
NRPerson: A Non-Registered Multi-Modal Benchmark for Tiny Person Detection and Localization

 , , and
, , and
Abstract
:1. Introduction
- We establish a large-scale NRPerson benchmark, introducing the concept of non-registration in multi-modal data handling for tiny person detection and localization, thereby promoting tasks that align closer to real-world scenarios.
- We perform a comprehensive evaluation of state-of-the-art detection and localization models on this new benchmark, demonstrating the potential and limitations of existing technologies when applied to non-registered multi-modal data.
- We develop a set of diverse natural multi-modal baselines that effectively utilize non-registered data, laying a robust foundation for future research in multi-modal detection and localization.
2. Related Work
2.1. Multi-Modal Person Detection
2.2. Tiny Object Detection
2.3. Point-Based Object Localization
2.4. Other Public Datasets
3. The NRPerson Dataset
3.1. Data Collection and Annotation
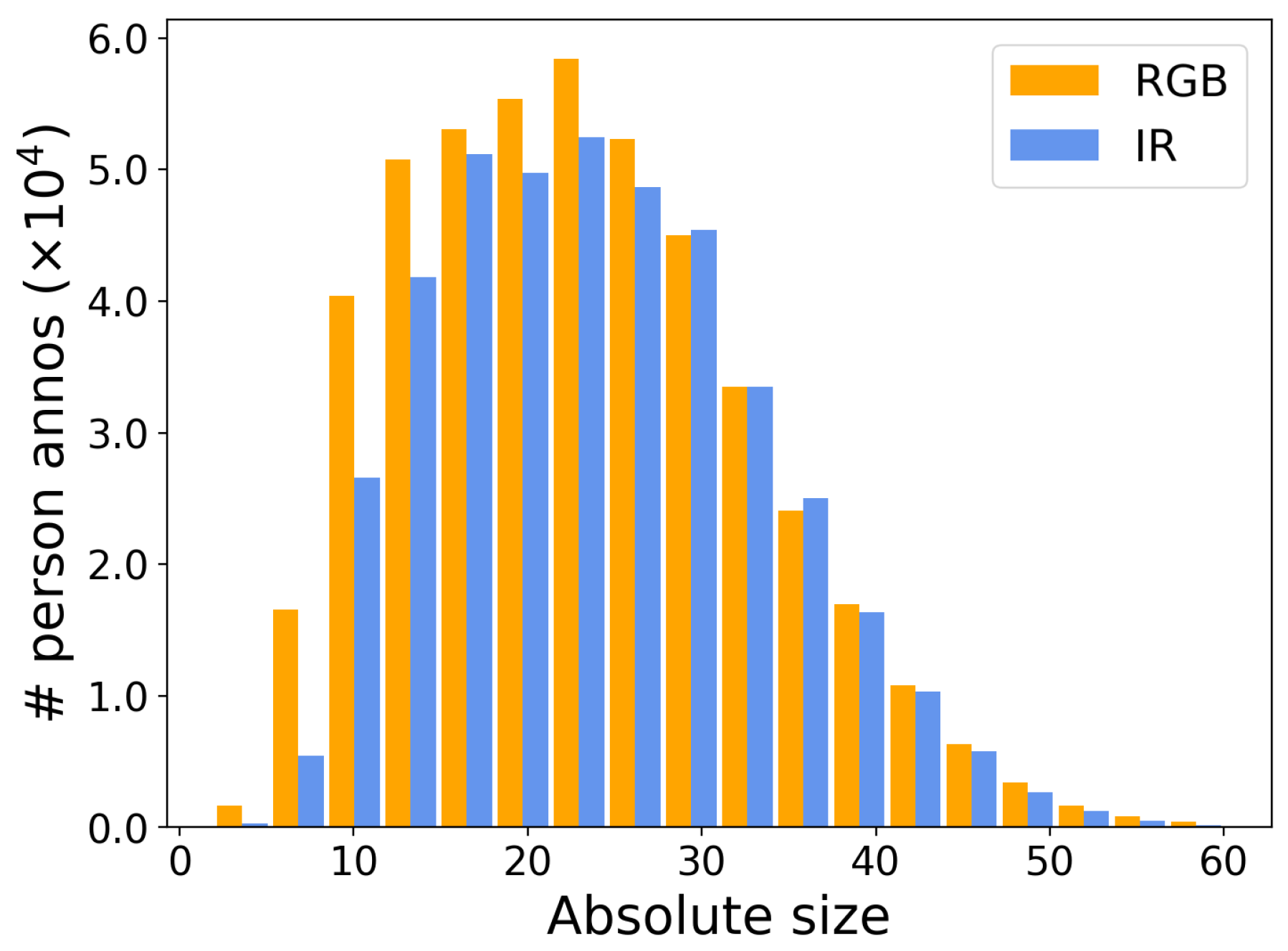
3.2. Dataset Properties
- (1)
- Position shift: Sensor differences and external factors lead to position shifts between corresponding instances in image pairs. This is the most common phenomenon, and even manually registered data often cannot completely eliminate it.
