An Artificial Neural Network Approach and a Data Augmentation Algorithm to Systematize the Diagnosis of Deep-Vein Thrombosis by Using Wells’ Criteria

 , , , ,
, , , ,  , , and
, , and 
Abstract
:1. Introduction
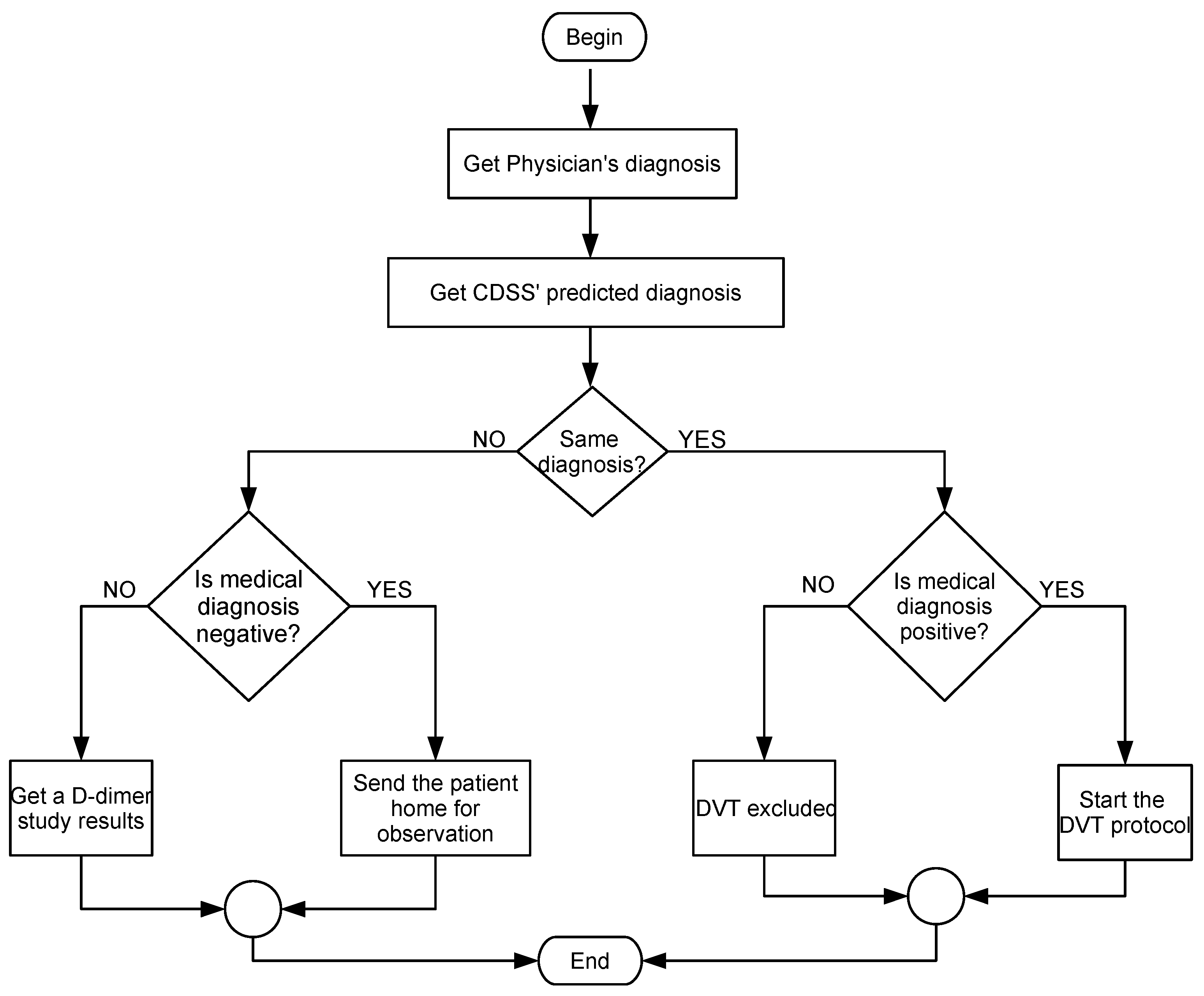
2. Hospital Protocol for DVT Diagnosis
3. Proposed Method
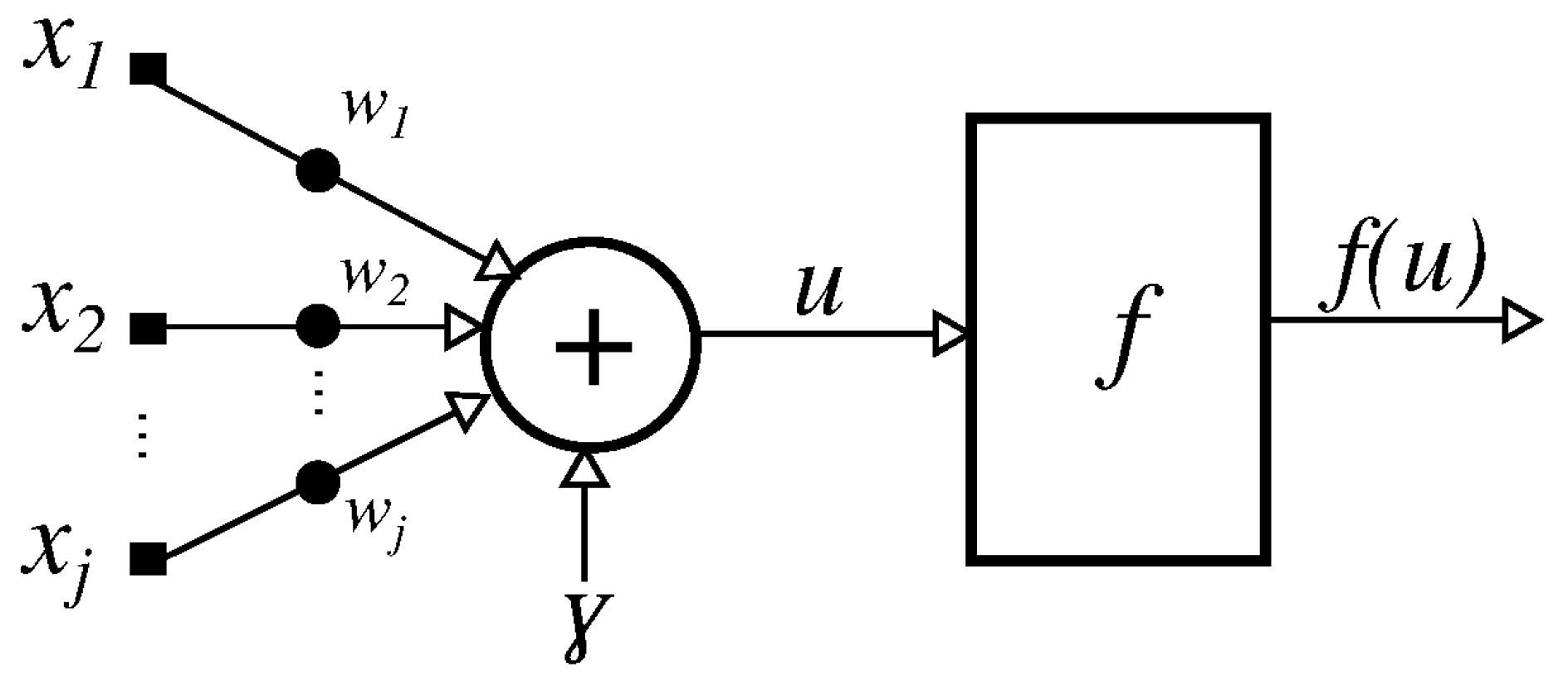
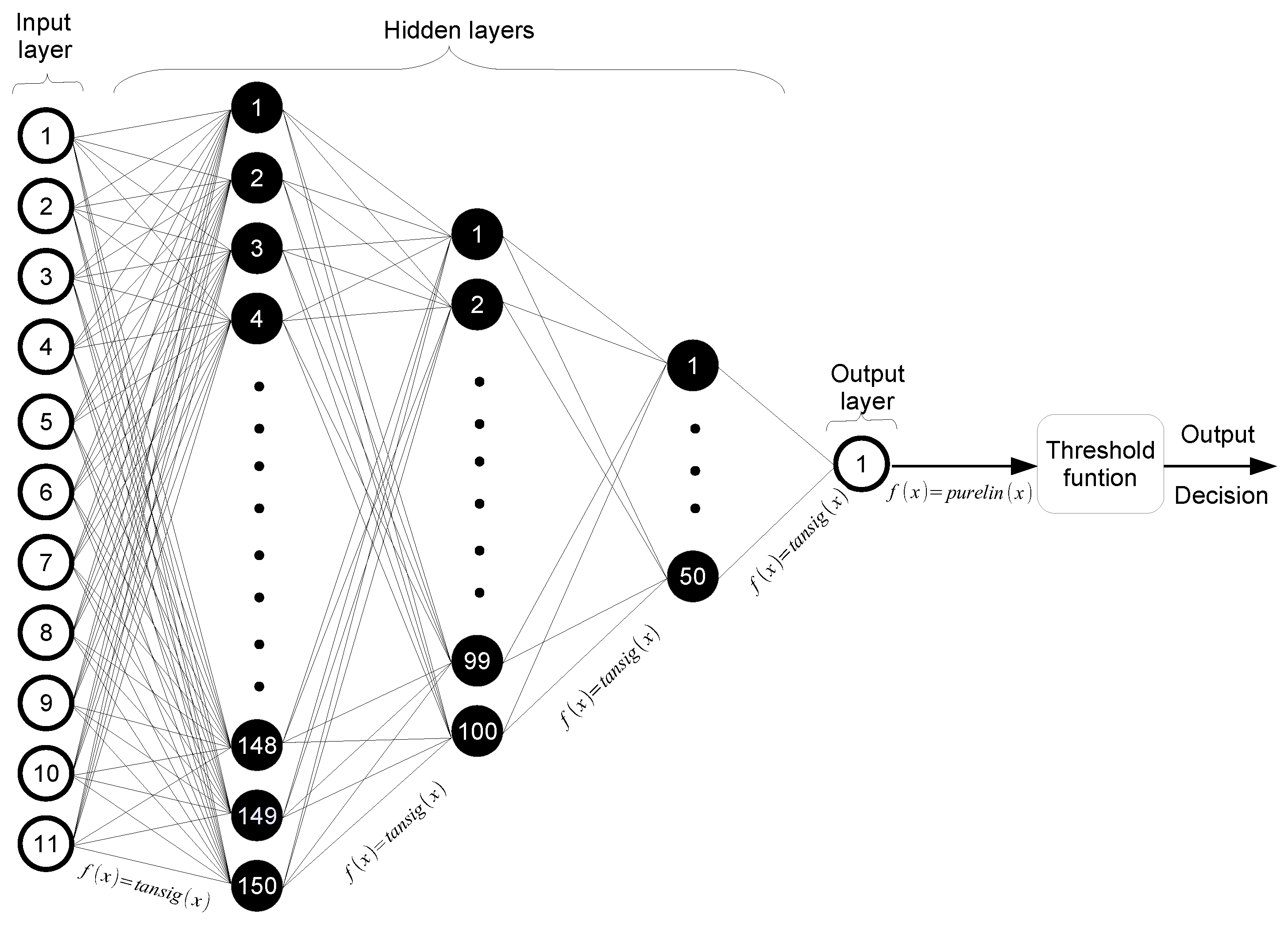
3.1. Artificial Neural Network
3.2. Data Augmentation Algorithm
| Algorithm 1 Data Augmentation |
|
3.3. Pre-Processing Scheme of the Dataset
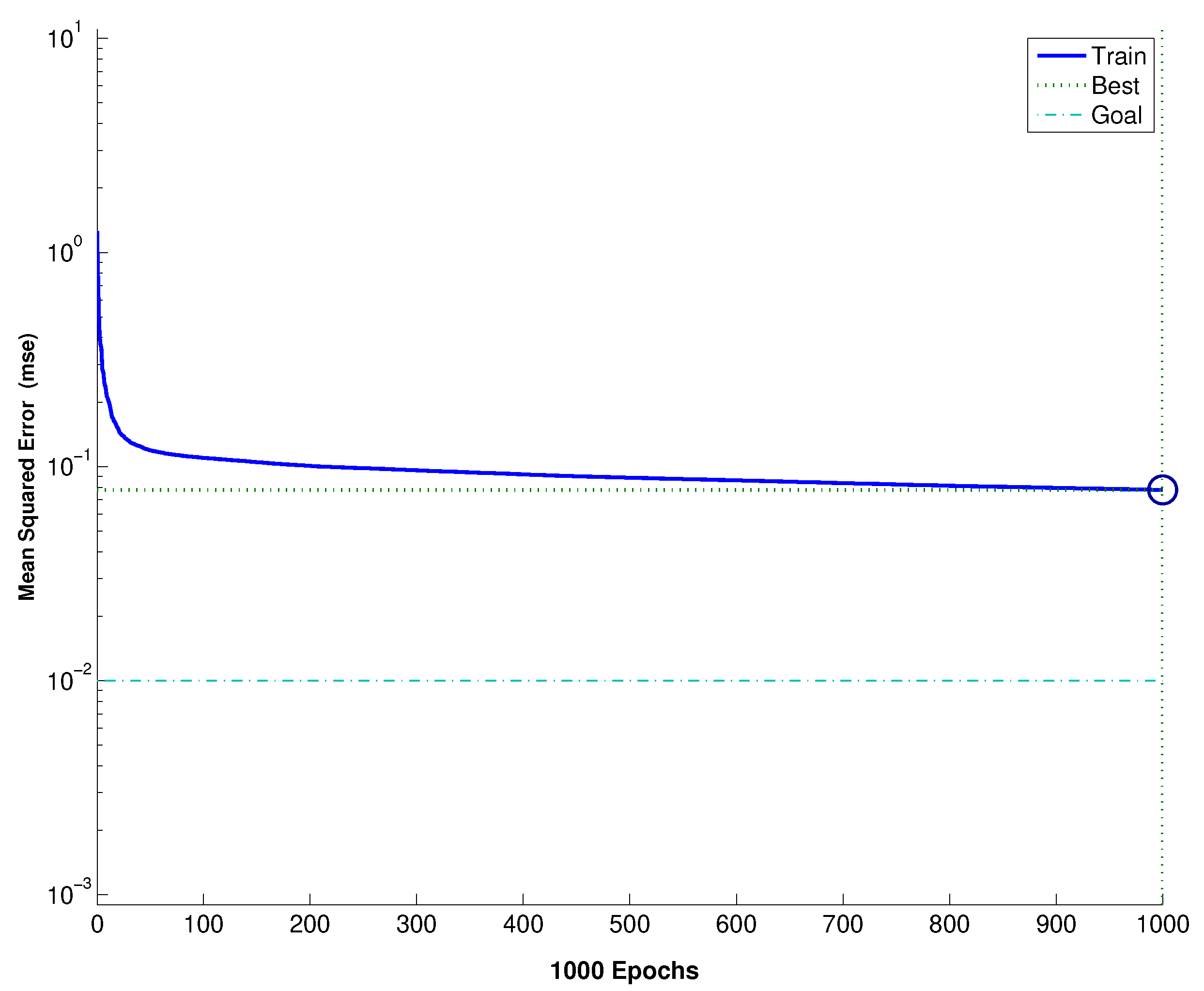
3.4. Training Process for DVT Diagnostic
3.5. Algorithm to Improve Accuracy/Recall
| Algorithm 2 Maximizing Accuracy or Sensitivity/Recall |
|
4. Results
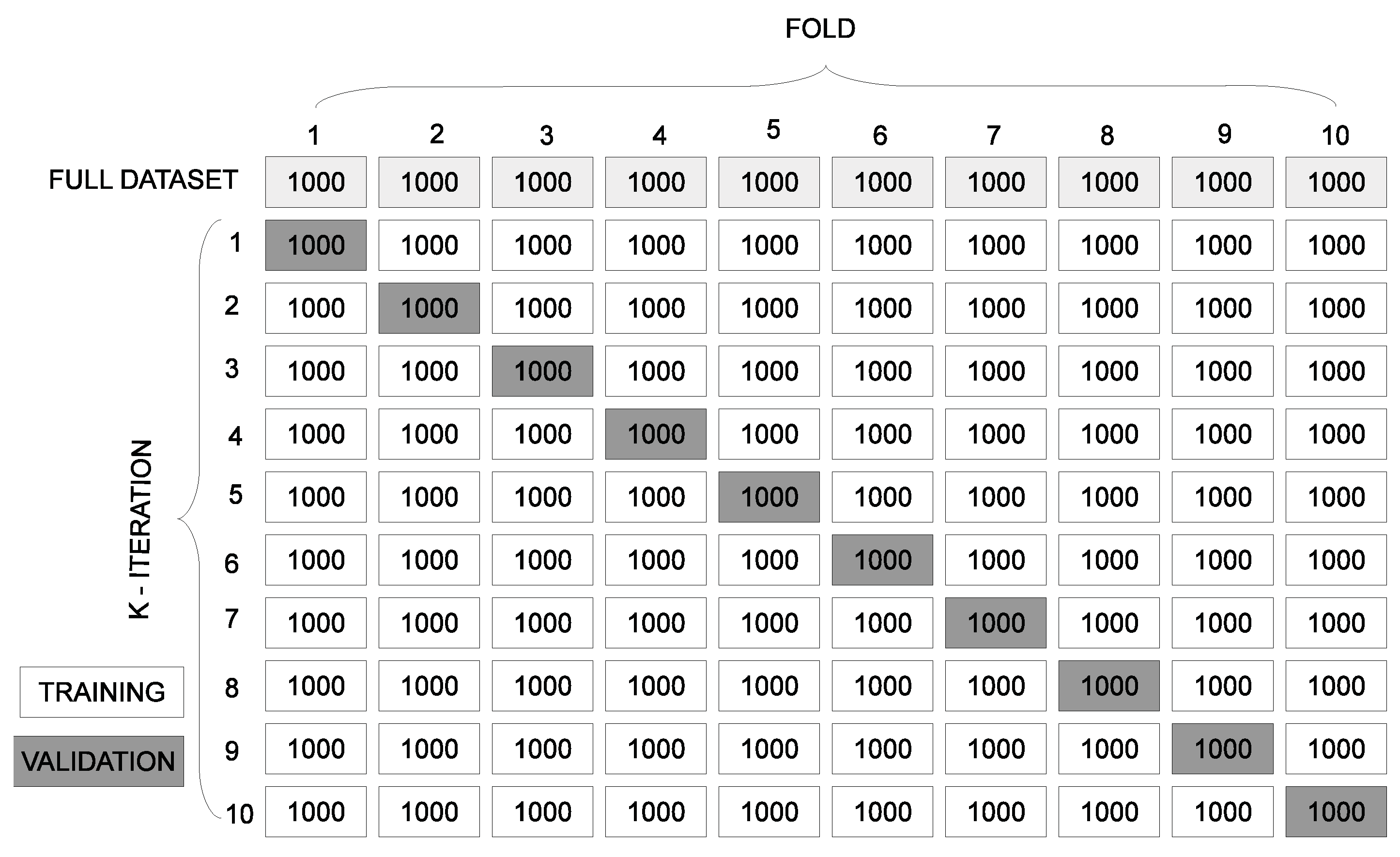
4.1. K-Fold Cross Validation
4.2. Results from the Perspective of the Dataset
4.3. Results Comparison
4.4. External Validation
4.5. Usage Scenario
4.6. Limitations of the Proposed Approach
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Myers, D.J.; Lester, P.; Adili, R.; Hawley, A.; Durham, L.; Dunivant, V.; Reynolds, G.; Crego, K.; Zimmerman, Z.; Sood, S.; et al. A new way to treat proximal deep venous thrombosis using E-selectin inhibition. J. Vasc. Surg. Venous Lymphat Disord. 2020, 8, 268–278. [Google Scholar] [CrossRef]
- Taha, M.A.; Busuttil, A.; Bootun, R.; Davies, A.H. A systematic review on the use of deep venous stenting for acute venous thrombosis of the lower limb. Phlebology 2019, 34, 115–127. [Google Scholar] [CrossRef]
- Lopes Goularte, F.F.C.; Caroliny Torres, G.; Carvalho, R.D.P. Evaluation of deep vein thrombosis prophylaxis in a general hospital. J. Vasc. Bras. 2018, 17. [Google Scholar] [CrossRef] [Green Version]
- White, R.H. The epidemiology of venous thromboembolism. Circulation 2003, 107, I-4–I-8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clarke, M.J.; Broderick, C.; Hopewell, S.; Juszczak, E.; Eisinga, A. Compression stockings for preventing deep vein thrombosis in airline passengers. Cochrane Database Syst. Rev. 2016, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kean, J.; Pearton, A.; Fell, J.; Adams, M.; Kitic, C.; Wu, S.; Stone, S.; Zadow, E. Deep vein thrombosis in a well-trained masters cyclist, is popliteal vein entrapment syndrome to blame? J. Thromb. Thrombolysis 2019, 47, 301–304. [Google Scholar] [CrossRef] [PubMed]
- Abood, K.K.; Paul, M.R.; Kuo, D.J. Deep Vein Thrombosis in a Young, Healthy Baseball Catcher: A Case Report and Review of the Literature. J. Pediatr. Hematol. Oncol. 2019, 41, 321–323. [Google Scholar] [CrossRef] [PubMed]
- Lippi, G.; Mattiuzzi, C.; Franchini, M. Sleep apnea and venous thromboembolism, A systematic review. Thromb. Haemost. 2015, 114, 958–963. [Google Scholar] [CrossRef] [PubMed]
- Middeldorp, S.; Levi, M. Thrombophilia: An Update. Semin. Thromb. Hemost. 2007, 33, 563–572. [Google Scholar] [CrossRef]
- Chaudhuri, R.; Salari, R. Baker’s cyst simulating deep vein thrombosis. Clin. Radiol. 1990, 41, 400–404. [Google Scholar] [CrossRef]
- Gunderson, C.G.; Chang, J.J. Overuse of compression ultrasound for patients with lower extremity cellulitis. Thromb. Res. 2014, 134, 846–850. [Google Scholar] [CrossRef]
- Harder, E.M.; Desai, O.; Marshall, P.S. Clinical Probability Tools for Deep Venous Thrombosis, Pulmonary Embolism, and Bleeding. Clin. Chest Med. 2018, 39, 473–482. [Google Scholar] [CrossRef] [PubMed]
- Do, D.D.; Husmann, M. Diagnostik venöser Erkrankungen, (Diagnosis of Venous Disease). Herz Kardiovaskuläre Erkrank. 2007, 32, 10–17. [Google Scholar] [CrossRef] [Green Version]
