Performance of Two Approaches of Embedded Recommender Systems




Abstract
:1. Introduction
2. Related Works
3. Recommender Systems: Two Approaches
3.1. Basic Algorithm

3.2. BNMF Algorithm
- is a K dimensional vector from a Dirichlet distribution. This random variables are used to represent the probability that a user belongs to each group.
- from the Beta distribution used to represent the probability that a user in the group k likes the item i.
- from the Categorical distribution used to represents that the user u rates the item i as if he or she belongs to the group k.
- from the Binomial distribution used to represent the observable rating of the user u to the item i.
- is related to the possibility of obtaining overlapping groups of users sharing the same preferences.
- is related to the amount of evidences required to belong to a group.
- K is related to the number of groups (i.e., number of latent factors) that exists in the dataset.
- R is related to the Binomial distribution which take values from 0 to R.

4. Hardware Designs for Embedded Applications
4.1. PMF Design
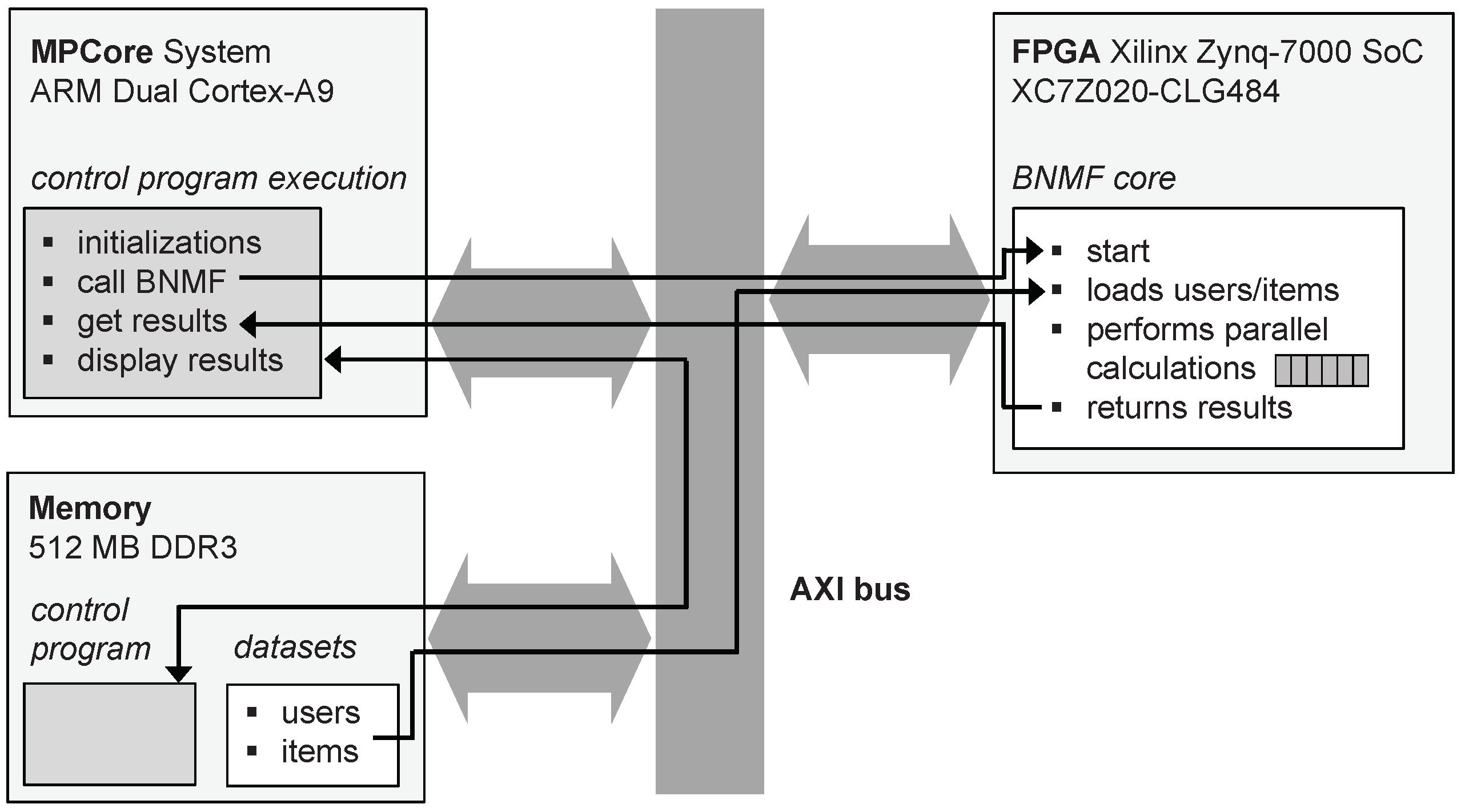
4.2. BNMF Design
- The memory of type DDR3 can store up to 512 MB. It hosts the datasets that provide the users and items to the RS, as well as the main program to control the BNMF flow. Storing the datasets in the external memory instead of in the internal memory blocks of the FPGA frees up space in the programmable logic to implement the BNMF core. In addition, an AXI interface was chosen to implement parallel access to memory so as not to limit bandwidth excessively. However, very large datasets may exceed the available memory capacity; in this case, the dataset is hosted on the SD card together with Linaro OS.
- The multiprocessor system is based on an ARM Dual Cortex-A9. It just runs the main control program: basic operations for initializing and starting the BNMF core implemented in the FPGA, as well as getting and displaying the results returned by it.
- The SoC block implements the BNMF core. The main advantage of this block is the high parallelization level of the operations described in Algorithm 2. Thus, the expected performance of this design would be higher than the performance given by a simple sequential code in the same main control program.
4.3. Parallelization Strategy
5. Performance Comparison
5.1. Datasets
5.2. Experimental Procedure
5.3. Timing Results
5.4. Power Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BNMF | Bayesian Non-negative Matrix Factorization |
| CF | Collaborative Filtering |
| CNN | Convolutional Neural Networks |
| DL | Deep Learning |