- (2)
- Size difference: Differences in the field of view and image pixels captured by RGB and IR sensors lead to the size difference of the corresponding instances. This can basically be eliminated through manual calibration.
- (3)
- No correspondence: There is no correspondence between the pixel coordinates of non-registered image pairs. Hence, instances between different modalities cannot be matched and paired.
- (1)
- Sharing dataset images on the Internet in any form without permission is prohibited;
- (2)
- Identifiable images of people cannot be used to make demos or promotions;
- (3)
- Use face obfuscation or shield face regions when applicable and study its impact on detection and localization [47].
4. Tracks and Metrics
4.1. Mono-Modal Track
4.2. Non-Registered Multi-Modal Track
4.3. Advantages and Challenges of Non-Registration
- (1)
- Multi-modal images often have different resolutions and fields of view due to the different sensors in the cameras. Therefore, it is almost impossible to achieve image registration simply by calibrating the inner parameters. It is also difficult to ensure that the image acquisition process is free from external disturbances even after the parameter calibration.
- (2)
- (Automatic feature matching methods may not work well on data with complicated scenes and across modalities. A typical example is shown in Figure 4, where we use SURF [51] to achieve feature point extraction and matching. Our dataset cannot rely on such unsatisfactory matching results for automatic registration. Further, for tiny object analysis, matching key points for registration will be more difficult due to the low signal-to-noise ratio.
- (3)
- The above two problems illustrate the difficulty of achieving the automatic alignment of multi-modal images. Therefore, the existing multi-modal dataset [3,21,46] almost relies on manual registration that requires processing each image pair and relies on a large amount of manpower. In addition, research shows that in practice, even well-processed data still suffer from weak alignment problems [36] (i.e., position shifts), which degrades model performance.
- (4)
- Our dataset focuses on tiny objects at a distance. In this case, registration becomes more complicated since long-distance shots amplify small deviations. In scenes with dense and minute-scale objects, slight positional offsets may confuse the correspondence between objects in different modes.
5. Experiments
5.1. Experimental Settings
5.1.1. Mono-Modal Tiny Person Detection
5.1.2. Mono-Modal Tiny Person Localization
5.1.3. Result Analysis
5.2. Non-Registered Multi-Modal Track
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision. arXiv 2021, arXiv:2108.10831. [Google Scholar]
- Zhang, Y.; Bai, Y.; Ding, M.; Xu, S.; Ghanem, B. KGSNet: Key-Point-Guided Super-Resolution Network for Pedestrian Detection in the Wild. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2251–2265. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Torabi, A.; Massé, G.; Bilodeau, G.A. An iterative integrated framework for thermal–visible image registration, sensor fusion, and people tracking for video surveillance applications. Comput. Vis. Image Underst. 2012, 116, 210–221. [Google Scholar] [CrossRef]
- Wu, Z.; Fuller, N.; Theriault, D.; Betke, M. A thermal infrared video benchmark for visual analysis. In Proceedings of the CVPRW, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- FLIR, T. Free Flir Thermal Dataset for Algorithm Training. 2018. Available online: https://www.flir.com/oem/adas/adas-dataset-form/ (accessed on 29 March 2024).
