
Containerization in Edge Intelligence: A Review




Abstract
:1. Introduction
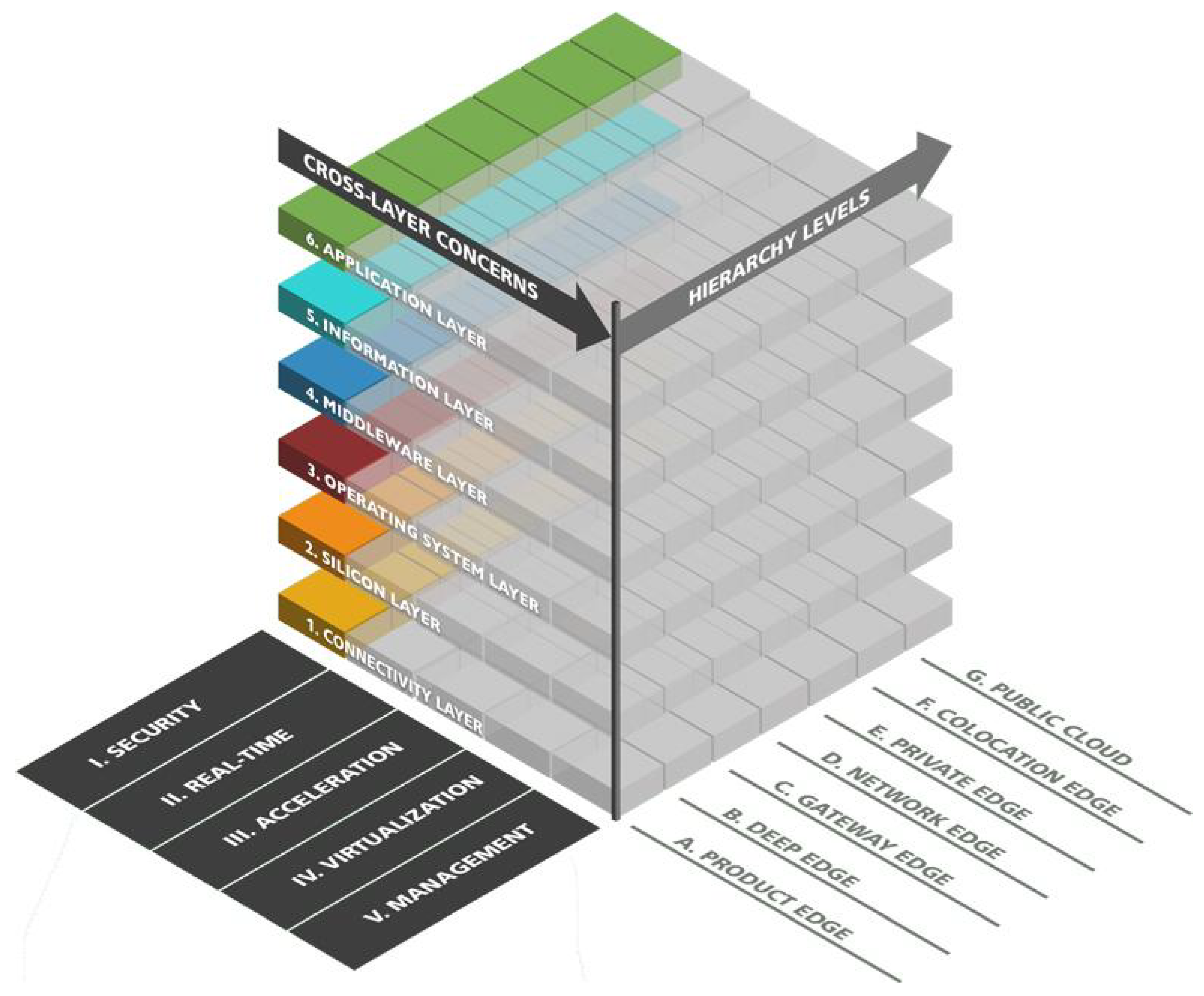
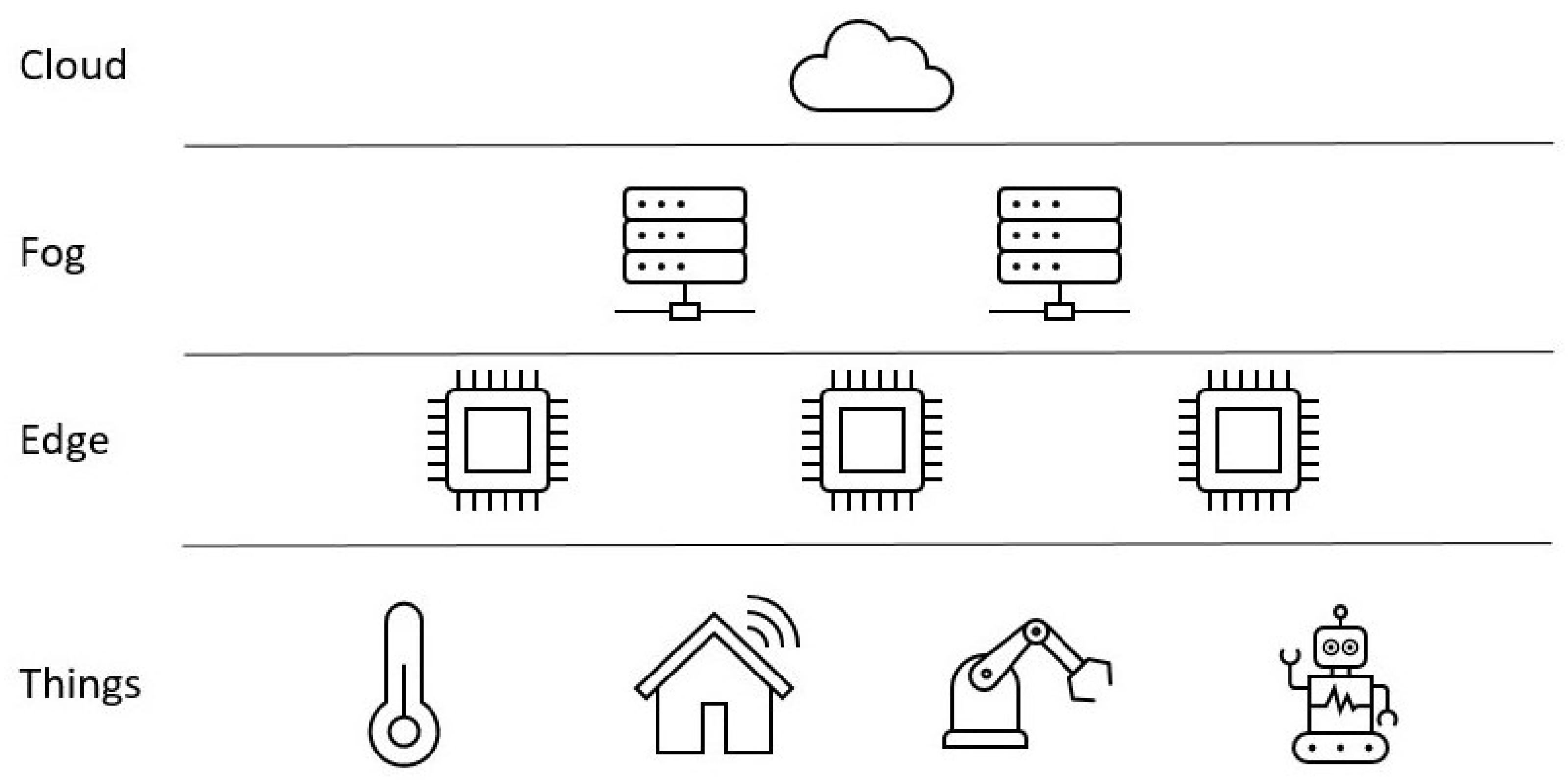
2. Edge Intelligence
- Size—Edge devices often need to be smaller as they need to be placed closer to the data source without being intrusive.
- Power—Edge devices use less power as they do not have the space for a large cooling solution or can be battery-powered.
- Computing performance—Both of the previously mentioned factors result in lower performance of the device as it has to deal with limited resources and space.
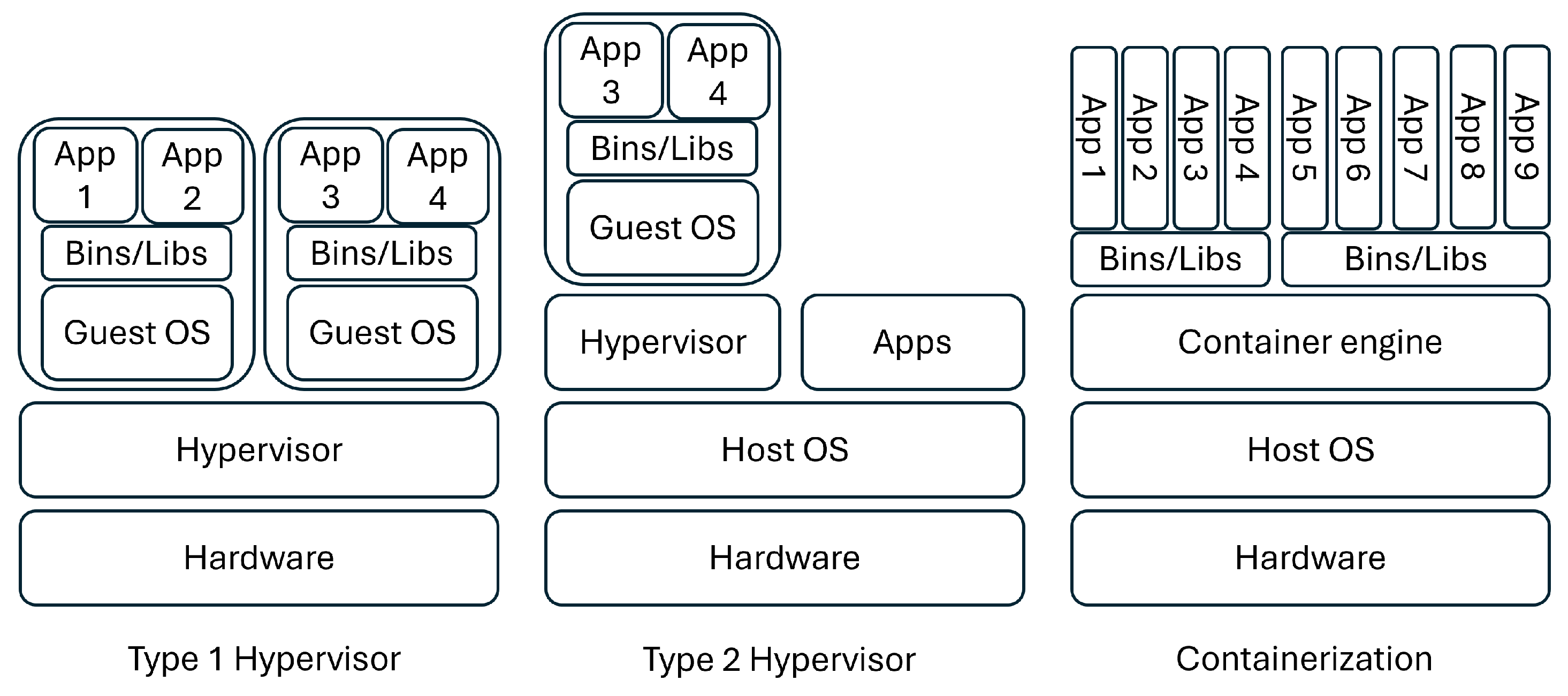
3. Containerization
3.1. Hardware Virtualization
3.1.1. Type 1 Hypervisor
3.1.2. Type 2 Hypervisor
3.1.3. Performance Comparison of Type 1 vs. Type 2
3.2. Containerization—Operating System Level Virtualization
3.2.1. Definition
3.2.2. Namespaces
3.2.3. Cgroups
3.3. Performance of OS-Level Virtualization
3.4. Containers and Data
3.5. DevOps
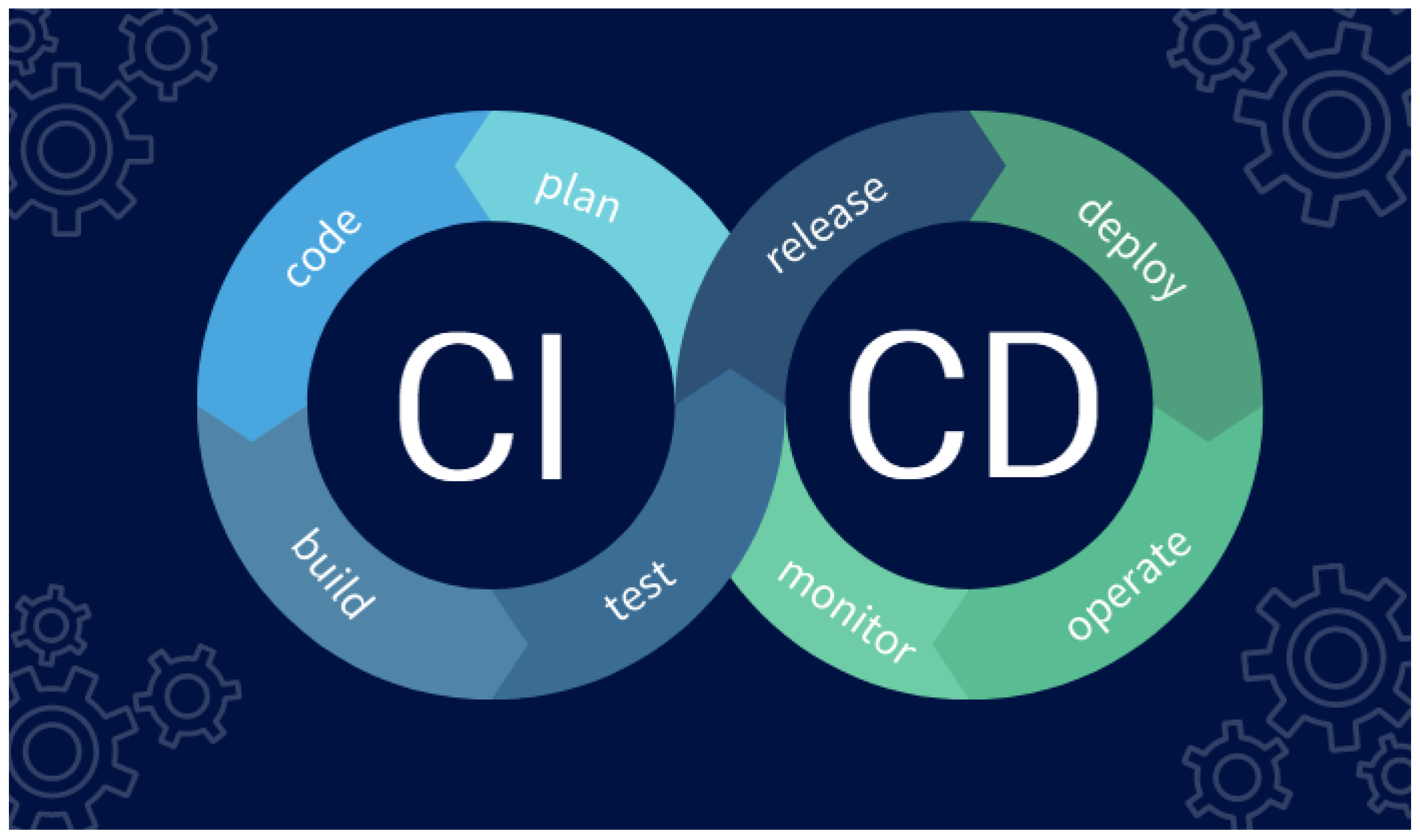
3.6. CI/CD
3.7. Security
3.8. Creating a Container Image
| Listing 1. Dockerfile Example. |
 |
4. Tools
4.1. Docker
