
Mapping Mineral Prospectivity Using a Hybrid Genetic Algorithm–Support Vector Machine (GA–SVM) Model


Abstract
:1. Introduction
2. Methodology
2.1. Support Vector Machine
2.2. GA–SVM Model
- •
- Data processing. After constructing a geospatial database, geological maps and geochemical data were analyzed to map five evidence layers and generate training and testing datasets.
- •
- GA optimization. After setting the initial parameters for GA and SVM, the training dataset was used to train an SVM model, while the fitness was calculated by k-fold cross-validation classification accuracy. If the termination conditions were satisfied, the optimal parameters of SVM were determined. Otherwise, the selection, crossover, and mutation operations were performed to create a new population, and the GA optimization process was repeated.
- •
- Classification. An SVM model was trained with the optimal parameters, and a prospectivity map was produced. Ultimately, the F1 score and spatial efficiency were combined to evaluate the classification ability of the GA–SVM model.
2.3. Performance Evaluation
3. Study Area and Evidence Layers
3.1. Study Area
3.2. Mapping Evidence
3.2.1. Data
3.2.2. Evidence Layers
4. Application of GA–SVM Model
4.1. Target Variable and Feature Vectors
4.2. Mineral Prospectivity Mapping
5. Conclusions
- •
- Since SVM generalization performance is heavily dependent on parameters σ and C, it is necessary to adopt GA as an objective function to select better combinations of the two parameters for SVM.
- •
- Owing to the characteristic of P-A plot, it can be used for classifying evidence layers into binary patterns. It is important to note that the knowledge of the metallogenic model should be applied to differentiate favorable and unfavorable areas in the binary maps.
- •
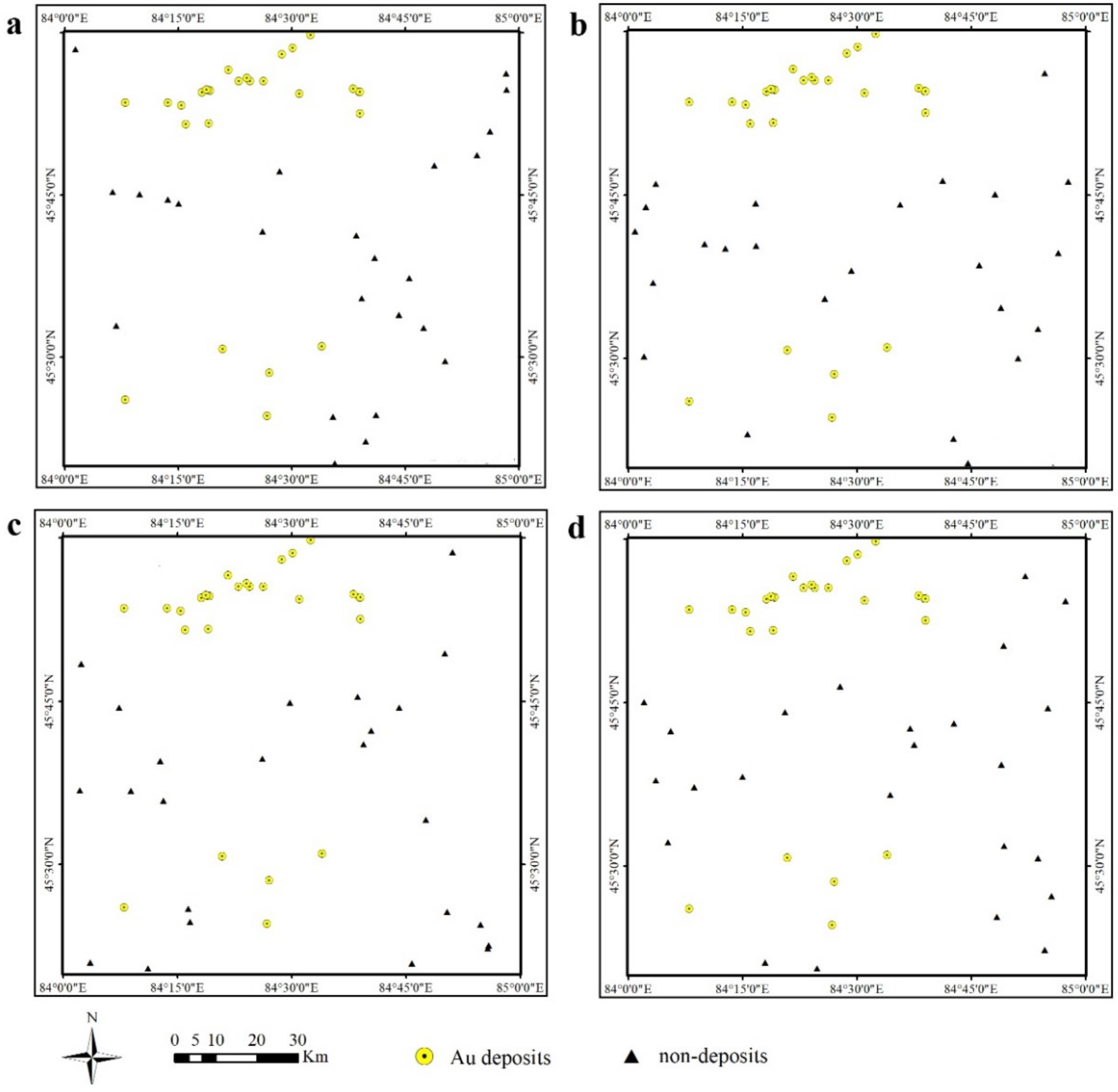
- A key procedure in implementing the GA–SVM model was the selection of the training dataset, especially the ‘non-mineralized’ locations. In complex geological environments, it is impossible to identify non-mineralized locations; thus, point pattern analysis is a useful measure for determining the optimal distance at which non-mineralized locations can be randomly selected based on the selection criteria.
- •
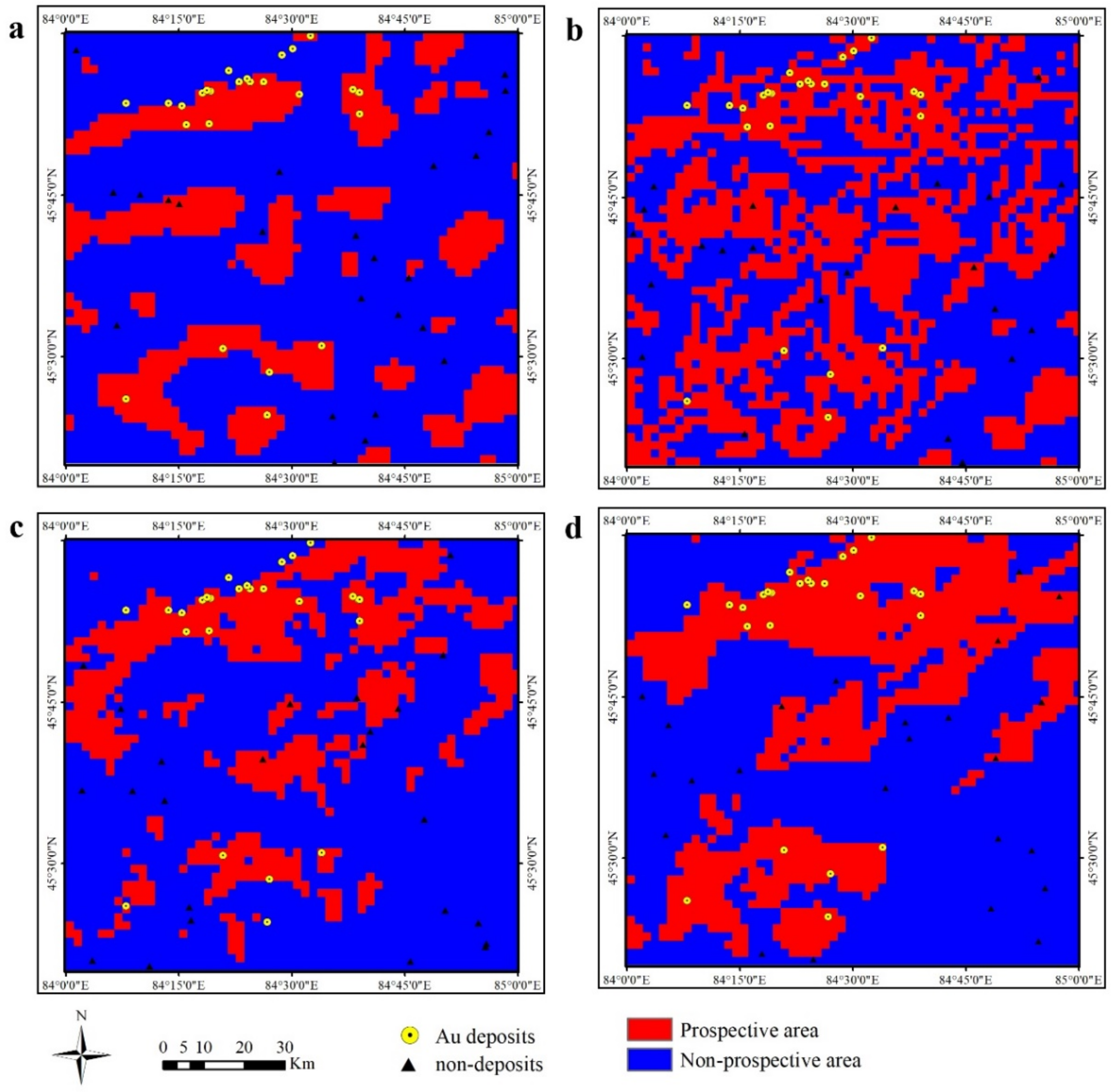
- The performance of the GA–SVM model for distinguishing prospective areas in the study area was evaluated using both the F1 score and spatial efficiency. The best prospectivity model predicted 95.83% of the known Au deposits within prospective areas, occupying 35.68% of the study area.
