1. Introduction
Supervisory control and data acquisition (SCADA) systems control and monitor the information systems of industrial and critical infrastructure (such as electricity, gas, and water). Recently, there has been an increase in attacks targeting these systems. Compromising the information systems of SCADA can lead to large financial losses and serious impacts on public safety and the environment. The attack on a sewage treatment system in Maroochy Shire, Queensland, is an obvious example of the seriousness of cyber attacks on critical infrastructure [
1]. Therefore, securing and protecting these systems is
extremely important [
2,
3,
4]. The new generation of intrusion detection systems (IDSs) will need to detect ad-hoc SCADA-specific attacks that cannot be detected by existing security technologies [
5]. Due to the differences between the nature and the characteristics of traditional IT and SCADA systems, there is a need for the development of SCADA-specific IDSs, and in recent years this has become an interesting research area [
6,
7,
8].
A SCADA system monitors and controls a series of process parameters. The values of these supervised parameters can reflect the internal representation of the SCADA system. The values are called ”SCADA data” which are found in [
6,
8,
9,
10,
11,
12,
13] to be a good information source to monitor the internal behaviour of the given system and protect it from malicious actions that are intended to sabotage or disturb the proper functionality of the targeted system. Therefore, the monitoring of the behaviour of SCADA systems through the evolution of SCADA data has attracted the attention of researchers. In [
9,
10], a predefined threshold (e.g, minimum, maximum) is proposed to monitor each process parameter individually, and any reading that is not inside a prescribed threshold is considered as an anomaly. These approaches are good for monitoring one single process parameter. However, the value of an individual process parameter may not be abnormal, but in combination with other process parameters, may produce an abnormal observation, which very rarely occurs. These types of parameters are called multivariate parameters, and are assumed to be directly (or indirectly) ”correlated”.
In [
11], the authors proposed an analytical approach to manually identify the range of critical states for multivariate process parameters, and the identified ranges are then used to monitor the critical state of the analysed process parameters. However, analytical approaches require expert involvement, and this results in time-intensive processing that is prone to human error. To avoid the aforementioned issues, purely ”normal” SCADA data are used to model the normal behaviours. For example, Rrushi [
12] applied probabilistic models to estimate the normalcy of the evolution of multivariate process parameters. Zhanwei et al. [
6] proposed a combination of a normal control behaviour model and a normal process behaviour model to build SCADA data-driven detection models to monitor abnormal behaviours in industrial equipment. Gao et al. [
8] proposed a neural network-based model to learn the normal behaviours for water tank control systems. Similarly, Zaher et al. [
13] proposed the same technique to build the normal behaviours for a wind turbine to identify faults or unexpected behaviours (anomalies).
However, it is difficult to build the ”normal” behaviours of a given system using observations of the raw SCADA data because, firstly, it cannot be guaranteed that all observations represent one behaviour as either ”normal” or ”abnormal”, and therefore domain experts are required for the labelling of each observation, and this process is prohibitively expensive; secondly, in order to obtain purely ”normal” observations that comprehensively represent "normal" behaviours, this requires a given system to be run for a long period under normal conditions, and this is not practical; and finally, it is challenging to obtain observations that will cover all possible abnormal behaviours that can occur in the future. Therefore, we strongly believe that the development of a SCADA-specific IDS that uses SCADA data and operates in unsupervised mode, where the labelled data is not available, has great potential as a means of addressing the aforementioned issues.
The unsupervised IDS can be a time and cost-efficient means of building detection models from unlabelled data; however, this requires an efficient and accurate technique to differentiate between the normal and abnormal observations without the involvement of experts, which is costly and prone to human error. Then, from observations of each behaviour, either normal or abnormal, the detection models can be built. Two assumptions must be made in unsupervised anomaly detection approaches [
14,
15,
16]: (i) the number of normal observations in the dataset vastly outperforms the abnormal observations, and (ii) the abnormal observations must be statistically different from normal ones. Therefore, the performance of the proposed detection models relies mainly on the two aforementioned to distinguish between normal and abnormal behaviours. The reporting of anomalies in the unsupervised mode can be done either by scoring-based or binary-based techniques [
17].
