
Improved Transformer-Based Deblurring of Commodity Videos in Dynamic Visual Cabinets
 ,
,
Abstract
:1. Introduction
- A multi-scale Transformer structure is defined to deal with the non-uniform blur caused by different degrees of motion when picking up the goods;
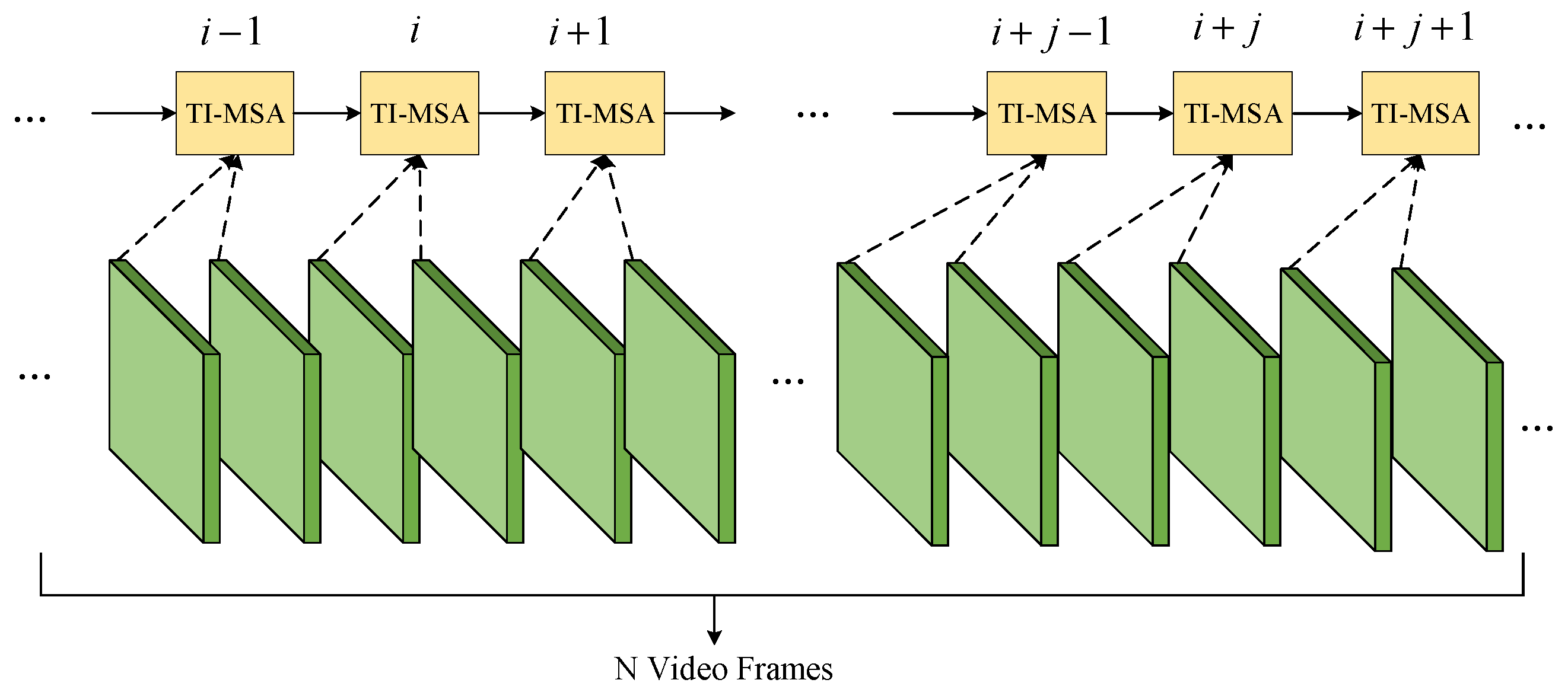
- A temporal interactive attention mechanism (TI-MSA) is proposed based on the remote modeling relation of the Transformer to solve the problem that some blurred video frames of small commodities cannot be aligned;
- A feature recurrent fusion mechanism is proposed to construct the global modeling relation of commodity video frames to solve the problem of losing valid information in reconstructed commodity video frames.
