1. Introduction
A key role in the regulatory of expression machinery is covered by transcription factors (TFs), proteins that recognize target DNA sequences called response elements and establish specific interactions with additional factors to activate or inhibit the transcription process [
1,
2,
3,
4]. The species involved in the process have been unambiguously identified [
5,
6], but significant information is still lacking on the effects of structure/dynamics on specific recognition and mechanism of action. The Protein Data Bank contains the high-resolution structures of at least 483 TFs from different species [
7], which include less than 10% of all predicted human TFs [
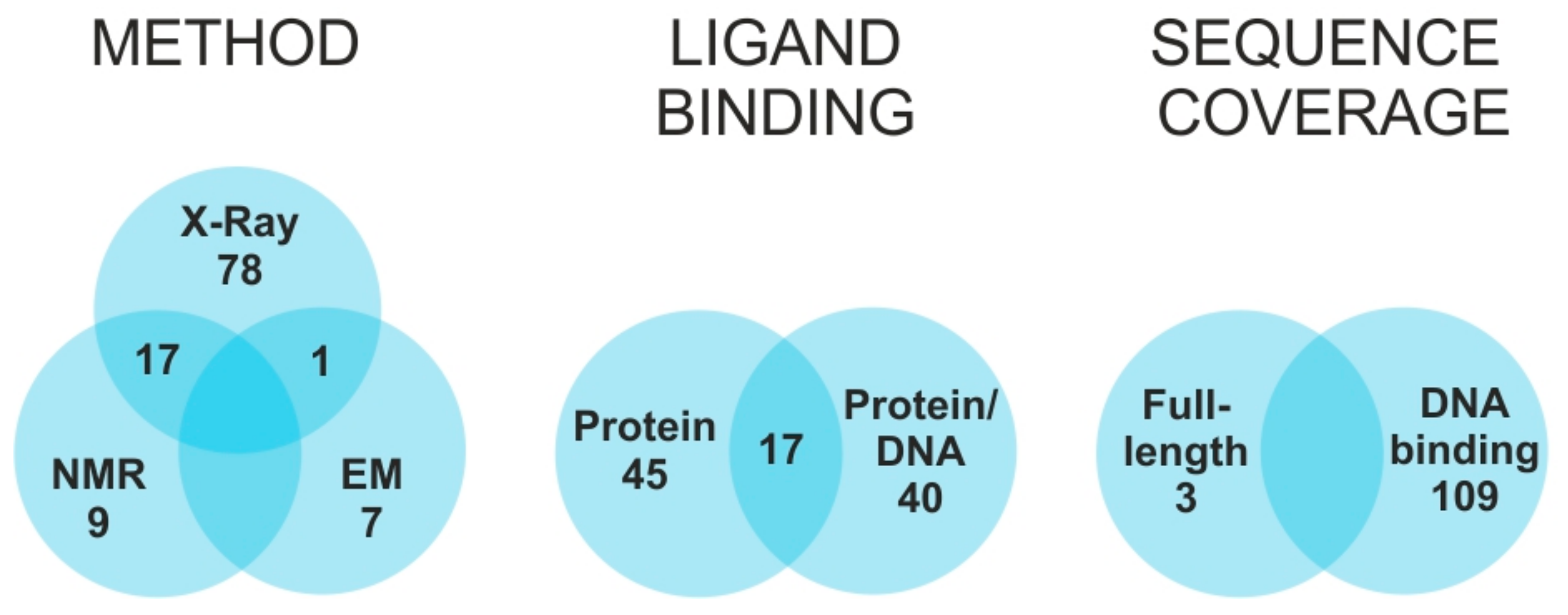
6]. Of such structures, only one third also include the cognate DNA response element, and only one fifth are available in both bound and unbound states (
Figure 1). Due to the size and complexity of such systems, most solved structures do not include the entire TF sequence, but consist almost exclusively of the DNA binding domain (DBD). This fact reflects the modular organization of TFs, which includes discrete domains acting in rather independent manner [
8,
9]. While DBDs tend to be highly structured, other regions responsible for either modulating transcription activity, or supporting facultative ligand interactions, are rather flexible and assume well-defined conformations only upon binding to the intended factor [
10]. The unstructured nature of these regions poses many challenges to conventional high-resolution approaches, which require adequate conformational stability and homogeneity. In most cases, the natural interactions established in vivo, which are responsible for stabilizing well-defined functional conformations, cannot be properly replicated in vitro. These challenges explain the chronic lack of comprehensive information on full-fledged TF structures, which still hampers the elucidation of their mechanism of action at the molecular level.
Powered by the development of new experimental strategies and mass spectrometric (MS) instrumentation, structural proteomics has rapidly become an essential approach for gathering valuable structural information for species that are not directly amenable to conventional high-resolution techniques [
11,
12,
13,
14]. In addition to hydrogen-deuterium exchange (HDX) [
15], a combination of chemical and biochemical techniques broadly known as MS3D [
16,
17,
18] have been effectively utilized to identify the regions of contact between bound biomolecules and reveal their mutual spatial organization. In HDX experiments, the exchange rate of backbone amide hydrogens, which is affected by solvent accessibility and possible involvement in hydrogen bonding, can be directly determined by MS analysis. This technique has been broadly employed to study conformational changes [
19,
20], protein folding [
21] and protein-protein interactions [
22,
23], as well as nucleic acid-protein complexes [
24,
25,
26,
27,
28,
29]. Among the MS3D techniques, chemical and photo-activated cross-linking (XL) are employed to generate stable covalent bridges between contiguous functional groups, which can reveal their mutual placement in the targeted assembly [
13,
16]. A variety of bifunctional reagents with different spacing between reactive groups have been developed to determine the distance between susceptible residues. In this way, the sequence position of cross-linked residues and the length of the respective cross-linker provide valid constraints for building accurate molecular models through established computational methods [
17,
18,
30,
31,
32]. The excellent versatility of these approaches has prompted the development of reagents capable of targeting functional groups present on protein, as well as nucleic acid substrates [
33,
34,
35,
36,
37,
38,
39]. Over time, capture tags and isotopic labels have been included in the cross-linker design to facilitate the isolation and analysis of cross-linked products [
40,
41]. Isotope-labelling, in particular, has provided a valuable tool for highlighting the presence of different conformational states and quantifying their partitioning on the basis of cross-linking probability [
13].
