
Leveraging Neighbor Attention Initialization (NAI) for Efficient Training of Pretrained LLMs

Abstract
:1. Introduction
2. Related Work
3. Method
3.1. Preliminary
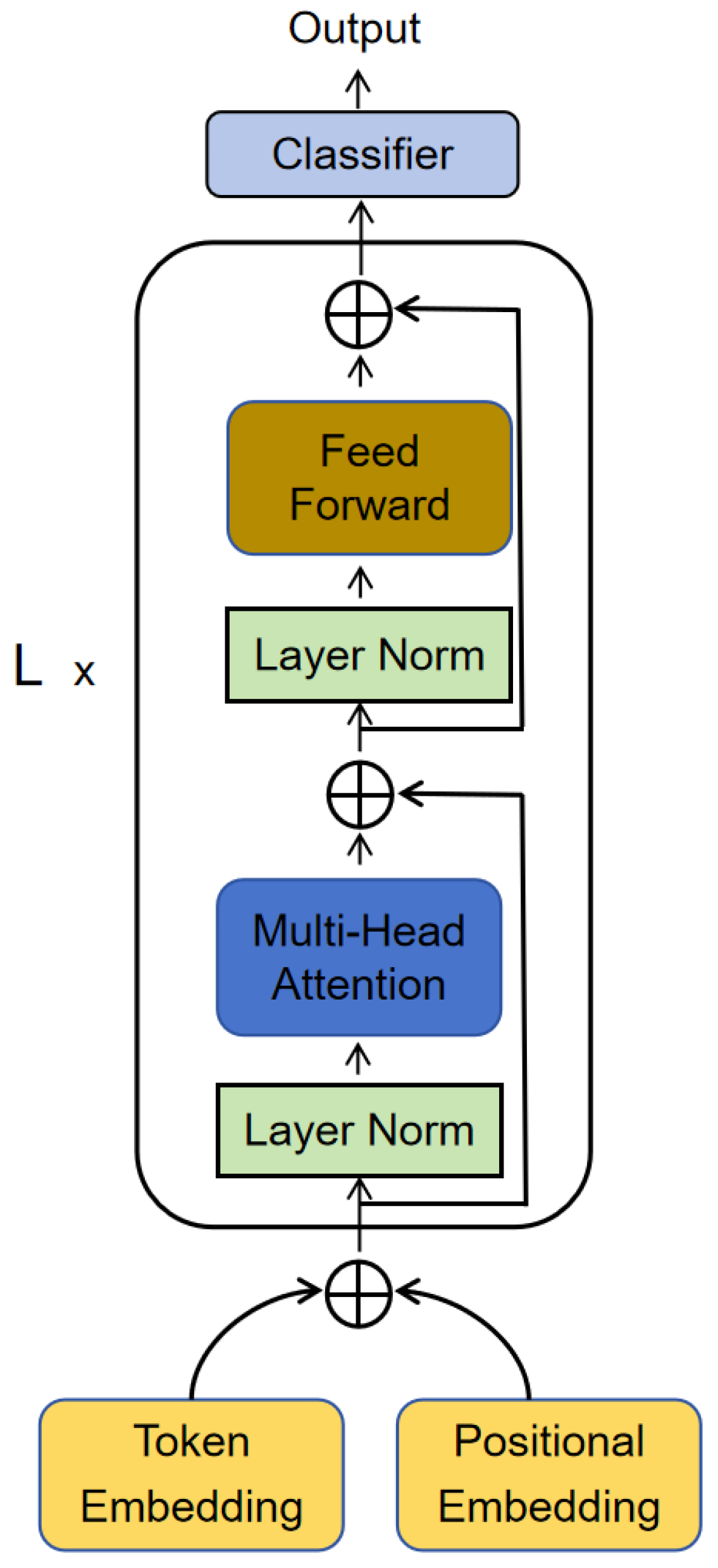
3.1.1. Embedding Layer
3.1.2. Transformer Layer
3.2. Overview
3.3. NAI
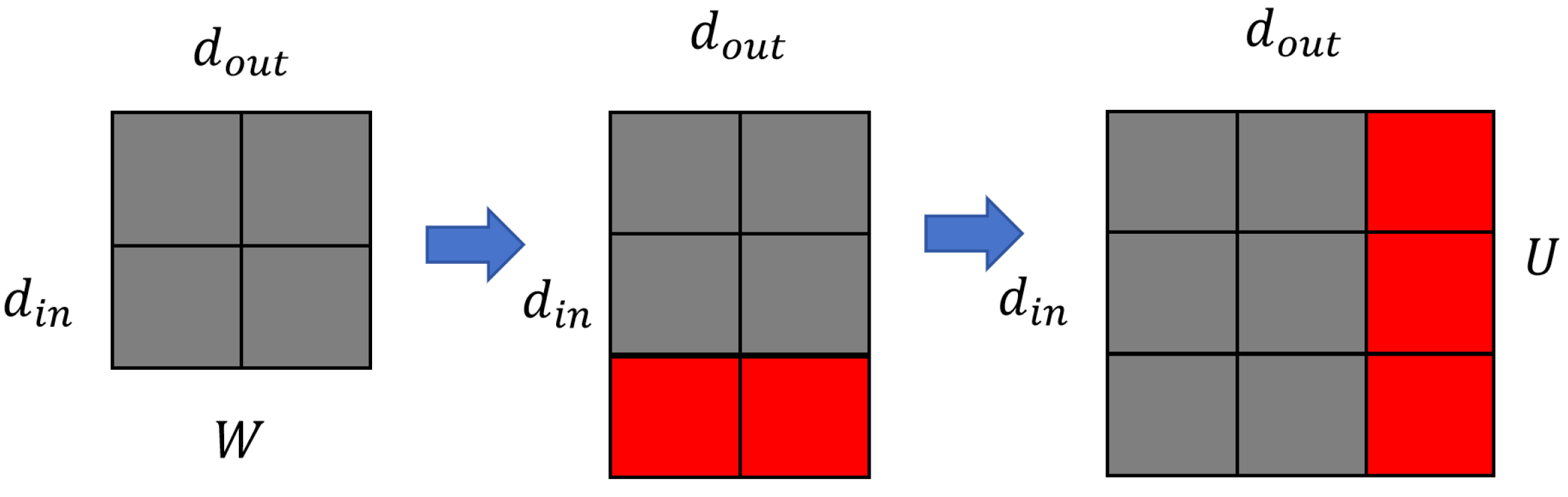
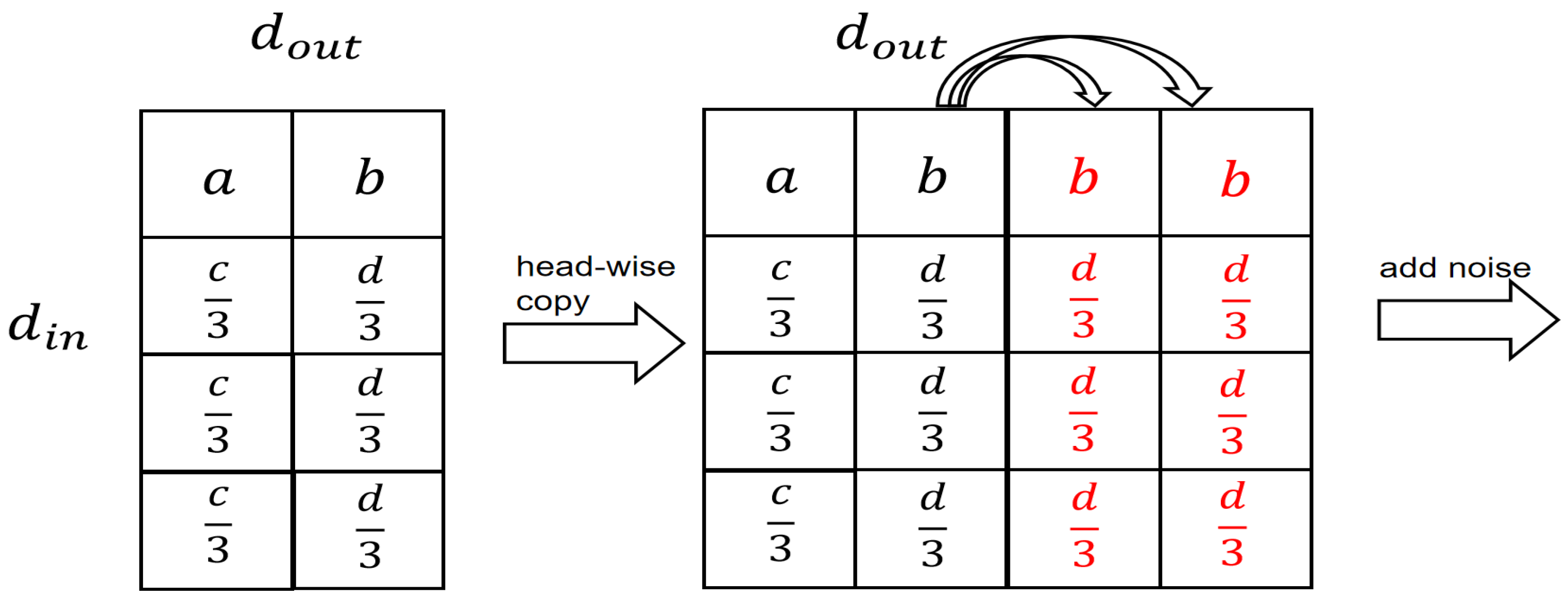
3.3.1. Width-Wise Expansion
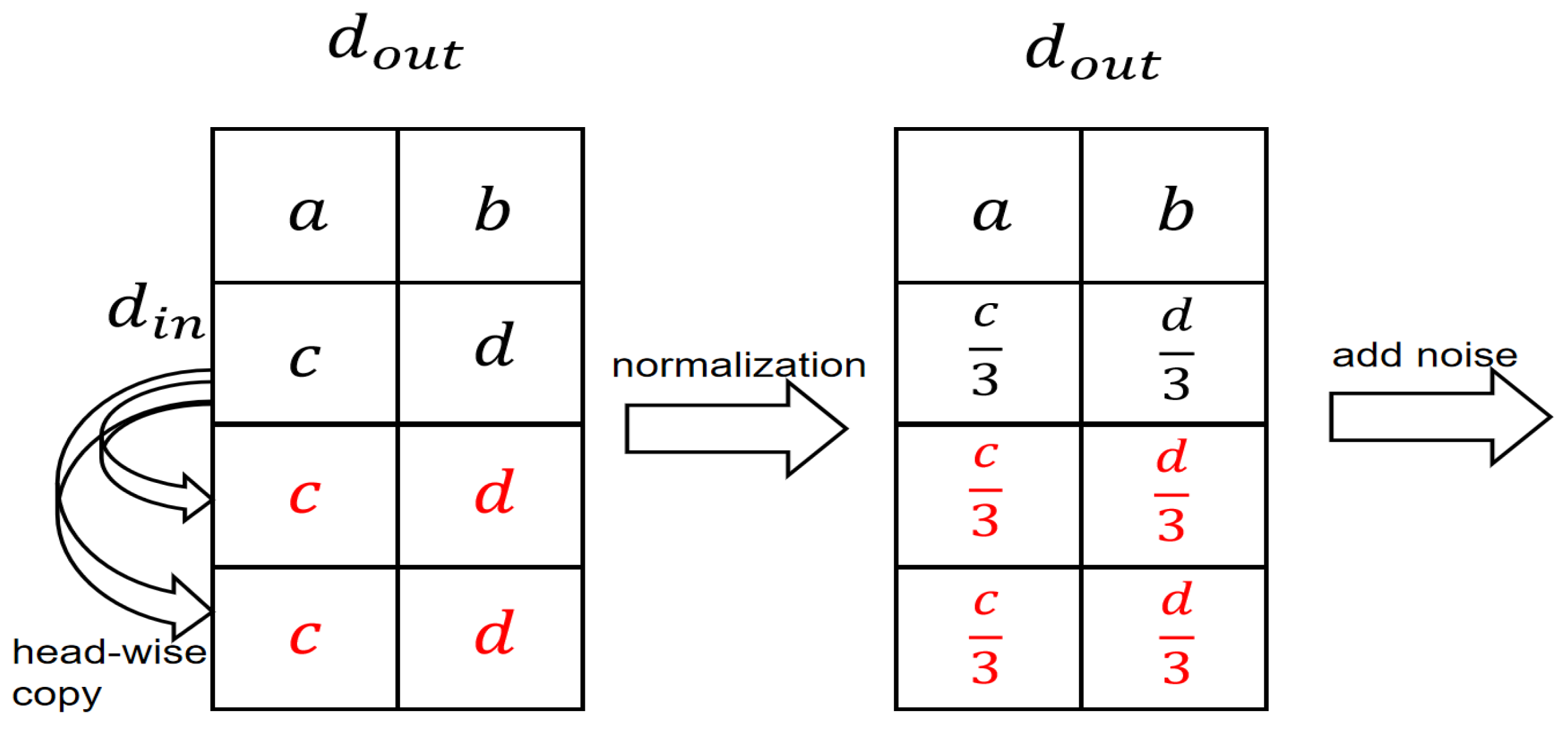