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Yu, X.; Chen, P.; Wu, D.; Hassan, N.; Li, G.; Yan, J.; Shi, H.; Ye, Q.; Han, Z. Object Localization under Single Coarse Point Supervision. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the CVPR, Las Vegas, NV, USA, 17–30 June 2016. [Google Scholar]
- Song, Q.; Wang, C.; Jiang, Z.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Wu, Y. Rethinking counting and localization in crowds: A purely point-based framework. In Proceedings of the ICCV, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Gong, Y.; Yu, X.; Ding, Y.; Peng, X.; Zhao, J.; Han, Z. Effective fusion factor in FPN for tiny object detection. In Proceedings of the WACV, Waikoloa, HI, USA, 3–8 January 2021. [Google Scholar]
- Jiang, N.; Yu, X.; Peng, X.; Gong, Y.; Han, Z. SM+: Refined Scale Match for Tiny Person Detection. In Proceedings of the ICASSP, Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Yu, X.; Han, Z.; Gong, Y.; Jan, N.; Zhao, J.; Ye, Q.; Chen, J.; Feng, Y.; Zhang, B.; Wang, X.; et al. The 1st tiny object detection challenge: Methods and results. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the ICGIP, Chengdu, China, 12–24 December 2018. [Google Scholar]
- Duan, K.; Du, D.; Qi, H.; Huang, Q. Detecting small objects using a channel-aware deconvolutional network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1639–1652. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted sparse representation regularized graph learning for RGB-T object tracking. In Proceedings of the ACM MM, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T object tracking: Benchmark and baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.; Zheng, W.S.; Gong, S.; Lai, J. RGB-IR person re-identification by cross-modality similarity preservation. Int. J. Comput. Vis. 2020, 128, 1765–1785. [Google Scholar] [CrossRef]
- Jiang, N.; Wang, K.; Peng, X.; Yu, X.; Wang, Q.; Xing, J.; Li, G.; Zhao, J.; Guo, G.; Han, Z. Anti-UAV: A large multi-modal benchmark for UAV tracking. arXiv 2021, arXiv:2101.08466. [Google Scholar]
- Sun, Z.; Zhao, F. Counterfactual attention alignment for visible-infrared cross-modality person re-identification. Pattern Recognit. Lett. 2023, 168, 79–85. [Google Scholar] [CrossRef]
- Luo, X.; Jiang, Y.; Wang, A.; Wang, J.; Zhang, Z.; Wu, X. Infrared and visible image fusion based on Multi-State contextual hidden Markov Model. Pattern Recognit. 2023, 138, 109431. [Google Scholar] [CrossRef]
- Xu, M.; Tang, L.; Zhang, H.; Ma, J. Infrared and visible image fusion via parallel scene and texture learning. Pattern Recognit. 2022, 132, 108929. [Google Scholar] [CrossRef]
- Dollár, P.; Appel, R.; Belongie, S.J.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. In Proceedings of the BMVC, York, UK, 19–22 September 2016. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully convolutional region proposal networks for multispectral person detection. In Proceedings of the CVPRW, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, D.; Ouyang, W.; Ricci, E.; Wang, X.; Sebe, N. Learning cross-modal deep representations for robust pedestrian detection. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-modality interactive attention network for multispectral pedestrian detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly aligned cross-modal learning for multispectral pedestrian detection. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, Y.T.; Shi, J.; Ye, Z.; Mertz, C.; Ramanan, D.; Kong, S. Multimodal object detection via probabilistic ensembling. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 139–158. [Google Scholar]
- Xiao, J.; Guo, H.; Zhou, J.; Zhao, T.; Yu, Q.; Chen, Y.; Wang, Z. Tiny object detection with context enhancement and feature purification. Expert Syst. Appl. 2023, 211, 118665. [Google Scholar] [CrossRef]
- Ribera, J.; Guera, D.; Chen, Y.; Delp, E.J. Locating objects without bounding boxes. In Proceedings of the CVPR, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, X.; Chen, P.; Wang, K.; Han, X.; Li, G.; Han, Z.; Ye, Q.; Jiao, J. CPR++: Object Localization via Single Coarse Point Supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2024. [Google Scholar] [CrossRef] [PubMed]
- Leykin, A.; Ran, Y.; Hammoud, R. Thermal-visible video fusion for moving target tracking and pedestrian classification. In Proceedings of the CVPR, Virtual, 19–25 June 2007. [Google Scholar]
- Toet, A. TNO Image Fusion Dataset. 2014. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029/1 (accessed on 29 March 2024).
