1. Introduction
The success of an autonomous, robotic mission can be measured by the effectiveness and efficiency in completing the mission [
1]. While physical resources (e.g., time, energy, power, and space) have historically dominated the metrics of success, more capable, complex cyber-physical agents require the judicious allocation of cyber resources (e.g., communication and computation) as well. Without a strongly coupled co-design strategy, cyber and physical resources are typically optimized either independent of one another, or perhaps in an iterative design loop until requirements are satisfied [
2]. For example, controllers are typically designed to handle worst-case conditions or maneuvers while providing good margins of stability and robustness [
3,
4]. Selection of sampling rate, or period of execution of the control law often becomes a software or real-time system implementation issue [
5]. However, even if co-designed, cyber and physical resources should be co-regulated at run-time, in conjunction with holistic (i.e., both physical and cyber) system performance. The situation is further complicated in the case of multi-agent, or distributed systems. Concisely, current design methods do not allow for dynamic adjustment of physical, communication, and cyber resources in response to changing conditions, objectives, or system faults.
Motivating Example
During a prescribed burn, building a temperature profile of the area enables detection of areas that are too hot (e.g., fires that may damage the crown of the trees) and helps monitor which areas need a different ignition profile. Sometimes, thermocouple loggers equipped with probes are buried underground in the area of the burn to log the fire temperatures [
6]. Alternatively, small wearable temperature sensors can be used by firefighters to build a shallow, but serviceable temperature profile. However, this offline data gathering method does not help in monitoring the live fire and requires physical access to the area selected for the burn.
We are interested in utilizing a team of Unmanned Aircraft Systems (UAS) to build a temperature profile of a fire. Teams of UASs are already being tasked with igniting controlled burns in areas where access is challenging or unsafe [
7,
8,
9]. A natural additional capability is to leverage the distributed, multi-agent system to simultaneously build the temperature profile by moving and sensing multiple locations. Information consensus [
10] provides an excellent strategy for estimating the temperature profile with multiple, moving agents in a decentralized fashion. In this strategy, improved measurements can be obtained by being closer to the point of interest, which also may restrict communication with other agents given the topography. As a result, there are times when it is prudent for each agent to fly close to the area in question, change its frequency of communication, or fly higher to communicate its value with others. In this scenario, an online co-regulated and co-designed information consensus algorithm can dynamically adjust cyber, physical, and communication resources in response to holistic, multi-agent system performance.
Summary of Approach
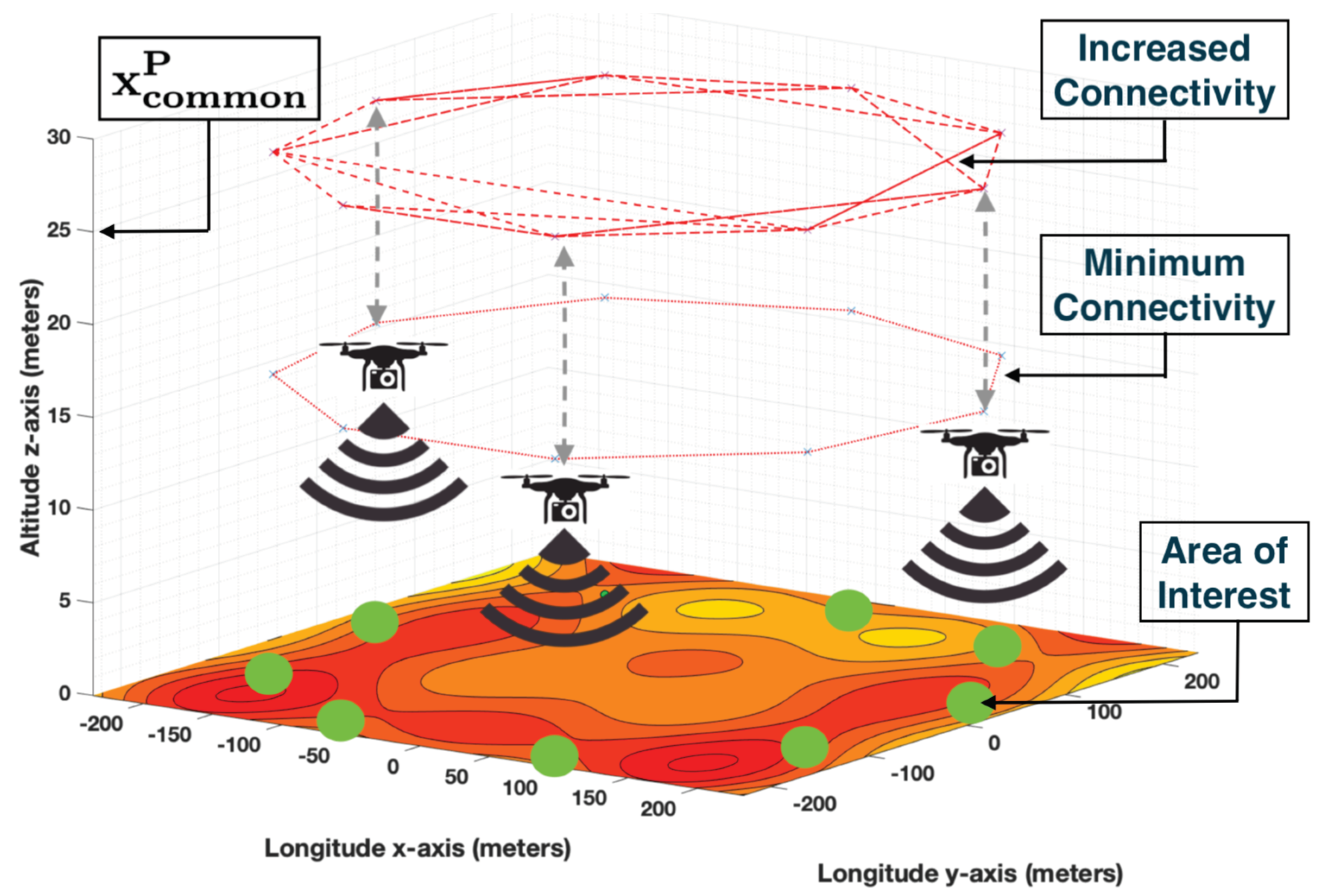
To solve this challenge, we propose co-regulated consensus controllers which allocate cyber, physical, and communication resources with the goal of obtaining fast convergence and high accuracy, but that require fewer resources than traditional approaches. The resources are adjusted in accordance with the difference between the agents’ shared, sensed values. In consensus algorithms, convergence time depends upon the rate of communication between agents as well as the connectivity of the entire group of agents. We co-regulate both the communication frequency and the positions of the agents to change connectivity.
Connectivity and communication rate of the agents are traded off to improve both time to convergence and convergence value against the need to be at a particular altitude for sensing. Specifically, when connectivity becomes sparse, the shared value may only be propagated through a small number of neighboring agents—thereby converging more slowly. Connectivity of the network can be improved either by using long range communicating devices or by changing the physical location of the agent. In the case of UASs, increasing the altitude can improve connectivity; however, this can reduce the accuracy or reliability of the sensing.
