Nonlinear Model Predictive Control for Mobile Robot Using Varying-Parameter Convergent Differential Neural Network



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A varying parameter convergent differential neural network method is proposed to solve the time varying QP problem of MPC and all state variables can converge quickly to the optimal value using the neural network with physical. This is the first time that be presented to optimize the MPC problem.
- The convergence analysis of VPCDNN and the simulation results demonstrate good performance on the convergence speed and robustness of VPCDNN.
2. Model Predictive Control Scheme
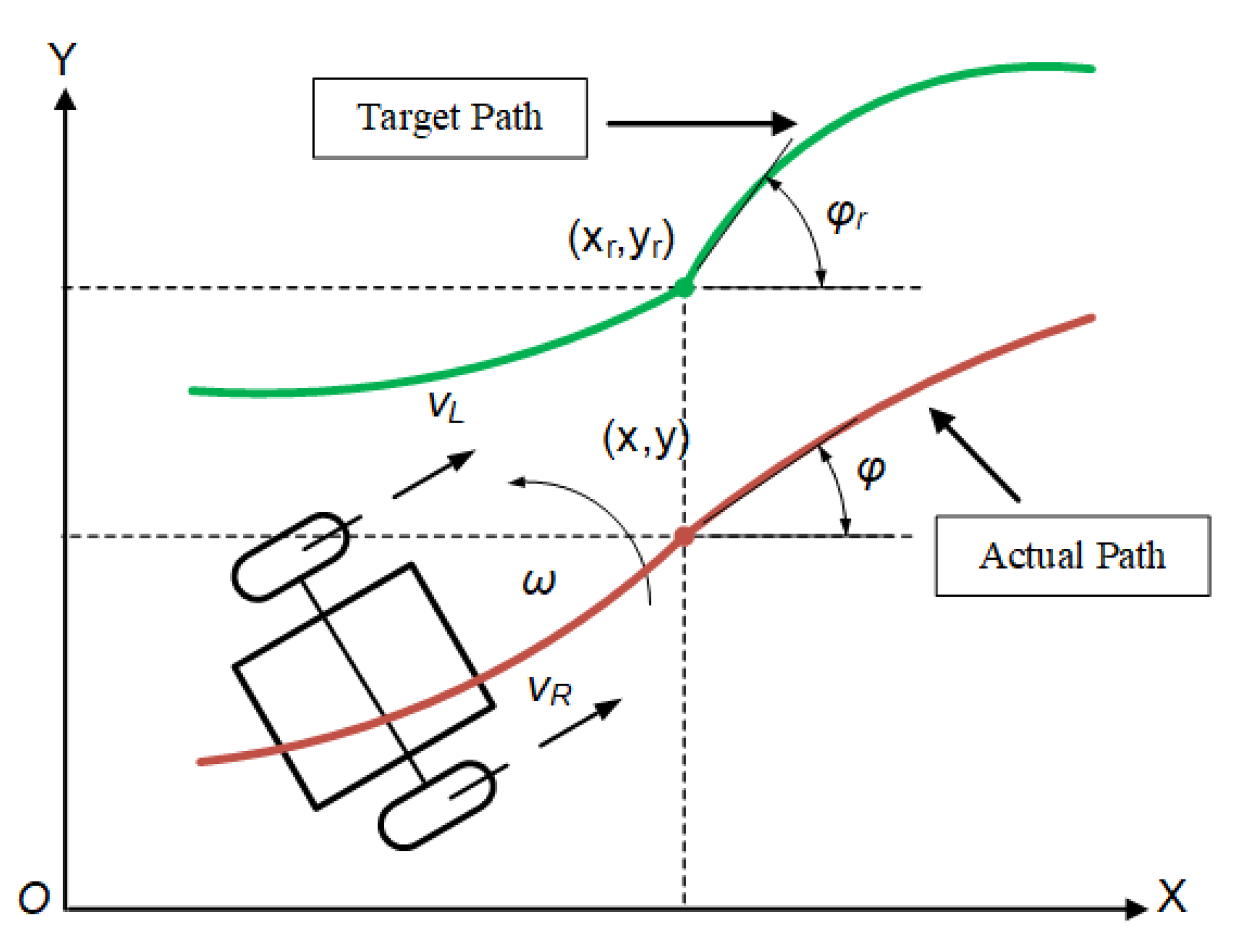
2.1. Mobile Robot Control System
2.2. Nonlinear Model Predictive Control
3. Varying-Parameter Convergent Differential Neural Network (VPCDNN)
4. Convergence and Robustness Analysis of VPCDNN
4.1. Convergence Analysis
4.2. Robustness Analysis
- if , so . It is obvious that the error variable converges to zero from the Lyapunov theorem and the state variable p converges to the optimal solution .
