
MM-NeRF: Large-Scale Scene Representation with Multi-Resolution Hash Grid and Multi-View Priors Features

 ,
,
Abstract
:1. Introduction
- We propose a new optimization NeRF variant, called MM-NeRF, that is specifically designed for large-scale unbounded scene modeling.
- We introduce a new pipeline that integrates complementary features from 3D hash grids and scene priors to achieve efficient and accurate large-scene modeling.
- Our MM-NeRF achieves good scene synthesis representation without requiring a large number of views, indicating the superior performance of our model.
2. Related Work
2.1. NeRF
2.2. Large-Scale Scene NeRF
2.3. Grid-Based NeRF
2.4. Generalizable NeRF
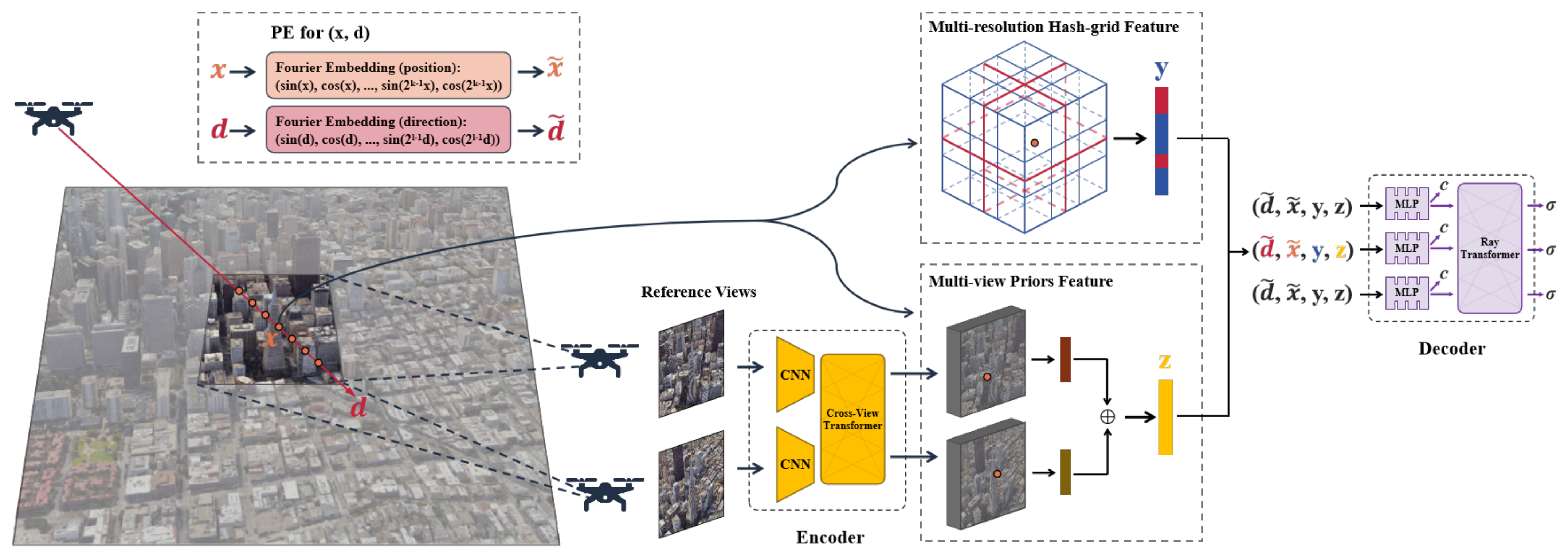
3. Methods
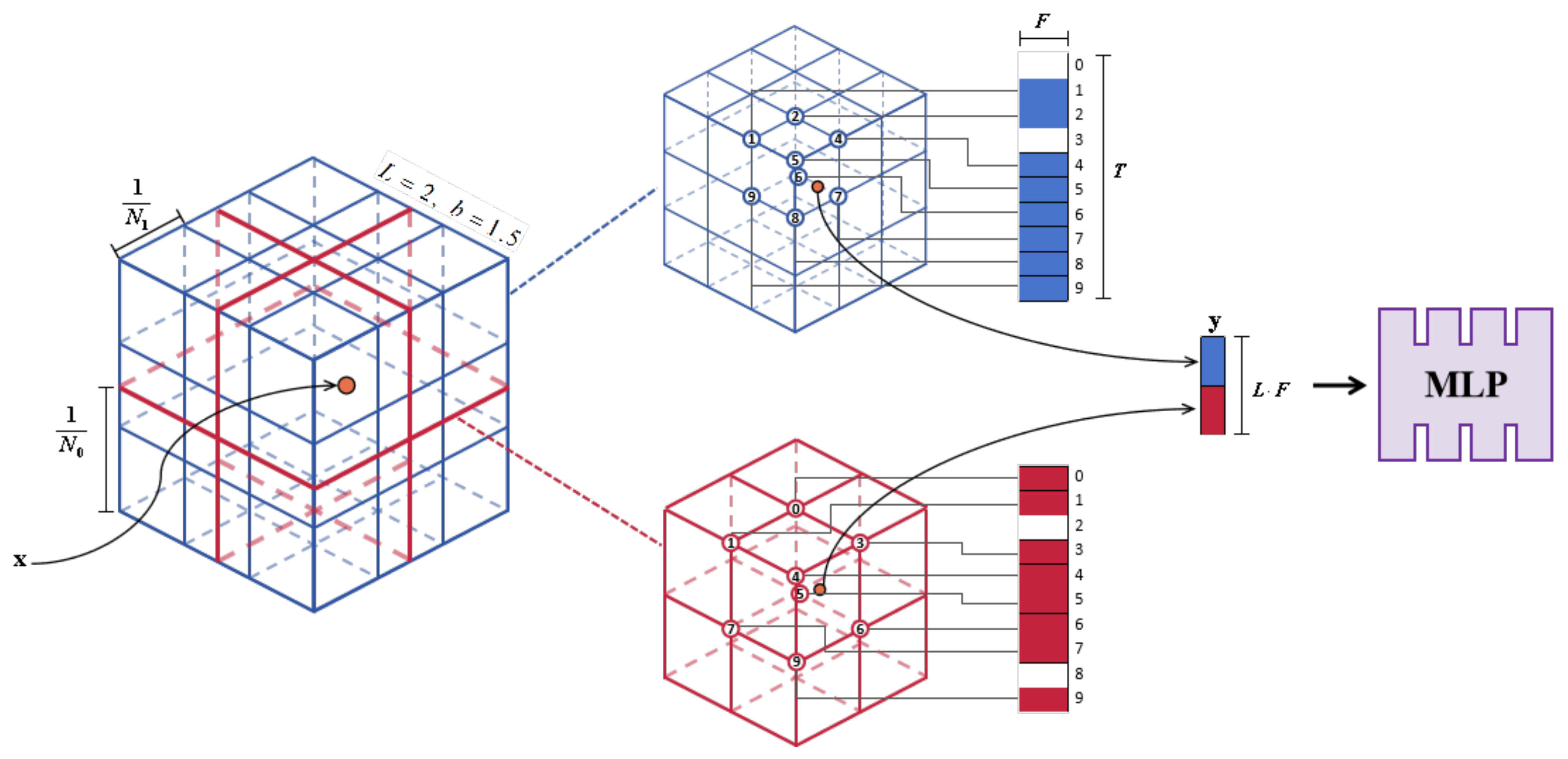
3.1. Multi-Resolution Hash Grid Feature
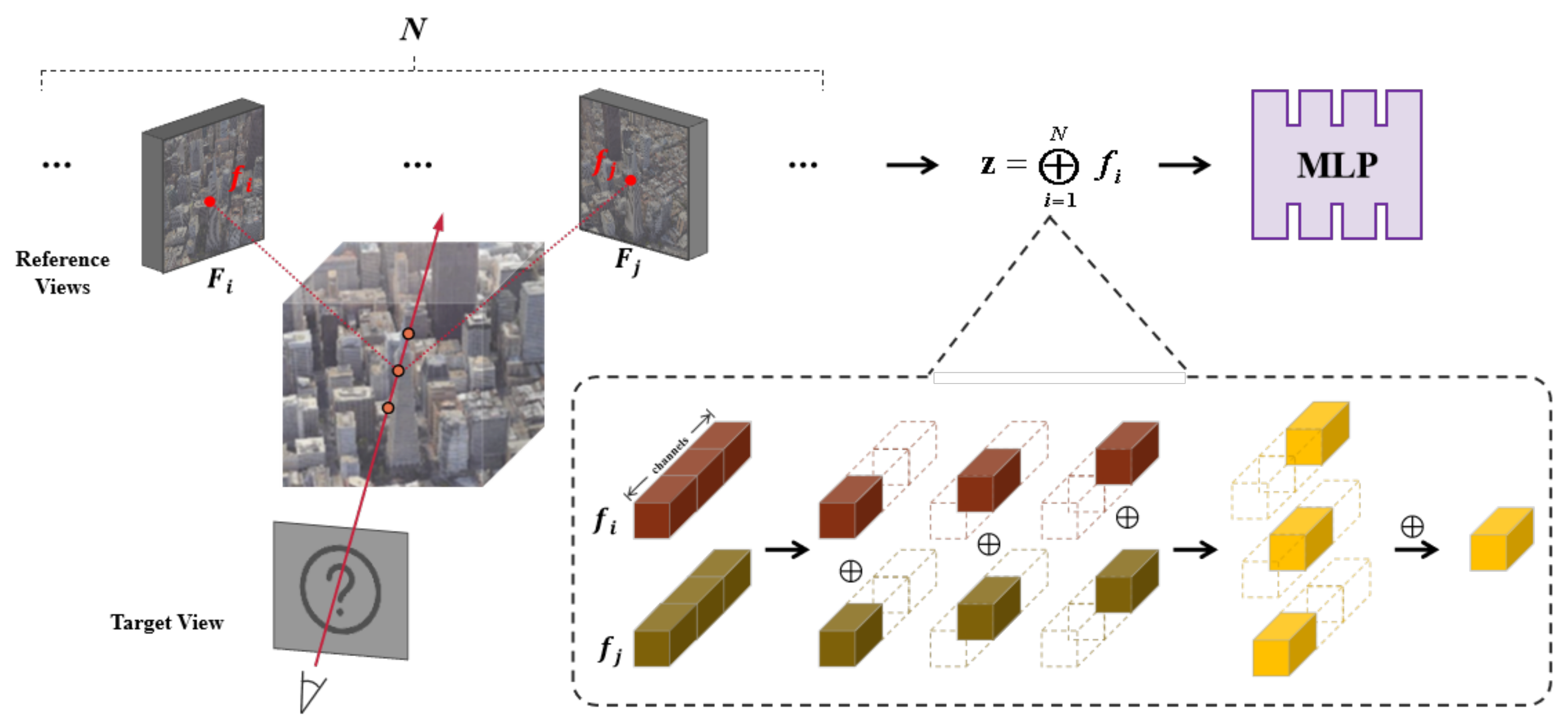
3.2. Multi-View Priors Feature
3.3. NeRF Render Network
| Algorithm 1 Optimization process of MM-NeRF. | |
| Input: multi-view images , camera poses , system initialization parameters Parameter: number of sampling points N, max frequency for PE , angle threshold of the reference view , hash parameter L, T, F, grid resolutions range , | |
| 1: 2: 3: for iter = 1, 2,… do 4: 5: 6: 7: 8: 9: 10: 11: 12: , = PE(, ) 13: 14: 15: 16: ← 17: end for Output: | ▹ Formulas (2) and (3) ▹ Ray parameters ▹ Sampling points ▹ Surrounding voxel vertices ▹ Formula (1) ▹ Grid Feature ▹ Reference views ▹ Formula (4) ▹ Priors feature ▹ Position encoding ▹ Formula (6) ▹ Formulas (7) and (8) ▹ Formula (9) |
4. Results
4.1. Data
4.2. Evaluation
4.3. Ablation
5. Discussion
6. Conclusions
- (1)
- We combined an MLP-based NeRF with explicitly constructed feature grids and introduced a multi-resolution hash grid feature branch to effectively encode local and global scene information, significantly improving the accuracy of large-scale scene modeling.
