
Machine Learning Methods Applied to the Prediction of Pseudo-nitzschia spp. Blooms in the Galician Rias Baixas (NW Spain)

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
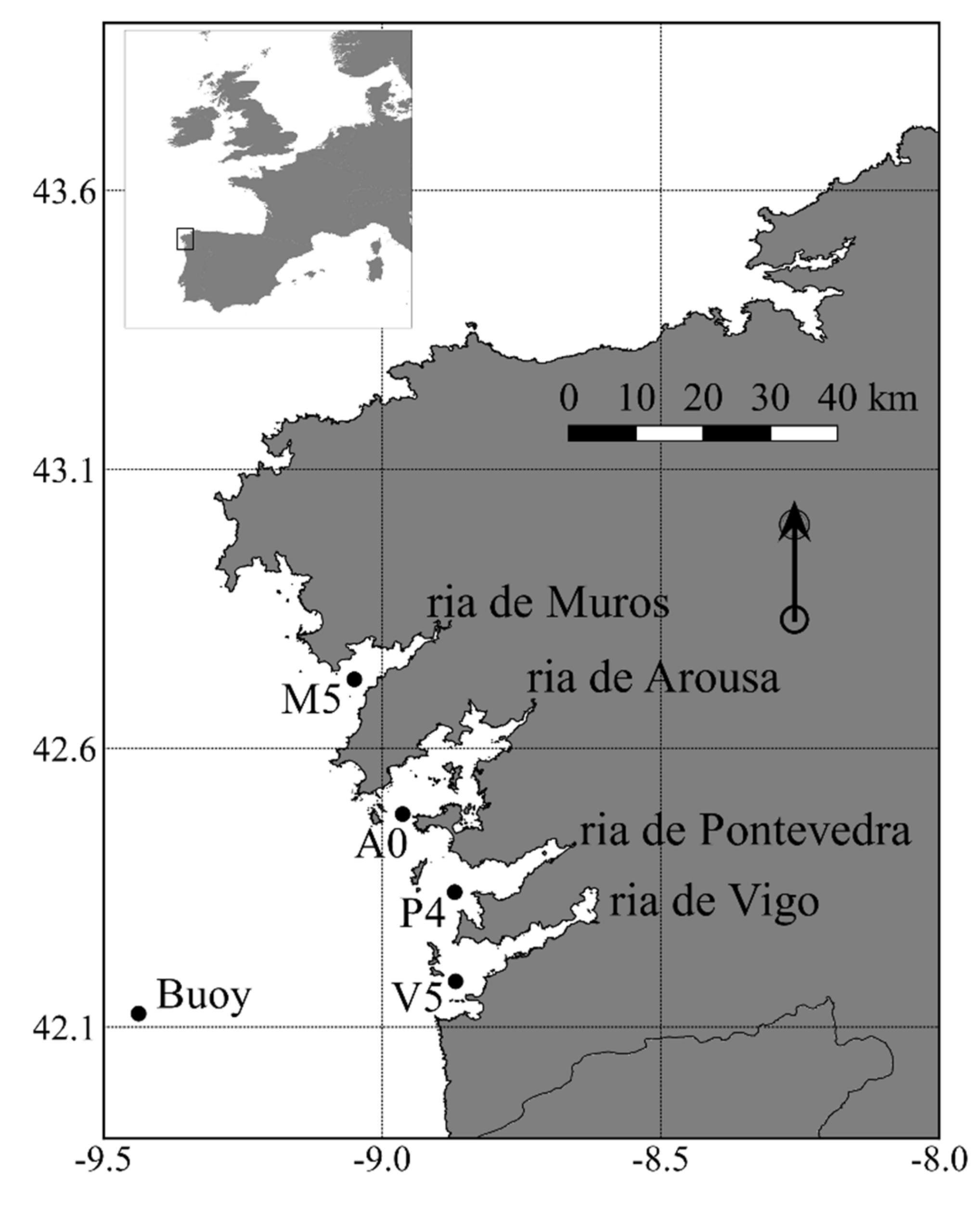
2.1. Study Area
2.2. Dataset
2.3. Model Selection
2.4. Performance Measurements
2.5. Machine Learning Methods
2.5.1. Support Vector Machines (SVM)
2.5.2. Multilayer Perceptron (MLP)
- Number of hidden layers in the neural network: from 1 to 10.
- Number of iterations in the backpropagation algorithm: 50, 100, 500, 1000, 1500 and 2000.
- Lambda regularization factor: 0.00001, 0.00005, 0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, and 1.
2.5.3. Random Forest (RF)
- Number of bags for bootstrapping: 30, 40, 50, 60, 70, 80, 100, 200, 300, 400, 500 and 1000.
- Number of weak predictors selected as subset for each tree: between 2 and 4.
2.5.4. AdaBoost
- Type of boosting variant: GentleBoost, AdaBoostM1 and RUSBoost.
- Number of cycles (parameter directly related to the number of weak classifiers): 10, 50, 100, 150, 200, 500, 1000 and 2000.
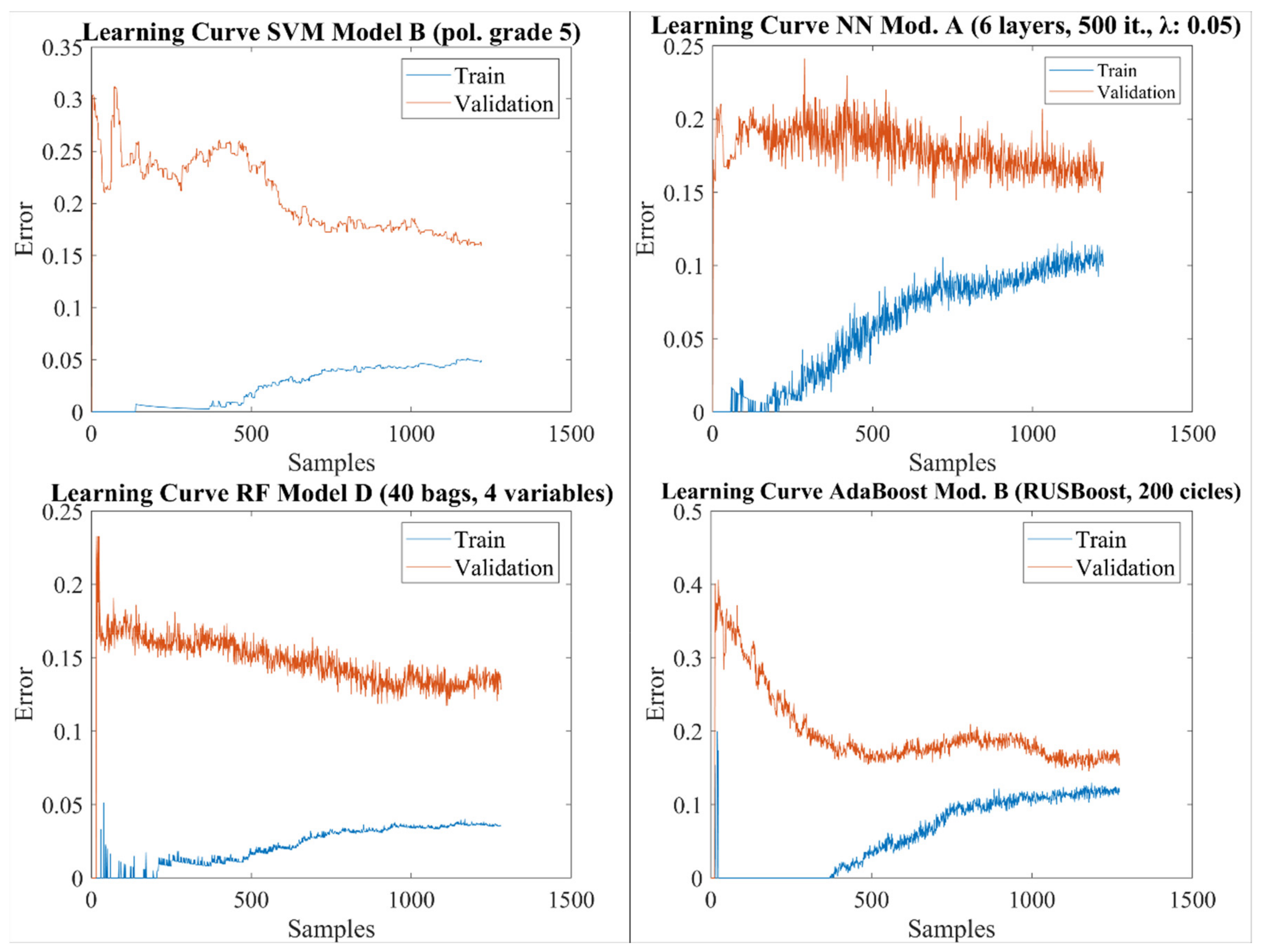
2.6. Learning Curves
3. Results
3.1. Observations
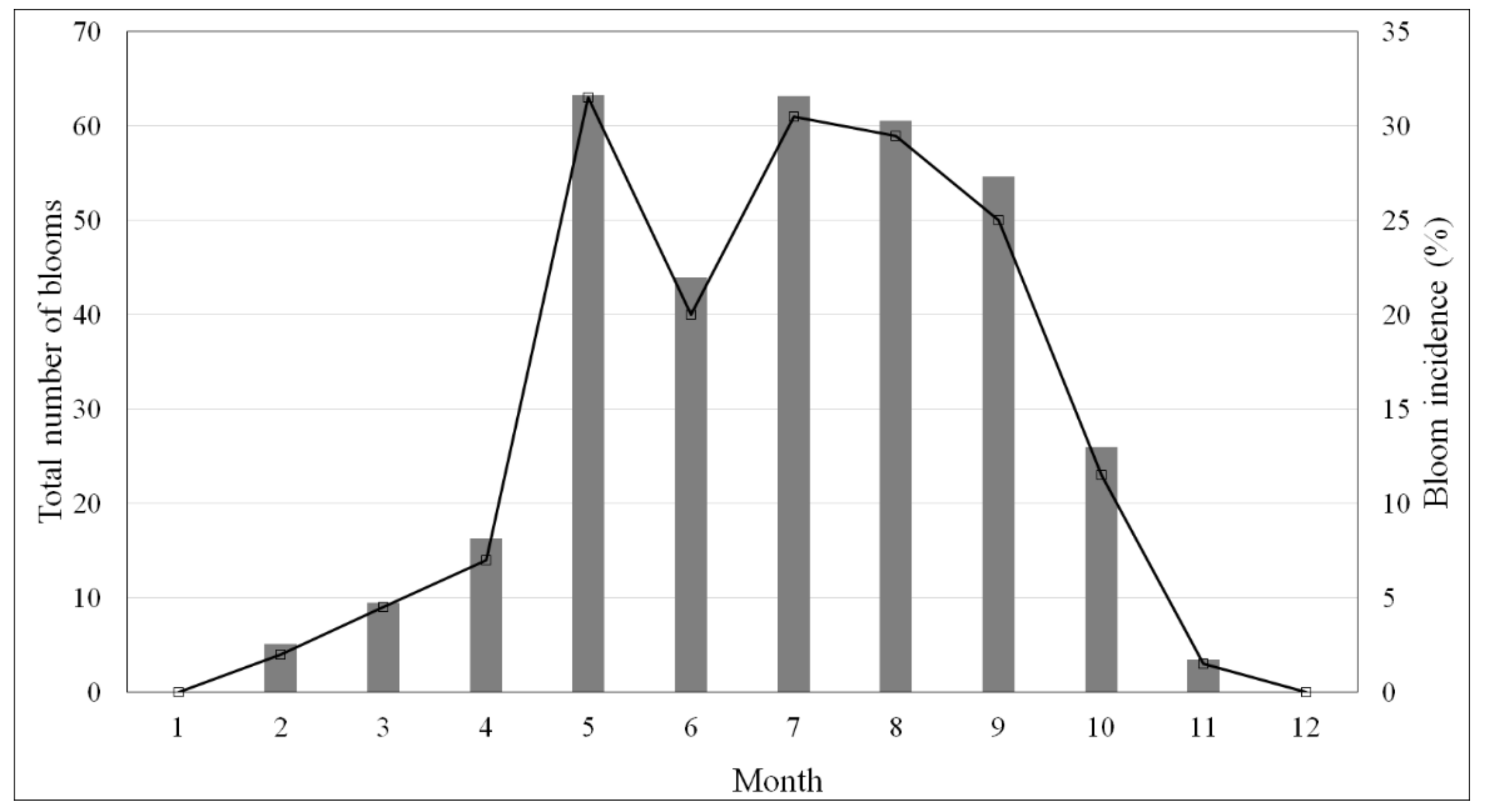
3.1.1. Pseudo-nitzschia Spp. Distribution
3.1.2. Input Variables
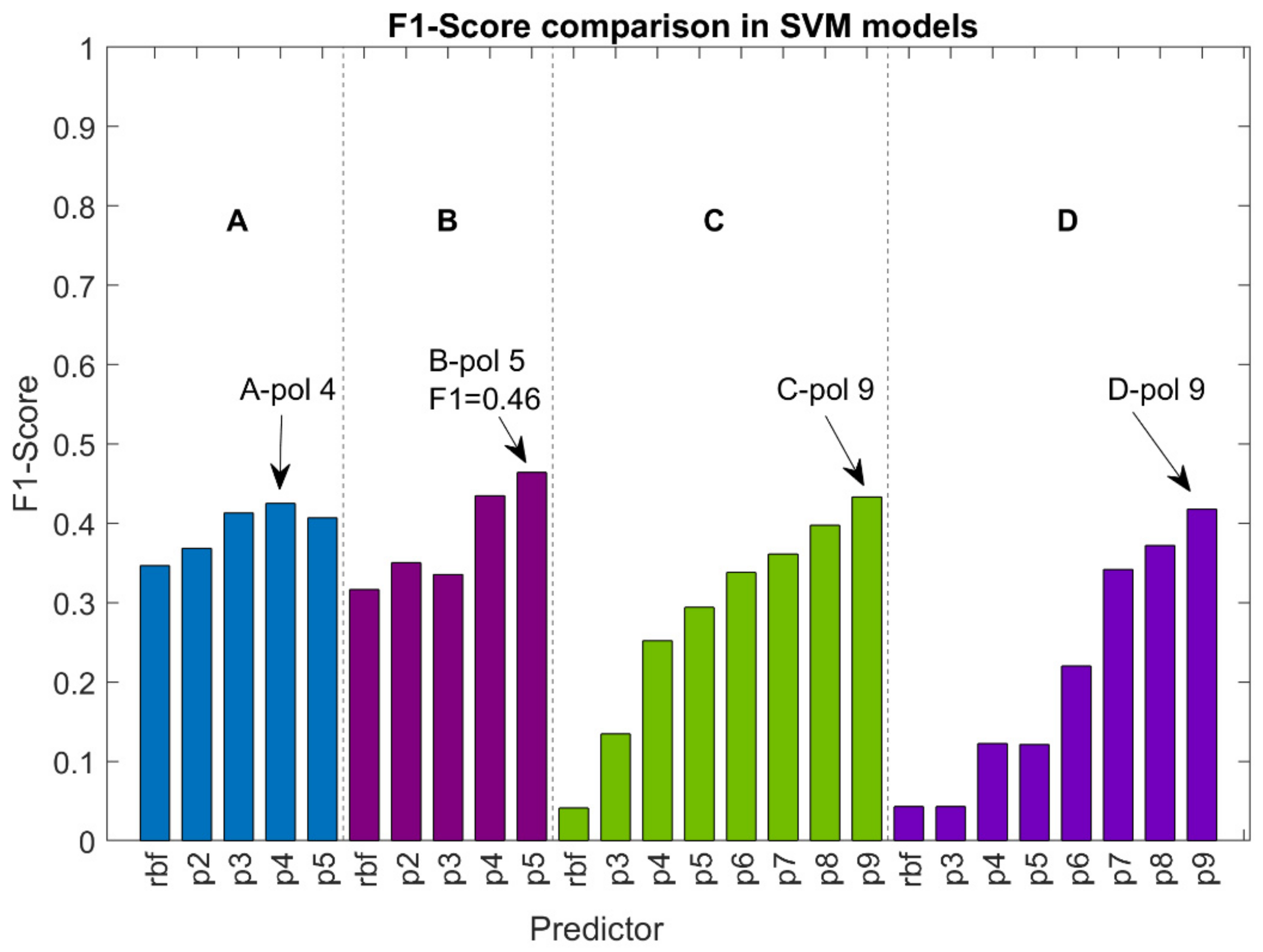
3.2. Support Vector Machines (SVM)
3.3. Neural Networks (NN)
3.4. Random Forest (RF)
3.5. AdaBoost
4. Discussion
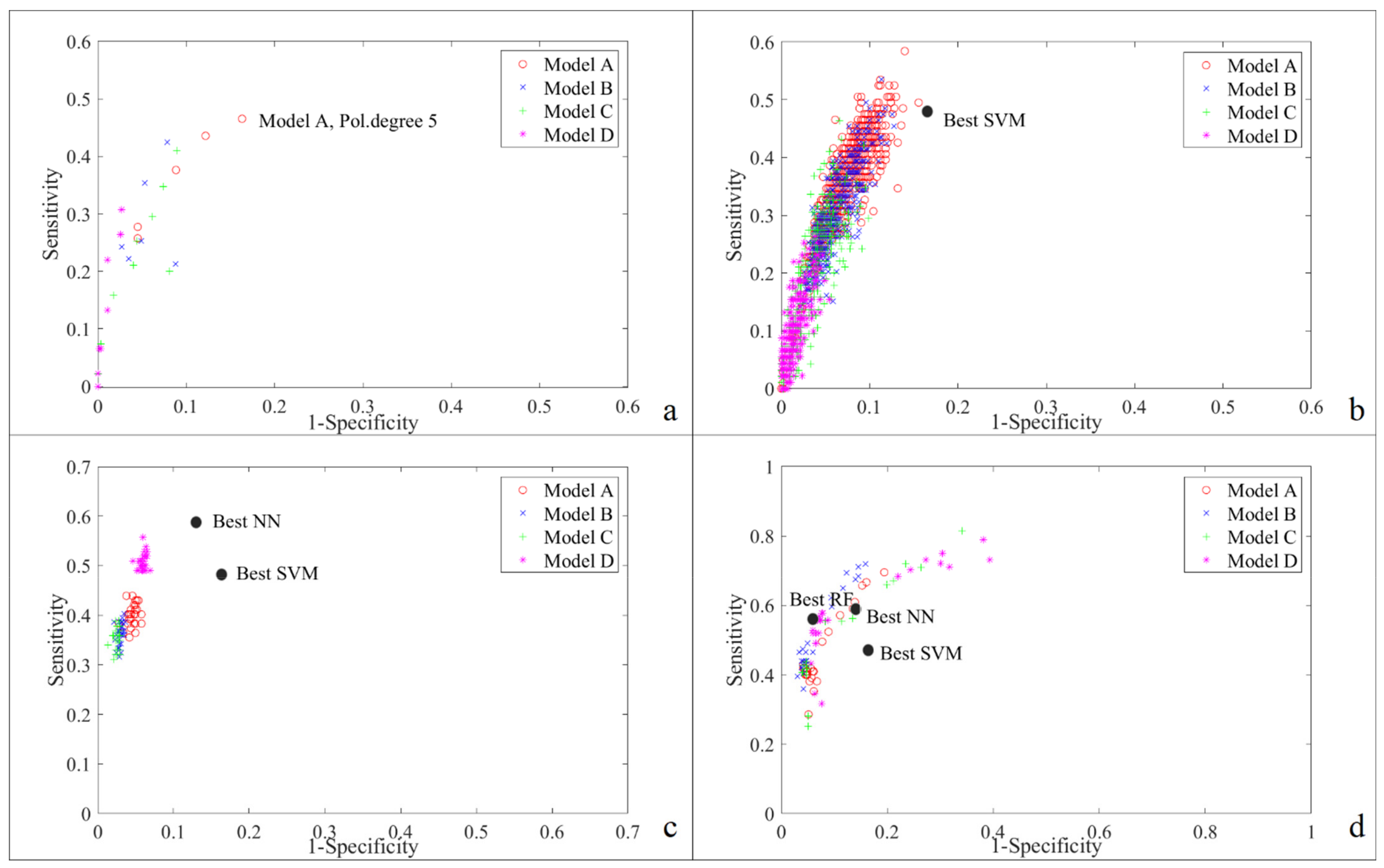
4.1. Models’ Performance
4.2. Variable Contribution
4.3. Comparison with Other Works
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gobler, C.J.; Doherty, O.M.; Hattenrath-Lehmann, T.K.; Griffith, A.W.; Kang, Y.; Litaker, R.W. Ocean warming since 1982 has expanded the niche of toxic algal blooms in the North Atlantic and North Pacific oceans. Proc. Natl. Acad. Sci. USA 2017, 114, 4975–4980. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Griffith, A.W.; Gobler, C.J. Harmful algal blooms: A climate change co-stressor in marine and freshwater ecosystems. Harmful Algae 2020, 91, 101590. [Google Scholar] [CrossRef] [PubMed]
- Anderson, D.; Cembella, A.; Hallegraeff, G. Progress in understanding harmful algal blooms: Paradigm shifts and new technologies for research, monitoring, and management. Ann. Rev. Mar. Sci. 2012, 4, 143–176. [Google Scholar] [CrossRef] [Green Version]
- Anderson, D.M. Approaches to monitoring, control and management of harmful algal blooms (HABs). Ocean Coast Manag. 2009, 52, 342. [Google Scholar] [CrossRef] [Green Version]
- Anderson, C.R.; Moore, S.K.; Tomlinson, M.C.; Silke, J.; Cusack, C.K. Living with harmful algal blooms in a changing world: Strategies for modeling and mitigating their effects in coastal marine ecosystems. In Coastal and Marine Hazards, Risks, and Disasters; Shroeder, J.F., Ellis, J.T., Sherman, D.J., Eds.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 495–561. [Google Scholar]
- Anderson, C.R.; Mathew Sapiano, R.P.; Krishna Prasad, M.B.; Long, W.; Tango, P.J.; Brown, C.W.; Murtugudde, R. Predicting potentially toxigenic Pseudo-nitzschia blooms in the Chesapeake Bay. J. Mar. Syst. 2010, 83, 127–140. [Google Scholar] [CrossRef]
- Manning, N.F.; Wang, Y.-C.; Long, C.M.; Bertani, I.M.; Sayers, J.; Bosse, K.R.; Shuchman, R.A.; Scavia, D. Extending the forecast model: Predicting Western Lake Erie harmful algal blooms at multiple spatial scales. J. Great Lakes Res. 2019, 45, 587–595. [Google Scholar] [CrossRef]
