EPSim-C: A Parallel Epoch-Based Cycle-Accurate Microarchitecture Simulator Using Cloud Computing


Abstract
:1. Introduction
- We explore the parallelism of EPSim and accelerate its simulation significantly using cloud computing to exploit the massive parallelism.
- We present a Hadoop-based implementation of EPSim-C simulator to utilize the parallelism by applying the MapReduce programming model.
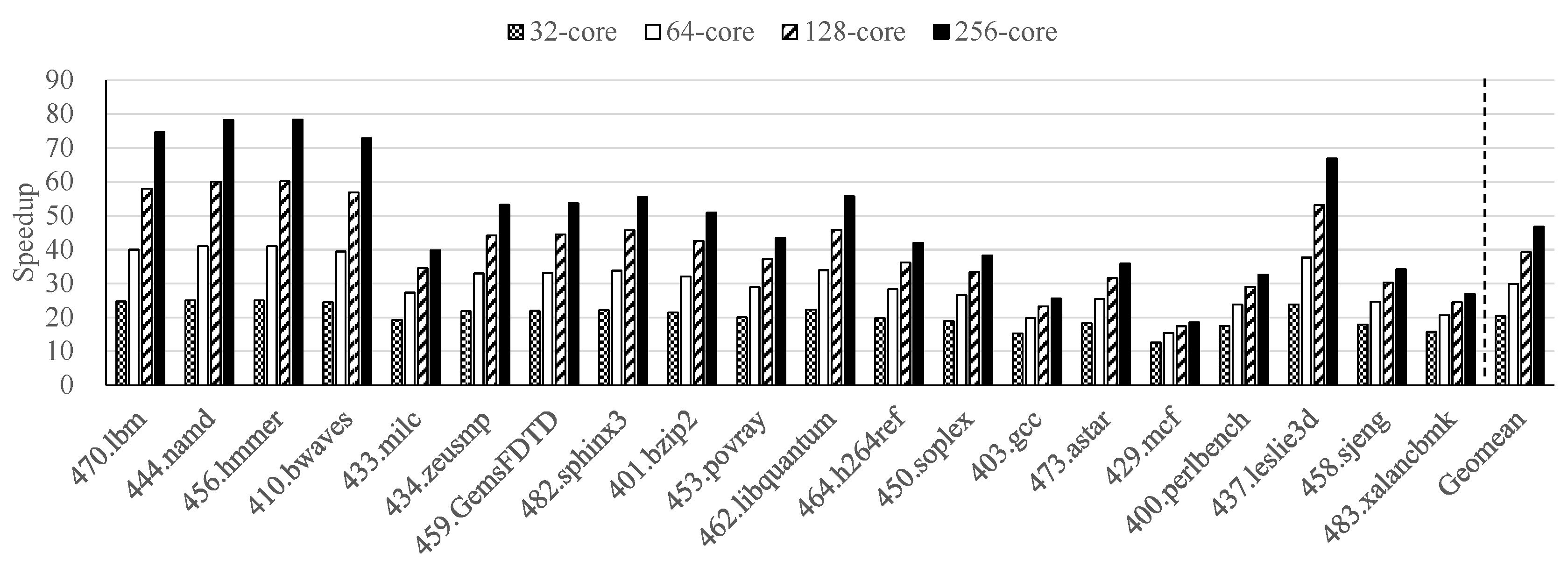
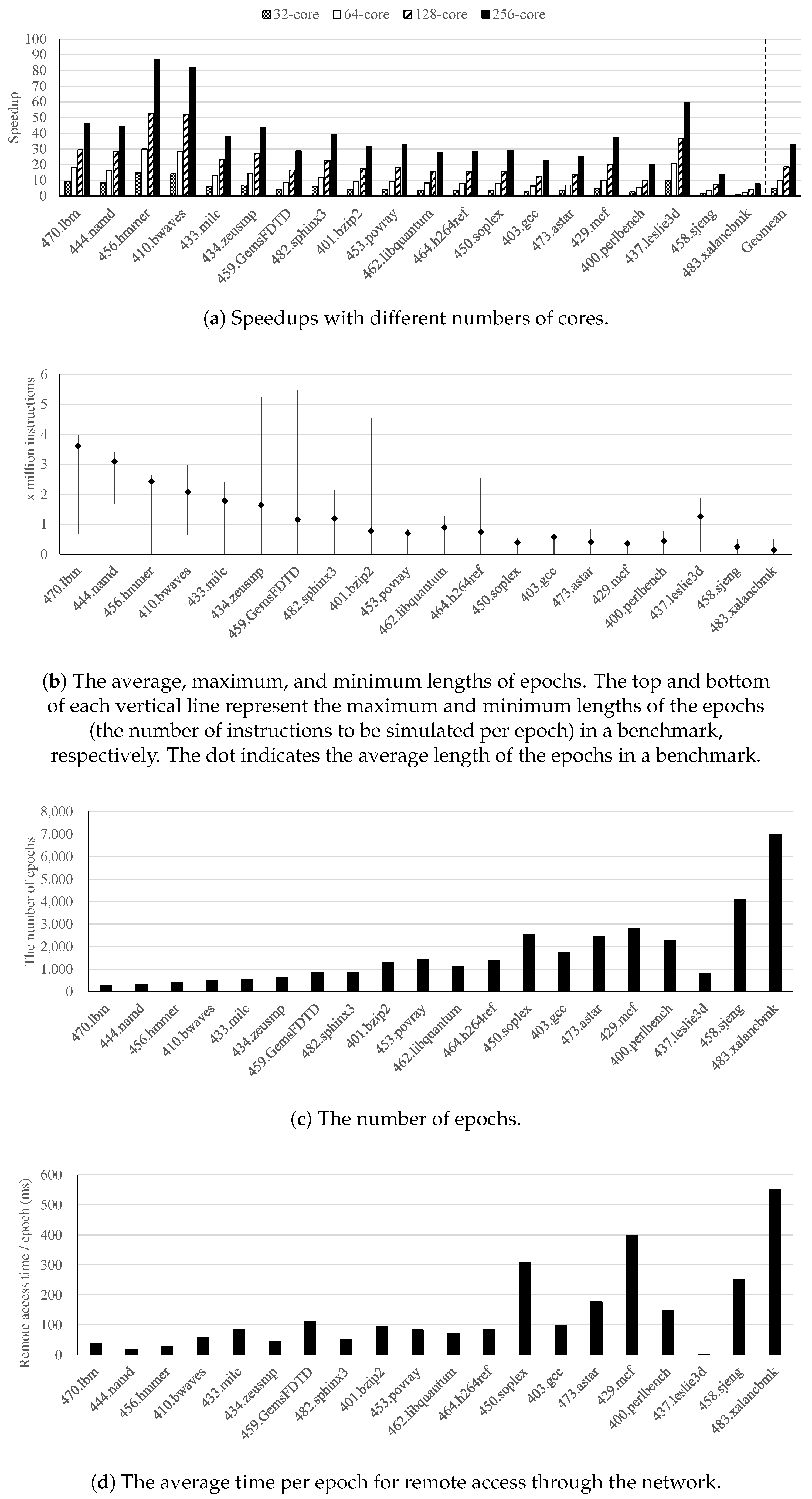
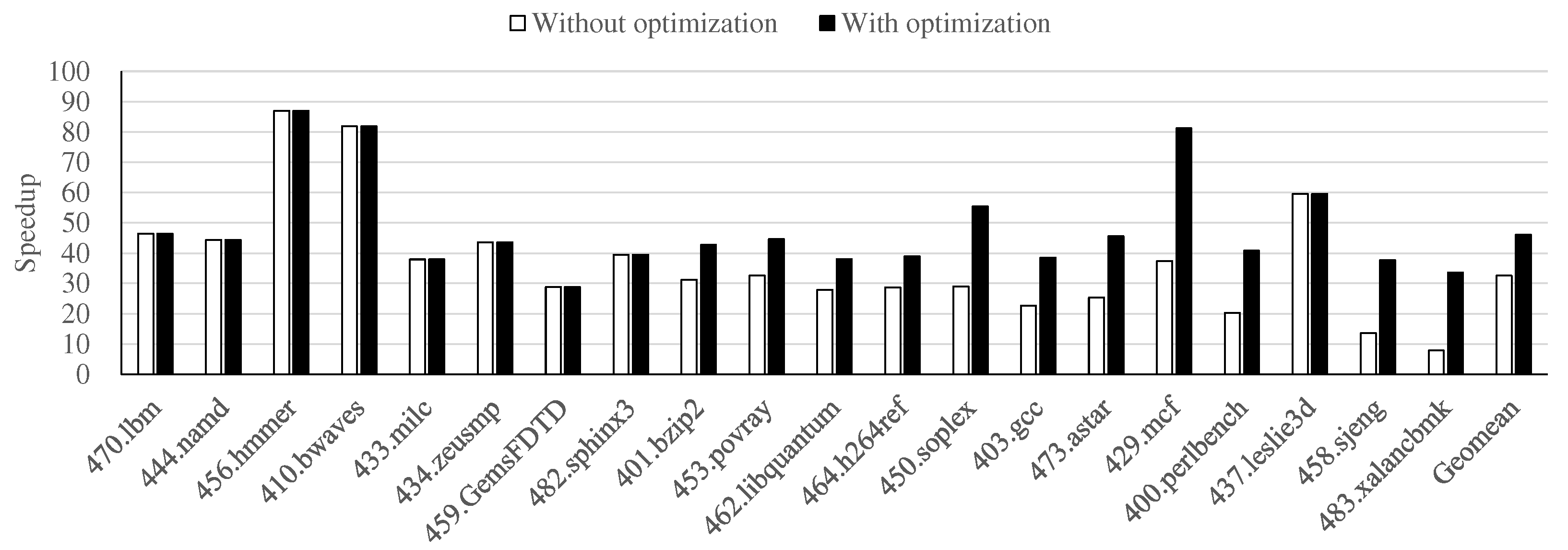
