3. SCATTER PHY
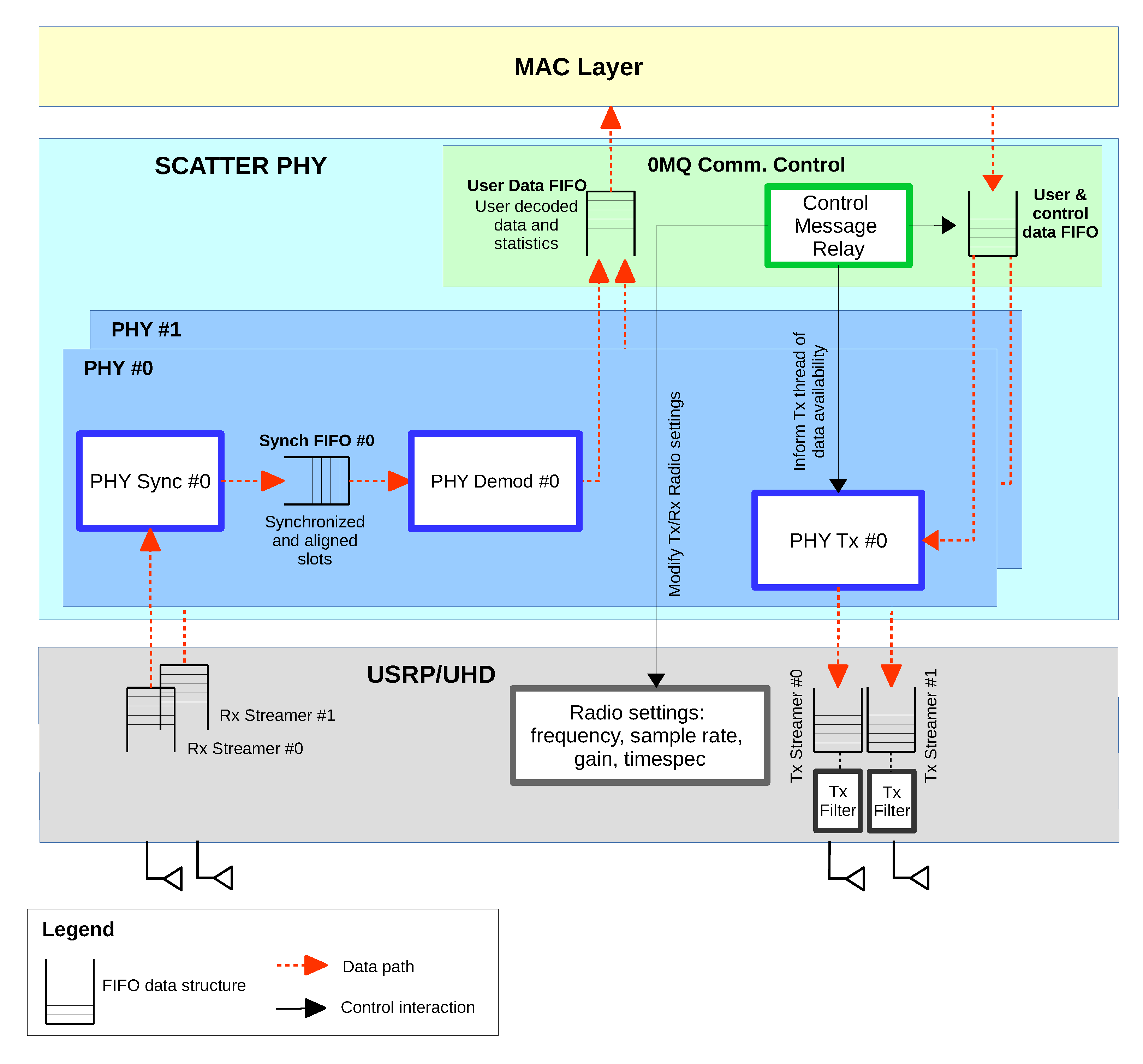
Figure 1 depicts the architecture of SCATTER PHY at a high level. The figure shows the several hardware and software layers making up SCATTER PHY and the different threads running inside of them.
Black arrows indicate the exchange of control and/or information between the threads, while red dashed arrows indicate data paths. SCATTER PHY is a bursty based PHY that transmits data bursts in short intervals. Each bursty transmission interval contains at least one or several transport units, which we call subframes. A subframe is a container through which control and user data are exchanged, over the air, in the network. Therefore, a subframe is the basic transmission unit of SCATTER PHY, and each one is 1 ms long.
The SCATTER PHY is an open-source software defined physical layer [
7]. Its implementation makes use of the Universal Software Radio Peripheral (USRP) Hardware Driver (UHD) software Application Programming Interface (API) [
6,
13], which makes it possible for the PHY to run on top of several Ettus SDR devices such as the Ettus USRP X family of SDRs and National Instruments’ (NI) RIO devices [
14,
15]. SCATTER PHY accesses the SDR device through the UHD driver and its APIs [
16]. As can be seen in the figure, the independent PHY layers are connected to a module responsible for managing the exchange of data, control, and statistics messages with the MAC layer, and the module is known as the ZeroMQ Data/Control Communications module. The exchange messages with the MAC layer are performed through a ZeroMQ bus, also known as 0MQ [
5].
In order to establish communications independently with the MAC layer, i.e., decouple the implementation of both layers, a well defined interface (i.e., a set of pre-defined messages) was designed with Google’s Protocol Buffers (protobuf) [
17]. Protobuf was used for data serialization and worked perfectly with the 0MQ messaging library [
5]. Together, protobuf and 0MQ created a means for a distributed and decoupled exchange of control, statistics, and data messages between SCATTER PHY and MAC layers. SCATTER PHY provides the MAC layer with the ability of real-time configuration of all its parameters and reading of several statistics it measures through the implementation of the 0MQ push-pull message-exchanging pattern [
5]. The implementation of this message-exchanging pattern provides upper layers with the ability of locally to configure/read PHY parameters/statistics remotely, i.e., upper layers (e.g., MAC layer) do not need to be run on the same physical radio. The 0MQ push-pull pattern allows MAC and PHY to implement a non-blocking message communications paradigm, i.e., MAC and PHY can exchange data and control messages without having their processing blocked for long periods, and with this paradigm, each layer decides when to check the availability of a new message. The implementation of the 0MQ push-pull pattern and the adoption of the protobuf message library allow SCATTER PHY to be designed and implemented totally independently and decoupled from the MAC layer, i.e., SCATTER PHY’s implementation decisions do not impose any kind of constraints on the programming language, software, or hardware employed by the MAC layer.
SCATTER PHY presents the following set of main features:
Bursty transmissions: Short periods of activity (i.e., discontinuous transmissions) allow a better/improved usage of the available spectrum bandwidths. It makes it possible for the radios/networks to coordinate the spectrum access/usage among them in a collaborative, intelligent, or even opportunistic manner.
Dual-concurrent PHYs: A Multi-Concurrent-Frequency Time-Division Multiple Access (McF-TDMA) scheme can be implemented by the MAC layer by having two PHYs simultaneously transmitting and receiving at independent frequencies. This ability for concurrent allocations allows for a smarter spectrum utilization as vacant disjoint frequency chunks can be concurrently used.
FPGA based filtered transmissions: Filtering the transmitted signal effectively minimizes OOBE, which allows for a better spectrum utilization, once radios can have their transmissions nearer to each other in the frequency domain, helping to mitigate the wastage of spectrum bands.
Out-of-band full-duplex operation: Both PHYs operate totally independently of each other, meaning that Tx and Rx modules are able to transmit and receive at different channels, set different Tx and Rx gains, and use different PHY BWs.
Timed-commands: This feature allows the configuration in advance of the exact time to (i) start a transmission and (ii) change Tx/Rx frequencies/gains. This allows the MAC layer to implement a TDMA scheme.
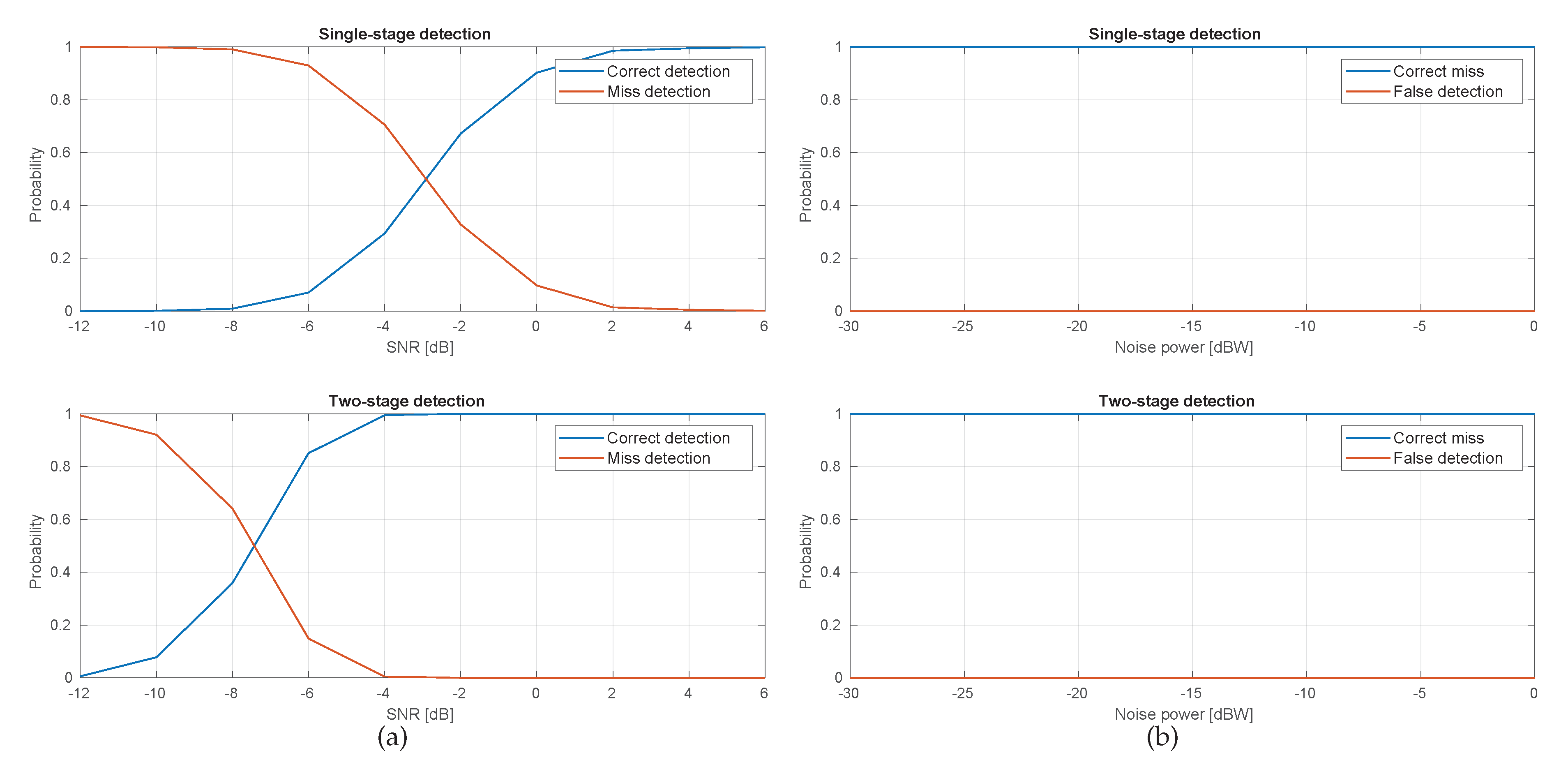
Improved synchronization: Through the design and implementation of a novel two-stage synchronization algorithm, it is possible to improve the packet detection ratio when compared to the single-stage approach.