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Xu, Z.; Zhuang, J.; Liu, Q.; Zhou, J.; Peng, S. Benchmarking a large-scale FIR dataset for on-road pedestrian detection. Infrared Phys. Technol. 2019, 96, 199–208. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; Volume 8693, pp. 740–755. [Google Scholar]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef]
- Yang, K.; Yau, J.; Fei-Fei, L.; Deng, J.; Russakovsky, O. A study of face obfuscation in imagenet. arXiv 2021, arXiv:2103.06191. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Chen, P.; Yu, X.; Han, X.; Hassan, N.; Wang, K.; Li, J.; Zhao, J.; Shi, H.; Han, Z.; Ye, Q. Point-to-Box Network for Accurate Object Detection via Single Point Supervision. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the ECCV, Crete, Greece, 5–11 September 2006. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the ICLR, Virtual Event, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the ICCV, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 ICCV, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient Non-Maximum Suppression. In Proceedings of the ICPR, Hong Kong, China, 20–24 August 2006. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Annotations | RGB | IR | TA | SO | NR | Task | Year |
|---|---|---|---|---|---|---|---|---|---|
| Multi-modal dataset | |||||||||
| OSU-CT [41] | 17,088 | – | ✓ | ✓ | ✓ | ✓ | × | Fusion | 2007 |
| LITIV [6] | 12,650 | – | ✓ | ✓ | ✓ | ✓ | × | Fusion | 2012 |
| TNO [42] | 480 | – | ✓ | ✓ | ✓ | ✓ | × | Fusion | 2014 |
| RGB-T210 [22] | 210,000 | 210,000 | ✓ | ✓ | ✓ | ✓ | × | OT | 2017 |
| RGB-T234 [23] | 233,800 | 233,800 | ✓ | ✓ | ✓ | ✓ | × | OT | 2019 |
| RegDB [24] | 8240 | 8240 | ✓ | ✓ | – | – | – | Re-ID | 2017 |
| SYSU-MM01 [25] | 45,863 | 45,863 | – | – | – | Re-ID | 2020 | ||
| Person detection/localization dataset | |||||||||
| Caltech [1] | 249,884 | 346,621 | ✓ | × | – | – | – | PD | 2009 |
| KITTI [5] | 14,999 | 80,256 | ✓ | × | – | – | – | OD | 2012 |
| COCOPersons [45] | 64,115 | 273,469 | ✓ | × | – | – | – | PD | 2014 |
| CityPersons [2] | 5000 | 35,016 | ✓ | × | – | – | – | PD | 2017 |
| CrowdHuman [43] | 24,370 | 456,098 | ✓ | × | – | – | – | PD | 2018 |
| SCUT-FIR [44] | 211,011 | 477,907 | × | ✓ | – | – | – | PD | 2019 |
| TinyPerson [9] | 1610 | 72,651 | ✓ | × | – | – | – | PD | 2019 |
| SeaPerson [10] | 12,032 | 619,627 | × | – | – | – | PL | 2022 | |
| Multi-modal person detection/localization dataset | |||||||||
| KAIST [21] | 190,656 | 103,128 | ✓ | ✓ | ✓ | ✓ | × | PD | 2015 |
| CVC-14 [46] | 17,002 | 17,929 | ✓ † | ✓ | ✓ ∗ | ✓ | × | PD | 2016 |
| FLIR [8] | 28,267 | 119,491 | ✓ | ✓ | ✓ ∗ | ✓ | × | OD | 2018 |
| LLVIP [3] | 30,976 | 41,579 | ✓ | ✓ | ✓ | ✓ | × | PD | 2021 |
| NRPerson | 17,096 | 889,207 | PD & PL | 2022 | |||||