- •
- The best prospectivity map, as classified by the GA–SVM model, displayed a strong spatial correlation between prospective areas and proximity to NE-trending faults. This conforms to the characterization of spatial associations between geological features and Au deposits, indicating that the results emphasize the strong control of Au mineralization by NE-trending faults within the study area.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, T.; Xia, Q.; Zhao, M.; Gui, Z.; Leng, S. Prospectivity mapping for Tungsten Polymetallic mineral resources, Nanling Metallogenic Belt, South China: Use of random forest algorithm from a perspective of data imbalance. Nat. Resour. Res. 2020, 29, 203–227. [Google Scholar] [CrossRef]
- Parsa, M.; Maghsoudi, A. Assessing the effects of mineral systems-derived exploration targeting criteria for random Forests-based predictive mapping of mineral prospectivity in Ahar-Arasbaran area, Iran. Ore Geol. Rev. 2021, 138, 104399. [Google Scholar] [CrossRef]
- Porwal, A.; Carranza, E.J.M. Introduction to the Special Issue: GIS-based mineral potential modelling and geological data analyses for mineral exploration. Ore Geol. Rev. 2015, 71, 477–483. [Google Scholar] [CrossRef]
- Bonham-Carter, G.F. Geographic Information Systems for Geoscientists Modelling with GIS; Pergamon: Oxford, UK, 1994. [Google Scholar]
- Carranza, E.J.M. Geochemical anomaly and mineral prospectivity mapping in GIS. In Handbook of Exploration and Environmental Geochemistry; Elsevier: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Carranza, E.J.M.; Mangaoang, J.C.; Hale, M. Application of mineral exploration models and GIS to generate mineral potential maps as input for optimum land-use planning in the Philippines. Nat. Resour. Res. 1999, 8, 165–173. [Google Scholar] [CrossRef]
- Sadeghi, B.; Khalajmasoumi, M. A futuristic review for evaluation of geothermal potentials using fuzzy logic and binary index overlay in GIS environment. Renew. Sustain. Energy Rev. 2015, 43, 818–831. [Google Scholar] [CrossRef]
- An, P.; Moon, W.M.; Rencz, A. Application of fuzzy set theory for integration of geological, geophysical and remote sensing data. Can. J. Explor. Geophys. 1999, 27, 1–11. [Google Scholar]
- Knox-Robinson, C.M. Vectorial fuzzy logic: A novel technique for enhanced mineral prospectivity mapping, with reference to the orogenic gold mineralisation potential of the Kalgoorlie Terrane, Western Australia. Aust. J. Earth Sci. 2000, 47, 929–941. [Google Scholar] [CrossRef]
- Mutele, L.; Billay, A.; Hunt, J.P. Knowledge-driven prospectivity mapping for Granite-Related Polymetallic Sn–F–(REE) mineralization, Bushveld Igneous Complex, South Africa. Nat. Resour. Res. 2017, 26, 535–552. [Google Scholar] [CrossRef]
