
Offloading Decision and Resource Allocation in Mobile Edge Computing for Cost and Latency Efficiencies in Real-Time IoT

 , , ,
, , , 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Research Problem and Contribution
- The proposed Lagrange Duality Resource Optimization Algorithm (LDROA) has a unique workflow because the algorithm can make intelligent offloading decisions and optimize resources for tasks on edge servers, thereby reducing the total cost and total latency. This method guarantees that the collective resources of the MEC servers adequately fulfills the task demands and time limitations, all the while conserving energy on the user devices. This method can achieve superior performance by reducing energy consumption in user devices and achieving optimal latency for IoT applications.
- The joint resource allocation and offloading decision can minimize the total computing overhead of tasks, including completion time, according to time constraints of IoT applications. The proposed approach aims to provide benefits for user device energy consumption, which can increase battery lifetime without the need for frequent charging. LDROA can solve the problem well by providing smart offloading decision and optimal resource allocation for tasks offloaded to MEC.
- Our optimization technique enables the conversion of a constrained optimization problem into an unconstrained one by introducing Lagrange multipliers to form a dual problem, which allows for the optimization of the minimization to lower bound for energy, latency, and cost. The simulation setup is executed for multiple congestion conditions with optimal performance in terms of total latency and costs.
- The algorithm demonstrates superior performance compared to existing methods, such as Random Offloading, Load Balancing, and Greedy Latency scheme, particularly in terms of reducing total latency and achieving cost savings. It pursues a dual optimization strategy, aiming to simultaneously address both latency reduction and energy consumption efficiency. By considering these two crucial aspects, the algorithm ensures not only improved system responsiveness, but also enhanced energy efficiency across the network.
2. Related Works
3. Proposed System Model
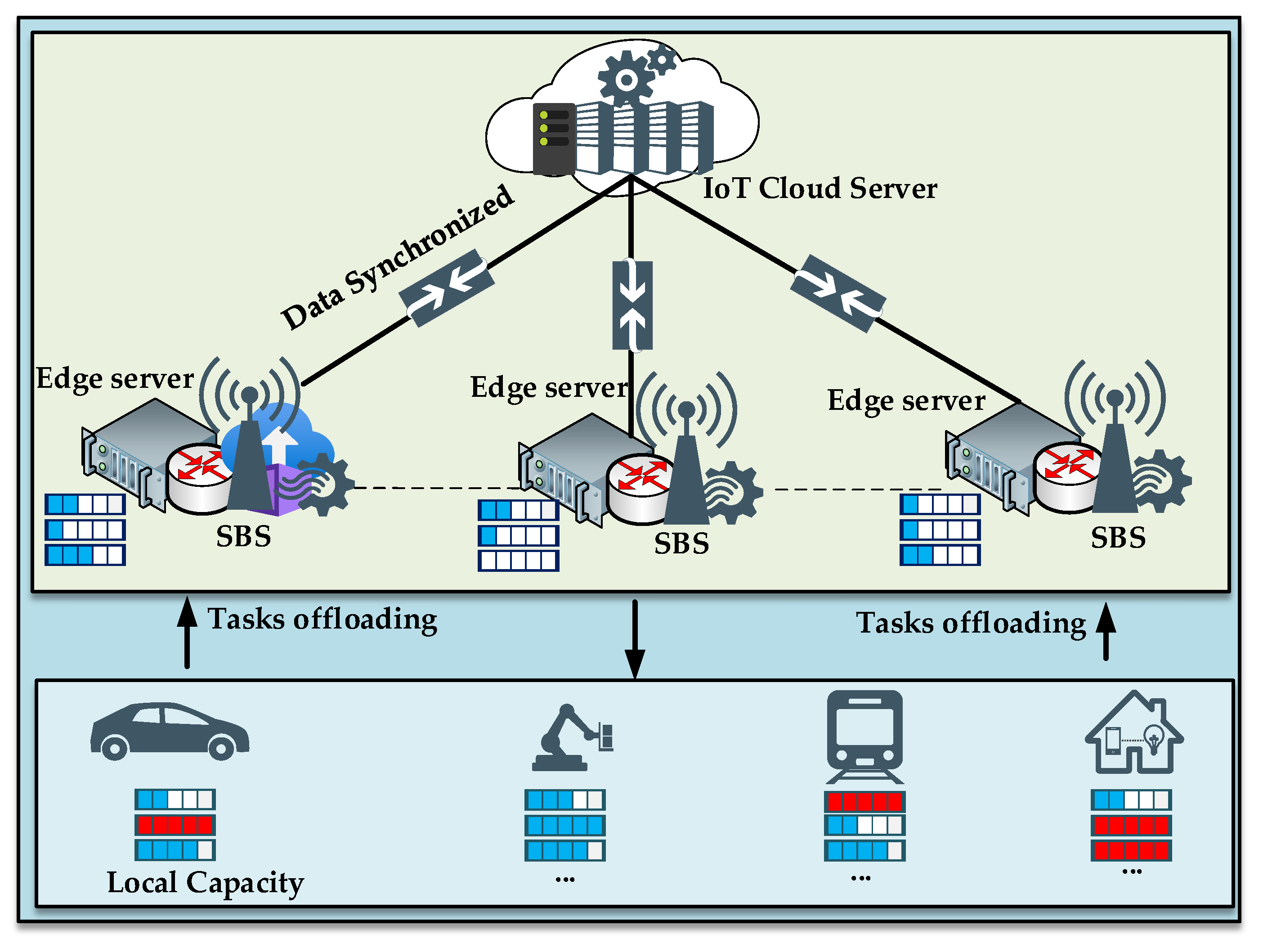
3.1. System Architecture
3.2. Communication Model
3.3. Task Offloading Model
3.4. Computation Offloading Model at the Edge Server
3.5. Offloading Problem Formulation and Analysis
3.6. Offloading Decision Sub Problem
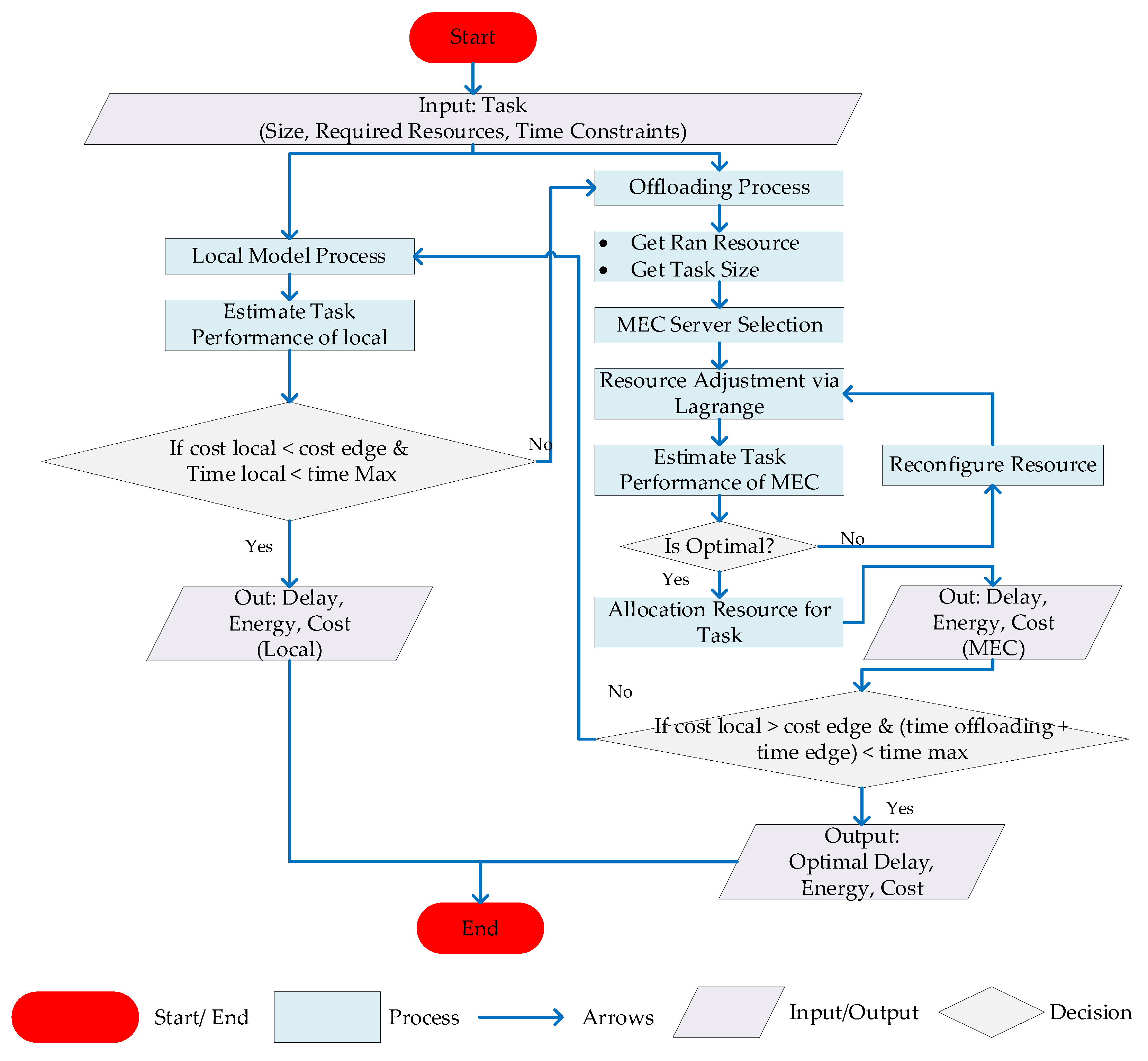
3.7. Lagrange Duality Resource Optimization Algorithm (LDROA)
3.8. Proposed Solution and Algorithm Design
| Algorithm 1: Local and edge server computation time, energy, and cost. |
 |
4. Experimentation and Result Evaluations
4.1. Simulation Setting and Parameters
4.2. Proposed and Reference Schemes
5. Simulation Result and Discussion
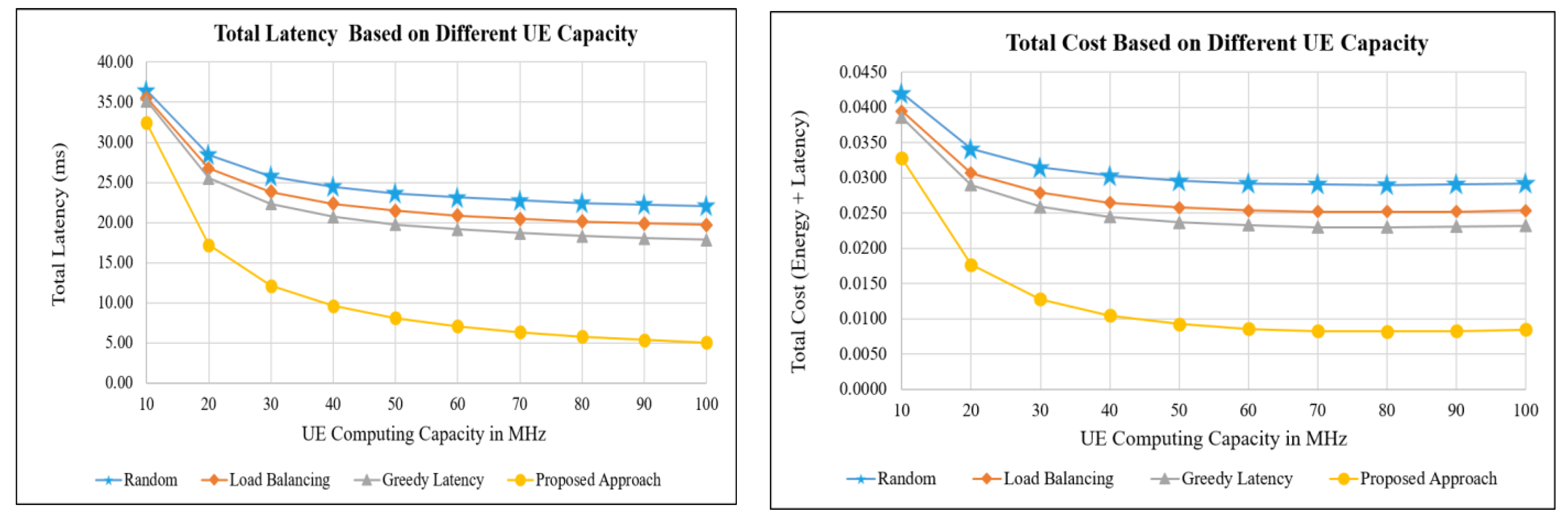
5.1. Simulation Based on User Device Computing Capacity
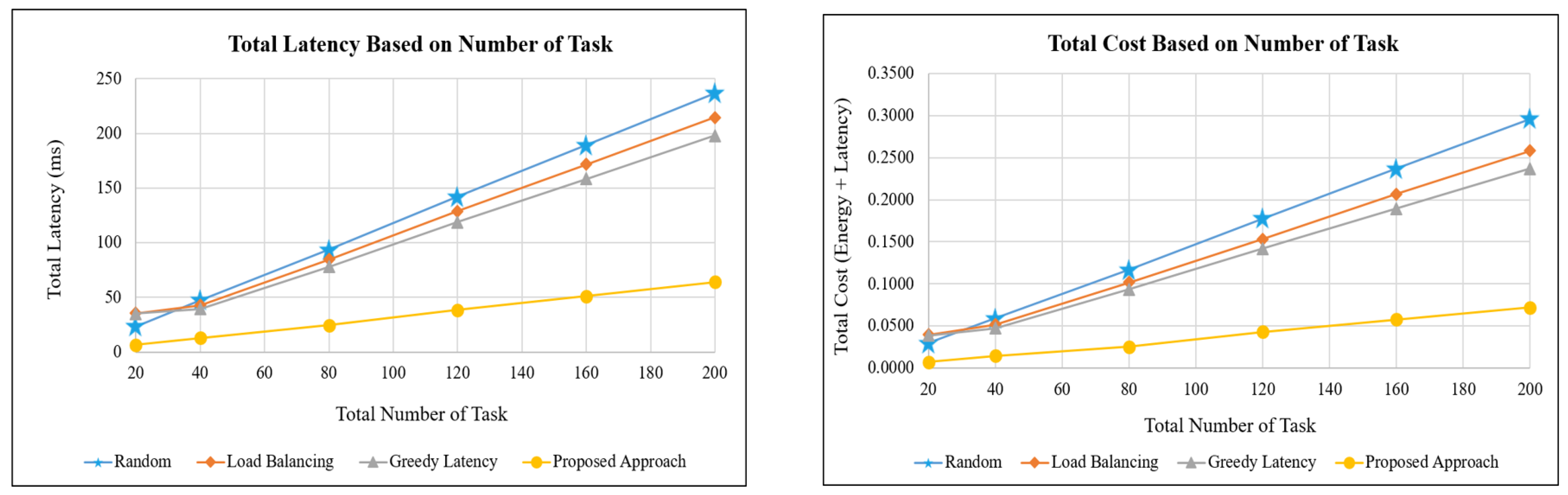
5.2. Simulation Based on Different Numbers of Tasks
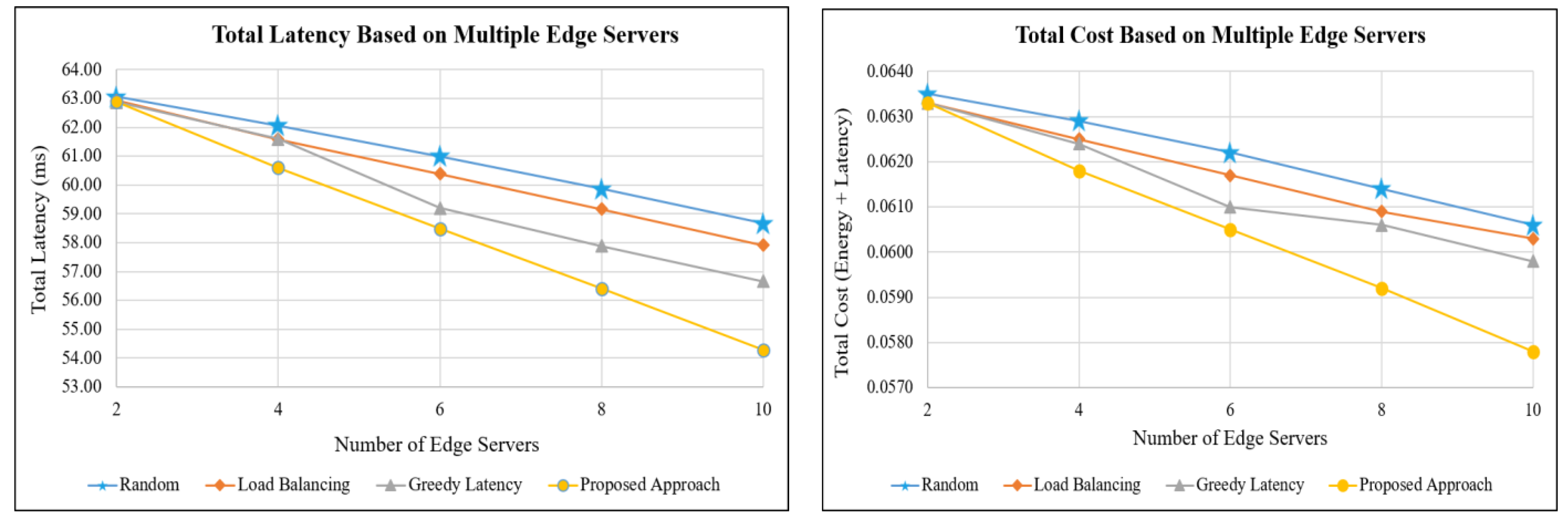
5.3. Simulation Based on Different Numbers of MEC Servers
5.4. Simulation Based on Congestion Condition
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brown, G. Mobile Edge Computing Use Cases and Deployment Options; Juniper White Paper; Heavy Reading: New York, NY, USA, 2016. [Google Scholar]