| NRPerson | Train | Valid | Test | Total |
|---|---|---|---|---|
| image pairs | 4614 | 375 | 3559 | 8548 |
| annos | 346,413 | 33,385 | 509,408 | 889,207 |
| RGB annos | 174,312 | 16,943 | 280,669 | 471,924 |
| IR annos | 172,101 | 16,442 | 228,739 | 417,282 |
| Dataset | Absolute Size | Relative Size | Aspect Ratio |
|---|---|---|---|
| KAIST [21] | 54.2 ± 24.8 | 0.10 ± 0.05 | 0.45 ± 0.10 |
| FLIR [8] | 26.6 ± 23.1 | 0.05 ± 0.04 | 0.43 ± 0.19 |
| LLVIP [3] | 146.1 ± 32.4 | 0.13 ± 0.03 | 0.47 ± 0.19 |
| CityPersons [2] | 79.8 ± 67.5 | 0.56 ± 0.05 | 0.41 ± 0.01 |
| TinyPerson [9] | 18.0 ± 17.4 | 0.01 ± 0.01 | 0.68 ± 0.42 |
| SeaPerson [10] | 22.6 ± 10.8 | 0.02 ± 0.01 | 0.72 ± 0.42 |
| NRPerson | 23.7 ± 9.6 | 0.02 ± 0.01 | 0.81 ± 0.45 |
| Detection | RGB-Modal | IR-Modal | ||||||
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [48] | 64.7 | 75.8 | 74.3 | 57.1 | 51.1 | 66.7 | 60.6 | 44.5 |
| RetinaNet [55] | 64.4 | 74.9 | 74.7 | 57.5 | 49.3 | 66.0 | 62.3 | 39.3 |
| Adaptive RetinaNet [55] | 65.5 | 74.1 | 74.3 | 61.2 | 51.4 | 66.5 | 62.5 | 44.6 |
| RepPoints [56] | 66.8 | 74.5 | 76.7 | 60.3 | 51.4 | 67.9 | 64.2 | 40.6 |
| Adaptive RepPoints [56] | 67.1 | 76.1 | 76.3 | 63.5 | 51.9 | 67.2 | 64.8 | 42.9 |
| Sparse R-CNN [57] | 66.4 | 77.3 | 76.1 | 53.7 | 48.1 | 63.2 | 59.3 | 43.9 |
| Deformable DETR [58] | 65.9 | 75.1 | 77.9 | 55.2 | 48.5 | 63.6 | 58.8 | 42.8 |
| Swin-T (Faster R-CNN) [59] | 67.2 | 75.8 | 77.1 | 57.7 | 49.2 | 67.9 | 58.8 | 42.6 |
| Localization | RGB-Modal | IR-Modal | ||||||
| Faster R-CNN [48] | 71.5 | 21.1 | 56.2 | 77.5 | 74.8 | 33.8 | 66.9 | 72.3 |
| RetinaNet [55] | 76.0 | 27.1 | 64.4 | 80.3 | 75.5 | 37.9 | 69.8 | 71.8 |
| Adaptive RetinaNet [55] | 74.5 | 25.6 | 61.5 | 79.5 | 74.7 | 35.3 | 67.3 | 71.8 |
| RepPoints [56] | 76.2 | 26.1 | 64.4 | 81.2 | 76.5 | 35.1 | 69.8 | 73.7 |
| Adaptive RepPoints [56] | 75.1 | 25.9 | 63.2 | 80.4 | 74.5 | 33.0 | 66.8 | 71.8 |
| Sparse R-CNN [57] | 76.4 | 27.8 | 65.3 | 80.2 | 74.2 | 34.0 | 68.1 | 70.1 |
| Deformable DETR [58] | 78.0 | 29.7 | 68.2 | 83.2 | 77.7 | 40.9 | 73.1 | 75.8 |
| Swin-T (Faster R-CNN) [59] | 72.7 | 23.2 | 58.4 | 76.9 | 76.3 | 41.6 | 71.1 | 72.6 |
| P2PNet [12] w/o CPR [10] | 71.4 | 25.9 | 51.9 | 82.1 | 66.4 | 26.3 | 54.2 | 72.0 |
| P2PNet [12] w/CPR [10] | 80.1 | 33.6 | 71.4 | 77.9 | 81.5 | 46.5 | 77.6 | 72.6 |
| Detection | Multi-Test | RGB-Test | IR-Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [48] | 60.1 | 71.8 | 70.4 | 52.0 | 66.5 | 77.3 | 77.1 | 55.1 | 50.9 | 66.2 | 57.6 | 35.9 |
| RetinaNet [55] | 58.9 | 70.3 | 72.0 | 49.6 | 65.4 | 74.6 | 76.9 | 53.0 | 49.4 | 65.0 | 58.5 | 32.0 |
| Adaptive RetinaNet [55] | 60.6 | 70.6 | 71.5 | 53.8 | 67.0 | 74.8 | 76.6 | 56.8 | 51.1 | 64.8 | 58.1 | 36.7 |