In this study, we evaluated the concerted application of complementary structural proteomics techniques to overcome the challenges posed by full-fledged complexes between TFs and respective DNA response elements. We selected a model system consisting of the human transcription factor FOXO4 and its cognate Daf-16 family member-binding element (DBE) [
42]. FOXO4 is part of the “O” subfamily of the forkhead box (FOX) class of transcription factors [
42,
43,
44]. The DBD regions of this class are characterized by winged helix structures, which comprise by approximately 100 amino acids folded into helix-turn-helix motifs and β-sheet-bordered loops that make them resemble butterfly wings [
45]. The first high-resolution structure of FOXO4-DBD, which was obtained by NMR spectroscopy, confirmed the presence of a typical forkhead, winged helix fold [
46]. At the same time, however, the report indicated that the N- and C- terminal regions of the DBD displayed chemical shifts consistent with highly flexible, disordered structures. The more recent identification of consensus sequences for the FOXO family [
47] enabled the crystallization of a complex comprising a selected DBE duplex and a FOXO4-DBD construct that lacked the C-terminal region to facilitate crystal formation [
48]. This high-resolution structure provided valuable details on the protein-DNA interaction, but revealed also numerous discrepancies with the binding modes exhibited by other members of the FOXO family [
44], which were attributed to possible crystal-packing issues [
48]. For these reasons, the FOXO4-DBD•DBE system offered an excellent opportunity for testing the ability of structural proteomics to probe the conformational effects of binding, which would help rectify or corroborate the observed discrepancies. On the other hand, it also afforded sufficient structural information to determine the validity of the new experimental constraints and evaluate the merits of the selected approaches.
The experimental strategies were selected for their ability to provide specific information on a typical protein-DNA complex. For instance, HDX was applied to recognize the regions of the protein affected by DNA binding, either through direct protection of the contact interface, or through allosteric conformational changes involving distal regions of the protein. Quantitative XL was used instead to identify possible variations between free and DNA-bound DBD structures, which would help elucidate the effects of the interaction on overall structure topology. In the case of the DNA component, the fast rate of back-exchange characteristic of nucleic acid hydrogens prevented the application of HDX to recognize the surface of the DBE duplex in direct contact with the DBD. As a possible alternative, we explored the application of transplatin (trans-dichlorodiamineplatinum(II), tPt) to generate protein-DNA cross-links that would help locate the mutual positions of interacting structural features [
49]. The spatial constraints afforded by these determinations were combined to guide model-building operations and obtain a full-fledged structure for the complex. The results were compared to the available high-resolution structures to assess possible discrepancies and highlight the new information afforded by the selected techniques. It is necessary to point out, here, that the FOXO4-DBD protein construct used in this study was identical to protein constructs used in previous high-resolution structural studies [
46,
48]. The outcome clearly demonstrated the benefits of structural proteomics to tackle the elucidation of structure and dynamics in systems that elude established high-resolution techniques.
3. Results and Discussion
The crystal structure available for the FOXO4-DBD•DBE complex does not cover the entire sequence of the DNA binding domain [
48], which spans only the 82–207 section of FOXO4 and omits flanking regions that have been hypothesized to promote the recruiting of additional components of the transcription machinery. At the same time, the NMR structure of full-length FOXO4-DBD provides limited information on the G
138–A
144, E
166–K
170, and the N- and C-terminal regions, which were described as rather flexible and disordered in solution [
46]. Although DNA binding has been credited with stabilizing at least some of these regions, the structure of the bound form still displayed significant discrepancies with those of homologous members of the FOXO family [
44], which were possibly caused by crystal packing [
48]. For this reason, we investigated such discrepancies by implementing biochemical approaches to probe the effects of ligand binding directly in solution. The study employed recombinant full-length DBD (i.e., residues G
82–A
207) and a duplex DNA construct containing the 5′-TAC CCA A-3′ consensus sequence, which was obtained by annealing commercial oligo-deoxyribonucleotides. As shown in
Figure S1A and Figure S2 of Supplementary Materials, mixing equimolar amounts of protein and duplex DNA provided the expected 1:1 species corresponding to the desired FOXO4-DBD•DBE complex. These samples were submitted to hydrogen-deuterium exchange, quantitative protein-protein cross-linking, protein-DNA cross-linking, and docking experiments to obtain complementary information on their mutual interactions and spatial arrangement. The results were compared to those obtained from the individual FOXO4-DBD protein to investigate the effects induced by specific DNA binding.
