1. Introduction
Neutron stars (NS) are fascinating objects; with a typical mass
and radius
km [
1], they represent the ideal laboratory to study the properties of nuclear matter under extreme conditions. Due to a strong pressure gradient, the matter within the NS arranges itself into layers with different properties [
2]. Going from the most external regions of the star to its centre, the matter density
spans several orders of magnitude from ≈
to
, where
is the typical value of density at the centre of an atomic nucleus [
3].
The external region of a cold nonaccreting NS is named the
outer crust. It consists of a Coulomb lattice of fully-ionized atoms with
Z protons and
N neutrons. As discussed in Refs. [
4,
5], at
-equilibrium, the composition of each layer of the crust at a given pressure
P is obtained by minimising the Gibbs free energy per nucleon. The latter is the sum of three main contributions: the
nuclear,
electronic, and
lattice. The effects of considering the system at a finite temperature have been presented in Ref. [
6]. Since a large fraction of nuclei present in the outer crust are extremely neutron-rich, their binding energies are not known experimentally, and consequently, one has to rely on a nuclear mass model. We refer the reader to Ref. [
7] for a review of the properties of various equations of state (EoS) used to describe dense stellar matter.
Several mass models are available within the scientific literature with a typical accuracy, i.e., the root mean square (RMS) deviation of the residuals, of 500 keV [
8]. In recent years, some of these mass models have been equipped with additional algorithms such as kernel ridge regression [
9] or radial basis function interpolation [
10,
11], thus reducing the typical RMS to ≈
. Although such an RMS is remarkably low compared to the typical binding energy of a nucleus, the discrepancies between various models are still important, especially when used to predict the composition of the outer crust of a NS [
12].
Analysis of the residuals of various mass models shows that they do not present chaotic behaviour [
13], thus, it should be possible to further improve their accuracy, at least up to the level of Garvey–Kelson relations [
14], by adding additional terms to account for the missing physics. This may be a very complex task, but machine learning methods can provide major support in achieving this goal.
In recent years, several authors have tried to reduce the discrepancy between theory and experiment by supplementing various mass models with neural networks (NNs) [
15,
16,
17,
18,
19,
20], where the NN learns the behaviour of the residuals. NNs are excellent interpolators [
21], but they should be used with great care for extrapolation. The major problem is the presence of an unwanted trend (on top of the residuals) related to the particular choice of the activation function. See Refs. [
22,
23] for a more detailed discussion on the topic.
A possible alternative to NNs has been discussed in Ref. [
19], and it is based on Gaussian processes (GPs) [
24,
25,
26]. This GP method assumes that the residuals originate from some multivariate Gaussian distribution, whose covariance matrix contains some parameters to be adjusted in order to maximise the likelihood for the GP’s fit to the residuals. The main advantage of a GP over a NN is that its predictions do not contain unwanted trends in extrapolation (other than the trend of the underlying model), but instead will always return to 0 after a predictable extrapolation distance. Moreover, GP predictions come naturally equipped with error bars. This is not the case for a standard NN (only Bayesian neural networks are equipped with posterior distributions that can be interpreted as error bars [
27]), and a more involved procedure is required to obtain an estimate [
23].
In the current article, we present a new mass table, made by combining the predictions of a Duflo–Zucker [
28] mass model with a GP, in order to further reduce the RMS of the residuals. We use the resulting model to analyse the composition of the outer crust of a NS. As previously conducted in Ref. [
20], we perform a full error analysis of the mass model and use a Monte Carlo procedure to propagate these statistical uncertainties through to the final EoS.
The article is organised as follows: In
Section 2, we briefly introduce the concept of GPs and their use for regression, and in
Section 3, we discuss the nuclear mass model and the improvement provided by the GP. In
Section 4, we illustrate our results concerning the outer crust; finally, we present our conclusions in
Section 5.
2. Gaussian Process Regression
We now introduce Gaussian processes, and their use as a regression tool. A Jupyter notebook is available as a
Supplementary Material; it was used to create
Figure 1 and
Figure 2, and contains additional plots that give a step-by-step introduction.
A Gaussian process is an infinite-dimensional Gaussian distribution. Similar to how a one dimensional (1D) Gaussian distribution has a mean and variance , a GP has a mean function and a covariance function , also known as the kernel. In principle, can be a vector of length d representing a point in a d-dimensional input space, but for now, we will just consider the case , i.e., where x is a single number. Just as we can draw random samples (numbers) from a 1D Gaussian distribution, we can also draw random samples from a GP, which are functions . The kernel tells us the typical correlation between the value of f at any two inputs x and , and entirely determines the behaviour of the GP (relative to the mean function). For simplicity, we use here a constant mean function of 0.
GPs can be used for regression of data if the underlying process generating the data is smooth and continuous. See Ref. [
29] for a thorough introduction to GPs for regression and machine learning. Many software packages are available for GP regression; in the current article, we use the Python package
GPy [
30]. For a set of data
, instead of assuming a fixed functional form for the interpolating function, we treat the data as originating from a Gaussian process
:
No parametric assumption is made about the shape of the interpolating function, making GPs a very flexible tool. We adopt the commonly used
RBF (radial basis function) kernel, also known as the squared exponential or Gaussian, which yields very smooth samples
and has the form
where
are parameters to be optimised for a given
. Both have easily interpretable meanings:
gives the typical magnitude of the oscillations of
, and
ℓ gives the typical correlation length in
x. When
is small, the correlation is large, and we expect
and
to have similar values. As
grows beyond a few correlation lengths
ℓ, the correlation between
and
drops rapidly to 0.
