1. Introduction
With the drastic development of sensors and wireless communication techniques, there is explosive growth in the number of mobile devices accessing wireless networks. It is foreseen that the mobile data traffic will increase even more significantly in the coming years [
1]. Furthermore, user quipments(UEs) will be smarter and their accompanied novel, sophisticated applications will be more ubiquitous and pervasive, such as face recognition, interactive game and augmented reality [
2]. However, these emerging applications and services need not only extensive computing capabilities and infer vast battery consumption but also high data rate, which throws out a challenge to UEs as their computing power and battery capability are constrained. The previous signal processing and transmission techniques applied in the conventional cellular networks may not be efficient to meet UEs’ requirements of high throughput and adequate computational power. To improve the delay performance and operational costs of services in fifth-generation (5G) wireless networks, future communication networks not only need to support seamless wireless access but also to offer the provisioning of computational offloading for UEs [
3,
4].
To meet with such a challenge of limited computational capability of UEs, a typical paradigm of mobile edge computing (MEC) is proposed which combines wireless network service and cloud computing at the edge of the small cell networks (SCNs) [
5]. In an MEC system, a huge number of heterogeneous ubiquitous and decentralized devices are enabled to communicate, potentially cooperate and perform computation offloading by uploading their computational tasks to the MEC server via access ratio networks [
6,
7]. UEs no longer need to offload all of their tasks (e.g., high-quality video streaming, mobile gaming, etc.) to the central and remote cloud. Thus their requirement can be satisfied at any time and anywhere. However, the limited computational capabilities of edge servers may not be sufficient when there exists competition for resources by a large number of devices. The hierarchical edge-cloud framework is effective in overcoming this problem. Compared with traditional MEC frameworks, the central cloudlets is set in the hierarchical edge-cloud framework are seen as supplements of the computing resources [
8,
9]. This architecture allows a chance of offloading the workload to high-tier servers and partially relieves the competition among UEs who are requesting delay-sensitive services. However, offloading to higher-tier servers will incur extra overheads of delay and energy consumption in the uplink wireless transmission. Therefore, the central cloud server is indispensable for tasks with a large amount of computation workload and with a small data size [
10]. As the UEs’ tasks are heterogeneous, the competition of resources for other type of tasks (e.g., tasks with a large data size) is still universal in the RAN, thus how to further relieve the competition is an urgent problem to be solved [
11].
Device-to-device (D2D) communication and caching are proposed as technological components to tackle the data-rate problem. D2D enables devices to communicate directly and obtain the proximity gain, reuse gain, and hop gain [
12,
13,
14]. Moreover, since requests of UEs are not simultaneous in the time domain, so in each period of task requesting, a large number of idle UEs would exist. The idle UEs can enable the requesting UEs to offload part of computation tasks to neighbor devices via D2D communication links. Applying caching to heterogeneous network nodes can satisfy the request of UEs in the local networks. By proactively predicting and caching the most popular contents in the storage facilities, the distances between the UEs and contents are shortened, which improves the performance of content delivering.
From now on, several recent works have investigated computation offloading and resource allocation strategies in the mobile edge systems [
15,
16,
17,
18,
19,
20]. The authors of [
15,
16,
17] focused on the computation offloading strategy. By the optimization of offloading mode (e.g., local computing or edge offloading mode), the service delay and energy consumption would be largely saved. Some researchers investigated the communication resources allocation [
18], computational resource allocation [
19,
20] in MEC-enabled systems to improve the resource efficiency. As wireless channel conditions of UEs have significant differences, the communication resource allocation and computational resource allocation can improve communication and computing efficiency, respectively. Some works addressed the joint allocation of radio and server resource allocation algorithms in various MEC systems [
21,
22,
23,
24,
25,
26]. The joint computation and communication resources can balance the delay cost and computation cost according to the UEs’ servicing delay and energy cost. Recently, the authors of [
27,
28,
29] integrated caching technology with computation offloading to optimize the offloading policy in MEC systems. By task caching, the transmission cost can be largely saved, the offloading cost can be largely saved and UEs’ experience can be further improved.
Although the benefits of D2D communication and caching have received much attention in the MEC computing networks, the two technologies are considered separately in most works. Moreover, in their works about task offloading, server offloading mode and local offloading mode are mainly two considered modes with the assumption that the hardware and software resources can support all computing tasks. This assumption is impractical, because computing power of edge servers and UEs are both limited, which may result in poor performance, especially in a scenario of resource competition among a large number of UEs. Furthermore, the advantages of task caching in small base stations (SBSs) have been investigated in some works, but the potential benefits of task caching in UEs and how much gain will be obtained by cache-enabled D2D communication are still not explored in the scenario of MEC systems.
Therefore, this research focuses on the computation offloading and resource allocation in a cache-aided hierarchical edge-cloud system, featured by its SCN architecture. We consider tasks which can be partially offloaded and processed. Specially, four offloading modes are considered in this paper named cloud partial offloading, MEC partial offloading, cache-matched D2D partial offloading and cache-mismatched D2D partial offloading. Our aim to minimize the system cost with a trade-off between the energy consumption and serving delay while meeting the computation constraints of servers. The offloading strategy, CPU-cycle assignment in the cloud server and MEC server, and task offloading ratio are jointly optimized.
The contributions of this paper are listed as follows.
(1) We present the considered hierarchical edge-cloud models, which include cloud partial offloading, MEC partial offloading, cache-matched D2D partial offloading, and cache-mismatched D2D partial offloading. A joint optimization problem is established to minimize the total offloading cost. Particularly, the offloading cost is defined as a linear combination of the total energy consumption and the total offloading latency. We focus on the joint design of CPU cycle frequency, the offloading decision, and the offloading ration allocation with the constraints of the computational resources.