- (2)
- We noticed that previous NeRF methods do not fully utilize the potential of multi-view prior information. We designed a view encoder to extract and integrate features from multiple views to obtain better results.
- (1)
- A slow training phase: although hash mapping is faster than MLP queries, the entire system requires more training epochs (about 200–300 epochs for different scenes) since the other feature branch has a more complex encoder structure.
- (2)
- Handling a large number of high-resolution images: we adopt the existing mixed-ray batch sampling method for training, which is very inefficient without distributed training.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NeRF | Nerual Radiance Field |
| MLP | Multi-Layer Perception |
| CNN | Convolutional Neural Network |
| PE | Position Encoding |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity |
| LPIPS | Learned Perceptual Image Patch Similarity |
References
- Rudnicka, Z.; Szczepanski, J.; Pregowska, A. Artificial Intelligence-Based Algorithms in Medical Image Scan Segmentation and Intelligent Visual Content Generation—A Concise Overview. Electronics 2024, 13, 746. [Google Scholar] [CrossRef]
- Mhlanga, D. Industry 4.0 in Finance: The Impact of Artificial Intelligence (AI) on Digital Financial Inclusion. Int. J. Financ. Stud. 2020, 8, 45. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, C.; Chow, M.Y.; Li, X.; Tian, J.; Luo, H.; Yin, S. A Data-Model Interactive Remaining Useful Life Prediction Approach of Lithium-Ion Batteries Based on PF-BiGRU-TSAM. IEEE Trans. Ind. Inform. 2024, 20, 1144–1154. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, J.; Yan, P.; Wu, S.; Luo, H.; Yin, S. Multi-hop graph pooling adversarial network for cross-domain remaining useful life prediction: A distributed federated learning perspective. Reliab. Eng. Syst. Saf. 2024, 244, 109950. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Xiangli, Y.; Xu, L.; Pan, X.; Zhao, N.; Rao, A.; Theobalt, C.; Dai, B.; Lin, D. BungeeNeRF: Progressive Neural Radiance Field for Extreme Multi-scale Scene Rendering. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; pp. 106–122. [Google Scholar]
- Zhang, X.; Bi, S.; Sunkavalli, K.; Su, H.; Xu, Z. NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5449–5458. [Google Scholar]
- Tancik, M.; Casser, V.; Yan, X.; Pradhan, S.; Mildenhall, B.; Srinivasan, P.P.; Barron, J.T.; Kretzschmar, H. Block-NeRF: Scalable Large Scene Neural View Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8248–8258. [Google Scholar]
- Turki, H.; Ramanan, D.; Satyanarayanan, M. Mega-NERF: Scalable Construction of Large-Scale NeRFs for Virtual Fly-Throughs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12922–12931. [Google Scholar]
- Fridovich-Keil, S.; Yu, A.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance Fields without Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5501–5510. [Google Scholar]
- Sun, C.; Sun, M.; Chen, H.T. Direct Voxel Grid Optimization: Super-Fast Convergence for Radiance Fields Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5459–5469. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Yu, A.; Ye, V.; Tancik, M.; Kanazawa, A. pixelNeRF: Neural Radiance Fields From One or Few Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 4578–4587. [Google Scholar]
