Deep Learning-Based Object Classification and Position Estimation Pipeline for Potential Use in Robotized Pick-and-Place Operations


Abstract
:1. Introduction
2. Related Work
2.1. Recent Works with RGB-D Data
2.2. Deep Learning Approach
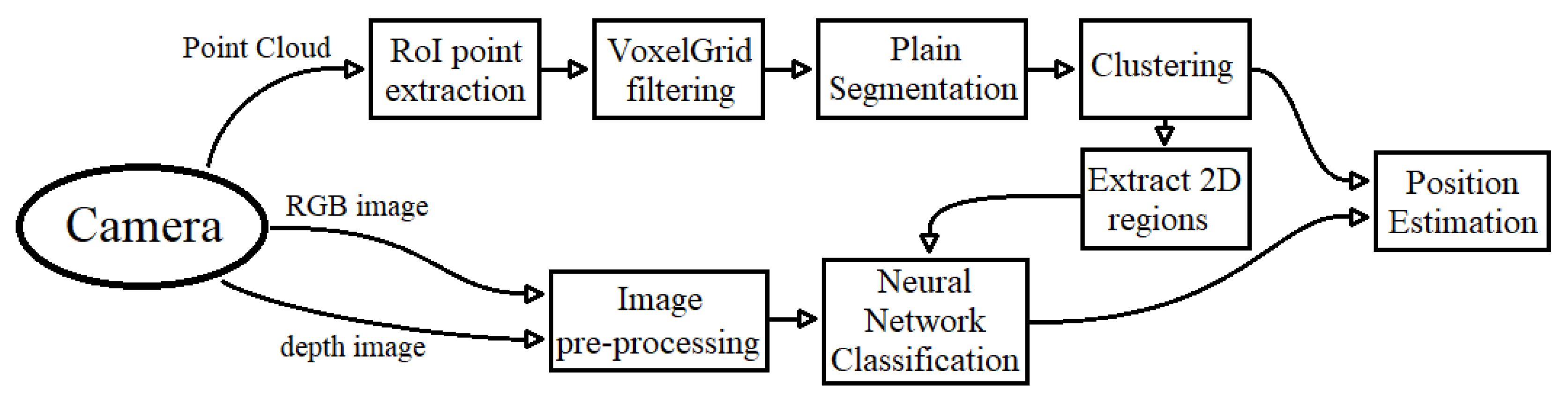
3. Proposed Unified Framework
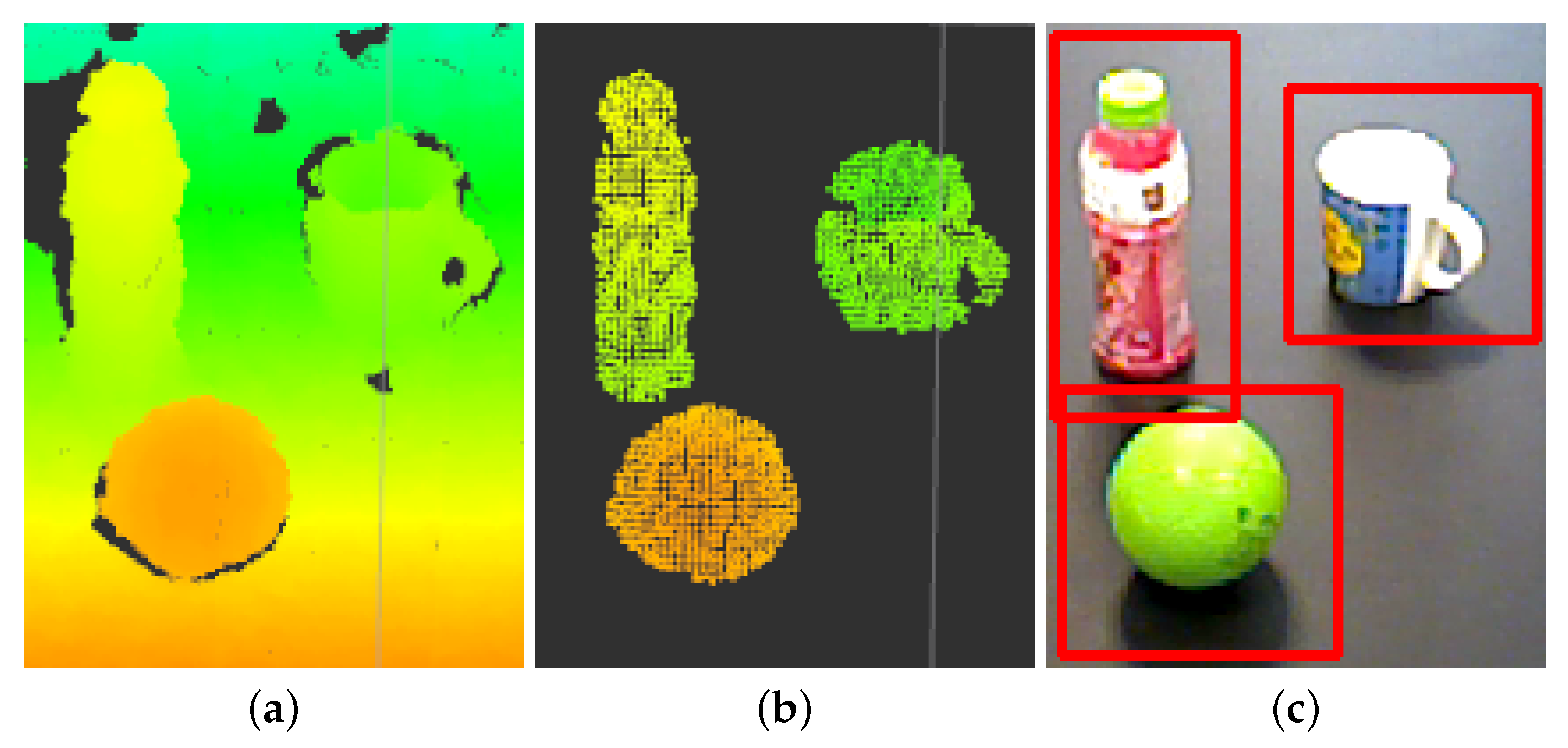
3.1. Object Segmentation Pipeline
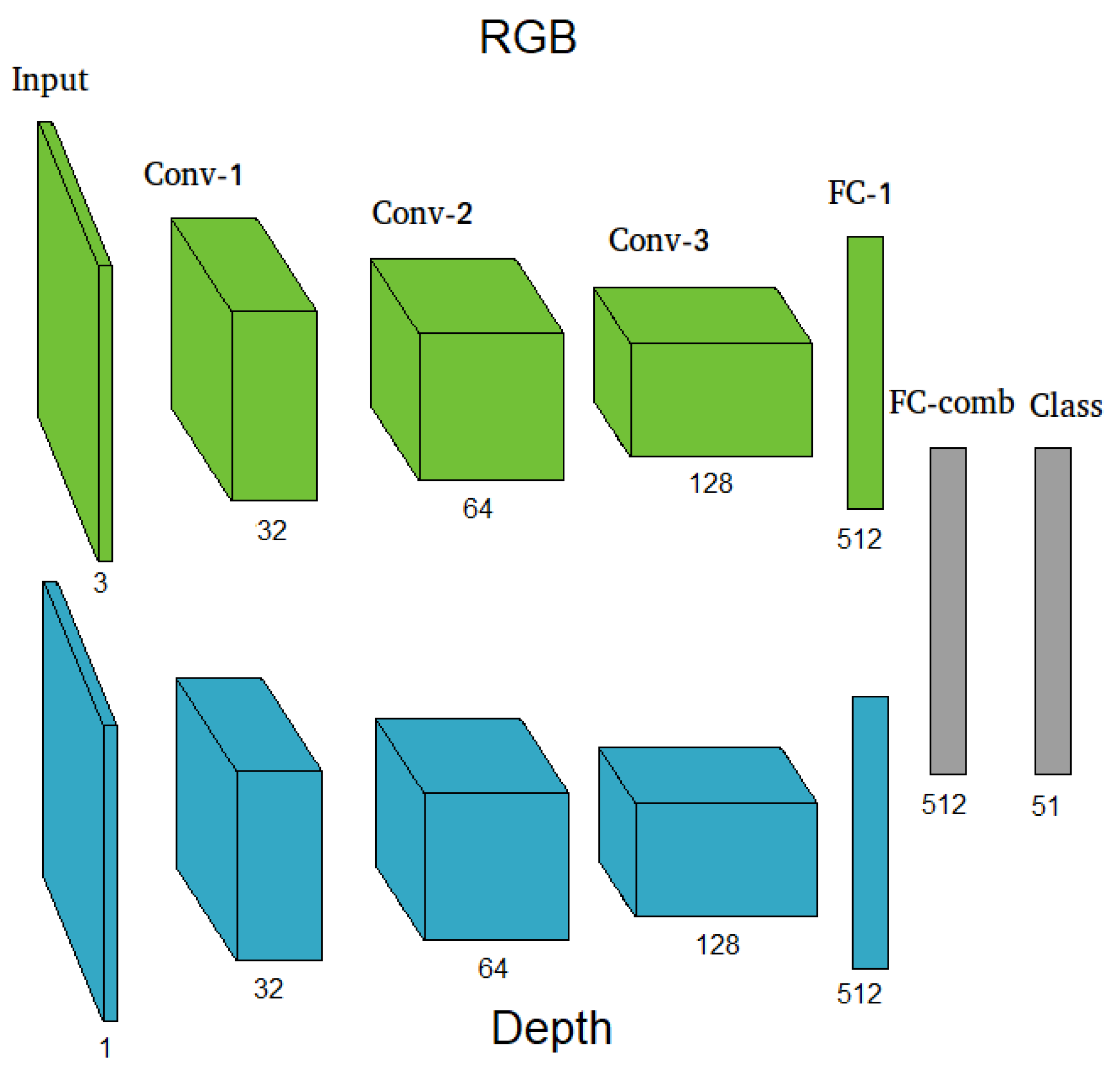
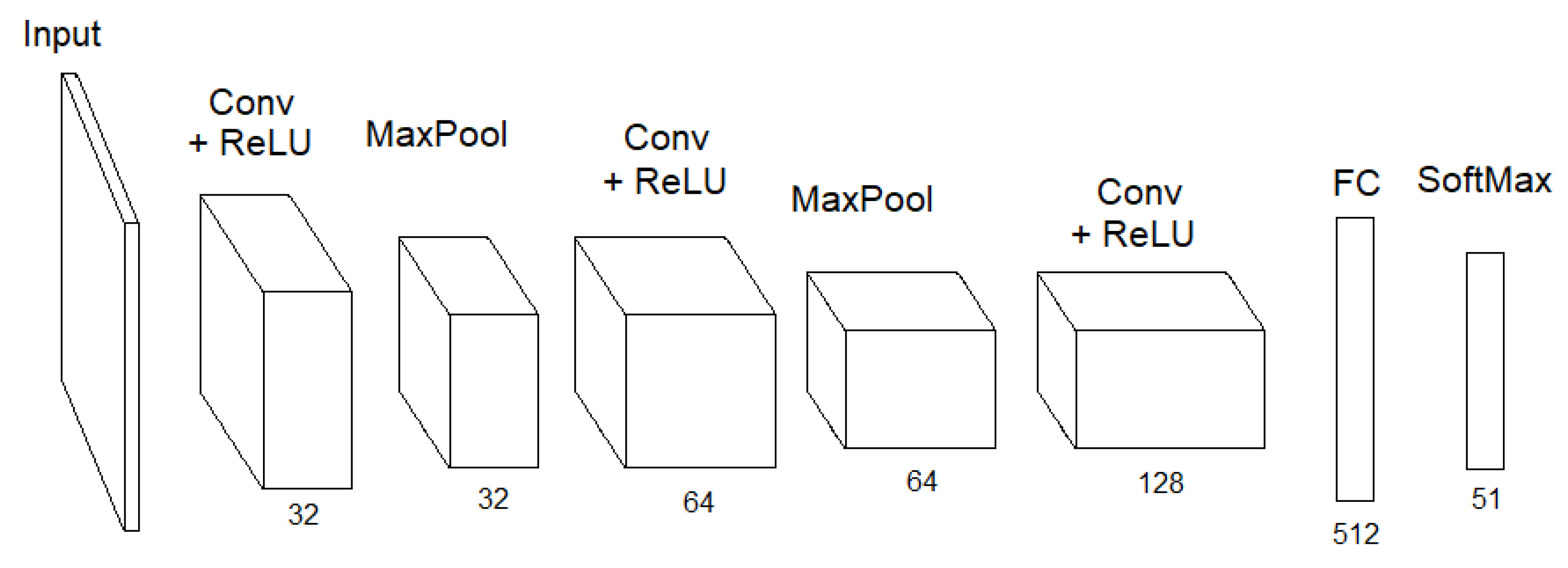
3.2. Object Classification
3.3. Image Pre-Processing
3.4. Network Training
4. Experiments
4.1. Network Training and Evaluation
4.2. Experimental Robot-Manipulation Setup
5. Results and Discussion
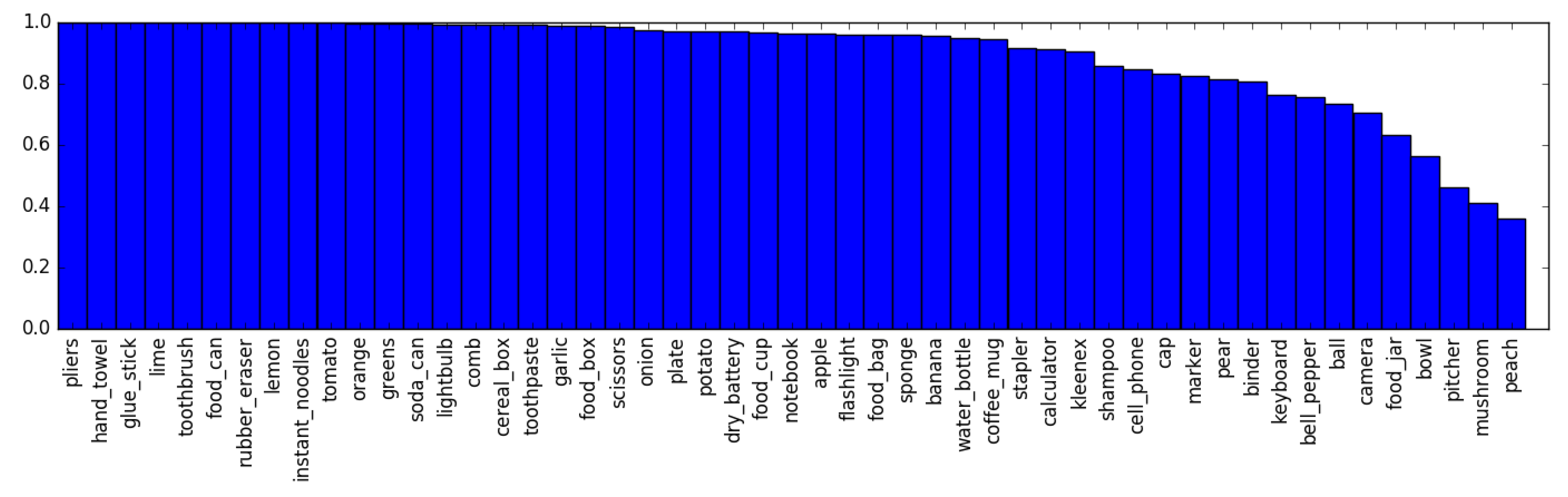
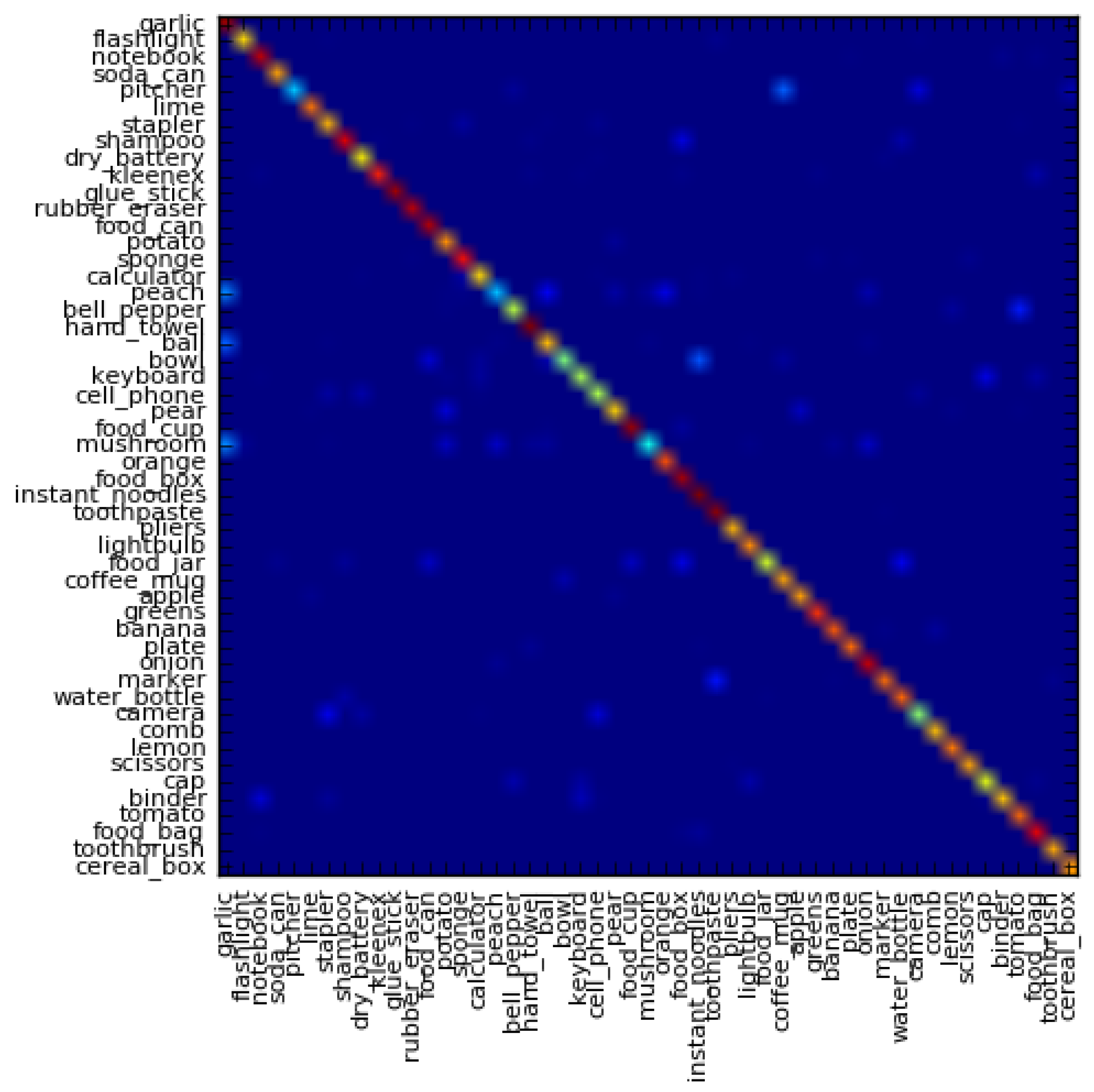
5.1. Classification Accuracy
5.2. Computation Performance
5.3. Experimental Verification
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hossain, D.; Capi, G.; Jindai, M.; Kaneko, S.I. Pick-place of dynamic objects by robot manipulator based on deep learning and easy user interface teaching systems. Ind. Robot. Int. J. 2017, 44, 11–20. [Google Scholar] [CrossRef]
- Shi, J.; Koonjul, G.S. Real-Time Grasping for Robotic Bin-Picking and Kitting Applications. IEEE Trans. Autom. Sci. Eng. 2017, 14, 809–819. [Google Scholar] [CrossRef]