4.2. Kubernetes
4.3. Anaconda
5. Solutions and Architectures on Edge
- On-demand self-service—The user can automatically provision resources and services through an online interface.
- Broad network access—Access to the resources and services is available through standard networks and interfaces, such as the Internet.
- Resource pooling—The provider’s resources are pooled to serve multiple consumers, with dynamic assignment and reassignment of virtual and physical resources according to consumer demand.
- Rapid elasticity—The resources available to the user should be scalable both up and down without much user configuration. The process should be available at any time.
- Measured service—The usage is monitored according to appropriate criteria (storage, processing time, bandwidth, etc.), and these metrics are available to the user at any time, together with the associated costs.
- Security—Additional security to ensure safe, trusted transactions.
- Cognition—Awareness of client-centric objectives to enable autonomy.
- Agility—Rapid innovation and affordable scaling under a common infrastructure.
- Latency—Real-time processing and cyber-physical system control.
- Efficiency—Dynamic pooling of local unused resources from participating end-user devices.
- Cloud-Edge Coinference and Cloud Training—the model is trained in the cloud, where the performance allows for faster and better performance of the model. The data from the edge is partially offloaded to the cloud for inference.
- In-Edge Coinference and Cloud training—the model is trained in the cloud, as in the previous level. The inference occurs in-edge, where the data can be fully or partially offloaded to nearby nodes or devices without leaving the edge.
- On-Device Inference and Cloud Training—the model is trained in the cloud, but the inference occurs on the edge device itself. No data offloading is conducted.
- Cloud-Edge Cotraining and Inference—both the model training and inference are conducted in cooperation between the edge and the cloud.
- All In-Edge—Both the training and the inference are conducted in-edge, with edge devices cooperating and offloading data.
- All On-Device—Both the training and the inference are conducted on-device, with each device working by itself.