- Abedi, M.; Mohammadi, R.; Norouzi, G.H.; Mohammadi, M.S.M. A comprehensive VIKOR method for integration of various exploratory data in mineral potential mapping. Arab. J. Geosci. 2016, 9, 482. [Google Scholar] [CrossRef]
- Abedi, M.; Ali Torabi, S.; Norouzi, G.H.; Hamzeh, M.; Elyasi, G.R. PROMETHEE II: A knowledge-driven method for copper exploration. Comput. Geosci. 2012, 46, 255–263. [Google Scholar] [CrossRef]
- Pazand, K.; Hezarkhani, A.; Ataei, M. Using TOPSIS approaches for predictive porphyry Cu potential mapping: A case study in Ahar-Arasbaran area (NW, Iran). Comput. Geosci. 2012, 49, 62–71. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, Q.; Xia, Q.; Wang, X. Mineral potential mapping for tungsten polymetallic deposits in the Nanling metallogenic belt, South China. J. Earth Sci. 2014, 25, 689–700. [Google Scholar] [CrossRef]
- Zuo, R. Regional exploration targeting model for Gangdese porphyry copper deposits. Resour. Geol. 2011, 61, 296–303. [Google Scholar] [CrossRef]
- Carranza, E.J.M. Data-driven evidential belief modeling of mineral potential using few prospects and evidence with missing values. Nat. Resour. Res. 2015, 24, 291–304. [Google Scholar] [CrossRef]
- Carranza, E.J.M.; Hale, M. Evidential belief functions for data-driven geologically constrained mapping of gold potential, Baguio district, Philippines. Ore Geol. Rev. 2003, 22, 117–132. [Google Scholar] [CrossRef]
- Zhang, D.; Ren, N.; Hou, X. An improved logistic regression model based on a spatially weighted technique (ILRBSWT v1.0) and its application to mineral prospectivity mapping. Geosci. Model Dev. 2018, 11, 2525–2539. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Y.; Zuo, R. GIS-based rare events logistic regression for mineral prospectivity mapping. Comput. Geosci. 2018, 111, 18–25. [Google Scholar] [CrossRef]
- Abedi, M.; Norouzi, G.H.; Bahroudi, A. Support vector machine for multi-classification of mineral prospectivity areas. Comput. Geosci. 2012, 46, 272–283. [Google Scholar] [CrossRef]
- Shabankareh, M.; Hezarkhani, A. Application of support vector machines for copper potential mapping in Kerman region, Iran. J. Afr. Earth Sci. 2017, 128, 116–126. [Google Scholar] [CrossRef]
- Zuo, R.; Carranza, E.J.M. Support vector machine: A tool for mapping mineral prospectivity. Comput. Geosci. 2011, 37, 1967–1975. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Huang, C.; Wang, C.J. A GA-based feature selection and parameters optimizationfor support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Sun, Y.; Wong, A.K.; Kandrewamel, M. Classification of imbalanced data: A review. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Rahimi, H.; Abedi, M.; Yousefi, M.; Bahroudi, A.; Elyasi, G.R. Supervised mineral exploration targeting and the challenges with the selection of deposit and non-deposit sites thereof. Appl. Geochem. 2021, 128, 104940. [Google Scholar] [CrossRef]