A simple way to understand GP is to make use of Bayes’ theorem. Before doing the
experiments we have a prior distribution of
, characterised by the kernel given in Equation (
2). We can then draw sample functions from this prior, which are fully determined by the parameters
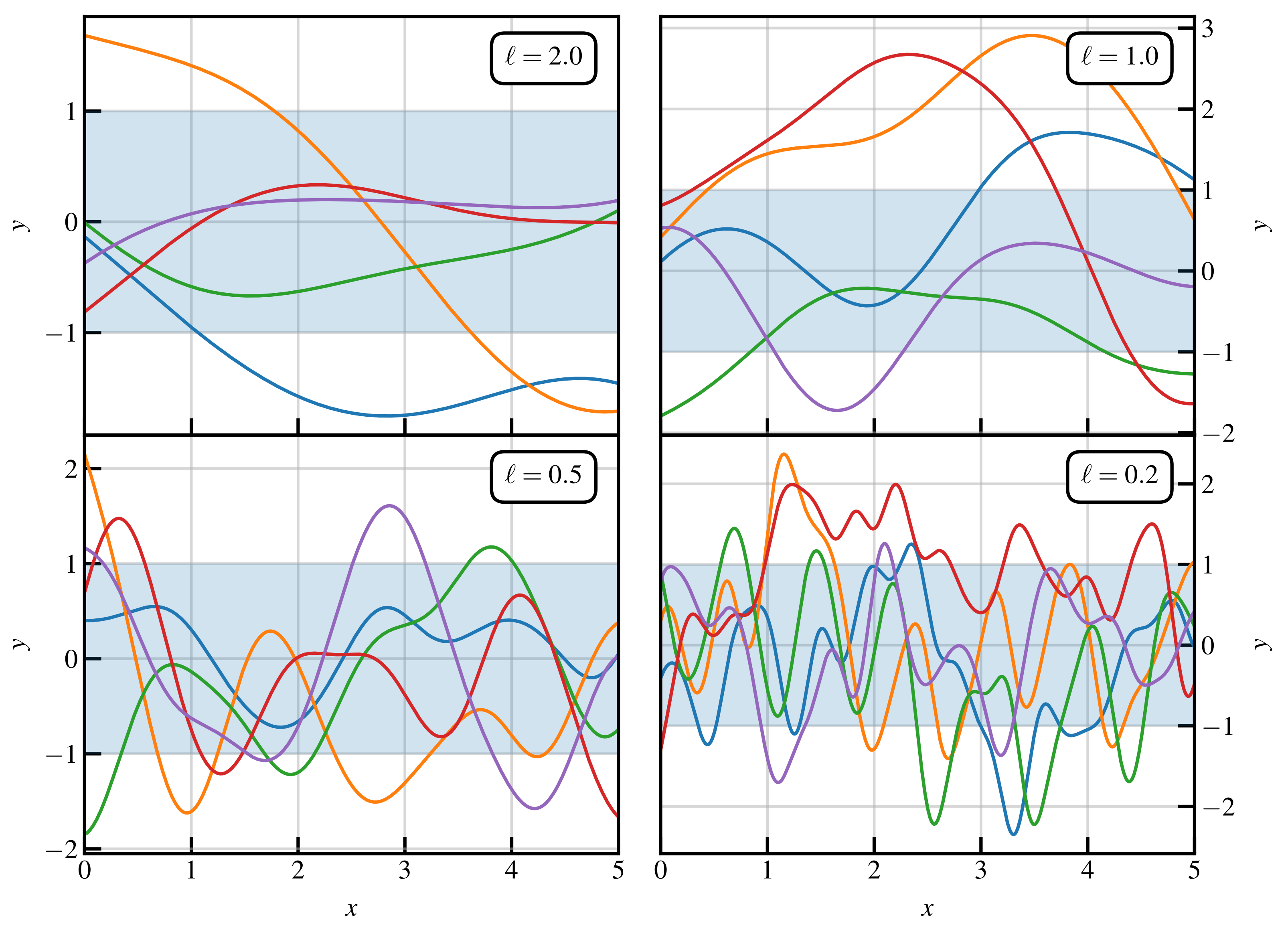
. In
Figure 1, we show five sample draws of functions
from some priors, which have
and various choices of
ℓ. We observe that by varying
ℓ, we can have very different shapes in the prior samples. On average, they all lie within the shaded area representing the
confidence interval 68% of the time.
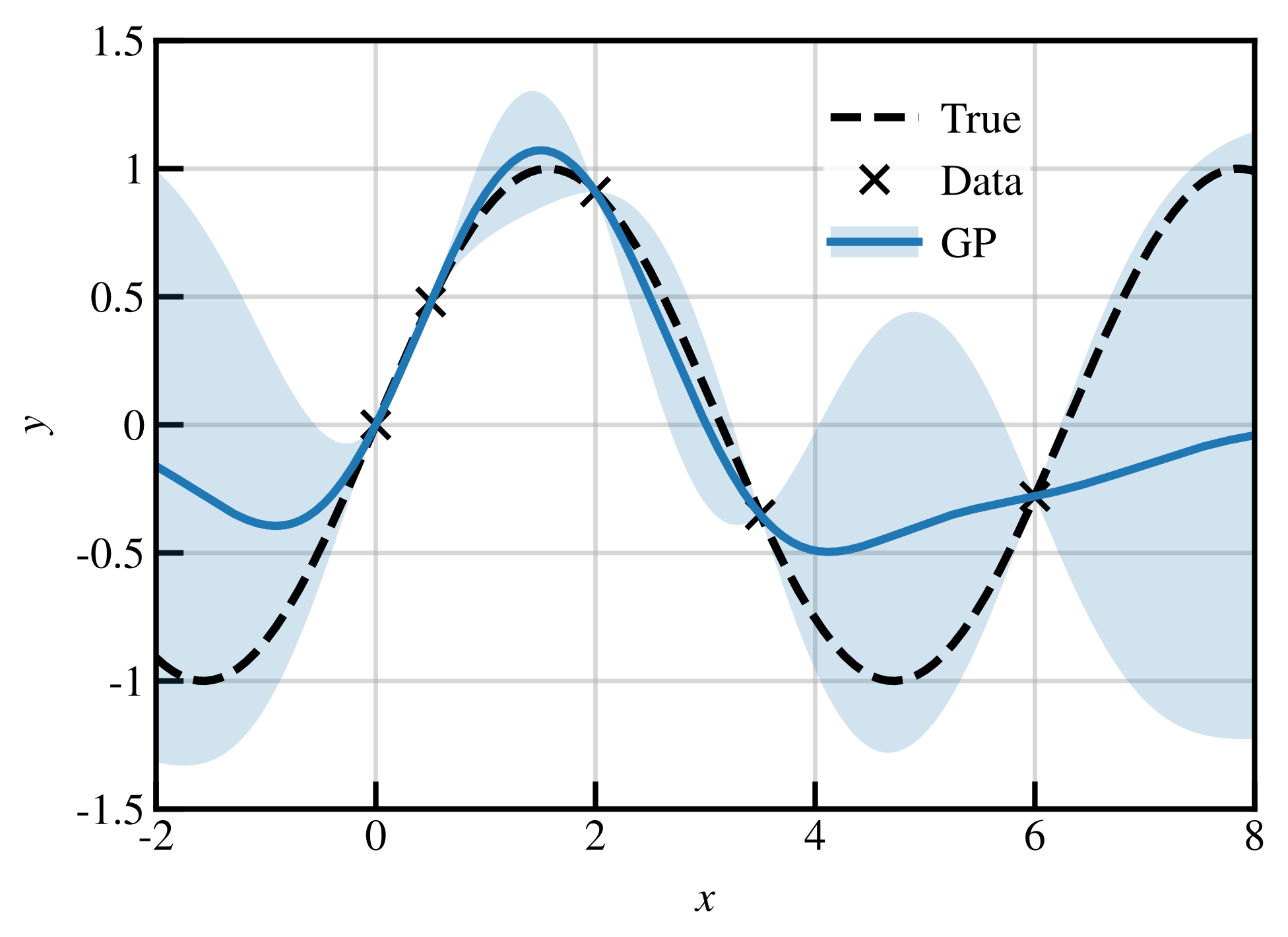
In
Figure 2, we show a simple demonstration of GP regression, where the underlying true function generating the data (dotted line) is simply
. We perform the
experiment and extract five data points, indicated by crosses on the figure. The GP is fully characterised by two kernel parameters; clearly, some sets of these parameters lead to better regression. For example, if
ℓ is smaller than the typical data spacing, the GP mean will approach 0 between data points, making it useless for interpolation (overfitting); if
is too large, the size of the confidence intervals will be overestimated. These parameters are determined using likelihood maximisation, as discussed in Ref. [
31]. We provide the expression for the log-likelihood in
Appendix A.
The GP mean (solid line) here represents the average of all possible samples (from the posterior distribution of ) passing through the data (crosses), i.e., the mean prediction. Since both the likelihood and the prior are Gaussian, so is the posterior. The GP mean is smooth, and interpolates all data points exactly. Outside the input domain, it approaches 0. As we would expect, the quality of the GP regressions is greatest where there is more data available, in this case, .