The communication rate can be increased to improve convergence time as well, but will impact convergence value if the shared value does not change at a similar frequency. This has given way to the idea of event-triggered consensus wherein the shared value is only communicated between agents when current and sensed value differ more than some threshold [
11]. While potentially minimally allocating communication resources, event-triggered and self-triggered consensus algorithms may not react quickly enough to changes in the shared state and typically are more difficult to analyze.
In this paper, we propose an information consensus control scheme in which position of the agents (i.e., connectivity), communication frequency, and the shared information state are simultaneously co-regulated in a single framework. Motion of the agents, and hence connectivity, is co-regulated based on shared state error. When shared state error is high agents are moved to positions that increase network connectivity, and as error diminishes the agents are moved back to a more effective position that increases their ability to closely sense the shared state. Simultaneously, for each agent, propagation of the shared value occurs at a time-varying communication rate. This rate is increased when shared state error is high, and lowered as error diminishes, thus preserving computation and communication when not needed. The result is a dynamic algorithm that provides a densely connected network with high communication rates during transient periods of the shared state, and a more loosely connected, slower communicating network during quiescent periods of the shared state.
Previously, we introduced an initial co-regulated consensus controller strictly for communication frequency [
12]. This paper uses the same controller to co-regulate the communication frequency when the information state changes. While the controller achieved improved convergence times and lower communication costs, it does not dynamically adjust connectivity. The work presented here builds on this result in a significant way by adding a co-regulated position controller to maneuver agents in their physical position to achieve higher connectivity. This is then combined with the co-regulated communication frequency controller to improve both convergence rate and accuracy of convergence value. Our algorithm provides a new capability to design controllers that can optimize new performance criteria—an issue we explore in depth in this paper. This paper makes the following contributions:
Introduction of a position controller to move agents in physical space to adjust connectivity
Proofs for the convergence of the proposed algorithm
Introduction of new cost metrics to assess distributed, cyber-physical co-regulation performance
Comparison of the effectiveness of the proposed co-regulation algorithm against non co-regulated and event-triggered consensus strategies
2. Related Work
Consensus algorithms rely on exchanging state information among the agents. Exchanged states are used to update the state of each agent. The update model used in the paper is similar to the models proposed in [
13,
14]. Both are predecessors of the distributed coordination algorithms presented in [
15,
16]. Vicsek’s model in [
16] studies a leader follower problem where every agent is initialized with a similar speed and a different heading. The state update model adjusts the headings of the agents to the heading of the leader agent. Both Jadbabaie et al. [
15] and Ren and Beard [
13] improved this model to accommodate leader-less coordination. The consensus model in [
13] introduced the information consensus that considered the shared state value as an observation made by the agents of a random variable. The convergence properties of the model are proved for both continuous and discrete time domains.