- Zuo, R.; Wang, Z. Effects of random negative training samples on mineral prospectivity mapping. Nat. Resour. Res. 2020, 29, 3443–3455. [Google Scholar] [CrossRef]
- Carranza, E.J.M.; Hale, M.; Faassen, C. Selection of coherent deposit-type locations and their application in data-driven mineral prospectivity mapping. Ore Geol. Rev. 2008, 33, 536–558. [Google Scholar] [CrossRef]
- Nykänen, V.; Lahti, I.; Niiranen, T.; Korhonen, K. Receiver operating characteristics (ROC) as validation tool for prospectivity models—A magmatic Ni–Cu case study from the Central Lapland Greenstone Belt, Northern Finland. Ore Geol. Rev. 2015, 71, 853–860. [Google Scholar] [CrossRef]
- Hariharan, S.; Tirodkar, S.; Porwal, A.; Bhattacharya, A.; Joly, A. Random forest-based prospectivity modelling of Greenfield Terrains using sparse deposit data: An example from the Tanami Region, Western Australia. Nat. Resour. Res. 2017, 26, 489–507. [Google Scholar] [CrossRef]
- Prado, E.M.G.; de Souza Filho, C.R.; Carranza, E.J.M.; Motta, J.G. Modeling of Cu-Au prospectivity in the Carajás mineral province (Brazil) through machine learning: Dealing with imbalanced training data. Ore Geol. Rev. 2020, 124, 103611. [Google Scholar] [CrossRef]
- Yousefi, M.; Carranza, E.J.M. Data-driven index overlay and boolean logic mineral prospectivity modeling in Greenfields exploration. Nat. Resour. Res. 2016, 25, 3–18. [Google Scholar] [CrossRef]
- Yousefi, M.; Carranza, E.J.M. Prediction–area (P–A) plot and C–A fractal analysis to classify and evaluate evidential maps for mineral prospectivity modeling. Comput. Geosci. 2015, 79, 69–81. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Cao, Y.; Yin, K.; Zhou, C.; Ahmed, B. Establishment of landslide groundwater level prediction model based on GA-SVM and influencing factor analysis. Sensors 2020, 20, 845. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Zheng, X.; Ma, L.; Wang, H.; Huang, Q.; Leng, G.; Meng, E.; Guo, Y. Quantitative contribution of climate change and human activities to vegetation cover variations based on GA-SVM model. J. Hydrol. 2020, 584, 124687. [Google Scholar] [CrossRef]
- Min, S.H.; Lee, J.; Han, I. Hybrid genetic algorithms and support vector machines for bankruptcy prediction. Expert Syst. Appl. 2006, 31, 652–660. [Google Scholar] [CrossRef]
