1. Introduction
Hippocampal traveling waves propagate through the hippocampus, a region of the brain associated with learning, memory, and spatial navigation. The generation and propagation of hippocampal traveling waves are believed to play essential roles in information processing and memory consolidation. Experimental studies using techniques such as electrophysiology experiments and functional imaging have provided valuable insights into the mechanisms underlying hippocampal traveling waves. These waves are characterized by synchronized oscillations of neuronal firing and can occur in various frequency and speed ranges, such as theta (4–12 Hz) or gamma (30–100 Hz) frequencies [
1]. Through in vitro electrical stimulation experiments, two distinct types of hippocampal traveling waves have been identified. The two types of traveling waves exhibit a significant difference in speed, and they are commonly differentiated based on the terms “fast spikes” and “slow waves” [
2]. Further in vitro experiments have revealed that the propagation of these two types of waves does not depend on synaptic transmission but rather resembles electrical field conduction [
3,
4]. However, these experiments are constrained by factors such as cost, reproducibility, and ethical limitations. Furthermore, in vitro experiments are prone to accidental errors in experimental conditions and procedural variability, leading to poor reproducibility of results. To address this issue, the academic community has proposed the idea of using model simulations as a substitute for in vitro hippocampal electrical stimulation experiments.
To overcome the limitations of in vitro experiments [
1], researchers have conducted modeling and simulation studies on hippocampal arrays to investigate the mechanisms underlying hippocampal traveling waves [
5]. By establishing dual-cell models, replication of both fast and slow waves in the hippocampus has been achieved. In larger-scale simulations, the Hodgkin-Huxley neuron model (also abbreviated as H-H model) has been used to replace hippocampal pyramidal neurons, revealing the involvement of calcium ion channels in the generation of hippocampal slow waves [
6]. Through the use of membrane potential heatmaps, the propagation process of hippocampal fast spike sequences has been replicated, and the wave sources of fast spikes are believed to be in a continuous motion [
3]. These findings have significantly advanced our understanding of hippocampal traveling waves. Further experiments using hippocampal network simulations have been conducted to study the working mechanism of the human brain.A systematic study was conducted on the hippocampal sharp wave by combining model simulation and cognitive map experiments [
7]. A small-scale two-dimensional model was established to simulate the state-dependent conduction of hippocampal traveling waves [
8]. In silico simulations often require high computational power and memory resources and may not perform well in certain applications that require high real-time performance and convenience. In order to conduct hippocampal electrical stimulation simulations more efficiently, this study attempts to integrate simulation with an embedded semi-physical simulation platform.
A semi-physical simulation platform is a technology used for conducting simulation experiments that combines the characteristics of physical and computational models [
9]. It can reduce the cost and risks associated with experiments by avoiding the need for expensive physical equipment and potential damage [
10]. Secondly, it provides a more flexible experimental environment that allows for the simulation of various scenarios and conditions by adjusting model parameters and settings [
11,
12]. It finds wide application in research and development in fields such as transportation, aerospace, and energy [
11,
12]. In the context of hippocampal research, the semi-physical simulation platform also holds promise as an excellent alternative to in vitro electrical stimulation experiments. Researchers used an in-the-loop simulation system to control the neuron system of a person with tetraplegia [
13]. The in-the-loop simulation platform has been deployed to stimulate the temporal lobe of the hippocampus in an attempt to treat brain diseases and improve brain performance [
14]. However, there are several challenges associated with applying semi-physical simulation to hippocampal electrical stimulation experiments. The huge scale of hippocampal computing models poses higher demands on the computational power and real-time performance of simulation platforms [
15,
16].
Many previous studies have attempted to optimize the integration of semi-physical simulation platforms with neuronal models to achieve a better fit. In previous research [
17], the authors summarized and reviewed a semi-physical simulation of a flight system on embedded microprocessors. However, specific recommendations were not provided for platform construction for specific microprocessors. In addition to improving the computational capability of individual microprocessors, improving system architecture and enhancing communication and data transmission efficiency can also significantly enhance the computational capability of simulation platforms. Optimizations of the hippocampal array two-compartment model have also been conducted, such as upgrading the model from one-dimensional to two-dimensional and transforming the single-compartment model into a dual-compartment model, making the simulation of the neuronal array closely resemble the physiological functioning of the hippocampus [
18]. In a study by [
19], the authors discussed several techniques for reducing the computational complexity of H-H model neurons, including network pruning and structural simplification, making these models more suitable for deployment on resource-constrained devices such as smartphones or embedded systems. Efficient real-time simulation has been achieved under limited computing resources to simulate the behavior of neural dynamics in real-time in embedded systems like FPGA and Raspberry Pi [
20,
21]. These studies provide insights into the simplification of the hippocampal neuronal array and making it more suitable for small-scale embedded computing platforms.
In this work, we aim to build a hardware platform for simulating hippocampal arrays based on ARM, providing the possibility of building a semi-physical simulation system suitable for hippocampal electrical stimulation experiments. Solutions to several key issues in the implementation process are proposed. A distributed computing method for the hippocampal array is attempted to be proposed, and a parallel computing hardware platform based on ARM is built for simulating epilepsy, thereby providing the possibility of embedded edge computing for epileptic focus localization. Solutions to several key issues in the implementation process are presented.
The remaining sections of this article are organized as follows. In
Section 2, we introduce the hippocampal neuron array used in the semi-physical simulation platform and present the simulation results on a GPU platform. We analyze the advantages of this model in terms of simulation. In
Section 3, we describe the structure of the semi-physical simulation platform and discuss how the parallel computing platform is utilized to enhance the overall computational power of the platform, providing a computational foundation for simulations conducted on the platform.
Section 3 focuses on the algorithm simplification and task allocation mechanism for the hippocampal pyramidal neuron model suitable for the simulation platform. We optimize the floating-point computation process in the network, enabling the platform to overcome some of the difficulties associated with virtual simulation. Moving forward, in
Section 4, we present the experimental validation and results analysis. The experiments aim to demonstrate the feasibility and effectiveness of the semi-physical simulation platform. Finally, in
Section 5, we provide a summary of this article.