Confidence intervals are also shown in
Figure 2, representing
(≈
) here. The confidence intervals are 0 at each data point, and grow in between data points, more rapidly so when data are further apart. At the edges of the input domain, they also grow rapidly, representing the uncertainty in extrapolation, until reaching a maximum of
. A very important aspect of the GP is the confidence intervals: in this case, we see that the
true function does not always match the GP mean, but
% of the true function falls within the
interval.
The expressions for the GP mean and confidence intervals are provided in
Appendix A.
3. Nuclear Masses
Nuclear mass models are used to reproduce the nuclear binding energies of all known nuclei, ≈3200, given in the AME2016 database [
32]. Within the mass database, we distinguish two types of data: nuclear masses that have been directly measured (≈2400) and the extrapolated ones (≈750). The latter, referred to in Ref. [
32] as
trends from the mass surface, are obtained from nearby masses and from reaction and decay energies, under several constraints explained in
Section 4 of this reference. We will use them to benchmark our extrapolations.
In the current article, we use the Duflo–Zucker mass model [
28]; it consists of 10 terms (DZ10 model), and is able to reproduce all known masses with a root mean square deviation of
MeV [
20]. We refer the reader to Refs. [
33,
34] for a detailed discussion on the different terms in the models.
The parameters of the DZ10 model were adjusted in Ref. [
20] using the block bootstrap (BB) method [
35], yielding the optimal parameter set
. The reason for using BB is that it provides robust error bars on the parameters that take into account correlations between them [
36,
37].
The assumption used to fit DZ10, as with any other mass model, is that the experimental binding energies
are equal to the theoretical ones
up to a Gaussian error
:
where
is the binding energy calculated using DZ10. In
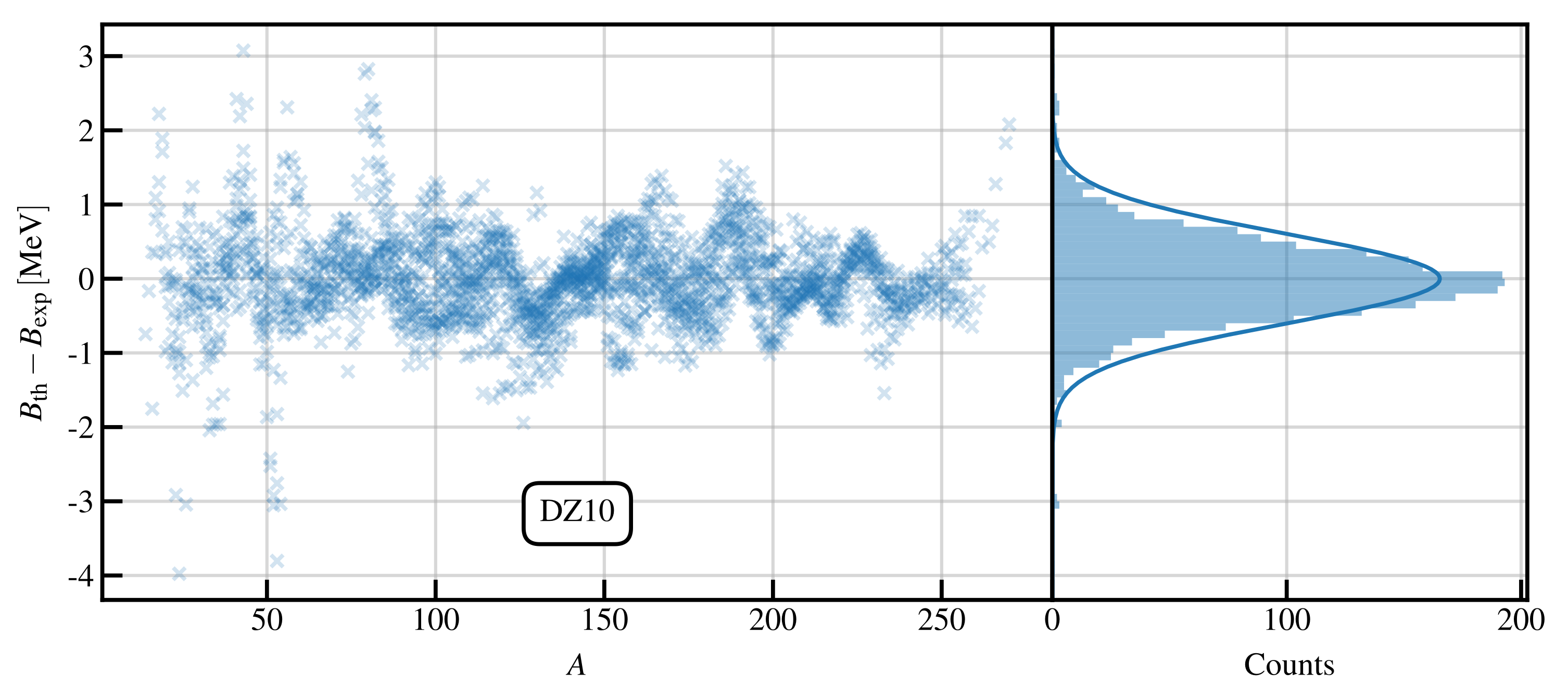
Figure 3, we illustrate the residuals for DZ10 as a function of the nucleon number
. One clearly sees that these residuals show structure, thus indicating the presence of some missing
physics that is not properly accounted for by the model. In the right panel of the same figure, we plot the same residuals as a histogram, and we draw a Gaussian with mean 0 and width fixed to the RMS of the residuals. The height of the Gaussian is fitted on the residuals.
A more detailed statistical test can be performed on these residuals to verify that they do not follow a regular Gaussian distribution (see, for example, Refs. [
20,
38] for more details) but for the current discussion, a qualitative analysis is sufficient.
Having identified that there is room to improve the accuracy of the model, the most natural option to take is to add new terms [
34]. For example, a version of the Duflo–Zucker model with 33 parameters is available. Although the RMS reduces to ≈300 keV, the extra terms appear poorly constrained [
34], and therefore, the model is unsuitable for extrapolation. We refer the reader to Ref. [
39] for a detailed discussion on poorly constrained parameters.
Instead of explicitly
creating new terms for a given mass model, we can take advantage of machine learning methods. For example, in Refs. [
18,
20], the authors adjusted a NN on the residuals of the DZ10 model in order to reduce the discrepancy between theory and experiment. The NN is able to reduce this discrepancy to a typical RMS of ≈350 keV [
20].
NNs are often very complex models, with several hundred free parameters. As discussed in [
19], a Gaussian process represents a valid alternative to a NN; the main advantages are the very small number of adjustable parameters, as discussed in
Section 2, and the superior performance on the database of nuclear masses when compared with a NN [
19].
3.1. Augmenting the DZ10 Model with a GP
Having introduced the GP in
Section 2, we now apply it to the case of nuclear masses. As done in Ref. [
19], we consider the same kernel given in Equation (
1), but now in the 2D case, meaning there are three adjustable parameters. We also use a fourth parameter
, named the
nugget. The use of the nugget carries several advantages, including numerical stability [
40] and improved predictions [
41]. The kernel we use is then given by
where in the present case,
and
are the adjustable parameters. Following Ref. [
19],
and
are interpreted as correlation lengths in the neutron and proton directions, while
gives the strength of the correlation between neighbouring nuclei.
The addition of the nugget means that the GP mean does not necessarily pass directly through each data point. After performing a preliminary investigation using a full likelihood maximisation with all four parameters, we found that the optimal value is MeV. We decided to fix this value in order to simplify the analysis of the posterior distribution.
