Elastic Computing in the Fog on Internet of Things to Improve the Performance of Low Cost Nodes


 , ,
, ,
Abstract
:1. Introduction
2. Related Work
3. Analysis of the System
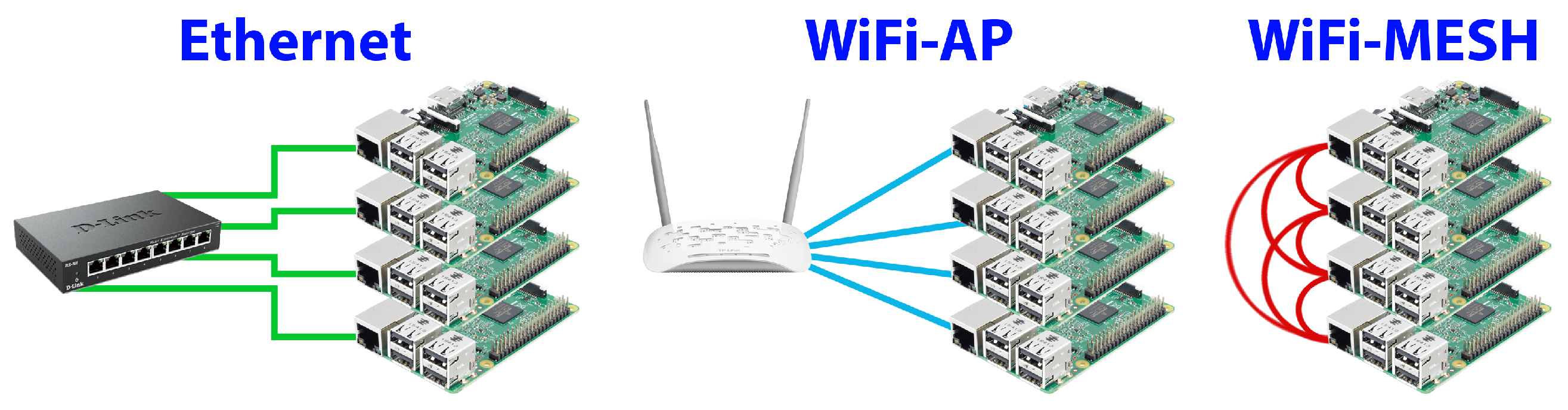
3.1. Clustering Options for Nodes in the Fog
3.2. Linux Containers and Orchestration
4. Design and Implementation
4.1. Hardware, Operating System, and Network Configuration of the Nodes
4.2. Cluster Configuration to Manage Containers and Their Orchestration
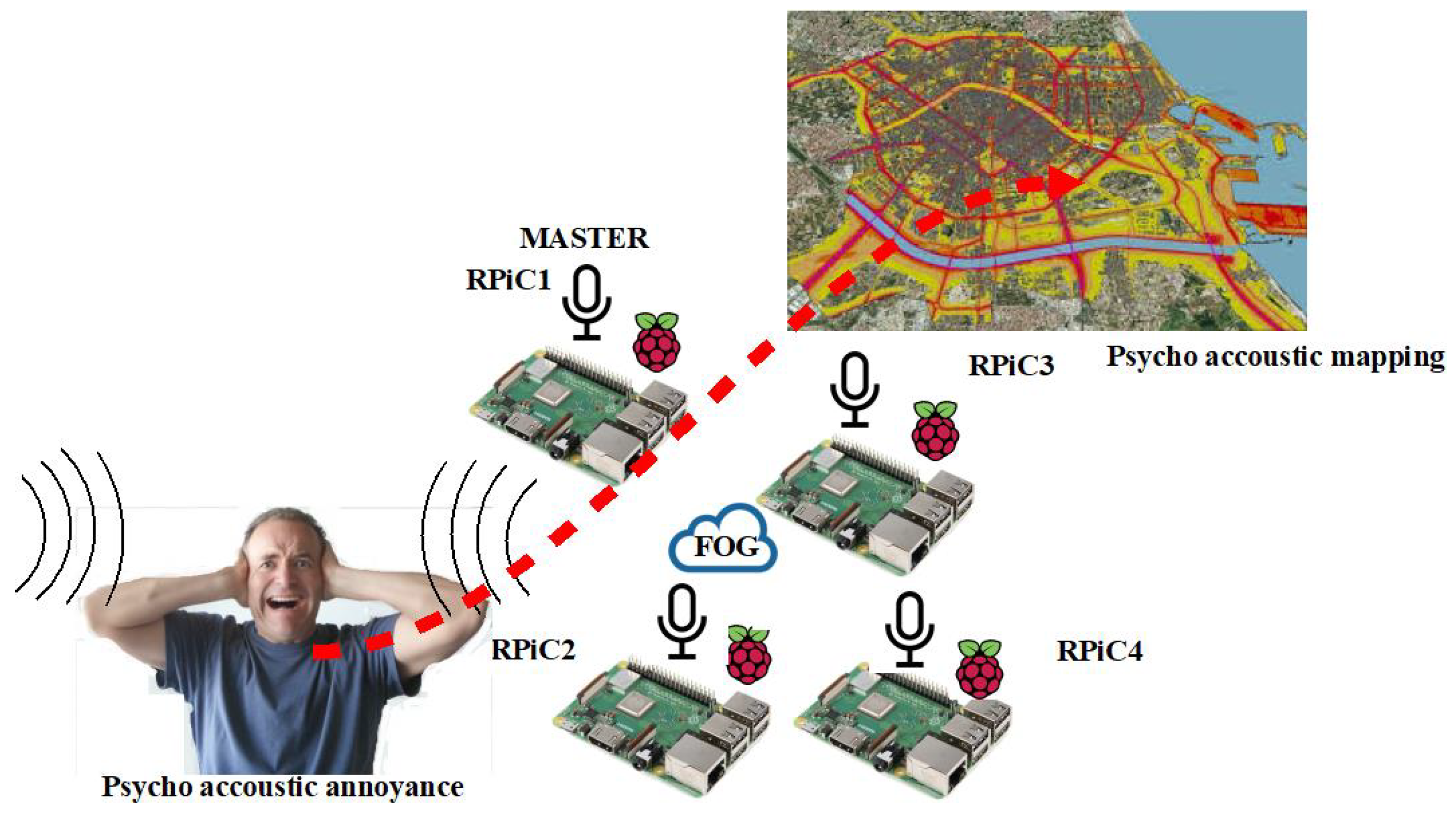
5. Test Bed for Soundscape Monitoring and Its Performance Analysis
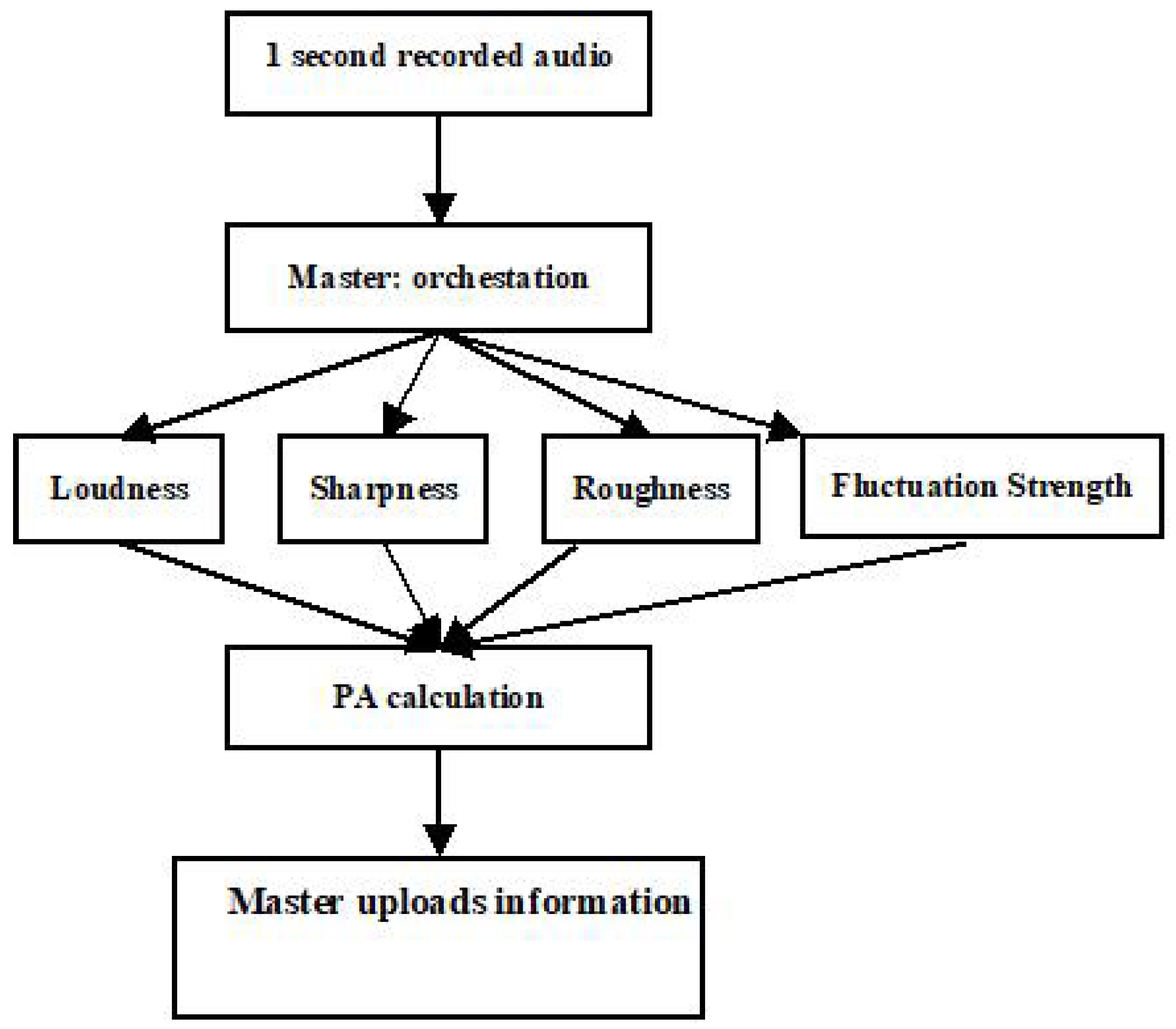
5.1. Analyzing Parallelization and Granularity
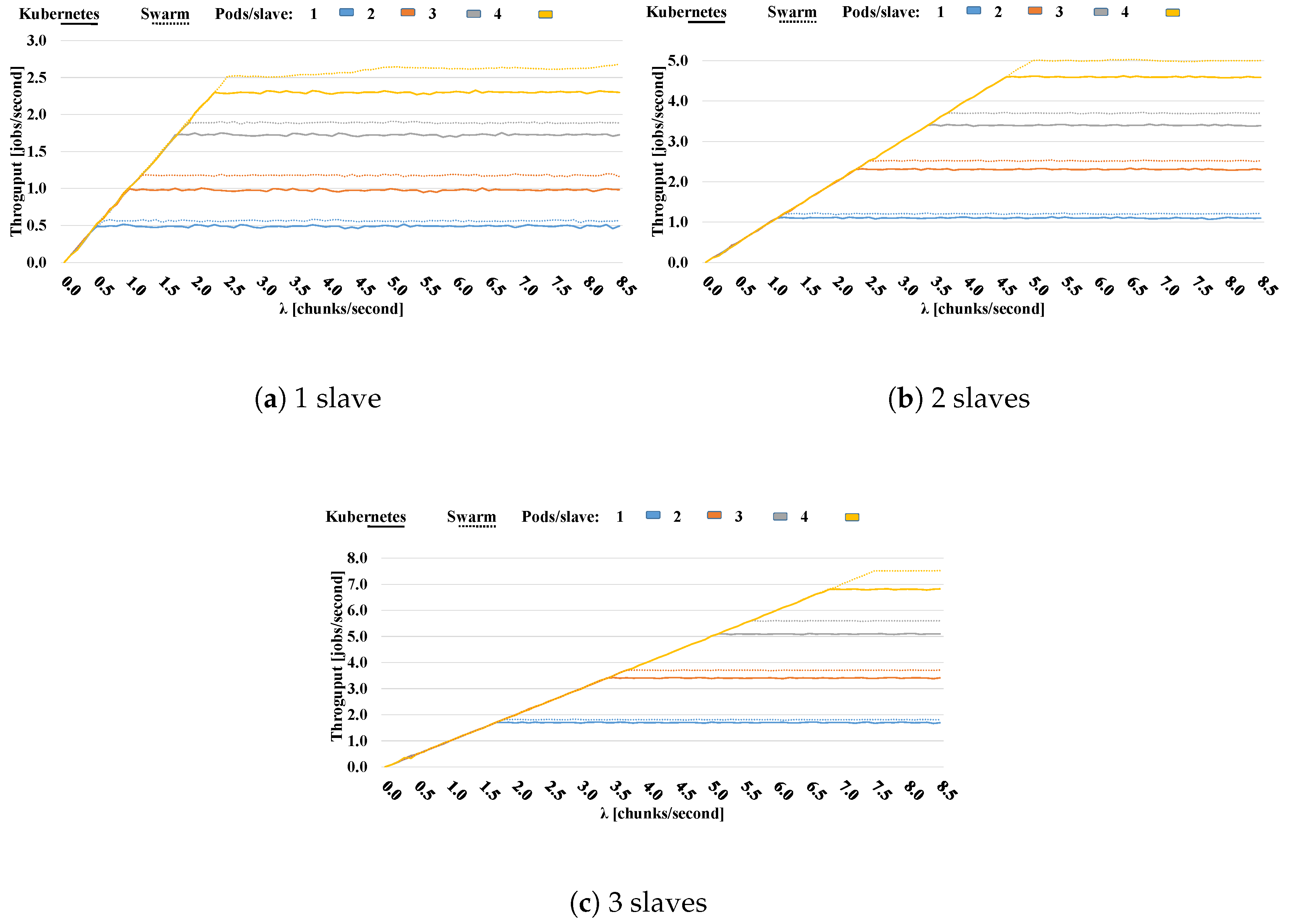
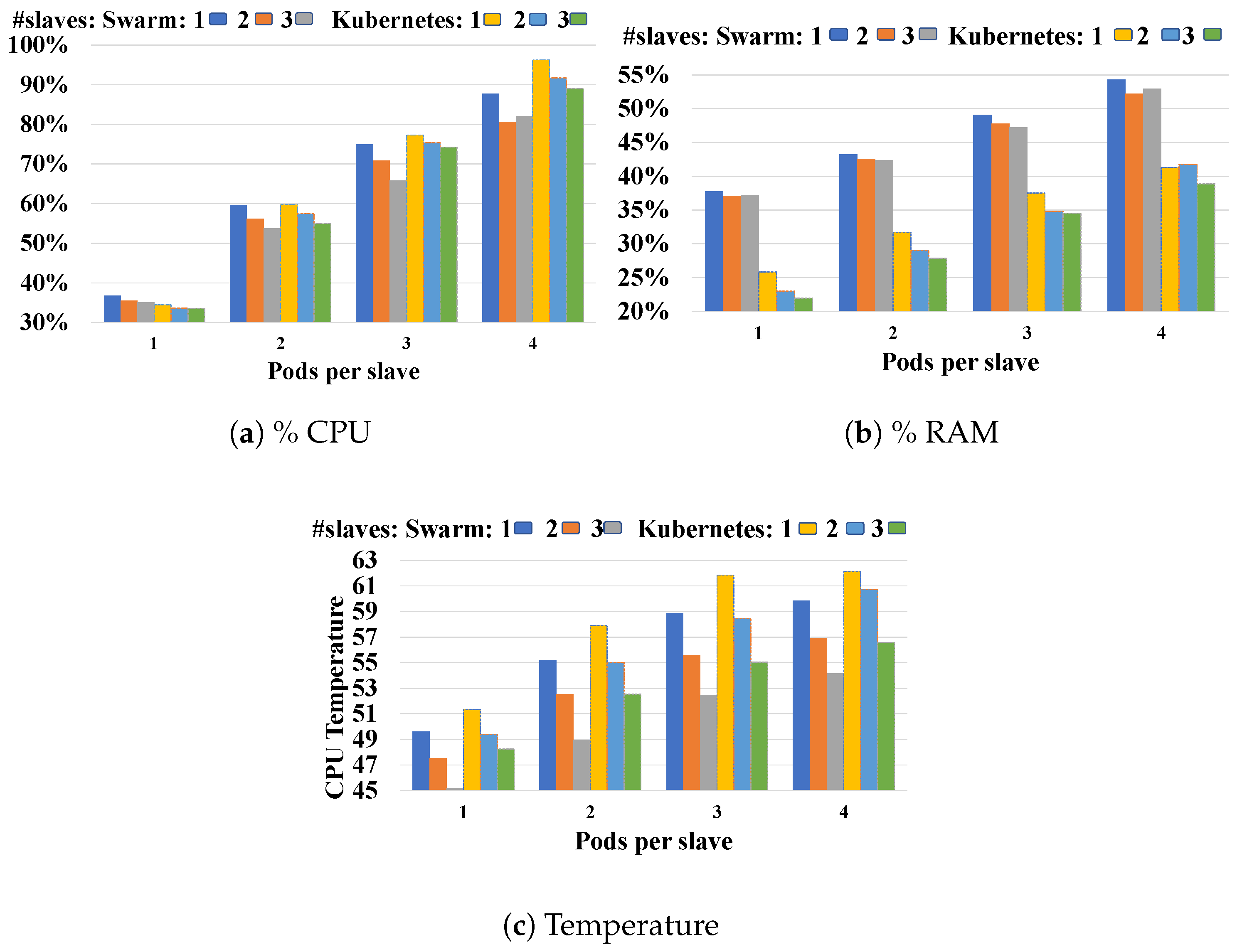
5.2. Performance Evaluation of the Cluster in the Fog