- if , then . Therefore, may be positive or negative.
- (a)
- if , we know the error variable converges to zero, also the state variable p will converge to optimal solution .
- (b)
- if , and consider the linear activation function , and , so we can obtain,
5. Simulation
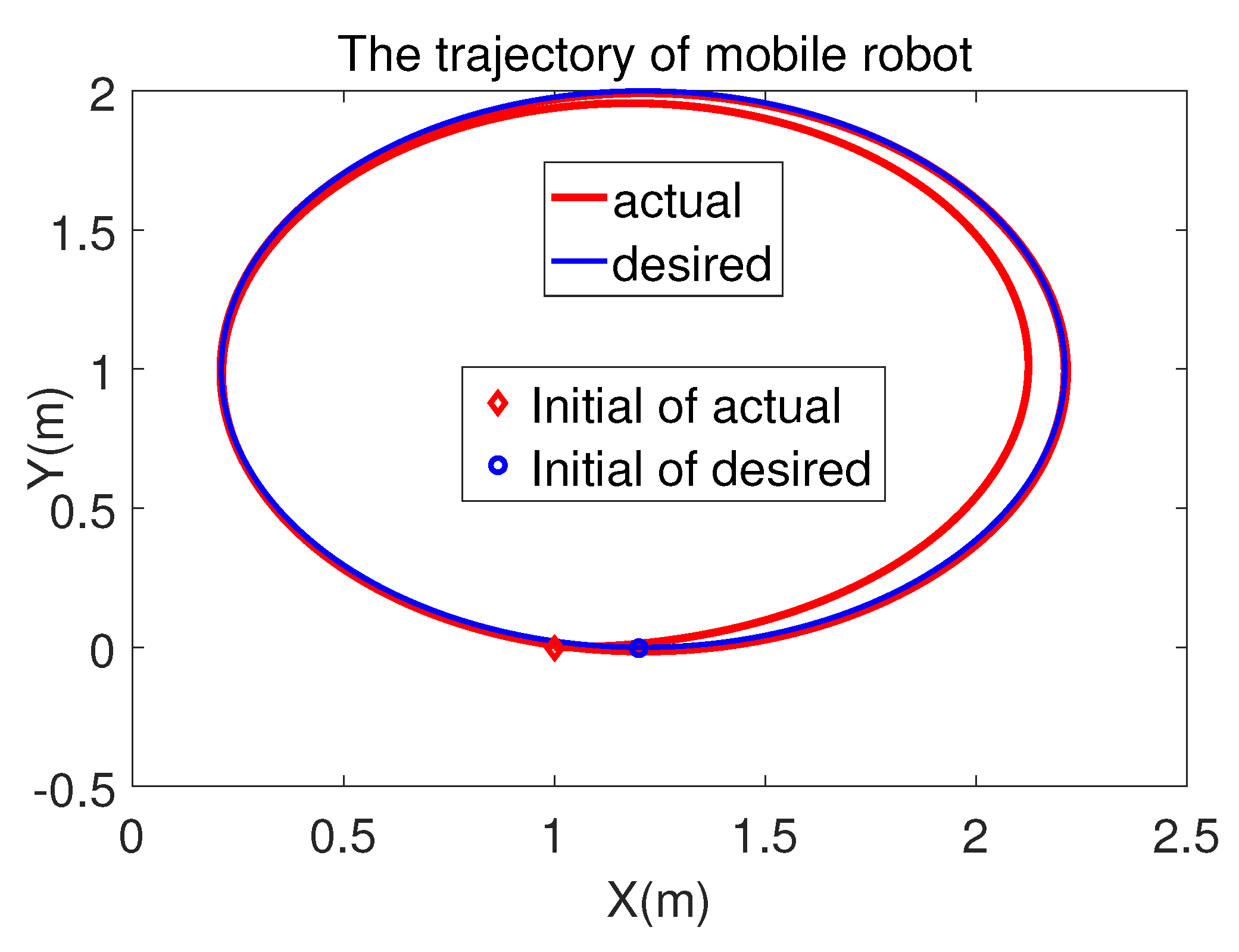
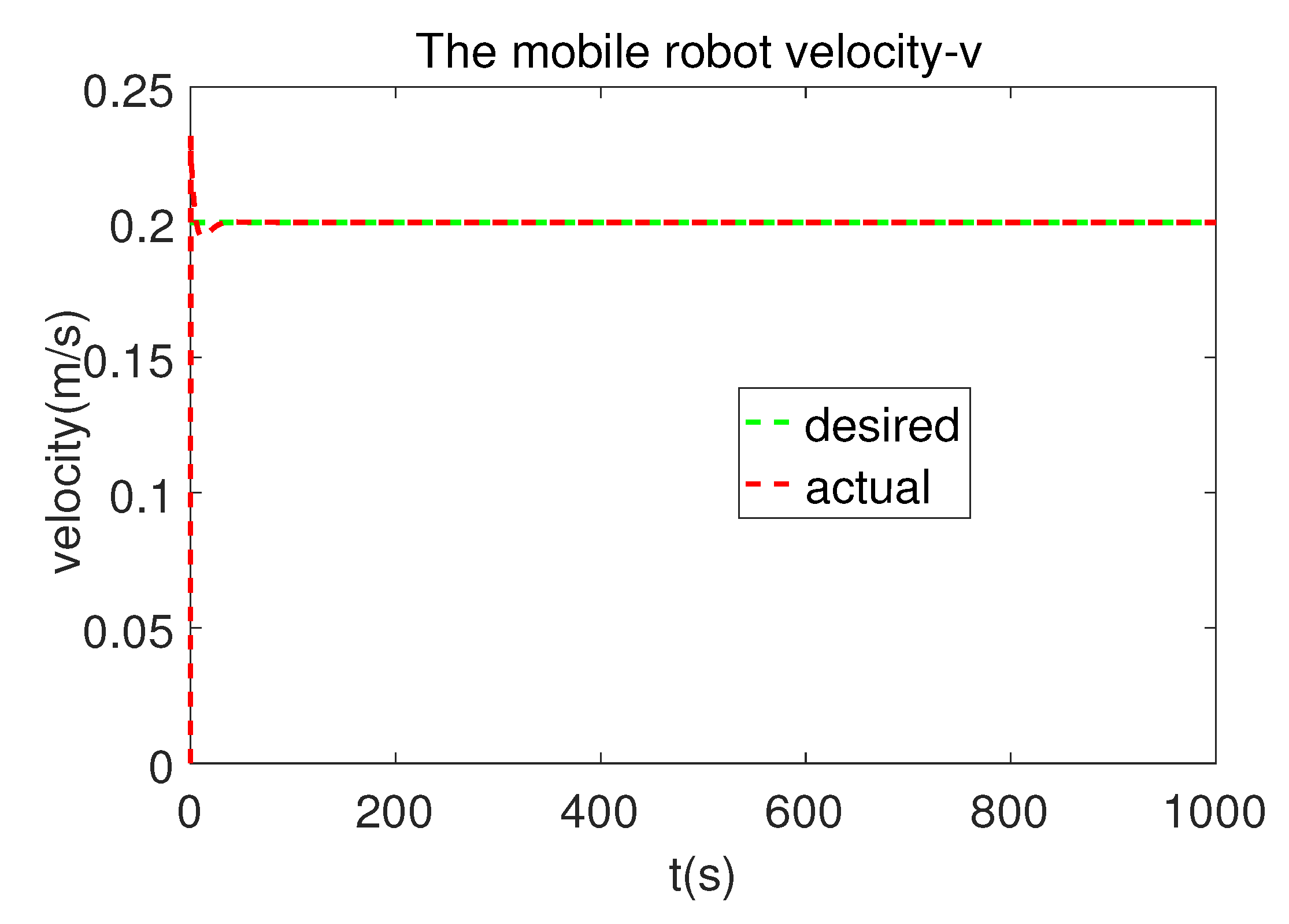
5.1. Circle-Shape Tracking
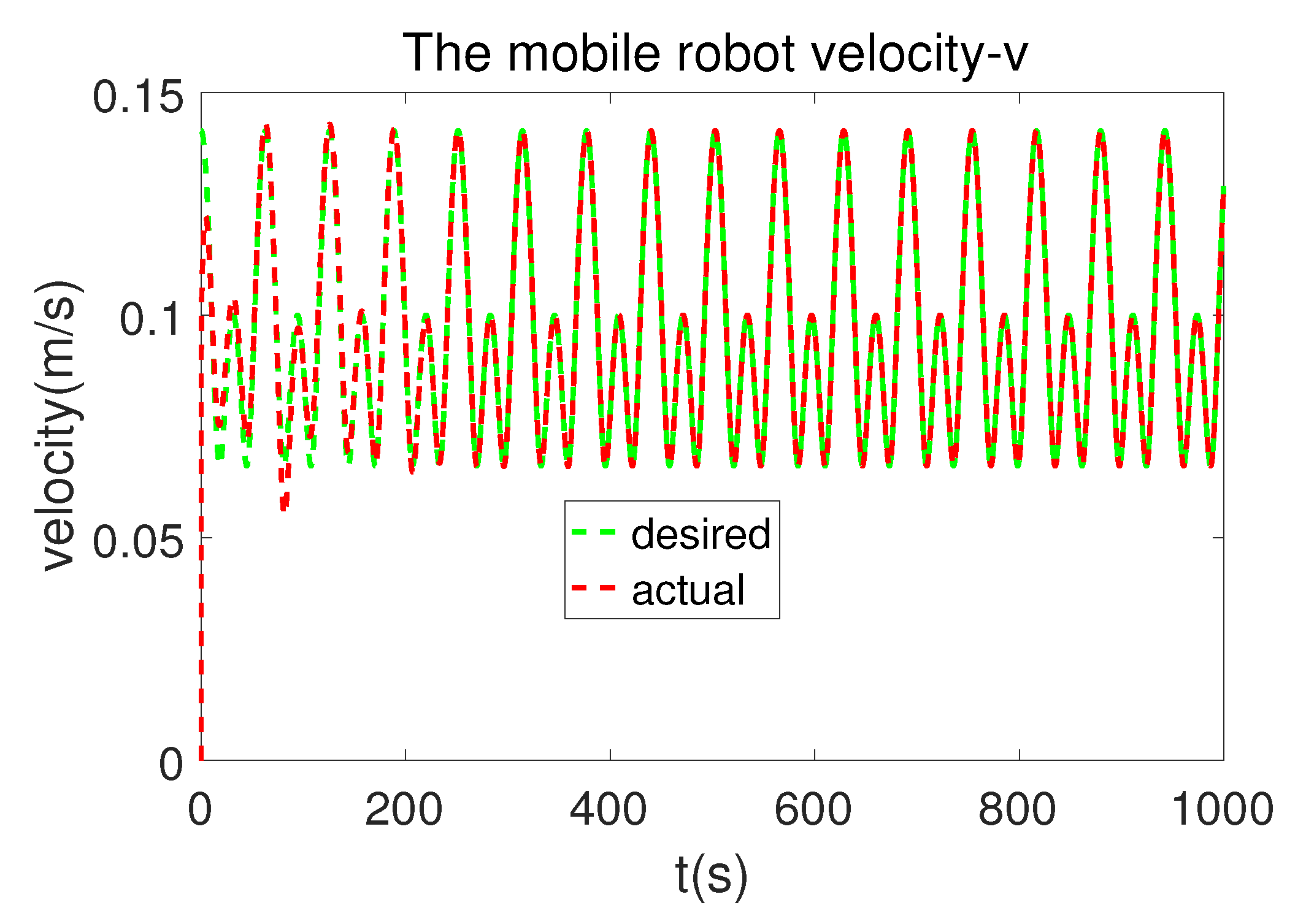
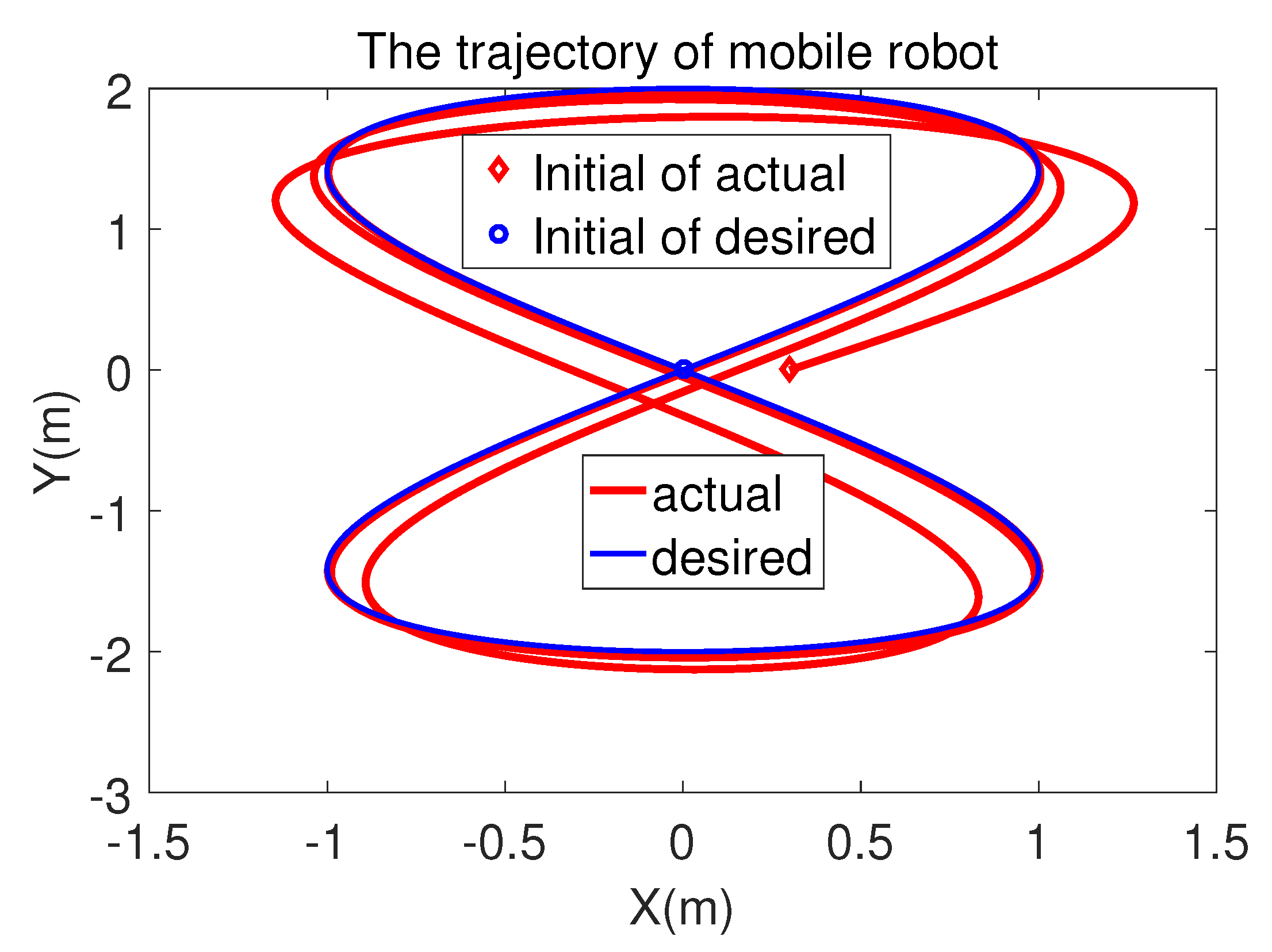
5.2. ‘8’-Shape Tracking
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| NMPC | nonlinear model predictive control |
| VPCDNN | varying-parameter convergent differential neural network |
| QP | quadratic programming |
| SMC | sliding mode control |
| GPNN | general projection neural network |
| PDNN | primal dual neural network |
References
- Brockett, R.W. Asymptotic stability andfeedback stabilization. Differ. Geom. Control Theory 1983, 27, 181–208. [Google Scholar]
- Al-Araji, A.S. Development of kinematic path-tracking controller design for real mobile robot via back-stepping slice genetic robust algorithm technique. Arab. J. Sci. Eng. 2014, 39, 8825–8835. [Google Scholar] [CrossRef]
- Fukushima, H.; Muro, K.; Matsuno, F. Sliding-mode control for transformation to an inverted pendulum mode of a mobile robot with wheel-arms. IEEE Trans. Ind. Electron. 2014, 62, 4257–4266. [Google Scholar] [CrossRef]