(2) From the observation of the joint optimization problem, it is mixed-integer nonlinear optimization problem (MINLP) and non-convex. To solve it, we decouple it into the offloading ratio allocation problem (ORAP), resource allocation problem (RAP) and offloading mode selection problem (OMSP), according to each offloading mode.
(3) We design an efficient distributed joint computation offloading and resource allocation optimization (JORA) scheme to solve the original optimization problem. Especially for the resource allocation problems in MEC and cloud partial offloading modes, the Lagrange multiplier method is adopted. With the solution of resource allocation problems, an alternative optimization algorithm is proposed to obtain an optimal solution to the offloading ratio problem. For the two D2D offloading modes, we use reformulation linearization-technique (RLT) to reformulate the ratio allocation problems into four linear optimization problems which can be solved in polynomial time. At last, we formulate the offloading optimization problem as a potential game and propose a distributed algorithm to obtain the optimal solution.
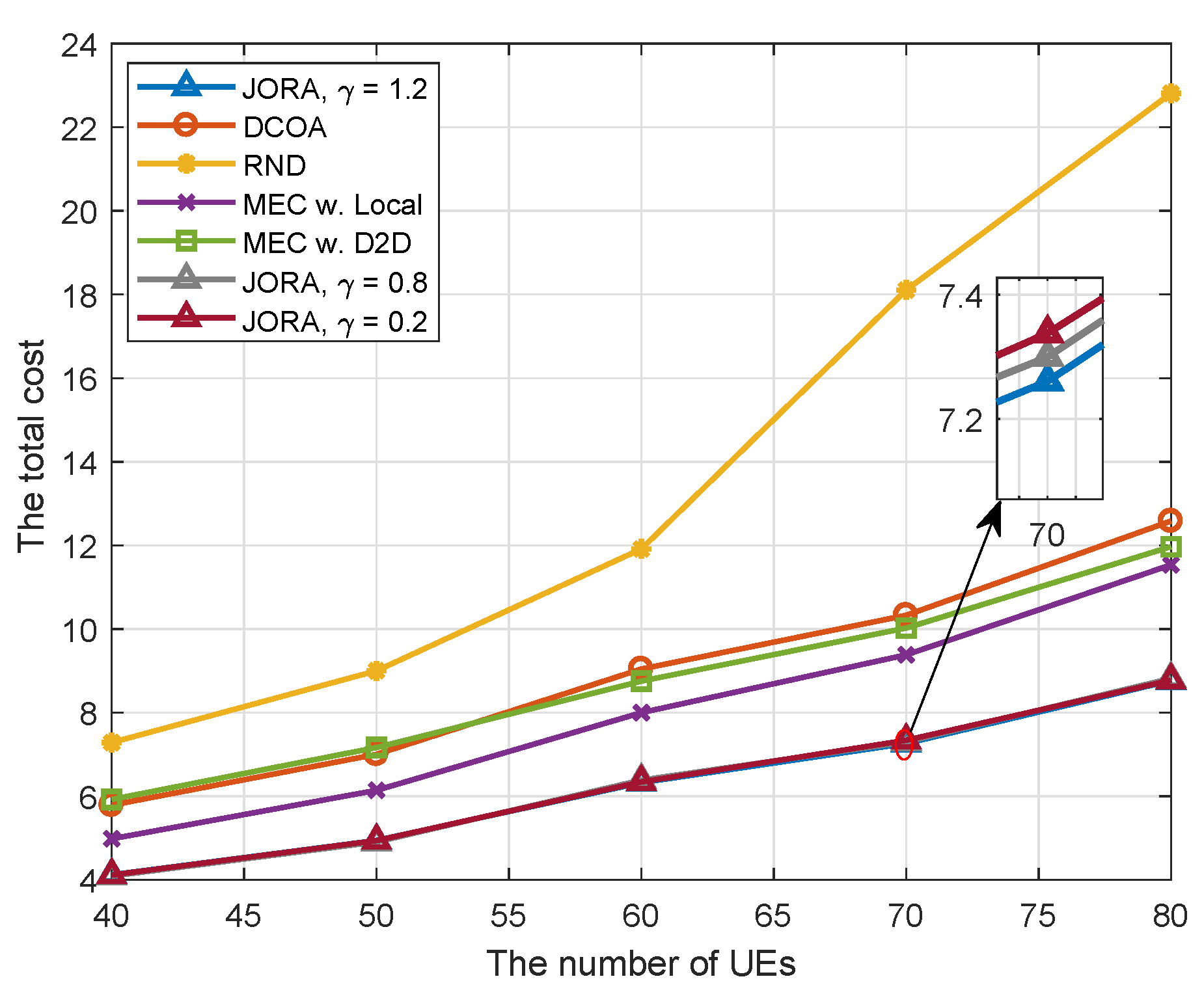
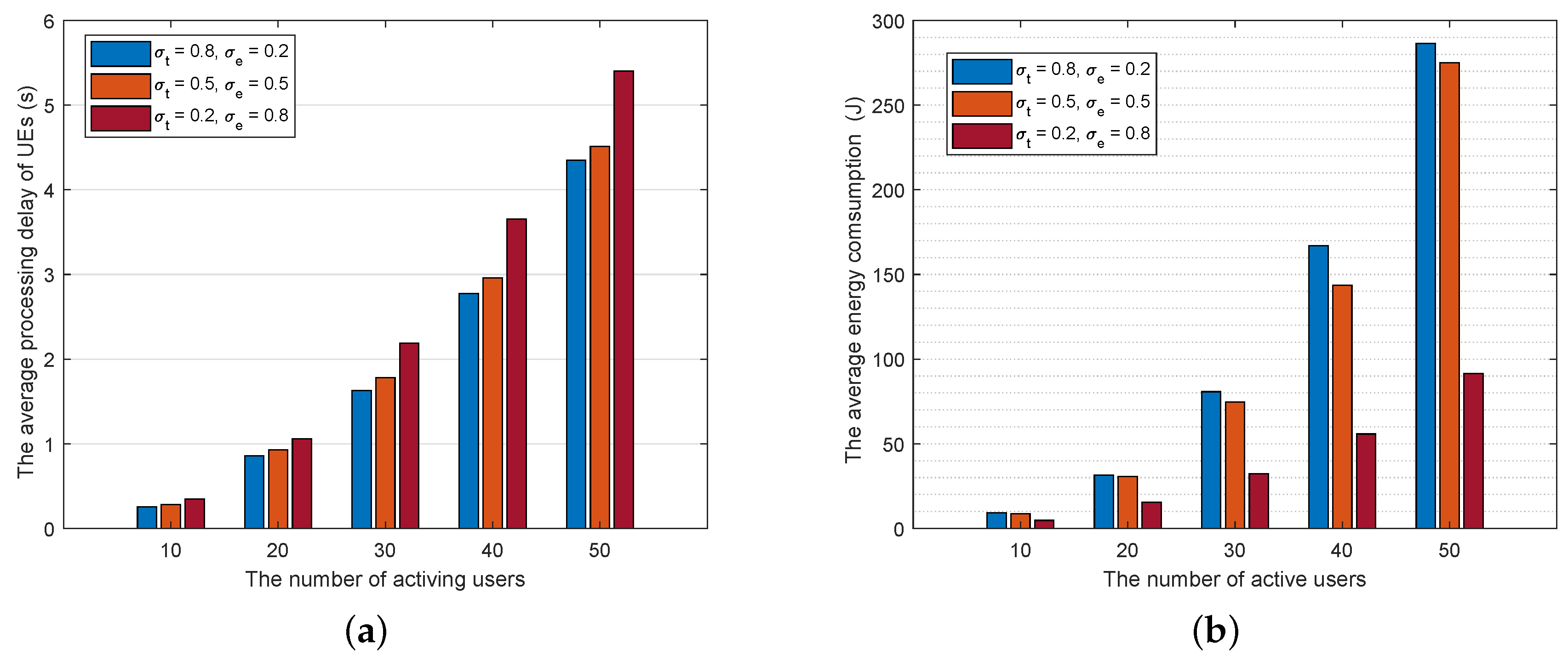
(4) We investigate the performance of the proposed scheme through extensive numerical experiments. Simulation results show that the proposed scheme outperforms other existing benchmark schemes.
The paper is organized as follows. In
Section 2, we review the related works. The system model is presented in
Section 3. The problem formulation and decomposition are given in
Section 4.