4. Optimization of Hippocampal Network Model for Real-Time Operation in Embedded Computing Platform
The hippocampal neural array is a novel simulated neural model that employs the Hodgkin-Huxley (H-H) model, which closely approximates the physiological state of pyramidal neurons, to simulate the states of pyramidal neurons within the hippocampus. A typical hippocampal array represents pyramidal neurons spanning from the temporal to septal regions of the hippocampus. The hippocampal model used for simulating epilepsy focuses primarily on the electric field propagation among pyramidal neurons, which differs from traditional synaptic and chemical transmission. Due to the influence of electric field propagation, the behavior of pyramidal neurons is no longer solely dictated by direct connections with neighboring layers, but rather determined collectively by all pyramidal neurons within the neural array. On a multi-core embedded parallel computing platform, the neural array needs to perform segmented computations and integrate the computed results. The algorithm implemented on the routing board determines the location and movement speed of the current epileptic focus based on the real-time membrane potentials of pyramidal neurons within the array, transmitted by the computing cores. The forward computation process of the model involves extensive matrix multiplication and floating-point calculations. As the dimension and size of the model used in simulations increase, the computational complexity of the pyramidal neural array exhibits exponential growth. Conducting sequential computations on a single chip would result in substantial time costs. Furthermore, the limited storage space on the embedded platform requires significant storage resources to preserve weight parameters during each iteration step. Prior to integrating the model into the parallel computing platform, these two challenges must be addressed. To address these challenges, we propose mechanisms for dimensionality reduction initialization and model weight distribution for the hippocampal model, aiming to resolve the storage and computational limitations that restrict the application of the model.
4.1. Computation Reduction Initialization of Hippocampal Pyramidal Neuronal Networks
On a multi-core embedded hardware platform, there are several challenges in implementing distributed parallel computation for hippocampal models. When implementing hippocampal models on hardware platforms, the first consideration is the hardware storage resources [
28]. The memory size of STM32F4 series chips is 192 KB, including 128 KB of RAM and 64 KB of CCRAM. In the computation of each pyramidal neuron layer, memory needs to be allocated for the input and output data of that layer, i.e., the initialization of the network layer.
To address the challenge of limited memory resources, we propose a method that combines dynamic memory allocation and dimensionality reduction initialization. Dynamic memory allocation is a technique used for allocating and managing computer memory resources. It allocates the required memory from a memory pool when executing a memory application. After processing the data, the memory resources are released and reclaimed. However, due to the non-continuous addresses of the two random access memory (RAM) modules, the actual RAM size that supports dynamic memory allocation is limited to 128 KB. Therefore, the amount of data allocated through dynamic memory allocation cannot exceed this limit at any time.
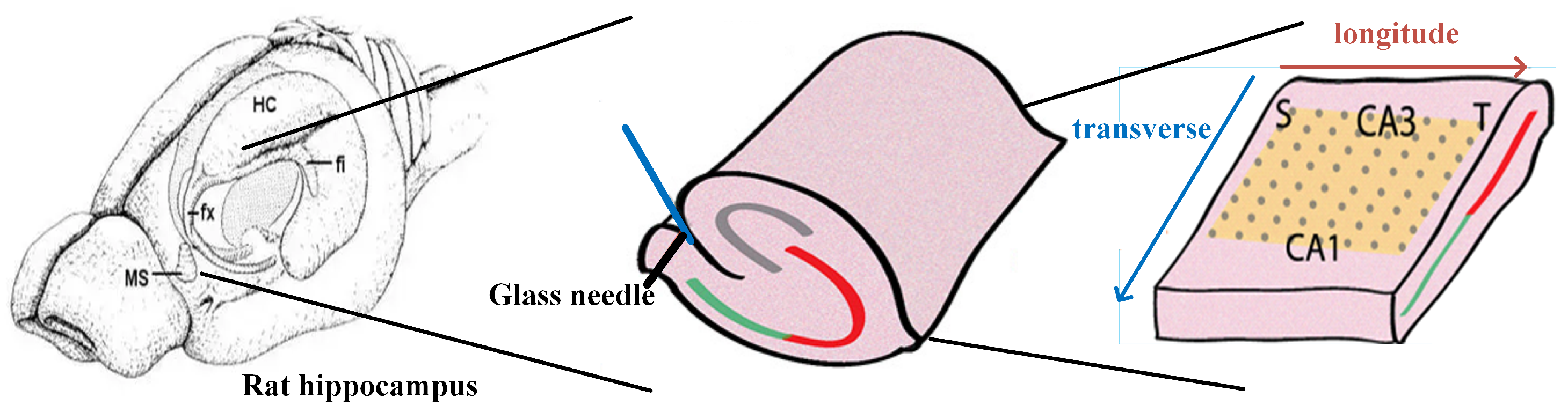
Since individual network layers typically involve a large amount of data, relying solely on dynamic memory allocation is not sufficient. To address this issue, we propose a dimensionality reduction initialization method. Typically, the physiological structure of the hippocampal array is a curved spiral, which is often flattened into a rectangular slice in experiments, and the model simulates a pyramidal neuronal array within a cuboid between the temporal lobe and the septum. The electric field propagation in the hippocampal pyramidal neuronal network is represented as three-dimensional conduction, where the electric field can propagate in any direction within the cuboid. Through dimensionality reduction initialization, we allocate memory only for a two-dimensional matrix (i.e., a single feature map) when initializing an individual network layer. Once the computation within a single stride is completed, we transfer the data to dual-port RAM, erase the data of the current stride, and write the data for the next stride. If the amount of data generated within a single iteration stride is still too large, we can further reduce the dimensionality of the matrix allocation by allocating memory for multiple two-dimensional arrays, avoiding the creation of large three-dimensional arrays and reducing the amount of data transmitted during the communication process. This approach minimizes the impact on the hippocampal network while optimizing the utilization of platform memory.
4.2. The Memory Allocation Mechanism in the Hippocampal Pyramidal Neuron Network
For large-scale neural networks like the hippocampal pyramidal neuron network, the storage consumption of membrane potential parameters typically increases exponentially with network size. In order to achieve a trade-off between network accuracy and computational cost, the hippocampal neuron network adopts two strategies: potential value quantization and efficient memory mapping, to reduce the computational, communication, and storage overhead.
