Multi-Modality Global Fusion Attention Network for Visual Question Answering


Abstract
:1. Introduction
- We propose a novel MGFAN for VQA that can compute attention considering global information.
- In the MGFAN, we combine self-attention and co-attention into a unified attention framework.
- Our proposed approach outperforms the previous state-of-the-art methods on the most used benchmark for VQA: VQA-v2.
2. Related Work
2.1. Representation Learning for VQA
2.2. Attention Mechanism
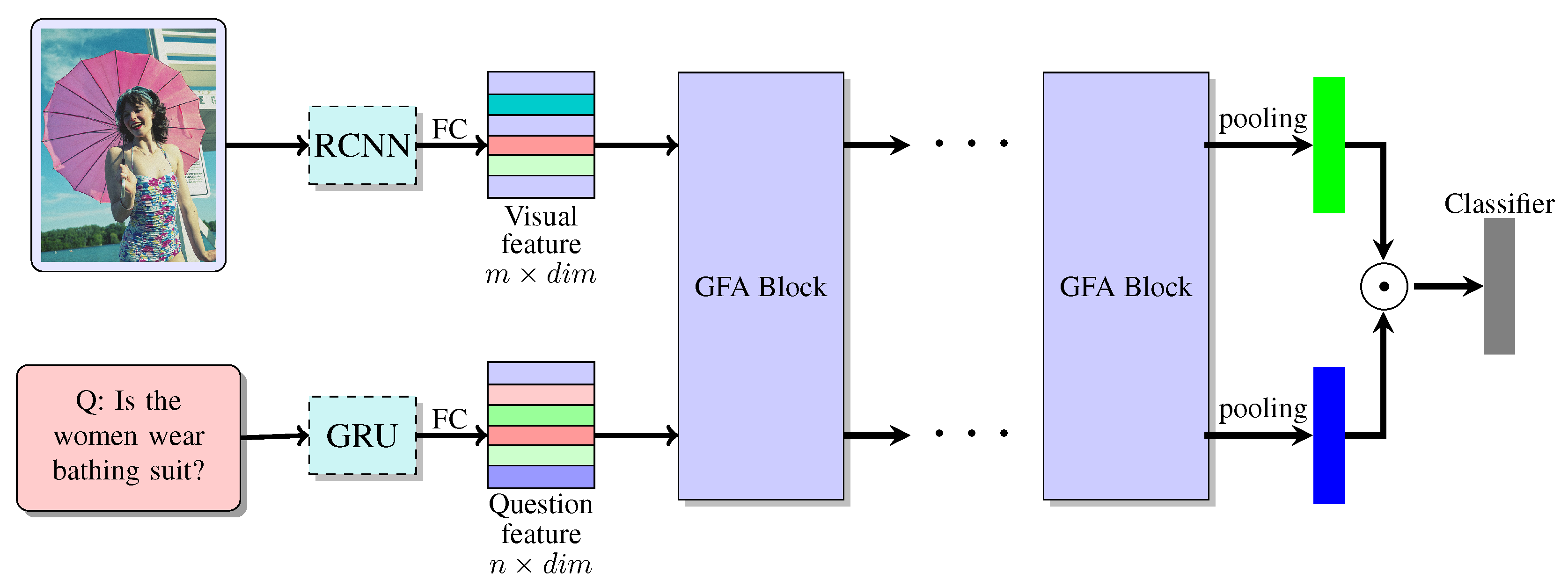
3. Multi-Modality Global Fusion Attention Network
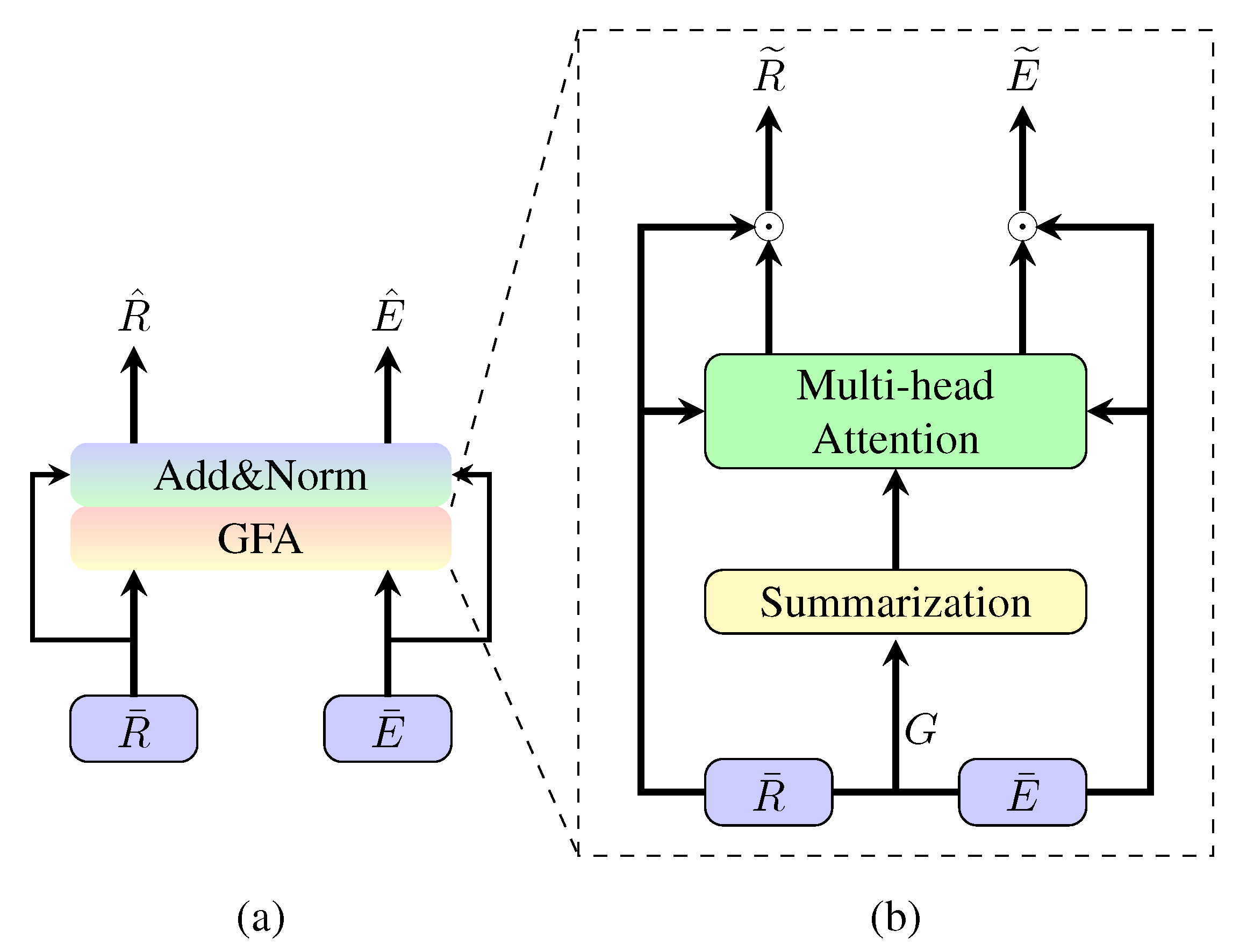
3.1. Global Fusion Attention Block
3.2. Network Architecture
4. Experiment
4.1. Datasets
4.2. Experimental Setup
4.3. Ablation Studies
5. Results
5.1. Visualization
5.2. Comparison with State-of-The-Art
5.3. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2016; pp. 21–37. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2015; pp. 1693–1701. [Google Scholar]
- Wang, W.; Yang, N.; Wei, F.; Chang, B.; Zhou, M. Gated self-matching networks for reading comprehension and question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 189–198. [Google Scholar]
- Bhutani, N.; Jagadish, H.; Radev, D. Nested propositions in open information extraction. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 55–64. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 2625–2634. [Google Scholar]
- Ding, S.; Qu, S.; Xi, Y.; Sangaiah, A.K.; Wan, S. Image caption generation with high-level image features. Pattern Recognit. Lett. 2019, 123, 89–95. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, M.; Wang, Z.; Zuo, L.; Li, B.; Yang, Y. Leveraging unpaired out-of-domain data for image captioning. Pattern Recognit. Lett. 2018, 132, 132–140. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, J.; Xiang, C.; Zhao, Z.; Tian, Q.; Tao, D. Rethinking diversified and discriminative proposal generation for visual grounding. arXiv 2018, arXiv:1805.03508. [Google Scholar]
- Toor, A.S.; Wechsler, H.; Nappi, M. Biometric surveillance using visual question answering. Pattern Recognit. Lett. 2019, 126, 111–118. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, J.; Hu, H.; Hu, H.; Qin, Z. Multimodal feature fusion by relational reasoning and attention for visual question answering. Inf. Fusion 2020, 55, 116–126. [Google Scholar] [CrossRef]