3.1. Combined Online Digestion by Pepsin and Nepenthesin I Improves the HDX Resolution
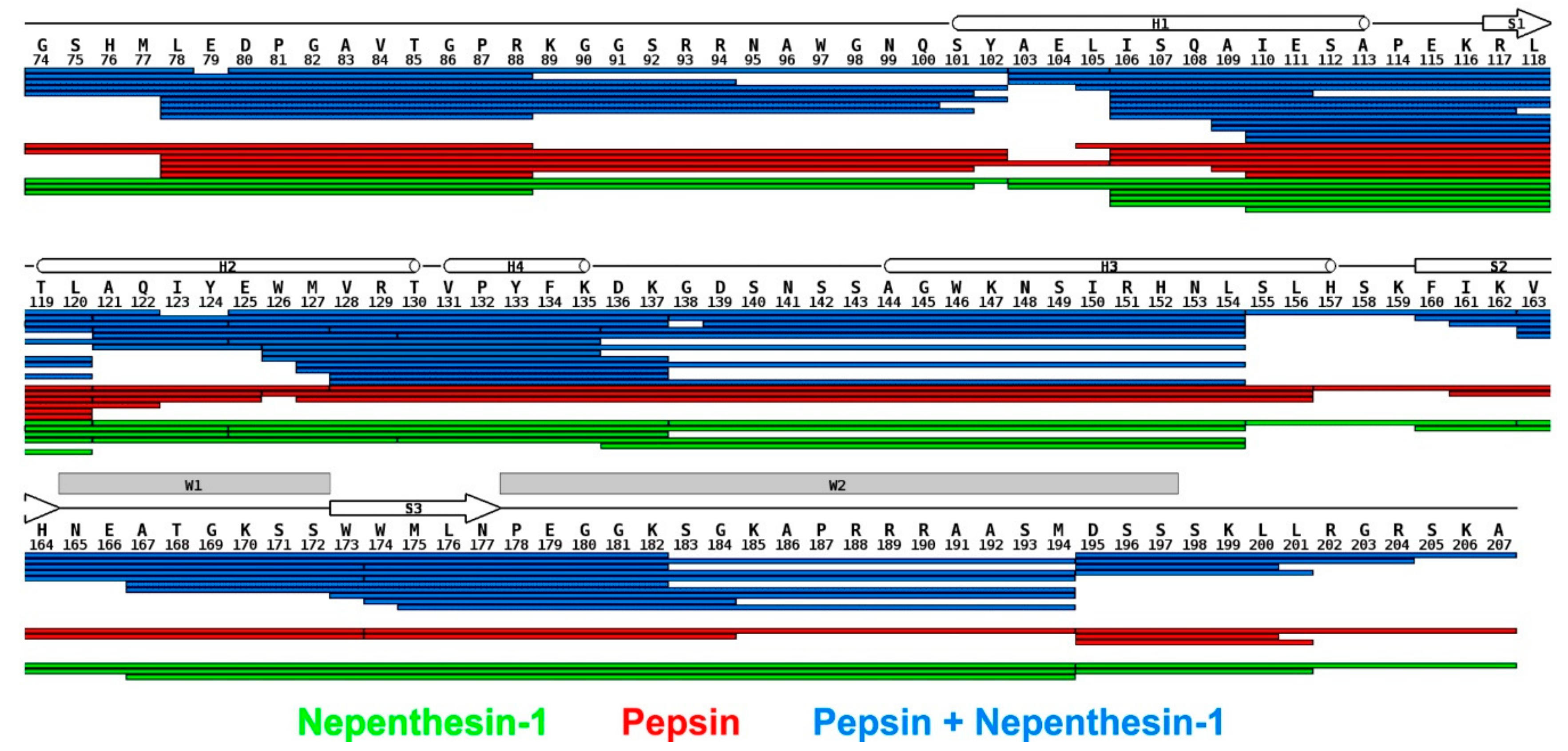
We initially pursued the identification of the regions of FOXO4-DBD, which were making direct contact with the DBE duplex, or were subjected to detectable microenvironment variations upon binding. Hydrogen-deuterium exchange (HDX) was performed on both free and bound forms of full-length FOXO4-DBD. The determinations followed a well-established protocol in which the exchange process was stopped at predetermined intervals to monitor the rate of exchange. Since hydrogen-deuterium exchange has not yet been widely used to study the complex of protein and duplex DNA, we first tuned conditions for on-line digestion in order to obtain the best spatial resolution. It was achieved using the combination of nepenthesin I and pepsin, where rather small and overlapping peptides were observed. The robustness of the setup was approved by multiple injections. The final analysis was carried out at low pH and temperature to minimize back-exchange. The protocol included protein digestion in consecutive on-line columns containing immobilized proteases (i.e., pepsin and nepenthesin-1), followed by LC-MS/MS and LC-MS analysis of digested peptides (see Materials and Methods and
Supplementary Materials) [
66]. Since HDX has not been widely used to study complexes comprising protein and duplex DNA, the conditions for on-line digestion required fine-tuning to obtain the best possible spatial resolution. This task was accomplished by combining nepenthesin I with pepsin to obtain rather small, overlapping peptides. Multiple analysis were carried out to evaluate the robustness of this approach. The ensuing peptide map demonstrated that the procedure afforded full coverage of the FOXO4-DBD sequence (
Figure 2).
3.2. HDX Identified the Interaction Interface and Revealed Long-Distance Structure Stabilization
For each digestion product, a relative deuteration rate was calculated by considering the number of hydrogens exchanged with deuterium atoms against the total number of exchangeable amide hydrogens in the peptide. Relative deuteration rates versus exchange time were calculated at both the peptide and amino acid levels to recognize possible variations between free and bound FOXO4-DBD (see
Figures S3–S6 of Supplementary Materials, respectively). This task was facilitated by calculating actual differences for each amino acid in the sequence, which were visualized in a 3D model of FOXO4-DBD•DBE by using an appropriate color palette (
Figure S7 of Supplementary Materials).
