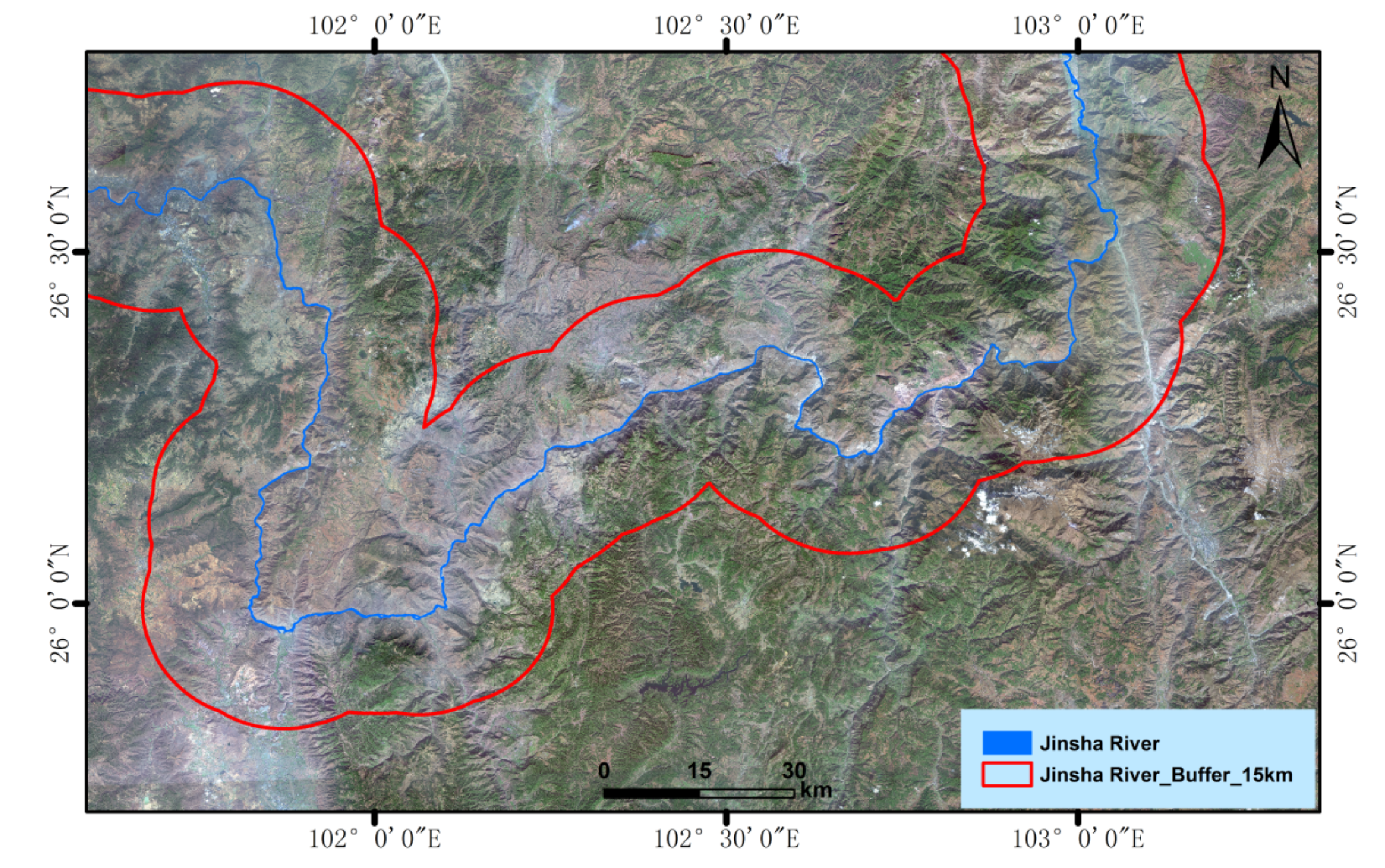
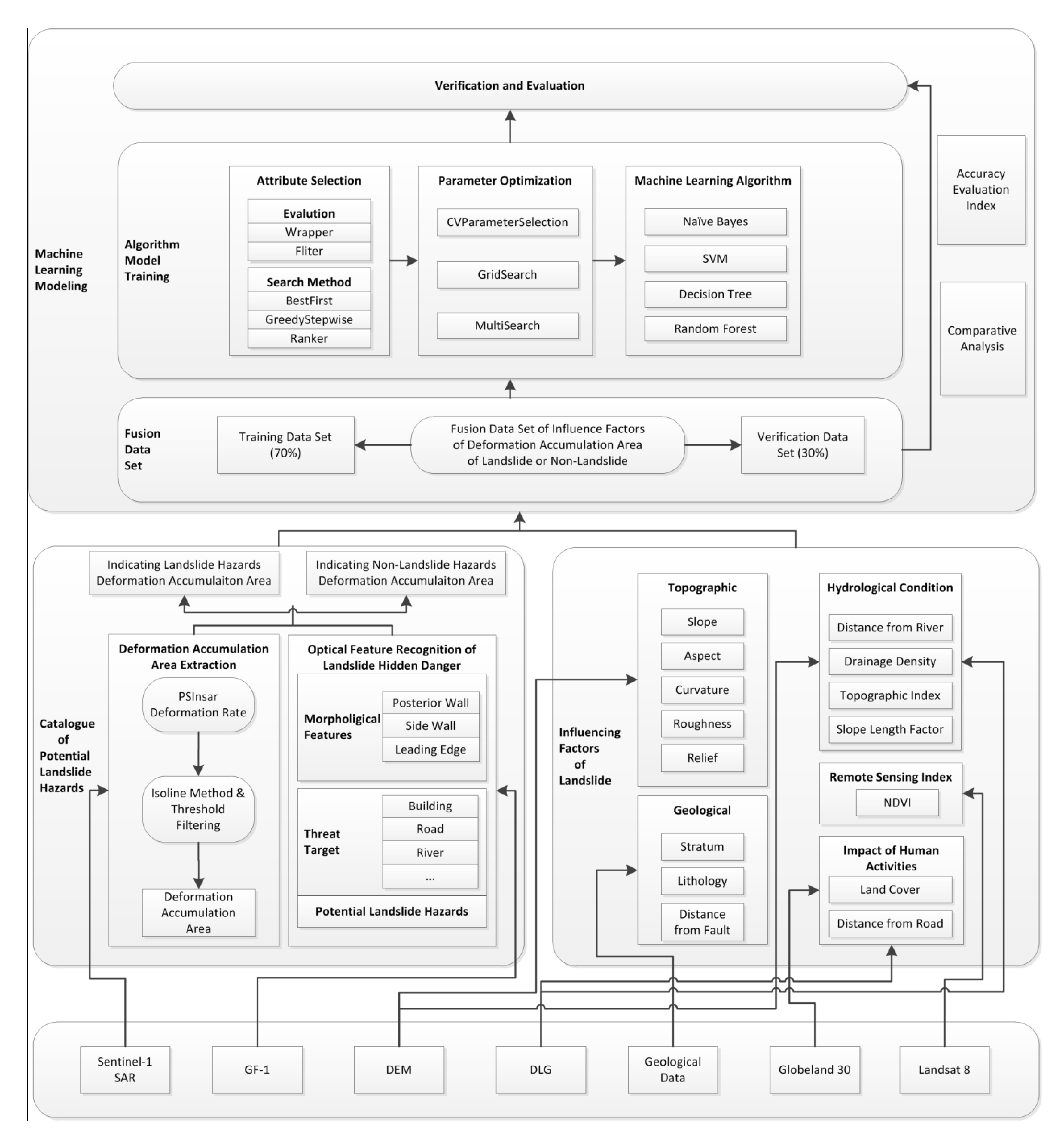
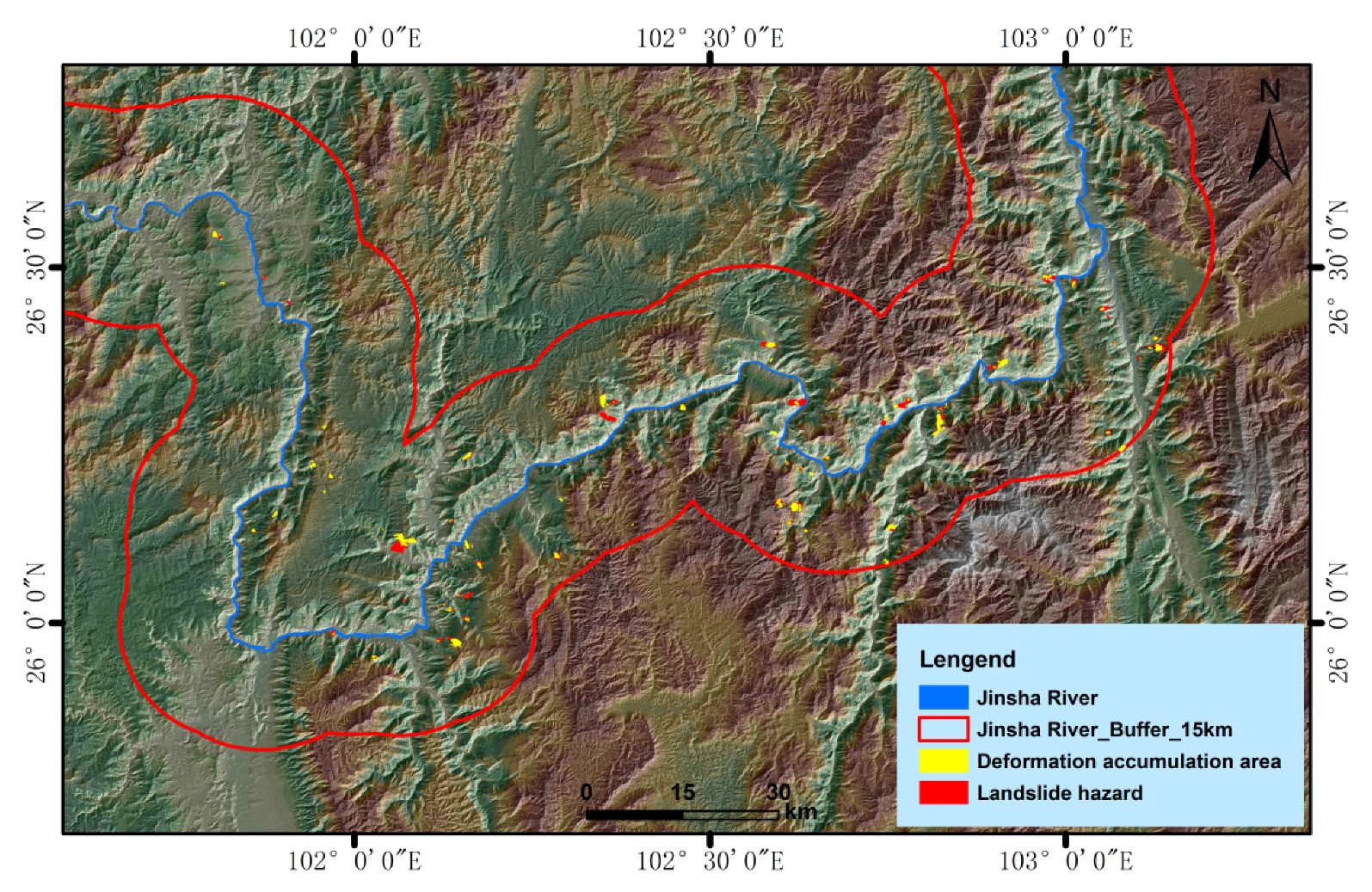
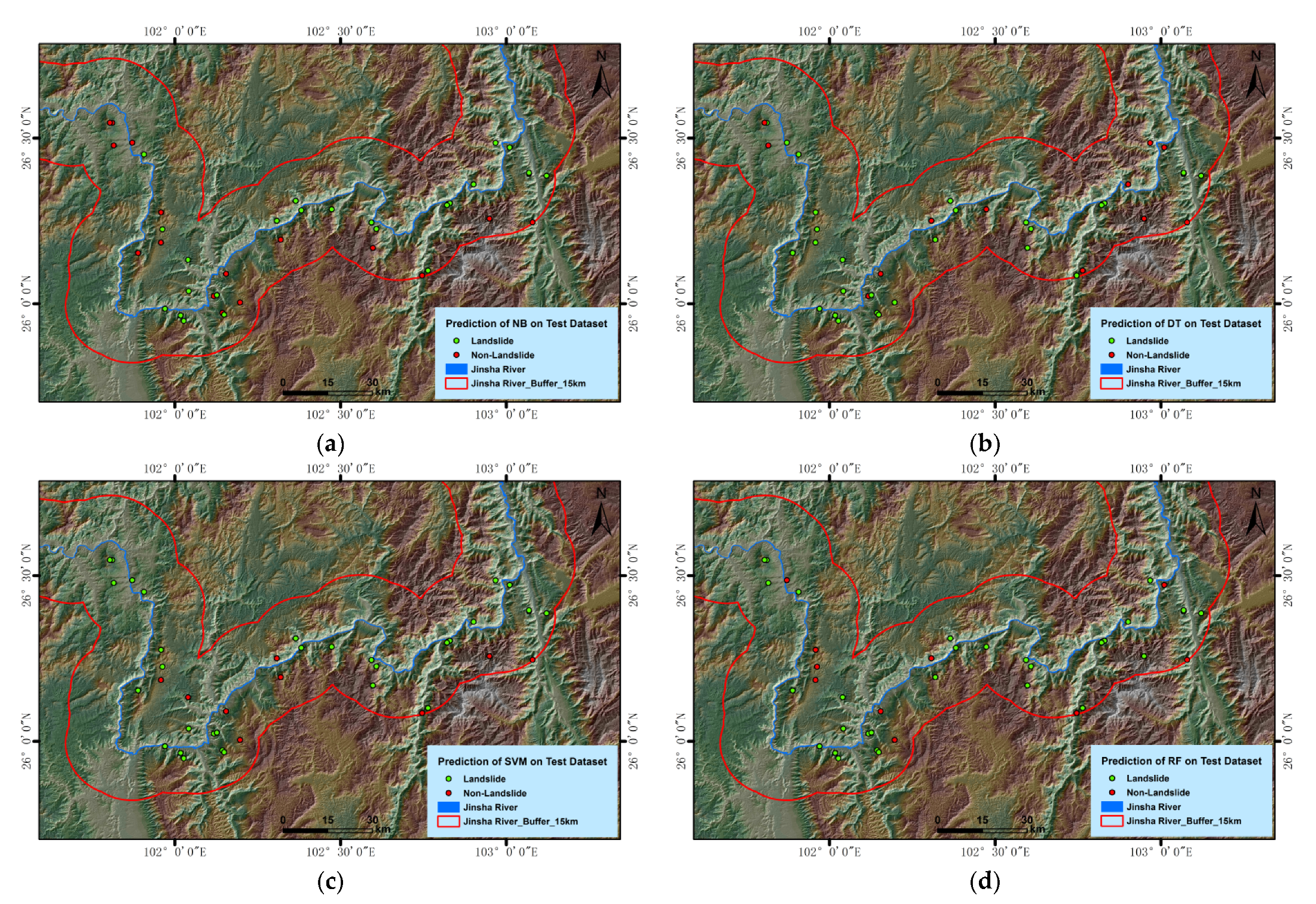
With the help of InSAR deformation data, high-resolution optical remote sensing data, geological background and other multi-source data combined with ground survey data, this study carried out a comprehensive investigation of the active landslide hazards in the study area following the