Section 5 provides the formulation of task offloading and resource optimization problem. Meanwhile, the solution to the problem is also given. Simulation results are described in
Section 6. Finally,
Section 6 concludes this paper.
3. System Model
In this section, we introduce a cache-aided hierarchical edge-cloud system. In such a system, the SBSs installed with an MEC server can provide a set of UEs seamless access and an abundance of computing resources in their proximity. The cloud is seen as a supplement to MEC as it has sufficient computing resources and provides service via a fiber backhaul link with the relay of SBSs.
3.1. Network Model
We assume there are several SBSs that connecting the remote cloud server via a fiber backhaul link. The remote cloud center has sufficient computing resources but is far away from UEs, while the MEC server close to the UEs, has limited computing power. We model the cloud server as a large number of virtual machines. Each of them has a dedicated processing capacity of
(in cycles per time unit) [
41]. Similarly, we model each of the MEC servers as a virtual machine with a processing power of
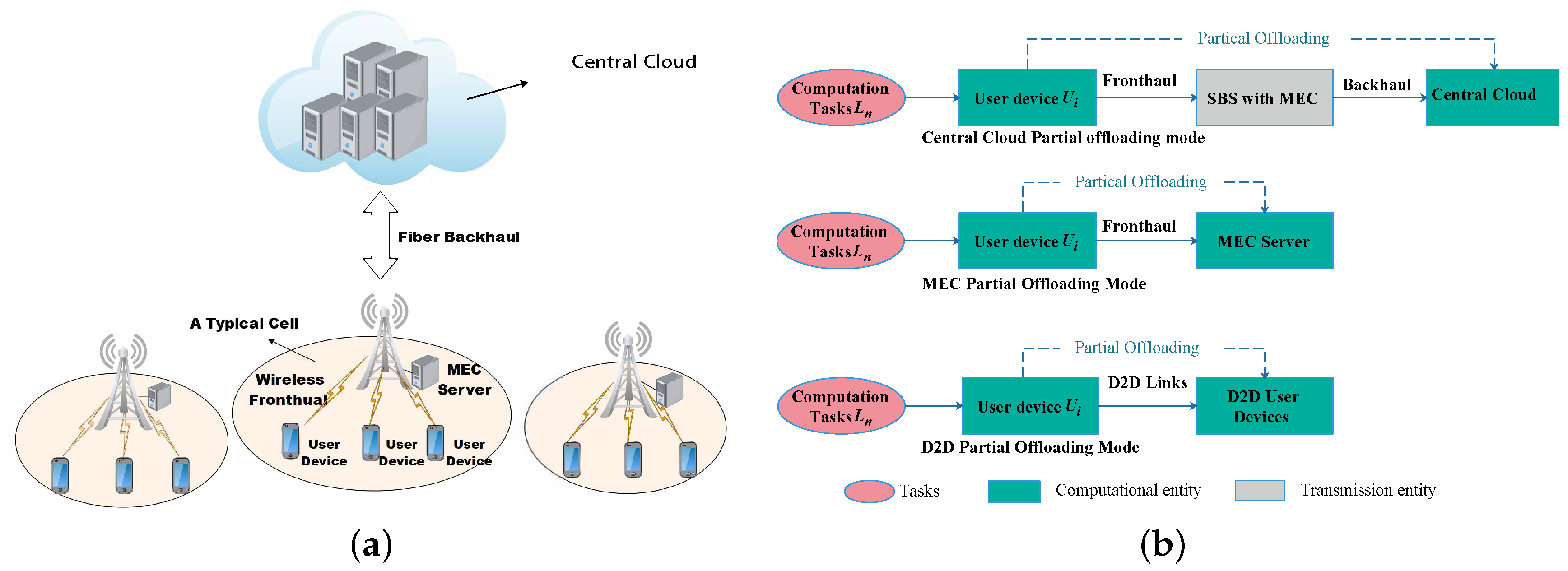
(in cycles per time unit). The SBSs help UEs relay their tasks to cloud server or MEC servers for processing. If there is more than one UE access to the same MEC server, the processing power of the associated server will be shared. Without loss of generality, we focus on a typical small cell and its associated UEs, as shown in
Figure 1. Assume there are
K UEs in the range of the typical cell, the set of UEs is denoted by
.
