
Non-Prehensile Manipulation Actions and Visual 6D Pose Estimation for Fruit Grasping Based on Tactile Sensing †


Abstract
:1. Introduction
1.1. Related Work on Robotic Pushing
- A compensation delay strategy to make the control system able to reach the desired goal with the expected performance despite the delays arising from a digital implementation of the perception and communication pipeline;
- A chattering avoidance strategy to reduce as much as possible the oscillations in high frequency arising from the hybrid nature of the considered system;
- A novel trajectory generation approach to make the control system design independent of the particular trajectory to be tracked.
1.2. Related Work on Object Detection
2. Object Recognition and 6D Localization
2.1. Network Training
2.2. Pose Refinement
3. Pushing Control
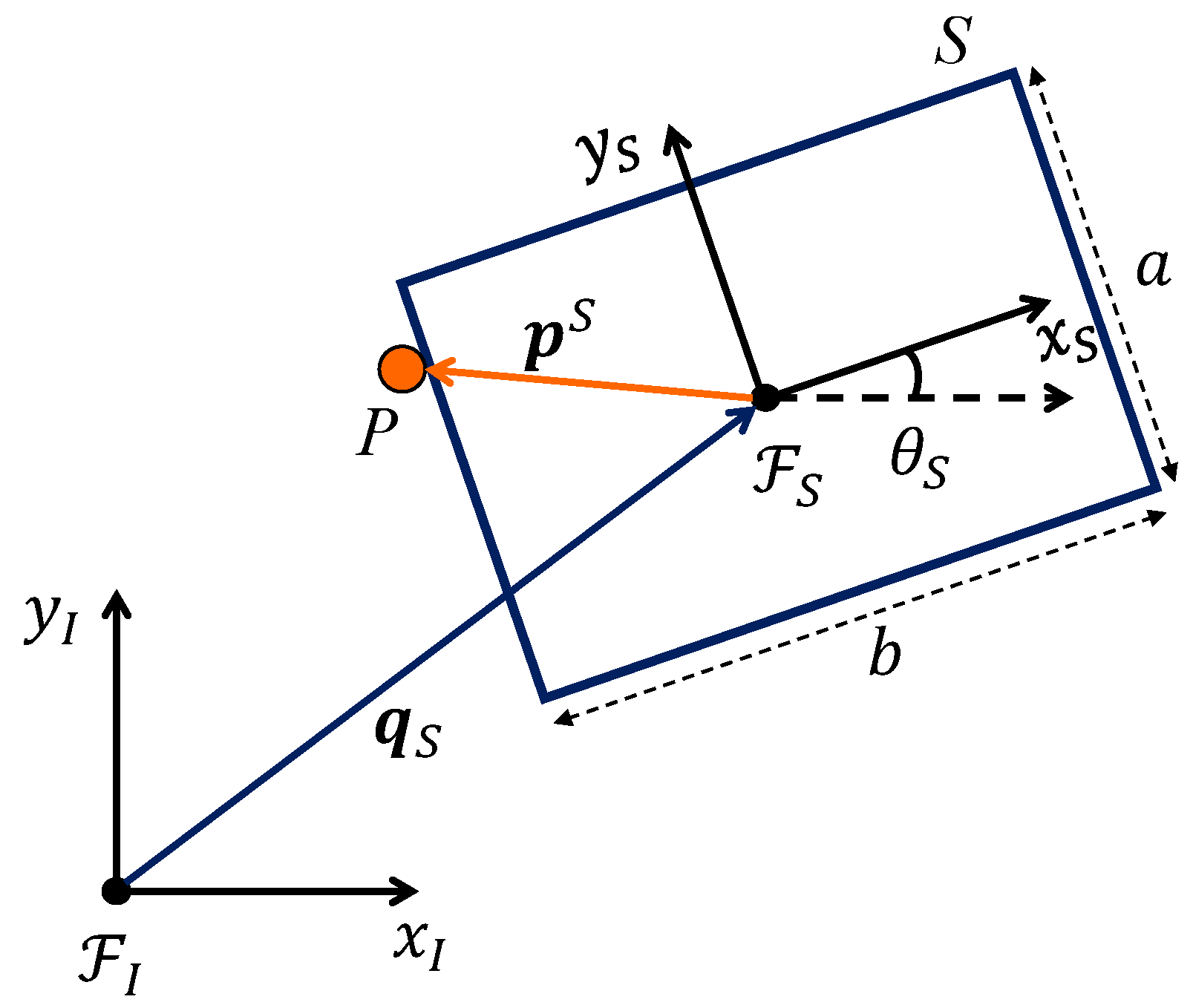
3.1. Dynamic Model
- The pusher and the slider move in the horizontal plane normal to the gravity vector and all forces lie in this plane.
- Pusher motion is slow enough that inertial forces are negligible compared to frictional forces (quasi-static assumption).
- The friction forces are governed by the Coulomb’s Law: the tangential force of friction during sliding lies along the opposite direction to the direction of motion, with magnitude proportional to the normal force.
