Open-Source Coprocessor for Integer Multiple Precision Arithmetic


Abstract
:1. Introduction
- Solving ill-conditioned linear systems of equations; many scientific problems involve ill-conditioned linear systems that give rise to numerical errors even when using 64-bit floating-point arithmetic.
- Executing large-scale simulations; computations that are well-behaved on modest-size problems may exhibit significant numerical errors when scaled up to massively parallel systems, because making numerical computations parallel is not trivial [12].
- Resolving small-scale phenomena; very fine-scale resolutions can result in numerical problems.
- ”Experimental mathematics” computations; numerous recent results in experimental mathematics could not be obtained without MPA computations.
- Generation of special mathematical functions applicable in scientific computations (e.g., discrete Green’s function (DGF), Bessel functions, etc.).
- Cryptography and cryptanalysis.
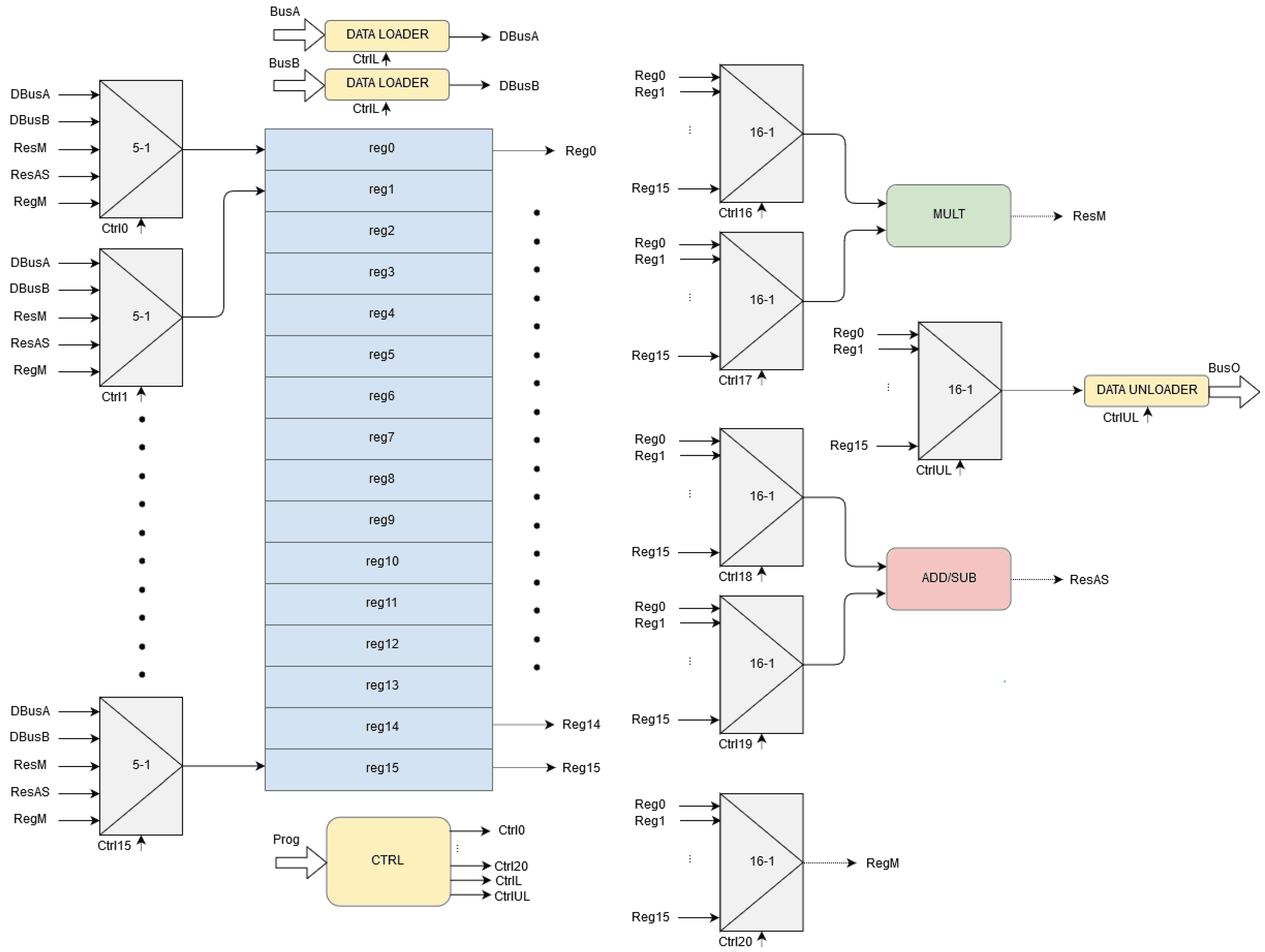
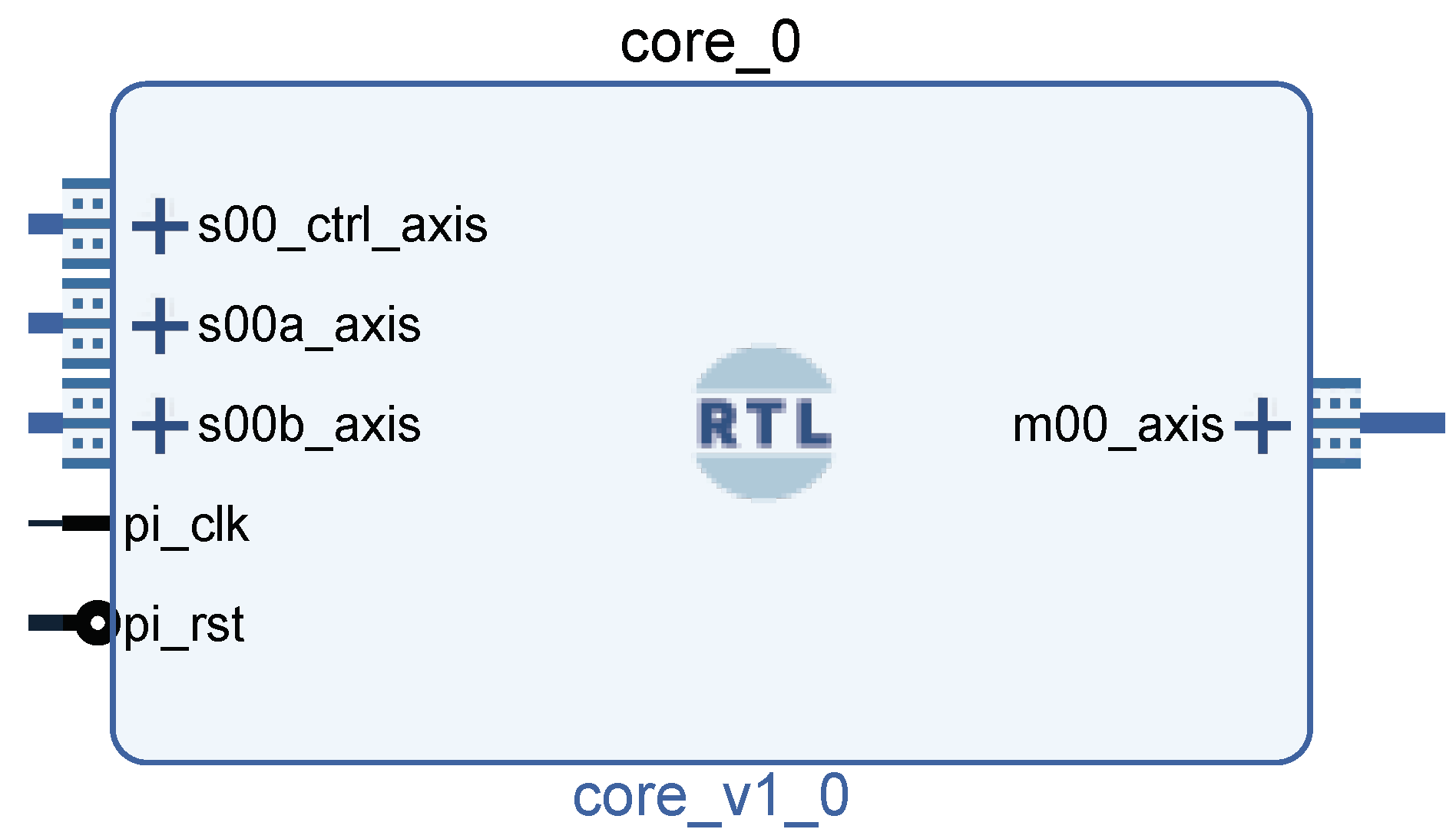
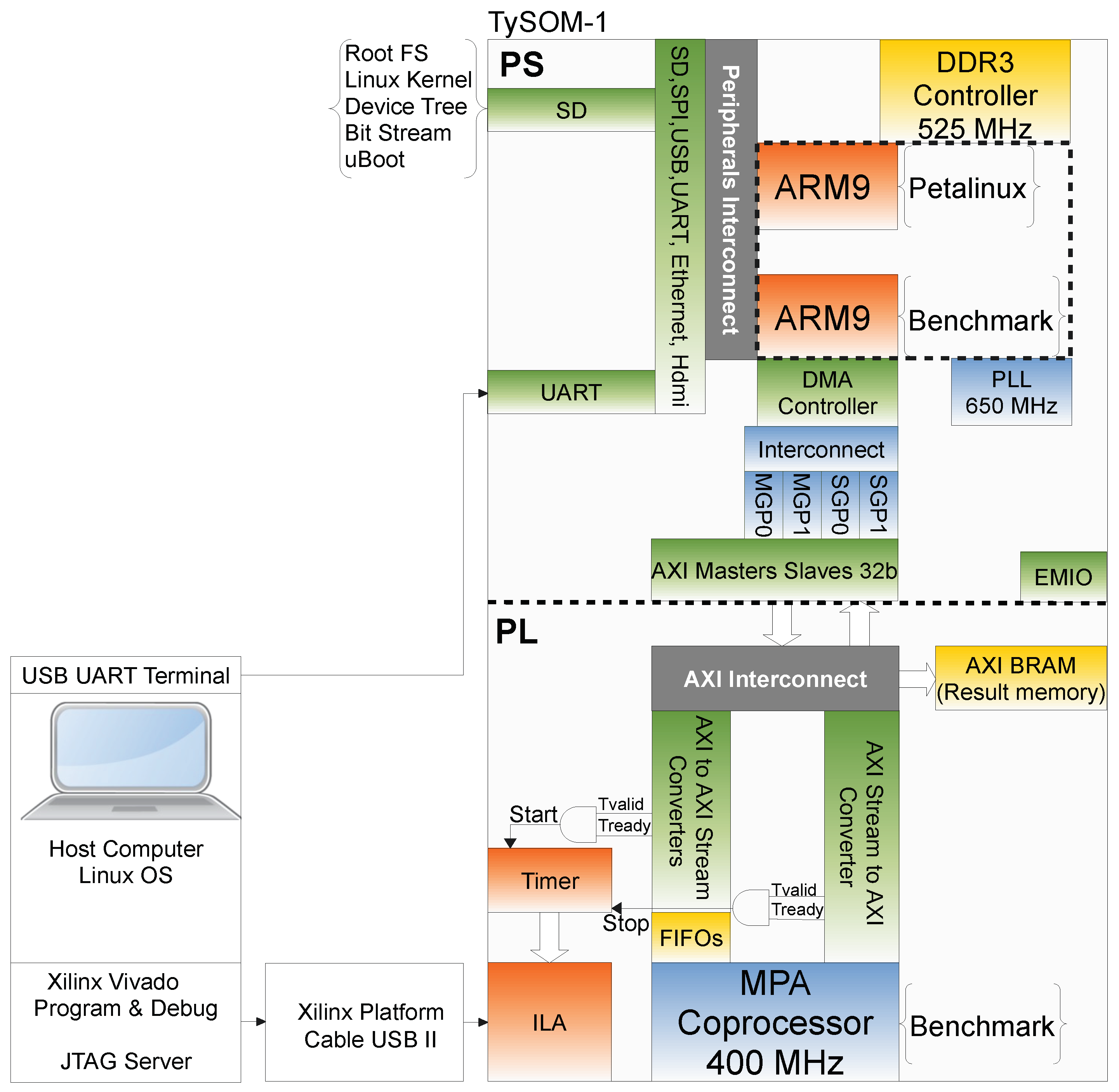
2. Architecture of Coprocessor
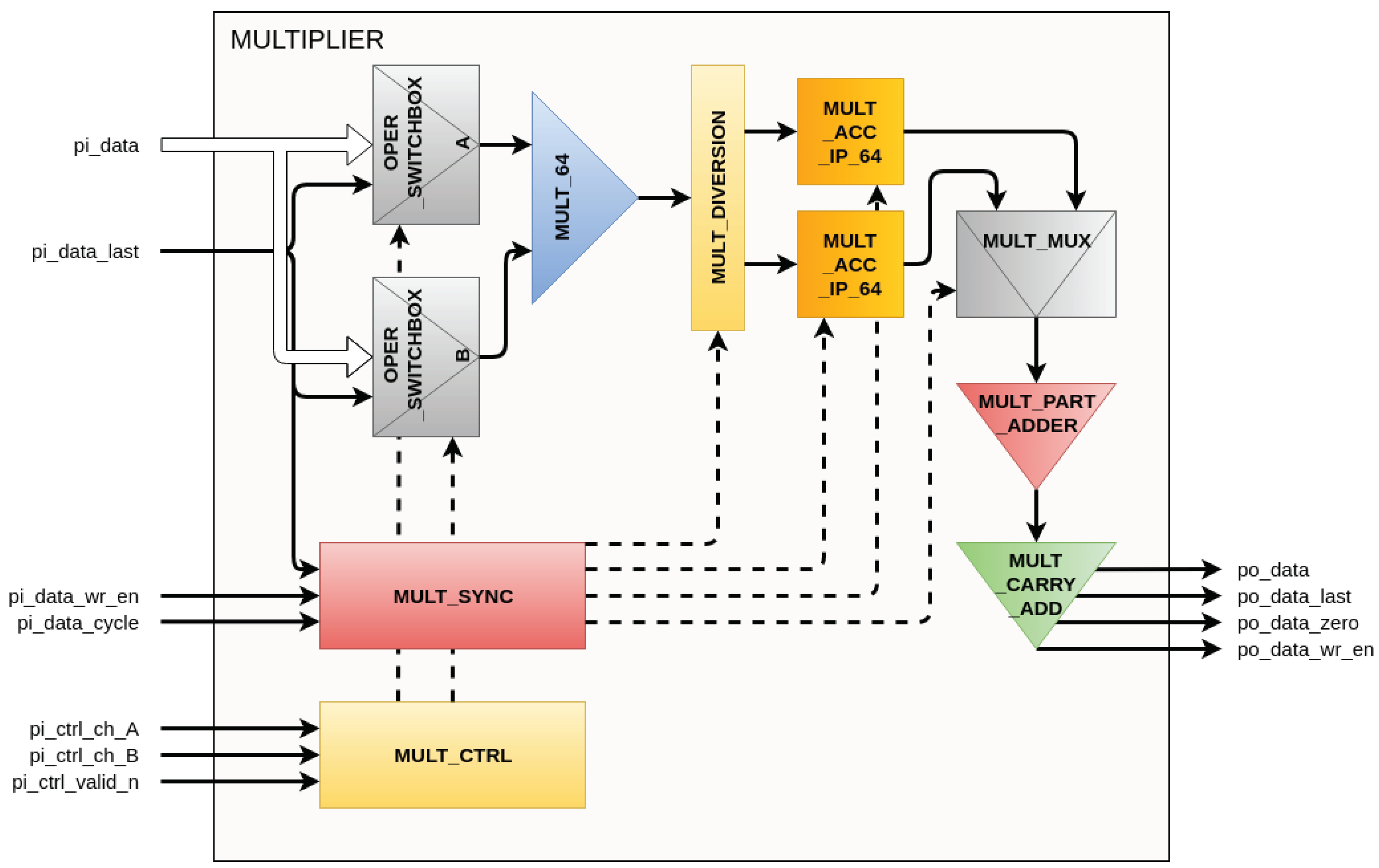
2.1. Multiplier Unit
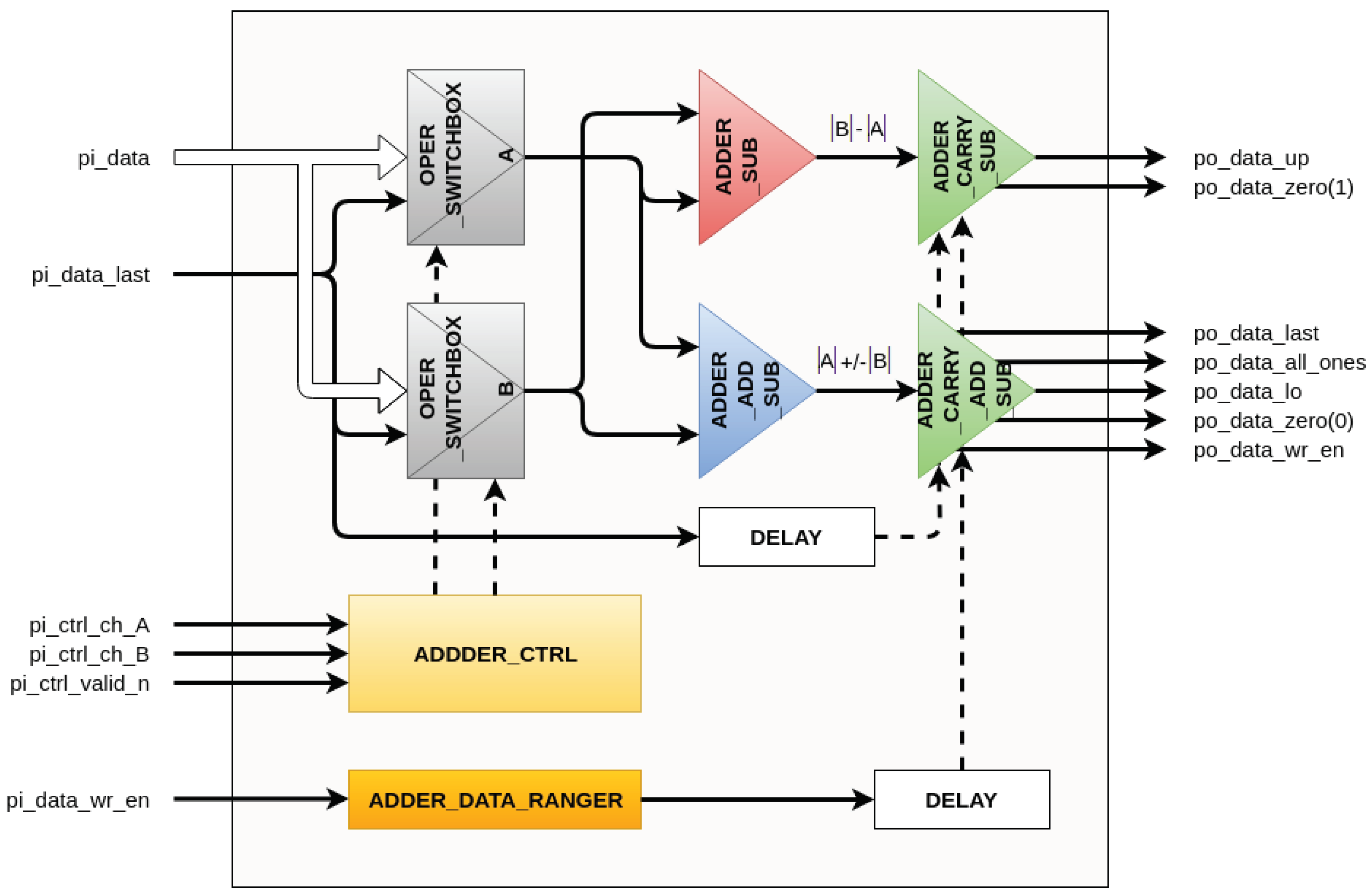