- Dolezal, J.; Becvar, Z.; Zeman, T. Performance evaluation of computation offloading from mobile device to the edge of mobile network. In Proceedings of the 2016 IEEE Conference on Standards for Communications and Networking (CSCN), Berlin, Germany, 31 October–2 November 2016. [Google Scholar]
- Kekki, S.; Featherstone, W.; Fang, Y.; Kuure, P.; Li, A.; Ranjan, A.; Purkayastha, D.; Jiangping, F.; Frydman, D.; Verin, G.; et al. MEC in 5g Networks; ETSI White Paper; ETSI: Valbonne, France, 2018. [Google Scholar]
- Yadav, R.; Zhang, W.; Elgendy, I.A.; Dong, G.; Shafiq, M.; Laghari, A.A.; Prakash, S. Smart Healthcare: RL-Based Task Offloading Scheme for Edge-Enable Sensor Networks. IEEE Sens. J. 2021, 21, 24910–24918. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Kim, S. Adaptive partial task offloading and virtual resource placement in SDN/NFV-based network softwarization. Comput. Syst. Sci. Eng. 2023, 45, 2141–2154. [Google Scholar] [CrossRef]
- Shahzadi, S.; Iqbal, M.; Dagiuklas, T.; Qayyum, Z.U. Multi-access edge computing: Open issues, challenges and future perspectives. J. Cloud Comput. 2022, 6, 30. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, F.; Lu, Y.; Chen, X. Dynamic Task Offloading for Mobile Edge Computing with Hybrid Energy Supply. Tsinghua Sci. Technol. 2023, 28, 421–432. [Google Scholar] [CrossRef]
- Medhat, A.M.; Taleb, T.; Elmangoush, A.; Carella, G.A.; Covaci, S.; Magedanz, T. Service Function Chaining in Next Generation Networks: State of the Art and Research Challenges. IEEE Commun. Mag. 2017, 55, 216–223. [Google Scholar] [CrossRef]
- Ren, Y.; Guo, A.; Song, C. Multi-Slice Joint Task Offloading and Resource Allocation Scheme for Massive MIMO Enabled Network. KSII Trans. Internet Inf. Syst. 2023, 17, 794–815. [Google Scholar]