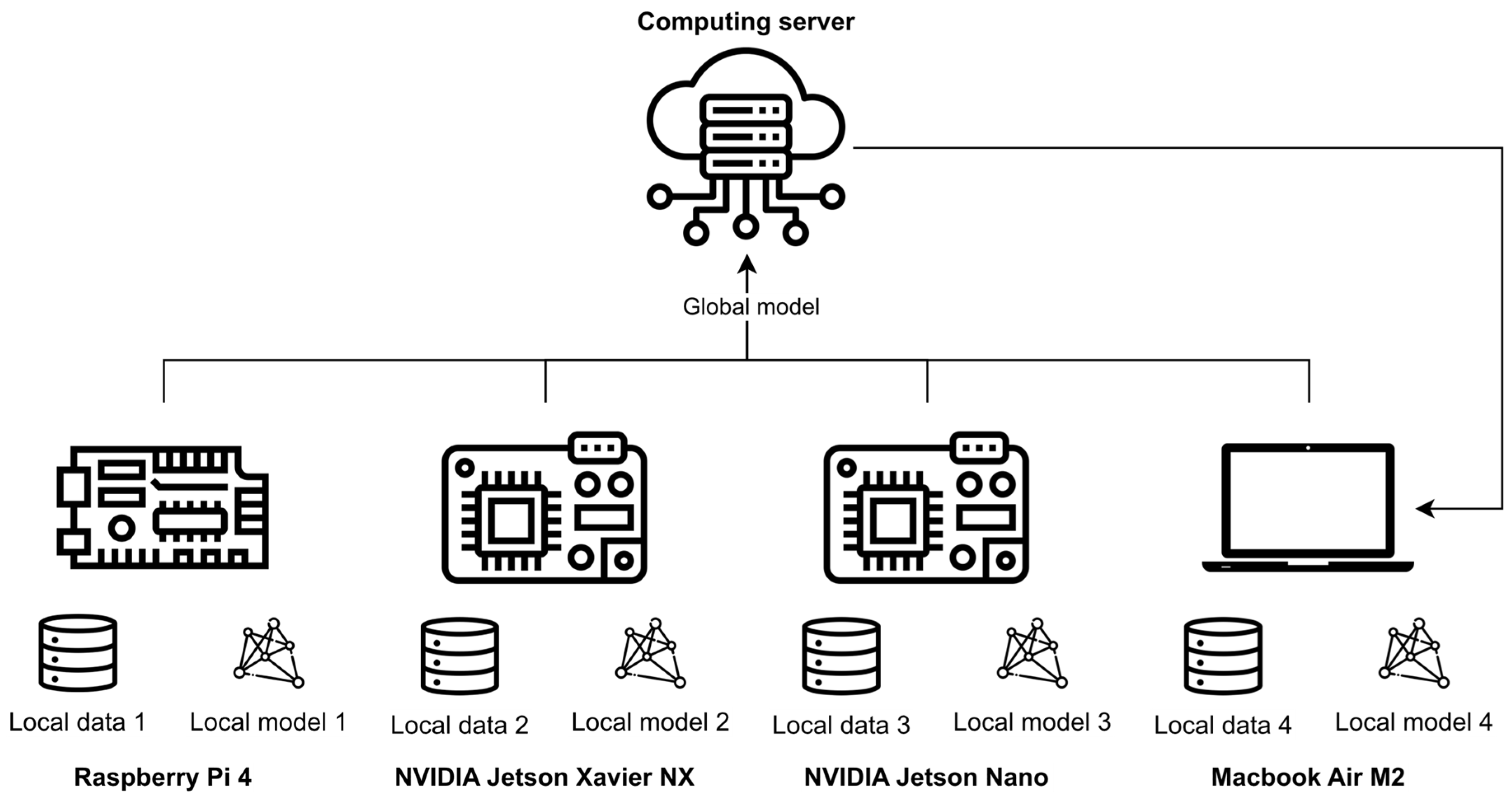
5.1. Federated Learning
- Population density—simply put: more people, more devices. The population density affects the number of available devices in a certain location.
- Country location—people from different countries may behave differently.
- Housing—people living in flats and houses exhibit different behaviors.
- Modes of transportation—stemming from the previously mentioned factors, the modes of transportation.
5.2. Robotics
5.3. Healthcare
5.4. Virtual Assistants
5.5. Composite AI
6. Discussion and Challenges
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application programming interface |
| AI | Artificial Intelligence |
| CI/CD | Continuous Integration and Continuous Delivery |
| EC | Edge Computing |
| EI | Edge Intelligence |
| FL | Federated Learning |
| IaaS | Infrastructure as a Service |
| IoT | Internet of Things |
| K8s | Kubernetes |
| ML | Machine Learning |
| MCU | Microcontroller Unit |
| NN | Neural Network |
| OCI | Open Container Initiative |
| OS | Operating System |
| PaaS | Platform as a Service |
| PC | Personal Computer |
| ROS | Robot Operating System |
| SBC | Single Board Computer |
| SaaS | Software as a Service |
| VM | Virtual Machine |
References
- Arthur, C. Tech giants may be huge, but nothing matches big data. The Guardian, 23 August 2013. [Google Scholar]
- Hirsch, D.D. The glass house effect: Big Data, the new oil, and the power of analogy. Maine Law Rev. 2013, 66, 373. [Google Scholar]
- Vailshery, L.S. Public Cloud Services End-User Spending Worldwide from 2017 to 2024; Statista: New York, NY, USA, 2023. [Google Scholar]
- Berisha, B.; Mëziu, E.; Shabani, I. Big data analytics in Cloud computing: An overview. J. Cloud Comput. 2022, 11, 24. [Google Scholar] [CrossRef]
- Alexander, E. Essential Internet Traffic Statistics in 2024; ZipDo: Aichach, Germany, 2023. [Google Scholar]
- Quy, N.M.; Ngoc, L.A.; Ban, N.T.; Hau, N.V.; Quy, V.K. Edge Computing for Real-Time Internet of Things Applications: Future Internet Revolution. Wirel. Pers. Commun. 2023, 132, 1423–1452. [Google Scholar] [CrossRef]
- AWS. What Is Containerization?—Containerization Explained; AWS: Seattle, WA, USA, 2023. [Google Scholar]
- Angel, N.A.; Ravindran, D.; Vincent, P.M.D.R.; Srinivasan, K.; Hu, Y.C. Recent Advances in Evolving Computing Paradigms: Cloud, Edge, and Fog Technologies. Sensors 2022, 22, 196. [Google Scholar] [CrossRef]
- Bourechak, A.; Zedadra, O.; Kouahla, M.N.; Guerrieri, A.; Seridi, H.; Fortino, G. At the Confluence of Artificial Intelligence and Edge Computing in IoT-Based Applications: A Review and New Perspectives. Sensors 2023, 23, 1639. [Google Scholar] [CrossRef]
- Shirazi, S.N.; Gouglidis, A.; Farshad, A.; Hutchison, D. The Extended Cloud: Review and Analysis of Mobile Edge Computing and Fog From a Security and Resilience Perspective. IEEE J. Sel. Areas Commun. 2017, 35, 2586–2595. [Google Scholar] [CrossRef]
- Marinescu, D.C. Cloud Computing: Theory and Practice; Morgan Kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Iftikhar, S.; Gill, S.S.; Song, C.; Xu, M.; Aslanpour, M.S.; Toosi, A.N.; Du, J.; Wu, H.; Ghosh, S.; Chowdhury, D.; et al. AI-based fog and edge computing: A systematic review, taxonomy and future directions. Internet Things 2023, 21, 100674. [Google Scholar] [CrossRef]
- Rosendo, D.; Costan, A.; Valduriez, P.; Antoniu, G. Distributed intelligence on the Edge-to-Cloud Continuum: A systematic literature review. J. Parallel Distrib. Comput. 2022, 166, 71–94. [Google Scholar] [CrossRef]
- Kang, P.; Jo, J. Benchmarking Modern Edge Devices for AI Applications. IEICE Trans. Inf. Syst. 2021, E104.D, 394–403. [Google Scholar] [CrossRef]
- Hussain, H.; Tamizharasan, P.S.; Rahul, C.S. Design possibilities and challenges of DNN models: A review on the perspective of end devices. Artif. Intell. Rev. 2022, 55, 5109–5167. [Google Scholar] [CrossRef]
- M Computers s.r.o. NVIDIA Jetson. Available online: https://mcomputers.cz/en/products-and-services/nvidia/jetson/ (accessed on 8 January 2024).
- Microway. Comparison of NVIDIA GeForce GPUs and NVIDIA Tesla GPUs. Available online: https://www.microway.com/knowledge-center-articles/comparison-of-nvidia-geforce-gpus-and-nvidia-tesla-gpus/ (accessed on 8 January 2024).