- We obtained on average 46.1× and up to 87.0× of the simulation speedup with 256 cores in a representative commercial cloud computing environment, i.e., AWS.
2. Background and Motivation
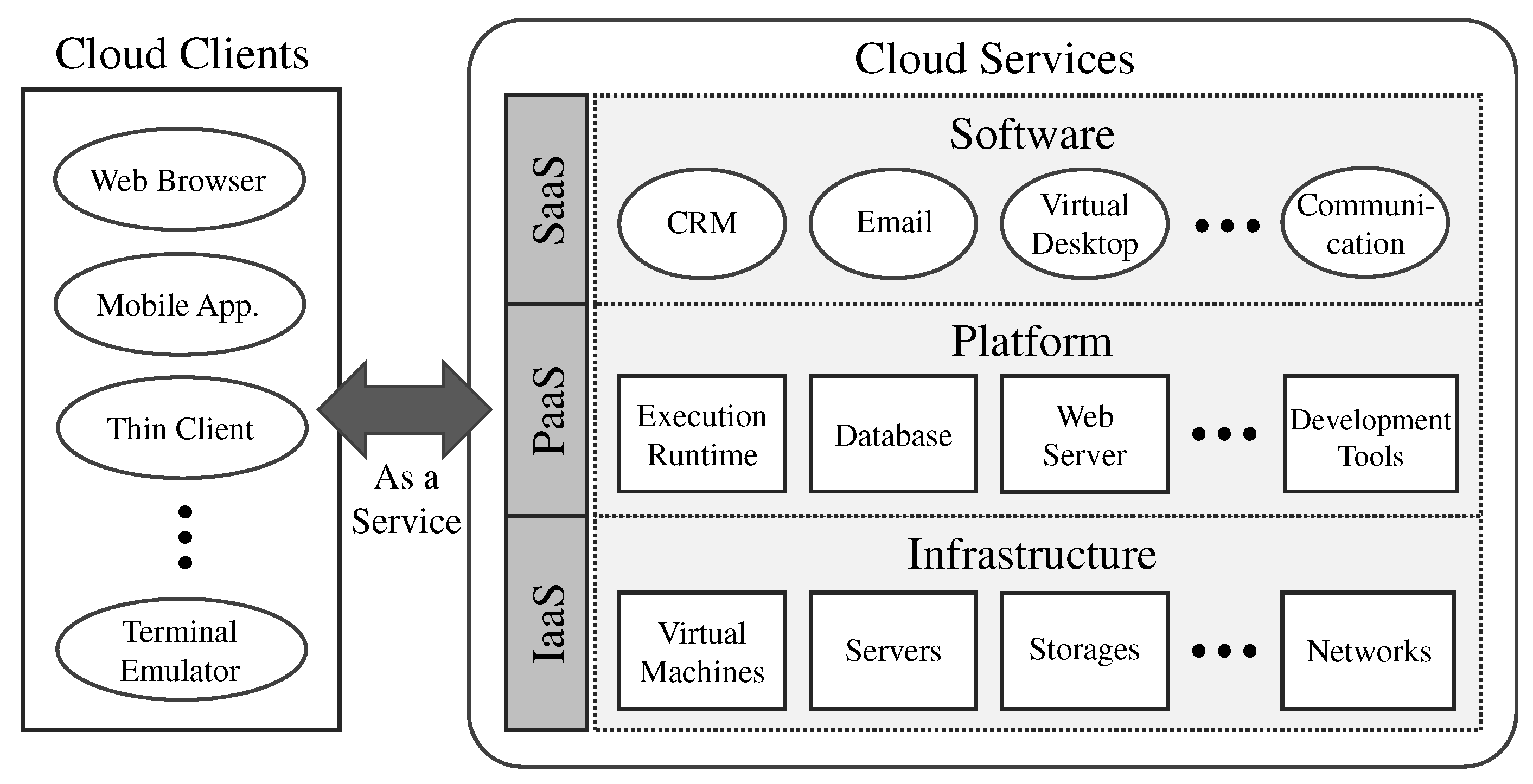
2.1. Cloud Computing
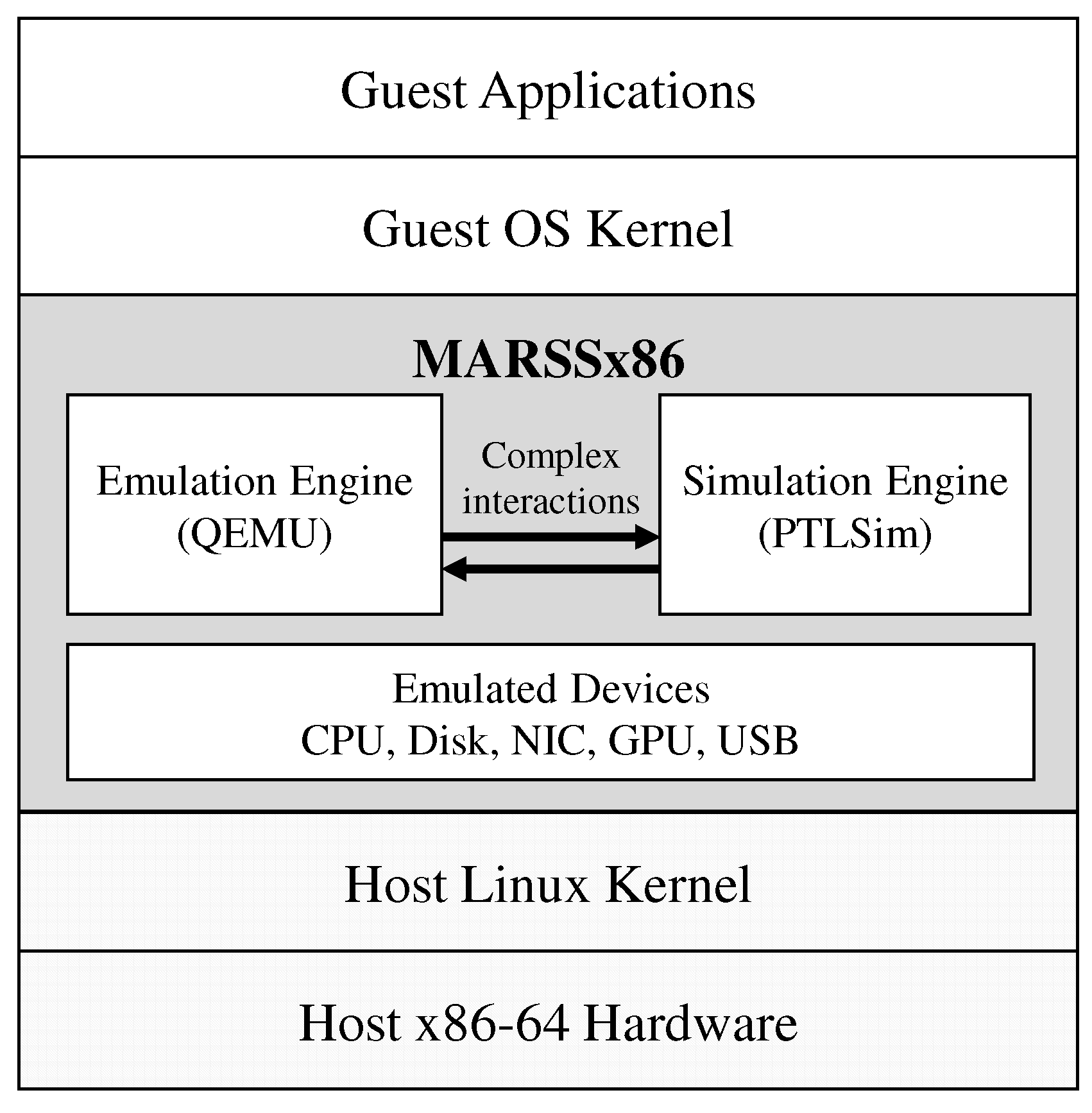
2.2. Microarchitecture Simulation: MARSSx86
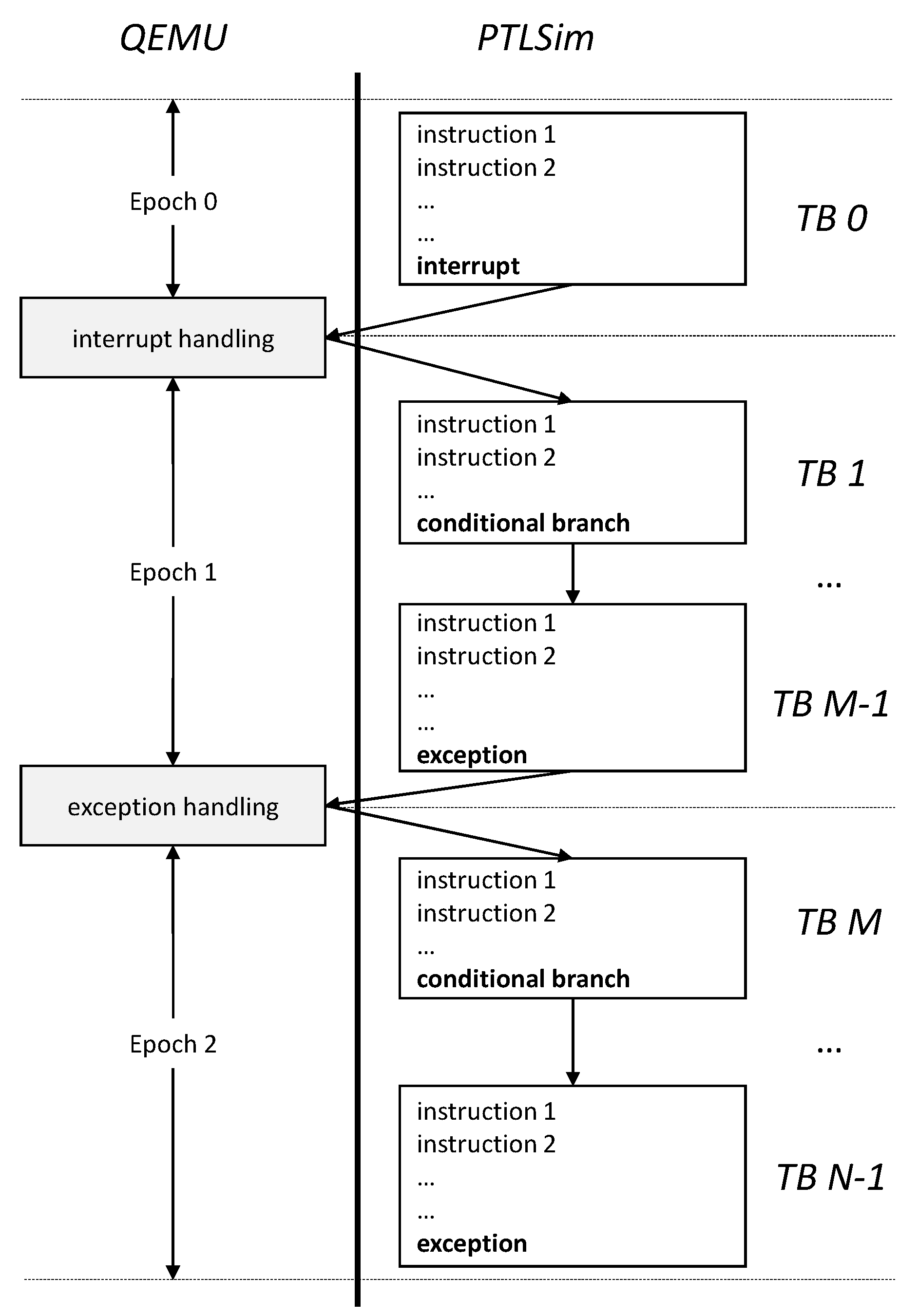
2.3. EPSim: Epoch-Based Parallel MARSSx86 Simulator
2.4. Motivation
3. Parallel Microarchitecture Simulation Using Cloud Computing
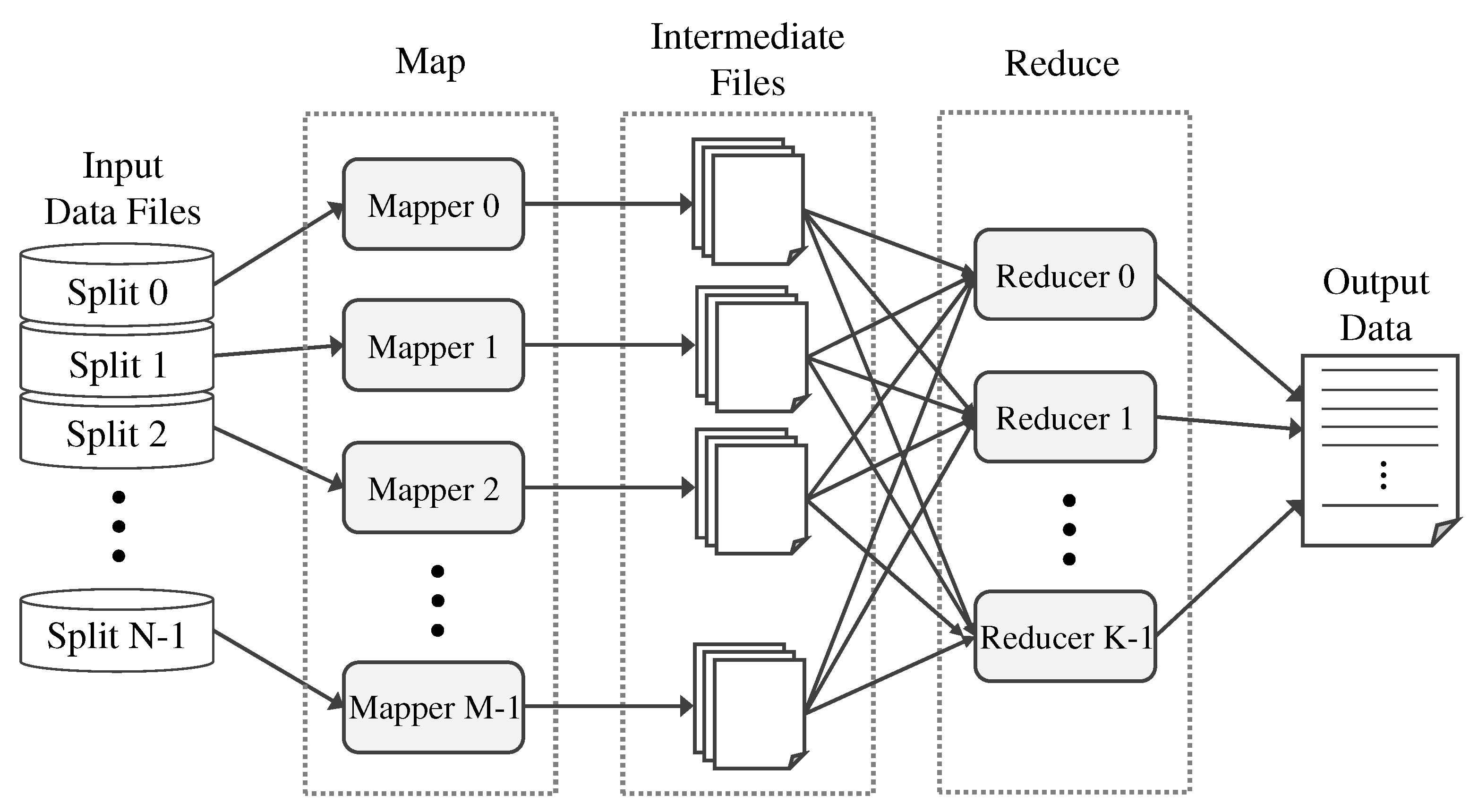
3.1. Exploring Massive Parallelism Using MapReduce
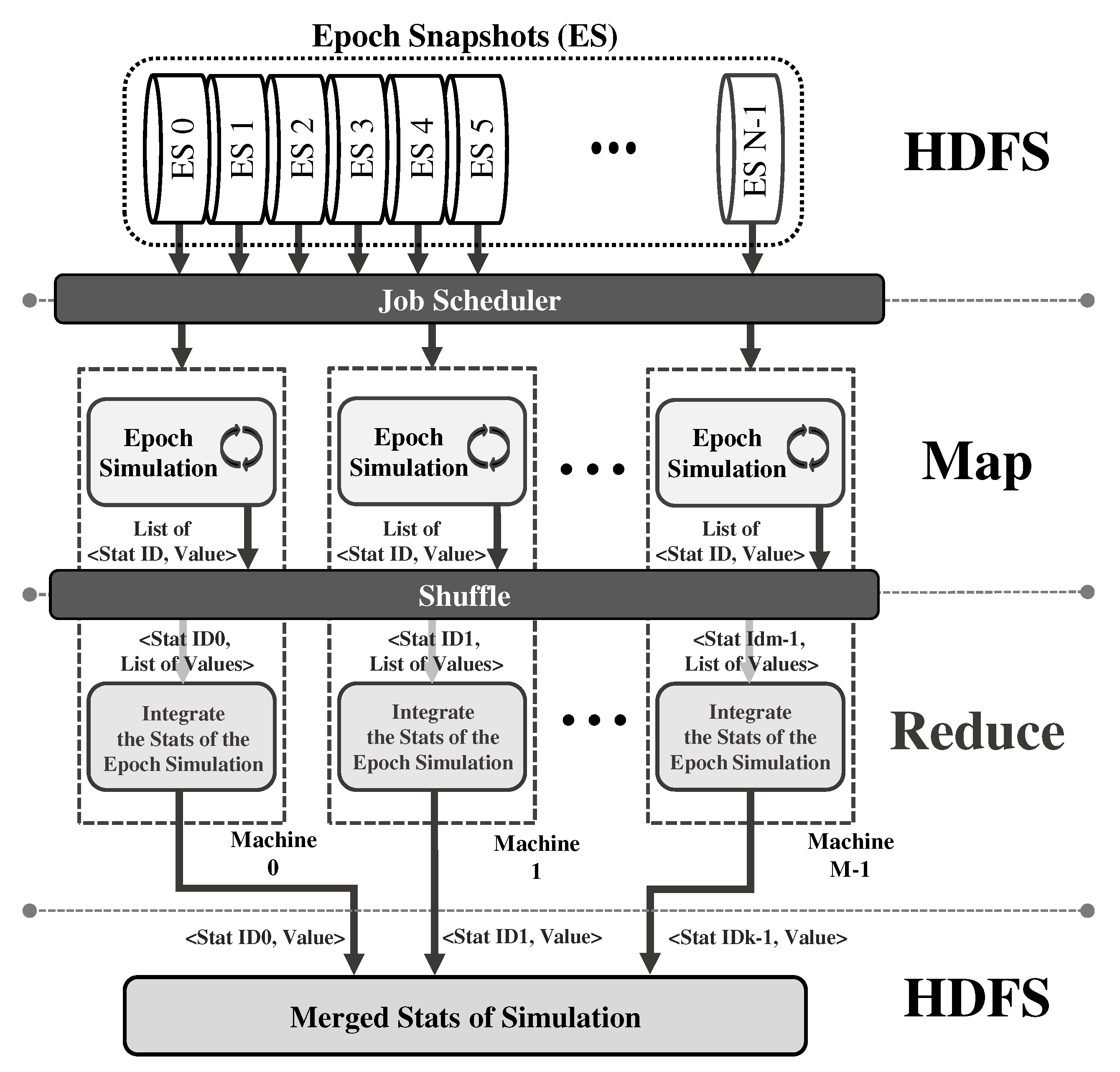