Most of the theoretical work in consensus assumes
continuous communication between the agents is possible. Continuous communication assumes the agents broadcast and receive the state values and update their individual states continuously. Guaranteeing convergence properties of such systems requires continuous mathematics and is well established [
11]. In recent work, systems with higher-order, or nonlinear dynamics are studied for their convergence properties [
17]. If communication and computation rates are sufficiently fast the assumption of continuous communication holds and the aforementioned theoretical analysis is sound. However, in real systems, communication and computation are not continuous but digital, and are inherently discrete (e.g., WiFi and Xbee) [
18]. Particularly at slow communication rates, this reality may invalidate convergence guarantees based on continuous mathematics.
Consensus algorithms with discrete-time communication traditionally use a fixed communication period to simplify the analysis of the system [
19]. Agents communicate, receive, and update states at these periodic intervals. This period can either be synchronous between agents [
20] or asynchronous [
21]. Discrete time algorithms are also simple to schedule as periodic tasks in a real-time computing system [
22], and convergence properties are easily analyzed using conditions of the Laplacian matrix [
23]. Asynchronous communication among the agents is more realistic in real world implementations with the presence of packet losses, communication delays, and clock synchronization errors. When analyzing the convergence of asynchronous systems, the collectively connected topologies are used. In this case “frequent enough” communication by all agents is sufficient to make the network collectively connected [
13,
24].
Achieving fast convergence times are essential once a multi-agent system is deployed in the real world. There have been extensive studies carried out both on the rate of convergence and the time to converge. The definitions for both the convergence rate and convergence time are stated in [
25]. The authors of [
26] quantified the convergence rate of an averaging consensus algorithm to be the second eigenvalue (sorted in descending order) of the Laplacian matrix drawn from the connectivity graph. This second eigenvalue, also known as the
Fiedler eigenvalue, increases with the connectivity of the graph. The more densely the agents are connected, the bigger the second eigenvalue will be. Hence, increasing the number of connections within the multi-agent system yields faster convergence. Increasing the connectivity of agents has been popular in power-grid-related research. For example, consensus algorithms with added innovative methods are used in power management of a micro-grid in [
27]. The connectivity of the network is increased by creating additional links between nodes which are at the opposite end of the communication network. This effort has led to faster convergence rates in these types of systems.
Research into improving connectivity through repositioning can be done in the mobile network/robotics domain. In [
28], mobile ad-hoc networks move autonomous and mobile agents to positions where the network will maintain maximum connectivity using a flocking-based heuristic algorithm. Underwater multi-agent communication is challenging, and, as a result, in [
29], a mobile surface vehicle provides a linkage between underwater agents to improve connectivity of the network. Optimal waypoints are generated and followed by the surface vehicle to ensure high connectivity [
29]. Algorithmically, a semi-definite programming approach to move agents’ location to improve the algebraic connectivity of the network has been proposed [
30]. The pairwise distances between the agents decide the movement. In similar work, potential fields have been used to position agents to gain higher connectivity in a consensus example [
31]. The method is resilient even when the network is dynamic. These works are related to our proposed methodology by dynamically adjusting position to modify connectivity. However, our strategy offers a low-level reactive coupled feedback mechanism that adjusts position based on consensus error. This does not require computationally complex optimization or trajectory generation algorithms since low-level feedback is used.
In the work presented here, we build on ideas in [
27] and our previous work [
12] to produce a novel, holistic model for co-design and analysis of co-regulated shared information consensus controllers. The motivating example for our work is a team of UASs monitoring temperatures of a fire at multiple locations.
3. Background
Here, we summarize the key concepts for consensus control, namely: graph theory and matrix theory for consensus, discrete information consensus, and linear quadratic regulators (LQR).
3.1. Graph Theory in Consensus
Graph theory has been used to abstract the communication network among the group of agents by representing agents as nodes and communication as edges of a graph. Analyzing the matrix representation of the same graph helps prove certain consensus properties such as convergence.
Let
N-node graph
represent a
N-agent communication system where the set of nodes represents the set of agents
. Each edge in
represents a communication link between two agents and is denoted by
. The edge is directed to represent one-way communication [
32]. The adjacency matrix
of the graph
is defined as
Define as the finite set of all possible communication subgraphs between N agents. Let be the union of simple graphs for . We define a simple graph to be a single communication instance between two agents. The edge set of is given by the union of the edge set of where .