- Ostafew, C.J.; Schoellig, A.P.; Barfoot, T.D. Visual teach and repeat, repeat, repeat: Iterative learning control to improve mobile robot path tracking in challenging outdoor environments. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 176–181. [Google Scholar]
- Li, T.H.; Chang, S.J.; Tong, W. Fuzzy target tracking control of autonomous mobile robots by using infrared sensors. IEEE Trans. Fuzzy Syst. 2004, 12, 491–501. [Google Scholar] [CrossRef]
- Khalaji, A.K.; Moosavian, S.A.A. Robust adaptive controller for a tractor–trailer mobile robot. IEEE/ASME Trans. Mechatron. 2013, 19, 943–953. [Google Scholar] [CrossRef]
- Park, B.S.; Yoo, S.J.; Park, J.B.; Choi, Y.H. A simple adaptive control approach for trajectory tracking of electrically driven nonholonomic mobile robots. IEEE Trans. Control Syst. Technol. 2010, 18, 1199–1206. [Google Scholar] [CrossRef]
- Armesto, L.; Girbés, V.; Sala, A.; Zima, M.; Šmídl, V. Duality-based nonlinear quadratic control: Application to mobile robot trajectory-following. IEEE Trans. Control Syst. Technol. 2015, 23, 1494–1504. [Google Scholar] [CrossRef]
- Hendzel, Z.; Penar, P. Optimal Control of a Wheeled Robot. In Conference on Automation; Springer: Cham, Switzerland, 2019; pp. 473–481. [Google Scholar]
- Patrinos, P.; Bemporad, A. An accelerated dual gradient-projection algorithm for embedded linear model predictive control. IEEE Trans. Autom. Control. 2013, 59, 18–33. [Google Scholar] [CrossRef]