| FPGA | Field-Programmable Gate Array |
| HLS | High-Level Synthesis |
| MF | Matrix Factorisation |
| ML | Machine Learning |
| PMF | Probabilistic Matrix Factorization |
| RC | Reconfigurable Computing |
| RMSE | Root Mean Squared Error |
| RS | Recommender Systems |
| RTL | Register Transfer Level |
| SGD | Stochastic Gradient Descent |
| SoC | System-on-Chip |
| WWW | World Wide Web |
References
- Jannach, D.; Felfernig, A.; Zanker, M.; Friedrich, G. Recommender Systems. An Introduction; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2015; pp. 191–226. [Google Scholar]
- Thai-Nghe, N.; Drumond, L.; Horvath, T.; Krohn-Grimberghe, A.; Nanopoulos, A.; Schmidt-Thieme, L. Factorization techniques for predicting student performance. In Educational Recommender Systems and Technologies: Practices and Challenges; IGI-Global: Hershey, PA, USA, 2012; pp. 129–153. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–35. [Google Scholar]
- Bobadilla, J.; Serradilla, F.; Bernal, J. A new collaborative filtering metric that improves the behavior of recommender systems. Knowl. Based Syst. 2010, 23, 520–528. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. TOIS 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Hernando, A.; Bobadilla, J.; Ortega, F. A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowl. Based Syst. 2016, 97, 188–202. [Google Scholar] [CrossRef]
- Rendle, S.; Schmidt-Thieme, L. Online-updating regularized kernel matrix factorization models for large-scale recommender systems. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lousanne, Switzerland, 23–25 October 2008; pp. 251–258. [Google Scholar]
- Unsalan, C.; Tar, B. Digital System Design with FPGA: Implementation Using Verilog and VHDL; McGraw-Hill: New York, NY, USA, 2017. [Google Scholar]
- Tessier, R.; Pocek, K.; DeHon, A. Reconfigurable computing architectures. Proc. IEEE 2015, 103, 332–354. [Google Scholar] [CrossRef]
- Goeders, J.; Holland, G.M.; Shannon, L.; Wilton, S.J.E. Systems-on-chip on FPGAs. In FPGAs for Software Programmers; Koch, D., Hannig, F., Ziener, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 261–283. [Google Scholar] [CrossRef]
- Vestias, M.; Neto, H. Trends of CPU, GPU and FPGA for high-performance computing. In Proceedings of the IEEE 24th International Conference on Field Programmable Logic and Applications, Munich, Germany, 2–4 September 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Terveen, L.; Hill, W.; Amento, B.; McDonald, D.; Creter, J. PHOAKS: A system for sharing recommendations. Commun. ACM 1997, 40, 59–62. [Google Scholar] [CrossRef]