discrimination principle of deformation, shape and threat. Based on the potential landslide hazards and the typical deformation accumulation area filtered by an isoline threshold, 137 data records of potential and non-potential landslide hazards were recorded, including 83 records of deformation accumulation area and 54 records of non-landslide deformation accumulation area. The multi-source attribute characteristics of 137 deformation accumulation areas were extracted by calculating and extracting landslide influencing factors such as landform, basic geology, hydrological conditions, and NDVI. Training sets (n = 96, 70%) and validation sets (n = 41, 30%) were randomly established. Four machine-learning methods, namely NB, DT, SVM and RF, were trained to identify potential landslide hazards after attribute selection and parameter optimization. Finally, the optimal model of potential landslide hazard identification in the study area, which is indicated by the deformation accumulation area, was obtained through the verification and comparison evaluation. The overall study methodology flow is shown in
Figure 5.
2.3.2. Influencing Factors of Landslide
The occurrence of landslides is often related to geological factors, hydrological conditions, topography, land cover, human activities, and so on. The published literature on landslide sensitivity at global or regional scale identifies a number of factors related to the occurrence of landslides. These factors include elevation, slope, aspect, curvature, geology, structure, land cover, distance from rivers and roads, among others [
1,
26].
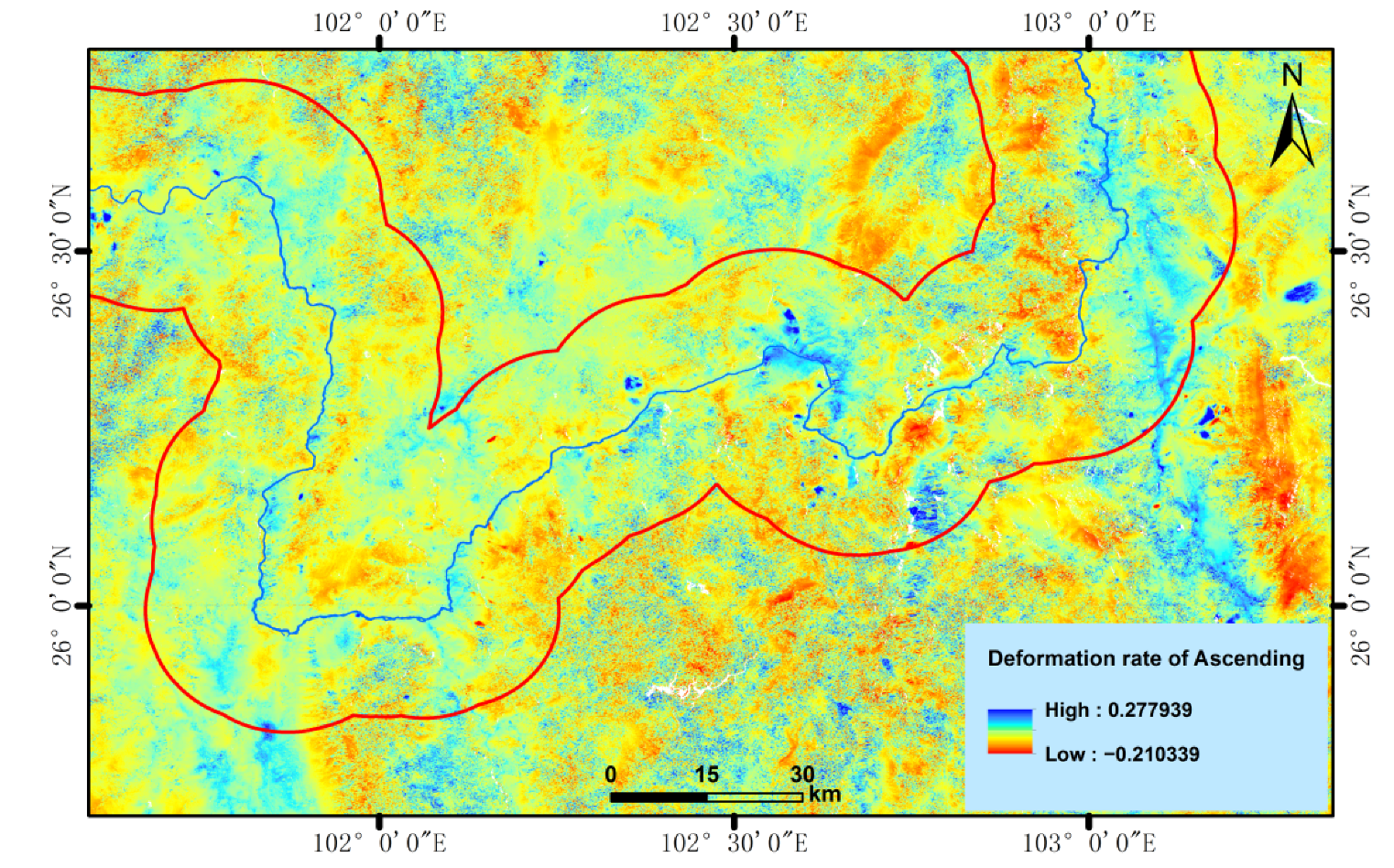
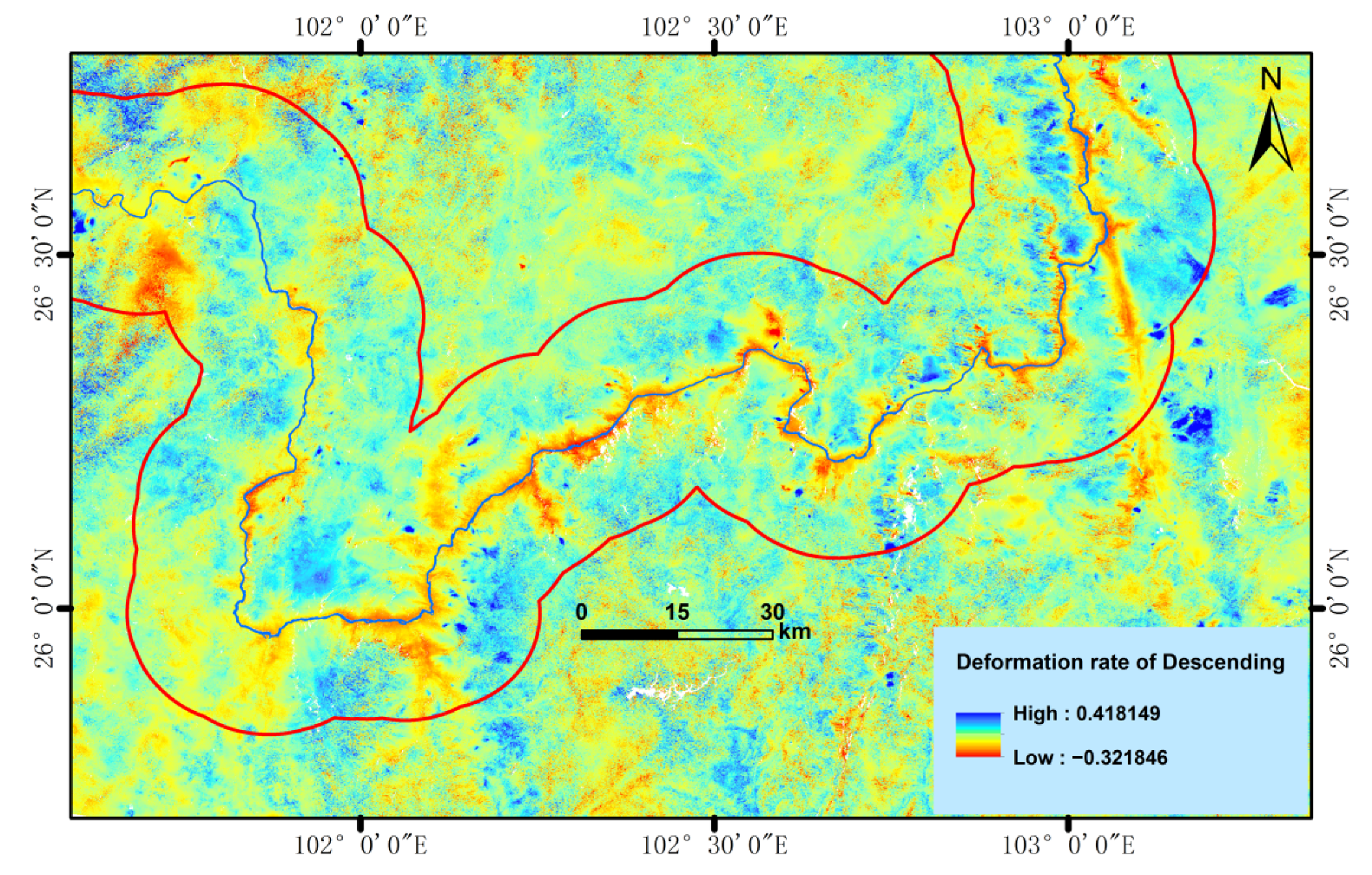
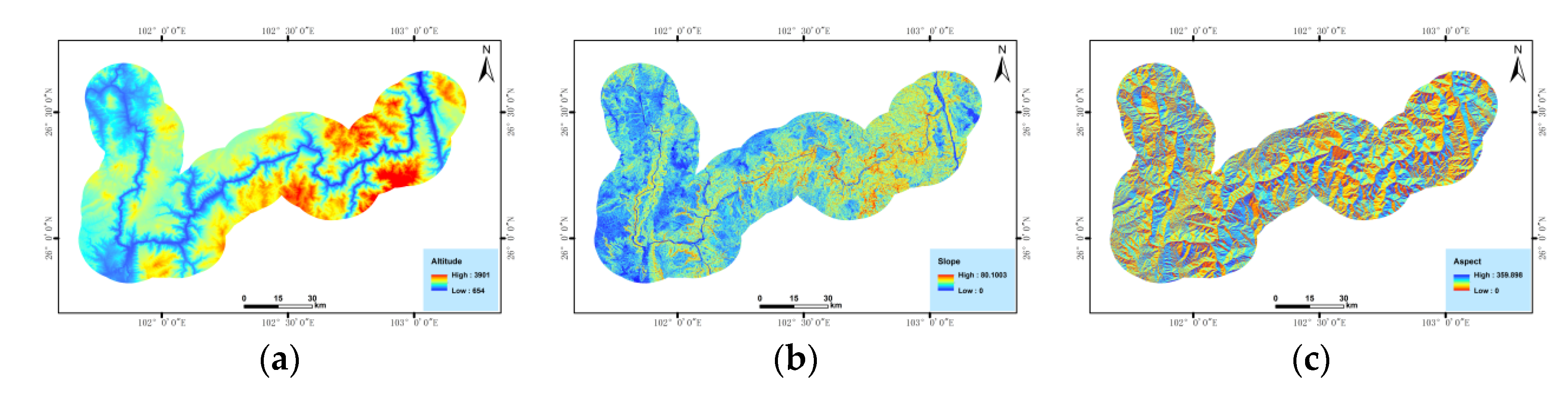
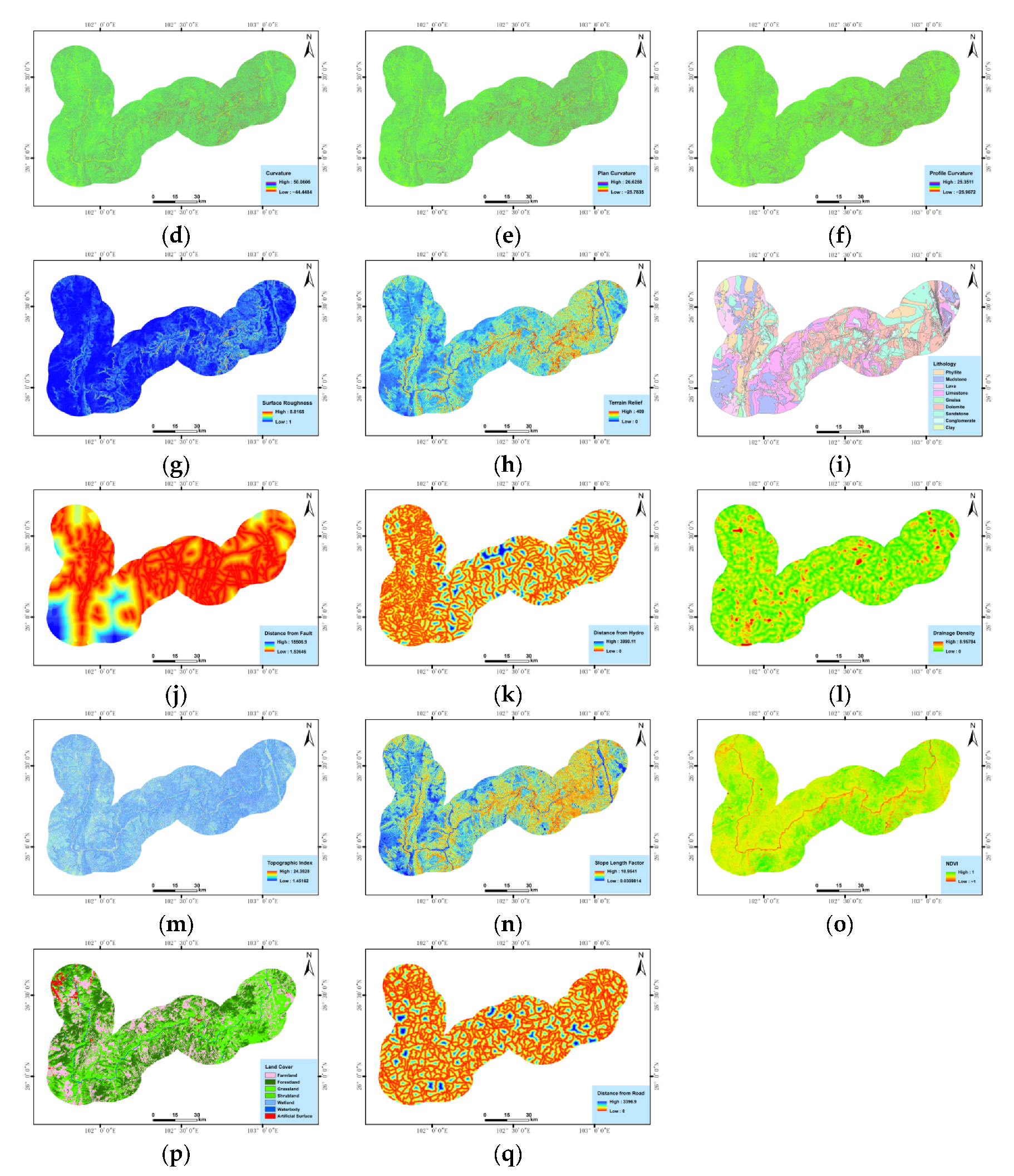
In addition to the optical remote sensing image data and InSAR deformation monitoring data, this study identified 17 influencing factors, including topography, geological background, hydrological conditions, remote sensing data, and human activities as input variables to the machine learning algorithms to perform a “data driven” landslide hazard identification rather than an “expert experience-driven” landslide evaluation and analysis, as shown in
Figure 7 and
Table 2.