In a strongly connected graph, there exist bi-directional paths between any pair of nodes in the graph. A graph wherein all nodes except one have at least one parent is known as a tree and the orphan node is named the root. In a spanning tree, there exists at least one path through all the nodes in the graph.
3.2. Matrix Theory for Consensus
A nonnegative matrix, denoted denoted as
, only contains entries greater than or equal to zero. A
stochastic matrix is a nonnegative matrix with all its row sums equal to one [
33]. Let matrix
be a
stochastic matrix.
is said to be
stochastic indecomposable aperiodic (SIA) if
for some column vector
where
is a
column vector with all the entries equal to one [
34].
3.3. Discrete Information Consensus
The graph
is assigned with
N agents, each node representing an agent. Let
denote the set of neighbors of agent
i. An agent
j is considered a neighbor of agent
i if and only if
. We assume each agent is connected to itself and hence every agent
i is a member of
. Let
denote the information state of the agents.
will be shared among the agents and eventually be agreed upon via consensus. Assuming the communication to be either synchronous or asynchronous, we use the discrete time consensus algorithm presented in [
13],
is the discrete time step. Given a set of initial conditions
, the system is said to achieve consensus asymptotically [
10] if,
Further, if the convergence value is equal to the average of the initial state values, it is known as the average consensus problem and formally denoted as
3.4. Linear Quadratic Regulator Problem
A Linear Quadratic Regulator (LQR) solves an optimal control problem for a linear, time-invariant system. We use LQR to construct the controller which co-regulates the agents’ physical positions. For a linear time invariant system, the infinite-horizon LQR control input,
u, is given by,
where
is the state to be regulated and
is the constant feedback gain matrix [
35]. The control input
minimizes the cost function
and
are two weighting matrixes and chosen to represent the desired performance—a tradeoff between control effort and state error. The feedback gain matrix is calculated as
where
is the system matrix,
is the input matrix, and the
is a solution to the Algebraic Riccati equation (ARE),
4. Co-Regulation for Information Consensus
This section develops the control strategies to vary the agents’ position and communication frequency to achieve faster convergence on the information state. We layout the control strategy on regulating the communication frequency followed by the strategy on regulating the position. Then, the convergence guarantees of the proposed control strategies are analyzed.
4.1. Co-Regulated Communication Consensus
A digital communication task requires computational resources to form a message, encode it, and transmit it via a channel. This means the scheduled communication tasks onboard the computer are what dictate the allocation of communication resources. This creates a powerful mechanism for dynamically allocating communication resources by adjusting the scheduling of the communication task. We leverage this capability to design our co-regulated communication strategy. We assume that the task schedule onboard the computer can be dynamically adjusted to increase or decrease how often an agent communicates.
Quicker convergence times are realized through higher communication rates as it facilitates rapid exchange of information. However, upon reaching consensus, exchanging the same information adds no value and will simply occupy computational cycles and bandwidth that might be otherwise allocated to other tasks. On the other hand, higher rates of communication are required once a change in state variable is detected. This suggests a strategy that varies communication rate in accordance with consensus value could improve resource allocation. Hence, we make use of the following controller on the communication rate to satisfy the co-regulated communication objective [
12].
Let
be the time period between two successive communications of agent
i, which evolves as a discrete time system
where the frequency of communication is denoted by
, and a control input, which modifies the rate for each agent is denoted by
. The control input is calculated by the following controller,
The convergence guarantees for the above controller are proved in [
12].
4.2. Co-Regulated Position Consensus
Connectivity of the multi-agent system can be modified either by changing the existing communication mechanisms (e.g., more powerful antenna), or by moving toward or away from neighboring agents. Given our agents have fixed communication resources onboard during a mission, in this strategy we leverage the mobility of each agent to change proximity to neighboring agents and subsequently adjust the connectivity of the communication network.
In co-regulated position consensus, we manipulate the agents’ connectivity by changing their physical position, based on the local value of the shared state. In this scenario, sparsely distributed agents are moved to a prior known location with good connectivity so that each agent would have a larger set of neighbors to connect to. For a particular mission, it is possible the agents are required to maintain a formation with certain distances, be tied to a fixed geographical position, or perhaps need to improve proximity to sensed phenomena. Such external reasons may prohibit the agents from having full connectivity. As a result, once the states converge, the agents are moved back to their initial positions.
Let
and
denote the position and the velocity of agent
i. Let
denotes the physical control input for agent
i. We model each agent’s dynamics as a double integrator:
We now introduce a controller to regulate each agent’s position depending on the difference in the shared state of each agent. This state difference is caused either when a neighbor updates its state upon communicating with another agent or sensing a new state value as a result of an external event. The need to increase connectivity is governed by error in the shared state. Once the state error is reduced, the increased connectivity has no real benefits. As a result, the connectivity can be decreased without affecting the shared state value.