- Zhang, K.; Mao, Y.; Leng, S.; He, Y.; Zhang, Y. Mobile-Edge Computing for Vehicular Networks: A Promising Network Paradigm with Predictive Off-Loading. IEEE Veh. Technol. Mag. 2017, 12, 36–44. [Google Scholar] [CrossRef]
- Song, I.; Tam, P.; Kang, S.; Ros, S.; Kim, S. DRL-Based Backbone SDN Control Methods in UAV-Assisted Networks for Computational Resource Efficiency. Electronics 2023, 12, 2984. [Google Scholar] [CrossRef]
- Hazarika, B.; Singh, K.; Biswas, S.; Li, C.-P. DRL-Based Resource Allocation for Computation Offloading in IoV Networks. IEEE Trans. Ind. Inform. 2022, 18, 8027–8038. [Google Scholar] [CrossRef]
- Sha, Y.; Hu, J.; Hao, S.; Wang, D. Joint Relay Selection and Resource Allocation for Delay-Sensitive Traffic in Multi-Hop Relay Networks. KSII Trans. Internet Inf. Syst. 2022, 16, 3008–3028. [Google Scholar]
- Tong, L.; Li, Y.; Gao, W. A hierarchical edge cloud architecture for mobile computing. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016. [Google Scholar]
- Fatemi Moghaddam, F.; Rohani, M.B.; Ahmadi, M.; Khodadadi, T.; Madadipouya, K. Cloud computing: Vision, architecture and Characteristics. In Proceedings of the 2015 IEEE 6th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 10–11 August 2015. [Google Scholar]
- Chen, L.; Tang, H.; Zhao, Y.; You, W.; Wang, K. A Privacy-preserving and Energy-efficient Offloading Algorithm based on Lyapunov Optimization. KSII Trans. Internet Inf. Syst. 2022, 16, 2490–2506. [Google Scholar]
- Pham, Q.-V.; Fang, F.; Ha, V.N.; Piran, M.J.; Le, M.; Le, L.B.; Hwang, W.-J.; Ding, Z. A Survey of Multi-Access Edge Computing in 5G and Beyond: Fundamentals, Technology Integration, and State-of-the-Art. IEEE Access 2020, 8, 116974–117017. [Google Scholar] [CrossRef]