The main role of the nugget is to avoid overfitting, which manifests itself via a correlation length smaller than the typical separation of the data. For example, setting
MeV would lead to a perfect reproduction of the data, but the resulting model would be totally useless; it would not be able to perform any kind of prediction, since the correlation lengths would be smaller than one (i.e., the separation between nuclear mass data). The nugget gives us extra flexibility in identifying the residual correlations between the data as discussed in Ref. [
23]. For a more detailed discussion on GP and the role of the nugget, we refer to Ref. [
19].
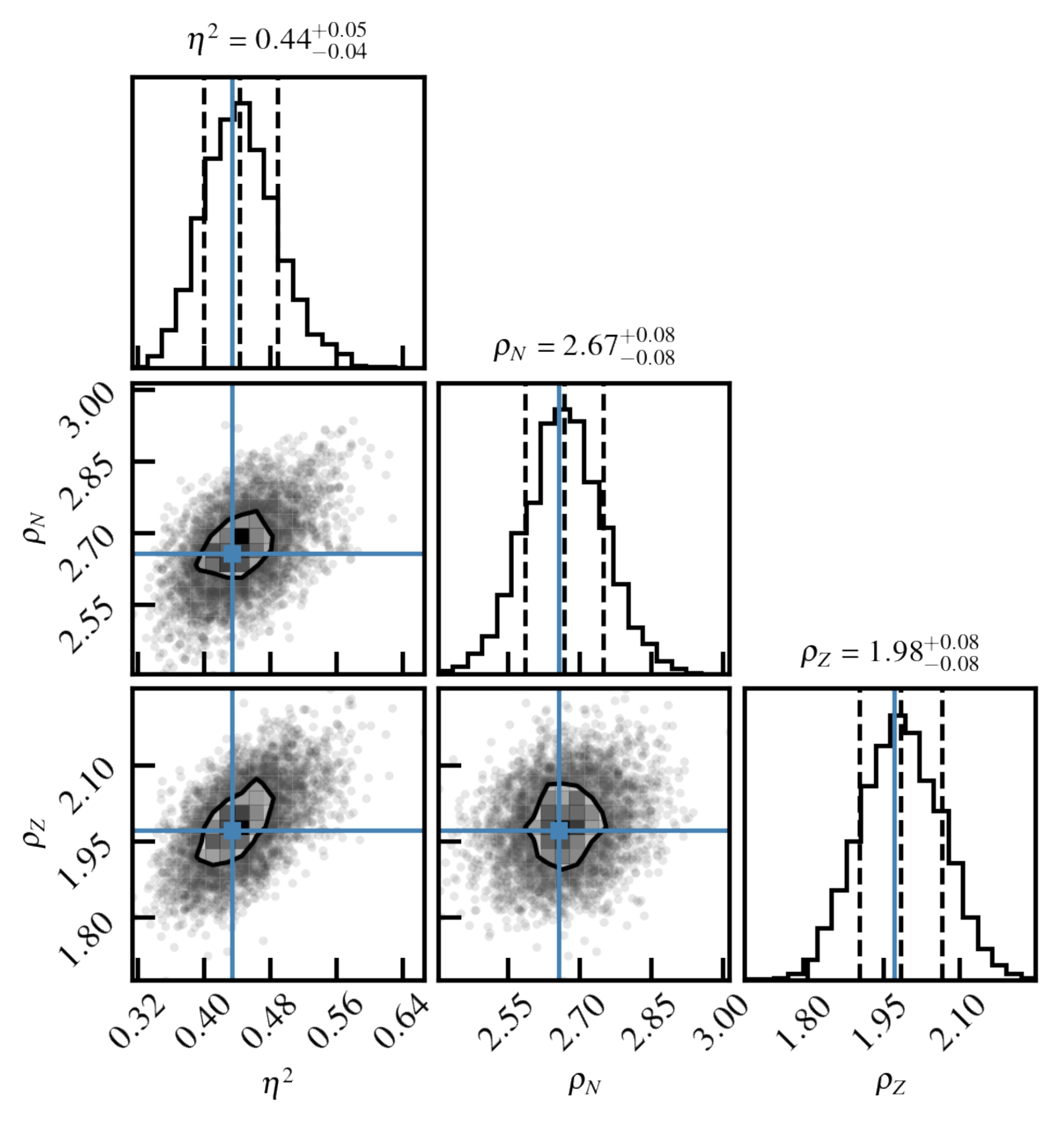
As discussed previously, we adjust the parameters of the GP on the residuals of the DZ10 model (shown in
Figure 3). The parameters
are determined through maximising the likelihood for the GP. See Ref. [
31] for details. In
Figure 4, we illustrate the posterior distribution of the parameters in the form of a corner plot. The distributions were obtained with Markov chain Monte Carlo (MCMC) sampling [
42]. The plot illustrates the shapes of the distributions around the optimal parameter set and provides us with error bars for the parameters and information about their correlations. In this case, we see that all parameters are very well determined by the residuals data, and a weak correlation is observed between
and
and between
and
.
A very interesting result is that the two correlation lengths
are as large as, or greater than, 2. This means that, if we know the residual for a nucleus with mass number
A, we can infer properties of the nucleus with
. This result is in agreement with the analysis done in Ref. [
20], which was based on the autocorrelation coefficients.