Fine-grained CP based CFO estimation: By generating a complex exponential sequence with smaller sampling steps, it is possible to synthesize the frequency offset more accurately, consequently improving the correction.
Channel emulator: Through the implementation of an abstraction layer between the USRP hardware and the software based PHY, it is possible to create a channel emulator that connects the transmission side to the receiving side without the necessity of any hardware. Through the use of the channel emulator, it is possible to test novel PHY layer algorithms with the addition of white Gaussian noise, multi-paths, frequency offsets, etc.
SCATTER PHY was implemented based on the srsLTE library [
18]. srsLTE is an open-source and free LTE software based library that was developed by the Software Radio Systems (SRS) Limited company [
18]. It implements LTE release 10 and a few narrow-band Internet-of-Things (IoT) and 5G features. As SCATTER PHY was built on an LTE-like library, it consequently absorbed and evolved on top of the existing 4/5G features.
We employed OFDM as the SCATTER PHY waveform. OFDM is a full blown technology that is present in a huge number of commercial products due to various advantages it offers such as low implementation complexity, robustness to severe multi-path fading, simple channel estimation, easy integration with Multiple-Input Multiple-Output (MIMO) technology, etc. [
19]. User and control data are mapped into subcarriers over 14 OFDM symbols spanning 1 ms. The control data signal carries the used MCS for the current transmission and the number of subsequent subframes with user data modulated with that specific MCS.
The control data signal is used by the independent PHY receivers to detect the number of allocated RBs automatically (i.e., control is embedded into the transmitted data signal), the MCS value selected to transmit data of a specific device/radio, and the location of the allocated RBs in the subframe’s resource grid.
By embedding the control information into the transmitted signal, the Medium Access Control (MAC) layer does not need to know in advance the number of subframes and MCS in a given Channel Occupancy Time (COT). After successful user data decoding, each one of the PHYs independently notifies the MAC layer about the corresponding decoded MCS value, the number of received data bytes, and decoding statistics (e.g., RSSI, SINR, number of detection/decoding errors, etc.).
SCATTER PHY works with two types of subframes, namely synchronization and data-only subframes. A synchronization subframe carries the synchronization signal, reference signal, control, and user data. A data-only subframe carries the reference signal and user data. The synchronization signal is a 72 symbol long sequence that is generated using Zadoff–Chu (ZC) sequences [
20,
21]. Therefore, the synchronization sequence is generated according to:
where
n is the sequence sample index,
u is the ZC sequence index, and
is the length of the synchronization sequence.
The control signal is based on Maximum length sequences (M-sequences) [
22], where two M-sequences, each of length 31, are used to transmit the information necessary to decode the user data. The reference signal is used to estimate the channel and then equalize the received signal so that channel interference to the desired signal is minimized.
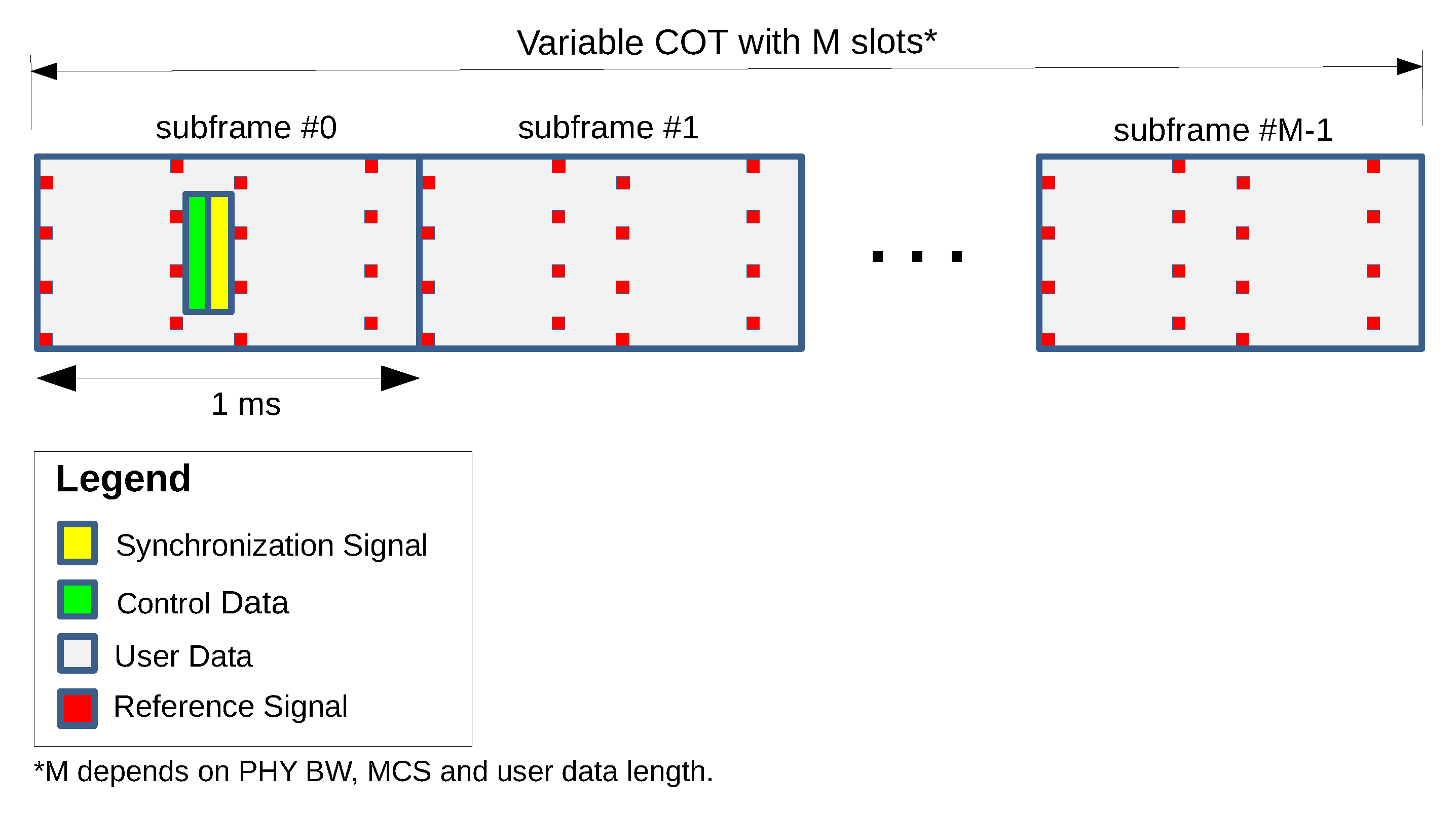
The SCATTER PHY allows bursty transmissions with a variable Channel Occupancy Time (COT), i.e., the number of subframes to be transmitted in a row without any idle time (i.e., gap) among consecutive subframes is variable and depends on how many bytes the MAC layer has to transmit. The number of subframes in a COT is calculated based on the number of data bits to be transmitted, PHY BW, and MCS parameters forwarded by the MAC layer to each PHY layer in the control messages. The smallest COT value is equal to 1 ms and corresponds to the transmission of a synchronization subframe. Having a variable COT allows SCATTER PHY to support various types of traffic loads. Every subframe carries a pre-defined number of bytes. The number of bytes is calculated based on the subframe type, selected MCS, and configured PHY BW.
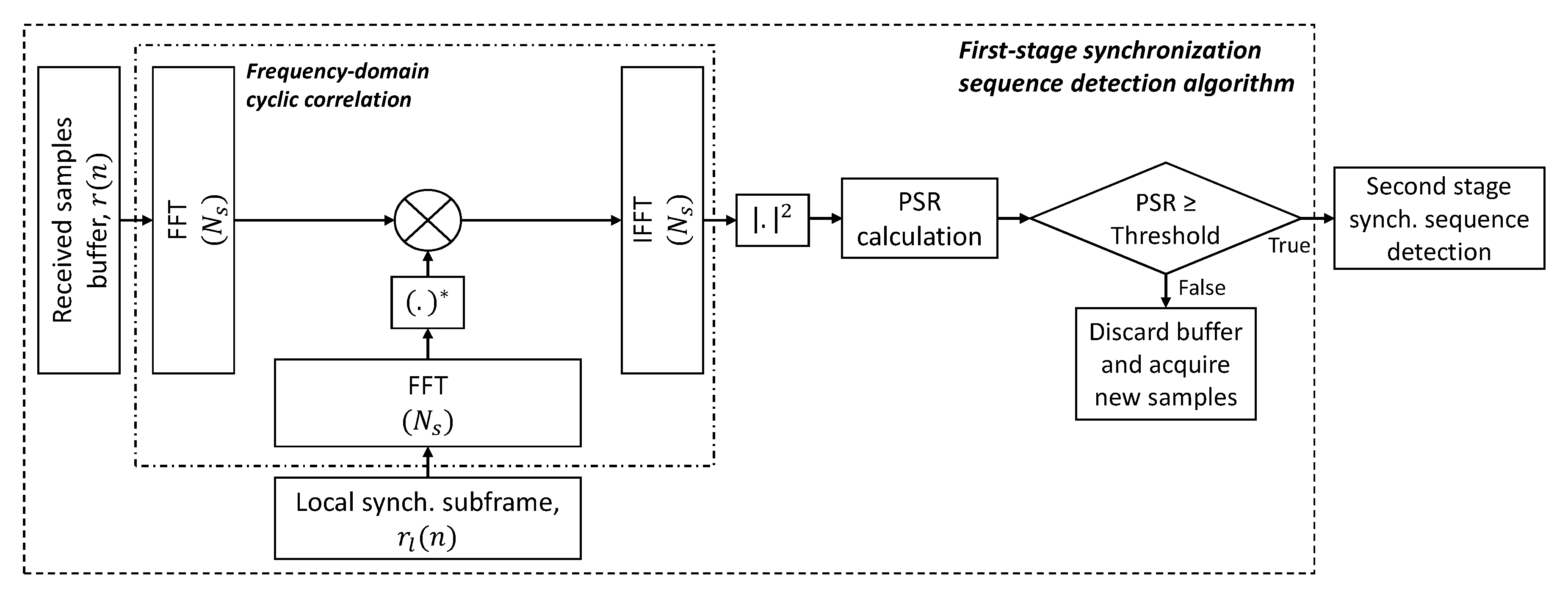
As can be seen in
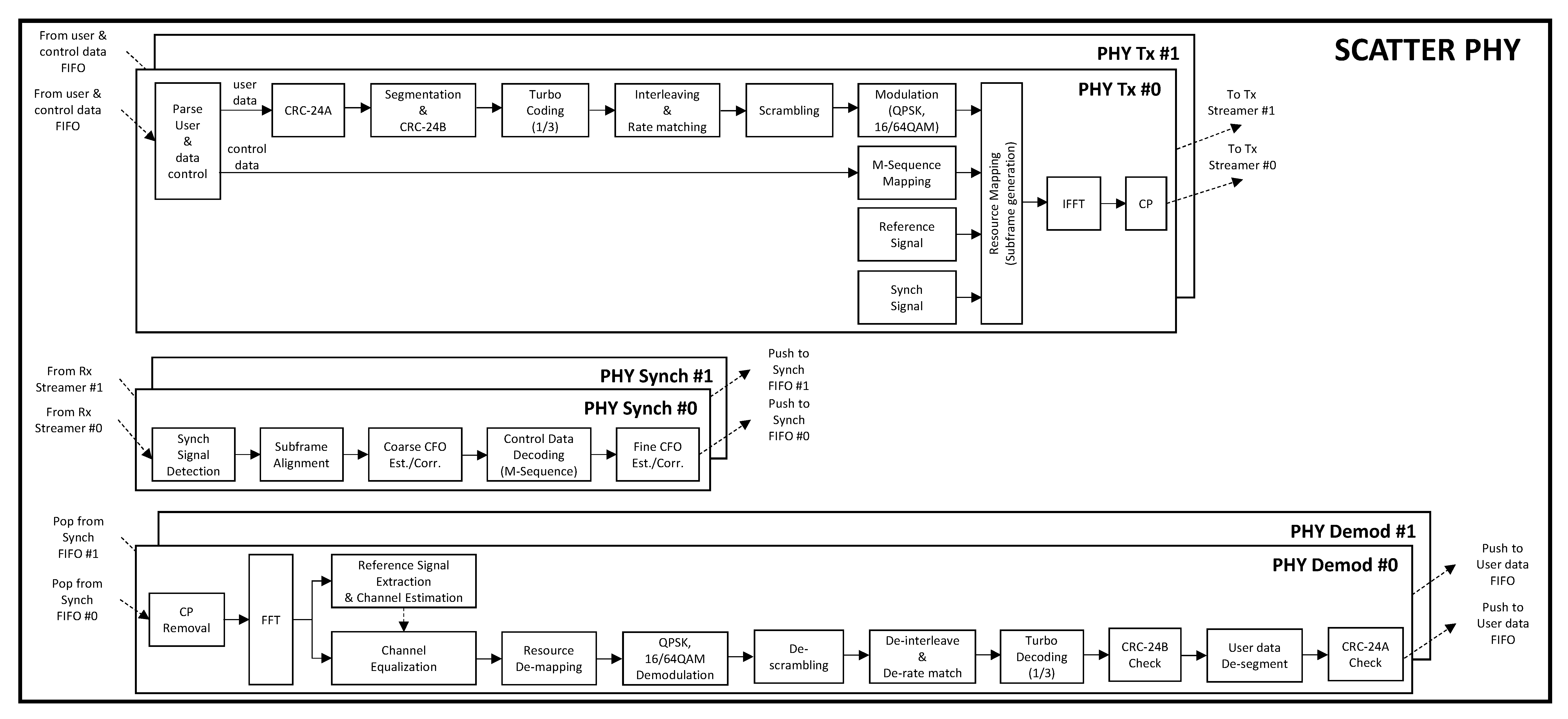
Figure 1, each one of the PHY modules is divided into three sub-modules, namely PHY Rx synchronization, PHY Rx demodulation, and PHY Tx. Each one of the sub-modules runs on a standalone and exclusive thread. A multi-threaded PHY implementation allows independent, time-consuming, and critical processing tasks to be executed concurrently (i.e., simultaneously), improving efficiency and computing performance. In combination with multi-core enabled CPUs, the multi-threaded PHY modules straightforwardly support communications in full-duplex mode, i.e., each individual and independent PHY is able to receive and transmit simultaneously at different frequencies. The direct consequence of the full-duplex mode is that it results in higher throughput. Each PHY Tx thread (
and
) is responsible for modulating and transmitting data (i.e., control and user data). On the other hand, each PHY Rx synchronization thread is responsible for detecting the Synchronization (Synch) sequence, decoding the control data, frequency offset estimation/correction, and time-alignment of the detected subframes. Detection of the Synch signal is carried out through a two-stage detection algorithm, which at the first stage correlates the received signal with a locally stored version of the synchronization subframe with no data and control signals. If the Peak-to-Side-lobe Ratio (PSR) is greater than a constant threshold, then the second stage applies a CA-CFAR algorithm to the OFDM symbol carrying the Synch signal [
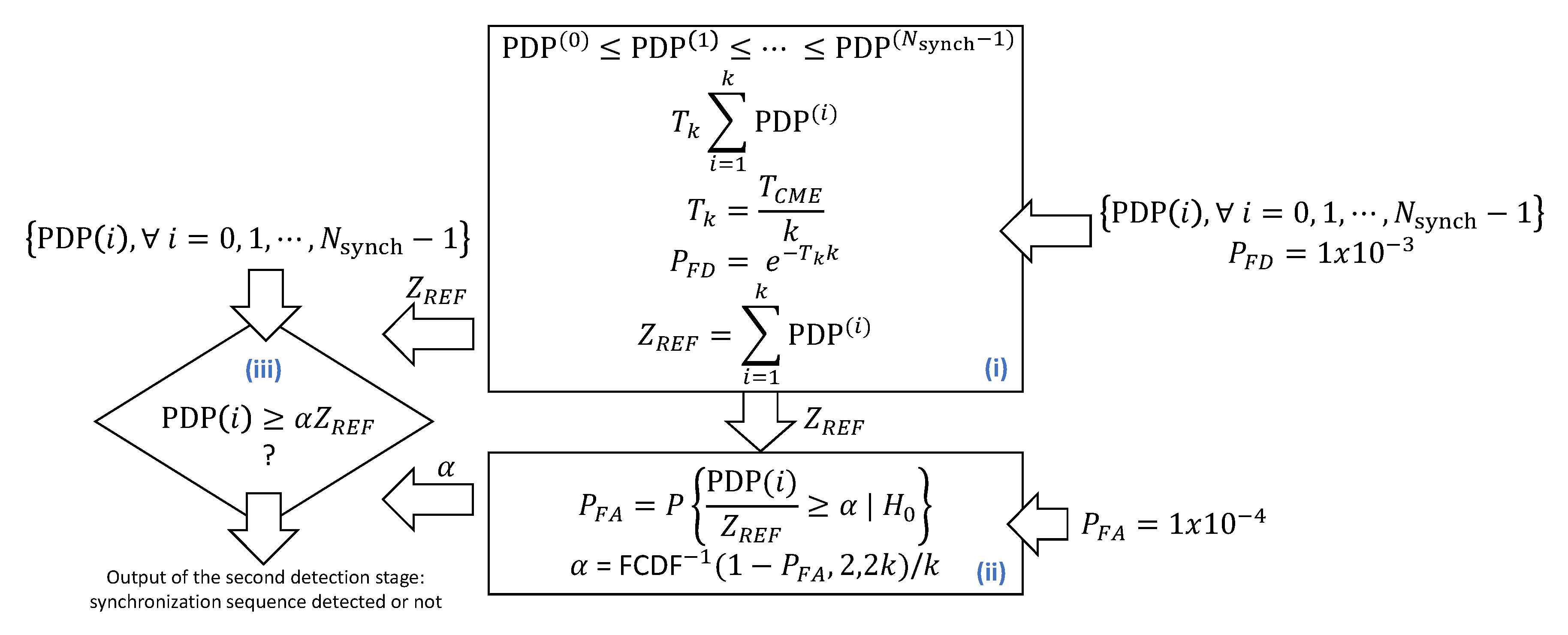