2. The Algorithms
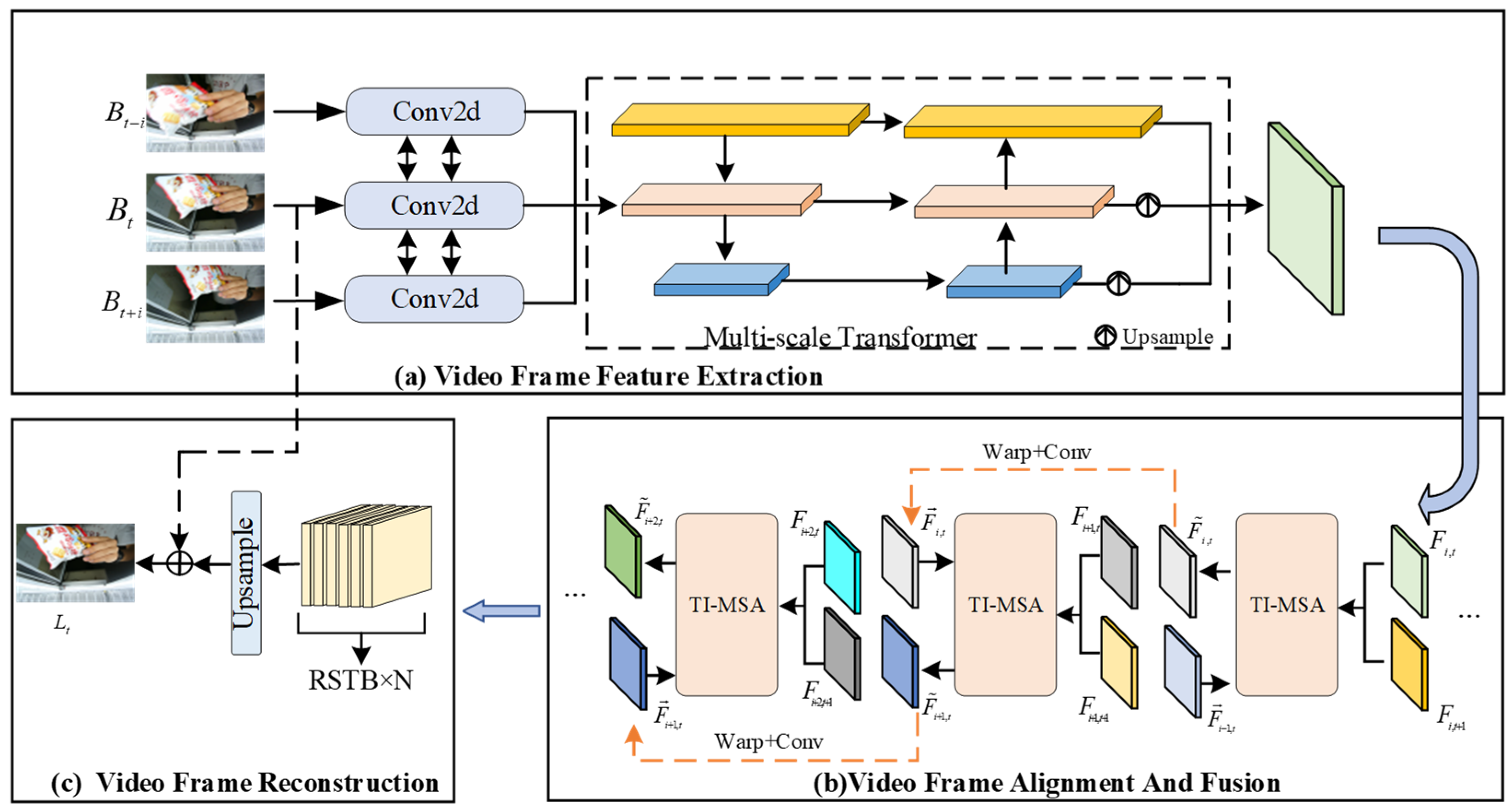
2.1. Video Frame Feature Extraction
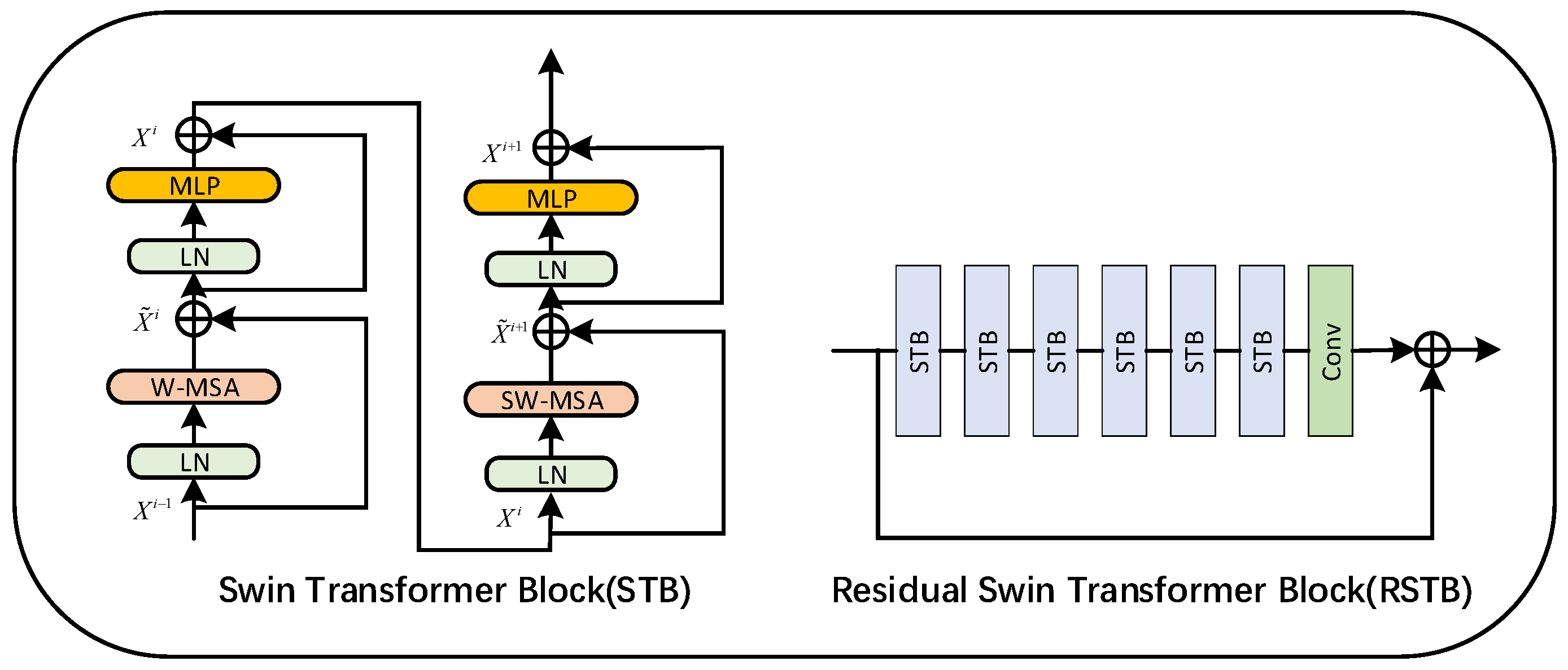
2.1.1. RSTB
2.1.2. Multi-Scale Transformer
2.2. Alignment and Fusion of Video Frames
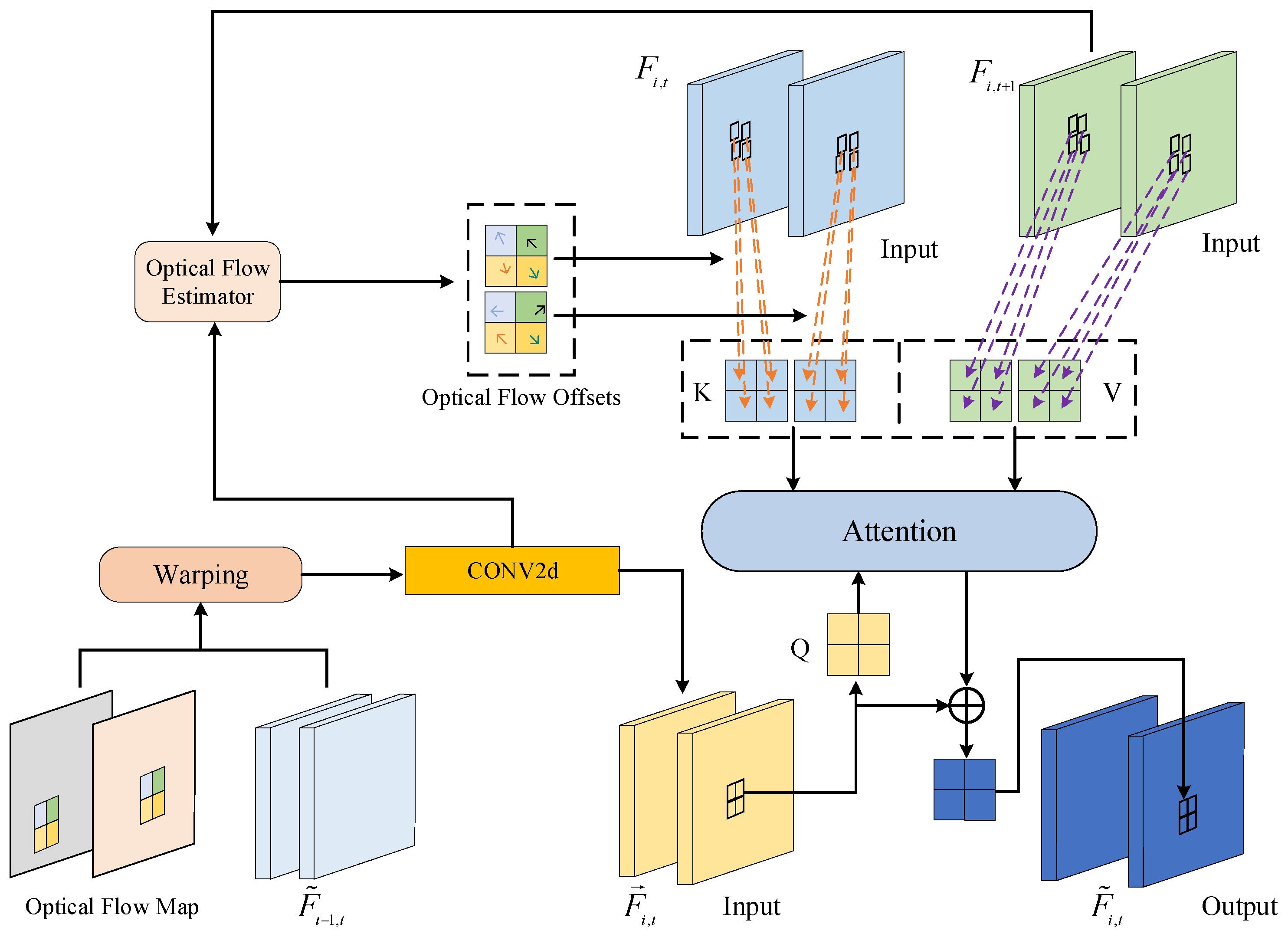
2.2.1. Time-Interaction Attention Mechanism
2.2.2. Feature Recurrent Fusion Mechanism
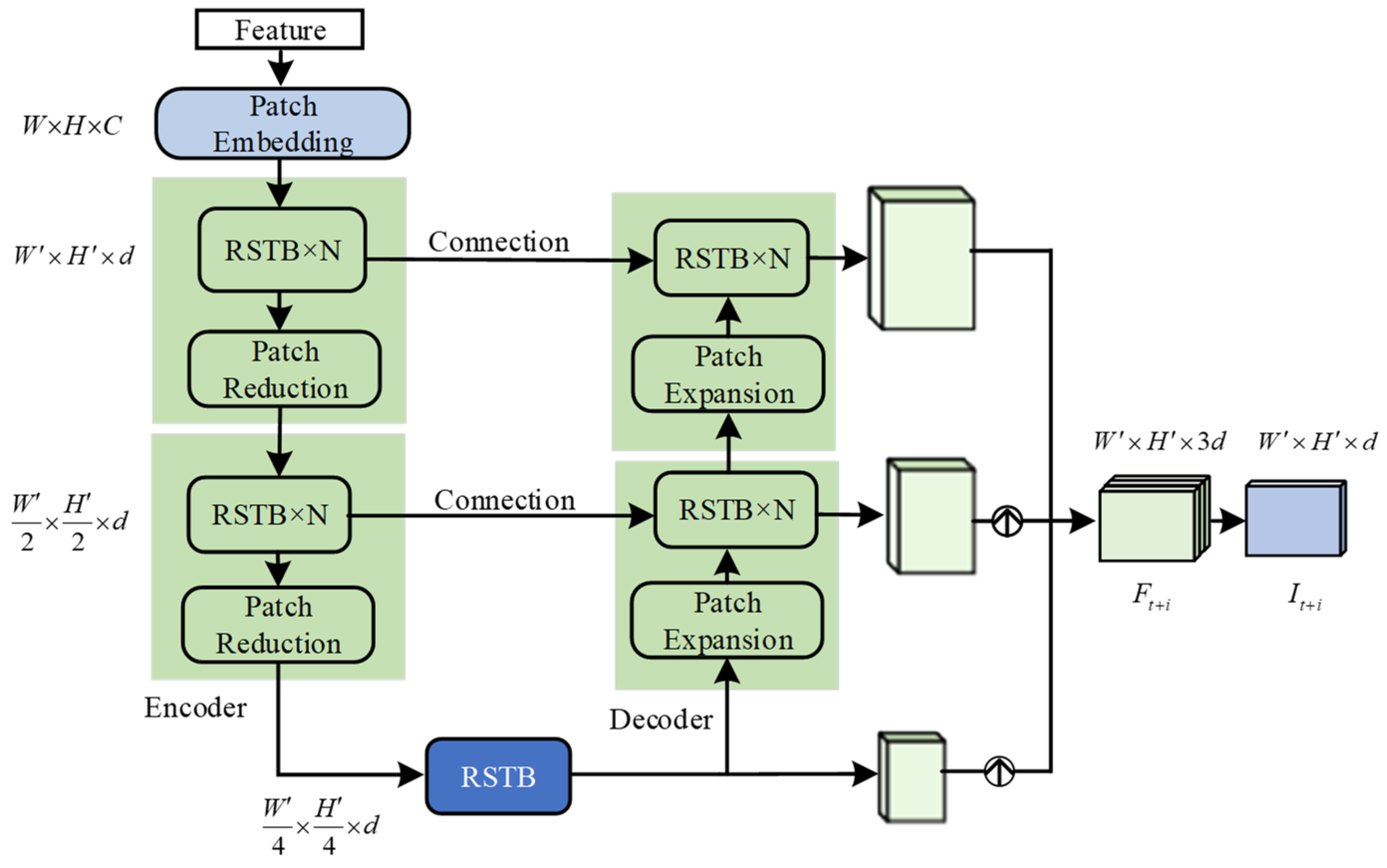
2.3. Video Frame Reconstruction
2.4. Loss Functions
3. Experiment Result and Analysis
3.1. Experimental Platform and Dataset
3.2. Dataset Introduction
3.2.1. Fuzzy Commodity Dataset
3.2.2. Public Dataset
3.3. Controlled Experiment
3.3.1. Evaluation Index
3.3.2. The Details of the Training
3.3.3. Comparative Study of Different Algorithms
3.3.4. Dataset Visualization Comparison
3.4. Ablation Study
3.4.1. Multi-Scale Transformer Structure Experiment
3.4.2. Performance Experiment of the TI-MSA Module
3.5. Motion Blur Commodity Detection
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Li, D.; Ji, Y.; Zhou, H.; Wu, W.; Liu, K. Toward new retail: A benchmark dataset for smart unmanned vending machines. IEEE Trans. Ind. Inform. 2019, 16, 7722–7731. [Google Scholar] [CrossRef]
