SEEK: A Framework of Superpixel Learning with CNN Features for Unsupervised Segmentation





Abstract
:1. Introduction
- Design of CNN architecture to capture spatially distinct features, so that depth-wise feature maps are not redundant.
- Unlike traditional frameworks, no prior exhaustive training is required for making segments. Rather, for each image, we generate pseudo labels and make the CNN learn those labels iteratively.
- We introduce a segmentation refinement step using K-means clustering for better spatial contrast and continuity of the predicted segmentation results.
2. Related Work
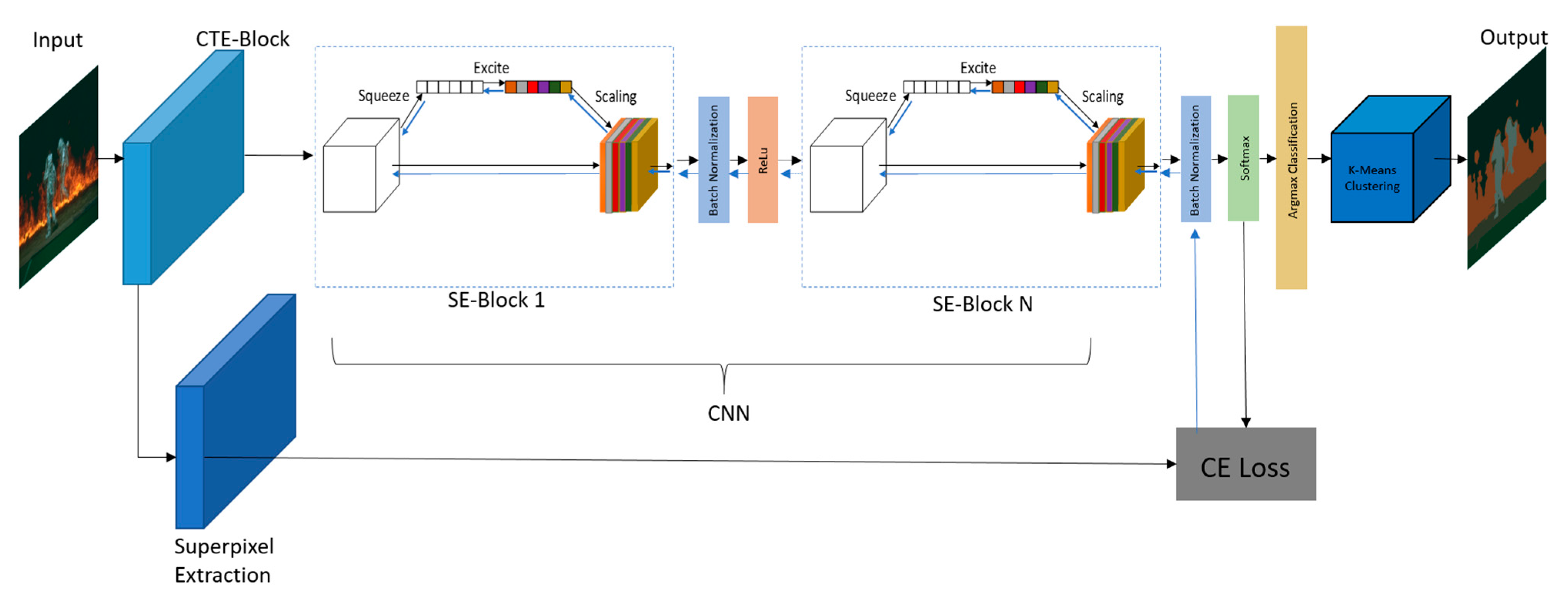
3. Method
3.1. Contrast and Texture Enhancement (CTE)
3.2. Superpixel Extraction
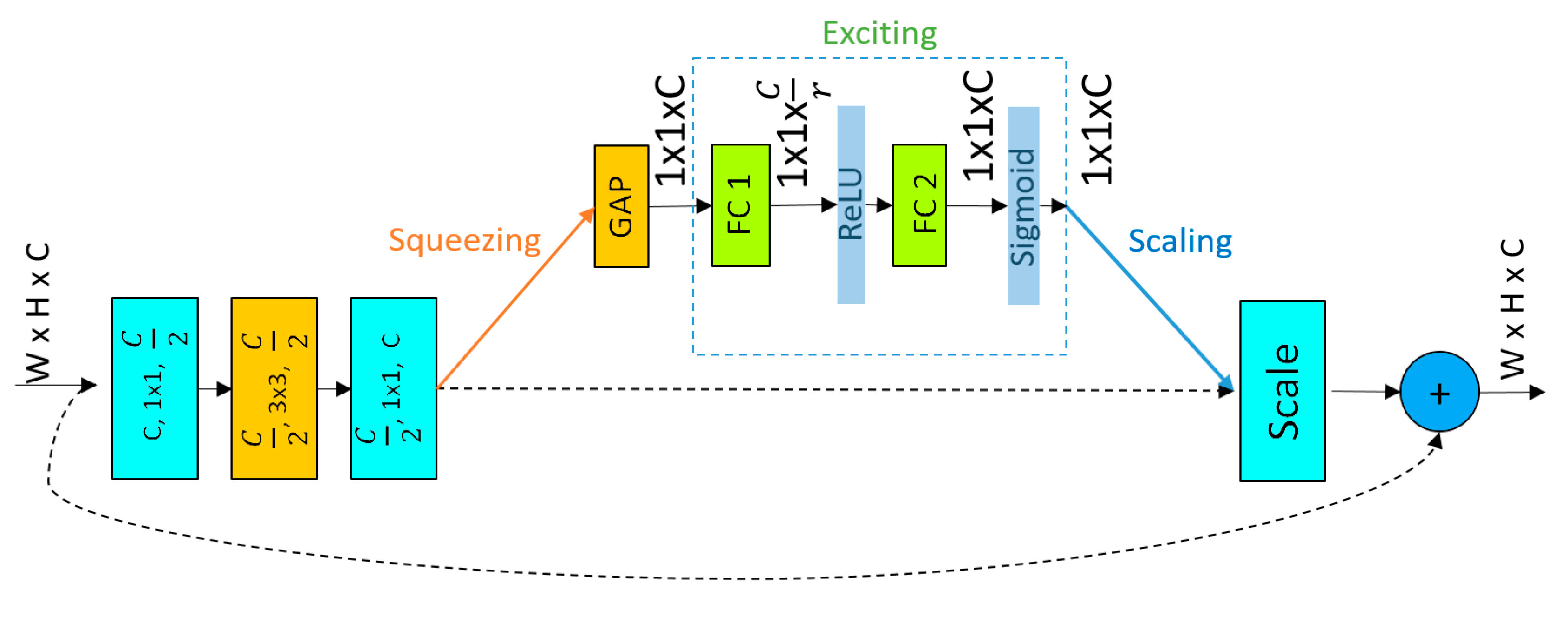
3.3. Network Architecture
3.4. K-Means Clustering
4. Network Training
| Learning Algorithm: Unsupervised Semantic Segmentation |
 |
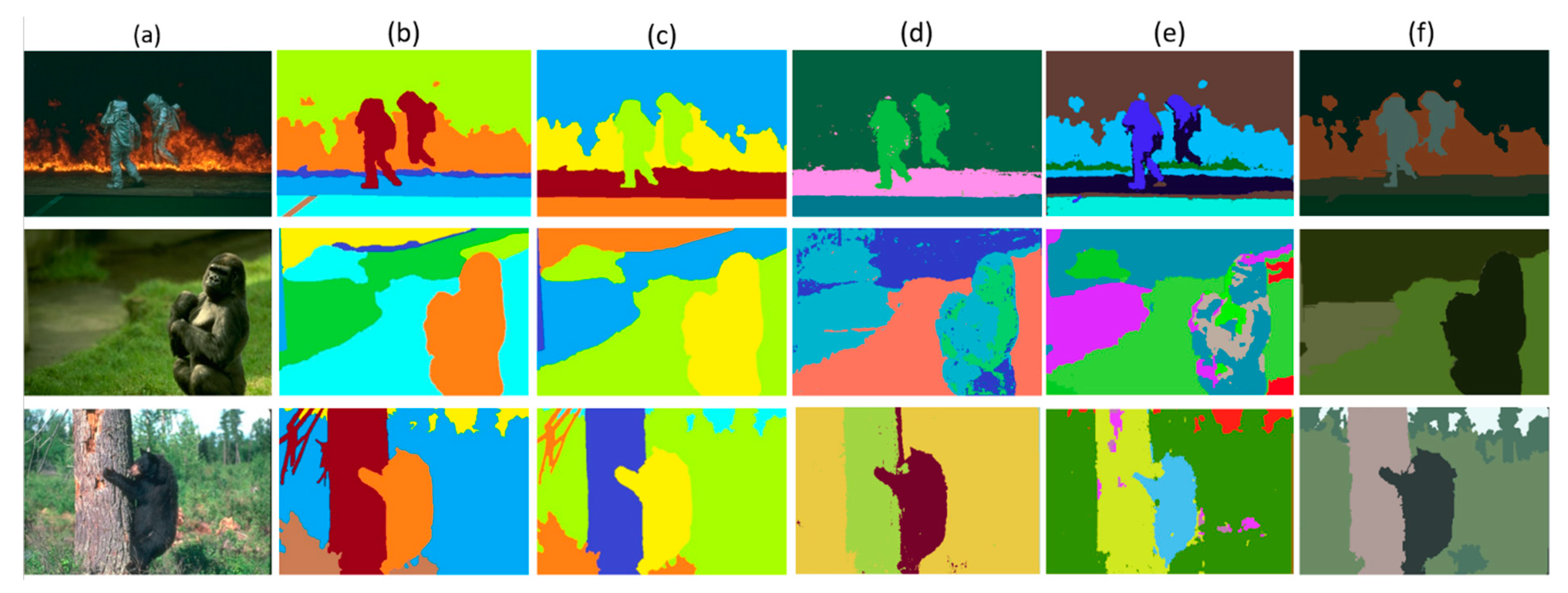
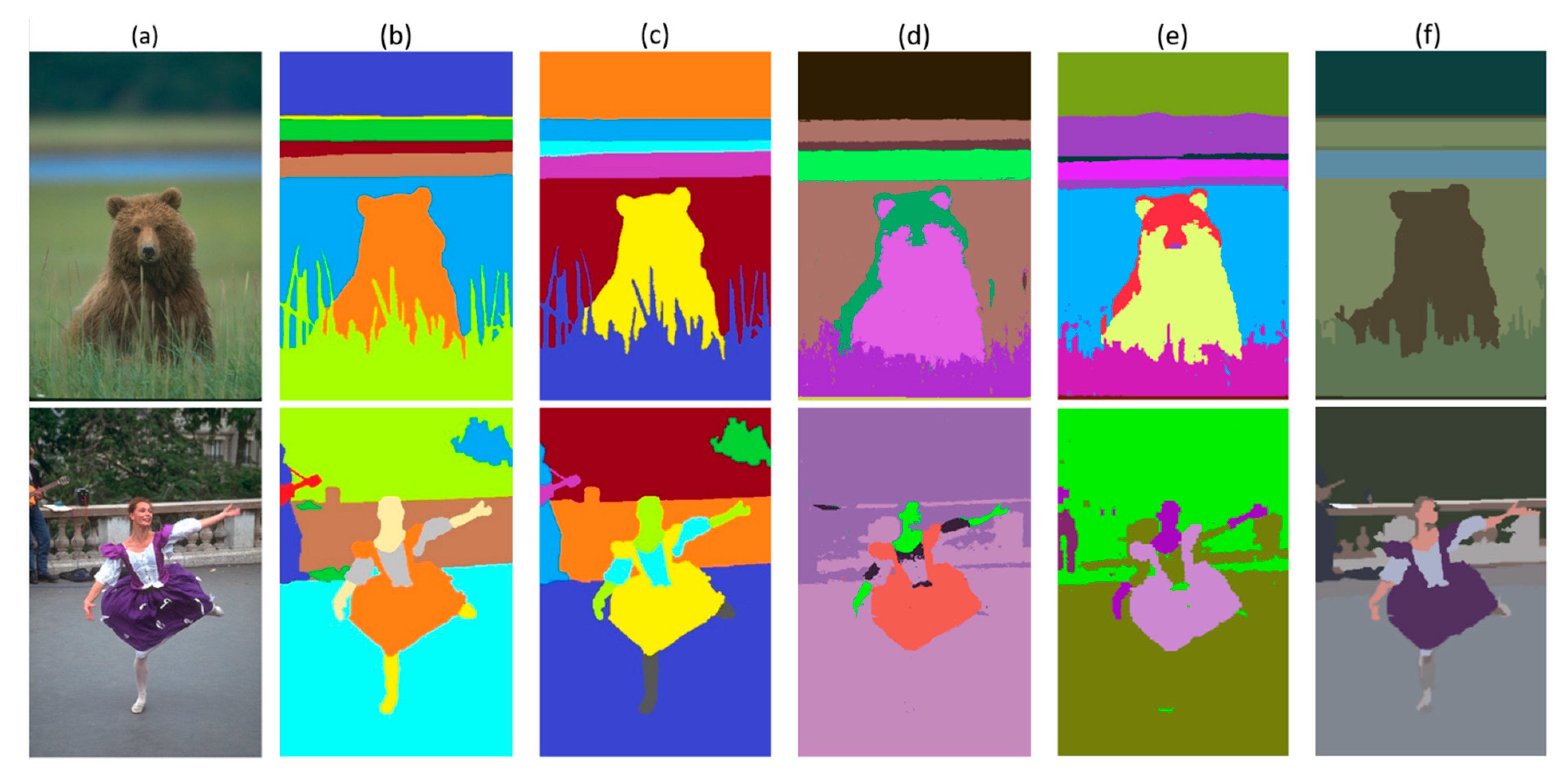
5. Results and Discussion
5.1. Performance Assessment
5.1.1. Variation of Information
5.1.2. Precision and Recall
5.1.3. Jaccard Index
5.1.4. Dice Coefficient
6. Ablation Study
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kauanova, S.; Vorobjev, I.; James, A.P. Automated image segmentation for detecting cell spreading for metastasizing assessments of cancer development. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin, Germany, 2015. [Google Scholar]
- Işın, A.; Direkoğlu, C.; Şah, M. Review of MRI-based brain tumor image segmentation using deep learning methods. Procedia Comput. Sci. 2016, 102, 317–324. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Sodha, V.; Siddiquee, M.M.R.; Feng, R.; Tajbakhsh, N.; Gotway, M.B.; Liang, J. Models genesis: Generic autodidactic models for 3d medical image analysis. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin, Germany, 2019. [Google Scholar]