2.2. Adder-Subtractor Unit
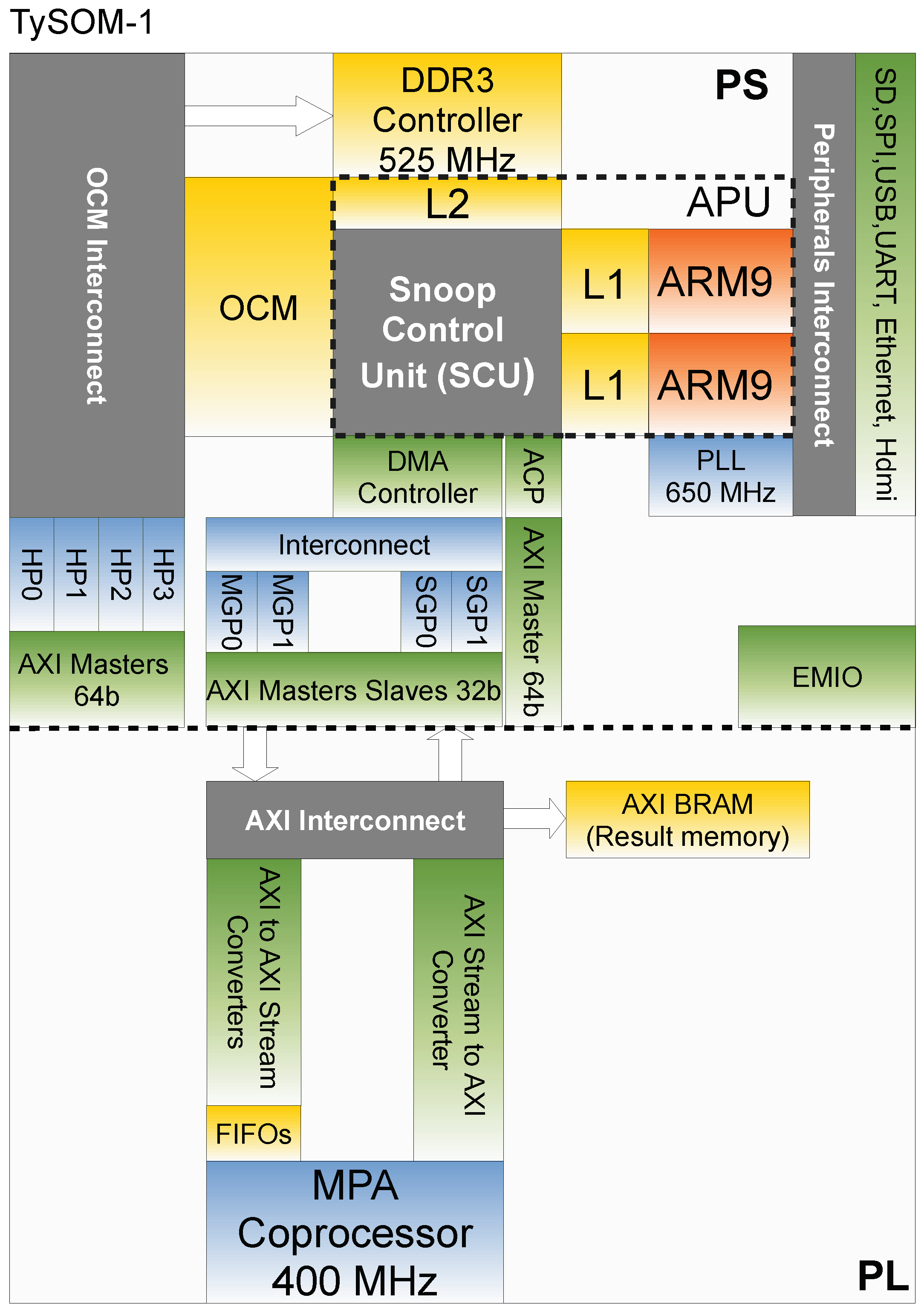
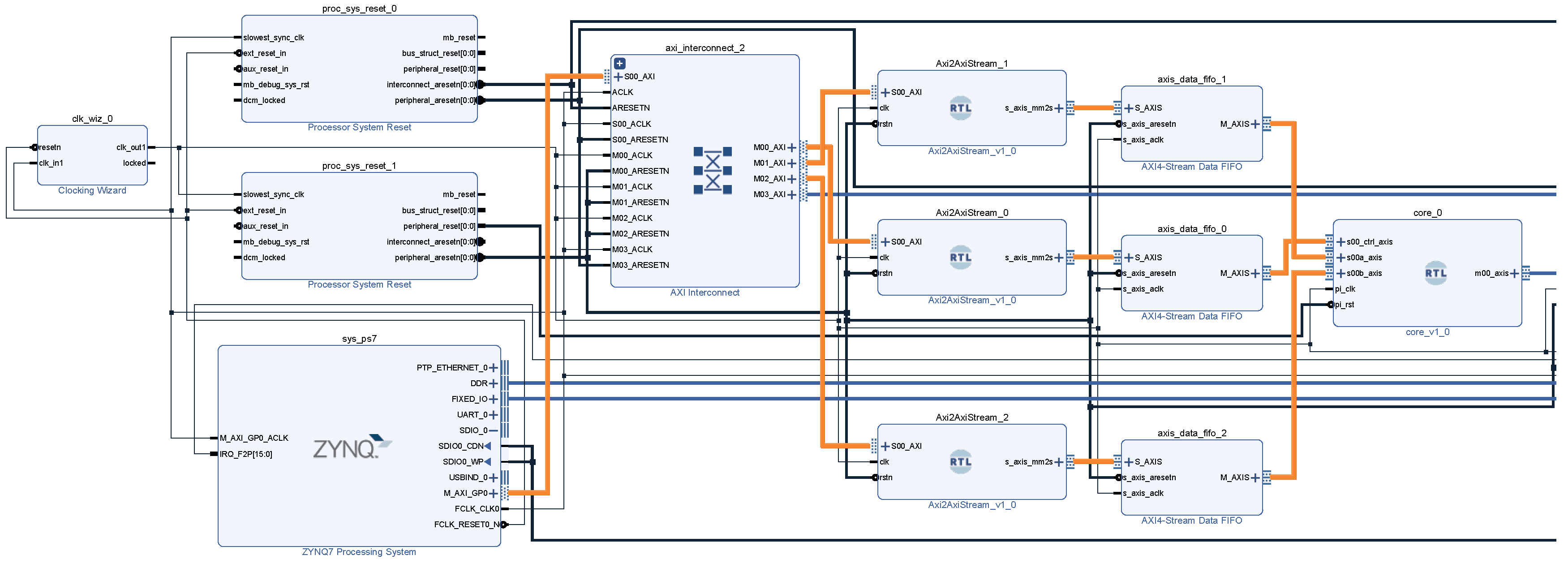
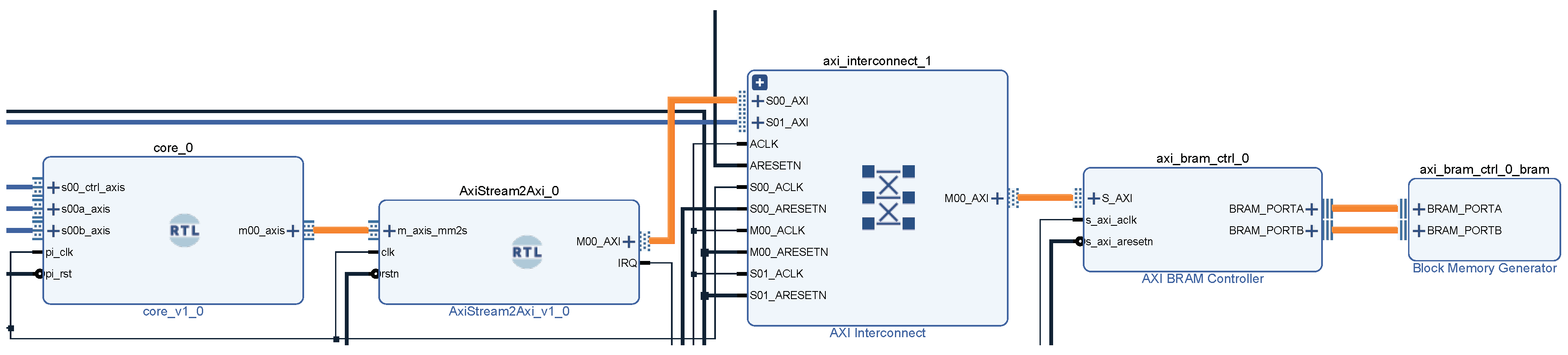
3. Hardware Implementation
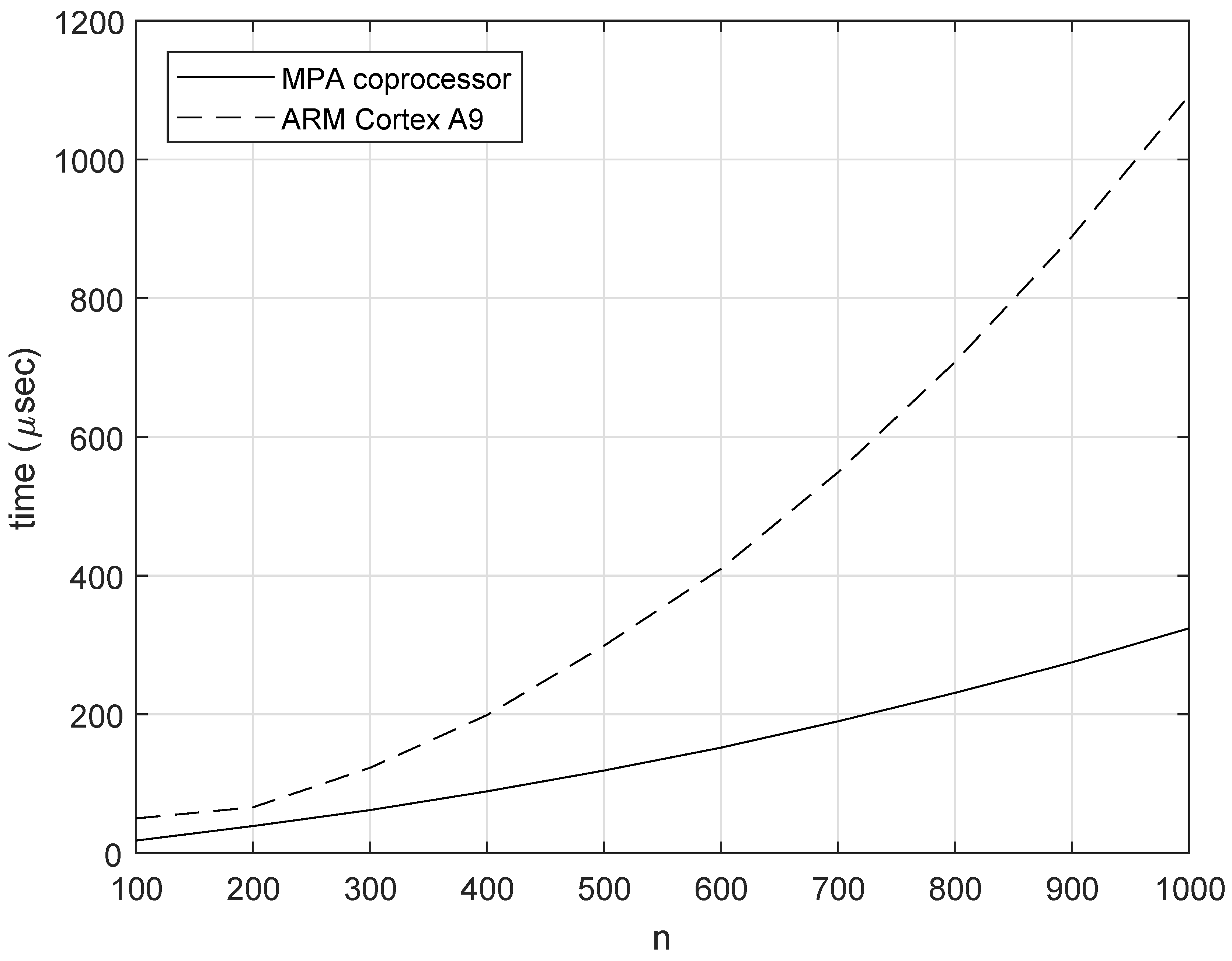
4. Results
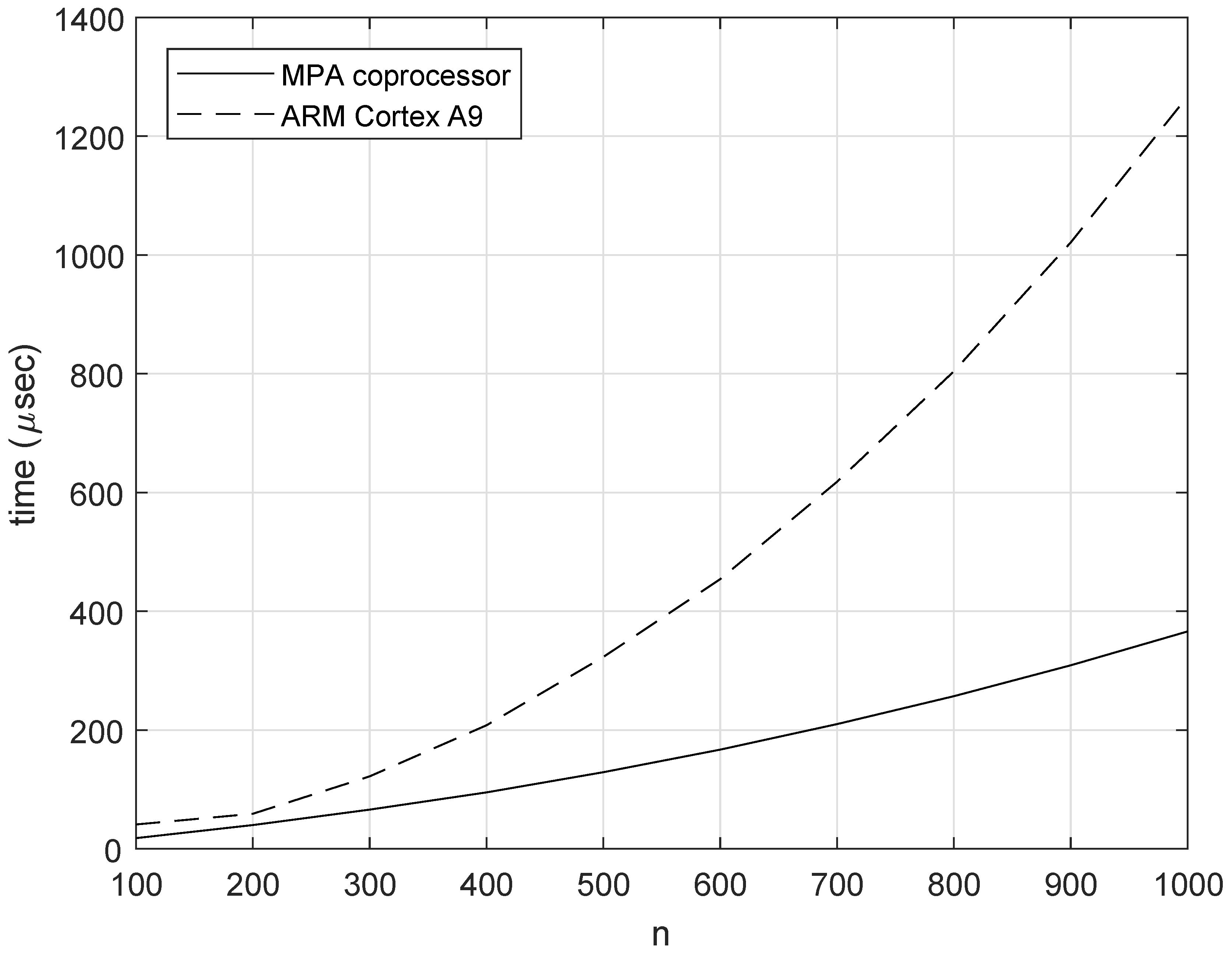
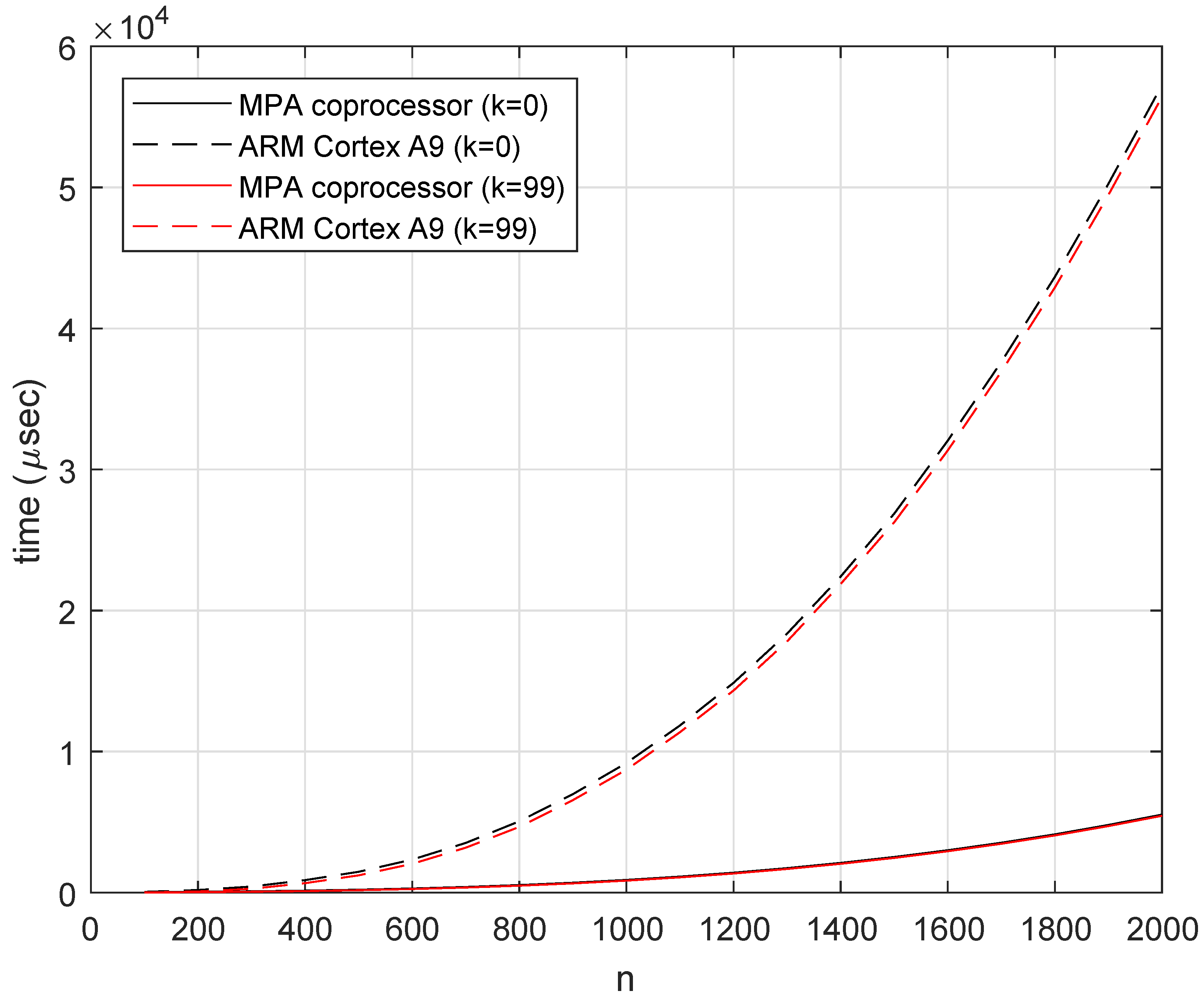
4.1. Computations of Factorial
4.2. Computations of Exponentiation
4.3. Computations of DGF
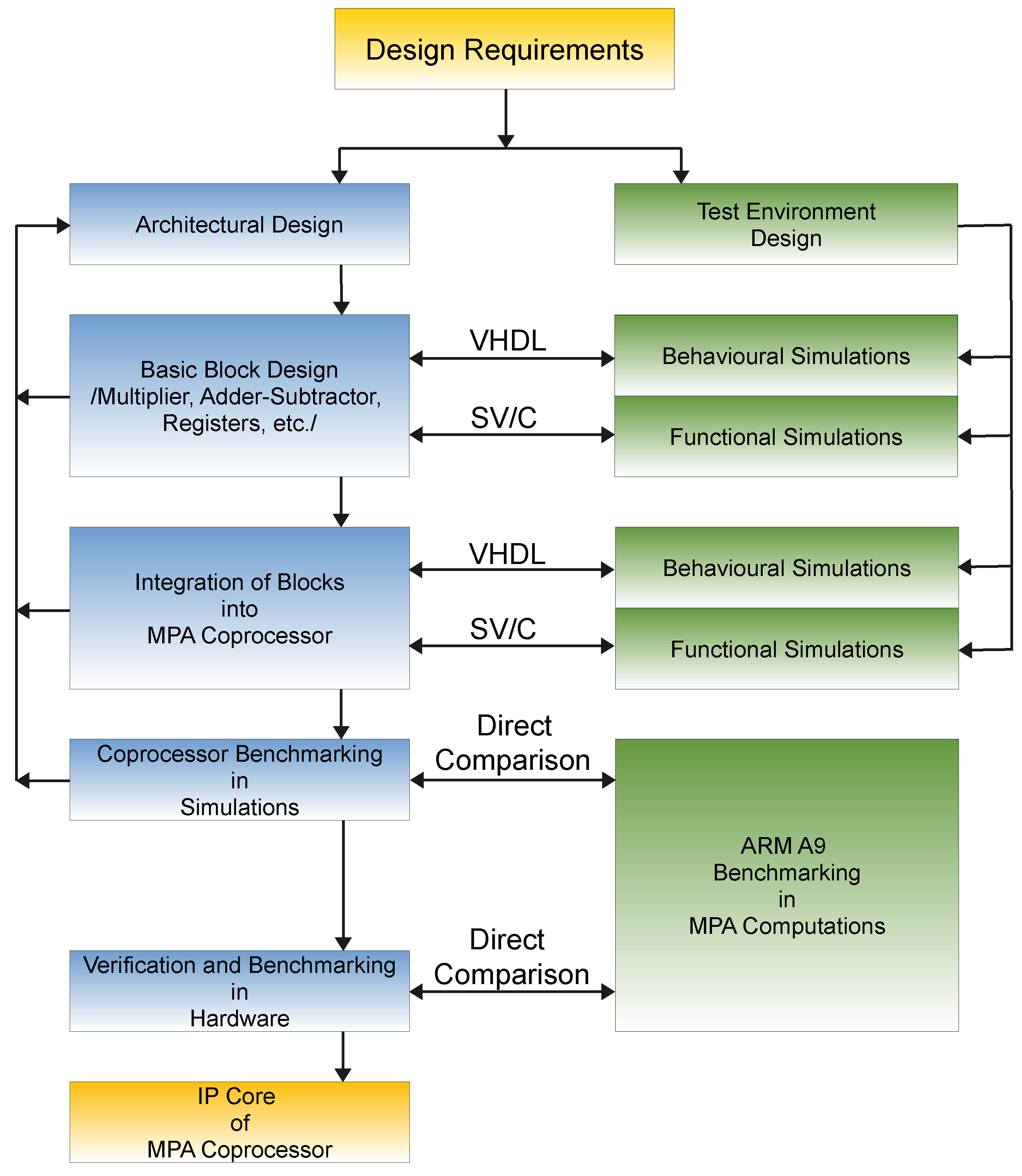
5. Materials and Methods
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bailey, D.; Barrio, R.; Borwein, J. High-precision computation: Mathematical physics and dynamics. Appl. Math. Comput. 2012, 218, 10106–10121. [Google Scholar] [CrossRef] [Green Version]
- Stefański, T.P. Electromagnetic Problems Requiring High-Precision Computations. IEEE Antennas Propag. Mag. 2013, 55, 344–353. [Google Scholar] [CrossRef]
- Stefanski, T.P. Fast Implementation of FDTD-Compatible Green’s Function on Multicore Processor. IEEE Antennas Wirel. Propag. Lett. 2012, 11, 81–84. [Google Scholar] [CrossRef]
- Stefański, T.P.; Krzyzanowska, K. Implementation of FDTD-Compatible Green’s Function on Graphics Processing Unit. IEEE Antennas Wirel. Propag. Lett. 2012, 11, 1422–1425. [Google Scholar] [CrossRef]