- Lane, J.; Raimondi, P.T.; Kudela, R.M. Development of a logistic regression model for the prediction of toxigenic Pseudo-nitzschia blooms in Monterey Bay, California. Mar. Ecol. Prog. Ser. 2009, 383, 37–51. [Google Scholar] [CrossRef] [Green Version]
- Raine, R.; McDermott, G.; Silke, J.; Lyons, K.; Nolan, G.; Cusack, C. A simple short range model for the prediction of harmful algal events in the bays of southwestern Ireland. J. Mar. Syst. 2010, 83, 150–157. [Google Scholar] [CrossRef]
- Volf, G.; Atanasova, N.; Kompare, B.; Precali, R.; Ožanić, N. Descriptive and prediction models of phytoplankton in the northern Adriatic. Ecol. Model. 2011, 222, 2502–2511. [Google Scholar] [CrossRef]
- McGowan, J.A.; Deyle, E.R.; Ye, H.; Carter, M.L.; Perretti, C.T.; Seger, K.D.; de Verneil, A.; Sugihara, G. Predicting coastal algal blooms in southern California. Ecology 2017, 98, 1419–1433. [Google Scholar] [CrossRef] [Green Version]
- Derot, J.; Yajima, H.; Jacquet, S. Advances in forecasting harmful algal blooms using machine learning models: A case study with Planktothrix rubescens in Lake Geneva. Harmful Algae 2020, 99, 101906. [Google Scholar] [CrossRef]
- Huettmann, F.; Craig, E.H.; Herrick, K.A.; Baltensperger, A.P.; Humphries, G.R.W.; Lieske, D.J.; Miller, K.; Mullet, T.C.; Oppel, S.; Resendiz, C.; et al. Use of machine learning (ML) for predicting and analyzing ecological and ‘presence only’ data: An overview of applications and a good outlook. In Machine Learning for Ecology and Sustainable Natural Resource Management; Humphries, G., Magness, D.R., Huettmann, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 27–61. [Google Scholar]
- Ralston, R.; Moore, S.K. Modeling harmful algal blooms in a changing climate. Harmful Algae 2020, 91, 101729. [Google Scholar] [CrossRef]
- Rousso, B.Z.; Bertone, E.; Stewart, R.; Hamilton, D.P. A systematic literature review of forecasting and predictive models for cyanobacteria blooms in freshwater lakes. Water Res. 2020, 182, 115959. [Google Scholar] [CrossRef]
- Yu, P.; Gao, R.; Zhang, D.; Liu, Z.-P. Predicting coastal algal blooms with environmental factors by machine learning methods. Ecol. Indic. 2021, 123, 107334. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; Association for Computing Machinery: New York, NY, USA, 1992. [Google Scholar]
- Vapnik, V. The Support Vector method of function estimation. In Nonlinear Modeling; Suykens, J.A.K., Vandewalle, J., Eds.; Springer: Boston, MA, USA, 1998; pp. 55–85. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2000. [Google Scholar]
- González Vilas, L.; Spyrakos, E.; Torres Palenzuela, J.M.; Pazos, Y. Support Vector Machine-based method for predicting Pseudo-nitzschia spp. blooms in coastal waters (Galician rias, NW Spain). Prog. Oceanogr. 2014, 124, 66–77. [Google Scholar] [CrossRef]
- Chen, S.; Xie, Z.; Lou, I.; Ung, W.K.; Mok, K.M. Freshwater Algal Bloom Prediction by Support Vector Machine in Macau Storage Reservoirs. Math. Probl. Eng. 2012, 2012, 397473. [Google Scholar]
- García Nieto, P.J.; Alonso Fernández, J.R.; González Suárez, V.M.; Díaz Muñiz, C.; García-Gonzalo, E.; Mayo Bayón, R. A hybrid PSO optimized SVM-based method for predicting of the cyanotoxin content from experimental cyanobacteria concentrations in the Trasona reservoir: A case study in Northern Spain. Appl. Math. Comput. 2015, 260, 170–187. [Google Scholar]
- Ribeiro, R.; Torgo, L. A comparative study on predicting algae blooms in Douro River, Portugal. Ecol. Model. 2008, 212, 86–91. [Google Scholar] [CrossRef] [Green Version]
