1. Introduction
Speech emotion recognition (SER) is a technology designed to identify and classify the emotional content conveyed through speech. Its primary objective is to accurately discern the emotional state of the speaker, distinguishing between emotions such as happiness, sadness, anger, or neutrality. This technology finds widespread application across various real-world scenarios, including emotion voice conversion [
1,
2,
3,
4], emotional text-to-speech [
5], and speech emotion applications in movie dubbing [
6].
Similar to speaker recognition and speech recognition tasks, an SER system typically comprises a front-end feature extractor and a back-end classifier. In the context of SER, feature extraction and classification are two pivotal components that collaborate to accurately recognize and classify emotional content in speech. Feature extraction involves identifying relevant attributes of the speech signal that are most effective in representing the emotional state of the speaker. On the other hand, the classifier refers to the algorithm used to categorize the extracted features into specific emotional categories.
Previous studies have identified several popular feature extraction techniques for SER, including low-level descriptors (LLDs), the mel spectrogram, the wav2vec representation [
7], and feature selection based on genetic algorithms [
8,
9,
10,
11]. LLDs have been used in studies [
12,
13,
14], while the mel spectrogram has been used in studies such as [
15,
16,
17,
18,
19]. Wav2vec, on the other hand, has been used in studies [
20,
21,
22,
23,
24,
25]. A LLD is a combination of features extracted by the openSMILE toolkit [
26], which typically includes the zero-crossing rate, the root-mean-square of the frame energy, the pitch frequency, the harmonics-to-noise ratio, and mel-frequency cepstral coefficients (MFCC). The LLD aims to capture various acoustic characteristics of speech that are relevant to emotion recognition. The mel spectrogram, on the other hand, is a type of spectrogram that is computed using a mel-scale filter bank. This technique is commonly used in speech processing and music analysis, as it is designed to mimic the human auditory system by emphasizing frequencies that are more perceptually relevant. Mel spectrograms have been shown to be effective in capturing both spectral and temporal information in speech, making them a popular choice for feature extraction in SER. Wav2vec is a self-supervised speech representation (S3R) technique that uses waveform data as input under a pre-trained model. This technique is designed to learn representations of speech that are useful for a variety of downstream tasks, including emotion recognition. Wav2vec has shown promising results in recent studies, as it is able to capture both phonetic and acoustic properties of speech.
Unlike LLDs and the mel spectrogram, which fall into the category of handcrafted features and require significant prior knowledge to design effective extraction methods, wav2vec, like other self-supervised speech representation learning (S3R) approaches, only requires ample unlabeled training data and a Transformer encoder [
27] to extract representations. In recent years, S3R has gained significant research attention in the speech and audio signal processing field, with applications including automatic speech recognition (ASR) [
7,
28,
29], phoneme classification [
30,
31], speaker recognition [
28,
30,
31], voice conversion, and SER [
20,
21,
22], phoneme segmentation [
32], and audio classification [
33]. Generally, S3R tends to outperform handcrafted features under the same classifier because it can reveal more comprehensive information within speech, which is often not possible with handcrafted features [
30]. This is why S3R has become increasingly popular in the speech and audio signal processing community, including for SER applications.
Previous studies have motivated us to investigate the use of S3R features for SER. The first observation is that only wav2vec has been used for SER, despite being initially proposed for ASR and primarily used for downstream tasks related to preserving source speaker content information, such as in the field of voice conversion [
34,
35]. However, SER not only involves content information but also speaker-related information [
18]. Therefore, wav2vec may not necessarily be the best S3R feature for SER. The second observation is that emotion embedding is typically extracted from a trained classifier based on fully connected (FC) layers, emotion training data, and corresponding label information, with S3R as the input, as seen in [
20]. Emotion embedding can be extracted from the trained classifier because different emotions can be well classified and discriminated during classifier training. However, contextual information related to emotion is often neglected in previous studies of emotion embedding extraction. Therefore, there is potential to extract better emotion embedding with contextual information from S3R features for SER. The third observation is that no studies have been conducted on cross-lingual SER using S3R features to date. The features commonly used in the community, such as the mel spectrogram [
16], usually contain some unhelpful information for SER, such as language information. In contrast, language information may even degrade performance. Therefore, it is expected that emotion embedding without language information extracted from S3R features will yield better performance for cross-lingual SER.