- Stefanski, T.P. Implementation of FDTD-Compatible Green’s Function on Heterogeneous Cpu-GPU Parallel Processing System. Prog. Electromagn. Res. 2013, 135, 297–316. [Google Scholar] [CrossRef] [Green Version]
- Ergül, Ö.; ı şcan Karaosmanoğlu, B. Low-Frequency Fast Multipole Method Based on Multiple-Precision Arithmetic. IEEE Antennas Wirel. Propag. Lett. 2014, 13, 975–978. [Google Scholar] [CrossRef]
- Kalfa, M.; Ergül, Ö.; Ertürk, V.B. Error Control of Multiple-Precision MLFMA. IEEE Trans. Antennas Propag. 2018, 66, 5651–5656. [Google Scholar] [CrossRef]
- Kalfa, M.; Ertürk, V.B.; Ergül, Ö. Error Control of MLFMA within a Multiple- Precision Arithmetic Framework. In Proceedings of the 2018 IEEE International Symposium on Antennas and Propagation USNC/URSI National Radio Science Meeting, Boston, MA, USA, 8–13 July 2018; pp. 2299–2300. [Google Scholar]
- Wolfe, J.M. Reducing Truncation Errors by Programming. Commun. ACM 1964, 7, 355–356. [Google Scholar] [CrossRef]
- Kahan, W. Pracniques: Further Remarks on Reducing Truncation Errors. Commun. ACM 1965, 8, 40. [Google Scholar] [CrossRef]
- Goodman, J.; Heggie, D.C.; Hut, P. On the Exponential Instability of N-Body Systems. Astrophys. J. 1993, 415, 715. [Google Scholar] [CrossRef]
