2. Related Work
Several notable studies were analysed related to the firmware updates management, optimisation of the update files transmission, and improving the process of writing to the microcontroller’s program memory. In the field of firmware update management, Mahfoudhi [
5] describes an over-the-air firmware update management model for
NB-IoT networks as the number of end devices increases significantly, seeking improvements in flexibility, installation time, efficiency, and cost reduction. In a similar context, Frisch [
6] proposes a set of models and rules for the firmware update process based on secure distribution and automatic installation mechanisms. Kachman [
7] addresses energy efficiency and its impact on firmware update processes as well as explores the evolution of this method based on delta transmission. In the area of optimising the transmission of update files, several significant studies stand out. Wee [
8] presents a methodology for transmitting update files that is based on the differences between the new and old firmware, with the aim of optimising the firmware update process. Moreover, a high speed compression and decompression algorithm to significantly speed up the update time is described. Ji [
9] refers to a study that focuses on the incremental firmware update method by modules. This method is based on assigning memory zones to each module and introducing the concept of static allocation of functions and relevant security considerations. This innovative approach improves the efficiency and security of firmware updates. Regarding the optimising of the writing process of to the microcontroller’s program memory, several studies have made significant contributions. Jisu Kwon [
10] presents a method of updating the microcontroller’s program memory based on updating by functional blocks. This makes possible a partial update of the program memory instead of completely rewriting it, avoiding downtime during the update process. Xia [
11] presents the concept of function addressing by means of a module orientated programming model. In this model, the code is organised around modes and modules for a generic dispatching procedure. Xia also introduces the concept of multimode application management, grouping together applications with similar behaviour and analysing performance evaluation techniques and metrics. Dhakal [
12] presents an architecture based on delta updates and incremental mode for large scale
IoT systems and refers to the ability to verify firmware integrity, highlighting the advantages of delta updates and identifying scenarios in which this method may not be efficient. Sun [
13] reveals the limits of conventional firmware update methods and proposes a method that uses partial updates, optimising the lifetime of program memory. This method is based on partitioning the program memory into several sections, updating only the relevant section, and classifying each partition as a component. The study addresses security mechanisms, such as encryption, signing, and validation before and after the update, as well as solutions for the static allocation of functions in scenarios where the function addresses are different between the two firmware versions; in addition, the update method is based on packets that include the functions or modules to be updated, and the study presents a statistical analysis of update times as a function of the transmission channel. Kwon [
14] proposes partitioning the firmware into functional blocks, introducing the concept of a function map. The method aims to update only the functional blocks with differences, reducing the use of program memory, energy consumption, and update time. This involves sending a functional block, where the updating application checks for differences and updates only what is necessary, then updating the function map to reflect the new state. Baldassari [
15] explores delta firmware updates in scenarios with bandwidth constraints by updating only small memory files of the firmware. The study details the delta update process, which requires one application to build the delta file and another to rebuild the new firmware from the received deltas. Although this approach offers the advantage of updating the firmware with small memory files, it also has disadvantages, such as greater complexity compared to traditional methods, a higher probability of failure, and the need to keep a copy of the original version of the firmware in the microcontroller. In addition, it requires substantial resources on the microcontroller side, including memory and processing to handle delta updates and corrections.
3. Method Development
The underlying idea of the proposed new method consists of the
Non Volatile Memory (NVM) controller usage to directly update parts of the existent program code. The
NVM controller is a hardware resource present in the majority of microcontrollers that is responsible for the management of non-volatile memory—also known as flash memory—the type of memory that retains data even when the microcontroller is turned off. The above mentioned
NVM controller acts over the available flash memory blocks allowing one to read, write, and erase the existing data in memory. The use of this
NVM controller allow us to update the existent firmware during runtime in the same way we can read and write
NVM user data without compromising the operation of the applications. Consequently, an update task application is added that aims to receive the data blocks associated with the code of a particular application and update them in the flash program memory, as illustrated in
Figure 1.
The non-volatile memory of a microcontroller is usually segmented or organised into several sectors, most of them devoted to the program memory. The program memory can be configured with different partitions, sizes, and write protection attributes. These partitions can be configured to implement the boot area, the application area, and the user memory data. In this paper, a
PIC18F27K42 microcontroller is used as a testbed platform to validate the proposed techniques. This microcontroller has a non-volatile memory control mechanism that uses an internal timer and voltage generator to perform writing operations. Reading program memory is executed byte by byte. The writing process is, however, more complex, as it requires the operation to be performed on a row of bytes. The content of this row must be previously erased or available for writing if it is its first use. The writing operation also requires that a write unlock sequence be activated [
4]. Writing or erasing program memory will halt the microcontroller central processing unit
CPU, making it impossible to execute instructions from the memory row that is being erased, as the microcontroller
CPU is blocked until the process is completed [
4]. For the above mentioned
PIC18F27K42, the measured erasing and writing procedures take 10 ms per row.
Table 1 illustrates the size and number of rows [
4].