20]. The two-stage approach employed by SCATTER PHY improves the Synch signal detection when compared to a detection approach that only uses the PSR of the correlation calculated at the first stage. The two-stage approach employed by SCATTER PHY is described in
Appendix A.
The CFO estimation task is split into coarse and fine estimations/corrections, where the coarse estimation is based on the Synch signal and the fine estimation is based on the Cyclic Prefix (CP) portion of the OFDM symbols [
23]. The integer part of the frequency offset (i.e., integer multiples of the subcarrier spacing) is estimated and corrected by the coarse CFO algorithm, which is based on the maximization of the correlation of the received synchronization signal with several locally generated frequency offset versions of it. On the other hand, the fractional frequency offset (i.e., offset values less than one half of the subcarrier spacing) is estimated and corrected by the fine CFO algorithm, which is based on the phase difference of the correlation between the CP and the last part of the OFDM symbol (i.e., the portion used to create the CP). Integer and fractional CFO estimation methods are described in
Appendix B.
Each PHY Rx demodulation thread is responsible for OFDM demodulation (CP removal and FFT processing), i.e., user data demodulation, channel estimation/equalization, resource de-mapping, symbol demodulation, de-scrambling, de-interleaving/de-rate matching, turbo decoding, de-segmentation, and finally, cyclic redundancy check (CRC) checking. Each one of the independent PHYs receives control and data messages from the 0MQ Communications Data/Control module. Decoded user data and Tx/Rx statistics are sent directly to the MAC layer through the 0MQ bus within a protobuf pre-defined message.
Figure 2 presents the block-diagram of SCATTER PHY. It shows the blocks making up the receiver (PHY Synch and PHY Demodulation (Demod) threads) and transmitter (PHY Tx thread) sides of each independent PHY.
When it comes to numerology, SCATTER PHY adopts a subcarrier spacing of 15 kHz, a CP of 5.2
s, and supports
,
,
, and 9 MHz bandwidths, which are equivalent to the LTE bandwidths of 6, 15, 25, and 50 resource blocks, respectively [
19]. Each one of the PHY’s transmission channel Bandwidth (BW) can be configured in real time, through the Tx control messages or via command line at the system’s startup. The OFDM modulation parameters adopted by SCATTER PHY are summarized in
Table 1.
The only difference between the OFDM modulation parameters listed in
Table 1 and the LTE ones [
19] is the FFT size and, consequently, the resulting sampling rate for the PHY BWs of
and 9 MHz. The reason for employing these non-standard sampling rates is to reduce the computational load of SCATTER PHY and to reduce the data transfer rate required to move base-band IQ (i.e., In-phase/Quadrature) samples between the RF front-end (i.e., the USRP device) and the base-band processor (i.e., the host PC) and vice versa. For example, for a PHY BW of
MHz, the standard LTE sampling rate would be equal to 512 FFT points × a subcarrier spacing of 15 kHz =
MHz. However, out of the 512 subcarriers, only 300 are useful subcarriers, where the remaining ones are left unused as guard-band subcarriers. Therefore, by employing a smaller FFT size and, consequently, a lower sampling rate, while keeping the same subcarrier spacing, SCATTER PHY can still successfully demodulate all occupied subcarriers. Therefore, the computational load is lower due to the fact that fewer base-band samples have to be moved between the USRP and the host PC.
The frame structure employed by SCATTER PHY is presented in
Figure 3. As can be seen, signals regarding synchronization and control data are only added to the first subframe of a COT, while the subsequent subframes carry only reference signals and data symbols. With this frame structure, synchronization (i.e., detection of synchronization signal, time-alignment, and CFO estimation/correction) and control data decoding only happen for Subframe
, i.e., the synchronization subframe. The differences between the proposed frame structure and LTE’s are (i) no modulated control data (i.e., LTE’s PDCCH channel) being added to first OFDM symbols, (ii) a longer synchronization signal, which improves the subframe detection performance, (iii) control data sent via M-sequences, which makes the control data decoding more robust against interference and noise, and (iv) no division of the subcarriers into resource blocks, once all subcarriers are allocated to a single user only. As shown in
Figure 3, and differently from LTE, SCATTER PHY’s frame structure does not carry control data in the first OFDM symbols, which, consequently, gives more room, i.e., subcarriers, for user data transmission. Therefore, it is possible to achieve higher throughput when compared to the LTE standard.
The Payload Data Unit (PDU) employed by SCATTER PHY is known as the Transport Block (TB). A TB is the container carrying data that are created at the MAC layer and transferred to the individual PHYs to be encoded and transmitted. One TB is composed of a number of bytes that can be accommodated inside a 1 ms long subframe, given the configured MCS and PHY BW parameters. Therefore, given the PHY BW and the desired MCS, the MAC layer can calculate the number of bytes that can be handled by a 1 ms long subframe.
Table 2 presents the coding rate for each one of the 32 defined MCS values.
The differences between SCATTER PHY’s modulation code scheme and LTE’s are (i) 32 different MCS values instead of the 29 defined in the LTE standard, where the three additional MCS values allow SCATTER PHY to reach higher data rates in high SNR scenarios, and (ii) the greater number of subcarriers per subframe, which are used for user data transmission and, consequently, increase the final achieved throughput. However, even though being able to carry more user data per subframe, we kept the same coding rate of the LTE standard for MCS values ranging from zero to 28.