- Gustafson, J. The End of Error: Unum Computing; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Tenca, A.F.; Ercegovac, M.D. A variable long-precision arithmetic unit design for reconfigurable coprocessor architectures. In Proceedings of the IEEE Symposium on FPGAs for Custom Computing Machines (Cat. No.98TB100251), Napa Valley, CA, USA, 17 April 1998; pp. 216–225. [Google Scholar] [CrossRef]
- Schulte, M.J.; Swartzlander, E.E. A family of variable-precision interval arithmetic processors. IEEE Trans. Comput. 2000, 49, 387–397. [Google Scholar] [CrossRef]
- Lei, Y.; Dou, Y.; Guo, S.; Zhou, J. FPGA Implementation of Variable-Precision Floating-Point Arithmetic. In Advanced Parallel Processing Technologies; Temam, O., Yew, P.C., Zang, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 127–141. [Google Scholar]
- Daisaka, H.; Nakasato, N.; Makino, J.; Yuasa, F.; Ishikawa, T. GRAPE-MP: An SIMD Accelerator Board for Multi-precision Arithmetic. Procedia Comput. Sci. 2011, 4, 878–887. [Google Scholar] [CrossRef] [Green Version]
- Daisaka, H.; Nakasato, N.; Ishikawa, T.; Yuasa, F. Application of GRAPE9-MPX for High Precision Calculation in Particle Physics and Performance Results. Procedia Comput. Sci. 2015, 51, 1323–1332. [Google Scholar] [CrossRef] [Green Version]