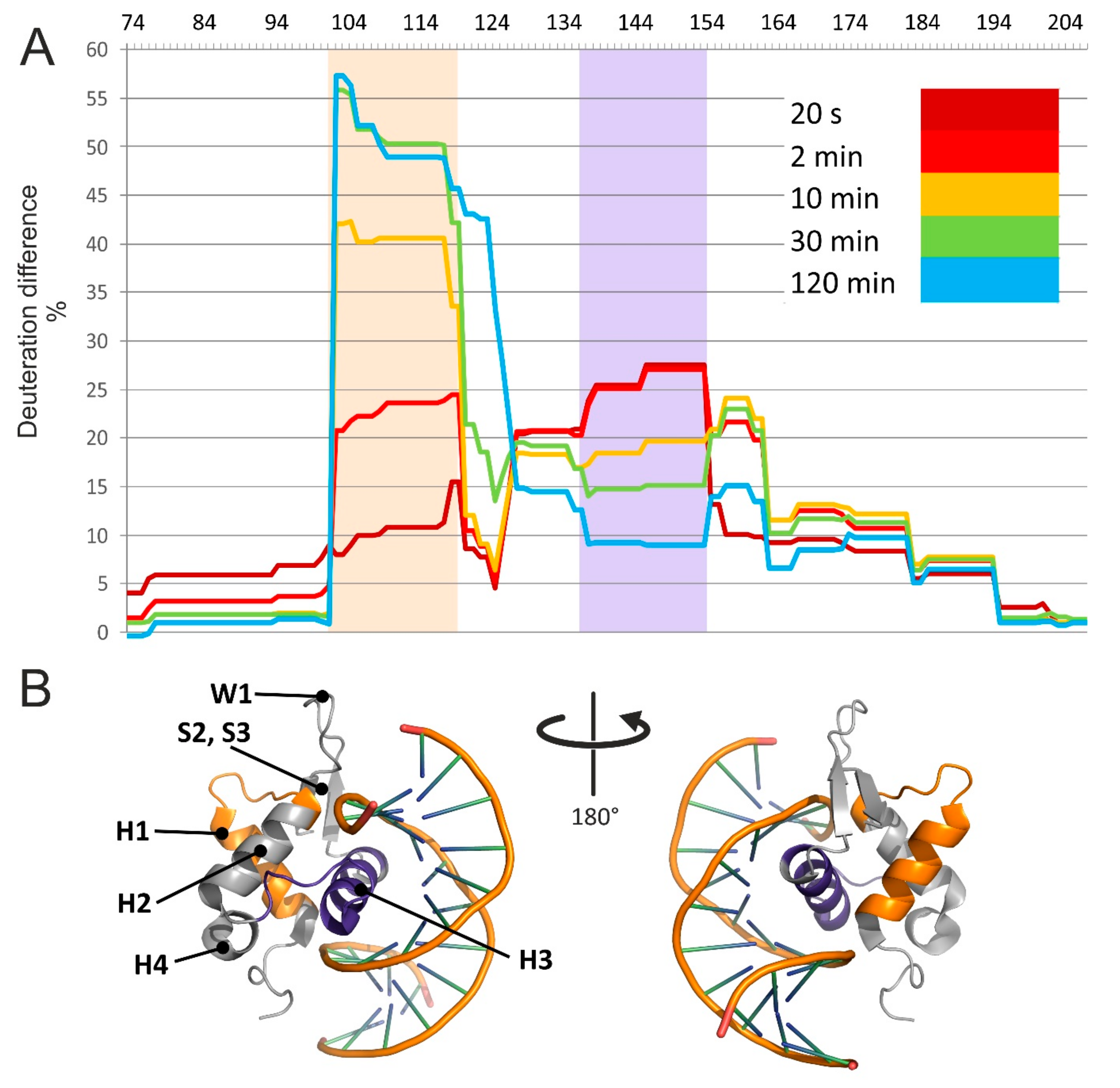
The results are summarized in an HDX difference plot that provided a comprehensive view of the variations of solvent accessibility induced by the specific interactions between FOXO4-DBD and its cognate DBE duplex (
Figure 3). Starting from the N-terminus, the G
74–Y
102 region displayed relatively high levels of deuteration, regardless of reaction time, with no significant differences between free and bound forms. These observations indicated that this region was rather exposed and capable of exchanging freely with the solvent in both forms. In contrast, the next section spanning the A
103–T
130 residues displayed the most extensive differences in deuteration rates, which increased significantly as a function of time. This sequence folds helix H1 and H2, strand S1, and intervening loops (see topology annotation in
Figure 2). According to the crystal structure, none of these distinctive features is supposed to make direct contact with the duplex DNA [
48], which would help explain the drop in deuteration by invoking a simple protection effect. In the absence of direct contact, the observed loss of solvent accessibility must be attributed to indirect conformational effects induced by binding. The fact that the difference in deuteration levels increased gradually with time and stabilized after 30 min suggests that, in the free form, this set of secondary structures may undergo slow mutual dynamics that delay the exchange of susceptible hydrogens. In the bound form, such dynamics may be stabilized by interactions with contiguous structures that, in turn, make direct contact with the DNA ligand. Like falling dominoes, a series of relatively minor conformational variations linked together may ultimately induce observable inhibition of the exchange reaction. This long-distance effect is clearly evident, for example, in the relative deuteration plot of peptide A
103–L
118 (2–3), which shows increasing uptake in the free FOXO4-DBD as a function of time, but constant low-level deuteration in the bound form (
Figure S3 of Supplementary Materials).
The next region, spanning the V
131–K
159 residues, also manifested significant differences between free and bound forms, but their time dependence displayed a rapid increase at shorter intervals, followed by a decline near initial levels at longer reaction times (
Figure 3A). In particular, the residues forming helix H3, which the crystal structure places directly in the major groove of the DBE duplex [
48], experienced the largest differences. For this reason, direct steric protection induced by bound DNA could explain the uptake inhibition observed for such residues. In contrast, the outcome observed for the contiguous helix H4 and intervening loop could indirectly result from the stabilization of the H3 conformation, which could constrain the placement of such residues and restrict their solvent accessibility. The crystal structure also identified a handful of contacts that were mediated by water molecules trapped in the binding interface. While these interactions have been suggested to further stabilize the dynamics of helix H3 and flanking regions, it is not clear how trapping D
2O versus H
2O present in the solvent may affect the observed deuteration rates. It should be also pointed out that FOXO4 differs from other FOXO homologues by the insertion of five amino acids (K
137–N
141) in the H4–H3 loop (
Figure 2). It is not clear whether this insertion may be responsible for the unusual conformation assumed by helix H3 in the bound form, which differs from those assumed in other members of the family [
48]. In any case, the observed inhibition pattern supports a role in stabilizing the fold of FOXO4-DBD and reducing its overall flexibility upon complex formation.
The F
160–D
195 section corresponds to sequences located on the C-terminal side of helix H3, which manifested smaller but still perceptible differences of deuteration rates. This region contains strands S2 and S3, as well as the W1 and W2 wings, which the crystal structure placed far removed from the DNA binding interface. Also in this case, an overall decrease of structural flexibility upon binding could explain the reduced deuterium uptake. It should be noted that, in addition to conferring FOXO4-DBD its winged look and fine tuning of the interaction with DNA [
47], W1 and W2 could contribute to constitute possible regions of contact for auxiliary components of the transcription complex. The final section covered by HDX determinations consisted of the S
196–A
207 sequence and displayed marginal deuteration differences. This observation indicated the absence of any protection or conformational effects induced by DNA binding.
