DrawerPipe: A Reconfigurable Pipeline for Network Processing on FPGA-Based SmartNIC

Abstract
:1. Introduction
- We present a reconfigurable network processing pipeline for SmartNIC, i.e., DrawerPipe, which abstracts packet processing into multiple “drawers” with the same interface, and provides high flexibility to add, remove, or replace modules in the “drawers” to implement custom NFs.
- We design a Programmable Module Indexing mechanism, i.e., PMI, and a PMI compiler, which allow developers to specify the module execution order for each flow to perform required NFs.
- We implement a DrawerPipe prototype with five reusable modules on an FPGA integrated platform, and extend four example NFs (firewall, stateful firewall, load balancer, IDS). We then evaluate the PMI by constructing multiple service chains.
2. Requirements and Approach
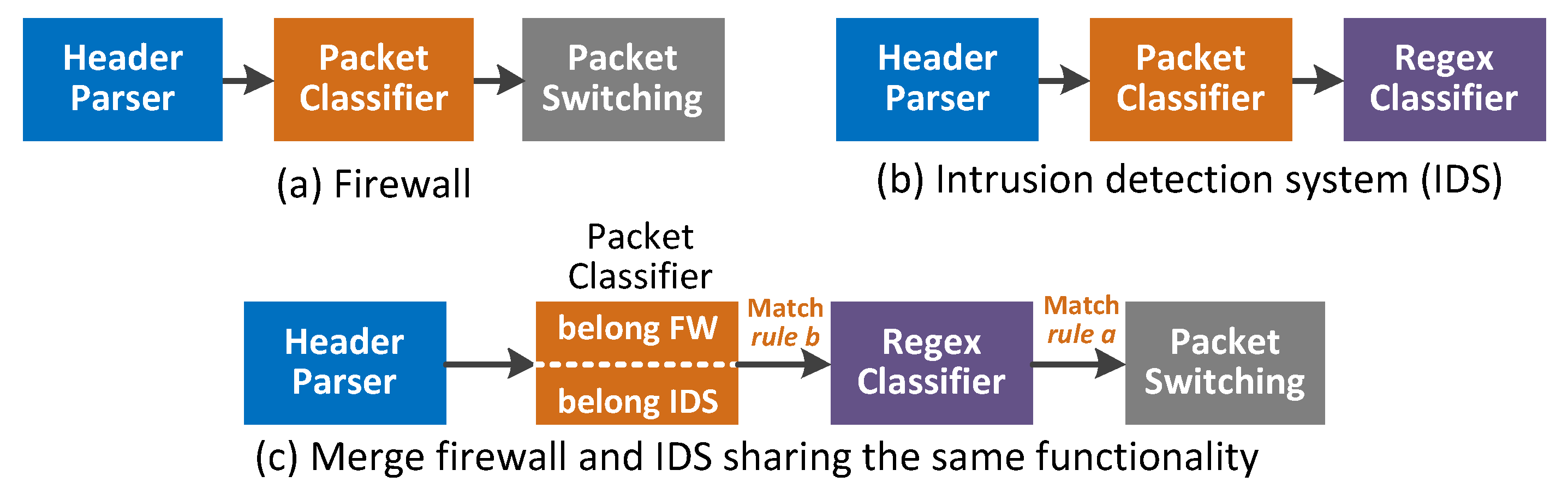
- Modular and reconfigurable pipeline: According to the characteristics of packet processing existed in commonly deployed NFs, DrawerPipe abstract packet processing into multiple “drawers” with the same interface, and provides several highly reusable modules for low-level packet processing. DrawerPipe allows NFs sharing similar functionalities while ensuring data areolation using two methods. First, to ensure matching isolation, every rule table is divided into multiple logic tables for NFs, and each NF can only visit its own table. Second, to ensure action isolation, DrawerPipe attached metadata before each packet to carry intermediate processing result generated by modules. (R1).
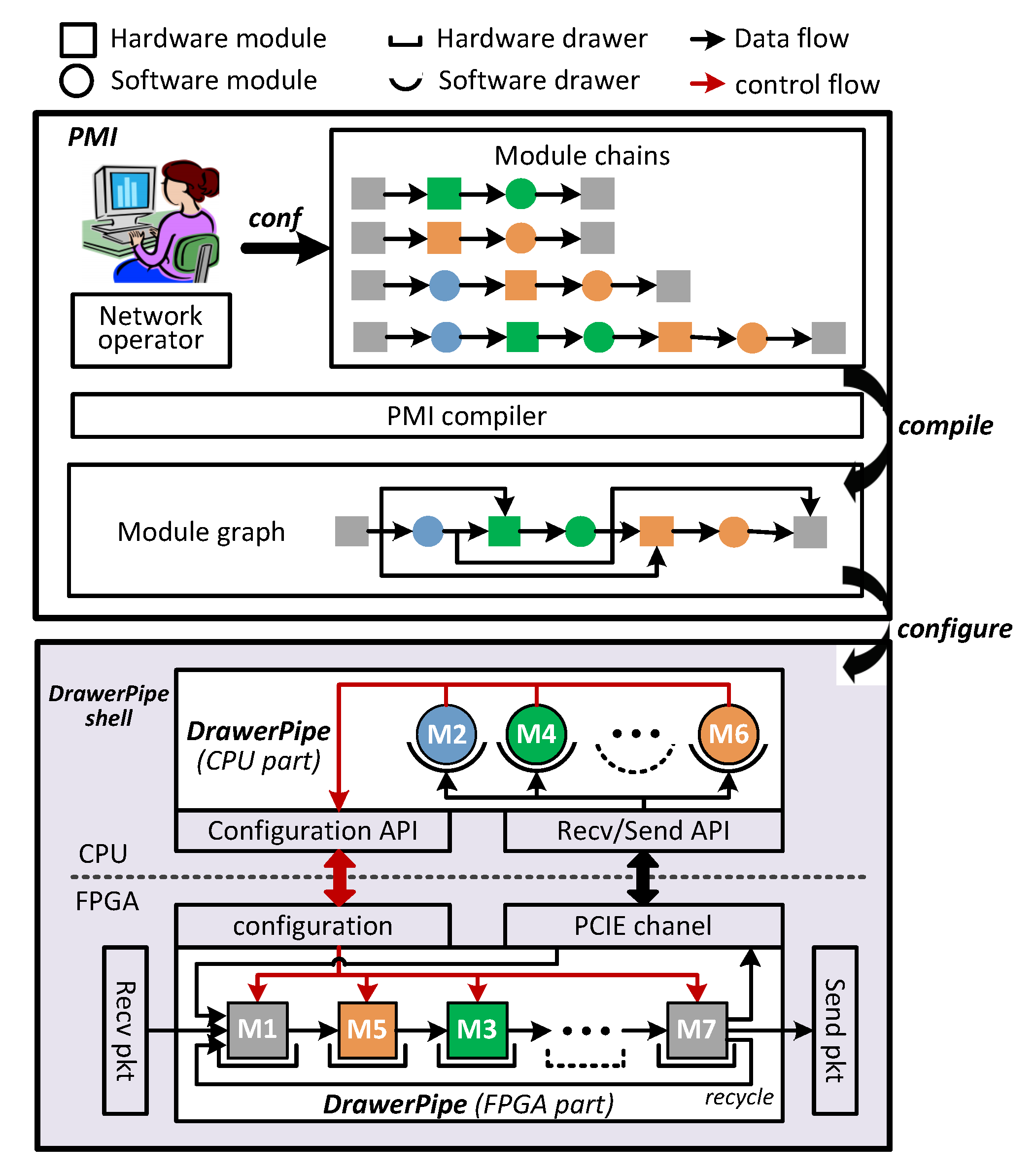
- DrawerPipe shell is the platform-related logic around DrawerPipe. DrawerPipe shell provides a set of target-agnostic APIs for receiving/sending packets, memory management, FPGA-CPU communication. Thus, developers can focus on the core application logic and write a modular code that is easily reusable (R1). In addition, we find that NF may perform three kinds of actions on packets including reading, writing, or dropping, and two independent NFs (without reading or writing the same fields) can be executed in any order. Thus, DrawerPipe merges the FPGA-CPU communication of independent NFs, and writes the intermediate processing result in the metadata. (R2).