- Xie, A.; Xie, K.; Dong, H.-N.; He, J.-B. Detection of Commodities Based on Multi-Feature Fusion and Attention Screening by Entropy Function Guidance. IEEE Access 2023, 11, 90595–90612. [Google Scholar] [CrossRef]
- Dong, H.; Xie, K.; Xie, A.; Wen, C.; He, J.; Zhang, W.; Yi, D.; Yang, S. Detection of Occluded Small Commodities Based on Feature Enhancement under Super-Resolution. Sensors 2023, 23, 2439. [Google Scholar] [CrossRef]
- Sun, L.; Cho, S.; Wang, J.; Hays, J. Edge-based blur kernel estimation using patch priors. In Proceedings of the IEEE International Conference on Computational Photography (ICCP), Cambridge, MA, USA, 19–21 April 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Chakrabarti, A. A neural approach to blind motion deblurring. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 221–235. [Google Scholar] [CrossRef]
- Matsushita, Y.; Ofek, E.; Ge, W.; Tang, X.; Shum, H.-Y. Full-frame video stabilization with motion inpainting. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1150–1163. [Google Scholar] [CrossRef] [PubMed]
- Cho, S.; Wang, J.; Lee, S. Video deblurring for hand-held cameras using patch-based synthesis. ACM Trans. Graph. (TOG) 2012, 31, 64. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, J.; Ren, W.; Zuo, W.; Cao, X. Accurate transmission estimation for removing haze and noise from a single image. IEEE Trans. Image Process. 2019, 29, 2583–2597. [Google Scholar] [CrossRef] [PubMed]
