Software-Based Approach towards Automated Authorship Acknowledgement—Chi-Square Test on One Consonant Group


Abstract
:1. Introduction
2. Mathematical Support of Software System
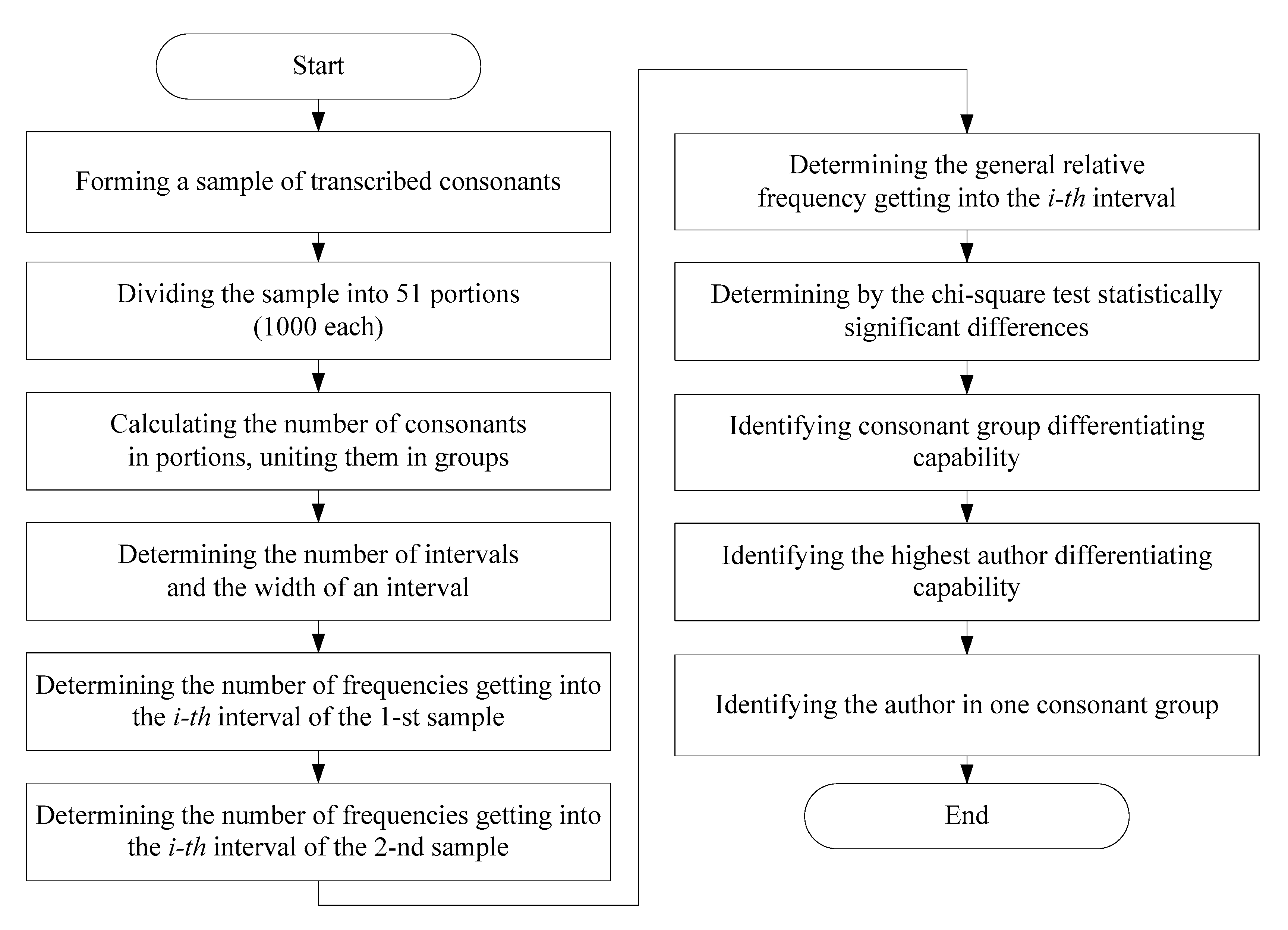
2.1. The Method Developed
2.2. The Developed Model
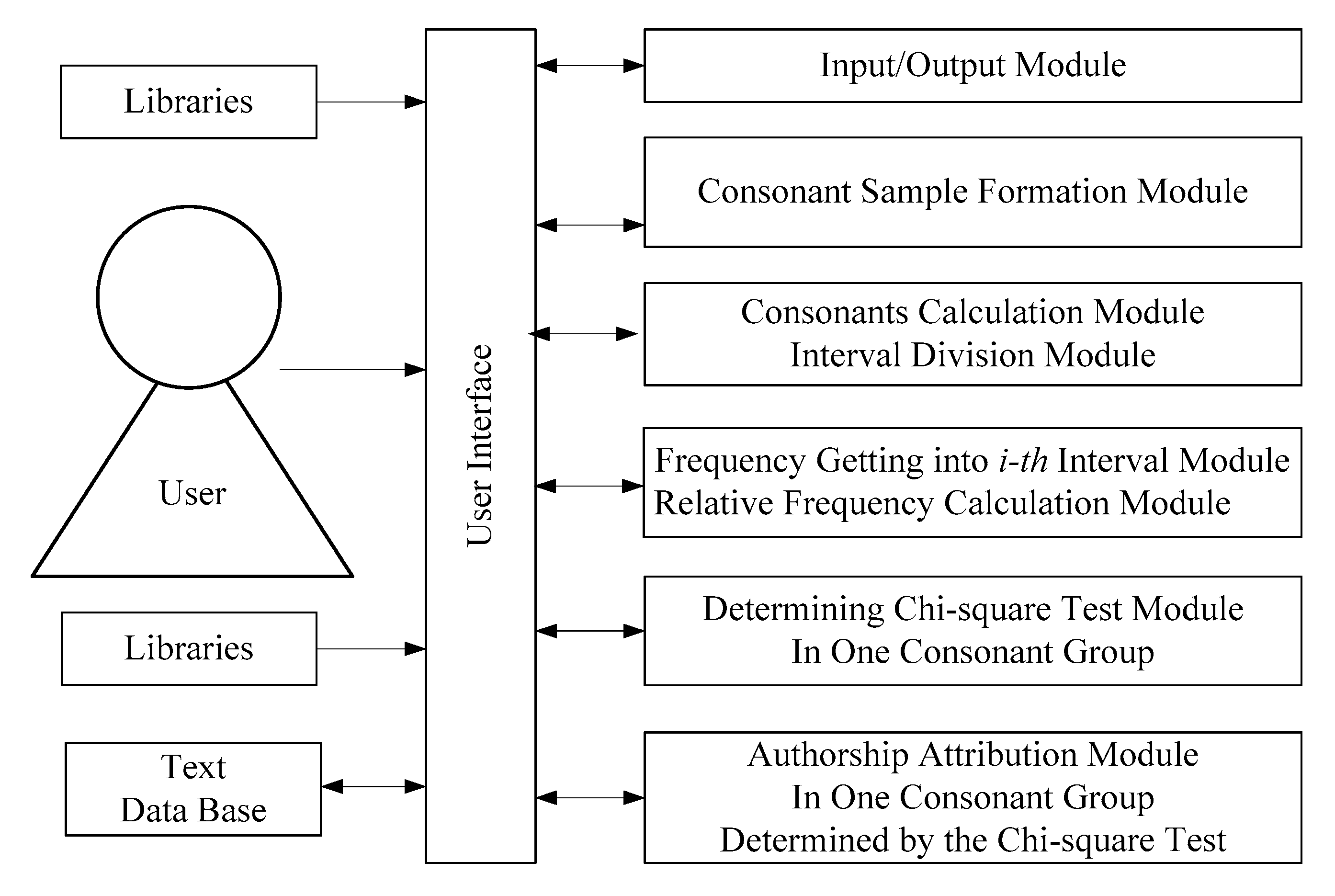
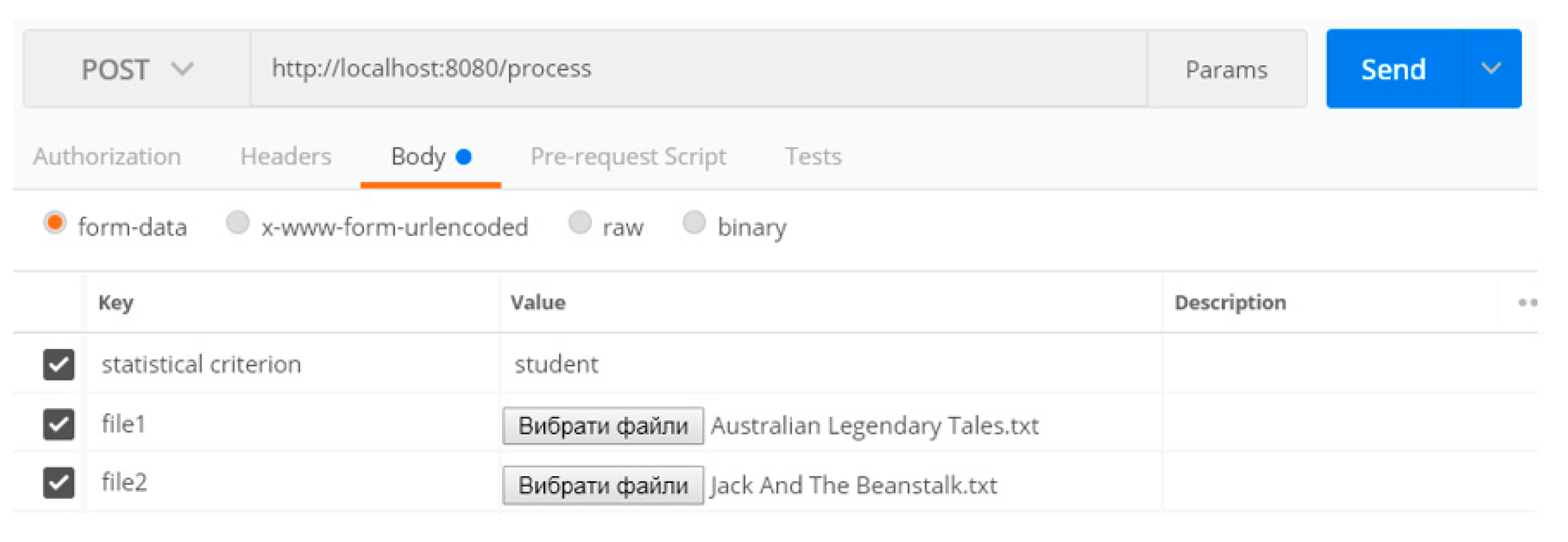
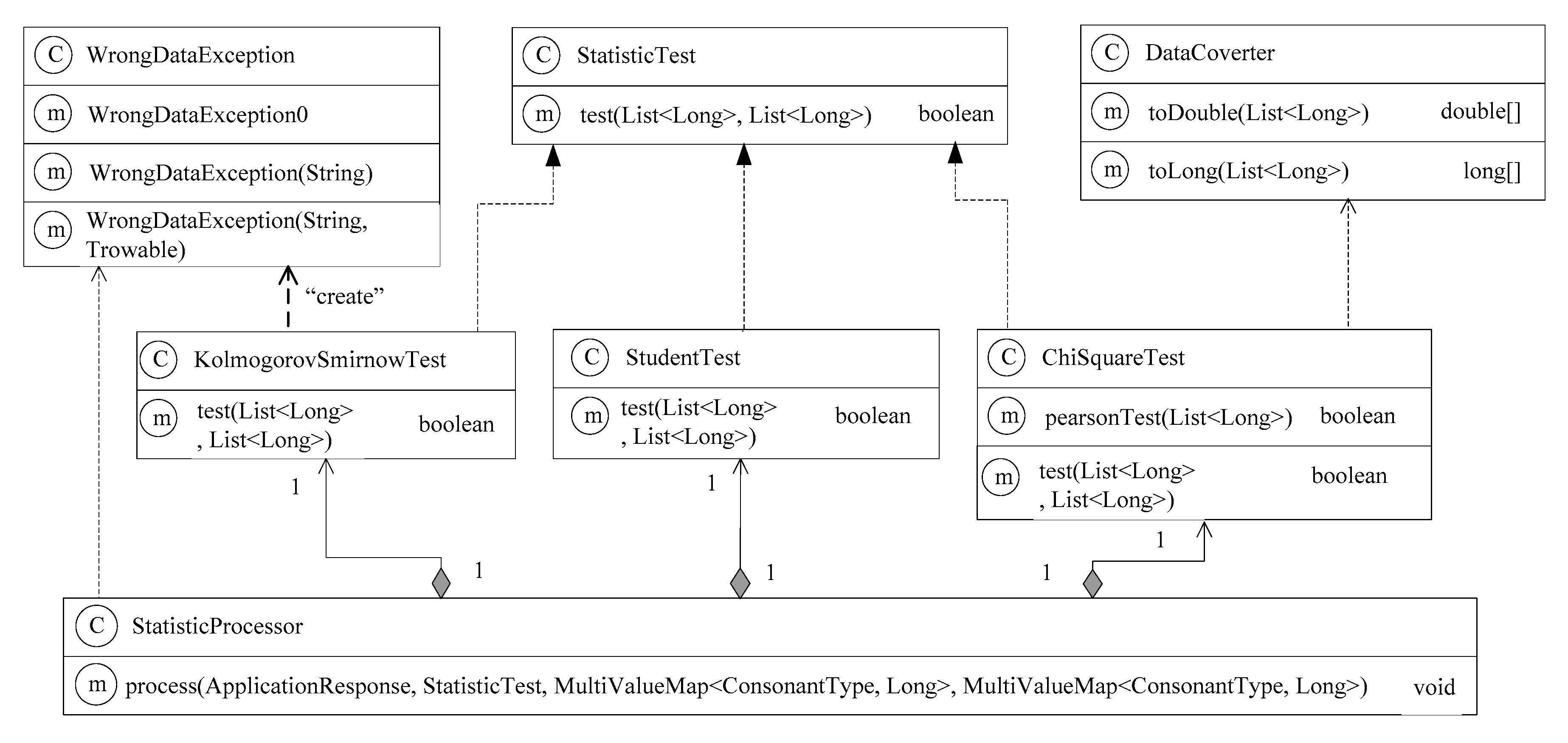
3. The Developed Software
4. Results of the Study
5. Discussion
6. Conclusions
7. Prospects for Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Bevendorff, J.; Ghanem, B.; Giachanou, A.; Kestemont, M.; Manjavacas, E.; Potthast, M.; Rangel, F.; Rosso, P.; Specht, G.; Stamatatos, E.; et al. Shared Tasks on Authorship Analysis at PAN 2020. In Proceedings of the European Conference on Information Retrieval, Lisbon, Portugal, 14–17 April 2020; pp. 508–516. [Google Scholar] [CrossRef] [Green Version]
- Lytvyn, V. Development of a method for the recognition of author’s style in the ukrainian language texts based on linguometry, stylemetry and glottochronology. East. -Eur. J. Enterp. Technol. 2017, 4, 10–18. [Google Scholar] [CrossRef]
- Vysotska, V.; Burov, Y.E.; Lytvyn, V.; Demchuk, A. Defining Author’s Style for Plagiarism Detection in Academic Environment. In Proceedings of the IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 128–133. [Google Scholar] [CrossRef]