- Kraaijpoel, N.; Carrier, M.; Le Gal, G.; McInnes, M.; Salameh, J.P.; McGrath, T.; Van Es, N.; Moher, D.; Büller, H.R.; Bossuyt, P.; et al. Diagnostic accuracy of three ultrasonography strategies for deep vein thrombosis of the lower extremity: A systematic review and meta-analysis. PLoS ONE 2020, 15, e0228788. [Google Scholar] [CrossRef] [PubMed]
- Lewiss, R.E.; Kaban, N.L.; Saul, T. Point-of-care ultrasound for a deep venous thrombosis. Glob. Heart 2013, 8, 329–333. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fuentes Camps, E.; Luis Del Val García, J.; Bellmunt Montoya, S.; Hmimina Hmimina, S.; Gómez Jabalera, E.; Muñoz Pérez, M.Á. Cost-effectiveness of the deep vein thrombosis diagnosis process in primary care. Aten Primaria 2016, 48, 251–257. [Google Scholar] [CrossRef] [PubMed]
- Wilson, E.; Phair, J.; Carnevale, M.; Koleilat, I. Common Reasons for Malpractice Lawsuits Involving Pulmonary Embolism and Deep Vein Thrombosis. J. Surg. Res. 2020, 245, 212–216. [Google Scholar] [CrossRef] [Green Version]
- Modi, S.; Deisler, R.; Gozel, K.; Reicks, P.; Irwin, E.; Brunsvold, M.; Banton, K.; Beilman, G.J. Wells criteria for DVT is a reliable clinical tool to assess the risk of deep venous thrombosis in trauma patients. World J. Emerg. Surg. 2016, 11. [Google Scholar] [CrossRef] [Green Version]
- Oudega, R.; Moons, K.G.M.; Hoes, A.W. Ruling out deep venous thrombosis in primary care. A simple diagnostic algorithm including D-dimer testing. Thromb. Haemost. 2005, 94, 200–205. [Google Scholar] [CrossRef]
- Van der Hulle, T.; Dronkers, C.E.; Huisman, M.V.; Klok, F.A. Current standings in diagnostic management of acute venous thromboembolism: Still rough around the edges. Blood Rev. 2016, 30, 21–26. [Google Scholar] [CrossRef]
- Tan, J.H.; Fujita, H.; Sivaprasad, S.; Bhandary, S.V.; Rao, A.K.; Chua, K.C.; Acharya, U.R. Automated segmentation of exudates, haemorrhages, microaneurysms using single convolutional neural network. Inf. Sci. 2017, 420, 66–76. [Google Scholar] [CrossRef]
- Kadhim, M.A. ScienceDirect FNDSB: A fuzzy-neuro decision support system for back pain diagnosis. Cogn. Syst. Res. 2018, 52, 691–700. [Google Scholar] [CrossRef]
- Jabez Christopher, J.; Khanna Nehemiah, H.; Kannan, A. A clinical decision support system for diagnosis of Allergic Rhinitis based on intradermal skin tests. Comput. Biol. Med. 2015, 65, 76–84. [Google Scholar] [CrossRef]
- Simões, A.S.; Maia, M.R.; Gregório, J.; Couto, I.; Asfeldt, A.M.; Simonsen, G.S.; Póvoa, P.; Viveiros, M.; Lapão, L.V. Participatory implementation of an antibiotic stewardship programme supported by an innovative surveillance and clinical decision-support system. J. Hosp. Infect. 2018, 100, 257–264. [Google Scholar] [CrossRef]
- Hsu, W.Y. A decision-making mechanism for assessing risk factor significance in cardiovascular diseases. Decis. Support Syst. 2018, 115, 64–77. [Google Scholar] [CrossRef]
- However, B.; Bastani, K.; Raharjo, H.; Lifvergren, S.; Marsh, W.; Bergman, B. Decision support system for Warfarin therapy management using Bayesian networks. Decis. Support Syst. 2013, 55, 488–498. [Google Scholar] [CrossRef]
- Xiao, Y.; Wu, J.; Lin, Z.; Zhao, X. A deep learning-based multi-model ensemble method for cancer prediction. Comput. Methods Programs Biomed. 2018, 153, 1–9. [Google Scholar] [CrossRef]
- Cao, C.; Liu, F.; Tan, H.; Song, D.; Shu, W.; Li, W.; Zhou, Y.; Bo, X.; Xie, Z. Deep Learning and Its Applications in Biomedicine. Genom. Proteom. Bioinform. 2018, 16, 17–32. [Google Scholar] [CrossRef]
- Cruz-Vega, I.; Hernandez-Contreras, D.; Peregrina-Barreto, H.; Rangel-Magdaleno, J.; Ramirez-Cortes, J. Deep Learning Classification for Diabetic Foot Thermograms. Sensors 2020, 20, 1762. [Google Scholar] [CrossRef] [Green Version]