- Frison, G.; Sørensen, H.H.B.S.; Dammann, B.; Jørgensen, J.B.J. High-performance small-scale solvers for linear model predictive control. In Proceedings of the 2014 European Control Conference (ECC), Strasbourg, France, 24–27 June 2014; pp. 128–133. [Google Scholar]
- Nascimento, T.P.; Dórea, C.E.T.; Goncalves, L.M.G. Nonholonomic mobile robots’ trajectory tracking model predictive control: A survey. Robotica 2018, 36, 676–696. [Google Scholar] [CrossRef]
- Nascimento, T.P.; Moreira, A.P.; Conceição, A.G.S. Multi-robot nonlinear model predictive formation control: Moving target and target absence. Robot. Auton. Syst. 2013, 61, 1502–1515. [Google Scholar] [CrossRef]
- Vajedi, M.; Azad, N.L. Ecological adaptive cruise controller for plug-in hybrid electric vehicles using nonlinear model predictive control. IEEE Trans. Intell. Transp. Syst. 2015, 17, 113–122. [Google Scholar] [CrossRef]
- Lima, P.U.; Ahmad, A.; Dias, A.; Conceição, A.G.; Moreira, A.P.; Silva, E.; Nascimento, T.P. Formation control driven by cooperative object tracking. Robot. Auton. Syst. 2015, 63, 68–79. [Google Scholar] [CrossRef]
- Nascimento, T.P.; Dórea, C.E.T.; Goncalves, L.M.G. Nonlinear model predictive control for trajectory tracking of nonholonomic mobile robots: A modified approach. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418760461. [Google Scholar] [CrossRef]
