Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles



Abstract
:1. Introduction
2. Background
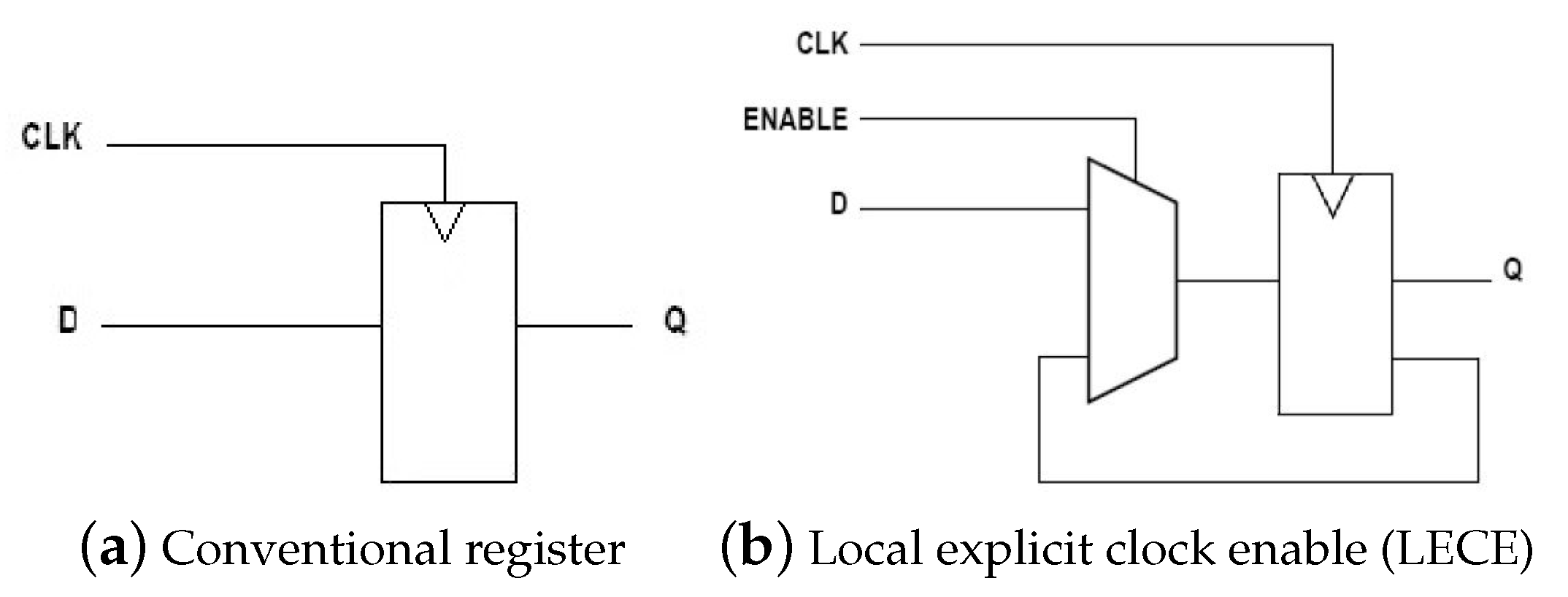
2.1. Clock Gating
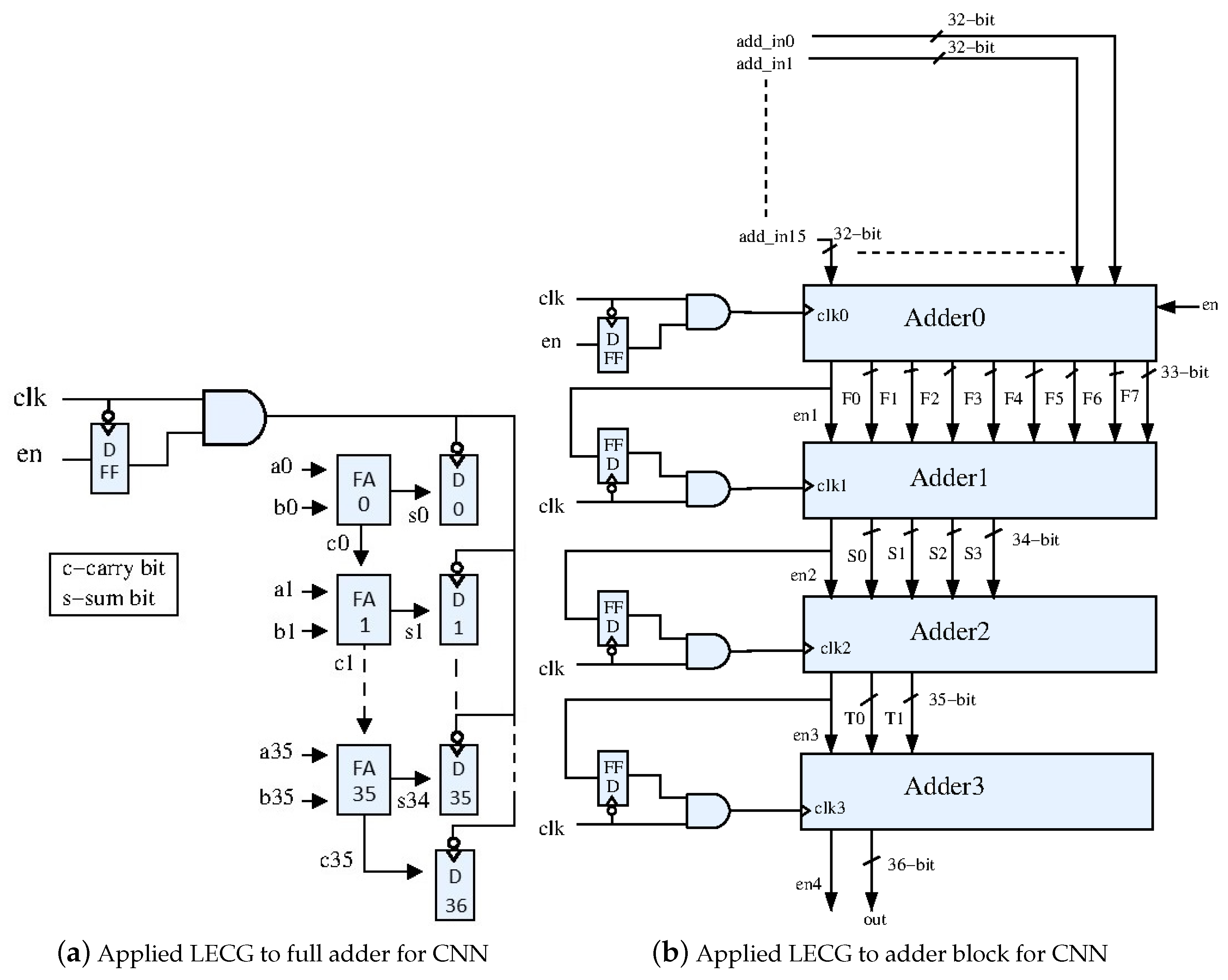
2.2. Local Explicit Clock Enable
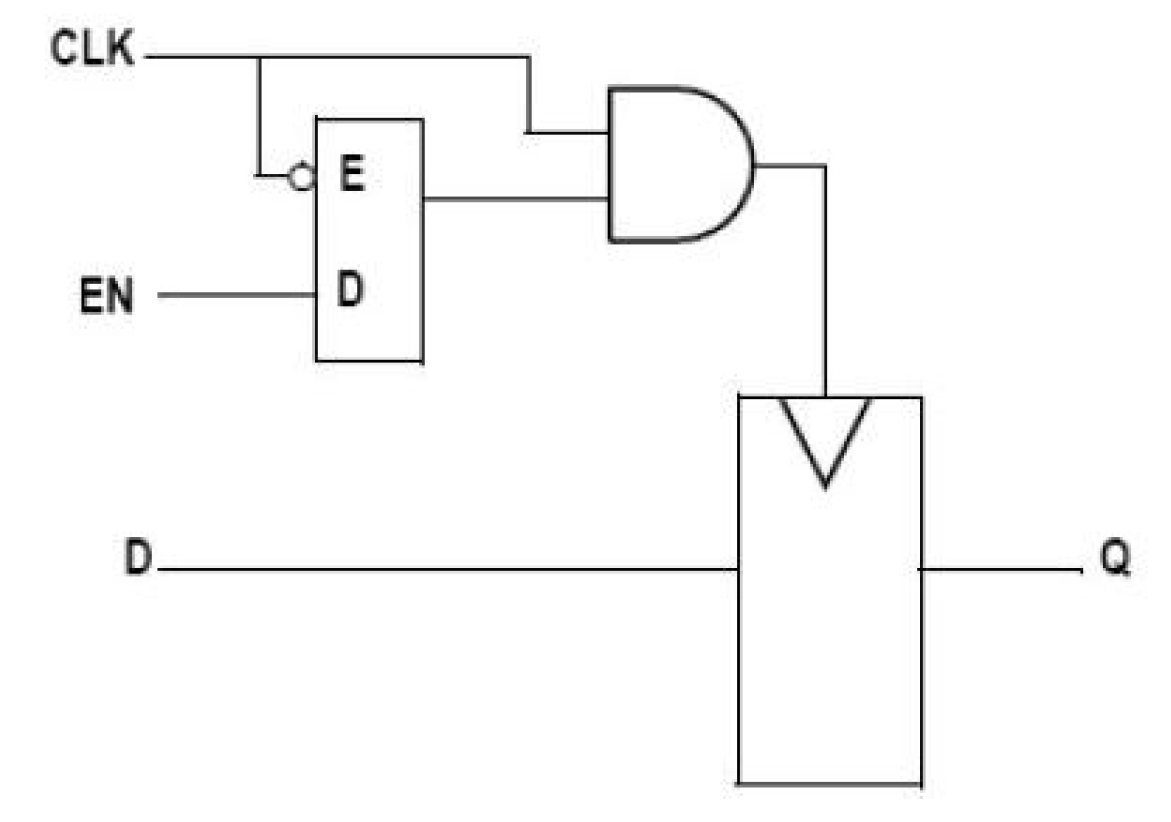
2.3. Local Explicit Clock Gating
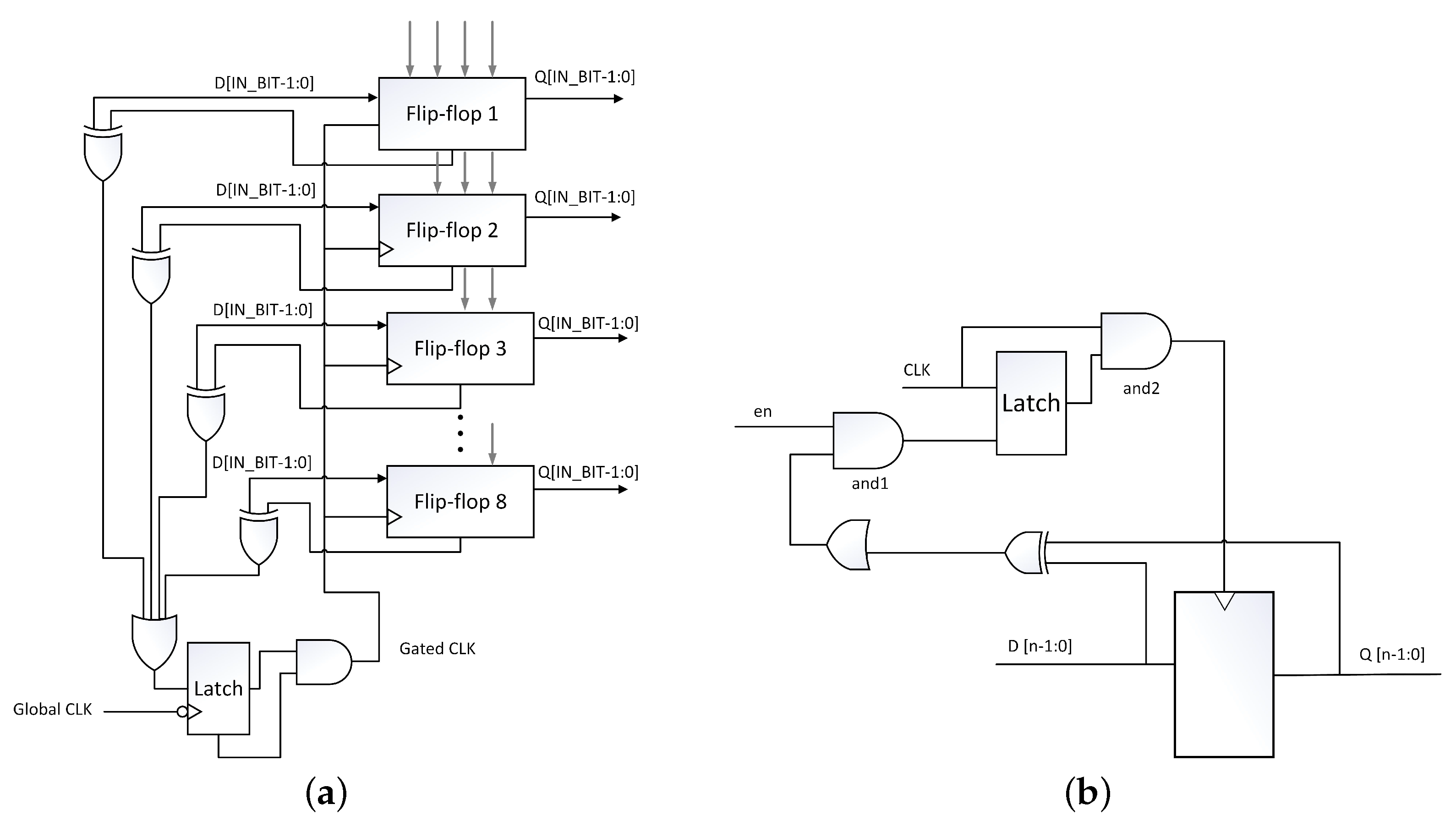
2.4. Bus-Specific Clock Gating
2.5. Enhanced Clock Gating
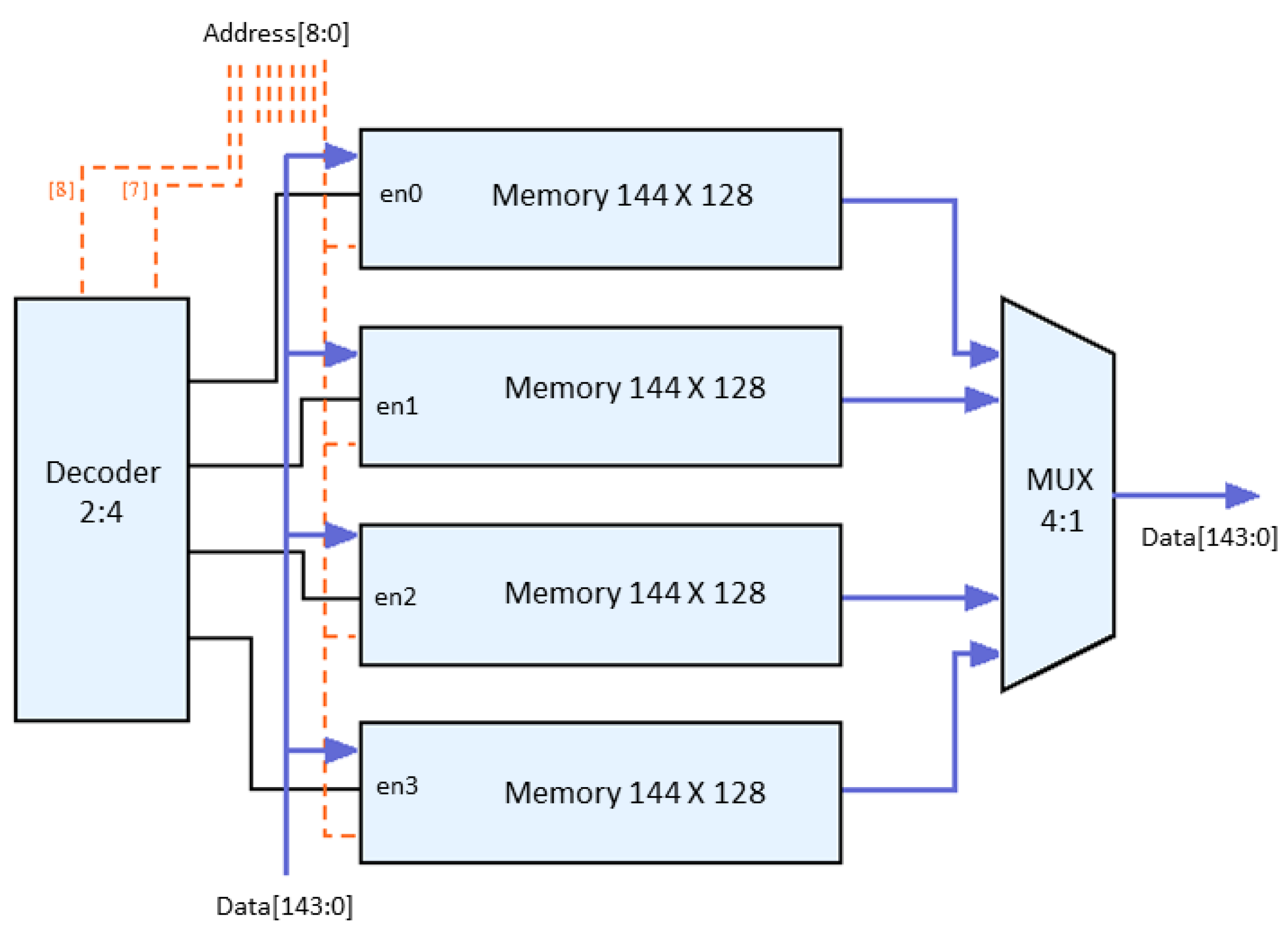
2.6. Memory Split
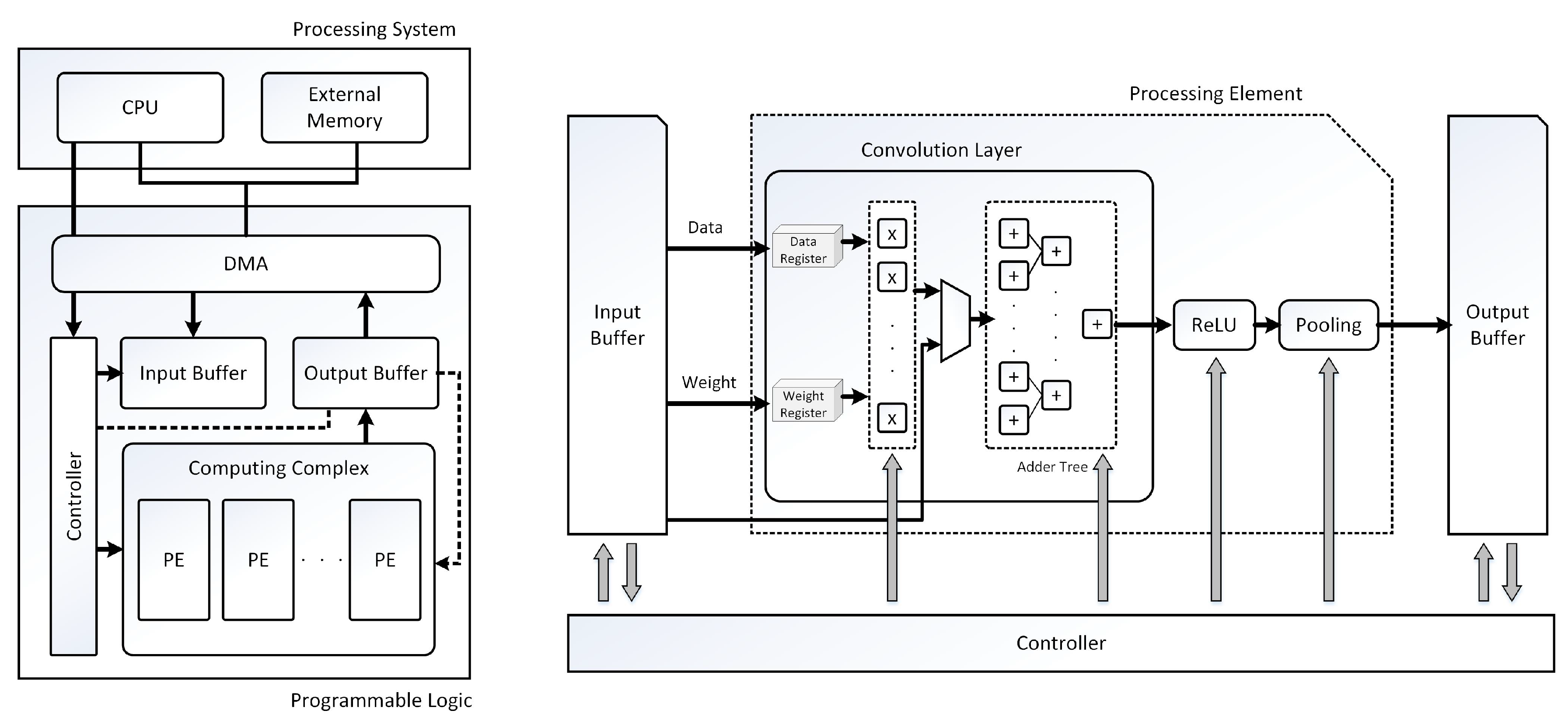
3. CNN Accelerator Industrial Model: Low-Power RTL Approach
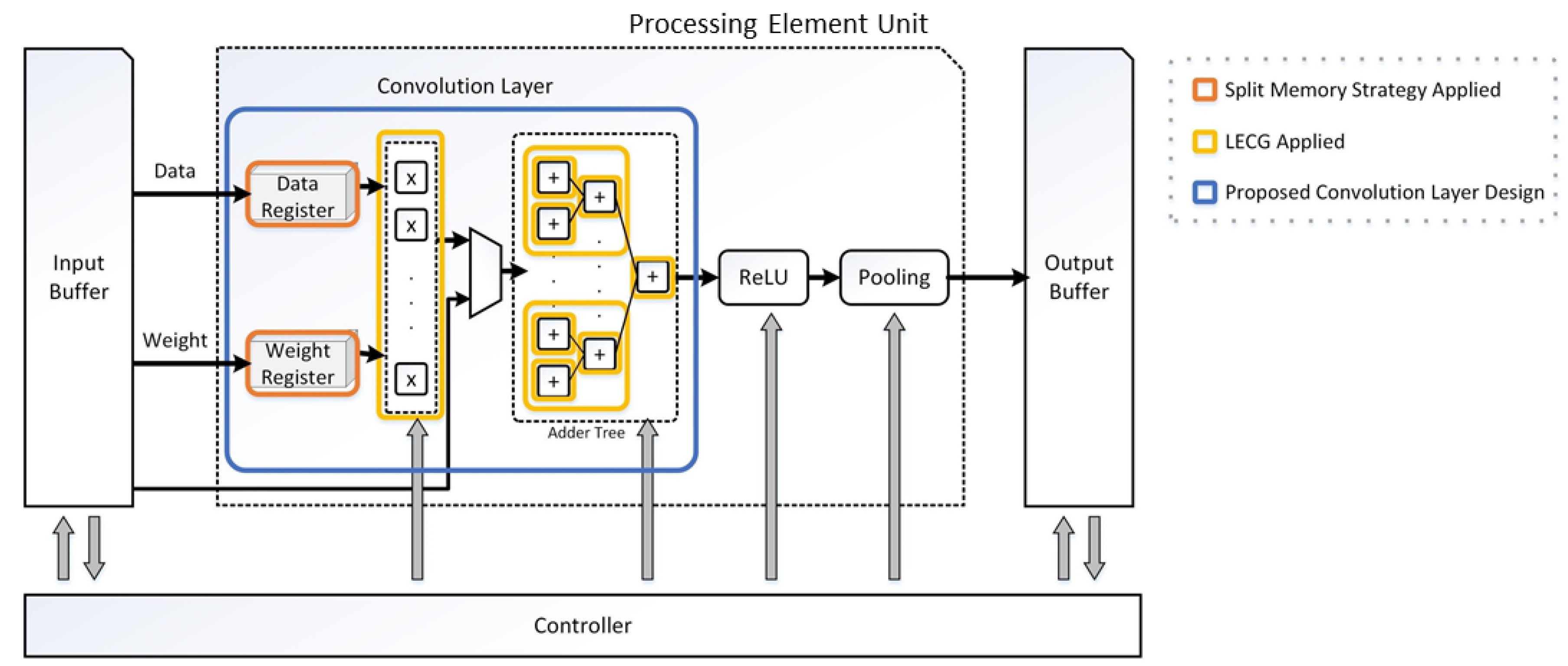
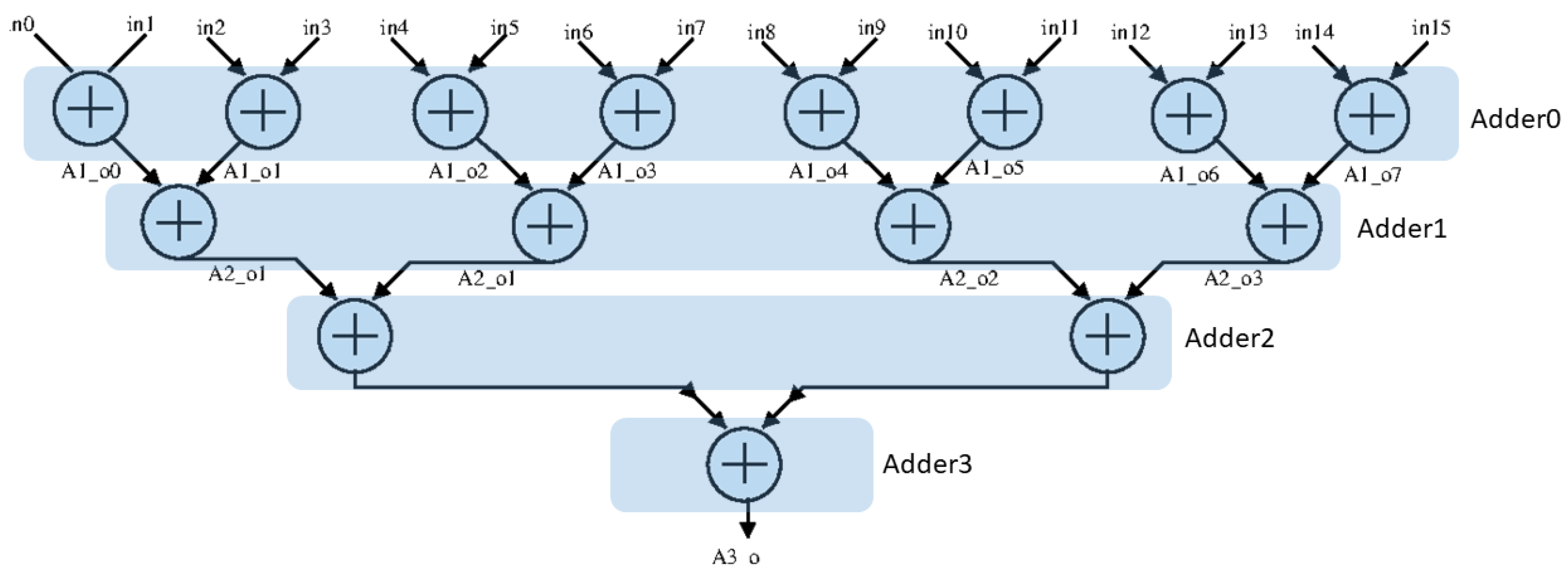
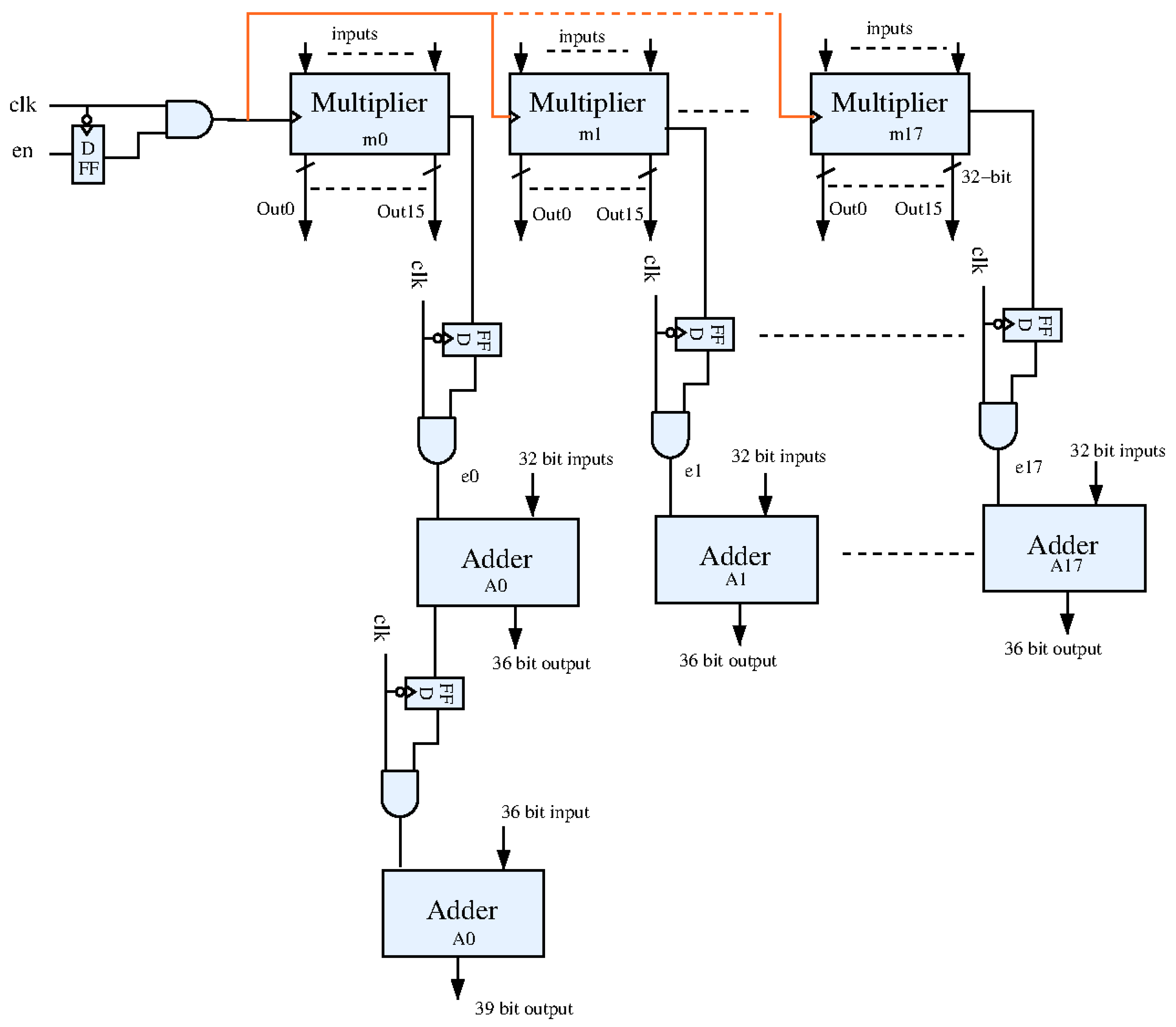
3.1. Proposed CNN Accelerator
3.2. Practical Application of the Industrial CNN Accelerator
4. Experiment Results
4.1. Testing Environment
4.2. FPGA Implementation Result
4.3. ASIC Implementation Result