- Su, S.; Delbracio, M.; Wang, J.; Sapiro, G.; Heidrich, W.; Wang, O. Deep video deblurring for hand-held cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1279–1288. [Google Scholar] [CrossRef]
- Hyun Kim, T.; Mu Lee, K.; Scholkopf, B.; Hirsch, M. Online video deblurring via dynamic temporal blending network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4038–4047. [Google Scholar] [CrossRef]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Liu, W.; Li, H. Adversarial spatio-temporal learning for video deblurring. IEEE Trans. Image Process. 2018, 28, 291–301. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Bai, H.; Tang, J. Cascaded deep video deblurring using temporal sharpness prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3043–3051. [Google Scholar] [CrossRef]
- Zhou, S.; Zhang, J.; Pan, J.; Xie, H.; Zuo, W.; Ren, J. Spatio-temporal filter adaptive network for video deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2482–2491. [Google Scholar] [CrossRef]
- Wang, X.; Chan, K.C.; Yu, K.; Dong, C.; Change Loy, C. EDVR: Video restoration with enhanced deformable convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1954–1963. [Google Scholar] [CrossRef]
- Li, D.; Xu, C.; Zhang, K.; Yu, X.; Zhong, Y.; Ren, W.; Suominen, H.; Li, H. Arvo: Learning all-range volumetric correspondence for video deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7721–7731. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Fan, Y.; Zhang, K.; Ranjan, R.; Li, Y.; Timofte, R.; Van Gool, L. Vrt: A video restoration transformer. arXiv 2022, arXiv:2201.12288. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar] [CrossRef]
- Sun, D.; Yang, X.; Liu, M.-Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar] [CrossRef]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | PSNR | SSIM |
|---|---|---|
| EDVR | 31.82 | 0.916 |
| STFAN | 31.15 | 0.905 |
| ARVo | 32.80 | 0.935 |
| VRT | 33.13 | 0.936 |
| CVDT | 33.36 | 0.947 |
| Algorithms | PSNR | SSIM |
|---|---|---|
| EDVR | 27.62 | 0.796 |
| STFAN | 26.97 | 0.784 |
| ARVo | 27.73 | 0.853 |
| VRT | 28.16 | 0.811 |
| CVDT | 28.97 | 0.833 |
| RSTB | PSNR | SSIM |
|---|---|---|
| 1 | 28.44 | 0.814 |
| 2 | 28.53 | 0.817 |
| 3 | 28.97 | 0.833 |
| 4 | 28.72 | 0.821 |
| Times | PSNR | SSIM |
|---|---|---|
| 0 | 27.07 | 0.788 |
