
Cosmological Parameter Estimation with Genetic Algorithms

 , and
, and
Abstract
:1. Introduction
2. Fundamentals of Genetic Algorithms
2.1. Biological Fundamentals
- Natural selection—This is the central principle in the theory of evolution. Just as better-adapted organisms are more likely to survive and reproduce in nature, GAs favor the fittest or most promising solutions from a population of candidate solutions. In nature, over several generations, the most promising characteristics of individuals survive to be inherited by the new generations. This is what genetic algorithms seek to do to have better solutions as more generations pass by.
- Crossing—Also called recombination, it is a process in which genes from two parents are combined to create offspring with characteristics inherited from both parents. GAs apply the idea of crossover by combining partial solutions from two individuals in the population to generate new solutions that can inherit desirable characteristics from both parents.
- Mutation—A mutation is recognized as the stochastic alterations in an organism’s genetic material. In the GAs, a mutation introduces random changes in a small part of the candidate solutions, e.g., it may change the value of a bit, which increases the diversity of possible solutions and improves the exploration of the search space.
- Reproduction and inheritance—In the same sense as in nature, in genetic algorithms, these operations allow for the transmission of some characteristics of the parent solutions to the solutions of the next generation (offspring).
2.2. Genetic Algorithm Operations
- Crossover—It is also called recombination, which generates a new possible solution given two previously selected parents. There are several crossover methods, such as one point, two points, N points, uniform, three parents, random, and order. The crossover operation has an associated probability () that determines how many individuals recombine given the population, with indicating that all the products come from the recombination and , meaning they are exact copies of the parents.
- Mutation—After crossover, mutations make it possible to maintain diversity in the population and prevent it from stagnating at the local optima [72]. There are several types of mutation operators, such as flipping a gene if it is in the same position as in the parent; swapping values at random positions; flipping values from left to right, or in a random sequence; and shuffling random positions. Mutation also has a probability associated with it that indicates how likely it is to randomly change a gene (bit) of a possible solution. The mutation value must be low for an efficient search within the genetic algorithm1.
- Replacement—The last step is the replacement, which keeps the population size constant by eliminating individuals after recombination. There are three methods: strong replacement (random), weak replacement (the two fittest), and replacing both parents (the children replace both parents).