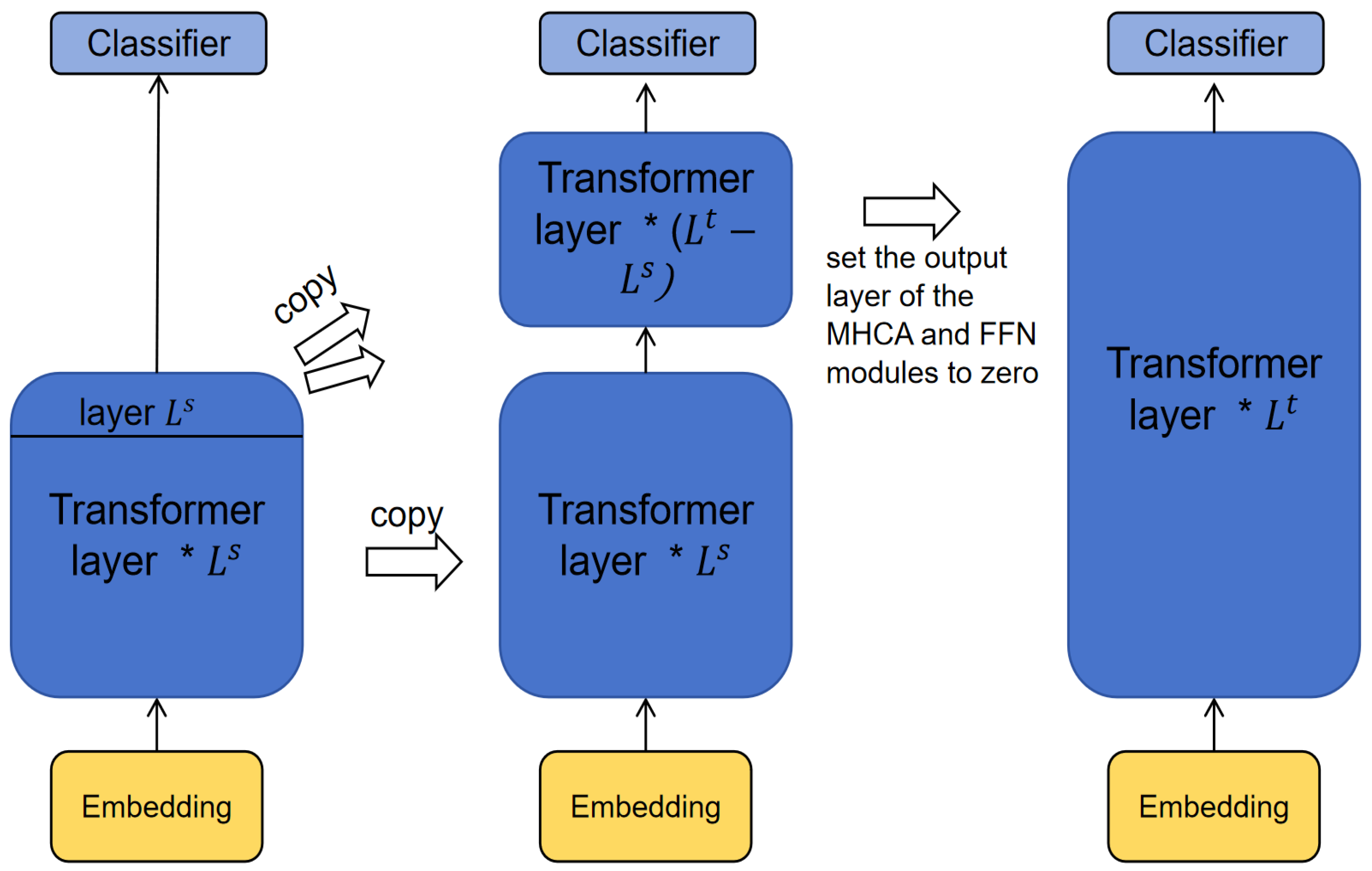
3.3.2. Depth-Wise Expansion
| Algorithm 1 NAI algorithm |
|
4. Experiment
4.1. Experimental Setup
| Algorithm 2 StackBERT |
|
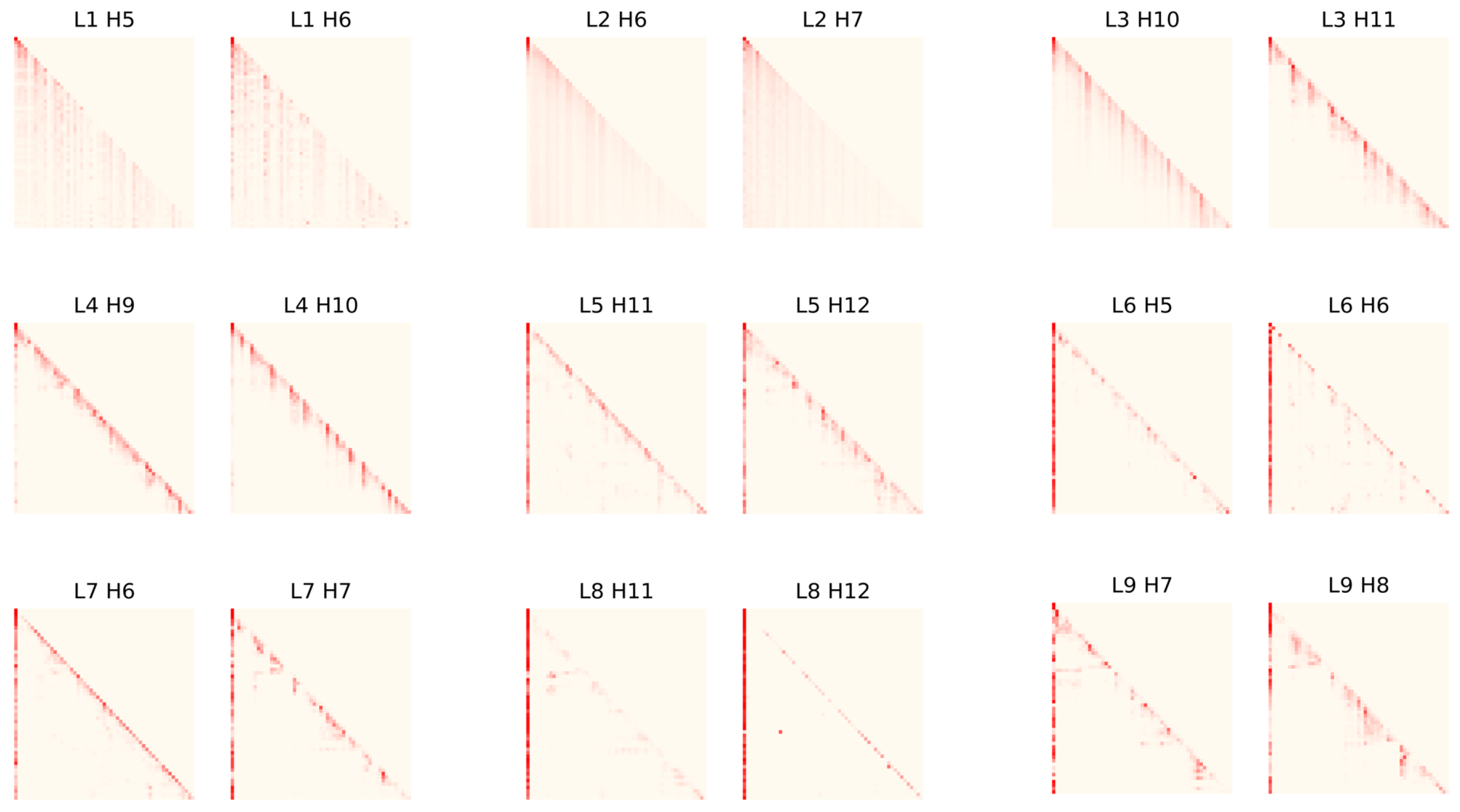
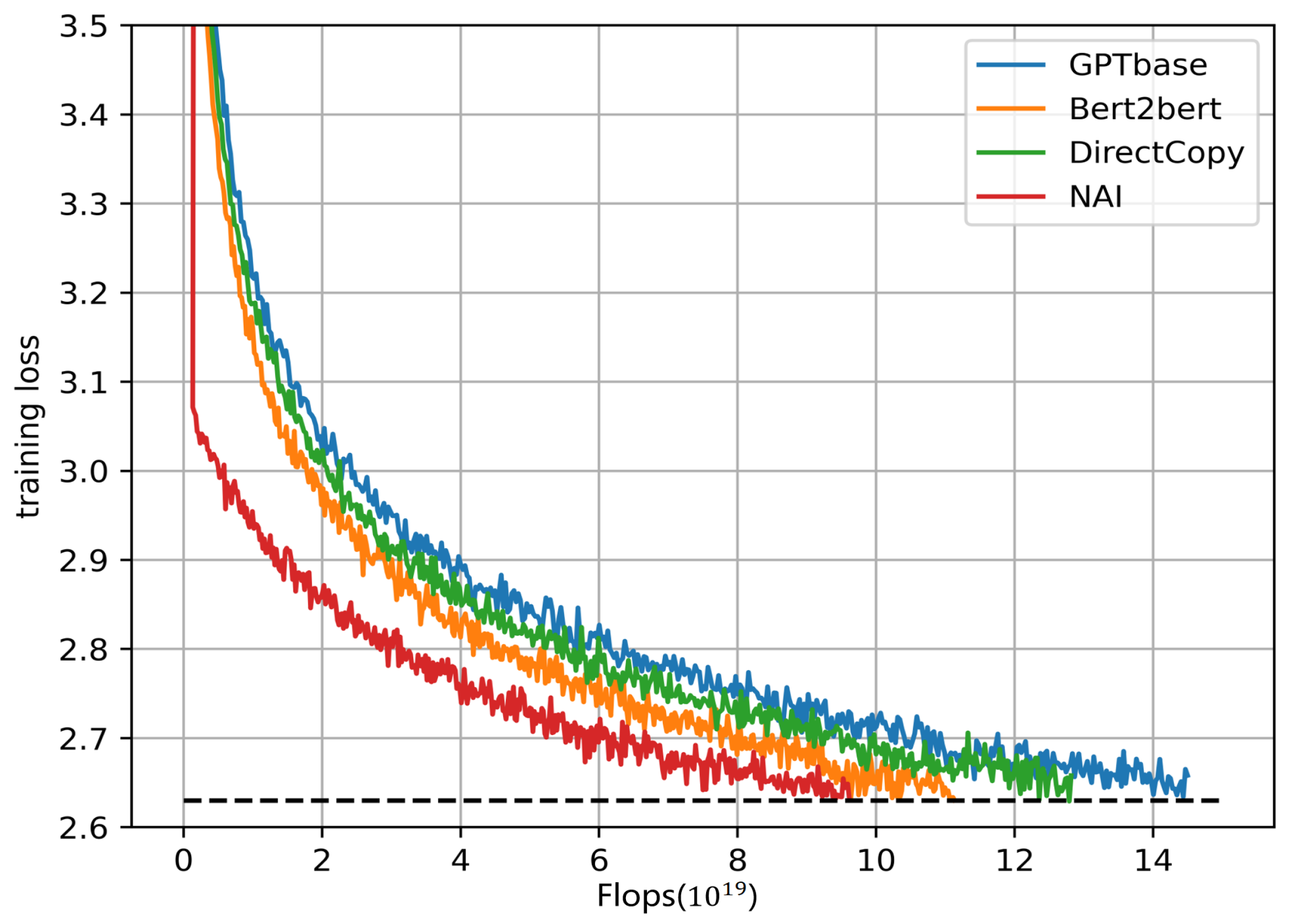
4.2. Results and Analysis
5. Potential Limitations and Challenges of NAI
- Architectural Limitations: NAI is inherently tailored for Transformer-based