- Wang, Q.; Wang, Z.; Genova, K.; Srinivasan, P.P.; Zhou, H.; Barron, J.T.; Martin-Brualla, R.; Snavely, N.; Funkhouser, T. IBRNet: Learning Multi-View Image-Based Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 4690–4699. [Google Scholar]
- Trevithick, A.; Yang, B. GRF: Learning a General Radiance Field for 3D Representation and Rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 15182–15192. [Google Scholar]
- Chibane, J.; Bansal, A.; Lazova, V.; Pons-Moll, G. Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 7911–7920. [Google Scholar]
- Kajiya, J.T.; Von, H.B.P. Ray tracing volume densities. ACM SIGGRAPH Comput. Graph. 1984, 18, 165–174. [Google Scholar] [CrossRef]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Verbin, D.; Hedman, P.; Mildenhall, B.; Zickler, T.; Barron, J.T.; Srinivasan, P.P. Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5481–5490. [Google Scholar]
- Kai, Z.; Gernot, R.; Noah, S.; Vladlen, K. NeRF++: Analyzing and Improving Neural Radiance Fields. arXiv 2020, arXiv:2010.07492. [Google Scholar]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J. FastNeRF: High-Fidelity Neural Rendering at 200FPS. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 14346–14355. [Google Scholar]
- Reiser, C.; Peng, S.; Liao, Y.; Geiger, A. KiloNeRF: Speeding Up Neural Radiance Fields With Thousands of Tiny MLPs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 14335–14345. [Google Scholar]
- Wadhwani, K.; Kojima, T. SqueezeNeRF: Further Factorized FastNeRF for Memory-Efficient Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 2717–2725. [Google Scholar]
- Chen, A.; Xu, Z.; Zhao, F.; Zhang, X.; Xiang, F.; Yu, J.; Su, H. MVSNeRF: Fast Generalizable Radiance Field Reconstruction From Multi-View Stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 14124–14133. [Google Scholar]
- Jain, A.; Tancik, M.; Abbeel, P. Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 5885–5894. [Google Scholar]
- Yen-Chen, L.; Florence, P.; Barron, J.T.; Rodriguez, A.; Isola, P.; Lin, T.Y. iNeRF: Inverting Neural Radiance Fields for Pose Estimation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 28–30 September 2021; pp. 1323–1330. [Google Scholar]
- Lin, C.H.; Ma, W.C.; Torralba, A.; Lucey, S. BARF: Bundle-Adjusting Neural Radiance Fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 5741–5751. [Google Scholar]
- Zirui, W.; Shangzhe, W.; Weidi, X.; Min, C.; Victor, A.P. NeRF–: Neural Radiance Fields without Known Camera Parameters. arXiv 2022, arXiv:2102.07064. [Google Scholar]
- Pumarola, A.; Corona, E.; Pons-Moll, G.; Moreno-Noguer, F. D-NeRF: Neural Radiance Fields for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 10318–10327. [Google Scholar]
- Fridovich-Keil, S.; Meanti, G.; Warburg, F.R.; Recht, B.; Kanazawa, A. K-Planes: Explicit Radiance Fields in Space, Time, and Appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 12479–12488. [Google Scholar]
- Niemeyer, M.; Geiger, A. GIRAFFE: Representing Scenes As Compositional Generative Neural Feature Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 11453–11464. [Google Scholar]
- Mirzaei, A.; Aumentado-Armstrong, T.; Derpanis, K.G.; Kelly, J.; Brubaker, M.A.; Gilitschenski, I.; Levinshtein, A. SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting With Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 20669–20679. [Google Scholar]