- Kautz, H.; Selman, B.; Shah, M. Referral web: Combining social networks and collaborative filtering. Commun. ACM 1997, 40, 63–65. [Google Scholar] [CrossRef]
- Balabanovic, M.; Shoham, Y. Fab: Content-based, collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Pudhiyaveetil, A.K.; Gauch, S.; Luong, H.P.; Eno, J. Conceptual recommender system for CiteSeerX. In Proceedings of the 2009 ACM Conference on Recommender Systems, RecSys 2009, New York, NY, USA, 23–25 October 2009; Bergman, L.D., Tuzhilin, A., Burke, R.D., Felfernig, A., Schmidt-Thieme, L., Eds.; ACM: New York, NY, USA, 2009; pp. 241–244. [Google Scholar] [CrossRef]
- Luettin, J.; Rothermel, S.; Andrew, M. Future of in-vehicle recommendation systems @ Bosch. In Proceedings of the 13th ACM Conference on Recommender Systems; RecSys ’19, Copenhagen, Denmark, 15–20 September 2019; Association for Computing Machinery: New York, NY, USA, 2019; p. 524. [Google Scholar] [CrossRef]
- Ostuni, V.C. “Just play something awesome”: The personalization powering voice interactions at Pandora. In Proceedings of the 13th ACM Conference on Recommender Systems; RecSys ’19, Copenhagen, Denmark, 15–20 September 2019; Association for Computing Machinery: New York, NY, USA, 2019; p. 523. [Google Scholar] [CrossRef]
- Verma, R.; Ghosh, S.; Saketh, M.; Ganguly, N.; Mitra, B.; Chakraborty, S. Comfride: A smartphone based system for comfortable public transport recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems; RecSys ’18, Vancouver, BC, Canada, 2–7 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 181–189. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Du, X.; He, X.; Yuan, F.; Tian, Q.; Chua, T. Adversarial training towards robust multimedia recommender system. In IEEE Transactions on Knowledge and Data Engineering; IEEE: Piscataway, NJ, USA, 2019; p. 1. [Google Scholar] [CrossRef] [Green Version]
- Raja, D.R.K.; Pushpa, S. Diversifying personalized mobile multimedia application recommendations through the Latent Dirichlet Allocation and clustering optimization. Multim. Tools Appl. 2019, 78, 24047–24066. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, V.; Picariello, A.; Sperli’ì, G. Extreme events management using multimedia social networks. Future Gen. Comput. Syst. 2019, 94, 444–452. [Google Scholar] [CrossRef]
- Kuhl, N.; Lobana, J.; Meske, C. Do you comply with AI? —Personalized explanations of learning algorithms and their impact on employees’ compliance behavior. arXiv 2020, arXiv:2002.087772020. [Google Scholar]
- Meske, C.; Bunde, E. Using explainable artificial intelligence to increase trust in computer vision. arXiv Prepr. 2020, arXiv:cs.HC/2002.01543. [Google Scholar]