- Mesbah, A. Stochastic model predictive control: An overview and perspectives for future research. IEEE Control Syst. Mag. 2016, 36, 30–44. [Google Scholar]
- Nascimento, T.P.; Basso, G.F.; Dorea, C.; Goncalves, L.M.G. Perception-driven Motion Control Based on Stochastic Nonlinear Model Predictive Controllers. IEEE/ASME Trans. Mechatron. 2019, 1, 1–11. [Google Scholar] [CrossRef]
- Rubagotti, M.; Patrinos, P.; Bemporad, A. Stabilizing linear model predictive control under inexact numerical optimization. IEEE Trans. Autom. Control 2014, 59, 1660–1666. [Google Scholar] [CrossRef]
- Park, H.; Sun, J.; Pekarek, S.; Stone, P.; Opila, D.; Meyer, R.; DeCarlo, R. Real-time model predictive control for shipboard power management using the IPA-SQP approach. IEEE Trans. Control Syst. Technol. 2015, 23, 2129–2143. [Google Scholar] [CrossRef]
- Sekiguchi, S.; Yorozu, A.; Kuno, K.; Okada, M.; Watanabe, Y.; Takahashi, M. Nonlinear model predictive control for two-wheeled service robots. In International Conference on Intelligent Autonomous Systems; Springer: Cham, Switzerland, 2018; pp. 452–463. [Google Scholar]
- Pan, Y.; Wang, J. Model predictive control of unknown nonlinear dynamical systems based on recurrent neural networks. IEEE Trans. Ind. Electron. 2012, 59, 3089–3101. [Google Scholar] [CrossRef]