- Lou, I.; Xie, Z.; Ung, W.K.; Mok, K.M. Integrating support vector regression with particle swarm optimization for numerical modeling for algal blooms of freshwater. Appl. Math. Model. 2015, 39, 5907–5916. [Google Scholar] [CrossRef]
- Shen, J.; Qin, Q.; Wang, Y.; Sisson, M. A data-driven modeling approach for simulating algal blooms in the tidal freshwater of James River in response to riverine nutrient loading. Ecol. Model. 2019, 398, 44–54. [Google Scholar] [CrossRef] [Green Version]
- Bourel, M.; Crisci, C.; Martínez, A. Consensus methods based on machine learning techniques for marine phytoplankton presence–absence prediction. Ecol. Inf. 2017, 42, 46–54. [Google Scholar] [CrossRef]
- Gokaraju, B.; Durbha, S.S.; King, R.L.; Younan, N.H. A machine learning based spatio-temporal data mining approach for detection of harmful algal blooms in the Gulf of Mexico. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 710–720. [Google Scholar] [CrossRef]
- Hill, P.R.; Kumar, A.; Temimi, M.; Bull, D.R. HABNet: Machine Learning, Remote Sensing-Based Detection of Harmful Algal Blooms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3229–3239. [Google Scholar] [CrossRef]
- Li, X.; Yu, J.; Jia, Z.; Song, J. Harmful algal blooms prediction with machine learning models in Tolo Harbour. In Proceedings of the International Conference on Smart Computing, Hong Kong, China, 3–5 November 2014; IEEE Computer Society: Washington, DC, USA, 2015; pp. 245–250. [Google Scholar]
- Lek, S.; Delacoste, M.; Baran, P.; Lauga, J.; Aulagnier, S. Application of neural network for nonlinear modeling in ecology. Ecol. Model. 1996, 90, 39–52. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biol. 1990, 52, 99–115. [Google Scholar] [CrossRef]
- Recknagel, F.; Bobbin, J.; Whigham, P.; Wilson, H. Comparative application of artificial neural networks and genetic algorithms for multivariate time-series modelling of algal blooms in freshwater lakes. J. Hydroinform. 2002, 4, 125–133. [Google Scholar] [CrossRef] [Green Version]
- Wei, B.; Sugiura, N.; Maekawa, T. Use of artificial neural network in the prediction of algal blooms. Water Res. 2001, 35, 2022–2028. [Google Scholar] [CrossRef]
- Xiao, X.; He, J.; Huang, H.; Miller, T.R.; Christakos, G.; Reichwaldt, E.S.; Ghadouani, A.; Lin, S.; Xu, X.; Shi, J. A novel single-parameter approach for forecasting algal blooms. Water Res. 2017, 108, 222–231. [Google Scholar] [CrossRef]
- Brown, C.W.; Hood, R.R.; Long, W.; Jacobs, J.; Ramers, D.; Wazniak, C.; Wiggert, J.; Wood, R.; Xu, J. Ecological forecasting in Chesapeake Bay: Using a mechanistic–empirical modeling approach. J. Mar. Syst. 2013, 125, 113–125. [Google Scholar] [CrossRef]
- Guallar, C.; Delgado, M.; Diogène, J.; Fernández-Tejedor, M. Artificial neural network approach to population dynamics of harmful algal blooms in Alfacs Bay (NW Mediterranean): Case studies of Karlodinium and Pseudo-nitzschia. Ecol. Model. 2016, 338, 37–50. [Google Scholar] [CrossRef]
- Lee, J.H.W.; Huang, Y.; Dickman, M.; Jayawardena, A.W. Neural network modelling of coastal algal blooms. Ecol. Model. 2003, 159, 179–201. [Google Scholar] [CrossRef]
- Velo-Suarez, L.; Gutierrez-Estrada, J.C. Artificial neural network approaches to one-step weekly prediction of Dinophysis acuminata blooms in Huelva (Western Andalucia, Spain). Harmful Algae 2007, 6, 361–371. [Google Scholar] [CrossRef]
- Coad, P.; Cathers, B.; Ball, J.E.; Kadluczka, R. Proactive management of estuarine algal blooms using an automated monitoring buoy coupled with an artificial neural network. Environ. Model. Softw. 2014, 61, 393–409. [Google Scholar] [CrossRef]