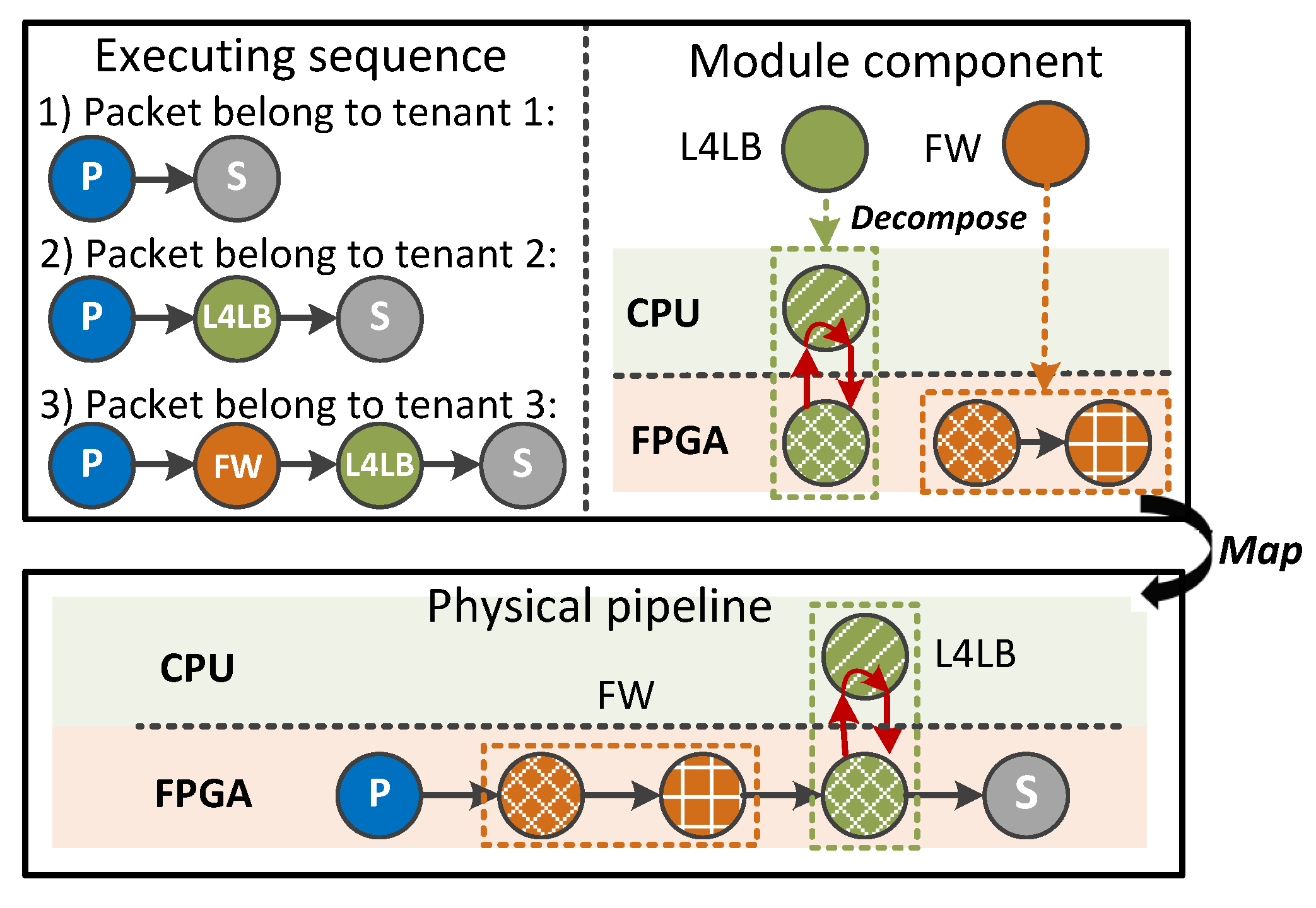
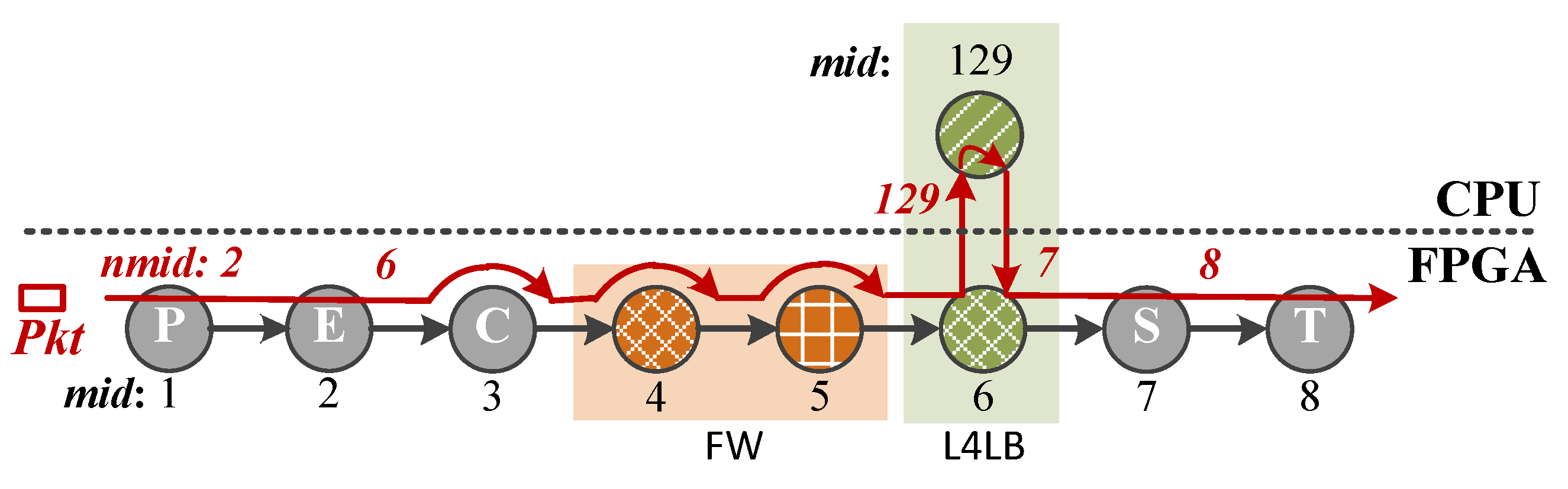
- Programmable module indexing mechanism: Motivated by the idea of building linked list in C/C++, PMI allows users to configure the next module to process packets one by one. Thus, users can specify the module chain traversed by packets to obtain any required service chain for multiple tenants (R3). To reduce FPGA-CPU communication times, PMI steers packets through as many hardware modules as possible before passing through software ones (R2). Furthermore, we use PMI to distinguish flows or tenants that need to look up different logic rule tables for data areolation between NFs (R1).