3.3. Protein-DNA Cross-Linking Revealed the Mutual Placement of Protein and DNA Components
The HDX experiments identified the regions affected directly and indirectly by DNA binding, which experienced clearly detectable variations of solvent accessibility. However, these types of determinations could not identify the structures responsible for limiting the access of solvent to a specific region. In other words, these experiments could not reveal the mutual spatial relationships between such structures, nor assess the effects of binding on such relationships. For this reason, we employed different types of cross-linking strategies to probe the organization of the various structures and recognize their mutual placement in the overall fold. The first approach employed transplatin to generate putative protein-DNA conjugates that may be capable of constraining the position of the DBE ligand onto the FOXO4-DBD substrate. The reactivity of platinum compounds towards specific functional groups of nucleic acids is well documented [
67] and involves the preferential attack of the N7 position of guanine base [
68]. Although the characteristics of their reactivity towards protein residues are still unclear [
49], amino acids with electron-rich S, N and O atoms, such as Cys, Met, His, and Thr, have been described as preferred targets [
69]. We treated samples of FOXO4-DBD•DBE complex, as well as free FOXO4-DBD and DBD, with a 10:1 transplatin to substrate molar ratio in 150 mM ammonium acetate (pH 6.85) and incubated at 18 °C for 14 h (see Materials and Methods and
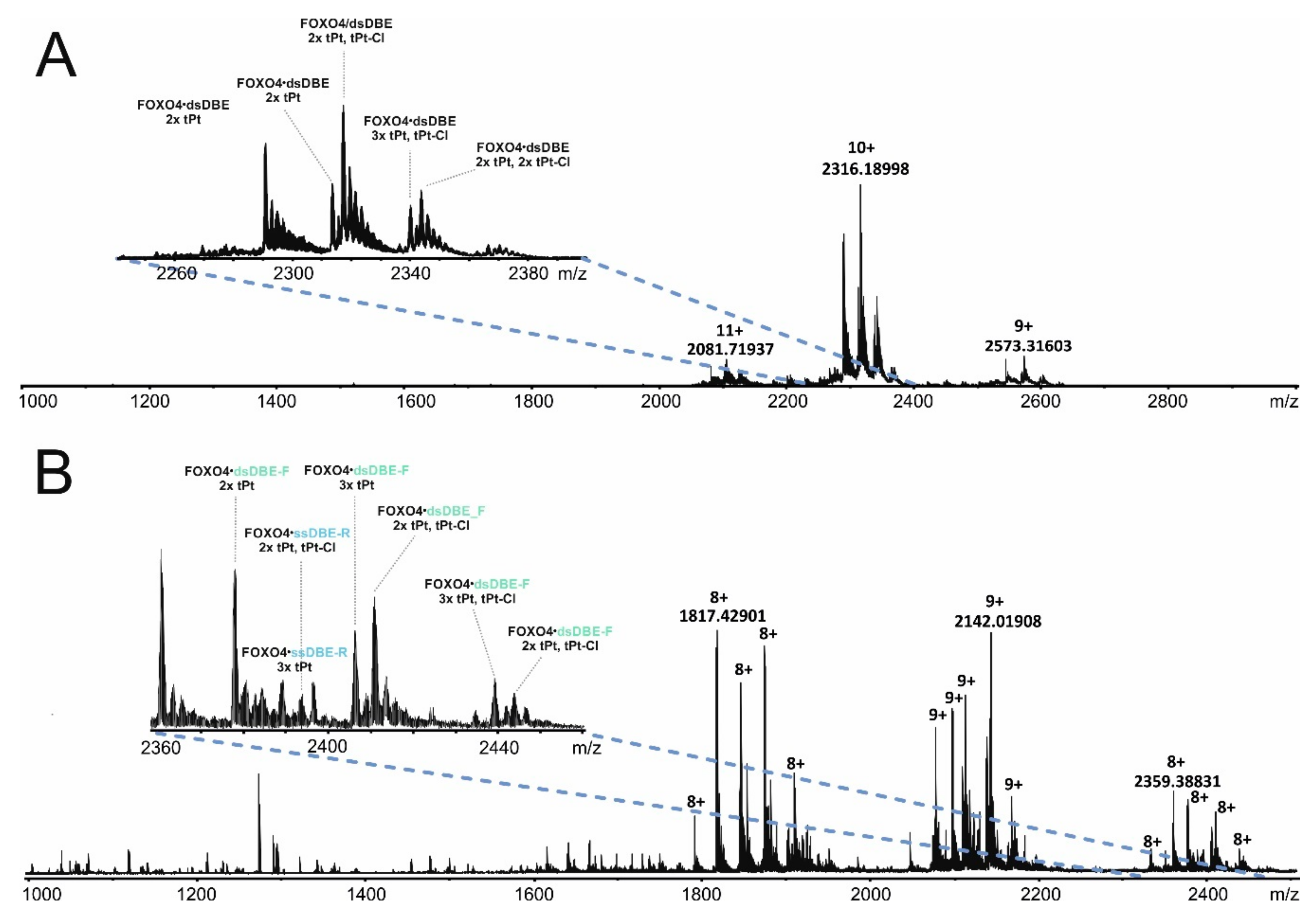
Supplementary Materials). The sample mixtures were analyzed by both ESI-MS and SDS-PAGE to assess the distribution of transplatin adducts to estimate the proportion of sought-after intermolecular cross-links. The representative data in
Figure 4A provides a view of the typical product distributions obtained from these probing reactions, which included monofunctional “dangling” adducts containing a still unreacted chloride function (i.e., marked as tPt-Cl adducts), as well as bifunctional conjugates in which both functions had effectively reacted (i.e., marked as tPt adducts).