- Hutchinson, S.; Hager, G.; Corke, P.I. A Tutorial on Visual Servo Control. IEEE Trans. Robot. Autom. 1996, 12, 651–670. [Google Scholar] [CrossRef] [Green Version]
- Hager, G.D.; Chang, W.C.; Morse, A.S. Robot Hand-Eye Coordination Based on Stereo Vision. IEEE Control Syst. Mag. 1995, 15, 30–39. [Google Scholar]
- Tsai, C.Y.; Wong, C.C.; Yu, C.J.; Liu, C.C.; Liu, T.Y. A Hybrid Switched Reactive-Based Visual Servo Control of 5-DOF Robot Manipulators for Pick-and-Place Tasks. IEEE Syst. J. 2015, 9, 119–130. [Google Scholar] [CrossRef]
- Bellandi, P.; Docchio, F.; Sansoni, G. Roboscan: A combined 2D and 3D vision system for improved speed and flexibility in pick-and-place operation. Int. J. Adv. Manuf. Technol. 2013, 69, 1873–1886. [Google Scholar] [CrossRef]
- Saudabayev, A.; Khassanov, Y.; Shintemirov, A.; Varol, H.A. An Intelligent Object Manipulation Framework for Industrial Tasks. In Proceedings of the 2013 IEEE International Conference on Mechatronics and Automation, Takamatsu, Japan, 4–7 August 2013; pp. 1708–1713. [Google Scholar]
