Spellcaster Control Agent in StarCraft II Using Deep Reinforcement Learning



Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution
2. Background
2.1. Deep Reinforcement Learning
2.2. StarCraft II and Spellcasters
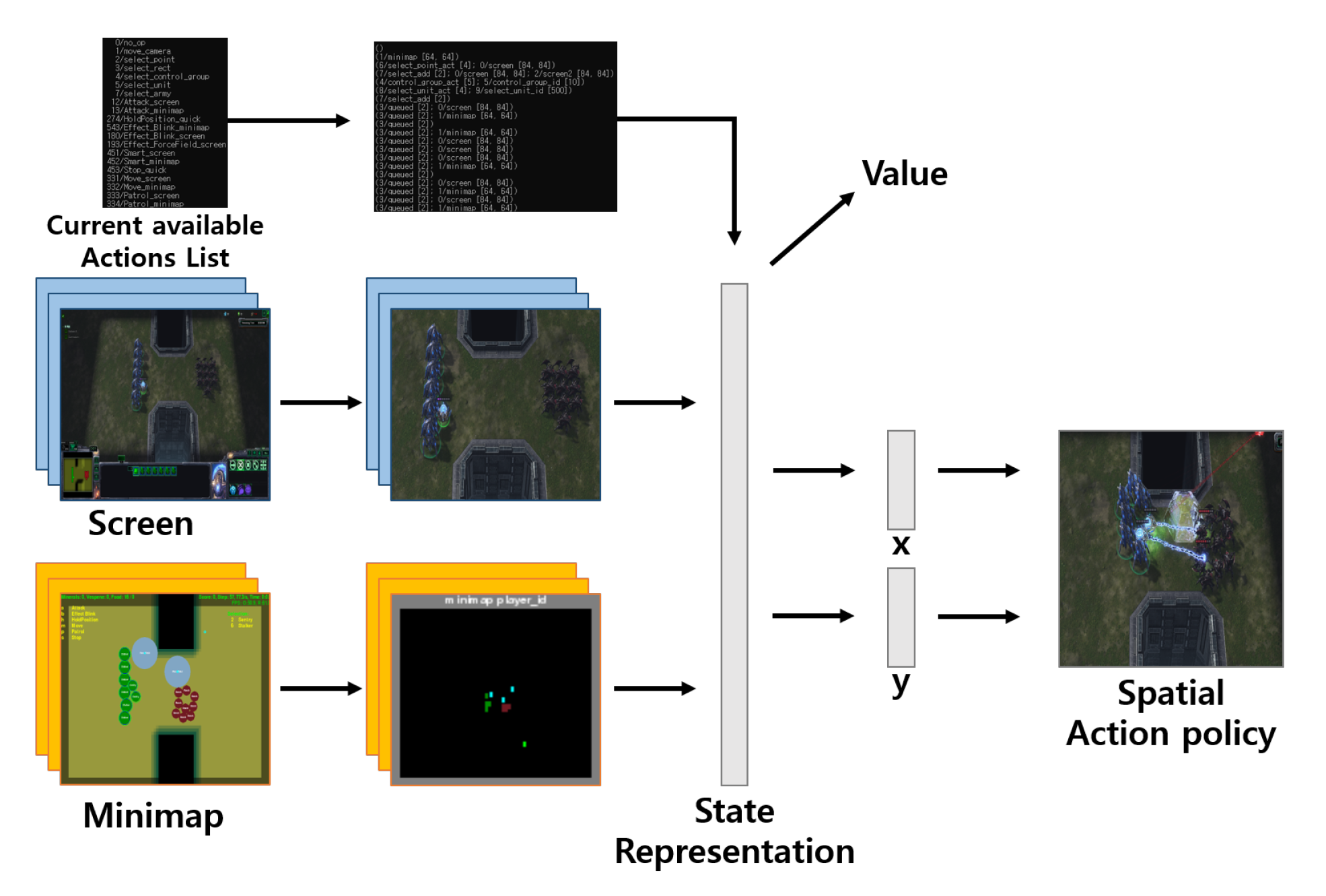
3. Method
| Algorithm 1 A3C Minigame Training Method |
Require: Num of Workers , Num of Episodes , Epsilon , Minigame size M, Replay Buffer
|
4. Experiment
4.1. Minigame Setup
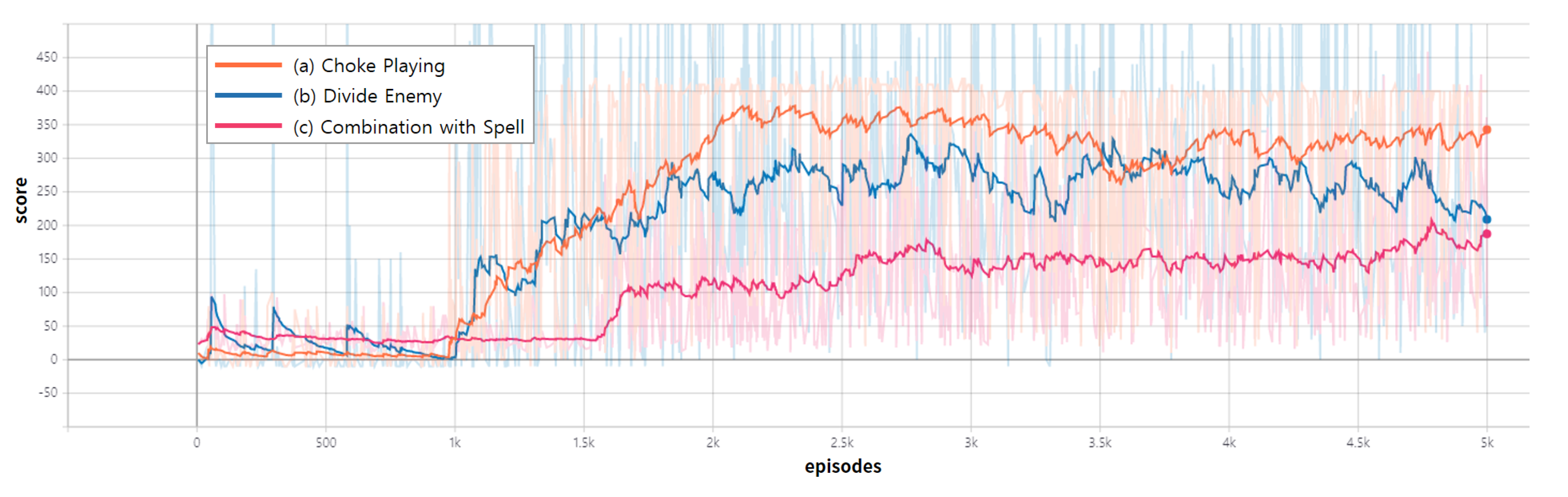
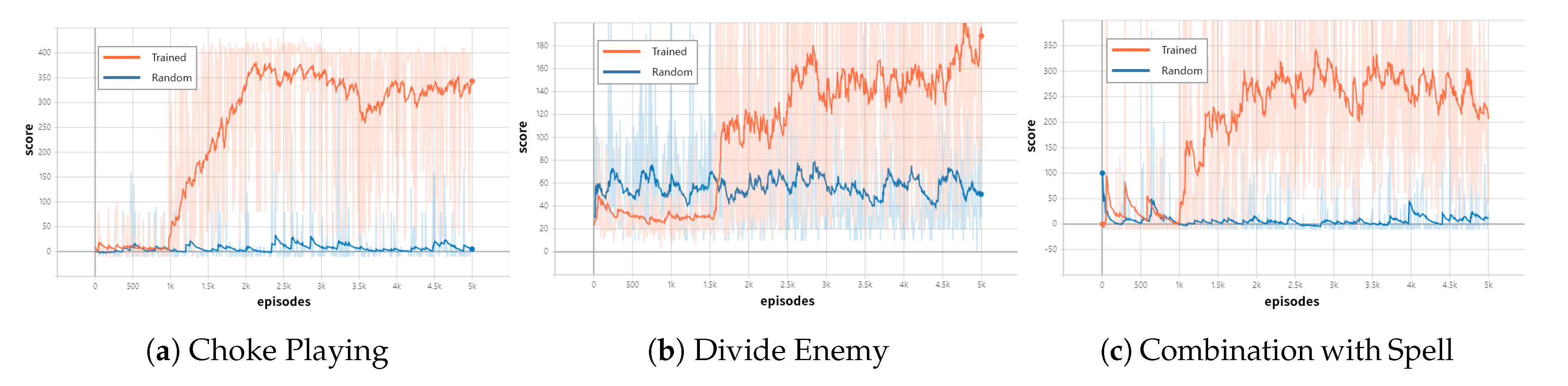
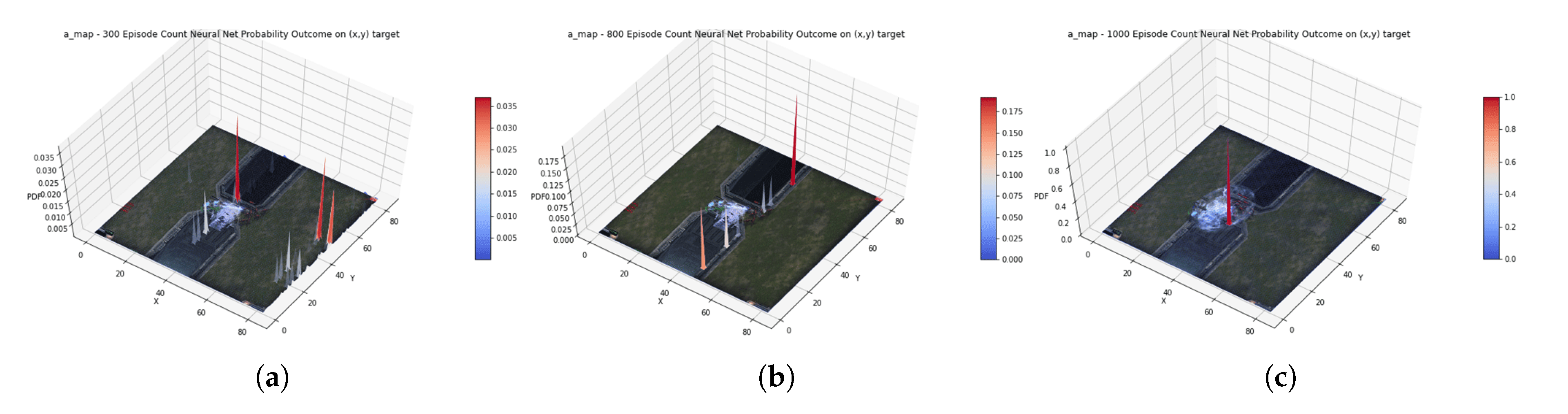
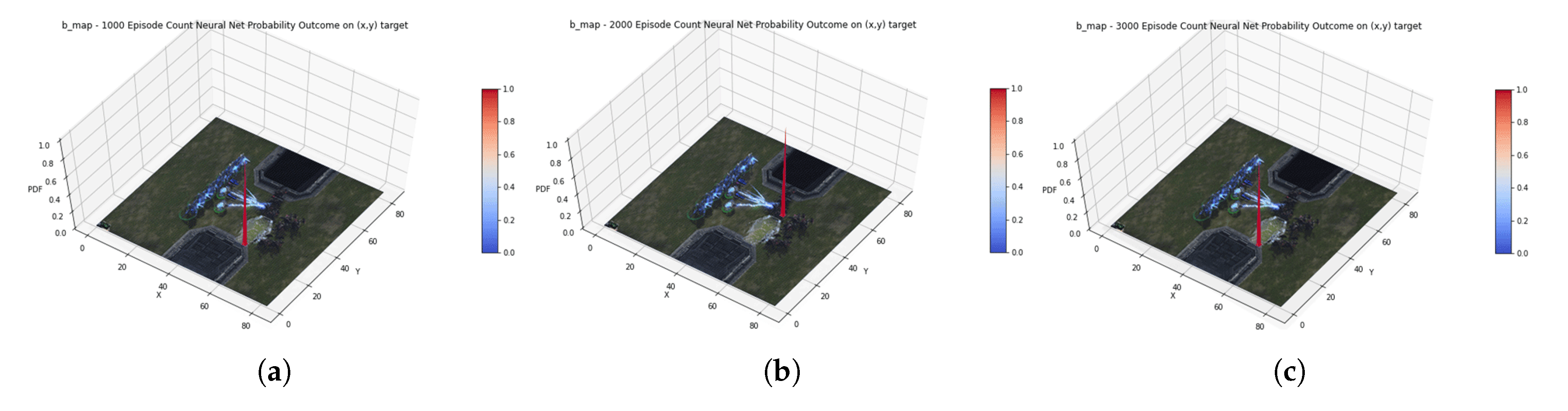
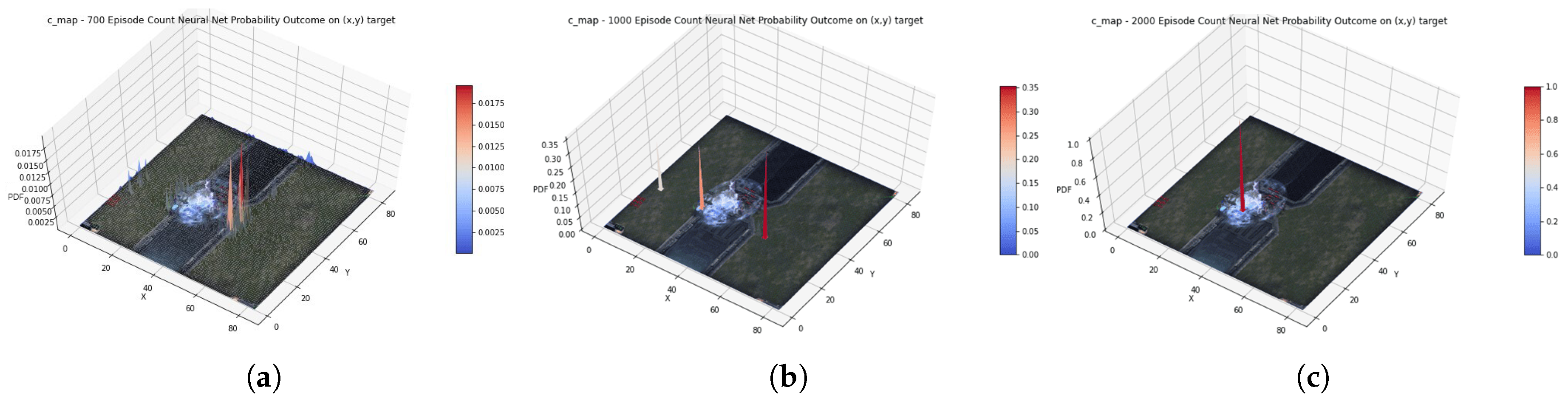
4.2. Result
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- OpenAI. OpenAI Five. 2018. Available online: https://openai.com/blog/openai-five/ (accessed on 7 June 2020).
