A Hierarchical Modeling and Analysis Framework for Availability and Security Quantification of IoT Infrastructures



Abstract
:1. Introduction
- proposed a hierarchical framework for availability and security quantification of IoT infrastructures consisting of integrated cloud/fog/edge computing paradigms. The hierarchical modeling and analysis framework for IoT infrastructures is composed of three phases, (i) phase I. requirements: to comprehend system architecture and operative behavior hypotheses and extract necessary parameters and system configuration information, (ii) phase II. modeling: to develop hierarchical models of subsystems, member systems and the overall IoT infrastructure, and (iii) phase III. analysis: to compute analysis results for evaluation and assessment.
- proposed a three-level hierarchical model for a three-layer cloud/fog/edge architecture of IoT infrastructures. In accordance with the three-layer hierarchical nature of the IoT infrastructures in consideration, the developed hierarchical model consists of three-level models including (i) RBD model at the top level to involve the IoT infrastructure’s member systems under a pre-defined relevance to each other, (ii) FT model at the middle level to capture the detailed architectures of the member systems, and (iii) CTMC model at the bottom level to capture operative states and transitions of the subsystems in a complete manner.
- applied and demonstrated the feasibility of the proposed hierarchical modeling and analysis framework on availability and security quantification and assessment of a specific case study of IoT smart factory infrastructure.
- performed different analyses to comprehend the characteristics of the IoT smart factory infrastructure and to show the trade-offs between availability and security. The numerical analyses include (i) steady state availability (SSA), (ii) sensitivity analysis of availability wrt. selected impacting factors (mean time to failure equivalent (MTTFeq) or mean time to recovery equivalent (MTTReq)), and (iii) security analysis wrt. attack intensity (mean time to an attack (MTTA)).
- pinpointed essential parameters representing operative properties of subsystems that expose the most impact on availability and security of the IoT smart factory infrastructure in order to support the decision-making process in design and implementation in practice.
- More frequent failures in cloud can cause more severe drops of the considered IoT infrastructure’s overall availability in comparison to the failures in other member systems.
- Quick recovery of edge can help avoid severe drop of the overall availability compared to the recovery of other member systems.
- In the cloud, hardware failures of cloud servers, cloud gateway, and cloud storage expose great impact of decreasing the IoT smart factory infrastructure’s availability, while fast recovery of cloud servers’ VM and VMM secure higher values of the availability.
- In fog, hardware failures of the fog server cause severe consequences while recoveries of fog gateway’s software and fog server’s OS help avoid severe drops of the overall availability.
- In edge, failures of IoT devices cause higher impact on the overall availability compared to failures in IoT sensors or IoT gateway. On the other hand, quick recovery of IoT gateway’s software secures higher values of availability for the IoT smart factory infrastructure.
- In terms of security measures, cloud servers’ VMM and VM, and fog server’s OS are the most vulnerable to cyber-attack intensity in comparison to other subsystems in the considered IoT smart factory infrastructure.
- In general, failures of hardware components and recovery of software components are significant factors to secure higher availability for the IoT smart factory infrastructure in consideration, while necessary countermeasures should be implemented in cloud and fog’s software components to reduce attack intensity and enhance the overall availability.
2. Related Work
3. Background on Internet of Things
- In general, an IoT infrastructure is assumed to consist of a huge number of software/hardware subsystems and components playing in different roles.
- Cloud member system mainly consists of virtualized server systems connected to a number of network devices (routers/hubs/switches) acting as cloud gateways for bi-directional connectivity with fog member system. The processing of data are often featured with advanced processing capabilities and superior technologies in centralized/multi-hop cloud centers which are remotely located in safe regions far away from data sources. The virtualized cloud servers host cloud services running constantly to perform long-term in-depth data analysis tasks including business intelligence, simulation and scheduling, etc. A huge number of heterogeneous sources are all connected to the cloud while a persistent internet connection is required for uninterrupted access of system users from different parts of the world.
- Fog member system consists of (mostly) non-virtualized servers or computing devices/platforms or workstation in some cases along with local network equipment to process multiple data streams at mid-volume size. The fog member system is expected to provide distributed and one-hop computing platforms suitable with mid/short-term data processing tasks and mission-critical/near real-time applications that require low-latency and rapid system response in data processing. Furthermore, due to the nature of high-performance computing capabilities, the fog member system is suited to many applications requiring local-context awareness and dynamic adaption, thus it is often located in specific regions for specific applications, for instance, for smart hospitals, smart buildings, or smart factories. The fog member system is expected to play a role of a man in the middle to handle extremely high-rate data transactions generated from many local sources with the lower edge member system.
- Edge member system consists of IoT sensors/devices and IoT gateways featured with a decentralized and embedded organization. The end devices are at the edge of the computing infrastructure enhanced with the capabilities of monitoring, data pre-processing, and data filtering to handle low-volume of local and raw data streams. The edge member system is featured by autonomy, collaboration and self-awareness built in IoT devices and thus, it is suited with hard real-time/transient tasks, but simple and non-optimal solutions.
4. A Hierarchical Framework for Security and Availability Quantification
4.1. Hierarchical Models
4.2. Modeling and Analysis Framework
5. A Case-Study of IoT Infrastructures
5.1. Architecture Description
- Operative dependencies and sophisticated interactions among different member systems and subsystems are usually involved in performance/performability evaluation, and thus diminished in the reliability/availability quantification of the considered IoT smart factory.
- Networking topologies are not taken into account to avoid complexities in modeling the overall IoT infrastructure.
- Detailed architectures of building blocks at the lowest level are disregarded to reduce the complexity of the overall model.