| RepPoints [56] | 61.6 | 73.0 | 73.3 | 52.7 | 66.4 | 72.7 | 74.2 | 60.1 | 52.4 | 65.1 | 60.2 | 36.0 |
| Adaptive RepPoints [56] | 62.6 | 72.3 | 72.0 | 50.4 | 69.6 | 79.4 | 79.4 | 58.8 | 52.7 | 67.4 | 61.1 | 35.7 |
| Sparse R-CNN [57] | 59.8 | 70.5 | 71.0 | 51.4 | 67.1 | 78.4 | 77.4 | 53.8 | 48.8 | 61.3 | 57.0 | 37.7 |
| Deformable DETR [58] | 60.1 | 71.3 | 71.4 | 51.7 | 67.9 | 78.3 | 78.5 | 54.4 | 49.3 | 63.9 | 57.8 | 36.9 |
| Swin-T (Faster R-CNN) [59] | 59.1 | 69.6 | 70.1 | 49.7 | 68.6 | 77.2 | 77.9 | 56.0 | 47.1 | 64.2 | 58.9 | 38.5 |
| Localization | Multi-Test | RGB-Test | IR-Test | |||||||||
| Faster R-CNN [48] | 73.9 | 30.6 | 63.3 | 76.0 | 73.5 | 26.3 | 60.8 | 79.2 | 74.4 | 33.7 | 66.5 | 71.8 |
| RetinaNet [55] | 76.3 | 34.6 | 66.9 | 77.8 | 77.0 | 31.8 | 66.1 | 81.3 | 75.5 | 37.5 | 69.4 | 72.2 |
| Adaptive RetinaNet [55] | 75.5 | 33.2 | 65.5 | 77.1 | 75.9 | 29.9 | 64.1 | 80.7 | 75.0 | 36.4 | 68.6 | 71.5 |
| RepPoints [56] | 75.6 | 29.8 | 65.1 | 77.0 | 76.2 | 28.5 | 64.8 | 80.8 | 75.9 | 33.6 | 67.5 | 73.3 |
| Adaptive RepPoints [56] | 74.5 | 30.3 | 63.8 | 77.0 | 74.7 | 27.0 | 62.2 | 80.5 | 74.5 | 33.5 | 67.0 | 71.5 |
| Sparse R-CNN [57] | 78.4 | 34.4 | 70.1 | 78.8 | 80.1 | 32.9 | 70.9 | 83.2 | 76.6 | 35.9 | 70.1 | 72.7 |
| Deformable DETR [58] | 77.1 | 34.5 | 69.5 | 80.5 | 77.5 | 30.0 | 68.3 | 83.2 | 77.7 | 39.6 | 73.0 | 76.1 |
| Swin-T (Faster R-CNN) [59] | 72.6 | 33.3 | 63.0 | 75.0 | 72.0 | 24.0 | 58.2 | 77.2 | 73.3 | 42.4 | 68.3 | 71.3 |
| P2PNet [12] w/o CPR [10] | 66.2 | 24.0 | 48.9 | 75.0 | 68.9 | 25.8 | 49.4 | 80.4 | 63.4 | 22.9 | 49.2 | 67.2 |
| P2PNet [12] w/CPR [10] | 80.3 | 39.4 | 74.4 | 76.0 | 80.8 | 35.3 | 73.8 | 79.6 | 78.6 | 43.8 | 74.3 | 69.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Han, X.; Wang, K.; Yu, X.; Yu, W.; Wang, Z.; Li, G.; Han, Z.; Jiao, J. NRPerson: A Non-Registered Multi-Modal Benchmark for Tiny Person Detection and Localization. Electronics 2024, 13, 1697. https://doi.org/10.3390/electronics13091697
Yang Y, Han X, Wang K, Yu X, Yu W, Wang Z, Li G, Han Z, Jiao J. NRPerson: A Non-Registered Multi-Modal Benchmark for Tiny Person Detection and Localization. Electronics. 2024; 13(9):1697. https://doi.org/10.3390/electronics13091697
Chicago/Turabian StyleYang, Yi, Xumeng Han, Kuiran Wang, Xuehui Yu, Wenwen Yu, Zipeng Wang, Guorong Li, Zhenjun Han, and Jianbin Jiao. 2024. "NRPerson: A Non-Registered Multi-Modal Benchmark for Tiny Person Detection and Localization" Electronics 13, no. 9: 1697. https://doi.org/10.3390/electronics13091697
APA StyleYang, Y., Han, X., Wang, K., Yu, X., Yu, W., Wang, Z., Li, G., Han, Z., & Jiao, J. (2024). NRPerson: A Non-Registered Multi-Modal Benchmark for Tiny Person Detection and Localization. Electronics, 13(9), 1697. https://doi.org/10.3390/electronics13091697