- Wang, Y.; Wan, X.; Du, X.; Chen, X.; Lu, Z. A Resource Allocation Strategy for Edge Services Based on Intelligent Prediction. In Proceedings of the 2021 IEEE 6th International Conference on Smart Cloud (SmartCloud), Virtual, 6–8 November 2021. [Google Scholar]
- Ros, S.; Eang, C.; Tam, P.; Kim, S. ML/SDN-Based MEC Resource Management for QoS Assurances. In Advances in ComputerScience and Ubiquitous Computing; Springer: Singapore, 2023; Volume 1028, pp. 591–597. [Google Scholar]
- Tam, P.; Corrado, R.; Eang, C.; Kim, S. Applicability of Deep Reinforcement Learning for Efficient Federated Learning in Massive IoT Communications. Appl. Sci. 2023, 13, 3083. [Google Scholar] [CrossRef]
- Huynh, L.N.T.; Pham, Q.-V.; Pham, X.-Q.; Nguyen, T.D.T.; Hossain, M.D.; Huh, E.-N. Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach. Appl. Sci. 2020, 10, 203. [Google Scholar] [CrossRef]
- Ros, S.; Tam, P.; Kim, S. Modified Deep Reinforcement Learning Agent for Dynamic Resource Placement in IoT Network Slicing. J. Internet Comput. Serv. 2022, 23, 17–23. [Google Scholar]
- Guo, H.; Liu, J.; Qin, H. Collaborative Mobile Edge Computation Offloading for IoT over Fiber-Wireless Networks. IEEE Netw. 2018, 32, 66–71. [Google Scholar] [CrossRef]
- Chen, C.; Zeng, Y.; Li, H.; Liu, Y.; Wan, S. A Multi-hop Task Offloading Decision Model in MEC-enabled Internet of Vehicles. IEEE Internet Things J. 2022, 10, 3215–3230. [Google Scholar] [CrossRef]
- Ryu, J.-W.; Pham, Q.-V.; Luan, H.N.T.; Hwang, W.-J.; Kim, J.-D.; Lee, J.-T. Multi-Access Edge Computing Empowered Heterogeneous Networks: A Novel Architecture and Potential Works. Symmetry 2019, 11, 842. [Google Scholar] [CrossRef]
