1. Introduction
Radar is an active detection sensor. It is not disturbed by natural light, fog, or rainy weather [
1]. It can recognize targets of interest by transmitting and receiving electromagnetic waves. Therefore, radar automatic target recognition technology plays an important role in human–machine interaction designs of various intelligent devices such as autonomous driving [
2,
3,
4], intelligent wheelchair [
5,
6], and so on.
High-resolution range profile (HRRP) is a one-dimensional signal that can represent the geometric shape of the target in the direction of the radar line of sight. Recognition of the target represented in HRRP is an important approach for radars to monitor targets of interest. Compared with two-dimensional imaging of radars [
7,
8,
9], HRRP has the advantages of easy acquisition, processing, and storage; hence using HRRP to achieve radar target recognition is more suitable for human–machine interaction designs of intelligent machine. However, HRRP has shortcomings such as target aspect, translation and amplitude sensitivity [
10,
11]. Therefore, radar target recognition based on HRRP is a complex and nonlinear classification problem.
As one-dimensional signals, the target information provided by HRRP is very limited. In this paper, we are interested to construct a new classifier based on the limited information. In response to this problem, many researchers have conducted extensive research and proposed many landmark methods. These are usually based on: (1) the distribution features of HRRP; (2) the data domain of HRRP; (3) different types of HRRP.
The recognition algorithms based on HRRP distribution features use statistical theory as the main analysis tool to identify the target of interest. For example, it was reported that the HRRP signal has specific distributions under some conditions. These distributions included
distribution [
12], Gaussian distribution [
13],
distribution [
14], double distribution composite model [
15] and so on. Subsequently, the target of interest can be identified by extracting statistical features such as center distance and invariant moment. In addition, some researchers attempted to construct statistical modeling of HRRP from the target. When the position of the radar observation is unchanged, the aspect changes of the target were considered to be a random non-stationary process, given that the angular changes of these aspects exceed a certain range. Otherwise, they can be approximated as a stationary process. These processes can be described by a Hidden Markov Model (HMM), which has been widely used in target recognition based on multi-aspect HRRP sequences [
16,
17,
18]. The recognition algorithms based on HRRP data domain mainly explore their characteristics from different data domains of HRRP. These data domains include time, frequency, and time-frequency domain, and result in different classification outcomes. For example, Liao et al. [
16] used the time-domain amplitude features of HRRP to train HMMs, and obtained 82% recognition accuracy in 3° aperture data, and 92% recognition accuracy in 6° aperture data. Albrecht et al. [
17] used the frequency-domain power spectrum features derived from the time-domain HRRP to train HMMs. Due to the translation invariance property of the power spectrum features, 94% recognition accuracy was obtained in [
17]. Zhang et al. [
18] used time-frequency domain (T-F) features to train HMMs. With more abundant features, 95% recognition accuracy was obtained in [
18]. The recognition algorithms based on multi-look HRRP are also constructed from the aspect angle of the target of interests. However, unlike the recognition algorithms based on HRRP distribution features, they mainly perform non-coherent superposition of multiple HRRPs within a certain aspect angle range of the target, to suppress noise and fuse multi-look aspect features to improve the recognition performance. There are many strategies for multi-look processing, which can generally be performed on the sample level [
19,
20,
21] or the feature level [
22,
23]. Sample level multi-look processing generally uses the method of averaging multiple samples, while feature level multi-look processing first needs to extract features from individual samples separately, and then fuse these features. Compared with single-look algorithms, multi-look algorithms improve the recognition accuracy to a certain extent, in both sample and feature levels. For example, in [
20], a 97% correct identification rate was achieved using the multi-look method, while only a 37% accuracy rate was obtained using the single-look method.
The above traditional recognition algorithms explore HRRP signals from different perspectives and have achieved promising success. However, these algorithms usually produce single features, which makes it difficult to further improve the recognition performance. In state-of-the-art recognition algorithms based on HRRP data domain, combining the advantages of several data domains has not been well investigated. On the other hand, in recognition algorithm based on multi-look HRRP, sample level multi-look processing makes it difficult control the number that needs to be averaged. If these quantities are too large, the processing time of the recognition algorithms will increase, and conversely, it is difficult to improve the recognition performance. Feature level multi-look processing has the potential to improve recognition performance, but the implementation of such algorithms is difficult.
“End-to-End” feature learning using deep learning provides a solution to the problems of feature extraction and fusion in conventional algorithms mentioned above. The essence is to use multi-layer neural networks to automatically extract basic features of the original data, or use multi-branch neural networks to automatically fuse multiple features [
24]. In recent years, many researchers have proposed several deep learning models based on different applications, such as Deep Convolutional Neural Network (CNN) [
25], Stacked Autoencoders (SAE) [
26], Restricted Boltzmann machines(RBMs) [
27], and Long Short-Term Memory (LSTM) Recurrent Neural Network [
28]. CNN is considered one of the best models to solve the “perception” problem, but is mainly used to extract two-dimensional data features [
29]. The SAE and RBMs models are unsupervised learning methods, which have been used for HRRP target recognition [
30,
31]. However, due to lack of prior knowledge, these unsupervised learning methods are unable to maintain high recognition accuracy when dealing with multi-class recognition problems. LSTM is an improved recurrent neural network. It solves the problem of gradient disappearance of traditional recurrent neural networks using long-span prior information. Thus, LSTM has unique advantages in processing sequential data [
32]. At present, LSTM is mainly used in speech recognition [
33] and natural language processing [
34]. Some researchers [
35,
36] used HRRP as a one-dimensional signal, and applied LSTM to HRRP target recognition. In dealing with different types of targets, Jithesh et al. and Bin et al. [
35,
36] have achieved good classification performance. These algorithms provide insights into exploring the sequence feature of HRRP. Further, some researchers combined LSTM with CNN by a fully connected layer with sequence characteristics [
37,
38]. Such combined algorithms can, on the one hand, exploit advantages of both LSTM and CNN; and on the other hand, effectively and automatically fuse the features that are irrelevant in a physical sense, thereby greatly improving the recognition performance. These algorithms also provide ideas for exploring the feature fusion of different data domains in HRRP. Furthermore, in recent years, some researchers e.g., [
39] have proposed a bidirectional LSTM (BLSTM) algorithm based on the LSTM. The current features of sequential data were not only dependent on the past information, but also related to future information. This context-dependent relationship can further improve the ability of LSTM to process sequential data.
In summary, the construction of an optimal classifier based on limited HRRP signals to correctly extract, learn, and fuse HRRP features for improving target recognition, is still an open question. In contrast to traditional recognition algorithms, we first extract 2-D sequence features from the formation process of HRRP, and then generate different data domains from these 2-D sequence features. Based on these sequence features, a novel target identification method is presented by combining bidirectional Long Short-Term Memory (BLSTM) and a Hidden Markov Model (HMM). The proposed algorithm first learns and fuses the sequence features of different data domains, and then combines these with the sequence features of the target multi-aspect, to achieve recognition. It consists of a shallow CNN, a multi-input BLSTM, and multiple HMMs. The shallow CNN is used for learning and dimensionality reduction of two-dimensional features in the time-frequency domain; the multi-input BLSTM is used for feature fusion of different data domains; and HMMs are used for target multi-aspect sequence feature learning and final target recognition.
The rest of this paper is organized as follows.
Section 2 gives a brief review of the approaches involved.
Section 3 describes the proposed method in detail.
Section 4 presents a pipeline of transforming the real synthetic aperture radar (SAR) image to HRRP and then generating multi-domain HRRP sequences.
Section 5 reports comparative experimental results for radar target recognition. Finally, concluding remarks are given in
Section 6.
2. LSTM and BLSTM
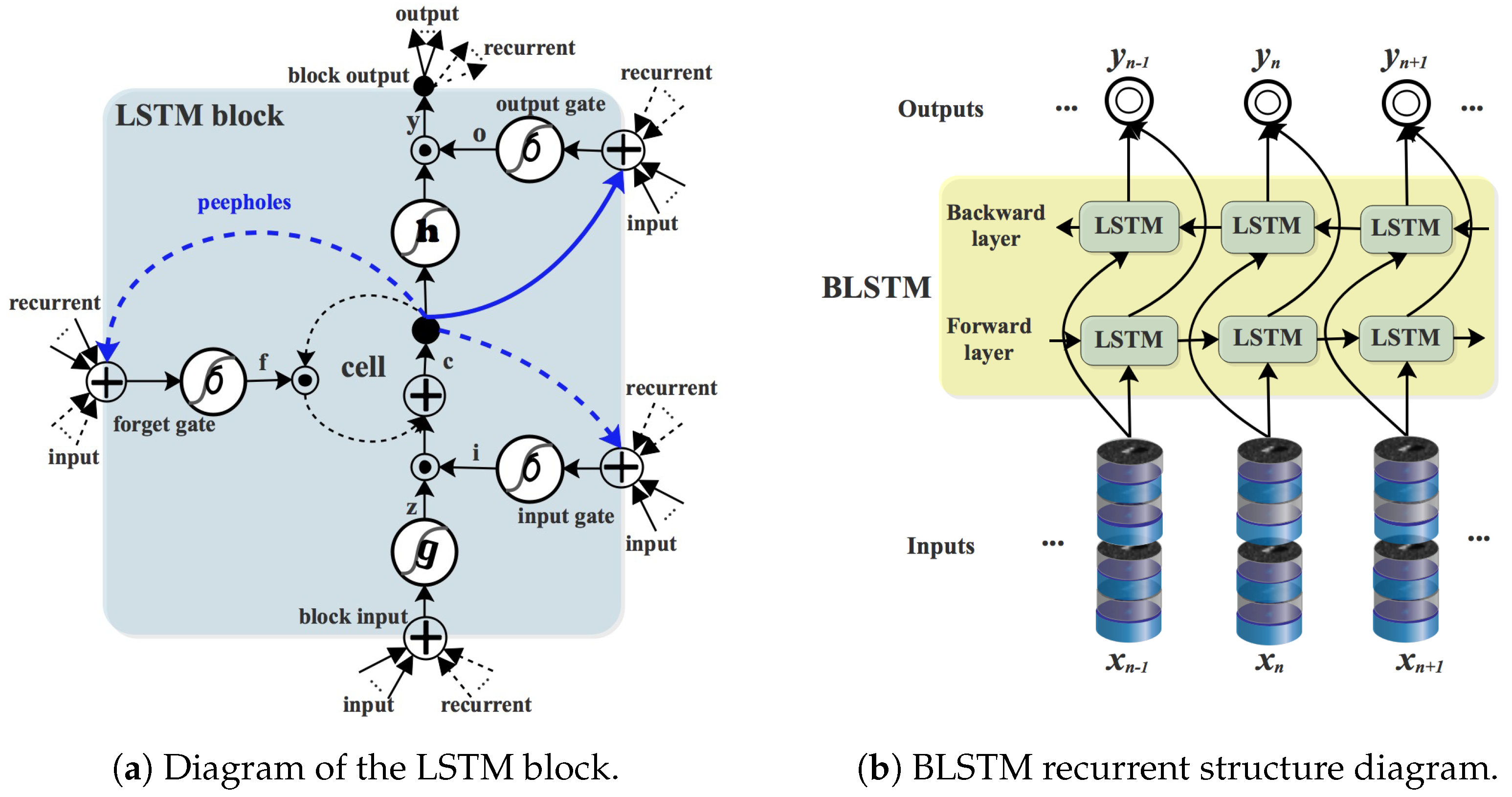
LSTM is a special recurrent neural network model. Through a special gate structure, it can store and retrieve information for a long time.
