

Parallel Implementation of Lightweight Secure Hash Algorithm on CPU and GPU Environments


Abstract
:1. Introduction
2. Contributions
- Word-level parallel implementation methods of LSH-512 using AVX-512We executed LSH internal processes in parallel processing logic via AVX-512 instructions. We analyzed the 64-bit bitrate repetitive operations that occur in the LSH core function and, for the first time, designed AVX-512 processing logic to process them in parallel. We analyzed LSH compression process and proposed the first AVX-512-instruction-based implementation methods applicable to the compression process. To the best of our knowledge, this method has not previously been used or presented in the literature. Our implementation parallelizes the processing of message blocks and hash-chaining values during the compression process. Four AVX-512 registers are employed for parallelizing message block operations, while two AVX-512 registers are utilized for handling hash-chaining values. We further analyzed applicable AVX-512 instructions for internal operations, including permutation, and assessed the clock cost incurred during these internal operations. As a result, our LSH-512/512 implementation achieves a performance of 1.62 Clock Per Byte (CPB) for a 16 MB message. Notably, our first implementation demonstrates a performance improvement of up to 50.37% compared to other AVX-2-based LSH-512/512 implementations on the Intel Rocket Lake CPU device [42];
- Data parallel implementation methods of LSH-512 using CUDAWe designed logic to process LSH hash operations for multiple messages in parallel, leveraging GPU architecture resources. In other words, we leveraged CUDA to design the LSH data parallel processing logic. Additionally, we proposed a method to accelerate the LSH operation performed by each thread and efficiently handled performance bottlenecks that may occur in GPU architecture. In more detail, we proposed efficient memory handling methods for memory access in NVIDIA GPU architecture. We analyzed