- The friction coefficient between the slider and the support surface, , is uniform. It means that the CF is simply the projection of the center of mass (CM) in the plane.
- The pusher is assumed always be in contact with the slider in a point .
3.2. Control System Design
| Algorithm 1: Chattering avoidance. |
Data: |
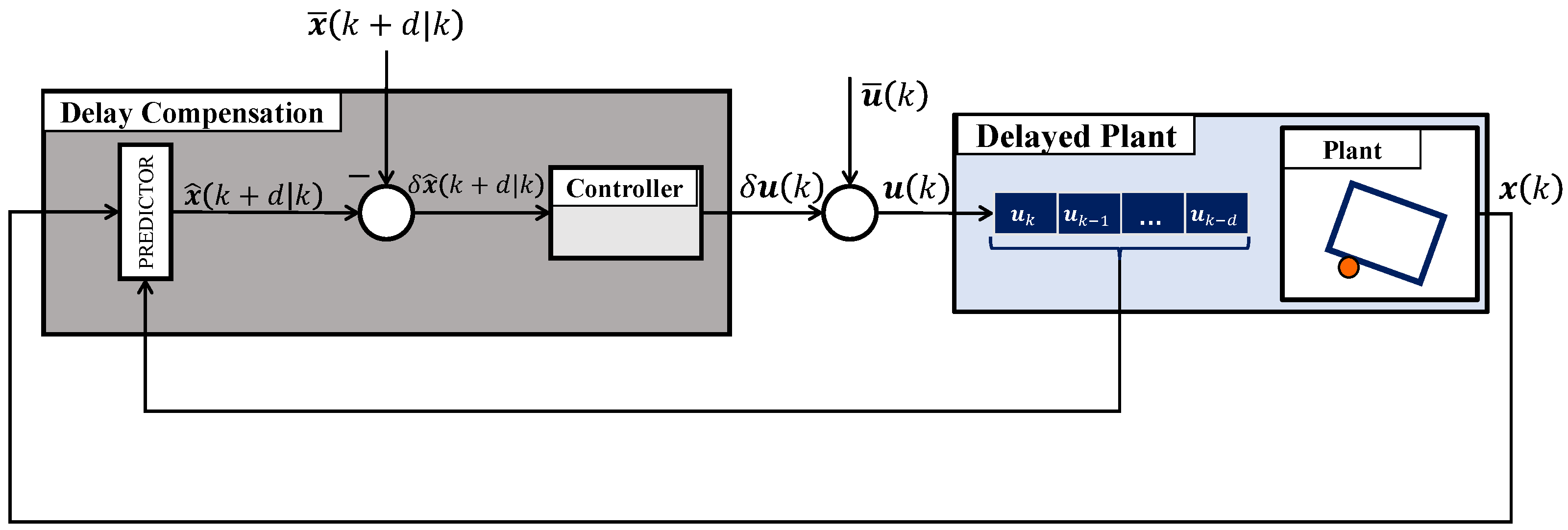
3.3. Explicit Delay Compensation
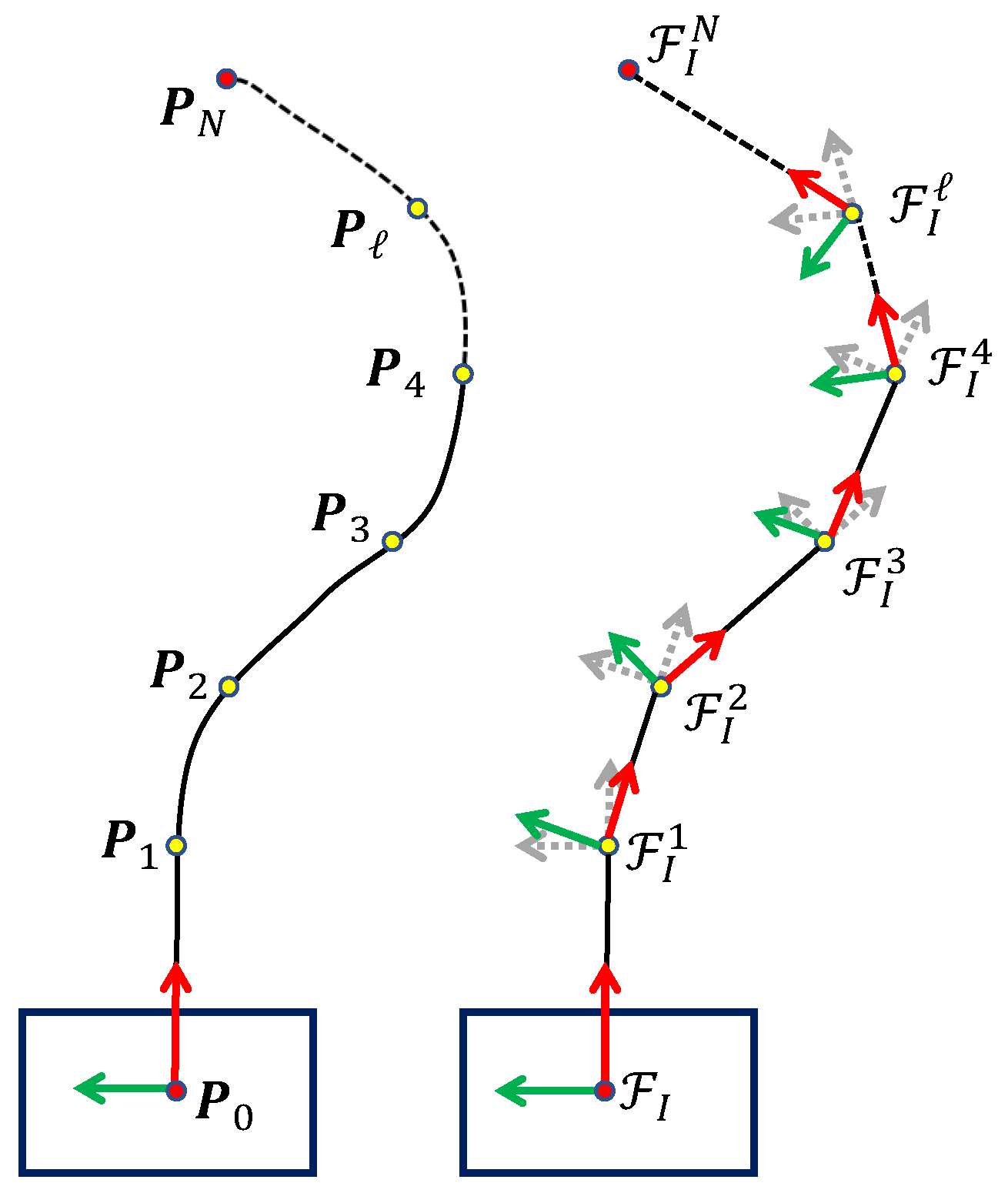
3.4. Trajectory Generation
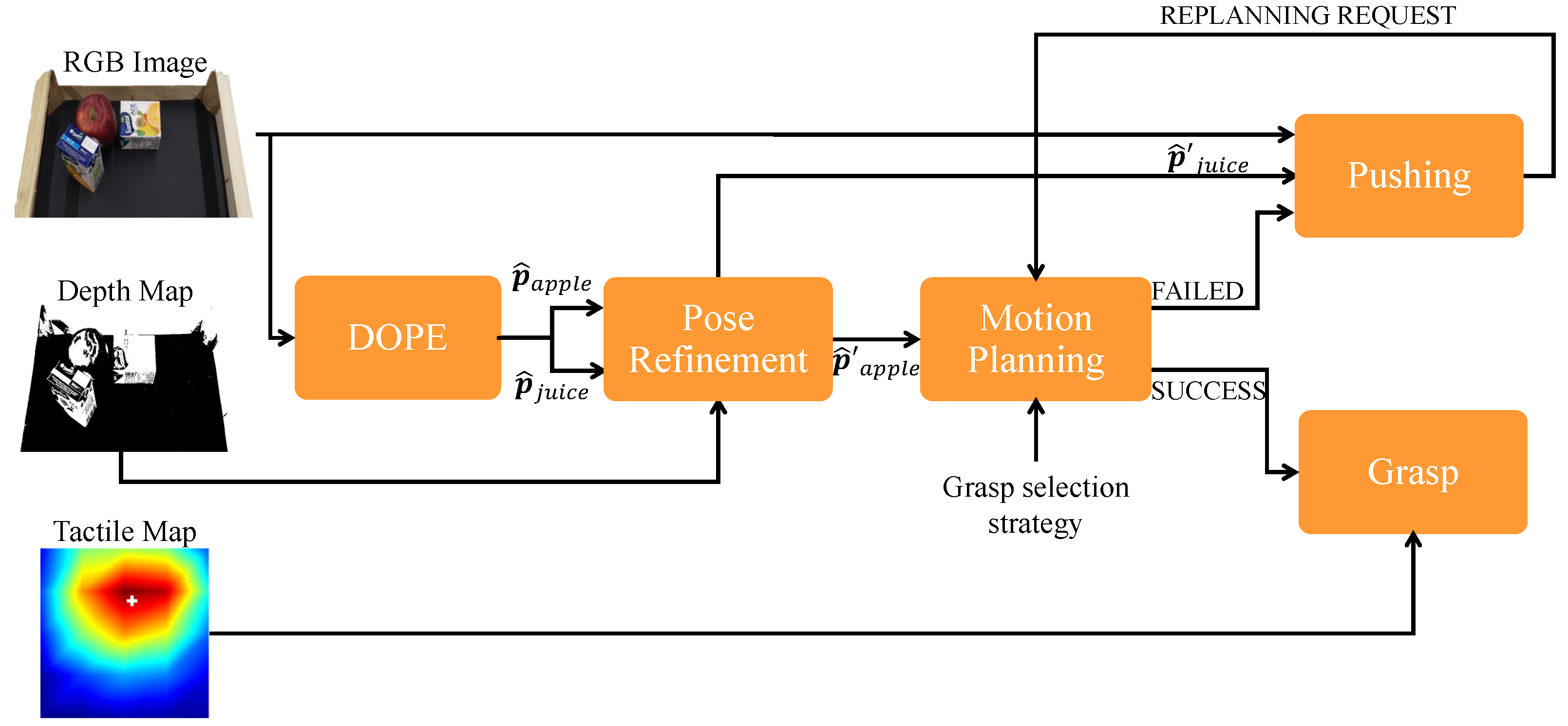
4. Pipeline for Pick-and-Place of Fruits
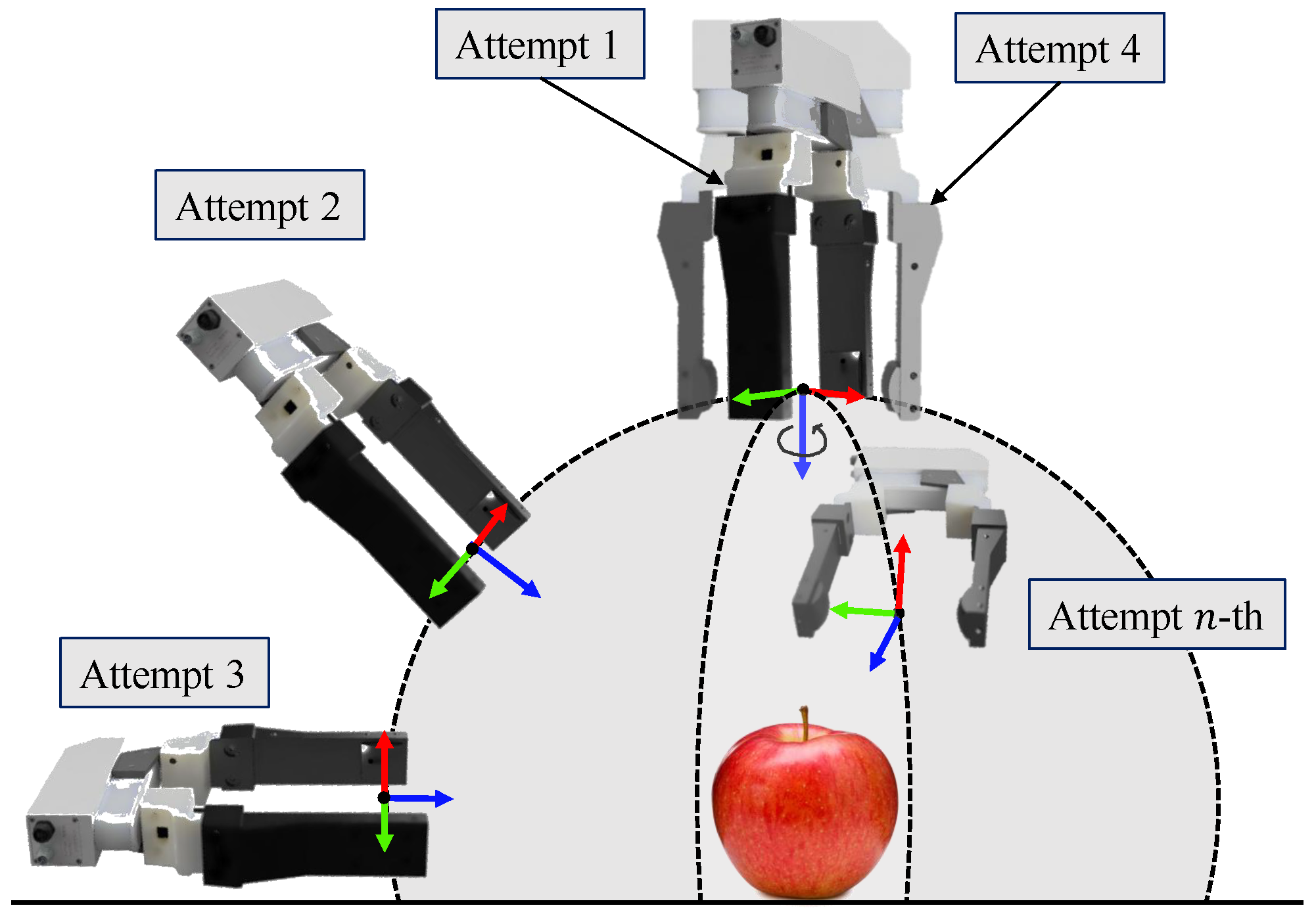
4.1. Grasp Force Control and Grasp Selection Strategy
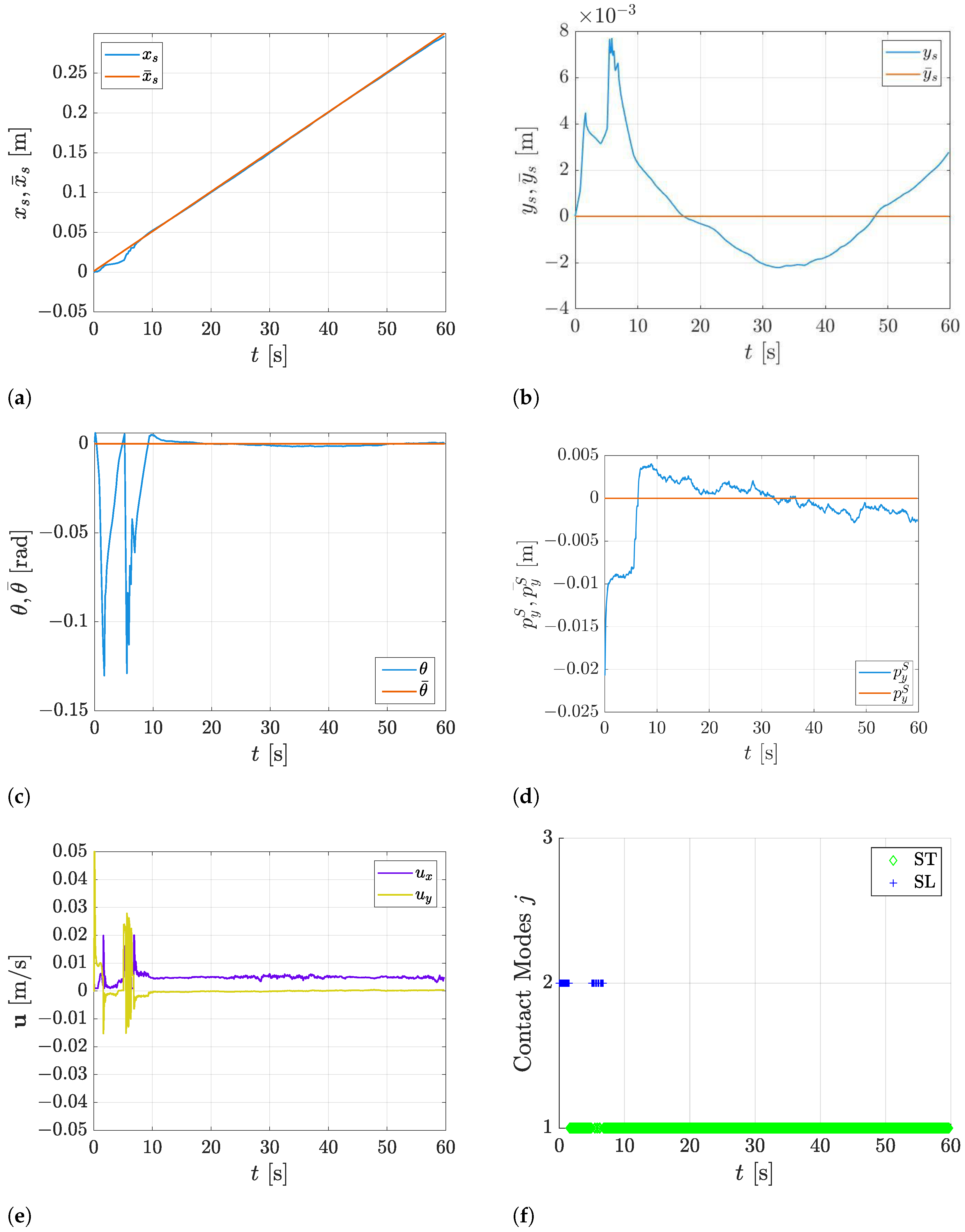
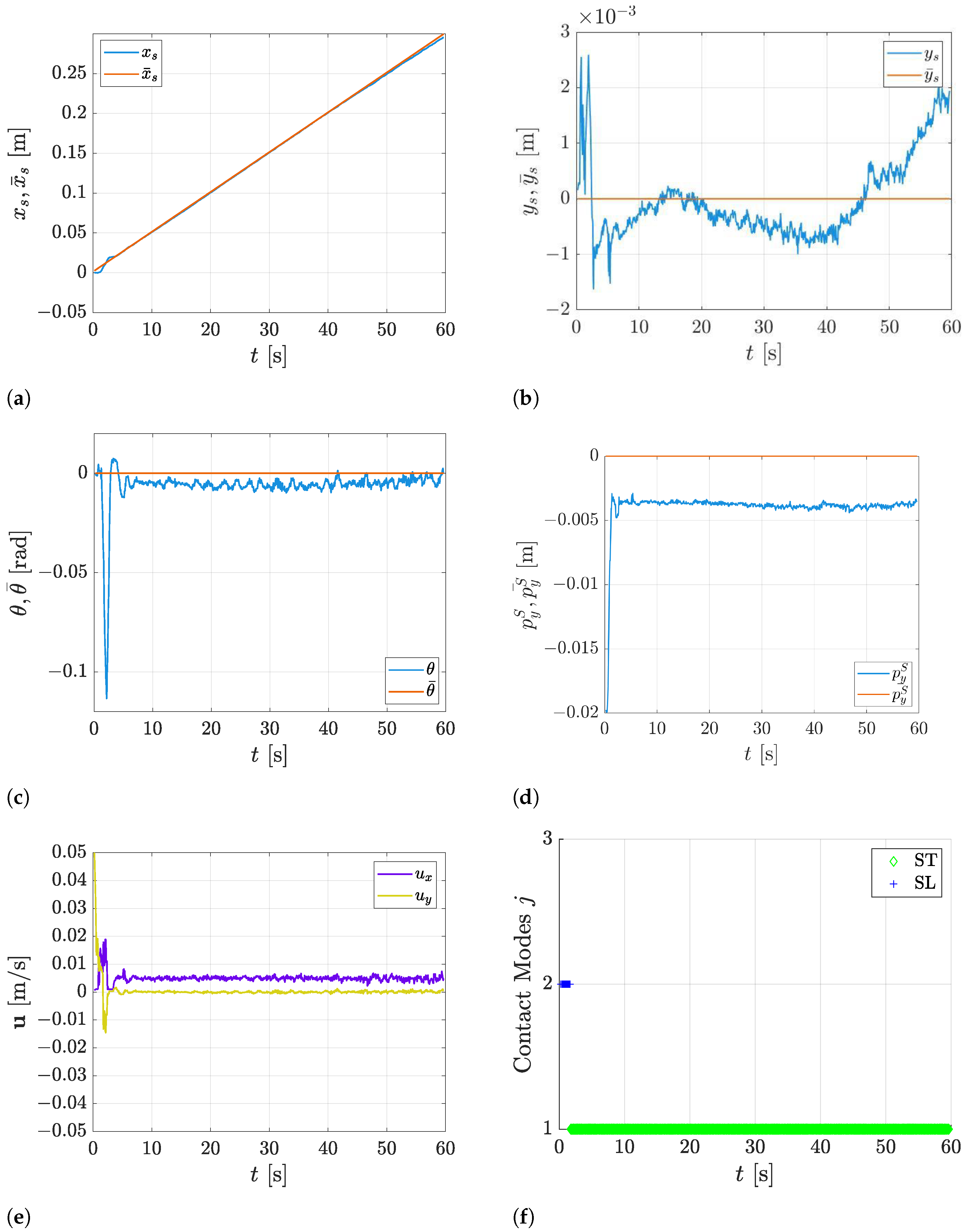
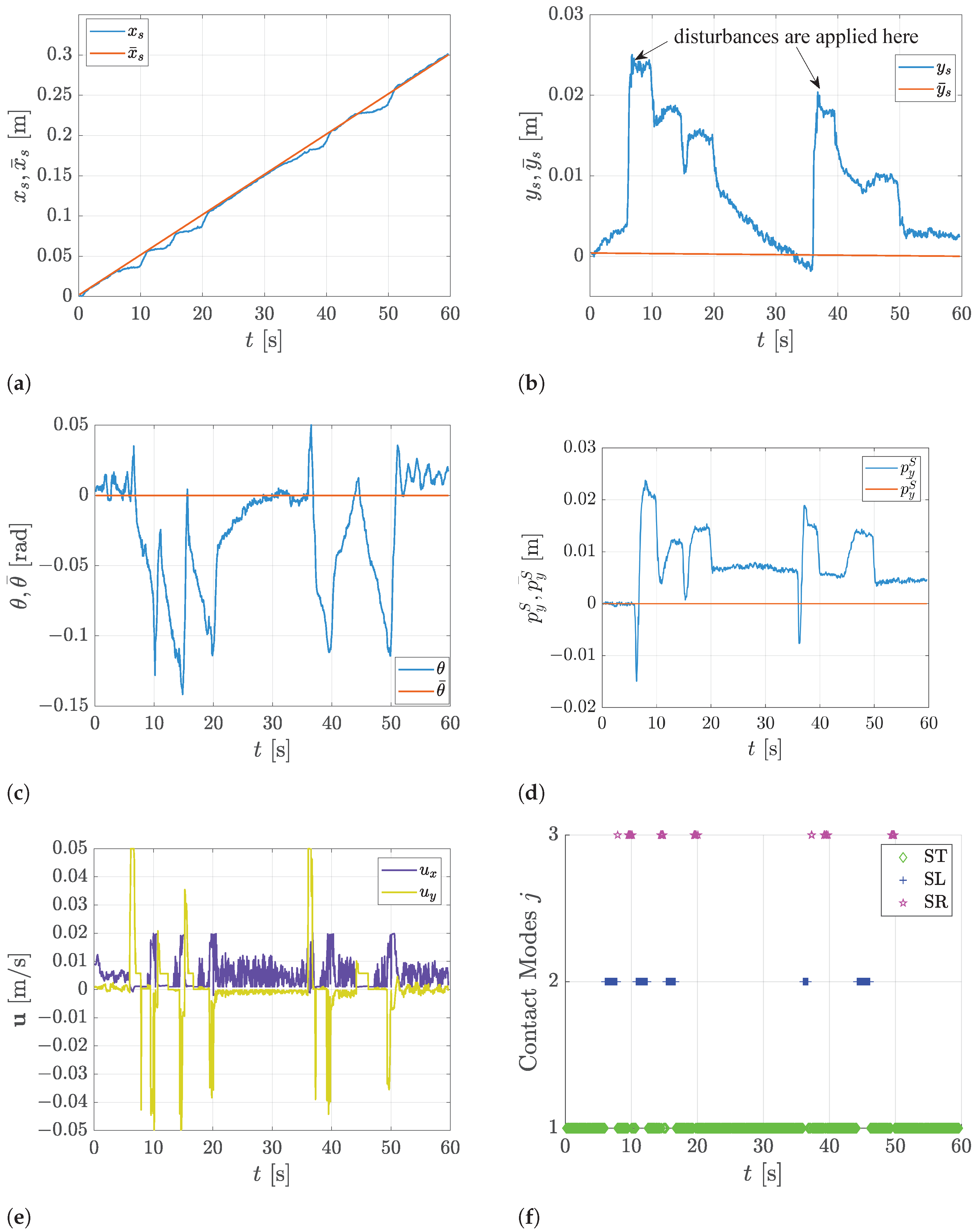
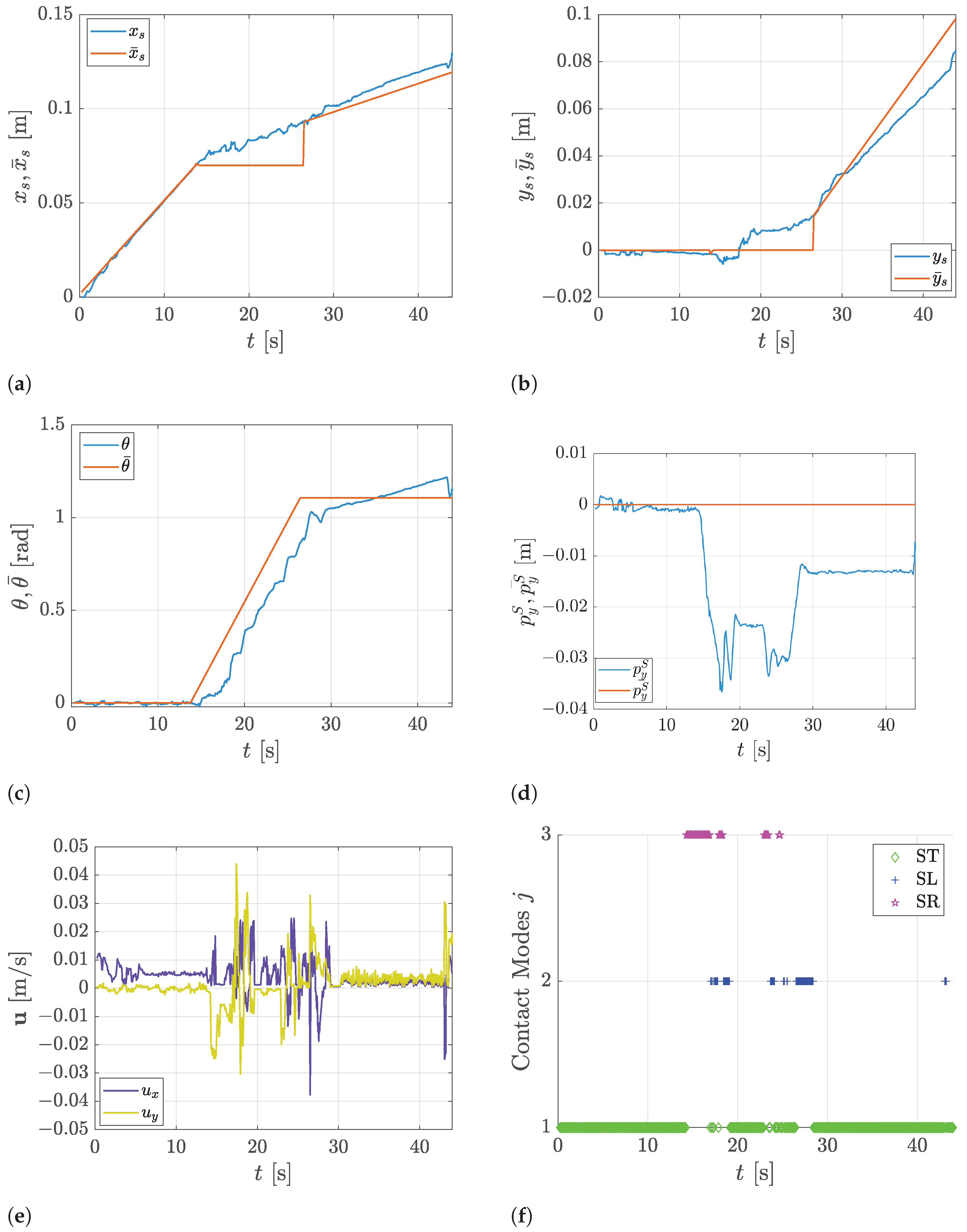
5. Experimental Results
5.1. Comparison with the State-of-the-Art Approaches
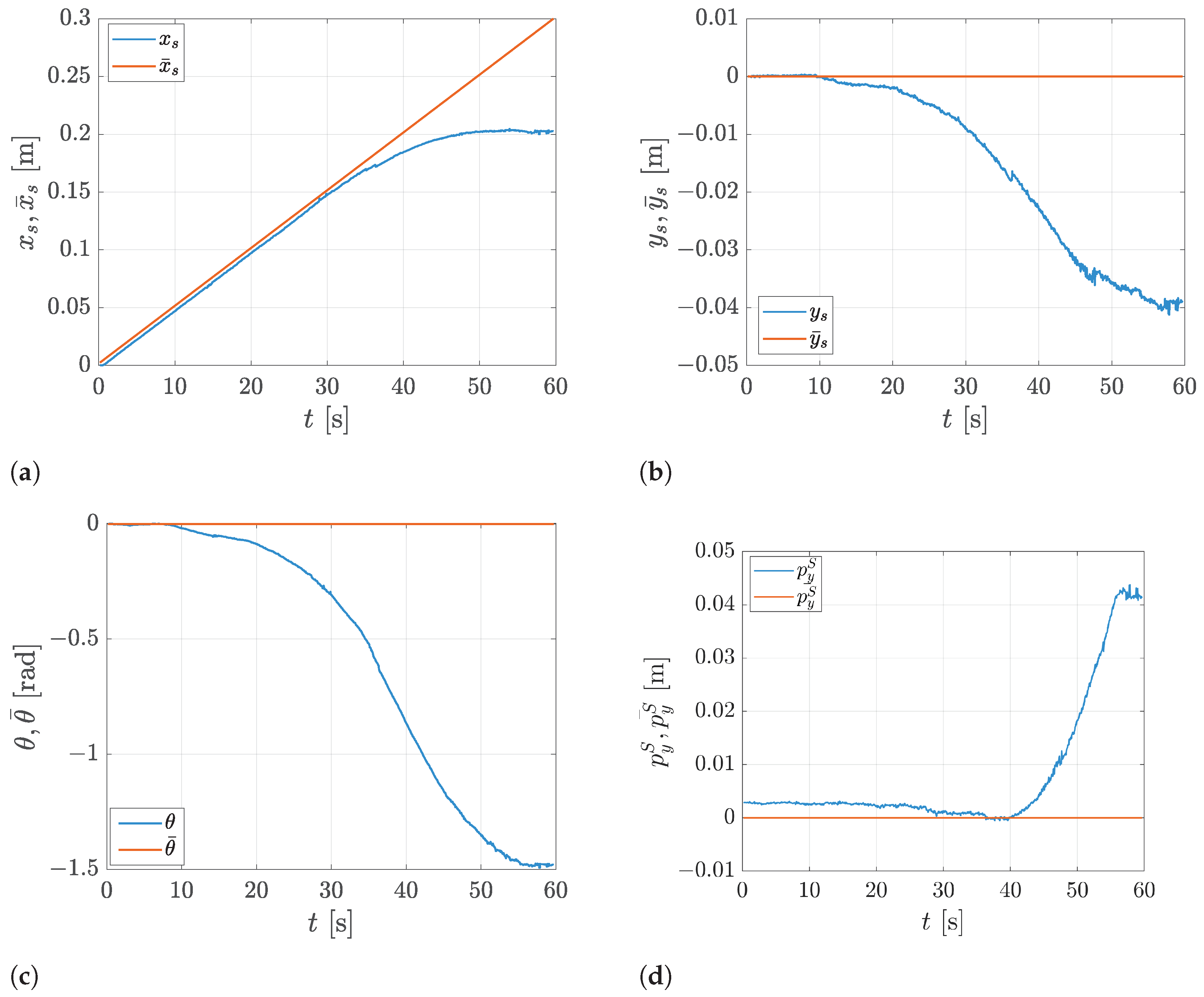
5.2. Straight Line Tracking with Disturbances
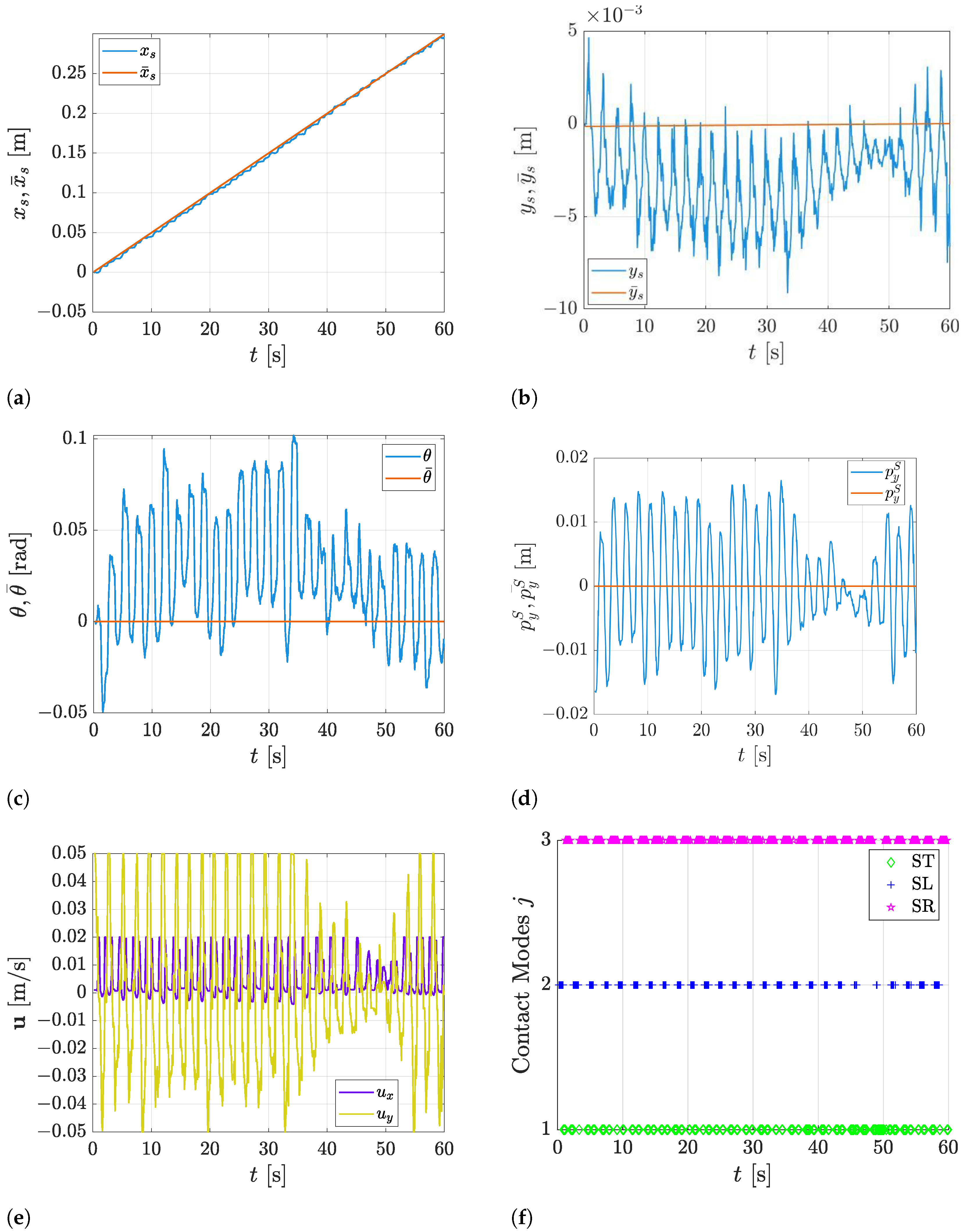
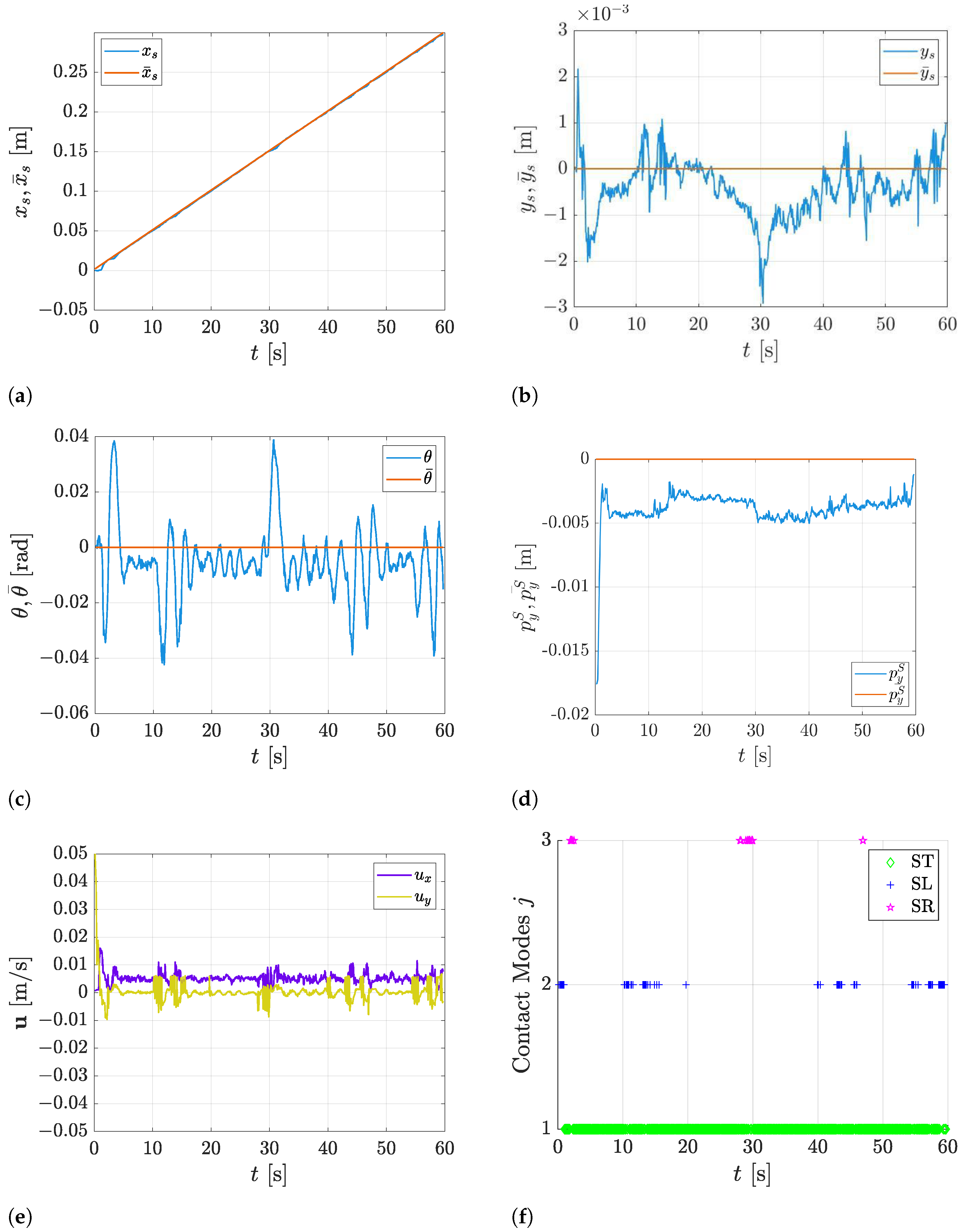
5.3. Trajectory Tracking
6. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Lynch, K.; Mason, M. Stable Pushing: Mechanics, Controllability, and Planning. Int. J. Robot. Res. 1999, 15, 533–556. [Google Scholar] [CrossRef]
