
Damage Detection in Structural Health Monitoring Using an Integrated ANNIRSA Approach

Abstract
:1. Introduction
- We developed an enhanced IRSA algorithm integrated with an ANN.
- We successfully implemented the ANNIRSA algorithm for diagnosing structural damage.
- We extracted a new dataset of damages from the Nam O bridge model, encompassing a range of designated damage elements.
- We evidenced the precision and efficacy of the advanced methodology via a comprehensive suite of numerical simulations and empirical evaluations, encompassing a spectrum of scenarios ranging from isolated- to multiple-damage instances.
- We executed a systematic comparative evaluation of the advanced ANNIRSA method relative to established algorithms, notably, the traditional ANN and ANNRSA.
2. Materials and Methods
- Adaptive alpha and beta values;
- A reduction function based on the global best solution;
- The incorporation of chaotic random sequences;
- Adaptive hunting probability;
- The implementation of a killer hunt strategy.
2.1. Artificial Neural Network
2.2. Reptile Search Algorithm (RSA)
2.3. Improved RSA
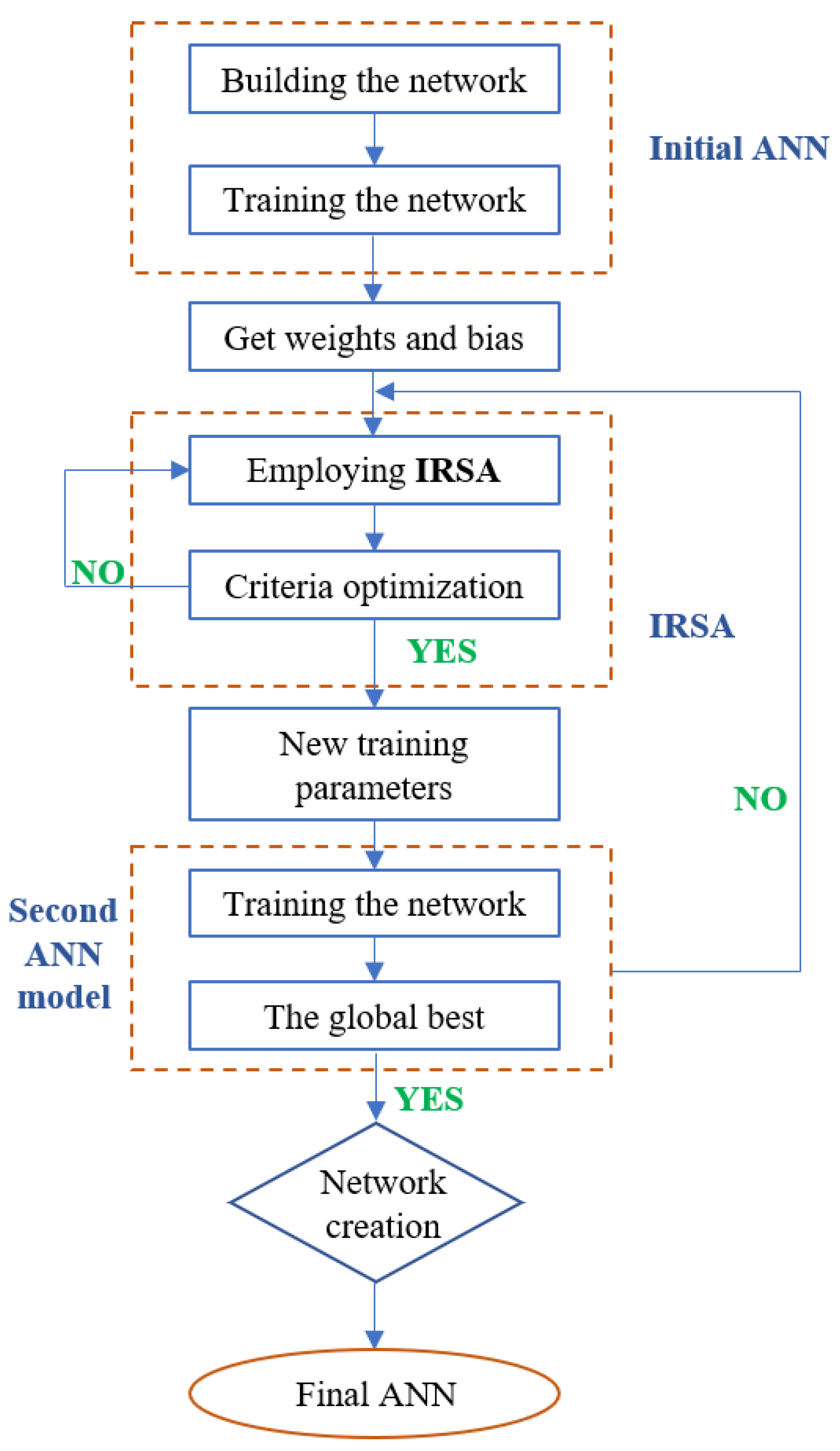
2.4. Proposed Hybrid ANN and IRSA Method