We now construct our new model for
(appearing in Equation (
3)) as
, which we name
DZ10-GP. In
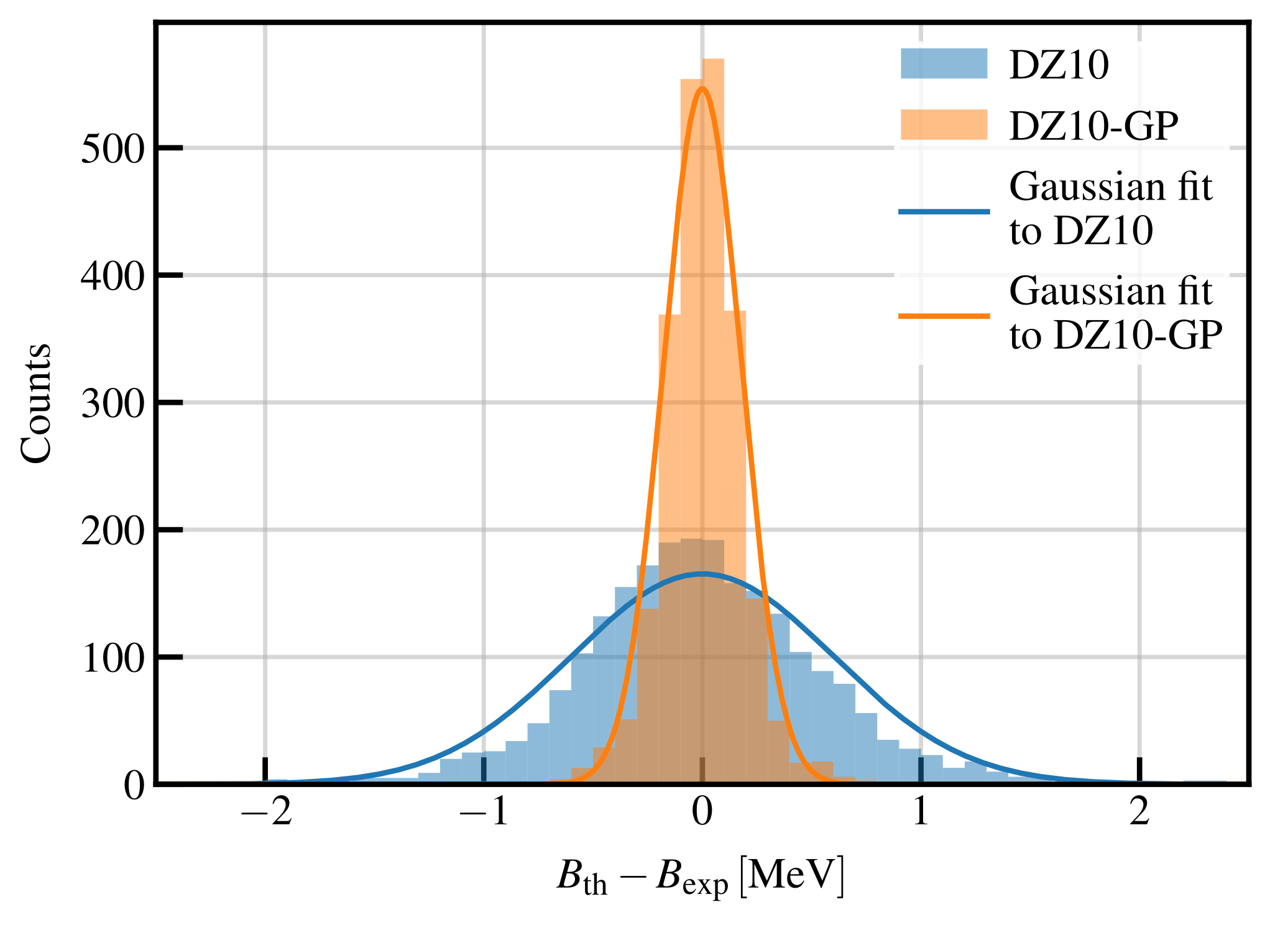
Figure 5, we compare the residual distributions for the DZ10 and DZ10-GP models for measured masses. We see that the RMS of the DZ10 model has been greatly reduced. The total RMS of the DZ10-GP model is
keV, which until now is probably among the lowest values ever obtained using a mass model fitted on all the available masses, with a total of
adjustable parameters. It is worth stressing that, contrary to a standard mass model that relies on several hypotheses in order to describe the data, the GP takes information directly from the data, and therefore, the dataset is an important ingredient of the model. Consequently, the number of parameters quoted here should not be directly compared with that of a
standard mass model.
In
Figure 6, we illustrate the residuals obtained from the DZ10-GP model as a function of mass number
A. We clearly see that the GP has been able to capture the missing physics of the DZ10 model, in particular, smoothing out the spikes observed in
Figure 3. We observe that the maximum discrepancy between theory and experiment is now always lower than 1 MeV, and the structure observed in
Figure 3 has now disappeared, with the new residuals exhibiting behaviour close to white noise. The presence or lack thereof of white noise in the model may represent a lower bound on the accuracy one can achieve with a theoretical model, as discussed in Ref. [
13]; we leave such an interesting analysis for a future investigation.
3.2. Extrapolation Using the DZ10-GP Model
Having created the DZ10-GP model, we now benchmark its extrapolations on the set of ≈750 nuclear masses estimated in Ref. [
32]. The results are presented in
Figure 7. The original DZ10 model gives an RMS of
MeV; the inclusion of GP corrections reduces the RMS to
MeV. It is worth noting that some outliers are still present. We confirm that the six nuclei with a residual larger than 6 MeV are all in the region of super-heavy nuclei with
.
Since the main goal of this article is the study of the outer crust of a neutron star, in
Figure 8, we illustrate in great detail the evolution of the residuals for two isotopic chains—copper and nickel—that play a very important role in determining the composition of the outer crust [
12].
We observe that the original DZ10 model reproduces the data in the middle of the isotopic chains fairly well, and that it tends to give large discrepancies at the edges. Even the inclusion of the statistical error bars of DZ10 are not enough to explain such discrepancies. We refer the reader to Ref. [
20] for a detailed discussion on how these error bars have been obtained. On the contrary, the use of the GP helps to flatten out the discrepancies and produces predictions very close to the data in the extrapolated region. By considering the experimental and theoretical error bars, we observe that our DZ10-GP model reproduces these data reasonably well. The error bars of the DZ10-GP model have been obtained using a
näive approach, i.e., summing the statistical error bars of the original DZ model and the confidence intervals of the GP model in quadrature.
As done in Ref. [
20], we validate the error bars by comparing with experimental masses. In particular, we expect that 68% of known masses differ from the model prediction no more than
, where
is the theoretical error bar of the DZ10-GP model and
is the experimental error bar. By increasing the error bar by a factor of 2 and 3, we should obtain 95% and 99.7% of experimental binding energies falling into the interval.
From
Table 1, we observe that most of the nuclei fall within these error bars, as expected, although we still underestimate in some relevant regions of the chart, such as
, which is important for outer crust calculations. This discrepancy may be a sign of other contributions to the error bar that were not taken into account here, for example, correlations between the DZ10 and GP error bars.
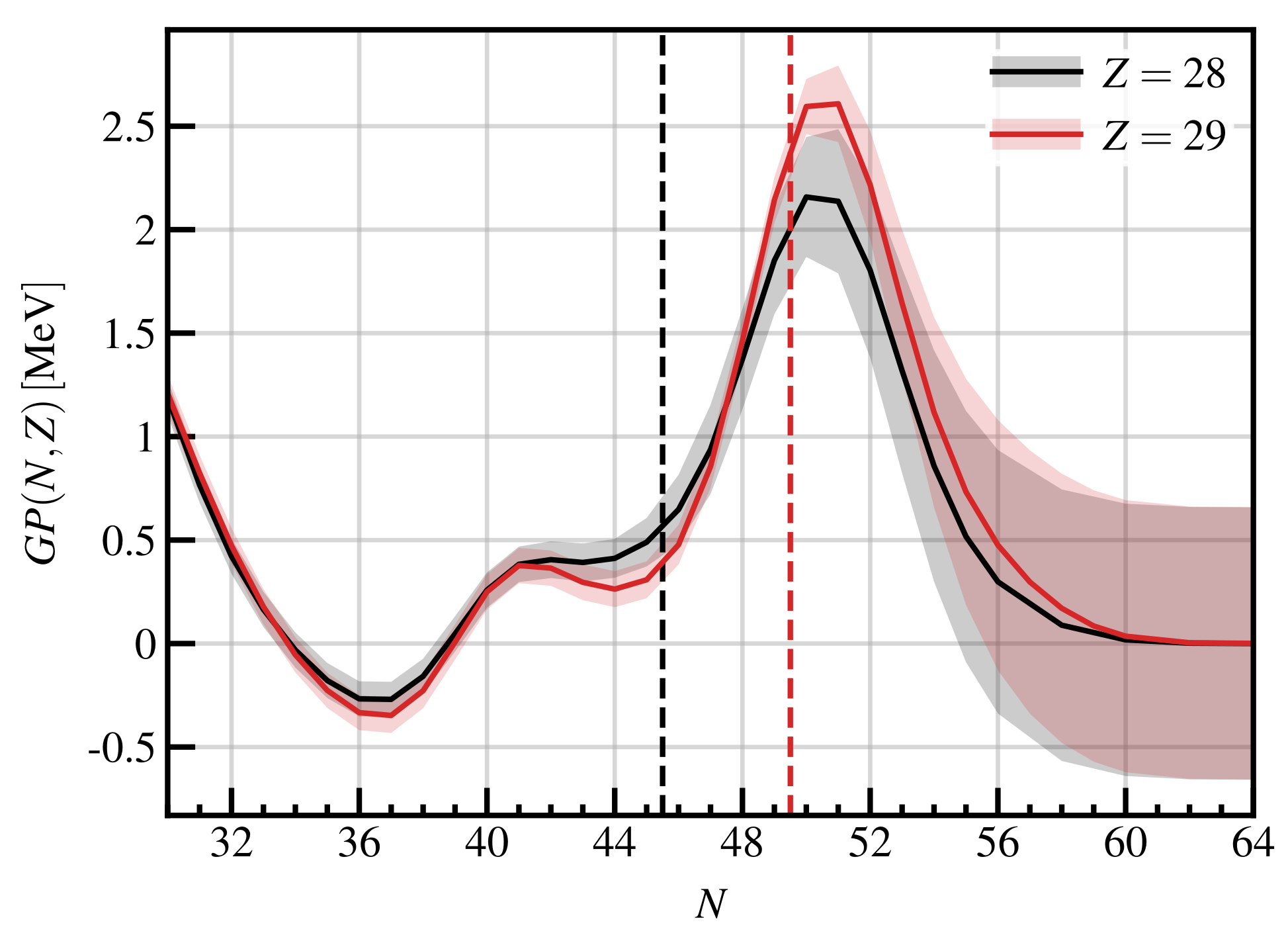
In
Figure 9, we show the evolution, along two isotopic chains, of the GP’s contribution to binding energy. We see that these contributions drop to 0 as the neutron-rich region is approached. On the same figure, we also report the evolution of a
error bar provided by the GP. As discussed previously, we notice that the error bars grow towards the neutron drip-line, where we have little or no available data to constrain the GP.