- Yu, K.T.; Bauza, M.; Fazeli, N.; Rodriguez, A. More than a million ways to be pushed. A high-fidelity experimental dataset of planar pushing. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 30–37. [Google Scholar] [CrossRef] [Green Version]
- Yu, K.T.; Leonard, J.; Rodriguez, A. Shape and pose recovery from planar pushing. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1208–1215. [Google Scholar] [CrossRef] [Green Version]
- Lynch, K. Estimating the friction parameters of pushed objects. In Proceedings of the 1993 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’93), Yokohama, Japan, 26–30 July 1993; Volume 1, pp. 186–193. [Google Scholar] [CrossRef]
- Mason, M.T. Mechanics and Planning of Manipulator Pushing Operations. Int. J. Robot. Res. 1986, 5, 53–71. [Google Scholar] [CrossRef]
- Akella, S.; Mason, M. Posing polygonal objects in the plane by pushing. In Proceedings of the 1992 IEEE International Conference on Robotics and Automation, Nice, France, 12–14 May 1992; Volume 3, pp. 2255–2262. [Google Scholar] [CrossRef]
- Lynch, K.; Maekawa, H.; Tanie, K. Manipulation And Active Sensing By Pushing Using Tactile Feedback. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Raleigh, NC, USA, 7–10 July 1992; Volume 1, pp. 416–421. [Google Scholar] [CrossRef] [Green Version]