- Tian, W.; Liao, Z.; Zhang, J. An optimization of artificial neural network model for predicting chlorophyll dynamics. Ecol. Model. 2017, 364, 42–52. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wu, H. Water bloom warning model based on random forest. In Proceedings of the 2017 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 24–26 November 2017; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2018; pp. 45–48. [Google Scholar]
- Evans, J.S.; Murphy, M.A.; Holden, Z.A.; Cushman, S.A. Modeling Species Distribution and Change Using Random Forest. In Predictive Species and Habitat Modeling in Landscape Ecology; Drew, C., Wiersma, Y., Huettmann, F., Eds.; Springer: New York, NY, USA, 2011; pp. 139–159. [Google Scholar]
- Wei, C.L.; Rowe, G.T.; Escobar-Briones, E.; Boetius, A.; Soltwedel, T.; Caley, M.J.; Soliman, Y.; Huettmann, F.; Qu, F.; Yu, Z.; et al. Global Patterns and Predictions of Seafloor Biomass Using Random Forests. PLoS ONE 2010, 5, 15323. [Google Scholar] [CrossRef] [PubMed]
- Derot, J.; Yajima, H.; Schmitt, J. Benefits of machine learning and sampling frequency on phytoplankton bloom forecasts in coastal areas. Ecol. Inf. 2020, 60, 101174. [Google Scholar] [CrossRef]
- Harley, J.R.; Lanphier, K.; Kennedy, E.; Whitehead, C.; Bidlack, J.R. Random forest classification to determine environmental drivers and forecast paralytic shellfish toxins in Southeast Alaska with high temporal resolution. Harmful Algae 2020, 99, 101918. [Google Scholar] [CrossRef]
- Valbi, E.; Ricci, F.; Capellacci, S.; Casabianca, S.; Scardi, M.; Penna, A. A model predicting the PSP toxic dinoflagellate Alexandrium minutum occurrence in the coastal waters of the NW Adriatic Sea. Sci. Rep. 2019, 9, 4166. [Google Scholar] [CrossRef] [Green Version]
- Yñiguez, A.T.; Ottong, Z.J. Predicting fish kills and toxic blooms in an intensive mariculture site in the Philippines using a machine learning model. Sci. Total Environ. 2020, 707, 136173. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Kadavi, P.R.; Lee, C.-W.; Lee, S. Application of Ensemble-Based Machine Learning Models to Landslide Susceptibility Mapping. Remote Sens. 2018, 10, 1252. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Liu, K.; Cao, J.; Zhu, Y.; Li, F.; Liu, L. Combining GF-2 and RapidEye satellite data for mapping mangrove species using ensemble machine-learning methods. Int. J. Remote Sens. 2020, 41, 813–838. [Google Scholar] [CrossRef]
- Tran, T.; Hoang, N. Predicting algal appearance on mortar surface with ensembles of adaptive neuro fuzzy models: A comparative study of ensemble strategies. Int. J. Mach. Learn. Cyber. 2019, 10, 1687–1704. [Google Scholar] [CrossRef]
- Stumpf, R.P.; Tomlinson, M.C.; Calkins, J.A.; Kirkpatrick, B.; Fisher, K.; Nierenberg, K.; Currier, R.; Wynne, T.T. Skill assessment for an operational algal bloom forecast system. J. Mar. Syst. 2009, 76, 151–161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hallegraeff, G.M. Harmful Algal Blooms: A global overview. In Manual on Harmful Marine Microalgae; Hallegraeff, G.M., Anderson, D.M., Cembella, E.D., Eds.; UNESCO: Paris, France, 2004; Volume 33, pp. 25–80. [Google Scholar]
- Bates, S.S.; Garrison, D.L.; Horner, R.A. Bloom dynamics and physiology of domoic-acid-producing Pseudo-nitzschia species. In The Physiological Ecology of Harmful Algal Blooms; Anderson, D.M., Cembella, E.D., Hallegraeff, G.M., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 267–292. [Google Scholar]