- Elitism and Hall-of-Fame—The elitism method ensures that the best individuals are not discarded but transferred directly to the next generation. Hall-of-Fame is an integer that indicates how many individuals are considered under elitism to be retained in the next generation. Elitism is necessary to ensure that genetic algorithms always find the best solution [19]. Elitism and Hall-of-Fame are often considered distinct from the general replacement strategy. While the replacement strategy primarily focuses on selecting individuals for reproduction and forming the next generation, the elitism and Hall-of-Fame mechanisms specifically address preserving the best-performing individuals.
- Stopping criteria—A mechanism is needed to finalize the execution of the genetic algorithm. Some ways to perform it are to stop after a fixed number of generations, after a specific time-lapse, to finish the process if the best fitness does not change for several generations (steady fitness), or to stop it if there are no improvements in the objective function for several consecutive generations (generation stagnation).
2.3. Schema Theorem
3. Genetic Algorithm Application
| Algorithm 1 Simple Genetic Algorithm |
Parents ← {randomly generated population} While not (termination) Calculate the fitness of each parent in the population Children while |Children| < |Parents| Use fitness to probabilistically select a pair of parents for mating Mate the parents to create children and Children ← Children Loop Randomly mutate some of the children Parents ← Children Next generation |
3.1. Single Variable Functions
- ;
- ;
- .
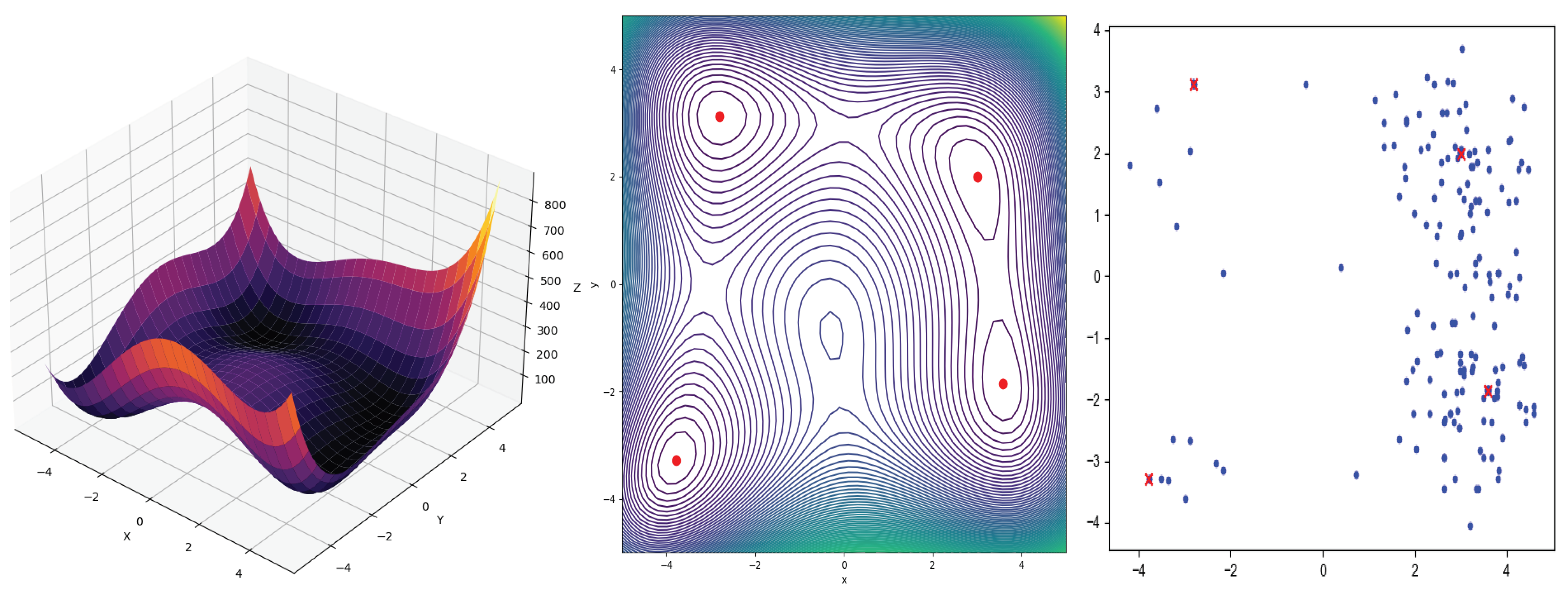
3.2. Multimodal Functions
3.3. Statistical Analysis
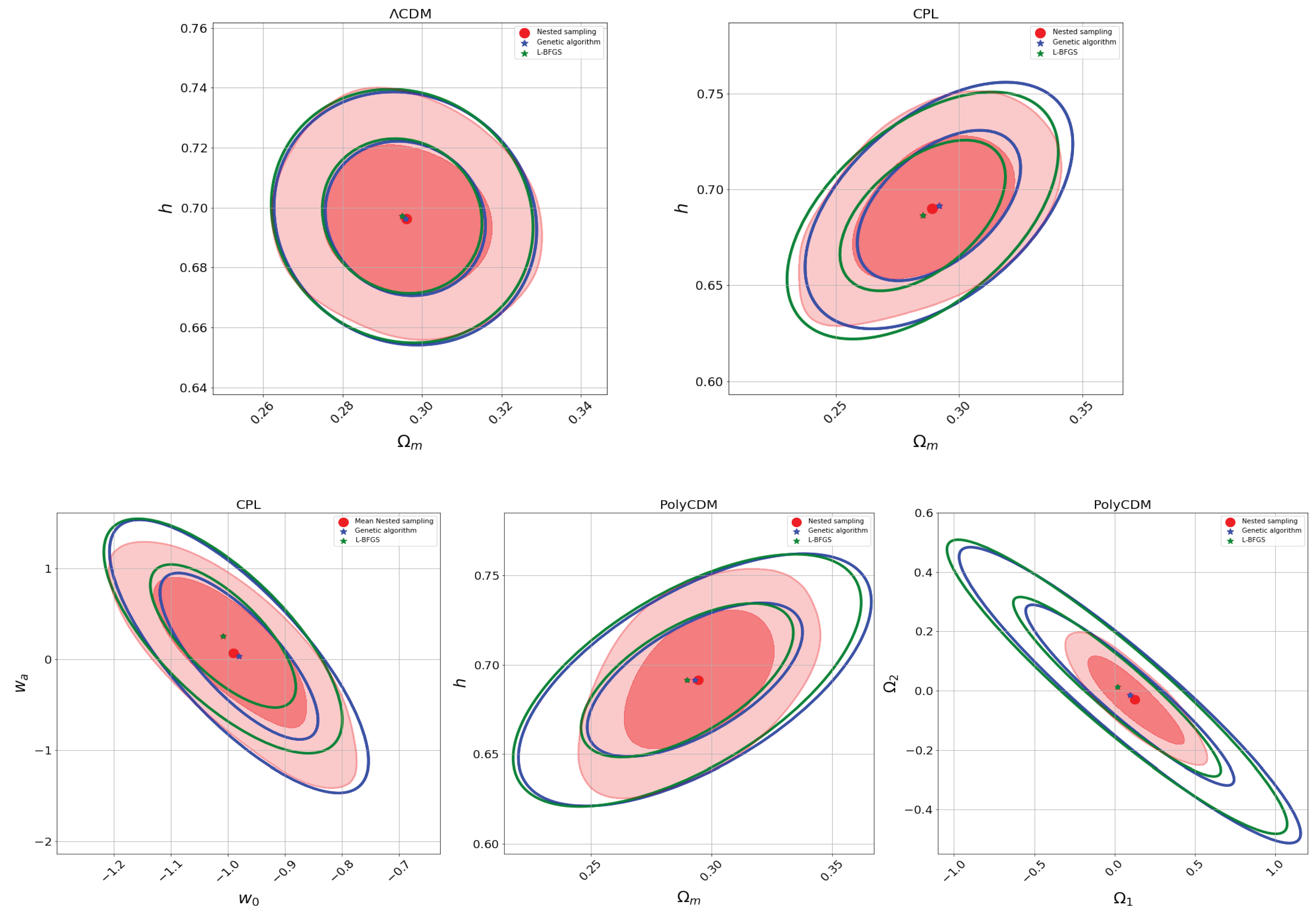
4. Application in Cosmology
4.1. Cosmological Parameter Estimation
- CDM. The CDM model serves as the standard cosmological model and comprises two primary components: cold dark matter (CDM), which plays a pivotal role in the universe’s structure formation, and dark energy, which exhibits a counter-gravitational behavior, leading to the universe’s accelerated expansion. The cosmological constant, denoted by , is the simplest and most straightforward representation of dark energy, which exerts a pressure equal in magnitude but opposite in sign to the universe’s energy density (). For a flat universe in the late stages of its evolution, the equation governing its expansion is given by , where a represents the scale factor, the dot denotes the derivative with respect to time, signifies the density of dark matter and baryons, and accounts for the dark energy content in the form of a cosmological constant. These two parameters describe the evolution of the universe’s content. Incorporating their initial conditions denoted with a subscript 0, this equation can be re-expressed in terms of the redshift as follows:where denotes the Hubble constant, providing the present rate of expansion of the universe. The parameters and are specific to the CDM model. The former represents the current dimensionless density of dark matter (plus baryons), while the latter signifies the dimensionless density of dark energy. These parameters are subject to the constraint ; when this equality holds, we have a flat universe [105]. Consequently, for this model, we effectively have two free parameters, namely, h and , which we simplify by denoting as for brevity.