- Tamboli, M.S.; Prasad, R.S. Authorship Identification with Multi Sequence Word Selection Method. In: Abraham, A., Cherukuri, A., Melin, P., Gandhi, N., Eds.; Intelligent Systems Design and Applications. ISDA 2018. Adv. Intell. Syst. Comput. 2020, 940, 653–661. [Google Scholar] [CrossRef]
- Bisikalo, O.V. Sentence syntactic analysis application to keywords identification ukrainian texts. Radio Electron. Comput. Sci. Control. 2016, 3, 54–65. [Google Scholar] [CrossRef] [Green Version]
- Bhargava, M.; Mehndiratta, P.; Asawa, K. Stylometric Analysis for Authorship Attribution on Twitter. In Proceedings of the Second International Conference on Big Data Analytics, Mysore, India, 16–18 December 2013; pp. 37–47. [Google Scholar] [CrossRef]
- Bozkurt, I.N.; Baghoglu, O.; Uyar, E. Authorship attribution. In Proceedings of the 22nd International Symposium on Computer and Information Sciences (ISCIS), Ankara, Turkey, 7–9 November 2007; pp. 1–5. [Google Scholar] [CrossRef]
- Khomytska, I.; Teslyuk, V.; Kryvinska, N.; Beregovskyi, V. The Nonparametric Method for Differentiation of Phonostatistical Structures of Authorial Style. Procedia Comput. Sci. 2019, 160, 38–45. [Google Scholar] [CrossRef]