We introduce the following controller for each agent’s physical position,
where
is the state feedback gain produced from an LQR control design strategy (see
Section 3.4). We define
to be a reference to the position where an agent should move to.
is bounded above by the maximum position an agent can move to,
, and bounded below by
, which is the initial position of an agent
i. We define
to be the common position for increased connectivity. We select
and
such that
.
is changed according to:
Upon choosing proper grains for
and
, the first term of Equation (
11) increases the reference when a state difference is present. The increase is capped by the upper bound
. Hence, the agents are moved towards the maximum position by Equation (
10) and the agents move beyond
. This results the agents to increase the connectivity. Once the agents’ states converge, the error term
, and the second term in Equation (
11) pushes
back to its lower bound
, moving the agent back to its initial position. Once the agents retrieve from
, connectivity falls back to the initial level of connectivity.
4.3. Convergence Guarantees
Lemma 1. If the union of a set of simple graphs has a spanning tree, then the matrix product is SIA, where is a matrix corresponding to each simple graph , . This proof is provided in [13]. Lemma 2. Let be a finite set of SIA matrices with the property that for each sequence of positive length, the matrix product is SIA. Then, for each infinite sequence there exists a column vector such that The proof can be read in full in [34]. Lemmas 1, and 2 are, respectively, stated as lemmas 3.5, and 3.2 in [13]. Theorem 1. Let be the communication graph of N agents. Assume each agent is connected to at least one other agent, making a spanning tree. Assume each agent i’s communication radius is r and the straight line distance between two agents is (). Let each agent’s communication frequency, , evolve as in Equation (7). Let each agent change position according to Equations (10) and (11). Define the maximum straight line distance an agent can travel, , to be within a circle of radius centered around agent i. The discrete consensus algorithm in Equation (1) achieves global asymptotic consensus if there exists a non-overlapping infinite sequence of hyperperiods, denoted as , where , and the union of communication subgraphs in has a spanning tree within each . Proof. Three cases are produced to analyze the convergence of Equation (
1) under the variable communication frequency, which is regulated by Equation (
7) [
12]:
Synchronized and fixed ;
Synchronous and time-varying ; and
Asynchronous and time-varying .
The controller for agent position in Equation (
11) is not directly coupled with Equation (
7), however, both are indirectly coupled through the state error
. Under Equations (
10) and (
11), varying agent positions would add or remove connections from the connectivity matrix. Hence, added or removed connections would make
time-varying. Let
be the matrix representation of a subgraph in
where
. Define
to be the product of any permutations of subgraph matrices at a hyperperiod
l,
From Lemma 1,
is a SIA matrix. As all agents have communicated once at each hyperperiod
, the subgraph represented by the matrix product
at each hyperperiod
will have a minimum spanning tree. Let the information consensus protocol be applied for
k steps in Equation (
1). As
, when
,
. The propagation of the initial information throughout the network for
k steps can be written,
By substituting the matrix product at each hyperperiod with
,
From Lemma 2, the product of
matrixes can be substituted with,
where
is some constant column vector of positive entries. Therefore,
The convergence is guaranteed as long as the necessary condition is not violated by Equations (
10) and (
11). The necessary condition to achieve consensus is to maintain a spanning tree in the agent connectivity graph [
36]. Once the distance between any two agents becomes greater than
r, the agent is unreachable and the agent connectivity graph no longer maintains the spanning tree property. Equations (
10) and (
11) vary the agent positions between
and
. By defining an upper bound at
and a lower bound at
for
to be within a circle of radius
,
is restricted to move agents to unreachable locations. This preserves the spanning tree property of the connectivity graph of the agents. Therefore, by Equation (
7) together with Equations (
10) and (
11), the system defined in Equation (
1) achieves consensus. ☐
7. Results
We now present the experiments and results depicting the effectiveness of the proposed method. We applied the proposed co-regulated consensus methods in a simulated prescribed fire. We discuss the cost savings of the proposed methods against event-triggered and traditional fixed-rate consensus strategies.