- The authors specifically consider a simplified architecture of the IoT smart factory infrastructure which consists of a limited number of cloud/fog servers, gateways and IoT sensors/devices.
- Cloud: A cloud member system consists of two physical cloud servers ( and ), three cloud gateways (, and ), and one cloud storage (). comprises underlying physical hardware () and upper VMM (). Similarly, is composed of and . The servers host two VM including and , respectively. The cloud servers enable cloud services to run constantly on the physical cloud platform which is mainly hosted on the cloud storage. The cloud gateways not only perform networking tasks required among the cloud servers and the cloud storage but also secure data communication (send/receive) from/to the fog member system. We assume that, even if a cloud server goes down, the remaining server has a spare space for hosting the two VMs. Furthermore, it is also assumed that, among three cloud gateways, the failure of two different cloud gateways at once is considered to not secure the networking inside the cloud member system and from the cloud to fog member system, thus leading a failure of the cloud. A single failure of the cloud storage is also considered a fatal failure of the cloud. The total outage of all VMs on the physical cloud servers also causes a total failure of the cloud, whereas a cloud goes down if all of its cloud servers reside in a failure state at once.
- Fog: A fog member system is supposed to simply comprise a fog server and a fog gateway . A fog server directly handles computing tasks of local data transactions in the IoT smart factory for instant effectiveness and high performance with infinitesimal latency, while a fog gateway takes the role of high-speed communication between the fog and edge member systems and performs asynchronous data transactions to the cloud member systems. A fog server is considered to fail if either its physical hardware () or its operating system with embedded fog applications/services () fails. A fog gateway fails if either its hardware () or embedded software () fails.
- Edge: The edge member system consists of a specific number of IoT sensors () and IoT devices () used in smart factories which are all connected to an IoT gateway (). A failure of causes a fatal failure of the IoT smart factory infrastructure since it plays the role of connecting IoT sensors/devices in a smart factory to fog and cloud member systems. In addition, it is assumed that, in order to secure fundamental functionalities and services provided in an IoT smart factory, at least a specific number of both IoT sensors and IoT devices functions at a time. Therefore, if IoT sensors experience a failure at once or on the other hand if IoT devices fails to function properly, the edge member system is considered to undergo a service outage in the IoT smart factory.
5.2. Hierarchical Models
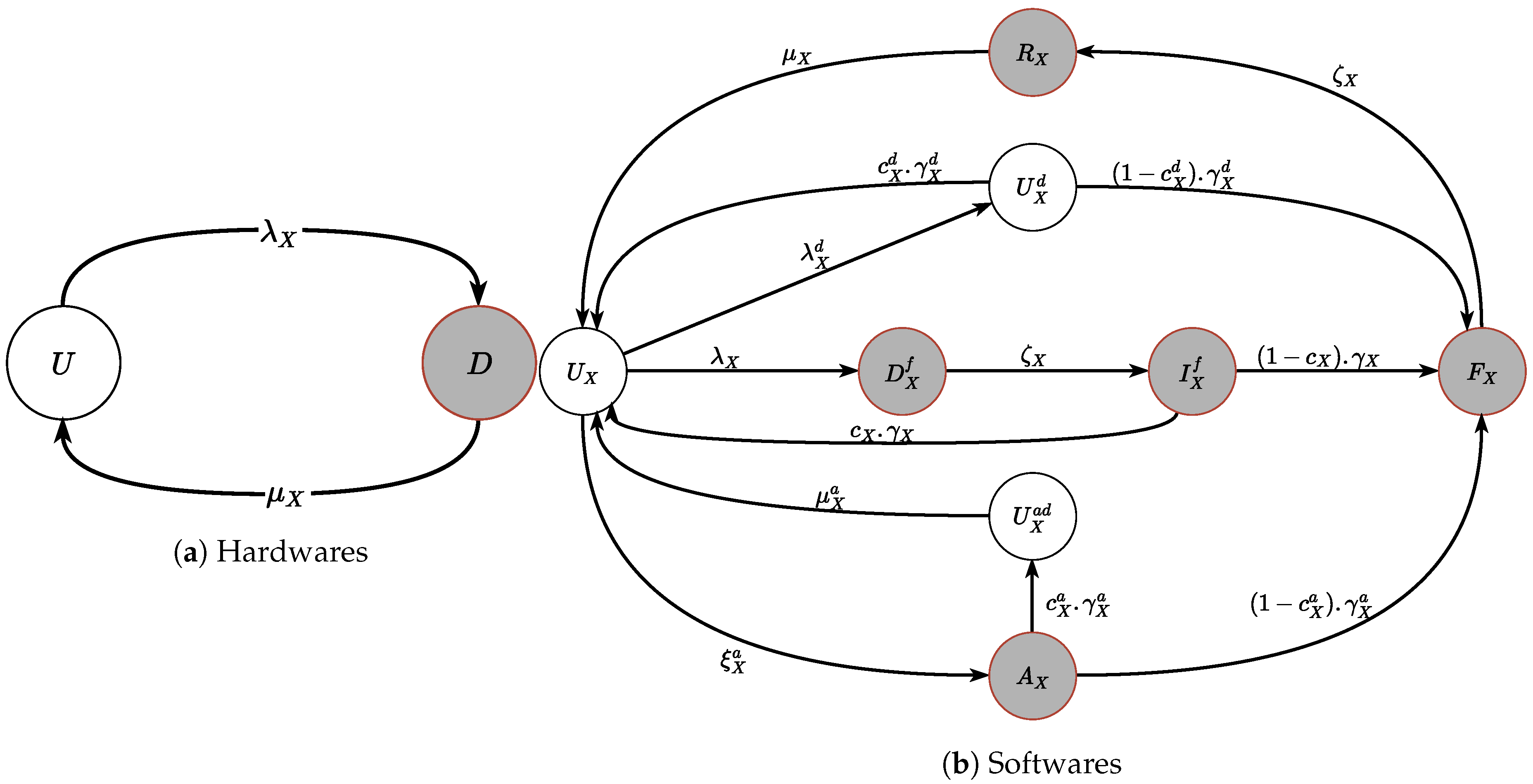
- Hardware subsystems:In order to model physical hardware parts of member systems, a simplification is required to consider only two-state operations (UP or DOWN) of the physical hardware as shown in Figure 5a since those parts often operate constantly in the long run without confronting with severe faults and the maintenance of those parts normally consists of rapid detection and replacement processes [56,57]. The two operative states include up-state (U) and down-state (D). When an uncertain failure occurs, the state transits from U to D with a transition rate , whereas, as a failed physical hardware is recovered, the operative state transits from D to U with a transition rate . The two-state model is used to capture the operative states of physical hardware in the IoT infrastructure over a long period of time including cloud servers’ hardware (cHW), cloud gateways’ hardware (cgHW), fog server’s hardware (fHW), fog gateway’s hardware (fgHW), IoT gateway’s hardware (igHW), IoT sensors’ hardware (iS), and IoT devices’ hardware (iD). The simplification is that, even though the hardware is different from each other, the modeling of these different types of hardware is identical using the above-described two-state model but with different input parameters of MTTFeq () and MTTReq () of each corresponding hardware. The values of those input parameters are mainly referred from previous works and some values are referred mostly from based practical experiences. As computing output results, the indicator X is replaced by the notation of the respective hardware. For instance, is the failure rate of cloud servers’ hardware while is the recovery rate of IoT devices. The values of input parameters are presented in Table 1, Table 2 and Table 3.