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Hsieh, J.L.; Sun, C.T. Building a player strategy model by analyzing replays of real-time strategy games. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 3106–3111. [Google Scholar]
- Synnaeve, G.; Bessiere, P.A. Bayesian model for plan recognition in RTS games applied to StarCraft. In Proceedings of the Seventh Artificial Intelligence and Interactive Digital Entertainment Conference, Stanford, CA, USA, 10–14 October 2011. [Google Scholar]
- Usunier, N.; Synnaeve, G.; Lin, Z.; Chintala, S. Episodic exploration for deep deterministic policies: An application to starcraft micromanagement tasks. arXiv 2016, arXiv:1609.02993. [Google Scholar]
- Pang, Z.; Liu, R.; Meng, Z.; Zhang, Y.; Yu, Y.; Lu, T. On Reinforcement Learning for Full-length Game of StarCraft. In Proceedings of the Thirty-First AAAI Conference on Innovative Applications of Artificial Intelligence (AAAI’19), Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Lee, D.; Tang, H.; Zhang, J.O.; Xu, H.; Darrell, T.; Abbeel, P. Modular Architecture for StarCraft II with Deep Reinforcement Learning. In Proceedings of the Fourteenth Artificial Intelligence and Interactive Digital Entertainment Conference, Edmonton, AB, Canada, 13–17 November 2018. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Zambaldi, V.; Raposo, D.; Santoro, A.; Bapst, V.; Li, Y.; Babuschkin, I.; Babuschkin, I.; Tuyls, K.; Reichert, D.; Lillicrap, T.; et al. Relational deep reinforcement learning. arXiv 2018, arXiv:1806.01830. [Google Scholar]
- Shao, K.; Zhu, Y.; Zhao, D. Starcraft micromanagement with reinforcement learning and curriculum transfer learning. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 3, 73–84. [Google Scholar] [CrossRef] [Green Version]
- Stanescu, M.; Hernandez, S.P.; Erickson, G.; Greiner, R.; Buro, M. Predicting army combat outcomes in StarCraft. In Proceedings of the Ninth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Boston, MA, USA, 14–18 October 2013. [Google Scholar]
- Alburg, H.; Brynfors, F.; Minges, F.; Persson Mattsson, B.; Svensson, J. Making and Acting on Predictions in Starcraft: Brood War. Bachelor’s Thesis, University of Gothenburg, Gothenburg, Sweden, 2014. [Google Scholar]
- Sun, P.; Sun, X.; Han, L.; Xiong, J.; Wang, Q.; Li, B.; Zheng, Y.; Liu, J.; Liu, Y.; Liu, H.; et al. Tstarbots: Defeating the cheating level builtin ai in starcraft ii in the full game. arXiv 2018, arXiv:1809.07193. [Google Scholar]
- Justesen, N.; Risi, S. Learning macromanagement in starcraft from replays using deep learning. In Proceedings of the 2017 IEEE Conference on Computational Intelligence and Games (CIG), New York, NY, USA, 22–25 August 2017; pp. 162–169. [Google Scholar]
- Games Today. Spellcasters in Starcraft 2. 2019. Available online: https://gamestoday.info/pc/starcraft/spellcasters-in-starcraft-2/ (accessed on 7 June 2020).