- Radchenko, G.I.; Alaasam, A.B.A.; Tchernykh, A.N. Comparative Analysis of Virtualization Methods in Big Data Processing. Supercomput. Front. Innov. 2019, 6, 48–79. [Google Scholar] [CrossRef]
- Willner, A.; Gowtham, V. Towards a Reference Architecture Model for Industrial Edge Computing. IEEE Commun. Stand. Mag. 2020, 4, 42–48. [Google Scholar] [CrossRef]
- Willner, A. The European Edge Computing Consortium (EECC) Presented the Reference Architecture Model Edge Computing (RAMEC). Fraunhofer FOKUS. 24 October 2019. Available online: https://www.fokus.fraunhofer.de/en/ngni/news/ecf-eecc_2019_12 (accessed on 15 February 2024).
- Desai, A.; Oza, R.; Sharma, P.; Patel, B. Hypervisor: A survey on concepts and taxonomy. Int. J. Innov. Technol. Explor. Eng. 2013, 2, 222–225. [Google Scholar]
- Schlosser, D.; Duelli, M.; Goll, S. Performance Comparison of Hardware Virtualization Platforms. In NETWORKING 2011; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6640, pp. 393–405. [Google Scholar] [CrossRef]
- Takabi, H.; Joshi, J.B.; Ahn, G.J. Security and Privacy Challenges in Cloud Computing Environments. IEEE Secur. Priv. 2010, 8, 24–31. [Google Scholar] [CrossRef]
- Dhule, C.; Shrawankar, U. Impact Analysis of Hypervisors on the Performance of Virtualized Resources. In Proceedings of the Integrated Intelligence Enable Networks and Computing; Algorithms for Intelligent Systems; Singh Mer, K.K., Semwal, V.B., Bijalwan, V., Crespo, R.G., Eds.; Springer: Singapore, 2021; pp. 421–427. [Google Scholar] [CrossRef]
- De Lauretis, L. From Monolithic Architecture to Microservices Architecture. In Proceedings of the 2019 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Berlin, Germany, 27–30 October 2019; pp. 93–96. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Krishna, C.R. Virtualization in Cloud Computing: Moving from Hypervisor to Containerization—A Survey. Arab. J. Sci. Eng. 2021, 46, 8585–8601. [Google Scholar] [CrossRef]
- Dua, R.; Raja, A.R.; Kakadia, D. Virtualization vs Containerization to Support PaaS. In Proceedings of the 2014 IEEE International Conference on Cloud Engineering, Boston, MA, USA, 11–14 March 2014; pp. 610–614. [Google Scholar] [CrossRef]
- Jain, S.M. Namespaces. In Linux Containers and Virtualization: A Kernel Perspective; Apress: Berkeley, CA, USA, 2020; pp. 31–43. [Google Scholar] [CrossRef]
- Martin, A.; Raponi, S.; Combe, T.; Di Pietro, R. Docker ecosystem—Vulnerability Analysis. Comput. Commun. 2018, 122, 30–43. [Google Scholar] [CrossRef]
- Đorđević, B.; Timčenko, V.; Sakić, D.; Davidović, N. File system performance for type-1 hypervisors on the Xen and VMware ESXi. In Proceedings of the 2022 21st International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 16–18 March 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Sharma, P.; Chaufournier, L.; Shenoy, P.; Tay, Y.C. Containers and Virtual Machines at Scale: A Comparative Study. In Proceedings of the 17th International Middleware Conference, Trento, Italy, 12–16 December 2016; Middleware ’16. ACM: New York, NY, USA, 2016; pp. 1–13. [Google Scholar] [CrossRef]
- Aniruddh, M.; Dinkar, A.; Mouli, S.C.; Sahana, B.; Deshpande, A.A. Comparison of Containerization and Virtualization in Cloud Architectures. In Proceedings of the 2021 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 9–11 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Abuabdo, A.; Al-Sharif, Z.A. Virtualization vs. Containerization: Towards a Multithreaded Performance Evaluation Approach. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Watada, J.; Roy, A.; Kadikar, R.; Pham, H.; Xu, B. Emerging Trends, Techniques and Open Issues of Containerization: A Review. IEEE Access 2019, 7, 152443–152472. [Google Scholar] [CrossRef]
- Jabbari, R.; bin Ali, N.; Petersen, K.; Tanveer, B. What is DevOps? A Systematic Mapping Study on Definitions and Practices. In Proceedings of the Scientific Workshop Proceedings of XP2016, Edinburgh, UK, 24 May 2016; XP ’16 Workshops. ACM: New York, NY, USA, 2016; pp. 1–11. [Google Scholar] [CrossRef]
- Luz, W.P.; Pinto, G.; Bonifácio, R. Adopting DevOps in the real world: A theory, a model, and a case study. J. Syst. Softw. 2019, 157, 110384. [Google Scholar] [CrossRef]