- CPL model. One can discern dark energy’s characteristics by investigating its state equation, denoted as , where p and represent the pressure and dark energy density, respectively [106]. Chevallier, Polarski, and Linder introduced the following parametrization for the equation of state, , where signifies the current value of the equation of state. In contrast, represents its rate of change over time [106]. This equation of state leads to the following derivation:Now, the parameter estimation consists of finding the free parameters , , and and .
- PolyCDM. We can consider an extension of dynamical dark energy by introducing spatial curvature, , which adapts to the evolution of dark energy at low redshifts [41]. By performing a Taylor series expansion of the Equation (4) [107], we arrive at the PolyCDM model:where represents the dark matter; and baryon, contribution, and can be interpreted as the “lost matter” [107]. PolyCDM can be considered a parametrization of the Hubble parameter [108].
4.2. Multimodal Models
4.3. Derived Functions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | Let us consider a binary representation of a genetic algorithm where each individual is a sequence of binary values representing a potential solution. Suppose an individual’s chromosome (binary sequence) is 101010. A mutation operation might involve flipping one of the bits, resulting in a new chromosome, like 111010 or 100010. A mutation probability determines the choice of which bit to flip. If the mutation probability is low, only a few bits are expected to change, maintaining some of the original information. This process introduces diversity in the population, allowing the algorithm to explore different regions of the search space and preventing premature convergence to suboptimal solutions. In a genetic algorithm, a bit denotes the smallest unit of information representing a decision within a solution. Unlike a bit in memory, it symbolizes binary choices in a solution space rather than directly storing data. |
| 2 | https://igomezv.github.io/SimpleMC (accessed on 18 December 2023). |
References
- Srinivas, M.; Patnaik, L.M. Genetic algorithms: A survey. Computer 1994, 27, 17–26. [Google Scholar] [CrossRef]
- Tomassini, M. A survey of genetic algorithms. In Annual Reviews of Computational Physics III; World Scientific: Singapore, 1995; pp. 87–118. [Google Scholar]
- Mitchell, M. Genetic algorithms: An overview. Complex 1995, 1, 31–39. [Google Scholar] [CrossRef]
- Kumar, M.; Husain, M.; Upreti, N.; Gupta, D. Genetic Algorithm: Review and Application; SSRN: New York, NY, USA, 2010. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Dumitrescu, D.; Lazzerini, B.; Jain, L.C.; Dumitrescu, A. Evolutionary Computation; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Yang, X.S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: Bristol, UK, 2010. [Google Scholar]
- Sadeeq, H.T.; Abdulazeez, A.M. Metaheuristics: A Review of Algorithms. Int. J. Online Biomed. Eng. 2023, 19, 142–164. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Sadeeq, H.T.; Abdulazeez, A.M. Giant trevally optimizer (GTO): A novel metaheuristic algorithm for global optimization and challenging engineering problems. IEEE Access 2022, 10, 121615–121640. [Google Scholar] [CrossRef]
- Sadeeq, H.T.; Abdulazeez, A.M. Car side impact design optimization problem using giant trevally optimizer. Structures 2023, 55, 39–45. [Google Scholar] [CrossRef]
- Hashish, M.S.; Hasanien, H.M.; Ullah, Z.; Alkuhayli, A.; Badr, A.O. Giant Trevally Optimization Approach for Probabilistic Optimal Power Flow of Power Systems Including Renewable Energy Systems Uncertainty. Sustainability 2023, 15, 13283. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Q.; Zhang, Z.; Mirjalili, S.; Zhao, W. Artificial rabbits optimization: A new bio-inspired meta-heuristic algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. 2022, 114, 105082. [Google Scholar] [CrossRef]
- Alsaiari, A.O.; Moustafa, E.B.; Alhumade, H.; Abulkhair, H.; Elsheikh, A. A coupled artificial neural network with artificial rabbits optimizer for predicting water productivity of different designs of solar stills. Adv. Eng. Softw. 2023, 175, 103315. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Holland, J.H. Genetic algorithms and the optimal allocation of trials. SIAM J. Comput. 1973, 2, 88–105. [Google Scholar] [CrossRef]
- Langdon, W.B. Genetic Programming and Data Structures: Genetic Programming + Data Structures = Automatic Programming! Kluwer Academic Publishers: Boston, MA, USA, 1998. [Google Scholar]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies—A comprehensive introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Rudolph, G. Convergence analysis of canonical genetic algorithms. IEEE Trans. Neural Netw. 1994, 5, 96–101. [Google Scholar] [CrossRef]