Figure 1a shows an LSTM storage module. It comprises three gate structures (input
, forget
, and output
), a memory unit controller cell, two input and output activation units, and three peepholes connections. The input and output gates are used to control the block input and output of the cell, and the forgetting gates are used to control the memory and forgetting state of the cell. The peephole is connected with status information before all the doors, to obtain Constant Error Carousel information [
40] that allows the cell to record more sequential information. Finally, the block output information is recurrent, and connects to the block input and all other gates, which enables LSTM to model complex and long-term dynamic features, and solves the gradient disappearance problem caused by long sequences in traditional recurrent neural networks [
41]. The forward mechanism of the LSTM can be expressed by the following equation [
42]:
where
,
,
,
,
, and
represent the
block input,
input gate,
forget gate,
memory cells,
output gate, and
block output respectively.
n is the number of sequential data.
is the input feature at the
nth sequence.
W is the weight matrix.
R is the recurrent weight matrix.
b is the bias vector.
p is the peephole weight vector, and the subscript
I,
i,
f,
o respectively represent the
block input,
input gate,
forget gate, and
output gate.
is the logistic sigmoid activation function.
h is the hyperbolic tangent activation function, and ⊙ denotes point-wise product with the gate value.
The LSTM has a disadvantage that it can only get past information but not future information. Compared with the LSTM, BLSTM solves this problem. As shown in
Figure 1b, there are two independent LSTM networks in a BLSTM module. These two LSTM networks have different directions, one is a forward LSTM, and the other is a reverse LSTM. The forward LSTM is mainly used to extract the future information of sequence data, while the reverse LSTM is mainly used to extract past information of the sequence data. Finally, their results are connected to the same output unit, and future and past features are fused to produce the output. In this way, the BLSTM is able to extract and fuse future and past features of the sequence data, which can be expressed by the following formulas [
43]:
where
is the forward hidden sequence,
is the backward hidden sequence, and
is implemented by Equation (
1).
In this paper, the BLSTM is used to extract future and past features of the sequence data to implement learning of multi-domain HRRP sequence features. However, in high-dimensional sequence data, the BLSTM is computationally inefficient and has limited ability to extract features. Therefore, choice of appropriate feature extraction and dimensionality reduction algorithms, combined with the BLSTM, are key to solving this problem.
3. Proposed Methods
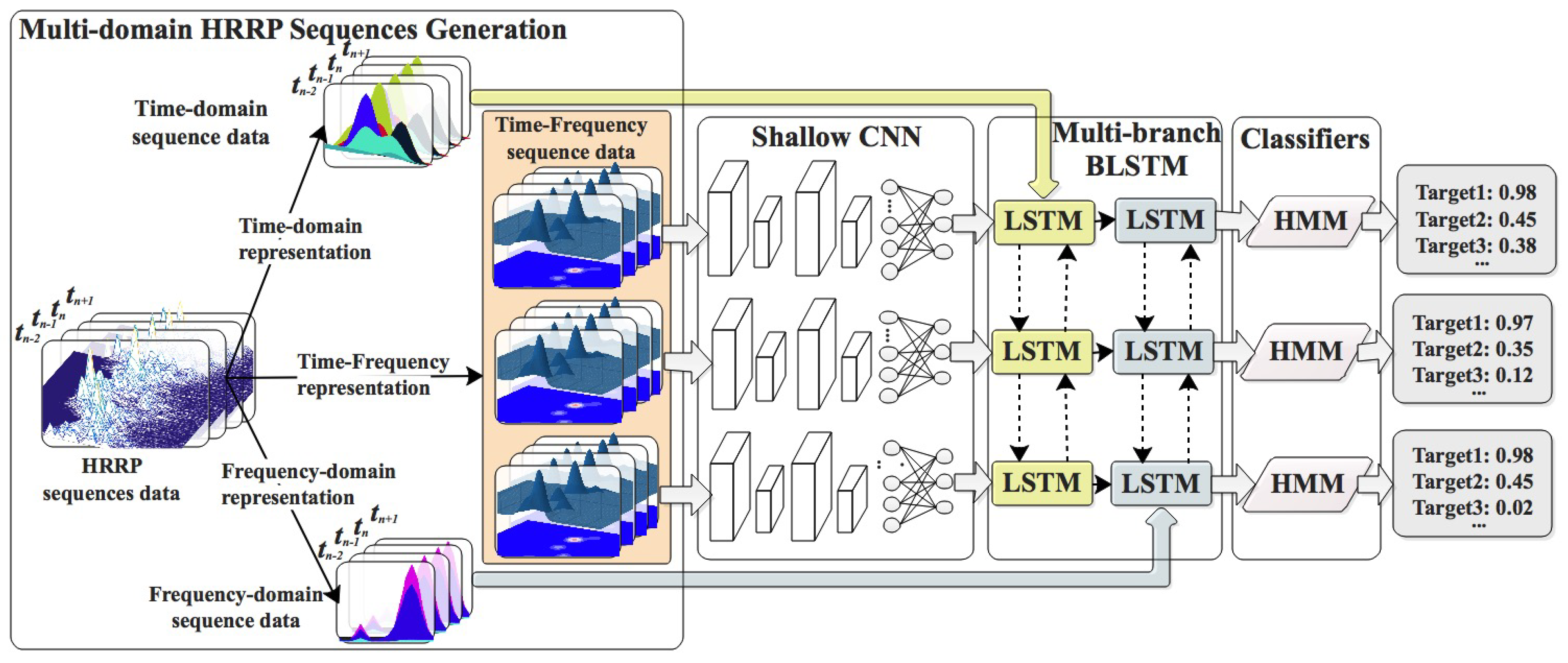
The proposed target recognition framework, termed MIBL-HMM, is illustrated in
Figure 2, including four processing steps, specifically: generating a multi-domain HRRP sequence, reducing feature dimensionality using a shallow CNN, fusing multi-domain sequence features with the multi-input BLSTM, and determining the category of each target sample via a HMM classifier.
3.1. Multi-Domain HRRP Sequence Generation
The generation of a multi-domain HRRP sequence is divided into two steps: (1) extraction of the HRRP sequence; (2) Based on the HRRP sequence, multiple data domains are generated, termed the multi-domain HRRP sequence. Details are given next.
(1) Extraction of the HRRP sequence:
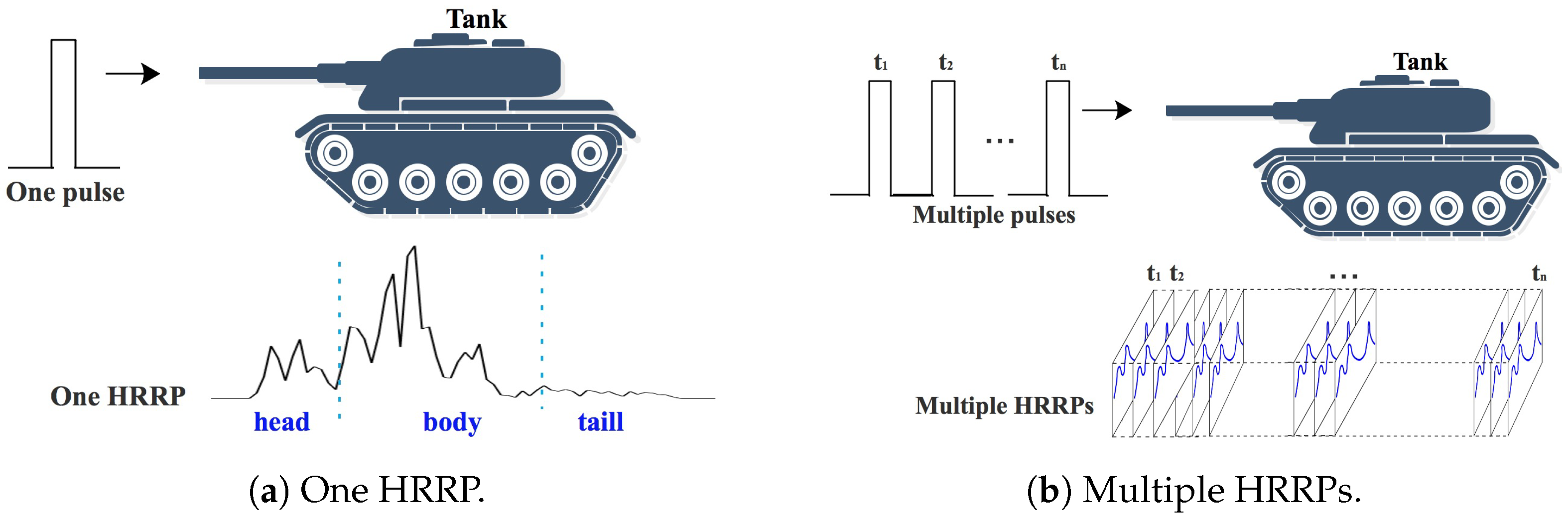
HRRP is a one-dimensional signal that reflects different scatters of the target in the direction of the line of sight radar. One HRRP represents the target’s response to one high range resolution radar pulse. In one HRRP, the amplitude of each range unit represents the intensity of the electromagnetic wave reflected by different scatters of the target. In a certain range of observation angles, the order of these intensities reflects the order of different scatters of the target in the direction of line of sight radar.
Figure 3a shows one HRRP generated by a tank in response to one pulse of the radar. In this HRRP, these range units present the features of tank components in the order of the line of sight radar, specifically: first, the head of the tank; secondly, the body of the tank; and finally, the tail of the tank. Therefore, the range units contained in one HRRP have obvious sequence characteristics. This conclusion is consistent with [
35,
36]. In contrast to the literature, as shown in
Figure 3b, we believe multiple HRRPs also possess timing sequence characteristics. This is because the electromagnetic pulses emitted by the radar have obvious timing sequence characteristics, so the HRRPs collected continuously also exhibit time-series characteristics. Subsequently, integrated with the sequence characteristics of a single HRRP, multiple HRRPs continuously acquired by the radar, will have obvious 2-D sequence characteristics. In this paper, we will extract HRRP sequences from these multiple HRRPs with 2-D sequence characteristics.