Communications between SCATTER PHY and the MAC layer are performed through four pre-defined (i.e., protobuf) messages. The first two messages, named Rx and Tx control, are employed, as the name suggests, to control/configure subframe reception and transmission, respectively. The parameters transported by these two control messages are set and sent to the individual PHYs by the MAC layer before the transmission of every new COT, hence allowing on-line parameter configuration. The other two messages, named Rx and Tx statistics messages, are employed to provide the MAC layer with real-time feedback from each independent PHY, providing critical information that is necessary for such a layer to take important actions.
Tx control messages transport the TBs (i.e., user data) to be transmitted and Tx parameters regarding that transmission, that is PHY ID, Tx gain, Tx channel, data length, MCS, Tx PHY BW, and transmission timestamp. The transmission timestamp parameter allows time scheduled transmissions, which consequently enable the MAC layer to implement a Multi-Frequency (MF) Time Division Multiple Access (TDMA) medium access scheme. Rx control messages are employed to configure Rx gain, the Rx channel, the maximum number of turbo decoder iterations, enable or disable Rx combining, and Rx PHY BW of a specific PHY, addressed through the PHY ID parameter. The PHY ID parameter is used to specify for each one of the two PHYs a control message.
Tx statistics messages inform the MAC layer about transmission statistics like data coding-time and the total number of transmitted subframes of each independent PHY. Rx statistics messages transport the received data, PHY ID, and reception statistics regarding the received data such as Received Signal Strength Indication (RSSI), Channel Quality Indicator (CQI), decoded MCS, decoding time, subframe error counter, number of turbo decoder iterations, etc. The real-time configurable parameters and statistics offered by SCATTER PHY are summarized in
Table 3.
3.1. COT-Based Filtering
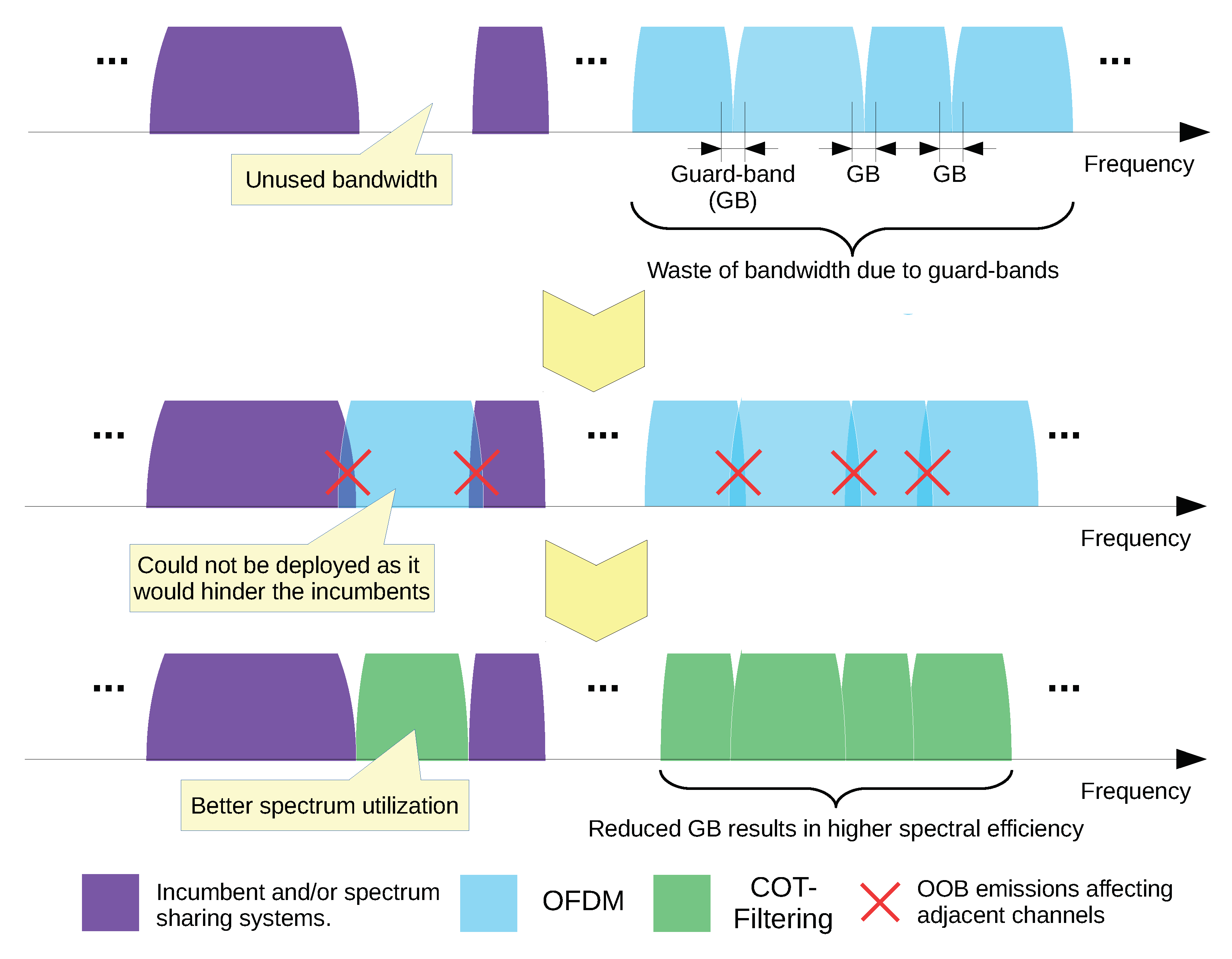
Due to their poor spectral localization, OFDM based wave-forms are not suited for spectral coexistence [
24]. This issue is due to the rectangular pulse-shape intrinsically employed by the OFDM wave-form, which leads, in the frequency domain, to a sync-pulse property with a very low second-lobe attenuation of approximately
dB [
25].
Therefore, in order to guarantee lower OOBE, i.e., improved spectral-localization, and still maintain the orthogonality of the OFDM symbols, it is necessary to filter the generated subframes before their transmission [
6]. The filtering process is applied to each COT of each PHY independently. The subframes comprising a COT are generated at the SW level and then filtered at the HW level, by a 128 order FPGA based FIR filter. The COT based filtering improves the closer coexistence with other radios (either belonging to our team or others), allowing radio transmissions to be closer in frequency. The filter used in SCATTER PHY was designed and explained in [
6].
This co-design SW/HW is used so that fast processing high order filters can be implemented adding up very low latency to the transmission chain and still allowing the flexibility of the software defined PHYs.
The coefficients of the filters applied to the COT are automatically selected in real time based on the Tx PHY BW parameter carried by the Tx control message. The coefficients are automatically chosen as the filters’ cut-off frequencies have to match and exactly filter the desired signal’s bandwidth, i.e., the configured PHY transmit BW.
The normalized FIR filter’s coefficients used in the COT based filtering are given in time domain by [
6]:
where
is the impulse response of the sincsignal and
is the window used to truncate the sinc signal. These two signals are given as:
where
is the number of useful subcarriers (see
Table 1),
is the length of the FFT used in the OFDM modulation (see
Table 1),
is the excess bandwidth in the number of subcarriers,
L is the length of the FIR filter, and
. The excess bandwidth is used to extend the flat region of the filter so that the subcarriers at the left and right borders of the OFDM symbols suffer less attenuation.
The filter,
, exhibits the following properties: (i) a time duration that is comparable to a small fraction of an OFDM symbol’s duration, (ii) a sharp transition-band, which minimizes the necessary guard-bands, (iii) a flat pass-band over the useful subcarriers, and (iv) fair stop-band attenuation [
6].
3.2. Benefits of SCATTER PHY
In this section, we describe the two main advantages of SCATTER PHY. The first advantage is that the COT based filtering mitigates OOBE, making SCATTER PHY more spectrally efficient. OOBE might interfere with radios using adjacent channels, decreasing the quality of the signals received by them. Therefore, the interference caused by OOBE impacts directly on the throughput achieved by those radios. The reduced OOBE allows SCATTER PHY to operate closer, in the frequency domain, to radios transmitting at adjacent channels. This, in turn, reduces spectrum band wastage by increasing the spectral efficiency, as depicted in
Figure 4. The second advantage offered by SCATTER PHY is that it is possible to configure all PHY parameters in real time through the control messages. This makes SCATTER PHY a very flexible and agile SDR based PHY, allowing higher layers to configure the available parameters based on spectrum band availability, for instance.
4. Experiment Results
In this section, we demonstrate the effectiveness and usability of SCATTER PHY by presenting the results of several experiments. The experiments were executed with SCATTER PHY running on servers equipped with Intel Xeon E5-2650 v4 CPUs (@
GHz, 30 M cache,
GT/s QPI, turbo, HT, 12 cores/ 24 threads, 105 Watts), 128 GB of RAM memory connected to x310 USRPs with 10 Gigabit Ethernet links, and equipped with CBX-120 RF daughter-boards [
26].
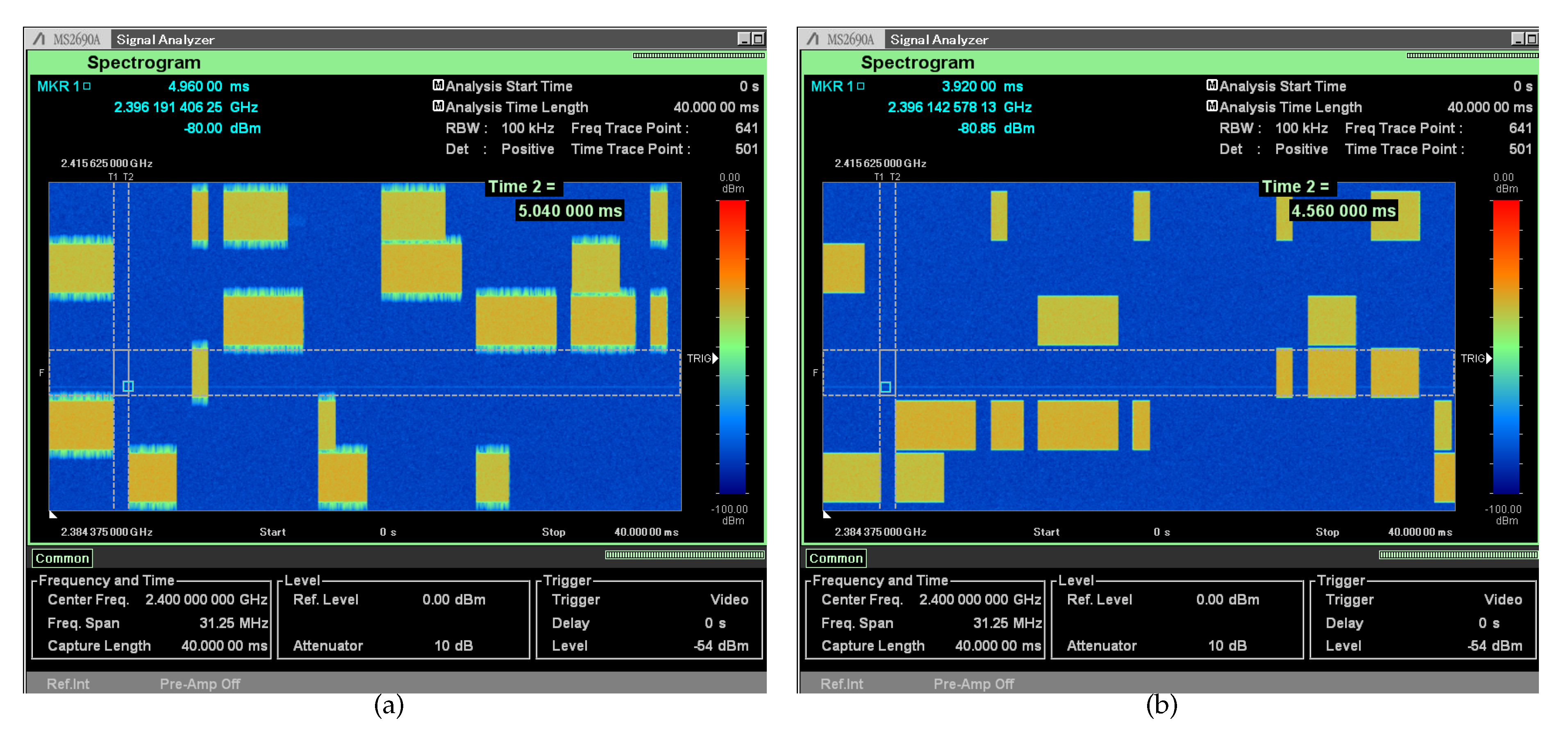
Figure 5 depicts two spectrograms (i.e., the visual representation of the spectrum of frequencies of a signal as it varies over time) saved for 40 ms over a
MHz bandwidth with both PHYs set to operate concurrently, at each instant, at two of six
MHz channels. This experiment intends to show that SCATTER PHY is able to generate two concurrent and independent transmit channels per node. For this experiment, each PHY transmits at randomly selected channels a random number of subframes. The number of transmitted subframes, i.e., COT, and the channel number are randomly selected between the ranges of 1–3 and 0–5, respectively. Here, a gap of 1 ms between consecutive transmission is used. The figures were saved with the center frequency of both Tx PHYs set to
GHz, equal Tx gains of 3 dB, and both USRP Tx outputs connected to the signal-analyzer via an RF combiner and a coaxial cable presenting a 20 dB attenuation. As can be seen in both figures,
Figure 5a,b, SCATTER PHY was able to independently transmit at two distinct channels with a different number of subframes.
