
Infrastructure-Aided Localization and State Estimation for Autonomous Mobile Robots



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Design of a computationally efficient ROI-based pose estimator using 3D point clouds from a stationary stereo camera with a wide-angle (fisheye) lens.
- Developing an infrastructure-aided localization framework which is scalable for large systems with multiple robots using communication between a slip-aware onboard observer and the stationary sensing unit.
2. Background and System Overview
2.1. Visual Tracking Thread
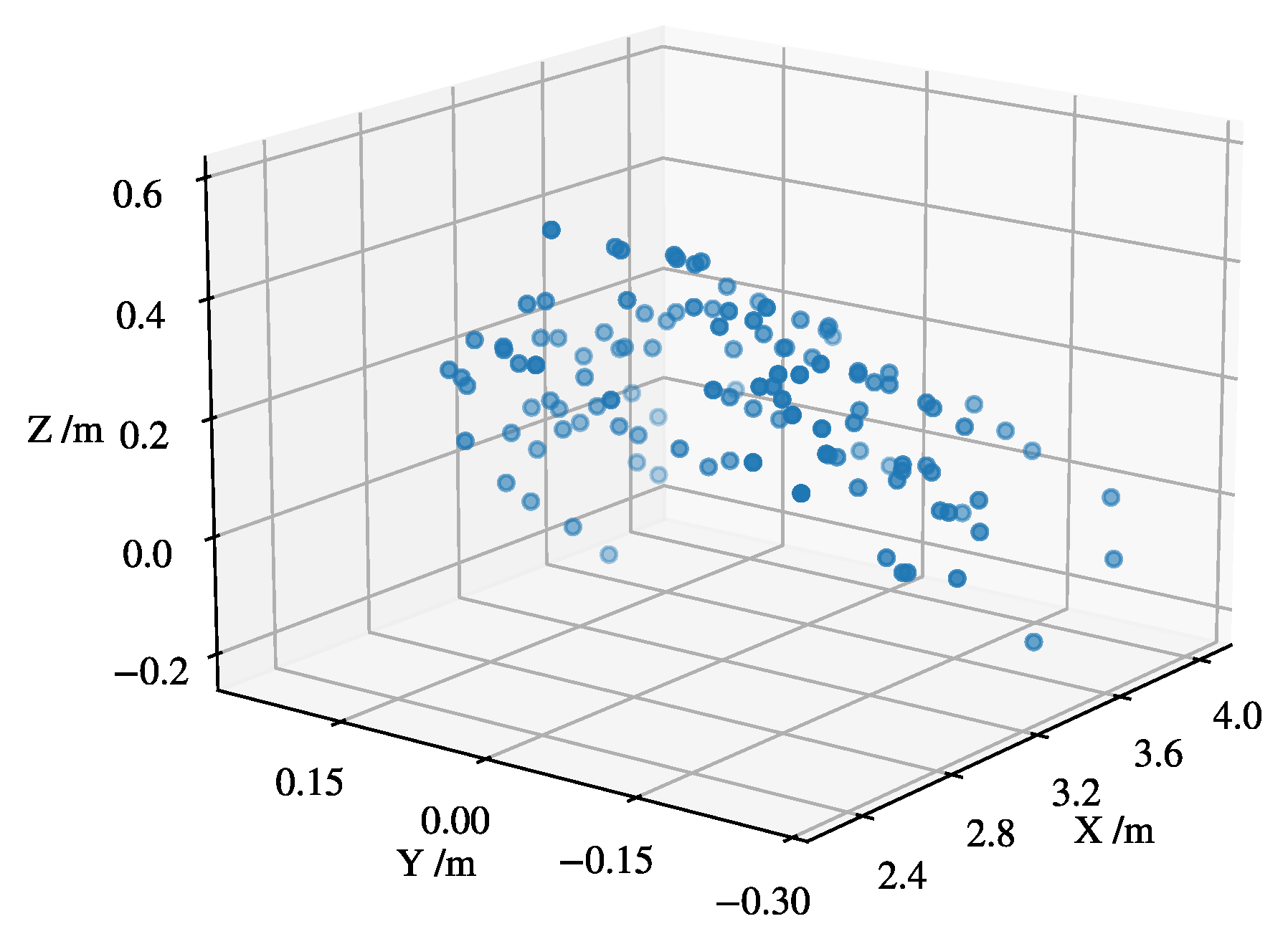
2.2. Point Cloud Computation and Post Processing
3. Infrastructure-Aided State Estimation
3.1. Slip-Aware Motion Model
3.2. Pose Prediction
3.3. Augmented Localization
| Algorithm 1: Augmented Slip-Aware Localization |
 |
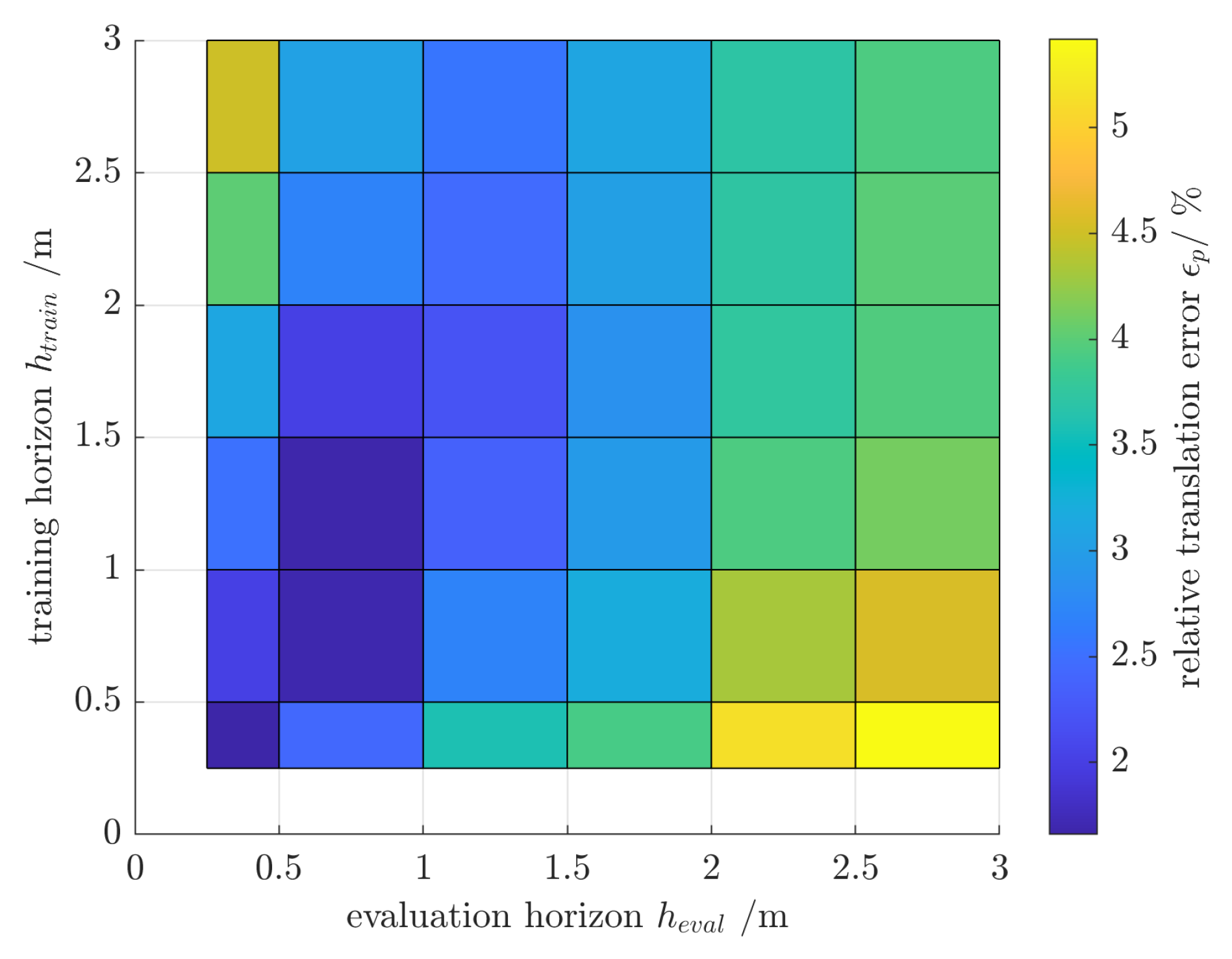
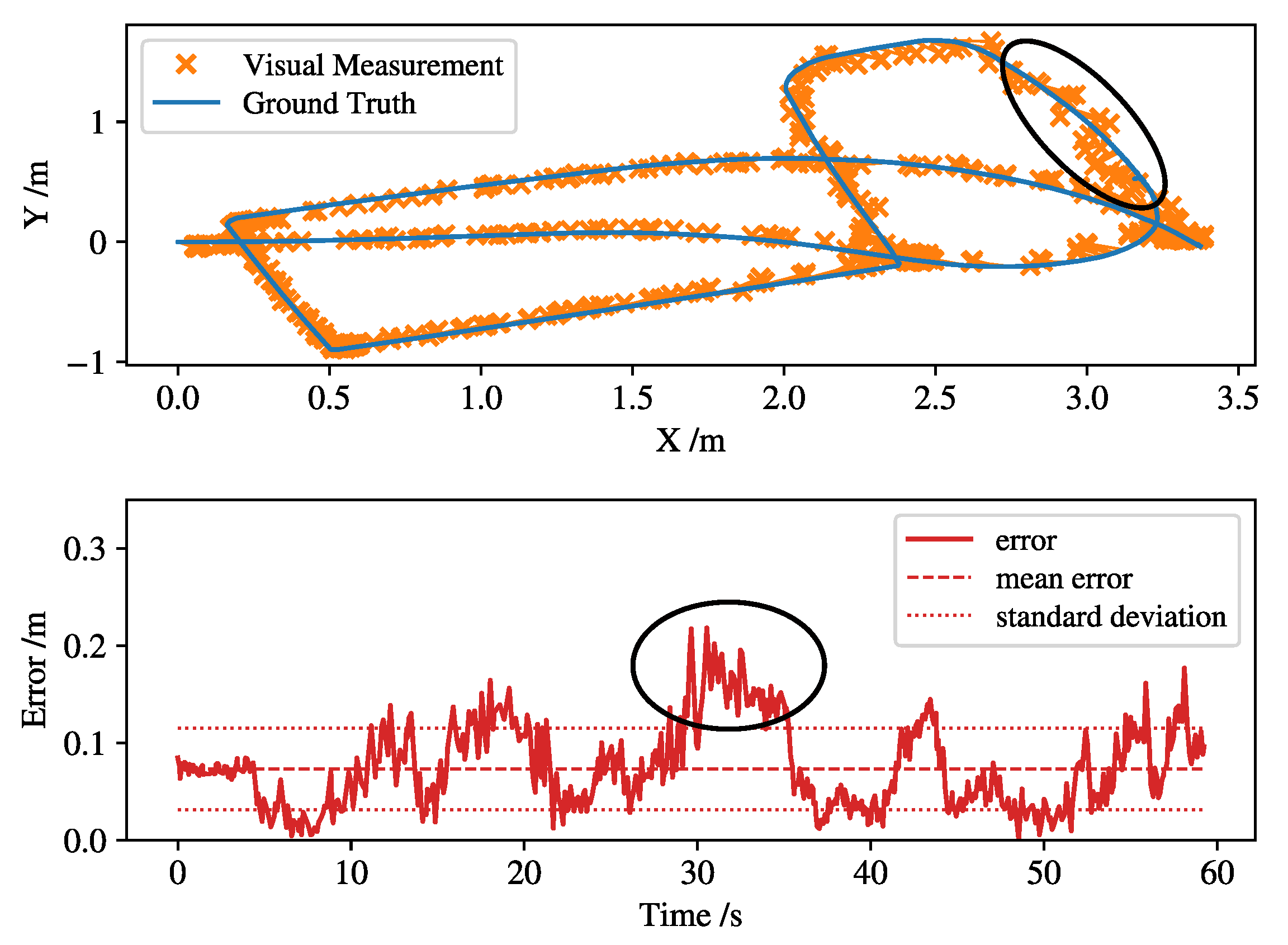
4. Experiments and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, D.; Geißer, F.; Nebel, B. Towards effective localization in dynamic environments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4517–4523. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Yang, P.; Freeman, R.A.; Lynch, K.M. Multi-agent coordination by decentralized estimation and control. IEEE Trans. Autom. Control 2008, 53, 2480–2496. [Google Scholar] [CrossRef]
- He, X.; Hashemi, E.; Johansson, K.H. Event-Triggered Task-Switching Control Based on Distributed Estimation. IFAC-PapersOnLine 2020, 53, 3198–3203. [Google Scholar] [CrossRef]