- Rennie, C.; Shome, R.; Bekris, K.E.; De Souza, A.F. A Dataset for Improved RGBD-Based Object Detection and Pose Estimation for Wirehouse Pick-and-Place. IEEE Robot. Autom. Lett. 2016, 1, 1179–1185. [Google Scholar] [CrossRef] [Green Version]
- Wurman, P.R.; Romano, J.M. The Amazon Picking Challenge 2015. AI Mag. 2016, 37, 97. [Google Scholar] [CrossRef] [Green Version]
- Correll, N.; Bekris, K.E.; Berenson, D.; Brock, O.; Causo, A.; Hauser, K.; Okada, K.; Rodriguez, A.; Romano, J.M.; Wurman, P.R. Analysis and Observations from the First Amazon Picking Challenge. IEEE Trans. Autom. Sci. Eng. 2018, 15, 172–188. [Google Scholar] [CrossRef]
- He, R.; Rojas, J.; Guan, Y. A 3D object detection and pose estimation pipeline using RGB-D images. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics (ROBIO), Macau, China, 5–8 December 2017; pp. 1527–1532. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3750–3757. [Google Scholar]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef] [Green Version]
- Rusu, R.B.; Cousins, S. 3D is Here: Point cloud library (PCL). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Aldoma, A.; Marton, Z.C.; Tombari, F.; Wohlkinger, W.; Potthast, C.; Zeisl, B.; Rusu, R.B.; Gedikli, S.; Vincze, M. Tutorial: Point Cloud Library: Three-Dimensional Object