- Hudson, D.A.; Manning, C.D. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6700–6709. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar]
- Yu, Z.; Yu, J.; Xiang, C.; Fan, J.; Tao, D. Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5947–5959. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Gao, P.; Jiang, Z.; You, H.; Lu, P.; Hoi, S.C.; Wang, X.; Li, H. Dynamic Fusion With Intra-and Inter-Modality Attention Flow for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6639–6648. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep Modular Co-Attention Networks for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6281–6290. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2016; pp. 289–297. [Google Scholar]
- Xiong, C.; Zhong, V.; Socher, R. Dynamic coattention networks for question answering. arXiv 2016, arXiv:1611.01604. [Google Scholar]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-Modal Factorized Bilinear Pooling With Co-Attention Learning for Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Farazi, M.R.; Khan, S.H. Reciprocal attention fusion for visual question answering. arXiv 2018, arXiv:1805.04247. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2015; pp. 91–99. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Teney, D.; Anderson, P.; He, X.; van den Hengel, A. Tips and tricks for visual question answering: Learnings from the 2017 challenge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4223–4232. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2017; pp. 4967–4976. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yu, Z.; Cui, Y.; Yu, J.; Tao, D.; Tian, Q. Multimodal unified attention networks for Vision-and-Language interactions. arXiv 2019, arXiv:1908.04107. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ben-Younes, H.; Cadene, R.; Cord, M.; Thome, N. Mutan: Multimodal tucker fusion for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2612–2620. [Google Scholar]
- Kim, J.H.; On, K.W.; Lim, W.; Kim, J.; Ha, J.W.; Zhang, B.T. Hadamard product for low-rank bilinear pooling. arXiv 2016, arXiv:1610.04325. [Google Scholar]
- Bai, Y.; Fu, J.; Zhao, T.; Mei, T. Deep attention neural tensor network for visual question answering. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–35. [Google Scholar]