During the iteration process of the hippocampal array, there are a significant number of floating-point operations. Although the STM32F4 series microprocessors are compatible with floating-point operation modules, the transmission cost and memory usage of floating-point numbers are much higher than those of integer numbers. When using random inputs, inference can be achieved using low-bit-width weights without significant loss in discrimination accuracy. Similarly, in the process of discerning the location of wave sources, reducing the data bit width can be employed by using binary weights instead of full-precision floating-point weights. To maintain computational accuracy, floating-point parameters are still used in the calculation board, but the number of bits for floating-point numbers is reduced from 32 bits on the CPU platform to 8 bits, reducing the data overhead during communication and memory processes. After the computation is completed, the calculation results of the pyramidal neurons are quantized by the calculation core. The quantization function used in this paper can be represented as:
where
represents the initial continuous weight, and
represents the quantized weight. This formula allows the mapping of the neuron’s weights to k-bit binary numbers in
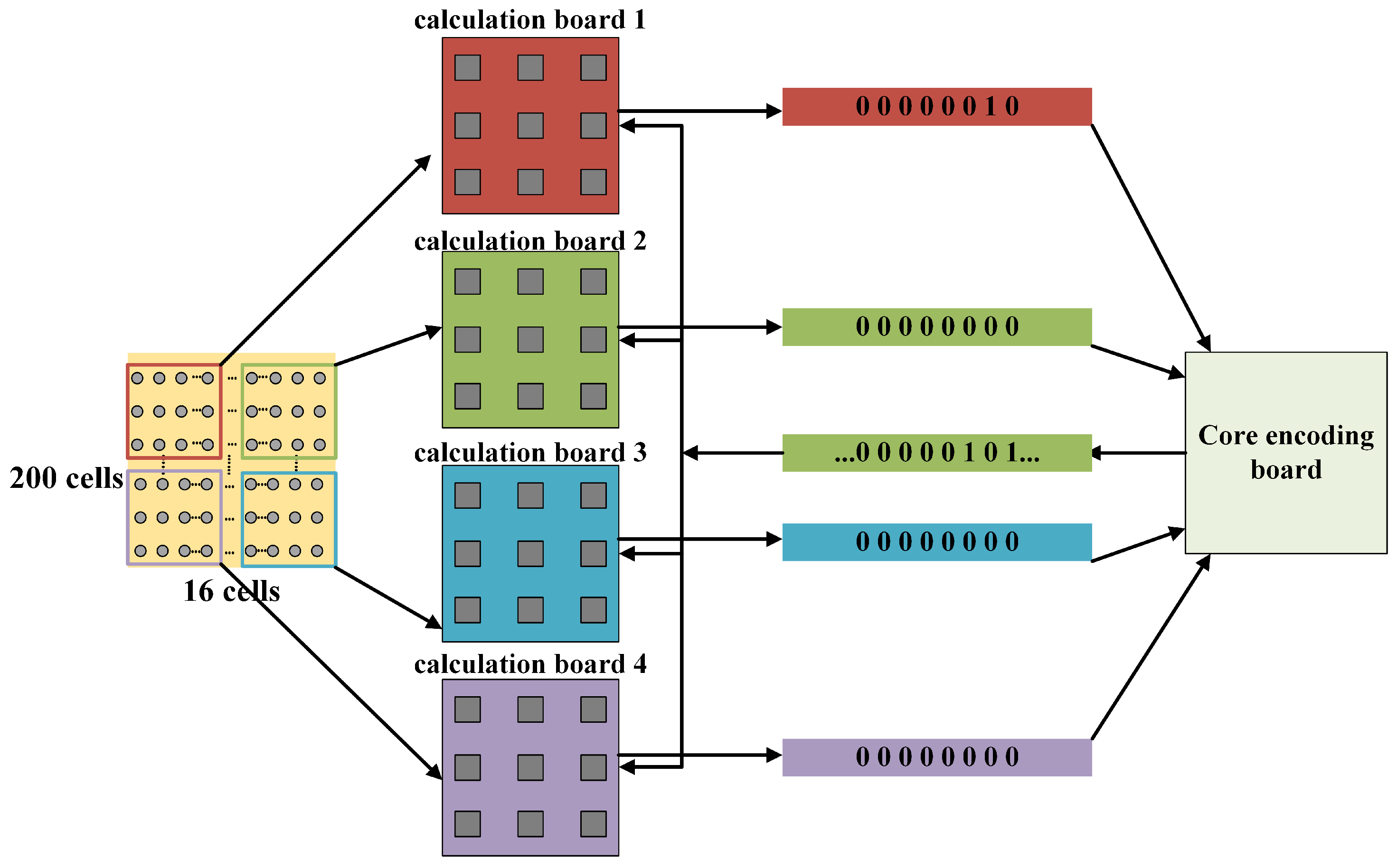
Figure 8. A smaller quantized weight bit width has a greater impact on the accuracy of position determination. The calculation board transmits these binary weight values to the routing board, which locates the current fast and slow wave sources within the array based on the binary weight values of the neuron array.