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nishani, E.; Çiço, B. Computer vision approaches based on deep learning and neural networks: Deep neural networks for video analysis of human pose estimation. In Proceedings of the 2017 6th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 11–15 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Zhao, C.; Xiong, W.; Li, Q.; Yang, J. Robust Real-Time Object Detection Based on Deep Learning for Very High Resolution Remote Sensing Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1314–1317. [Google Scholar] [CrossRef]
- Zhang, Y.; Ming, Y.; Zhang, R. Object Detection and Tracking based on Recurrent Neural Networks. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; pp. 338–343. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Pan, S.; Shi, L.; Guo, S.; Guo, P.; He, Y.; Xiao, R. A low-power SoC-based moving target detection system for amphibious spherical robots. In Proceedings of the 2015 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 2–5 August 2015; pp. 1116–1121. [Google Scholar] [CrossRef]
- Liu, W.; Chen, H.; Ma, L. Moving object detection and tracking based on ZYNQ FPGA and ARM SOC. In Proceedings of the IET International Radar Conference 2015, Hangzhou, China, 14–16 October 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Padmanabha, M.; Schott, C.; Rößler, M.; Kriesten, D.; Heinkel, U. ZYNQ flexible platform for object recognition tracking. In Proceedings of the 2016 13th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 19–20 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Desmouliers, C.; Aslan, S.; Oruklu, E.; Saniie, J.; Vallina, F.M. HW/SW co-design platform for image and video processing applications on Virtex-5 FPGA using PICO. In Proceedings of the 2010 IEEE International Conference on Electro/Information Technology, Normal, IL, USA, 20–22 May 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Nakahara, H.; Yonekawa, H.; Fujii, T.; Sato, S. A Lightweight YOLOv2: A Binarized CNN with A Parallel Support Vector Regression for an FPGA. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 31–40. [Google Scholar] [CrossRef]
- Hardware Acceleration of Deep Neural Networks: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP and Other Letters. Available online: https://itnesweb.com/article/hardware-acceleration-of-deep-neural-networks-gpu-fpga-asic-tpu-vpu-ipu-dpu-npu-rpu-nnp-and-other-letters (accessed on 12 March 2020).
- Pedram, M.; Abdollahi, A. Low-power RT-level synthesis techniques: A tutorial. IEE Proc. Comput. Digit. Tech. 2005, 152, 333–343. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FP GA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar] [CrossRef]
- Alwani, M.; Chen, H.; Ferdman, M.; Milder, P. Fused-layer CNN accelerators. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar] [CrossRef]
- Sun, F.; Wang, C.; Gong, L.; Xu, C.; Zhang, Y.; Lu, Y.; Li, X.; Zhou, X. A High-Performance Accelerator for Large-Scale Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Guangzhou, China, 12–15 December 2017; pp. 622–629. [Google Scholar] [CrossRef]
- Shen, Y.; Ferdman, M.; Milder, P. Maximizing CNN Accelerator Efficiency Through Resource Partitioning. arXiv 2016, arXiv:1607.00064. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Choi, K.; Park, S.; Chung, M. Selective clock gating by using wasting toggle rate. In Proceedings of the 2009 IEEE International Conference on Electro/Information Technology, Windsor, ON, Canada, 7–9 June 2009; pp. 399–404. [Google Scholar] [CrossRef]
- Wang, W.; Tsao, Y.-C.; Choi, K.; Park, S.M.; Chung, M.-K. Pipeline power reduction through single comparator-based clock gating. In Proceedings of the 2009 International SoC Design Conference (ISOCC), Busan, Korea, 22–24 November 2009; pp. 480–483. [Google Scholar] [CrossRef]