The program memory read operation does not modify data; therefore, it is very simple to carry out, simply defining the memory area to be accessed. To complete this operation, we need to previously select the program flash memory and set the address to be read using the
TBLPTR register, then read the contents of that position. Note that the reading is performed byte to byte, but each program memory position has a size of two bytes; therefore, it is necessary to increment the pointer of the reading table
TBLRD for each byte read. The result is in the register
TABLAT: the first byte corresponds to the less significant byte and the second to the most significant byte of the specified memory position content [
4]. To read the contents of a particular program memory address, the following sequence of operations must be completed, as illustrated in the flowchart of
Figure 2.
The write operation follows the same principle as the read operation, but operates over rows instead of bytes. The write operation is performed on an entire row, but it is implemented byte by byte [
4]. As a recommended practice, in a write operation in which only part of the row is changed, it is suggested that the row be read and stored in volatile memory
RAM before being erased. The copied row is then updated with the portion of the data that differs from the original version. Finally, the
NVM row should be deleted and rewritten with the updated version. For the writing process to be successful, we must first make sure that the row is available for writing; in other words, the row is formatted. Thereafter, it is necessary to define the
NVM area to be used for writing, where through the
TBLPTR register we define the address we want to write; as with reading, the writing is also done byte by byte, and, in the writing process, the least significant byte is copied to the register
TABLAT followed by the increment of the writing table
TBLWR. That process is repeated for the most significant byte. After copying the row, the next step involves activating the
NVMCON1bits.WREN write permission bit as well as selecting the
NVMCON1bits.FREE write bit command, followed by sending the write unblock sequence to the
NVM. The actual write is initiated by activating the
NVMCON1bits.WR bit [
4]; see the flowchart in
Figure 3.
To erase a row of non-volatile memory, a specific
NVM controller command is used devoted for that purpose. The
FREE bit of the
NVMCON1 register, if enabled, indicates that on the next enable the
WR bit of the same register will erase the row specified by the address contained in the
TBLPTR register. Moreover, it is necessary to previously unlock a specific range of rows to accommodate the program code and thereafter complete the erase procedure [
4], as depicted in the flowchart in
Figure 4.
The
NVM memory locking mechanism prevents unintended self-write programming or erasing. Thus, to promote memory integrity, any write and erase operation performed by the
NVM controller must be preceded by an unlocking process. This process must be executed sequentially and without interruptions. If the sequence, for some reason, is interrupted, the writing or erasing process is cancelled [
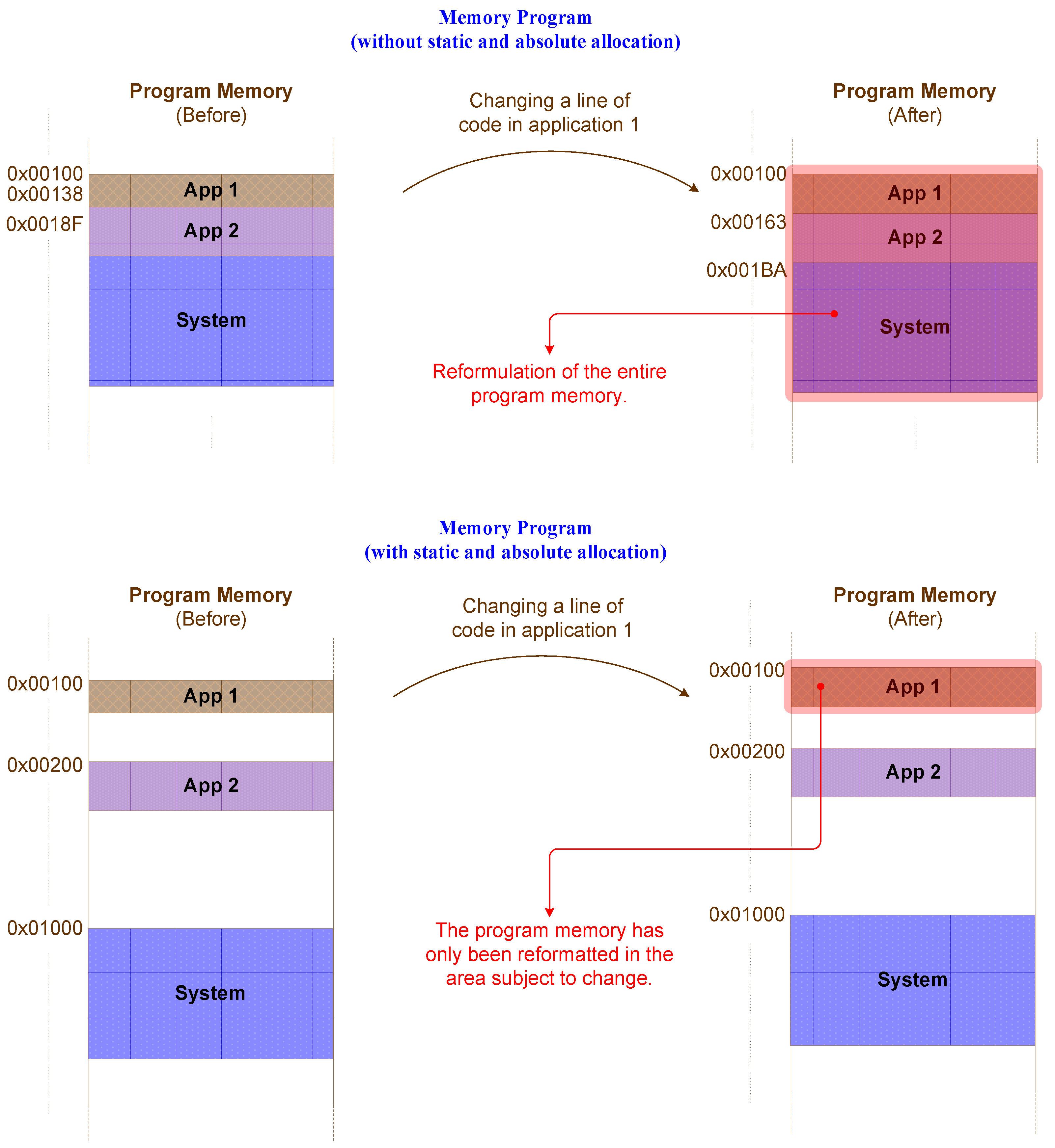
4]. To implement this method successfully, two non-mandatory but highly recommended requirements must be met to facilitate its implementation. The first one concerns the static and absolute allocation of the functions. Typically, a compiler, in order to optimise the space of the memory of the program, leans all the code to minimise the used memory space, making it more difficult to identify the location of the block of code that will need to be updated. By allocating the function’s code in a static and absolute way, an absolute reference of the location of each function of program is set, facilitating the identification of the code block in an
Intel Hex file (see
Figure 5).