- Manogaran, G.; Mohamed Shakeel, P.; Hassanein, A.S.; Malarvizhi Kumar, P.; Chandra Babu, G. Machine Learning Approach-Based Gamma Distribution for Brain Tumor Detection and Data Sample Imbalance Analysis. IEEE Access 2019, 7, 12–19. [Google Scholar] [CrossRef]
- Stefan Jianu, S.R.; Ichim, L.; Popescu, D. Automatic Diagnosis of Skin Cancer Using Neural Networks. In Proceedings of the 2019 11th International Symposium on Advanced Topics in Electrical Engineering (ATEE), Bucharest, Romania, 28–30 March 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Syed-Abdul, S.; Firdani, R.P.; Chung, H.J.; Uddin, M.; Hur, M.; Park, J.H.; Kim, H.W.; Gradišek, A.; Dovgan, E. Artificial Intelligence based Models for Screening of Hematologic Malignancies using Cell Population Data. Sci. Rep. 2020, 10, 4583. [Google Scholar] [CrossRef] [PubMed]
- Shen, J.; Chen, J.; Zheng, Z.; Zheng, J.; Liu, Z.; Song, J.; Wong, S.Y.; Wang, X.; Huang, M.; Fang, P.H.; et al. An Innovative Artificial Intelligence–Based App for the Diagnosis of Gestational Diabetes Mellitus (GDM-AI): Development Study. J. Med. Internet Res. 2020, 22, e21573. [Google Scholar] [CrossRef]
- Kumar Srivastava, A.; Kumar, Y.; Kumar Singh, P. Computer aided diagnostic system based on SVM and K harmonic mean based attribute weighting method. Obes. Med. 2020, 19, 100270. [Google Scholar] [CrossRef]
- Doma, V.; Pirouz, M.A. A comparative analysis of machine learning methods for emotion recognition using EEG and peripheral physiological signals. J. Big. Data 2020, 7. [Google Scholar] [CrossRef] [Green Version]
- Janghel, R.; Verma, A.; Rathore, Y. Performance Comparison of Machine Learning Techniques for Epilepsy Classification and Detection in EEG Signal. In Data Management, Analytics and Innovation. Advances in Intelligent Systems and Computing; Sharma, N., Chakrabarti, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1042. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Li, Y.; Xiao, X.; Qiu, Q.; Yang, M.; Zhao, Y.; Cui, L. Automatic diagnosis of fungal keratitis using data augmentation and image fusion with deep convolutional neural network. Comput. Methods Programs Biomed. 2020, 187, 105019. [Google Scholar] [CrossRef]
- Sun, H.; Zeng, X.; Xu, T.; Peng, G.; Ma, Y. Computer-Aided Diagnosis in Histopathological Images of the Endometrium Using a Convolutional Neural Network and Attention Mechanisms. IEEE J. Biomed. Health Inf. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nafee, T.; Gibson, C.M.; Travis, R.; Yee, M.K.; Kerneis, M.; Chi, G.; AlKhalfan, F.; Hernandez, A.F.; Hull, R.D.; Cohen, A.T.; et al. Machine learning to predict venous thrombosis in acutely ill medical patients. Res. Pr. Thromb. Haemost. 2020, 4, 230–237. [Google Scholar] [CrossRef] [Green Version]
- Martins, T.; Annichino-Bizzacchi, J.; Romano, A.; Maciel Filho, R. Artificial neural networks for prediction of recurrent venous thromboembolism. Int. J. Med. Inf. 2020, 141, 104221. [Google Scholar] [CrossRef]
- Mishra, A.; Ashraf, M. Using Artificial Intelligence to Manage Thrombosis Research, Diagnosis, and Clinical Management. Semin. Thromb. Hemost. 2020, 46, 410–418. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.Q.; Liu, S.H.; Hong, X.Y.; Sun, X.F.; Shi, J.H. Comparing different venous thromboembolism risk assessment machine learning models in Chinese patients. J. Eval. Clin. Pract. 2019, 21, 26–34. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, F.; Xie, L.; Wang, Y.; Xiang, Q.; Yue, Z.; Feng, Y.; Yang, Y.; Li, J.; Luo, L.; et al. Machine learning approaches for risk assessment of peripherally inserted Central catheter-related vein thrombosis in hospitalized patients with cancer. Int. J. Med. Inf. 2019, 129, 175–183. [Google Scholar] [CrossRef] [PubMed]