- García, J.; Acosta, C.; Mesa, M. Genetic algorithms for mathematical optimization. J. Phys. Conf. Ser. 2020, 1448, 012020. [Google Scholar] [CrossRef]
- Anastasio, M.A.; Yoshida, H.; Nagel, R.; Nishikawa, R.M.; Doi, K. A genetic algorithm-based method for optimizing the performance of a computer-aided diagnosis scheme for detection of clustered microcalcifications in mammograms. Med. Phys. 1998, 25, 1613–1620. [Google Scholar] [CrossRef]
- Bevilacqua, A.; Campanini, R.; Lanconelli, N. A distributed genetic algorithm for parameters optimization to detect microcalcifications in digital mammograms. In Proceedings of the Workshops on Applications of Evolutionary Computation, Como, Italy, 18–20 April 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 278–287. [Google Scholar]
- Ghaheri, A.; Shoar, S.; Naderan, M.; Hoseini, S.S. The applications of genetic algorithms in medicine. Oman Med. J. 2015, 30, 406. [Google Scholar] [CrossRef]
- Zelenkov, Y.; Reshettsov, I. Analysis of the COVID-19 pandemic using a compartmental model with time-varying parameters fitted by a genetic algorithm. Expert Syst. Appl. 2023, 224, 120034. [Google Scholar] [CrossRef]
- Esquivel, R.M.; Gómez-Vargas, I.; Montalvo, T.R.; Vázquez, J.A.; García-Salcedo, R. The inverse problem of a dynamical system solved with genetic algorithms. J. Phys. Conf. Ser. 2021, 1723, 012021. [Google Scholar] [CrossRef]
- Simpson, A.R.; Priest, S.D. The application of genetic algorithms to optimisation problems in geotechnics. Comput. Geotech. 1993, 15, 1–19. [Google Scholar] [CrossRef]
- Drachal, K.; Pawłowski, M. A review of the applications of genetic algorithms to forecasting prices of commodities. Economies 2021, 9, 6. [Google Scholar] [CrossRef]
- Victorino, I.R.d.S.; Maciel Filho, R. Application of Genetic Algorithms To the Optimization of an Industrial Reactor. IFAC Proc. Vol. 2006, 39, 857–862. [Google Scholar] [CrossRef]
- Kuri-Morales, A. Closed determination of the number of neurons in the hidden layer of a multi-layered perceptron network. Soft Comput. 2017, 21, 597–609. [Google Scholar] [CrossRef]
- Whitley, D.; Starkweather, T.; Bogart, C. Genetic algorithms and neural networks: Optimizing connections and connectivity. Parallel Comput. 1990, 14, 347–361. [Google Scholar] [CrossRef]
- Gómez-Vargas, I.; Andrade, J.B.; Vázquez, J.A. Neural networks optimized by genetic algorithms in cosmology. Phys. Rev. D 2023, 107, 043509. [Google Scholar] [CrossRef]
- Abel, S.; Constantin, A.; Harvey, T.R.; Lukas, A. Evolving Heterotic Gauge Backgrounds: Genetic Algorithms versus Reinforcement Learning. Fortschritte Der Phys. 2022, 70, 2200034. [Google Scholar] [CrossRef]
- Bourilkov, D. Machine and deep learning applications in particle physics. Int. J. Mod. Phys. A 2019, 34, 1930019. [Google Scholar] [CrossRef]
- Akrami, Y.; Scott, P.; Edsjö, J.; Conrad, J.; Bergström, L. A profile likelihood analysis of the constrained MSSM with genetic algorithms. J. High Energy Phys. 2010, 2010, 57. [Google Scholar] [CrossRef]
- Charbonneau, P. Genetic algorithms in astronomy and astrophysics. Astrophys. J. Suppl. 1995, 101, 309. [Google Scholar] [CrossRef]
- Fridman, P. Radio astronomy image enhancement in the presence of phase errors using genetic algorithms. In Proceedings of the 2001 International Conference on Image Processing (Cat. No. 01CH37205), Thessaloniki, Greece, 7–10 October 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 3, pp. 612–615. [Google Scholar]
- Rajpaul, V. Genetic algorithms in astronomy and astrophysics. arXiv 2012, arXiv:1202.1643. [Google Scholar]
- Holl, B.; Sozzetti, A.; Sahlmann, J.; Giacobbe, P.; Ségransan, D.; Unger, N.; Delisle, J.B.; Barbato, D.; Lattanzi, M.; Morbidelli, R.; et al. Gaia Data Release 3-Astrometric orbit determination with Markov chain Monte Carlo and genetic algorithms: Systems with stellar, sub-stellar, and planetary mass companions. Astron. Astrophys. 2023, 674, A10. [Google Scholar] [CrossRef]
- Axiak, M.; Kitching, T.; van Hemert, J. Evolution Strategies for Cosmology: A Comparison of Nested Sampling Methods. arXiv 2011, arXiv:1101.0717. [Google Scholar]
- Luo, X.L.; Feng, J.; Zhang, H.H. A genetic algorithm for astroparticle physics studies. Comput. Phys. Commun. 2020, 250, 106818. [Google Scholar] [CrossRef]
- Gómez-Vargas, I.; Medel-Esquivel, R.; García-Salcedo, R.; Vázquez, J.A. Neural network reconstructions for the Hubble parameter, growth rate and distance modulus. Eur. Phys. J. C 2023, 83, 304. [Google Scholar] [CrossRef]
- Kamerkar, A.; Nesseris, S.; Pinol, L. Machine learning cosmic inflation. Phys. Rev. D 2023, 108, 043509. [Google Scholar] [CrossRef]
- Chacón, J.; Gómez-Vargas, I.; Méndez, R.M.; Vázquez, J.A. Analysis of dark matter halo structure formation in N-body simulations with machine learning. Phys. Rev. D 2023, 107, 123515. [Google Scholar] [CrossRef]