Based on mass alone, it is not typically possible to distinguish the desired intermolecular conjugates from intramolecular crosslinks, which share the same elemental composition. For this reason, ESI-MS analysis was repeated in the presence of 50% methanol to achieve mild denaturing conditions. In this way, products stabilized by bridging bifunctional cross-links were still detected intact, such as the conjugates containing FOXO4-DBD and individual DBE-F or DBE-R strands. In contrast, no signal was observed for complexes devoid of any intermolecular conjugation, whereas adducts of their free unbound components were individually detected, such as those of FOXO4-DBD protein, DBE-F, and DBE-R strand (
Figure 4B). In analogous fashion, the reaction mixtures were also analyzed by PAGE under both native and denaturing conditions (
Figure S1 of Supplementary Materials). Direct data comparison enabled the identification of bands that eluded dissociation by elevated concentrations of SDS or urea and, thus, could be attributed to the presence of bridging bifunctional crosslinks. These data enabled us to estimate that the desired intermolecular cross-links amounted to less than 5% of the total material submitted to transplatin reaction.
A classic bottom-up strategy was carried out to complete the characterization of cross-linked products, which included digesting the material with protein- and nucleic acid-specific enzymes to obtain samples amenable to LC-MS and LC-MS/MS analysis. In particular, reaction mixtures were treated with trypsin to map the position of peptides conjugated to DNA strands (see Materials and Methods and
Supplementary Materials). In subsequent experiments, the size of the oligonucleotide moieties was reduced by treatment with Bal-31 nuclease to facilitate analysis. The representative data in
Figure S8 of
Supplementary Materials illustrates the challenges faced by the MS/MS analysis of these types of hetero-conjugates. Upon gas-phase activation, a precursor ion consisting of G
74–R
88 cross-linked to the DBE-R strand underwent dissociation around the bridging Pt atom, rather than along the backbones of the bridged moieties. The absence of sequence information afforded by this type of fragmentation prevented the identification of the actual residues involved in the cross-linking reaction. Nevertheless, the identity of the conjugated components still represented valuable information on the mutual relationships between contiguous regions (summarized in
Figure S9 of Supplementary Materials).
The detected peptide-oligonucleotide conjugates were examined in the context of the results afforded by the HDX determinations and other structural information available for the system. For instance, peptide N
148–K
159 spanning helix H3 was found conjugated to the forward strand of DBE, consistent with the placement of H3 directly into the major groove of the DNA duplex in the crystal structure [
48]. This finding agreed also with the prominent protection effects observed in this region during HDX experiments (
Figure 3A). Peptide F
160–K
170, covering the end of S2 and beginning of W1, was also cross-linked to the forward strand of DBE, despite the absence of any direct contact in the crystal structure. In this peptide, reactivity and orientation considerations would point towards H164 and T168 as possible conjugation sites, if their distances from susceptible DNA structures were sufficiently favorable. In this direction, the HDX data indicated that this region experienced a detectable decline in deuterium uptake consistent with the adoption of a rather constrained conformation upon DNA binding (
Figure 3A). The new conformation could place susceptible groups within mutual striking distance, thus promoting the formation of the observed cross-linked product. A similar explanation is applicable also to the S
171–K
182 peptide spanning the end of W1, beginning of W2, and intervening S3 strand, which formed cross-links with both forward and reverse strands of DBE. Also, this region experienced a significant decrease of deuterium exchange upon binding, which was not explainable by direct steric protection, but rather by indirect conformational effects transmitted through contiguous structures. The crystal structure orients S
171 and S
172 to face the minor groove of the duplex construct, which would represent prime positions for promoting conjugation with either strand. Also in this case, the respective functional groups could be placed within striking distance by the more constrained conformation revealed by HDX experiments. The remaining products consisted of the G
74–R
88 peptide cross-linked to either the forward or reverse strand. These products address the flexibility of the N-terminal loop, which was supported by the lack of any significant variation of deuteration patterns reported by the HDX experiments.
3.4. DNA Binding Induced Significant Effects on Protein Conformation
The observed protein-DNA cross-links provided valuable information not only on the reciprocal positions of protein and DNA components, but also on the significant changes induced by binding on the initial protein conformation. We employed protein-specific reagents to evaluate the extent of such variations and enable a better appreciation of indirect conformational effects. Our quantitative crosslinking approach involved the concerted application of the homobifunctional reagents DSGd0/d4 and DSSd0/d4 [di(N-succinimidyl) suberate and di(N-succinimidyl) glutarate] to bridge susceptible amino or hydroxy groups that may be respectively placed within 20.5 ± 3.0 or 24.2 ± 3.0 Å of one another (see
Supplementary Materials). The utilization of reagents with different bridging spans provided the ability to determine an average distance between residues. At the same time, the isotopic labels facilitated the identification of cross-linked products in complex digestion mixtures from their characteristic 4-Da spacing and enabled the acquisition of unbiased quantitative data on the incidence of cross-linking in the free or bound FOXO4-DBD. Initially, separate samples were treated with 1:1 mixtures of matching unlabeled/labelled reagents of the same length to complete a survey of the regions susceptible to cross-linking (see section Materials and Methods and
Supplementary Materials). A total of 39 conjugates were identified, which bridged lysine and serine residues, as well as the N-terminal amino group (
Table S1, Figures S10–S26 of Supplementary Materials). The majority of them were detected in matching pairs generated by reagents of either length, and were observed in both free and bound samples. However, a small portion was unique to just one form and/or cross-linker length. Next, individual aliquots of free FOXO4-DBD were treated with either DSGd0 or DSSd0, whereas those of FOXO4-DBD•DBE complex were separately treated with either DSGd4 or DSSd4 (see Materials and Methods and
Supplementary Materials). Corresponding samples treated with the same unlabeled/labelled reagent were mixed in a 1:1 molar ratio prior to protease digestion and analysis to compare the incidence of each conjugate in either free or bound samples. The proportion of each of the 39 conjugates identified earlier was determined for at least one of the cross-linker lengths, as summarized in (
Table S2 of Supplementary Materials).