Assume each UE has a virtual reality application task (e.g., rendering scenes, or tracking objects) from a determinant task library need to be processed, and the requesting tasks are are heterogeneous in data size and computation capacity requirement. In our setting, UEs have a caching ability. A random caching scheme is adopted to keep the heterogeneity of tasks among UEs (e.g., uniformly probability random caching), which means all the UEs random cache tasks according to a determined probability distribution until the caching spaces are filled up. Task caching refers to caching the completed task applications and their related data onto UEs’ local caching entities. In each offloading period, the UEs can choose to offload their tasks to MEC server, remote cloud, or perform them in the D2D networks. We call these UEs who have a task to be processed active UEs and treat the other UEs as idle UEs.
Figure 1a illustrates an instant of such a cache-aided edge-cloud system with D2D communications.
The direct discovery strategy is considered in D2D networks [
42]. In the requesting period, UEs participated in the device discovery process, periodically and synchronously transmit/receive discovery signals. In a device discovery period, an active UE would transmit discovery signals that may be detected by other UEs. The information in the discovery signals should include identity and application-related information (e.g., cache state). Thus, the active UEs would accurately establish connections with the most proper cache-matched or mismatched idle UEs. It should be mentioned that the device discovery period and the connection establishment period are all under control of UEs’ serving SBS.A quasi-static scenario is considered where the set of UEs remains unchanged during a computation offloading period.
For each UE, there are four offloading modes that can choose, as shown in
Figure 1b and
Figure 2:
(1) MEC partial offloading (mode 1)
In general, if an active UE cannot find adequate computing resources from the idle UEs nearby, no matter they have cached the requested task or not, the UE may be associated with Mode 1. After the allocation of offloading ratio, the offloading part of the task would be relayed and processed in the MEC server while the left part will be performed locally. It should be emphasized that the offloading and local processing are implemented simultaneously. To ensure the active UEs to experience a short delay and low energy consumption, the offloading ratio should be optimized with the consideration of competition between other active UEs in the same offloading mode. Moreover, the allocated CPU cycles should also be carefully designed.
(2) Cloud partial offloading (mode 2)
Similar to mode 1, for each UE with mode 2, they would additionally experience the transmission delay of backhaul link between SBSs and cloud center, but needn’t consider the competition from other UEs compared with mode 1. The offloading part and the left part of the task are also be processed simultaneously. But different from mode 1, there is no competition for resources as there is no share of resources in the virtual machine of cloud centers. UEs are preferred to be associated with this mode if they cannot find adequate computing resources and the size of their request tasks is generally small, which results in a tiny transmit cost.
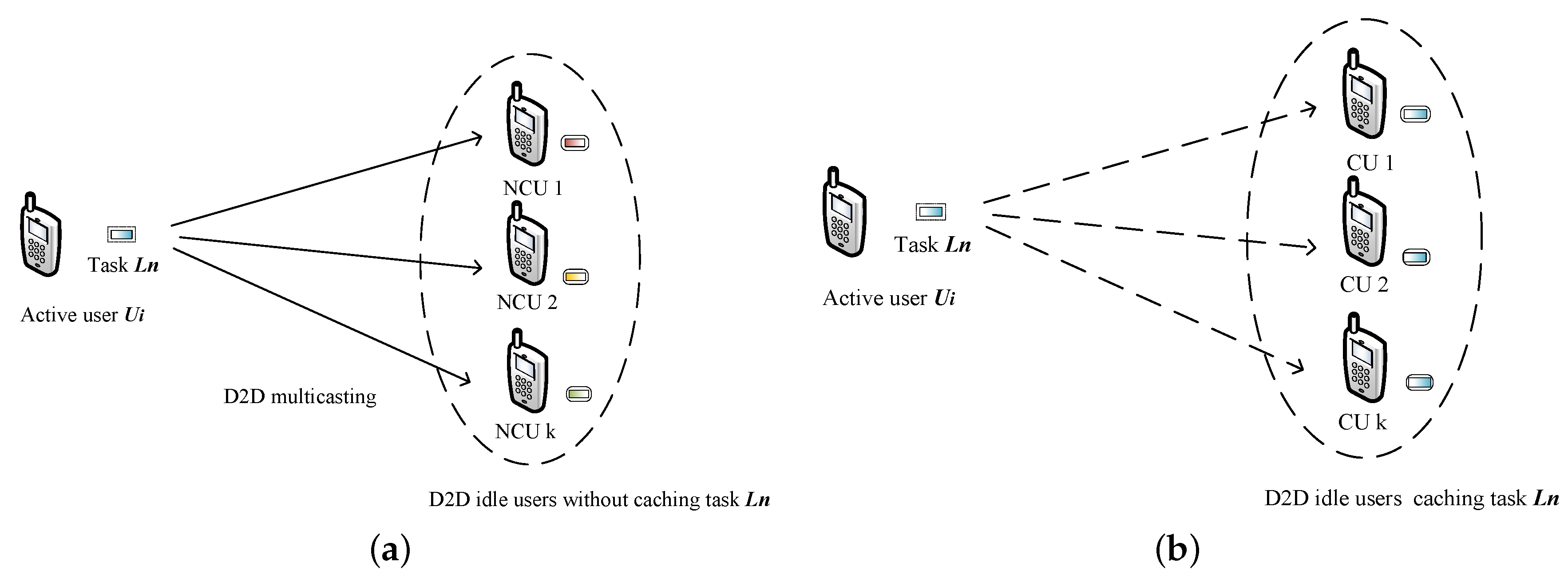
(3) Cache-mismatched D2D partial offloading (mode 3)
In this mode, the active UE would requisition all the computing resources of idle UEs nearby. In this case, as the allocated idle UEs have not cached the requesting task, the transmission from the active UEs to the occupied idle UEs for the offloading part should be involved in. For an active UEs, all the idle UEs have not cached the requesting task would formulate a potential collaborative offloading group. After the offloading ratio allocation, the idle UEs with nonzero offloading ratio would keep in the original group and the others would be released. The multicast scheme is adopted for offloading in this paper with a consideration of spectral efficiency. The size of tasks is considerable and the transmission cost should not be ignored which is different from that in the cache-matched D2D offloading mode. It should be emphasized that the whole data of task(e.g., the task-related database for computing) and the computing correlative parameters should be delivered to the hired UEs. The correlative computing parameters may include the input parameters and the computing ratio allocation decision for each hired UE. When the cache-mismatched UEs receive the data, they will decode the signal by a carefully designed decoding function. After the decoding period, they can get their workloads and perform processing.
(4) Cache-matched D2D partial offloading mode (mode 4)