3. Numerical Examples
3.1. Description of the Bridge
3.2. Dataset
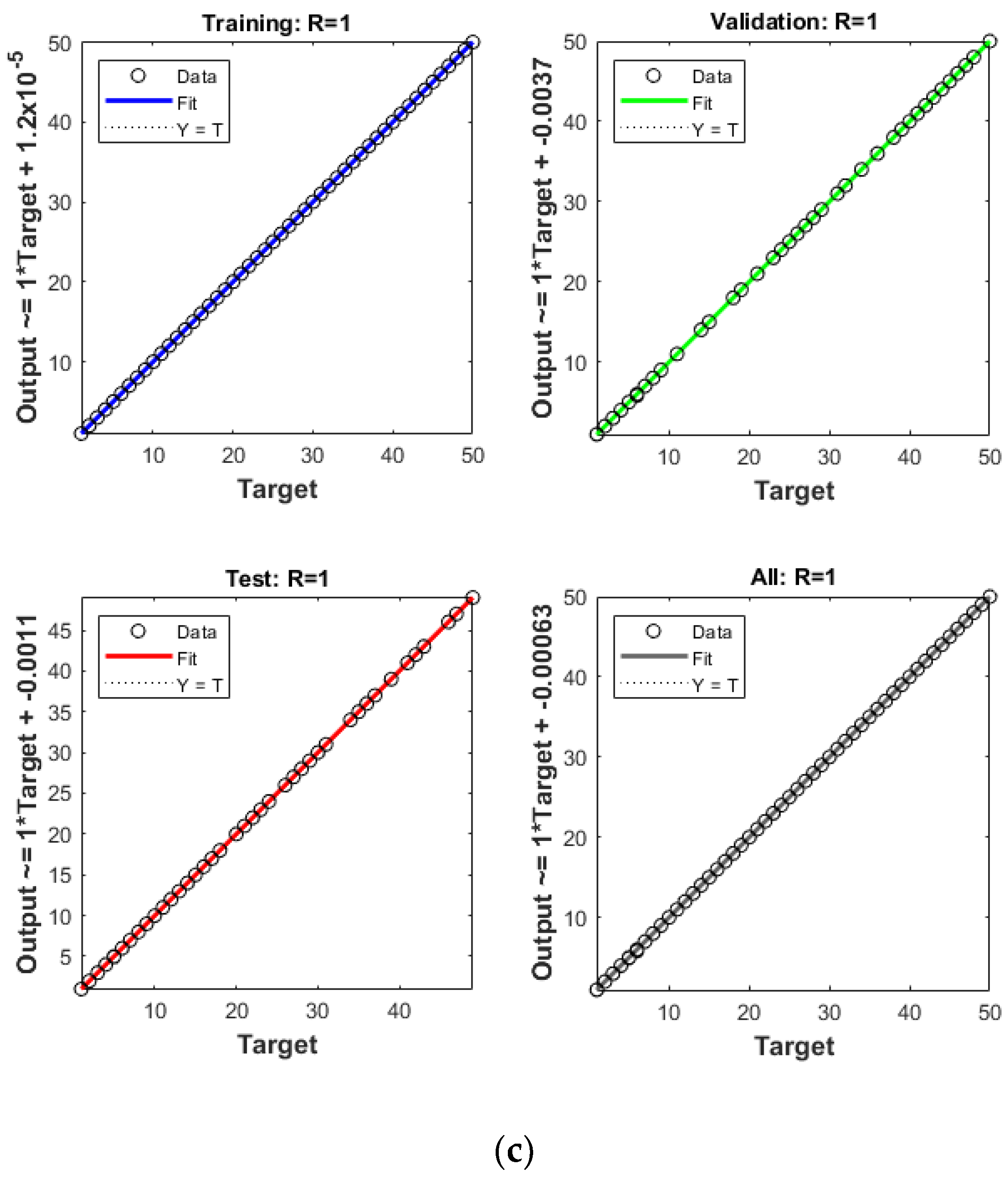
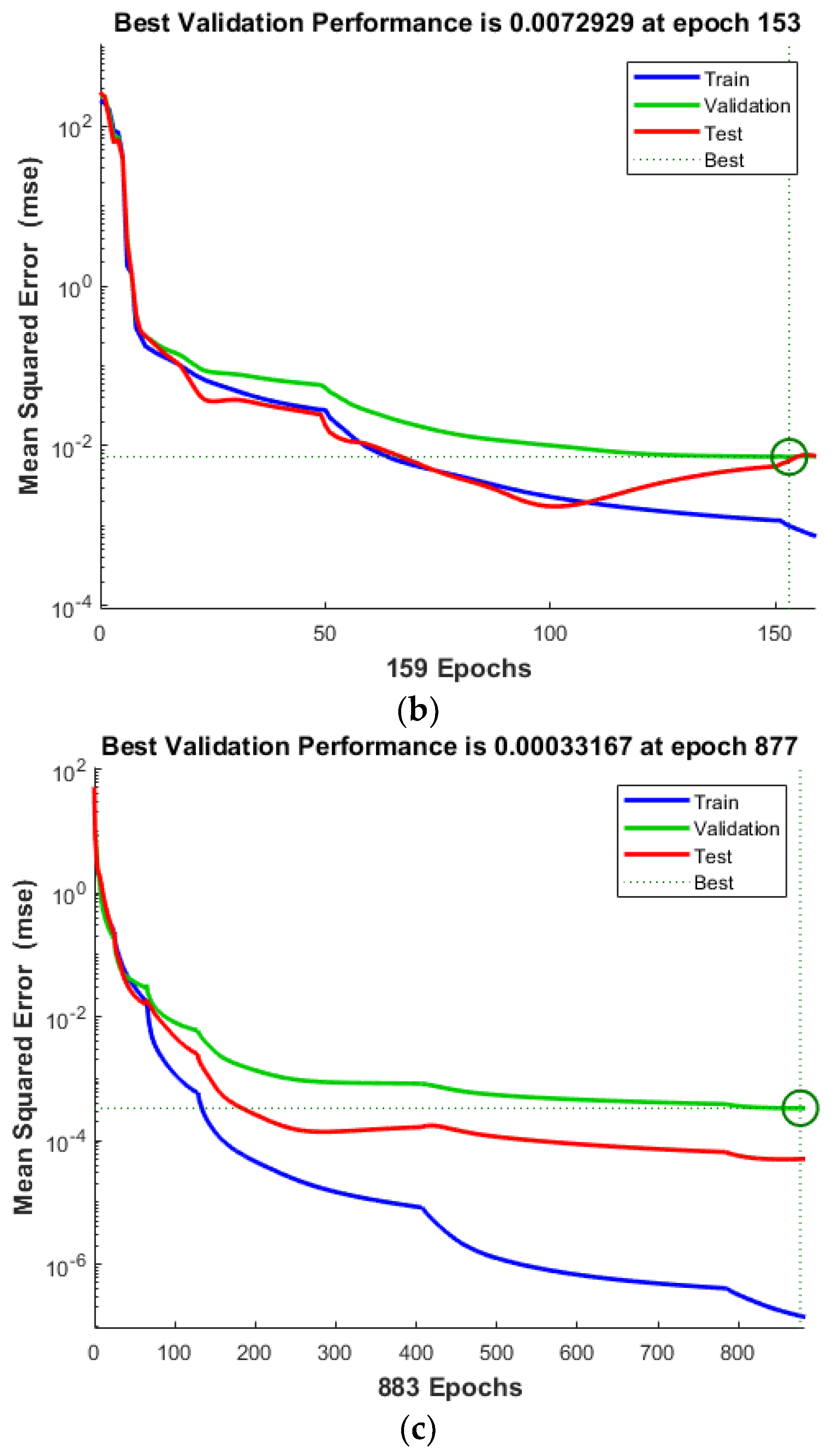
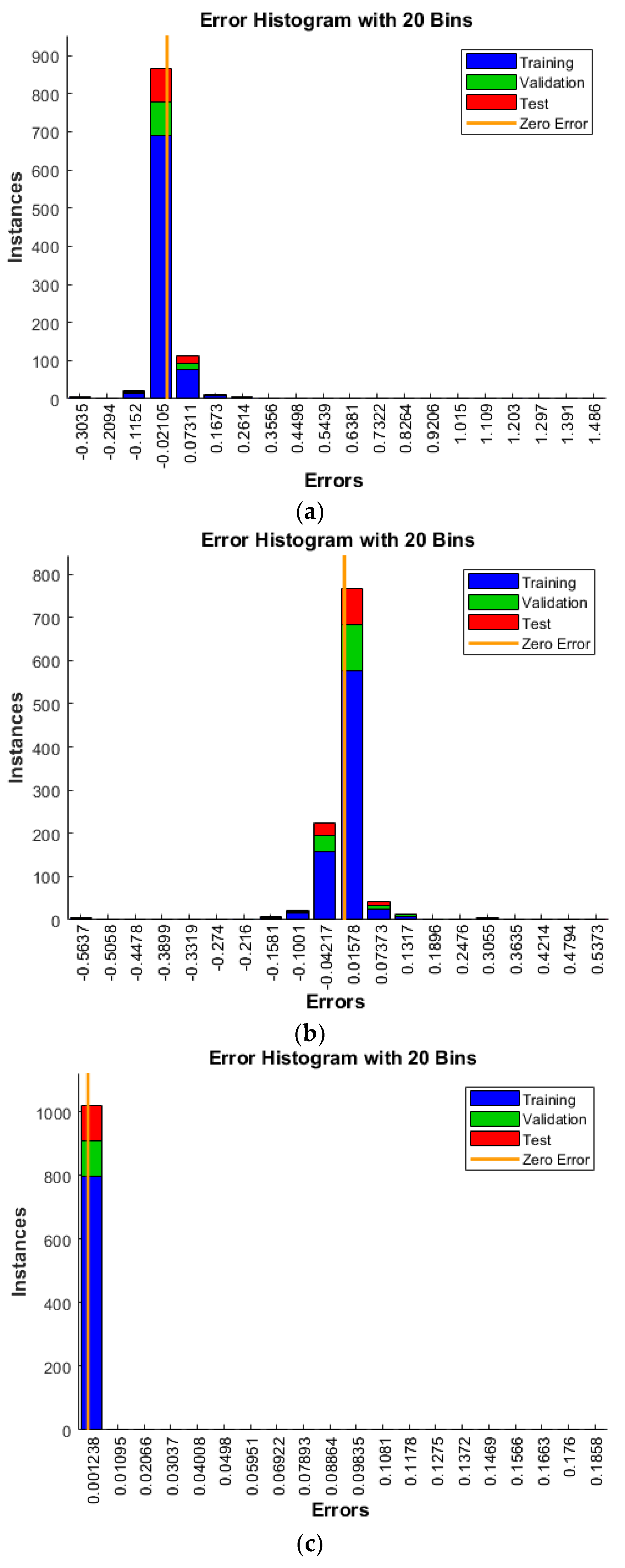
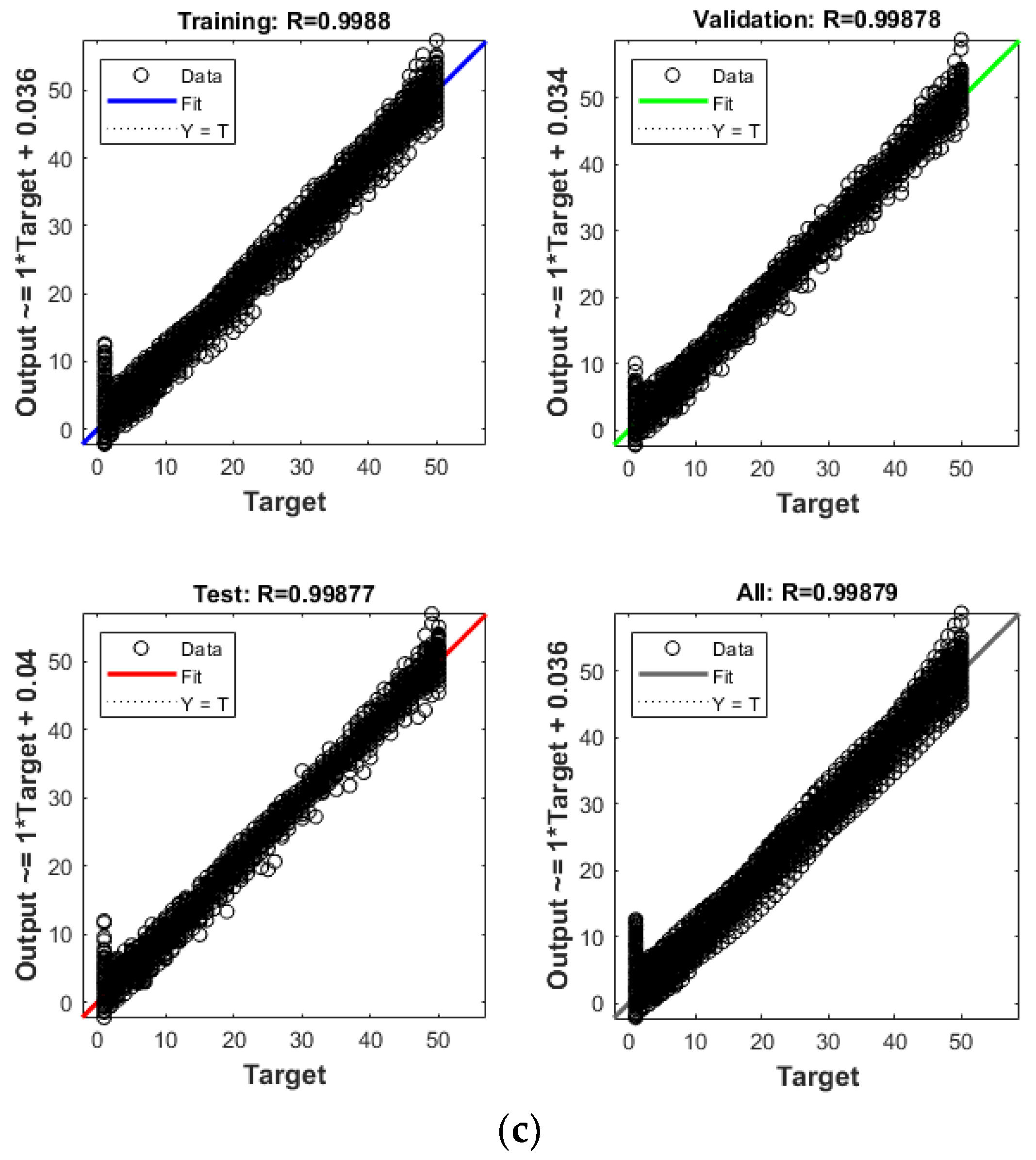
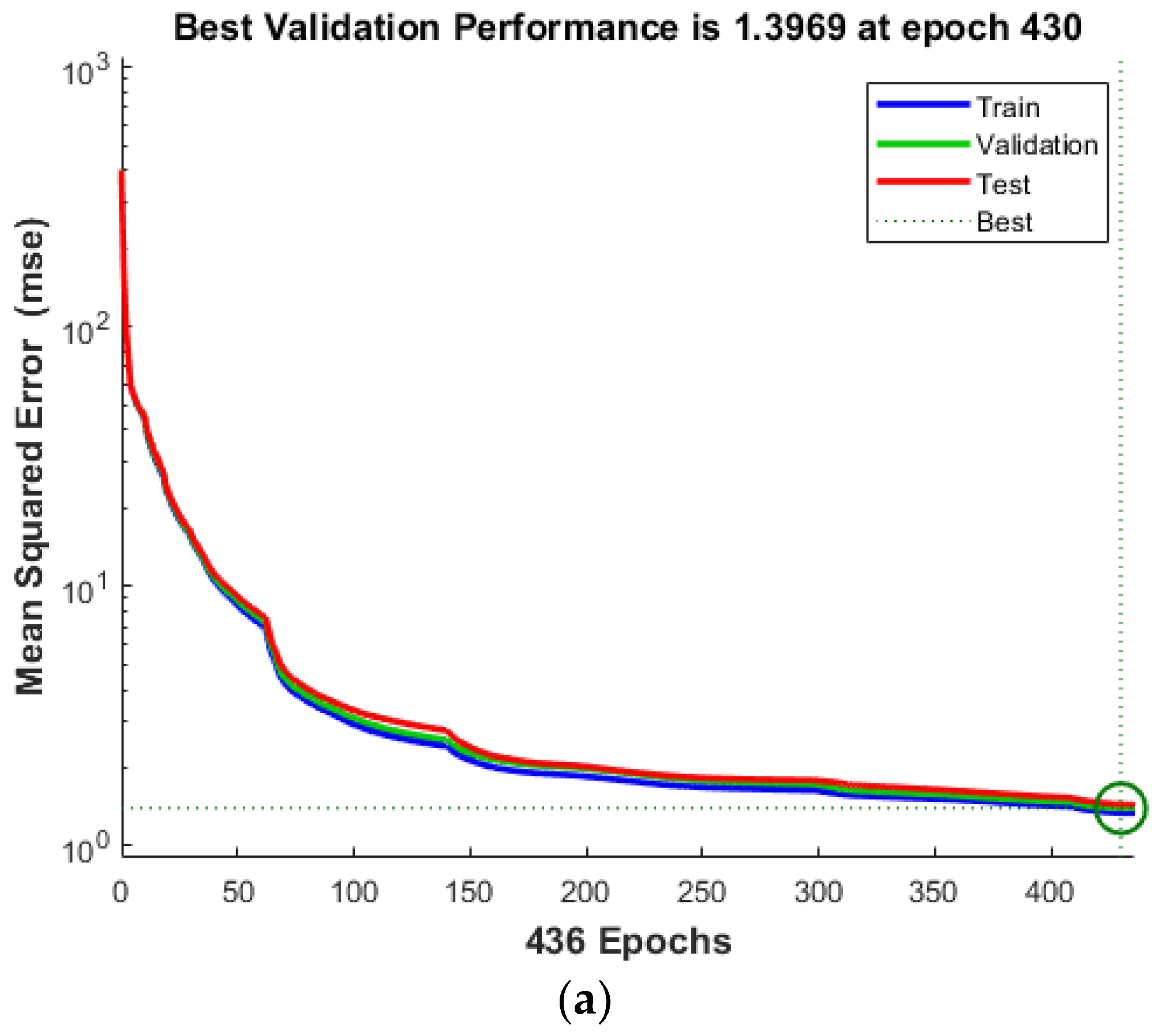
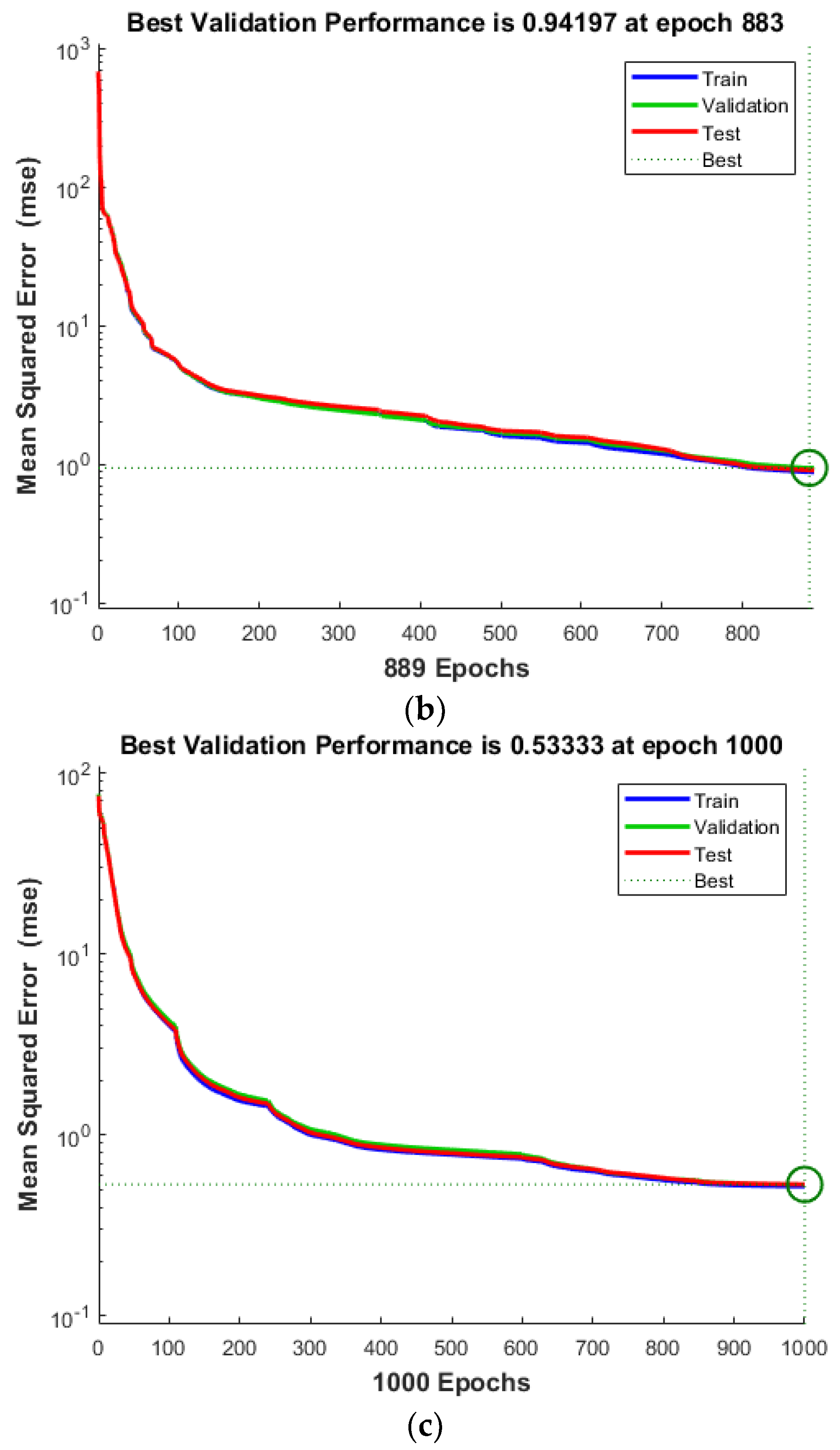
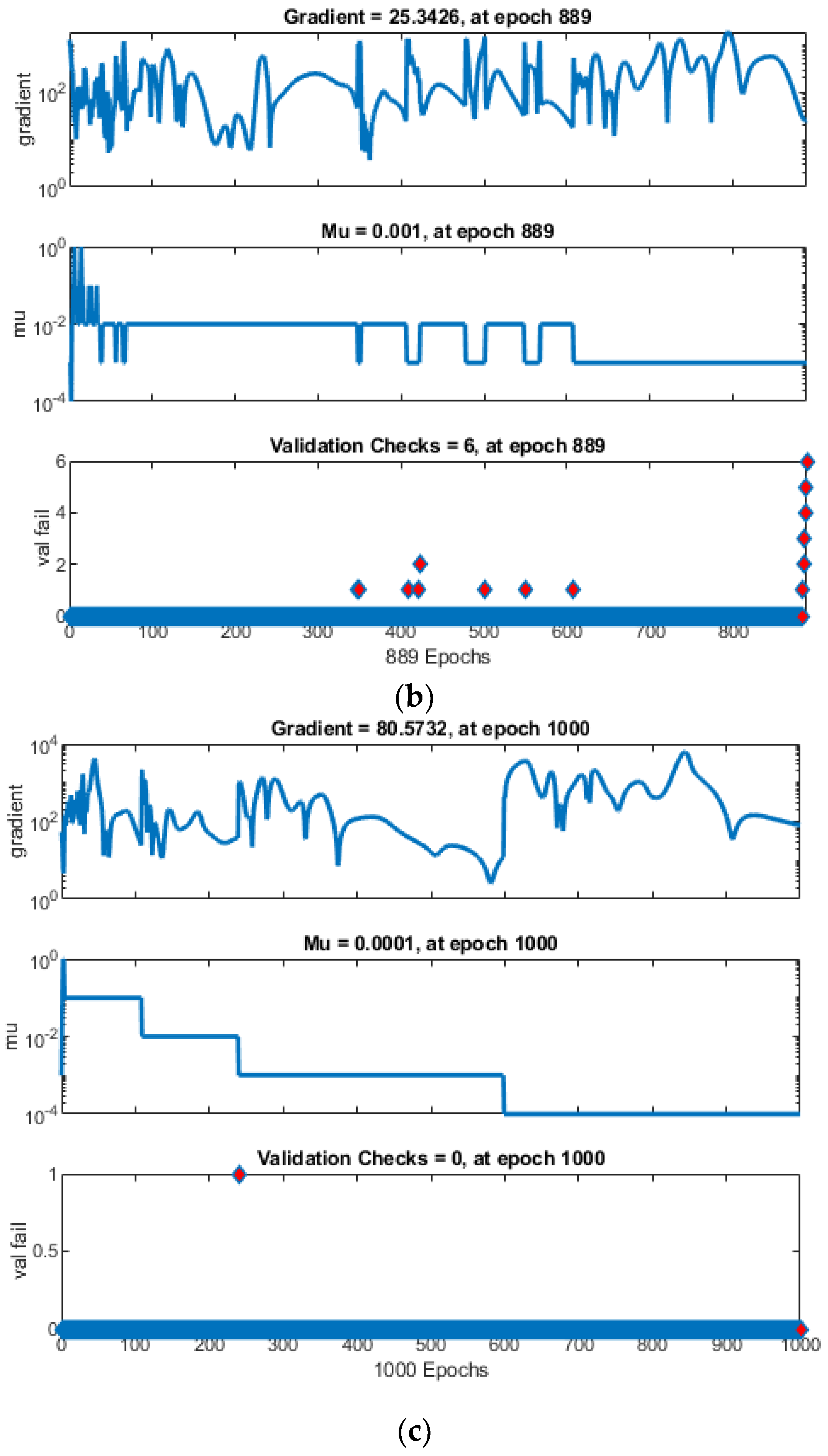
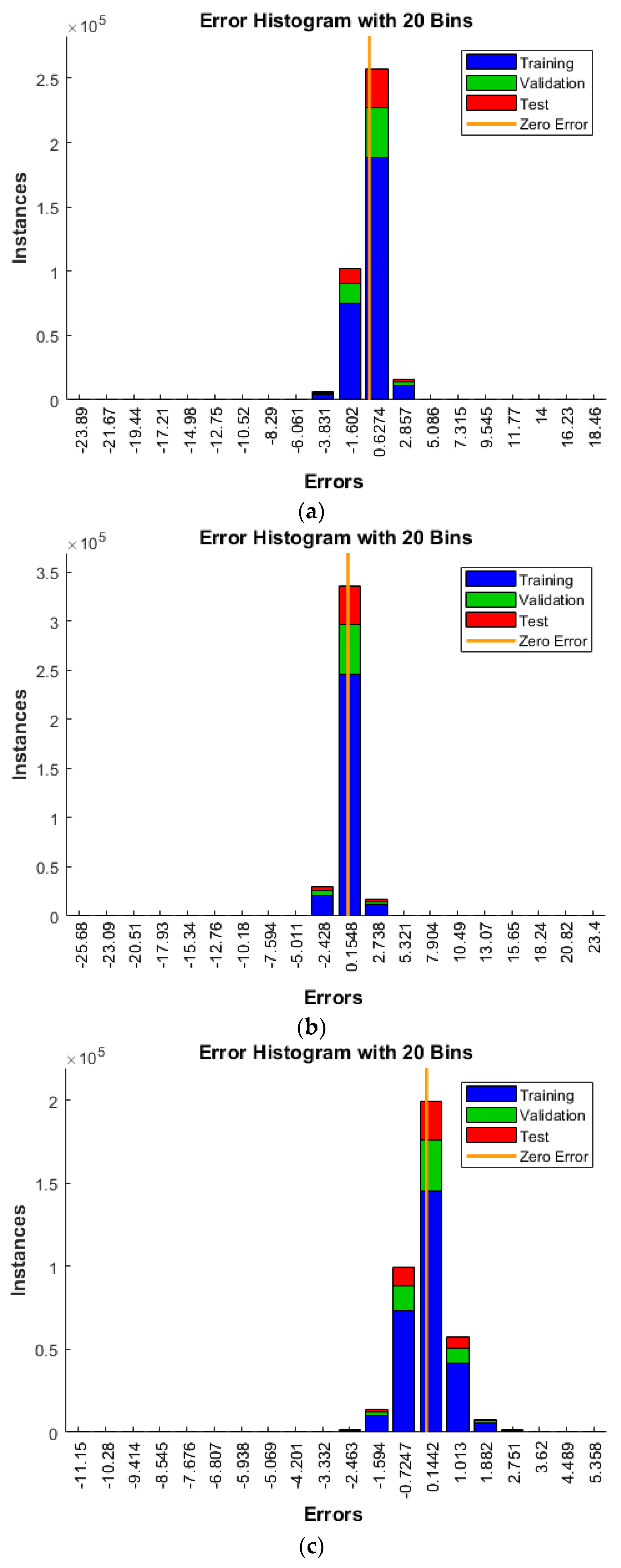
4. Results and Discussion
4.1. Single Damage
4.2. Multiple Damage
5. Conclusions and Future Works
- All the algorithms evaluated—ANN, ANNRSA, and ANNIRSA—demonstrated proficiency in identifying structural damage. The R values for all scenarios surpassed 0.99, indicating high correlation, and the MSE values were notably low.
- The dependency of the ANN on GD techniques leads to a propensity to being trapped in local minima. This limitation manifests as inaccuracies in damage detection when the ANN is applied, especially in scenarios where the network architecture is intricate and beset with a multitude of local optima.
- IRSA proved its mettle by enhancing the ANN, bolstering accuracy in the damage detection using the numerical model.