Recognition and 6 DOF Pose Estimation. IEEE Robot. Autom. Mag. 2012, 19, 80–91. [Google Scholar] [CrossRef]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal Deep Learning for Robust RGB-D Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687. [Google Scholar]
- Schwarz, M.; Schulz, H.; Behnke, S. RGB-D Object Recognition and Pose Estimation Based on Pre-Trained Convolutional Neural Network Features. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1329–1335. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A Large-Scale Hierarchical Multi-View RGB-D Object Dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- Bo, L.; Ren, X.; Fox, D. Depth Kernel Descriptors for Object Recognition. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 821–826. [Google Scholar]
- Blum, M.; Springenberg, J.T.; Wülfing, J.; Riedmiller, M. A Learned Feature Descriptor for Object Recognition in RGB-D Data. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1298–1303. [Google Scholar]
- Bo, L.; Ren, X.; Fox, D. Unsupervised Feature Learning for RGB-D Based Object Recognition. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: Dutchess County, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning Rich Features From RGB-D Images for Object Detection and Segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zia, S.; Yuksel, B.; Yuret, D.; Yemez, Y. RGB-D Object Recognition Using Deep Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 896–903. [Google Scholar]
- Rubagotti, M.; Taunyazov, T.; Omarali, B.; Shintemirov, A. Semi-Autonomous Robot Teleoperation With Obstacle Avoidance via Model Predictive Control. IEEE Robot. Autom. Lett. 2019, 4, 2746–2753. [Google Scholar] [CrossRef]
- Andersen, T.T. Optimizing the Universal Robots ROS Driver; Technical University of Denmark, Department of Electrical Engineering: Kongens Lyngby, Denmark, 2015. [Google Scholar]
- Telegenov, K.; Tlegenov, Y.; Shintemirov, A. A Low-Cost Open-Source 3-D Printed Three-Finger Gripper Platform for Research and Educational Purposes. IEEE Access 2015, 3, 638–647. [Google Scholar] [CrossRef]
- Bo, L.; Lai, K.; Ren, X.; Fox, D. Object Recognition With Hierarchical Kernel Descriptors. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 1729–1736. [Google Scholar]