Figure 5a shows the case where no filtering was enabled. As can be noticed, OOBE might cause interference to radios operating at adjacent channels and consequently decrease their throughput.
Figure 5b shows the case when the FPGA based FIR filters were enabled. As can be noticed, when filtering was enabled, OOBE was mitigated. Therefore, by enabling filtering, the interference that could be impacting radios operating at adjacent channels was mitigated. Moreover, another direct consequence of using filters was that the channel spacing, i.e., the guard-band between adjacent channels, could be decreased, decreasing the wastage of spectrum band, consequently.
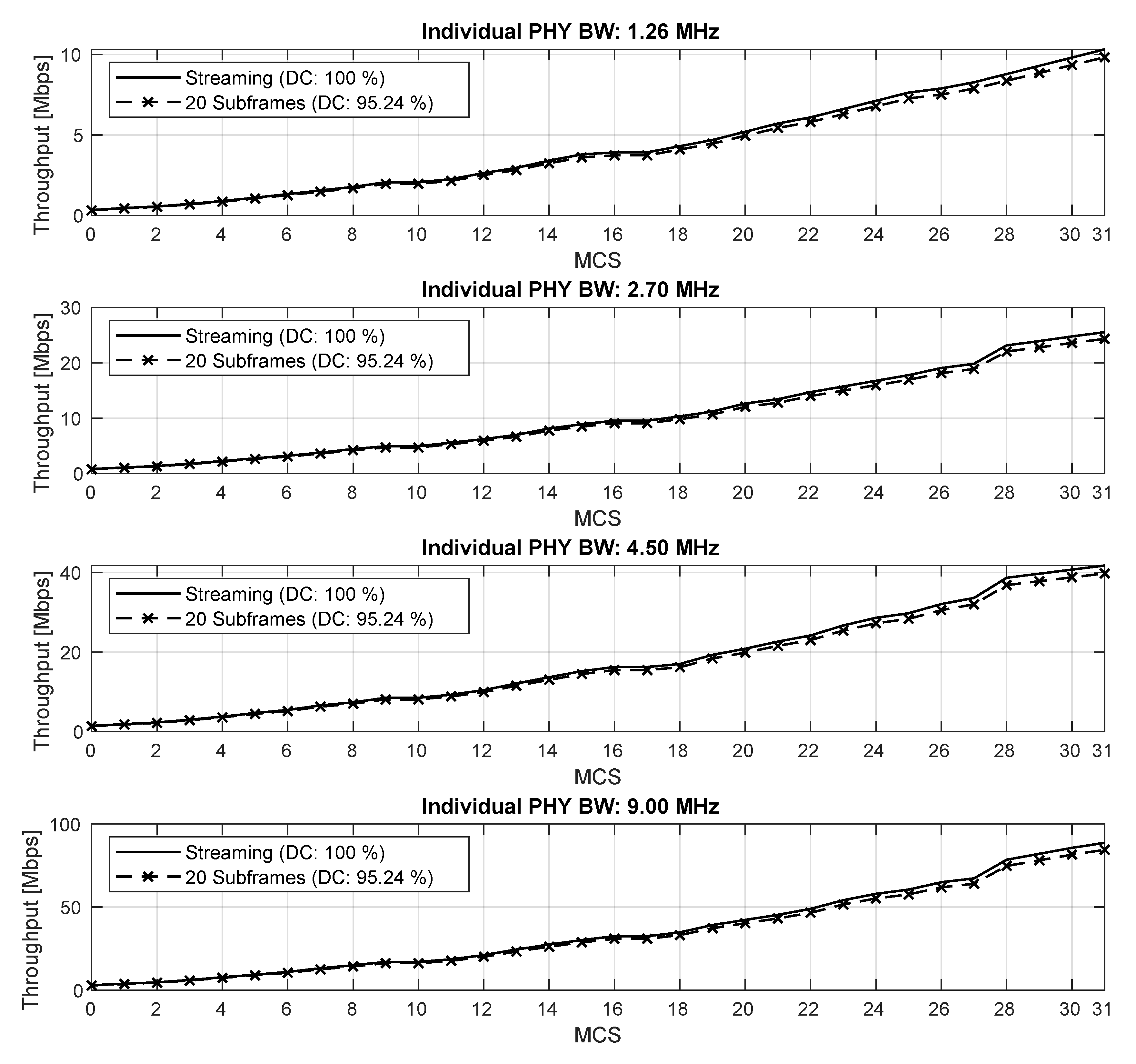
Figure 6 shows measurements of the throughput, which were taken with SCATTER PHY working in full-duplex mode, where the two independent PHYs simultaneously and concurrently receive and transmit, for several MCS and PHY BW values. The full-duplex mode was used so that we could check if it somehow impacted the throughput measurements, once, in this mode, SCATTER PHY was fully utilized. The throughput measurements were taken for COTs of 20 ms with gaps of 1 ms between subsequent COT transmissions, which resulted in a Duty-Cycle (DC) of 95.24%. The final throughput was calculated as the average over 10 throughput measurement intervals of 10 seconds each. For each measurement interval, the number of bits received during that interval was counted and then divided by the length of the interval, resulting in a throughput measurement. This procedure was repeated 10 times, and then, the individual measurements were averaged. The SNR on the link was set to 30 dB so that the packet reception rate for all MCS values was equal to one. For the sake of comparison, we added to the figure the theoretical maximum throughput achieved when a DC of 100% was used; we called it streaming mode, due to the fact that there was no gap between subsequent subframes. The theoretical maximum throughput was obtained by dividing the size of the TB, given in number of bits for each MCS value, by the subframe time interval, i.e., 1 ms. As expected, the throughput measured with SCATTER PHY was close to that of the streaming mode for all PHY BW and MCS values, achieving more than 84 Mbps for MCS 31 and a PHY BW of 9 MHz. Moreover, full-duplex mode operation had no visible impact on SCATTER PHY’s achieved throughput. This result comes from the fact that SCATTER PHY ran on a powerful server, with 12 cores and 128 GB of RAM memory.
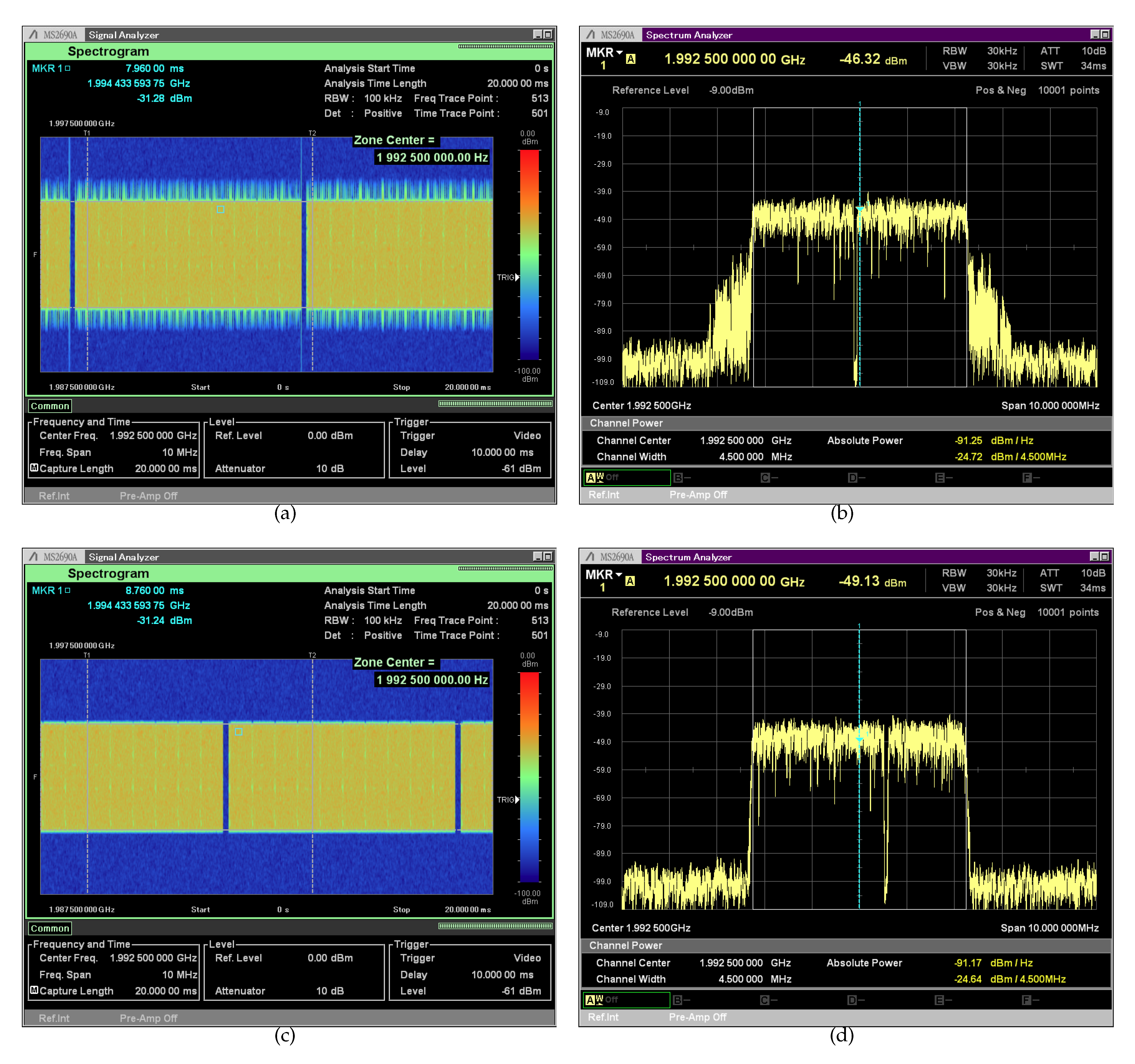
Figure 7 depicts the comparison of the spectrogram and spectrum of filtered versus unfiltered transmissions. SCATTER PHY was able to enable or disable the FPGA based transmission filters at the command line. These results were saved with an Anritsu MS2690A Signal Analyzer. In the experiment, the signal analyzer sat beside the USRP hardware. The shown results were saved with SCATTER PHY’s Tx gain set to 3 dB (this was configured through the control messages), Tx center frequency set to
GHz (this was configured through at command line at start-up), and with the USRP’s Tx output connected to the signal analyzer via a coaxial-cable connected to an attenuator with 20 dB of attenuation. As can be seen, OOBE (i.e., the OFDM lateral skirts) were mitigated when the 128 order FPGA based FIR filters were enabled. The results show the transmission of only one of two PHYs, the outcome being the same for the other PHY.