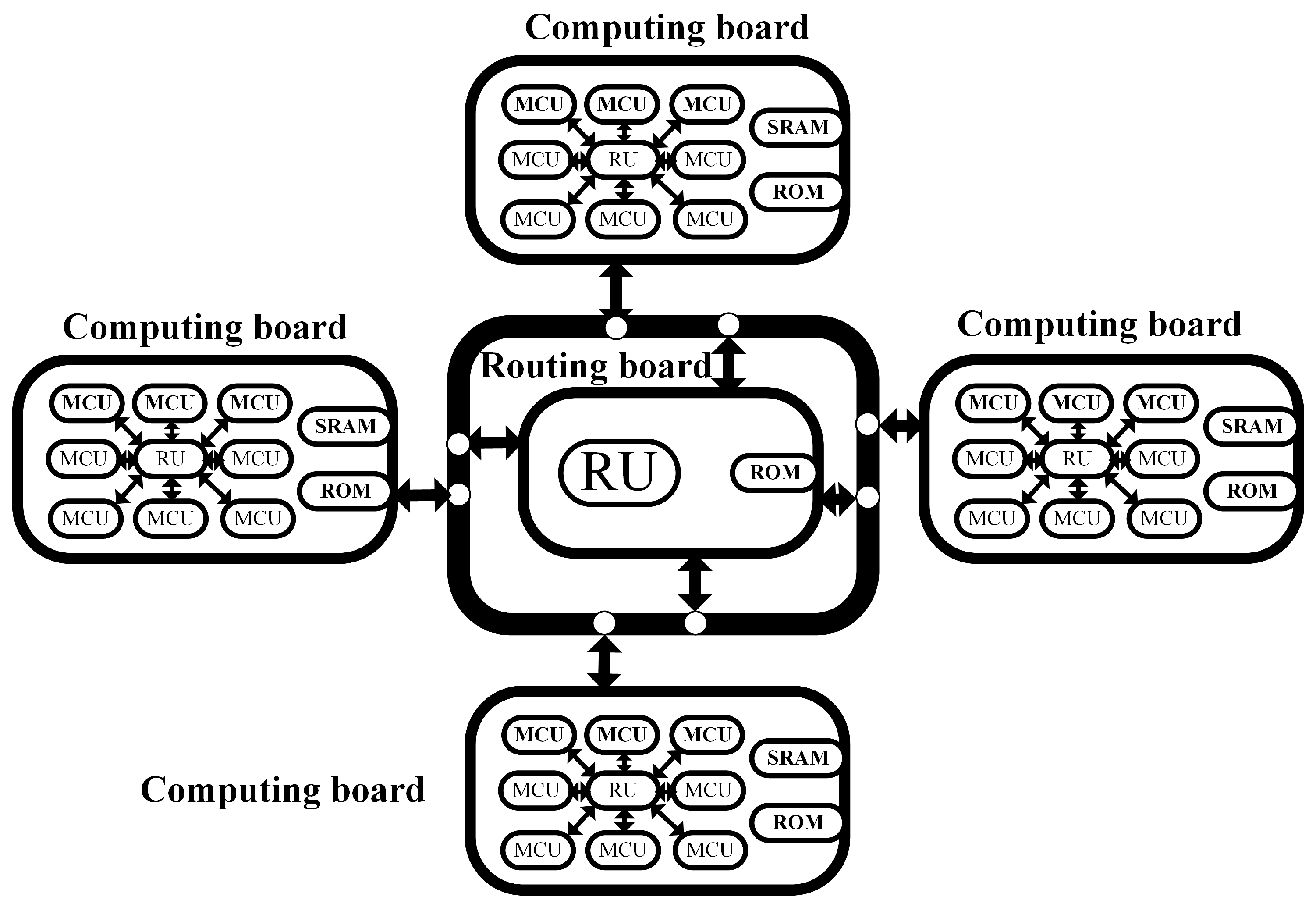
Another key aspect of implementing the CNN model on a multi-core embedded hardware platform is how to effectively map the neuron array to multiple computing units. We propose a hippocampal array distribution mechanism based on the computing and communication capabilities of the calculation cores. This mechanism includes horizontal layering, bidirectional conduction, and weight calculation. Through this approach shown in
Figure 9, the entire network can be gradually dispersed.
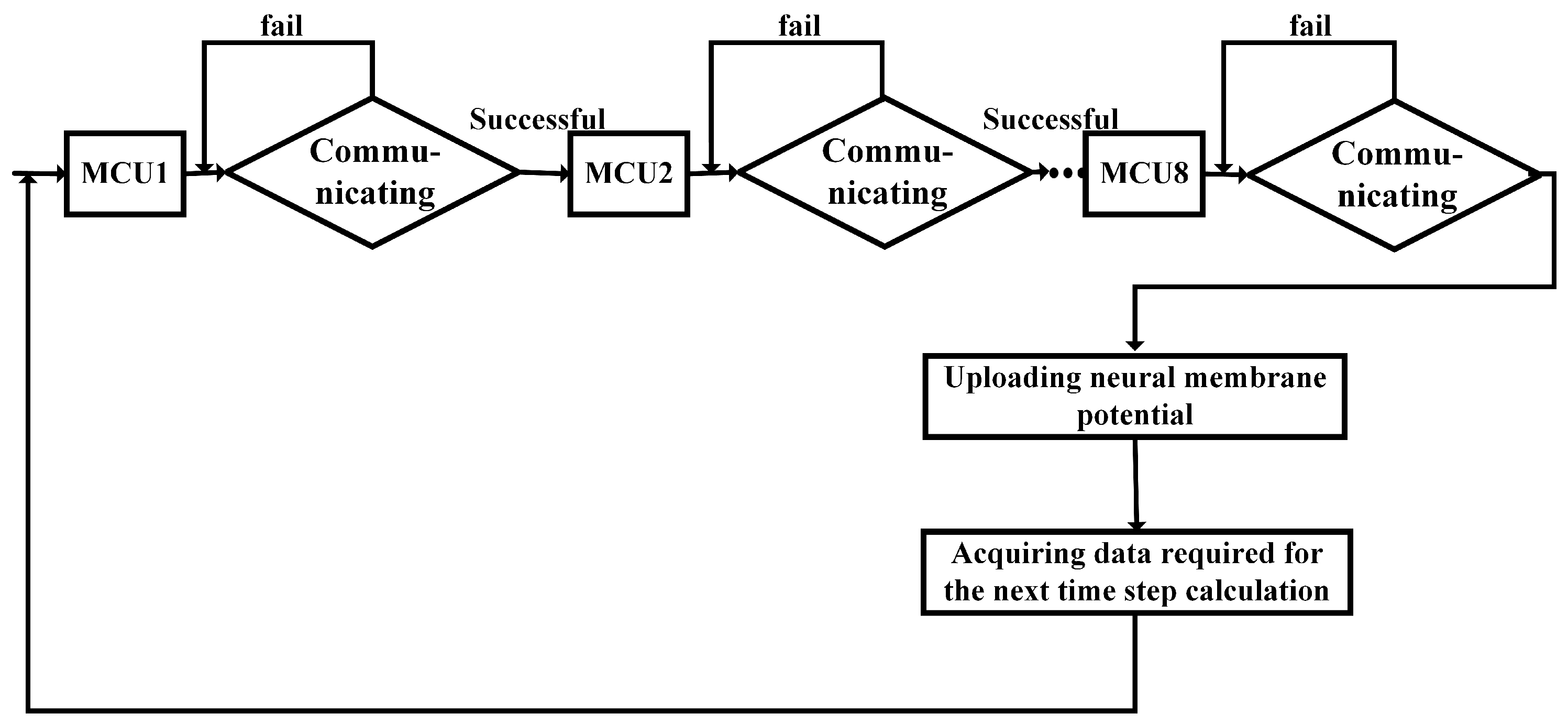
As a parallel network model, the hippocampal neuron array itself does not have a hierarchical structure, and the pyramidal neurons are influenced by all the neurons within the array. At the same time, all neurons complete one time-step iteration in different computing cores. Due to the fixed computational tasks of each computing unit, when executing the hippocampal network mapping, issues such as inter-module data dependencies and load balancing need to be considered. All neurons in the four calculation boards complete the computation of the first iteration step based on the initial conditions provided by the routing board, and the membrane potential weight conversion is performed within the calculation board. The calculation board stores the current time-step neuron potentials in dual-port SRAM, transfers the weights to the routing board for wave source determination, and waits in the routing board for permission from the host computer to transmit the computation results. This process is looped for the next time step.