As in this mode, cache-matched idle UEs have already cached the requesting tasks (e.g., task-related database). Thus the active UEs need only to transmit the related computation parameters as in mode 3. The parameters have a tiny data size compared with the whole task. We ignored the transmission delay and transmit energy consumption of UEs as they are far less than that of sending and processing the whole task [
29]. So we only need to focus on the computing delay and energy consumption of each processing UEs. It needs to state that in all offloading modes if the offloading ratio is zero, that means the task will be processed locally.
We define the set of offloading strategies each UE could be associated with by . Specially, The indicators , , M and C mean cache-matched D2D partial offloading mode, cache-mismatched D2D partial offloading mode, MEC partial offloading mode and cloud partial offloading mode, respectively. In this paper, we don’t consider the simultaneously offloading in different offloading modes as it will increase the complexity of signal scheduling, and the spectrum resources are limited which may not be enough to support simultaneous and multi-mode access for a large number of UEs.
3.2. Task Caching Model
Assume there is a task library consists of N computation tasks denoted by , and all the tasks have different task size and computation requirements. Tasks can be divided and be partially offloaded. Let presents n of the tasks, where denotes the total number of instructions to be executed (in CPU cycles). Furthermore, means the data sizes in bits of the task . As the assumption in many works, we do not consider the transmission delay of task results and packer loss as the data size after processing. In this paper, the caching capacities of UEs are normalized as the number of caching tasks. Moreover, the caching capacities of all UEs are equally denoted by M.
The distribution of many Internet services was proven to follow Zipf’s law. Similar to Internet services, the distribution of computing services also follows Zipf’s law [
43]. As the assumption in [
29], in this paper, we assume that the requests of UEs follow the same Zipf distribution. The popularity set of tasks is denoted by
, in which the popularity is ranked in descending order. The popularity of tasks can be calculated by
where the exponent
is the popularity distribution parameter, which reflects the skewness of popularity.
3.3. The Communication and the Computation Models
There are two communication modes, including D2D communication and cellular communication. In this paper, all the UEs occupy the orthogonal spectrum in both D2D links and cellular links, and the cell reuses the bandwidth resources of another cell. That ensures the intercell interference among UEs can be removed no matter which mode they are associated with.
3.3.1. Mode 1: MEC Partial Offloading Mode
If an active UE is associated with MEC partial offloading mode, the UE would firstly offload its task to the SBS and then process it in MEC server. In this case, cellular communication will be applied. For a typical UE
i in this case with the task
, the transmit rate
can be calculated by
where
represents the bandwidth in cellular communication for each UEs,
is the transmit power of UE
i,
is the additive white Gaussian noise.
denotes the interference coming from other adjacent cells. For the sake of simplicity, we regard
as a constant.
According to the Formula (
2), the delay for UE
i offloading task
to MEC server can be calculated by
where
is the offloading ratio of UE
i in MEC offloading mode. Specially,
means task will be totally processed locally (in the server).
The energy consumption of transmission can be represented as
Let
denote the allocated computational resources in MEC server for UE
i, the processing time can be expressed as
According the works in [
26], we can also get the energy consumption of partial processing task
in MEC server which can be calculated by
where
is the energy effective switched capacitance of MEC server.
Similarly, let
denote the computing power of UE
i, the computation delay and the energy consumption for processing local part of tasks can be expressed as
where
and
denote the computing delay and energy consumption by local computing,
denotes the energy effective switched capacitance of UE
i.
3.3.2. Mode 2: Cloud Partial Offloading Mode
The offloading procedure in this mode can be divided into two phases named as the access phase and the backhaul phase, respectively. The active UEs in this mode should firstly access the serving SBS and transmit their offloading part by wireless access front link, then relay them to cloud center for processing by fiber backhaul link. Therefore, the communication latency includes two parts, fronthaul transmission delay and backhaul transmission delay.