A close examination of the results revealed distinctive cross-linking patterns associated with the presence of bound DNA. In particular, the incidence of some conjugates decreased significantly upon binding, while others increased. Among the former, the DGS conjugates bridging K
147 to either K
170 or N-term dropped from 95.9% and 92.8% to 4.1% and 7.2%, respectively (
Table S2 of Supplementary Materials). The cross-linking inhibition manifested by K
147 cannot be merely ascribed to its location on helix H3, in direct contact with the duplex construct, because this residue was still capable of supporting conjugation with both K
135 and K
137. A more plausible explanation could be that DNA binding forced K
147 out of the reach of either K
170 on helix H2, or K
162 on the adjacent S2 region. The limited nature of such conformational changes was revealed by the fact that K
147 was pushed out of N-term’s reach for the shorter DSG reagent, but was still sufficiently close for the longer DSS, with incidence of cross-linking dropping from 92.8 to 7.2% and from 72.7 to 27.3%, respectively (see
Table S2 of Supplementary Materials). The limited extent of these changes was also evident in the subtler cross-linking variations between K
147 and either K
135 or K
137 located on the H3-H4 intervening loop.
In other cases, DNA binding increased the incidence of specific conjugates by placing residues within mutual striking distance in the complex, which were marginally susceptible or inert in the free protein. For example, the conjugates bridging residue K
182 with N-term, K
89, K
116, K
159, K
162, or K
182 were greatly enhanced by the presence of DNA duplex (
Table S2 of Supplementary Materials). For the majority of these positions, the levels of cross-linking observed with the longer DSS reagent displayed more significant variations than those with the shorter DSG. Considering that K
182 is located on the W2 wing region, these observations offered further evidence of the long-range conformational effects of DNA binding suggested by the results of HDX and protein-DNA cross-linking experiments. Another example was provided by the numerous conjugates involving the N-term, which suggested that DNA binding had prominent stabilizing effects on a region that was rather flexible in free FOXO4-DBD. Consistent with the HDX data, the variations of cross-linking patterns confirmed that DNA binding induced significant effects on protein conformation not only within the contact interface, but also in rather distal positions.
3.5. Structural Proteomics Could Effectively Guide Model-Building Operations to Produce Very High-Quality 3D Models
The HDX and XL experiments provided a wealth of information that was used to guide the molecular modelling of a full-fledged FOXO4-DBD and FOXO4-DBD•DBE complex. Our approach took advantage of available high-resolution structures that, although incomplete in their coverage of the protein sequence, still represented excellent templates for homology modelling operations (see Materials and Methods and
Supplementary Materials). In particular, the templates were used to obtain the coordinates of what could be defined as the structured core of the complex, a region spanning approximately from R
93 to N
177, which displayed limited discrepancies across the available structures. In contrast, the regions that were either absent from the templates, or displayed significant variations, or had been predicted to possess a high degree of flexibility by PSIPRED [
70], were modeled according to the HDX and cross-linking information (see Materials and Methods and
Supplementary Materials). These regions corresponded to the G
74–Q
100 and N
177–A
207 sections located respectively at the N- and C-terminal ends of the DBD sequence. These operations were performed in the Modeller suite [
57], which was also used to eliminate possible strains and steric clashes introduced during model building. The program applied the DOPE scoring algorithm to identify the best possible structures that were subsequently employed in docking and simulated annealing procedures. The former was carried out to place the DBE structure, which was created separately by using the make-na server (
http://structure.usc.edu/make-na/), onto the putative binding site of the protein. This operation was accomplished in HADDOCK [
58] by designating as active those residues that had experienced reduced rates of exchange upon DNA binding (
Figure 3A and
Figure S27 of Supplementary Materials). The mutual positioning between the DBE and FOXO4-DBD components was further refined according to the results of the protein-DNA cross-linking experiments, which were introduced by using Modeller. Finally, the structures of both FOXO4-DBD and FOXO4-DBD•DBE complex were submitted to simulated annealing and energy minimization in CNS [
60] to generate the sought-after model ensembles (
Figure 5).
The structures obtained for FOXO4-DBD and FOXO4-DBD•DBE complex were compared to the corresponding high-resolution structures to assess the robustness of our structural proteomics approach. In the case of individual FOXO4-DBD, the overall topology of the ensemble reflected the typical forkhead structure of the FOXO family and matched very closely that of the NMR structure used as homology template (see
Figure S28A,B of Supplementary Materials), thus supporting the validity of the HDX and cross-linking constraints. A more detailed comparison was obtained by calculating the root mean square deviation (RMSD) between the coordinates of corresponding heavy atoms located in the backbone of each ensemble model and the various templates. The representative plot in
Figure S29 of Supplementary Materials, for example, shows that the model obtained from the 1e17 structure deviated very little from the initial template. The fact that the experimental constraints introduced during modelling did not force any significant variation of the initial coordinates indicates that the probing operations did not cause any perturbation of the substrate’s 3D structure and corroborated the excellent stability of the structured core of FOXO4-DBD. In contrast, larger RMSD values were obtained when models based on other templates were compared with the initial FOXO4 models used in the study (3L2C, 1E17), as expected from the discrepancies between the various NMR and crystal structures available (see
Figure S30 in Supplementary Materials). Although this type of analysis was not possible for the regions that were absent from the templates, the excellent match manifested by the regions present in both model and template warranted a high level of confidence in the entire structures produced by our approach.