- Team, F.B.U. Continuous Integration and Continuous Deployment. In Cloud-Native Application Architecture: Microservice Development Best Practice; Springer Nature: Singapore, 2024; pp. 351–382. [Google Scholar] [CrossRef]
- Poth, A.; Werner, M.; Lei, X. How to Deliver Faster with CI/CD Integrated Testing Services? In Proceedings of the Systems, Software and Services Process Improvement, Bilbao, Spain, 5–8 September 2018; Communications in Computer and Information Science. Larrucea, X., Santamaria, I., O’Connor, R.V., Messnarz, R., Eds.; Springer: Cham, Switzerland, 2018; pp. 401–409. [Google Scholar] [CrossRef]
- JetBrains. The State of Developer Ecosystem in 2023 Infographic; JetBrains: Prague, Czech Republic, 2023. [Google Scholar]
- Shu, R.; Gu, X.; Enck, W. A Study of Security Vulnerabilities on Docker Hub. In Proceedings of the Seventh ACM on Conference on Data and Application Security and Privacy, Scottsdale, AZ, USA, 22–24 March 2017; pp. 269–280. [Google Scholar] [CrossRef]
- Combe, T.; Martin, A.; Di Pietro, R. To Docker or Not to Docker: A Security Perspective. IEEE Cloud Comput. 2016, 3, 54–62. [Google Scholar] [CrossRef]
- Chamoli, S.; Sarishma. Docker Security: Architecture, Threat Model, and Best Practices. In Soft Computing: Theories and Applications; Advances in Intelligent Systems and Computing; Sharma, T.K., Ahn, C.W., Verma, O.P., Panigrahi, B.K., Eds.; Springer: Singapore, 2021; pp. 253–263. [Google Scholar] [CrossRef]
- Tank, D.; Aggarwal, A.; Chaubey, N. Virtualization vulnerabilities, security issues, and solutions: A critical study and comparison. Int. J. Inf. Technol. 2022, 14, 847–862. [Google Scholar] [CrossRef]
- The Linux Foundation. About the Open Container Initiative; The Linux Foundation: San Francisco, CA, USA, 2015. [Google Scholar]
- Dockerfile Reference. 2024. Available online: https://docs.docker.com/reference/dockerfile/ (accessed on 7 March 2024).
- Merkel, D. Docker: Lightweight Linux containers for consistent development and deployment. Linux J. 2014, 2014. [Google Scholar]
- Ismail, B.I.; Mostajeran Goortani, E.; Ab Karim, M.B.; Ming Tat, W.; Setapa, S.; Luke, J.Y.; Hong Hoe, O. Evaluation of Docker as Edge computing platform. In Proceedings of the 2015 IEEE Conference on Open Systems (ICOS), Melaka, Malaysia, 24–26 August 2015; pp. 130–135. [Google Scholar] [CrossRef]
- Docker Documentation. Review of the Docker Daemon Attack Surface. 2023. Available online: https://docs.docker.com/engine/security/#docker-daemon-attack-surface (accessed on 30 December 2023).
- Docker Documentation. Run the Docker Daemon as a Non-Root User (Rootless Mode). 2023. Available online: https://docs.docker.com/engine/security/rootless/ (accessed on 30 December 2023).
- Rahmansyah, R.; Suryani, V.; Arif Yulianto, F.; Hidayah Ab Rahman, N. Reducing Docker Daemon Attack Surface Using Rootless Mode. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–26 August 2021; pp. 499–502. [Google Scholar] [CrossRef]
- Casalicchio, E. Container Orchestration: A Survey. In Systems Modeling: Methodologies and Tools; EAI/Springer Innovations in Communication and Computing; Springer International Publishing: Cham, Switzerland, 2018; pp. 221–235. [Google Scholar] [CrossRef]
- Nguyen, P. Update Docker Who? By Acquiring CoreOS, Red Hat Aims to Be the Kubernetes Company. The New Stack, 5 February 2018. [Google Scholar]
- Burns, B.; Beda, J.; Hightower, K.; Evenson, L. Kubernetes: Up and Running; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Riggins, J.; Williams, A. Will Kubernetes Play a Role in Edge Computing? The New Stack, 20 December 2019. [Google Scholar]
- Rolon-Mérette, D.; Ross, M.; Rolon-Mérette, T.; Church, K. Introduction to Anaconda and Python: Installation and setup. Quant. Methods Psychol. 2020, 16, S3–S11. [Google Scholar] [CrossRef]
- Conda. Getting Started with Conda. Available online: https://docs.conda.io/projects/conda/en/latest/user-guide/getting-started.html (accessed on 8 March 2024).
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing. 2011. Available online: http://faculty.winthrop.edu/domanm/csci411/Handouts/NIST.pdf (accessed on 22 January 2024).