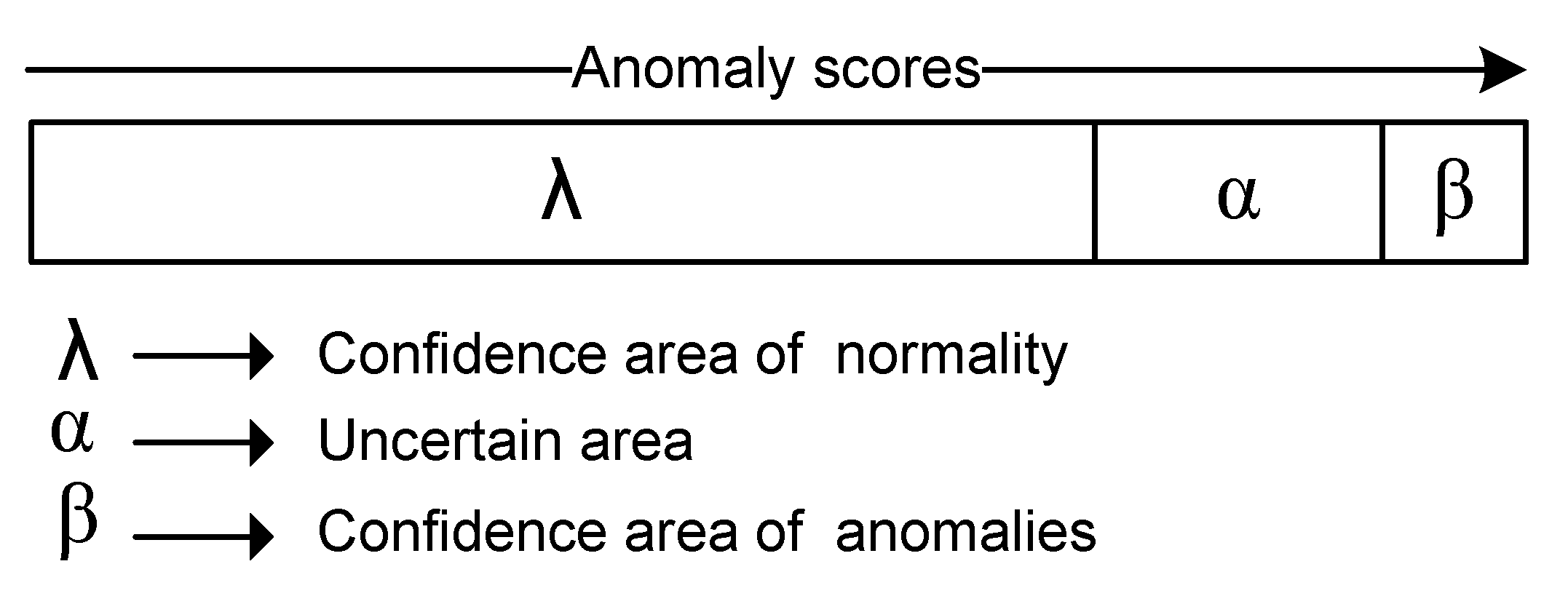
Anomaly scoring techniques are categorised into two broad classes: the distance-based and the density-based scoring techniques. The basic idea of the distance-based technique is to distinguish an observation as outlier on the base of the distance to its nearest neighbours, while in the density-based one, an observation is considered as outlier when it lies in a low-density area of its nearest neighbours [
17]. All observations in a dataset are given an anomaly score, and therefore actual anomalies are assumed to have the highest scores. The key problem is how to find the best cut-off threshold that minimises the false positive rate while maximising the detection rate. On the one hand, binary-based techniques [
14] group similar observations together into a number of clusters. Abnormal observations are identified by making use of the fact that abnormal observations will be considered as outliers, and therefore will not be assigned to any cluster, or they will be grouped into small clusters that have some characteristics which are different from normal clusters. However, labelling an observation as an outlier or a cluster as anomalous is controlled through some parameter choices within each detection technique. For instance, given the top 50% of the observations which have the highest anomaly scores, these are assumed as outliers. In this case, both detection and false positive rates will be higher. Similarly, labelling a low percentage of largest clusters as normal in clustering-based intrusion detection techniques, will result in higher detection and false positive rates. Therefore, the effectiveness of unsupervised intrusion approaches is sensitive to parameter choices, especially when the boundaries between normal and abnormal behaviours are not clearly distinguishable.