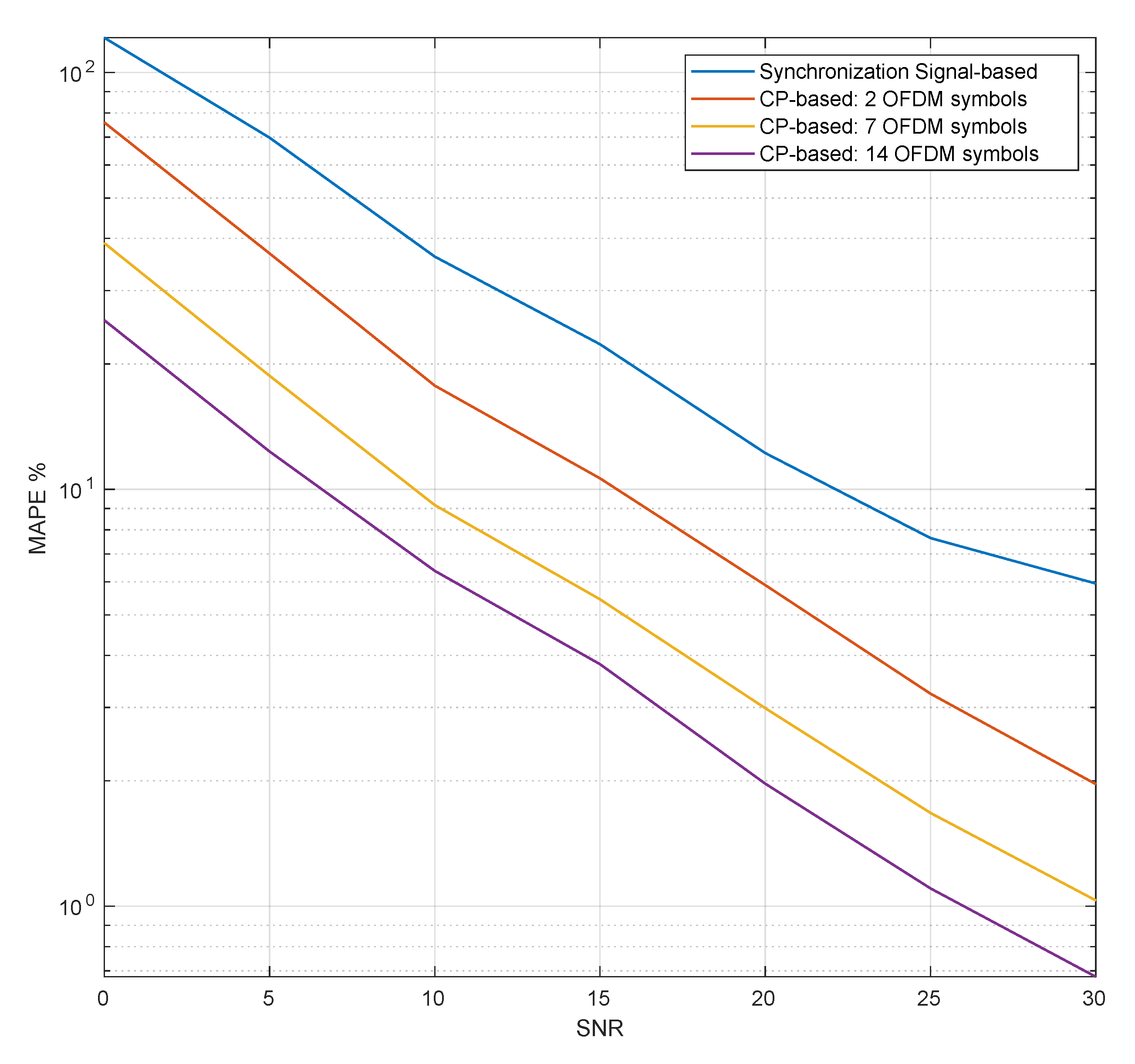
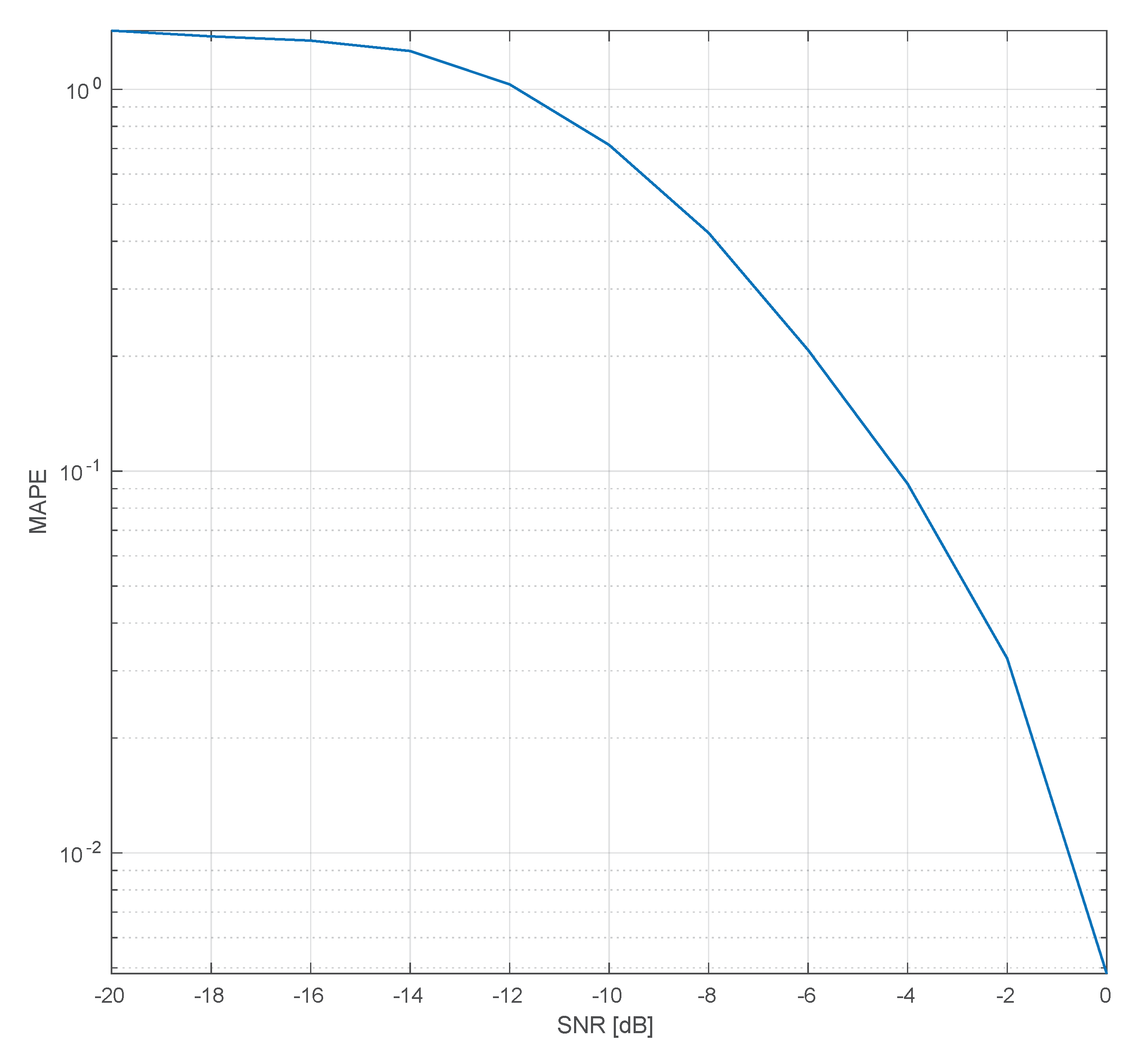
Figure 8 compares the Mean Absolute Percentage Error (MAPE) of the fine CP based fractional CFO estimation method against fractional CFO estimation based on the synchronization signal. The MAPE for the CFO estimation is defined as:
where
is the estimated CFO value for the
trial,
is the randomly generated CFO, which is applied to the transmitted signal, for the
trial, and
N is the number of trials over which the CFO is averaged. The results were obtained by connecting the Tx port to the Rx port of the same USRP so that the frequency offset caused by the HW was minimal or nonexistent and adding Additive White Gaussian Noise (AWGN) plus the desired frequency offset at the SW level just before the subframes were transmitted. The CFO applied to the signal was drawn from a uniform distribution varying from
kHz to
kHz, i.e.,
half subcarrier spacing. As can be seen, the fine CFO estimation algorithm, which was based on the CP portion of the OFDM symbols, outperformed the Synch based CFO algorithm even when only two consecutive CPs were averaged. Additionally, we see that the performance of the CP based estimation improved as the number of averaged CPs increased; however, the downside of averaging more CPs was an increase in the processing time. The CP based CFO estimation method employed by SCATTER PHY was an improvement over the CFO estimation implemented by srsLTE. The SCATTER PHY implementation employed Single-Instruction Multiple-Data (SIMD) instructions in order to decrease the CFO estimation and correction computational time, allowing it to use more averaged CPs. Additionally, SCATTER PHY implemented a more accurate and fine-grained complex exponential signal for generating the correction signal, making it possible to generate signals with frequencies that were closer to the estimated ones.