3.2. Hadoop-Based Implementation of Epoch-Based Parallel MARSSx86 Simulation
4. Evaluation
4.1. Experimental Setup
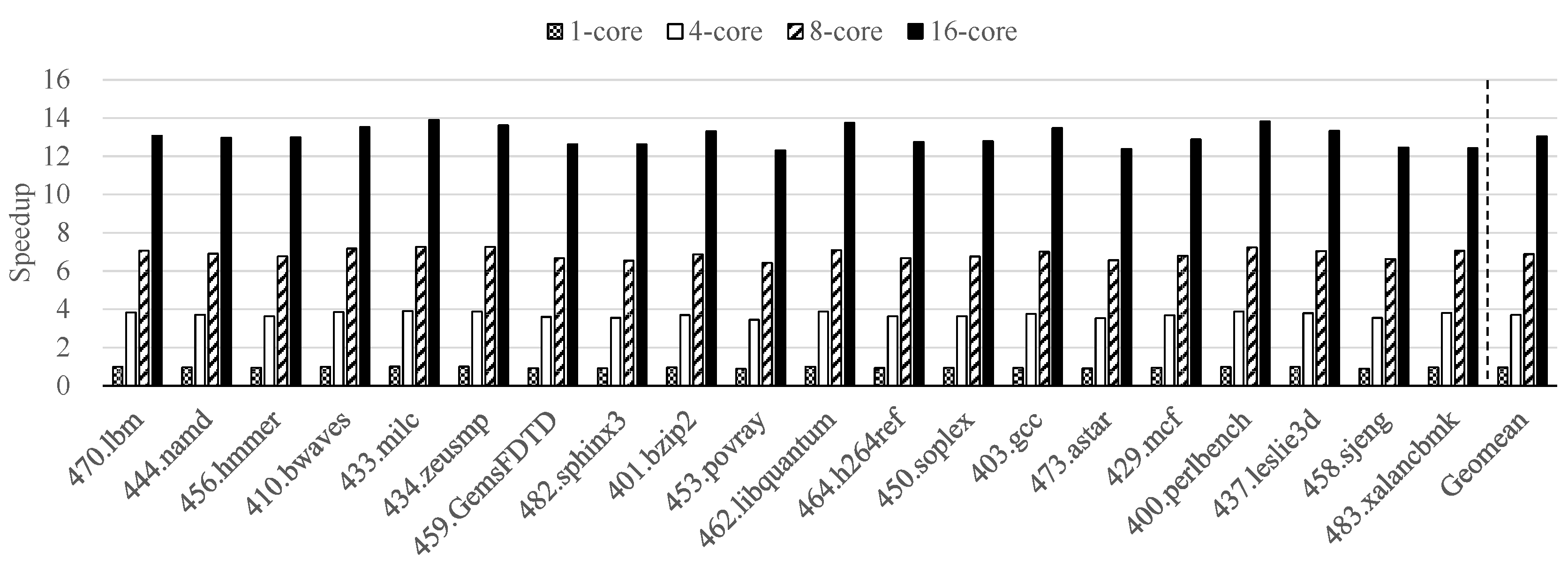
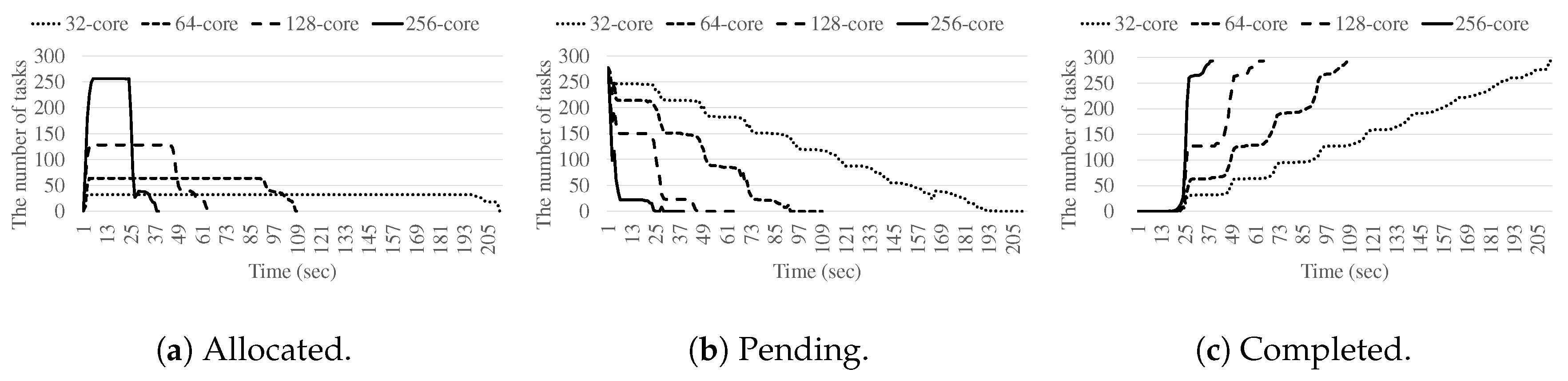
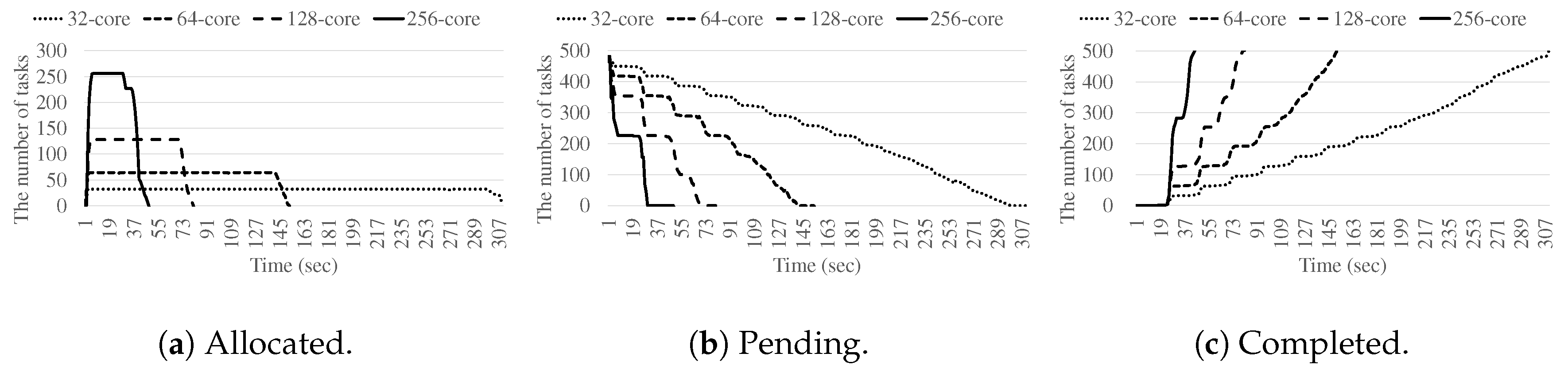
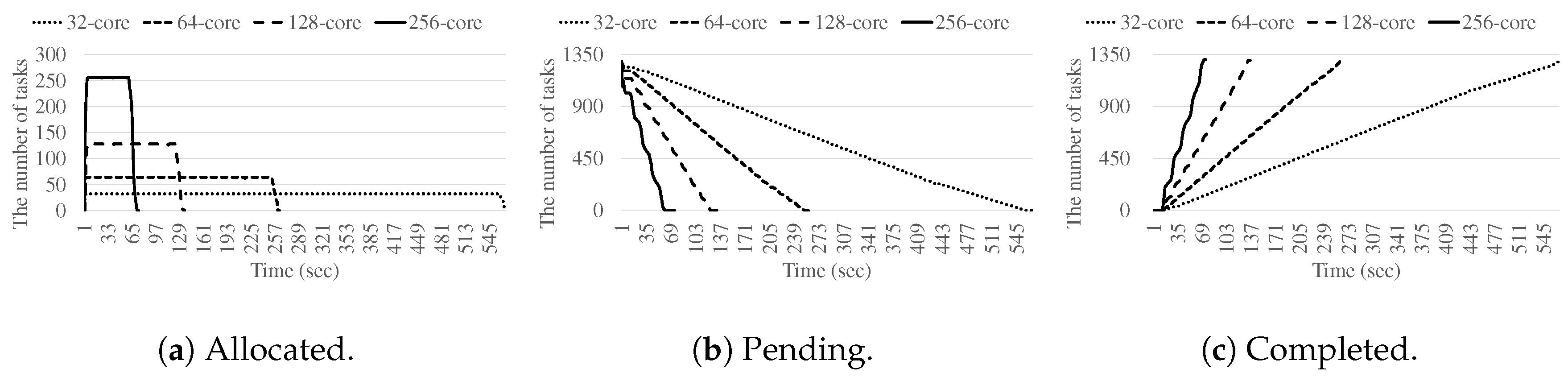
4.2. Performance Results
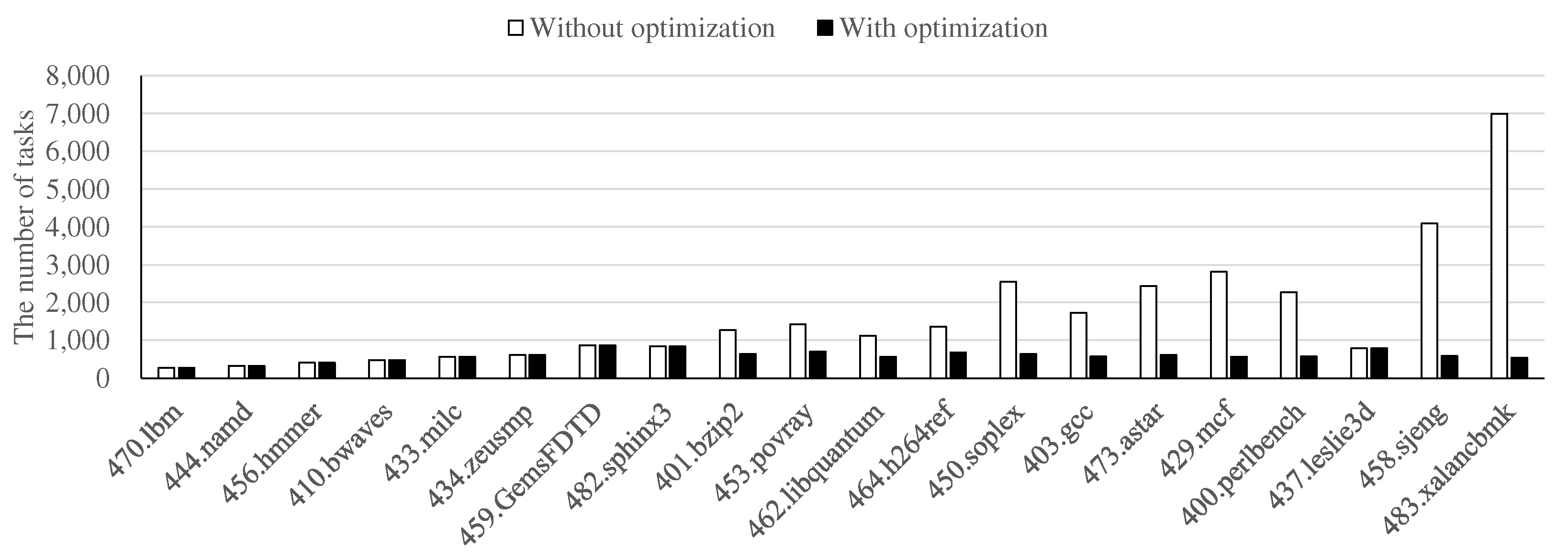
4.3. Task Management Optimization
5. Related Works and Discussion
5.1. Multicore and Multithreading Simulation
5.2. Sampling-Based Simulation
5.3. High-Abstraction-Level Modeling
5.4. Hardware Acceleration
