Research on Integrated Learning Fraud Detection Method Based on Combination Classifier Fusion (THBagging): A Case Study on the Foundational Medical Insurance Dataset


Abstract
:1. Introduction
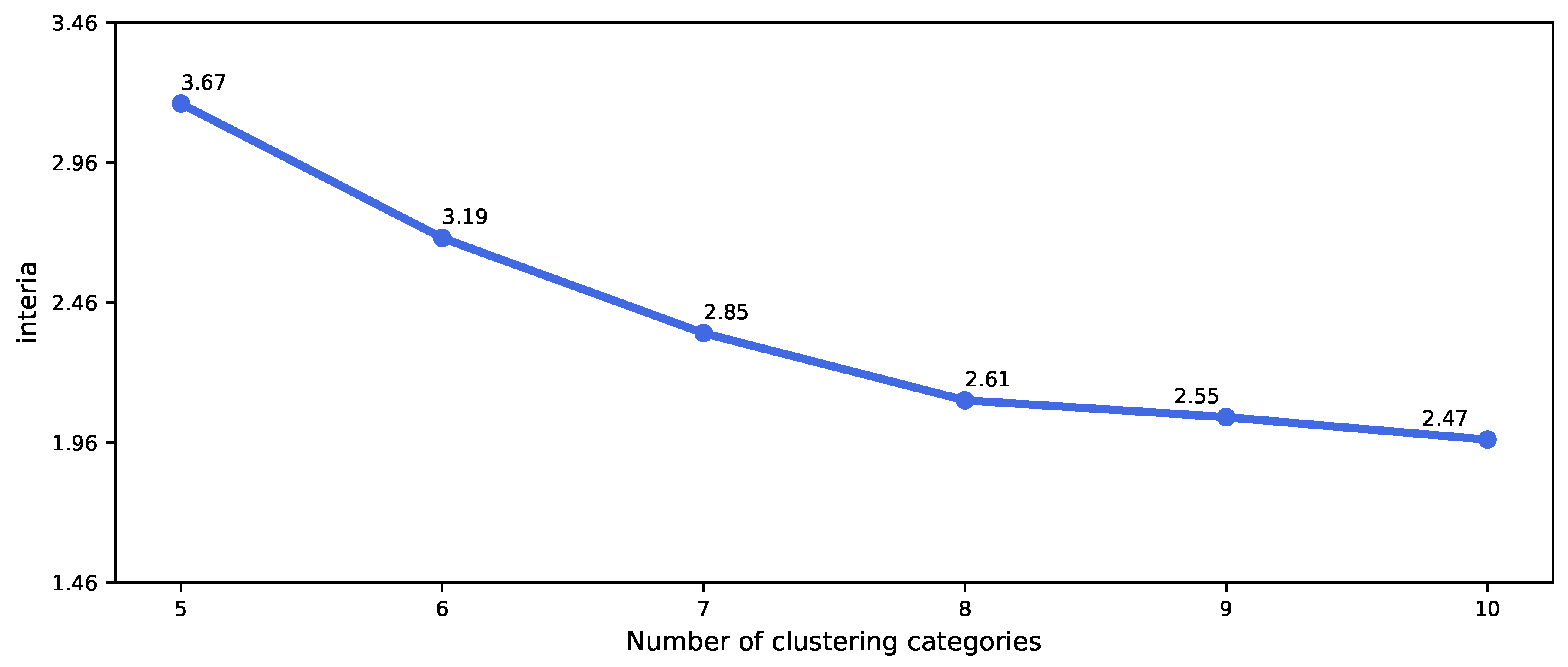
- We propose a novel idea of sample equalization to deal with the problem of category imbalance in medical insurance identification. The sample data were extracted using the combination of smote and K-means. For negative samples, we use the smote method to solve the over-fitting problem of random sampling through synthetic samples. For positive samples, we use K-means clustering algorithm to select data according to the proportion of each category.
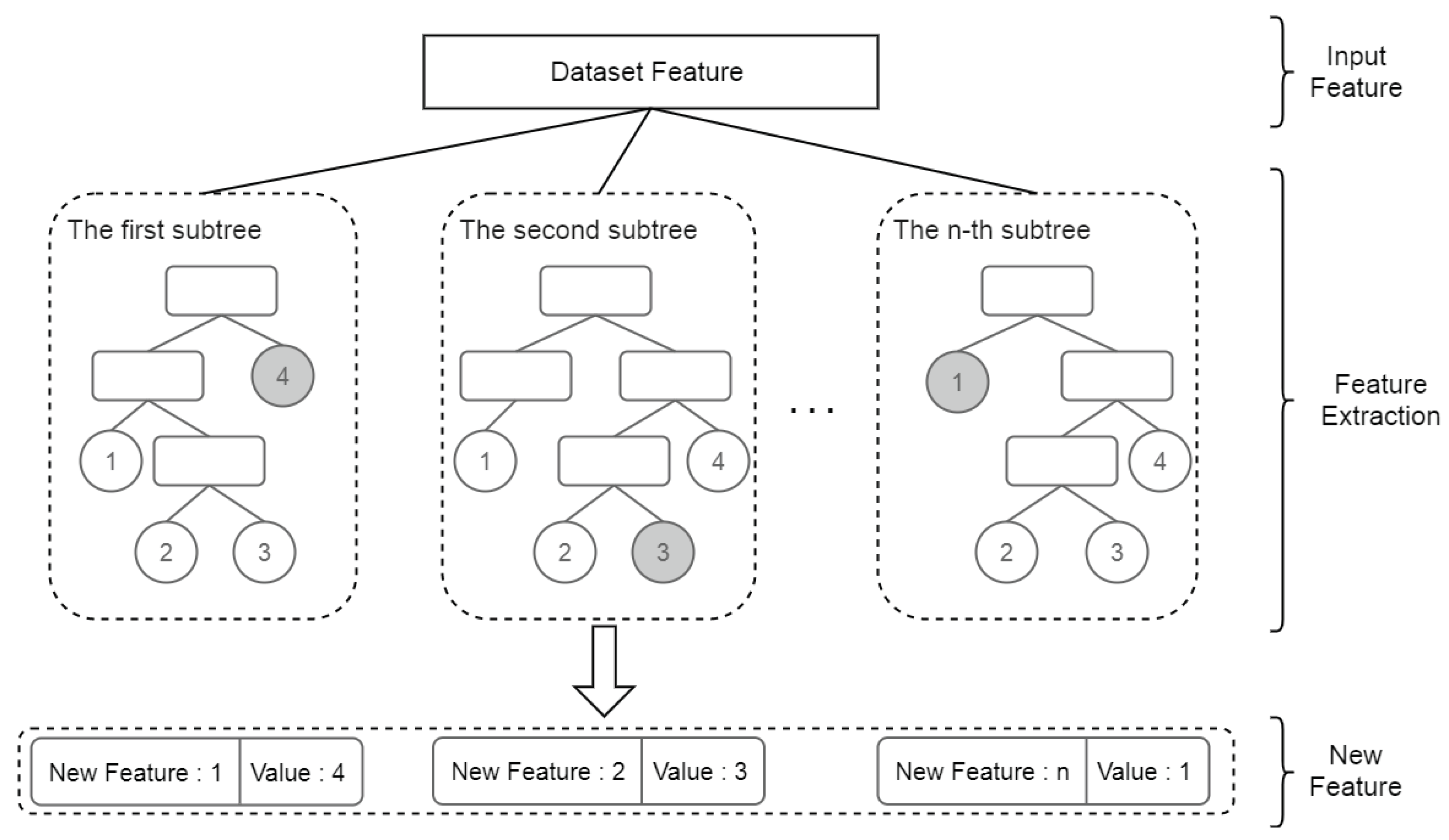
- Aiming at the difficulty of feature selection in the basic medical insurance fraud recognition scenario, we propose a second-level feature extraction algorithm based on the classification tree model, which uses the path information represented by the leaf nodes in the tree model to compress and represent various user behavior. The result data generated by the algorithm provides data input for subsequent model training.