- Hogan, F.R.; Rodriguez, A. Reactive planar non-prehensile manipulation with hybrid model predictive control. Int. J. Robot. Res. 2020, 39, 755–773. [Google Scholar] [CrossRef]
- Hogan, F.R.; Rodriguez, A. Feedback Control of the Pusher-Slider System: A Story of Hybrid and Underactuated Contact Dynamics. In Algorithmic Foundations of Robotics XII: Proceedings of the Twelfth Workshop on the Algorithmic Foundations of Robotics; Springer International Publishing: Cham, Switzerland, 2020; pp. 800–815. [Google Scholar] [CrossRef]
- Costanzo, M.; Simone, M.D.; Federico, S.; Natale, C.; Pirozzi, S. Enhanced 6D Pose Estimation for Robotic Fruit Picking. In Proceedings of the 9th International Conference on Control, Decision and Information Technologies (CoDIT’23), Rome, Italy, 3–6 July 2023. [Google Scholar]
- Mason, M. Manipulator Grasping and Pushing Operations; Technical Report; Massachusetts Institute of Technology: Cambridge, MA, USA, 1986. [Google Scholar]
- Goyal, S.; Ruina, A.; Papadopoulos, J. Planar sliding with dry friction Part 1. Limit surface and moment function. Wear 1991, 143, 307–330. [Google Scholar] [CrossRef]
- Lee, S.H.; Cutkosky, M.R. Fixture planning with friction. J. Eng. Ind. 1991, 113, 320–327. [Google Scholar] [CrossRef]