CUDA’s memory area and suggested several approaches to minimize memory load/store times. Specifically, we introduced a method to reduce the time of global memory accesses during command processing in CUDA warp units. Additionally, our implementation utilizes CUDA streams to minimize the performance overhead associated with memory access on GPU architectures through asynchronous operations. Finally, our LSH implementation is designed using PTX, a CUDA inline assembly. To the best of our knowledge, this method has not previously been used or presented in the literature. In our LSH-512/512 implementation performance experiments using CUDA, we found the optimal CUDA block/thread performance. Furthermore, we examined the optimal usage of CUDA streams through performance experiments by varying the number of CUDA streams. Our first LSH-512/512 implementation on the RTX 3090 architecture achieves a performance of up to 171.35 MH/s. This first implementation demonstrates up to a 180.62% performance improvement over the benchmark version of the LSH-512 implementation.
3. Preliminary
3.1. Notation
3.2. Lightweight Secure Hash
| Algorithm 1 j-round LSH Mix function |
| Require: Ensure:
|
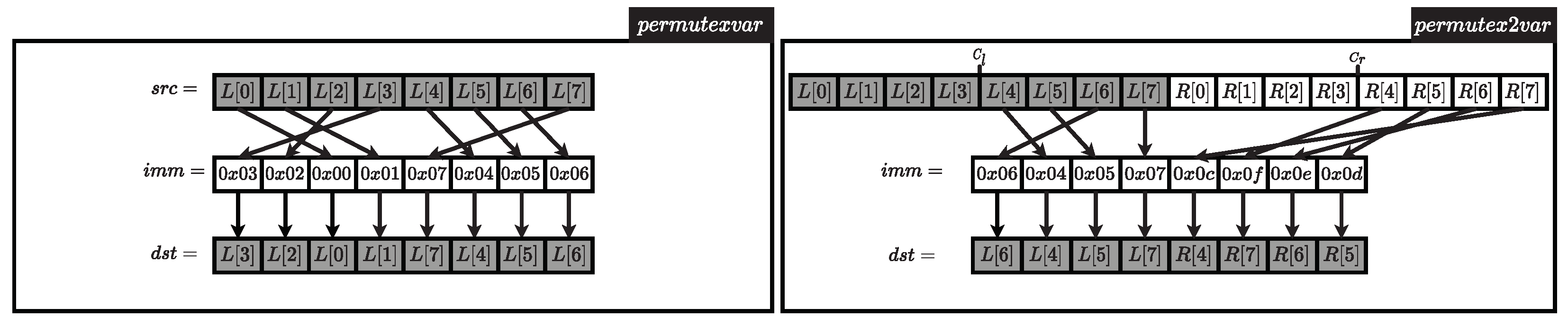
3.3. Advanced-Extension Vector-512
3.4. Graphics Processing Units and Compute Unified Device Architecture
4. Proposed Implementation Methods of LSH in AVX-512
4.1. LSH Structure Analysis
4.2. LSH Compression Process
| Algorithm 2 LSH Compress Function |
| Require: Message block Require: Hash chaining values , Ensure:
|
| Algorithm 3 LSH-512 function using AVX-512 instructions |
| Require: Message registers (, ) or (, ) Require: Message Permutation value Ensure: Updated Message registers or
|
| Algorithm 4 LSH process using AVX-512 instructions |
| Require: , Require: Ensure:
|
| Algorithm 5 LSH-512 process using AVX-512 instructions |
| Require: , Ensure:
|
4.3. Proposed Implementation Clock Cost Analysis
5. Proposed Implementation Methods of LSH in GPU
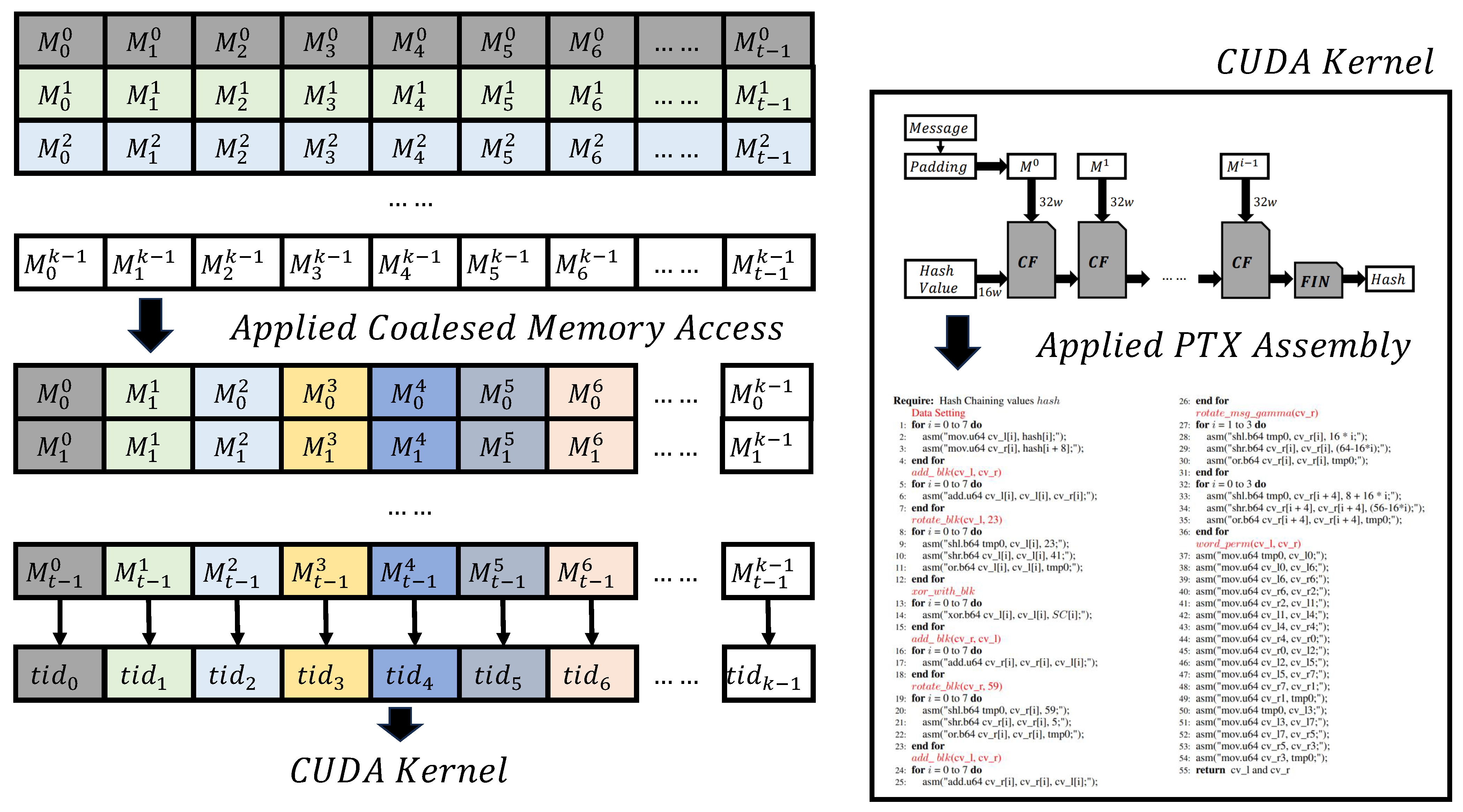