The usage of static and absolute function allocation also improves the code organisation. Without static and absolute allocation, even small changes in source code can result in a hex file completely reformulated by the compiler. The usage of static and absolute allocation avoids major changes. Now, small code changes in specific functions will only affect the associated allocated memory areas, as illustrated in
Figure 6.
Static and absolute allocation of functions requires well designed system architecture and a complete knowledge of the program’s memory map in order to avoid overlaps between the functions or applications code blocks. In order to prevent an accidental overlap of two or more functions, the compiler warns us by displaying a message with the functions that are at stake, promoting the necessary changes in the memory map. The following error message was generated by the compiler under the above mentioned conditions [
16].
error: (596)
segment “_Reset_CNT_TMR_text” (19574-195A3)
overlaps segment “_TMR0_Interrupt_Handling_text” (194F6-1958F)
The second requirement concerns the size allocated to each function, which must be an integer multiple of row size; in the considered microcontroller, that size is equal to 128 bytes [
4]. An example of a program memory map is depicted in
Figure 7.
The following step, after the program memory map definition, comprises setting the function’s indexes addresses in the above mentioned range. To allocate a function in a static and absolute way, one simply needs to add before the function name the method __at(address); from here, the compiler will place that function in that specific address, as illustrated in the following function prototype.
void __at(APP_1_Start_Address) App_1(void)
To validate this method, a testbed was developed comprising a circuit board with the microcontroller, two push buttons, and an
ICSP header (depicted in
Figure 8).
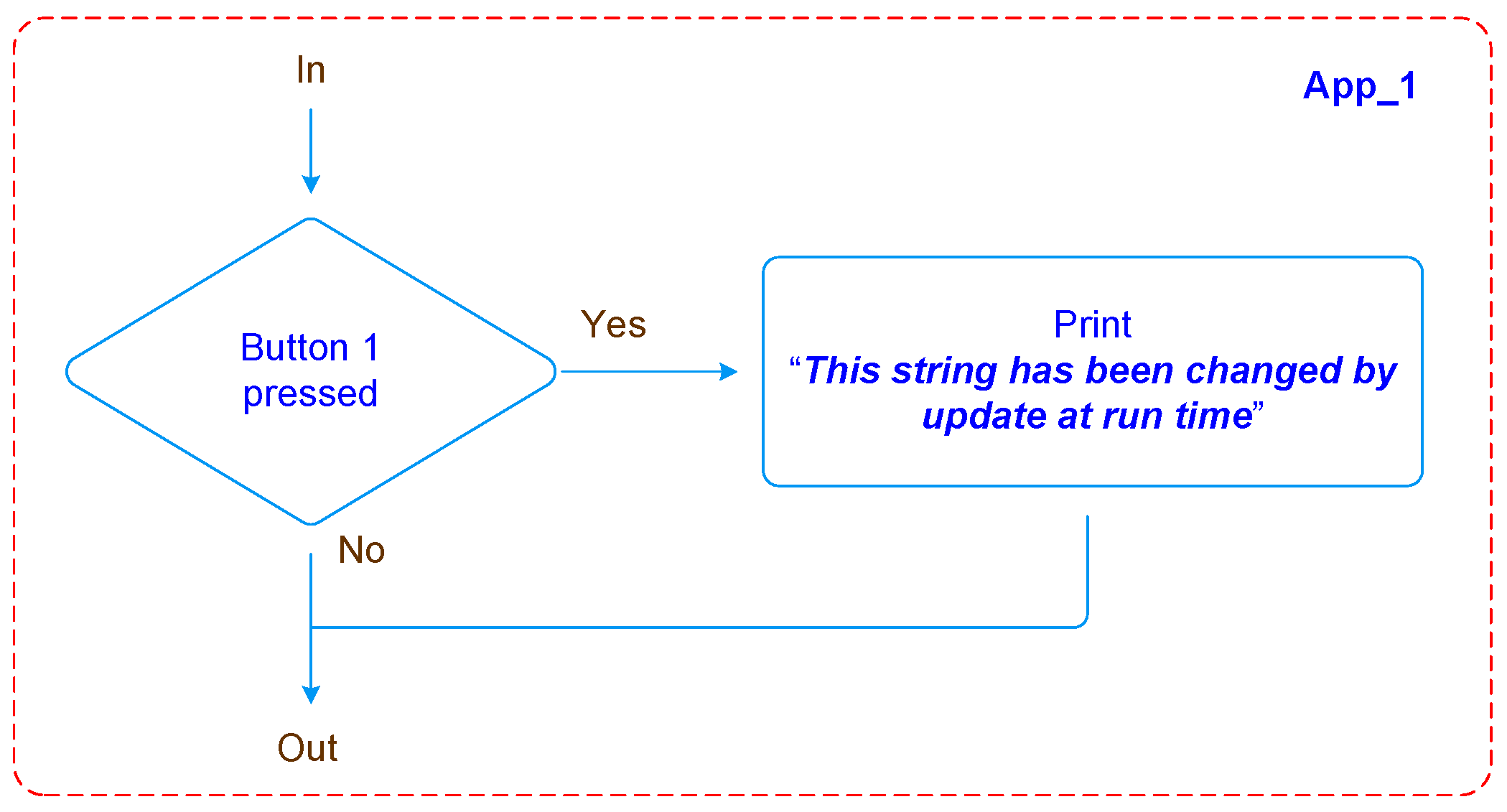
The firmware project comprises three applications: two similar applications associated to different hardware resources, in this case push buttons, and In Application Programming
(IAP) that performs an update of the firmware by means of a runtime self programming process. The first application prints in the serial port the message
“Button 1 has been pressed” when button 1 is pressed. Similarly, the second application prints the message
“Button 2 has been pressed” in the serial port when button 2 is pressed. These messages are defined and saved in the microcontroller flash memory.
Figure 9 illustrates the flowchart of the implemented program.
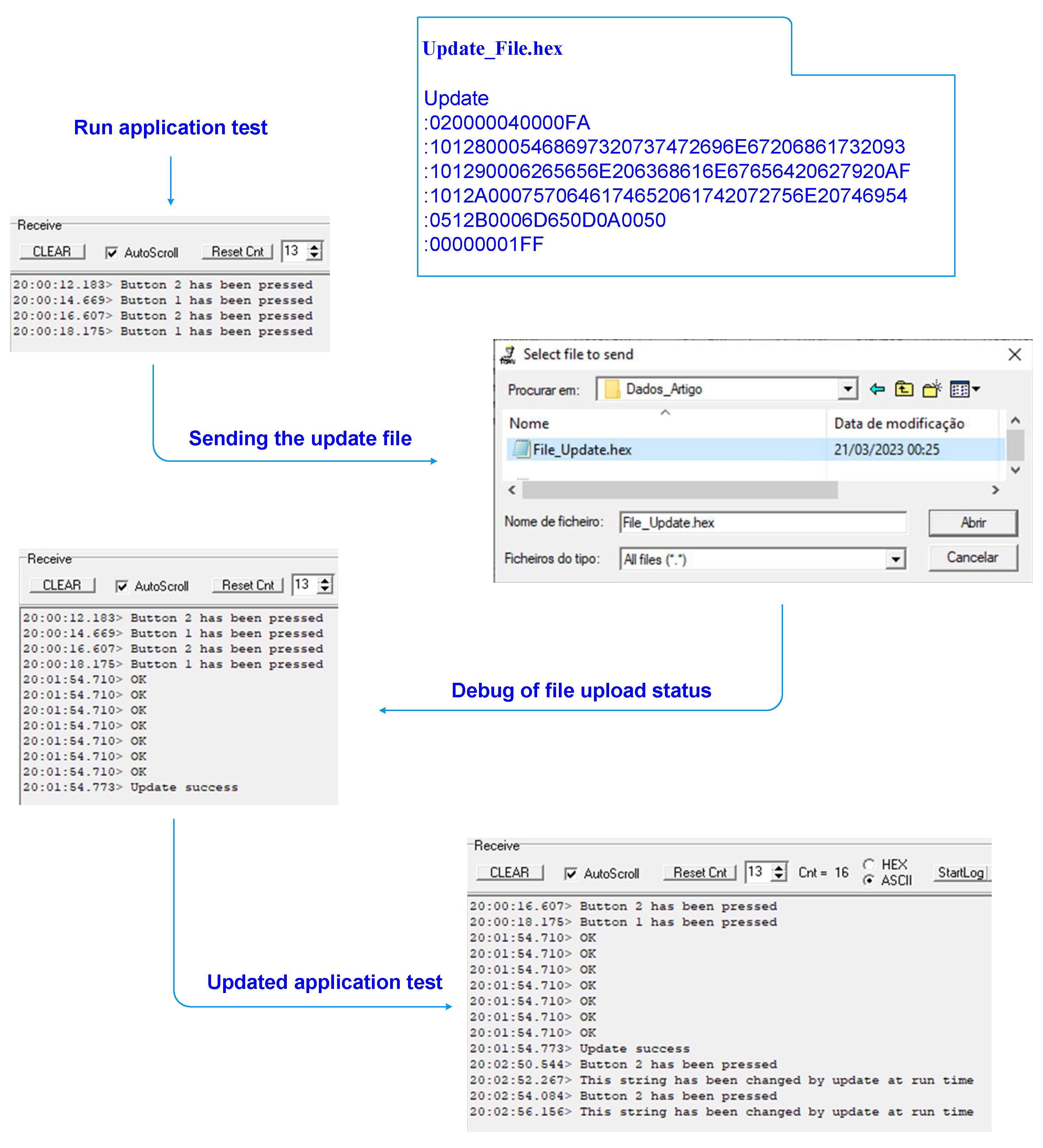
After executing a firmware upgrade operation, it is intended to update the message printed by the first application from
“Button 1 has been pressed” to
“This string has been changed by update at run time”, whenever the hardware button 1 is pressed (see
Figure 10).