For a period of time, there is little difference, in theory, between multiple HRRPs continuously collected by the radar in a certain pose of the same target. However, due to various factors such as the environment, the difference between these HRRPs is relatively large. To alleviate these gaps and remove noise, the HRRPs collected during this period are arbitrarily divided into n groups which are not intersecting with each other. Next, each group is averaged by the multi-look processing strategy at the sample level. Under the condition that the original order is unchanged, a new set of n HRRPs is obtained, which is called a HRRP sequence. Such a HRRP sequence contains n elements, and the amount of information contained in each element is related to the average number of HRRPs. The larger the number, the more the amount of information. The information contained in each HRRP can be expressed by the radar aperture angle. For example, the radar aperture angle corresponding to each HRRP is . When the average number of HRRPs is 10, the information contained in each element in the HRRP sequence is aperture. It should be noted that this average number is limited for different purposes of HRRP. When HRRPs are used as training sets, the average number can take a large value, which is beneficial for the learning of target features. However, when HRRPs are used as test sets, this average number generally does not take a larger value. In this case, it is only necessary to select the corresponding number in each group of the split, to generate a test HRRP sequence. Currently, although each sequence of the training set and the test set contain the same elements, each element of the test set sequence contains less information than each element of the training set sequence. This is to save time of data processing in the recognition algorithm and speed up recognition speed.
(2) Generation of multi-domain HRRP sequence:
The various data domains considered in this paper include time domain, frequency domain, and time-frequency domain. Therefore, it is only necessary to generate these three data domains for each element of the HRRP sequence to obtain the multi-domain HRRP sequence. For the time domain and frequency domain features, the amplitude, value and power spectrum of the HRRP signal are used, respectively. For the time-frequency domain features, there are many extraction methods, such as short-time Fourier transform (STFT), Wigner-Ville distribution (WVD), and Adaptive Gaussian representation (AGR). STFT is the most commonly used time-frequency domain analysis method. It represents the signal characteristics at a certain moment, by a segment of the signal in the time window. However, the precision of time-frequency domain features obtained by the STFT method in time resolution and frequency resolution, is not available at the same time. The WVD method makes up for the shortcomings of the STFT method, but it leads to the problem of “cross-term interference”. Compared with these time-frequency domain feature extraction methods, the AGR method can decompose the echo signal into time-frequency center and local resonance of time-frequency domain resolution, and adjust the corresponding parameters using a Gaussian basis function to optimize the relationship between them. It can not only solve the “cross-term interference” problem faced by the WVD method, but also extract the adaptive spectrogram features effectively in the time-frequency plane. To-date, it has been successfully applied to ISAR imaging and radar target recognition [
44,
45]. Therefore, in this work, we use the AGR method to extract the time-frequency features of HRRP, as in [
18].
3.2. Feature Dimensionality Reduction Using a Shallow CNN
A key step in radar target recognition based on time-frequency data is the dimensionality reduction of time-frequency features. Dimensionality reduction of data generally faces such dilemma: on the one hand, we hope to reduce the dimensionality of data as much as possible to avoid redundancy and complexity; on the other hand, we hope to retain as many features of data as possible to expand the learning space for extracting effective features. To alleviate this problem, this paper uses a shallow CNN to reduce the dimensionality of time-frequency features.
The shallow CNN comprises an input layer, two convolution layers, and a fully connected layer. In the input layer, the number of neurons is equal to the dimension of time-frequency features. In the fully connected layer, the number of neurons is equal to the dimension of the BLSTM’s neural network input layer. To train the weights between the input layer and the hidden layer, we add the
classifier on the fully connected layer. The number of the classifiers is equal to the number of target categories. The shallow CNN model can be expressed as follows:
where
X is the input feature vector of a time-frequency matrix,
indicates class
i,
is the probability of
X belonging to class
i,
represents the softmax function,
is the bias of the
kth layer,
represents weights between the
and (
k + 1)
th layers, ⊗ represents the convolution operation,
is a function which connects the convolution layer and the fully connected layer by collapsing an array into one dimension, and
R indicates the Rectified Linear Unit (ReLU) activation function.
In the training stage, the weights of the convolution layer and the fully connected layer are initialized with random values, and then continuously adjusted by the back-propagation algorithm, under the condition of decreasing the cross-entropy loss. The training process is repeated till the learning error falls below a moderate tolerance level. Then, the dimensionality-reduced features
x can be obtained using the feed-forward CNN network:
Unlike common dimensionality reduction methods (such as principal component analysis, linear discriminant analysis, etc.), the shallow CNN has obvious advantages. It can not only reduce the dimensionality of data, but also extract spatial features of data by connecting with the fully connected layer in a non-linear way, which effectively enhances the feature preservation of data after dimensionality reduction.
3.3. Multi-Domain Features Fusing with Multi-Input BLSTM
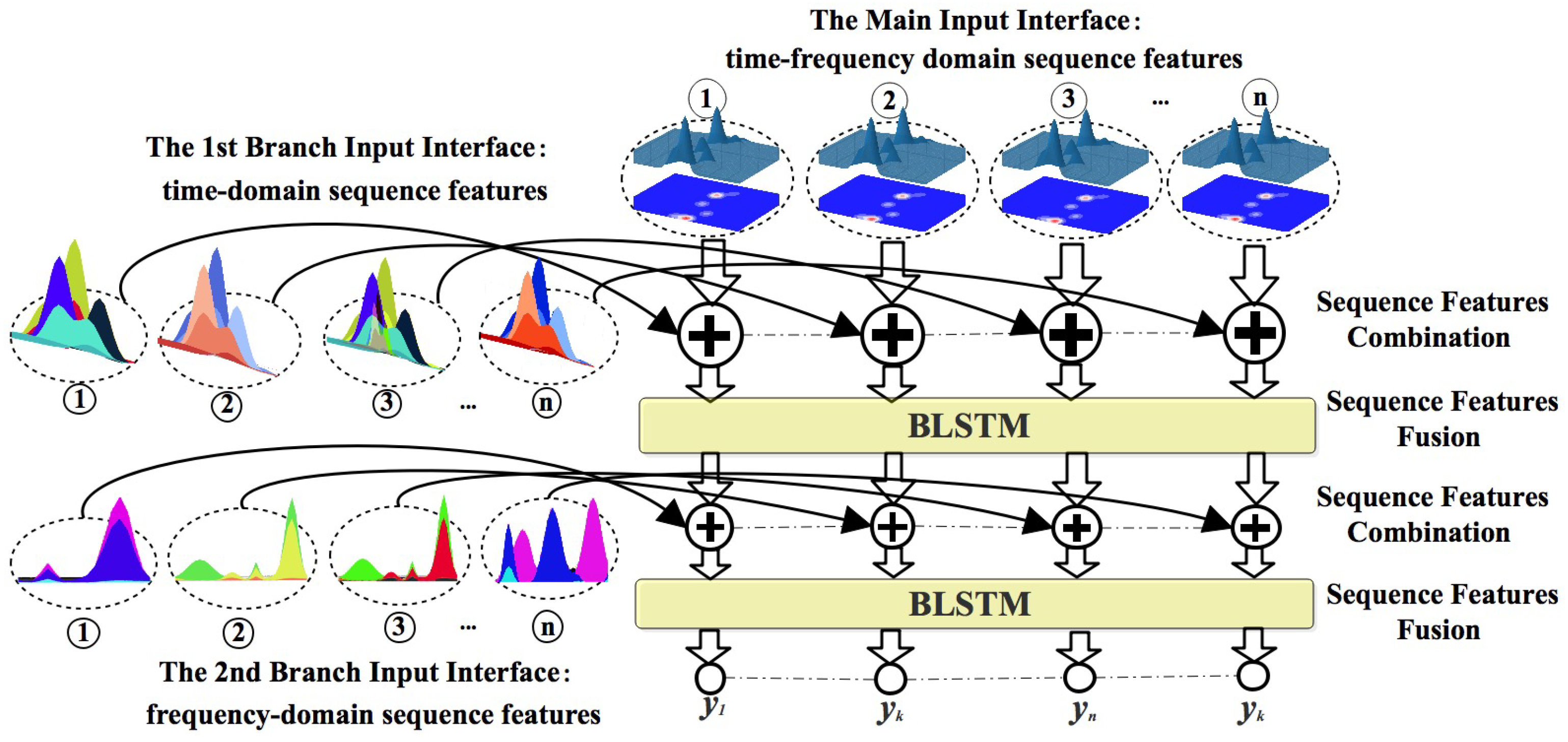
The aim of the multi-input BLSTM is to learn and fuse the features of multi-domain HRRP sequences. It consists of two parts:
(1) Multi-input, i.e., the algorithm has multiple input interfaces. These are divided into a main input and branch inputs. There is only one main input, which is located in the first layer, and there are many branch inputs, which are in subsequent layers other than the first layer. In terms of the importance level of features, the most important features are input from the main input interface, and secondary features are input from the branch input interface. The deeper the branch interface, the less important feature input is received. The design of the multi-input, on the one hand side, ensures the most important features are learned using the whole neural network, i.e., by extracting the most abstract and easily recognizable features; and on the other hand, in the process of learning the most important features, it gradually fuses other features in order to suppress the neural network over-fitting, and finally improves the recognition performance of the algorithm.
Figure 4 shows the multi-input BLSTM used in our algorithm. It contains three input interfaces: one main input and two branch inputs. The main input interface receives time-frequency sequence features after dimensionality reduction, the first branch interface receives the time-domain sequence features, and the second branch interface receives the frequency-domain features. The important levels of these three different data domain features will be discussed in the experimental section.
(2) Features combination and fusion. In the process of learning the main input features, the multi-input BLSTM needs to gradually fuse features. At this time, it will face the problem of combining and fusing the features of two different data domains. There are many ways to combine sequence data, such as element-wise addition, subtraction, multiplication, or concatenation. Here, we use element-wise addition, which is the addition of the corresponding elements, as shown in
Figure 4. In this way, simple linear addition does not destroy the features of different data domain sequences; and, the value of each range bin in HRRP is small, and can be appropriately increased by the addition with highlighted features. After the combination, the sequence features will go into the BLSTM network to automate the fusion of different data domain sequence features. Since each BLSTM network consists of two recurrent neural networks, one is forward processing data, the other is the backward processing data, both of which are connected to the same output layer so that each BLSTM network has the ability to learn the past and future information from data. Therefore, in the process of sequence feature fusion, the multi-input BLSTM cannot only learn and fuse the sequence features of different data domains at the current time, but also fuse the past and future information of these sequence features.