Table 2 also showed the numerical statistics (Mean, Minimum, Maxi-mum) of landslide area in the study area. The processing of the 17 factors in the dataset was implemented in ArcGIS 10.5.
Then, based on
Section 2.3.1 and
Section 2.3.2, the study calculated the attribute fusion dataset of surface deformation area by a zonal mean statistics method, which can transform the polygon-based surface deformation area into samples.
Generally, in terms of topography and geomorphology, a moderately gentle land-form with a steep top is prone to landslide development. In terms of geological back-ground, landslide development is mainly affected by the angle of the strata and by the geological structure. Different strata present different hardness, compactness and susceptibility to weathering, and contribution of material to a landslide. Slope discontinuities caused by a fault in the structural plane create the conditions for landslide occurrence. Hydrological conditions are the main determinants for the development of landslides. The difference between active landslides and rainfall-induced landslides lies in the softening of rocks and soil caused by the long-term action of surface water and groundwater, which reduces the strength of rocks and soil, produces hydrodynamic pressure and pore water pressure, increases the bulk density of rock and soil mass, and produces buoyancy forces on permeable strata, especially on the sliding surface (zone), which reduces the strength of the composite. Changes in land cover and the influence of human activities also promote the formation of landslides, especially the destruction of vegetation, excavation at the base of a slope, slope accumulation and other risky human engineering activities are among the important factors affecting the occurrence of landslides.
2.3.3. Machine Learning Algorithms
The following is a brief introduction to the four machine learning methods used in this study.
Naive Bayes is a statistical analysis machine learning algorithm based on Bayes criterion. It uses the “attribute conditional independence assumption” to construct a classifier from a probability model and determine the maximum posterior probability (MAP) decision criterion, so as to realize the optimal decision classification for uncertain factors.
Assume an item to be classified as
X =
f1,
f2, ⋯,
fn, where each
f is a characteristic attribute of
X, and the category set is
C1,
C2, ⋯,
Cm, calculate conditional probability separately
P(
fn|
Cm). If
P(
Ck|
X) =
MAX(
P(
C1|
X),
P(
C2|
X),…,
P(
Cm|
X)), then
X∊
Ck, the one with the largest probability is the Bayesian classification result. Naive Bayes assumes that each feature is independent, according to Bayes’ theorem, it can be derived:
P(
Ci|
X) =
P(
X|
Ci)
P(
Ci)/
P(
X) [
30]. Finally, the classifier formula corresponding to the Naive Bayes algorithm is defined as follows:
Among them, fn is the characteristic attribute of X, p(C) is the prior probability, and p(F|C) is the posterior probability.
- 2.
Decision Tree
Decision Tree uses one of the characteristic attributes of the sample data as the classification condition, divides the sample into two subsets, and then continuously loops the classification until each subset belongs to the same label. The tree structure can effectively handle the classification problem. The key to building a Decision Tree is feature-selected. Common feature selection algorithms for a Decision Tree include ID3, C4.5 and CART. Among them, the core of the ID3 algorithm is to apply information gain criteria on each node of the decision tree to select features, and recursively build the decision tree; the C4.5 algorithm is similar to the ID3 algorithm decision tree generation process, and it improves the ID3 algorithm, the maximum information gain rate (ratio) is used to select features; the CART algorithm will be introduced in the random forest section [
31].
This research uses the C4.5 Decision Tree algorithm. The split information defined by the algorithm is as follows, which is a definition of entropy:
According to the above formula, the information gain rate formula defined by the C4.5 algorithm is as follows:
- 3.
Support Vector Machine
Support Vector Machine aims to obtain a separation hyperplane that correctly divides the dataset and has the largest geometric interval through nonlinear transformation. The largest separation boundary is the support vector. The classification results of SVM depend on the selection of different kernel functions, such as polynomial functions, sigmoid functions, and radial basis functions [
32]. The kernel function used in this study was a radial basis function.