| 1 | 28.22 | 0.815 |
| 2 | 28.97 | 0.833 |
| 3 | 28.70 | 0.820 |
| Mechanisms | PSNR | SSIM |
|---|---|---|
| MSA | 27.08 | 0.789 |
| W-MSA | 27.62 | 0.803 |
| TMSA | 28.16 | 0.811 |
| TI-MSA | 28.82 | 0.827 |
| TI-MSA+ | 28.97 | 0.833 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Liang, Q.; Xie, K.; He, Z.; Wen, C.; He, J.; Zhang, W. Improved Transformer-Based Deblurring of Commodity Videos in Dynamic Visual Cabinets. Electronics 2024, 13, 1440. https://doi.org/10.3390/electronics13081440
Huang S, Liang Q, Xie K, He Z, Wen C, He J, Zhang W. Improved Transformer-Based Deblurring of Commodity Videos in Dynamic Visual Cabinets. Electronics. 2024; 13(8):1440. https://doi.org/10.3390/electronics13081440
Chicago/Turabian StyleHuang, Shuangyi, Qianjie Liang, Kai Xie, Zhengfang He, Chang Wen, Jianbiao He, and Wei Zhang. 2024. "Improved Transformer-Based Deblurring of Commodity Videos in Dynamic Visual Cabinets" Electronics 13, no. 8: 1440. https://doi.org/10.3390/electronics13081440
APA StyleHuang, S., Liang, Q., Xie, K., He, Z., Wen, C., He, J., & Zhang, W. (2024). Improved Transformer-Based Deblurring of Commodity Videos in Dynamic Visual Cabinets. Electronics, 13(8), 1440. https://doi.org/10.3390/electronics13081440