- Ren, J.; Mahfujul, K.M.; Lyu, F.; Yue, S.; Zhang, Y. Joint Channel Allocation and Resource Management for Stochastic Computation Offloading in MEC. IEEE Trans. Veh. Technol. 2021, 69, 8900–8913. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Nam, C.; Kim, S. Adaptive Resource Optimized Edge Federated Learning in Real-Time Image Sensing Classifications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10929–10940. [Google Scholar] [CrossRef]
- Li, J.; Lv, T. Deep Neural Network Based Computational Resource Allocation for Mobile Edge Computing. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar]
- Naouri, Y.A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A Novel Framework for Mobile-Edge Computing by Optimizing Task Offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, N.; Zhang, Y.; Chen, X.; Wu, W.; Shen, X. Energy Efficient Dynamic Offloading in Mobile Edge Computing for Internet of Things. IEEE Trans. Cloud Comput. 2021, 9, 1050–1060. [Google Scholar] [CrossRef]
- Wang, Z.; Li, P.; Shen, S.; Yang, K. Task Offloading Scheduling in Mobile Edge Computing Networks. Procedia Comput. Sci. 2021, 184, 322–329. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, W.; Wang, C.; Li, M.; Yang, R. Deep Reinforcement Learning-Based Offloading Decision Optimization in Mobile Edge Computing. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019. [Google Scholar]
- Lakew, D.S.; Tuong, V.D.; Dao, N.-N.; Cho, S. Adaptive Partial Offloading and Resource Harmonization in Wireless Edge Computing-Assisted IoE Networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3028–3044. [Google Scholar] [CrossRef]
- Wan, Z.; Xu, D.; Xu, D.; Ahmad, İ. Joint Computation Offloading and Resource Allocation for NOMA-Based Multi-Access Mobile Edge Computing Systems. Comput. Netw. 2021, 196, 108256. [Google Scholar] [CrossRef]