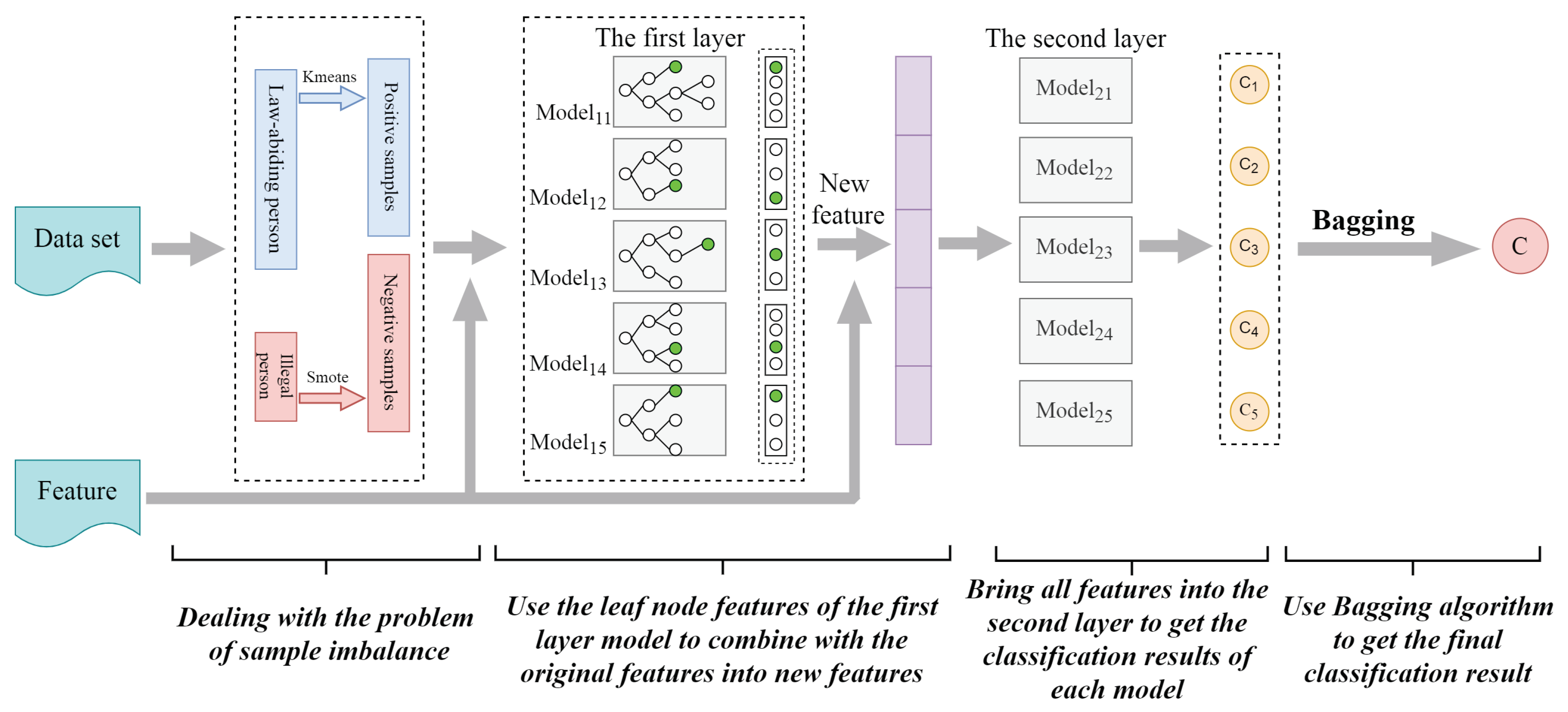
- This paper proposes a new model fusion algorithm (tree hybrid bagging, THBagging). The algorithm is based on the fusion of integrated learning theory and existing models. The strategy of “excellent and different” is integrated organically, which effectively improves the values of and -.
- In order to facilitate further research on this task, we publicly provide the source code and data of the model on the GitHub community as contributions to the community (The experimental details and source code of the model are publicly available at https://github.com/zhanghekai/THBagging).
2. Related Work
2.1. Medical Insurance Fraud Identification
2.2. Dataset Division
3. Dataset
3.1. Dataset
3.2. Data Preprocessing
- Clean the original data. The purpose of data cleaning is to screen out the required data from the perspective of medical insurance fraud and related needs of modeling. Therefore, this step eliminates unnecessary data. Mainly includes: (a) Of all the consumption record information, 94.5% of the consumption record information does not get blood transfusion costs, so the data related to blood transfusion costs will be eliminated. (b) In the original data, there are date and time fields such as declaration acceptance time, transaction time and operation time, and in the extraction of short-term dimensions, the date and time fields are relatively important. Therefore, the date field in the data is converted to a unified standard date format.
- Deal with missing values in the original data. This paper finds that there are 3000 missing values in 13 variables. The meaning of missing values should be the amount without the item, so the missing value part of the above variables is replaced with 0, which means that the amount is zero.
- Handle the outliers of the original data. Outliers refer to data that does not conform to normal rules and has abnormalities. Considering that in the actual situation, the declared amount must be less than the amount that occurred. Therefore, this article defines the value of the declared amount of each amount greater than the occurred amount as an abnormal value. However, because it is impossible to confirm whether it is the declared amount or the abnormality caused by the amount error, and the abnormal value is rare, it is a record that does not affect other expense items, so the amount field of this fee for this record is reset to 0.