- ANNIRSA effectively tackled the challenge of local minima typically encountered in traditional ANN models. Consequently, the proposed approach presents considerable potential for practical applications in solving real-world problems.
- Subsequent studies should apply this methodology in damage detection research on actual structures such as buildings, bridges, etc.
- IRSA can be implemented to optimize global search capabilities and improve the effectiveness of deep learning network models.
- Researchers can further develop and refine the IRSA algorithm by adjusting weights, incorporating search techniques like Levy flights, and strategically distributing operational groups to achieve greater efficiency.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ngoc, L.N.; Huu, Q.N.; Ngoc, L.N.; Tran, H.N. Performance evaluation of the artificial hummingbird algorithm in the problem of structural damage identification. Transp. Commun. Sci. J. 2023, 74, 413–427. [Google Scholar] [CrossRef]
- Viet, L.H.; Thi, T.T.; Xuan, B.H. Swarm intelligence-based technique to enhance performance of ANN in structural damage detection. Transp. Commun. Sci. J. 2022, 73, 1–15. [Google Scholar] [CrossRef]
- Việt, H.H.; Anh, T.; Đức, T.P. Utilizing artificial neural networks to anticipate early-age thermal parameters in concrete piers. Transp. Commun. Sci. J. 2023, 74, 445–455. [Google Scholar] [CrossRef]
- Mohammadi, N.; Mirabedini, S.J. Comparison of Particle Swarm Optimization and Backpropagation Algorithms for Training Feedforward Neural Network. J. Math. Comput. Sci. 2014, 12, 113–123. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar] [CrossRef]
- Prabowo, A.S.; Sihabuddin, A.; Sn, A. Adaptive Moment Estimation on Deep Belief Network for Rupiah Currency Forecasting. Indones. J. Comput. Cybern. Syst. 2019, 13, 31–42. [Google Scholar] [CrossRef]
- Wang, R.-L.; Guo, S.-S.; Okazaki, K. A hill-jump algorithm of Hopfield neural network for shortest path problem in communication network. Soft Comput. 2009, 13, 551–558. [Google Scholar] [CrossRef]
- Sathasivam, S.; Alzaeemi, S.A.; Velavan, M. Mean-Field Theory in Hopfield Neural Network for Doing 2 Satisfiability Logic Programming. IJMECS 2020, 12, 27–39. [Google Scholar] [CrossRef]
- Ojha, V.K.; Abraham, A.; Snášel, V. Metaheuristic design of feedforward neural networks: A review of two decades of research. Eng. Appl. Artif. Intell. 2017, 60, 97–116. [Google Scholar] [CrossRef]