- Software Subsystems:Due to operative complexity and normally short state transitions, it is required to capture detailed operative states and transitions of the software subsystems at different levels in evaluating availability/security of the overall IoT infrastructure as shown in Figure 5b. A common model is used to model different software subsystems in Figure 4 including cloud servers’ VMM (cVMM), cloud servers’ VM (cVM), cloud gateways’ software (cgSW), fog server’s operating system (fOS), fog gateway’s software (fgSW), and IoT gateway’s software (igSW). The subscript letter X in states is replaced by the corresponding subscript letters representing the respective softwares and the values of transition rates with the respectively replaced subscript letters can be referred to the tables of input parameters in Table 1, Table 2 and Table 3. The description of the analytical models for the above-mentioned software subsystems is based on the description of the common model using the subscript letter X in Figure 5b. In the modeling of software subsystems in the IoT infrastructure, three main causes to software failures are considered and modeled, including: (i) uncertain failures due to flaws in software development stage, (ii) aging failures due to performance-degraded errors during software run-time, and (iii) security failures due to security attacks. We assume to take into account the security attack intensity rather than security attacker’s behaviors and threat model in modeling security related matters. Assuming that all software subsystems initially operate in a normal state depicted by . When an uncertain failure happens with a mean time to failure (MTTF) of , the software’s operations transit to a down state . Afterwards, a repair person is summoned with a rate , thus the state transits from the down state to the under-investigation state . The subsequent recovery of the software due to uncertain failures may succeed with a coverage factor of and a recovery rate of . The successful recovery of a failed software at this time causes a state transition from back to the up state . If the recovery process fails to complete, the state of the software transits from the under-investigation state to the complete failure state .In another case when the software resides in the up state , the software often confronts with a variety of software aging-related errors which cause the software to not operate in the healthy state after a mean time of but operate in a failure-probable state (but this state is still considered as an up state). In this situation, different software rejuvenation techniques can be performed to recovery the software state from the aging state to the healthy state with a coverage factor of and a recovery rate of . Thus, the mean time of a successful recovery from the aging state is . If it fails to recover the aging software, the software eventually fails due to performance-degraded failures and its state transits from to under the rate .In the case that a cyber attacker performs a malicious and active attack which is to damage system resources or to take control of system operations and eventually to take down the software subsystems, the software subsystem’s state transits from the healthy state to the under-attack state with an assumption of an attack frequency of . We assume that several cyber-security attack adaption techniques would be implemented as soon as the software subsystem is recognized as being in under-attack state, the success of these techniques could uphold previously running services thus maintain up-time operations of the software subsystem with existing cyber-security vulnerabilities. The adaption success is supposed to have a coverage factor of and the adaption process to an attack would take a mean time of . The state of the software subsystem transits from the under-attack to an up state with cyber-security vulnerabilities after a successful adaption. The vulnerabilities can be removed by software patches afterwards with a mean time of . Subsequently, the software subsystem state returns to initially healthy state . In the case of cyber-security adaption failure, the software subsystem state transits from to a complete failure state with a transition rate of .When the software subsystem resides in the complete failure state , it is essential to summon a repair person quickly and it still takes a mean time of . The software subsystem goes into a under-recovery state which is also a down state. The recovery of a failed software subsystem after that cost a mean time of and the state of the software subsystem returns to its initially healthy state .
