1. Introduction
Software-Defined Networking (SDN) is an innovative network architecture that divides the network into a control plane and a data plane and provides flexible flow control over network traffic. Different packet-processing rules manage the traffic flows in switches. These rules, based on the match-action format, according to various packet-header fields, define packets’ action such as forwarding, modification, or directing to the central controller [
1].
OpenFlow is a representative technology in SDN. In OpenFlow switch, match-action rules are stored in the flow tables in the form of entries. An OpenFlow switch can have Multiple Flow Tables (MFTs). OpenFlow rules as flow table entries describe how OpenFlow switch process packets [
2]. Specifically, an OpenFlow rule can decide where the packet will be transferred or drop the packet according to the packet L1, L2, L3, and L4 headers, including physical switch ports, MAC addresses, IP addresses, TCP/UDP ports, and other headers. Before transferring the packet, OpenFlow Switch can change its packet header information [
3,
4,
5].
In theory, all the match-actions can be handled by a single flow table. However, the combination of all the match fields causes an explosion of the flow table entries. From OpenFlow 1.1, the OpenFlow switch can set MFTs and let one packet be matched by MFTs, which provides more fine-grained and flexible flow control to switch. In OpenFlow 1.1, MFTs are organized as a pipeline and process the incoming packets successively. OpenFlow 1.1 defines the action set as a set of a series of actions corresponding to each packet. Before each packet arriving at the OpenFlow switch and matching with the MFTs, the action set will be initialized to empty. These corresponding actions will be added to the action set successively in the process of matching with the MFTs and performed at the end of the pipeline processing [
6].
MFTs matching built on generic CPU allows a single OpenFlow switch to execute complex actions for a packet. Despite the flexibility of MFTs matching in software, the need for high processing speed remains challenging for generic CPU [
7]. The exact matching scheme can avoid the limitation of the general CPU’s performance degradation in MFTs matching. Open vSwitch (OVS) [
8] and the Virtual Filtering Platform (VFP) [
9] use a single hash table to store the correspondence relationship between flows and their actions instead of packet headers and actions. This scheme works well when elephant flow is the absolute dominant role in the traffic. However, when the packet fields change often, the flow caching scheme based on the exact match cannot meet the high cache hit rate requirement [
7].
To avoid these shortcomings of exact match, wildcard match is now widely adopted. In the industry-standard, commodity OpenFlow switches use Ternary Content Addressable Memory (TCAM) [
10,
11] to store rules and perform wire-speed parallel matching. TCAM is a high-speed memory that supports parallel matching for both exact-match and wildcard-match. Compared with exact-match rules, wildcard-match rules can match more rules and improve the reusability of rules. Since TCAM is expensive, power-hungry, and takes up too much silicon space [
12,
13], there is only limited TCAM size in commodity OpenFlow switches, which causes the TCAM size capacity problem.
For the problem of TCAM size capacity, many solutions have been proposed. Considering the high speed and limited capacity of TCAM, many works [
14,
15,
16,
17,
18] use the TCAM hardware flow table as a cache to store the popular rules and use the software flow table to store all of the rules. The combination of hardware and software can achieve both high-speed matching and high capacity, which has become the most popular style of OpenFlow switch. Their works focus on solving the rule dependency problem and proposed lots of different algorithms. Unfortunately, all of these wildcard-match solutions assume that there is only one flow table in an OpenFlow switch. None of them addressed the MFTs wildcard-match scheme. However, to reduce the number of rules and improve the flexibility of flow control, the MFTs have been widely used in OpenFlow switches, which remain a challenge for caching schemes based on wildcard-match. Since the existing rule caching scheme based on wildcard-match cannot be directly applied in the MFTs.
Here, we propose PipeCache to solve the problem of an MFTs rule-caching scheme based on wildcard-match. In our design, we logically split the TCAM resources and assign them to each flow table according to the size of each flow table. Each flow table will cache the most popular rules into their assigned TCAM resources. To preserve the semantics of the forwarding policies, we use the Cover-Set algorithm [
15] to handle the rule dependency problem. Our structure can take the advantages of both MFTs and wildcard-match scheme and achieve the balance between high-speed matching and high capacity without causing the problem of match fields combination explosion. We compare our structure with the exact-match scheme and the wildcard-match scheme based on one flow table. Experiment results show that our design has the highest cache hit rates.