5. Results
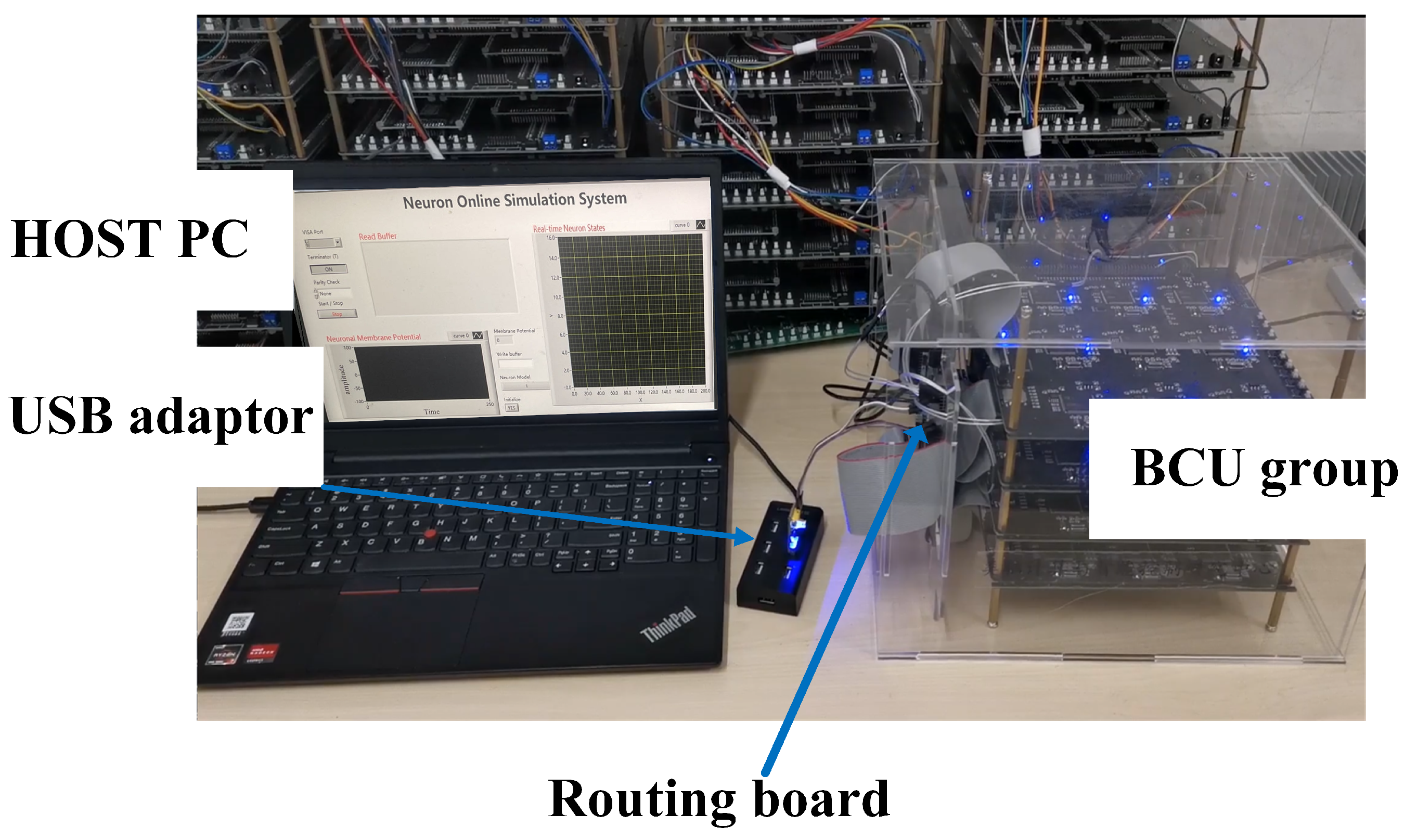
In the experiment, real-time electrical stimulation simulation of hippocampal arrays was successfully conducted on an embedded platform, and real-time display of simulation results was achieved on the host computer (
Figure 10). The membrane potential of neurons was displayed in the lower-left corner, while the discharge status of the current neuron array was displayed in the upper-right corner. By observing the discharge patterns, the current wave source situation within the array can be inferred. The real-time display of membrane potentials in different compartments of neurons revealed slow wave oscillations in the apical dendritic membrane potential and fast wave oscillations in the basal dendritic membrane potential. By modifying the conductance of relevant neuron channels, similar physiological changes in the propagation of fast and slow waves were observed, consistent with previous model simulation results. Furthermore, by displaying the discharge patterns of the neuron array on the host computer, the researchers were able to observe the propagation of fast waves within the neuron array, as depicted in
Figure 10. This demonstrated the correctness and rationality of the semi-physical simulation platform throughout the entire simulation process.
