




Aurora Classification in All-Sky Images via CNN–Transformer


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
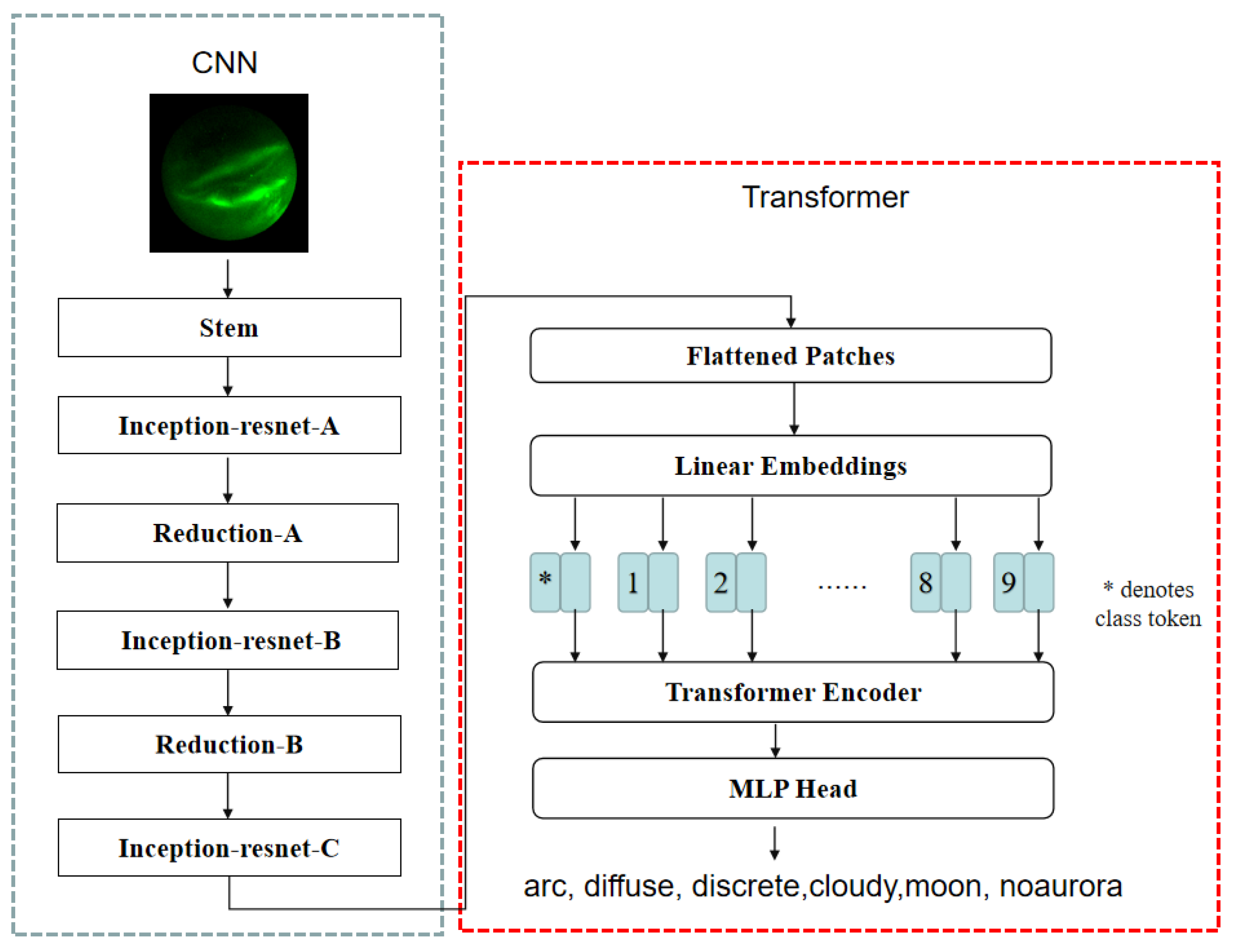
2.2. CNN–Transformer Model
2.3. Training and Fine-Tuning
3. Results
3.1. Implementation Details and Evaluation Metrics
3.2. Experimental Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LDA | Linear discriminant analysis |
| SVM | Support vector machine |
| SIFT | Scale-invariant feature transform |
| THEMIS | Time History of Events and Macroscale Interactions during Substorms |
| OATH | Oslo Auroral THEMIS |
| CNN | Convolutional neural network |
| MLP | Multi-layer perceptron |
| MSA | Multi-head self-attention |
| GPU | Graphical processing unit |
| TP | True positive |
| TN | True negative |
| FP | False positive |
| FN | False negative |
References
- Clausen, L.B.; Nickisch, H. Automatic classification of auroral images from the Oslo Auroral THEMIS (OATH) data set using machine learning. J. Geophys. Res. Space Phys. 2018, 123, 5640–5647. [Google Scholar] [CrossRef]
- Seki, S.; Sakurai, T.; Omichi, M.; Saeki, A.; Sakamaki, D. High-Energy Charged Particles; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Borovsky, J.E.; Valdivia, J.A. The Earth’s magnetosphere: A systems science overview and assessment. Surv. Geophys. 2018, 39, 817–859. [Google Scholar] [CrossRef]
- Qian, W. Image Classification and Dynamic Process Analysis for Dayside Aurora on All-sky Image. Ph.D. Thesis, Xidian University, Xi’an, China, 2011. [Google Scholar]
- Akasofu, S.I. The development of the auroral substorm. Planet. Space Sci. 1964, 12, 273–282. [Google Scholar] [CrossRef]
- Syrjasuo, M.; Partamies, N. Numeric image features for detection of aurora. IEEE Geosci. Remote Sens. Lett. 2011, 9, 176–179. [Google Scholar] [CrossRef]
- Syrjasuo, M.; Pulkkinen, T.I. Determining the skeletons of the auroras. In Proceedings of the 10th International Conference on Image Analysis and Processing, Venice, Italy, 27–29 September 1999; pp. 1063–1066. [Google Scholar]
- Syrjäsuo, M.; Donovan, E. Analysis of auroral images: Detection and tracking. Geophysica 2002, 38, 3–14. [Google Scholar]
- Yang, Q.; Liang, J.; Hu, Z.; Zhao, H. Auroral sequence representation and classification using hidden Markov models. IEEE Trans. Geosci. Remote Sens. 2012, 50, 5049–5060. [Google Scholar] [CrossRef]