- Mclnnes, G.; Daneshjou, R.; Katsonis, P.; Lichtarge, O.; Srinivasan, R.; Rana, S.; Radivojac, P.; Mooney, S.D.; Pagel, K.A.; Stamboulian, M.; et al. Predicting venous thromboembolism risk from exomes in the Critical Assessment of Genome Interpretation (CAGI) challenges. Hum. Mutat. Var. Inf. Dis. 2019, 40, 1314–1320. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Willan, J.; Katz, H.; Keeling, D. The use of artificial neural network analysis can improve the risk-stratification of patients presenting with suspected deep vein thrombosis. Br. J. Haematol. 2019, 185, 289–296. [Google Scholar] [CrossRef] [PubMed]
- Wells, P. Predictive analytics by deep machine learning: A call for next-gen tools to improve health care. Res. Pract. Thromb. Haemost. 2020, 4, 181–182. [Google Scholar] [CrossRef]
- Zhao, H.; Hua, Q.; Chen, H.B.; Ye, Y.; Wang, H.; Tan, S.X.D.; Tlelo-Cuautle, E. Thermal-Sensor-Based Occupancy Detection for Smart Buildings Using Machine-Learning Methods. ACM Trans. Des. Autom. Electron. Syst. 2018, 23. [Google Scholar] [CrossRef]
- Horng, M.F.; Kung, H.Y.; Chen, C.H.; Hwang, F.J. Deep Learning Applications with Practical Measured Results in Electronics Industries. Electronics 2020, 9, 501. [Google Scholar] [CrossRef] [Green Version]
- Tlelo-Cuautle, E.; De la Fraga, L.; Rangel-Magdaleno, J. Engineering Applications of FPGAs; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Al-Shayea, Q.K. Artificial Neural Networks in Medical Diagnosis. Int. J. Comput. Sci. Issues 2011, 8, 150–154. [Google Scholar]
- Shahid, N.; Rappon, T.; Berta, W. Applications of artificial neural networks in health care organizational decision-making. PLoS ONE 2019, 14, e0212356. [Google Scholar] [CrossRef]
- Choquenaira Florez, A.Y.; Scabora, L.; Amer-Yahia, S.; Rodrigues Júnior, J.F. Augmentation Techniques for Sequential Clinical Data to Improve Deep Learning Prediction Techniques. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 597–602. [Google Scholar] [CrossRef]
- Qatawneh, Z.; Alshraideh, M.; Almasri, N.; Tahat, L.; Awidi, A. Clinical decision support system for venous thromboembolism risk classification. Appl. Comput. Inf. 2019, 15, 12–18. [Google Scholar] [CrossRef]
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Al Masry, Z.; Benaggoune, K.; Meraghni, S.; Zerhouni, N. A CNN-based methodology for breast cancer diagnosis using thermal images. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2020. [Google Scholar] [CrossRef]
- De Souza, L.A.; Passos, L.A.; Mendel, R.; Ebigbo, A.; Probst, A.; Messmann, H.; Palm, C.; Papa, J.P. Assisting Barrett’s esophagus identification using endoscopic data augmentation based on Generative Adversarial Networks. Comput. Biol. Med. 2020, 126, 104029. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Li, J.; Guo, J.; Chen, Y.; Yi, Z.; Zhong, J. Diagnosis of Diabetic Retinopathy Using Deep Neural Networks. IEEE Access 2019, 7, 3360–3370. [Google Scholar] [CrossRef]
- Yoon, J.; Drumright, L.N.; Van der Schaar, M. Anonymization Through Data Synthesis Using Generative Adversarial Networks (ADS-GAN). IEEE J. Biomed. Health Inf. 2020, 24, 2378–2388. [Google Scholar] [CrossRef]
- Goncalves, A.; Ray, P.; Soper, B.; Stevens, J.; Coyle, L.; Sales, A.P. Generation and evaluation of synthetic patient data. BMC Med. Res. Methodol. 2020, 20, 108. [Google Scholar] [CrossRef]
- Wells, P.S.; Owen, C.; Doucette, S.; Fergusson, D.; Tran, H. Does this patient have deep vein thrombosis? JAMA 2006, 295, 199–207. [Google Scholar] [CrossRef]
- Yang, L.; Tao, L.; Chen, X.; Gu, X. Multi-scale semantic feature fusion and data augmentation for acoustic scene classification. Appl. Acoust. 2020, 163. [Google Scholar] [CrossRef]