- Bocco, A.; Durand, Y.; De Dinechin, F. SMURF: Scalar Multiple-Precision Unum Risc-V Floating-Point Accelerator for Scientific Computing. In CoNGA’19, Proceedings of the Conference for Next Generation Arithmetic 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Bocco, A.; Durand, Y.; de Dinechin, F. Dynamic Precision Numerics Using a Variable-Precision UNUM Type I HW Coprocessor. In Proceedings of the 2019 IEEE 26th Symposium on Computer Arithmetic (ARITH), Kyoto, Japan, 10–12 June 2019; pp. 104–107. [Google Scholar]
- Bocco, A.; Jost, T.T.; Cohen, A.; de Dinechin, F.; Durand, Y.; Fabre, C. Byte-Aware Floating-point Operations through a UNUM Computing Unit. In Proceedings of the 2019 IFIP/IEEE 27th International Conference on Very Large Scale Integration (VLSI-SoC), Cuzco, Peru, 6–9 October 2019; pp. 323–328. [Google Scholar]
- Asanović, K.; Avizienis, R.; Bachrach, J.; Beamer, S.; Biancolin, D.; Celio, C.; Cook, H.; Dabbelt, D.; Hauser, J.; Izraelevitz, A.; et al. The Rocket Chip Generator; Technical Report UCB/EECS-2016-17; EECS Department, University of California: Berkeley, CA, USA, 2016. [Google Scholar]