- Pimenidis, E.; Polatidis, N.; Mouratidis, H. Mobile recommender systems: Identifying the major concepts. J. Inf. Sci. 2019, 45, 387–397. [Google Scholar] [CrossRef]
- Yu, Z.; Zhou, X.; Zhang, D.; Chin, C.-Y.; Wang, X.; Men, J. Supporting context-aware media recommendations for smart phones. IEEE Pervas. Comput. 2006, 5, 68–75. [Google Scholar] [CrossRef]
- Lemos, F.; Carmo, R.; Viana, W.; Andrade, R. Towards a context-aware photo recommender system. CEUR Workshop Proc. 2012, 889. [Google Scholar]
- Sotsenko, A.; Jansen, M.; Milrad, M. Using a rich context model for a news recommender system for mobile users. CEUR Workshop Proc. 2014, 1181, 13–16. [Google Scholar]
- Wang, X.; Rosenblum, D.; Wang, Y. Context-aware mobile music recommendation for daily activities. In Proceedings of the 20th ACM International Conference on Multimedia; MM ’12, Nara, Japan, 29 October–2 November 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 99–108. [Google Scholar] [CrossRef]
- Baltrunas, L.; Ludwig, B.; Peer, S.; Ricci, F. Context relevance assessment and exploitation in mobile recommender systems. Perso. Ubiquit. Comput. 2012, 16, 507–526. [Google Scholar] [CrossRef]
- Ma, Y.; Suda, N.; Cao, Y.; Vrudhula, S.; Seo, J.S. ALAMO: FPGA acceleration of deep learning algorithms with a modularized RTL compiler. Integration 2018, 62, 14–23. [Google Scholar] [CrossRef]
- Gankidi, P.R.; Thangavelautham, J. FPGA architecture for deep learning and its application to planetary robotics. In Proceedings of the 2017 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2017; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Canilho, J.; Véstias, M.; Neto, H. Multi-core for K-means clustering on FPGA. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Winterstein, F.; Bayliss, S.; Constantinides, G.A. FPGA-based K-means clustering using tree-based data structures. In Proceedings of the 2013 23rd International Conference on Field programmable Logic and Applications, Porto, Portugal, 2–4 September 2013; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Lo, C.; Chow, P. K-means implementation on FPGA for high-dimensional data using triangle inequality. In Proceedings of the 22nd International Conference on Field Programmable Logic and Applications (FPL), Oslo, Norway, 29–31 August 2012; pp. 437–442. [Google Scholar] [CrossRef]
- Nagarajan, K.; Holland, B.; George, A.D.; Slatton, K.C.; Lam, H. Accelerating machine-learning algorithms on FPGAs using pattern-based decomposition. J. Signal Proc. Syst. 2011, 62, 43–63. [Google Scholar] [CrossRef]
- Amazon EC2 F1 Instances. 2019. Available online: https://aws.amazon.com/cn/ec2/instance-types/f1/ (accessed on 22 February 2020).