6. Numerical Results and Discussion
6.1. Steady State Availability Analysis
6.2. Availability Sensitivity with Respect to Impacting Factors
6.3. Security Analysis with Respect to Attack Intensity
6.4. Further Discussions
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A Survey on Internet of Things: Architecture, Enabling Technologies, Security and Privacy, and Applications. IEEE Internet Things J. 2017. [Google Scholar] [CrossRef]
- Ray, P. A survey on Internet of Things architectures. J. King Saud Univ. Comput. Inf. Sci. 2016. [Google Scholar] [CrossRef]
- Botta, A.; de Donato, W.; Persico, V.; Pescapé, A. Integration of Cloud computing and Internet of Things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Botta, A.; de Donato, W.; Persico, V.; Pescape, A. On the Integration of Cloud Computing and Internet of Things. In Proceedings of the 2014 International Conference on Future Internet of Things and Cloud, Barcelona, Spain, 27–29 August 2014; pp. 23–30. [Google Scholar] [CrossRef]
- Mineraud, J.; Mazhelis, O.; Su, X.; Tarkoma, S. A gap analysis of Internet-of-Things platforms. Comput. Commun. 2016, 89–90, 5–16. [Google Scholar] [CrossRef] [Green Version]
- Sanislav, T.; Mois, G.; Miclea, L. An approach to model dependability of cyber-physical systems. Microprocess. Microsyst. 2016, 41, 67–76. [Google Scholar] [CrossRef]
- Andrade, E.; Nogueira, B. Dependability evaluation of a disaster recovery solution for IoT infrastructures. J. Supercomput. 2018. [Google Scholar] [CrossRef]
- Tigre, M.F.F.d.S.L.; Santos, G.L.; Lynn, T.; Sadok, D.; Kelner, J.; Endo, P.T. Modeling the availability of an e-health system integrated with edge, fog and cloud infrastructures. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC), Natal, Brazil, 25–28 June 2018; pp. 00416–00421. [Google Scholar] [CrossRef]
- Santos, G.L.; Takako Endo, P.; Ferreira da Silva Lisboa Tigre, M.F.; Ferreira da Silva, L.G.; Sadok, D.; Kelner, J.; Lynn, T. Analyzing the availability and performance of an e-health system integrated with edge, fog and cloud infrastructures. J. Cloud Comput. 2018, 7, 16. [Google Scholar] [CrossRef] [Green Version]
- Nicol, D.; Sanders, W.; Trivedi, K. Model-based evaluation: From dependability to security. IEEE Trans. Dependable Secur. Comput. 2004, 1, 48–65. [Google Scholar] [CrossRef]
- Matos, R.; Andrade, E.C.; Maciel, P. Evaluation of a disaster recovery solution through fault injection experiments. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics, San Diego, CA, USA, 5–8 Octorber 2014; pp. 2675–2680. [Google Scholar] [CrossRef]
- Sallhammar, K.; Helvik, B.; Knapskog, S. Towards a stochastic model for integrated security and dependability evaluation. In Proceedings of the First, International Conference on Availability, Reliability and Security (ARES’06), Vienna, Austria, 20–22 April 2006; pp. 8–165. [Google Scholar] [CrossRef] [Green Version]
- Trivedi, K.S.; Kim, D.S.; Roy, A.; Medhi, D. Dependability and security models. In Proceedings of the 2009 7th International Workshop on the Design of Reliable Communication Networks, DRCN 2009, Washington, DC, USA, 25–28 Octorber 2009; pp. 11–20. [Google Scholar] [CrossRef]
- Montecchi, L.; Nostro, N.; Ceccarelli, A.; Vella, G.; Caruso, A.; Bondavalli, A. Model-based Evaluation of Scalability and Security Tradeoffs: A Case Study on a Multi-Service Platform. Electron. Notes Theor. Comput. Sci. 2015, 310, 113–133. [Google Scholar] [CrossRef] [Green Version]
- Ge, M.; Kim, H.K.; Kim, D.S. Evaluating Security and Availability of Multiple Redundancy Designs when Applying Security Patches. In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Denver, CO, USA, 26–29 June 2017. [Google Scholar]
- Torquato, M.; Maciel, P.; Vieira, M. A Model for Availability and Security Risk Evaluation for Systems with VMM Rejuvenation enabled by VM Migration Scheduling. IEEE Access 2019, 7, 138315–138326. [Google Scholar] [CrossRef]
- Sahner, R.; Trivedi, K.S.; Puliafito, A. Hierarchical Models. In Performance and Reliability Analysis of Computer Systems; Springer US: Boston, MA, USA, 1996; pp. 261–311. [Google Scholar] [CrossRef]
- Nguyen, T.A.; Min, D.; Choi, E.; Thang, T.D. Reliability and Availability Evaluation for Cloud Data Center Networks using Hierarchical Models. IEEE Access 2019, 7, 9273–9313. [Google Scholar] [CrossRef]
- Nguyen, T.A.; Eom, T.; An, S.; Park, J.S.; Hong, J.B.; Kim, D.S. Availability Modeling and Analysis for Software Defined Networks. In Proceedings of the 2015 IEEE 21st Pacific Rim International Symposium on Dependable Computing (PRDC), Zhangjiajie, China, 18–20 November 2015; pp. 159–168. [Google Scholar] [CrossRef]
- Smith, W.E.; Trivedi, K.S.; Tomek, L.A.; Ackaret, J. Availability analysis of blade server systems. IBM Syst. J. 2008, 47, 621–640. [Google Scholar] [CrossRef] [Green Version]
- Matos, R.; Araujo, J.; Oliveira, D.; Maciel, P.; Trivedi, K. Sensitivity analysis of a hierarchical model of mobile cloud computing. Simul. Model. Pract. Theory 2015, 50, 151–164. [Google Scholar] [CrossRef]