Our contributions include an innovative rule-caching scheme based on multi-stage cache tables named PipeCache and corresponding algorithms. Under different cache sizes and traffic locality conditions, PipeCache has achieved the highest cache hit rates compared with other rule-caching schemes based on MFTs. Furthermore, we organize the rest of this paper as follows. In
Section 2, we introduce the background and motivation of our work. In
Section 3, we present our rule-caching scheme PipeCache. Experiment results are shown in
Section 4. We describe the related works in
Section 5.
Section 6 is the conclusion of this paper.
3. The Design and Algorithms
In this section, we presented our MFTs wildcard-match scheme named PipeCache, which addresses the problem of generic CPU speed limitation and insufficient TCAM capacity.
3.1. Problem Statement
Flow tables are all organized as match fields, actions, priority, and counter. Each table is used to match different packet header fields. In the definition of OpenFlow 1.0, there are 12 match fields in OpenFlow rules. In OpenFlow 1.3, the number of match fields has reached 40, which makes it nearly impossible to do match-action operations in just one flow table. Many OpenFlow switches have adopted the MFTs to reduce the number of OpenFlow rules and improve the flexibility of flow control. However, if all the incoming packets are handled by the OpenFlow pipeline stored in the software and processed by generic CPUs, the processing speed will be limited. A representative way to avoid the problem is the caching scheme. By utilizing the localities of flows, we can cache the most popular flows or rules in the cache to accelerate the processing speed. TCAM is a high-speed hardware resource and suitable for the cache structure. Although TCAM can process matching in wire speed, it is an expensive and power-hungry resource. It is impossible to store all the flows or OpenFlow rules in the TCAM.
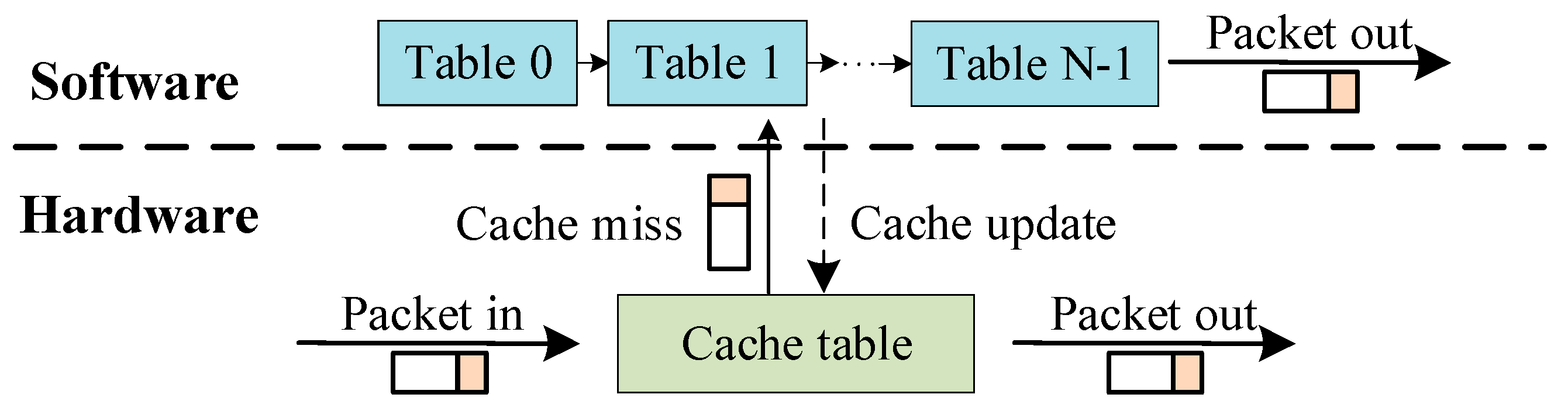
In an OpenFlow switch, the OpenFlow pipeline is stored in the software and the cache is stored in the TCAM. The incoming packets first match in cache, and then the OpenFlow switch executes the corresponding actions if the packets hit a rule in the cache. The packets will be sent to the software and go through the MFTs if packets cannot find a match in the cache. After finishing matching in the OpenFlow pipeline, the OpenFlow switch executes the actions and updates the cache entries. The matching process is shown in
Figure 3.