- Yin, J.; Mao, H.; Xie, Y. Segmentation Methods of Fruit Image and Comparative Experiments. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Hubei, China, 12–14 December 2008. [Google Scholar]
- Lamb, N.; Chuah, M.C. A strawberry detection system using convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Bargoti, S.; Underwood, J.P. Underwood, Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lee, W.S.; Gan, H.; Peres, N.A.; Fraisse, C.W.; Zhang, Y.; He, Y. Strawberry Yield Prediction Based on a Deep Neural Network Using High-Resolution Aerial Orthoimages. Remote Sens. 2019, 11, 1584. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.W.; Li, C.H. Color image segmentation method based on statistical pattern recognition for plant disease diagnose [J]. J. Jilin Univ. Technol. 2004, 2, 28. [Google Scholar]
- Hofmarcher, M.; Unterthiner, T.; Arjona-Medina, J.; Klambauer, G.; Hochreiter, S.; Nessler, B. Visual scene understanding for autonomous driving using semantic segmentation. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin, Germany, 2019; pp. 285–296. [Google Scholar]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Imai, T. Legal regulation of autonomous driving technology: Current conditions and issues in Japan. IATSS Res. 2019, 43, 263–267. [Google Scholar] [CrossRef]
- Leo, M.; Furnari, A.; Medioni, G.G.; Trivedi, M.; Farinella, G.M. Deep Learning for Assistive Computer Vision. In Proceedings of the Computer Vision; Springer: Berlin, Germany, 2019; pp. 3–14. [Google Scholar]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Ji, K.; Kang, M.; Leng, X.; Zou, H. Deep Convolutional Highway Unit Network for SAR Target Classification With Limited Labeled Training Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1–5. [Google Scholar] [CrossRef]
- Zhao, H.; Kit, C. Integrating unsupervised and supervised word segmentation: The role of goodness measures. Inf. Sci. 2011, 181, 163–183. [Google Scholar] [CrossRef]