In conclusion, compared with the standard multi-layer BLSTM, the multi-input BLSTM enhances the ability of the standard multi-layer BLSTM with multi-input functionality. Compared with traditional HRRP target recognition methods, the multi-input BLSTM can deeply learn rich features contained in the HRRP data. Here, we use a multi-input BLSTM network consisting of three layers: input, hidden, and output layer. The input layer is three inputs mentioned above, the hidden layer includes two BLSTM networks, and the output layer is a fully connected layer with sequence features. The multi-input BLSTM is trained in the same way as the shallow CNN. Finally, the multi-domain HRRP sequences go into the trained multi-input BLSTM to produce the fused feature sequences, which are sent to a HMM classifier to learn and classify the multi-aspect features.
3.4. Multi-Aspect Features Learning and Classification with HMM
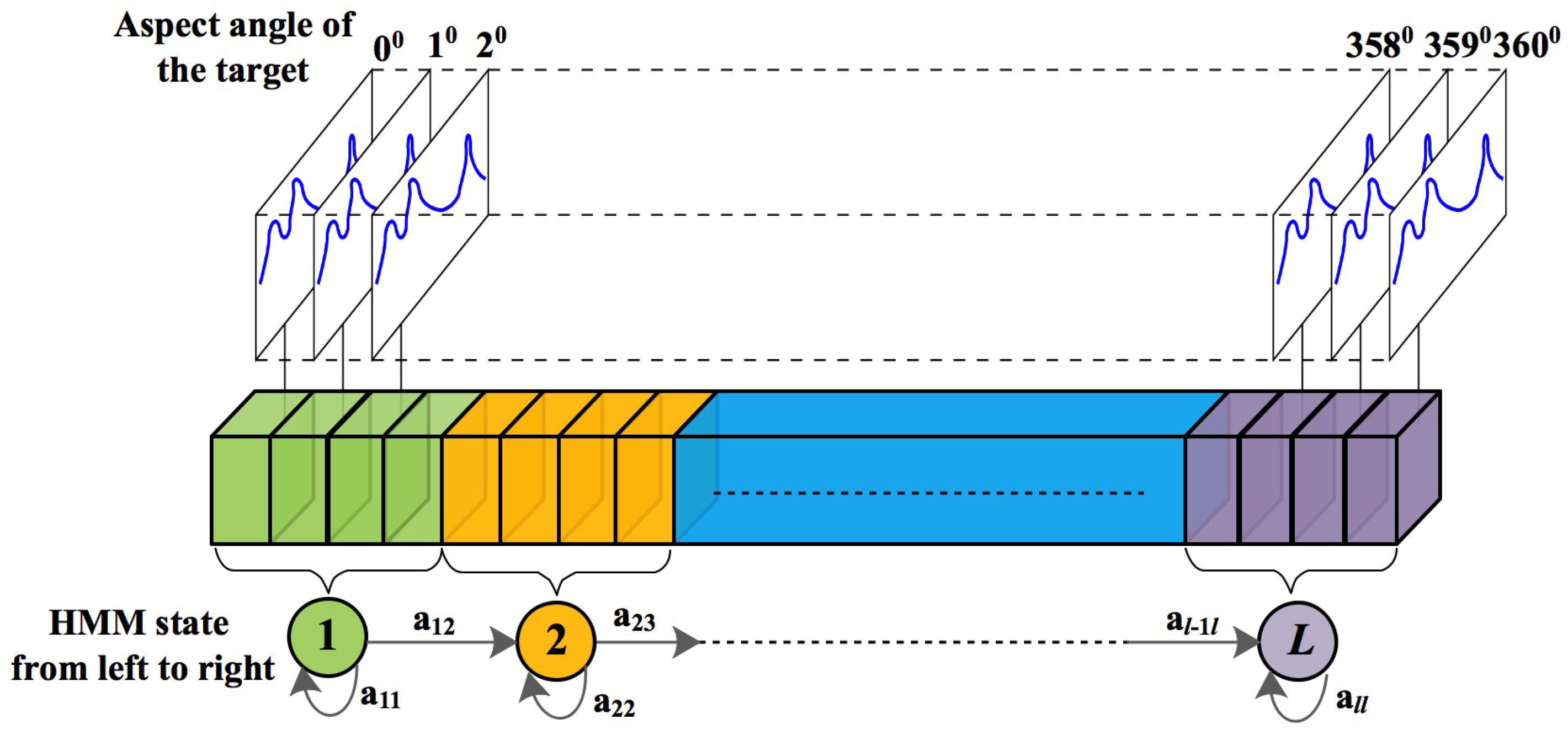
Multi-domain HRPP sequences are fused by the multi-input BLSTM to obtain a sequence feature. Each sequence feature corresponds to an aspect angle of the target. Before entering the HMM classifier, these sequence features need to be processed as follows.
In the HMM training stage, these sequence features are connected in series to form a matrix. As shown in
Figure 5, the horizontal direction represents the aspect angle and the vertical direction represents the sequence features. Here, we use this feature matrix to construct the HMM model, i.e., to establish the state of HMM and the mode of transition of these states, and then calculate the probability
and transition probability matrix
of the initial state of the corresponding HMM model. Since the details of the HMM-based multi-aspect feature classification algorithm used here have been described in several papers [
16,
17,
18], we briefly summarize the basic concepts in this section.
(1) Establishing the state of the HMM model and the mode of these state transitions. Using the average aspect angle, the omni-directional angular space of the radar observation target, namely 360 degrees, is divided into
L states, and the angular extent of each state is
degrees. In addition, to reduce the parameters of the HMM model, the initial transition mode of the HMM model is from left to right, as shown in
Figure 5.
(2) Calculating the probability
and transition probability matrix
of the initial state of the HMM model. When the radar observation position is constant, let
represent the range of the target aspect change when the radar continuously measures the target. Let
represent the range of the state
i (angle change). Regarding the state transition of the HMM, the state
i is subjected to
<
. Assuming that
,
represents the probability of state
i to the next state
j, then the initial value of
is as follows:
Moreover, the initial orientation of the target is generally considered to be uniformly distributed, so the probability of the initial state can be calculated:
As discussed above, Equations (
5) and (
6) constitute the initial estimates of
and
. These parameters can be better estimated by the Baum-Welch method. Through the above methods, the HMM model can be established and trained. Each type of target corresponds to an HMM model, i.e., the number of HMM models depend on the type of targets. In addition, it should be noted that this paper adopts the continuous HMM model. This is because when HRRP is vectorized to obtain discrete signals, HRRP will be distorted, which reduces the recognition performance of the HMM.
In the HMM test phase, the sequence features obtained by the multi-input BLSTM are directly go into the trained HMM model, and the likelihood estimates in the output of each HMM model are obtained. If the
i-th HMM yields the largest likelihood, then we declare the sequence features are associated with the
i-th target type. For example, if we obtain the following aspect sequence
from the unknown target type
T, then the probability of the observation sequence
is given by summing the joint probability
over all possible state paths
.
If the target type
gives the maximum likelihood for the observation sequence
, i.e.,
Then we declare the sequence
belongs to the target type
.
Compared with the traditional HMM-based HRRP target recognition algorithm, this paper builds the aspect sequence of HRRP based on the fusion of multi-domain sequence features, so the HMM can fully learn the features of HRRP to provide the recognition outcome.
4. Benchmark MSTAR Dataset
Due to the lack of open HRRP real data, we use the benchmark real data of moving and stationary targets for acquisition and recognition (MSTAR) SAR images published by the US Department of Defense to test the proposed algorithm. MSTAR is the standard database for evaluating SAR image target recognition algorithms. According to the header information provided with the database, the radar frequency of the collected data is 9.599000 GHz. We know that the radar target’s characteristic dimension is 1 m if we use the high frequency band of 30 MHz–300 MHz, and 0.1 m if using the high frequency band of 300 MHz–3 GHz, and about 0.03 m by using the high frequency band of 9.599000 GHz. Therefore, the HRRP signals generated from the MSTAR database contain sufficient information about vehicle targets such as tanks, artillery, or trucks, which can be used for target recognition research [
44,
45,
46,
47,
48]. The MSTAR database includes 10 types of military vehicle targets: BMP2, BRT70, T72, BTR60, 2S1, BRDM2, D7, T62, ZIL131, and ZSU234. Among them, the BMP2 contains three different variants: BMP2_9563, BMP2_9566 and BMP2_c21; the T72 also contains three different variants: T72_132, T72_812 and T72_s7. Although these variants have the same design blueprint, they come from different manufacturers and still have some differences in color and shape. In addition to the military vehicle targets, MSTAR also includes a type of man-made target: SLICY. The SLICY is often used as the interference target to test the generalization ability of the proposed recognition algorithm. The optical images of these 11 types of targets are shown in
Figure 6.
The MSTAR data is acquired by the X-band spotlight mode SAR. At a certain depression angle, the SAR circles the target several times, and collects images from the target multiple-aspect angles in the range of
. The aspect angle change intervals are not uniform. Even the same target is different at different depression angles, which will increase the recognition difficulty of the proposed algorithm. In addition, in the experiments, the observation data at
depression angles are generally used for training, while
are used for testing.
Table 1 shows the acquisition of SAR images in the MSTAR database.