- Anderson, C.R.; Brzezinski, M.A.; Washburn, L.; Kudela, R. Circulation and environmental conditions during a toxigenic Pseudo-nitzschia australis bloom in the Santa Barbara Channel, California. Mar. Ecol. Prog. Ser. 2006, 327, 119–133. [Google Scholar] [CrossRef]
- Fraga, S.; Alvarez, M.J.; Míguez, A.; Fernández, M.L.; Costas, E.; Lopez-Rodas, V. Pseudo-nitzschia species isolated from Galician waters: Toxicity, DNA content and lectin binding assay. In Harmful Algae; Reguera, B., Blanco, B., Fernández, M.L., Wyatt, T., Eds.; Xunta de Galicia and Intergovernmental Commission of UNESCO: Santiago de Compostela, Spain, 1998; pp. 270–273. [Google Scholar]
- Palma, S.; Mouriño, H.; Silva, A.; Barao, M.; Moita, M.T. Can Pseudo-nitzschia blooms be modeled by coastal upwelling in Lisbon Bay? Harmful Algae 2010, 9, 294–303. [Google Scholar] [CrossRef]
- Louw, D.C.; Doucette, G.J.; Lundholm, N. Morphology and toxicity of Pseudo-nitzschia species in the northern Benguela Upwelling System. Harmful Algae 2018, 75, 118–128. [Google Scholar] [CrossRef] [PubMed]
- Blum, I.; Rao, D.S.; YouLian, P.; Swaminathan, S.; Adams, N.G.; Subba Rao, D.V. Development of statistical models for prediction of the neurotoxin domoic acid levels in the pennate diatom Pseudo-nitzschia pungens f. multiseries utilizing data from cultures and natural blooms. In Algal Cultures, Analogues of Blooms and Applications; Subba Rao, D.V., Ed.; Science Publishers: Enfield, CT, USA, 2006; Volume 2, pp. 891–916. [Google Scholar]
- Anderson, C.R.; Seigel, D.A.; Kudela, R.; Brzezinski, M.A. Empirical models of toxigenic Pseudo-nitzschia blooms: Potential use as a remote detection tool in the Santa Barbara Channel. Harmful Algae 2009, 8, 478–492. [Google Scholar] [CrossRef]
- Terseleer, N.; Gypens, N.; Lancelot, C. Factors controlling the production of domoic acid by Pseudo-nitzschia (Bacillariophyceae): A model study. Harmful Algae 2013, 24, 45–53. [Google Scholar] [CrossRef]
- Sacau-Cuadrado, M.; Conde-Pardo, P.; Otero-Tranchero, P. Forecast of red tides off the Galician coast. Acta Astronaut. 2003, 53, 439–443. [Google Scholar] [CrossRef]
- Cusack, C.; Mouriño, H.; Moita, M.T.; Silke, J. Modelling Pseudo-nitzschia events off southwest Ireland. J. Sea Res. 2015, 105, 30–41. [Google Scholar] [CrossRef]
- Cusack, C.; Dabrowski, T.; Lyons, K.; Berry, A.; Westbrook, G.; Salas, R.; Duffy, C.; Nolan, G.; Silke, J. Harmful algal bloom forecast system for SW Ireland. Part II: Are operational oceanographic models useful in a HAB warning system. Harmful Algae 2016, 53, 86–101. [Google Scholar] [CrossRef]
- Giddings, S.N.; MacCready, P.; Hickey, B.M.; Banas, N.S.; Davis, K.A.; Siedlecki, S.A.; Trainer, V.L.; Kudela, R.M.; Pelland, N.A.; Connolly, T.P. Hindcasts of potential harmful algal bloom transport pathways on the Pacific Northwest coast. J. Geophys. Res. Ocean. 2014, 119, 2439–2461. [Google Scholar] [CrossRef]
- Townhill, B.L.; Tinker, J.; Jones, M.; Pitois, S.; Creach, V.; Simpson, S.D.; Dye, S.; Bear, E.; Pinnegar, J.K. Harmful algal blooms and climate change: Exploring future distribution changes. Ices J. Mar. Sci. 2018, 75, 1882–1893. [Google Scholar] [CrossRef] [Green Version]
- Wooster, W.S.; Bakun, A.; McLain, D.R. The seasonal upwelling cycle along the Eastern boundary of the North Atlantic. J. Mar. Res. 1976, 34, 131–141. [Google Scholar]
- Fraga, F. Upwelling off the Galician coast, northwest Spain. In Coastal Upwelling; Richardson, F.A., Ed.; American Geophysical Union: Washington, DC, USA, 1981; pp. 176–182. [Google Scholar]