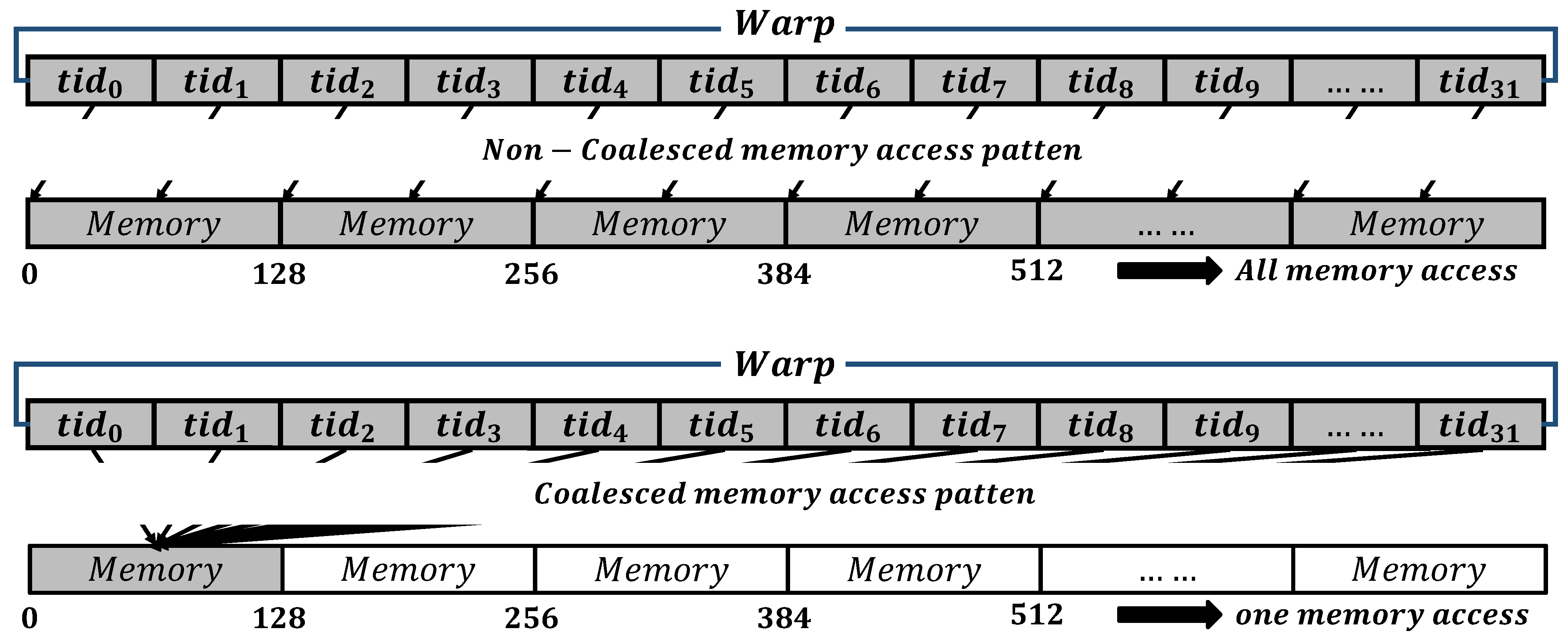
5.1. Coalesced Memory Access Methods
| Algorithm 6 LSH-512 coalesced memory access |
| Require: Input Message Ensure: LSH-512 Hash value
|
5.2. Cuda Stream
5.3. Ptx Inline Assembly
| Algorithm 7 LSH-512 function implementation method using PTX inline assembly |
 |
6. Performance Analysis
6.1. LSH-512 Performance Measurement Evaluation Using AVX-512
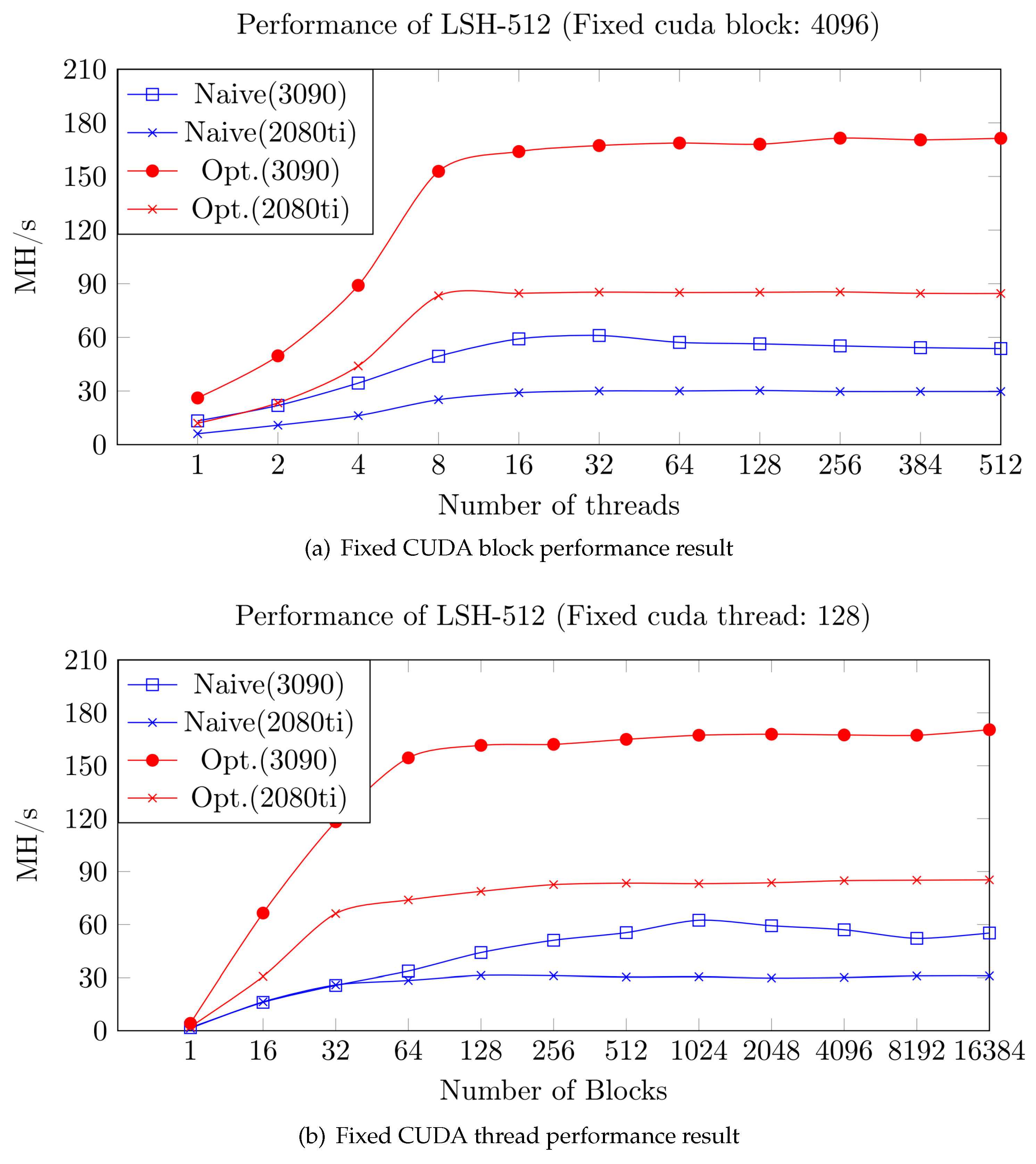
6.2. LSH-512/512 Performance Measurement Evaluation Using CUDA
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turner, J.M. The keyed-hash message authentication code (HMAC). Fed. Inf. Process. Stand. Publ. 2008, 198, 1–13. [Google Scholar]
- Kaliski, B. PKCS# 5: Password-Based Cryptography Specification Version 2.0; Technical Report; The Internet Society: Reston, VI, USA, 2000. [Google Scholar]
- Barker, E.B.; Kelsey, J.M. Recommendation for Random Number Generation Using Deterministic Random Bit Generators (Revised); US Department of Commerce, Technology Administration, National Institute of Standrads and Technology: Gaithersburg, MD, USA, 2007. [Google Scholar]
- Kerry, C.F.; Gallagher, P.D. FIPS PUB 186-2; Digital Signature Standard (DSS). Federal Information Processing Standards Publications: Gaithersburg, MD, USA, 2013; pp. 186–194.
- Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-DILITHIUM—Submission to Round 3 of NIST’s Post-Quantum Cryptography Standardization Process; Rep.(NISTIR)-8413; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2020. [Google Scholar]
- Fouque, P.A.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Pornin, T.; Prest, T.; Ricosset, T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-Based Compact Signatures over NTRU. Submiss. NIST Post-Quantum Cryptogr. Stand. Process 2018, 36, 1–75. [Google Scholar]
- Avanzi, R.; Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS Kyber. Submission to the NIST Post-Quantum Cryptography Standardization Project; NIST National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [Google Scholar]