- Bauza, M.; Hogan, F.R.; Rodriguez, A. A Data-Efficient Approach to Precise and Controlled Pushing. In Proceedings of the 2nd Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; Billard, A., Dragan, A., Peters, J., Morimoto, J., Eds.; Volume 87, pp. 336–345. [Google Scholar]
- Kopicki, M.; Zurek, S.; Stolkin, R.; Mörwald, T.; Wyatt, J. Learning to predict how rigid objects behave under simple manipulation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 5722–5729. [Google Scholar] [CrossRef]
- Byravan, A.; Fox, D. SE3-nets: Learning rigid body motion using deep neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 173–180. [Google Scholar] [CrossRef] [Green Version]
- Zeng, A.; Song, S.; Welker, S.; Lee, J.; Rodriguez, A.; Funkhouser, T. Learning Synergies between Pushing and Grasping with Self-Supervised Deep Reinforcement Learning. In Proceedings of the 2018 Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4238–4245. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-Time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Rios-Cabrera, R.; Tuytelaars, T. Discriminatively Trained Templates for 3D Object Detection: A Real Time Scalable Approach. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2048–2055. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In Proceedings of the XIV Robotics Science and Systems Conference (RSS), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Tremblay, J.; To, T.; Sundaralingam, B.; Xiang, Y.; Fox, D.; Birchfield, S. Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects. In Proceedings of the 2nd Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; Billard, A., Dragan, A., Peters, J., Morimoto, J., Eds.; Volume 87, pp. 336–345. [Google Scholar]
- Hou, T.; Ahmadyan, A.; Zhang, L.; Wei, J.; Grundmann, M. MobilePose: Real-Time Pose Estimation for Unseen Objects with Weak Shape Supervision. arXiv 2020, arXiv:2003.03522. [Google Scholar]
- Lin, Y.; Tremblay, J.; Tyree, S.; Vela, P.A.; Birchfield, S. Single-Stage Keypoint-based Category-level Object Pose Estimation from an RGB Image. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K.G.; Daniilidis, K. 6-DoF object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2011–2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Sridhar, S.; Huang, J.; Valentin, J.; Song, S.; Guibas, L.J. Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Manhardt, F.; Nickel, M.; Meier, S.; Minciullo, L.; Navab, N. CPS: Class-level 6D Pose and Shape Estimation From Monocular Images. arXiv 2020, arXiv:2003.0584. [Google Scholar]