- Hu, T.; Tang, T.; Lin, R.; Chen, M.; Han, S.; Wu, J. A simple data augmentation algorithm and a self-adaptive convolutional architecture for few-shot fault diagnosis under different working conditions. Measurement 2020, 156, 107539. [Google Scholar] [CrossRef]
- Gómez-Ríos, A.; Tabik, S.; Luengo, J.; Shihavuddin, A.S.; Krawczyk, B.; Herrera, F. Towards highly accurate coral texture images classification using deep convolutional neural networks and data augmentation. Expert Syst. Appl. 2019. [Google Scholar] [CrossRef] [Green Version]
- Cao, B.; Wang, N.; Li, J.; Gao, X. Data Augmentation-Based Joint Learning for Heterogeneous Face Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1731–1743. [Google Scholar] [CrossRef]
- Wells, P.S.; Anderson, D.R.; Bormanis, J.; Guy, F.; Mitchell, M.; Gray, L.; Clement, C.; Robinson, K.S.; Lewandowski, B. Value of assessment of pretest probability of deep-vein thrombosis in clinical management. Lancet 1997, 350, 1795–1798. [Google Scholar] [CrossRef]
- Hardy, T.J.; Bevis, P.M. Deep vein thrombosis. Vasc. Surg. 2019, 37, 67–72. [Google Scholar] [CrossRef]
- Bernardi, E.; Camporese, G. Diagnosis of deep-vein thrombosis. Thromb. Res. 2018, 163, 201–206. [Google Scholar] [CrossRef]
- Fox, J.C.; Bertoglio, K.C. Emergency Physician Performed Ultrasound for DVT Evaluation. Thrombosis 2011, 2011, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zubiate, P.; Urrutia, A.; Zamarreño, C.R.; Egea-Urra, J.; Fernández-Irigoyen, J.; Giannetti, A.; Baldini, F.; Díaz, S.; Matias, I.R.; Arregui, F.J.; et al. Fiber-based early diagnosis of venous thromboembolic disease by label-free D-dimer detection. Biosens. Bioelectron. X 2019, 2, 100026. [Google Scholar] [CrossRef]
- Sun, M.C.; Li, M.S. Intervention for Diagnosis of Deep Vein Thrombosis in Acute Stroke Patients: A Hospital-Based Study. PLoS ONE 2014, 9, e114094. [Google Scholar] [CrossRef]
- Pedraza García, J.; Valle Alonso, J.; Ceballos García, P.; Rico Rodríguez, F.; Aguayo López, M.Á.; Muñoz-Villanueva, M.D.C. Comparison of the Accuracy of Emergency Department-Performed Point-of- Care-Ultrasound (POCUS) in the Diagnosis of Lower-Extremity Deep Vein Thrombosis. J. Emerg. Med. 2018, 54, 656–664. [Google Scholar] [CrossRef]
- Garcia, R.; Labropoulos, N. Duplex Ultrasound for the Diagnosis of Acute and Chronic Venous Diseases. Surg. Clin. N. Am. 2018, 98, 201–218. [Google Scholar] [CrossRef]
- Jain, A.K.; Soult, M.C.; Resnick, S.A.; Desai, K.; Astleford, P.; Eskandari, M.K.; Rodriguez, H.E. Detecting iliac vein thrombosis with current protocols of lower extremity venous duplex ultrasound. J. Vasc. Surg. Venous Lymphat. Disord. 2018, 6, 724–729. [Google Scholar] [CrossRef]
- Segal, J.B.; Eng, J.; Tamariz, L.J.; Bass, E.B. Review of the evidence on diagnosis of deep venous thrombosis and pulmonary embolism. Ann. Fam. Med. 2007, 5, 63–73. [Google Scholar] [CrossRef] [Green Version]
- Landefeld, C. Noninvasive diagnosis of deep vein thrombosis. JAMA 2008, 300, 1696–1697. [Google Scholar] [CrossRef]
- Stevenson, J.G. The Development of Color Doppler Echocardiography: Innovation and Collaboration. J. Am. Soc. Echocardiogr. 2018, 31, 1344–1352. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Pano-Azucena, A.; Tlelo-Cuautle, E.; Tan, S.D.; Ovilla-Martinez, B.; De la Fraga, L. FPGA-Based Implementation of a Multilayer Perceptron Suitable for Chaotic Time Series Prediction. Technologies 2018, 6, 90. [Google Scholar] [CrossRef] [Green Version]
- Masters, T. Practical Neural Networks Recipes in C++; Morgan Kaufmann: Bossdun, MA, USA, 1993; p. 493. [Google Scholar] [CrossRef]