- Li, Z.; Xiao, H.; Yang, C.; Zhao, Y. Model predictive control of nonholonomic chained systems using general projection neural networks optimization. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 1313–1321. [Google Scholar] [CrossRef]
- Xiao, H.; Li, Z.; Chen, C.P. Formation control of leader-follower mobile robots’ systems using model predictive control based on neural-dynamic optimization. IEEE Trans. Ind. Electron. 2016, 63, 5752–5762. [Google Scholar] [CrossRef]
- Ke, F.; Li, Z.; Yang, C. Robust Tube-Based Predictive Control for Visual Servoing of Constrained Differential-Drive Mobile Robots. IEEE Trans. Ind. Electron. 2018, 65, 3437–3446. [Google Scholar] [CrossRef]
- Li, Z.; Yuan, Y.; Ke, F.; He, W.; Su, C. Robust Vision-Based Tube Model Predictive Control of Multiple Mobile Robots for Leader-Follower Formation. IEEE Trans. Ind. Electron. 2019, in press. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J. A dual neural network for convex quadratic programming subject to linear equality and inequality constraints. Phys. Lett. A 2002, 298, 271–278. [Google Scholar] [CrossRef]
- Hu, Y.; Li, Z.; Li, G.; Yuan, P.; Yang, C.; Song, R. Development of sensory-motor fusion-based manipulation and grasping control for a robotic hand-eye system. IEEE Trans. Syst. Man Cybern. Syst. 2017, 7, 1169–1180. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Coddington, E.A.; Levinson, N.; Teichmann, T. Theory of ordinary differential equations. Phys. Today 1956. [Google Scholar] [CrossRef]