- Wang, G.; Manhardt, F.; Shao, J.; Ji, X.; Navab, N.; Tombari, F. Self6D: Self-supervised Monocular 6D Object Pose Estimation. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 108–125. [Google Scholar]
- Costanzo, M.; De Maria, G.; Natale, C.; Pirozzi, S. Design and Calibration of a Force/Tactile Sensor for Dexterous Manipulation. Sensors 2019, 19, 966. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Costanzo, M.; De Maria, G.; Natale, C. Two-Fingered In-Hand Object Handling Based on Force/Tactile Feedback. IEEE Trans. Robot. 2020, 36, 157–173. [Google Scholar] [CrossRef]
- Costanzo, M. Control of robotic object pivoting based on tactile sensing. Mechatronics 2021, 76, 102545. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An accurate O(n) solution to the PnP problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Morrical, N.; Tremblay, J.; Lin, Y.; Tyree, S.; Birchfield, S.; Pascucci, V.; Wald, I. NViSII: A Scriptable Tool for Photorealistic Image Generation. arXiv 2021, arXiv:2105.13962. [Google Scholar]
- Rao, C.; Wright, S.; Rawlings, J. Application of interior-point methods to model predictive control. J. Optim. Theory Appl. 1998, 99, 723–757. [Google Scholar] [CrossRef] [Green Version]
- Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual. Available online: https://www.gurobi.com (accessed on 22 June 2023).