In the exact-match scheme, the cache table’s content is the correspondence between the flow ID and the action. To maximize the use of TCAM resources in commodity switches, we chose to use the wildcard-match scheme to solve the rule-caching problem of MFTs. Our goal is to design the suitable cache structure and compatible algorithms to select part of rules from the MFTs and cache them in TCAM. We want to maximize the traffic that hits TCAM while preserving the forwarding actions.
3.2. Handling Rule Dependency Problem
As we mentioned in
Section 2.2, when using the wildcard-match scheme, solving the rule dependency problem is inevitable. When the match fields of two rules overlap, and we only cache the one with the lower priority, and do not cache the rule with the higher priority that overlaps the match field, a forwarding error will occur. Many works proposed their algorithms with different cache structures in different contexts. Since handling the rule dependency problem is not our key point, we can use our predecessors’ great work. Considering the similar traffic environment and the simplicity of implementation, we chose the Cover-Set algorithm in CacheFlow [
15].
The main idea of the Cover-Set algorithm is to build the dependency graph and break the long dependency chain to solve the rule dependency problem. Rules are regarded as nodes in the graph, and edges with arrows are regarded as dependency relationships. We traverse all the rules in the ruleset. If two rules overlap on their match fields, we add an edge between the two rules.
When caching a rule, we cannot just cache the current one in the cache but cache the one with all its direct children nodes. The action fields of these direct children nodes will be all changed to “forwarding to software”, thereby avoiding caching all the long dependency chains in the cache table.