Given that WavLM [
28] was initially developed as a large-scale, self-supervised pre-training model for full-stack speech processing, encompassing both ASR and speaker-related tasks such as speaker verification and speaker diarization, it is reasonable to posit that improved emotion embedding can be derived from the WavLM representation for SER. This can be achieved through the incorporation of contextual information, FC, training data, and corresponding label information. To this end, contextual transformation is employed in this study to extract emotion embedding from the WavLM representation. Moreover, single- and cross-lingual emotion embeddings are extracted to facilitate single- and cross-lingual emotion recognition. Multi-task learning is utilized to extract cross-lingual emotion embedding by eliminating language information, as it is irrelevant for cross-lingual SER and can be expected to yield promising performance outcomes.
The contribution of the work can be summarized as:
Firstly, contextual transformation has been applied for the first time in the field of emotion embedding extraction for SER.
A novel single-lingual WavLM domain emotion embedding (SL-WDEE) is proposed for single-lingual speech emotion recognition. This is achieved by combining an emotional encoder and an emotion classifier at the base of the WavLM representation. The emotional encoder is used to encode the input WavLM representation, while the emotion classifier is employed in the training stage to classify the emotion. The emotion encoder comprises a contextual transformation module, two FCs, and corresponding sigmoid modules.
A novel cross-lingual WavLM domain emotion embedding (CL-WDEE) is proposed for cross-lingual speech emotion recognition. This is achieved by utilizing multi-task learning from the WavLM representation to extract emotion embedding and simultaneously remove the language information. The CL-WDEE extractor is realized by combining a shared encoder, an emotion encoder, a language encoder, an emotion classifier, and a language classifier. The shared encoder is used to encode the input WavLM representation, while the emotion encoder and the language encoder are employed to encode the shared feature obtained from the shared encoder to extract the CL-WDEE and WavLM domain language embedding (WDLE), respectively. Both the emotion encoder and the language encoder consist of contextual transformation modules, FCs, and sigmoid modules. The emotion classifier and the language classifier are used to classify emotion and language in the training stage, respectively.
The rest of the paper is organized as follows:
Section 2 introduces WavLM, and
Section 3 introduces the WavLM domain emotion embedding extraction. The experimental result and analysis are given in
Section 4, and the conclusion is given in
Section 5.
2. WavLM
In this section, we provide an overview of WavLM, including its structure and denoising masked speech modeling.
WavLM is a model that learns universal speech representations from a vast quantity of unlabeled speech data. It has been shown to be effective across multiple speech processing tasks, including both ASR and non-ASR tasks. The framework of WavLM is based on denoising masked speech modeling, where some inputs are simulated to be noisy or overlapped with masks, and the target is to predict the pseudo-label of the original speech masked region. This approach enables the WavLM model to learn not only ASR-related information but also non-ASR knowledge during the pre-training stage [
28].