- Koppel, M.; Schler, J.; Argamon, S.H. Authorship Attribution: What’s Easy and What’s Hard? SSRN Electron. J. 2013, 21, 317–331. [Google Scholar] [CrossRef] [Green Version]
- Azarbonyad, H.; Dehghani, M.; Marx, M.; Kamps, J. Time-Aware Authorship Attribution for Short Text Streams. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 727–730. [Google Scholar] [CrossRef]
- Jamak, A.; Alen, S.; Can, M. Principal Component Analysis for Authorship Attribution. Bus. Syst. Res. 2012, 3, 49–56. [Google Scholar]
- Nieto, V.G.; Sierra, C.V.; Juan, M.P.; Barco, P.M.; Cueto, A.S. Exploring State-of-the-Art Software for Forensic Authorship Identification. Int. J. Engl. Stud. 2008, 8, 1–28. [Google Scholar]
- Schmid, M.R.; Farkhund Iqbal, B.; Fung, C.M. E-mail authorship attribution using customized associative classification. DFRWS 2015, 14, S116–S126. [Google Scholar] [CrossRef]
- Argamon, S.H.; Koppel, M.; Pennebaker, J.; Schler, J. Automatically Profiling the Author of an Anonymous Text. Commun. ACM 2009, 52, 119–123. [Google Scholar] [CrossRef]
- Juala, P. Authorship Attribution. Found. Trends® Inf. Retr. 2008, 1, 233–334. [Google Scholar] [CrossRef]
- Khomytska, I.; Teslyuk, V. The Method of Statistical Analysis of the Scientific, Colloquial, Belles-Lettres and Newspaper Styles on the Phonological Level. In Advances in Intelligent Systems and Computing; Shakhovska, N., Ed.; Springer: Lviv, Ukraine, 2016; Volume 512, pp. 149–163. [Google Scholar]