- Epifanio, I.; Soille, P. Morphological Texture Features for Unsupervised and Supervised Segmentations of Natural Landscapes. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1074–1083. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Badrinarayanan, V.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. In Proceedings of the 2014 International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H.S.; Shuai, Z.; Sadeep, J.; et al. Conditional Random Fields as Recurrent Neural Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Boston, MA, USA, 7–12 June 2015; pp. 1529–1537. [Google Scholar]
- Pont-Tuset, J.; Barron, J.T.; Malik, J.; Marques, F.; Arbelaez, P. Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 128–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xia, X.; Kulis, B. W-net: A deep model for fully unsupervised image segmentation. arXiv 2017, arXiv:1711.08506. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, X.; Lei, Q.; Yao, R.; Gong, Y.; Yin, Q. Image segmentation based on adaptive K-means algorithm. EURASIP J. Image Video Process. 2018, 2018, 68. [Google Scholar] [CrossRef]
- Zhu, J.; Mao, J.; Yuille, A.L. Learning from weakly supervised data by the expectation loss svm (e-svm) algorithm. In Advances in Neural Information Processing Systems 27; NeurIPS: San Diego, CA, USA, 2014. [Google Scholar]
- Chang, F.-J.; Lin, Y.-Y.; Hsu, K.-J. Multiple structured-instance learning for semantic segmentation with uncertain training data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation; Cornell University: Ithaca, NY, USA, 2016. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected Crfs with Gaussian Edge Potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Wei, X.; Yang, Q.; Gong, Y.; Ahuja, N.; Yang, M.H. Superpixel hierarchy. IEEE Trans. Image Process. 2018, 27, 4838–4849. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Liu, T.; Liu, S.; Meng, H.; Nandi, A. Adaptive Morphological Reconstruction for Seeded Image Segmentation. IEEE Trans. Image Process. 2019, 28, 5510–5523. [Google Scholar] [CrossRef] [Green Version]