- Chung, H.Y.; Hou, C.C.; Chen, Y.S. Indoor intelligent mobile robot localization using fuzzy compensation and Kalman filter to fuse the data of gyroscope and magnetometer. IEEE Trans. Ind. Electron. 2015, 62, 6436–6447. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Berntorp, K. Joint wheel-slip and vehicle-motion estimation based on inertial, GPS, and wheel-speed sensors. IEEE Trans. Control Syst. Technol. 2016, 24, 1020–1027. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, Z.; Suo, C.; Wang, H.; Zhao, H.; Liu, Y.H. Vision-based dynamic control of car-like mobile robots. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6631–6636. [Google Scholar]
- Chae, H.W.; Choi, J.H.; Song, J.B. Robust and Autonomous Stereo Visual-Inertial Navigation for Non-Holonomic Mobile Robots. IEEE Trans. Veh. Technol. 2020, 69, 9613–9623. [Google Scholar] [CrossRef]
- Tian, Y.; Sarkar, N. Control of a mobile robot subject to wheel slip. J. Intell. Robot. Syst. 2014, 74, 915–929. [Google Scholar] [CrossRef]
- Kubelka, V.; Oswald, L.; Pomerleau, F.; Colas, F.; Svoboda, T.; Reinstein, M. Robust data fusion of multimodal sensory information for mobile robots. J. Field Robot. 2015, 32, 447–473. [Google Scholar] [CrossRef]
- Delibasis, K.K.; Plagianakos, V.P.; Maglogiannis, I. Real time indoor robot localization using a stationary fisheye camera. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Berlin/Heidelberg, Germany, 2013; pp. 245–254. [Google Scholar]