4.1. Inversing HRRP from the SAR Image
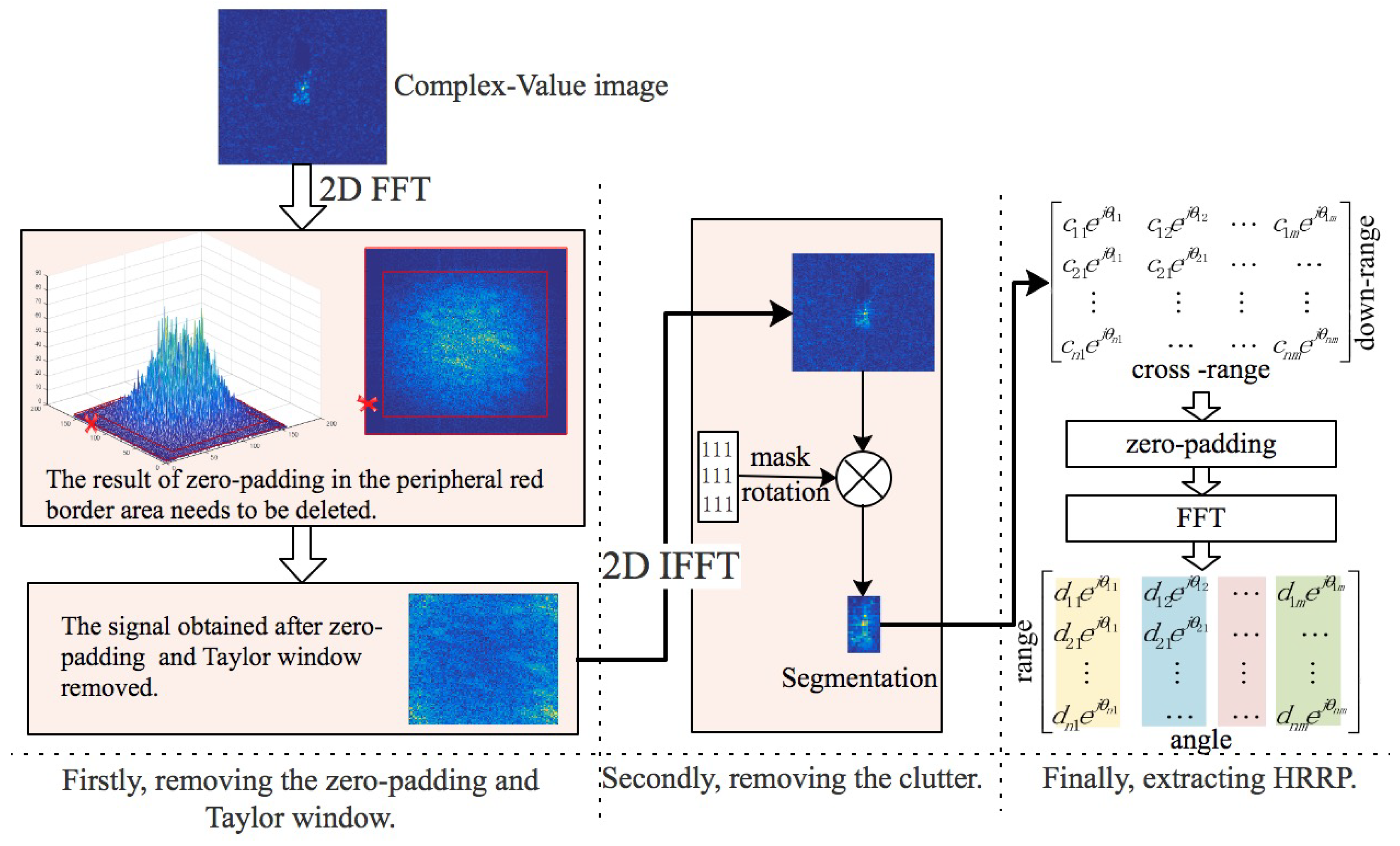
Figure 7 shows the basic process of inversing HRRP from the SAR image, which comprises three steps:
Firstly, we remove the zero padding and the Taylor window. The MSTAR images are formed by taking a 2-D inverse fast Fourier transform (IFFT) of the Taylor-windowed and zero-padded phase data on a rectangular grid. The 2-D FFT is undertaken at first. Then the transformed signal is shifted so that the low frequencies occur in the center.
Figure 7 shows the resulting 2-D signal of an example of the MSTAR SAR images. A noticeable band of near-zero values appears at the border of the 2-D signal, as shown in
Figure 7. This band is the zero-padding result, which must be removed from the border of the signal. Next, we remove the Taylor window based on its parameters (35 dB sidelobe suppression level).
Secondly, we remove the clutter. Once zero padding and the Taylor window have been removed, a 2-D inverse FFT is applied to produce a de-convolved and Nyquist-sampled SAR image. Then the target segmentation procedure is undertaken to achieve the clutter removal.
Finally, we extract the HRRP. Before extracting the HRRP, the segmented SAR image requires zero padding to restore the original image size. Then, the zero-padding SAR image is transformed using the FFT, and the HRRP is extracted.
Table 1 shows the number of HRRP that can be extracted from each SAR image for each type of target.
In
Table 1, the number of HRRPs extracted from different sized SAR images is different. However, since all SAR images have the same down-range and cross-range resolutions, i.e.,
, the radar aperture angle represented by HRRP generated from each SAR image is equal, i.e.,
where
GHz, the center frequency of the radar waveform, and
c is the speed of light.
4.2. Generating a Multi-Domain HRRP Sequence
According to the description in
Section 3.1, the construction of the MSTAR multi-domain HRRP sequence goes through two steps.
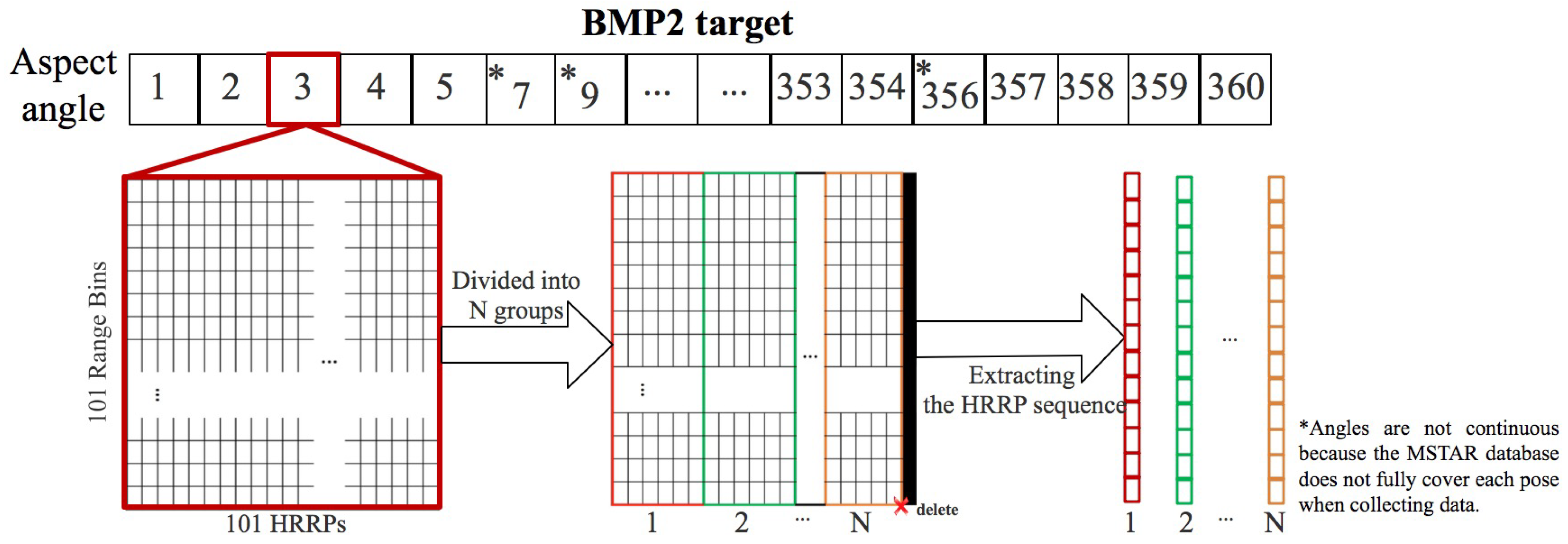
First, the HRRP sequence is extracted. The HRRPs obtained from a slice of SAR image are taken as a set of HRRPs collected continuously by the radar over a period of time.
Figure 8 shows the basic process of extracting a HRRP sequence from the BMP2 target. 101 HRRPs are divided into
N groups. For ease of calculation, if 101 is not divisible by
N, the remaining HRRP will be deleted. If
, an HRRP sequence containing four elements is generated. In the training set, each element is the average result of 25 HRRPs, which contains
aperture information. In the test set, if not averaged, then each element is selected from one of the original 25 HRRPs, which contains
aperture information. Alternatively, an appropriate averaging number can be selected. For example, we select the amount of information for each element to be
aperture, i.e., 10 of the original 25 HRRPs for each element. This ensures that each element of the test set contains a certain amount of information to improve the recognition accuracy. Each element of the test set in this paper takes
aperture.
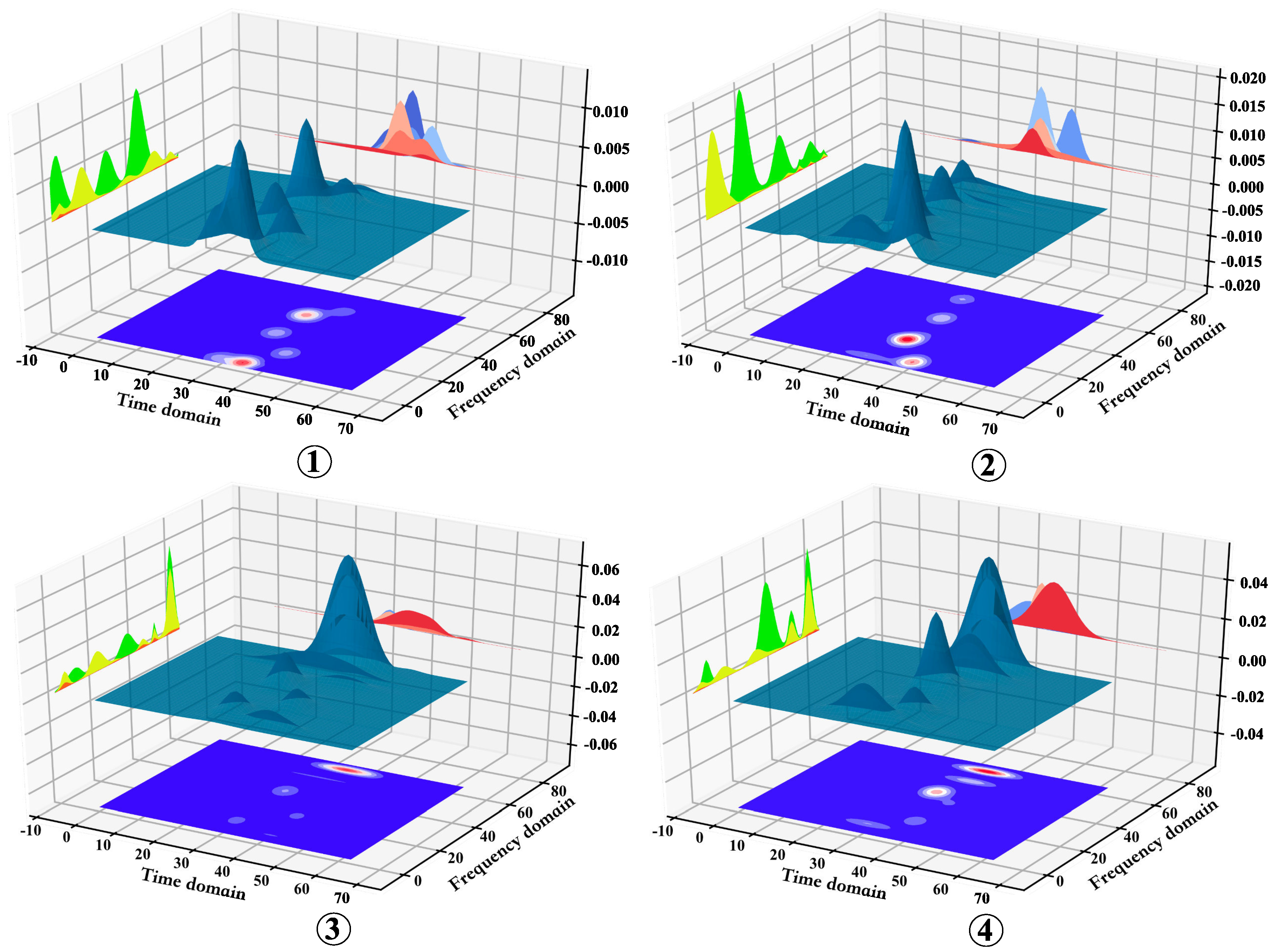
Secondly, we generate multi-domain HRPP data. The data domains in this paper include: time-, frequency-, and time-frequency (T-F)-domains. The amplitude in the time domain and the power spectrum in the time-frequency domain are used as target features for identification. For the T-F domain, we adopt AGR to extract T-F features of HRRP. In
Figure 8, if
N = 4, the 4-element multi-domain HRPP sequence in these three domains will be generated respectively, as shown in
Figure 9. For each subfigure, the top-left part is the power spectrum in the frequency domain, the top-right part is the amplitude in the time domain, the middle part is the 3-D T-F feature generated from the power spectrum and the amplitude, and the middle-lower part shows 2-D T-F features.