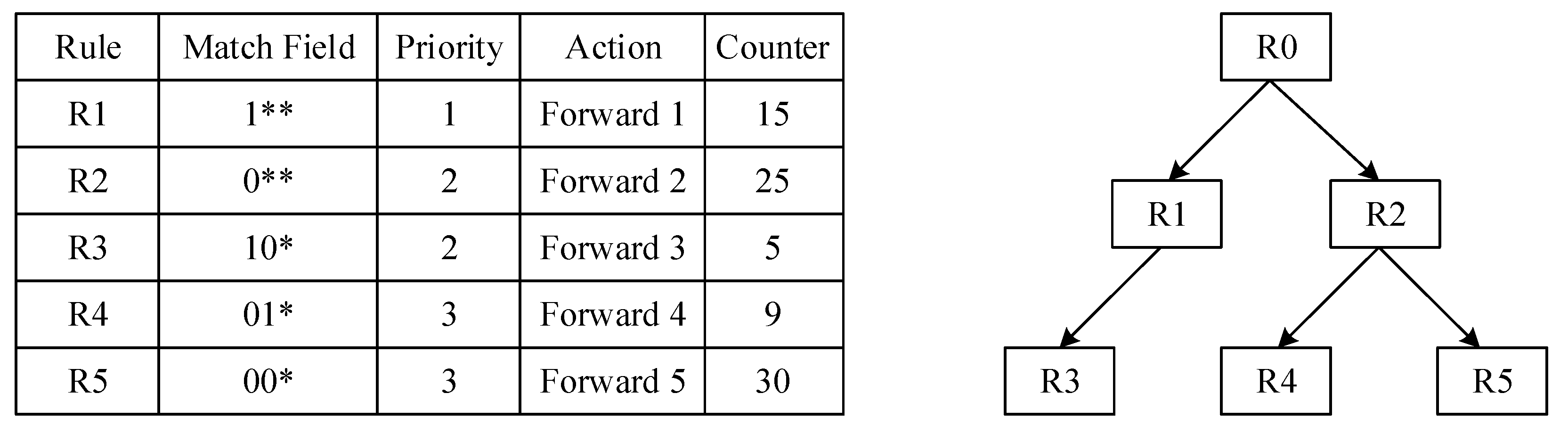
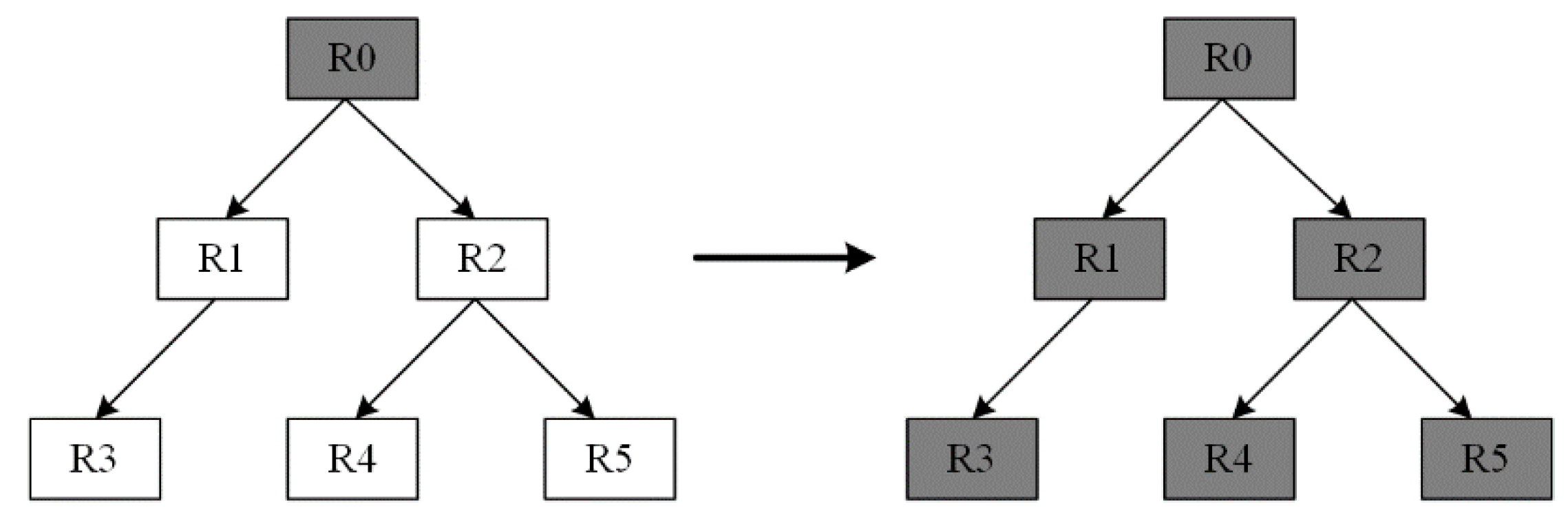
For example, in
Figure 4, if R0 is in the cache table and other rules are not cached, a forwarding error occurs when a packet that should be processed according to R5 is processed according to R0 in the cache table. So, according to the dependency relationships, when caching R0, R1 to R5 all should be cached.
Under the Cover-Set algorithm, after caching R0, only R1* and R2* are cached, which is shown in
Figure 5. R1* and R2* have the same match fields with R1 and R2, but different action fields. The action fields of these two rules are set as “forwarding to software”, thus avoiding caching R3, R4, and R5 in the cache table. When a packet hits R0 in the cache, the packet is forwarded according to R0. A packet is forwarded to software when it hits R1* or R2*. This method saves the correctness of forwarding without caching all interdependent rules and saves many cache table entries.
3.3. PipeCache Strucure and Algorithm
To make the most use of MFTs and based on the fact that the TCAM resources can be formed as an arbitrary number of independent fractions, we designed the MFTs wildcard-match scheme named PipeCache. PipeCache logically splits the TCAM resources and assigns them to these flow tables as caches. The assigned TCAM size of each flow table is based on the size of the corresponding flow table. The structure of PipeCache is shown in
Figure 6.
Although the flow tables in the OpenFlow pipeline can be formed as the combination of arbitrary match fields, we assume that each rule table only contains one match field for simplicity. The 12 match fields of OpenFlow 1.0 lead to 12 flow tables in the OpenFlow pipeline. Additionally, the form of flow tables will not influence the results of the experiments.