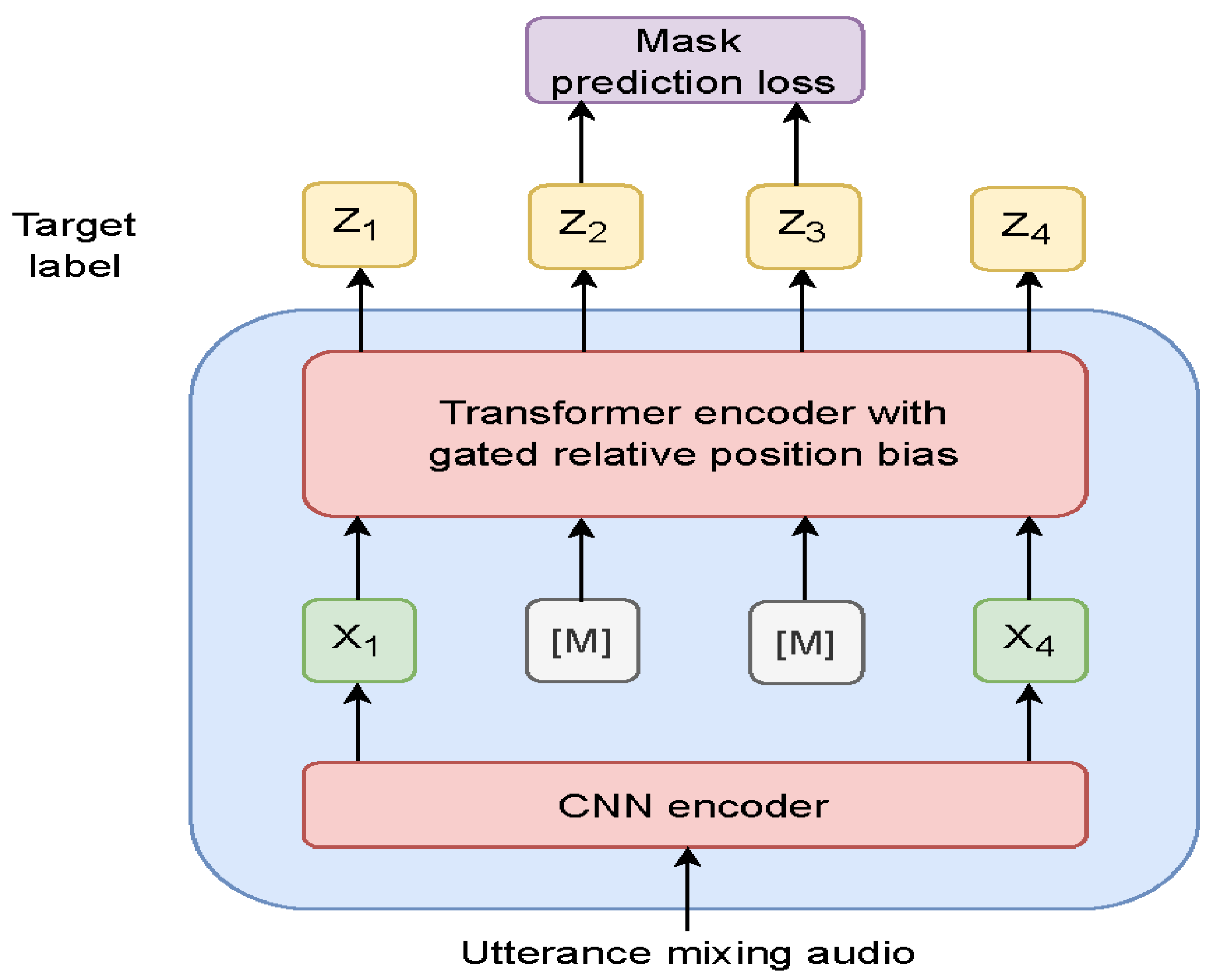
The model architecture of WavLM is depicted in
Figure 1, consisting of two key components for encoding the input data. The first component is a CNN encoder, and the second component is a Transformer encoder, which serves as the backbone of WavLM. The output of the first component serves as the input to the second component. The first component comprises seven blocks of temporal convolutional layers with layer normalization and a GELU activation layer. The temporal convolutions utilize 512 channels with strides (5,2,2,2,2,2) and kernel widths (10,3,3,2,2,2,2) [
28]. The second component is equipped with a convolution-based relative-position embedding layer with a kernel size of 128 and 16 groups at the bottom. Additionally, a gated relative-position bias is employed to enhance the performance of WavLM [
28].
To enhance the robustness of the model to complex acoustic environments and to preserve speaker identity, denoising masked speech modeling has been proposed for WavLM [
28]. To achieve this, the utterance mixing strategy is utilized to simulate noisy speech with multiple speakers and various background noises during self-supervised pre-training, particularly when only single-speaker pre-training data are available. Moreover, some utterances from each training batch are chosen at random to generate noisy speech. These utterances are then mixed with either a randomly selected noise audio or a secondary utterance at a randomly chosen region.