- Lamport, L. Constructing Digital Signatures from a One Way Function; 1979. Available online: https://www.microsoft.com/en-us/research/publication/constructing-digital-signatures-one-way-function/ (accessed on 30 October 2023).
- Buchmann, J.; Dahmen, E.; Ereth, S.; Hülsing, A.; Rückert, M. On the security of the Winternitz one-time signature scheme. Int. J. Appl. Cryptogr. 2013, 3, 84–96. [Google Scholar] [CrossRef]
- Merkle, R.C. A Certified Digital Signature. In Advances in Cryptology—CRYPTO ’89, 9th Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 1989, Proceedings; Brassard, G., Ed.; Lecture Notes in Computer Science; Springer: New York, NY, USA, 1989; Volume 435, pp. 218–238. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Hopwood, D.; Hülsing, A.; Lange, T.; Niederhagen, R.; Papachristodoulou, L.; Schneider, M.; Schwabe, P.; Wilcox-O’Hearn, Z. SPHINCS: Practical Stateless Hash-Based Signatures. In Advances in Cryptology—EUROCRYPT 2015—34th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Sofia, Bulgaria, 26–30 April 2015, Proceedings; Part I; Oswald, E., Fischlin, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9056, pp. 368–397. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Hülsing, A.; Kölbl, S.; Niederhagen, R.; Rijneveld, J.; Schwabe, P. The SPHINCS+ Signature Framework. In Proceedings of the CCS ’19: 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; Cavallaro, L., Kinder, J., Wang, X., Katz, J., Eds.; ACM: New York, NY, USA, 2019; pp. 2129–2146. [Google Scholar] [CrossRef]
- Kim, D.C.; Hong, D.; Lee, J.K.; Kim, W.H.; Kwon, D. LSH: A new fast secure hash function family. In Information Security and Cryptology-ICISC 2014: 17th International Conference, Seoul, Republic of Korea, 3–5 December 2014; Revised Selected Papers 17; Springer: Berlin/Heidelberg, Germany, 2015; pp. 286–313. [Google Scholar]
- ISO/IEC 19790:2012; Information Technology—Security Techniques Security Requirements for Cryptographic Modules. Korea Standards Association: Seoul, Republic of Korea, 2012.