- Blanton, J.O.; Tenore, K.R.; Castillejo, F.F.; Atkinson, L.P.; Schwing, F.B.; Lavín, A. The relationship of upwelling to mussel production in the rías of western coast of Spain. J. Mar. Res. 1987, 45, 497–511. [Google Scholar] [CrossRef] [Green Version]
- Bode, A.; Varela, M.; Barquero, S.; Ossorio-Alvarez, M.; Gonzalez, N. Preliminary Studies on the Export of Organic Matter During Phytoplankton Blooms off La Coruña (Northwestern Spain). J. Mar. Biol. Assoc. UK 1998, 78, 1–15. [Google Scholar] [CrossRef]
- Labarta, U.; Fernández-Reiriz, M.J. The Galician mussel industry: Innovation and changes in the last forty years. Ocean Coast. Manag. 2019, 167, 208–218. [Google Scholar] [CrossRef]
- Avdelas, L.; Avdic-Mravlje, E.; Borges Marques, A.C.; Cano, S.; Capelle, J.J.; Carvalho, N.; Cozzolino, M.; Dennis, J.; Ellis, T.; Fernández Polanco, J.M.; et al. The decline of mussel aquaculture in the European Union: Causes, economic impacts and opportunities. Rev. Aquacult. 2021, 13, 91–118. [Google Scholar] [CrossRef]
- Spyrakos, E.; González Vilas, L.; Torres Palenzuela, J.M.; Barton, E.D. Remote sensing chlorophyll a of optically complex waters (rias Baixas, NW Spain): Application of a regionally specific chlorophyll an algorithm for MERIS full resolution data during an upwelling cycle. Remote Sens. Environ. 2011, 115, 2471–2485. [Google Scholar] [CrossRef] [Green Version]
- Margalef, R. Estructura y dinámica de la “purga de mar” en Ría de Vigo. Investig. Pesq. 1956, 5, 113–134. [Google Scholar]
- Tilstone, G.H.; Figueiras, F.G.; Fraga, F. Upwelling-Downwelling Sequences in the Generation of Red Tides in a Coastal Upwelling System. Mar Ecol. Progr. Ser. 1994, 112, 241–253. [Google Scholar] [CrossRef]
- Figueiras, F.G.; Jones, K.J.; Mosquera, A.M.; Alvarez-Salgado, X.A.; Edwards, A.; Macdougall, N. Red Tide Assemblage Formation in an Estuarine Upwelling Ecosystem—Ria-De-Vigo. J. Plankton Res. 1994, 16, 857–878. [Google Scholar] [CrossRef]
- GEOHAB. Global Ecology and Oceanography of Harmful Algal Blooms. In GEOHAB Core Research Project: HABs in Upwelling Systems; Pitcher, P., Moita, T., Trainer, V.L., Kudela, R., Figueiras, P., Probyn, T., Eds.; IOC: Paris, France; SCOR: Baltimore, MD, USA, 2005; pp. 11–82. [Google Scholar]
- Figueiras, F.G.; Pazos, Y. Hydrography and phytoplankton of the Ría de Vigo before and during a red tide of Gymnodinium catenatum Graham. J. Plankton Res. 1991, 13, 589–608. [Google Scholar] [CrossRef]
- Alvarez-Salgado, X.A.; Labarta, U.; Fernández-Reiriz, M.J.; Figueiras, F.G.; Roson, G.; Piedracoba, S.; Filgueira, R.; Cabanas, J.M. Renewal time and the impact of harmful algal blooms on the extensive mussel raft culture of the Iberian coastal upwelling system (SW Europe). Harmful Algae 2008, 7, 849–855. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez, G.R.; Villasante, S.; García-Negro, M.C. Are red tides affecting economically the commercialization of the Galician (NW Spain) mussel farming? Mar. Policy 2011, 35, 252–257. [Google Scholar] [CrossRef]
- Utermöhl, H. Zur vervollkommnung der quantitativen phytoplankton-methodik. Mitt. Int. Ver. Theor. Unde Amgewandte Limnol. 1958, 9, 1–38. [Google Scholar] [CrossRef]
- Herrera, J.L.; Piedracoba, S.; Varela, R.A.; Roson, G. Statial analysis of the wind field on the western coast of Galicia (NW Spain) from in situ measurements. Cont. Shelf Res. 2005, 25, 1728–1748. [Google Scholar] [CrossRef]
- Bakun, A. Coastal Upwelling Indexes, West Coast of North America, 1946–1971; NOAA Technical Report NMFS SSRF-671; U.S. Department of Commerce: Seattle, WA, USA, 1973; pp. 1–103.