- Rudnicki, K.; Stefański, T.P. FPGA implementation of the multiplication operation in multiple-precision arithmetic. In Proceedings of the 2017 MIXDES—24th International Conference Mixed Design of Integrated Circuits and Systems, Bydgoszcz, Poland, 22–24 June 2017; pp. 271–275. [Google Scholar] [CrossRef]
- Rudnicki, K.; Stefanski, T.P. IP Core of Coprocessor for Multiple-Precision-Arithmetic Computations. In Proceedings of the 2018 25th International Conference Mixed Design of Integrated Circuits and System (MIXDES), Gdynia, Poland, 21–23 June 2018; pp. 416–419. [Google Scholar] [CrossRef]
- Rudnicki, K.; Stefanski, T.P. Implementation of Addition and Subtraction Operations in Multiple Precision Arithmetic. In Proceedings of the 2019 26th International Conference Mixed Design of Integrated Circuits and System (MIXDES), Rzeszów, Poland, 27–29 June 2019. [Google Scholar]
- Xilinx Inc. Zynq-7000 All Programmable SoC Data Sheet: Overview—Product Specification. 2017. Available online: www.xilinx.com (accessed on 8 August 2019).
- Rudnicki, K.; Stefański, T.P.; Żebrowski, W. Integer-MPA-Coprocessor. 2020. Available online: https://github.com/stafan26/integer-MPA-coprocessor (accessed on 13 July 2020).