- Sim, M.; Eum, S.; Song, G.; Kwon, H.; Jang, K.; Kim, H.; Kim, H.; Yang, Y.; Kim, W.; Lee, W.K.; et al. K-XMSS and K-SPHINCS+: Hash based Signatures with Korean Cryptography Algorithms. Cryptol. Eprint Arch. 2022. [Google Scholar]
- NVIDIA. CUDA C++ Programming Guide. 2024. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (accessed on 8 January 2024).
- Owens, J.D.; Houston, M.; Luebke, D.; Green, S.; Stone, J.E.; Phillips, J.C. GPU computing. Proc. IEEE 2008, 96, 879–899. [Google Scholar] [CrossRef]
- Keckler, S.W.; Dally, W.J.; Khailany, B.; Garland, M.; Glasco, D. GPUs and the future of parallel computing. IEEE Micro 2011, 31, 7–17. [Google Scholar] [CrossRef]
- Kim, D.; Jung, Y.; Ju, Y.; Song, J. Fast implementation of LSH with SIMD. IEEE Access 2019, 7, 107016–107024. [Google Scholar] [CrossRef]
- Park, T.; Seo, H.; Kim, H. Fast implementation of simeck family block ciphers using avx2. In Proceedings of the 2018 International Conference on Platform Technology and Service (PlatCon), Jeju, Republic of Korea, 29–31 January 2018; pp. 1–6. [Google Scholar]
- Cabral, R.; López, J. Implementation of the SHA-3 family using AVX512 instructions. In Proceedings of the Anais do XVIII Simpósio Brasileiro de Segurança da Informação e de Sistemas Computacionais. SBC, Natal, Brazil, 25 October 2018; pp. 25–32. [Google Scholar]
- Cheng, H.; Großschädl, J.; Tian, J.; Rønne, P.B.; Ryan, P.Y. High-throughput elliptic curve cryptography using AVX2 vector instructions. In Selected Areas in Cryptography: 27th International Conference, Halifax, NS, Canada, 21–23 October 2020; Revised Selected Papers 27; Springer: Cham, Switzerland, 2021; pp. 698–719. [Google Scholar]
- Alter, D.M.; Schwabe, P.; Daemen, J. Optimizing the NIST Post Quantum Candidate SPHINCS+ Using AVX-512. 2021. Available online: https://www.cs.ru.nl/bachelors-theses/2021/Dor_Mariel_Alter___1027021 (accessed on 25 August 2021).
- Duong-Ngoc, P.; Tan, T.N.; Lee, H. Efficient NewHope cryptography based facial security system on a GPU. IEEE Access 2020, 8, 108158–108168. [Google Scholar] [CrossRef]
- Lee, W.K.; Seo, H.; Zhang, Z.; Hwang, S.O. Tensorcrypto: High throughput acceleration of lattice-based cryptography using tensor core on gpu. IEEE Access 2022, 10, 20616–20632. [Google Scholar] [CrossRef]
- Lee, K.; Gowanlock, M.; Cambou, B. SABER-GPU: A Response-Based Cryptography Algorithm for SABER on the GPU. In Proceedings of the 2021 IEEE 26th Pacific Rim International Symposium on Dependable Computing (PRDC), Perth, Australia, 1–4 December 2021; pp. 123–132. [Google Scholar]
- Gupta, N.; Jati, A.; Chauhan, A.K.; Chattopadhyay, A. Pqc acceleration using gpus: Frodokem, newhope, and kyber. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 575–586. [Google Scholar] [CrossRef]
- Seo, S.C. SIKE on GPU: Accelerating supersingular isogeny-based key encapsulation mechanism on graphic processing units. IEEE Access 2021, 9, 116731–116744. [Google Scholar] [CrossRef]
- An, S.; Seo, S.C. Efficient parallel implementations of LWE-based post-quantum cryptosystems on graphics processing units. Mathematics 2020, 8, 1781. [Google Scholar] [CrossRef]
- Ji, X.; Dong, J.; Zhang, P.; Tonggui, D.; Jiafeng, H.; Xiao, F. HI-Kyber: A Novel High-Performance Implementation Scheme of Kyber Based on GPU. Cryptology ePrint Archive, Paper 2023/1194. 2023. Available online: https://eprint.iacr.org/2023/1194 (accessed on 7 August 2023).