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gomes, M.; Pardal, M.L. Cloud vs. Fog: Assessment of alternative deployments for a latency-sensitive IoT application. Procedia Comput. Sci. 2018, 130, 488–495. [Google Scholar] [CrossRef]
- Verba, N.; Chao, K.M.; James, A.; Goldsmith, D.; Fei, X.; Stan, S.D. Platform as a service gateway for the Fog of Things. Adv. Eng. Inform. 2017, 33, 243–257. [Google Scholar] [CrossRef] [Green Version]
- Pastor-Aparicio, A.; Segura-Garcia, J.; Lopez-Ballester, J.; Felici-Castell, S.; Garcia-Pineda, M.; Pérez-Solano, J.J. Psycho-Acoustic Annoyance Implementation with Wireless Acoustic Sensor Networks for Monitoring in Smart Cities. IEEE Internet Things J. 2019. [Google Scholar] [CrossRef]
- Segura-Garcia, J.; Perez-Solano, J.J.; Cobos, M.; Navarro, E.; Felici-Castell, S.; Soriano, A.; Montes, F. Spatial Statistical Analysis of Urban Noise Data from a WASN Gathered by an IoT System: Application to a Small City. Appl. Sci. 2016, 6, 380. [Google Scholar] [CrossRef]
- Pérez-Solano, J.J.; Felici-Castell, S. Improving time synchronization in Wireless Sensor Networks using Bayesian Inference. J. Netw. Comput. Appl. 2017, 82, 47–55. [Google Scholar] [CrossRef]
- Cobos, M.; Perez-Solano, J.J.; Felici-Castell, S.; Segura, J.; Navarro, J.M. Cumulative-Sum-Based Localization of Sound Events in Low-Cost Wireless Acoustic Sensor Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1792–1802. [Google Scholar] [CrossRef]