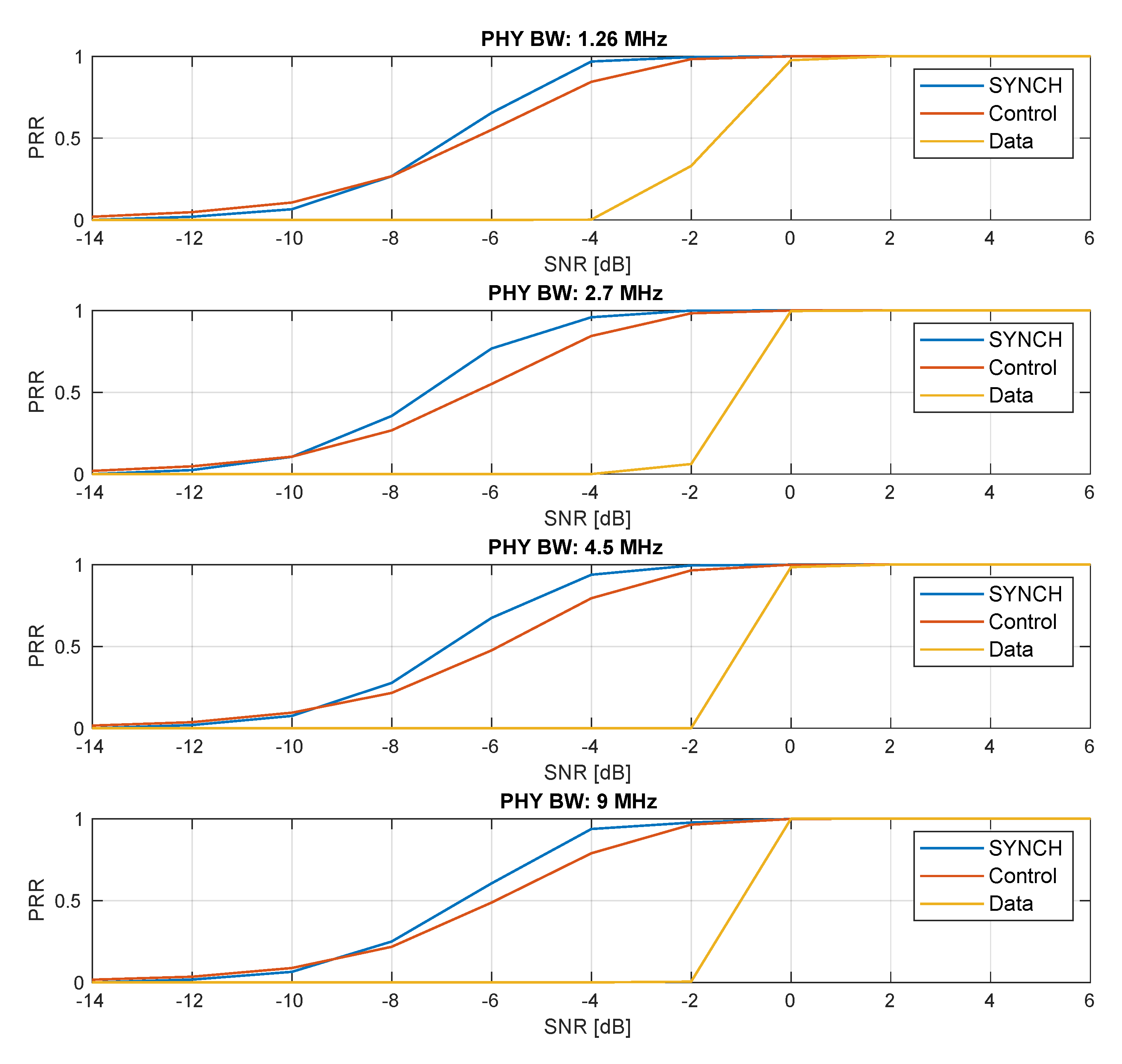
Figure 9 presents the comparison of the Packet Reception Rate (PRR) for each one of the signals carried by a SCATTER PHY subframe, namely synchronization, control, and data signals over several SNR and BW values. The SNR was calculated based on the power of a 1 ms subframe; therefore, before adding noise to the transmitted subframe, the subframe power was calculated, and then, the necessary noisy power to achieve the desired SNR was calculated. The MCS used for modulating the user data was set to zero, which was the most robust coding scheme, allowing SCATTER PHY to decode data in low SNR scenarios. The purpose of this experiment was to identify the lowest possible SNR at which SCATTER PHY could still correctly decode the user data. This experiment was run by adding a channel emulator between the Tx and Rx sides of a single PHY instance. At the Tx side, the generated subframes, instead of being sent to the USRP HW, were sent to an abstraction layer that emulated the HW and added AWGN noise to the transmitted signal. Next, the abstraction layer transferred the noisy signal to the receiving side of the PHY. The PRR was averaged over
trials, where at each trial, the Tx side of the PHY sent a single synchronization subframe. As can be seen, synchronization and control signals had a better PRR performance than that of the data decoding; however, SCATTER PHY’s PRR performance was limited by the ability to decode correctly the data section of a subframe. Additionally, we see that the data PRR was better for the
MHz case, which was due to the fact that compared to the other BW values, MCS 0 for the
MHz case carried more redundancy bits, as shown by
Table 2, making it more robust against noise. The other two signals, synchronization and control, presented similar PRR curves for all BW values. Moreover, it is noticeable that the data PRR was equal to 1 for SNR values greater than or equal to 0 dB.
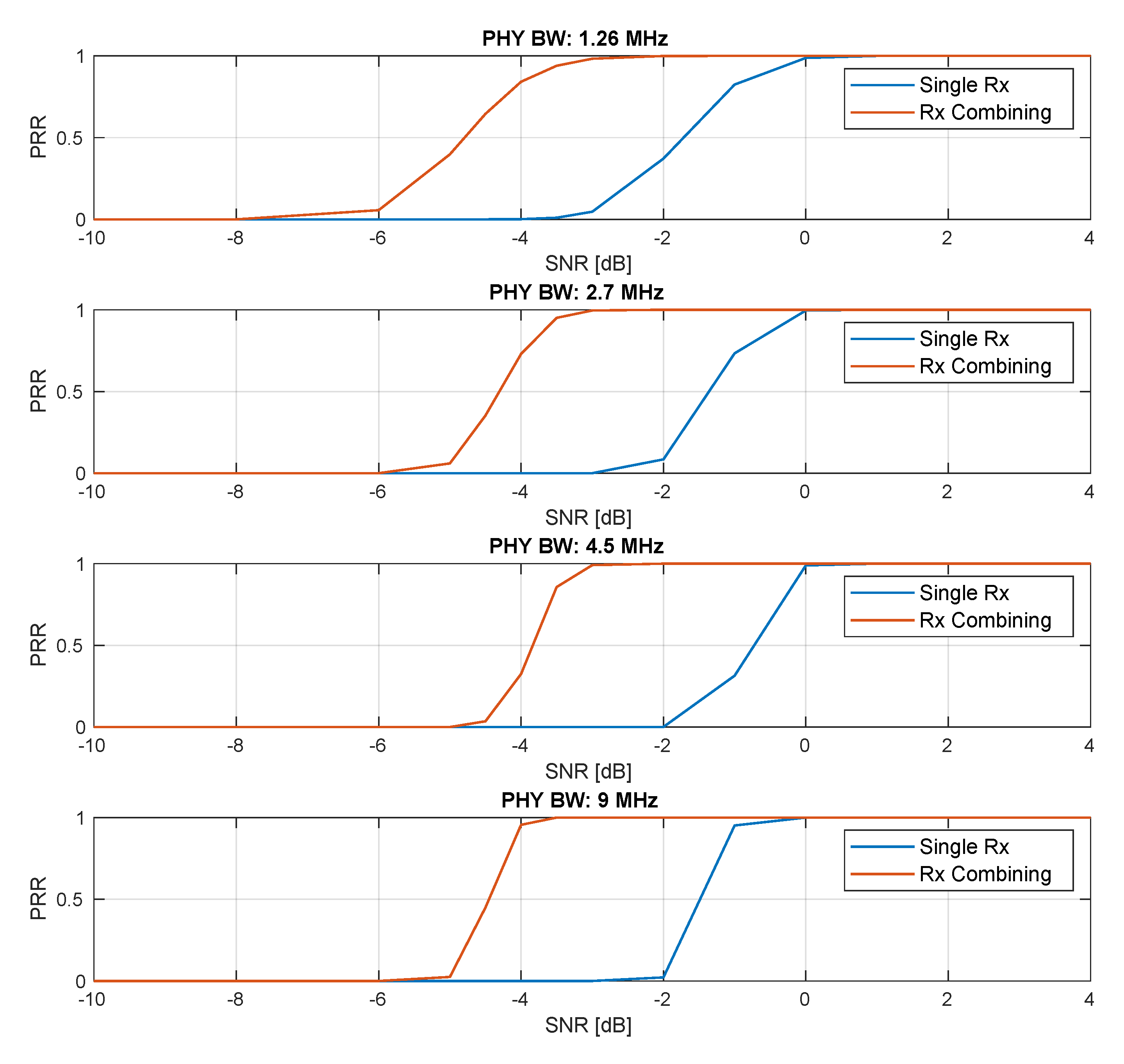
Figure 10 presents the result of the comparison of single Rx data decoding and that of a simple Rx combining scheme that can be implemented with SCATTER PHY. The figure shows data decoding PRR results for both receiving schemes. Here in this case, after synchronization (Synch signal detection, CFO estimation/correction, control data decoding, and subframe alignment), the two independently synchronized subframes were combined through a simple average of both subframes as defined in (
6).
where
is the number of Rx antennas (in our case,
),
is the subframe synchronized at the
antenna, and
is the resulting combined subframe signal. The MCS value used in this experiment for all PHY BWs was zero. As can be seen, the Rx combining scheme employed in this experiment provided a processing gain ranging from
to 3 dB over the single Rx approach. With this scheme, SCATTER PHY was able to combine the received subframes for improved performance in low SNR scenarios.
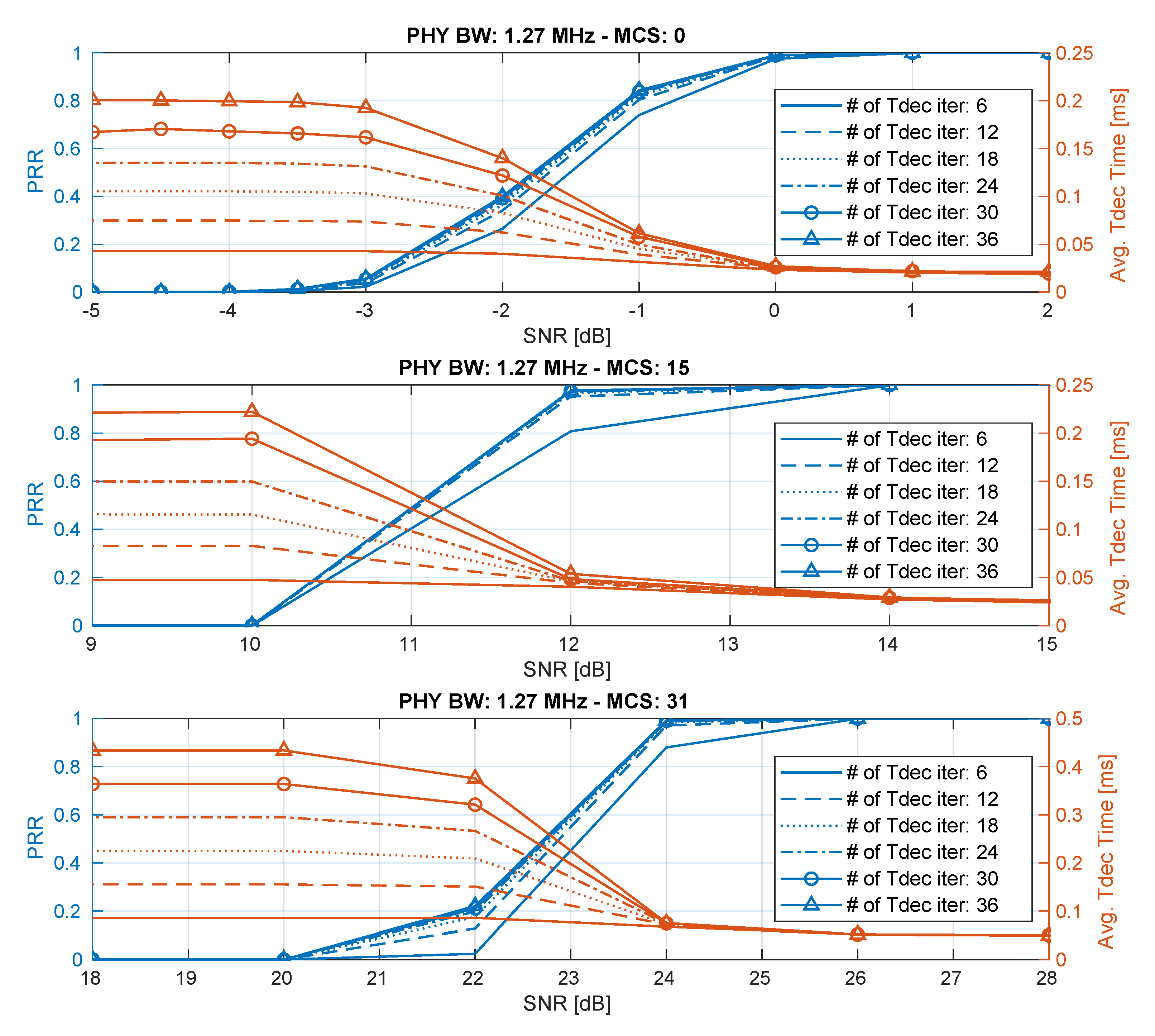
Figure 11 presents the results on the variation of the maximum number of turbo decoding iterations for a PHY Tx BW of
MHz and three different MCS values, 0 (QPSK), 15 (16QAM), and 31 (64QAM). As can be seen, the PRR improved as the number of maximum iterations also increased. As can be also noticed, the PRR improvement was higher for higher MCS values, 15 and 31. This was due to the fact that as the MCS increased, the code rate increased, and consequently, the number of redundancy bits decreased, making the transmit data more prone to errors. Therefore, the probability of successful data decoding increased as the number of maximum turbo decoding iterations increased. Another important point is the trade-off between PRR improvement and the increase in decoding time. As can be verified, the PRR improved at the cost of longer decoding times for low to medium SNR values.