- Khomytska, I.; Teslyuk, V. Statistical Models for Authorship Attribution. In Advances in Intelligent Systems and Computing; Shakhovska, N., Medykovskyy, M., Eds.; Springer: Lviv, Ukraine, 2019; Volume 1080, pp. 579–592. [Google Scholar]
- Watanabe, S. Probability Theory and Mathematical Statistics; Springer: Kyoto, Japan, 1988. [Google Scholar]
- Gries, T.H.S. Statistics for Linguistics with R: A Practical Introduction (Trends in Linguistics: Studies & Monographs); Mouton de Gruyter: Berlin, Germany, 2009; p. 348. [Google Scholar]
- Rozanov, I.A.; Silverman, R.A. Probability Theory: A Concise Course; Dover Publications Inc: New York, NY, USA, 1977. [Google Scholar]
- Jorgensen, P.E.T. Analysis and Probability: Wavelets, Signals, Fractals; Springer Science + Business Media LLC: New York, NY, USA, 2006. [Google Scholar]
- Bhattacharya, R.N.; Waymire, E.C. A Basic Course in Probability Theory, 2nd ed.; Springer: Cham, Switzerland, 2016; ISBN 978-3-319-47974-3. [Google Scholar]
- Everitt, B.S. Cambridge Dictionary of Statistics; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Kaczor, S.; Kryvinska, N. It is all about Services - Fundamentals, Drivers, and Business Models. J. Serv. Sci. Res. 2013, 5, 125–154. [Google Scholar] [CrossRef]