Figure 6a describes how the packets are processed in PipeCache. When a packet comes, it firstly matches in the MFTs in the cache in sequence. If and only if the packet hits every flow table in the cache be a cache hit. Whenever a cache miss happens, the packet will be sent to the corresponding flow table in software, and the rest of the matching process will be handled in software. Each matching in the software will lead to a cache update in TCAM. When caching a rule in TCAM, we adopt the Cover-Set algorithm to handle the rule dependency problem.
We must replace the less frequently used entries in the cache table to free up more space.
Figure 6b shows the process of the cache update. We use the Cover-Set algorithm to process the matched rules in the software flow table and all direct nodes. Additionally, then, we can get the new rules to be stored in TCAM. These new rules will replace some victim rules. Many replacement algorithms [
16,
22,
23,
24] have been proposed. Since the replacement algorithm is not the focus of our research. Here, we use the most representative Least Recently Used (LRU) algorithm to replace the least recently used rule in the cache with the new rules in software. We can also choose another algorithm, as long as it is consistent with our comparison schemes in evaluation. In the whole process, the OpenFlow switch records the matching result of each flow table. Moreover, PipeCache executes all of the recorded actions after the packet matching with the last flow table. The pseudo-code of the PipeCache algorithm is shown in Algorithm 1.
| Algorithm 1 PipeCache algorithm |
Input: p: an incoming packet;
Output: the Cache_Table _Entries in TCAM; the actions of the incoming packet;
// n: the number of MFTs;
// m: the number of rules in a rule set of a flow table;
// RS: Rule Set;
// R: Rule;
// Avail_TCAM: available TCAM entries;for each RSi in cache (from RS0 to RSn-1) do Cover-Set (RSi); while a packet p comes do //when a packet comes for each RSi in cache (from RS0 to RSn-1) do // search in cache for each Rj in RSi (from R0 to Rm-1) in descending priority order: do if p matches with Rj then Add 1 to the counter of Rj; Update the LRU identifier of Rj; Continue; if p cannot find a match in Rj then for each RSi in software (from RSi to RSn-1): do // search in software for each Rj in RSi (from R0 to Rm-1) in descending priority order: do if p matches with Rj then Set the counter of Rj to 1; Update the LRU identifier of Rj; Rules_to_cache = Rj + Rj.direct_children; if Avail_TCAM > the number of Rules_to_cache then add Rules_to_cache in TCAM; else delete the last recently used R for the number of Rules_to_cache times; add Rules_to_cache in TCAM; Continue;
|
We first used the Cover-Set function to build the dependency graph for each flow table in software, and we can get each rule’s direct children (Lines 1–2). The Cover-Set function is defined in Algorithm 1. Additionally, then, we start to handle the incoming packets. Each packet will be sent to the cache and match the MFTs in the cache in sequence. When the packet matches with a rule in a flow table, the OpenFlow switch will add 1 to the counter of the matched rule and update the LRU identifier, and then the packet will be sent to the next flow table (Lines 3–9). If a packet cannot find a match in the cache’s flow table, it will be sent to the corresponding flow table in the software. Moreover, all the remainder matching processes will be handled by software, which is defined as a cache miss (Lines 10–12). A cache hit happens only when a packet can hit every flow table in the cache. When the packet matches with a rule in the software flow table, the switch sets the rule’s counter to 1, updates the LRU identifier, and defines the rule with its direct children as the rules to cache (Lines 13–16). If there is enough space for the rules to cache, the switch directly adds them to the cache. If not, the switch will delete the last recently used rule for the number of rules to cache times before adding the rules to the cache (Lines 17–22).
4. Evaluation
In this section, we presented the simulations of our PipeCache and the strawman algorithms. We will compare our proposed algorithms with the exact-match scheme and the wildcard-match scheme based on one flow table.