- Aldec Inc. TySOM-1-7Z030—Technical Specification, Revision 1.7. 2017. Available online: www.aldec.com (accessed on 8 August 2019).
- Xilinx Inc. Vivado Design Suite—AXI Reference Guide, UG1037 (v4.0). 2017. Available online: www.xilinx.com (accessed on 8 August 2019).
- Granlund, T.; GMP Development Team. The GNU Multiple Precision Arithmetic Library (Edition 6.1.2). 2016. Available online: www.gmplib.org (accessed on 8 August 2019).
- Xilinx Inc. 7 Series DSP48E1 Slice—User Guide, UG479 (v1.10). 2018. Available online: www.xilinx.com (accessed on 8 August 2019).
- Xilinx Inc. Vivado Design Suite User Guide—Getting Started, UG910 (v2018.3). 2018. Available online: www.xilinx.com (accessed on 8 August 2019).
- Gulgowski, J.; Stefański, T.P. Recurrence scheme for FDTD-compatible discrete Green’s function derived based on properties of Gauss hypergeometric function. J. Electromagn. Waves Appl. 2019, 33, 637–653. [Google Scholar] [CrossRef]
- Taflove, A.; Hagness, S.C. Computational Electrodynamics: The Finite-Difference Time-Domain Method, 3rd ed.; Artech House: Norwood, MA, USA, 2005. [Google Scholar]
- Aldec Inc. Riviera-PRO Manual. 2017. Available online: www.aldec.com (accessed on 8 August 2019).