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Baxter, J.; Tridgell, A.; Weaver, L. Knightcap: A chess program that learns by combining td (lambda) with game-tree search. arXiv 1999, arXiv:cs/9901002. [Google Scholar]
- Tanley, K.O.; Miikkulainen, R. Evolving neural networks through augmenting topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.V.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. arXiv 2015, arXiv:1511.06581. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; De Maria, A.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; et al. Massively parallel methods for deep reinforcement learning. arXiv 2015, arXiv:1507.04296. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Lillicrap, T.P.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The arcade learning environment: An evaluation platform for general agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Boston, MA, USA, 1998; ISBN 978-02-6203-924-6. [Google Scholar]
- Alghanem, B. Asynchronous Advantage Actor-Critic Agent for Starcraft II. arXiv 2018, arXiv:1807.08217. [Google Scholar]
- Wang, G.G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.G.; Deb, S.; dos Santos Coelho, L. Earthworm optimisation algorithm: A bio-inspired metaheuristic algorithm for global optimisation problems. IJBIC 2018, 12, 1–22. [Google Scholar] [CrossRef]
- Wang, G.G.; Deb, S.; Coelho, L.D.S. Elephant herding optimization. In Proceedings of the 3rd International Symposium on Computational and Business Intelligence (ISCBI 2015), Bali, Indonesia, 7–9 December 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, G.G. Moth search algorithm: A bio-inspired metaheuristic algorithm for global optimization problems. Memetic Comput. 2018, 10, 151–164. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentry | High Templar | Stalker | Zergling | Roaches | |
|---|---|---|---|---|---|
| Race | Protoss | Protoss | Protoss | Zerg | Zerg |
| Unit Type | SpellCaster | SpellCaster | Combat Unit | Combat Unit | Combat Unit |
| Hit Point (Shield/HP) | 40/40 | 40/40 | 80/80 | 35 | 145 |
| Damage Factor (DPS) | 6 (6) | 4 (2.285) | 18 (9.326) | 5 (7.246) | 16 (8) |
| Fire Range | 5 | 6 | 6 | 1 | 4 |
| Agent | Metric | (a) Choke | (b) Divide | (c) Combination |
|---|---|---|---|---|
| Playing | Enemy | with Spell | ||
| WIN RATE | 94% | 85% | 87% | |
| Trained | MEAN | 250.08 | 111 | 207.59 |
| MAX | 430 | 459 | 1515 | |
| WIN RATE | 5.36% | 30.96% | 5.88% | |
| Random | MEAN | 6.67 | 58.39 | 6.918 |
| MAX | 380 | 265 | 900 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, W.; Suh, W.H.; Ahn, C.W. Spellcaster Control Agent in StarCraft II Using Deep Reinforcement Learning. Electronics 2020, 9, 996. https://doi.org/10.3390/electronics9060996
Song W, Suh WH, Ahn CW. Spellcaster Control Agent in StarCraft II Using Deep Reinforcement Learning. Electronics. 2020; 9(6):996. https://doi.org/10.3390/electronics9060996
Chicago/Turabian StyleSong, Wooseok, Woong Hyun Suh, and Chang Wook Ahn. 2020. "Spellcaster Control Agent in StarCraft II Using Deep Reinforcement Learning" Electronics 9, no. 6: 996. https://doi.org/10.3390/electronics9060996
APA StyleSong, W., Suh, W. H., & Ahn, C. W. (2020). Spellcaster Control Agent in StarCraft II Using Deep Reinforcement Learning. Electronics, 9(6), 996. https://doi.org/10.3390/electronics9060996