4.1. Experiment Setup
Our design is based on OpenFlow rules, but we cannot get real OpenFlow switches traffic. We tried to use the widely adopted rules and traces generator ClassBench [
25] to generate synthetic rule policies. However, ClassBench cannot generate OpenFlow rules and traces. Moreover, the new tool ClassBench-ng [
26] can only generate OpenFlow rules, which cannot meet our requirements. So, we changed the source code of ClassBench trace generator to generate OpenFlow traces. To preserve fairness and effectiveness, we do not change the procedures and mechanisms of trace generation. The traces generated by the trace generator of ClassBench follow the Pareto distribution [
25]. There are two parameters a and b in the Pareto distribution function. To fit the flow distribution of Internet traffic, the parameter a is set to 1. Additionally, the parameter b is used to adjust the locality of the generated traces. From 0 to 1, a greater value of b means higher traffic locality.
In our simulations, we use ClassBench-ng to generate multiple-stage OpenFlow rules files based on two seed files with different sizes. As shown in
Table 3, for each seed file, we generate OpenFlow rule sets in three scales of 1 k, 5 k, and 10 k, and we generate ten sets of data in each scale to take the average as the results. Each OpenFlow rule has 12 match fields (Ingress port, Ethernet source address, Ethernet destination address, Ethernet type, VLAN id, VLAN priority, IP source address, IP destination address, IP protocol, ToS, transport source port, and transport destination port). We then set the locality parameter b from 10% to 20%, increasing by 2% each time to generate different trace files with different localities. Each trace file is about ten times the size of the corresponding ruleset.
Theoretically, MFTs can be formed as an equivalent big flow table. Likewise, we can split the big flow table into an equivalent pipeline of MFTs. The big flow table can be divided into combinations of arbitrary match fields. A sub flow table can be formed with single or multiple-stage match fields. Since the combinations of match fields do not influence our algorithms, we split the big flow separately by the match field for simplicity. In each flow table, we only store one entry for the same match fields. The priority of a rule is defined by its order in its flow table. The total number of rules is the sum of the number of rules in each flow table. The TCAM size is set as a parameter to evaluate the cache hit rates, which scales from 5% to 30% of the total rules number.
4.2. Experiment Results
To evaluate the performance of PipeCache, we compare it with the exact-match scheme and the wildcard-match scheme based on one flow table in terms of the cache hit rate. Here we call them MicroCache and MegaCache respectively for simplicity.
The cache hit rate is an important criterion to indicate cache algorithms. In the three caching schemes, TCAM is used as a cache in the OpenFlow switch. So, the size of TCAM is positively correlated with the cache hit rates. Moreover, different trace localities can lead to different test results. We generate multiple-stage trace files based on a range of trace localities to test the relationship between the performance of different caching schemes and the size of trace localities.
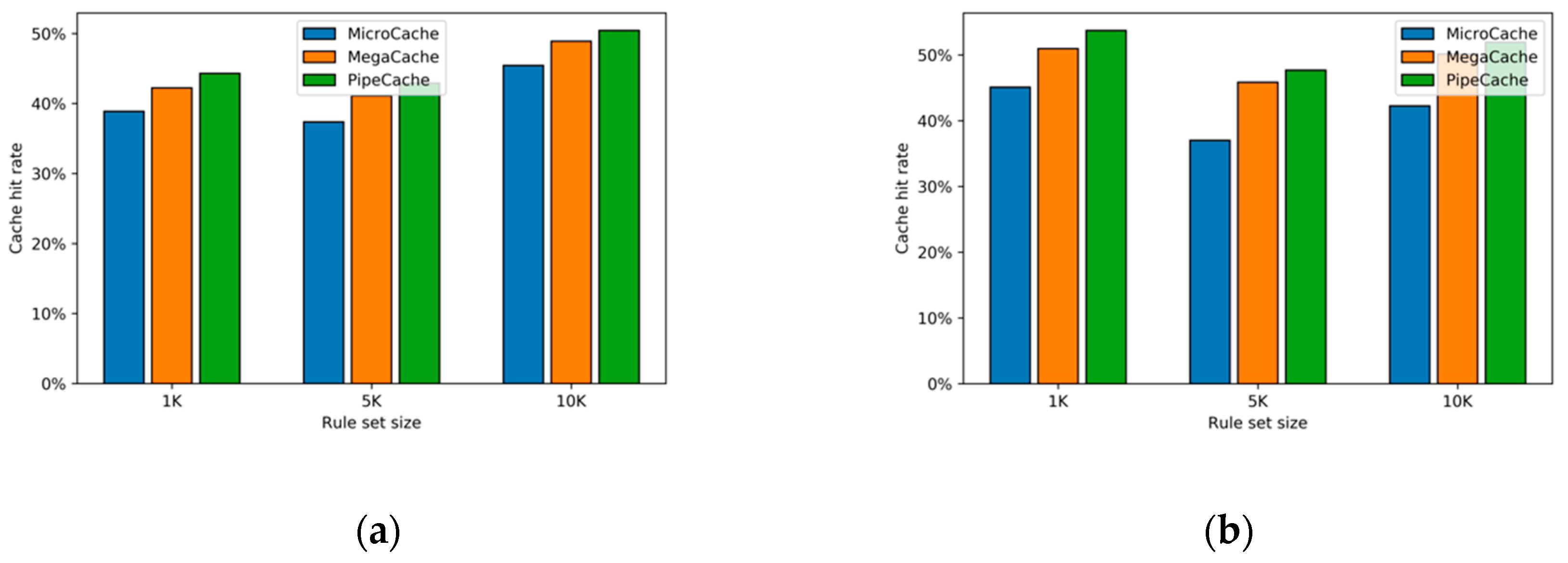