- de Dios Rojas Olvera, J.; Gómez-Vargas, I.; Vázquez, J.A. Observational cosmology with artificial neural networks. Universe 2022, 8, 120. [Google Scholar] [CrossRef]
- Arjona, R.; Nesseris, S. What can Machine Learning tell us about the background expansion of the Universe? Phys. Rev. D 2020, 101, 123525. [Google Scholar] [CrossRef]
- Nesseris, S.; Garcia-Bellido, J. A new perspective on Dark Energy modeling via Genetic Algorithms. J. Cosmol. Astropart. Phys. 2012, 2012, 033. [Google Scholar] [CrossRef]
- Wang, K.; Guo, P.; Yu, F.; Duan, L.; Wang, Y.; Du, H. Computational intelligence in astronomy: A survey. Int. J. Comput. Intell. Syst. 2018, 11, 575. [Google Scholar] [CrossRef]
- Bogdanos, C.; Nesseris, S. Genetic algorithms and supernovae type Ia analysis. J. Cosmol. Astropart. Phys. 2009, 2009, 6. [Google Scholar] [CrossRef]
- Nesseris, S.; Shafieloo, A. A model-independent null test on the cosmological constant. Mon. Not. R. Astron. Soc. 2010, 408, 1879–1885. [Google Scholar] [CrossRef]
- Alestas, G.; Kazantzidis, L.; Nesseris, S. Machine learning constraints on deviations from general relativity from the large scale structure of the Universe. Phys. Rev. D 2022, 106, 103519. [Google Scholar] [CrossRef]
- Pellejero-Ibáñez, M.; Angulo, R.E.; Aricó, G.; Zennaro, M.; Contreras, S.; Stücker, J. Cosmological parameter estimation via iterative emulation of likelihoods. Mon. Not. R. Astron. Soc. 2020, 499, 5257–5268. [Google Scholar] [CrossRef]
- Wraith, D.; Wraith, D.; Kilbinger, M.; Benabed, K.; Capp’e, O.; Cardoso, J.F.; Cardoso, J.F.; Fort, G.; Prunet, S.; Robert, C.P. Estimation of cosmological parameters using adaptive importance sampling. Phys. Rev. D 2009, 80, 023507. [Google Scholar] [CrossRef]
- Graff, P.; Feroz, F.; Hobson, M.P.; Lasenby, A. BAMBI: Blind accelerated multimodal Bayesian inference. Mon. Not. R. Astron. Soc. 2012, 421, 169–180. [Google Scholar] [CrossRef]
- Nygaard, A.; Holm, E.B.; Hannestad, S.; Tram, T. CONNECT: A neural network based framework for emulating cosmological observables and cosmological parameter inference. J. Cosmol. Astropart. Phys. 2023, 2023, 025. [Google Scholar] [CrossRef]
- Gómez-Vargas, I.; Esquivel, R.M.; García-Salcedo, R.; Vázquez, J.A. Neural network within a bayesian inference framework. J. Phys. Conf. Ser. 2021, 1723, 012022. [Google Scholar] [CrossRef]
- Alsing, J.; Charnock, T.; Feeney, S.; Wandelt, B. Fast likelihood-free cosmology with neural density estimators and active learning. Mon. Not. R. Astron. Soc. 2019, 488, 4440–4458. [Google Scholar] [CrossRef]
- Leclercq, F. Bayesian optimization for likelihood-free cosmological inference. Phys. Rev. D 2018, 98, 063511. [Google Scholar] [CrossRef]
- Bagavathi, C.; Saraniya, O. Evolutionary Mapping Techniques for Systolic Computing System. In Deep Learning and Parallel Computing Environment for Bioengineering Systems; Elsevier: Amsterdam, The Netherlands, 2019; pp. 207–223. [Google Scholar]
- Passino, K.M. Biomimicry of bacterial foraging for distributed optimization and control. IEEE Control Syst. Mag. 2002, 22, 52–67. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Faris, H.; Aljarah, I.; Al-Betar, M.A.; Mirjalili, S. Grey wolf optimizer: A review of recent variants and applications. Neural Comput. Appl. 2018, 30, 413–435. [Google Scholar] [CrossRef]
- Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 2008, 12, 702–713. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Waddington, C.H. An Introduction to Modern Genetics; Routledge: London, UK, 2016. [Google Scholar]
- Kumar, A. Encoding schemes in genetic algorithm. Int. J. Adv. Res. Eng. 2013, 2, 1–7. [Google Scholar]
- Beasley, D.; Bull, D.R.; Martin, R.R. An overview of genetic algorithms: Part 1, fundamentals. Univ. Comput. 1993, 15, 56–69. [Google Scholar]
- Mirjalili, S.; Mirjalili, S. Genetic algorithm. Evolutionary Algorithms and Neural Networks: Theory and Applications; Springer: Cham, Switzerland, 2019; pp. 43–55. [Google Scholar]
- Sivanandam, S.; Deepa, S.; Sivanandam, S.; Deepa, S. Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Goldberg, D.E.; Deb, K. A comparative analysis of selection schemes used in genetic algorithms. In Foundations of Genetic Algorithms; Elsevier: Amsterdam, The Netherlands, 1991; Volume 1, pp. 69–93. [Google Scholar]
- Miller, B.L.; Goldberg, D.E. Genetic algorithms, tournament selection, and the effects of noise. Complex Syst. 1995, 9, 193–212. [Google Scholar]
- Lee, C.Y. Entropy-Boltzmann selection in the genetic algorithms. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2003, 33, 138–149. [Google Scholar]
- Marsili Libelli, S.; Alba, P. Adaptive mutation in genetic algorithms. Soft Comput. 2000, 4, 76–80. [Google Scholar] [CrossRef]
- Fortin, F.A.; De Rainville, F.M. Distributed Evolutionary Algorithms. Available online: https://github.com/deap (accessed on 18 December 2023).