3. WavLM Domain Emotion Embedding Extraction
In this section, we introduce the detailed process of extracting the SL-WDEE and CL-WDEE from the WavLM representation, respectively.
3.1. SL-WDEE
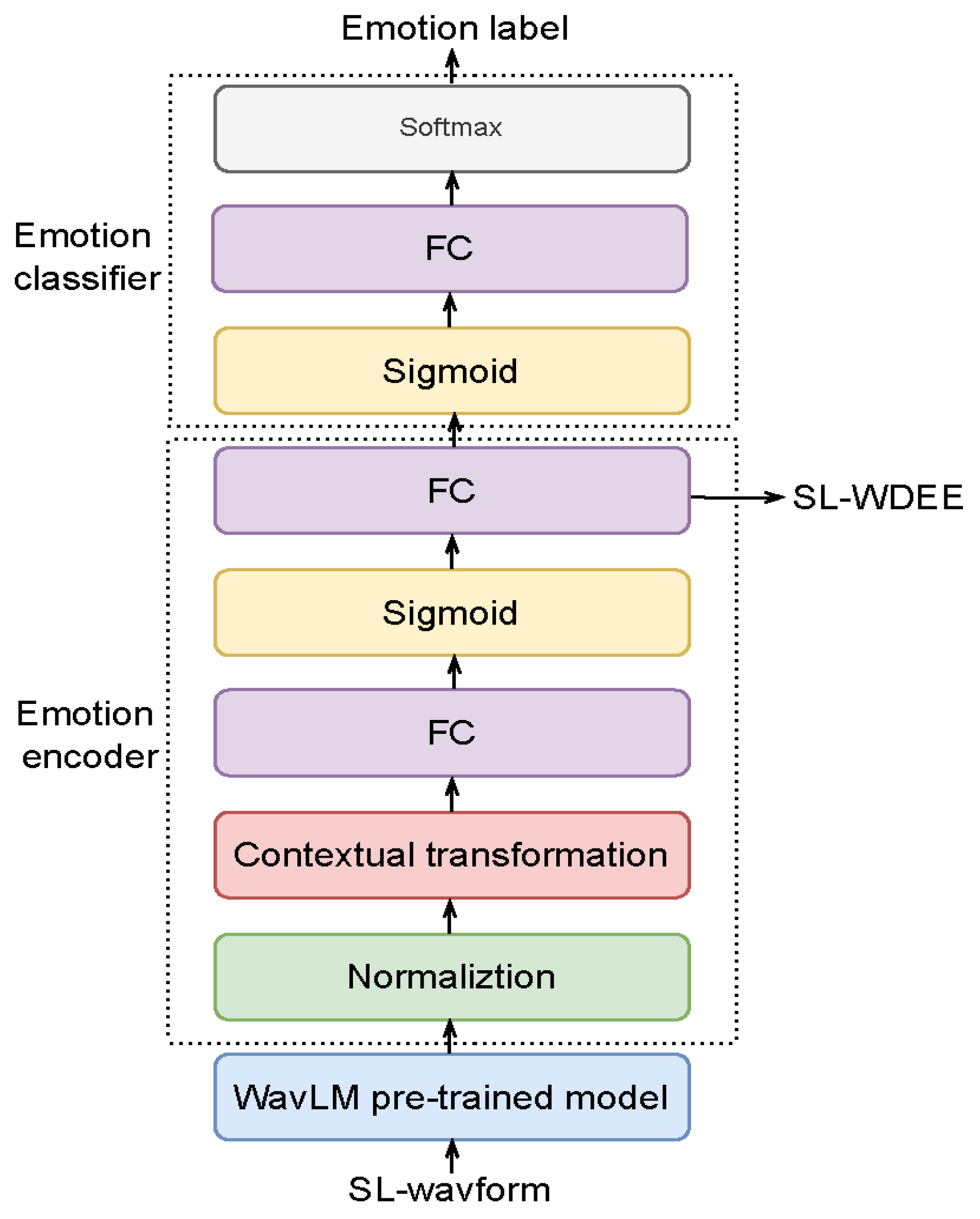
The framework of the proposed SL-WDEE extraction method in the training stage is depicted in
Figure 2. Here, SL-waveform and SL-WDEE refer to a single-lingual waveform and a single-lingual WavLM domain emotion embedding, respectively. The framework comprises one WavLM pre-trained model, one emotional encoder, and one emotion classifier for the extraction of the SL-WDEE. The emotional encoder comprises the modules of normalization, contextual transformation, two FCs, and one sigmoid module. The emotion classifier only contains one sigmoid, one FC, and one softmax module.