- Xu, D.; Xu, D. Cooperative Task Offloading and Resource Allocation for UAV-Enabled Mobile Edge Computing Systems. Comput. Netw. 2023, 223, 109574. [Google Scholar] [CrossRef]
- Xu, D. Device Scheduling and Computation Offloading in Mobile Edge Computing Networks: A Novel NOMA Scheme. IEEE Trans. Veh. Technol. 2024, 1–6. [Google Scholar] [CrossRef]
- Abkenar, F.S.; Iranmanesh, S.; Bouguettaya, A.; Raad, R.; Jamalipour, A. ENERGENT: An Energy-Efficient UAV-Assisted Fog-IoT Framework for Disaster Management. J. Commun. Netw. 2022, 24, 698–709. [Google Scholar] [CrossRef]
- Abkenar, F.S.; Ramezani, P.; Iranmanesh, S.; Murali, S.; Chulerttiyawong, D.; Wan, X.; Jamalipour, A.; Raad, R. A Survey on Mobility of Edge Computing Networks in IoT: State-of-The-Art, Architectures, and Challenges. IEEE Commun. Surv. Tutor. 2022, 24, 2329–2365. [Google Scholar] [CrossRef]
- Jan, T.; Iranmanesh, S.; Sajeev, A.S.M. Ensemble of Semi-Parametric Models for IoT Fog Modeling. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019. [Google Scholar]
- Pham, Q.-V.; Leanh, T.; Tran, N.H.; Park, B.J.; Hong, C.S. Decentralized Computation Offloading and Resource Allocation for Mobile-Edge Computing: A Matching Game Approach. IEEE Access 2018, 6, 75868–75885. [Google Scholar] [CrossRef]
- Zhang, K.; Mao, Y.; Leng, S.; Zhao, Q.; Li, L.; Peng, X.; Pan, L.; Maharjan, S.; Zhang, Y. Energy-Efficient Offloading for Mobile Edge Computing in 5G Heterogeneous Networks. IEEE Access 2016, 4, 5896–5907. [Google Scholar] [CrossRef]
- Wang, K.; Yang, K. Power-Minimization Computing Resource Allocation in Mobile Cloud-Radio Access Network. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016. [Google Scholar]