4. The Proposed Approach
4.1. The Overall Framework
4.2. THBagging Model
4.2.1. The First Layer of the THBagging Model
4.2.2. Second-Level Feature Extraction
4.2.3. The Second Layer of the THBagging Model
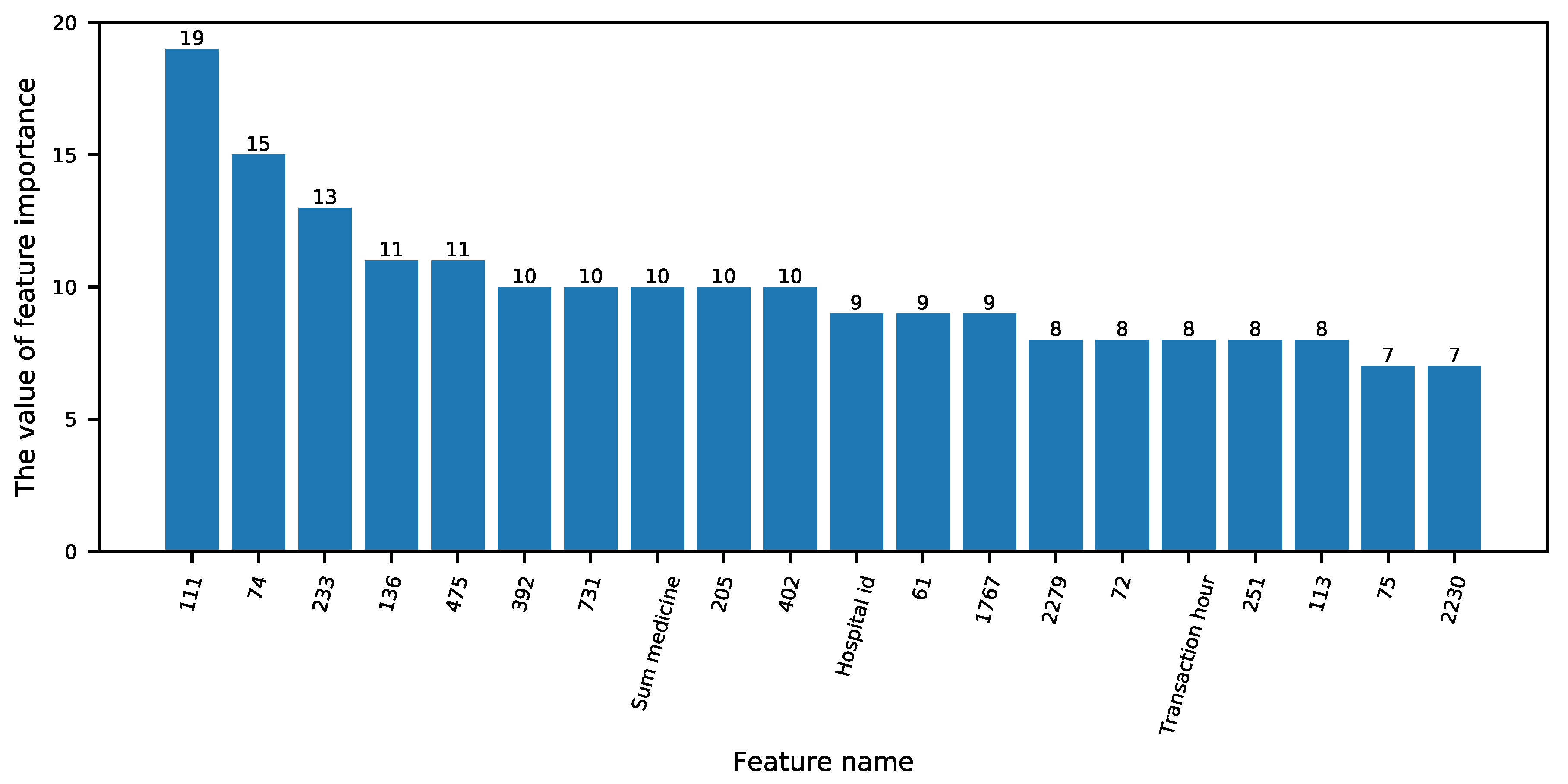
4.2.4. Feature Importance Calculation
5. Experiments
5.1. Evaluation Metrics
5.1.1. F-Measure
5.1.2. Macro-F
5.1.3. Area under the Receiver Operator Characteristic Curve
5.2. Compared Baseline Methods
5.3. Implementation Details
5.4. Analysis and Comparison of Experimental Results
5.4.1. Second-Level Feature Extraction Importance Analysis
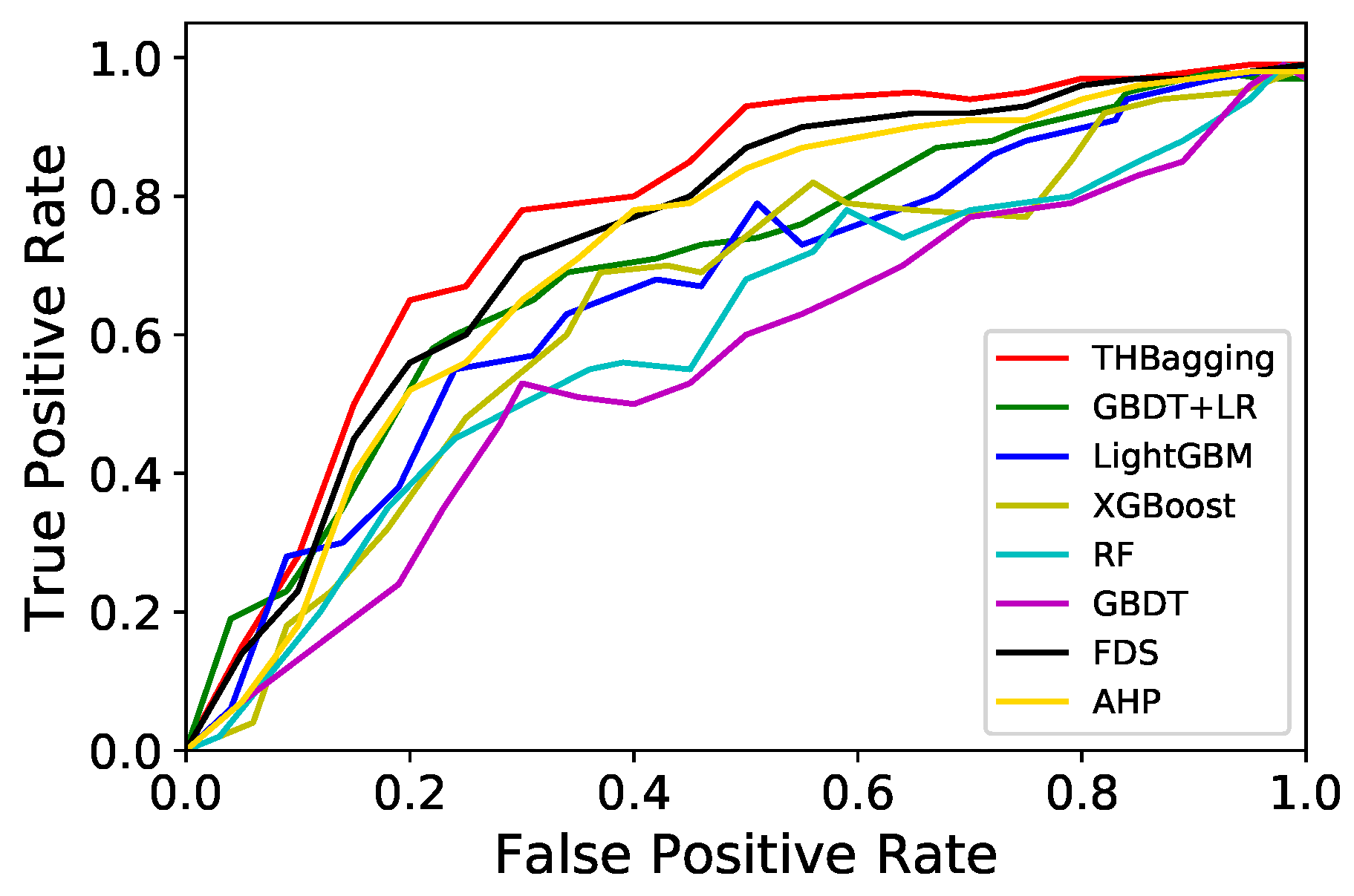
5.4.2. Analysis of Performance Results for Different Models
6. Future and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhu, S.; Wang, Y.; Wu, Y. Health care fraud detection using nonnegative matrix factorization. In Proceedings of the 2011 6th International Conference on Computer Science & Education (ICCSE), Singapore, 3–5 August 2011; pp. 499–503. [Google Scholar]
- Zhiwei, L.; Yingtong, D.; Yutong, D.; Hao, P.; Philip, S.Y. Alleviating the Inconsistency Problem of Applying Graph Neural Network to Fraud Detection. arXiv 2020, arXiv:2005.00625. [Google Scholar]
- Liu, C.; Zhu, X.Y. Medical Insurance Fraud Identification Based on BP Neural Network. Comput. Syst. Appl. 2018, 27, 34–39. [Google Scholar]
- Xu, W.; Wang, S.; Zhang, D.; Yang, B. Random rough subspace based neural network ensemble for insurance fraud detection. In Proceedings of the 2011 Fourth International Joint Conference on Computational Sciences and Optimization, Yunnan, China, 15–19 April 2011; pp. 1276–1280. [Google Scholar]
- Yali, G.; Xiaoyong, L.; Hao, P.; Bingxing, F.; Yu, P.S. HinCTI: A Cyber Threat Intelligence Modeling and Identification System Based on Heterogeneous Information Network. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Zhong, X.; Ma, S.; Zhang, Y.; Yu, R. Data Mining Overview. Intern. J. Pattern. Recognit. Artif. Intell. 2018, 32, 50–57. [Google Scholar]
- Carbonell, J.G. Machine Learning Research. ACM SIGART Bull. 1981. [Google Scholar] [CrossRef]
- Sithic, H.L.; Balasubramanian, T. Survey of insurance fraud detection using data mining techniques. arXiv 2013, arXiv:1309.0806. [Google Scholar]
- Verma, A.; Taneja, A.; Arora, A. Fraud detection and frequent pattern matching in insurance claims using data mining techniques. In Proceedings of the 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, India, 10–12 August 2017; pp. 1–7. [Google Scholar]
- Muhammad, S.A. Fraud: The affinity of classification techniques to insurance fraud detection. Int. J. Innov. Technol. Explor. Eng. 2014, 3, 62–66. [Google Scholar]
- Yang, R.; Hu, C.; Wo, T.; Wen, Z.; Peng, H.; Xu, J. Performance-aware Speculative Resource Oversubscription for Large-scale Clusters. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1499–1517. [Google Scholar] [CrossRef] [Green Version]
- Fashoto Stephen, G.; Olumide, O.; Sadiku, J.; Gbadeyan Jacob, A. Application of Data Mining Technique for Fraud Detection in Health Insurance Scheme Using Knee-Point K-Means Algorithm. Aust. J. Basic Appl. Sci. 2013, 7, 140–144. [Google Scholar]
- Chen, Y.; Wang, X. Research on medical insurance fraud early warning model based on data mining. Comput. Knowl. Technol. 2016, 12, 1–4. [Google Scholar]
- He, J. Mining of Medical Insurance Gathering Behaviors. Comput. Appl. Softw. 2011, 28, 124–138. [Google Scholar]