- Janković, N.V.; Ćirić, S.V.; Jovičić, N.S. System for indoor localization of mobile robots by using machine vision. In Proceedings of the 2015 23rd Telecommunications Forum Telfor (TELFOR), Belgrade, Serbia, 24–26 November 2015; pp. 619–622. [Google Scholar]
- Mamduhi, M.H.; Hashemi, E.; Baras, J.S.; Johansson, K.H. Event-triggered Add-on Safety for Connected and Automated Vehicles Using Road-side Network Infrastructure. IFAC-PapersOnLine 2020, 53, 15154–15160. [Google Scholar] [CrossRef]
- Zickler, S.; Laue, T.; Birbach, O.; Wongphati, M.; Veloso, M. SSL-vision: The shared vision system for the RoboCup Small Size League. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2009; pp. 425–436. [Google Scholar]
- Shim, J.H.; Cho, Y.I. A mobile robot localization via indoor fixed remote surveillance cameras. Sensors 2016, 16, 195. [Google Scholar] [CrossRef]
- Ramer, C.; Sessner, J.; Scholz, M.; Zhang, X.; Franke, J. Fusing low-cost sensor data for localization and mapping of automated guided vehicle fleets in indoor applications. In Proceedings of the 2015 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), San Diego, CA, USA, 14–16 September 2015; pp. 65–70. [Google Scholar]
- Ordonez, C.; Gupta, N.; Reese, B.; Seegmiller, N.; Kelly, A.; Collins, E.G., Jr. Learning of skid-steered kinematic and dynamic models for motion planning. Robot. Auton. Syst. 2017, 95, 207–221. [Google Scholar] [CrossRef]