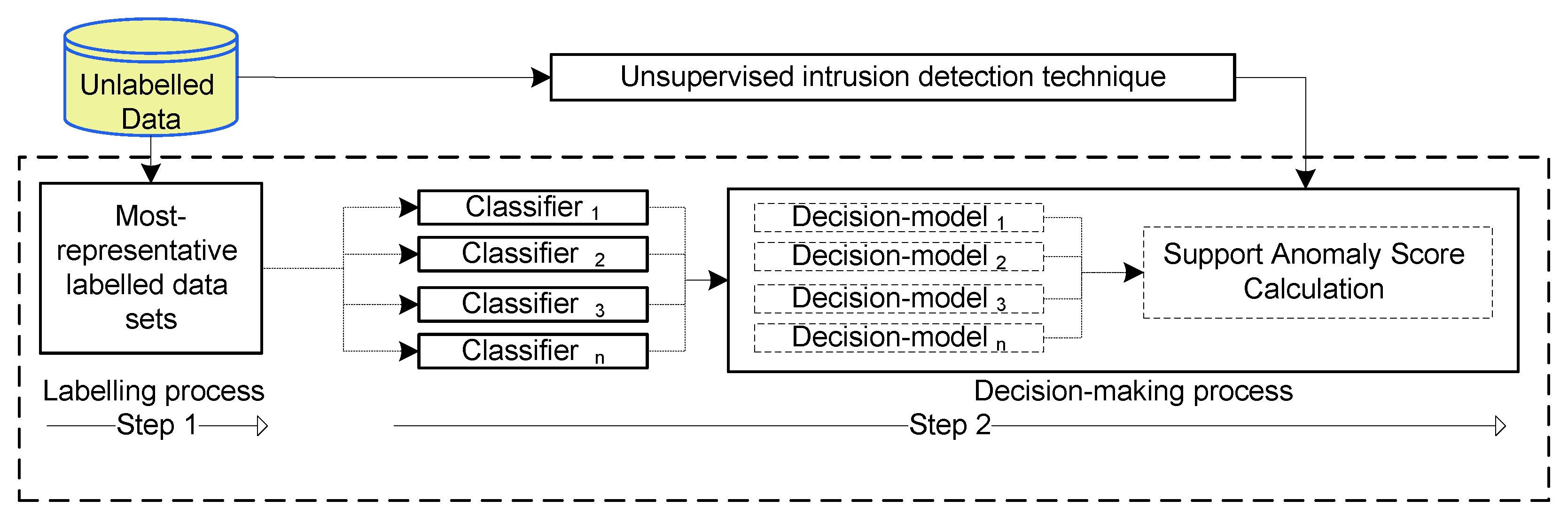
This paper proposes the global anomaly threshold to unsupervised detection (GATUD) that is based on anomaly density-based technique because it is considered as one of the anomaly scoring techniques in network anomaly detection [
18]. The proposed GATUD approach can be used as an add-on threshold technique to allow unsupervised anomaly scoring-based techniques to set the value of the cut-off threshold parameter at a satisfactory level to guarantee a high detection rate, while minimising the resulting high false positive rate. In addition, it can be used as a robust technique for labelling clusters to improve the accuracy of clustering-based intrusion detection systems.
Figure 1 shows that GATUD involves two steps: (i) establishing two small most-representative datasets, where each dataset represents one-class problem (normal or abnormal) with high-confidence; and (ii) using the established datasets to build an ensemble-based decision-making model using a set of supervised classifiers.
This paper is organised as follows.
Section 2 presents an overview of related work.
Section 3 introduces GATUD.
Section 4 presents the experimental set-up, followed by results and discussion in
Section 5.
Section 6 concludes the paper.
2. Related Work
An intrusion detection system (IDS) is a main component in securing computer systems and networks. In the case of SCADA systems, a number of tailored IDSs have been proposed (refer to a survey paper [
19]). There are two categories of IDSs: signature-based and anomaly-based. The former detects only known attacks because it monitors the system against specific attack patterns. The latter attempts to build models from the normal behaviour of the systems, and any deviation from this behaviour is assumed to be a malicious activity. Both approaches have advantages and disadvantages. The former achieves good accuracy, but fails to detect attacks that are new or the patterns of which are not learned. Although the latter is able to detect novel attacks, the overall detection accuracy of this approach is low.