- Yuan, L. Analysis on the status of medical insurance fraud research at home and abroad. Insur. Res. 2010, 12, 115–122. [Google Scholar]
- Bisker, J.H.; Dietrich, B.L.; Ehrlich, K.; Helander, M.E.; Lin, C.Y.; Williams, P. Health Insurance Fraud Detection Using Social Network Analytics. U.S. Patent Application US20080172257A1, 17 July 2008. [Google Scholar]
- Anbarasi, M.; Dhivya, S. Fraud detection using outlier predictor in health insurance data. In Proceedings of the 2017 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 23–24 Febuary 2017; pp. 1–6. [Google Scholar]
- Roy, R.; George, K.T. Detecting insurance claims fraud using machine learning techniques. In Proceedings of the 2017 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–6. [Google Scholar]
- Bodaghi, A.; Teimourpour, B. The detection of professional fraud in automobile insurance using social network analysis. arXiv 2018, arXiv:1805.09741. [Google Scholar]
- Goleiji, L.; Tarokh, M. Identification of influential features and fraud detection in the Insurance Industry using the data mining techniques (Case study: Automobile’s body insurance). Majlesi J. Multimed Process. 2015, 4, 1–5. [Google Scholar]
- Peng, H.; Li, J.; Wang, S.; Wang, L.; Gong, Q.; Yang, R.; Li, B.; He, L.; Yu, P.S. Hierarchical Taxonomy-Aware and Attentional Graph Capsule RCNNs for Large-Scale Multi-Label Text Classification. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Wang, J.; Peng, H.; Wu, R. Prediction of academic performance associated with internet usage behaviors using machine learning algorithms. Comput. Hum. Behav. 2019, 98, 166–173. [Google Scholar] [CrossRef]
- Bao, M.; Li, J.; Zhang, J.; Peng, H.; Liu, X. Learning Semantic Coherence for Machine Generated Spam Text Detection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Francis, C.; Pepper, N.; Strong, H. Using support vector machines to detect medical fraud and abuse. In Proceedings of the International Conference of the IEEE Engineering in Medicine & Biology Society, Boston, MA, USA, 30 August–3 September 2011. [Google Scholar]
- Tang, Y.; Sun, Y.; Zhou, H. Active detection of medical insurance fraud. Coop. Econ. Technol. 2016, 32, 188–190. [Google Scholar]
- Rawte, V.; Anuradha, G. Fraud detection in health insurance using data mining techniques. In Proceedings of the 2015 International Conference on Communication, Information & Computing Technology (ICCICT), Mumbai, India, 15–17 January 2015. [Google Scholar]
- Liou, F.M.; Tang, Y.C.; Chen, J.Y. Detecting hospital fraud and claim abuse through diabetic outpatient services. Health Care Manag. Sci. 2008, 11, 353–358. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C.; Burch, M.D. Use of artificial neural networks for modelling cyanobacteria Anabaena spp. in the River Murray, South Australia. Ecol. Model. 1998, 105, 257–272. [Google Scholar] [CrossRef]
- Panigrahi, S.; Kundu, A.; Sural, S.; Majumdar, A.K. Credit card fraud detection: A fusion approach using Dempster–Shafer theory and Bayesian learning. Inf. Fusion 2009, 10, 354–363. [Google Scholar] [CrossRef]
- Chiu, C.C.; Tsai, C.Y. A web services-based collaborative scheme for credit card fraud detection. In Proceedings of the IEEE International Conference on e-Technology, e-Commerce and e-Service, Taipei, Taiwan, 28–31 March 2004; pp. 177–181. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl. Based Syst. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Drummond, C.; Holte, R.C. C4. 5, class imbalance, and cost sensitivity: Why under-sampling beats over-sampling. In Workshop on Learning from Imbalanced Datasets II; Citeseer: University Park, PA, USA, 2003; Volume 11, pp. 1–8. [Google Scholar]