Similar to the Formula (
3), let
denotes the offloading ratio of
i in cloud offloading mode, the fronthaul transmission delay and energy consumption which are denoted as
,
, can be defined as the same as (
3) and (
4) by following the same notations.
For the backhaul link transmission, we consider the delay in backhaul from local access networks to the cloud center as a constant value. Moreover, the transmission energy consumption in backhaul link can be neglected as it is insignificant compared with the energy consumption of computation. Let denote the backhaul link transmission delay for all tasks. So the total offloading delay can be expressed as .
The computation delays for processing the offloading part and the rest part of task
are denoted by
and
which can be expressed as
where
represents the allocated computational power in cloud center for UE
i.
Similar to the Formulas (
6) and (
8), we can get the computation energy consumption for the offloading part and the rest part of task
where
and
denote the energy consumption for cloud processing and local processing,
denotes the energy effective switched capacitance of cloud servers.
3.3.3. Mode 3: Cache-Mismatched D2D Partial Offloading Mode
For an active UE in cache-mismatched D2D partial computing mode, the UE will offload part of its task to nearby idle UEs who have not cached the requesting task. The multicast scheme will be adopted for transmission. So the transmission rate is depending on the UE with the worst channel state.
Furthermore, some idle UEs may satisfy more than one active UE’s demands because the D2D coverage of active UEs may overlap. To simplify, in this paper, if an idle UE can be selected by one more active UE, it would associate to the nearest active UE.
For an active UE
i in mode 3, let
denote the set of potential idle UEs nearby who are within the D2D coverage of
i without caching the requesting task
. So the multicasting transmit rate can be expressed as
where
denotes the channel gain between UE
i and the idle UE
j,
is the interfere from other D2D links with the same channel in other cells.
is the bandwidth for each active UE in the D2D offloading modes.
Let
denote the allocated offloading ratio of the task requested by
i to the UE
j. Especially, the local process ratio of the task can be repressed as
. Then we can get the multicasting delay of
i which can be calculated by
Let
denotes the energy consumption of multicasting. Thus we have
The computation delay of UE
j for helping process the task
can be calculated by
The energy consumption of UE
j for processing a part of task
can be expressed as
3.3.4. Mode 4: Cache-matched D2D Partial Offloading Mode
In cache-matched D2D partial computing mode, the offloading and processing procedure are similar to that of the cache-mismatched D2D partial offloading mode. The only difference is that the multicasting of tasks is not needed because the hired UEs have already cached the request tasks of the active UEs. Thus, the transmission delay can be neglected. Let
denote the set of idle UEs cached the requesting task
, the computation delay and energy cost in this mode can be expressed as the same formulations as Formulas (
16) and (
17) respectively by replacing
by
.
4. Problem Formulation and Solutions
In this section, we formulate the joint offloading and resource allocation problem. Considering the non-convexity of the joint optimization problem, we decompose it into multiple subproblems and propose corresponding algorithms to solve these problems. Then, a distributed joint optimization algorithm is presented to solve the joint offloading and resource allocation problem.
4.1. Problem Formation
Our aim is minimizing the system cost with a trade-off between task processing delay and energy consumption. Considering the fact that the different properties and performance criterions of delay and energy consumption, we use a weighted cost of delay and energy consumption of the system for task processing. We let and denote the normalized weight coefficients of the total process latency and the total energy consumption(). They are used to characterize the impact of delay and energy consumption on the total cost. The values of these parameters are depend on the type of tasks. For example, for a delay-sensitive application, the system may set and .
As introduced previously, a computation task can be offloaded in different modes. Thus for a typical active UE i, we denote its offloading strategies by ( , ). Especially, , means UE i is associated with offloading mode o.
For an active UE
i, as its task can be computed at multiple computing entities (e.g., MEC server, cloud center or other idle UEs nearby), the total delay for processing tasks should be the maximum one of the handling delay in the involved entities. Thus, we have the total processing delay in different modes.
Similarly, the total energy consumption can be expressed as
In (
18) and (
19), the indicators
,
,
,
present the total processing delay in cache-matched D2D partial offloading mode, cache-mismatched D2D partial offloading mode, MEC partial offloading mode and cloud partial offloading mode, respectively. Indicators
,
,
,
present the total processing energy consumption in such four partial offloading modes, respectively.
Let
and
denote the sets of allocated offloading ratio to idle UEs of UE
i in mode 3 and mode 4. To minimize the total cost of computation offloading in such system, the following optimization problem can be established
where
C denotes the value of the total cost. Constraints (20b) and (20c) ensure each UE can only choose one offloading mode in each task processing period. Constraints (20d) and (20f) mean the allocated computational capacity in MEC server and cloud server for each UE should be bounded within zero and its maximum computational power. Similarly, constraint (20e) bound the total allocated computational power for all UEs in MEC particle offloading mode. Constraints (20g) and (20h) state that offloading ratio in MEC partial offloading mode and cloud partial offloading mode should be limited between 0 and 1. Constraints (20i) and (20j) are proposed to guarantee the offloading ratio of each entitie for each active UE in cache-matched D2D offloading mode or cache-mismatched D2D offloading mode are limited between 0 and 1. Futhermore, constraints (20k) and (20l) are proposed to limit the total offloading ratio.
From the observation of task offloading optimization problem, we can see that is binary, resulting in the nonconvexity of objective function. These attributes makes (20) become a mixed-integer nonlinear optimization problem (MINLP). Moreover, joint consideration of offloading ratio allocation, offloading mode selection and resource allocation makes centralized algorithms commonly with a high computation complexity. Furthermore, as the adoption of game theory, a centralized algorithm needs a large number of iterations to obtain the NE solution, which is impractical. So a distributed mechanism is extremely urgent to be designed to ensure the efficiency of the solution.