- Aylward, S.; Anderson, R.A.Y. An algorithm for neural network architecture generation. In Proceedings of the 8th Computing in Aerospace Conference, Baltimore, MD, USA, 21–24 October 1991. [Google Scholar] [CrossRef]
- Yao, X. Evolving artificial neural networks. Proc. IEEE 1999, 87, 1423–1447. [Google Scholar] [CrossRef] [Green Version]
- Brush, J.; Sherbino, J.; Norman, G.R. How Expert Clinicians Intuitively Recognize a Medical Diagnosis. Am. J. Med. 2017, 130, 629–634. [Google Scholar] [CrossRef]
- Jung, Y. Multiple predicting K-fold cross-validation for model selection. J. Nonparametric Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Rodríguez, J.D.; Pérez, A.; Lozano, J.A. Sensitivity Analysis of k-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Sadrawi, M.; Sun, W.Z.; Ma, M.M.; Yeh, Y.T.; Abbod, M.; Shieh, J.S. Ensemble Genetic Fuzzy Neuro Model Applied for the Emergency Medical Service via Unbalanced Data Evaluation. Symmetry 2018, 10, 71. [Google Scholar] [CrossRef] [Green Version]
- Fu, G.H.; Xu, F.; Zhang, B.Y.; Yi, L.Z. Stable variable selection of class-imbalanced data with precision-recall criterion. Chemom. Intell. Lab. Syst. 2017, 171, 241–250. [Google Scholar] [CrossRef]
- Schrynemackers, M.; Küffner, R.; Geurts, P. On protocols and measures for the validation of supervised methods for the inference of biological networks. Front. Genet. 2013, 4, 262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, M.; Wang, M.; Wang, J.; Li, D. Comparison of random forest, support vector machine and back propagation neural network for electronic tongue data classification: Application to the recognition of orange beverage and Chinese vinegar. Sens. Actuators B Chem. 2013, 177. [Google Scholar] [CrossRef]
- Luo, J.; Yan, X.; Tian, Y. Unsupervised quadratic surface support vector machine with application to credit risk assessment. Eur. J. Oper. Res. 2020, 280, 1008–1017. [Google Scholar] [CrossRef]
- Barbon, A.P.A.C.; Barbon, S.J.; Mantovani Gomes, R.; Mayumi Fuzyi, E.; Manha Peres, L.; Bridi, A.M. Storage time prediction of pork by Computational Intelligence. Comput. Electron. Agric. 2016, 127, 368–375. [Google Scholar] [CrossRef]
- Cascarano, G.; Debitonto, F.; Lemma, R.; Brunetti, A.; Buongiorno, D.; De Feudis, I.; Guerriero, A.; Rossini, M.; Pesce, F.; Gesualdo, L.; et al. An Innovative Neural Network Framework for Glomerulus Classification Based on Morphological and Texture Features Evaluated in Histological Images of Kidney Biopsy; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2019; pp. 727–738. [Google Scholar] [CrossRef]
- Areiza-Laverde, H.; Castro-Ospina, A.; Peluffo-Ordóñez, D. Voice pathology detection using artificial neural networks and support vector machines powered by a multicriteria optimization algorithm. Commun. Comput. Inf. Sci. 2018, 915, 148–159. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
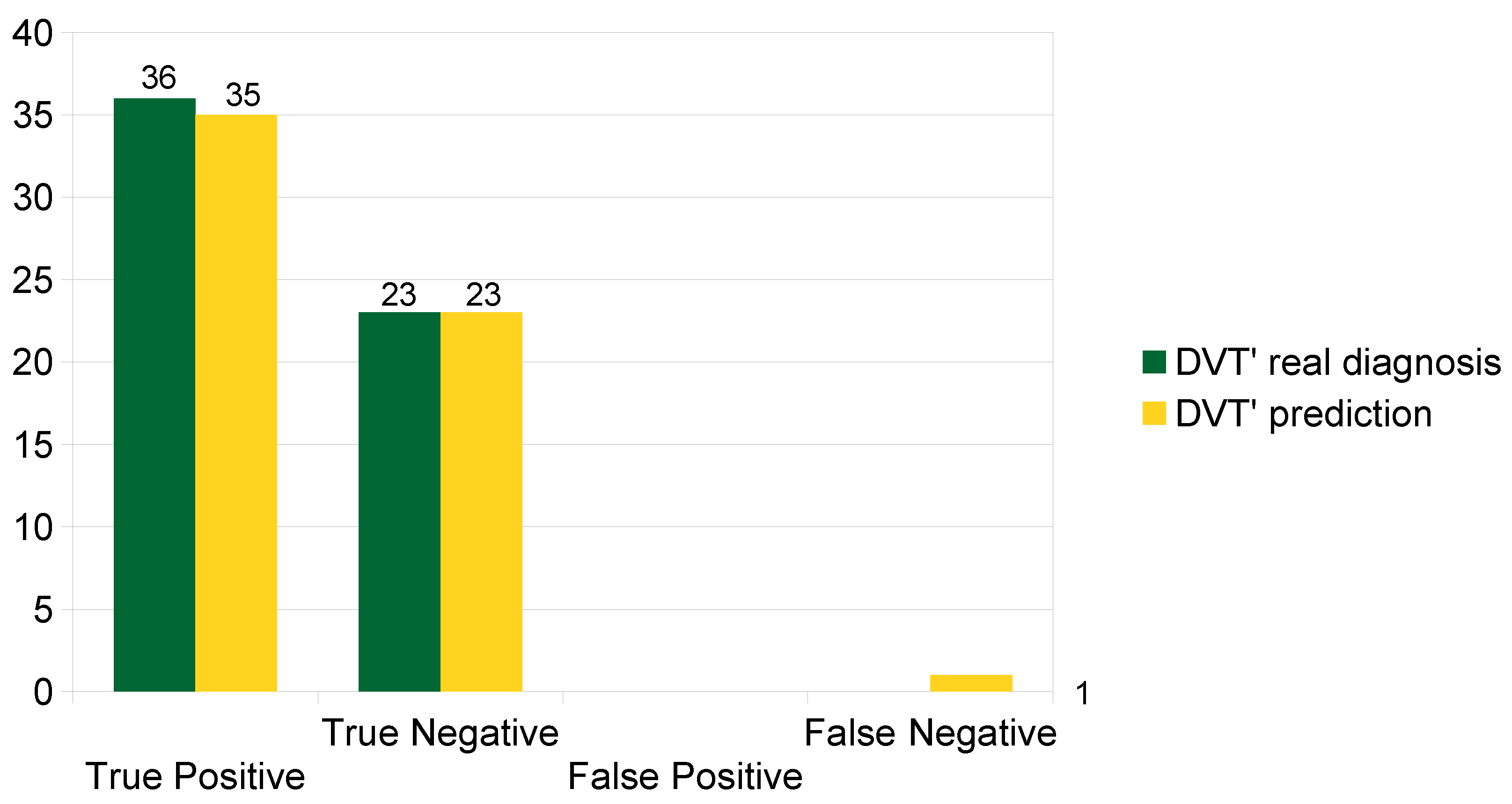{kind=link}
{kind=link}
| Clinical Feature | Score |
|---|---|
| Active cancer (patient either receiving treatment for cancer within the | 1 |
| previous 6 months or currently receiving palliative treatment) | |
| Paralysis, paresis, or recent cast immobilization of the lower extremities | 1 |
| Recently bedridden for ≥3 days, or major surgery within the previous | 1 |
| 12 weeks requiring general or regional anesthesia | |
| Localised tenderness along the distribution of the deep venous system | 1 |
| Entire leg swollen | 1 |
| Calf swollen at least 3 cm larger than that on the asymptomatic side | 1 |
| (measured 10 cm below tibial tuberosity) | |
| Pitting edema confined to the symptomatic leg | 1 |
| Collateral superficial veins (non-varicose) | 1 |
| Previously documented deep vein thrombosis | 1 |
| Alternative diagnosis at least as likely as deep vein thrombosis | −2 |