- Polastre, J.; Szewczyk, R.; Culler, D. Telos: Enabling Ultra-low Power Wireless Research. In Proceedings of the 4th International Symposium on Information Processing in Sensor Networks, Los Angeles, CA, USA, 24–27 April 2005; IEEE Press: Piscataway, NJ, USA, 2005; pp. 364–369. [Google Scholar]
- Raspberry Pi 3B+. 2018. Available online: https://www.raspberrypi.org/documentation/ (accessed on 2 January 2019).
- Bellavista, P.; Berrocal, J.; Corradi, A.; Das, S.K.; Foschini, L.; Zanni, A. A survey on fog computing for the Internet of Things. Pervasive Mob. Comput. 2019, 52, 71–99. [Google Scholar] [CrossRef]
- Mukherjee, M.; Shu, L.; Wang, D. Survey of Fog Computing: Fundamental, Network Applications, and Research Challenges. IEEE Commun. Surv. Tutor. 2018, 20, 1826–1857. [Google Scholar] [CrossRef]
- Erskine, S.K.; Elleithy, K.M. Secure Intelligent Vehicular Network Using Fog Computing. Electronics 2019, 8, 455. [Google Scholar] [CrossRef] [Green Version]
- Docker Containers. 2018. Available online: https://docs.docker.com/engine/examples (accessed on 2 March 2019).
- Docker Swarm. 2017. Available online: https://docs.docker.com/swarm (accessed on 11 November 2018).
- Apache Mesos. 2018. Available online: http://mesos.apache.org (accessed on 11 January 2019).
- Kubernetes (K8s). 2018. Available online: https://kubernetes.io (accessed on 11 October 2018).
- Medel, V.; Tolosana-Calasanz, R.; Ángel Bañares, J.; Arronategui, U.; Rana, O.F. Characterising resource management performance in Kubernetes. Comput. Electr. Eng. 2018, 68, 286–297. [Google Scholar] [CrossRef] [Green Version]
- Taherizadeh, S.; Grobelnik, M. Key influencing factors of the Kubernetes auto-scaler for computing-intensive microservice-native cloud-based applications. Adv. Eng. Softw. 2020, 140, 102734. [Google Scholar] [CrossRef]
- Kim, D.; Muhammad, H.; Kim, E.; Helal, S.; Lee, C. TOSCA-Based and Federation-Aware Cloud Orchestration for Kubernetes Container Platform. Appl. Sci. 2019, 9, 191. [Google Scholar] [CrossRef] [Green Version]
- Strazdins, G.; Elsts, A.; Nesenbergs, K.; Selavo, L. Wireless Sensor Network Operating System Design Rules Based on Real-World Deployment Survey. J. Sens. Actuator Netw. 2013, 2, 509–556. [Google Scholar] [CrossRef]
- Foundation, R.P. Download Raspbian for Raspberry Pi. 2019. Available online: https://www.raspberrypi.org/downloads/raspbian/ (accessed on 3 December 2019).