- Zhang, Y.; Hare, J.; Prügel-Bennett, A. Learning to count objects in natural images for visual question answering. arXiv 2018, arXiv:1802.05766. [Google Scholar]
- Kim, J.H.; Jun, J.; Zhang, B.T. Bilinear attention networks. In Advances in Neural Information Processing Systems; MIT Press: Wayne, PA, USA, 2018; pp. 1564–1574. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Component | Setting | Accuracy (%) |
|---|---|---|
| Bottom-up | Bottom-up | 63.37 |
| Stacked blocks | GFA-3 | 66.18 |
| GFA-5 | 66.34 | |
| GFA-8 | 66.49 | |
| GFA-12 | 66.26 | |
| Relation modeling | Yes | 66.34 |
| No | 65.41 | |
| Fused vectors | 4 | 65.67 |
| 6 | 66.21 | |
| 8 | 66.34 | |
| Parallel heads | 1 head each 512 | 65.98 |
| 4 heads each 128 | 66.22 | |
| 8 heads each 64 | 66.34 | |
| Final feature | Addition | 66.25 |
| fusion | Concatenation | 66.29 |
| Multiplication | 66.34 | |
| Embedding | 512 | 66.34 |
| dimension | 1024 | 66.13 |
| Model | Test-Dev | Test-Std | |||
|---|---|---|---|---|---|
| Y/N | Num | Other | All | All | |
| BUTP [15] | 81.82 | 44.21 | 56.05 | 65.32 | 65.67 |
| MUTAN [36] | 82.88 | 44.54 | 56.50 | 66.01 | 66.38 |
| MLB [37] | 83.58 | 44.92 | 56.34 | 66.27 | 66.62 |
| DA-NTN [38] | 84.29 | 47.14 | 57.90 | 67.56 | 67.94 |
| Counter [39] | 83.14 | 51.62 | 58.97 | 68.09 | 68.41 |
| BAN [40] | 85.46 | 50.66 | 60.50 | 69.66 | n/a |
| DFAF [19] | 86.09 | 53.32 | 60.49 | 70.22 | 70.34 |
| MGFAN (ours) | 86.32 | 53.30 | 60.77 | 70.45 | 70.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Wu, W.; Wang, Y.; Zhou, H. Multi-Modality Global Fusion Attention Network for Visual Question Answering. Electronics 2020, 9, 1882. https://doi.org/10.3390/electronics9111882
Yang C, Wu W, Wang Y, Zhou H. Multi-Modality Global Fusion Attention Network for Visual Question Answering. Electronics. 2020; 9(11):1882. https://doi.org/10.3390/electronics9111882
Chicago/Turabian StyleYang, Cheng, Weijia Wu, Yuxing Wang, and Hong Zhou. 2020. "Multi-Modality Global Fusion Attention Network for Visual Question Answering" Electronics 9, no. 11: 1882. https://doi.org/10.3390/electronics9111882
APA StyleYang, C., Wu, W., Wang, Y., & Zhou, H. (2020). Multi-Modality Global Fusion Attention Network for Visual Question Answering. Electronics, 9(11), 1882. https://doi.org/10.3390/electronics9111882