3. Design of DrawerPipe and DrawerPipe Shell
3.1. DrawerPipe Model
3.2. DrawerPipe Shell
4. Design of PMI
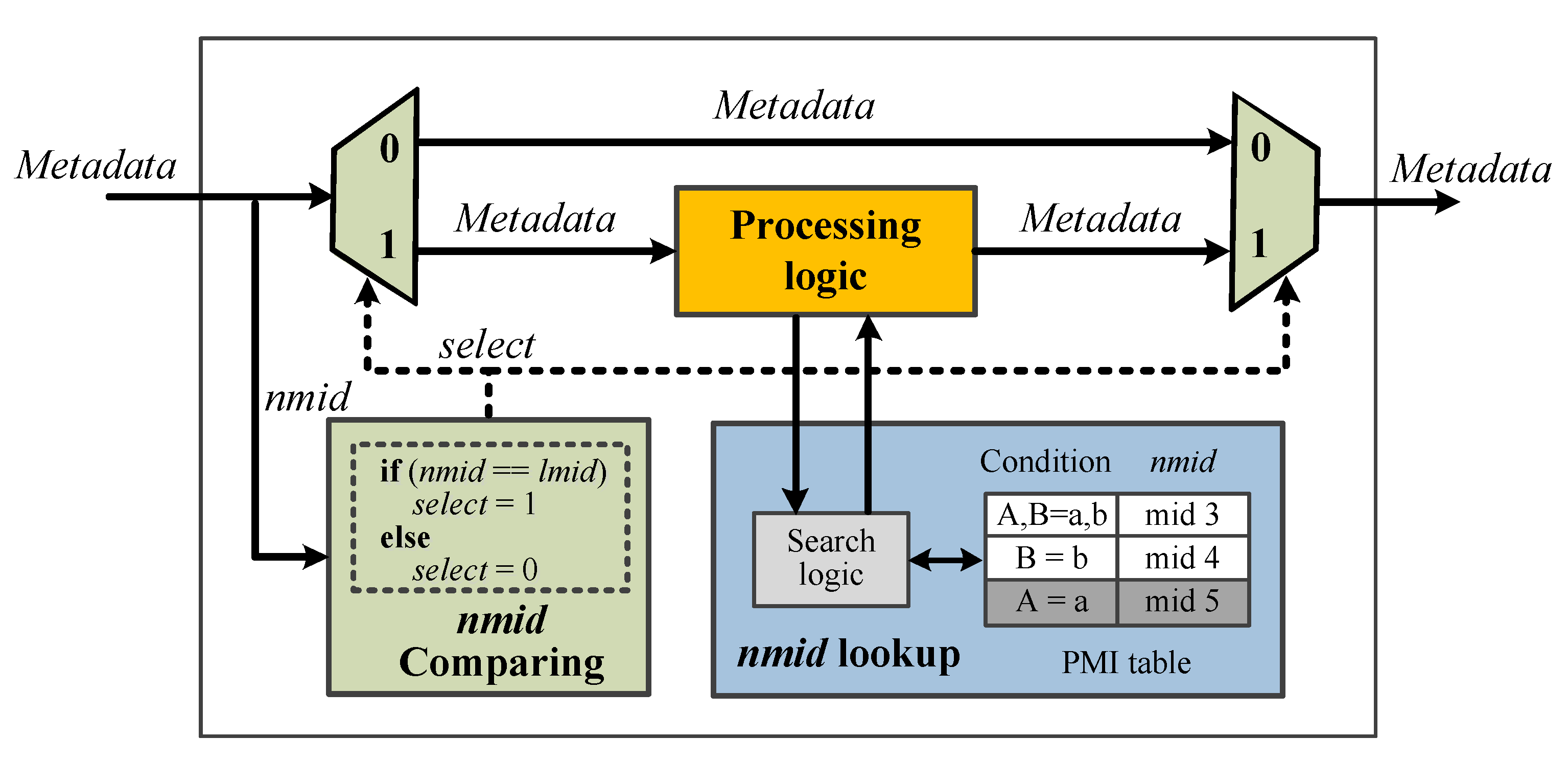
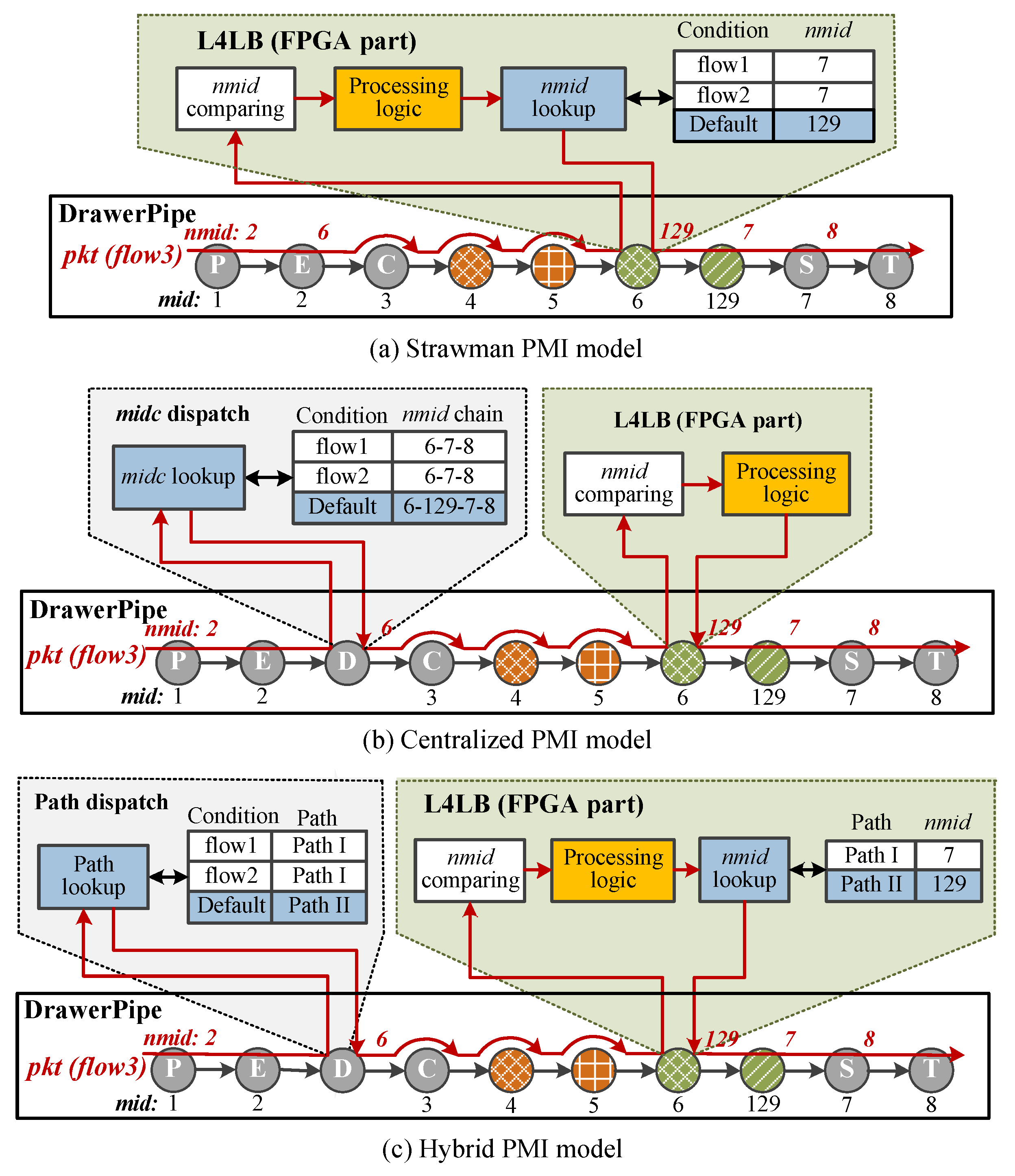
4.1. Strawman Design of PMI
4.2. Optimizations of PMI
4.2.1. Centralized PMI Model
4.2.2. Hybrid PMI Model
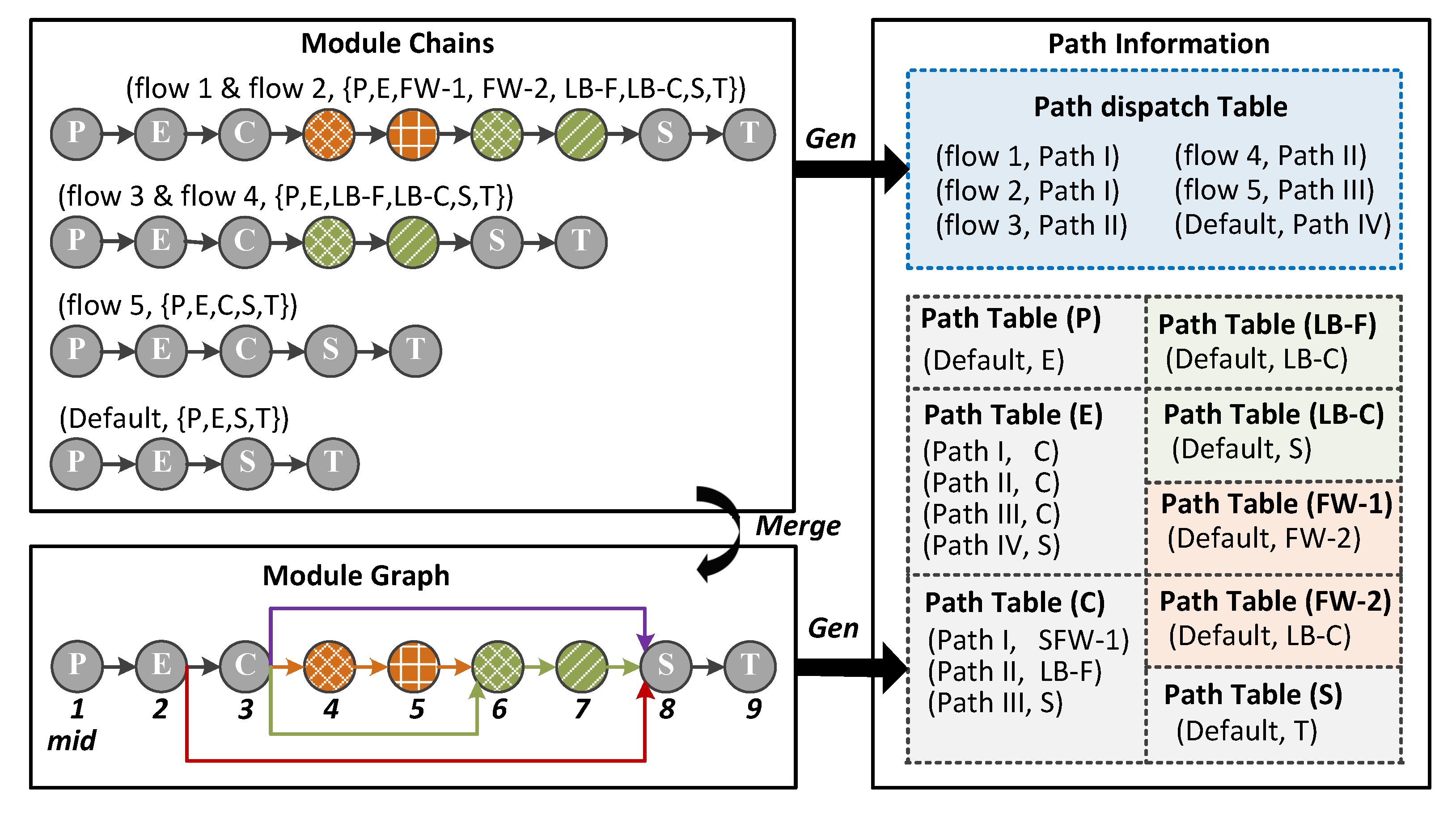
4.3. PMI Compiler Design
| Algorithm 1 Generate module graph based on module chains |
| 1: |
| 2: NULL |
| 3: for to Length() do |
| 4: |
| 5: while NULL do |
| 6: if not in then |
| 7: |
| 8: ,) |
| 9: end if |
| 10: |
| 11: end while |
| 12: AssignPathID) |
| 13: end for |
| 14: for to Length() do |
| 15: |
| 16: while NULL do |
| 17: |
| 18: |
| 19: end while |
| 20: end for |
| Algorithm 2 Generate path information based on module chains and module graph |
| 1: for to Length() do |
| 2: |
| 3: |
| 4: end for |
| 5: for in do |
| 6: if then |
| 7: |
| 8: else |
| 9: for to Length() do |
| 10: |
| 11: end for |
| 12: end if |
| 13: end for |
5. Evaluation
5.1. Applications
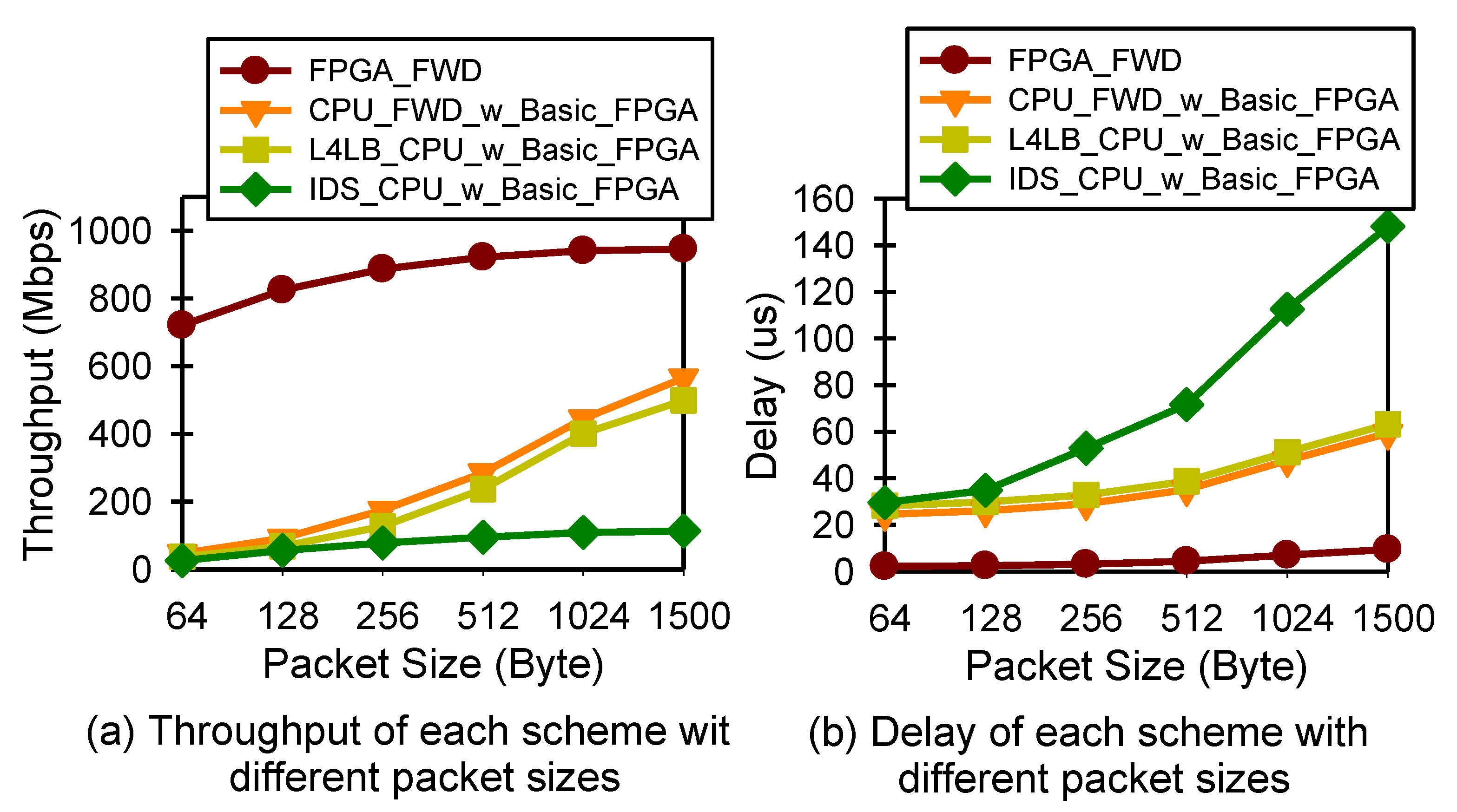
5.2. Performance and Resource Utilization
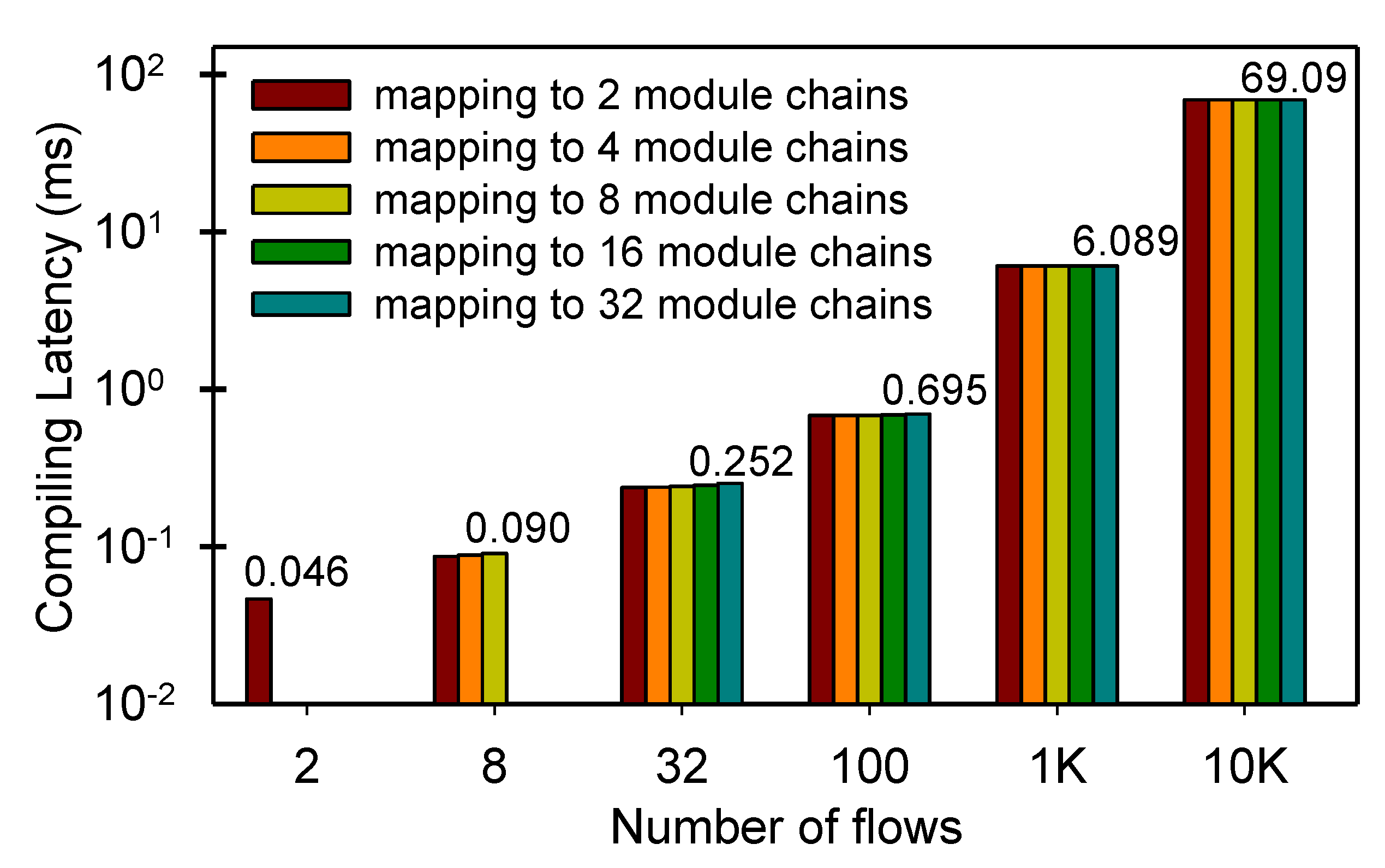
5.3. PMI Evaluation
6. Related Work
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Firestone, D. VFP: A Virtual Switch Platform for Host SDN in the Public Cloud. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 315–328. [Google Scholar]
- Li, B.; Tan, K.; Luo, L.L.; Peng, Y.; Luo, R.; Xu, N.; Xiong, Y.; Cheng, P.; Chen, E. Clicknp: Highly flexible and high performance network processing with reconfigurable hardware. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 1–14. [Google Scholar]