From the analysis of the compiled program code, it can be seen where each function of the first application is allocated in the program memory (see
Figure 11 and example of program memory map in
Figure 7).
Additionally, it is also possible to identify and locate application 1 in the hexadecimal file generated from the compiler (see
Figure 12).
From the analysis of the modified program hexadecimal file, it can be concluded that only a well defined area of the program memory was changed; all the remaining program memory stays intact.
Figure 13 presents the original and upgraded code versions of the aforementioned application 1, demonstrating the code blocks that have been removed on the original version and the ones that have been inserted on the modified one.
Using the static and absolute function allocation allows one to control and manipulate the entire program memory, making the updating task easier and keeping the firmware update circumscribed to a well defined block of program memory between addresses 0x00001280 and 0x000012B0. The update process consists of receiving a hexadecimal file in the
Intel Hex File format [
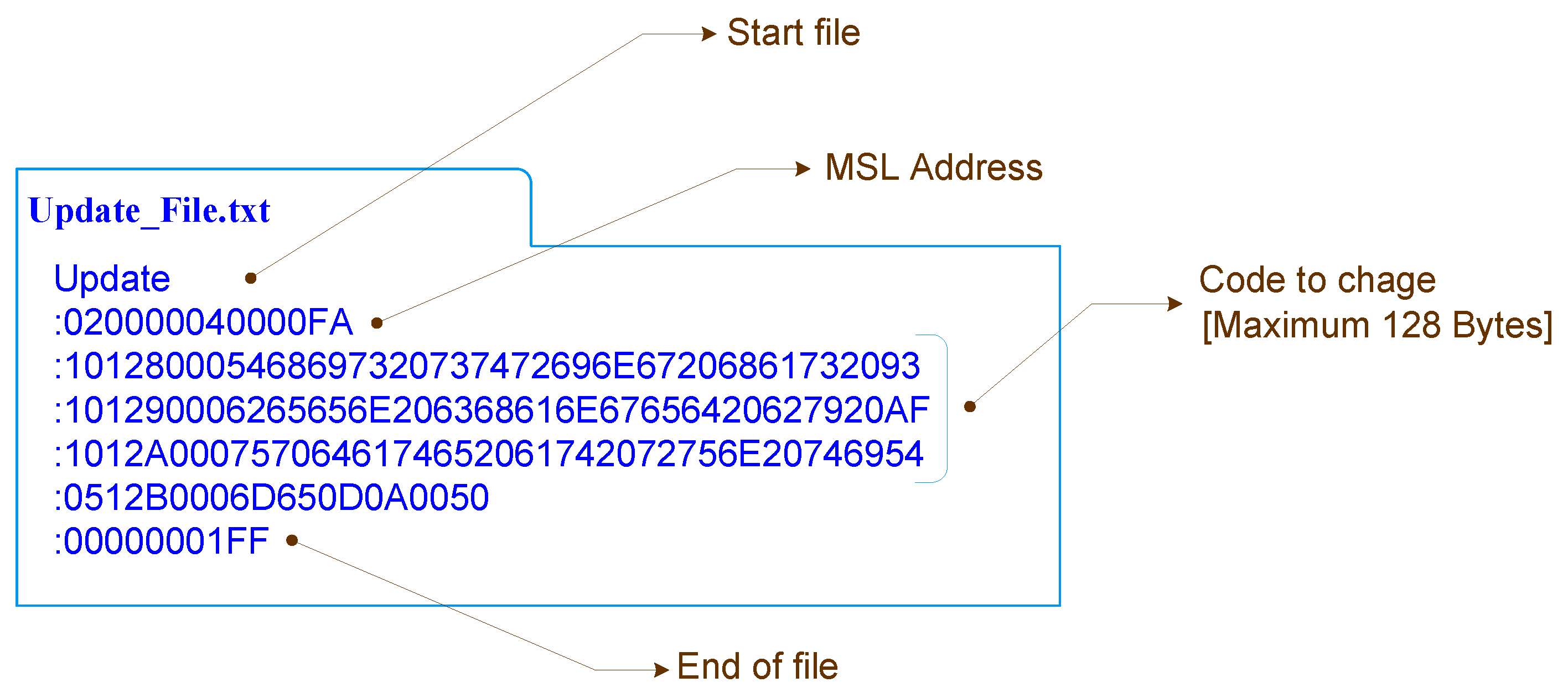
17] over the serial channel. However, as only one block of the program’s memory is to be updated and the hexadecimal file is not formatted to send a single block but the entire file, some changes need to be made so that the update process application can interpret the file correctly. Those changes include the addition of a start file, followed by the most significant word of the address and the end of file, as illustrated in
Figure 14.