The modules utilized in the proposed SL-WDEE extraction framework play different roles.
The WavLM pre-trained model is responsible for converting the input SL-waveform into a WavLM representation, which serves as the input for the emotional encoder. The normalization module is utilized to normalize the WavLM representation.
The contextual transformation module is used to transform the input frame-by-frame information into contextual frame information. Specifically, for each frame, the current frame, its left five frames, and its right five frames are used to form contextual frames. Thus, every input frame information is transformed into 11-frame information by using the contextual transformation.
The FC module is employed to apply a linear transformation to the input data.
The sigmoid module is utilized to prevent the generation of values that are too large due to the FC module and transform the input into a range between 0 and 1. For example, given an input
x, its sigmoid is as follows:
where
is the sigmoid of
x.
The softmax module is used to convert the input into a probability, for instance, given an input
Y = {
}, the softmax of
(
i = 1, 2, …,
N) is as follows:
In the inference stage, the SL-WDEE can be extracted from the emotional encoder by feeding the input SL-waveform into the WavLM pre-trained model and then into the emotional encoder. In this stage, the output of the emotion classifier is not considered, as it is only used for training.
3.2. CL-WDEE
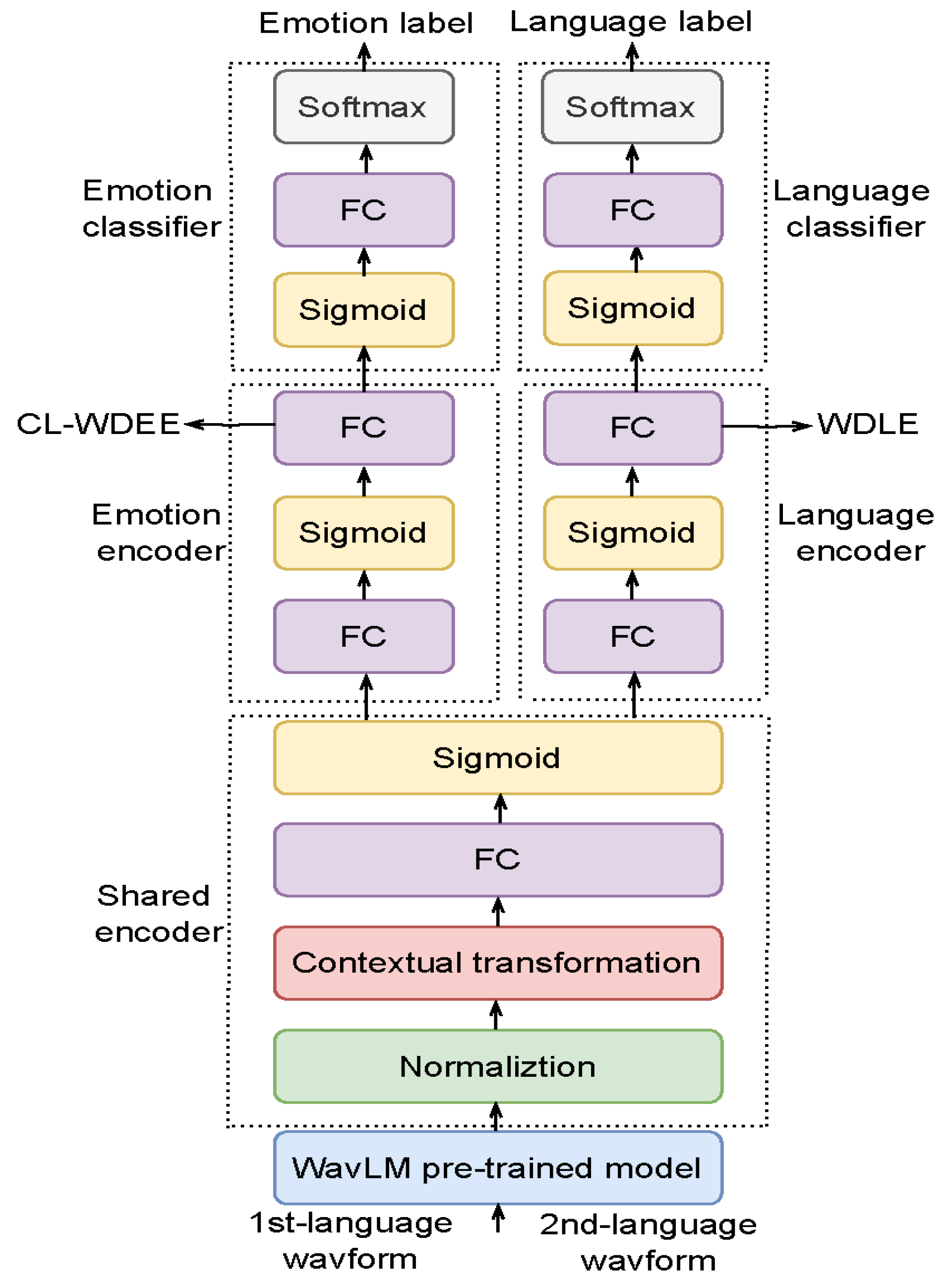
The proposed framework for CL-WDEE extraction based on multi-task learning is illustrated in
Figure 3. As depicted in the figure, the framework comprises three encoders and two classifiers.
The three encoders are the shared encoder, the emotion encoder, and the language encoder. Each encoder serves a different purpose, with the shared encoder being utilized for all tasks, and the emotion and language encoders being specifically designed for emotion classification and language identification, respectively. The differences among the three encoders are as follows:
In terms of modules, the shared encoder consists of four modules, whereas both the emotion encoder and the language encoder consist of three modules. Specifically, the shared encoder contains the
normalization module,
the contextual transformation module,