- OpenFog Consortium Architecture Working Group. OpenFog Reference Architecture for Fog Computing, 2017. Available online: https://www.iiconsortium.org/pdf/OpenFog_Reference_Architecture_2_09_17.pdf (accessed on 22 January 2024).
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence With Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Bilan, M. Statistics of ChatGPT & Generative AI in Business: 2024 Report. 2023. Master of Code. Available online: https://masterofcode.com/blog/statistics-of-chatgpt-generative-ai-in-business-2023-report (accessed on 2 January 2024).
- Mehta, R.; Shorey, R. DeepSplit: Dynamic Splitting of Collaborative Edge-Cloud Convolutional Neural Networks. In Proceedings of the 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 720–725. [Google Scholar] [CrossRef]
- Banitalebi-Dehkordi, A.; Vedula, N.; Pei, J.; Xia, F.; Wang, L.; Zhang, Y. Auto-Split: A General Framework of Collaborative Edge-Cloud AI. arXiv 2021, arXiv:2108.13041. [Google Scholar]
- Yang, X.; Qi, Q.; Wang, J.; Guo, S.; Liao, J. Towards Efficient Inference: Adaptively Cooperate in Heterogeneous IoT Edge Cluster. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; pp. 12–23. [Google Scholar] [CrossRef]
- Alqahtani, A.; Xie, X.; Jones, M.W. Literature Review of Deep Network Compression. Informatics 2021, 8, 77. [Google Scholar] [CrossRef]
- Su, W.; Li, L.; Liu, F.; He, M.; Liang, X. AI on the edge: A comprehensive review. Artif. Intell. Rev. 2022, 55, 6125–6183. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Li, Z.; Li, H.; Meng, L. Model Compression for Deep Neural Networks: A Survey. Computers 2023, 12, 60. [Google Scholar] [CrossRef]
- Douch, S.; Abid, M.R.; Zine-Dine, K.; Bouzidi, D.; Benhaddou, D. Edge Computing Technology Enablers: A Systematic Lecture Study. IEEE Access 2022, 10, 69264–69302. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, Z.; Kadoch, M.; Cheriet, M. A collaborative cloud-edge computing framework in distributed neural network. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 211. [Google Scholar] [CrossRef]
- Galanopoulos, A.; Salonidis, T.; Iosifidis, G. Cooperative Edge Computing of Data Analytics for the Internet of Things. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1166–1179. [Google Scholar] [CrossRef]
- Dutta, D.L.; Bharali, S. TinyML Meets IoT: A Comprehensive Survey. Internet Things 2021, 16, 100461. [Google Scholar] [CrossRef]
- Lin, J.; Chen, W.; Lin, Y.; Cohn, J.; Gan, C.; Han, S. MCUNet: Tiny Deep Learning on IoT Devices. arXiv 2020, arXiv:2007.10319. [Google Scholar]
- Brecko, A.; Kajati, E.; Koziorek, J.; Zolotova, I. Federated Learning for Edge Computing: A Survey. Appl. Sci. 2022, 12, 9124. [Google Scholar] [CrossRef]
- Oliveira, F. Docker on Android, 2021. Available online: https://gist.github.com/FreddieOliveira/efe850df7ff3951cb62d74bd770dce27 (accessed on 31 December 2023).
- Chahoud, M.; Sami, H.; Mourad, A.; Otoum, S.; Otrok, H.; Bentahar, J.; Guizani, M. On-Demand-FL: A Dynamic and Efficient Multicriteria Federated Learning Client Deployment Scheme. IEEE Internet Things J. 2023, 10, 15822–15834. [Google Scholar] [CrossRef]
- Lumpp, F.; Panato, M.; Fummi, F.; Bombieri, N. A Container-based Design Methodology for Robotic Applications on Kubernetes Edge-Cloud architectures. In Proceedings of the 2021 Forum on Specification & Design Languages (FDL), Antibes, France, 8–10 September 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Murphree, D.H.; Quest, D.J.; Allen, R.M.; Ngufor, C.; Storlie, C.B. Deploying Predictive Models In A Healthcare Environment—An Open Source Approach. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 6112–6116. [Google Scholar] [CrossRef]
- Kleftakis, S.; Mavrogiorgou, A.; Mavrogiorgos, K.; Kiourtis, A.; Kyriazis, D. Digital Twin in Healthcare Through the Eyes of the Vitruvian Man. In Innovation in Medicine and Healthcare; Smart Innovation, Systems and Technologies; Chen, Y.W., Tanaka, S., Howlett, R.J., Jain, L.C., Eds.; Springer: Singapore, 2022; pp. 75–85. [Google Scholar] [CrossRef]
- Beňo, L.; Pribiš, R.; Drahoš, P. Edge Container for Speech Recognition. Electronics 2021, 10, 2420. [Google Scholar] [CrossRef]
- OpenAI Blog. Available online: https://openai.com/blog (accessed on 15 February 2024).