This paper focuses on the anomaly detection techniques since they are able to address the problem of the zero-day attacks. Rrushi [
12] applied statistics and probability theory to estimate the normality of the evolution of values of correlated process parameters. In the work of [
20], the authors assumed that communication patterns among SCADA components are well-behaved, and combined the normal behaviour of SCADA network traffic with artificial intrusion observations to learn the boundaries of the normal behaviour using the neural network technique. There are two types of anomaly detection techniques: supervised and unsupervised modes. In the former mode, training data are labelled, while in the latter, data are not labelled. In contrast to conventional information technology (IT), the unsupervised mode has not been used much in SCADA systems. This is because SCADA security research is relatively new compared with IT. In addition, the security requirements of such systems require a high detection accuracy which this mode lacks.
Recently, machine learning techniques have been successfully applied in unsupervised IDS for industrial control systems [
21,
22]. Bhatia et al [
21] proposed an unsupervised model that uses deep learning autoencoders based on artificial neural networks not for dimension reduction only, but for classification to learn the benign network traffic. The key contribution of their proposed model is to identify the minimal latent subspace that contains the essential characteristics of the benign traffic. Similarly, in [
22], the authors proposed unsupervised model that utilises the sparse and denoising auto-encoder (DAE) to obtain the robust latent representations by introducing a stochastic noise to the original data. In [
23,
24,
25], unsupervised anomaly scoring approaches based on clustering techniques were proposed to detect normal and abnormal behaviours of industrial control systems at network and environmental parameters levels. Each observation is given an anomaly score, and therefore actual anomalies are assumed to have the highest scores. However, the key problem is how to find the near-optimal cut-off threshold that minimises the false positive rate while maximising the detection rate. In order to overcome this issue, this paper proposes an approach inspired by the work proposed in [
26]. The authors assign an anomaly-scoring score for each observation in the unlabelled data; the observations that have the highest anomaly scores are labelled as outliers, while the rest are labelled as normal. They randomly selected a subset of normal data and combined it with outliers to create labelled data. Afterwards, a supervised technique was trained with the labelled data to build an outlier filtering rule that differentiates outliers from normal data. However, our approach differs in that we learn the labelled data from data about which we have no prior knowledge, and a set of supervised classifiers are used to build a robust decision-maker because each classifier can capture different knowledge [
27]. Finally, our approach is proposed as an add-on component (not an independent technique) for unsupervised learning algorithms in order to benefit from the inherent characteristics of each algorithm.
5. Results and Discussion
Clearly, GATUD is intended to improve the accuracy of unsupervised anomaly detection systems in general and our proposed SDAD approach [
25] in particular. In this evaluation, we demonstrate how GATUD can address the limitations that have been discussed in [
25], where a global anomaly threshold is required to work with all datasets that vary in distribution, the number of abnormal observations, and the application domain, when the
scoring-based technique is adapted. Furthermore, as mentioned earlier, GATUD can be used as an add-on component to help improve the accuracy of the unsupervised anomaly detection approach. We demonstrate its performance when it is used with
k-means algorithm [
29] that is considered as one of the most useful and promising techniques that can be adapted to build an unsupervised clustering-based anomaly detection technique [
40,
41]. The proposed approach is intended to improve the accuracy of unsupervised intrusion detection systems. Therefore, we evaluate the accuracy of the proposed approach on two types of unsupervised modes:
scoring-based and
clustering-based intrusion detection techniques. In this evaluation, the
precision,
recall, and
F-measure metrics are used to quantitatively measure the performance of the proposed approach, because these metrics are not dependent on the size of the training and testing datasets. The metrics used are defined as follows:
where
TP is the number of anomalies that are correctly detected,
FN is the number of anomalies that have occurred but not detected, and
FP is the normal observations that are incorrectly flagged as anomalies. The recall (detection rate) is the proportion of number of anomalies correctly detected to the actual number of anomalies in the testing dataset. The precision metric is used to demonstrate the robustness of the IDS in minimising the false positive rate. However, the system can obtain a high precision score while a number of anomalies are being missed. Similarly, the system can obtain a high recall score, while the false positive rate is higher. Therefore, the F-measure, which is the harmonic mean of precision and recall, would be a more an appropriate metric to demonstrate the accuracy of the proposed approach in this paper and ease the comparison with the other results, because it is the weighted average of the precision and recall rates. Therefore, the F-measure metric takes both false positives and false negatives into account.