5. Experiments
To test the validity and generalization capability of the proposed algorithm, we designed a series of experiments under extended operating conditions (EOC) [
49,
50]. The so-called EOC is to test the algorithm according to various conditions in reality. These test conditions are different from those of the training algorithms. Specific EOC are set as follows:
(1) The test set is very different from the training set. Generally, the data of the depression angle is selected as the training set, and the depression angle is used as the test set. More stringently, one of the variants of BMP2 and T72 is used as the training set, while the other two variants are used as the test set.
(2) The aspect information of the target in the test set is assumed to be unknown and covers aspect during the test. This hypothesis is meaningful in reality. First, it reduces dependence of the radar on other resources. For example, an auxiliary device such as a moving target indicator, a tracker, or the like is not required to acquire the azimuth information of the target. The azimuth coverage of the target is generally required to be . However, this will increase the difficulty of the recognition algorithm, and will represent a significant challenge to our algorithm.
(3) The target in the test set is considered to be a non-cooperative target. This means that the target type that appears in the test set may not be present in the training set. This situation is inevitable in reality. Because of the incompleteness of the database, a new test sample may not find its similarity in the database. Therefore, the recognition algorithm needs evaluation criteria to determine whether the test sample belongs to the library (in-targets) or not (out-targets).
In this paper, three groups of experiments are set up under the above EOC: baseline experiments, validity verification experiments, and robustness evaluation experiments. These are described next.
5.1. Baseline Experiments
To verify the validity of the proposed multi-domain HRRP sequence features, we designed two sets of comparative experiments:
(1) B1 experiment: Comparing the validity of the HRRP random data and the sequence data in a single data domain;
(2) B2 experiment: Comparing the validity of the HRRP sequence data in the same data domain with different data domains.
5.1.1. B1 Experiment
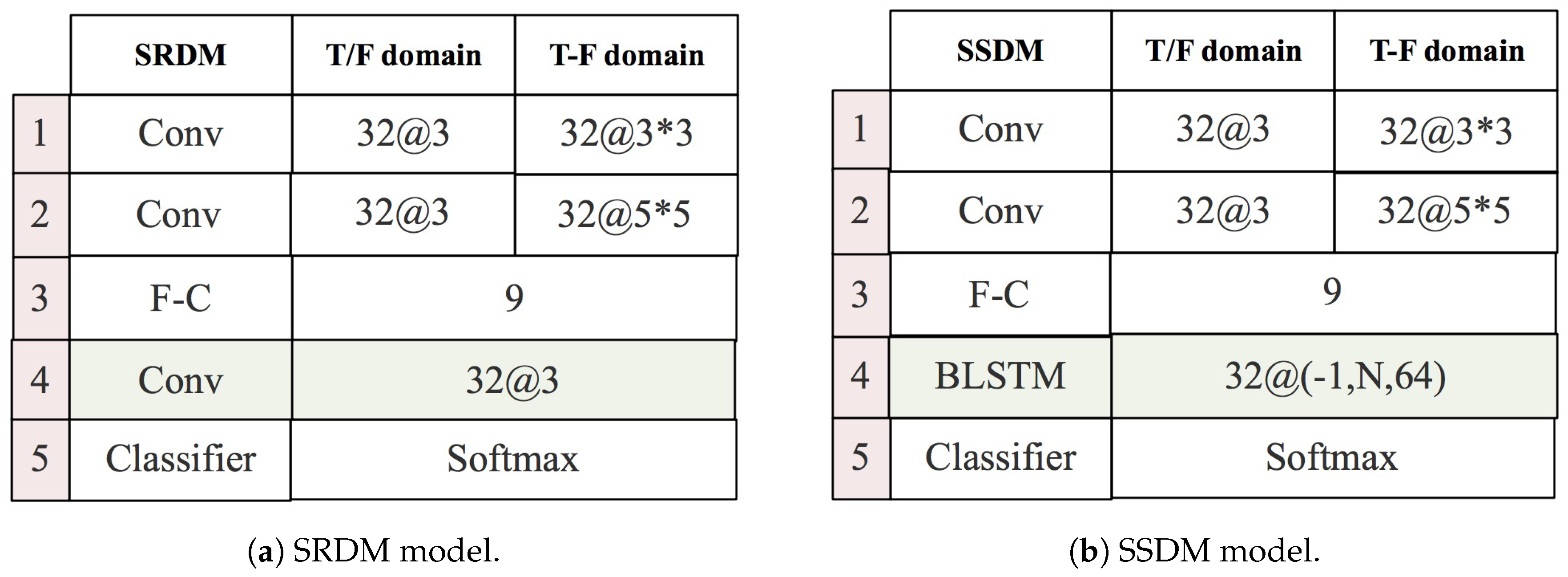
To compare the validity of the HRRP random data and sequence data in a single data domain, we constructed two similar test models, namely single-domain random data model (SRDM) and single-domain sequential data model (SSDM). The design of these two models is shown in
Figure 10.
Figure 10a represents the SRDM model and
Figure 10b shows the SSDM model.
In
Figure 10a,b, the first column shows the number of layers of the model; the second column shows the name of the model and its structure; the third and fourth columns show which data domains are entered and configuration of the model in the current data domain. Overall, the two models have similar structures and configurations. They comprise five layers; the first four layers are for data preprocessing and the fifth layer is the classifier.
,
, and
F-
C represent a convolutional layer, a bidirectional LSTM layer, and a fully connected layer, respectively. Since HRRP is one-dimensional data in the time and frequency domain, but two-dimensional data in time-frequency domain,
has two configurations:
represents one-dimensional convolution of convolution kernel 3, which results in 32 features;
represents a two-dimensional convolution of the convolution kernel
, and also results in 32 features, after this convolution operation has been implemented. In the
configuration,
means that 32 features are obtained after the processing of this layer, −1 indicates that the number of the input sequence samples is not limited,
N denotes that each sequence sample contains
N elements, 64 implies each element is a 64-dimensional vector. In these two models, the configuration of the first three layers is identical, while the configuration of the fourth layer is different. In the fourth layer, the SRDM model uses a convolution layer, while the SSDM model uses the
layer. This is because, unlike the SRDM model, the SSDM model needs to extract sequence features. After the first four layers are set up for preprocessing, the two models eventually use the same classifier for recognition. The SRDM and SSDM models are designed in this way to ensure their experimental results are comparable. In the test results of the SRDM model, the validity of HRRP in time domain, frequency domain, and time-frequency domain can be compared under random conditions. In the test results of the SSDM model, the validity of HRRP in these domains can be compared under ordered conditions. In the test results of these two models, the effectiveness of HRRP in the same data domain under random and sequential conditions can be compared.
From
Table 1, the training and test sets containing the “out-targets” are selected to test the SRDM and SSDM models. In the training set, we choose 9 types of targets; in the test set, because of the non-cooperative characteristics of the targets, we choose 2 types as the “out-targets” and the remaining as “in-targets”. These target types are shown in
Table 2. In
Table 2, the targets except “Others” in the first line, are the targets of the training set, i.e., 9 types of “in-targets”. In addition, the targets in the first column are the targets of the test set, in total 10 types, including 2 types of “out-targets”. In addition, to better demonstrate the validity of the data, the HRRP data of these targets are respectively generated into four sets of data to train and test the two models, according to the description in
Section 4. In these four sets of data, each sequence of the training set contains 5, 4, 2, and 1 elements, which correspond to the aperture angles of
,
,
and
respectively. The aperture angle of each element in the test set is
. The order of the HRRP sequence is ignored in the SRDM model. Under such conditions, the experimental results of the SRDM and SSDM models are shown in
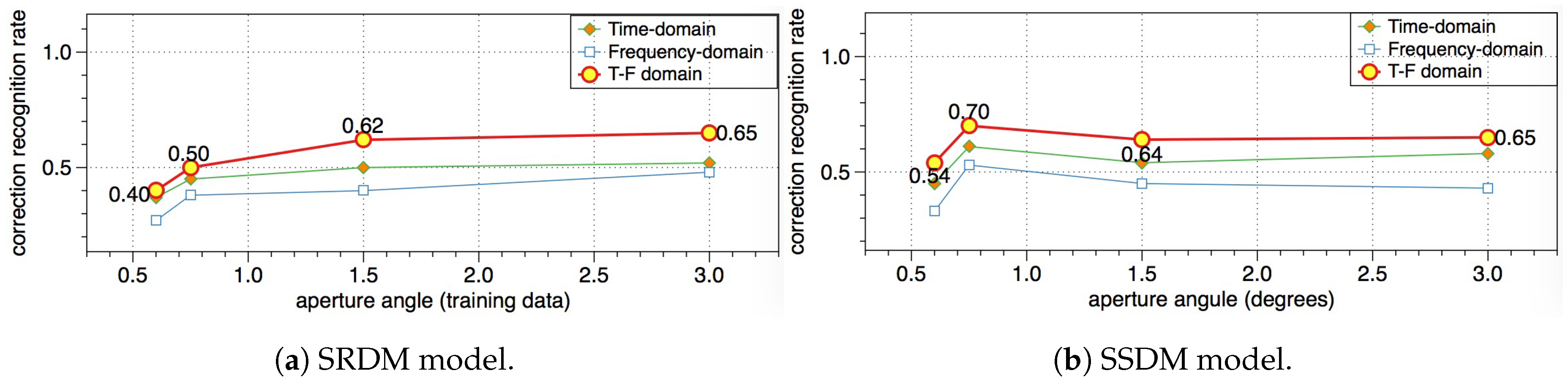
Figure 11a,b, respectively. The horizontal axis represents the aperture angle of the training set corresponding to different experiments, and the vertical axis represents the recognition rate of the model.