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of 19th International Conference on Computational Statistics; Springer: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Kara, K.; Alistarh, D.; Alonso, G.; Mutlu, O.; Zhang, C. FPGA-accelerated dense linear machine learning: A precision-convergence trade-off. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; pp. 160–167. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Unsupervised learning by convex and conic coding. In Advances in Neural Information Processing Systems; IEEE: Piscatawy, NJ, USA, 1997; pp. 515–521. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems; IEEE: Piscatawy, NJ, USA, 2008; pp. 1257–1264. [Google Scholar]
- Hoffman, M.D.; Blei, D.M.; Wang, C.; Paisley, J. Stochastic variational inference. J. Mach. Learn. Res. 2013, 14, 1303–1347. [Google Scholar]
- Cong, J.; Liu, B.; Neuendorffer, S.; Noguera, J.; Vissers, K.; Zhang, Z. High-level synthesis for FPGAs: From prototyping to deployment. IEEE Trans. Comput. Aided Des. Integr. Circ. Syst. 2011, 30, 473–491. [Google Scholar] [CrossRef] [Green Version]
- Xilinx Inc. Vivado Design Suite User Guide: High-Level Synthesis; Technical Report UG902 (v2019.2); Xilinx Inc.: San Jose, CA, USA, 2020. [Google Scholar]
- O’Loughlin, D.; Coffey, A.; Callaly, F.; Lyons, D.; Morgan, F. Xilinx Vivado High Level Synthesis: Case studies. In Proceedings of the 25th IET Irish Signals Systems Conference 2014 and 2014 China-Ireland International Conference on Information and Communications Technologies (ISSC 2014/CIICT 2014), Limerick, Ireland, 26–27 June 2014; pp. 352–356. [Google Scholar] [CrossRef]
- Pajuelo-Holguera, F.; Gómez-Pulido, J.A.; Ortega, F.; Granado-Criado, J.M. Recommender system implementations for embedded collaborative filtering applications. Microproce. Microsyst. 2020, 73, 102997. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Zedboard Zynq-7000 | SoC: | Xilinx Zynq XC7Z020 |
|---|---|---|---|
| Elements: | HDMI, VGA, Audio, Ethernet, SD, USB … | ||
| Memory: | 512 MB DDR3 | ||
| Oscillators: | 100 MHz and 33.3 MHz | ||
| Operating System | Linaro OS | ||
| Software | Xilinx Vivado HLS |
| Dataset | Kaggle | Movielens-100k | Movielens-1M | Netflix-100M |
|---|---|---|---|---|
| Ratings | 100,000 | 100,000 | 1,000,000 | 10,000,000 |
| Users | 700 | 943 | 6,000 | 480,188 |
| Items | 9000 | 1682 | 4000 | 17,691 |
| Dataset | Kaggle | Movielens-100k | Movielens-1M | Netflix-100M | ||||
|---|---|---|---|---|---|---|---|---|
| Algorithm | PMF | BNMF | PMF | BNMF | PMF | BNMF | PMF | BNMF |
| CPU (s) | 76.12 | 284.38 | 33.62 | 152.22 | 113.41 | 504.01 | 96,381.80 | 405,843.84 |
| FPGA (s) | 1129.70 | 313.82 | 831.04 | 163.72 | 2934.57 | 105.93 | 98,649.80 | 50,625.32 |
| FPGA speedup | ×0.07 | ×0.91 | ×0.04 | ×0.93 | ×0.04 | ×4.76 | ×0.98 | ×8.02 |
| Dataset | Kaggle | Movielens-100k | Movielens-1M | Netflix-100M | ||||
|---|---|---|---|---|---|---|---|---|
| Algorithm | PMF | BNMF | PMF | BNMF | PMF | BNMF | PMF | BNMF |
| CPU (w) | 8.21 | 11.33 | 7.33 | 10.81 | 12.31 | 16.26 | 32.21 | 41.20 |
| FPGA (w) | 0.95 | 2.52 | 0.82 | 2.24 | 1.64 | 4.41 | 3.03 | 7.37 |
| FPGA power reduction | 88% | 78% | 89% | 80% | 87% | 73% | 91% | 83% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pajuelo-Holguera, F.; Gómez-Pulido, J.A.; Ortega, F. Performance of Two Approaches of Embedded Recommender Systems. Electronics 2020, 9, 546. https://doi.org/10.3390/electronics9040546
Pajuelo-Holguera F, Gómez-Pulido JA, Ortega F. Performance of Two Approaches of Embedded Recommender Systems. Electronics. 2020; 9(4):546. https://doi.org/10.3390/electronics9040546
Chicago/Turabian StylePajuelo-Holguera, Francisco, Juan A. Gómez-Pulido, and Fernando Ortega. 2020. "Performance of Two Approaches of Embedded Recommender Systems" Electronics 9, no. 4: 546. https://doi.org/10.3390/electronics9040546
APA StylePajuelo-Holguera, F., Gómez-Pulido, J. A., & Ortega, F. (2020). Performance of Two Approaches of Embedded Recommender Systems. Electronics, 9(4), 546. https://doi.org/10.3390/electronics9040546