architectures, which are distinguished mainly by their self-attention mechanisms. These architectural elements are pivotal for the function-preserving initialization process that NAI employs. The self-attention mechanism, in particular, enables the model to weigh the importance of different parts of the input data, whereas layer normalization facilitates the stabilization of the learning process by reducing the internal covariate shift. Given the constraints of computational resources, the empirical validation of NAI has been primarily confined to the GPT-2 model, which is a decoder-only PLMs. This limitation necessitates a cautious extrapolation of NAI’s efficacy to other PLM architectures, such as those based on encoder-only or encoder–decoder configurations. Encoder-only models, such as BERT, utilize a bidirectional training strategy that contrasts with the unidirectional nature of GPT-2, while encoder–decoder models, akin to sequence-to-sequence frameworks, are designed to handle input–output mapping tasks that diverge from the autoregressive generation focus of GPT-2. The transference of NAI to these alternative architectures entails a rigorous examination of potential modifications required to align with their distinct operational mechanisms. For instance, the adaptation of NAI to encoder-only models may necessitate strategies that effectively capture and preserve the bidirectional context during the initialization process. Similarly, encoder–decoder models may demand a reconceptualization of the NAI approach to accommodate the dual-input and dual-output structure characteristic of these architectures.
- Data Availability and Quality: NAI’s efficiency is contingent on the availability and quality of the smaller PLMs used for initialization. In domains where high-quality, well-pretrained models are scarce, the effectiveness of NAI may be compromised. Additionally, the method assumes a certain level of overlap in the knowledge domains between the smaller and larger models, which might not always be the case, especially in niche or rapidly evolving domains.