To solve the problem (20), We propose a distributed joint computation offloading and resource allocation optimization (JORA) scheme. In this scheme, we decompose it into three subproblems, which mean offloading ratio allocation problem (ORAP), resource allocation problem (RAP) and offloading mode selection problem (OMSP).
4.2. Resource Allocation Problem (RAP) in JORA
Recalling (20), the optimization of the CPU-cycles frequency of servers for each UE is related to the offloading ratio allocation strategies.
Now we discuss the resource allocation problem in JORA. Since the constraints given by (20b), (20c) and (20g)–(20i) are not related to the CPU-cycle frequency, so they can be overlooked in this subproblem. So the problem of computing resource optimization is equivalent to the following problem when
are fixed:
It is obvious that if the offloading strategies of active UEs are fixed, the problem (20) is equivalent to minimize the cost accumulation of active UEs in their respective modes.
4.2.1. RAP in MEC Partial Offloading Mode
Now we discuss the resource allocation problem of the UEs in MEC offloading mode. By separating the cost of the system in MEC offloading mode from (
22), the resource allocation problem of UEs in MEC partial offloading mode can be expressed as
The problem of (
22) is continuous and non-differentiable due to the function of max{·}. The value of max{·} is respected to the offloading ratio
. For a typical UE
i, the total delay is related to the numerical relationship between local computing delay and offloading delay decided by the value of
.
In order to solve the problem (
22), we present a lemma as follows
Lemma 1. The problem (22) is a convex optimization problem with respect to and it is equivalent to the following optimization problem for all UEs with ,. For the problem (
23), we adopt Lagrange multiplier method to solve it. By applying the Karush–Kuhn–Tucker(KKT) conditions, the Lagrangian of problem of (
23) can be expressed as
where
and
are values larger than 0.
For
and
, the KKT conditions are as follows
Let
, combined with the condition (
25), the Lagrange multipliers update as below.
where
t is the current times of iteration,
represents the step of
t-th iteration. By utilizing the KKT conditions, the optimal resource allocation solution can be found.
4.2.2. RAP in Cloud Partial Offloading Mode
Similar to RAP in MEC partial offloading, the resource allocation in cloud partial offloading mode can be separated from problem (20), and can be expressed as
By recalling Lemma 1, for the RAP in cloud partial offloading mode, we have a similar conclusion.
Lemma 2. The problem (27) is a convex optimization problem with respect to and it is equivalent to the following optimization problem for all UEs with , . Proof. Please refer to the proof of Lemma 1. □
Then the following optimum solution can be obtained by solving the following equation:
By solving the Equation (
29), we can get:
Based on (
30), a closed-form solution of (
27) can be expressed as follows:
4.3. Offloading Ratio Allocation Problem (ORAP)
In order to trade off the delay cost and energy cost, the offloading ratio allocation in different offloading modes should be carefully optimized.
4.3.1. ORAP in MEC and Cloud Partial Offloading Modes
As discussed above, the cost of the system in different offloading modes are independent. For all active UEs in mode 1 and mode 2, if the offloading strategies
and resource allocation policies
are fixed, the problem (20) in such two types of offloading modes can be equivalently seemed as solving the following offloading ratio allocation problem.
As the offloading proportions of UEs
are independent, the (
32) is equivalent to minimizing the cost of each UE (e.g.,
).
Assume for any active UE associated with MEC partial offloading mode. If the optimal solution have reached, it must fall into two cases as follows.
Case 1:
In this case, the local processing delay is larger than the offloading delay. We can get the constraint on
as follows
where
which meets that the value that
.
The problem (
32) can be rewritten as
By discussing the first derivative of the cost
to
,
, we can get the optimal solution of offloading ratio as follows
Case 2:
In this case, the local processing delay is smaller than the offloading delay. We can get the constraint on
as follows
The problem (
33) can be rewritten as
As same as case 1, we can get the optimal solution by discussing the first derivative. The optimal solution in this case can be expressed as follows
By summarizing the solutions in case 1 and case 2, the optimal offloading ratio
can be obtained by
The process of solving ORAP in cloud partial offloading mode is similar to that in MEC edge partial offloading mode. We can get a similar conclusion about the optimal offloading ratio, which is expressed as follows
4.3.2. ORAP in D2D Partial Offloading Modes
For all active UEs in D2D offloading modes, the computing resources are fixed, we only consider the ratio allocation to minimize the total cost in such modes.
Firstly, we discuss the D2D cache-mismatched partial offloading mode, as offloading delay is not needed in D2D cache-matched partial offloading mode which is the only difference.
For each UE in this mode, their cost are independent. Thus, the problem (20) in such offloading mode can be equivalently seemed as solving the offloading ratio allocation for each UE. For a UE
i requesting task
, the offloading ratio allocation problem can be equivalently expressed as
Assume the problem
is an optimal solution of the offloading ratio policy of (
41).
Next, we analyze the cache-matched idle UE candidate with the maximum processing delay when the offloading ratio problem reaches the optimal solution.
Theorem 1. For an active UE , when the optimal solution to the problem (41) is reached, the idle UEs with the worst computing power would experience the maximum processing delay compared with other idle UEs in the same group. Assume the idle UE
j is the UE with a maximum processing delay in the offloading group of
i (e.g.,
). Under this condition we can further discuss the optimal solution to the problem (
41). The problem (
41) can be rewritten as
where (
42b) ensures
j is the cache-mismatched idle UE with the maximum processing delay which is the necessary condition of the optimal solution.
Similar to the UEs in cloud and MEC offloading modes, we analyze the cache-mismatched D2D ratio offloading mode in two cases. The optimal cost will be the smaller one of the costs in these two cases.