- Ribeiro, V.H.A.; Reynoso-Meza, G. Ensemble learning by means of a multi-objective optimization design approach for dealing with imbalanced data sets. Expert Syst. Appl. 2020, 147, 113232. [Google Scholar] [CrossRef]
- Capó, M.; Pérez, A.; Lozano, J.A. An efficient approximation to the K-means clustering for massive data. Knowl. Based Syst. 2017, 117, 56–69. [Google Scholar] [CrossRef] [Green Version]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Kai-wen, Z.; Chao, Y. Research of short-term load forecasting based on Gradient Boosting Decision Tree (GBDT). Guizhou Electr. Power Technol. 2017, 2, 82–84. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y. Xgboost: Extreme Gradient Boosting. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Thirty-first Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Dougherty, E.R.; De Valpine, P.; Carlson, C.J.; Blackburn, J.K.; Getz, W.M. Commentary to: A cross-validation-based approach for delimiting reliable home range estimates. Mov. Ecol. 2018, 6, 10. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Kuhl, N.; Lobana, J.; Meske, C. Do you comply with AI?–Personalized explanations of learning algorithms and their impact on employees’ compliance behavior. arXiv 2020, arXiv:2002.08777. [Google Scholar]
- Meske, C.; Bunde, E. Transparency and Trust in Human-AI-Interaction: The Role of Model-Agnostic Explanations in Computer Vision-Based Decision Support. IEEE Trans. Knowl. Data Eng. 2020, 32, 216–231. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Van Asch, V. Macro-and micro-averaged evaluation measures [[basic draft]]. Belgium CLiPS 2013, 49, 230–257. [Google Scholar]
- Obuchowski, N.A.; Lieber, M.L.; Wians, F.H. ROC curves in clinical chemistry: Uses, misuses, and possible solutions. Clin. Chem. 2004, 50, 1118–1125. [Google Scholar] [CrossRef] [PubMed]
- Sheng, Y.; Xu, Z.; Wang, Y.; de Melo, G. MuReX: Multi-Document Semantic Relation Extraction for News Analytics. WWW J. 2020. [Google Scholar] [CrossRef]
- Archer, K.J.; Kimes, R.V. Empirical characterization of random forest variable importance measures. Comput. Stat. Data Anal. 2008, 52, 2249–2260. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Feng, F.; Nie, L.; Chua, T.S. Tem: Tree-enhanced embedding model for explainable recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1543–1552. [Google Scholar]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–235. [Google Scholar]
- Mejdoub, M.; Amar, C.B. Classification improvement of local feature vectors over the KNN algorithm. Multimed. Tools Appl. 2013, 64, 197–218. [Google Scholar] [CrossRef]
- Tanha, J.; van Someren, M.; Afsarmanesh, H. Semi-supervised self-training for decision tree classifiers. Int. J. Mach. Learn. Cybern. 2017, 8, 355–370. [Google Scholar] [CrossRef] [Green Version]
- Bursac, Z.; Gauss, C.H.; Williams, D.K.; Hosmer, D.W. Purposeful selection of variables in logistic regression. Source Code Biol. Med. 2008, 3, 17. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description | Type | Ranges | Avg |
|---|---|---|---|---|
| Medical records | ||||
| Regular visits | ||||
| Medical Interval | Effective interval between two consultations between patients within the consultation time | int | [0, 60] | 35 |