- Costa, P.; Migliavacca, M.; Pietzuch, P.; Wolf, A.L. NaaS: Network-as-a-Service in the Cloud. In Proceedings of the part of the 2nd USENIX Workshop on Hot Topics in Management of Internet, Cloud, and Enterprise Networks and Services, San Jose, CA, USA, 24 April 2012. [Google Scholar]
- Benson, T.; Akella, A.; Shaikh, A.; Sahu, S. CloudNaaS: A cloud networking platform for enterprise applications. In Proceedings of the 2nd ACM Symposium on Cloud Computing, Cascais, Portugal, 26–28 October 2011; p. 8. [Google Scholar]
- Varadharajan, V.; Tupakula, U. Security as a service model for cloud environment. IEEE Trans. Netw. Serv. Manag. 2014, 11, 60–75. [Google Scholar] [CrossRef]
- A New Walmart ’Cloud Factory’ Will Accelerate Digital Innovation, Boost Business Efficiency 2018. Available online: https://news.microsoft.com/transform/new-walmart-cloud-factory-innovation-business-efficiency/ (accessed on 5 November 2018).
- Da Silva, L.B.; Almeida, D.; Nacif, J.A.M.; Sánchez-Osorio, I.; Hernández-Martínez, C.A.; Ferreira, R. Exploring the dynamics of large-scale gene regulatory networks using hardware acceleration on a heterogeneous CPU-FPGA platform. In Proceedings of the 2017 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 4–6 December 2017; pp. 1–7. [Google Scholar]
- Firestone, D.; Putnam, A.; Mundkur, S.; Chiou, D.; Dabagh, A.; Andrewartha, M.; Angepat, H.; Bhanu, V.; Caulfield, A.; Chung, E.; et al. Azure accelerated networking: SmartNICs in the public cloud. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Rention, WA, USA, 9–11 April 2018; pp. 51–66. [Google Scholar]
- Gandhi, R.; Liu, H.H.; Hu, Y.C.; Lu, G.; Padhye, J.; Yuan, L.; Zhang, M. Duet: Cloud scale load balancing with hardware and software. In Proceedings of the ACM SIGCOMM Symposium, Chicago, IL, USA, 17–22 August 2014; Volume 44, pp. 27–38. [Google Scholar]