The
Intel Hex File format is one of the formats used to update microcontrollers’ firmware, but there are also other possible formats, such as the binary
.bin file. The
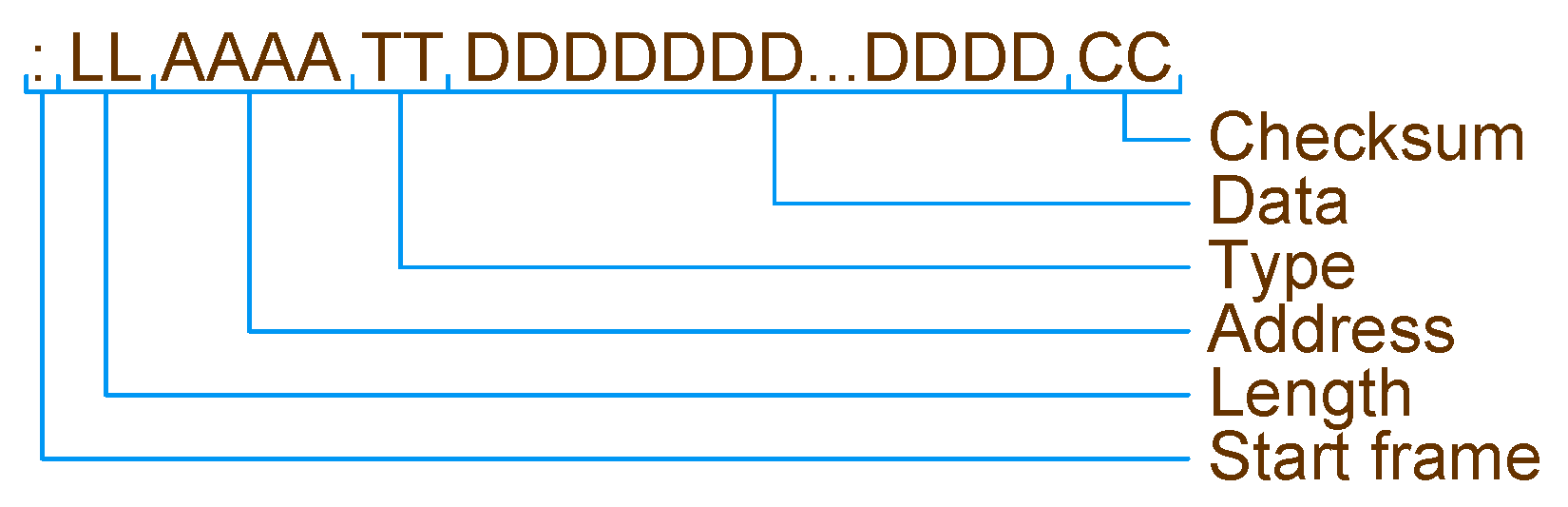
Intel Hex File format is characterized by the lines being in hexadecimal format; all the lines start with the character
‘:’ followed by the data field length, start address, data type, the associated data (for each specific data type), and, finally, the error control checksum mechanism [
17].