- Tara, A.; Taban, N.; Turesson, H. Performance Analysis of an Ontology Model Enabling Interoperability of Artificial Intelligence Agents. In Proceedings of the Artificial Intelligence Trends in Systems; Lecture Notes in Networks and Systems; Silhavy, R., Ed.; Springer: Cham, Switzerland, 2022; pp. 395–406. [Google Scholar] [CrossRef]
- Al-Rakhami, M.; Alsahli, M.; Hassan, M.M.; Alamri, A.; Guerrieri, A.; Fortino, G. Cost Efficient Edge Intelligence Framework Using Docker Containers. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress(DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 800–807. [Google Scholar] [CrossRef]
- Chen, C.H.; Liu, C.T. Person Re-Identification Microservice over Artificial Intelligence Internet of Things Edge Computing Gateway. Electronics 2021, 10, 2264. [Google Scholar] [CrossRef]
- Altintas, I.; Perez, I.; Mishin, D.; Trouillaud, A.; Irving, C.; Graham, J.; Tatineni, M.; DeFanti, T.; Strande, S.; Smarr, L.; et al. Towards a Dynamic Composability Approach for using Heterogeneous Systems in Remote Sensing. In Proceedings of the 2022 IEEE 18th International Conference on e-Science (e-Science), Salt Lake City, UT, USA, 11–14 October 2022; pp. 336–345. [Google Scholar] [CrossRef]
- Huang, Y.; Cai, K.; Zong, R.; Mao, Y. Design and implementation of an edge computing platform architecture using Docker and Kubernetes for machine learning. In Proceedings of the 3rd International Conference on High Performance Compilation, Computing and Communications, Xi’an, China, 8–10 March 2019; pp. 29–32. [Google Scholar] [CrossRef]
- Zhang, J.; Tao, D. Empowering Things with Intelligence: A Survey of the Progress, Challenges, and Opportunities in Artificial Intelligence of Things. IEEE Internet Things J. 2021, 8, 7789–7817. [Google Scholar] [CrossRef]
- Filho, C.P.; Marques, E.; Chang, V.; Dos Santos, L.; Bernardini, F.; Pires, P.F.; Ochi, L.; Delicato, F.C. A Systematic Literature Review on Distributed Machine Learning in Edge Computing. Sensors 2022, 22, 2665. [Google Scholar] [CrossRef]
- Hoffpauir, K.; Simmons, J.; Schmidt, N.; Pittala, R.; Briggs, I.; Makani, S.; Jararweh, Y. A Survey on Edge Intelligence and Lightweight Machine Learning Support for Future Applications and Services. J. Data Inf. Qual. 2023, 15, 20. [Google Scholar] [CrossRef]
- Huang, K.; Chen, B.; Wu, S.; Cao, J.; Ma, L.; Peng, X. Demystifying Dependency Bugs in Deep Learning Stack. arXiv 2023, arXiv:2207.10347. [Google Scholar]
- Surianarayanan, C.; Chelliah, P.R. Delineating Cloud-Native Edge Computing. In Essentials of Cloud Computing: A Holistic, Cloud-Native Perspective; Springer International Publishing: Cham, Switzerland, 2023; pp. 347–357. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Training | Training Description | Inference | Inference Description |
|---|---|---|---|---|
| 1 | Cloud | Data are aggregated in the cloud, where the entire model is trained | Cloud-Edge | The model is split between the edge and the cloud, utilizing methods such as network splitting |
| 2 | Cloud | Data are aggregated in the cloud where the entire model is trained | In-Edge | The model can be split between multiple edge devices like network splitting, or use dedicated inference nodes to which the data are offloaded |
| 3 | Cloud | Data are aggregated in the cloud, where the entire model is trained | On-Device | The cloud-trained model is deployed on a single device, often utilizing methods such as pruning, quantization, or knowledge distillation to achieve better performance |
| 4 | Cloud-Edge | Data are shared between the cloud and the edge; both parts are responsible for a part of the training, utilizing methods such as network splitting | Cloud-Edge | The model is split between the edge and the cloud, utilizing methods such as network splitting |
| 5 | In-Edge | Data are shared between edge devices with part of the training taking place at each device or a subset of dedicated training devices | In-Edge | The model can be split between multiple edge devices in a manner similar to network splitting or use dedicated inference nodes to which the data is offloaded |
| 6 | On-Device | Data are not shared anywhere, and a single device is responsible for the entire training, which is often optimized for that specific device | On-Device | The model is deployed on a single device, often utilizing approaches such as TinyML |
| Level | Title | Reference |
|---|---|---|
| 1 | DeepSplit: Dynamic Splitting of Collaborative Edge-Cloud Convolutional Neural Networks | [61] |
| Auto-Split: A General Framework of Collaborative Edge-Cloud AI | [62] | |
| 2 | Towards Efficient Inference: Adaptively Cooperate in Heterogeneous IoT Edge Cluster | [63] |
| 3 | Literature Review of Deep Network Compression | [64] |
| AI on the edge: a comprehensive review | [65] | |
| A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS | [66] | |
| Model Compression for Deep Neural Networks: A Survey | [67] | |
| Edge Computing Technology Enablers: A Systematic Lecture Study | [68] | |
| 4 | A collaborative cloud-edge computing framework in distributed neural network | [69] |
| 5 | Cooperative Edge Computing of Data Analytics for the Internet of Things | [70] |
| 6 | TinyML Meets IoT: A Comprehensive Survey | [71] |
| MCUNet: Tiny Deep Learning on IoT Devices | [72] |
| Reference | Year | Application Area | Description | EI Level |
|---|---|---|---|---|
| [75] | 2023 | Federated learning | Dynamic FL deployment and learning scheme | 4 |
| [76] | 2021 | Robotics | Design methodology for ROS-based applications | 4 |
| [77] | 2021 | Healthcare | Readmission prediction system for healthcare facilities | 3 |
| [78] | 2022 | Healthcare | Electronic health records decomposing the patient’s body into containers | - |
| [79] | 2021 | Virtual assistant | Voice control for human-machine interaction | 3 |
| [81] | 2022 | Composite AI | Ontology model for development of multi-agent AI systems | - |
| [82] | 2018 | Healthcare | Human activity recognition | 3 |
| [83] | 2021 | Security | Re-identification of people across multiple cameras | 2 |
| [84] | 2022 | Wildfire modelling | A federation architecture to enable a composable infrastructure | - |
| [85] | 2019 | Computer vision | Architecture for image processing | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urblik, L.; Kajati, E.; Papcun, P.; Zolotová, I. Containerization in Edge Intelligence: A Review. Electronics 2024, 13, 1335. https://doi.org/10.3390/electronics13071335
Urblik L, Kajati E, Papcun P, Zolotová I. Containerization in Edge Intelligence: A Review. Electronics. 2024; 13(7):1335. https://doi.org/10.3390/electronics13071335
Chicago/Turabian StyleUrblik, Lubomir, Erik Kajati, Peter Papcun, and Iveta Zolotová. 2024. "Containerization in Edge Intelligence: A Review" Electronics 13, no. 7: 1335. https://doi.org/10.3390/electronics13071335
APA StyleUrblik, L., Kajati, E., Papcun, P., & Zolotová, I. (2024). Containerization in Edge Intelligence: A Review. Electronics, 13(7), 1335. https://doi.org/10.3390/electronics13071335