Energy-Efficient Gabor Kernels in Neural Networks with Genetic Algorithm Training Method


Abstract
:1. Introduction
2. Related Work
2.1. Gabor Filters
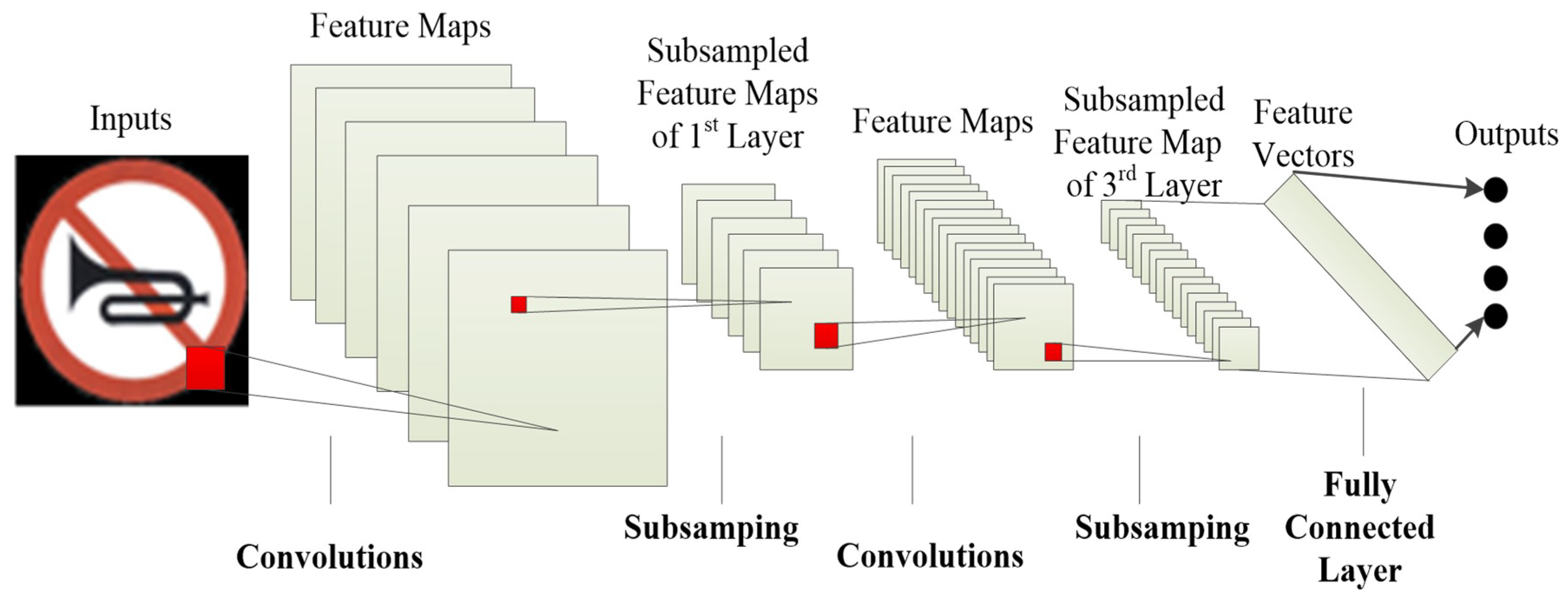
2.2. Convolutional Neural Network: Basics
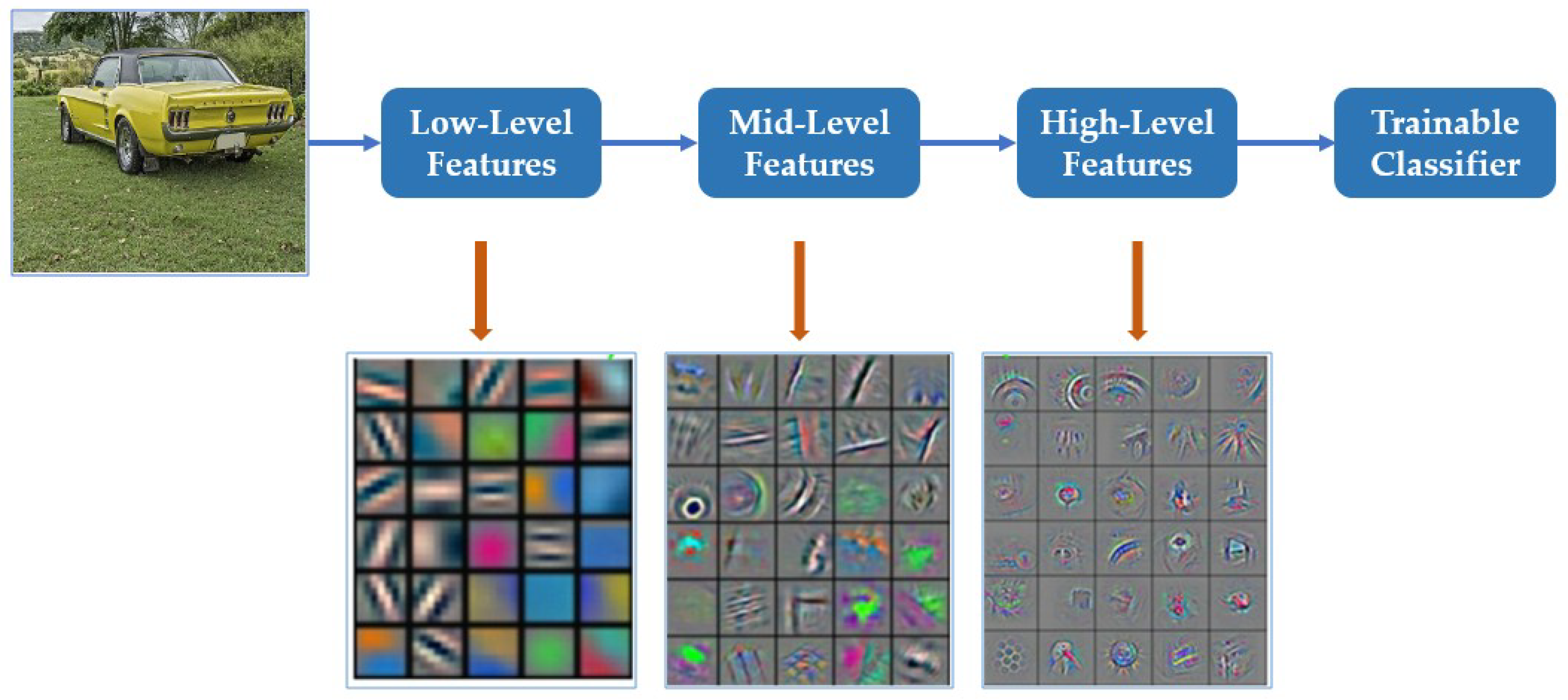
2.3. Combination of Gabor Filters and CNNs