5.1. Integrating GATUD into SDAD
The separation of the most relevant abnormal observations from normal ones in order to extract proximity detection rules for a given system, is the initial part of the proposed data-driven clustering technique (SDAD) in [
25]. However, a cut-off threshold parameter
is required to be given, and in fact this parameter plays a major role in separating the most relevant abnormal observations. The demonstrated results were significant; however, various cut-off thresholds
for a number of datasets have been used, where some datasets work with a small value of
, while others work with large values. Therefore, we evaluate how the integration of GATUD into SDAD can help to find a global and efficient anomaly threshold
that can work with all datasets, regardless of their variant characteristics, such as distribution, the number of abnormal observations, and the application domain, and meanwhile produces significant results.
It is well-known that the larger the value of the cut-off threshold , the higher the detection rate and the higher the false positive rate as well. This, however, will result in poor performance. The determination of an appropriate cut-off threshold that maximises and minimises the detection rate and the false positive rate respectively, is the challenging problem. GATUD addresses this problem by allowing the anomaly scoring technique to choose a large value of cut-off thresholds in order to ensure that the detection rate is higher, while minimising the false positive rate without degrading the detection rate.
In the following, we demonstrate the separation accuracy results with/without the integration of GATUD into SDAD. Then, we demonstrate how this integration has a significant impact on the accuracy of the generation step of proximity detection rules, which is the second phase following the separation process.
5.1.1. The Results of the Separation Process with/without GATUD
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 show the separation accuracy results with/without the integration of GATUD. Clearly, as shown in the result tables, the larger the value of the cut-off threshold
, the higher the detection rate of abnormal observations. This is because the observations are sorted by their anomaly scores in ascending order and the consideration of the top large portion of the sorted list increases the chance to obtain the actual abnormal observations. However, this will result in a large number of normal observations existing in this portion, and this definitely increases the false positive rate. On the another hand, it can be seen that the use of GATUD can benefit from the larger value of the cut-off threshold
in order to maximise the detection rate of abnormal observations and the obtained list of the assumed abnormal observations is passed through the decision-making model to rejudge whether each observation is abnormal or normal. This, as can be seen in the result tables, nearly sustains the detection rate, and meanwhile minimises the false positive rate.
Table 2 shows that the better accuracy results of separation of abnormal observations without the integration of GATUD are achieved when the cut-off threshold
is set to
%,
%, or
%. Moreover, it can be observed that the setting of
with larger values, such as
% and
%, has not demonstrated any better results, even though the detection rates of the abnormal observations were high. This is because, as demonstrated, the false positive rates were relatively high. On the other hand, when GATUD was integrated, the high false positive rates were significantly reduced, and meanwhile, the detection rates were sustained at significantly acceptable levels. Similarly, the remaining results for each dataset (as shown in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8) demonstrated that the integration of GATUD significantly reduced the high false positive rates when larger values of
were used, and meanwhile maintained the detection rates at a satisfactory and significant level. However, the results for the dataset
MORD in
Table 7 were not significant whether GATUD was integrated or not. We would have expected the integration of GATUD to produce significant results, if the cut-off threshold
was set to a value that is greater than
%. However, this value is assumed as the maximum percentage of abnormal observations in an unlabelled dataset. Therefore, this dataset is considered to be an exceptional case.
5.1.2. The Results of Proximity Detection Rules with/without GATUD
As mentioned previously, the generation process of proximity detection rules comes after and relies on the separation process. Therefore, the robustness of these proximity detection rules is influenced by the accuracy of the separation process, and as shown earlier, the integration of GATUD demonstrated significant results in the separation process even with large cut-off thresholds
. Therefore, the detection accuracy results of the proximity detection rules, which are extracted from the abnormal and normal observations that were separated using such these large cut-off thresholds
, are expected to be significant.
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15 show the detection accuracy results.
Each table represents the results of the detection accuracy results for each individual dataset, and also they are divided into two parts: the first part shows the results of the proximity-detection rules that were extracted by separating abnormal from normal observations where GATUD was not integrated in the separation process. The second part shows the results obtained after the integration of GATUD. The result tables show that the integration of GATUD into the separation process helps to generate robust proximity-detection rules even with large cut-off thresholds .
Overall,
Table 16 highlights the acceptable thresholds
through which the extracted proximity- detection rules demonstrated significant detection accuracy results, where GATUD was integrated into the separation process of abnormal and normal observations. From this table, the determination of the near-optimal value of a cut-off threshold
will not be problematic because the value of
can be set to
, which is assumed as the maximum percentage of abnormal observations in an unlabelled dataset. The resultant high positive rate that might result from this large value can significantly be reduced by the integration of GATUD.