- Zhang, Y.; Tong, Q.; Li, L.; Wang, W.; Choi, K.; Jang, J.; Jung, H.; Ahn, S. Automatic Register Transfer level CAD tool design for advanced clock gating and low power schemes. In Proceedings of the 2012 International SoC Design Conference (ISOCC), Jeju Island, Korea, 4–7 November 2012; pp. 21–24. [Google Scholar] [CrossRef]
- Kim, H.; Choi, K. The Implementation of a Power Efficient BCNN-Based Object Detection Acceleration on a Xilinx FPGA-SoC. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; pp. 240–243. [Google Scholar] [CrossRef]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J. Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H. A High-Throughput and Power-Efficient FPGA Implementation of YOLO CNN for Object Detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Fraser, N.J.; Umuroglu, Y.; Gambardella, G.; Blott, M.; Leong, P.H.W.; Jahre, M.; Vissers, K.A. Scaling Binarized Neural Networks on Reconfigurable Logic. arXiv 2017, arXiv:1701.03400. [Google Scholar]
- Lin, D.D.; Talathi, S.S.; Annapureddy, V.S. Fixed Point Quantization of Deep Convolutional Networks. arXiv 2015, arXiv:1511.06393. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Aydonat, U.; O’Connell, S.; Capalija, D.; Ling, A.C.; Chiu, G.R. An OpenCL(TM) Deep Learning Accelerator on Arria 10. arXiv 2017, arXiv:1701.03534. [Google Scholar]
- Zhao, Y.; Zhang, X.; Fang, X.; Li, L.; Li, X.; Guo, Z.; Liu, X. A Deep Residual Networks Accelerator on FPGA. In Proceedings of the 2019 Eleventh International Conference on Advanced Computational Intelligence (ICACI), Guilin, China, 7–9 June 2019; pp. 13–17. [Google Scholar] [CrossRef]
- Kim, H.; Choi, K. Low Power FPGA-SoC Design Techniques for CNN-based Object Detection Accelerator. In Proceedings of the 2019 IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference, New York City, NY, USA, 10–12 October 2019. [Google Scholar]
- FreePDK45:Contents. Available online: https://www.eda.ncsu.edu/wiki/FreePDK45:Contents (accessed on 12 March 2020).