the fully connected (FC) module, and
the sigmoid module. Conversely,
the emotion encoder and the language encoder comprise
two FC modules and
one sigmoid module. It should be noted that each module in
Figure 3 serves the same function as that in
Figure 2.
From a functional perspective, the shared encoder is responsible for extracting shared features that are utilized by both the emotion encoder and the language encoder. The emotion encoder and the language encoder, on the other hand, are used to encode the shared features and extract the CL-WDEE and WDLE, respectively.
The emotion classifier and the language classifier share the same architecture, which consists of one sigmoid module, one FC module, and one softmax module. Nevertheless, their roles differ, with the emotion classifier being utilized to classify emotions, and the language classifier being employed to classify languages.
During the inference stage, the input cross-lingual waveform is processed through the emotion encoder to extract the CL-WDEE, with the outputs of the emotion classifier, language classifier, and language encoder being disregarded. This is because the outputs of the emotion classifier, language classifier, and language encoder are not relevant for SER, whereas the output of the emotion encoder, i.e., the CL-WDEE, is crucial for SER.
When comparing the extraction of the SL-WDEE in
Figure 2 and that of the CL-WDEE in
Figure 3, several conclusions can be drawn,
The common ground between them is that both SL-WDEE and CL-WDEE are extracted from the WavLM domain, and that the contextual transformation, FC, and sigmoid modules are utilized in their extraction.
The main difference between them lies in the fact that multi-task learning is employed for the CL-WDEE to eliminate language information with the aid of the language encoder, as depicted in
Figure 3. Conversely, there is no need to eliminate language information in the extraction of the SL-WDEE, as shown in
Figure 2.
The structure of the two extraction methods differs, with the SL-WDEE extraction consisting of two parts, namely the emotion encoder and the emotion classifier, while the CL-WDEE extraction comprises five parts, which are the emotion encoder, the emotion classifier, the shared encoder, the language encoder, and the language classifier, respectively.





{kind=link}
{kind=link}
{kind=link}