Figure 13 depicts the hexadecimal file obtained from the compiled modified code, which is sent to the microcontroller according to the aforementioned Intel Hex File format described in
Figure 15 and
Table 2. As explained previously, with the inclusion of all the fields, the file sent to the microcontroller is the one presented in
Figure 14. The update file results from the extraction of a block of program memory of the hexadecimal file with the updated code; the file is started with a start file named
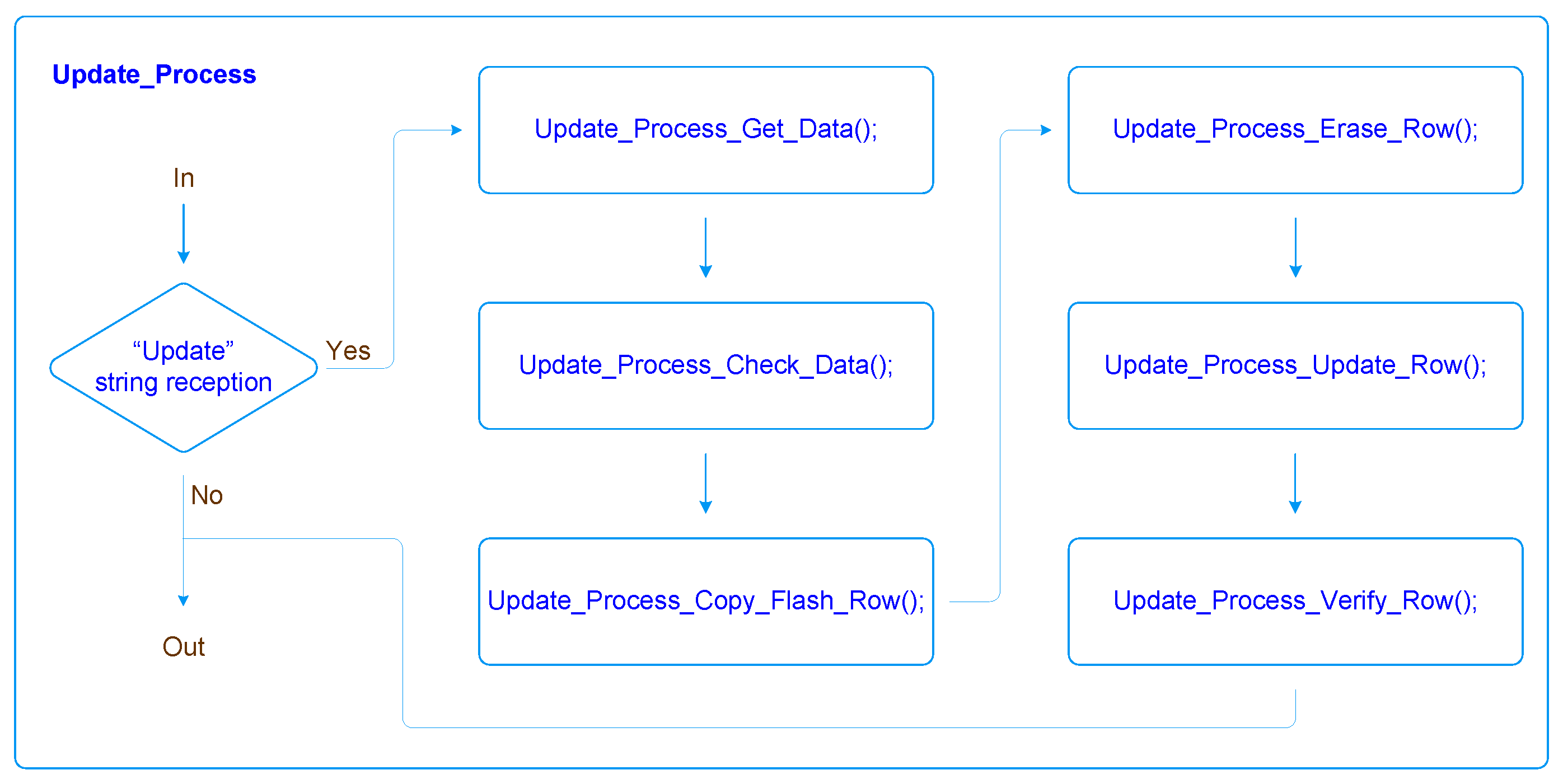
Update, followed by the most significant word of the address, the data to update, and, finally, the end of file indicator. The update process application is responsible for the file receiving and processing. The initial state of the update process app waits for the reception of a start file, “Update” string, to proceed to the data acquisition state. In this state, the process waits until it receives a complete record and verifies its integrity using the checksum mechanism. If the line is valid, the process thereafter extracts the address, the type, and the data contained in the line. Depending on the type of data, the process reacts accordingly. For
Extended Linear Address type, the MSW of the address is defined; if the type is
“Data_Record”, it updates the LSW of the address and copies the data to a process buffer; finally, if the type is
End of file, the process proceeds to the next stage, updating the program memory block. First, it copies the area of the program memory block to be updated to volatile memory
RAM for final verification purposes of the update integrity; in the next operation, it erases the memory block to be updated, followed by updating with the data received by the update file; finally, a verification is performed between the data in the update file received and the data stored in the updated memory block. The update process application can be seen in the flowchart in
Figure 16.
If the process was completed successfully, it reports
“Update success”; otherwise, it reports
“Update failure” through the serial channel.