The membrane potentials obtained from in silico simulations will be imported into data analysis software for further analysis. By comparing the results with those obtained from previous in silico simulations, the following results, as shown in
Figure 11,
Figure 12,
Figure 13 and
Figure 14, were obtained. In
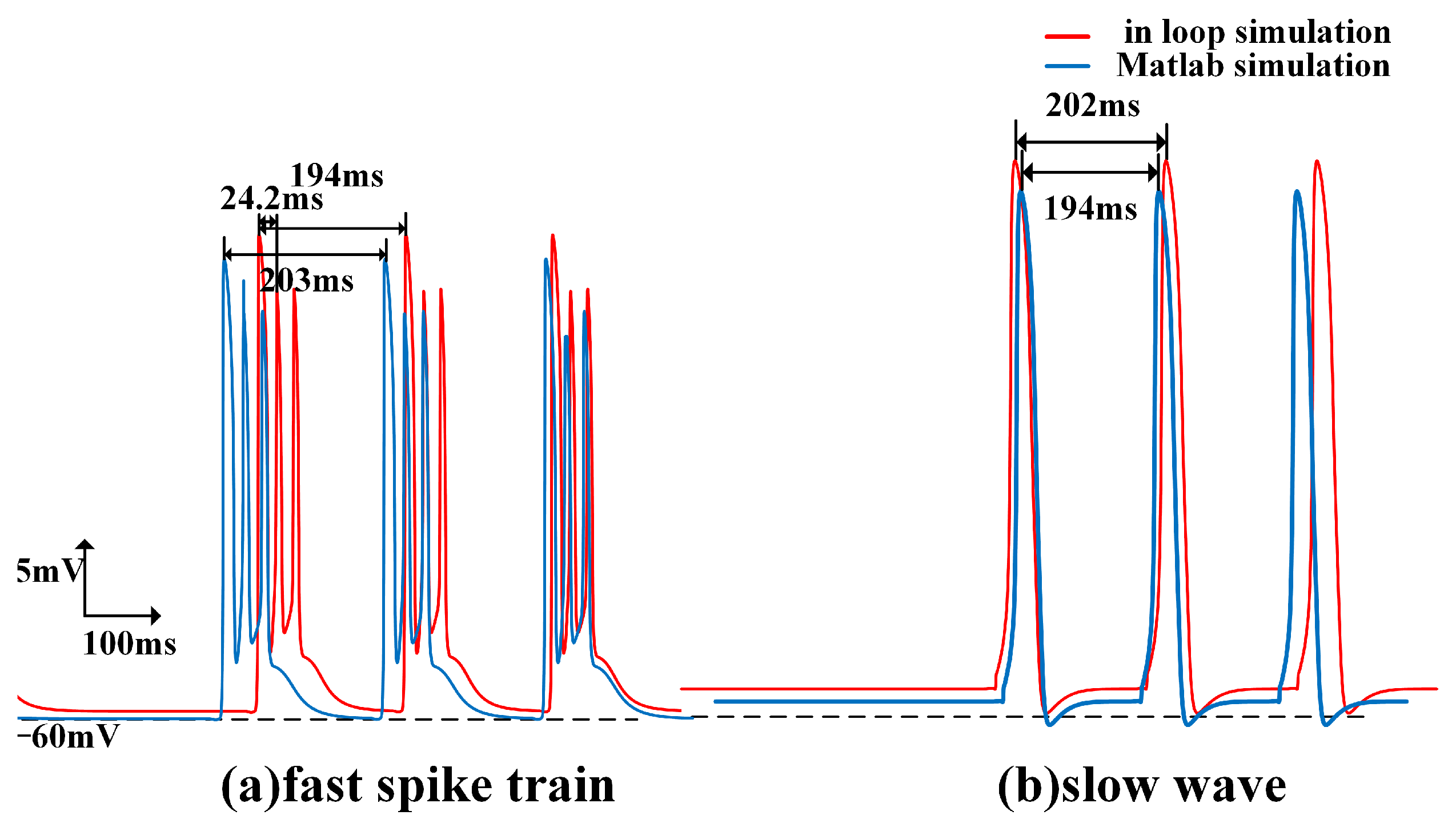
Figure 11, the fast spike and slow wave obtained from the in-loop simulation showed similarities with the results obtained from in silico simulations. The traveling waves obtained from platform simulation have the same waveform and similar traveling wave speed.
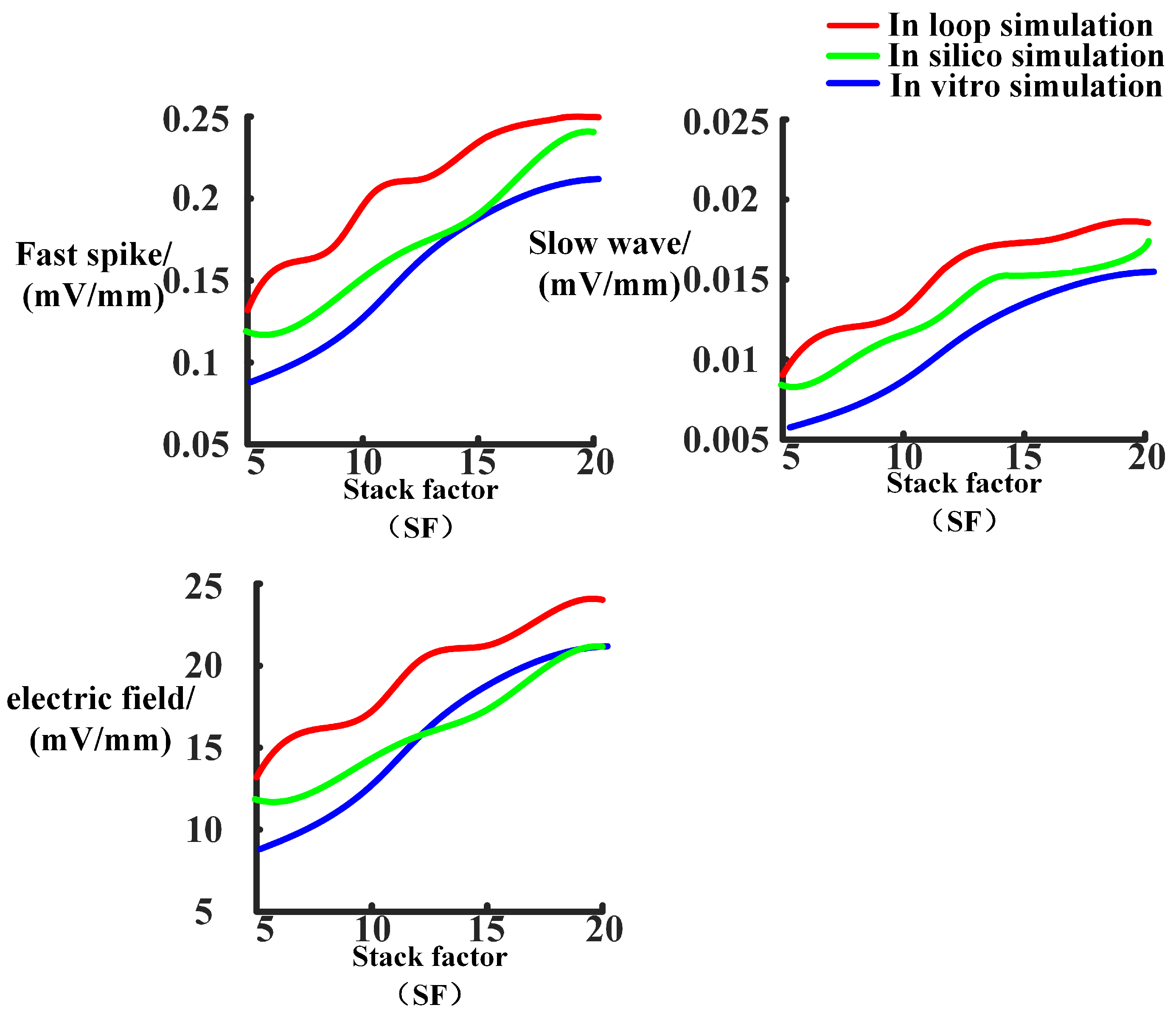
Figure 12 illustrates the changes in the excitability of fast and slow waves and the coupling strength of the electric field within the neuron array after adjusting the model stacking coefficient. The in-loop simulation platform, in silico platform, and in vitro experimental results show the same trend of change which proved the reliability of simulation platform.
Figure 13 illustrated the comparison of parameters related to fast spikes and slow waves, showing that the in-loop simulation results were consistent with the in silico simulation results.
Figure 14 illustrated the comparison of parameters related to fast spikes and slow waves, showing that the in-loop simulation results were consistent with the in vitro experiment results. Within the neuronal array, the propagation of fast spikes and slow waves could be observed, as shown in
Figure 15 and
Figure 16. The simulation revealed that the source of fast waves was not located at a fixed position. Over the 300 ms of simulated observation, two instances of fast wave propagation with different source positions within the array were detected. On the other hand, during the simulation of slow waves, the position of the slow wave source remained relatively constant, and the velocity was significantly slower compared to fast waves. The obtained results are consistent with the simulated results within the computer.
When compared to in silico simulations, the in-loop simulation exhibits an increase in variance in the measured data and a decrease in measurement accuracy due to parameter and model simplifications (
Figure 13). Compared with the results obtained from the same scale model simulation conducted on the computer, the average error of fast and slow wave velocities is 4.6%, and the variance of wave velocity measurement has increased by 8.2%. However, considering the optimization of computational power and memory achieved through these simplifications, the minor sacrifice in accuracy is acceptable. Regarding the propagation of waves, the simplified model scales result in changes to the observed wave propagation process. The phenomenon of fast wave source movement within a single cycle is observed only once. Nevertheless, the in silico simulation on the embedded platform still adequately reflects the conduction process of traveling waves within the hippocampus.