- Trivede, K.; Vasireddy, R.; Trindale, D.; Nathan, S.; Castro, R. Modeling High Availability. In Proceedings of the 2006 12th Pacific Rim International Symposium on Dependable Computing (PRDC’06), Riverside, CA, USA, 18–20 December 2006; pp. 154–164. [Google Scholar] [CrossRef]
- Jaatun, M.G.; Zhao, G.; Rong, C. Cloud Computing; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5931. [Google Scholar] [CrossRef]
- Wu, C.; Buyya, R.; Ramamohanarao, K. Cloud Pricing Models. ACM Comput. Surv. 2019, 52, 108. [Google Scholar] [CrossRef]
- Pham, C.; Kalbarczyk, Z.; Iyer, R.K. Toward a high availability cloud: Techniques and challenges. In Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN 2012), Boston, MA, USA, 25–28 June 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, T.A.; Kim, D.S.; Park, J.S. A Comprehensive Availability Modeling and Analysis of a Virtualized Servers System Using Stochastic Reward Nets. Sci. World J. 2014, 2014, 165316. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.A.; Kim, D.S.; Park, J.S. Availability modeling and analysis of a data center for disaster tolerance. Future Gener. Comput. Syst. 2016, 56, 27–50. [Google Scholar] [CrossRef]
- Dasari, K.; Rayaprolu, M. Fog computing: Overview, architecture, security issues and applications. Lecture Notes in Electrical Engineering. In Proceedings of the International Conference on Communications and Cyber Physical Engineering 2018, Hyderabad, India, 24–25 January 2018. [Google Scholar] [CrossRef]
- Naha, R.K.; Garg, S.; Georgakopoulos, D.; Jayaraman, P.P.; Gao, L.; Xiang, Y.; Ranjan, R. Fog Computing: Survey of Trends, Architectures, Requirements, and Research Directions. IEEE Access 2018, 6, 47980–48009. [Google Scholar] [CrossRef]
- Yi, S.; Li, C.; Li, Q. A Survey of Fog Computing. In Proceedings of the 2015 Workshop on Mobile Big Data—Mobidata ’15; ACM Press: New York, New York, USA, 2015; pp. 37–42. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- Ai, Y.; Peng, M.; Zhang, K. Edge computing technologies for Internet of Things: A primer. Digit. Commun. Netw. 2018. [Google Scholar] [CrossRef]
- Khan, W.Z.; Ahmed, E.; Hakak, S.; Yaqoob, I.; Ahmed, A. Edge computing: A survey. Future Gener. Comput. Syst. 2019, 97, 219–235. [Google Scholar] [CrossRef]
- El-Sayed, H.; Sankar, S.; Prasad, M.; Puthal, D.; Gupta, A.; Mohanty, M.; Lin, C.T. Edge of Things: The Big Picture on the Integration of Edge, IoT and the Cloud in a Distributed Computing Environment. IEEE Access 2018, 6, 1706–1717. [Google Scholar] [CrossRef]
- Wu, H.; Hu, J.; Sun, J.; Sun, D. Edge Computing in an IoT Base Station System: Reprogramming and Real-Time Tasks. Complexity 2019, 2019, 4027638. [Google Scholar] [CrossRef] [Green Version]
- Bruneo, D.; Distefano, S.; Longo, F.; Merlino, G.; Puliafito, A. I/Ocloud: Adding an IoT Dimension to Cloud Infrastructures. Computer 2018, 51, 57–65. [Google Scholar] [CrossRef]
- Maharaja, R.; Iyer, P.; Ye, Z. A hybrid fog-cloud approach for securing the Internet of Things. Clust. Comput. 2019, 22, 1–9. [Google Scholar] [CrossRef]
- Mahmud, R.; Koch, F.L.; Buyya, R. Cloud–Fog Interoperability in IoT-enabled Healthcare Solutions. In Proceedings of the 19th International Conference on Distributed Computing and Networking—ICDCN ’18; ACM Press: New York, New York, USA, 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Okay, F.Y.; Ozdemir, S. A fog computing based smart grid model. In Proceedings of the 2016 International Symposium on Networks, Computers and Communications (ISNCC), Yasmine Hammamet, Tunisia, 11–13 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Rahmani, A.M.; Gia, T.N.; Negash, B.; Anzanpour, A.; Azimi, I.; Jiang, M.; Liljeberg, P. Exploiting smart e-Health gateways at the edge of healthcare Internet-of-Things: A fog computing approach. Future Gener. Comput. Syst. 2018. [Google Scholar] [CrossRef]
- Mancini, R.; Tuli, S.; Cucinotta, T.; Buyya, R. iGateLink: A Gateway Library for Linking IoT, Edge, Fog and Cloud Computing Environments. arXiv 2019, arXiv:1911.08413. [Google Scholar]
- Villari, M.; Fazio, M.; Dustdar, S.; Rana, O.; Ranjan, R. Osmotic Computing: A New Paradigm for Edge/Cloud Integration. IEEE Cloud Comput. 2016, 3, 76–83. [Google Scholar] [CrossRef] [Green Version]
- Androcec, D. Systematic Mapping Study on Osmotic Computing. In Proceedings of the The 30th Central European Conference on Information and Intelligent Systems (CECIIS), Zagreb, Croatia, 2–4 October 2019; pp. 79–84. [Google Scholar]
- Mouradian, C.; Naboulsi, D.; Yangui, S.; Glitho, R.H.; Morrow, M.J.; Polakos, P.A. A Comprehensive Survey on Fog Computing: State-of-the-Art and Research Challenges. arXiv 2018, arXiv:cond-mat/0408151. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, R.; Kotagiri, R.; Buyya, R. Fog Computing: A Taxonomy, Survey and Future Directions. In Internet of Everything; Springer: Berlin/Heidelberg, Germany, 2018; pp. 103–130. [Google Scholar] [CrossRef] [Green Version]