- Neumann, A.; Aichele, C.; Lindner, M.; Wunderlich, S. Better Approach To Mobile Ad-hoc Networking (B.A.T.M.A.N.). IETF Draft. Available online: https://tools.ietf.org/html/draft-wunderlich-openmesh-manet-routing-00 (accessed on 3 December 2019).
- Noriega-Linares, J.E.; Rodriguez-Mayol, A.; Cobos, M.; Segura-García, J.; Felici-Castell, S.; Navarro, J.M. A Wireless Acoustic Array System for Binaural Loudness Evaluation in Cities. IEEE Sens. J. 2017, 17, 7043–7052. [Google Scholar] [CrossRef]
- Pastor-Aparicio, A.; Lopez-Ballester, J.; Segura-Garcia, J.; Felici-Castell, S.; Cobos, M.; Fayos-Jordan, R.; Perez-Solano, J. Zwicker’s annoyance model implementation in a WASN node. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings, Inter-Noise 2019, Madrid, Spain, 16–19 June 2019; Volume 1, pp. 1–11. [Google Scholar]
- ISO. Acoustics—Soundscape—Part 1: Definition and Conceptual Framework; ISO 12913-1:2014; International Organization for Standardization: Geneva, Switzerland, 2014. [Google Scholar]
- ISO. Acoustics—Soundscape—Part 2: Data Collection and Reporting Requirements; ISO 12913-2:2018; International Organization for Standardization: Geneva, Switzerland, 2018. [Google Scholar]
- Fastl, H.; Zwicker, E. Psychoacoustics: Facts and Models; Springer Series in Information Sciences; Springer-Verlag: Berlin/Heidelberg, Germany, 2007; Volume 22. [Google Scholar]
- Sanderson, C.; Curtin, R. A User-Friendly Hybrid Sparse Matrix Class in C++. Lect. Notes Comput. Sci. (LNCS) 2018, 10931, 422–430. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | L | S | R | F | PA (Total) | |
|---|---|---|---|---|---|---|
| Matlab | Computer | 0.058 | 0.000 | 0.288 | 0.404 | 0.699 |
| C++/Python | Computer | 0.003 | 0.000 | 0.128 | 0.235 | 0.238 |
| RPi3B | Single node | 0.018 | 0.000 | 0.849 | 0.742 | 1.479 |
| RPi3B+ | Single node | 0.017 | 0.000 | 0.794 | 0.694 | 1.406 |
| RPi3B | Cluster | 0.022 | 0.000 | 0.853 | 0.754 | 0.875 |
| RPi3B+ | Cluster | 0.021 | 0.000 | 0.802 | 0.703 | 0.824 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fayos-Jordan, R.; Felici-Castell, S.; Segura-Garcia, J.; Pastor-Aparicio, A.; Lopez-Ballester, J. Elastic Computing in the Fog on Internet of Things to Improve the Performance of Low Cost Nodes. Electronics 2019, 8, 1489. https://doi.org/10.3390/electronics8121489
Fayos-Jordan R, Felici-Castell S, Segura-Garcia J, Pastor-Aparicio A, Lopez-Ballester J. Elastic Computing in the Fog on Internet of Things to Improve the Performance of Low Cost Nodes. Electronics. 2019; 8(12):1489. https://doi.org/10.3390/electronics8121489
Chicago/Turabian StyleFayos-Jordan, Rafael, Santiago Felici-Castell, Jaume Segura-Garcia, Adolfo Pastor-Aparicio, and Jesus Lopez-Ballester. 2019. "Elastic Computing in the Fog on Internet of Things to Improve the Performance of Low Cost Nodes" Electronics 8, no. 12: 1489. https://doi.org/10.3390/electronics8121489
APA StyleFayos-Jordan, R., Felici-Castell, S., Segura-Garcia, J., Pastor-Aparicio, A., & Lopez-Ballester, J. (2019). Elastic Computing in the Fog on Internet of Things to Improve the Performance of Low Cost Nodes. Electronics, 8(12), 1489. https://doi.org/10.3390/electronics8121489