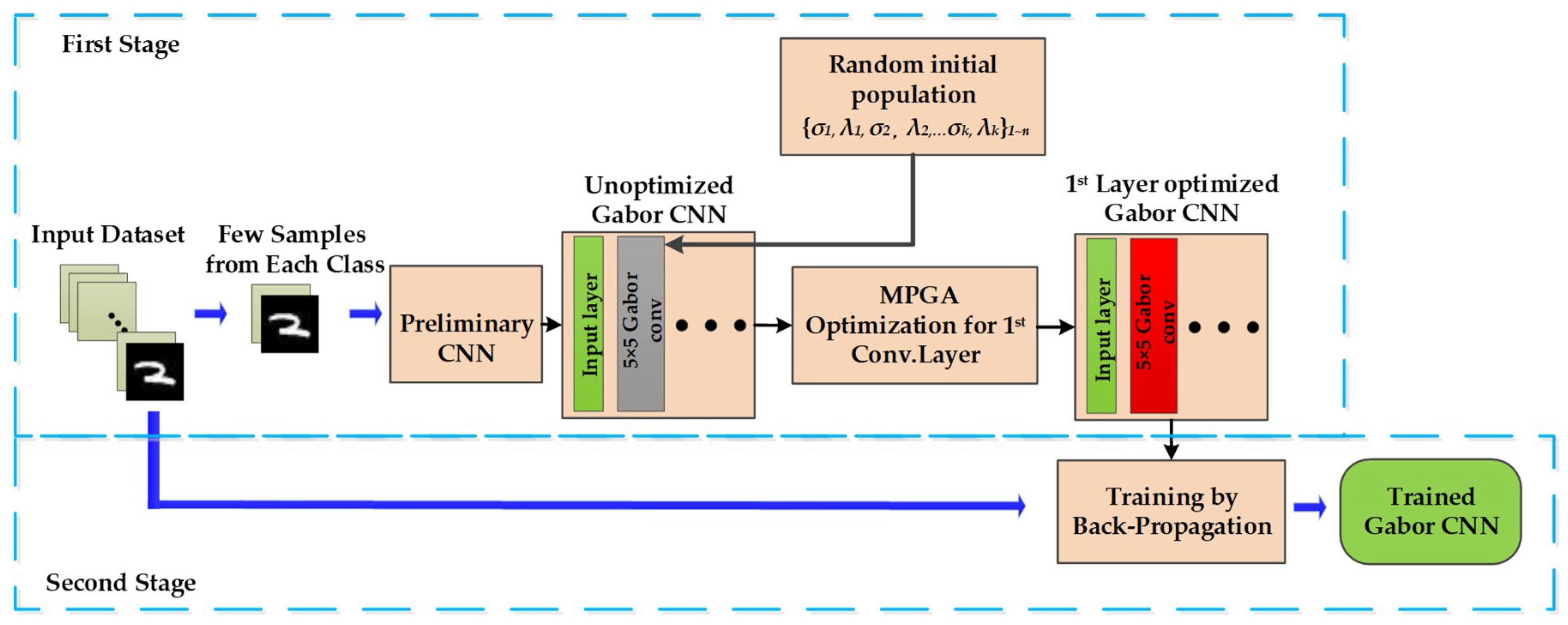
3. Proposed Method
3.1. Overview of Our Method
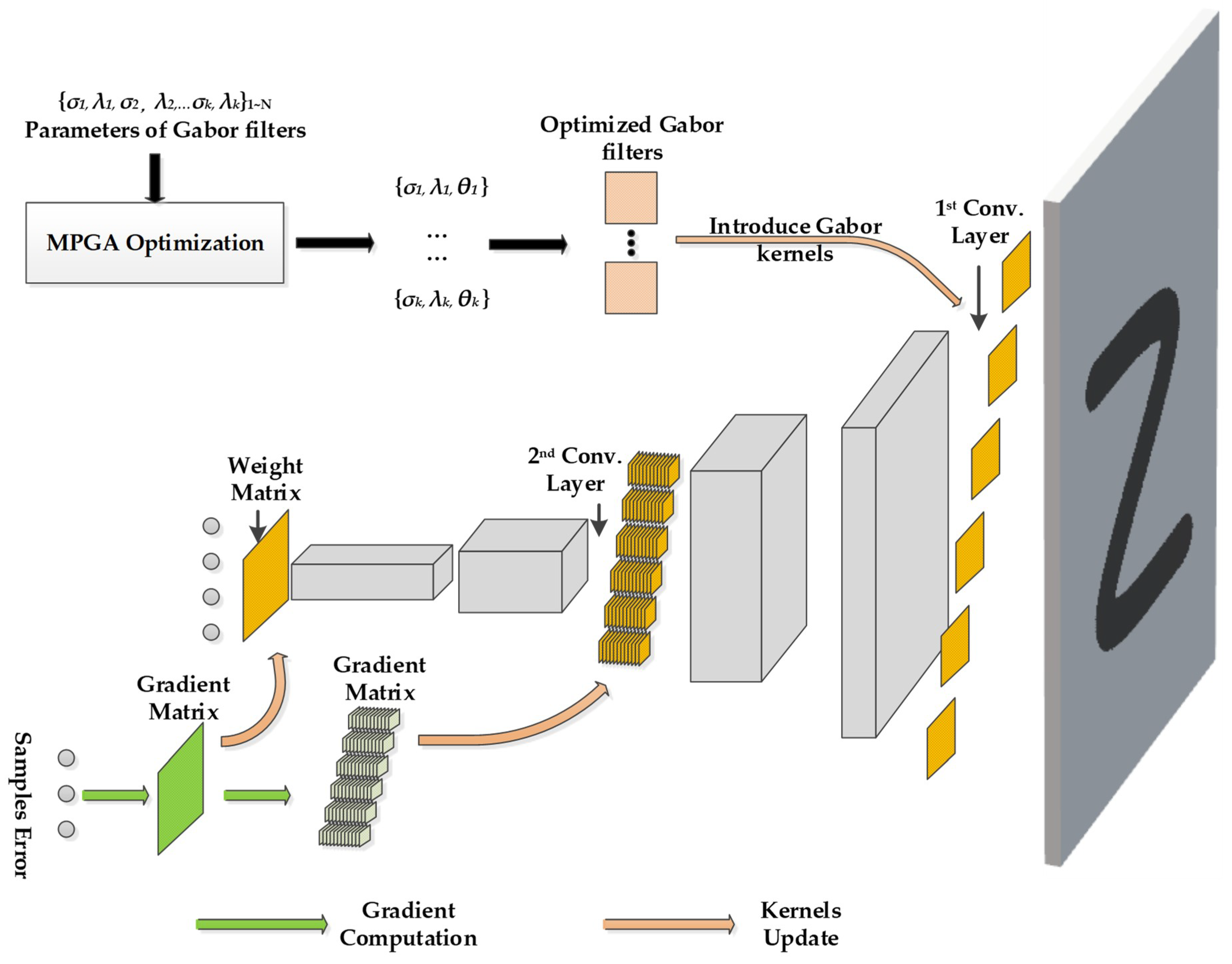
3.2. Improved Gabor Kernels in the First Convolutional Layer
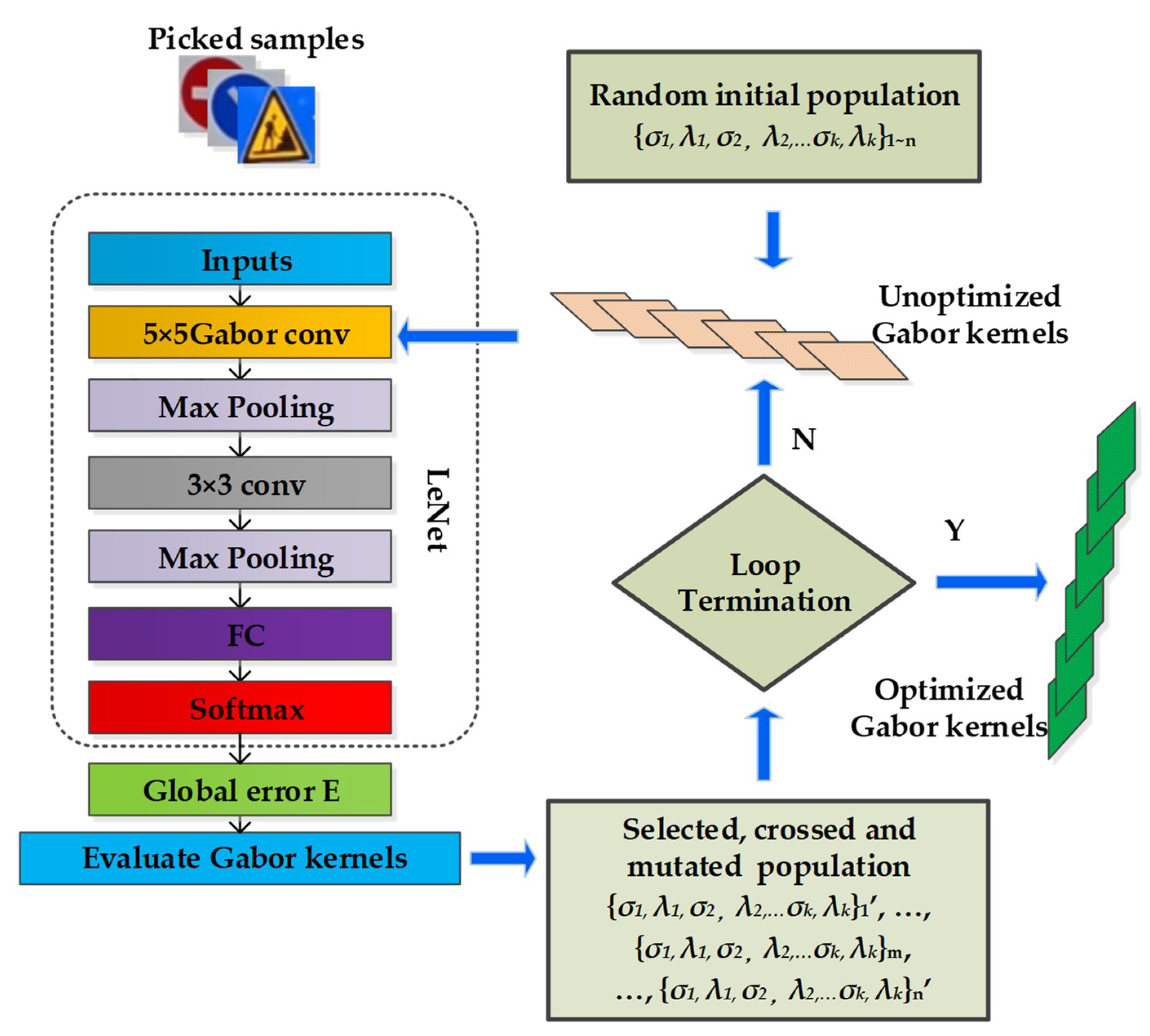
3.3. MPGA Optimization for Gabor Convolutional Kernels
- (1)
- An initial population P with a constant size 2k is randomly generated. k is the number of Gabor convolutional kernels in the first layer. Genes of individuals in the population represent the standard deviation of Gaussian envelope and the frequency of the span-limited sinusoidal grating of Gabor kernels.