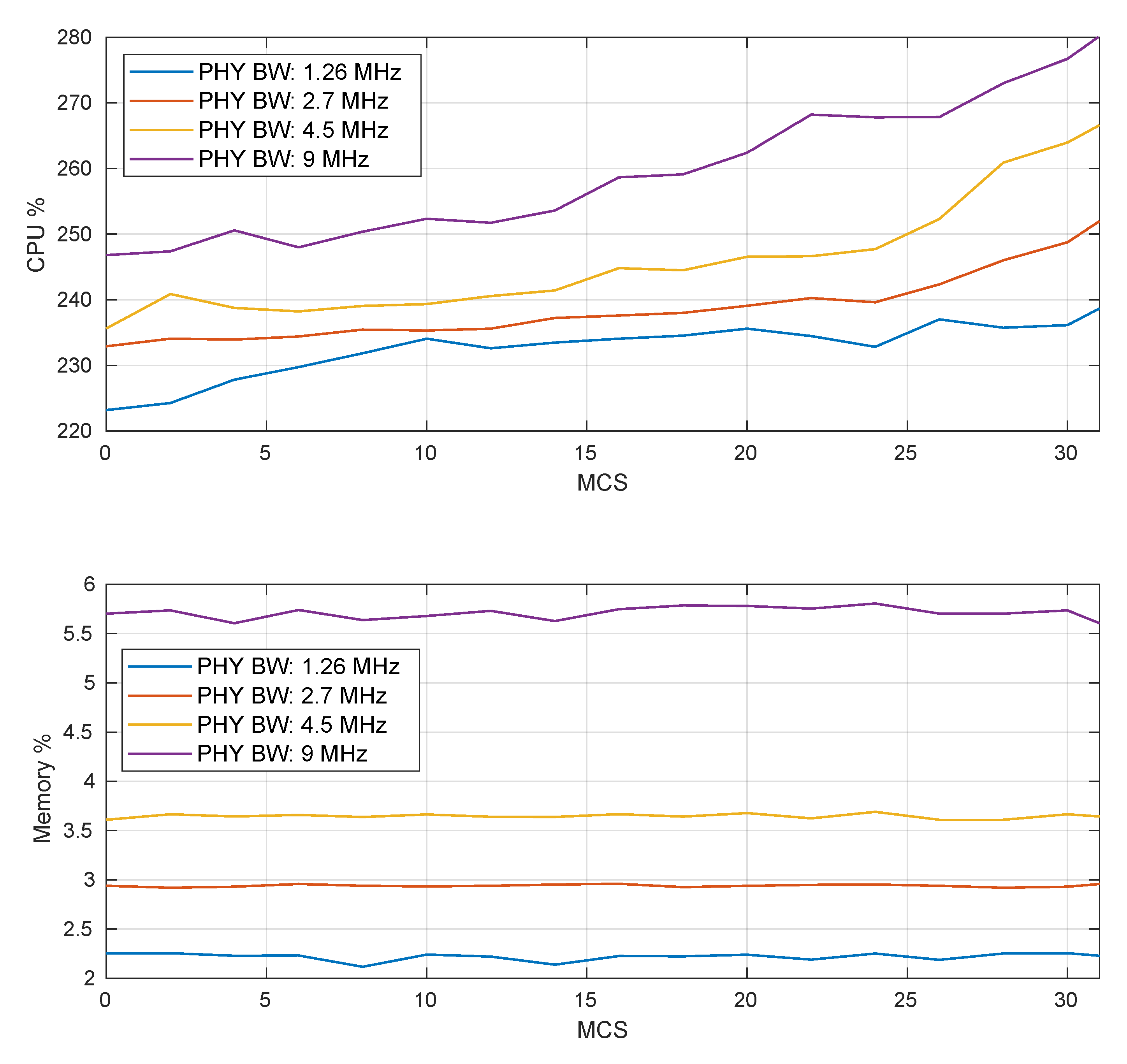
Figure 12 depicts the memory and CPU utilization of SCATTER PHY, using
,
,
, and 9 MHz bandwidths for several MCS values. The results presented in the figure were obtained by averaging memory and CPU usage values. The memory and CPU usage values were sampled every 200 ms for the experiment’s duration. In this experiment, we had SCATTER PHY operating in full-duplex mode, where one PHY transmitted to the other and vice versa. Each one of the PHYs transmitted 20 subframes in a row with a 1 ms gap between transmissions.
As can be noticed, as the selected PHY Tx BW increased, both CPU and memory utilization also increased; however, there was no memory nor CPU starvation for any of the used MCS and PHY Tx BW values. As can be also seen, for a given PHY Tx BW, as the MCS value increased, the CPU usage also increased. This was because the turbo encoding, turbo decoding, and synchronization processing tasks demanded much more CPU power for data processing as the MCS value increased, i.e., as data rates increased. For an MCS equal to 31 and a PHY Tx BW of 9 MHz, the CPU utilization of SCATTER PHY was approximately equal to 280%. That means that less than three CPU cores were being used, consequently leaving the other cores underused for long intervals.
In the case of memory usage, it can be noticed that for a given PHY Tx BW, the memory utilization was almost constant for all MCS values, and therefore, it was practically independent of the selected MCS value. This result was expected once all the RAM memory used by SCATTER PHY was pre-allocated during its initialization. Therefore, based on the results presented in
Figure 12, it can be concluded that SCATTER PHY did not exhaust memory or CPU resources as the configured MCS or PHY Tx BW values increased.
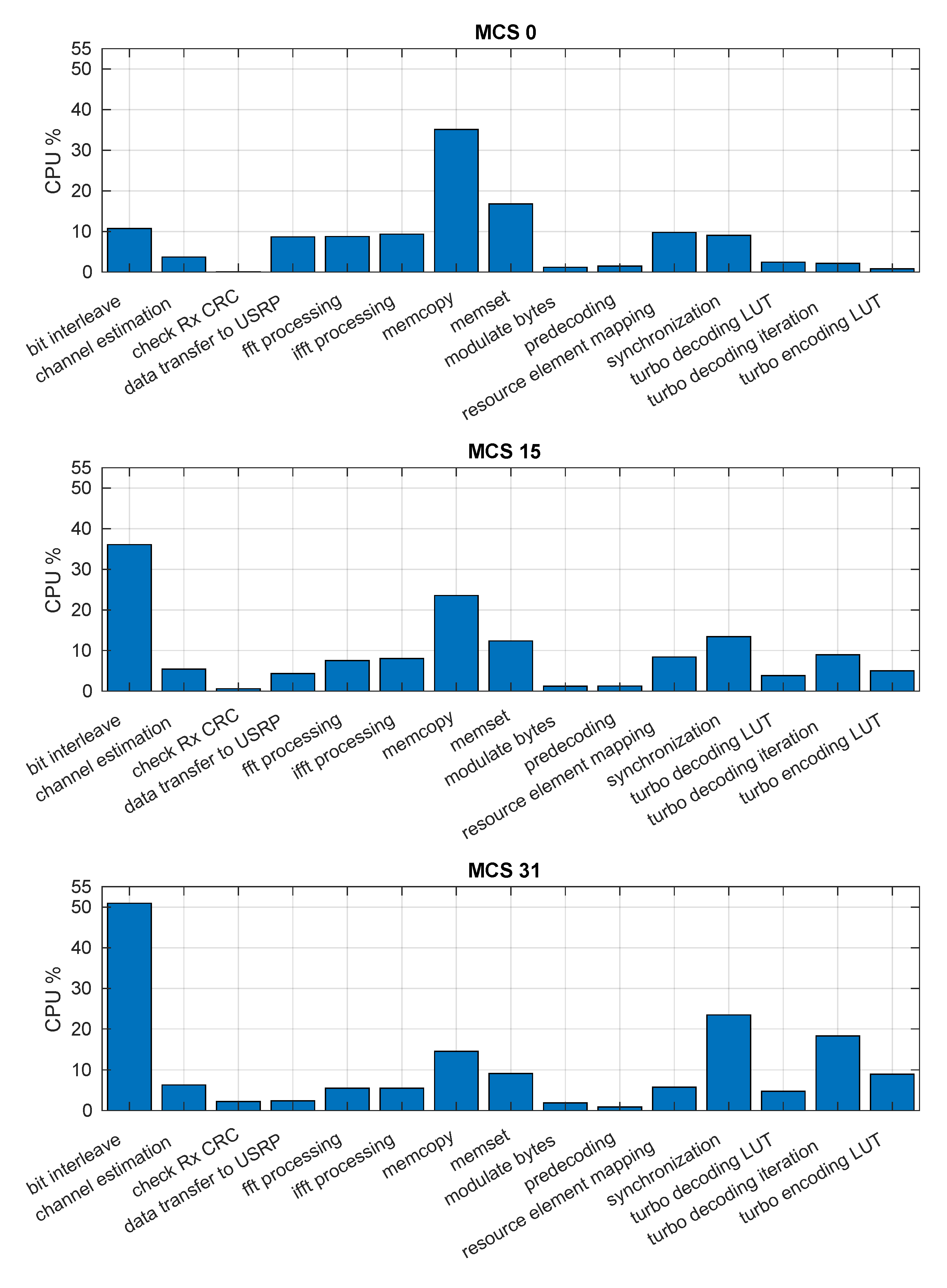
Figure 13 presents the results of the CPU consumption for the main SCATTER PHY’s functions for three different MCS values and a PHY Tx BW of
MHz. We used valgrind with its callgrind tool for the assessment of the CPU consumption [
27]. This experiment used the same setup used for the profiling of memory and CPU. The figure highlights the Rx and Tx functions with highest CPU processing load. By analyzing the figure, we see that the bit interleaving processing used more CPU as the MCS value increased. As can be seen, the CPU time-usage was approximately 11% when the MCS value was set to zero; however, it increased to approximately 51% when the MCS value was set to 31. The synchronization processing task required a considerable amount of CPU time for all considered MCS values. The CPU time consumption for the synchronization ranged from 9% to more than 23%. The CPU time for the synchronization was independent of the selected MCS due to the fact that this processing did not involve data coding/decoding. It can be also noticed that the turbo decoding iteration task consumed more CPU time as the MCS increased, going from 2% (MCS 0) to more than 18% (MCS 31). Additionally, we see that memory copy and setting functions consumed less CPU time as the MCS value increased. This was due to the fact that other functions started consuming more CPU when the MCS increased.

 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}