| Number of visits | The total number of visits by patients within the record time | int | [1, 50] | 24 |
| Number of hospitals | Number of hospitals visited during the time of all patient records | int | [1, 20] | 5 |
| Number of items | The total number of items that the patient has seen in all medical records | int | [0, 30] | 13 |
| Cost information | ||||
| Total cost | The sum of all medical items in the period of all medical records | double | [0, 45,239.00] | 25,624.24 |
| Amount of drug costs | The total amount of medicine purchased by the patient during the time period | double | [0, 32,535.43] | 14,263.78 |
| Amount of inspection fee | The total amount spent by the patient for the examination within the time period of the medical record | double | [0, 4495.67] | 2930.52 |
| Amount of treatment fee | The total amount the patient spent on treatment within the time period of the medical record | double | [0, 44,399.90] | 27,921.70 |
| Insurance reimbursemen | ||||
| Declaration information | ||||
| Total declared expenses | The total amount of expenses that the patient applied for reimbursement within the time period of the medical record | double | [0, 41,699.45] | 24,315.90 |
| Total declaration ratio | Patient reimbursement expenses as a proportion of total incurred expenses | double | [0, 95.25%] | 50.55% |
| Reimbursement information | ||||
| Drug reimbursement amount | Total reimbursement of drugs purchased by patients | double | [0, 32,532.88] | 16,374.40 |
| Subsidy amount | The total amount of subsidy received by the patient | double | [0, 13,652.88] | 6740.40 |
| Account reimbursement amount | Reimbursement amount available in account | double | [0, 11,623.14] | 5097.70 |
| Account payment amount | The amount paid by the co-ordination fund in the total cost of the patient’s medical record period | double | [0, 1623.14] | 597.70 |
| Deductible amount | The amount paid by the personal account in the total cost of the patient’s medical record period | double | [0, 7752.90] | 346.90 |
| Category | Number of Samples | Proportion of Each Category in the Total |
|---|---|---|
| 1 | 1297 | 8% |
| 2 | 2376 | 15% |
| 3 | 2568 | 16% |
| 4 | 647 | 4% |
| 5 | 6708 | 42% |
| 6 | 169 | 1% |
| 7 | 956 | 6% |
| 8 | 1279 | 8% |
| Algorithm | Description |
|---|---|
| LightGBM [39] | uses the amount and dimensions of compressed data to reduce the amount of training data. |
| GBDT [37] | achieves an algorithm for classifying or regressing data by using linear combinations of basis functions and continuously reducing residuals generated during the training process. |
| XGBoost [38] | adds a regularization term to the cost function based on the GBDT algorithm, and uses the exact or approximate method to greedily search for the highest-scoring segmentation point, perform the next segmentation and expand the leaf nodes. |
| RF [49] | used CART decision tree as a weak learner, and improved the establishment of decision tree. RF selects an optimal feature for left and right sub-tree partitioning of the decision tree, which further enhances the generalization ability of the model. |
| GBDT + LR [50] | uses GBDT to train the model to obtain new leaf nodes, and then combines the leaf node features with the original features into new features, and then inputs them to the logistic regression model for training. The proposed model is based on the model’s inspiration, so it is also used as a comparative experiment. |