After verifying the accuracy of the simulation results within the loop, the real-time performance and feasibility of the loop simulation platform are tested using various computations. A hippocampal pyramidal neuron array model with different input sizes was implemented on this hardware platform. The hippocampal models with varying input sizes are shown in
Figure 17A. Different experiments were designed to verify the effectiveness of dimensionality reduction initialization and the hippocampal distribution mapping mechanism during the implementation process. Finally, an analysis of the platform’s runtime, resource consumption, and power usage was conducted.
The effectiveness of the method was validated by comparing the memory usage of the models before and after dimensionality reduction initialization.
Figure 8 indicates the memory required by each model during the computational process when the input model size is a 200 × 16 three-dimensional array and a 200 × 16 three-dimensional array. For an input neuron matrix array size of 200 × 200, the memory required for data from 100 H-H neurons could be accommodated by a single chip. However, when the input pyramidal neuron matrix size is 200 × 200, the memory required for a single network layer exceeds the platform’s maximum memory capacity. Therefore, the experiments primarily focused on the 200 × 16 pyramidal neuron array.
Different sizes of hippocampal neural array models were implemented on an embedded platform without considering real-time performance. The algorithms used in this article are mostly linear operations on two-dimensional matrices. The time complexity of the algorithm is O (
) and the spatial complexity of the algorithm is also O (
). To evaluate the platform’s real-time performance, the neural network dynamics were simulated within a 100-second timescale, with a simulation time step of 1 ms and a total of 10,000 iterations of neuron computations.
Figure 17 illustrates the time consumption. When the model’s input size is 200 × 16 × 3 H-H pyramidal neurons, the model’s runtime reaches 154 s, exceeding the required 100 s for real-time performance. The majority of the network computation time is occupied by floating-point calculations and communications. After optimizing the floating-point calculations, the system’s real-time performance was further tested. As the number of H-H neurons increased, the simulation time on the platform also increased. When the number of H-H pyramidal neurons in the platform reached 3200, the simulation time reached 94 s, indicating that the model simulation has some level of real-time performance after lightweight improvements. Compared to two-dimensional matrix simulation, the simulation time of the reduced-dimensional three-dimensional neural network array exhibits a smaller increase.
For the embedded computing platform, memory resource consumption primarily includes SRAM and FLASH. When the input matrix size is 200 × 16, the platform’s memory requirements can be met. Therefore, dimensionality reduction initialization was performed on the hippocampal pyramidal neuron array to reduce the input size to a 200 × 16 two-dimensional matrix. The computation of the three-dimensional neuron array was transformed into a two-dimensional matrix computation using stacking coefficients.