- Dustdar, S.; Avasalcai, C.; Murturi, I. Invited Paper: Edge and Fog Computing: Vision and Research Challenges. In Proceedings of the 2019 IEEE International Conference on Service-Oriented System Engineering (SOSE), San Francisco, CA, USA, 4–9 April 2019. [Google Scholar] [CrossRef]
- Bittencourt, L.; Immich, R.; Sakellariou, R.; Fonseca, N.; Madeira, E.; Curado, M.; Villas, L.; DaSilva, L.; Lee, C.; Rana, O. The Internet of Things, Fog and Cloud continuum: Integration and challenges. Internet Things 2018, 3–4, 134–155. [Google Scholar] [CrossRef] [Green Version]
- Memon, R.A.; Li, J.P.; Nazeer, M.I.; Neyaz, A.; Ahmed, J.; Wali, S.; Basit, A. DualFog-IoT: Additional Fog Layer for Solving Blockchain Integration Problem in Internet of Things. IEEE Access 2019, 7, 169073–169093. [Google Scholar] [CrossRef]
- Queiroz, J.; Leitão, P.; Barbosa, J.; Oliveira, E. Distributing Intelligence among Cloud, Fog and Edge in Industrial Cyber-physical Systems. In Proceedings of the 16th International Conference on Informatics in Control, Automation and Robotics, Prague, Czech Republic, 29–31 July 2019; pp. 447–454. [Google Scholar] [CrossRef] [Green Version]
- Grottke, M.; Trivedi, K.S. Software faults, software aging and software rejuvenation. J. Reliab. Eng. Assoc. Jpn. 2005, 27, 425–438. [Google Scholar]
- Schroeder, B.; Gibson, G.A. Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? In Proceedings of the 5th USENIX Conference on File and Storage Technologies (FAST ’07), San Jose, CA, USA, 12–13 February 2007. [Google Scholar] [CrossRef]
- Rosendo, D.; Leoni, G.; Gomes, D.; Moreira, A.; Gonçalves, G.; Endo, P.; Kelner, J.; Sadok, D.; Mahloo, M. How to Improve Cloud Services Availability? Investigating the Impact of Power and It Subsystems Failures. In Proceedings of the 51st Hawaii International Conference on System Sciences (HICSS 2018), Hilton Waikoloa Village, HI, USA, 3–6 January 2018. [Google Scholar] [CrossRef] [Green Version]
- Gill, P.; Jain, N.; Nagappan, N. Understanding network failures in data centers: Measurement, analysis, and implications. In Proceedings of the ACM SIGCOMM, Toronto, ON, Canada, 15–19 August 2011. [Google Scholar] [CrossRef]
- Madan, B.; Gogeva-Popstojanova, K.; Vaidyanathan, K.; Trivedi, K. Modeling and quantification of security attributes of software systems. In Proceedings of the International Conference on Dependable Systems and Networks, Washington, DC, USA, 23–26 June 2002; pp. 505–514. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Zhang, L.; Xu, W. What Can We Learn from Four Years of Data Center Hardware Failures? In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Denver, CO, USA, 26–29 June 2017; pp. 25–36. [Google Scholar] [CrossRef]
- Miller, R. Failure Rates in Google Data Centers. Data Center Knowledge, Business. 30 May 2008. Available online: https://www.datacenterknowledge.com/archives/2008/05/30/failure-rates-in-google-data-centers (accessed on 1 December 2019).
- Trivedi, K. SHARPE 2002: Symbolic Hierarchical Automated Reliability and Performance Evaluator. In Proceedings of the International Conference on Dependable Systems and Networks, Washington, DC, USA, 23–26 June 2002; p. 544. [Google Scholar] [CrossRef]
- Trivedi, K.S.; Sahner, R. SHARPE at the age of twenty two. ACM SIGMETRICS Perform. Eval. Rev. 2009, 36, 52. [Google Scholar] [CrossRef]
- Kim, D.S.; Machida, F.; Trivedi, K.S. Availability Modeling and Analysis of a Virtualized System. In Proceedings of the 2009 15th IEEE Pacific Rim International Symposium on Dependable Computing, Shanghai, China, 16–18 November 2009; Volume 1, pp. 365–371. [Google Scholar] [CrossRef]
- Sebastio, S.; Trivedi, K.S.; Alonso, J. Characterizing machines lifecycle in Google data centers. Perform. Eval. 2018, 126, 39–63. [Google Scholar] [CrossRef]
- Matos, R.; Dantas, J.; Araujo, J.; Trivedi, K.S.; Maciel, P. Redundant Eucalyptus Private Clouds: Availability Modeling and Sensitivity Analysis. J. Grid Comput. 2016, 15, 1–22. [Google Scholar] [CrossRef]
- Bruneo, D.; Distefano, S.; Longo, F.; Merlino, G. An IoT Testbed for the Software Defined City Vision: The #SmartMe Project. In Proceedings of the 2016 IEEE International Conference on Smart Computing (SMARTCOMP), St. Louis, MO, USA, 18–20 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Dantas, J.; Matos, R.; Araujo, J.; Maciel, P. Eucalyptus-based private clouds: Availability modeling and comparison to the cost of a public cloud. Computing 2015, 97, 1121–1140. [Google Scholar] [CrossRef]
- Dantas, J.; Matos, R.; Araujo, J.; Maciel, P. An availability model for eucalyptus platform: An analysis of warm-standy replication mechanism. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; pp. 1664–1669. [Google Scholar] [CrossRef]
- Raei, H.; Yazdani, N. Analytical performance models for resource allocation schemes of cloudlet in mobile cloud computing. J. Supercomput. 2017, 73, 1274–1305. [Google Scholar] [CrossRef]
- Raei, H.; Yazdani, N.; Shojaee, R. Modeling and performance analysis of cloudlet in Mobile Cloud Computing. Perform. Eval. 2017, 107, 34–53. [Google Scholar] [CrossRef]