| FDS [29] | uses a combination of neural network and bayesian network to identify fraud. The suspicion score is updated by means of Bayesian learning using history database of both law-abiding person and illegal person. |
| AHP [17] | uses the back propagation (BP) neural network method. In addition, a logistic regression algorithm is used to improve the neural network. In order to reduce the interference of the neural network, a method of reducing weak factors is used, and only the normal data training method is used to solve the problem of sparse data in medical insurance data. |
| THBagging | replaced the integrated classifier in the second layer of the model with a common classification algorithm to prove the superiority of our choice of integrated classifier. We performed more than 40 different combinations of experiments and showed the best results in the results table. |
| THBagging | uses some existing data processing methods for experiments, instead of the second-level feature extraction we proposed. By comparing with other data processing methods, the effectiveness of the proposed method is proved. |
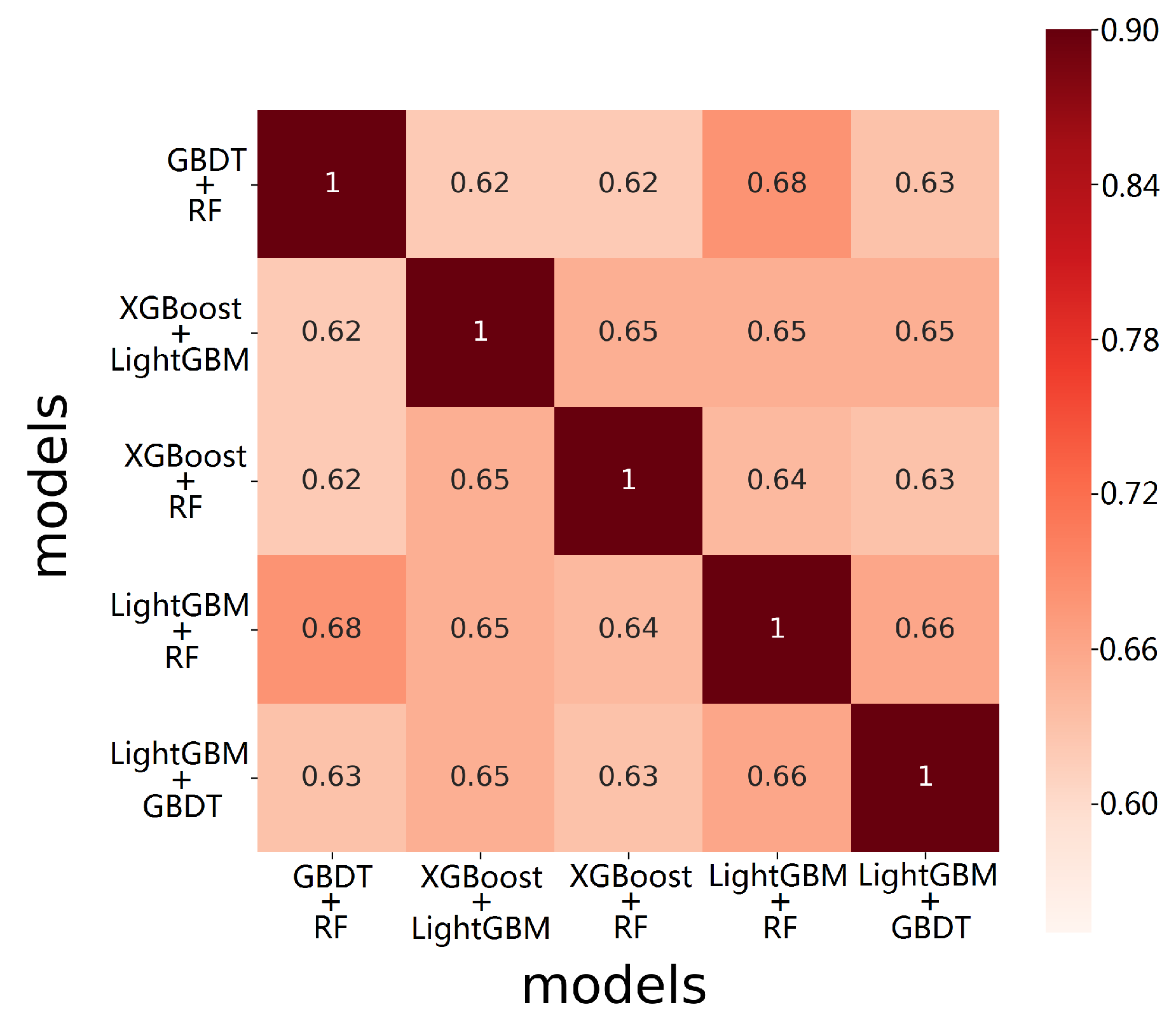
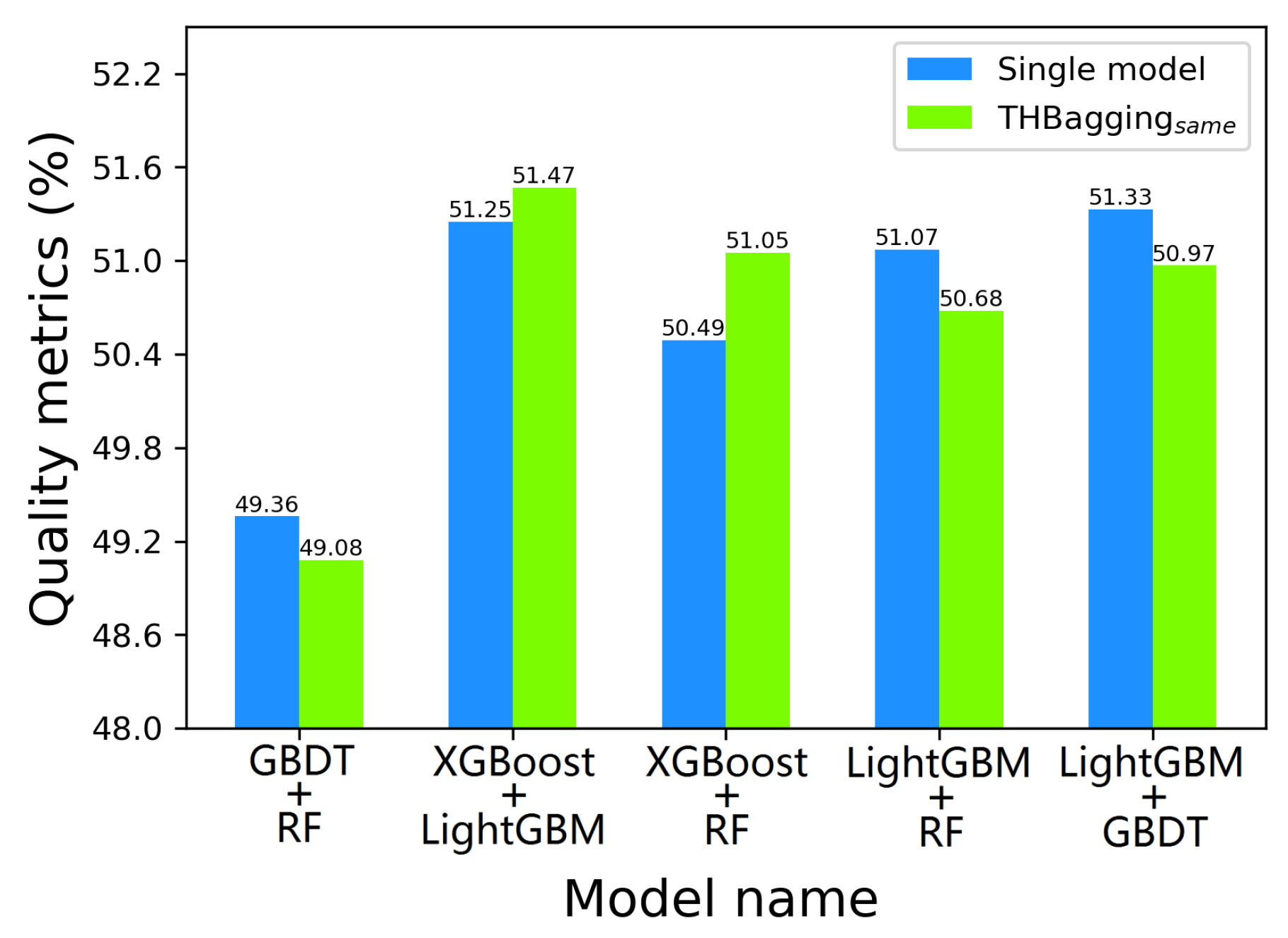
| THBagging | uses five groups of the same model combination as the base model. That is, the model of the first layer is exactly the same, and the model of the second layer is also the same. The combination of models uses the five basic models mentioned in THBagging. |
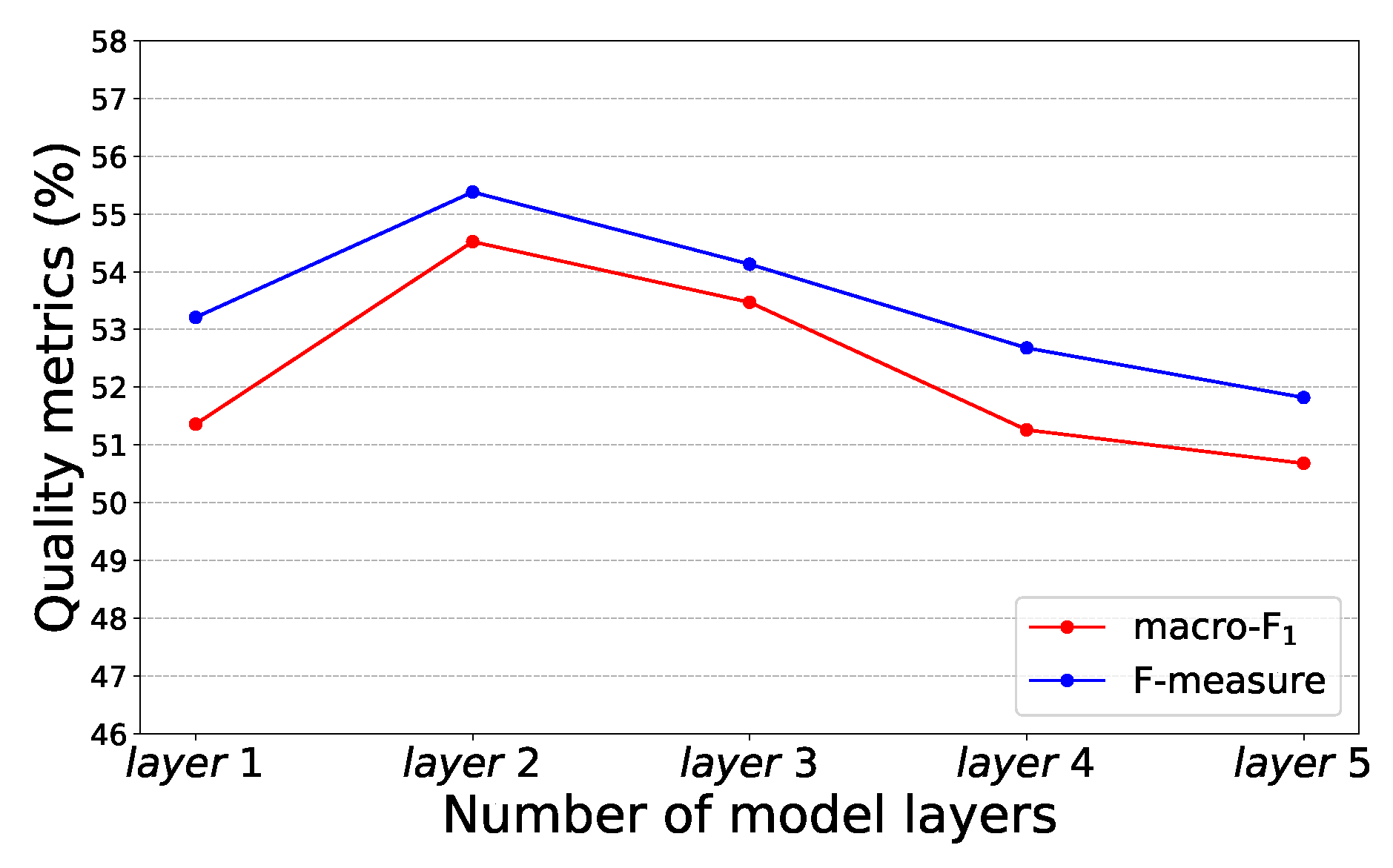
| THBagging | changed the number of model group sums, removed the base model with many classification errors, and added a new combination model. |
| THBagging | is a fusion model. After many experiments, it was found that the best model combination structure is GBDT + RF, XGBoost + LightGBM, XGBoost + RF, LightGBM + RF and LightGBM + GBDT. The final result uses Bagging fusion method. In order to judge the pros and cons of the proposed models, each group of submodels is set as a baseline algorithm for comparison. |
| Algorithm | Number of Base Classifiers | Tree Depth | Number of Nodes | Ranom Sampling Ratio |
|---|---|---|---|---|
| The First Layer | ||||
| GBDT | 128 | 5 | 20 | - |
| XGBoost | 256 | 7 | 10 | - |
| XGBoost | 128 | 5 | 20 | - |
| LightGBM | 128 | 3 | 10 | - |
| LightGBM | 500 | 3 | 10 | - |
| The Second Layer | ||||
| RF | 128 | 5 | 20 | 80% |
| LightGBM | 256 | 7 | 10 | - |
| RF | 128 | 5 | 20 | 90% |
| XGBoost | 128 | 3 | 10 | - |
| GBDT | 500 | 3 | 10 | - |
| Method | P | R | - | Running Time (s) | |
|---|---|---|---|---|---|
| LightGBM | 67.53 | 38.56 | 48.31 | 46.92 | 3.2 |
| XGBoost | 65.36 | 37.27 | 47.62 | 46.37 | 4.3 |
| GBDT | 73.23 | 33.02 | 45.46 | 44.28 | 6.8 |
| RF | 70.22 | 35.10 | 46.83 | 45.82 | 6.9 |
| GBDT + LR | 44.83 | 53.71 | 48.83 | 48.07 | 10.1 |
| GBDT + RF | 52.17 | 47.21 | 49.36 | 48.65 | 7.1 |
| XGBoost + LightGBM | 69.54 | 46.92 | 51.25 | 50.18 | 6.7 |
| XGBoost + RF | 49.82 | 55.24 | 50.49 | 49.67 | 7.4 |
| LightGBM + GBDT | 58.83 | 41.09 | 51.33 | 50.72 | 5.6 |
| LightGBM + RF | 66.34 | 38.14 | 51.07 | 49.86 | 5.8 |
| FDS | 64.47 | 41.61 | 52.48 | 52.67 | 14.3 |
| AHP | 63.39 | 42.28 | 51.07 | 50.44 | 15.0 |
| THBagging | 67.44 | 40.81 | 53.26 | 52.43 | 13.8 |
| THBagging | 70.21 | 48.32 | 55.41 | 54.67 | 14.2 |
| Method | / | / | / | / | |
|---|---|---|---|---|---|
| LightGBM | 0.3163 | 1.1613 | 0.3243 | 0.3421 | 2.4233 |