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, X.; Qiu, J. Cloud Computing for Data-Intensive Applications; Springer Publishing Company Incorporated: New York, NY, USA, 2014. [Google Scholar]
- Yang, X.; Wallom, D.; Waddington, S.; Wang, J.; Shaon, A.; Matthews, B.; Wilson, M.; Guo, Y.; Guo, L.; Blower, J.D.; et al. Cloud Computing in e-Science: Research Challenges and Opportunities. J. Supercomput. 2014, 70, 408–464. [Google Scholar] [CrossRef]
- Casanova, H.; Giersch, A.; Legrand, A.; Quinson, M.; Suter, F. Versatile, scalable, and accurate simulation of distributed applications and platforms. J. Parallel Distrib. Comput. 2014, 74, 2899–2917. [Google Scholar] [CrossRef] [Green Version]
- Bian, Z.; Wang, K.; Wang, Z.; Munce, G.; Cremer, I.; Zhou, W.; Chen, Q.; Xu, G. Simulating Big Data Clusters for System Planning, Evaluation, and Optimization. In Proceedings of the 2014 43rd International Conference on Parallel Processing, Minneapolis, MN, USA, 9–12 September 2014; pp. 391–400. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, J.; He, B.; Luo, Q.; Fang, W.; Govindaraju, N.K. GPU-Accelerated Cloud Computing for Data-Intensive Applications. In Cloud Computing for Data-Intensive Applications; Li, X., Qiu, J., Eds.; Springer: New York, NY, USA, 2014; pp. 105–129. [Google Scholar] [CrossRef]
- Li, B.; Mazur, E.; Diao, Y.; McGregor, A.; Shenoy, P. A Platform for Scalable One-pass Analytics Using MapReduce. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 985–996. [Google Scholar] [CrossRef]
- Yoon, D.H.; Kang, S.K.; Kim, M.; Han, Y. Exploiting Coarse-Grained Parallelism Using Cloud Computing in Massive Power Flow Computation. Energies 2018, 11, 2268. [Google Scholar] [CrossRef]
- Amazon. Amazon Elastic Compute Cloud—Cloud Server & Hosting. 2017. Available online: https://aws.amazon.com/ec2 (accessed on 30 November 2017).