- Marchand, E.; Spindler, F.; Chaumette, F. ViSP for visual servoing: A generic software platform with a wide class of robot control skills. IEEE Robot. Autom. Mag. 2006, 12, 40–52. [Google Scholar] [CrossRef] [Green Version]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
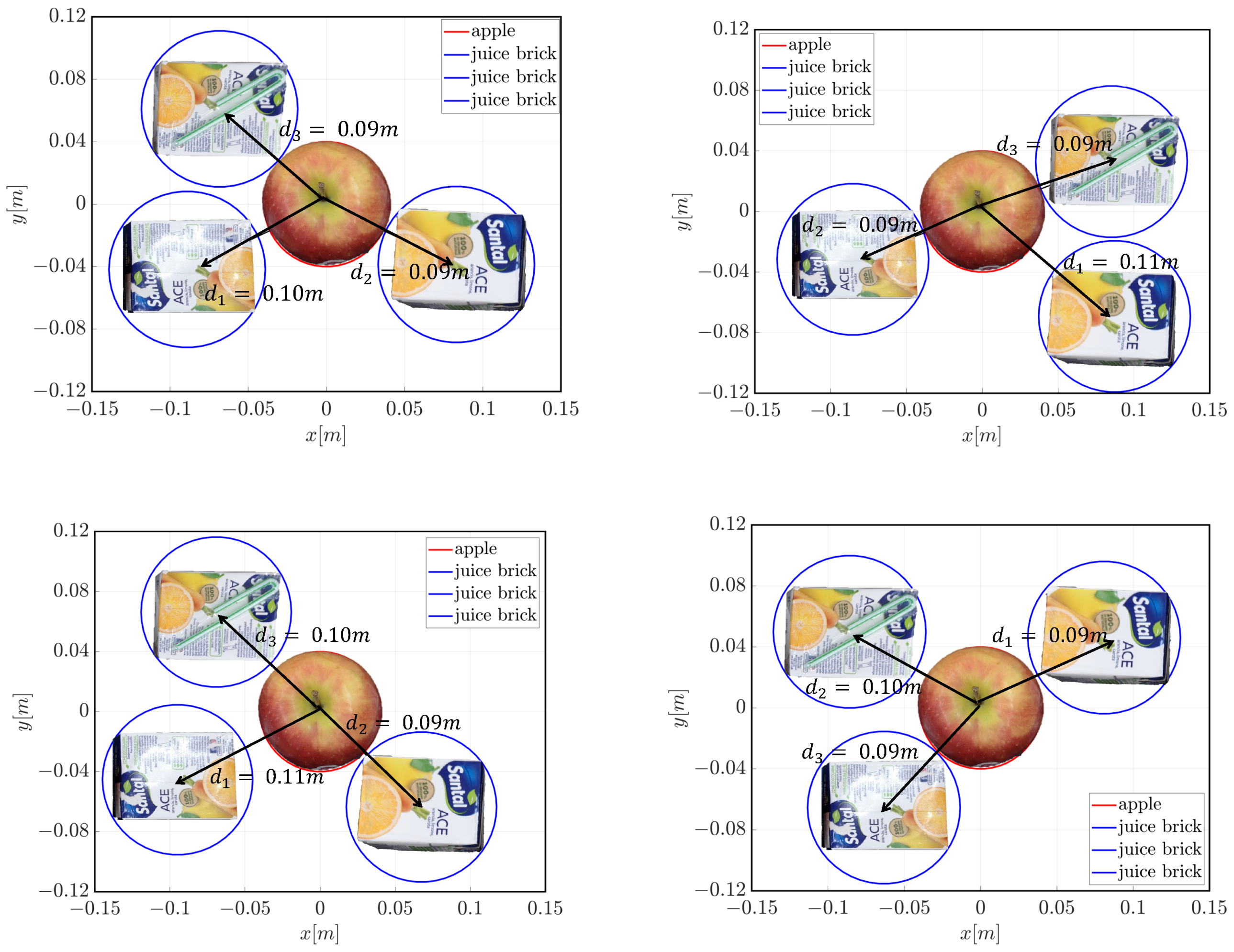{kind=link}
| Training parameters for the juice brick | |
| DR frames | k |
| PR frames | k |
| epochs | 70 |
| learning rate | |
| train batch size | 116 |
| test batch size | 32 |
| optimizer | Adam |
| training time | days |
| Training parameters for the red apple | |
| DR frames | k |
| PR frames | k |
| epochs | 120 |
| learning rate | |
| train batch size | 116 |
| test batch size | 32 |
| optimizer | Adam |
| training time | days |
| ATT. 1 | ATT. 2 | ATT. 3 | ATT. 4 | ATT. 5 | |
|---|---|---|---|---|---|
| Apple 1 | |||||
| Apple 2 | |||||
| Apple 3 | |||||
| Apple 4 | |||||
| Apple 5 |
| ATT. 1 | ATT. 2 | ATT. 3 | ATT. 4 | ATT. 5 | |
|---|---|---|---|---|---|
| Apple 1 | |||||
| Apple 2 | |||||
| Apple 3 | |||||
| Apple 4 | |||||
| Apple 5 |
| Dynamic model parameters | |
| a | |
| b | |
| m | |
| Controller parameters | |
| d | 3 |
| H | 20 |
| 3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Costanzo, M.; De Simone, M.; Federico, S.; Natale, C. Non-Prehensile Manipulation Actions and Visual 6D Pose Estimation for Fruit Grasping Based on Tactile Sensing. Robotics 2023, 12, 92. https://doi.org/10.3390/robotics12040092
Costanzo M, De Simone M, Federico S, Natale C. Non-Prehensile Manipulation Actions and Visual 6D Pose Estimation for Fruit Grasping Based on Tactile Sensing. Robotics. 2023; 12(4):92. https://doi.org/10.3390/robotics12040092
Chicago/Turabian StyleCostanzo, Marco, Marco De Simone, Sara Federico, and Ciro Natale. 2023. "Non-Prehensile Manipulation Actions and Visual 6D Pose Estimation for Fruit Grasping Based on Tactile Sensing" Robotics 12, no. 4: 92. https://doi.org/10.3390/robotics12040092
APA StyleCostanzo, M., De Simone, M., Federico, S., & Natale, C. (2023). Non-Prehensile Manipulation Actions and Visual 6D Pose Estimation for Fruit Grasping Based on Tactile Sensing. Robotics, 12(4), 92. https://doi.org/10.3390/robotics12040092