Case 1:
In this case, the problem (
41) can be rewritten as:
The problem (43) is a Linear programming problem(LP), which is solvable in polynomial time. We denote the optimal offloading ratio allocation policy by .
Case 2:
The problem (42) can be rewritten as:
The problem (44) is also a Linear programming problem(LP), which is solvable in polynomial time. We denote the optimal offloading ratio allocation policy by .
In summary, the optimal solution of problem (
41) can be got by comparing the cost obtained in two cases:
We can get the similar solution to the D2D cache-matched offloading mode:
where
is the cost in case 1 when the active local processing delay is larger than the offloading delay,
is the cost in case 2 when the active local processing delay is smaller than the offloading delay.
For the cache-matched D2D partial offloading mode, we can get the same conclusion as the only difference between the two modes is that the transmission delay is omitted in cache-matched D2D partial offloading mode.
The optimal allocated offloading ratio and optimal allocated computing resources are coupled in MEC and cloud partial offloading modes. An iteration-based algorithm is presented to find the optimal solution, which is shown in Algorithm 1.
| Algorithm 1 Iteration-based algorithm for offloading ratio and resource allocation. |
Require:,
Ensure: Current cost .
- 1:
Initialize the offloading ratio for each UEs. - 2:
for l = 1:L do - 3:
for i = 1 to K do - 4:
if then - 5:
Calculate optimal resource allocation policy according to Formula ( 25) for all UEs. - 6:
Obtain the optimal value of for according to ( 39). - 7:
else if then - 8:
Calculate optimal resource allocation policy according to Formula ( 31) for all UEs. - 9:
Obtain the optimal value of for according to ( 40). - 10:
else if then - 11:
Obtain the optimal value of for according to (46). - 12:
else if then - 13:
Obtain the optimal value of for according to (45). - 14:
end if - 15:
end for - 16:
Update the value of according to Formulas ( 25) and ( 26) - 17:
end for - 18:
return current cost according to the Formula (21b)
|
In Algorithm 1, the optimization results of the CPU-cycle frequency, the offloading ratio are updated alternately. In particular, during each iteration, the solutions of CPU-cycle frequency optimization can be obtained straightforwardly based on (
25), (
26) and (
31). The offloading ratio allocation is optimized according to (
39), (
40), (45) and (46).
4.4. Offloading Mode Selection Problem (OMSP)
When the allocated offloading ratio and allocated computing resources given by (20) are fixed, the offloading mode selection problem can be written as
As shown in (20), although the offloading ratio and the allocated resources are independent with the offloading decision , the competition of computing resources in MEC server and D2D idle UEs lead to an interaction between active UEs when they are making the offloading decisions.
To determine which tasks should be offloaded, we formulate the interactions between the UE users as a strategic game. In each iteration process of the game, every active UE would make their current best offloading decision according to the current UEs’ offloading decisions state.
We define game , , where is the set of players and is the feasible strategy space of player i, is the player i’s cost with consideration of delay and energy consumption, which decides its payoff achieved from using computing services.
In the offloading game, each UE is one player and would select the optimal mode to minimize its cost (e.g., ) in response to the other UEs’ strategies.
To obtain the strategies of all UEs, we first introduce the concept of the best response strategy.
Let matrix
denote the offloading strategies of all UEs, excluding UE
i. Each row of
represents the offloading vector of a UE. According to the definition of Game Theory [
44], the best response strategy for each UE can be expressed as
We now introduce the NE as follows.
Definition 1. ( [44]) An offloading strategy profile is a NE of game if no player can further decrease the cost by unilaterally altering its strategy, i.e., for all We next show that there exists an NE.
Definition 2. A game is called a potential game if it exists a potential function Q such that for and offloading vectors that satisfy: The Nash has self-stability properties which makes the UEs in the game derive mutually satisfactory solution at the equilibrium. At the equilibrium, no one can improve their utilities by changing the offloading policy since the UEs are selfish to act in their interests in the non-cooperative offloading problem.
Propotion 1. The following function is a potential function and are potential games for all UEs Proof. For each UE, it can choose four offloading modes for task processing. By substituting the value of into the Formula (51), we can get the cost variation by changing the offloading decision.
We first discuss the case that switching offloading decision between cloud offloading mode and MEC offloading mode. Assume the initial choice of UE i is MEC partial offloading mode and then change the offloading mode to cloud offloading partial mode,(e.g., .
By subtracting the Formulas (52) and (53), we can achieve that
From (54) we can find that the variation of (51) is equal to that of the cost function. Similarly, we can get that when switch the offloading decisions, same conclusion would be obtained, which proves that proposition 1 is established and the game must existence NE. When the iteration in this game increase to a certain number, the solution will reach the optimal solution. □
The distributed joint optimization algorithm is presented in the Algorithm 2. Now we analyze the complexity of Algorithms. Based on (
39), Algorithm 1 can approach the optimal solution of resource and offload ratio allocation problem via L iterations, thus the computational complexity of Algorithm 1 can be estimated as O(LK). As the Algorithm 2 is established by the iteration of Algorithm 1. The computational complexity of Algorithm 2 can be analyzed as O(
+
).
| Algorithm 2 The distributed joint optimization algorithm. |
Require:,
Ensure: Optimal offloading policy
- 1:
for i = 1 to K do - 2:
Each UEs switch the offloading modes. - 3:
Calculate the current cost of the system by Algorithm 1 and update the offloading mode to the optimal current mode . - 4:
end for - 5:
while or do - 6:
for i = 1 to K do - 7:
Set , calculate the cost by Algorithm 1 and update the offloading mode with minimum cost . - 8:
end for - 9:
end while - 10:
Output the optimal offloading policy and cost ;
|











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}