- Microsoft. Microsoft Azure Cloud Computing Platform & Services. 2017. Available online: https://azure.microsoft.com (accessed on 30 November 2017).
- IBM. IBM Cloud. 2017. Available online: https://www.ibm.com/cloud (accessed on 30 November 2017).
- Oracle. Oracle Cloud. 2017. Available online: https://www.oracle.com/cloud (accessed on 30 November 2017).
- Hazelhurst, S. Scientific Computing Using Virtual High-performance Computing: A Case Study Using the Amazon Elastic Computing Cloud. In Proceedings of the 2008 Annual Research Conference of the South African Institute of Computer Scientists and Information Technologists on IT Research in Developing Countries: Riding the Wave of Technology, Wilderness, South Africa, 6–8 October 2008; pp. 94–103. [Google Scholar] [CrossRef]
- Amazon. Amazon Web Services—Cloud Computing Services. 2017. Available online: https://aws.amazon.com (accessed on 30 November 2017).
- Sodani, A.; Gramunt, R.; Corbal, J.; Kim, H.S.; Vinod, K.; Chinthamani, S.; Hutsell, S.; Agarwal, R.; Liu, Y.C. Knights Landing: Second-Generation Intel Xeon Phi Product. IEEE Micro 2016, 36, 34–46. [Google Scholar] [CrossRef]
- Jeffers, J.; Reinders, J. Intel Xeon Phi Coprocessor High Performance Programming, 1st ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2013. [Google Scholar]
- Rahman, R. Intel Xeon Phi Coprocessor Architecture and Tools: The Guide for Application Developers, 1st ed.; Apress: Berkely, CA, USA, 2013. [Google Scholar]
- Nvidia. NVIDIA Tesla V100. 2017. Available online: https://www.nvidia.com/en-us/data-center/tesla-v100/ (accessed on 26 July 2017).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Subramaniyan, A.; Das, R. Parallel Automata Processor. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 600–612. [Google Scholar] [CrossRef]
- Micron. Micron Automata Processing. 2017. Available online: http://www.micronautomata.com (accessed on 20 July 2017).
- Wenisch, T.F.; Wunderlich, R.E.; Ferdman, M.; Ailamaki, A.; Falsafi, B.; Hoe, J.C. SimFlex: Statistical Sampling of Computer System Simulation. IEEE Micro 2006, 26, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Patel, A.; Afram, F.; Chen, S.; Ghose, K. MARSS: A full system simulator for multicore x86 CPUs. In Proceedings of the 2011 48th ACM/EDAC/IEEE Design Automation Conference (DAC), San Diego, CA, USA, 5–9 June 2011; pp. 1050–1055. [Google Scholar]
- Yourst, M.T. PTLsim: A Cycle Accurate Full System x86-64 Microarchitectural Simulator. In Proceedings of the 2007 IEEE International Symposium on Performance Analysis of Systems Software, San Jose, CA, USA, 25–27 April 2007; pp. 23–34. [Google Scholar] [CrossRef]
- Lee, K.; Cho, S. Accurately Modeling Superscalar Processor Performance with Reduced Trace. J. Parallel Distrib. Comput. 2013, 73, 509–521. [Google Scholar] [CrossRef]
- Chiou, D.; Sunwoo, D.; Kim, J.; Patil, N.A.; Reinhart, W.; Johnson, D.E.; Keefe, J.; Angepat, H. FPGA-Accelerated Simulation Technologies (FAST): Fast, Full-System, Cycle-Accurate Simulators. In Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), Chicago, IL, USA, 1–5 December 2007; pp. 249–261. [Google Scholar] [CrossRef]
- Sherwood, T.; Perelman, E.; Hamerly, G.; Calder, B. Automatically Characterizing Large Scale Program Behavior. In Proceedings of the 10th International Conference on Architectural Support for Programming Languages and Operating Systems, San Jose, CA, USA, 5–9 October 2002; pp. 45–57. [Google Scholar] [CrossRef]
- Carlson, T.E.; Heirmant, W.; Eeckhout, L. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis (SC), Seattle, WA, USA, 12–18 November 2011; pp. 1–12. [Google Scholar] [CrossRef]
- Genbrugge, D.; Eyerman, S.; Eeckhout, L. Interval simulation: Raising the level of abstraction in architectural simulation. In Proceedings of the HPCA-16—2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Han, M.; Kim, S.W.; Kim, M.; Han, Y. P-DRAMSim2: Exploiting Thread-level Parallelism in DRAMSim2. IEICE Electron. Express 2017. [Google Scholar] [CrossRef]
- Fang, Z.; Min, Q.; Zhou, K.; Lu, Y.; Hu, Y.; Zhang, W.; Chen, H.; Li, J.; Zang, B. Transformer: A functional-driven cycle-accurate multicore simulator. In Proceedings of the 2012 49th ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 3–7 June 2012; pp. 106–114. [Google Scholar]
- Wang, K.; Zhang, Y.; Wang, H.; Shen, X. Parallelization of IBM Mambo System Simulator in Functional Modes. SIGOPS Oper. Syst. Rev. 2008, 42, 71–76. [Google Scholar] [CrossRef]
- Kim, M.; Park, C.; Han, M.; Han, Y.; Kim, S.W. Epsim: A Scalable and Parallel MARSSx86 Simulator with Exploiting Epoch-Based Execution. IEEE Access 2019, 7, 4782–4794. [Google Scholar] [CrossRef]
- Chen, J.; Annavaram, M.; Dubois, M. SlackSim: A Platform for Parallel Simulations of CMPs on CMPs. SIGARCH Comput. Archit. News 2009, 37, 20–29. [Google Scholar] [CrossRef]
- Kainaga, M.; Yamada, K.; Inayoshi, H. Analysis of SPEC benchmark programs. In Proceedings of the Eighth TRON Project Symposium, Tokyo, Japan, 21–22 November 1991; pp. 208–215. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- The Apache Software Foundation. Welcome to Apache Hadoop. 2017. Available online: http://hadoop.apache.org (accessed on 3 August 2017).
- Cloudera. Machine Learning, Analytics, Cloud—Cloudera. 2017. Available online: https://www.cloudera.com (accessed on 3 August 2017).