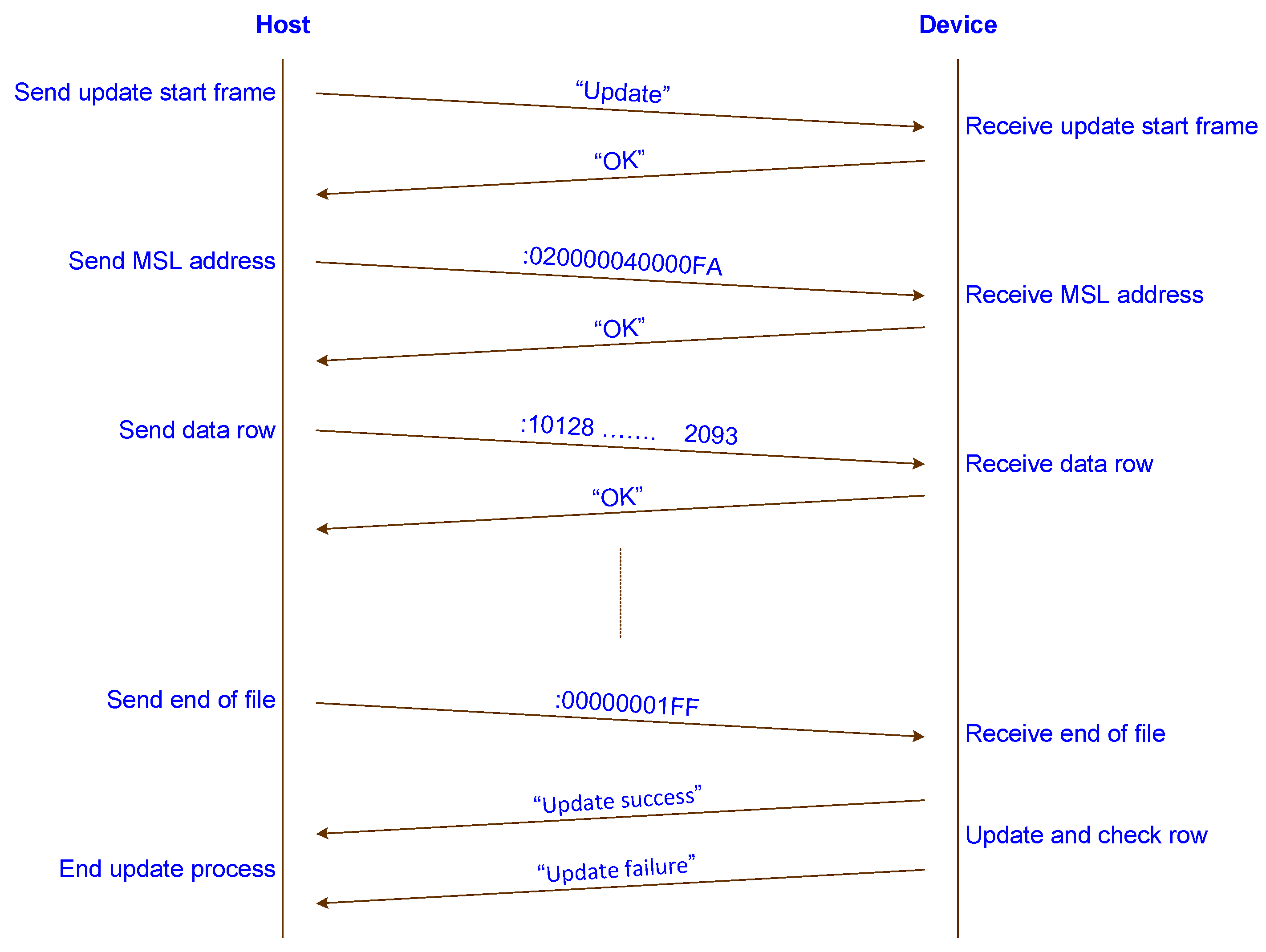
Figure 17 illustrates the update file transfer protocol implemented between the host and the device microcontroller.
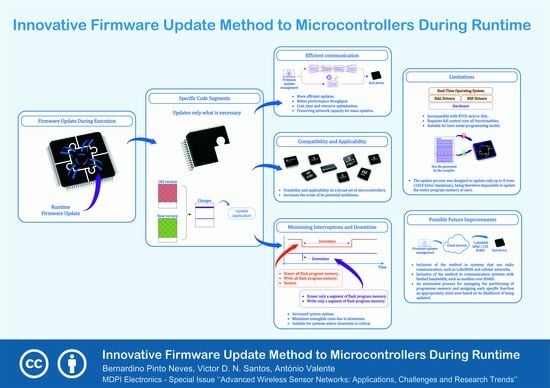
5. Conclusions
In this paper, a new firmware update method for microcontrollers is presented, implemented, and validated. This new method differs from existing ones because it allows for updating only specific code lines, blocks, or functions instead of replacing the entire program during runtime. This method is suited to band limited channels that take into account the attained reduction on the amount of data transmitted. The proposed update procedure offers additional advantages, such as a reduced downtime, less than 10 ms, and good recoverability in a failure scenario.
The planned method also presents some limitations; the update process was designed to update only up to eight rows (1024 bytes’ maximum), so it is therefore impossible to update the entire program memory at once.
This firmware update method is also incompatible with operating systems and/or intermediate hardware abstraction layers; it requires full control over all functionalities. Moreover, under a power failure event, the success of the update process is not guaranteed. Thus, it is advisable to include a supercapacitor-based backup power circuit to maintain module power and the upgrade process integrity.
This method was successfully and easily replicated on several microcontrollers, such as the MSP430, STM8, STM32, ATtiny, ATmega, SAMD21, and PIC32. This observation emphasises the feasibility and applicability of the method on a broad set of microcontrollers, thus increasing the scope of its potential usefulness. Future advances on the proposed method must consider the inclusion of radio transmission, using LoRaWAN or available cellular networks, to send the update file to remote sensor end-devices. An automated process to manage the partitioning of program memory and assign to each specific function an area of appropriated size based on its likelihood of being updated will also be investigated in the future. In conclusion, this article leaves an open door to a new generation of firmware updates for microcontrollers.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}