| XGBoost | 0.8632 | 0.6442 | 0.3012 | 0.3082 | 5.6425 |
| GBDT | 0.9003 | 1.2258 | 0.1812 | 0.2021 | 5.6892 |
| RF | 0.1003 | 0.8413 | 0.1545 | 0.1987 | 5.1233 |
| GBDT + LR | 1.6037 | 1.0471 | 1.7332 | 0.2032 | 8.4207 |
| GBDT + RF | 1.3284 | 0.8657 | 0.3246 | 0.3087 | 5.6687 |
| XGBoost + LightGBM | 0.9637 | 0.7931 | 0.2133 | 0.2436 | 4.9876 |
| XGBoost + RF | 0.8765 | 0.6842 | 0.2657 | 0.2564 | 5.2968 |
| LightGBM + GBDT | 1.1132 | 1.0746 | 0.1834 | 0.2081 | 4.8726 |
| LightGBM + RF | 1.0037 | 0.8693 | 0.1671 | 0.1773 | 5.3697 |
| FDS | 0.8243 | 0.8776 | 0.1332 | 0.2236 | 5.2132 |
| AHP | 0.8926 | 0.8453 | 0.1415 | 0.2580 | 0.5021 |
| THBagging | 0.8677 | 0.5687 | 0.1912 | 0.2824 | 4.8256 |
| THBagging | 0.7410 | 0.4238 | 0.1346 | 0.1856 | 4.6402 |
| Method | P | R | - | |
|---|---|---|---|---|
| SMOTE | 64.32 | 43.25 | 51.67 | 50.82 |
| LR-SMOTE | 67.54 | 45.22 | 52.65 | 51.96 |
| MOEL | 65.81 | 46.87 | 52.08 | 52.19 |
| SMOTE + K-means | 70.21 | 48.32 | 55.41 | 54.67 |
| Num | Model Combination | ||
|---|---|---|---|
| 3 | LightGBM + RF\LightGBM + GBDT\XGBoost + RF | 52.96 | 52.07 |
| 4 | XGBoost + LightGBM\XGBoost + RF\ LightGBM + RF\LightGBM + GBDT | 53.28 | 52.16 |
| 5 | GBDT + RF\XGBoost + LightGBM\XGBoost + RF\ LightGBM + RF\LightGBM + GBDT | 55.41 | 54.67 |
| 6 | GBDT + RF\XGBoost + LightGBM\XGBoost + RF\ LightGBM+ RF\LightGBM + GBDT\LightGBM + XGBoost | 54.16 | 53.37 |
| 7 | GBDT + RF\XGBoost + LightGBM\XGBoost + RF\LightGBM+ RF\ LightGBM + GBDT\LightGBM + XGBoost\XGBoost + GBDT | 52.47 | 51.43 |
| Num of Layers | Model Combination | ||
|---|---|---|---|
| 1 | GBDT\XGBoost\XGBoost\LightGBM\LightGBM | 53.96 | 53.06 |
| 2 | GBDT + RF\XGBoost + LightGBM\XGBoost + RF\LightGBM+ RF\LightGBM + GBDT | 55.41 | 54.67 |
| 3 | GBDT + RF + XGBoost\XGBoost + LightGBM + RF\XGBoost + RF + XGBoost\LightGBM + RF+ GBDT\LightGBM + GBDT + XGBoost | 54.13 | 53.47 |
| 4 | GBDT + RF + XGBoost + LightGBM\XGBoost + LightGBM + RF + XGBoost\XGBoost + RF + XGBoost + LightGBM\LightGBM + RF + GBDT + LightGBM\LightGBM + GBDT + XGBoost + RF | 52.68 | 51.26 |
| 5 | GBDT + RF + XGBoost + LightGBM + GBDT\XGBoost + LightGBM + RF + XGBoost + LightGBM\XGBoost + RF + XGBoost + LightGBM + DBDT\LightGBM + RF + GBDT+ LightGBM + GBDT \LightGBM + GBDT + XGBoost + RF + XGBoost | 51.82 | 50.68 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, J.; Zhang, H.; Du, W. Research on Integrated Learning Fraud Detection Method Based on Combination Classifier Fusion (THBagging): A Case Study on the Foundational Medical Insurance Dataset. Electronics 2020, 9, 894. https://doi.org/10.3390/electronics9060894
Gong J, Zhang H, Du W. Research on Integrated Learning Fraud Detection Method Based on Combination Classifier Fusion (THBagging): A Case Study on the Foundational Medical Insurance Dataset. Electronics. 2020; 9(6):894. https://doi.org/10.3390/electronics9060894
Chicago/Turabian StyleGong, Jibing, Hekai Zhang, and Weixia Du. 2020. "Research on Integrated Learning Fraud Detection Method Based on Combination Classifier Fusion (THBagging): A Case Study on the Foundational Medical Insurance Dataset" Electronics 9, no. 6: 894. https://doi.org/10.3390/electronics9060894
APA StyleGong, J., Zhang, H., & Du, W. (2020). Research on Integrated Learning Fraud Detection Method Based on Combination Classifier Fusion (THBagging): A Case Study on the Foundational Medical Insurance Dataset. Electronics, 9(6), 894. https://doi.org/10.3390/electronics9060894