- Xilinx Inc. Integrated Logic Analyzer v6.2—LogiCORE IP Product Guide, PG172. 2016. Available online: www.xilinx.com (accessed on 8 August 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instruction | Result |
|---|---|
| loaa regX | regX = data (busA) |
| loab regX | regX = data (busB) |
| loaab regX, regY | regX = data (busA) and regY = data (busB) |
| unl regX | data (busO) = regX |
| mult regX, regY, regZ | regZ = regX * regY |
| add regX, regY, regZ | regZ = regX + regY |
| sub regX, regY, regZ | regZ = regX − regY |
| |A| vs. |B| | A Sign | B Sign | Example | Correct Sign | Operations | Result Sign | Result Taken | Sign Change |
|---|---|---|---|---|---|---|---|---|
| |A|>|B| | A⩾ 0 | B⩾ 0 | 5 + 2 = 7 | + | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + − | √ × | × |
| |A|>|B| | A⩾ 0 | B< 0 | 5 + (−2) = 3 | + | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | + − | √ × | × |
| |A|>|B| | A< 0 | B⩾ 0 | −5 + 2 = 3 | − | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | + − | √ × | √ |
| |A|>|B| | A< 0 | B< 0 | −5 + (−2) = −7 | − | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + − | √ × | √ |
| |A|=|B| | A⩾ 0 | B⩾ 0 | 3 + 3 = 6 | + | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A|= 0 | + + | √ × | × |
| |A|=|B| | A⩾ 0 | B< 0 | 3 + (−3) = 0 | + (0) | ADDER_ADD_SUB: |A|−|B|= 0 ADDER_SUB: |B|−|A|= 0 | + + | √ × | × |
| |A|=|B| | A< 0 | B⩾ 0 | −3 + 3 = 0 | + (0) | ADDER_ADD_SUB: |A|−|B|= 0 ADDER_SUB: |B|−|A|= 0 | + + | √ × | × |
| |A|=|B| | A< 0 | B< 0 | −3 + (−3) = −6 | − | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A|= 0 | + + | √ × | √ |
| |A|<|B| | A⩾ 0 | B⩾ 0 | 2 + 5 = 7 | + | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + + | √ × | × |
| |A|<|B| | A⩾ 0 | B< 0 | 2 + (−5) = −3 | − | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | − + | × √ | √ |
| |A|<|B| | A< 0 | B⩾ 0 | −2 + 5 = 3 | + | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | − + | × √ | × |
| |A|<|B| | A< 0 | B< 0 | −2 + (−5) = −7 | − | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + + | √ × | √ |
| |A| vs. |B| | A Sign | B Sign | Example | Correct Sign | Operations | Result Sign | Result Taken | Sign Change |
|---|---|---|---|---|---|---|---|---|
| |A|>|B| | A⩾ 0 | B⩾ 0 | 5 − 2 = 3 | + | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | + − | √ × | × |
| |A|>|B| | A⩾ 0 | B< 0 | 5− (−2) = 7 | + | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + − | √ × | × |
| |A|>|B| | A< 0 | B⩾ 0 | −5 − 2 = −7 | − | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + − | √ × | √ |
| |A|>|B| | A< 0 | B< 0 | −5 − (−2) = −3 | − | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | + − | √ × | √ |
| |A|=|B| | A⩾ 0 | B⩾ 0 | 3 − 3 = 0 | + (0) | ADDER_ADD_SUB: |A|−|B|= 0 ADDER_SUB: |B|−|A|= 0 | + + | √ × | × |
| |A|=|B| | A⩾ 0 | B< 0 | 3 − (−3) = 6 | + | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A|= 0 | + + | √ × | × |
| |A|=|B| | A< 0 | B⩾ 0 | −3 − 3 = −6 | − | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A|= 0 | + + | √ × | √ |
| |A|=|B| | A< 0 | B< 0 | −3 − (−3) = 0 | + (0) | ADDER_ADD_SUB: |A|−|B|= 0 ADDER_SUB: |B|−|A|= 0 | + + | √ × | × |
| |A|<|B| | A⩾ 0 | B⩾ 0 | 2 − 5 = −3 | − | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | − + | × √ | √ |
| |A|<|B| | A⩾ 0 | B< 0 | 2 − (−5) = 7 | + | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + + | √ × | × |
| |A|<|B| | A< 0 | B⩾ 0 | −2 − 5 = −7 | − | ADDER_ADD_SUB: |A|+|B| ADDER_SUB: |B|−|A| | + + | √ × | √ |
| |A|<|B| | A< 0 | B< 0 | −2 − (−5) = 3 | + | ADDER_ADD_SUB: |A|−|B| ADDER_SUB: |B|−|A| | − + | × √ | × |
| MPA Coprocessor | Alone | With Infrastructure | ||||
|---|---|---|---|---|---|---|
| Resources | Used | Available | Utilization (%) | Used | Available | Utilization (%) |
| slice LUTs | 8745 | 78,600 | 11.13 | 15,735 | 78,600 | 20.02 |
| LUT as logic | 8673 | 78,600 | 11.03 | 14,238 | 78,600 | 18.11 |
| LUT as memory | 72 | 26,600 | 0.27 | 1497 | 26,600 | 5.63 |
| slice registers | 16,249 | 157,200 | 10.34 | 27,708 | 157,200 | 17.63 |
| register as flip flop | 16,249 | 157,200 | 10.34 | 27,705 | 157,200 | 17.62 |
| register as latch | 0 | 157,200 | 0 | 3 | 157,200 | <0.01 |
| F7 muxes | 482 | 39,300 | 1.23 | 813 | 39,300 | 2.07 |
| F8 muxes | 66 | 19,650 | 0.34 | 98 | 19,650 | 0.50 |
| block RAM tile | 18 | 265 | 6.79 | 27 | 265 | 10.19 |
| RAMB36/FIFO | 18 | 265 | 6.79 | 27 | 265 | 10.19 |
| DSPs | 34 | 400 | 8.50 | 34 | 400 | 8.50 |
| Line | Instruction |
|---|---|
| 1 | loaab reg0, reg2; |
| 2 | loaa reg3; |
| 3 | add reg2, reg3, reg4; |
| 4 | mult reg4, reg0, reg1; |
| 5 | add reg4, reg3, reg2; |
| 6 | mult reg2, reg1, reg0; |
| 7 | add reg2, reg3, reg4; |
| 8 | mult reg4, reg0, reg1; |
| 9 | unl reg1; |
| Line | Instruction |
|---|---|
| 1 | loaab reg0, reg1; |
| 2 | mult reg0, reg1, reg2; |
| 3 | mult reg2, reg1, reg0; |
| 4 | mult reg0, reg1, reg2; |
| 5 | unl reg2; |
| Line | Instruction |
|---|---|
| 1 | loaa reg4; |
| 2 | loaab reg0, reg1; |
| 3 | mult reg0, reg1, reg2; |
| 4 | add reg4, reg2, reg3; |
| 5 | loaab reg0, reg1; |
| 6 | mult reg0, reg1, reg2; |
| 7 | sub reg3, reg2, reg4; |
| 8 | loaab reg0, reg1; |
| 9 | mult reg0, reg1, reg2; |
| 10 | add reg4, reg2, reg3; |
| 11 | loaab reg0, reg1; |
| 12 | mult reg0, reg1, reg2; |
| 13 | sub reg3, reg2, reg4; |
| 14 | unl reg4; |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rudnicki, K.; Stefański, T.P.; Żebrowski, W. Open-Source Coprocessor for Integer Multiple Precision Arithmetic. Electronics 2020, 9, 1141. https://doi.org/10.3390/electronics9071141
Rudnicki K, Stefański TP, Żebrowski W. Open-Source Coprocessor for Integer Multiple Precision Arithmetic. Electronics. 2020; 9(7):1141. https://doi.org/10.3390/electronics9071141
Chicago/Turabian StyleRudnicki, Kamil, Tomasz P. Stefański, and Wojciech Żebrowski. 2020. "Open-Source Coprocessor for Integer Multiple Precision Arithmetic" Electronics 9, no. 7: 1141. https://doi.org/10.3390/electronics9071141
APA StyleRudnicki, K., Stefański, T. P., & Żebrowski, W. (2020). Open-Source Coprocessor for Integer Multiple Precision Arithmetic. Electronics, 9(7), 1141. https://doi.org/10.3390/electronics9071141