- Anguita, D.; Ghelardoni, L.; Ghio, A.; Oneto, L.; Ridella, S. The “K” in k-fold cross validation. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 25–27 April 2012. [Google Scholar]
- Bengio, Y.; Grandvalet, Y. No unbiased estimator of the variance of k-fold cross-validation. J. Mach. Learn. Res. 2004, 5, 1089–1105. [Google Scholar]
- Chen, K.Y.; Wang, C.H. A hybrid SARIMA and support vector machines in forecasting the production values of the machinery industry in Taiwan. Expert Syst. Appl. 2007, 32, 254–264. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R. Effects of misclassification costs on mapping mineral prospectivity. Ore Geol. Rev. 2017, 82, 1–9. [Google Scholar] [CrossRef]
- Rijsbergen, C. Information Retrieval, 2nd ed.; Butterworth-Heinemann: London, UK, 1979. [Google Scholar]
- An, F.; Zhu, Y. Native antimony in the Baogutu gold deposit (west Junggar, NW China): Its occurrence and origin. Ore Geol. Rev. 2010, 37, 214–223. [Google Scholar] [CrossRef]
- Shen, Y.; Jin, C. Magmatism and Gold Mineralization in Western Junggar; Science Press: Beijing, China, 1993. (In Chinese) [Google Scholar]
- Geng, H.; Sun, M.; Yuan, C.; Xiao, W.; Xian, W.; Zhao, G.; Zhang, L.; Wong, K.; Wu, F. Geochemical, Sr–Nd and zircon U–Pb–Hf isotopic studies of Late Carboniferous magmatism in the West Junggar, Xinjiang: Implications for ridge subduction? Chem. Geol. 2009, 266, 364–389. [Google Scholar] [CrossRef]
- Han, B.; Ji, J.; Song, B.; Chen, L.; Zhang, L. Late Paleozoic vertical growth of continental crust around the Junggar Basin, Xinjiang, China (Part I): Timing of post-collisional plutonism. Acta Petrol. Sin. 2006, 22, 1077–1086. (In Chinese) [Google Scholar]
- Su, Y.; Tang, H.; Hou, G.; Liu, C. Geochemistry of aluminous A-type granites along Darabut tectonic belt in West Junggar, Xinjiang. Geochimica 2006, 35, 55–67. (In Chinese) [Google Scholar]
- Dong, C. Characteristics of Forming Fluids and Metallogenic Prediction in the Depth of Hatu Gold Deposit. Master’s Thesis, Xinjiang University, Urumqi, China, 2012. (In Chinese). [Google Scholar]
- Liu, S.; Tao, M.; Zheng, G.; Zeng, K. Experiment study on mineral processing of some complex gold ore. Met. Mine 2009, 39, 98–103. (In Chinese) [Google Scholar]
- Xie, X.; Mu, X.; Ren, T. Geochemical mapping in China. J. Geochem. Explor. 1997, 60, 99–113. [Google Scholar]
- Cheng, Q. Mapping singularities with stream sediment geochemical data for prediction of undiscovered mineral deposits in Gejiu, Yunnan Province, China. Ore Geol. Rev. 2007, 32, 314–324. [Google Scholar] [CrossRef]
- Cheng, Q. Non-Linear theory and Power-Law models for information integration and mineral resources quantitative assessments. Math. Geosci. 2008, 40, 503–532. [Google Scholar] [CrossRef]