- (2)
- The fitness for each initial individual corresponding to Gabor kernels is calculated.
- (3)
- The next generation, including the best individual from the previous generation, is created through reproduction, crossover, and mutation.
- (4)
- Each individual in the new generation is evaluated and the best Gabor kernels corresponding to one individual are saved.
- (5)
- If the search goal is achieved, or an allowable generation is attained, the best individual corresponding to Gabor kernels is returned as the solution; otherwise, return to step (3).
3.4. Fast Training Method for Gabor Convolutional Neural Networks
4. Implementation and Experiment
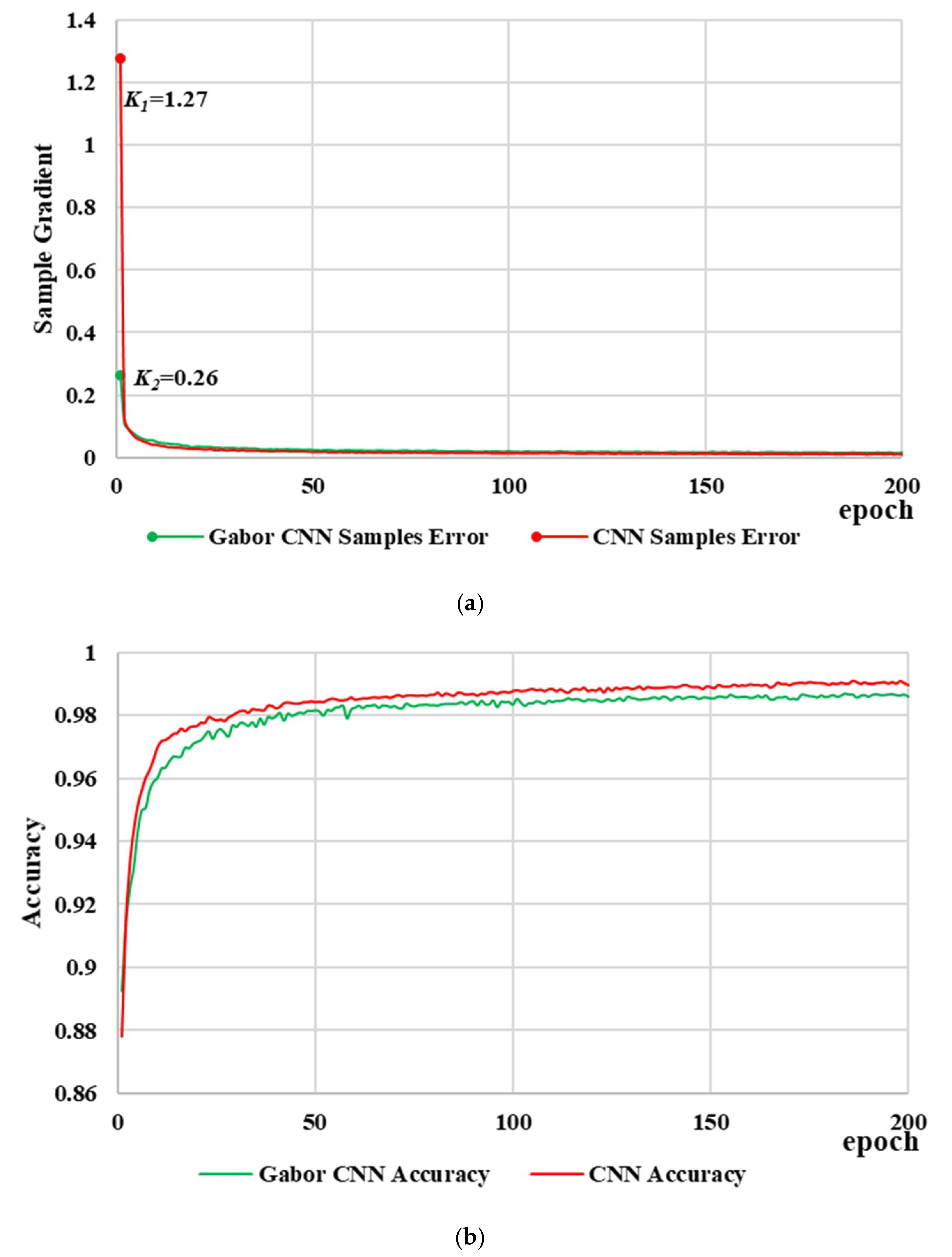
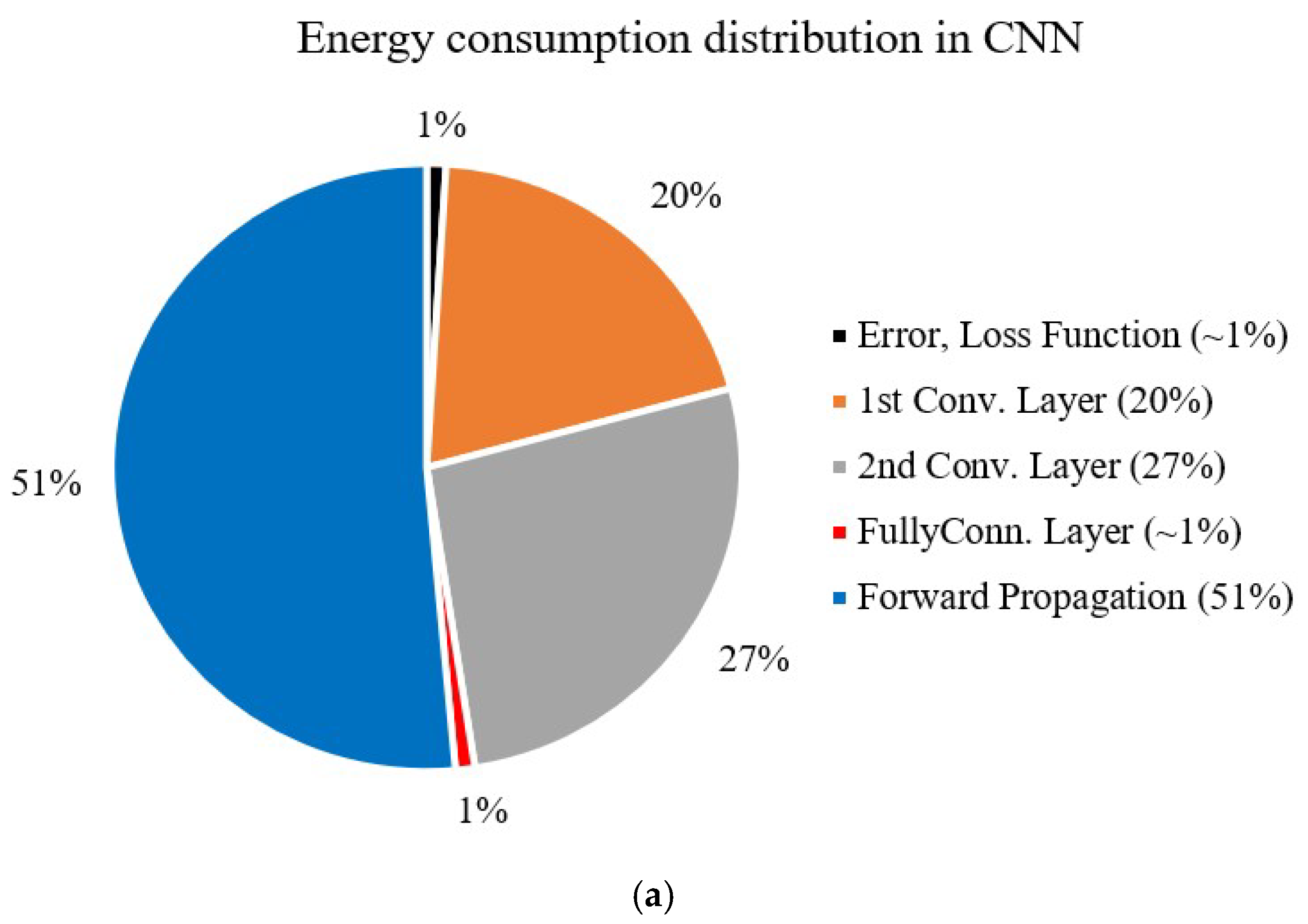
4.1. Energy Efficiency and Performance
4.2. Accuracy Comparison
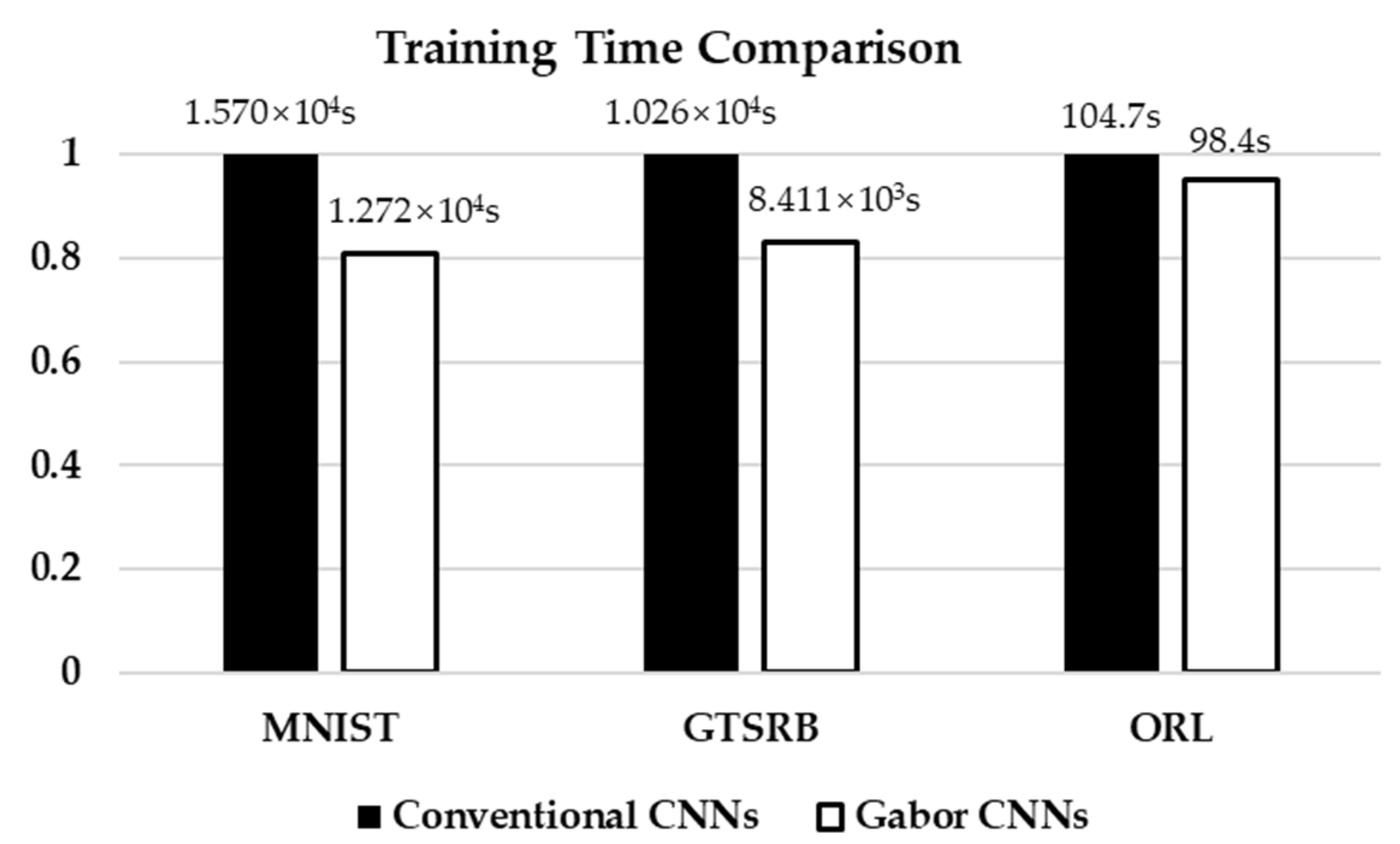
4.3. Training Time Comparison
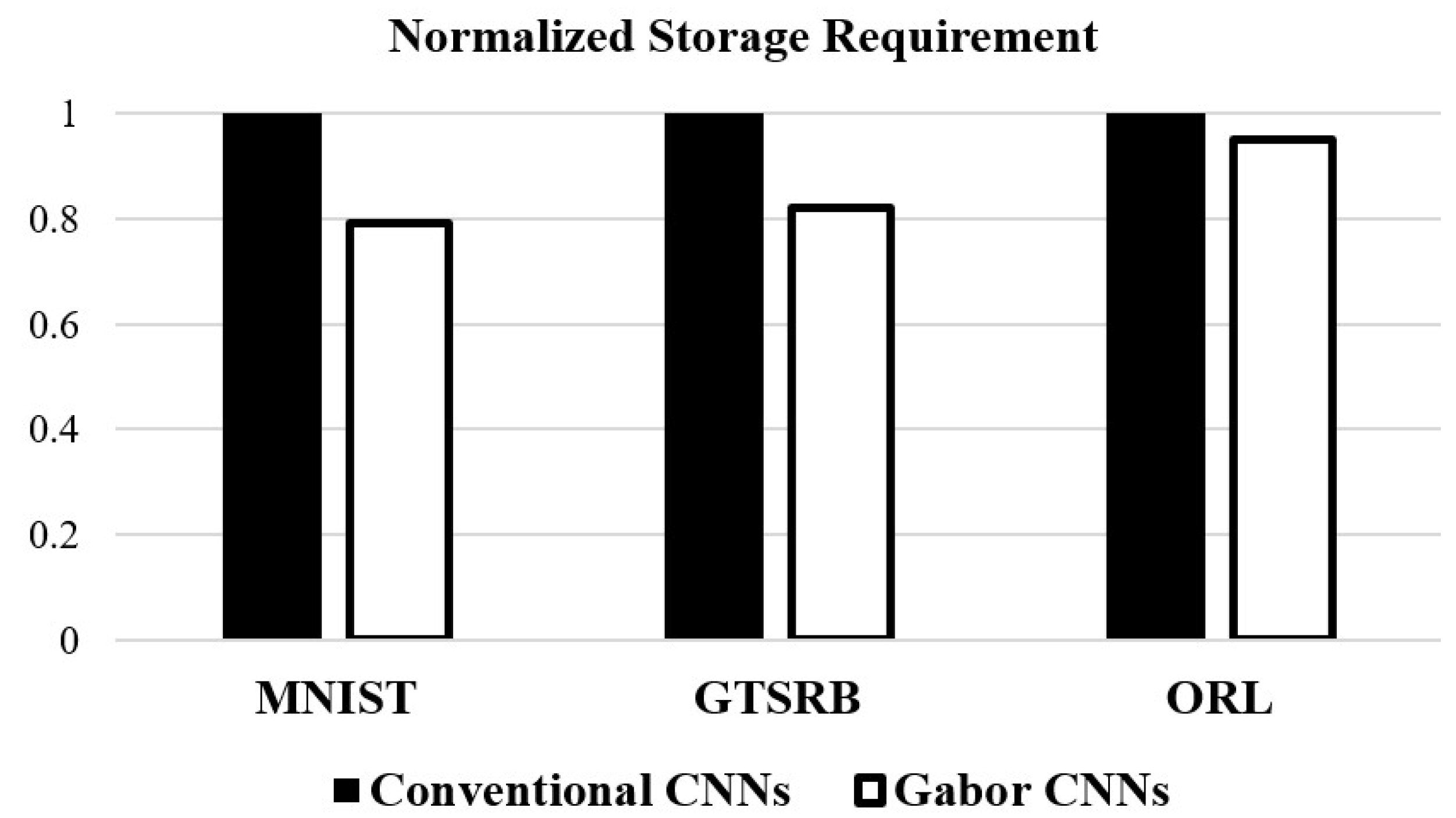
4.4. Storage Requirement Comparison
4.5. Effects of Iterations and Sampling Rate
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tom, Y.; Devamanyu, H.; Soujanya, P.; Erik, C. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Marcus, G. Deep Learning: A Critical Appraisal. arXiv, 2018; arXiv:1801.00631. [Google Scholar]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Asif, U.; Bennamoun, M.; Sohel, F. A multi-modal, discriminative and spatially invariant CNN for RGB-D object labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2051–2065. [Google Scholar] [CrossRef]
- Chin, T.W.; Yu, C.L.; Halpern, M.; Genc, H.; Tsao, S.L.; Reddi, V.J. Domain-Specific Approximation for Object Detection. IEEE Micro 2018, 38, 31–40. [Google Scholar] [CrossRef]
- Ranjan, R.; Sankaranarayanan, S.; Bansal, A.; Bodla, N.; Chen, J.-C.; Patel, V.M.; Castillo, C.D.; Chellappa, R. Deep learning for understanding faces: Machines may be just as good, or better, than humans. IEEE Signal Process. Mag. 2018, 35, 66–83. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 2014, 1, 541–551. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Object instance segmentation and fine-grained localization using hypercolumns. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 627–639. [Google Scholar] [CrossRef]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Li, H.; Fan, X.; Li, J.; Wei, C.; Zhou, X.; Wang, L. A high performance FPGA-based accelerator for large-scale Convolutional Neural Networks. In Proceedings of the International Conference on Field Programmable Logic & Applications, Lausanne, Switzerland, 29 August–2 September 2016. [Google Scholar] [CrossRef]
- Li, C.; Yang, Y.; Feng, M.; Srimat, C.; Zhou, H. Optimizing Memory Efficiency for Deep Convolutional Neural Networks on GPUs. In Proceedings of the International Conference for High Performance Computing, Networking, Storage & Analysis, Denver, CO, USA, 12–17 November 2017. [Google Scholar] [CrossRef]
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the International Joint Conference on IJCAI, Barcelona, Spain, 16–22 July 2011. [Google Scholar] [CrossRef]
- Chang, S.Y.; Morgan, N. Robust CNN-based speech recognition with Gabor filter kernels. In Proceedings of the Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 905–909. [Google Scholar]
- Sarwar, S.S.; Panda, P.; Roy, K. Gabor filter assisted energy efficient fast learning Convolutional Neural Networks. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design, Taipei, Taiwan, 24–26 July 2017. [Google Scholar] [CrossRef]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. Cudnn: Efficient primitives for deep learning. Comput. Sci. 2014. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Plaza, A.; Li, Y. Discriminative low-rank gabor filtering for spectral-spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1381–1395. [Google Scholar] [CrossRef]
- Rossovskii, L.E. Image filtering with the use of anisotropic diffusion. Comput. Math. Math. Phys. 2017, 57, 401–408. [Google Scholar] [CrossRef]
- Bovik, A.C.; Clark, M.; Geisler, W.S. Multichannel texture analysis using localized spatial filters. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 12, 55–73. [Google Scholar] [CrossRef]