| In patients with symptoms in both legs, the more symptomatic leg is used |
| Low Risk | Moderated Risk | High Risk | |
|---|---|---|---|
| DVT Diagnosis | 305 | 224 | 1373 |
| Other | 5785 | 1096 | 1217 |
| Age [Years Old] | Life Stage | Numerical Value |
|---|---|---|
| 0–5 | Childhood | 1 |
| 6–12 | Middle childhood | 2 |
| 13–20 | Youth | 3 |
| 21–39 | Young adults | 4 |
| 40–49 | Average adults | 5 |
| 50–59 | Mature adults | 6 |
| 60–69 | Initial old age | 7 |
| 70–84 | Intermediate old | 8 |
| 85–120 | Advanced old age | 9 |
| Clinical Feature | Present | Absent | Collected Data |
|---|---|---|---|
| Active cancer | 1 | 0 | Interview the patient |
| Paralysis, paresis, or recent cast immobilization of | 1 | 0 | Interview the patient |
| the lower extremities | |||
| Recently bedridden for ≥3 days, or major surgery | 1 | 0 | Interview the patient |
| within the previous 12 weeks requiring general or | |||
| regional anesthesia | |||
| Localised tenderness along the distribution of the | 1 | 0 | Interview the patient |
| deep venous system | |||
| Entire leg swollen | 1 | 0 | Interview the patient/Physical examination |
| Calf swollen at least 3 cm larger than that on the | 1 | 0 | Physical examination |
| asymptomatic side | |||
| Pitting edema confined to the symptomatic leg | 1 | 0 | Physical examination |
| Collateral superficial veins | 1 | 0 | Interview the paciente/Physical examination |
| Previously documented deep vein thrombosis | 1 | 0 | Interview the al paciente |
| Input Layer with 11 Predictors | Hidden Layer | Output Layer |
|---|---|---|
| Age, gender, cancer, immobilization, surgery, | 150-100-50 | DVT Diagnosis |
| tenderness, leg swollen, calf swollen, edema, | ||
| superficial veins, previous DVT |
| Predicted Diagnostic | ||
|---|---|---|
| True diagnostic | Positive DVT | Negative DVT |
| Positive DVT | True Positive | False Negative |
| Negative DVT | False Positive | True Negative |
| True | True | False | False | |||||
|---|---|---|---|---|---|---|---|---|
| K-Fold | Positive (TP) | Negative (TN) | Positive (FP) | Negative (FN) | [%] | (Recall) [%] | [%] | [%] |
| 1 | 136 | 778 | 26 | 60 | 96.77 | 69.39 | 83.95 | 91.40 |
| 2 | 116 | 801 | 24 | 59 | 97.09 | 66.29 | 82.86 | 91.70 |
| 3 | 150 | 769 | 37 | 44 | 95.41 | 77.32 | 80.21 | 91.90 |
| 4 | 152 | 761 | 32 | 55 | 95.96 | 73.43 | 82.61 | 91.30 |
| 5 | 122 | 791 | 15 | 72 | 98.14 | 62.89 | 89.05 | 91.30 |
| 6 | 116 | 790 | 23 | 71 | 97.17 | 62.03 | 83.45 | 90.60 |
| 7 | 112 | 805 | 19 | 64 | 97.69 | 63.64 | 85.50 | 91.70 |
| 8 | 150 | 763 | 42 | 45 | 94.78 | 76.92 | 78.13 | 91.30 |
| 9 | 116 | 793 | 25 | 66 | 96.94 | 63.74 | 82.27 | 90.90 |
| 10 | 69 | 761 | 43 | 127 | 94.65 | 35.20 | 61.61 | 83.00 |
| Avg. | 123.90 | 781.20 | 28.60 | 66.30 | 96.46 | 65.08 | 80.96 | 90.51 |
| Std. Dev. | 25.04 | 16.92 | 9.54 | 23.37 | 1.20 | 11.97 | 7.40 | 2.67 |
| Percentage [%] | 12.39 | 78.12 | 2.86 | 6.63 | - | - | - | - |
| Missing | True | True | False | False | MSE | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|---|---|---|---|---|
| Input Factor | Positive | Negative | Positive | Negative | MSE | [%] | [%] | [%] | [%] |
| Age | 2338 | 6121 | 952 | 589 | 0.11 | 84.59 | 79.88 | 86.54 | 71.06 |
| Gender | 1116 | 7779 | 319 | 786 | 0.95 | 88.95 | 58.68 | 96.06 | 77.77 |
| Cancer | 1233 | 7699 | 399 | 669 | 0.08 | 89.32 | 64.83 | 95.07 | 75.55 |
| Immobilization | 1159 | 7676 | 422 | 743 | 0.09 | 88.35 | 60.94 | 94.79 | 73.31 |
| Surgery | 1160 | 7677 | 421 | 742 | 0.09 | 88.37 | 60.99 | 94.80 | 73.37 |
| Pain | 1163 | 7669 | 429 | 739 | 0.09 | 88.32 | 61.15 | 94.70 | 73.05 |
| Leg swelling | 641 | 8230 | 155 | 974 | 0.09 | 88.71 | 39.69 | 98.15 | 80.53 |
