comput. 2009, 27, 1497–1503. [Google Scholar] [CrossRef]
- Salloum, R.; Ren, Y.; Kuo, C.-C.J. Image splicing localization using a multi-task fully convolutional network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9543–9552. [Google Scholar]
- Ding, H.; Chen, L.; Tao, Q.; Fu, Z.; Dong, L.; Cui, X. DCU-Net: A dual-channel U-shaped network for image splicing forgery detection. Neural Comput. Appl. 2023, 35, 5015–5031. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, G.; Wu, L.; Kwong, S.; Zhang, H.; Zhou, Y. Multi-task SE-network for image splicing localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4828–4840. [Google Scholar] [CrossRef]
- Faceswap. Available online: https://github.com/MarekKowalski/FaceSwap (accessed on 13 November 2021).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Recasting residual-based local descriptors as convolutional neural networks: An application to image forgery detection. In Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, Philadelphia, PA, USA, 20–21 June 2017; pp. 159–164. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3207–3216. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: New York, NY, USA, 2019; pp. 83–92. [Google Scholar]
- Li, X.; Lang, Y.; Chen, Y.; Mao, X.; He, Y.; Wang, S.; Xue, H.; Lu, Q. Sharp multiple instance learning for deepfake video detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1864–1872. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 667–684. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy |
|---|---|
| Feature extractor | 0.95 |
| Siamese network | 0.90 |
| Prediction\Truth | Forgery | Not Forgery |
|---|---|---|
| Forgery | True Positive (TP) | False Positive (FP) |
| Not Forgery | False Negative (FN) | True Negative (TN) |
| Method\Metrics | mAP | cIoU | MCC | F1 |
|---|---|---|---|---|
| CFA [57] | 0.24 | 0.46 | 0.16 | 0.29 |
| DCT [58] | 0.32 | 0.51 | 0.19 | 0.31 |
| NOI [59] | 0.38 | 0.50 | 0.25 | 0.34 |
| E-MFCN [60] | - | - | 0.41 | 0.48 |
| Mantranet [61] | - | 0.43 | 0.02 | 0.48 |
| DCUNet [62] | - | 0.53 | 0.27 | 0.62 |
| SENet [63] | - | 0.54 | 0.26 | 0.61 |
| EXIF-Consistency [40] | 0.52 | 0.63 | 0.42 | 0.52 |
| Ours | 0.58 | 0.83 | 0.56 | 0.63 |
| Method\Metrics | mAP | cIoU | MCC | F1 |
|---|---|---|---|---|
| Base | 0.43 | 0.72 | 0.36 | 0.46 |
| Base + SSIM | 0.45 | 0.75 | 0.41 | 0.48 |
| Base+SSIM + FBAmatting | 0.54 | 0.76 | 0.48 | 0.56 |
| Base+SSIM + FBAmatting + Refine | 0.58 | 0.83 | 0.56 | 0.63 |
| Method\Tests | DF [14] | F2F [19] | FS [64] | NT [65] |
|---|---|---|---|---|
| Steg. Features [66] | 0.736 | 0.737 | 0.689 | 0.633 |
| Cozzolino et al. [67] | 0.855 | 0.679 | 0.738 | 0.780 |
| Bayar and Stamm [39] | 0.846 | 0.737 | 0.825 | 0.707 |
| MesoNet [30] | 0.896 | 0.886 | 0.812 | 0.766 |
| Rossler et al. [32] | 0.976 | 0.977 | 0.968 | 0.922 |
| The proposed method | 0.984 | 0.984 | 0.932 | 0.972 |
| Method\Dataset | FF++ [32] | CDF [68] |
|---|---|---|
| Two-stream [29] | 0.701 | 0.538 |
| Meso4 [30] | 0.847 | 0.548 |
| MesoInception4 [30] | 0.830 | 0.536 |
| FWA [69] | 0.801 | 0.569 |
| DSP-FWA [69] | 0.930 | 0.646 |
| VA-MLP [70] | 0.664 | 0.550 |
| Headpose [38] | 0.473 | 0.546 |
| Capsule [31] | 0.966 | 0.575 |
| SMIL [71] | 0.968 | 0.563 |
| Two-branch [72] | 0.932 | 0.734 |
| SPSL [34] | 0.969 | 0.724 |
| The proposed scheme | 0.97 | 0.754 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, P.-C.; Huang, B.-H.; Kuo, T.-Y. UFCC: A Unified Forensic Approach to Locating Tampered Areas in Still Images and Detecting Deepfake Videos by Evaluating Content Consistency. Electronics 2024, 13, 804. https://doi.org/10.3390/electronics13040804
Su P-C, Huang B-H, Kuo T-Y. UFCC: A Unified Forensic Approach to Locating Tampered Areas in Still Images and Detecting Deepfake Videos by Evaluating Content Consistency. Electronics. 2024; 13(4):804. https://doi.org/10.3390/electronics13040804
Chicago/Turabian StyleSu, Po-Chyi, Bo-Hong Huang, and Tien-Ying Kuo. 2024. "UFCC: A Unified Forensic Approach to Locating Tampered Areas in Still Images and Detecting Deepfake Videos by Evaluating Content Consistency" Electronics 13, no. 4: 804. https://doi.org/10.3390/electronics13040804
APA StyleSu, P. -C., Huang, B. -H., & Kuo, T. -Y. (2024). UFCC: A Unified Forensic Approach to Locating Tampered Areas in Still Images and Detecting Deepfake Videos by Evaluating Content Consistency. Electronics, 13(4), 804. https://doi.org/10.3390/electronics13040804