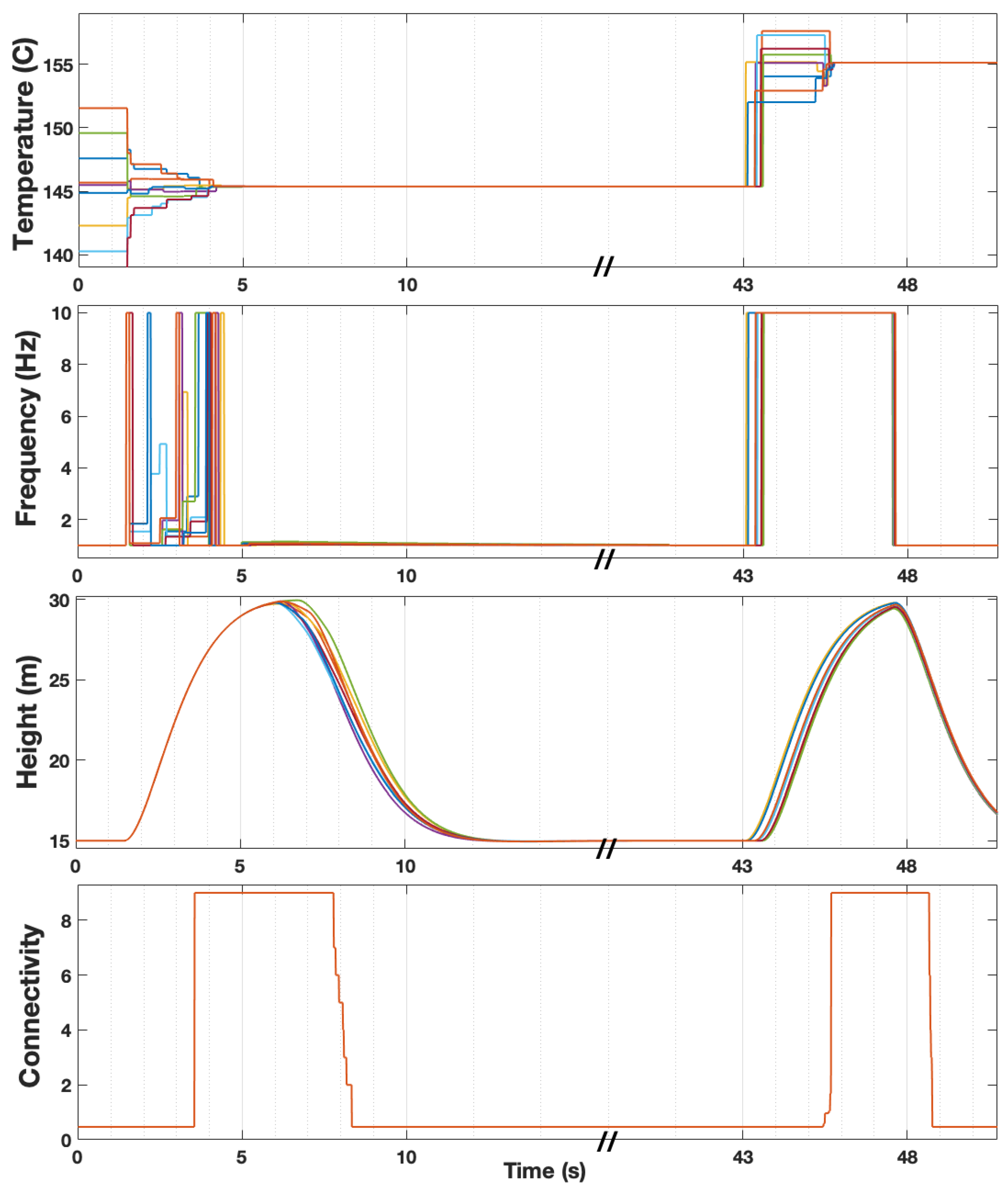
The overall behavior of the co-regulated consensus algorithm is plotted in
Figure 2 for two orbits. The temperature states are plotted only for Area 5 in
Table 2 (
,
). The agents took 43
to orbit the areas of interest once and to start communicating the individual temperature states. Agents repeated the process for each orbit. Throughout the orbit phase, the communication frequency and the vertical position were kept at the initial values. The initial values for the temperature states were the agents’ individual temperature measurements at each area. The co-regulation of communication frequency, agent connectivity, and the application of the consensus algorithm started after completing one round of orbit.
We selected
and
parameters for Equation (
8) and
and
parameters for Equation (
11) to simulate the system shown in the
Figure 2. The difference between the individual temperature measurements and the shared temperature caused the frequency controller in Equation (
8) to apply a negative control input to Equation (
7). As a result, the time period to communicate,
, decreased, which in turns increased the frequency of the communication, as shown in the “Frequency (Hz)” plot in
Figure 2. At the same time, the state error caused Equation (
11) to shift the reference position towards the maximum altitude causing the controller in Equation (
10) to move the agents, as shown in the “Height (m)” plot in
Figure 2. Once the agents moved towards the maximum altitude, they moved past the threshold altitude for increased connectivity
and could communicate with a larger subset of agents. The improved connectivity allowed rapid convergence of the shared temperature state values.
As the states converged, term
and the second term in Equation (
7) dominated. It applied a positive control input to lengthen the time interval of successive communications and the communication frequency was lowered to its minimum. Similarly, Equation (
11) pushed the reference position back to the initial altitudes. The agents lowered their altitude below
and reduced the connectivity to the initial ring-like topology.