- Han, B.; Yang, C.; Gao, X. Aurora image classification based on LDA combining with saliency information. J. Softw. 2013, 24, 2758–2766. [Google Scholar] [CrossRef]
- Rao, J.; Partamies, N.; Amariutei, O.; Syrjäsuo, M.; Van De Sande, K.E. Automatic auroral detection in color all-sky camera images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4717–4725. [Google Scholar] [CrossRef]
- Donovan, E.; Mende, S.; Jackel, B.; Frey, H.; Syrjäsuo, M.; Voronkov, I.; Trondsen, T.; Peticolas, L.; Angelopoulos, V.; Harris, S.; et al. The THEMIS all-sky imaging array—System design and initial results from the prototype imager. J. Atmos. Sol.-Terr. Phys. 2006, 68, 1472–1487. [Google Scholar] [CrossRef]
- Niu, C.; Zhang, J.; Wang, Q.; Liang, J. Weakly supervised semantic segmentation for joint key local structure localization and classification of aurora image. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7133–7146. [Google Scholar] [CrossRef]
- Zhong, Y.; Ye, R.; Liu, T.; Hu, Z.; Zhang, L. Automatic aurora image classification framework based on deep learning for occurrence distribution analysis: A case study of all-sky image data sets from the Yellow River Station. J. Geophys. Res. Space Phys. 2020, 125, e2019JA027590. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yang, Q.; Zhou, P. Representation and classification of auroral images based on convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 523–534. [Google Scholar] [CrossRef]
- Sado, P.; Clausen, L.B.N.; Miloch, W.J.; Nickisch, H. Transfer learning aurora image classification and magnetic disturbance evaluation. J. Geophys. Res. Space Phys. 2022, 127, e2021JA029683. [Google Scholar] [CrossRef]
- Yang, Q.; Wang, Y.; Ren, J. Auroral Image Classification With Very Limited Labeled Data Using Few-Shot Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shang, Z.; Yao, Z.; Liu, J.; Xu, L.; Xu, Y.; Zhang, B.; Guo, R.; Wei, Y. Automated Classification of Auroral Images with Deep Neural Networks. Universe 2023, 9, 96. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhang, H.; Hu, Z.; Hu, Y.; Zhou, C. Calibration and verification of all-sky auroral image parameters by star maps. Chin. J. Geophys. 2020, 63, 401–411. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollár, P. Tensormask: A foundation for dense object segmentation. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2061–2069. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6824–6835. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11936–11945. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Quantity | Hexagonal Classification | Binary Classification |
|---|---|---|---|
| arc | 774 | 0 | 0 |
| diffuse | 1102 | 1 | 0 |
| discrete | 1400 | 2 | 0 |
| cloudy | 852 | 3 | 1 |
| moon | 614 | 4 | 1 |
| no-aurora | 1082 | 5 | 1 |
| Total | 5824 | - | - |
| Method | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|
| U-Net [28] | 93.2 | 93.8 | 90.8 |
| Mask R-CNN [29] | 92.6 | 92.9 | 89.6 |
| ExtremeNet [30] | 91.7 | 94.7 | 92.1 |
| TensorMask [31] | 92.9 | 93.8 | 94.7 |
| Visual Transformer [32] | 92.6 | 94.2 | 95.0 |
| ViT [23] | 93.7 | 92.7 | 95.2 |
| MViT [33] | 92.4 | 93.5 | 96.3 |
| PVT [34] | 94.7 | 95.3 | 96.1 |
| PiT [35] | 95.4 | 95.5 | 97.8 |
| Swin Transformer [36] | 96.7 | 97.1 | 98.2 |
| The proposed approach | 97.6 | 98.1 | 99.4 |
| Method | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|
| U-Net [28] | 90.5 | 91.5 | 89.8 |
| Mask R-CNN [29] | 89.7 | 86.1 | 87.8 |
| ExtremeNet [30] | 91.2 | 93.6 | 91.3 |
| TensorMask [31] | 92.3 | 93.1 | 93.7 |
| Visual Transformer [32] | 91.4 | 92.2 | 93.8 |
| ViT [23] | 92.7 | 92.5 | 94.7 |
| MViT [33] | 91.6 | 92.2 | 93.1 |
| PVT [34] | 93.2 | 95.0 | 94.5 |
| PiT [35] | 95.1 | 94.9 | 96.1 |
| Swin Transformer [36] | 96.2 | 96.9 | 97.5 |
| The proposed approach | 97.3 | 98.4 | 98.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, J.; Liu, T.; Zhou, Y. Aurora Classification in All-Sky Images via CNN–Transformer. Universe 2023, 9, 230. https://doi.org/10.3390/universe9050230
Lian J, Liu T, Zhou Y. Aurora Classification in All-Sky Images via CNN–Transformer. Universe. 2023; 9(5):230. https://doi.org/10.3390/universe9050230
Chicago/Turabian StyleLian, Jian, Tianyu Liu, and Yanan Zhou. 2023. "Aurora Classification in All-Sky Images via CNN–Transformer" Universe 9, no. 5: 230. https://doi.org/10.3390/universe9050230
APA StyleLian, J., Liu, T., & Zhou, Y. (2023). Aurora Classification in All-Sky Images via CNN–Transformer. Universe, 9(5), 230. https://doi.org/10.3390/universe9050230