- Pan, W.; Zheng, F.; Zhao, Y.; Zhu, W.T.; Jing, J. An efficient elliptic curve cryptography signature server with GPU acceleration. IEEE Trans. Inf. Forensics Secur. 2016, 12, 111–122. [Google Scholar] [CrossRef]
- Dong, J.; Zheng, F.; Lin, J.; Liu, Z.; Xiao, F.; Fan, G. EC-ECC: Accelerating elliptic curve cryptography for edge computing on embedded GPU TX2. ACM Trans. Embed. Comput. Syst. (TECS) 2022, 21, 1–25. [Google Scholar] [CrossRef]
- Gao, L.; Zheng, F.; Emmart, N.; Dong, J.; Lin, J.; Weems, C. DPF-ECC: Accelerating elliptic curve cryptography with floating-point computing power of gpus. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), New Orleans, LA, USA, 18–22 May 2020; pp. 494–504. [Google Scholar]
- Chugh, G.; Saji, S.A.; Singh Bhati, N. Fast Implementation of AES Modes Based on Turing Architecture. In Advancements in Interdisciplinary Research: First International Conference, AIR 2022, Prayagraj, India, 6–7 May 2022; Revised Selected Papers; Springer: Cham, Switzerland, 2023; pp. 479–489. [Google Scholar]
- An, S.; Seo, S.C. Designing a new XTS-AES parallel optimization implementation technique for fast file encryption. IEEE Access 2022, 10, 25349–25357. [Google Scholar] [CrossRef]
- An, S.; Seo, S.C. Highly Efficient Implementation of Block Ciphers on Graphic Processing Units for Massively Large Data. Appl. Sci. 2020, 10, 3711. [Google Scholar] [CrossRef]
- Choi, H.; Seo, S.C. Fast implementation of SHA-3 in GPU environment. IEEE Access 2021, 9, 144574–144586. [Google Scholar] [CrossRef]
- Wang, C.; Chu, X. GPU accelerated Keccak (SHA3) algorithm. arXiv 2019, arXiv:1902.05320. [Google Scholar]
- Dat, T.N.; Iwai, K.; Matsubara, T.; Kurokawa, T. Implementation of high speed hash function Keccak on GPU. Int. J. Netw. Comput. 2019, 9, 370–389. [Google Scholar] [CrossRef]
- Kuznetsov, A.; Shekhanin, K.; Kolhatin, A.; Kovalchuk, D.; Babenko, V.; Perevozova, I. Performance of Hash Algorithms on Gpus for Use in Blockchain. In Proceedings of the 2019 IEEE international conference on advanced trends in information theory (ATIT), Kyiv, Ukraine, 18–20 December 2019; pp. 166–170. [Google Scholar]
- Iuorio, A.F.; Visconti, A. Understanding optimizations and measuring performances of PBKDF2. In 2nd International Conference on Wireless Intelligent and Distributed Environment for Communication: WIDECOM 2019; Springer: Cham, Switzerland, 2019; pp. 101–114. [Google Scholar]
- Kisa, K. Lightweight Secure Hash Function Open Source Code. 2023. Available online: https://seed.kisa.or.kr/kisa/Board/22/detailView.do (accessed on 31 January 2019).