5.2. Integrating GATUD into Clustering-Based Technique
Here we show how GATUD can be integrated not only with the scoring-based intrusion detection technique, but also with the clustering-based technique. The
k-means algorithm, which is considered as one of the most useful and promising techniques for building an unsupervised clustering-based intrusion detection model [
40,
41], is chosen to demonstrate the integration effectiveness of GATUD with an unsupervised clustering-based intrusion detection technique. This is because this algorithm already has been adapted by Almalawi et al. [
25] to build the unsupervised anomaly detection model to detect abnormal observations, and the results were compared with SDAD [
25]. Therefore, it is interesting to demonstrate detection accuracy results with/without the integration of GATUD. For more details about how this algorithm can be adapted to build an unsupervised anomaly detection model, see [
25].
In the adaptation of
k-means for building an unsupervised anomaly detection model, anomalies are assumed to be grouped in clusters that contain percentages,
, of the data. Let
be the sets of clusters that have been created. Then, the anomalous clusters are defined as follows:
The remaining clusters
are labelled as normal. In this evaluation, we assume the real anomalous cluster is the cluster where the majority of its members are actual abnormal observations. Assume that the number of abnormal observations
. Therefore, the labelling accuracy of the assumed percentage
of the data in anomalous clusters is measured by the Labelling Error Rate (LER) for clusters:
When integrating GATUD to label the clusters, the members of each individual cluster pass through the decision-making model to be labelled as either normal or abnormal. Then the cluster is labelled according to the label of the majority of its members. The labelling of clusters by GATUD is given as follows:
where
is the number of abnormal observations, which are judged by the decision-making model, in the cluster
. Then the anomalous clusters are defined as follows:
where
is the percentage of the abnormal observations in a cluster
to be labelled as abnormal. In this evaluation, it is set to 0.5.
We evaluate the integration of GATUD as an add-in component with
k-means, where this component is only used to label the produced clusters as either normal or abnormal. The
k-means requires two user-specified parameters
k and
to build the unsupervised anomaly detection model from unlabelled data.
k is the number of clusters, and
is the percentage of the data in a cluster to be assumed as malicious. However, the parameter
is not required when GATUD is integrated. In this evaluation, we demonstrate the detection accuracy of
k-means as an independent/dependent algorithm. In the independent use,
k-means is used to cluster the training dataset and labels each cluster using an assumption of the percentage of the data in a cluster to be assumed as malicious [
40,
41]. While in the dependent use, GATUD is used as a labelling technique for the produced clusters by
k-means. The parameters
k and
are set to the same values that have been used in paper [
25]. This is because the same datasets are used.
Table 17,
Table 18,
Table 19,
Table 20,
Table 21,
Table 22 and
Table 23 show the detection accuracy results of two parts: The first part (without GATUD) shows the detection accuracy results of
k-means. As shown, the the detection accuracy results of five values of
are demonstrated. For example, in the
Table 17, the dataset, which was referred to as DUWWTP, was clustered into 50, 60, 70, 80, 90, and 100 clusters using
k-means algorithm; then, when
was set to 0.01 the generated clusters that constitute an overwhelmingly large portion (≥99%) of the training dataset are labelled as normal clusters, and otherwise labelled as malicious ones. As see in the
Table 17, the labelling error rate (LER) when 50 clusters generated is 12.40% which means the average percentage of the clusters that were incorrectly labelled in 10 fold cross validation. This is because their respective labels are not the same as the labels of the majority of their respective members. In the second part (with GATUD), the detection accuracy results of
k-means when GATUD were integrated to label the clusters instead of the assumption that assumes normal clusters constitute an overwhelmingly large portion, as shown. We show only the results of F-measure, as they are the interesting results to compare. Clearly, the detection accuracy results of
k-means in detecting abnormal observations were very poor for all datasets when GATUD was not integrated. On the other hand, significant results for some datasets are obtained when GATUD is integrated to label the produced clusters. It is obvious from the results that GATUD can be a promising technique to improve the accuracy of an unsupervised anomaly detection approaches, not only with our SDAD approach proposed in [
25], but also, it can be integrated with unsupervised clustering-based anomaly detection models.

 ,
, 






{kind=link}
{kind=link}