- Randen, T.; Husoy, J.H. Filtering for texture classification: A comparative study. IEEE Trans Pattern Anal. Mach. Intell. 1999, 21, 291–310. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Springer: New York, NY, USA, 2014; pp. 818–833. [Google Scholar]
- Madhavi, D.; Ramesh Patnaik, M. Genetic Algorithm-Based Optimized Gabor Filters for Content-Based Image Retrieval. In Intelligent Communication, Control and Devices. Advances in Intelligent Systems and Computing, 2nd ed.; Singh, R., Choudhury, S., Gehlot, A., Eds.; Springer: Singapore, 2018; Volume 624, pp. 157–164. ISBN 978-981-10-5902-5. [Google Scholar]
- Ghodrati, H.; Dehghani, M.J.; Danyali, H. Iris feature extraction using optimized Gabor wavelet based on multi objective genetic algorithm. In Proceedings of the International Symposium on Innovations in Intelligent Systems and Applications, Istanbul, Turkey, 15–18 June 2011; pp. 159–163. [Google Scholar] [CrossRef]
- Riaz, F.; Hassan, A.; Rehman, S.; Qamar, U. Texture classification using rotation- and scale-invariant gabor texture features. IEEE Signal Process. Lett. 2013, 20, 607–610. [Google Scholar] [CrossRef]
- Tao, L.; Hu, G.H.; Kwan, H.K. Multiwindow real-valued discrete gabor transform and its fast algorithms. IEEE Trans. Signal Process. 2015, 63, 5513–5524. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Dasgupta, A.; Routray, A. Robust face recognition of inferior quality images using Local Gabor Phase Quantization. Technol. Symp. 2017. [Google Scholar] [CrossRef]
- Li, C.; Wei, W.; Li, J.; Song, W. A cloud-based monitoring system via face recognition using gabor and cs-lbp features. J. Supercomput. 2017, 73, 1532–1546. [Google Scholar] [CrossRef]
- Kaggwa, F.; Ngubiri, J.; Tushabe, F. Combined feature level and score level fusion Gabor filter-based multiple enrollment fingerprint recognition. In Proceedings of the International Conference on Signal Processing, Auckland, New Zealand, 27–30 November 2017. [Google Scholar] [CrossRef]