- Kusswurm, D. Modern Parallel Programming with C++ and Assembly; Apress: Berkeley, CA, USA, 2022. [Google Scholar] [CrossRef]
- Verma, R.; Vishnu, V.; Kataoka, K. Verifiable and Robust Monitoring and Alerting System for Road Safety by AI based Consensus Development on Blockchain. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; pp. 1–8. [Google Scholar]
- Qureshi, R.; Irfan, M.; Ali, H.; Khan, A.; Nittala, A.S.; Ali, S.; Shah, A.; Gondal, T.M.; Sadak, F.; Shah, Z.; et al. Artificial Intelligence and Biosensors in Healthcare and its Clinical Relevance: A Review. IEEE Access 2023, 11, 61600–61620. [Google Scholar] [CrossRef]
- Seng, K.P.; Ang, L.M. Embedded intelligence: State-of-the-art and research challenges. IEEE Access 2022, 10, 59236–59258. [Google Scholar] [CrossRef]
- Kumar, M.; Kaur, G. Containerized AI Framework on Secure Shared Multi-GPU Systems. In Proceedings of the 2022 Seventh International Conference on Parallel, Distributed and Grid Computing (PDGC), Solan, Himachal Pradesh, India, 25–27 November 2022; pp. 243–247. [Google Scholar]
- Kumar, M.; Kaur, G. Study of container-based JupyterLab and AI Framework on HPC with GPU usage. In Proceedings of the 2022 International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Bangalore, India, 23–25 December 2022; pp. 1–5. [Google Scholar]
- Li, H.; Ng, J.K.; Abdelzaher, T. Enabling Real-time AI Inference on Mobile Devices via GPU-CPU Collaborative Execution. In Proceedings of the 2022 IEEE 28th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Taipei, Taiwan, 23–25 August 2022; pp. 195–204. [Google Scholar]
- Bataineh, M.R.; Mardini, W.; Khamayseh, Y.M.; Yassein, M.M.B. Novel and secure blockchain framework for health applications in IoT. IEEE Access 2022, 10, 14914–14926. [Google Scholar] [CrossRef]
- Pandya, S.B.; Sanghvi, H.A.; Patel, R.H.; Pandya, A.S. GPU and FPGA Based Deployment of Blockchain for Cryptocurrency—A Systematic Review. In Proceedings of the 2022 International Conference on Computational Intelligence and Sustainable Engineering Solutions (CISES), Greater Noida, India, 20–21 May 2022; pp. 18–25. [Google Scholar]
- Morishima, S.; Matsutani, H. Accelerating blockchain search of full nodes using GPUs. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 244–248. [Google Scholar]
- Lessley, B.; Childs, H. Data-parallel hashing techniques for GPU architectures. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 237–250. [Google Scholar] [CrossRef]
- CUDA NVIDIA. NVIDIA CUDA Compute Unified Device Architecture Programming Guide. 2007. Available online: https://developer.download.nvidia.com/compute/cuda/1.0/NVIDIA_CUDA_Programming_Guide_1.0.pdf (accessed on 30 October 2023).
- Munshi, A. The opencl specification. In Proceedings of the 2009 IEEE Hot Chips 21 Symposium (HCS), Stanford, CA, USA, 23–25 August 2009; pp. 1–314. [Google Scholar]
- Intel. Intel Advanced Vector Extensions 512 Instructions. 2017. Available online: https://www.intel.com/content/www/us/en/developer/articles/technical/intel-avx-512-instructions.html?wapkw=AVX-512 (accessed on 20 June 2017).
- NVIDIA. CUDA C++ Best Practices Guide. 2023. Available online: https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html (accessed on 14 November 2023).
- NVIDIA. CUDA Toolkit v12.0.1 PTX ISA. 2023. Available online: https://docs.nvidia.com/cuda/parallel-thread-execution/index.html (accessed on 14 November 2023).
- Lightweight Secure Hash Function Source Codes. 2023. Available online: https://github.com/sjnst217/KISA_LSH (accessed on 27 September 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Operation |
|---|---|
| X & Y | Bitwise AND operation of X and Y |
| X|Y | Bitwise OR operation of X and Y |
| X⊕Y | Bitwise XOR operation of X and Y |
| X⊞Y | Modular addition of X and Y in |
| X‖Y | Concatenation of X and Y |
| X≪n | n-bit center shift operation on X |
| X≫n | n-bit right shift operation on X |
| n-bit center rotation operation on X | |
| n-bit right rotation operation on X |
| I | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 3 | 2 | 1 | 0 | 7 | 4 | 5 | 6 | |
| I | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 11 | 10 | 8 | 9 | 15 | 12 | 13 | 14 |
| I | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| [I] | 6 | 4 | 5 | 7 | 12 | 15 | 14 | 13 |