- Socher, R.; Huval, B.; Bath, B.; Manning, C.D.; Ng, A.Y. Convolutional-Recursive Deep Learning for 3D Object Classification. In Proceedings of the Advances in Neural Information Processing Systems 25, Stateline, NV, USA, 3–8 December 2012; pp. 656–664. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Xu, H.; Chen, G.; Wang, Z.; Sun, L.; Su, F. RGB-D-Based Pose Estimation of Workpieces with Semantic Segmentation and Point Cloud Registration. Sensors 2019, 19, 1873. [Google Scholar] [CrossRef] [Green Version]
- Ten Pas, A.; Gualtieri, M.; Saenko, K.; Platt, R. Grasp Pose Detection in Point Clouds. Int. J. Robot. Res. 2017, 36, 1455–1473. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RGB | Depth | RGB-D |
|---|---|---|---|
| Nonlinear SVM [18] | 74.5 ± 3.1 | 64.7 ± 2.2 | 83.9 ± 3.5 |
| HKDES [33] | 76.1 ± 2.2 | 75.7 ± 2.6 | 84.1 ± 2.2 |
| Kernel Desc. [19] | 77.7 ± 1.9 | 78.8 ± 2.7 | 86.2 ± 2.1 |
| CKM Desc. [20] | N/A | N/A | 86.4 ± 2.3 |
| CNN-RNN [34] | 80.8 ± 4.2 | 78.9 ± 3.8 | 86.8 ± 3.3 |
| CNN Features [17] | 83.1 ± 2.0 | N/A | 89.4 ± 1.3 |
| Fus-CNN (jet) [16] | 84.1 ± 2.7 | 83.8 ± 2.7 | 91.3 ± 1.4 |
| VGG3D [29] | 88.96 ± 2.1 | 78.43 ± 2.4 | 91.84 ± 0.89 |
| Proposed model | 76.3 ± 3.8 | 76.3 ± 2.1 | 86.2 ± 1.3 |
| Method | On GPU, ms | On CPU, ms | Parameters |
|---|---|---|---|
| VGG3D [29] | 4.491 | 812.918 | |
| Fus-CNN [16] | 2.260 | 217.595 | |