Estimation Using Gaussian Process
We assumed the area of the prescribed burn was in different stages of the burn process. We assigned nine UASs to orbit around nine areas of interest, which were positioned according to
Table 2. The true temperature of the fire at each area was approximated from the temperature readings provided in [
6]. The approximated values of the true temperature and erroneous temperature recording through thermal imagery by each UAS are recorded in
Table 3. We assumed the mean temperature of the fire over the interested area did not vary significantly during the time the UASs were in motion [
6]. Upon completing the orbit, UASs calculated the average temperature across all areas of interest using consensus algorithm and applied Gaussian process regression on converged temperature values.
Matlab’s
fitrgp() and
resubPredict() commands were used to fit a Gaussian regression model and predict the values from the trained model. The converged and estimated temperatures readings are recorded in
Table 3.
Comparison to Related Methods
It is important to find what choices for the parameters
and
yield the least cost. The cost metrics to be reduced are time to converge, average communication cost, and error in converged value (see
Section 5). After multiple simulations over a range of choices for
and
parameters,
and
resulted in the lowest cost.
These optimal choices were used to compare the proposed co-regulated method against four other methods.
Table 4 shows the results of the comparisons. Our full co-regulation consensus is in the bottom row, and compared against fixed-rate consensus, two variants of our co-regulation algorithm, and event-triggered consensus. In the first row, we show event-triggered control representing the most relevant comparison due to recent advances in that area [
38]. The event-triggered algorithm communicates when the error in shared state between an agent and its neighboring agents becomes greater than a threshold
.
In the second row in
Table 4, we compare against a traditional fixed-position and fixed-rate consensus algorithm. Rows 3 and 4 in
Table 4 are variations of our co-regulation algorithm where we hold either position or communication rate fixed while varying the other. This provides some intuition for the tradeoffs between changing connectivity and communication rate, and the subsequent impact on our metrics.
It is clear from the results in
Table 4 that the fastest convergence time was achieved through full co-regulation of both the communication frequency and the position (connectivity). The increased communication frequencies were aided by the increased connectivity to achieve faster convergence times where the time could have been
worse had the connectivity not been increased (see Row 4 in
Table 4). However, this benefit was realized at the cost of moving agents further. In the event-triggered approach, the smaller convergence time was achieved through very frequent communications (41.90 average number of communications in Row 1). In fact, event-triggered consensus communicated the most out of all methods we tried (There are many tuning parameters in event-triggered control and our implementation represents a basic event-triggered consensus strategy.). This disadvantage was avoided in the proposed co-regulation strategies as the co-regulation allowed the communication frequency to be lowered once the state errors diminished. Interestingly, fixed-rate and fixed-position consensus scored the worst in all metrics, wasting communication resources, and taking >10× longer to converge. Row 3 of
Table 4 shows a strategy with co-regulated position (connectivity) and fixed-rate communication. This strategy was only mildly worse than full co-regulation, demonstrating the power of improving connectivity to achieve fast convergence. In that case, the algorithm compensated for the fixed-rate communication by moving the agents further to improve the connectivity, and still did not manage to converge more quickly than full co-regulation. This suggests that it is likely better to increase connectivity and less aggressively increase communication frequency.
Comparison against Position-Only Co-Regulation
The results in
Table 4 suggest that co-regulating agent position only to improve the connectivity provides most of the benefit of co-regulation without having to co-regulate communication rate. However, often the agents may be unable to achieve full connectivity even though they travel towards the common location. This could be due to radio interference, topographical interference, or other issues.
Table 5 shows the cost of convergence and average cost of communication for agents connected with varying connectivity levels. When the agents are able to connect to only a small subset of agents at their common reference, co-regulating both the communication and position can achieve significantly shorter convergence times with smaller cost in communication compared with a fully connected network.
In short, if full connectivity cannot be achieved, improved convergence performance can be realized by additionally co-regulating the communication rate.
Error in Converged Value
The error between the converged value and the true mean of the initial temperature values were near zero in each of the methods, suggesting that consensus is indeed a good estimator in this multi-agent system. Our previous work using co-regulated communication rate [
12] showed that asynchronous communication can lead to converging to the wrong value. This occurs when an agent communicates more often than another—effectively over weighting its measurement in the consensus calculation. Here, we explore the impact of this phenomenon and how it is mitigated in our results above.