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache Hadoop YARN: Yet Another Resource Negotiator. In Proceedings of the 4th Annual Symposium on Cloud Computing, Santa Clara, CA, USA, 1–3 October 2013; p. 5. [Google Scholar] [CrossRef]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Anthony, S.; Liu, H.; Wyckoff, P.; Murthy, R. Hive: A Warehousing Solution over a Map-reduce Framework. Proc. VLDB Endow. 2009, 2, 1626–1629. [Google Scholar] [CrossRef]
- Rosenblum, M.; Bugnion, E.; Devine, S.; Herrod, S.A. Using the SimOS Machine Simulator to Study Complex Computer Systems. ACM Trans. Model. Comput. Simul. TOMACS 1997, 7, 78–103. [Google Scholar] [CrossRef]
- Kang, S.-H.; Yoo, D.; Ha, S. TQSIM: A fast cycle-approximate processor simulator based on QEMU. J. Syst. Archit. 2016, 66, 33–47. [Google Scholar] [CrossRef]
- Bellard, F. QEMU, a Fast and Portable Dynamic Translator. In Proceedings of the Annual Conference on USENIX Annual Technical Conference, Anaheim, CA, USA, 10–15 April 2005; p. 41. [Google Scholar]
- Zhang, W.; Wang, H.; Lu, Y.; Chen, H.; Zhao, W. A Loosely-Coupled Full-System Multicore Simulation Framework. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1566–1578. [Google Scholar] [CrossRef]
- Iosup, A.; Ostermann, S.; Yigitbasi, M.N.; Prodan, R.; Fahringer, T.; Epema, D. Performance Analysis of Cloud Computing Services for Many-Tasks Scientific Computing. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 931–945. [Google Scholar] [CrossRef] [Green Version]
- Le, H.H.; Hikida, S.; Yokota, H. NameNode and DataNode Coupling for a Power-Proportional Hadoop Distributed File System. In Database Systems for Advanced Applications; Meng, W., Feng, L., Bressan, S., Winiwarter, W., Song, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 99–107. [Google Scholar]
- Yin, J.; Wang, J.; Zhou, J.; Lukasiewicz, T.; Huang, D.; Zhang, J. Opass: Analysis and Optimization of Parallel Data Access on Distributed File Systems. In Proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium, Hyderabad, India, 25–29 May 2015; pp. 623–632. [Google Scholar] [CrossRef]
- Jackson, K.R.; Ramakrishnan, L.; Muriki, K.; Canon, S.; Cholia, S.; Shalf, J.; Wasserman, H.J.; Wright, N.J. Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud. In Proceedings of the 2010 IEEE Second International Conference on Cloud Computing Technology and Science, Indianapolis, IN, USA, 30 November–3 December 2010; pp. 159–168. [Google Scholar] [CrossRef]
- Lin, C.; Lin, Y. A Load-Balancing Algorithm for Hadoop Distributed File System. In Proceedings of the 2015 18th International Conference on Network-Based Information Systems, Taipei, Taiwan, 2–4 September 2015; pp. 173–179. [Google Scholar] [CrossRef]
- Bohrer, P.; Peterson, J.; Elnozahy, M.; Rajamony, R.; Gheith, A.; Rockhold, R.; Lefurgy, C.; Shafi, H.; Nakra, T.; Simpson, R.; et al. Mambo: A Full System Simulator for the PowerPC Architecture. ACM SIGMETRICS Perform. Eval. Rev. 2004, 31, 8–12. [Google Scholar] [CrossRef]
- Miller, J.E.; Kasture, H.; Kurian, G.; Gruenwald, C.; Beckmann, N.; Celio, C.; Eastep, J.; Agarwal, A. Graphite: A distributed parallel simulator for multicores. In Proceedings of the HPCA-16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Zheng, G.; Kakulapati, G.; Kale, L.V. BigSim: A parallel simulator for performance prediction of extremely large parallel machines. In Proceedings of the 18th International Parallel and Distributed Processing Symposium, Santa Fe, NM, USA, 26–30 April 2004; p. 78. [Google Scholar] [CrossRef]
- Wunderlich, R.E.; Wenisch, T.F.; Falsafi, B.; Hoe, J.C. SMARTS: Accelerating Microarchitecture Simulation via Rigorous Statistical Sampling. In Proceedings of the 30th Annual International Symposium on Computer Architecture, San Diego, CA, USA, 9–11 June 2003; pp. 84–97. [Google Scholar] [CrossRef]
- Chung, E.S.; Nurvitadhi, E.; Hoe, J.C.; Falsafi, B.; Mai, K. PROToFLEX: FPGA-accelerated Hybrid Functional Simulator. In Proceedings of the 2007 IEEE International Parallel and Distributed Processing Symposium, Long Beach, CA, USA, 26–30 March 2007; pp. 1–6. [Google Scholar] [CrossRef]
- Chung, E.S.; Papamichael, M.K.; Nurvitadhi, E.; Hoe, J.C.; Mai, K.; Falsafi, B. ProtoFlex: Towards Scalable, Full-System Multiprocessor Simulations Using FPGAs. ACM Trans. Reconfig. Technol. Syst. 2009, 2, 15. [Google Scholar] [CrossRef]
- Shang, Y. Resilient Multiscale Coordination Control against Adversarial Nodes. Energies 2018, 11, 1844. [Google Scholar] [CrossRef]
- Takabi, H.; Joshi, J.B.D.; Ahn, G. Security and Privacy Challenges in Cloud Computing Environments. IEEE Secur. Priv. 2010, 8, 24–31. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| Cloud computing platform | Amazon EC2 of AWS |
| Hadoop platform | Cloudera Manager, CDH |
| Hadoop framework | Hadoop YARN MR2, HDFS |
| Number of NameNodes | 1 NameNode with 4 cores |
| Number of DataNodes | 16 DataNodes with 2, 4, 8, 16 cores per node |
| Network bandwidth | 450 Mbps with 2 cores per node 750 Mbps with 4 cores per node 1000 Mbps with 8 cores per node 2000 Mbps with 16 cores per node |
| Category | Scheme | Parallelism | Scalability | Cloud Computing |
|---|---|---|---|---|
| High-abstraction-level modeling | Sniper [28] IntervalSim [29] | No | No | No |
| Sampling-based | SimPoints [27] | No | No | No |
| Hardware-assisted | FAST [26] | FM and TM | Bad | No |
| Parallelizing functional and timing simulations | Transformer [31,44] | FM and TM | Bad | No |
| Multicore and multithreading simulation | P-Mamabo [32] SlackSim [34] | Target core | Limited | No |
| Multicore and cloud computing simulation | EPSim [33] | Epoch (Massive) | Good | Yes |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Kim, S.W.; Han, Y. EPSim-C: A Parallel Epoch-Based Cycle-Accurate Microarchitecture Simulator Using Cloud Computing. Electronics 2019, 8, 716. https://doi.org/10.3390/electronics8060716
Kim M, Kim SW, Han Y. EPSim-C: A Parallel Epoch-Based Cycle-Accurate Microarchitecture Simulator Using Cloud Computing. Electronics. 2019; 8(6):716. https://doi.org/10.3390/electronics8060716
Chicago/Turabian StyleKim, Minseong, Seon Wook Kim, and Youngsun Han. 2019. "EPSim-C: A Parallel Epoch-Based Cycle-Accurate Microarchitecture Simulator Using Cloud Computing" Electronics 8, no. 6: 716. https://doi.org/10.3390/electronics8060716
APA StyleKim, M., Kim, S. W., & Han, Y. (2019). EPSim-C: A Parallel Epoch-Based Cycle-Accurate Microarchitecture Simulator Using Cloud Computing. Electronics, 8(6), 716. https://doi.org/10.3390/electronics8060716