From
Figure 9, we observe that the confidence interval provided by the GP model at large values of N becomes constant and equal to
. This means that at very large extrapolations, the GP error bar is most likely underestimating. In this case, the model error bar should become larger and be the dominant source of error (see, for example, Ref. [
43]).
This behaviour can be understood from the value of the GP’s correlation length for neutrons,
: by construction, the GP predictions tend to the mean of the data, in this case 0, after ≈
times
. This means that the GP will be effective in describing extrapolated neutron-rich nuclei with at most ≈
neutrons more than the last nucleus in our training set. This is clearly only a rule of thumb, but it is enough to cover most of the extrapolated nuclei that are present in the outer crust [
44] of a neutron star. For nuclei further away from the known dataset, the extrapolation is governed by the underlying nuclear mass model, i.e., the DZ10 model. This is not the case for other approaches, for example, with NNs that can introduce an additional trend on top of the model. Such a trend is difficult to predict
a priori, and may be strongly biased by the training method. See Ref. [
23] for a more detailed discussion.
3.3. Comparison with AME2020
Having trained and developed the DZ10-GP model on the AME2016 database [
32], we now benchmark the predictions against the newly published AME2020 database [
45]. Between the 2016 and 2020 database, we have 74 new isotopes.
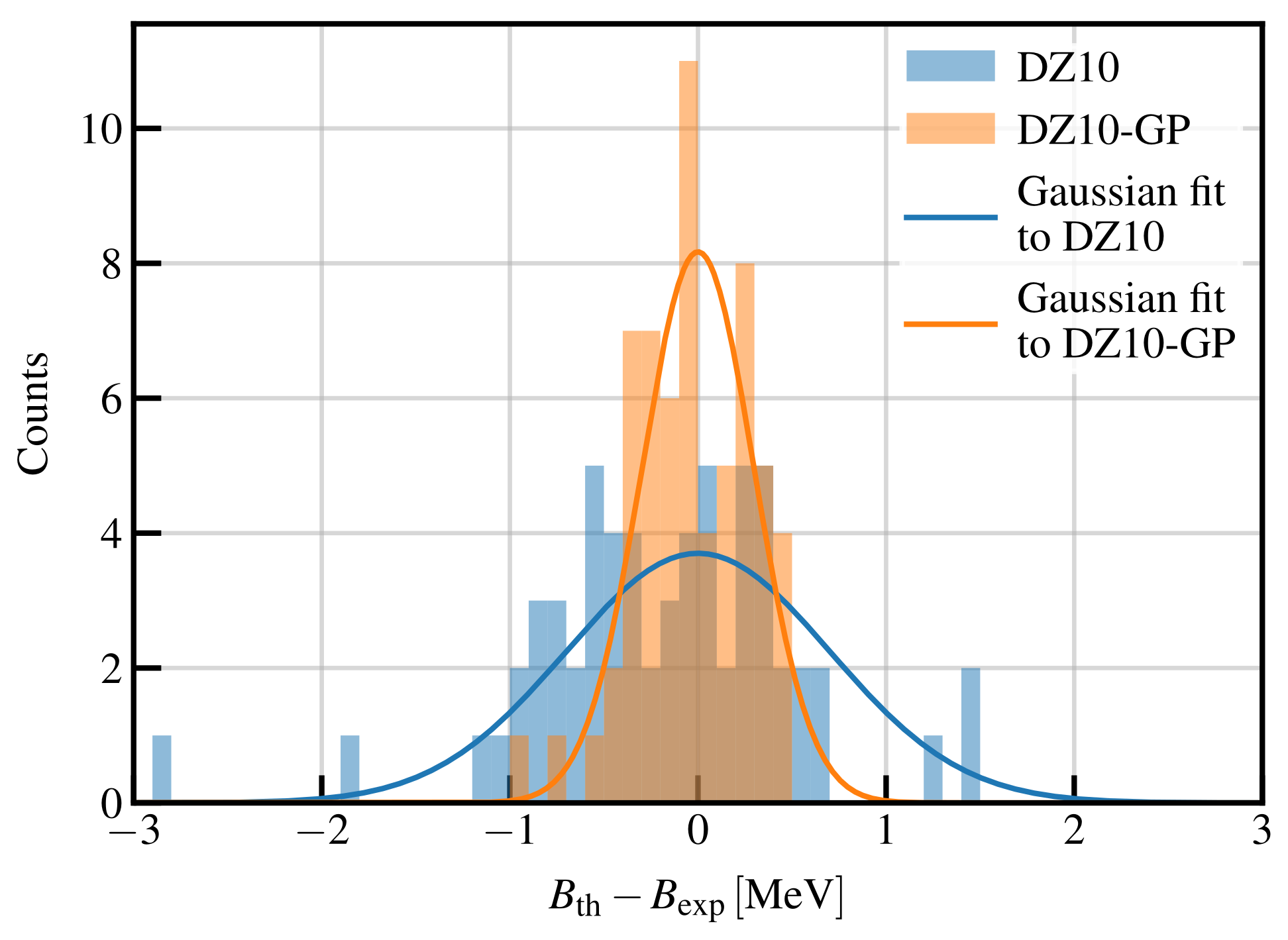
In
Figure 10, we report the distribution of the residuals for the new isotopes presented in AME2020 database, apart from the Cu measurements already published in Ref. [
46]. We observe that the RMS of the original DZ10 model for these new data is
keV, while for the DZ10-GP model, it is
keV. Notice that in this case, we do not readjust the GP model over the new data. This test clearly proves that the GP is not overfitting the data, but it was really able to grasp a signal in the residuals and is therefore capable of performing extrapolations in regions in the proximity of the dataset used for the training. We also observed that 50% of the new isotopes fall within the error bars of the original DZ10-GP model. This value is slightly lower than what is reported in
Table 1, but still reasonable compared to the expected 68%.