- Fei, L.; Teng, S.; Wu, J.; Rida, I. Enhanced minutiae extraction for high-resolution palmprint recognition. Int. J. Image Graph. 2017, 17, 1750020. [Google Scholar] [CrossRef]
- Kumari, P.A.; Suma, G.J. An experimental study of feature reduction using PCA in multi-biometric systems based on feature level fusion. In Proceedings of the International Conference on Advances in Electrical, Putrajaya, Malaysia, 28–30 September 2017. [Google Scholar] [CrossRef]
- Jia, S.; Shen, L.; Zhu, J.; Li, Q. A 3-D gabor phase-based coding and matching framework for hyperspectral imagery classification. IEEE Trans. Cybern. 2017, 48, 1176–1188. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Li, D. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process. 2014, 3, 1–29. [Google Scholar] [CrossRef]
- Palm, R.B. Prediction as a Candidate for Learning Deep Hierarchical Models of Data; Technical University of Denmark: Lyngby, Denmark, 2012. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Yeo, I.; Gi, S.G.; Lee, B.G.; Chu, M. Stochastic implementation of the activation function for artificial neural networks. In Proceedings of the Biomedical Circuits & Systems Conference, Torino, Italy, 19–21 October 2017. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurons in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, L.; Ghamisi, P.; Jia, X.; Li, G.; Tang, L. Hyperspectral images classification with gabor filtering and Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2355–2359. [Google Scholar] [CrossRef]
- Mahmoud, S.A. Arabic (Indian) handwritten digits recognition using Gabor-based features. In Proceedings of the International Conference on Innovations in Information Technology, Al-Ain, Abu Dhabi, 15–17 December 2009. [Google Scholar] [CrossRef]
- Palm, R.B. MATLAB/Octave Toolbox for Deep Learning. Available online: https://github.com/rasmusbergpalm/DeepLearnToolbox/ (accessed on 1 December 2015).