Cache hit rates with different ruleset sizes. First, we set the locality parameter b to 10% to generate the rule sets, set the TCAM size to 5% of the ruleset size, and show the cache hit rates of three schemes in different rule sets and traces.
Figure 7 shows the average cache hit rates with different sizes of rule sets. As shown in this figure, our design PipeCache achieves the highest cache hit rate under both seed files while the MegaCache achieves the second-highest cache hit rates. MicroCache has the most inferior performance. When the TCAM size is 5% of the rule size, and the locality parameter b is 10%, PipeCache can outperform the MegaCache and MicroCache 4.23% and 18.25% respectively on average.
Cache hit rates with different cache sizes. The size of the cache also plays an essential role in the performance of cache schemes. We set the TCAM size from 5% to 30% of the ruleset, increasing by 5% each time to test the performances of the three schemes with different cache sizes. As shown in
Figure 8, the cache hit rates of the three schemes increased as the cache sizes increased. When the locality parameter was 0.1, which is a relevantly low level, the cache hit rate of PipeCache started from 48.49% with the cache size 5% and increased to 57.53% when the cache size was 30%. When the locality parameter was 0.2, the cache hit rate of PipeCache went from 68.61% to 74.09%. The other two schemes also exhibited the same trend that when the traffic had a higher locality, the caching scheme has better performance. The PipeCache outperformed the other two schemes with all cache sizes. However, when the locality parameter of traffic was 0.1, and the cache size was 30% of the ruleset, MicroCache surprisingly had a higher cache hit rate than MegaCache.
Cache hit rates with different traffic localities. As shown in
Figure 8, the change in traffic locality can influence the performance of the three schemes. To show the performance of different schemes under different traffic localities, we set the locality parameter from 0.1 to 1.0, increasing 0.1 each time. We repeated the test three times with the cache rate at 10%, 20%, and 30%.
The results are shown in
Figure 9. These figures show that the cache hit rate increased as the locality of traffic increased. Additionally, PipeCache still achieved the best performance under various traffic localities. The hit rate of MicroCache could not exceed the schemes based on wildcard matching due to the inherent shortcomings of the exact match. However, when the locality of traffic was not greater than 0.2, the performance of the MicroCache would be remarkably close to MegaCache. This is because the locality of traffic was not large enough, limiting the performance of MegaCache. When the locality of the traffic was greater than 0.2, we could see that the performance of the two schemes based on wildcard matching far exceeded the MicroCache based on exact matching. When the cache rate was not greater than 40%, PipeCache had a more significant advantage than the MegaCache. As the locality of traffic gradually increased, the performance advantage of PipeCache over MicroCache gradually decreased. The higher the traffic locality, the more popular flows will occupy a larger proportion, which also improved the caching schemes. Under a typical network environment, the locality of traffic will be maintained in a limited range, which makes the advantages of our solution PipeCache more obvious.