- Bosch, M.B.; Gifford, C.; Dress, A.; Lau, C.; Skibo, J. Improved image segmentation via cost minimization of multiple hypotheses. arXiv 2018, arXiv:1802.00088. [Google Scholar]
- Fu, X.; Wang, C.-Y.; Chen, C.; Wang, C.; Kuo, C.-C.J. Robust Image Segmentation Using Contour-Guided Color Palettes. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Aracuano Park, Chile, 11–18 December 2015. [Google Scholar]
- Xu, Y.; Carlinet, E.; Géraud, T.; Najman, L. Hierarchical Segmentation Using Tree-Based Shape Spaces. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 457–469. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Bennamoun, M.; Boussaid, F.; An, S.; Sohel, F. An Improved Approach to Weakly Supervised Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Wang, W.; Xiang, D.; Ban, Y.; Zhang, J.; Wan, J. Superpixel-Based Segmentation of Polarimetric SAR Images through Two-Stage Merging. Remote Sens. 2019, 11, 402. [Google Scholar] [CrossRef] [Green Version]
- Soltaninejad, M.; Yang, G.; Lambrou, T.; Allinson, N.; Jones, T.L.; Barrick, T.R.; Howe, F.; Ye, X. Automated brain tumour detection and segmentation using superpixel-based extremely randomized trees in FLAIR MRI. Int. J. Comput. Assist. Radiol. Surg. 2016, 12, 183–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daoud, M.I.; Atallah, A.A.; Awwad, F.; Al-Najjar, M.; Alazrai, R. Automatic superpixel-based segmentation method for breast ultrasound images. Expert Syst. Appl. 2019, 121, 78–96. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, L.; Zheng, H.; Liang, P.; Mangold, C.; Loreto, R.G.; Hughes, D.P.; Chen, D.Z. SPDA: Superpixel-based data augmentation for biomedical image segmentation. arXiv 2019, arXiv:1903.00035. [Google Scholar]