- Staats, K. Karoo_gp. Available online: http://kstaats.github.io/karoo_gp/ (accessed on 18 December 2023).
- Sipper, M. Tiny Genetic Programming. Available online: https://github.com/moshesipper/tiny_gp (accessed on 18 December 2023).
- Bonson, J.P.C. Symbiotic Bid-Based GP. Available online: https://github.com/jpbonson/SBBFramework (accessed on 18 December 2023).
- Wirsansky, E. Hands-On Genetic Algorithms with Python: Applying Genetic Algorithms to Solve Real-World Deep Learning and Artificial Intelligence Problems; Packt Publishing: Birmingham, UK, 2020. [Google Scholar]
- Eiben, A.E.; Rudolph, G. Theory of evolutionary algorithms: A bird’s eye view. Theor. Comput. Sci. 1999, 229, 3–9. [Google Scholar] [CrossRef]
- Oliveto, P.S.; Witt, C. On the runtime analysis of the simple genetic algorithm. Theor. Comput. Sci. 2014, 545, 2–19. [Google Scholar] [CrossRef]
- Šílenỳ, J. Earthquake source parameters and their confidence regions by a genetic algorithm with a ‘memory’. Geophys. J. Int. 1998, 134, 228–242. [Google Scholar] [CrossRef]
- Esquivel, R.M.; Gómez-Vargas, I.; Vázquez, J.A.; Salcedo, R.G. An introduction to Markov Chain Monte Carlo. Boletín EstadíStica Investig. Oper. 2021, 1, 47–74. [Google Scholar]
- Hogg, D.W.; Foreman-Mackey, D. Data analysis recipes: Using markov chain monte carlo. Astrophys. J. Suppl. Ser. 2018, 236, 11. [Google Scholar] [CrossRef]
- Akarsu, Ö.; Barrow, J.D.; Escamilla, L.A.; Vazquez, J.A. Graduated dark energy: Observational hints of a spontaneous sign switch in the cosmological constant. Phys. Rev. D 2020, 101, 063528. [Google Scholar] [CrossRef]
- Jimenez, R.; Verde, L.; Treu, T.; Stern, D. Constraints on the equation of state of dark energy and the Hubble constant from stellar ages and the cosmic microwave background. Astrophys. J. 2003, 593, 622. [Google Scholar] [CrossRef]
- Simon, J.; Verde, L.; Jimenez, R. Constraints on the redshift dependence of the dark energy potential. Phys. Rev. D 2005, 71, 123001. [Google Scholar] [CrossRef]
- Stern, D.; Jimenez, R.; Verde, L.; Kamionkowski, M.; Stanford, S.A. Cosmic chronometers: Constraining the equation of state of dark energy. I: H(z) measurements. J. Cosmol. Astropart. Phys. 2010, 2010, 008. [Google Scholar] [CrossRef]
- Moresco, M.; Verde, L.; Pozzetti, L.; Jimenez, R.; Cimatti, A. New constraints on cosmological parameters and neutrino properties using the expansion rate of the Universe to z ∼ 1.75. J. Cosmol. Astropart. Phys. 2012, 2012, 053. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Yuan, S.; Liu, S.; Zhang, T.J.; Sun, Y.C. Four new observational H(z) data from luminous red galaxies in the Sloan Digital Sky Survey data release seven. Res. Astron. Astrophys. 2014, 14, 1221. [Google Scholar] [CrossRef]
- Moresco, M. Raising the bar: New constraints on the Hubble parameter with cosmic chronometers at z ∼ 2. Mon. Not. R. Astron. Soc. Lett. 2015, 450, L16–L20. [Google Scholar] [CrossRef]
- Moresco, M.; Pozzetti, L.; Cimatti, A.; Jimenez, R.; Maraston, C.; Verde, L.; Thomas, D.; Citro, A.; Tojeiro, R.; Wilkinson, D. A 6% measurement of the Hubble parameter at z ∼ 0.45: Direct evidence of the epoch of cosmic re-acceleration. J. Cosmol. Astropart. Phys. 2016, 2016, 014. [Google Scholar] [CrossRef]