| I | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| [I] | 2 | 0 | 1 | 3 | 8 | 11 | 10 | 9 |
| Operation | Unit | AVX-512 Instruction |
|---|---|---|
| XOR | 32-bit | _mm512_xor_epi32(x, y) |
| 64-bit | _mm512_xor_epi64(x, y) | |
| 512-bit | _mm512_xor_si512(x, y) | |
| OR | 32-bit | _mm512_or_epi32(x, y) |
| 64-bit | _mm512_or_epi64(x, y) | |
| 512-bit | _mm512_or_si512(x, y) | |
| AND | 32-bit | _mm512_and_epi32(x, y) |
| 64-bit | _mm512_and_epi64(x, y) | |
| 512-bit | _mm512_and_si512(x, y) | |
| Left Shift | 32-bit | _mm512_slli_epi32(x, y) |
| 64-bit | _mm512_slli_epi64(x, y) | |
| Modular Addition | 16-bit | _mm512_add_epi16(x, y) |
| 32-bit | _mm512_add_epi32(x, y) | |
| 64-bit | _mm512_add_epi64(x, y) | |
| Rotation | 32-bit | _mm512_rol_epi32(x, imm) |
| 64-bit | _mm512_ror_epi64(x, imm) |
| Operation | Latency | Throughput (CPI) |
|---|---|---|
| 1 | 0.5 | |
| 1 | 0.5 | |
| 1 | 1 | |
| 1 | 1 | |
| 3 | 1 | |
| 3 | 1 | |
| 8 | 0.5 |
| PTX Instruction | LSH-512 Type | Operation |
|---|---|---|
| mov.type dst, src | u64 | dst = src |
| xor.type dst, src1, src2 | b64 | dst = src1 ⊕ src2 |
| or.type dst, src1, src2 | b64 | dst = src1 | src2 |
| shl.type, dst, src, imm | b64 | dst = src ≪ imm |
| shr.type, dst, src, imm | b64 | dst = src ≫ imm |
| add.type, dst, src1, src2 | u64 | dst = src1 + src2 |
| Function | Hash Digest (Bit) | SIMD | Version | Performance (CPB) | ||
|---|---|---|---|---|---|---|
| 16 MB | 4 KB | 64-Byte | ||||
| LSH- 512/224 | 224 | AVX-2 | KISA [42,59] | 1.58 | 1.75 | 8.09 |
| Kim et al. [19] | 1.62 | 1.81 | 14.07 | |||
| AVX_512 | Our Works | 1.31 | 1.42 | 5.38 | ||
| LSH- 512/256 | 256 | AVX-2 | KISA [42,59] | 1.60 | 1.74 | 8.00 |
| Kim et al. [19] | 1.60 | 1.73 | 12.93 | |||
| AVX_512 | Our Works | 1.34 | 1.42 | 5.50 | ||
| LSH- 512/384 | 384 | AVX-2 | KISA [42,59] | 1.58 | 1.76 | 8.25 |
| Kim et al. [19] | 1.59 | 1.86 | 14.64 | |||
| AVX_512 | Our Works | 1.32 | 1.41 | 5.65 | ||
| LSH- 512/512 | 512 | AVX-2 | KISA [42,59] | 1.58 | 1.75 | 8.03 |
| Kim et al. [19] | 1.56 | 1.65 | 8.65 | |||
| AVX_512 | Our Works | 1.31 | 1.42 | 5.51 | ||
| Device | Number of CUDA Streams | |||||
|---|---|---|---|---|---|---|
| 2 | 4 | 8 | 16 | 24 | 32 | |
| RTX 3090 | 131.49 | 149.73 | 159.18 | 163.65 | 164.89 | 167.44 |
| RTX 2080ti | 64.71 | 75.53 | 80.73 | 81.12 | 81.54 | 84.87 |
| Version | Number of CUDA Threads | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 384 | 512 | |
| Naive (3090) | 13.30 | 21.90 | 34.43 | 49.44 | 59.17 | 61.06 | 57.20 | 56.39 | 55.25 | 54.25 | 53.75 |
| Naive (2080ti) | 6.11 | 10.87 | 16.23 | 25.14 | 29.05 | 30.04 | 30.04 | 30.28 | 29.72 | 29.74 | 29.72 |
| Opt. (3090) | 26.13 | 49.67 | 89.08 | 152.88 | 163.94 | 167.29 | 168.70 | 168.05 | 171.43 | 170.49 | 171.35 |
| Opt. (2080ti) | 12.02 | 23.35 | 44.02 | 83.27 | 84.65 | 85.30 | 85.08 | 85.21 | 85.41 | 84.61 | 84.55 |
| Version | Number of CUDA Blocks | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16,384 | |
| Naive (3090) | 1.73 | 16.08 | 25.64 | 33.69 | 44.14 | 51.09 | 55.42 | 62.43 | 59.31 | 57.02 | 52.17 | 55.20 |
| Naive (2080ti) | 1.37 | 16.36 | 25.92 | 28.41 | 31.26 | 31.08 | 30.33 | 30.49 | 29.77 | 30.09 | 30.96 | 30.98 |
| Opt. (3090) | 4.20 | 66.50 | 118.24 | 154.46 | 161.54 | 162.12 | 164.95 | 167.28 | 167.87 | 167.44 | 167.27 | 170.43 |
| Opt. (2080ti) | 2.20 | 30.70 | 66.20 | 73.93 | 78.79 | 82.61 | 83.45 | 83.16 | 83.68 | 84.87 | 85.14 | 85.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.; Choi, S.; Seo, S. Parallel Implementation of Lightweight Secure Hash Algorithm on CPU and GPU Environments. Electronics 2024, 13, 896. https://doi.org/10.3390/electronics13050896
Choi H, Choi S, Seo S. Parallel Implementation of Lightweight Secure Hash Algorithm on CPU and GPU Environments. Electronics. 2024; 13(5):896. https://doi.org/10.3390/electronics13050896
Chicago/Turabian StyleChoi, Hojin, SeongJun Choi, and SeogChung Seo. 2024. "Parallel Implementation of Lightweight Secure Hash Algorithm on CPU and GPU Environments" Electronics 13, no. 5: 896. https://doi.org/10.3390/electronics13050896
APA StyleChoi, H., Choi, S., & Seo, S. (2024). Parallel Implementation of Lightweight Secure Hash Algorithm on CPU and GPU Environments. Electronics, 13(5), 896. https://doi.org/10.3390/electronics13050896