- Kanezaki, A. Unsupervised image segmentation by backpropagation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Weiss, Y. Segmentation using eigenvectors: A unifying view. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkrya, Greece, 20–27 September 1999. [Google Scholar]
- Comaniciu, D.; Meer, P. Robust analysis of feature spaces: Color image segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997. [Google Scholar]
- Vergés, L.J. Color. Constancy and Image Segmentation Techniques for Applications to Mobile Robotics. Ph.D. Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2005. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. arXiv 2016, arXiv:1512.03385. [Google Scholar]
- Galloway, A.; Golubeva, A.; Tanay, T.; Moussa, M.; Taylor, G.W. Batch Normalization is a Cause of Adversarial Vulnerability. In Proceedings of the ICML Workshop on Identifying and Understanding Deep Learning Phenomena, Long Beach, CA, USA, 15 June 2019. [Google Scholar]
- Kaur, G.; Rani, J. MRI Brain Tumor Segmentation Methods—A Review; Infinite Study: Conshohocken, PA, USA, 2016. [Google Scholar]
- Yedla, M.; Pathakota, S.R.; Srinivasa, T.M. Enhancing K-means clustering algorithm with improved initial center. Int. J. Comp. Sci. Inf. Technol. 2010, 1, 121–125. [Google Scholar]
- Nazeer, K.A.; Sebastian, M. Improving the Accuracy and Efficiency of the k-means Clustering Algorithm. In Proceedings of the World Congress on Engineering; Association of Engineers: London, UK, 2009. [Google Scholar]
- Martín, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Wang, G.; De Baets, B. Superpixel Segmentation Based on Anisotropic Edge Strength. J. Imaging 2019, 5, 57. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.K.; Seal, A.; Khanna, P. Divergence based SLIC. Electron. Lett. 2019, 55, 783–785. [Google Scholar] [CrossRef]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. Bi-Directional Cascade Network for Perceptual Edge Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Donoser, M.; Schmalstieg, D. Discrete-Continuous Gradient Orientation Estimation for Faster Image Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Meila, M. Comparing Clusterings by the Variation of Information. In Learning Theory and Kernel Machines; Springer: Berlin, Germany, 2003; Volume 2777, pp. 173–187. [Google Scholar]
- Meilǎ, M. Comparing clusterings: An axiomatic view. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2015. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I.D. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Mean IoU | F1-Score | VI | Precision | Recall |
|---|---|---|---|---|---|
| SLIC* | 0.6751 | 0.7803 | 0.6508 | 0.7000 | 1 |
| Felzenswalb* | 0.6894 | 0.8037 | 0.6742 | 0.7078 | 1 |
| SE + CTE | 0.6960 | 0.8182 | 0.6607 | 0.7017 | 1 |
| SE + K | 0.7053 | 0.8235 | 0.6454 | 0.7156 | 1 |
| SEEK(SE + CTE + K) | 0.7088 | 0.8290 | 0.6310 | 0.7234 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ilyas, T.; Khan, A.; Umraiz, M.; Kim, H. SEEK: A Framework of Superpixel Learning with CNN Features for Unsupervised Segmentation. Electronics 2020, 9, 383. https://doi.org/10.3390/electronics9030383
Ilyas T, Khan A, Umraiz M, Kim H. SEEK: A Framework of Superpixel Learning with CNN Features for Unsupervised Segmentation. Electronics. 2020; 9(3):383. https://doi.org/10.3390/electronics9030383
Chicago/Turabian StyleIlyas, Talha, Abbas Khan, Muhammad Umraiz, and Hyongsuk Kim. 2020. "SEEK: A Framework of Superpixel Learning with CNN Features for Unsupervised Segmentation" Electronics 9, no. 3: 383. https://doi.org/10.3390/electronics9030383
APA StyleIlyas, T., Khan, A., Umraiz, M., & Kim, H. (2020). SEEK: A Framework of Superpixel Learning with CNN Features for Unsupervised Segmentation. Electronics, 9(3), 383. https://doi.org/10.3390/electronics9030383