- Fei, X.; Shuotao, H.; Hao, Z.; Daogang, P. A Comparative Research on Condenser Fault Diagnosis Based on Three Different Algorithms. TOEEJ 2014, 8, 183–189. [Google Scholar] [CrossRef]
- Chagas, S.H.; Martins, J.B.; de Oliveira, L.L. An approach to localization scheme of wireless sensor networks based on artificial neural networks and Genetic Algorithms. In Proceedings of the 10th IEEE International NEWCAS Conference, Montreal, QC, Canada, 17–20 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 137–140. [Google Scholar] [CrossRef]
- Tran-Ngoc, H.; Khatir, S.; Le-Xuan, T.; Tran-Viet, H.; De Roeck, G.; Bui-Tien, T.; Wahab, M.A. Damage assessment in structures using artificial neural network working and a hybrid stochastic optimization. Sci. Rep. 2022, 12, 4958. [Google Scholar] [CrossRef] [PubMed]
- Kumar, N.; Kumar, D. An Improved Grey Wolf Optimization-Based Learning of Artificial Neural Network for Medical Data Classification. J. Inf. Commun. Technol. 2021, 20, 213–248. [Google Scholar] [CrossRef]
- Ban, H.G. Variable neighbourhood search-based algorithm to solve the minimum back-walk-free latency problem. IJCAT 2021, 65, 55. [Google Scholar] [CrossRef]