4. Outer Crust
To determine the chemical composition of the outer crust, we minimise the Gibbs free energy per particle, which is defined as [
47]
where
is the baryonic density. The three terms
are the
nuclear,
electronic, and
lattice energies per nucleon, respectively [
48]. The pressure
P arises only from lattice and electron contributions as
. For more details, we refer to Ref. [
47], where the entire formalism has been discussed in great detail.
The novelty of the current approach is in the treatment of the nuclear term, which takes the form
where
is the mass of the proton (neutron) and
is the nuclear binding energy given by the mass model. In the current article, we use the mass model DZ10-GP, as discussed in
Section 2. The composition predicted by the mass models is given in
Table 2. By comparing the DZ10-GP results with those obtained using only the DZ10 model, we observe some discrepancies in the extrapolated region at low
P. In particular, we notice that the improved mass model (DZ10-GP) predicts the existence of
Zn, which is not considered in the original DZ10 model. At higher
P, the two mass models give very similar results. This is simple to understand since, as discussed in
Section 2, the GP correction tends to 0 for large extrapolations, as seen in
Figure 9.
Since our goal is to obtain the statistical uncertainties of the equation of state, we perform a simple Monte Carlo sampling of the error bars of our DZ10-GP model (under a Gaussian assumption). We generate new mass tables, and we use them to calculate the composition of the outer crust.
Using a
frequentist approach [
49], we define the existence probability of each nucleus as the ratio of the number of times a given nucleus appears in the various EoS at a given pressure, divided by the total number of mass tables. See Ref. [
20] for more details.
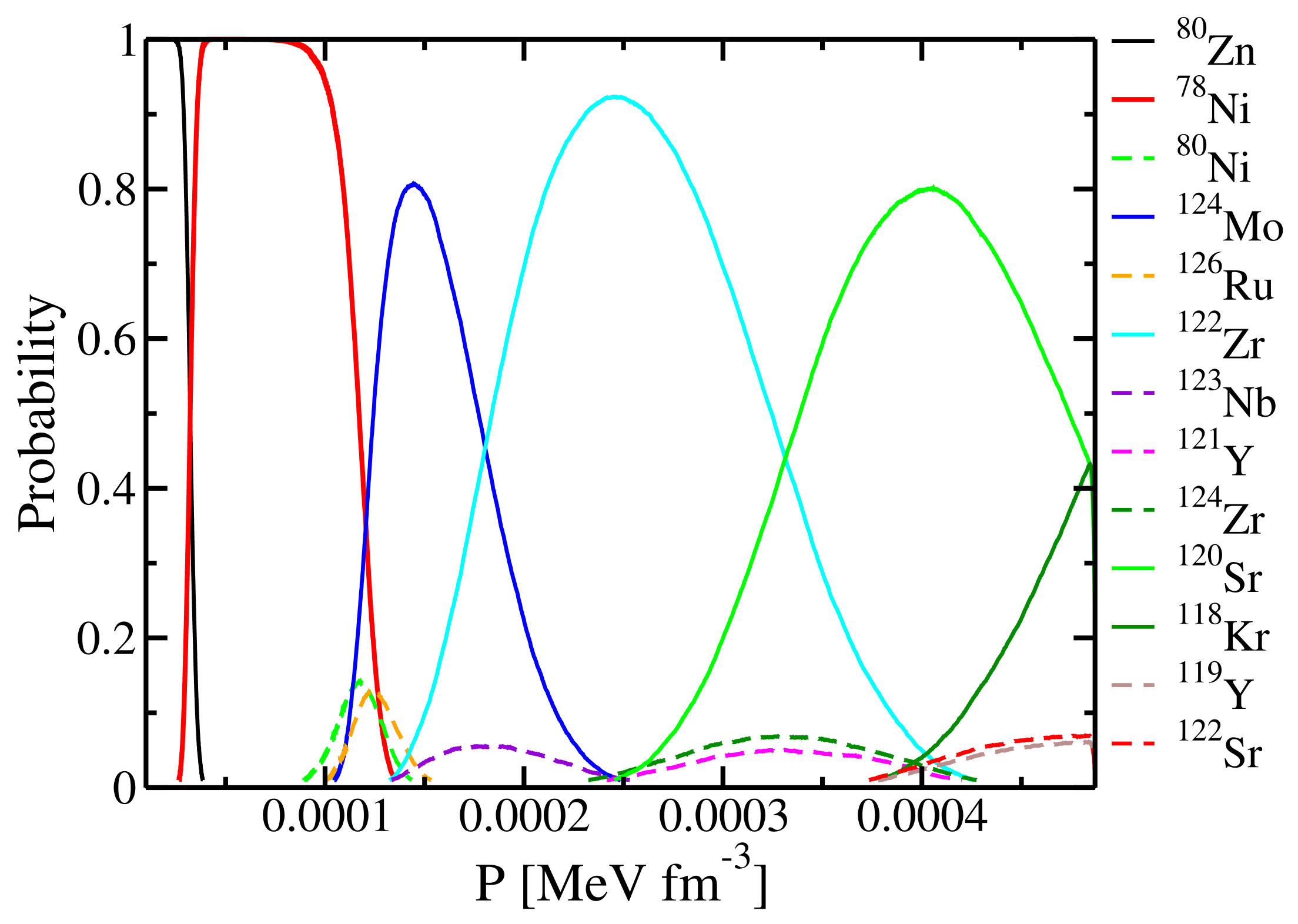
In
Figure 11, we show the evolution of the existence probability for each nucleus in the outer crust as a function of the pressure of the star. We notice that, as confirmed by other authors [
44], the favourable configurations are those close to the neutron shell closures at
and
. However, due to the large error bars, there is a non-negligible probability for several nuclei to be present within the outer crust.