- Data Plane Development Kit 2019. Available online: https://www.dpdk.org (accessed on 10 December 2019).
- Barach, D.; Linguaglossa, L.; Marion, D.; Pfister, P.; Pontarelli, S.; Rossi, D. High-speed software data plane via vectorized packet processing. IEEE Commun. Mag. 2018, 56, 97–103. [Google Scholar] [CrossRef]
- Towards Converged SmartNIC Architecture for Bare Metal and Public Clouds at Tencent Scale. In Proceedings of the Asia-Pacific Workshop on Networking (APNet), Beijing, China, 2–3 August 2018.
- Unnikrishnan, D.; Lu, J.; Gao, L.; Tessier, R. Reclick-a modular dataplane design framework for fpga-based network virtualization. In Proceedings of the 2011 ACM/IEEE Seventh Symposium on Architectures for Networking and Communications Systems, Brooklyn, NY, USA, 3–4 October 2011; pp. 145–155. [Google Scholar]
- Sultana, N.; Galea, S.; Greaves, D.; Wójcik, M.; Shipton, J.; Clegg, R.; Mai, L.; Bressana, P.; Soulé, R.; Mortier, R.; et al. Emu: Rapid prototyping of networking services. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC 17), Santa Clara, CA, USA, 12–14 July 2017; pp. 459–471. [Google Scholar]
- Rinta-Aho, T.; Karlstedt, M.; Desai, M.P. The click2netfpga toolchain. In Proceedings of the 2012 USENIX Annual Technical Conference (USENIX ATC 12), Boston, MA, USA, 13–15 June 2012; pp. 77–88. [Google Scholar]
- Sivaraman, A.; Cheung, A.; Budiu, M.; Kim, C.; Alizadeh, M.; Balakrishnan, H.; Varghese, G.; McKeown, N.; Licking, S. Packet transactions: High-level programming for line-rate switches. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 15–28. [Google Scholar]