- Abualigah, L.; Abd Elaziz, M.; Sumari, P.; Geem, Z.W.; Gandomi, A.H. Reptile Search Algorithm (RSA): A nature-inspired meta-heuristic optimizer. Expert Syst. Appl. 2022, 191, 116158. [Google Scholar] [CrossRef]
- Shirazi, M.I.; Khatir, S.; Benaissa, B.; Mirjalili, S.; Wahab, M.A. Damage assessment in laminated composite plates using modal Strain Energy and YUKI-ANN algorithm. Compos. Struct. 2023, 303, 116272. [Google Scholar] [CrossRef]
- Khatir, S.; Tiachacht, S.; Thanh, C.-L.; Bui, T.Q.; Wahab, M.A. Damage assessment in composite laminates using ANN-PSO-IGA and Cornwell indicator. Compos. Struct. 2019, 230, 111509. [Google Scholar] [CrossRef]
- Tran-Ngoc, H.; Khatir, S.; De Roeck, G.; Bui-Tien, T.; Nguyen-Ngoc, L.; Abdel Wahab, M. Model updating for Nam O bridge using particle swarm optimization algorithm and genetic algorithm. Sensors 2018, 18, 4131. [Google Scholar] [CrossRef] [PubMed]
- François, S.; Schevenels, M.; Dooms, D.; Jansen, M.; Wambacq, J.; Lombaert, G.; Degrande, G.; De Roeck, G. Stabil: An educational Matlab toolbox for static and dynamic structural analysis. Comput. Appl. Eng. Educ. 2021, 29, 1372–1389. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Outputs | Input Frequencies | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Damage (%) | Element | Young’s Modulus | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 | f10 |
| 1 | 1000 | 1.94 × 1011 | 1.45429 | 3.11483 | 3.27816 | 3.83716 | 4.54247 | 4.55502 | 4.90166 | 5.24107 | 6.88095 | 7.57328 |
| 2 | 1000 | 1.92 × 1011 | 1.45403 | 3.11481 | 3.27785 | 3.83630 | 4.54246 | 4.55499 | 4.90163 | 5.24104 | 6.88088 | 7.57160 |
| 3 | 1000 | 1.9 × 1011 | 1.45378 | 3.11479 | 3.27755 | 3.83543 | 4.54244 | 4.55496 | 4.90160 | 5.24101 | 6.88081 | 7.56991 |
| 4 | 1000 | 1.88 × 1011 | 1.45352 | 3.11477 | 3.27724 | 3.83455 | 4.54243 | 4.55494 | 4.90157 | 5.24098 | 6.88074 | 7.56819 |
| 5 | 1000 | 1.86 × 1011 | 1.45325 | 3.11475 | 3.27692 | 3.83366 | 4.54241 | 4.55491 | 4.90154 | 5.24095 | 6.88067 | 7.56646 |
| 6 | 1000 | 1.84 × 1011 | 1.45299 | 3.11474 | 3.27660 | 3.83276 | 4.54240 | 4.55488 | 4.90151 | 5.24092 | 6.88060 | 7.56470 |
| 7 | 1000 | 1.82 × 1011 | 1.45272 | 3.11472 | 3.27627 | 3.83185 | 4.54238 | 4.55485 | 4.90147 | 5.24089 | 6.88053 | 7.56292 |
| 8 | 1000 | 1.8 × 1011 | 1.45244 | 3.11470 | 3.27594 | 3.83093 | 4.54237 | 4.55482 | 4.90144 | 5.24086 | 6.88045 | 7.56112 |