- Niemeyer, P.; Knudsen, J. Learning Java; O’Reilly & Associates: Sebastopol, CA, USA, 2000. [Google Scholar]
- Batyuk, A.; Voityshyn, V.; Verhun, V. Software Architecture Design of the Real-Time Processes Monitoring Platform. In Proceedings of the Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 98–101. [Google Scholar]
- Molnár, E.; Molnár, R.; Kryvinska, N.; Greguš, M. Web Intelligence in practice. J. Serv. Sci. Res. 2014, 6, 149–172. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Compared Texts by Different Authors | Author-Differentiatng Capability |
|---|---|
| Obama-Trump | + |
| Obama-Webster | + |
| Obama-Logan | + |
| Trump-Webster | + |
| Trump-Logan | - |
| Webster-Logan | + |
| Bronte-Bronte | + |
| Compared Texts by Different Authors | Author-Differentiatng Capability |
|---|---|
| Obama-Trump | - |
| Obama-Webster | + |
| Obama-Logan | + |
| Trump-Webster | + |
| Trump-Logan | - |
| Webster-Logan | + |
| Bronte-Bronte | + |
| Compared Texts by Different Authors | Author-Differentiating Capability |
|---|---|
| Obama-Trump | + |
| Obama-Webster | + |
| Obama-Logan | - |
| Trump-Webster | + |
| Trump-Logan | + |
| Webster-Logan | + |
| Bronte-Bronte | - |
| Compared Texts by Different Authors | Author-Differentiating Capability |
|---|---|
| Obama-Trump | - |