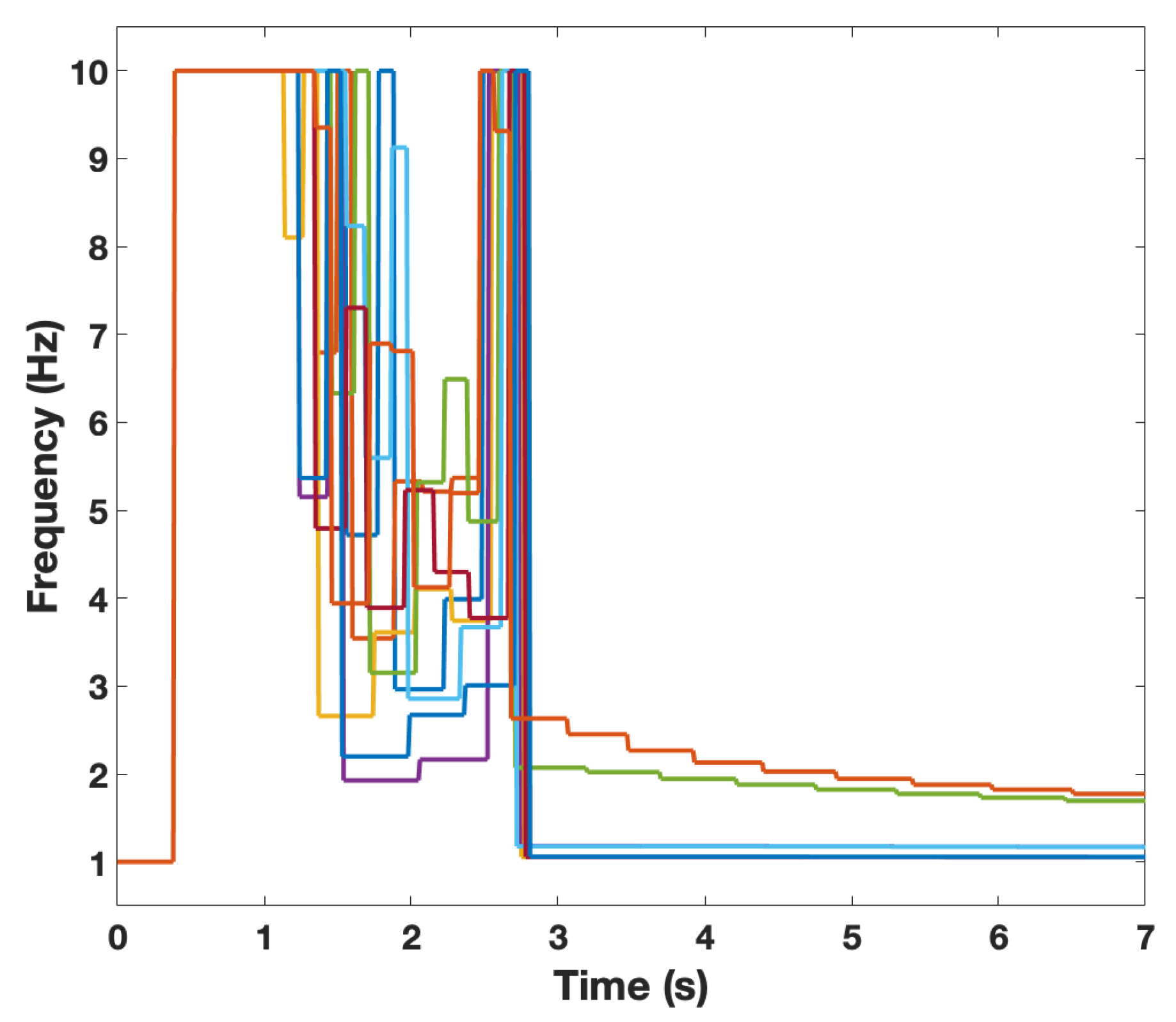
Figure 3 plots the co-regulated communication frequency using optimal alpha parameters (
and
). Synchronous and switching-like behavior of the communication frequency could be observed in all agents using this algorithm. This means once an error in shared state was observed, the frequency controller in Equation (
8) pushed the communication rate to its maximum. Once the error started to decrease, it subsequently pushed it to its minimum resulting in the switching-like behavior. This occurred multiple times before convergence was obtained. This synchronous behavior resulted in convergence with minimal error.
High
and
values may not be ideal for different applications, particularly if resources are scarce, cannot be allocated as quickly, or there are communication limitations. Under lower gain values, a switching behavior may not occur, and the asynchronous behavior would lead to a mismatch between the converged value and true mean of the initial values. We show an example co-regulated communication rate response in
Figure 4, which plots the communication frequency of nine agents under smaller (
and
) gains.
To provide insight into how this impacts the converged shared state, in
Table 6, we show the error in converged value (calculated using Equation (
15)) with varying
and
gains. As shown in the table, the error increased with decreasing
and
up to a certain point, after which the error was again reduced. This was because the system behaved more synchronously at the extreme values for the gains. This demonstrated the importance of finding optimal gain values in co-regulated multi-agent systems.
The power of our co-regulation framework is that this behavior can be adjusted using the gains and . These gains can be tuned to dampen, or sharpen, the response to achieve different objectives.







{kind=link}
{kind=link}
{kind=link}
{kind=link}