- Ratsimbazafy, A.; Loubser, S.; Crawford, S.; Cress, C.; Bassett, B.; Nichol, R.; Väisänen, P. Age-dating luminous red galaxies observed with the Southern African Large Telescope. Mon. Not. R. Astron. Soc. 2017, 467, 3239–3254. [Google Scholar] [CrossRef]
- Alam, S.; Ata, M.; Bailey, S.; Beutler, F.; Bizyaev, D.; Blazek, J.A.; Bolton, A.S.; Brownstein, J.R.; Burden, A.; Chuang, C.H.; et al. The clustering of galaxies in the completed SDSS-III Baryon Oscillation Spectroscopic Survey: Cosmological analysis of the DR12 galaxy sample. Mon. Not. R. Astron. Soc. 2017, 470, 2617–2652. [Google Scholar] [CrossRef]
- Ata, M.; Baumgarten, F.; Bautista, J.; Beutler, F.; Bizyaev, D.; Blanton, M.R.; Blazek, J.A.; Bolton, A.S.; Brinkmann, J.; Brownstein, J.R.; et al. The clustering of the SDSS-IV extended Baryon Oscillation Spectroscopic Survey DR14 quasar sample: First measurement of baryon acoustic oscillations between redshift 0.8 and 2.2. Mon. Not. R. Astron. Soc. 2018, 473, 4773–4794. [Google Scholar] [CrossRef]
- Blomqvist, M.; Des Bourboux, H.D.M.; de Sainte Agathe, V.; Rich, J.; Balland, C.; Bautista, J.E.; Dawson, K.; Font-Ribera, A.; Guy, J.; Le Goff, J.M.; et al. Baryon acoustic oscillations from the cross-correlation of Lyα absorption and quasars in eBOSS DR14. Astron. Astrophys. 2019, 629, A86. [Google Scholar] [CrossRef]
- de Sainte Agathe, V.; Balland, C.; Des Bourboux, H.D.M.; Blomqvist, M.; Guy, J.; Rich, J.; Font-Ribera, A.; Pieri, M.M.; Bautista, J.E.; Dawson, K.; et al. Baryon acoustic oscillations at z = 2.34 from the correlations of Lyα absorption in eBOSS DR14. Astron. Astrophys. 2019, 629, A85. [Google Scholar] [CrossRef]
- Beutler, F.; Blake, C.; Colless, M.; Jones, D.H.; Staveley-Smith, L.; Campbell, L.; Parker, Q.; Saunders, W.; Watson, F. The 6dF Galaxy Survey: Baryon acoustic oscillations and the local Hubble constant. Mon. Not. R. Astron. Soc. 2011, 416, 3017–3032. [Google Scholar] [CrossRef]
- Ross, A.J.; Samushia, L.; Howlett, C.; Percival, W.J.; Burden, A.; Manera, M. The clustering of the SDSS DR7 main Galaxy sample–I. A 4 per cent distance measure at z = 0.15. Mon. Not. R. Astron. Soc. 2015, 449, 835–847. [Google Scholar] [CrossRef]
- Scolnic, D.M.; Jones, D.; Rest, A.; Pan, Y.; Chornock, R.; Foley, R.; Huber, M.; Kessler, R.; Narayan, G.; Riess, A.; et al. The complete light-curve sample of spectroscopically confirmed SNe Ia from Pan-STARRS1 and cosmological constraints from the combined pantheon sample. Astrophys. J. 2018, 859, 101. [Google Scholar] [CrossRef]
- Betoule, M.; Kessler, R.; Guy, J.; Mosher, J.; Hardin, D.; Biswas, R.; Astier, P.; El-Hage, P.; Konig, M.; Kuhlmann, S.; et al. Improved cosmological constraints from a joint analysis of the SDSS-II and SNLS supernova samples. Astron. Astrophys. 2014, 568, A22. [Google Scholar] [CrossRef]
- Vazquez, J.; Gomez-Vargas, I.; Slosar, A. Updated Version of a Simple MCMC Code for Cosmological Parameter Estimation Where Only Expansion History Matters. 2023. Available online: https://github.com/ja-vazquez/SimpleMC (accessed on 18 December 2023).