- Sarle, W.S. Neural networks and statistical models. In Proceedings of the Nineteenth Annual SAS Users Group International Conference, Cary, NC, USA, 10–13 April 1994; SAS Institute: Cary, NC, USA, 1994; pp. 1538–1550. [Google Scholar]
- Kohavi, R.; Provost, F. Glossary of terms. Machine Learning—Special Issue on Applications of Machine Learning and the Knowledge Discovery Process. Mach. Learn. 1998, 30, 271–274. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning (ICML’06), Pittsburgh, PA, USA, 25–29 June 2006; Cohen, W.W., Moore, A., Eds.; Association for Computing Machinery: New York, NY, USA, 2006; pp. 161–168. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning. Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2017. [Google Scholar]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing Imbalanced Data—Recommendations for the Use of Performance Metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 245–251. [Google Scholar]
- Kubat, M. Introduction to Machine Learning, 2nd ed.; Springer: New York, NY, USA, 2018. [Google Scholar]
- Daskalaki, S.; Kopanas, I.; Avouris, N. Evaluation of classifiers for an uneven class distribution problem. Appl. Artif. Intell. 2006, 20, 381–417. [Google Scholar] [CrossRef]
- Ghoneim, S. Accuracy, Recall, Precision, F-Score & Specificity. Which to optimize on? Towards Data Science. 2 April 2019. Available online: https://towardsdatascience.com/accuracy-recall-precision-f-score-specificity-which-to-optimize-on-867d3f11124 (accessed on 18 January 2021).
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning: Applications and Solutions. ACM Comput. Surv. 2019, 52, 79. [Google Scholar] [CrossRef] [Green Version]
- López, V.; Fernandez, A.; Garcia, S.; Palade, V.; Herrera, F. An Insight into Classification with Imbalanced Data: Empirical Results and Current Trends on Using Data Intrinsic Characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Thorel, M.; Claquin, P.; Schapira, M.; Le Gendre, R.; Riou, P.; Goux, D.; Le Roy, B.; Raimbault, V.; Deton-Cabanillas, A.F.; Bazin, P.; et al. Nutrient ratios influence variability in Pseudo-nitzschia species diversity and particulate domoic acid production in the Bay of Seine (France). Harmful Algae 2017, 68, 192–205. [Google Scholar] [CrossRef] [PubMed]
- Torres Palenzuela, J.M.; González Vilas, L.; Bellas, F.M.; Garet, E.; González-Fernández, Á.; Spyrakos, E. Pseudo-nitzschia Blooms in a Coastal Upwelling System: Remote Sensing Detection, Toxicity and Environmental Variables. Water 2019, 11, 1954. [Google Scholar] [CrossRef] [Green Version]
- Doval, M.D.; López, A.; Madriñán, M. Temporal variation and trends of inorganic nutrients in the coastal upwelling of the NW Spain (Atlantic Galician rías). J. Sea Res. 2016, 108, 19–29. [Google Scholar] [CrossRef]
- Torres Palenzuela, J.M.; Gonzalez Vilas, L.; Bellas Aláez, F.M.; Pazos, Y. Potential Application of the New Sentinel Satellites for Monitoring of Harmful Algal Blooms in the Galician Aquaculture. Thalassas 2020, 36, 85–93. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable (Units) | #Records | #Valid Records | Min. Scale | Max. Scale |
|---|---|---|---|---|
| Temperature (°C) | 2065 | 2054 | 10 | 20 |
| Salinity (psu) | 2065 | 1976 | 24 | 36 |
| Upwelling indices (m3s−1km−1) (Day -4 to Day 0) | 4015 | 4015 | −2500 | 2500 |
| Pseudo-nitzschia spp. abundance (cell/L) | 2153 | 2153 | ||
| Day of the year | 1 | 366 | ||
| Ria code | 1 | 4 | ||
| bloom-1w, bloom-2w | 1 | 15 |
| Combination | Variables | #Records |
|---|---|---|
| A | day of the year; ria code; temperature; salinity; bloom-1w; bloom-2w; upwelling indices. | 1829 |
| B | temperature; salinity; bloom-1w; bloom-2w; upwelling indices. | 1829 |
| C | temperature; salinity; upwelling indices | 1831 |
| D | upwelling indices | 1920 |
| Training Set | Validation Set | |||||
|---|---|---|---|---|---|---|
| Total | No Bloom | Bloom | Total | No Bloom | Bloom | |
| A | 1220 | 1027 | 193 | 609 | 508 | 101 |
| B | 1220 | 1025 | 195 | 609 | 510 | 99 |
| C | 1221 | 1022 | 199 | 610 | 515 | 95 |
| D | 1280 | 1070 | 210 | 640 | 549 | 91 |
| Year | Tot. | Bloom | Vigo | Pontevedra | Arousa | Muros | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tot. | Bloom | Tot. | Bloom | Tot. | Bloom | Tot. | Bloom | |||
| 2002 | 51 | 17 | 51 | 9 | 51 | 10 | 51 | 12 | 45 | 10 |
| 2003 | 52 | 16 | 52 | 13 | 52 | 9 | 52 | 10 | 49 | 8 |
| 2004 | 51 | 13 | 51 | 7 | 51 | 7 | 51 | 4 | 48 | 7 |