- Tang, J.; Tay, W.P.; Wen, Y. Dynamic Request Redirection and Elastic Service Scaling in Cloud-Centric Media Networks. IEEE Trans. Multimed. 2014, 16, 1434–1445. [Google Scholar] [CrossRef]
- 3GPP TS 23.203, v. 17.1.0; Technical Specification Group Services and System Aspects. Policy and Charging Control Architecture; ETSI: Valbonne, France, 2021.
- Fan, X.; Cui, T.; Cao, C.; Chen, Q.; Kwak, K.S. Minimum-Cost Offloading for Collaborative Task Execution of MEC-Assisted Platooning. Sensors 2019, 19, 847. [Google Scholar] [CrossRef] [PubMed]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eang, C.; Ros, S.; Kang, S.; Song, I.; Tam, P.; Math, S.; Kim, S. Offloading Decision and Resource Allocation in Mobile Edge Computing for Cost and Latency Efficiencies in Real-Time IoT. Electronics 2024, 13, 1218. https://doi.org/10.3390/electronics13071218
Eang C, Ros S, Kang S, Song I, Tam P, Math S, Kim S. Offloading Decision and Resource Allocation in Mobile Edge Computing for Cost and Latency Efficiencies in Real-Time IoT. Electronics. 2024; 13(7):1218. https://doi.org/10.3390/electronics13071218
Chicago/Turabian StyleEang, Chanthol, Seyha Ros, Seungwoo Kang, Inseok Song, Prohim Tam, Sa Math, and Seokhoon Kim. 2024. "Offloading Decision and Resource Allocation in Mobile Edge Computing for Cost and Latency Efficiencies in Real-Time IoT" Electronics 13, no. 7: 1218. https://doi.org/10.3390/electronics13071218
APA StyleEang, C., Ros, S., Kang, S., Song, I., Tam, P., Math, S., & Kim, S. (2024). Offloading Decision and Resource Allocation in Mobile Edge Computing for Cost and Latency Efficiencies in Real-Time IoT. Electronics, 13(7), 1218. https://doi.org/10.3390/electronics13071218