Figure 17C demonstrates that the memory occupied by the initialization of a single network layer in the 200 × 16 pyramidal neuron model, after dimensionality reduction initialization, is effectively limited within the chip’s memory size. Each computing core, consisting of 100 H-H pyramidal neurons, occupies 7 kB of on-chip SRAM space and 24.4 kB of on-chip FLASH space. With the platform supporting 512 KB FLASH and 128 KB SRAM, the on-chip memory resources can accommodate the required size of the neuron cluster for this model computation. The analysis results demonstrate the effectiveness of dynamic memory allocation and dimensionality reduction initialization methods. This approach can fully address the issue of insufficient memory.
Through the aforementioned experimental tests, we have demonstrated the computational feasibility of the optimized hippocampal pyramidal neuron model on the parallel computing platform. We have obtained corresponding results through computations, and the discharge waveforms of the pyramidal neurons and the discharge point map of neurons within the array can be observed through the host computer platform. The routing board can determine the location of the current wave source based on the weights. It is evident that the pyramidal neuron array can perform its intended tasks excellently on the embedded parallel platform.
The time consumed during a single computation process by the MCU computing core includes both the polling communication time and the computation time. Under the assumption of constant computing power, a lower polling time indicates a smaller proportion of the computation cycle dedicated to polling, implying that more resources are allocated to the computation task, thereby improving computational efficiency. The Percentage of Polling Time (PCP) is defined as:
where
represents the polling time and
represents the computation cycle time. By varying the number of H-H neurons within the computing unit, the polling time during the iterative computation process is measured, as shown in
Figure 17D. It can be observed that when the number of neurons is small, a significant portion of system resources is allocated to polling communication. As the number of H-H neurons reaches around 100, the PCP approaches 50%, indicating that half of the resources are dedicated to computation. The curve demonstrates that deploying a large number of neurons in the MCU can reduce the impact of polling time on the experiment. However, an excessive number of neurons may compromise system real-time performance. Taking various factors into consideration, setting 100 H-H neurons within a single MCU is acceptable in terms of platform efficiency and system real-time performance.
Table 1 provides the power consumption of the hippocampal pyramidal neuron array platform before and after optimization in the experiments. The platform current is measured from the system’s power supply, and the consumption of storage components such as SRAM can be obtained through burning software.
Table 2,
Table 3 and
Table 4 compares the performance of embedded platform with computer simulation. The hippocampal traveling wave velocity obtained from embedded platform and CPU simulation were compared and the error between the two simulations was obtained. By comparison, it can be seen that the error of the embedded platform has increased by 1.2% compared to CPU simulation. CPU simulation speed is faster than embedded platforms. The energy consumption of CPU during simulation is much higher than that of embedded platforms. Notably, when the number of computational bits is increased, the simulation error between CPU simulation and embedded simulation becomes more comparable. However, increasing the number of computing bits on embedded platforms means a decrease in real-time simulation performance. After increasing the number of simulation bits to eight, the simulation time of the platform exceeds 100 s, and the platform no longer has real-time performance. From the data in the table, it can be inferred that after optimization such as dimensionality reduction and weight parameter compression, the hippocampal pyramidal neuron network can perform real-time simulation operations at a lower power consumption and relatively high speed within the acceptable range of a 1.2% decrease in accuracy. The platform accomplished the simulation computing task with a power consumption of 486.6 mW. It exhibits a significant advantage in power consumption while the power consumption of the Raspberry Pi Zero typically ranges from 1.0 to 1.5 watts and the Raspberry Pi 4B has relatively higher power consumption, typically ranging from 3.5 to 7.0 watts. This is one of the significant advantages of the platform in specific application scenarios.
6. Discussion and Conclusions
The loop simulation system provides a promising platform for simulating hippocampal electrical stimulation experiments. In this study, an embedded parallel computing platform was used to perform loop simulations of hippocampal electrical stimulation, and the simulation performance of the loop simulation system was evaluated. The experimental results demonstrate that the neural network parallel computing hardware platform can realize the hippocampal pyramidal neuron array. It offers advantages such as low power consumption, scalability, and low cost. Additionally, the effectiveness of dimensionality reduction initialization and pyramidal neuron distribution mechanism in achieving real-time simulation of epileptic neural networks has been validated. In future work, we will consider modifying the communication method and control chip of the board. Faster data transmission and higher-end chips can better guarantee real-time performance. Building upon the current architecture, we can replace the relatively low-frequency and computing-power STMF407 series chips currently used on the platform with more powerful chips to achieve more efficient computational capabilities.
The real-time of model computations is one of the core issues in convolutional neural network hardware acceleration. Real-time performance is mainly limited by computational capabilities and inter-core communication latency. In this experiment, we demonstrated the effectiveness of high-speed communication through shared RAM. However, the performance of the hardware platform has not been fully utilized, and future work needs to discuss methods for achieving higher computational capabilities. Introducing more powerful cores and larger chip external storage space under the current architecture can accommodate diverse inter-chip communication methods. Additionally, the platform currently only supports operations on large-scale hippocampal arrays, limiting its application scope. However, other physiological neural networks can perform distributed computations based on the structure of our platform.In the future, we will investigate the performance of other physiological neural networks on the platform. In this experiment, we demonstrated the effectiveness of high-speed communication through shared RAM. However, the performance of the hardware platform has not been fully utilized, and future work needs to explore methods for achieving higher computational capabilities. Under the current architecture, introducing more powerful cores and larger external storage space can accommodate more diverse external communication methods. In future research, we will continue to optimize our platform and adapted networks in two aspects: reducing network size and compressing weight parameters to achieve more diverse parallel computational capabilities.
In addition, we plan to further expand the application scenarios of the platform by adding hardware resources such as EEG monitoring and camera modules to enable real-time monitoring of epileptic patients. Furthermore, the current platform can only support operations on large-scale hippocampal arrays, limiting its application scope. However, other physiological neural networks can be distributed computations based on the structure of our platform. In future research, we will explore the performance of other physiological neural networks on the platform. Based on the hippocampal pyramidal neuron experiment, we also conducted experiments on more complex Rubin-Terman physiological neural networks on the platform. In addition to designing multi-core systems, we have also designed a lightweight physiological neural network for multi-core systems to optimize the model deployment process and make network design more suitable for the hardware. In future research, we will continue to optimize our platform and adapted networks in two aspects: reducing network size and compressing weight parameters to achieve more diverse parallel computational capabilities.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