The results are shown in
Figure 9. These figures show that the cache hit rate increased as the locality of traffic increased. Additionally, PipeCache still achieves the best performance under various traffic localities. The hit rate of MicroCache cannot exceed the schemes based on wildcard matching due to the inherent shortcomings of the exact match. However, when the locality of traffic is not greater than 0.2, the performance of the MicroCache will be remarkably close to MegaCache. This is because the locality of traffic is not large enough, limiting the performance of MegaCache. When the locality of the traffic was greater than 0.2, we can see that the performance of the two schemes based on wildcard matching far exceeded the MicroCache based on exact matching. When the cache rate was not greater than 40%, PipeCache had a more significant advantage than the MegaCache. As the locality of traffic gradually increased, the performance advantage of PipeCache over MicroCache gradually decreased. The higher the traffic locality, the more popular flows will occupy a larger proportion, which also improves the caching schemes. Under a typical network environment, the locality of traffic will be maintained in a limited range, which makes the advantages of our solution PipeCache more obvious.
5. Related Work
Our work was related to the rule caching schemes based on wildcard-match in OpenFlow switches. We reviewed related work in this area as follows.
CAB [
14] focuses on the problem of one rule may have too many direct descendants and utilizes a two-stage pipeline flow tables to solve the dependency problem. The main idea of CAB is to partition the full field space into logically independent structures named buckets, which are non-overlapping with each other, and cache buckets along with all the associated rules. CAB can not only preserve the correctness of packets forwarding but also save the control bandwidth and reduce the average flow set time.
Craft [
17] take the advantages of CAB’s two-stage pipeline structure and the idea of rule-partition, by adding a threshold to reduce the chances of storing multiple-stage overlapped rules in the cache to avoid generating too much rule fragments. Compared with CAB, Craft has much higher cache hit rates.
CacheFlow [
15] uses a compact data structure Directed Acyclic Graph (DAG) to capture all dependencies. The authors think the long dependency chains are the main point and come up with the concept of Cover-Set to handle the dependency problem. When caching a rule, its direct descendant in DAG will be cached together, but their actions are replaced with forwarding to the software. By breaking up the long dependency chains, CacheFlow achieves high cache hit rates while maintaining the forwarding correctness.
In Ref. [
16], based on the Cover-Set concept, the authors come up with a new cache replacement algorithm to improve cache hit rates. CuCa [
18] proposes a design that combines the ideas of Cover-Set and rule-partition to deploy rules in a single hybrid switch efficiently.
These works all assume that there is only one flow table in an OpenFlow switch. They cannot directly be used in the MFTs pipeline structure. A naïve way to adopt these caching schemes is to combine all the MFTs into one big flow table, which can cause an explosion of the number of flow table entries like we mentioned in
Section 2.
6. Conclusions and Future Work
In this paper, we proposed PipeCache, an innovative and efficient rule caching scheme designed for the OpenFlow switches with MFTs. To take the advantages of wildcard-match, PipeCache utilizes the feature that TCAM can be logically split into independent parts and creatively splits the TCAM resources in the form of a multi-stage pipeline. To make the most use of TCAM resources, we allocated TCAM to each stage of the flow table as a cache according to the size of the MFTs in the OpenFlow switch. To the best of our knowledge, this is the first attempt to adopt the rule caching scheme based on wildcard-match on the MFTs of OpenFlow switches. Experiment results show that our design PipeCache improves cache hit rate by up to 18.2% compared to the exact-match scheme and by up to 21.2% compared to the wildcard-match scheme based on a single flow table.
However, there are also some directions that suggest improvements. For example, we can improve the structure and algorithm of PipeCache so that it can be applied to the large-scale flow tables in the Wide-Area Networks [
27]. Additionally, we can analyze the per-flow statistics to adaptively store the rules [
28]. Moreover, many modern commodity switches have a variety of hardware resources so they can implement both exact match and wildcard match. Our future work will focus on designing a hybrid matching method, which can take advantage of both exact match and wildcard match so that the switch can achieve the highest packet processing performance in different traffic scenarios.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}