- Ge, M.; Cho, J.H.; Ishfaq, B.; Kim, D.S. Modeling and Analysis of Integrated Proactive Defense Mechanisms for Internet-of-Things. arXiv 2019, arXiv:1908.00327. [Google Scholar]
- Hong, J.B.; Enoch, S.Y.; Kim, D.S.; Nhlabatsi, A.; Fetais, N.; Khan, K.M. Dynamic Security Metrics for Measuring the Effectiveness of Moving Target Defense Techniques. Comput. Secur. 2018, 79, 33–52. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Values |
|---|---|---|
| —Cloud server’s physical hardware (cHW)— | ||
| Mean time to a failure of a cloud server’s physical hardware | 8 years | |
| Mean time to recover a failure of a cloud server’s physical hardware | 5 days | |
| —Cloud server’s VMM (cVMM)— | ||
| Mean time to a failure of a cloud server’s VMM | 365 days | |
| Mean time to summon a repair-person to detect a failure and/or | 3 h | |
| recover a failed cVMM | ||
| Mean time to investigate a failure and detect | 8 h | |
| Mean time to a performance-degradation issue of a cVMM | 120 days | |
| Mean time to detect and recover failure-probable faults after | 5 h | |
| performance-degradation | ||
| Mean time to a cyber-security attack on a cVMM VMM | 45 days | |
| Mean time to detect and adapt a security attack in order to restore a | 12 h | |
| part of operational services | ||
| Mean time to fully recover an attacked cVMM after preliminary adaption | 24 h | |
| Mean time to recover a failure of a cloud server’s VMM | 16 h | |
| Coverage factor of detection and recovery of uncertain failures of a cVMM | 0.95 | |
| Coverage factor of software rejuvenation techniques against | 0.95 | |
| performance-degradation issues on a cVMM | ||
| Coverage factor of attack detection and partial recovery after a | 0.80 | |
| cyber-security attack on a cVMM | ||
| —Cloud server’s VM (cVM)— | ||
| Mean time to a failure of a cloud server’s VMM | 180 days | |
| Mean time to summon a repair-person to detect a failure and/or | 3 h | |
| recover a failed cVM | ||
| Mean time to investigate a failure and detect uncertain failures of a cVM | 8 h | |
| Mean time to a performance-degradation issue of a cVM | 55 days | |
| Mean time to detect and recover failure-probable faults after | 3 h | |
| performance-degradation | ||
| Mean time to a cyber-security attack on a cVM VMM | 20 days | |
| Mean time to detect and adapt a security attack in order to restore a | 8 h | |
| part of operational services | ||
| Mean time to fully recover an attacked cVM after preliminary adaption | 12 h | |
| Mean time to recover a failure of a cloud server’s VMM | 6 h | |
| Coverage factor of detection and recovery of uncertain failures of a cVM | 0.90 | |
| Coverage factor of software rejuvenation techniques against | 0.90 | |
| performance-degradation issues on a cVM | ||
| Coverage factor of attack detection and partial recovery after a | 0.85 | |
| cyber-security attack on a cVM | ||
| —Cloud gateway’s physical hardware (cgHW)— | ||
| Mean time to a failure of a cloud gateway’s physical hardware | 10 years | |
| Mean time to recover a failure of a cloud gateway’s physical hardware | 10 days | |
| —Cloud gateway’s software (cgSW)— | ||
| Mean time to a failure of a cloud gateway software | 400 days | |
| Mean time to summon a repair-person to detect a failure and/or | 7 days | |
| recover a failed cgSW | ||
| Mean time to investigate a failure and detect uncertain failures of a cgSW | 12 h | |
| Mean time to a performance-degradation issue of a cgSW | 150 days | |
| Mean time to detect and recover failure-probable faults after | 8 h | |
| performance-degradation | ||
| Mean time to a cyber-security attack on a cgSW VMM | 20 days | |
| Mean time to detect and adapt a security attack in order to restore a | 18 h | |
| part of operational services | ||
| Mean time to fully recover an attacked cgSW after preliminary adaption | 30 h | |
| Mean time to recover a failure of a cloud server’s VMM | 15 h | |
| Coverage factor of detection and recovery of uncertain failures of a cgSW | 0.90 | |
| Coverage factor of software rejuvenation techniques against | 0.95 | |
| performance-degradation issues on a cgSW | ||
| Coverage factor of attack detection and partial recovery after a | 0.90 | |
| cyber-security attack on a cgSW | ||
| —Cloud storage (cStorage)— | ||
| Mean time to a failure of a cloud storage | 5 years | |
| Mean time to recover a failed cloud storage | 10 days | |
| Name | Description | Values |
|---|---|---|
| —Fog server’s physical hardware (fHW)— | ||
| Mean time to a failure of a fog server’s physical hardware | 5 years | |
| Mean time to recover a failure of a fog server’s physical hardware | 5 days | |
| —Fog server’s bare operating system (fOS)— | ||
| Mean time to an uncertain failure of a fog server’s bare operating system | 200 days | |
| Mean time to summon a repair-person to detect a failure and/or | 3 h | |
| recover a failed fOS | ||
| Mean time to investigate a failure and detect uncertain failures of a fOS | 15 min | |
| Mean time to a performance-degradation issue of a fOS | 150 days | |
| Mean time to detect and recover failure-probable faults after | 90 min | |