- Xiao, F.; Chen, J.; Zhang, Z.; Wang, C.; Wu, G.; Agterberg, F. Singularity mapping and spatially weighted principal component analysis to identify geochemical anomalies associated with Ag and Pb-Zn polymetallic mineralization in Northwest Zhejiang, China. J. Geochem. Explor. 2012, 122, 90–100. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, K.; Cui, Y.; Wang, J.; Ding, J. Exploratory data analysis and singularity mapping in geochemical anomaly identification in Karamay, Xinjiang, China. J. Geochem. Explor. 2015, 154, 171–179. [Google Scholar]
- Diggle, P.J. A kernel method for smoothing point process data. Appl. Stat. 1985, 34, 138–147. [Google Scholar] [CrossRef]
- Diggle, P.J. Statistical Analysis of Spatial Point Pattern; Academic Press: Cambridge, MA, USA, 1983. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction | ‘Mineralized’ | ‘Non-Mineralized’ |
|---|---|---|
| Known | ||
| ‘Mineralized’ | TP | FN |
| ‘Non-mineralized’ | FP | TN |
| Total | TP+FP | FN+TN |
| Metallogenic Factor | Description | |
|---|---|---|
| Regional geological background | Tectonic environment | The north-east fault is the main tectonic line in the region. The crustal uplift and depression transitional zone to the north of the Darabut fault shows evidence of intense magmatic and volcanic activities and is the main ore-forming material source of Au deposits. |
| Intrusive rocks | Intermediate-acid intrusive rocks are closely spatially related to mineral deposits. | |
| Ore-bearing strata | The vast majority of Au deposits are located in the Tailegula and Baogutu Formations of the upper Carboniferous in the Paleozoic. | |
| Ore-forming epoch | Middle and late Variscan age | |
| Wallrock alteration | Common forms of wallrock alteration include silicification, pyritization, arsenpyritization, and sericitization. | |
| Regional geochemical field | The geochemistry of this region is dominated by Au anomalies. High concentrations of Au exist distributed between Toli and Karamay, with clear concentration centers and zoning. | |
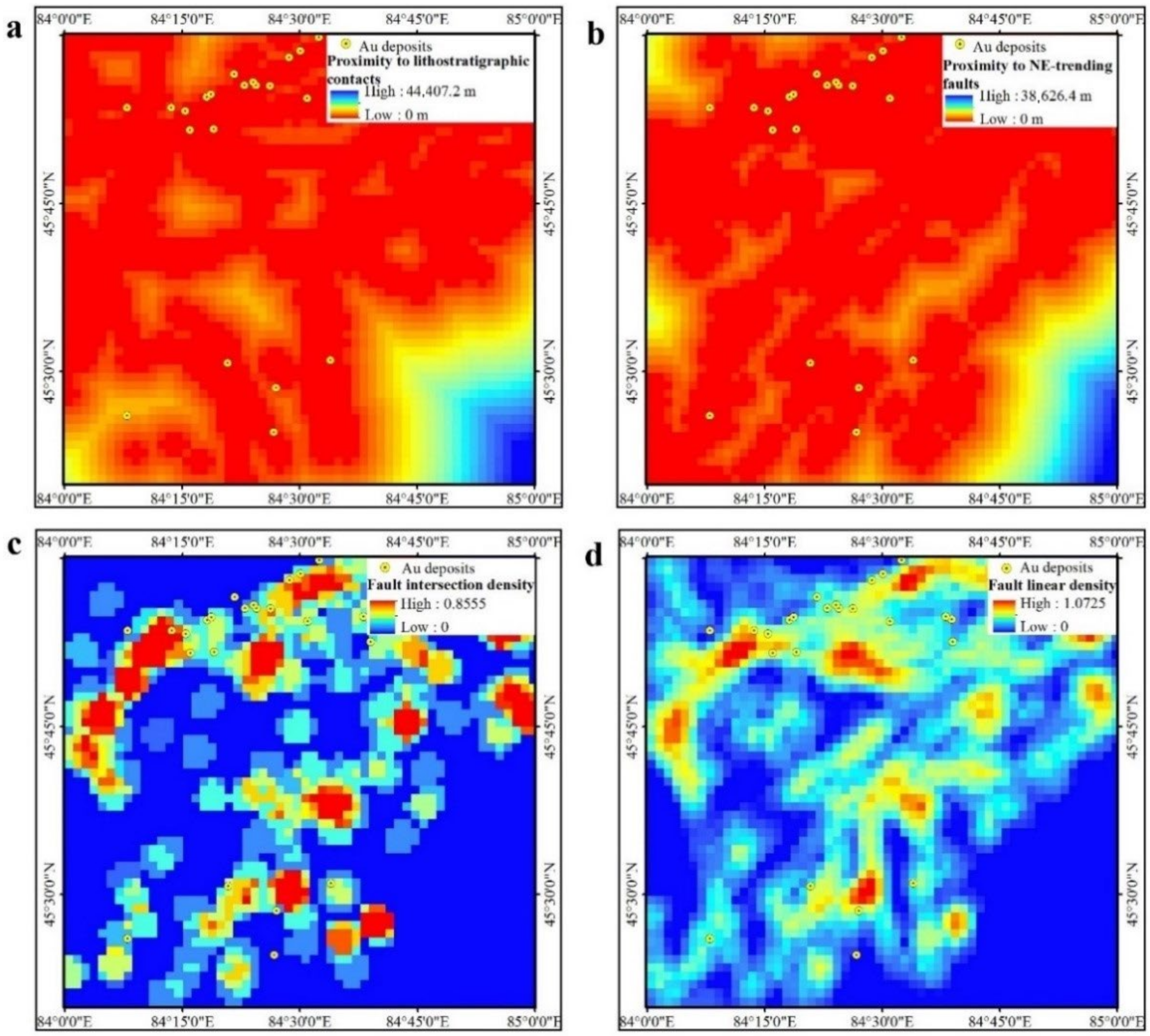
| Criteria | Evidence Layer | Relevance |
|---|---|---|
| Geology | Proximity to lithostratigraphic contacts | The ore-forming elements migrate to the lithostratigraphic contacts and accumulate, resulting in precipitation, enrichment, and mineralization. |
| Proximity to NE-trending faults | The region’s main tectonic line runs NE and provides the driving force, the migration channel, and the depositing space for the mineral flow. | |
| Fault intersection density | Fault density reflects the location of frequent magma and hydrothermal activity, and the frequent superimposition of ore-forming elements. | |