- Skilling, J. Nested sampling. AIP Conf. Proc. 2004, 735, 395–405. [Google Scholar]
- Padilla, L.E.; Tellez, L.O.; Escamilla, L.A.; Vazquez, J.A. Cosmological parameter inference with Bayesian statistics. Universe 2021, 7, 213. [Google Scholar] [CrossRef]
- Sivia, D.; Skilling, J. Data Analysis: A Bayesian Tutorial; OUP, Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. (TOMS) 1997, 23, 550–560. [Google Scholar] [CrossRef]
- Liddle, A. An Introduction to Modern Cosmology; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Linden, S.; Virey, J.M. Test of the Chevallier-Polarski-Linder parametrization for rapid dark energy equation of state transitions. Phys. Rev. D 2008, 78, 023526. [Google Scholar] [CrossRef]
- Vazquez, J.A.; Hee, S.; Hobson, M.; Lasenby, A.; Ibison, M.; Bridges, M. Observational constraints on conformal time symmetry, missing matter and double dark energy. J. Cosmol. Astropart. Phys. 2018, 2018, 062. [Google Scholar] [CrossRef]
- Zhai, Z.; Blanton, M.; Slosar, A.; Tinker, J. An evaluation of cosmological models from the expansion and growth of structure measurements. Astrophys. J. 2017, 850, 183. [Google Scholar] [CrossRef]
- Feroz, F.; Hobson, M.; Bridges, M. MultiNest: An efficient and robust Bayesian inference tool for cosmology and particle physics. Mon. Not. R. Astron. Soc. 2009, 398, 1601–1614. [Google Scholar] [CrossRef]
- Acquaviva, G.; Akarsu, Ö.; Katırcı, N.; Vazquez, J.A. Simple-graduated dark energy and spatial curvature. Phys. Rev. D 2021, 104, 023505. [Google Scholar] [CrossRef]
- Akarsu, Ö.; Kumar, S.; Özülker, E.; Vazquez, J.A. Relaxing cosmological tensions with a sign switching cosmological constant. Phys. Rev. D 2021, 104, 123512. [Google Scholar] [CrossRef]
- Akarsu, O.; Di Valentino, E.; Kumar, S.; Nunes, R.C.; Vazquez, J.A.; Yadav, A. LambdasCDM model: A promising scenario for alleviation of cosmological tensions. arXiv 2023, arXiv:2307.10899. [Google Scholar]
- Akarsu, Ö.; Kumar, S.; Özülker, E.; Vazquez, J.A.; Yadav, A. Relaxing cosmological tensions with a sign switching cosmological constant: Improved results with Planck, BAO, and Pantheon data. Phys. Rev. D 2023, 108, 023513. [Google Scholar] [CrossRef]
- Kreisch, C.D.; Park, M.; Calabrese, E.; Cyr-Racine, F.Y.; An, R.; Bond, J.R.; Dore, O.; Dunkley, J.; Gallardo, P.; Gluscevic, V.; et al. The Atacama Cosmology Telescope: The Persistence of Neutrino Self-Interaction in Cosmological Measurements. arXiv 2022, arXiv:2207.03164. [Google Scholar]
- Camarena, D.; Cyr-Racine, F.Y.; Houghteling, J. The two-mode puzzle: Confronting self-interacting neutrinos with the full shape of the galaxy power spectrum. arXiv 2023, arXiv:2309.03941. [Google Scholar]
- Cedeno, F.X.L.; Nucamendi, U. Revisiting cosmological diffusion models in Unimodular Gravity and the H0 tension. Phys. Dark Universe 2021, 32, 100807. [Google Scholar] [CrossRef]
- Park, M.; Kreisch, C.D.; Dunkley, J.; Hadzhiyska, B.; Cyr-Racine, F.Y. Λ CDM or self-interacting neutrinos: How CMB data can tell the two models apart. Phys. Rev. D 2019, 100, 063524. [Google Scholar] [CrossRef]
- de Cruz Pérez, J.; Park, C.G.; Ratra, B. Current data are consistent with flat spatial hypersurfaces in the Λ CDM cosmological model but favor more lensing than the model predicts. Phys. Rev. D 2023, 107, 063522. [Google Scholar] [CrossRef]
- Handley, W. fgivenx: A Python package for functional posterior plotting. arXiv 2019, arXiv:1908.01711. [Google Scholar] [CrossRef]
- Surendran, S.P.; Thomas, R.; Joy, M. Evolutionary optimization of cosmological parameters using metropolis acceptance criterion. arXiv 2022, arXiv:2205.01752. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Optimum | Optimum Found by GA |
|---|---|
| Data: CC + BAO + SNeIa | ||||
|---|---|---|---|---|
| Model | Parameters | L-BFGS Optimizer | Genetic | Nested |
| CDM | ||||
| CPL | ||||
| PolyCDM | ||||
| Nested Sampling | L-BFGS | Genetic | |
|---|---|---|---|
| 0.3264 | 0.2991 | 0.2959 | |
| h | 0.6947 | 0.6760 | 0.6765 |
| −0.0129 | 0.0000 | −0.0127 | |
| 55.8700 | 60.5781 | 61.6997 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medel-Esquivel, R.; Gómez-Vargas, I.; Morales Sánchez, A.A.; García-Salcedo, R.; Alberto Vázquez, J. Cosmological Parameter Estimation with Genetic Algorithms. Universe 2024, 10, 11. https://doi.org/10.3390/universe10010011
Medel-Esquivel R, Gómez-Vargas I, Morales Sánchez AA, García-Salcedo R, Alberto Vázquez J. Cosmological Parameter Estimation with Genetic Algorithms. Universe. 2024; 10(1):11. https://doi.org/10.3390/universe10010011
Chicago/Turabian StyleMedel-Esquivel, Ricardo, Isidro Gómez-Vargas, Alejandro A. Morales Sánchez, Ricardo García-Salcedo, and José Alberto Vázquez. 2024. "Cosmological Parameter Estimation with Genetic Algorithms" Universe 10, no. 1: 11. https://doi.org/10.3390/universe10010011
APA StyleMedel-Esquivel, R., Gómez-Vargas, I., Morales Sánchez, A. A., García-Salcedo, R., & Alberto Vázquez, J. (2024). Cosmological Parameter Estimation with Genetic Algorithms. Universe, 10(1), 11. https://doi.org/10.3390/universe10010011