| Calf Swelling | 1053 | 7793 | 305 | 849 | 0.08 | 88.46 | 55.36 | 96.23 | 77.54 |
| Edema | 1181 | 7629 | 469 | 721 | 0.08 | 88.10 | 62.09 | 94.21 | 71.58 |
| Vericose veins | 1199 | 7563 | 535 | 703 | 0.09 | 87.62 | 63.04 | 93.39 | 69.15 |
| Previous DVT | 1253 | 7652 | 446 | 649 | 0.08 | 89.05 | 65.88 | 94.49 | 73.75 |
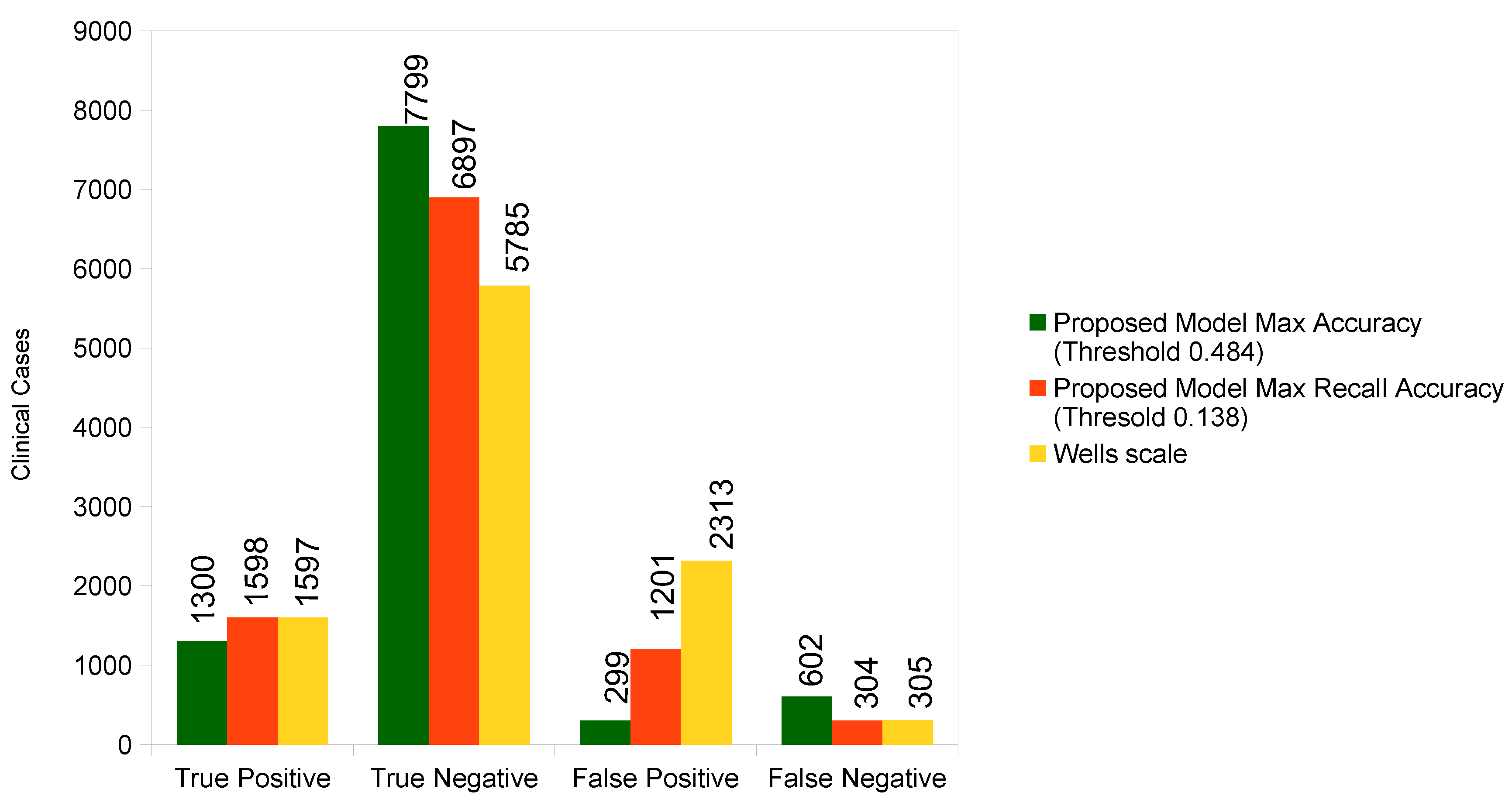
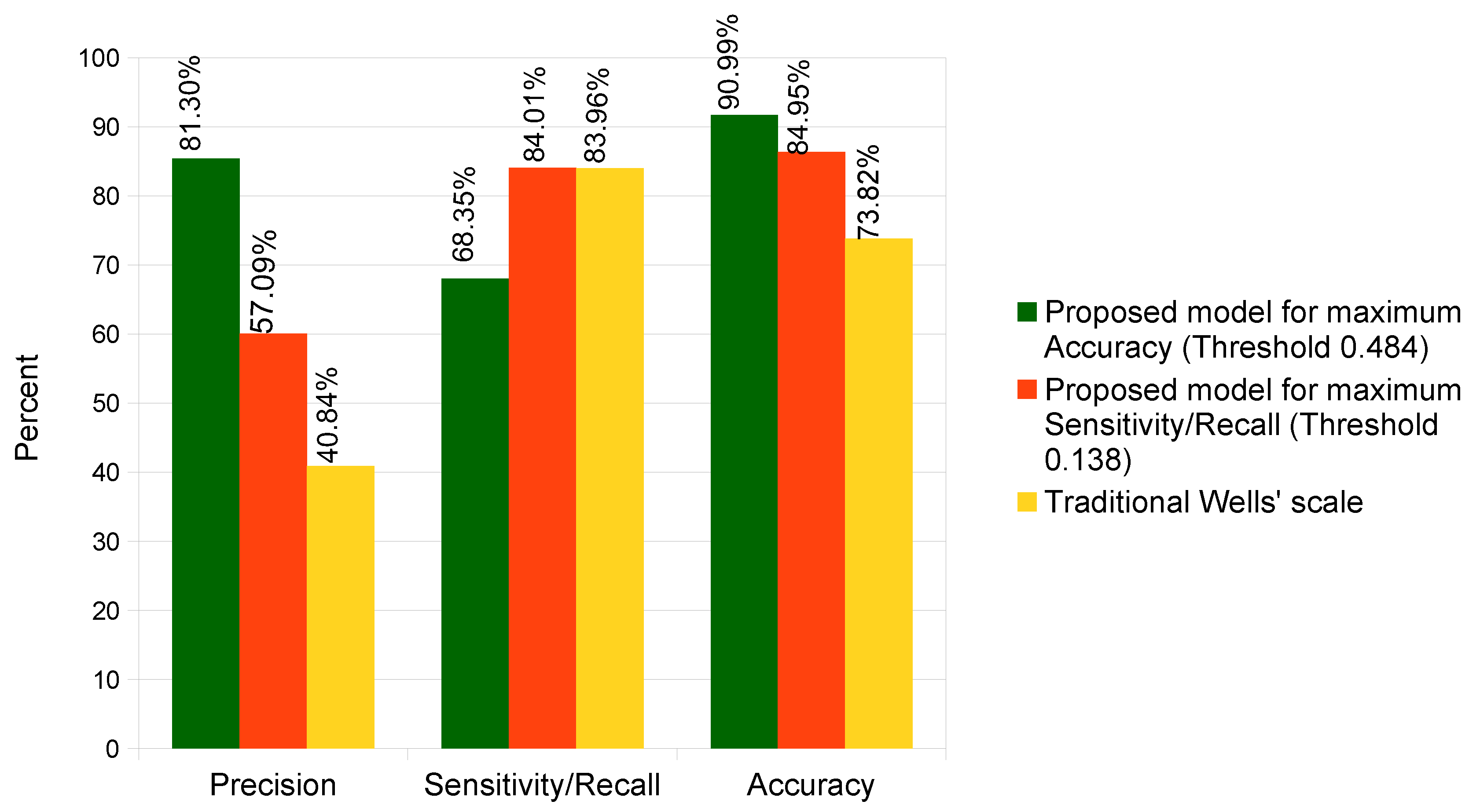
| Approach | Accuracy | Sensitivity/Recall | Specificity |
|---|---|---|---|
| Proposed approach for maximum Accuracy | 90.99 | 68.35 | 96.31 |
| Proposed approach for maximizing the Recall | 84.95 | 84.01 | 85.17 |
| Wells’ score in a traditional way [60] | 73.82 | 83.96 | 71.43 |
| True | True | False | False | |||||
|---|---|---|---|---|---|---|---|---|
| Machine-Learning Approach | Positive (TP) | Negative | Positive | Negative | [%] | (Recall) [%] | [%] | [%] |
| Proposed ANN | 1300 | 7799 | 299 | 602 | 96.31 | 68.35 | 81.30 | 90.99 |
| Related work | ||||||||
| Linear SVM [35,36,88] | 0 | 8098 | 0 | 1902 | 100 | 0 | 0 | 80.98 |
| Quadratic SVM [35,36,88,89] | 651 | 7553 | 545 | 1251 | 93.27 | 34.23 | 54.43 | 82.04 |
| Fine Gaussian SVM [36,88] | 569 | 7526 | 572 | 1333 | 92.94 | 29.92 | 49.87 | 80.95 |
| Simple Tree [35,36] | 685 | 7384 | 724 | 1217 | 91.07 | 31.01 | 48.62 | 80.69 |
| Complex Tree [35,36] | 740 | 7361 | 737 | 1162 | 90.90 | 38.91 | 50.10 | 81.01 |
| Weigthed KNN [35,36,90] | 710 | 7365 | 733 | 1192 | 90.95 | 37.33 | 49.20 | 80.75 |
| Fine KNN [35,36,90] | 801 | 6874 | 1224 | 1101 | 84.89 | 42.11 | 39.56 | 76.75 |
| Random Forest (RF) [32] | 1265 | 7658 | 316 | 761 | 96.04 | 62.44 | 80.01 | 89.23 |
| Stochastic Gradient Descent (SGD) [32] | 1157 | 7453 | 295 | 1095 | 96.19 | 51.38 | 79.68 | 86.10 |
| eXtreme Gradient Boosting (XGBoost) [33] | 1250 | 7625 | 312 | 813 | 96.07 | 60.59 | 80.03 | 88.75 |
| Gradient Boosting Decision Tree (GBDT) [33] | 1358 | 7583 | 294 | 765 | 96.27 | 63.97 | 82.20 | 89.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fong-Mata , M.B.; García-Guerrero , E.E.; Mejía-Medina, D.A.; López-Bonilla , O.R.; Villarreal-Gómez , L.J.; Zamora-Arellano, F.; López-Mancilla , D.; Inzunza-González , E. An Artificial Neural Network Approach and a Data Augmentation Algorithm to Systematize the Diagnosis of Deep-Vein Thrombosis by Using Wells’ Criteria. Electronics 2020, 9, 1810. https://doi.org/10.3390/electronics9111810
Fong-Mata MB, García-Guerrero EE, Mejía-Medina DA, López-Bonilla OR, Villarreal-Gómez LJ, Zamora-Arellano F, López-Mancilla D, Inzunza-González E. An Artificial Neural Network Approach and a Data Augmentation Algorithm to Systematize the Diagnosis of Deep-Vein Thrombosis by Using Wells’ Criteria. Electronics. 2020; 9(11):1810. https://doi.org/10.3390/electronics9111810
Chicago/Turabian StyleFong-Mata , María Berenice, Enrique Efrén García-Guerrero , David Abdel Mejía-Medina, Oscar Roberto López-Bonilla , Luis Jesús Villarreal-Gómez , Francisco Zamora-Arellano, Didier López-Mancilla , and Everardo Inzunza-González . 2020. "An Artificial Neural Network Approach and a Data Augmentation Algorithm to Systematize the Diagnosis of Deep-Vein Thrombosis by Using Wells’ Criteria" Electronics 9, no. 11: 1810. https://doi.org/10.3390/electronics9111810
APA StyleFong-Mata , M. B., García-Guerrero , E. E., Mejía-Medina, D. A., López-Bonilla , O. R., Villarreal-Gómez , L. J., Zamora-Arellano, F., López-Mancilla , D., & Inzunza-González , E. (2020). An Artificial Neural Network Approach and a Data Augmentation Algorithm to Systematize the Diagnosis of Deep-Vein Thrombosis by Using Wells’ Criteria. Electronics, 9(11), 1810. https://doi.org/10.3390/electronics9111810