| CNN Features [17] | 2.137 | 213.389 | |
| Proposed model | 1.522 | 106.369 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soltan, S.; Oleinikov, A.; Demirci, M.F.; Shintemirov, A. Deep Learning-Based Object Classification and Position Estimation Pipeline for Potential Use in Robotized Pick-and-Place Operations. Robotics 2020, 9, 63. https://doi.org/10.3390/robotics9030063
Soltan S, Oleinikov A, Demirci MF, Shintemirov A. Deep Learning-Based Object Classification and Position Estimation Pipeline for Potential Use in Robotized Pick-and-Place Operations. Robotics. 2020; 9(3):63. https://doi.org/10.3390/robotics9030063
Chicago/Turabian StyleSoltan, Sergey, Artemiy Oleinikov, M. Fatih Demirci, and Almas Shintemirov. 2020. "Deep Learning-Based Object Classification and Position Estimation Pipeline for Potential Use in Robotized Pick-and-Place Operations" Robotics 9, no. 3: 63. https://doi.org/10.3390/robotics9030063
APA StyleSoltan, S., Oleinikov, A., Demirci, M. F., & Shintemirov, A. (2020). Deep Learning-Based Object Classification and Position Estimation Pipeline for Potential Use in Robotized Pick-and-Place Operations. Robotics, 9(3), 63. https://doi.org/10.3390/robotics9030063