- Pontarelli, S.; Bifulco, R.; Bonola, M.; Cascone, C.; Spaziani, M.; Bruschi, V.; Sanvito, D.; Siracusano, G.; Capone, A.; Honda, M.; et al. FlowBlaze: Stateful Packet Processing in Hardware. In Proceedings of the NSDI, Boston, MA, USA, 26–28 February 2019; pp. 531–548. [Google Scholar]
- Wrold’s Fastest P4-Programmable Ethernet Switch ASICs 2019. Available online: https://www.barefootnetworks.com/products/brief-tofino (accessed on 10 December 2019).
- Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN 2019. Available online: https://www.barefootnetworks.com/products/brief-tofino/ (accessed on 10 December 2019).
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- The Snort Project 2019. Available online: https://www.snort.org (accessed on 10 December 2019).
- Virtex 7 Series FPGA White Paper 2019. Available online: https://www.xilinx.com/products/silicon-devices/fpga/virtex-7.html (accessed on 10 December 2019).
- Intel Stratix 10 FPGAs 2019. Available online: https://www.intel.cn/content/www/cn/zh/products/programmable/soc/stratix-10.html (accessed on 10 December 2019).
- Bremler-Barr, A.; Harchol, Y.; Hay, D. OpenBox: A software-defined framework for developing, deploying, and managing network functions. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 511–524. [Google Scholar]
- Sun, C.; Bi, J.; Zheng, Z.; Yu, H.; Hu, H. Nfp: Enabling network function parallelism in nfv. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 43–56. [Google Scholar]
- “Service Function Chaining (sfc) Architecture” in RFC 7665. 2015. Available online: https://datatracker.ietf.org/doc/rfc7665 (accessed on 10 November 2015).
- Vivado Design Suit 2019. Available online: https://www.xilinx.com/products/design-tools/vivado.html (accessed on 10 December 2019).