![Electronics 08 00535 i001]()
,
![Electronics 08 00535 i002]()
and
![Electronics 08 00535 i003]()
represent the recognition rate curves in time, frequency, and time-frequency domain, respectively.
In terms of the data domain,
Figure 11a,b show that the feature recognition results in the time-frequency domain are the best, followed by the time-domain features, and finally the frequency-domain features. The recognition rate of the sequence features shown in
Figure 11b is higher than that of the corresponding random features shown in
Figure 11a. This shows that the HRRP sequence proposed in this paper is effective, which can improve the recognition rate of the targets.
Figure 11a shows that the target recognition rate increases with the increase of aperture angles. When the aperture angle is
, i.e., all the HRRPs extracted from each SAR image in the training set are processed by the multi-look scheme at the sample layer to obtain one HRRP, where the target recognition rate is the highest. This is consistent with other conclusions reported in the literature [
51]. Unlike
Figure 11a, the target recognition rates shown in
Figure 11b do not increase with the increase in aperture angle. This shows that the improved target recognition rate is not caused by the increase in aperture angles, and is, in fact, due to the HRRP sequence proposed here.
In the above comparative experiments, the SSDM model trained with the HRRP sequence in the time-frequency domain with
aperture produces the highest recognition rate.
Table 2 shows the recognition results in the form of a confusion matrix. Since there are the “out-targets" in the test set, we need to use reasonable evaluation criteria.
The introduction of the “Others” type in the first line of
Table 2 is the strategy adopted in this paper. Given a test sample, we first determine whether or not it belongs to the “in-targets”. If so, we continue to determine which types it belongs to; if not, it is considered to belong to the “out-targets” and we classify it as the “Others” type. Ideally, the “in-targets” in the test set are correctly identified and the “out-targets” are correctly classified as the “Others”. However, in the actual test, the “in-targets” may be incorrectly recognized as the “Others” type, and the “out-targets” may be incorrectly recognized as the “in-targets”. Therefore, we need three evaluation criteria to evaluate the experimental results. The three criteria are defined as:
- (1)
Correct recognition rate of “in-targets”:
where
is the total number of “in-targets” in the test set,
is the total number of “in-targets” identified as “Others” type in the test set, and
is the total number of “in-targets” correctly identified in the test set.
- (2)
Detection rate of “in-targets”:
- (3)
False alarm rate of “out-targets”:
where
is the total number of “out-targets” identified as “in-targets” in the test set, and
is the total number of “out-targets” in the test set.
In
Table 2, we set
to 0.9, which means that 10% of “in-targets” in the test set are judged as “out-targets” when they are less than a certain threshold. In this way, on the one hand, the reliability of identification of “in-targets” in the test set can be improved; and on the other hand, a reference threshold can be found to judge the “in-targets” as “out-targets” for subsequent experiments. Under such conditions,
,
are obtained in
Table 2, which is still a long way from the ideal results (
,
). Therefore, in the next set of experiments, we explore the fusion of multi-domain HRRP sequence features to further improve the target recognition rate.
5.1.2. B2 Experiment
In
Section 5.1.1, both the SRDM and SSDM models have only one input, so these two models belong to the single-look processing type. The experimental results shown in
Section 5.1.1 show that the recognition rates of these two models are not satisfactory. Compared to the single-look processing model, the multi-look processing model uses multiple inputs to extract and fuse multi-view features of data, which can improve recognition performance. Normally, the input data of the multi-look processing model are from the same data domain. Here, we will build a multi-input BLSTM model, and then, on the one hand, we use the same data domain HRRP sequence data for testing; and on the other hand, we use different data domains’ HRRP sequence data for testing. The purpose is to compare the validity of sequence features in the same data domain and in different data domains.
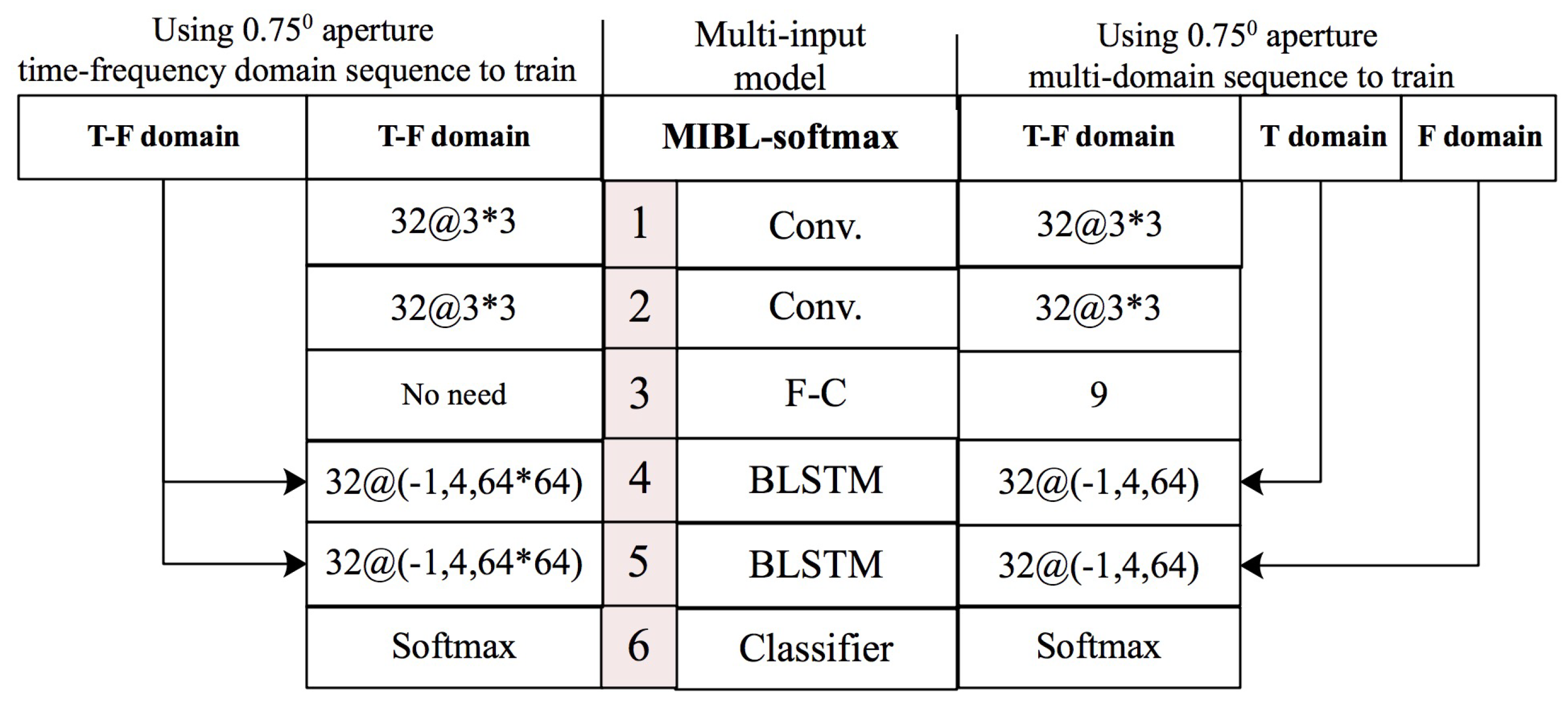
Figure 12 shows the multi-input BLSTM model built in this section. The middle column represent the structure of this model, and the left and right sides are the corresponding configurations under different input data. The model comprises six layers, where the first five layers represent data preprocessing, and the sixth layer is the classifier, with use of
. Therefore, we use MIBL-softmax to represent the model. The MIBL-softmax model has three input interfaces: one main input interface and two branch input interfaces. The main input interface is at Layer 1, the first branch input interface is at Layer 4, and the second branch input interface is at Layer 5. When the input data is from the same data domain HRRP sequence, these data do not need to distinguish the importance level, and directly feed in the input interface of the MIBL-softmax model. When the input data is from different data domains, we send them to the primary and secondary input interfaces of the MIBL-softmax model, from large to small, according to the importance level.
Looking at the experimental results shown in
Section 5.1.1, when the HRRP sequence is at
aperture, the time-frequency domain features are the best, followed by the time domain features, and finally the frequency domain features. Therefore, the HRRP sequence of
aperture in the time-frequency domain is used and sent to three input interfaces of the MIBL-softmax model. On the other hand, we use the time-frequency domain, time domain, and frequency domain HRRP sequence of
aperture as the data of the different data domains, and use the main input interface, the first branch input interface and the second branch input interface of the MIBL-softmax model respectively. The test results of these two sets of data in the MIBL-softmax model are represented by the confusion matrix as shown in
Table 3 and
Table 4.
Table 3 shows test results of the same data domain HRRP sequence in the MIBL-softmax model. The correct recognition rate
of the MIBL-softmax model is 0.8205, which is significantly higher than
shown in
Table 2. Under the same threshold as shown in
Section 5.1.1, the detection rate
of the MIBL-softmax model reaches 0.9078, which is higher than
shown in
Table 2. Regarding the “out-targets”, the
of the MIBL-softmax model is reduced to 0.5857, which is significantly lower than
shown in
Table 2. This shows that, compared to the single-look processing model, the multi-look processing model has a better confidence level and the recognition rate for “in-targets”, and a better distinction between “out-targets” and “in-targets”, for the traditional case of using the same data domain HRRP sequence as input. This is because the multi-look processing model extracts the features of the HRRP sequence several times and continuously fuses them to obtain the best discriminative features. This in turn, improves the recognition performance of the targets to some extent. However, due to the limitation of the HRRP sequence in the same data domain, the recognition performance of the MIBL-softmax model is difficult to be further improved.
Unlike
Table 3,
Table 4 shows the test results of different data domain HRRP sequence in the MIBL-softmax model. Compared to
Table 3, the three evaluation criteria shown in
Table 4 have been significantly improved. The correct recognition rate
of the “in-targets” increases from
to
; the detection rate
of the “in-targets” increases from
to
; and the false alarm rate
of the “out-targets” decreases from
to
. This indicates that in the same multi-look processing model, the different data domain HRRP sequence is more favorable for target recognition than the same data domain HRRP sequence. Specifically, the data with the highest importance level, i.e., the main input data, can be better extracted through the whole network; secondly, the data with the highest importance level are seen to be the non-linear transformation of input data from each branch, i.e., the time-frequency domain data is the non-linear transformation of the time-domain data and the frequency-domain data. When the multi-look processing model fuses the input features, then, firstly, the data of each branch can provide similar features to the system, which can enhance these features in the fusion process, and thus improve the target recognition rate. Secondly, they can also add the features of different data domains in the process of non-linear transformation, which makes the multi-look processing model exhibit better generalization ability and lower false alarm rate. Therefore, in the process of multi-look sequence recognition, the HRRP sequence features in different data domains are more effective than those in the same data domain.