| 9 | 1000 | 1.78 × 1011 | 1.45216 | 3.11468 | 3.27560 | 3.83000 | 4.54235 | 4.55479 | 4.90141 | 5.24083 | 6.88038 | 7.55929 |
| 10 | 1000 | 1.76 × 1011 | 1.45188 | 3.11466 | 3.27526 | 3.82905 | 4.54233 | 4.55477 | 4.90138 | 5.24080 | 6.88030 | 7.55745 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bui, N.D.; Dang, M.; Nguyen, T.H. Damage Detection in Structural Health Monitoring Using an Integrated ANNIRSA Approach. Electronics 2024, 13, 1241. https://doi.org/10.3390/electronics13071241
Bui ND, Dang M, Nguyen TH. Damage Detection in Structural Health Monitoring Using an Integrated ANNIRSA Approach. Electronics. 2024; 13(7):1241. https://doi.org/10.3390/electronics13071241
Chicago/Turabian StyleBui, Ngoc Dung, Minh Dang, and Tran Hieu Nguyen. 2024. "Damage Detection in Structural Health Monitoring Using an Integrated ANNIRSA Approach" Electronics 13, no. 7: 1241. https://doi.org/10.3390/electronics13071241
APA StyleBui, N. D., Dang, M., & Nguyen, T. H. (2024). Damage Detection in Structural Health Monitoring Using an Integrated ANNIRSA Approach. Electronics, 13(7), 1241. https://doi.org/10.3390/electronics13071241