- Zhijie, Y.; Lei, W.; Li, L.; Shiming, L.; Shasha, G.; Shuquan, W. Bactran: A Hardware Batch Normalization Implementation for CNN Training Engine. IEEE Embed. Syst. Lett. 2020. [Google Scholar] [CrossRef]
- Piyasena, D.; Wickramasinghe, R.; Paul, D.; Lam, S.; Wu, M. Reducing Dynamic Power in Streaming CNN Hardware Accelerators by Exploiting Computational Redundancies. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 354–359. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original | Proposed | Power Reduction | |
|---|---|---|---|
| Static Power | 0.639 W | 0.612 W | 4.22% |
| Dynamic Power | 3.230 W | 2.173 W | 32.72% |
| Total Power | 3.869 W | 2.785 W | 28.01% |
| S.No. | Static Power (W) | Dynamic Power (W) | Total Power (W) | Reference |
|---|---|---|---|---|
| 1 | 2.827 | 6.123 | 8.950 | [32] |
| 2 | – | 2.205 | – | [33] |
| 3 | 0.612 | 2.173 | 2.785 | This work |
| Original | Proposed | Power Reduction | |
|---|---|---|---|
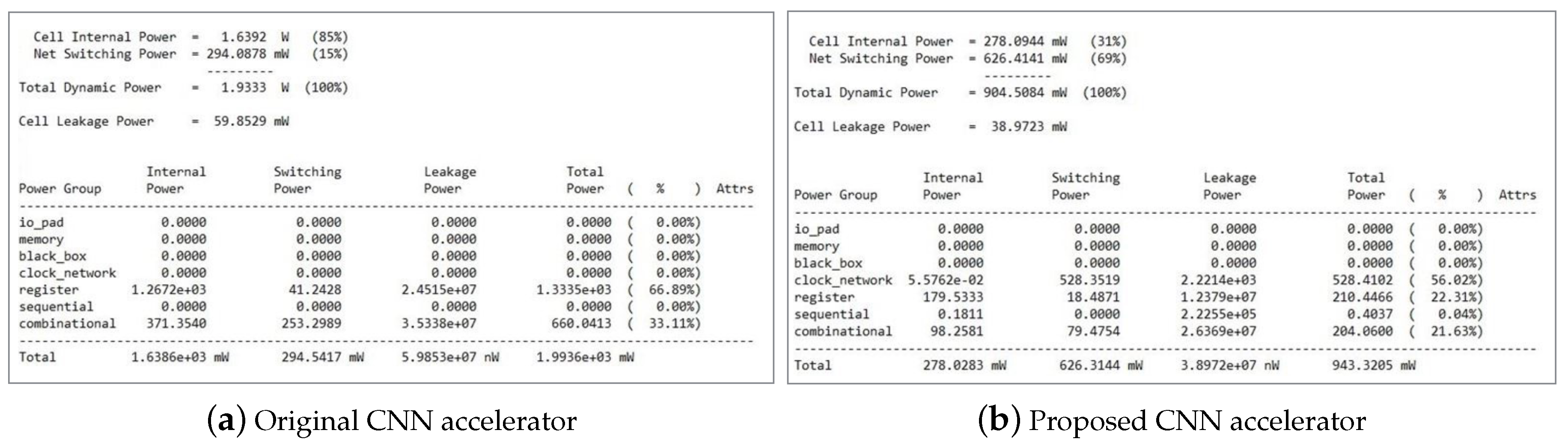
| Static Power | 0.0598 W | 0.0389 W | 34.9 % |
| Dynamic Power | 1.9333 W | 0.9045 W | 53.21 % |
| Total Power | 1.9936 W | 0.9432 W | 52.68 % |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Kim, H.; Yadav, N.; Li, S.; Choi, K.K. Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles. Electronics 2020, 9, 478. https://doi.org/10.3390/electronics9030478
Kim Y, Kim H, Yadav N, Li S, Choi KK. Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles. Electronics. 2020; 9(3):478. https://doi.org/10.3390/electronics9030478
Chicago/Turabian StyleKim, Youngbae, Heekyung Kim, Nandakishor Yadav, Shuai Li, and Kyuwon Ken Choi. 2020. "Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles" Electronics 9, no. 3: 478. https://doi.org/10.3390/electronics9030478
APA StyleKim, Y., Kim, H., Yadav, N., Li, S., & Choi, K. K. (2020). Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles. Electronics, 9(3), 478. https://doi.org/10.3390/electronics9030478