- Liu, F.; Li, X.; Yuan, S.; Lan, W. Slip-aware motion estimation for off-road mobile robots via multi-innovation unscented Kalman filter. IEEE Access 2020, 8, 43482–43496. [Google Scholar] [CrossRef]
- Gosala, N.; Bühler, A.; Prajapat, M.; Ehmke, C.; Gupta, M.; Sivanesan, R.; Gawel, A.; Pfeiffer, M.; Bürki, M.; Sa, I.; et al. Redundant perception and state estimation for reliable autonomous racing. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6561–6567. [Google Scholar]
- Wang, D.; Low, C.B. Modeling and analysis of skidding and slipping in wheeled mobile robots: Control design perspective. IEEE Trans. Robot. 2008, 24, 676–687. [Google Scholar] [CrossRef]
- Rabiee, S.; Biswas, J. A friction-based kinematic model for skid-steer wheeled mobile robots. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8563–8569. [Google Scholar]
- Huang, J.; Wen, C.; Wang, W.; Jiang, Z.P. Adaptive output feedback tracking control of a nonholonomic mobile robot. Automatica 2014, 50, 821–831. [Google Scholar] [CrossRef]
- Mandow, A.; Martinez, J.L.; Morales, J.; Blanco, J.L.; Garcia-Cerezo, A.; Gonzalez, J. Experimental kinematics for wheeled skid-steer mobile robots. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 1222–1227. [Google Scholar]
- Marín, L.; Vallés, M.; Soriano, Á.; Valera, Á.; Albertos, P. Multi sensor fusion framework for indoor-outdoor localization of limited resource mobile robots. Sensors 2013, 13, 14133–14160. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Kannala, J.; Brandt, S.S. A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1335–1340. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Gupta, S.; Kumar, M.; Garg, A. Improved object recognition results using SIFT and ORB feature detector. Multimed. Tools Appl. 2019, 78, 34157–34171. [Google Scholar] [CrossRef]
- Holz, D.; Ichim, A.E.; Tombari, F.; Rusu, R.B.; Behnke, S. Registration with the point cloud library: A modular framework for aligning in 3-D. IEEE Robot. Autom. Mag. 2015, 22, 110–124. [Google Scholar] [CrossRef]
- Munaro, M.; Rusu, R.B.; Menegatti, E. 3D robot perception with point cloud library. Robot. Auton. Syst. 2016, 78, 97–99. [Google Scholar] [CrossRef]















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flögel, D.; Bhatt, N.P.; Hashemi, E. Infrastructure-Aided Localization and State Estimation for Autonomous Mobile Robots. Robotics 2022, 11, 82. https://doi.org/10.3390/robotics11040082
Flögel D, Bhatt NP, Hashemi E. Infrastructure-Aided Localization and State Estimation for Autonomous Mobile Robots. Robotics. 2022; 11(4):82. https://doi.org/10.3390/robotics11040082
Chicago/Turabian StyleFlögel, Daniel, Neel Pratik Bhatt, and Ehsan Hashemi. 2022. "Infrastructure-Aided Localization and State Estimation for Autonomous Mobile Robots" Robotics 11, no. 4: 82. https://doi.org/10.3390/robotics11040082
APA StyleFlögel, D., Bhatt, N. P., & Hashemi, E. (2022). Infrastructure-Aided Localization and State Estimation for Autonomous Mobile Robots. Robotics, 11(4), 82. https://doi.org/10.3390/robotics11040082