| 2005 | 50 | 18 | 49 | 11 | 50 | 14 | 50 | 10 | 44 | 12 |
| 2006 | 51 | 7 | 51 | 3 | 51 | 4 | 51 | 4 | 44 | 1 |
| 2007 | 51 | 13 | 51 | 11 | 51 | 9 | 51 | 7 | 44 | 4 |
| 2008 | 51 | 11 | 51 | 6 | 50 | 6 | 50 | 7 | 43 | 6 |
| 2009 | 51 | 18 | 51 | 12 | 50 | 11 | 50 | 10 | 45 | 6 |
| 2010 | 48 | 11 | 48 | 5 | 48 | 1 | 48 | 6 | 41 | 7 |
| 2011 | 51 | 16 | 51 | 11 | 50 | 9 | 48 | 5 | 42 | 6 |
| 2012 | 52 | 9 | 52 | 6 | 52 | 4 | 51 | 1 | 41 | 5 |
| Total | 559 | 149 | 558 | 94 | 556 | 84 | 553 | 76 | 486 | 72 |
| Variable | Complete Dataset | No Bloom | Bloom | r |
|---|---|---|---|---|
| Temperature | 15.02 ± 1.77 | 14.95 ± 1.82 | 15.42 ± 1.43 | 0.25 ** |
| 11.09–20.81 | 11.09–20.81 | 11.74–19.62 | ||
| Salinity | 35.12 ± 0.92 | 35.06 ± 0.97 | 35.45 ± 0.4 | 0.30 ** |
| 25.46–38.05 | 25.46–38.05 | 33.49–36.03 | ||
| Upwelling | 170 ± 922 | 105 ± 904 | 512 ± 940 | 0.18 ** |
| −4500–6049 | −4500–3468 | −2445–6049 | ||
| Upwelling -1day | 103 ± 1005 | 27 ± 1021 | 501 ± 811 | 0.17 ** |
| −6270–6049 | −6270–3592 | −2198–6049 | ||
| Upwelling -2 days | 55 ± 1120 | −28 ± 1153 | 491 ± 804 | 0.23 ** |
| −6858–4336 | −6858–3592 | −3134–4336 | ||
| Upwelling -3 days | 35 ± 1101 | −56 ± 1129 | 512 ± 780 | 0.26 ** |
| −5042–4336 | −5042–4275 | −3134–4336 | ||
| Upwelling -4 days | 84 ± 1094 | −4 ± 1112 | 541 ± 860 | 0.25 ** |
| −7971–4275 | −7971–4275 | −4229–3128 |
| Model | Criteria | OA | Sens. | Spec. | Prec. | F1-Score | Dist. (0,1) |
|---|---|---|---|---|---|---|---|
| A | F1 | 0.86 | 0.47 | 0.94 | 0.60 | 0.53 | 0.57 |
| ROC | 0.81 | 0.58 | 0.86 | 0.45 | 0.51 | 0.44 | |
| B | F1/ROC | 0.83 | 0.54 | 0.89 | 0.48 | 0.51 | 0.48 |
| C | F1/ROC | 0.86 | 0.46 | 0.93 | 0.56 | 0.51 | 0.54 |
| D | F1 | 0.87 | 0.25 | 0.97 | 0.62 | 0.36 | 0.75 |
| ROC | 0.86 | 0.21 | 0.96 | 0.49 | 0.29 | 0.74 |
| Model | Criteria | OA | Sens. | Spec. | Prec. | F1-Score | Dist. (0,1) |
|---|---|---|---|---|---|---|---|
| A | F1/ROC | 0.87 | 0.44 | 0.96 | 0.71 | 0.54 | 0.56 |
| B | F1 | 0.86 | 0.47 | 0.94 | 0.60 | 0.53 | 0.61 |
| ROC | 0.87 | 0.36 | 0.98 | 0.76 | 0.49 | 0.60 | |
| C | F1/ROC | 0.88 | 0.39 | 0.98 | 0.77 | 0.52 | 0.61 |
| D | F1/ROC | 0.88 | 0.59 | 0.94 | 0.64 | 0.60 | 0.45 |
| Model | Criteria | OA | Sens. | Spec. | Prec. | F1-Score | Dist. (0,1) |
|---|---|---|---|---|---|---|---|
| A | F1 | 0.81 | 0.66 | 0.85 | 0.47 | 0.55 | 0.38 |
| ROC | 0.79 | 0.70 | 0.81 | 0.43 | 0.53 | 0.36 | |
| B | F1 | 0.84 | 0.69 | 0.88 | 0.55 | 0.61 | 0.33 |
| ROC | 0.82 | 0.72 | 0.84 | 0.50 | 0.59 | 0.32 | |
| C | F1 | 0.86 | 0.55 | 0.92 | 0.58 | 0.56 | 0.45 |
| ROC | 0.76 | 0.72 | 0.77 | 0.38 | 0.50 | 0.37 | |
| D | F1 | 0.87 | 0.57 | 0.93 | 0.61 | 0.59 | 0.44 |
| ROC | 0.73 | 0.73 | 0.73 | 0.34 | 0.47 | 0.38 |
| Method | Model | OA | Sens. | Spec. | Prec. | F1-Score | Dist. (0,1) |
|---|---|---|---|---|---|---|---|
| SVM (1992-2002) | A | 0.79 | 0.77 | 0.79 | 0.41 | 0.53 | 0.32 |
| SVM | B | 0.84 | 0.42 | 0.92 | 0.51 | 0.46 | 0.58 |
| NN F1 | A | 0.86 | 0.47 | 0.94 | 0.60 | 0.53 | 0.57 |
| NNROC | A | 0.81 | 0.58 | 0.86 | 0.45 | 0.51 | 0.44 |
| RF | D | 0.88 | 0.56 | 0.94 | 0.64 | 0.60 | 0.45 |
| AdaBoostF1 | BRUS 200 ci. | 0.84 | 0.69 | 0.88 | 0.55 | 0.61 | 0.33 |
| AdaBoostROC | BRUS 10 ci | 0.82 | 0.72 | 0.84 | 0.50 | 0.59 | 0.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aláez, F.M.B.; Palenzuela, J.M.T.; Spyrakos, E.; Vilas, L.G. Machine Learning Methods Applied to the Prediction of Pseudo-nitzschia spp. Blooms in the Galician Rias Baixas (NW Spain). ISPRS Int. J. Geo-Inf. 2021, 10, 199. https://doi.org/10.3390/ijgi10040199
Aláez FMB, Palenzuela JMT, Spyrakos E, Vilas LG. Machine Learning Methods Applied to the Prediction of Pseudo-nitzschia spp. Blooms in the Galician Rias Baixas (NW Spain). ISPRS International Journal of Geo-Information. 2021; 10(4):199. https://doi.org/10.3390/ijgi10040199
Chicago/Turabian StyleAláez, Francisco M. Bellas, Jesus M. Torres Palenzuela, Evangelos Spyrakos, and Luis González Vilas. 2021. "Machine Learning Methods Applied to the Prediction of Pseudo-nitzschia spp. Blooms in the Galician Rias Baixas (NW Spain)" ISPRS International Journal of Geo-Information 10, no. 4: 199. https://doi.org/10.3390/ijgi10040199
APA StyleAláez, F. M. B., Palenzuela, J. M. T., Spyrakos, E., & Vilas, L. G. (2021). Machine Learning Methods Applied to the Prediction of Pseudo-nitzschia spp. Blooms in the Galician Rias Baixas (NW Spain). ISPRS International Journal of Geo-Information, 10(4), 199. https://doi.org/10.3390/ijgi10040199