| Obama-Webster | + |
| Obama-Logan | + |
| Trump-Webster | - |
| Trump-Logan | + |
| Webster-Logan | - |
| Bronte-Bronte | + |
| Consonant Group | Author Differentiating Capability (ADC) |
|---|---|
| stop | 0.86 |
| nasal | 0.71 |
| sonorous | 0.71 |
| coronal | 0.57 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khomytska, I.; Teslyuk, V.; Kryvinska, N.; Bazylevych, I. Software-Based Approach towards Automated Authorship Acknowledgement—Chi-Square Test on One Consonant Group. Electronics 2020, 9, 1138. https://doi.org/10.3390/electronics9071138
Khomytska I, Teslyuk V, Kryvinska N, Bazylevych I. Software-Based Approach towards Automated Authorship Acknowledgement—Chi-Square Test on One Consonant Group. Electronics. 2020; 9(7):1138. https://doi.org/10.3390/electronics9071138
Chicago/Turabian StyleKhomytska, Iryna, Vasyl Teslyuk, Natalia Kryvinska, and Iryna Bazylevych. 2020. "Software-Based Approach towards Automated Authorship Acknowledgement—Chi-Square Test on One Consonant Group" Electronics 9, no. 7: 1138. https://doi.org/10.3390/electronics9071138
APA StyleKhomytska, I., Teslyuk, V., Kryvinska, N., & Bazylevych, I. (2020). Software-Based Approach towards Automated Authorship Acknowledgement—Chi-Square Test on One Consonant Group. Electronics, 9(7), 1138. https://doi.org/10.3390/electronics9071138