| performance-degradation | ||
| Mean time to a cyber-security attack on a fOS | 45 days | |
| Mean time to detect and adapt a security attack in order to restore | 3 h | |
| a part of operational services of the fOS | ||
| Mean time to fully recover an attacked fOS after preliminary adaption | 2 h | |
| Mean time to recover a failure of a fog operating system fOS | 6 h | |
| Coverage factor of detection and recovery of uncertain failures of a fOS | 0.90 | |
| Coverage factor of software rejuvenation techniques against | 0.90 | |
| performance-degradation issues on a fOS | ||
| Coverage factor of attack detection and partial recovery after | 0.85 | |
| a cyber-security attack on a fOS | ||
| —Fog gateway’s physical hardware (fgHW)— | ||
| Mean time to a failure of a fog gateway’s physical hardware | 8 years | |
| Mean time to recover a failure of a fog gateway’s physical hardware | 3 days | |
| —Fog gateway’s software (fgSW)— | ||
| Mean time to an uncertain failure of a fog gateway’s software | 250 days | |
| Mean time to summon a repair-person to detect a failure and/or | 3 h | |
| recover a failed fgSW | ||
| Mean time to investigate a failure and detect uncertain failures of a fgSW | 15 min | |
| Mean time to a performance-degradation issue of a fgSW | 100 days | |
| Mean time to detect and recover failure-probable faults after | 90 min | |
| performance-degradation | ||
| Mean time to a cyber-security attack on an fgSW | 45 days | |
| Mean time to detect and adapt a security attack in order to restore | 3 h | |
| a part of operational services of the fgSW | ||
| Mean time to fully recover an attacked fgSW after preliminary adaption | 2 h | |
| Mean time to recover a failure of a fog operating system fgSW | 6 h | |
| Coverage factor of detection and recovery of uncertain failures of a fgSW | 0.90 | |
| Coverage factor of software rejuvenation techniques against | 0.90 | |
| performance-degradation issues on an fgSW | ||
| Coverage factor of attack detection and partial recovery after | 0.85 | |
| a cyber-security attack on an fgSW | ||
| Name | Description | Values |
|---|---|---|
| —IoT sensors (iSensors)— | ||
| Mean time to a failure of an IoT sensor | 3 years | |
| Mean time to recover a failed IoT sensor | 15 min | |
| —IoT devices (iDevices)— | ||
| Mean time to a failure of an IoT device | 1 year | |
| Mean time to recover a failed IoT device | 3 days | |
| —IoT gateway’s physical hardware (igHW)— | ||
| Mean time to a failure of a IoT gateway’s physical hardware | 3 years | |
| Mean time to recover a failure of a IoT gateway’s physical hardware | 12 h | |
| —IoT gateway’s software (igSW)— | ||
| Mean time to an uncertain failure of a IoT gateway’s software | 300 days | |
| Mean time to summon a repair-person to detect a failure and/or | 2 h | |
| recover a failed igSW | ||
| Mean time to investigate a failure and detect uncertain failures of a igSW | 10 min | |
| Mean time to a performance-degradation issue of a igSW | 180 days | |
| Mean time to detect and recover failure-probable faults after | 75 min | |
| performance-degradation | ||
| Mean time to a cyber-security attack on a igSW | 20 days | |
| Mean time to detect and adapt a security attack in order to restore | 75 min | |
| a part of operational services of the igSW | ||
| Mean time to fully recover an attacked igSW after preliminary adaption | 2 h | |
| Mean time to recover a failure of a IoT gateway’s software igSW | 135 min | |
| Coverage factor of detection and recovery of uncertain failures of a igSW | 0.95 | |
| Coverage factor of software rejuvenation techniques against | 0.85 | |
| performance-degradation issues on a igSW | ||
| Coverage factor of attack detection and partial recovery after | 0.90 | |
| a cyber-security attack on a igSW | ||
| Systems | MTTFeq | MTTReq | SSA | #9s | |
|---|---|---|---|---|---|
| Cloud | 5.242 × | 1.681 × | 9.689 × | 1.508 | 272.249 |
| Fog | 3.638 × | 8.003 × | 9.784 × | 1.667 | 188.528 |
| Edge | 4.336 × | 3.948 × | 9.990 × | 3.041 | 7.970 |
| IoT Infra. | 1.436 × | 8.005 × | 9.472 × | 1.277 | 462.4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.A.; Min, D.; Choi, E. A Hierarchical Modeling and Analysis Framework for Availability and Security Quantification of IoT Infrastructures. Electronics 2020, 9, 155. https://doi.org/10.3390/electronics9010155
Nguyen TA, Min D, Choi E. A Hierarchical Modeling and Analysis Framework for Availability and Security Quantification of IoT Infrastructures. Electronics. 2020; 9(1):155. https://doi.org/10.3390/electronics9010155
Chicago/Turabian StyleNguyen, Tuan Anh, Dugki Min, and Eunmi Choi. 2020. "A Hierarchical Modeling and Analysis Framework for Availability and Security Quantification of IoT Infrastructures" Electronics 9, no. 1: 155. https://doi.org/10.3390/electronics9010155
APA StyleNguyen, T. A., Min, D., & Choi, E. (2020). A Hierarchical Modeling and Analysis Framework for Availability and Security Quantification of IoT Infrastructures. Electronics, 9(1), 155. https://doi.org/10.3390/electronics9010155