The ensemble of the FOXO4-DBD•DBE complex was examined in similar fashion. Also in this case, the overall topology matched very closely that of the corresponding high-resolution template (i.e., 3l2c), with the DBE component oriented in the proper direction and placed in the correct position onto the FOXO4-DBD’s binding site (see
Figure S28C,D of Supplementary Materials). RMSD comparisons between the model and crystal structure revealed excellent match for the regions present in both, thus ruling out the possibility of inadvertent perturbations introduced by the probing procedures. Additionally, we determined the distances between residues that had been conjugated by the cross-linking reagents, and then compared them with the corresponding distances measured on the crystal structure. The resulting RMSD values revealed excellent agreement across the board, with the sole exception of the distances between the DBE molecule (DBE-F) and specific residues of the H
164–M
175 loop (H
164, T
168, S
171, S
172 or M
175), which were somewhat longer in our model (see
Table S1 in Supplementary Materials). These discrepancies; however, were consistent with the high degree of flexibility possessed by the loop, which was manifest also in the higher B-factors displayed by this region in the crystal structure. In agreement with the crystal structure, the models showed that helix H3 represents the main interaction interface, as indicated by both HDX and cross-linking data (see
Table S1 in Supplementary Materials). The DBE structure employed here replicated the consensus binding sequences for all related FOX factors, which contain a general TGTTT motif surrounded by more variable sequences (see
Figure S31 in Supplementary Materials). Whereas FOXO3 and FOXO6 recognize two nucleotides located after this consensus sequence, FOXP1 only recognize the second nucleotide but not the first one. In contrast, our model indicates that FOXO4 may recognize one nucleotide before and one after the consensus motif, thus affording additional evidence of the uniqueness of the interactions established by this member of the FOXO family. These results were supported also by Position Count Matrix (PCM) values that estimated the binding probability of individual bases at each position in the sequence (see
Figure S31 in Supplementary Materials).
A close comparison of the structures of FOXO4-DBD and FOXO4-DBD•DBE complex obtained by our approach allowed us to further explore the effects of binding on protein conformation. The examination confirmed that the N- and C-terminal sequences remained largely unstructured even after DBE binding, as represented by the mesh regions of our models (
Figure 5). The main interface region consisting of H3 showed limited variations between unbound and bound forms. Similar outcomes were also observed for the contiguous H1–H2 loop and H2 helix. In contrast, loop H2–H4–H3 and the S2 and S3 strands of wing W1 showed rather large variations upon binding. Additionally, also the N- and C- terminal regions manifested extensive variations. These observations were consistent with the HDX data that revealed clearly peculiar time dependencies. For instance, the initially increasing rates in the H1 helix, H1–H2 loop, and H2 helix (A
103–T
130, in particular) suggested variations of dynamics upon DBE binding, whereas their subsequent decreasing rates were consistent with the actual structural stabilization resulting from the presence of bound DNA. The RMSD values calculated for corresponding heavy backbone atoms provided an excellent measure of these conformational effects (see
Figure S32 of Supplementary Materials). The values obtained from flanking regions near the interface, indicating major changes in loop H4–H3 and W1 wing and minor changes in loops H1–H2 and H3–S1, highlighted the indirect effects of binding, which were consistent with the results of HDX and XL experiments. The conformational changes revealed by this type of treatment were consistent with a classic adaptive binding mechanism by which rather sizeable conformational changes may be necessary to establish specific substrate-ligand interactions. The fact that the observed conformational changes were not limited only to the sequences in direct contact with the ligand DBE, but involved also contiguous regions, supports mechanisms by which binding events may trigger associated activities through allosteric effects, or place bordering regions in positions necessary to mediate the recruiting of additional factors, such as the acetyl transferases that are known to interact with other members of the FOXO family [
50,
71].
4. Conclusions
The structural investigation of FOXO4-DBD and FOXO4-DBD•DBE provided a thorough assessment of the ability of structural proteomics techniques to obtain valid information on systems that are not directly amenable to classic high-resolution approaches. The outcome showed that the concerted application of HDX and XL could effectively guide model-building operations to produce high-quality 3D models. Our multi-step strategy involved the utilization of high-resolution templates to carry out initial homology modelling. The sections that were not present in the templates were generated from experimental constraints and integrated with the initial structures to cover the entire DNA-binding domain. Although the high-resolution templates did not cover the entire structure folded by our construct, they still provided sufficient overlap to enable an unbiased assessment of the validity of the results afforded by our experimental/computational workflow. In fact, the excellent match between the templates and our structures ruled out the possibility that cross-linking procedures might have introduced unwanted artefacts or structure distortion. Further, an agreement between the templates and the corresponding portions of our models ruled out such possibilities and confirmed the ability of the selected computational strategies to translate these types of experimental constraints into actual 3D structures. Validating the approach on the “known” portions of the structures was essential in supporting the validity of the “unknown” sections that were conspicuously absent from the templates. The fact that the results of HDX and cross-linking experiments were in consistent mutual agreement provided further proof of the robustness of our concerted approach. For these reasons, our models represent comprehensive structures of full-fledged FOXO4-DBD and FOXO4-DBD•DBE.
The pictures painted by the high-resolution templates (identical protein construct was used), which were obtained by NMR and crystallography, are not only incomplete, but in the case of crystallography also static. Our extensive data provide a wealth of new information on the conformational dynamics of the protein in both unbound and bound forms. Our experiments clearly differentiated regions that were conformationally stable from those that underwent significant conformational changes upon DNA binding. The most important finding was that binding affected not only the interface region, but also the conformation of regions that were located away from the interface. This information might be essential to understand the allosteric properties of the complex and their role in recruiting additional transcriptional factors.
Our models confirmed that full-length FOXO4-DBD adopts the classic forkhead topology characteristic of this family of transcription factors, but corroborated also its unusual DNA binding mode that is unique among those manifested by the highly homologous FOXO proteins [
44]. The close match between our model and the crystal structure of FOXO4-DBD•DBE ruled out the possibility that crystal packing might be the cause of the significant differences noted between the types of interactions established by FOXO4 versus those involving the other members of the family [
48]. Our models confirmed the prominent role of helix H3 in such interactions and highlighted the involvement of neighboring regions, which may be responsible for fine-tuning the sequence-specific recognition of the correct DNA counterpart.
In conclusion, this study demonstrated the merits of structural proteomics approaches for the elucidation of protein-nucleic acid complexes. The utilization of specific hydrolytic procedures to complete the characterization of HDX and cross-linking products virtually eliminates any limitation pertaining the size of the species of interest. Propelled by continued advances in the computational approaches employed to translate the experimental results into all-atoms models, structural proteomics has rapidly emerged as a valid complement, and often alternative, to the classic high-resolution techniques. By clearly demonstrating the applicability to transcription factor-response element complexes, we hope that this study will lead to a broader utilization of structural proteomics to mitigate the chronic dearth of information on these essential regulatory systems.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