- FPGA Development Tools 2019. Available online: https://www.intel.com/content/www/us/en/software/programmable/quartus-prime/overview.html (accessed on 10 December 2019).
- Sekar, V.; Egi, N.; Ratnasamy, S.; Reiter, M.K.; Shi, G. Design and implementation of a consolidated middlebox architecture. In Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12), San Jose, CA, USA, 25–27 April 2012; pp. 323–336. [Google Scholar]
- Patel, P.; Bansal, D.; Yuan, L.; Murthy, A.; Greenberg, A.; Maltz, D.A.; Kern, R.; Kumar, H.; Zikos, M.; Wu, H.; et al. Ananta: Cloud scale load balancing. In Proceedings of the ACM SIGCOMM Symposium, Hong Kong, China, 12–16 August 2013; Volume 43, pp. 207–218. [Google Scholar]
- Neugebauer, R.; Antichi, G.; Zazo, J.F.; Audzevich, Y.; López-Buedo, S.; Moore, A.W. Understanding PCIe performance for end host networking. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 327–341. [Google Scholar]
- Panda, A.; Han, S.; Jang, K.; Walls, M.; Ratnasamy, S.; Shenker, S. NetBricks: Taking the V out of NFV. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 203–216. [Google Scholar]
- Jamshed, M.A.; Moon, Y.; Kim, D.; Han, D.; Park, K. mos: A reusable networking stack for flow monitoring middleboxes. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 113–129. [Google Scholar]
- Ganegedara, T.; Jiang, W.; Prasanna, V.K. A scalable and modular architecture for high-performance packet classification. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 1135–1144. [Google Scholar] [CrossRef]
- Taylor, D.E. Survey and taxonomy of packet classification techniques. ACM Comput. Surv. (CSUR) 2005, 37, 238–275. [Google Scholar] [CrossRef] [Green Version]
- Gupta, P.; McKeown, N. Packet classification using hierarchical intelligent cuttings. In Proceedings of the Hot Interconnects VII, Stanford, CA, USA, 18–20 August 1999; Volume 40. [Google Scholar]
- Singh, S.; Baboescu, F.; Varghese, G.; Wang, J. Packet classification using multidimensional cutting. In Proceedings of the 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Karlsruhe, Germany, 25–29 August 2003; pp. 213–224. [Google Scholar]
- Gupta, P.; McKeown, N. Packet classification on multiple fields. ACM SIGCOMM Comput. Commun. Rev. 1999, 29, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Srinivasan, V.; Suri, S.; Varghese, G. Packet classification using tuple space search. In Proceedings of the ACM SIGCOMM Symposium, Cambridge, MA, USA, 30 August–3 September 1999; pp. 135–146. [Google Scholar]
- Tang, P.P.; Tai, T.Y. Network traffic characterization using token bucket model. In Proceedings of the Conference on Computer Communications, Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies, The Future Is Now (Cat. No. 99CH36320) (IEEE INFOCOM’99), New York, NY, USA, 21–25 March 1999; pp. 51–62. [Google Scholar]
- Demers, A.; Keshav, S.; Shenker, S. Analysis and simulation of a fair queueing algorithm. In Proceedings of the ACM SIGCOMM Symposium, Austin, Texas, USA, 19–22 September 1989; pp. 1–12. [Google Scholar]
- Fu, W.; Li, T.; Yang, J.; Li, J.; Sun, Z. STRIDE: Single-Trip-Time Based Reliable Data Transport Protocol for the Reconfigurable Cloud. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Mao, J.; Han, B.; Sun, Z.; Lu, X.; Zhang, Z. Efficient mismatched packet buffer management with packet order-preserving for OpenFlow networks. Comput. Netw. 2016, 110, 91–103. [Google Scholar] [CrossRef]
- Yang, X.; Sun, Z.; Li, J.; Yan, J.; Li, T.; Quan, W.; Xu, D.; Antichi, G. FAST: Enabling fast software/hardware prototype for network experimentation. In Proceedings of the International Symposium on Quality of Service, Phoenix, Arizona, 24–25 June 2019; p. 32. [Google Scholar]
- Hardware/Software Co-Processing Platforms Designed by FAST Group 2019. Available online: www.fastswitch.org/platform/ (accessed on 10 December 2019).
- Zynq-7000 soc 2019. Available online: https://www.xilinx.com/products/silicon-devices/soc/zynq-7000.html (accessed on 10 December 2019).
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Zhu, S.; Bi, J.; Sun, C.; Wu, C.; Hu, H. Sdpa: Enhancing stateful forwarding for software-defined networking. In Proceedings of the 2015 IEEE 23rd International Conference on Network Protocols (ICNP), San Francisco, CA, USA, 10–13 November 2015; pp. 323–333. [Google Scholar]
- Xu, C.; Niu, D.; Muralimanohar, N.; Balasubramonian, R.; Zhang, T.; Yu, S.; Xie, Y. Overcoming the challenges of crossbar resistive memory architectures. In Proceedings of the 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), Burlingame, CA, USA, 7–11 February 2015; pp. 476–488. [Google Scholar]
- Catania, V.; Mineo, A.; Monteleone, S.; Palesi, M.; Patti, D. Cycle-accurate network on chip simulation with noxim. ACM Trans. Model. Comput. Simul. (TOMACS) 2016, 27, 4. [Google Scholar] [CrossRef]
- ixia emulator 2019. Available online: https://www.ixiacom.com/products/network-emulator-ii (accessed on 10 December 2019).