It is interesting to compare the composition obtained with DZ10-GP with the predictions of other mass models, since different mass models may yield different extrapolations. We have selected two popular mass models currently used in astrophysics: BSk20 [
44] and BPS [
50]. The results are reported in
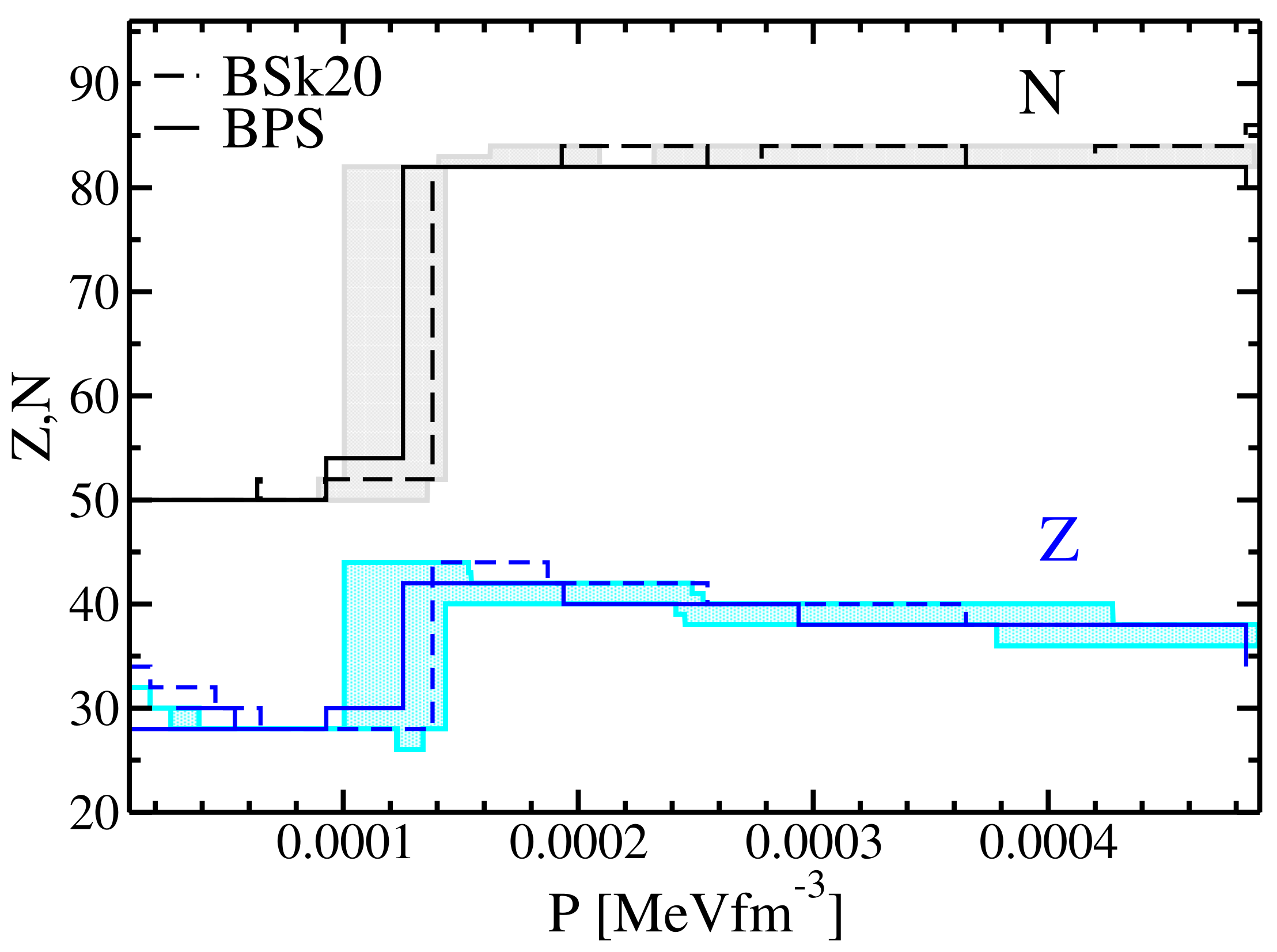
Figure 12. The shaded area on the figure represents all the possible EoSs obtained using the Monte Carlo procedure detailed above using a 1% cut-off on the existence probability. We observe that the results obtained with the different procedures are in good agreement with the DZ10-GP model once the error bars are properly taken into account. It is important to notice that the transition region between the outer and inner crust is mainly governed by the mass model and not by the GP correction. As a consequence, we may expect different results using the various models, as shown in
Figure 12.
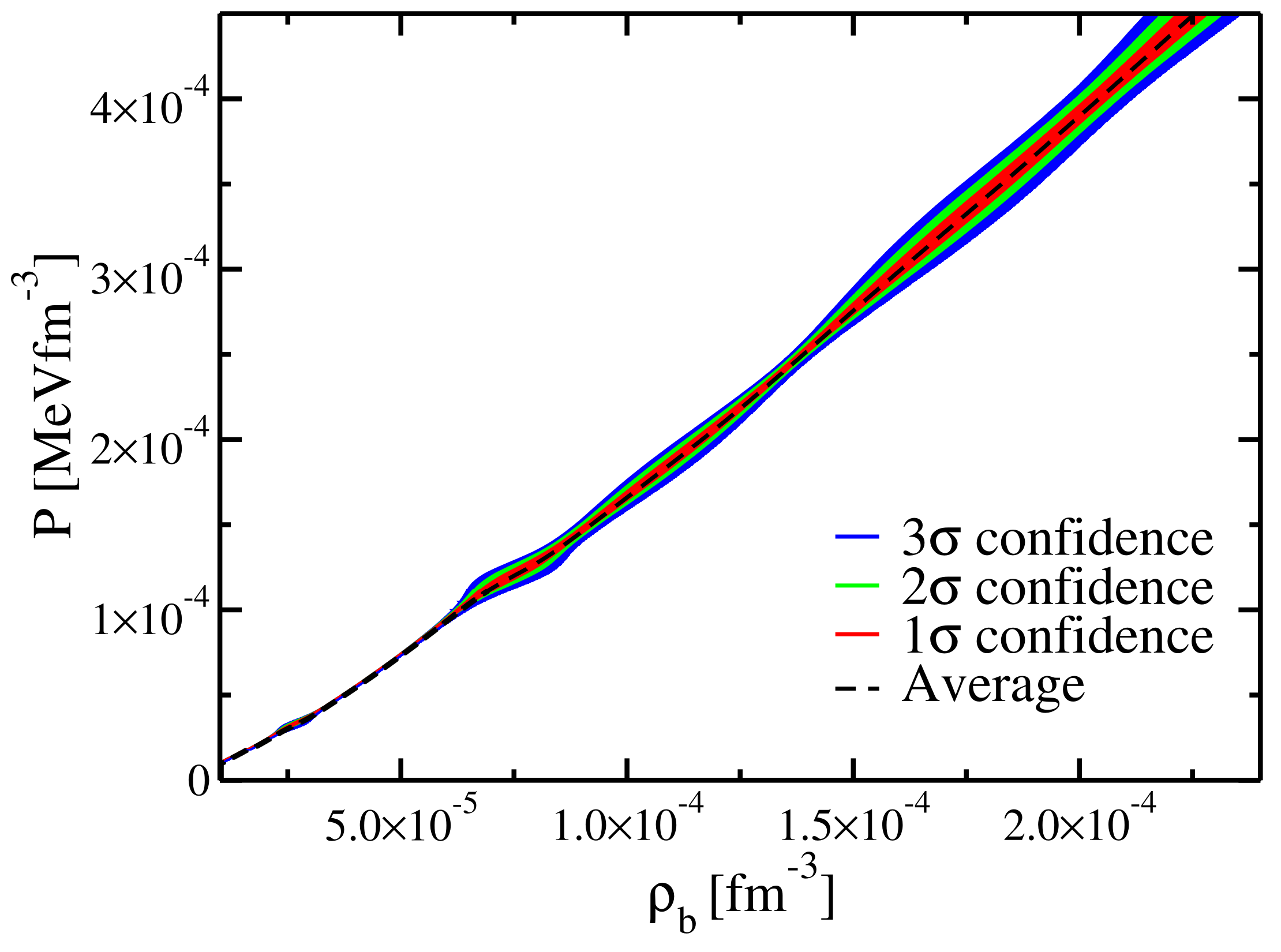
Using the same dataset, we also define a statistical uncertainty for the EoS: by counting the
EoS built before, we define the 68%, 95%, and 99% quantiles of the counts, i.e.,
,
, and
deviations, under the assumption that the errors follow a Gaussian distribution. The results are presented in
Figure 13. We observe that the largest uncertainties are located close to the transition from N = 50 to N = 82 at
and approaching the transition to the inner crust at
.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}