| Fault linear density | ||
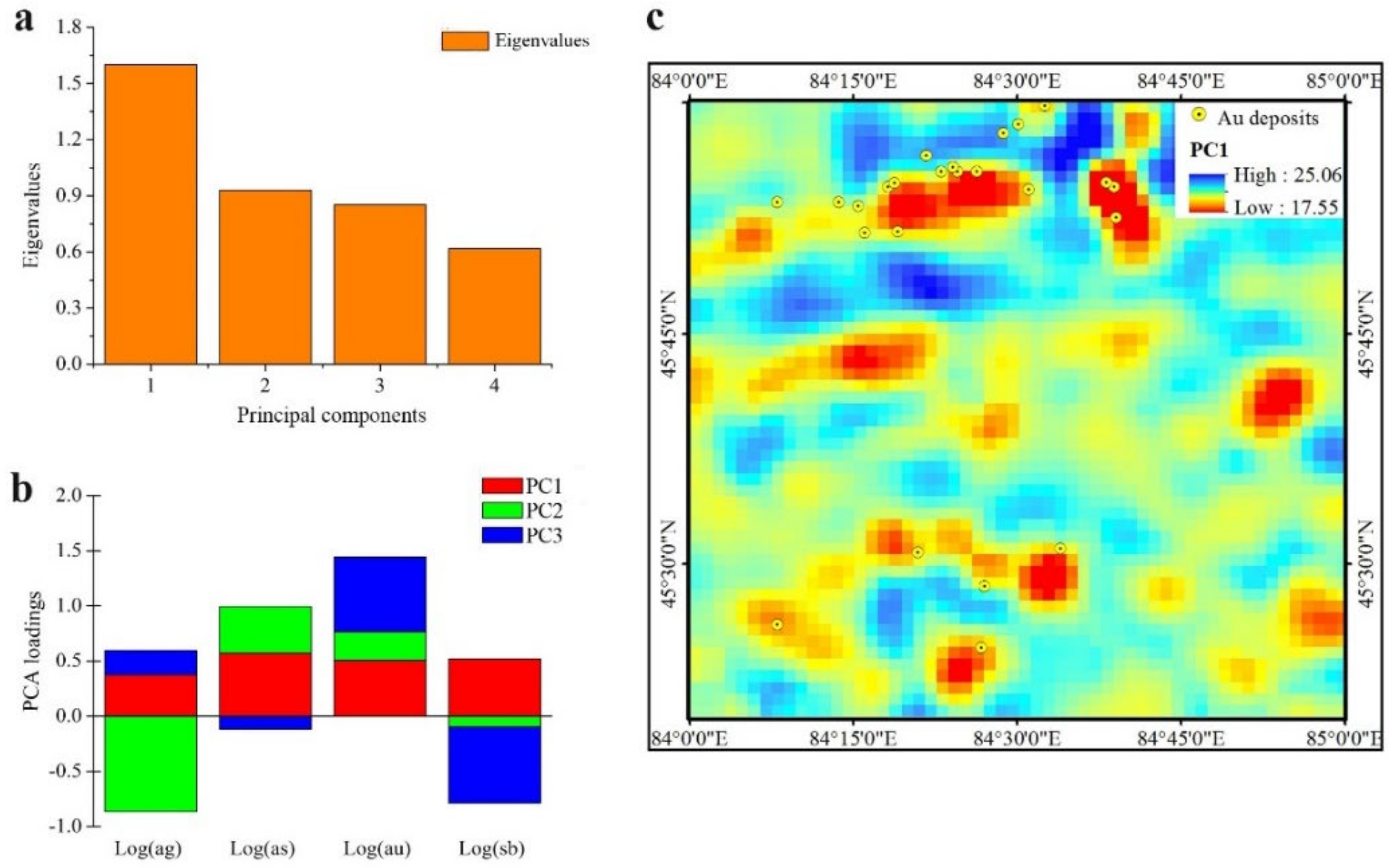
| Geochemistry | PC1 scores generated by singularity indices of ore-forming elements | Ag, As, Au, and Sb are present in high concentrations above ore bodies. These elements can be used to differentiate provenance characteristics, understand the migration and evolution patterns of elements, and distinguish geochemical anomalies. |
| Parameter | Description | Value |
|---|---|---|
| maxpop | Maximum number of population | 50 |
| maxgen | Maximum number of Generation | 200 |
| C | The penalty parameter of SVM | 0–100 |
| The kernel parameter of RBF for SVM | 0–100 | |
| k | k-fold cross-validation | 6 |
| Parameters | Training Dataset 1 | Training Dataset 2 | Training Dataset 3 | Training Dataset 4 |
|---|---|---|---|---|
| 0.0947 | 93.0015 | 0.1940 | 50.5152 | |
| Best C | 2.3241 | 2.1234 | 0.0547 | 1.2698 |
| Accuracy | 83.33% | 75% | 77.08% | 75% |
| Known | Training Dataset 1 | Training Dataset 2 | Training Dataset 3 | Training Dataset 4 | ||||
|---|---|---|---|---|---|---|---|---|
| Prediction | A | B | A | B | A | B | A | B |
| A | 18 | 2 | 22 | 2 | 18 | 4 | 23 | 5 |
| B | 6 | 22 | 2 | 22 | 6 | 20 | 1 | 19 |
| Precision | 0.75 | 0.92 | 0.75 | 0.96 | ||||
| Recall | 0.9 | 0.92 | 0.82 | 0.82 | ||||
| F1 | 0.82 | 0.92 | 0.78 | 0.88 | ||||
| Training Dataset 1 | Training Dataset 2 | Training Dataset 3 | Training Dataset 4 | |
|---|---|---|---|---|
| Number of known deposits | 18 | 22 | 18 | 23 |
| Prospective area (%) | 25.24% | 43.56% | 25.13% | 35.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Zhou, K.; Cui, Y.; Wang, J.; Zhou, S. Mapping Mineral Prospectivity Using a Hybrid Genetic Algorithm–Support Vector Machine (GA–SVM) Model. ISPRS Int. J. Geo-Inf. 2021, 10, 766. https://doi.org/10.3390/ijgi10110766
Du X, Zhou K, Cui Y, Wang J, Zhou S. Mapping Mineral Prospectivity Using a Hybrid Genetic Algorithm–Support Vector Machine (GA–SVM) Model. ISPRS International Journal of Geo-Information. 2021; 10(11):766. https://doi.org/10.3390/ijgi10110766
Chicago/Turabian StyleDu, Xishihui, Kefa Zhou, Yao Cui, Jinlin Wang, and Shuguang Zhou. 2021. "Mapping Mineral Prospectivity Using a Hybrid Genetic Algorithm–Support Vector Machine (GA–SVM) Model" ISPRS International Journal of Geo-Information 10, no. 11: 766. https://doi.org/10.3390/ijgi10110766
APA StyleDu, X., Zhou, K., Cui, Y., Wang, J., & Zhou, S. (2021). Mapping Mineral Prospectivity Using a Hybrid Genetic Algorithm–Support Vector Machine (GA–SVM) Model. ISPRS International Journal of Geo-Information, 10(11), 766. https://doi.org/10.3390/ijgi10110766