5.2. Validity Verification Experiments
In the baseline experiment of
Section 5.1, we validated the validity of the multi-domain HRRP sequence features. In this section, we will verify the validity of the proposed MIBL-HMM algorithm for multi-domain HRRP sequence feature learning. Here, we continue to use the
aperture multi-domain HRPP sequence shown in
Table 4 as the training data, and set up two sets of comparative experiments:
(1) V1 experiment: the comparative experiment between the MIBL-HMM algorithm and the MIBL-softmax algorithm. For the case of the multi-input BLSTM algorithm, the MIBL-HMM algorithm uses the HMM as the classifier, while the MIBL-softmax algorithm uses the as the classifier. To verify the effectiveness of the MIBL-HMM in further learning multi-aspect features contained in the multi-domain HRRP sequences, the MIBL-HMM and the MIBL-softmax are compared under the same design and configuration, except for the different classifiers.
(2) V2 experiment: comparisons between MIBL-HMM and MIL-HMM algorithms. The MIL-HMM algorithm is an algorithm in which the multi-input LSTM algorithm uses the HMM as a classifier. To validate the effectiveness of the MIBL-HMM in learning multi-domain HRPP sequence features, the MIBL-HMM and the MIL-HMM are compared under the same design and configuration, except for the different numbers of the directions of LSTM.
Before starting the comparison, we need to train the HMM models. The algorithms reviewed in
Section 3.4 are first used to construct the HMM models. These are then trained using the forward and reverse HRRP aspect sequences. The forward sequence is the aspect angle of the HRRP sequence sorted from small to large, i.e.,
...
, while the reverse sequence is arranged in the opposite direction. These sequences contain all HRRP aspect information and state statistics, and are able train HMM models quickly. The training set used in
Section 5.1 contains 9 types of targets. Therefore, 9 HMM models need to be trained, with each target type corresponding to one HMM model. In the training process, the Baum-Welch algorithm is used to estimate the parameter
and the state density function of the HMM, so that the HMM can better reflect the scattering characteristics of the targets.
5.2.1. V1 Experiment
In the test phase of the MIBL-HMM algorithm, the multi-domain fusion sequence features of the unknown targets are fed into the 9 trained HMM models, and the corresponding likelihood values are generated, respectively. If the maximum of these likelihood values is less than the threshold set shown in
Section 5.1.1, the unknown target is identified as an “out-targets”. Otherwise, it is identified as “in-targets”, and its specific type is the target type represented by the HMM model which obtains the maximum likelihood value.
Table 5 shows the recognition results of the MIBL-HMM algorithm. The correct recognition rate of the “in-targets” is seen to be
, the detection rate of the “in-targets” is
, and the false alarm rate of the “out-targets” is
. For the same test set, compared with the test results of the MIBL-softmax algorithm (
,
,
,
Table 4), the MIBL-HMM algorithm test results can be seen to have improved. The results show that the proposed method can further learn the multi-aspect features contained in the HRRP multi-domain sequence features to improve the recognition performance.
It should be noted that the HMM model is sensitive to the number of hidden states and the weight of the Gaussian probability density function. Changing these configurations will lead to additional complexity in the HMM model for sequential data processing.
Figure 13 shows the recognition rate of the HMM model using the MIBL-HMM algorithm under different hidden state numbers
S and weights
w of the Gaussian probability density function. When
S = 60 and
w = 2, the MIBL-HMM algorithm produces the best recognition outcome. The HMM model in the above experiments is set up in the same way. Therefore, in the following experiments, the parameters of the HMM model are set to
S = 60,
w = 2.
5.2.2. V2 Experiment
Similar to the testing of the MIBL-HMM algorithm,
Table 6 shows the recognition results of the MIL-HMM algorithm. The correct recognition rate of the “in-targets” is seen to be
= 0.8501, and the detection rate of the “in-targets” is
= 0.9132. The false alarm rate of the “out-targets” is
= 0.4525. Under the same test set, compared with the test results of the MIBL-HMM algorithm (
= 0.9132,
= 0.9211,
= 0.3467,
Table 5), the MIBL-HMM algorithm test results are significantly higher than the MIL-HMM algorithm. The results show that the proposed method can further learn the context features contained in the HRRP multi-domain sequence features to improve the recognition performance.
In addition, we compare the proposed algorithm with several state-of-the-art methods. In general, the recognition performance of the template matching method is used as the baseline for HRRP target recognition [
52]. As can be seen from
Table 5, the correct recognition rate of our algorithm is 91.32%, which is better than 90% of the template matching method presented in [
52]. Moreover, unlike the template matching method, our algorithm does not require aspect information of the target.
The algorithm proposed in this paper is also compared with the multi-look processing methods mentioned in
Section 1. [
20] used a multi-look processing method to identify the same 9 types of targets as those used in this paper, and obtained 97% recognition accuracy under the
aperture test set. In the HRRP sparse feature-based target recognition, [
16] also used the
aperture test set, and obtained 92% recognition accuracy. In time-frequency domain feature recognition, Zhang et al. [
18] used the
aperture test set, and obtained 95.62% recognition accuracy. Although the recognition accuracy of these algorithms is relatively high, they are all obtained at the expense of computational time of the algorithms. To compare with these algorithms, our proposed algorithm is also tested on a
aperture test set, and the recognition accuracy is found to be 96.2%, as shown in
Table 7. This recognition accuracy is higher than the results reported in literature, which demonstrates the superiority of this algorithm.
5.3. Robustness Evaluation Experiments
To verify the generalization ability of the proposed algorithm in multi-domain HRRP sequence feature recognition, we designed the following two sets of comparative experiments, with rigorous experimental conditions for robustness evaluation.
(1) R1 experiment: One of the variant types of BMP2 and T72 targets is used as the training set, while the other three variants are used as test sets. Under such conditions, the robustness of the recognition algorithms is evaluated and compared.
(2) R2 experiment: The training set is the same as the training set of the R1 experiment, while the targets of the test set are set to “out-targets”. Under such conditions, the robustness of the recognition algorithms is evaluated and compared.
In the experiments reported in
Section 5.2, although our MIBL-HMM algorithm outperforms the MIBL-softmax algorithm on three evaluation criteria, the comparative recognition accuracy has little difference. We will further compare the two algorithms in robustness evaluation experiments described next.
5.3.1. R1 Experiment
The
aperture HRRP multi-domain sequences are used to train the MIBL-softmax and MIBL-HMM algorithms respectively. Comparative recognition results are shown in
Table 8 and
Table 9, respectively.
Under the same threshold conditions, as can be seen from
Table 8 and
Table 9, the correct recognition rate
of MIBL-softmax and MIBL-HMM algorithms for the “in-targets” has reached 98%. This shows that both the MIBL-softmax and the MIBL-HMM algorithms can learn the common features of targets from
aperture multi-domain HRRP sequence to accurately identify the targets. It can also be seen by comparing the “in-targets” detection rate
, the MIBL-HMM algorithm obtains an accuracy of 0.9597, while the MIBL-softmax algorithm achieves an accuracy of 0.9274. The detection rate of the MIBL-HMM algorithm for “in-targets” is thus significantly higher than that of the MIBL-softmax algorithm. This shows that the MIBL-HMM algorithm is more robust than the MIBL-softmax algorithm based on the same multi-domain HRRP sequence. This is attributed to the ability of the MIBL-HMM algorithm to further learn the multi-aspect features contained in the multi-domain HRRP sequence, to enhance the generalization ability of target recognition.
5.3.2. R2 Experiment
The training set of the R2 experiment is the same as that of the R1 experiment, while the targets of the test set are the seven other types of targets shown in
Table 1. The latter are also used as “out-targets" in the R2 experiment. Further, the MIBL-softmax and the MIBL-HMM algorithms are still trained using the
aperture multi-domain HRRP sequence. Comparative recognition results are shown in
Table 10 and
Table 11, respectively.
Table 10 and
Table 11 show both, the total false alarm rate of “out-targets” in the whole test set, and the false alarm rate of each type of target. Overall, the total false alarm rate of the MIBL-softmax algorithm is 0.288, while that of the MIBL-HMM algorithm is approximately 10% less, at 0.191. This shows that the MIBL-HMM algorithm performs better in rejecting the “out-targets” test samples. In addition, it can also be seen that the MIBL-HMM algorithm can enhance the generalization capability of target recognition by more deeply learning the multi-aspect features contained in the multi-domain HRRP sequence. The MIBL-HMM algorithm more effectively rejects the “out-targets” compared to the MIBL-softmax algorithm. In
Table 11, the MIBL-HMM algorithm achieves an ideal false alarm rate (
) on the exclusion of three types of “out-targets”: D7, T62, and ZIL131, where D7 is a bulldozer, T62 is a main battle tank, and ZIL131 is a freight truck. In addition, it can be seen in
Table 11, that the MIBL-HMM algorithm does not demonstrate much improvement in detecting false alarm rate of the BTR60 target, which can be attributed to the test samples of BTR60 comprising abnormal samples [
53]. Therefore, it is reasonable to expect that the MIBL-HMM algorithm will not reduce the false alarm rate detection of BTR60.
In summary, we extract the sequence of HRRP and on this basis, generate multi-domain sequences which are effective for target recognition. At the same time, the results show our proposed algorithm can deeply learn and more effectively fuse features of HRRP sequences in multiple data domains.
6. Conclusions
The construction of an optimal classifier based on limited HRRP signals to correctly extract, learn, and fuse HRRP features, in order to improve the target recognition ability is an open research problem. In this paper, we propose to learn features contained in the HRRP data, by exploiting the acquisition process of HRRP to extract a HRRP sequence, and generate multi-domain sequence features in time-, frequency- and time-frequency domains. A novel algorithm for HRRP target recognition based on BLSTM and HMM is proposed, which, on the one hand, extracts and fuses the multi-domain HRRP sequence features effectively, using a multi-input approach with primary and secondary branches. On the other hand, our proposed algorithm improves recognition performance by combining multi-aspect sequence features contained in multi-domain HRRP sequences, with the standard HMM model.
In benchmark recognition tasks using the MSTAR database with 10 non-cooperative targets, our proposed algorithm achieves 91% correct recognition rate. Compared with other state-of-the-art methods, our approach exhibits enhanced recognition performance, lower false alarm rate, and higher confidence. In addition, our proposed algorithm is simple to implement and, in the future, can be explored for implementing real-time human–machine interaction designs.




 ,
,  and
and  represent the recognition rate curves in time, frequency, and time-frequency domain, respectively.
represent the recognition rate curves in time, frequency, and time-frequency domain, respectively.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}