- Generalization and Adaptability: The success of NAI hinges on the assumption that smaller PLMs have learned foundational language structures that are generalizable to larger models. However, the extent to which this generalization holds true across various tasks and languages remains an open question. Furthermore, adapting NAI to non-English languages or multilingual settings may require additional considerations to account for linguistic diversity.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 15 November 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Raffel, C.; Shazeer, N.M.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2019, 21, 1–67. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.R.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Zeng, W.; Ren, X.; Su, T.; Wang, H.; Liao, Y.; Wang, Z.; Jiang, X.; Yang, Z.; Wang, K.; Zhang, X.; et al. PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation. arXiv 2021, arXiv:2104.12369. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N.M. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. J. Mach. Learn. Res. 2021, 23, 1–39. [Google Scholar]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609. [Google Scholar]
- Chen, C.; Yin, Y.; Shang, L.; Jiang, X.; Qin, Y.; Wang, F.; Wang, Z.; Chen, X.; Liu, Z.; Liu, Q. bert2BERT: Towards Reusable Pretrained Language Models. arXiv 2021, arXiv:2110.07143. [Google Scholar]
- Chen, T.; Goodfellow, I.J.; Shlens, J. Net2Net: Accelerating Learning via Knowledge Transfer. arXiv 2015, arXiv:1511.05641. [Google Scholar]
- Gong, L.; He, D.; Li, Z.; Qin, T.; Wang, L.; Liu, T.Y. Efficient Training of BERT by Progressively Stacking. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- You, Y.; Li, J.; Reddi, S.J.; Hseu, J.; Kumar, S.; Bhojanapalli, S.; Song, X.; Demmel, J.; Keutzer, K.; Hsieh, C.J. Large Batch Optimization for Deep Learning: Training BERT in 76 minutes. arXiv 2019, arXiv:1904.00962. [Google Scholar]
- Gu, X.; Liu, L.; Yu, H.; Li, J.; Chen, C.; Han, J. On the transformer growth for progressive bert training. arXiv 2020, arXiv:2010.12562. [Google Scholar]
- Qin, Y.; Lin, Y.; Yi, J.; Zhang, J.; Han, X.; Zhang, Z.; Su, Y.; Liu, Z.; Li, P.; Sun, M.; et al. Knowledge Inheritance for Pre-trained Language Models. arXiv 2021, arXiv:2105.13880. [Google Scholar]
- Wu, L.; Liu, B.; Stone, P.; Liu, Q. Firefly Neural Architecture Descent: A General Approach for Growing Neural Networks. arXiv 2021, arXiv:2102.08574. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Zhang, M.; He, Y. Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping. arXiv 2020, arXiv:2010.13369. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, L.; Wang, D. Splitting Steepest Descent for Growing Neural Architectures. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both Weights and Connections for Efficient Neural Network. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Feng, A.; Panda, P. Energy-efficient and Robust Cumulative Training with Net2Net Transformation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ba, J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What Does BERT Learn about the Structure of Language? In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? An Analysis of BERT’s Attention. arXiv 2019, arXiv:1906.04341. [Google Scholar]
- Gokaslan, A.; Vanya Cohen, E.P.; Tellex, S. OpenWebText Corpus. Available online: https://skylion007.github.io/OpenWebTextCorpus/ (accessed on 1 December 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Flops () | LAMBADA | PTB | WikiText2 | WikiText103 |
|---|---|---|---|---|---|
| 6.2 | 33.7 | 68.9 | 28.7 | 38.6 | |
| DirectCopy | 5.8 | 33.4 | 68.3 | 28.4 | 38.5 |
| bert2BERT | 4.9 | 32.6 | 67.5 | 28.1 | 38.2 |
| NAI | 4.3 | 32.2 | 67.6 | 28.3 | 37.7 |
| Model | Flops () | LAMBADA | PTB | WikiText2 | WikiText103 |
|---|---|---|---|---|---|
| 14.4 | 18.2 | 45.6 | 23.2 | 26.6 | |
| DirectCopy | 12.7 | 17.6 | 45.8 | 23.4 | 25.7 |
| bert2BERT | 11 | 17.8 | 45.5 | 23.1 | 25.4 |
| NAI | 9.6 | 17.8 | 45.2 | 23.7 | 26.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Q.; Zhang, J. Leveraging Neighbor Attention Initialization (NAI) for Efficient Training of Pretrained LLMs. Electronics 2024, 13, 1550. https://doi.org/10.3390/electronics13081550
Tan Q, Zhang J. Leveraging Neighbor Attention Initialization (NAI) for Efficient Training of Pretrained LLMs. Electronics. 2024; 13(8):1550. https://doi.org/10.3390/electronics13081550
Chicago/Turabian StyleTan, Qiao, and Jingjing Zhang. 2024. "Leveraging Neighbor Attention Initialization (NAI) for Efficient Training of Pretrained LLMs" Electronics 13, no. 8: 1550. https://doi.org/10.3390/electronics13081550
APA StyleTan, Q., & Zhang, J. (2024). Leveraging Neighbor Attention Initialization (NAI) for Efficient Training of Pretrained LLMs. Electronics, 13(8), 1550. https://doi.org/10.3390/electronics13081550