- Martins, J.; Ahmed, M.; Raiciu, C.; Olteanu, V.; Honda, M.; Bifulco, R.; Huici, F. ClickOS and the art of network function virtualization. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), Seattle, WA, USA, 2–4 April 2014; pp. 459–473. [Google Scholar]
- Han, S.; Jang, K.; Park, K.; Moon, S. PacketShader: A GPU-accelerated software router. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 195–206. [Google Scholar]
- Song, H. Protocol-oblivious forwarding: Unleash the power of SDN through a future-proof forwarding plane. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 12–16 August 2013; pp. 127–132. [Google Scholar]
- Naous, J.; Gibb, G.; Bolouki, S.; McKeown, N. NetFPGA: Reusable router architecture for experimental research. In Proceedings of the ACM Workshop on Programmable Routers for Extensible Services of Tomorrow, Seattle, WA, USA, 22 August 2008; pp. 1–7. [Google Scholar]
- Rubow, E.; McGeer, R.; Mogul, J.; Vahdat, A. Chimpp: A click-based programming and simulation environment for reconfigurable networking hardware. In Proceedings of the 6th ACM/IEEE Symposium on Architectures for Networking and Communications Systems, San Diego, CA, USA, 25–26 October 2010; p. 36. [Google Scholar]
- Kachris, C.; Sirakoulis, G.; Soudris, D. Network Function Virtualization based on FPGAs: A Framework for all-Programmable network devices. arXiv 2014, arXiv:1406.0309. [Google Scholar]
- Betkaoui, B.; Thomas, D.B.; Luk, W. Comparing performance and energy efficiency of FPGAs and GPUs for high productivity computing. In Proceedings of the 2010 International Conference on Field-Programmable Technology, Beijing, China, 8–10 December 2010; pp. 94–101. [Google Scholar]
- Kestur, S.; Davis, J.D.; Williams, O. Blas comparison on fpga, cpu and gpu. In Proceedings of the 2010 IEEE Computer Society Annual Symposium on VLSI, Lixouri, Kefalonia, Greece, 5–7 July 2010; pp. 288–293. [Google Scholar]
- Shrivastav, V. Fast, scalable, and programmable packet scheduler in hardware. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 367–379. [Google Scholar]
- Jiang, Y.; Chen, H.; Yang, X.; Sun, Z.; Quan, W. Design and Implementation of CPU & FPGA Co-Design Tester for SDN Switches. Electronics 2019, 8, 950. [Google Scholar]
- Ibanez, S.; Brebner, G.; McKeown, N.; Zilberman, N. The P4-> NetFPGA Workflow for Line-Rate Packet Processing. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 1–9. [Google Scholar]
- Shu, R.; Cheng, P.; Chen, G.; Guo, Z.; Qu, L.; Xiong, Y.; Chiou, D.; Moscibroda, T. Direct Universal Access: Making Data Center Resources Available to FPGA. In Proceedings of the NSDI, Boston, MA, USA, 26–28 February 2019; pp. 127–140. [Google Scholar]
- De Matteis, T.; de Fine Licht, J.; Beránek, J.; Hoefler, T. Streaming Message Interface: High-performance distributed memory programming on reconfigurable hardware. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–19 November 2019; p. 82. [Google Scholar]
- Eran, H.; Zeno, L.; Tork, M.; Malka, G.; Silberstein, M. NICA: An Infrastructure for Inline Acceleration of Network Applications. In Proceedings of the 2019 USENIX Annual Technical Conference (USENIX ATC 19), San Diego, CA, USA, 10–12 July 2019; pp. 345–362. [Google Scholar]
- Phothilimthana, P.M.; Liu, M.; Kaufmann, A.; Peter, S.; Bodik, R.; Anderson, T. Floem: A programming system for NIC-accelerated network applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 663–679. [Google Scholar]
- Nobach, L.; Hausheer, D. Open, elastic provisioning of hardware acceleration in nfv environments. In Proceedings of the 2015 International Conference and Workshops on Networked Systems (NetSys), Cottbus, Germany, 9–12 March 2015; pp. 1–5. [Google Scholar]
- Filsfils, C.; Nainar, N.K.; Pignataro, C.; Cardona, J.C.; Francois, P. The segment routing architecture. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NF Name | LoC | Description | |
|---|---|---|---|
| Individual | Reusing | ||
| Firewall | 2358 | 294 | Filtering malicious packets based on five-tuple |
| Stateful Firewall | 5095 | 2129 | Filtering invalid packets according to flow’s status |
| L4 Load Balancer | 4277 | 805 | Balancing server accessing requests based on five-tuple |
| IDS | 4023 | 1686 | Inspecting traffic according to pre-configured rules |
| total | 15753 | 4914 | N/A |
| Module | HW/SW | Configuration | Performance | Resource (%) | ||||
|---|---|---|---|---|---|---|---|---|
| FMax ( MHz) | Throughput at 200 MHz | Delay (Cycles) | Slice LUTs | Slice Registers | Block Memory | |||
| L4_Parser | HW | N/A | 487.33 | 51.2 Gbps | 6 | 2.32% | 2.33% | 2.86% |
| Switching | HW | 100 entries | 313.87 | 51.2 Gbps | 7 | 2.20% | 1.68% | 8.58% |
| Transmitter | HW | N/A | 389.71 | 51.2 Gbps | 5 | 1.34% | 1.14% | 8.58% |
| pktBuffer_FIFO | HW | 16 KB | 438.02 | 51.2 Gbps | 3 | 0.31% | 0.68% | 2.86% |
| pktBuffer_RAM | HW | 32 KB | 460.62 | 51.2 Gbps | 4 | 0.38% | 0.72% | 12.86% |
| Extractor | HW | N/A | 421.41 | 100 Mpps | 2 | 0.27% | 0.63% | 0% |
| Packet Classifier | HW | 100 entries | 404.86 | 200 Mpps | 17 | 4.52% | 4.35% | 31.43% |
| Firewall | HW | 100 entries | 403.39 | 200 Mpps | 7 | 0.37% | 0.93% | 1.79% |
| Stateful Firewall | HW | 1 K flows | 232.88 | 100 Mpps | 26 | 2.58% | 2.84% | 13.93% |
| L4LB_FPGA | HW | 1 K flows | 314.86 | 100 Mpps | 5 | 0.83% | 0.80% | 4.64% |
| IDS_FPGA | HW | 100 entries | 399.36 | 200 Mpps | 7 | 0.36% | 0.93% | 1.79% |
| PMI Model | Main Modules | Resource (%) | |||
|---|---|---|---|---|---|
| Module Name | Num | Slice LUTs | Slice Registers | Block Memory | |
| Strawman | nmid comparing | 7 | 0.36% | 0.01% | 0.68% |
| nmid lookup | 7 | 0.78% | 0.006% | 6.43% | |
| total | 7.96% | 0.11% | 45.23% | ||
| Centralized | nmid dispatcher | 1 | 1.32% | 0.02% | 9.64% |
| nmid comparing | 7 | 0.43% | 0.006% | 3.21% | |
| total | 4.31% | 0.06% | 13.12% | ||
| Hybrid | path dispatcher | 1 | 1.20% | 0.01% | 7.86% |
| nmid comparing | 7 | 0.35% | 0.006% | 0.46% | |
| nmid lookup | 7 | 0.20% | 0.01% | 0% | |
| total | 5.07% | 0.08% | 10.90% | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Sun, Z.; Yan, J.; Yang, X.; Jiang, Y.; Quan, W. DrawerPipe: A Reconfigurable Pipeline for Network Processing on FPGA-Based SmartNIC. Electronics 2020, 9, 59. https://doi.org/10.3390/electronics9010059
Li J, Sun Z, Yan J, Yang X, Jiang Y, Quan W. DrawerPipe: A Reconfigurable Pipeline for Network Processing on FPGA-Based SmartNIC. Electronics. 2020; 9(1):59. https://doi.org/10.3390/electronics9010059
Chicago/Turabian StyleLi, Junnan, Zhigang Sun, Jinli Yan, Xiangrui Yang, Yue Jiang, and Wei Quan. 2020. "DrawerPipe: A Reconfigurable Pipeline for Network Processing on FPGA-Based SmartNIC" Electronics 9, no. 1: 59. https://doi.org/10.3390/electronics9010059
APA StyleLi, J., Sun, Z., Yan, J., Yang, X., Jiang, Y., & Quan, W. (2020). DrawerPipe: A Reconfigurable Pipeline for Network Processing on FPGA-Based SmartNIC. Electronics, 9(1), 59. https://doi.org/10.3390/electronics9010059