- Xia, Y.; Wang, J.; Fok, L.M. Grasping-force optimization for multifingered robotic hands using a recurrent neural network. IEEE Trans. Robot. Autom. 2004, 20, 549–554. [Google Scholar] [CrossRef]



















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Su, H.; Zhang, L.; Miao, S.; Chen, G.; Knoll, A. Nonlinear Model Predictive Control for Mobile Robot Using Varying-Parameter Convergent Differential Neural Network. Robotics 2019, 8, 64. https://doi.org/10.3390/robotics8030064
Hu Y, Su H, Zhang L, Miao S, Chen G, Knoll A. Nonlinear Model Predictive Control for Mobile Robot Using Varying-Parameter Convergent Differential Neural Network. Robotics. 2019; 8(3):64. https://doi.org/10.3390/robotics8030064
Chicago/Turabian StyleHu, Yingbai, Hang Su, Longbin Zhang, Shu Miao, Guang Chen, and Alois Knoll. 2019. "Nonlinear Model Predictive Control for Mobile Robot Using Varying-Parameter Convergent Differential Neural Network" Robotics 8, no. 3: 64. https://doi.org/10.3390/robotics8030064
APA StyleHu, Y., Su, H., Zhang, L., Miao, S., Chen, G., & Knoll, A. (2019). Nonlinear Model Predictive Control for Mobile Robot Using Varying-Parameter Convergent Differential Neural Network. Robotics, 8(3), 64. https://doi.org/10.3390/robotics8030064