- Wang, C.; Chai, M.; He, M.; Chen, D.; Liao, J. CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3835–3844. [Google Scholar]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.M.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 7210–7219. [Google Scholar]
- Xu, L.; Xiangli, Y.; Peng, S.; Pan, X.; Zhao, N.; Theobalt, C.; Dai, B.; Lin, D. Grid-Guided Neural Radiance Fields for Large Urban Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 8296–8306. [Google Scholar]
- Yuqi, Z.; Guanying, C.; Shuguang, C. Efficient Large-scale Scene Representation with a Hybrid of High-resolution Grid and Plane Features. arXiv 2023, arXiv:2303.03003. [Google Scholar]
- Johari, M.M.; Lepoittevin, Y.; Fleuret, F. GeoNeRF: Generalizing NeRF With Geometry Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18365–18375. [Google Scholar]
- Liu, Y.; Peng, S.; Liu, L.; Wang, Q.; Wang, P.; Theobalt, C.; Zhou, X.; Wang, W. Neural Rays for Occlusion-Aware Image-Based Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7824–7833. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Tao, D. GMFlow: Learning Optical Flow via Global Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8121–8130. [Google Scholar]
- Lin, L.; Liu, Y.; Hu, Y.; Yan, X.; Xie, K.; Huang, H. Capturing, Reconstructing, and Simulating: The UrbanScene3D Dataset. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; pp. 93–109. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-From-Motion Revisited. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4104–4113. [Google Scholar]
- Sitzmann, V.; Zollhoefer, M.; Wetzstein, G. Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS) 32, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 586–595. [Google Scholar]
- Chen, A.; Xu, Z.; Geiger, A.; Yu, J.; Su, H. TensoRF: Tensorial Radiance Fields. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; pp. 106–122. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Seminal Graphics: Pioneering Efforts That Shaped the Field; ACM SIGGRAPH: Chicago, IL, USA, 1998; pp. 347–353. [Google Scholar]
- Xatlas. Available online: https://github.com/jpcy/xatlas (accessed on 3 February 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene 1,2 | Building Height (m) | Viewing Height (m) | Number of Views |
|---|---|---|---|
| Aerospace Information Museum, Jinan | 21 | 20–30 | 65 |
| Yellow River Tower, Binzhou | 55.6 | 10–80 | 153 |
| Meixihu Arts Center, Changsha | 46.8 | 60–80 | 81 |
| Greenland Xindu Mall, Hefei | 188 | 100–200 | 169 |
| 56Leonard (Avg.) | Transamerica (Avg.) | |||||
|---|---|---|---|---|---|---|
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | |
| NeRF [5] | 21.107 | 0.335 | 0.611 | 21.420 | 0.344 | 0.625 |
| Mip-NeRF [18] | 21.642 | 0.299 | 0.695 | 21.820 | 0.331 | 0.687 |
| DVGO [11] | 21.317 | 0.323 | 0.631 | 21.467 | 0.337 | 0.606 |
| TensoRF [45] | 22.289 | 0.310 | 0.658 | 22.023 | 0.303 | 0.664 |
| Mega-NeRF [8] | 22.425 | 0.372 | 0.680 | 22.546 | 0.283 | 0.707 |
| BungeeNeRF [6] | 23.058 3 | 0.245 | 0.736 | 23.232 | 0.232 | 0.721 |
| MM-NeRF (ours) | 24.963 2 | 0.182 | 0.814 | 24.778 | 0.197 | 0.802 |
| UrbanScene3D-Campus | UrbanScene3D-Residence | UrbanScene3D-Sci-Art | |||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | |
| NeRF [5] | 21.276 | 0.357 | 0.579 | 20.937 | 0.415 | 0.528 | 21.104 | 0.456 | 0.580 |
| Mip-NeRF [18] | 21.322 | 0.298 | 0.607 | 21.193 | 0.394 | 0.585 | 21.284 | 0.418 | 0.542 |
| DVGO [11] | 22.105 | 0.254 | 0.643 | 21.919 | 0.344 | 0.628 | 22.312 | 0.427 | 0.629 |
| TensoRF [45] | 22.683 | 0.228 | 0.689 | 22.563 | 0.270 | 0.680 | 22.425 | 0.337 | 0.618 |
| Mega-NeRF [8] | 23.417 3 | 0.171 | 0.751 | 22.468 | 0.243 | 0.673 | 22.861 | 0.244 | 0.711 |
| BungeeNeRF [6] | 22.917 | 0.189 | 0.722 | 22.342 | 0.285 | 0.598 | 22.632 | 0.308 | 0.620 |
| MM-NeRF (ours) | 24.126 2 | 0.158 | 0.807 | 23.514 | 0.164 | 0.757 | 23.965 | 0.166 | 0.802 |
| AIM (Avg.) | YRT (Avg.) | MAC (Avg.) | GXM (Avg.) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | |
| NeRF [5] | 21.390 | 0.259 | 0.666 | 21.577 | 0.223 | 0.603 | 22.580 | 0.193 | 0.701 | 20.976 | 0.279 | 0.523 |
| Mip-NeRF [18] | 22.257 | 0.202 | 0.696 | 21.624 | 0.241 | 0.650 | 22.518 | 0.199 | 0.710 | 22.976 | 0.183 | 0.714 |
| DVGO [11] | 22.190 | 0.227 | 0.629 | 21.997 | 0.242 | 0.655 | 23.140 | 0.188 | 0.723 | 23.428 | 0.177 | 0.760 |
| TensoRF [45] | 22.374 | 0.211 | 0.729 | 22.224 | 0.189 | 0.715 | 23.304 | 0.177 | 0.731 | 23.576 | 0.169 | 0.784 |
| Mega-NeRF [8] | 22.612 | 0.172 | 0.769 | 22.641 | 0.209 | 0.677 | 23.381 | 0.174 | 0.726 | 24.316 | 0.156 | 0.807 |
| BungeeNeRF [6] | 22.955 3 | 0.185 | 0.716 | 23.525 | 0.147 | 0.774 | 23.465 | 0.167 | 0.742 | 24.119 | 0.161 | 0.814 |
| MM-NeRF (ours) | 24.125 2 | 0.152 | 0.834 | 24.872 | 0.150 | 0.801 | 24.322 | 0.133 | 0.884 | 25.149 | 0.137 | 0.844 |
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | |
|---|---|---|---|
| Without multi-resolution grid feature | 22.947 | 0.261 | 0.599 |
| With multi-resolution grid feature | 23.879 | 0.205 | 0.735 |
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | |
|---|---|---|---|
| 22.866 | 0.301 | 0.563 | |
| 22.890 | 0.289 | 0.616 | |
| 23.496 | 0.253 | 0.688 | |
| 23.879 | 0.205 | 0.735 |
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | |
|---|---|---|---|
| Without multi-view prior feature | 22.518 | 0.288 | 0.629 |
| With multi-view prior feature | 24.079 | 0.193 | 0.791 |
| PSNR↑ 1 | LPIPS↓ | SSIM↑ | |
|---|---|---|---|
| 23.264 | 0.279 | 0.702 | |
| 23.613 | 0.255 | 0.691 | |
| 23.892 | 0.223 | 0.727 | |
| 23.950 | 0.214 | 0.751 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, B.; Chen, K.; Wang, Z.; Yan, M.; Gu, J.; Sun, X. MM-NeRF: Large-Scale Scene Representation with Multi-Resolution Hash Grid and Multi-View Priors Features. Electronics 2024, 13, 844. https://doi.org/10.3390/electronics13050844
Dong B, Chen K, Wang Z, Yan M, Gu J, Sun X. MM-NeRF: Large-Scale Scene Representation with Multi-Resolution Hash Grid and Multi-View Priors Features. Electronics. 2024; 13(5):844. https://doi.org/10.3390/electronics13050844
Chicago/Turabian StyleDong, Bo, Kaiqiang Chen, Zhirui Wang, Menglong Yan, Jiaojiao Gu, and Xian Sun. 2024. "MM-NeRF: Large-Scale Scene Representation with Multi-Resolution Hash Grid and Multi-View Priors Features" Electronics 13, no. 5: 844. https://doi.org/10.3390/electronics13050844
APA StyleDong, B., Chen, K., Wang, Z., Yan, M., Gu, J., & Sun, X. (2024). MM-NeRF: Large-Scale Scene Representation with Multi-Resolution Hash Grid and Multi-View Priors Features. Electronics, 13(5), 844. https://doi.org/10.3390/electronics13050844