- Vedaldi, A.; Lenc, K. MatConvNet: Convolutional Neural Networks for MATLAB. In Proceedings of the 23rd Annual ACM Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 689–692. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Dataset | No. Training Samples | No. Testing Samples | Input Image Size |
|---|---|---|---|---|
| Digit Recognition | MNIST | 60,000 | 10,000 | 28 × 28 |
| Traffic Sign Recognition | GTSRB | 39,200 | 5000 | 32 × 32 (Normalized) |
| Face Recognition | ORL | 400 | 200 | 92 × 112 |
| Dataset | Network | Population & Individual | Crossover & Mutation | Sampling Rate |
|---|---|---|---|---|
| MNIST | [784 (5 × 5)6c 2s (5 × 5)12c 2s 10o] | 50 12 | 0.8 0.6 | 1% |
| GTSRB | [1024 (5 × 5)8c 2s (5 × 5)12c 2s 42o] | 50 16 | 0.8 0.6 | 1% |
| ORL | [4096 (11 × 11)8c 2s (5 × 5)12c 2s 40o] | 10 16 | 0.2 0.4 | 10% |
| Method | Conv in FP | Conv in BP | Iterations | All Conv |
|---|---|---|---|---|
| MPGA | 1.8 × 105 | -- | 10 | 1.8 × 106 |
| Preliminary CNN | 4.7 × 104 | 4.7 × 104 | 10 | 9.4 × 105 |
| Back-propagation | 3.6 × 105 | 3.6 × 105 | 200–500 | 1.5–3.6 × 108 |
| Dataset | Conventional CNN | Gabor CNN | Accuracy Change |
|---|---|---|---|
| MNIST | 99.11% | 98.66% | 0.45% |
| GTSRB | 98.70% | 96.24% | 2.46% |
| ORL | 98.60% | 99.10% | −0.50% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Wang, X.; Shao, F.; Wang, D.; Hua, X. Energy-Efficient Gabor Kernels in Neural Networks with Genetic Algorithm Training Method. Electronics 2019, 8, 105. https://doi.org/10.3390/electronics8010105
Meng F, Wang X, Shao F, Wang D, Hua X. Energy-Efficient Gabor Kernels in Neural Networks with Genetic Algorithm Training Method. Electronics. 2019; 8(1):105. https://doi.org/10.3390/electronics8010105
Chicago/Turabian StyleMeng, Fanjie, Xinqing Wang, Faming Shao, Dong Wang, and Xia Hua. 2019. "Energy-Efficient Gabor Kernels in Neural Networks with Genetic Algorithm Training Method" Electronics 8, no. 1: 105. https://doi.org/10.3390/electronics8010105
APA StyleMeng, F., Wang, X., Shao, F., Wang, D., & Hua, X. (2019). Energy-Efficient Gabor Kernels in Neural Networks with Genetic Algorithm Training Method. Electronics, 8(1), 105. https://doi.org/10.3390/electronics8010105