The basic idea of SVM is to calculate the separating hyperplane:
w × x +
b = 0, where
w is the normal vector and
b is the intercept. For a linearly separable dataset, there are infinitely many such hyperplanes which are perceptrons, but the separating hyperplane with the largest geometric interval is unique. For nonlinear classification problems, it can be transformed into a linear classification problem in a certain dimensional feature space by nonlinear transformation, and linear support vector machines can be learned in the high-dimensional feature space. Because of the dual problem of linear SVM, the objective function and the classification decision function only involve the inner product between the instance and the instance, so there is no need to explicitly specify the nonlinear transformation, but the inner product is replaced by the kernel function [
32,
33,
34]. Specifically,
K(
x,
z) is a function, which means that there is a mapping
ɸ(
x) from the input space to the feature space. For
x,
z in any input space,
In the dual problem of linear SVM learning, replacing the inner product with the kernel function
K(
x,
z), the result is nonlinear SVM:
- 4.
Random Forest
Random Forest is considered to be one of the most effective non-parametric ensemble learning methods in the field of machine learning. It is based on the Bagging strategy, introduces random attributes in the training process, and uses training datasets to generate multiple deep decision trees. Each decision tree that constitutes a random forest will predict an output result, which is determined by the weighted calculation of the number of votes. The majority vote of an output result and the degree of convergence of the fitting determine the final classification result [
35]. Random forests can prevent most overfitting problems by creating random feature subsets and using these subsets to build smaller decision trees, and then forming subtrees.
Specifically, Random Forest is modified on the basis of Bagging. First, use the Bootstrap method to sample
n samples from the dataset, then randomly select
k attributes from all attributes to build a CART tree, and finally repeat the above steps
m times to build
m CART trees. These
m CART trees form a random forest, and the result of voting determines which category the data belongs to. CART is basically similar to decision tree methods such as ID3.5 and C4.5. The difference is that CART uses Gini coefficient as the criterion for feature selection. The Gini coefficient is essentially an approximation of the information gain. The larger the Gini coefficient of an attribute, the stronger the attribute’s ability to reduce the entropy of the sample. This attribute makes the data stronger, from uncertainty to certainty. The formula is as follows:
Before model training, attribute selection and parameter optimization should be carried out first, in order to ensure that different algorithms perform classification tasks under the optimal attribute (subset) set and parameters. A feature evaluation strategy can be divided into Wrapper and Filter; the former focuses on the evaluation of the feature subset, the latter focuses on the evaluation of single attributes. Different evaluation strategies for Wrapper and Filter have different searching methods and attribute selection strategies should be selected according to different algorithms [
36,
37,
38,
39,
40]. For a specific algorithm, there are three main methods for parameter optimization: CV Parameter Selection, Grid-Search, and Multi Search. The selection principles of parameter optimization methods vary according to the number of parameters to be optimized:
(1) If there are no more than two parameters to be optimized, Grid-search is selected and the boundary is automatically expanded;
(2) If more than two parameters need to be optimized, Multi Search is selected;
(3) If the direct parameters of the classifier are optimized and the number of parameters is no more than two, the CV Parameter Selection can also be considered.
Different parameter optimization methods are chosen according to different algorithms [
38]. The attribute selection strategy and the parameter optimization method are shown in
Table 3.
The Feature Evaluation Function the study used were WrapperSubsetEval and CorrelationAttributeEval, WrapperSubsetEval evaluates attribute sets by using a learning scheme. Cross validation is used to estimate the accuracy of the learning scheme for a set of attributes [
38]; CorrelationAttributeEval evaluates the worth of an attribute by measuring its correlation (Pearson’s) with the class [
39].
The Search Strategy the study used were Ranker, BestFirst and GreedyStepwise. Ranker uses an attribute/subset evaluator to rank all attributes. If a subset evaluator is specified, then a forward selection search is used to generate a ranked list. From the ranked list of attributes, subsets of increasing size are evaluated, i.e., the best attribute, the best attribute plus the next best attribute, etc. The best attribute set is reported. RankSearch is linear in the number of attributes if a simple attribute evaluator is used such as GainRatioAttributeEval; BestFirst Searches the space of attribute subsets by greedy Hill_Climbing augmented with a backtracking facility. [
40] Setting the number of consecutive non-improving nodes allowed to control the level of backtracking done. Best first may start with the empty set of attributes and search forward, or start with the full set of attributes and search backward, or start at any point and search in both directions (by considering all possible single attribute additions and deletions at a given point); GreedyStepwise performs a greedy forward or backward search through the space of attribute subsets and ay start with no/all attributes or from an arbitrary point in the space. It stops when the addition/deletion of any remaining attributes results in a decrease in evaluation. It can also produce a ranked list of attributes by traversing the space from one side to the other and recording the order that attributes are selected. The Parameter Optimization Methods were CVParameterSelection and GridSearch. CVParameterSelection uses cross validation method, any number of parameters can be optimized; GridSearch is used instead of all the parameter combinations in the experiment to select the parameters, and two parameters can be optimized at most.
2.3.4. Accuracy Assessment
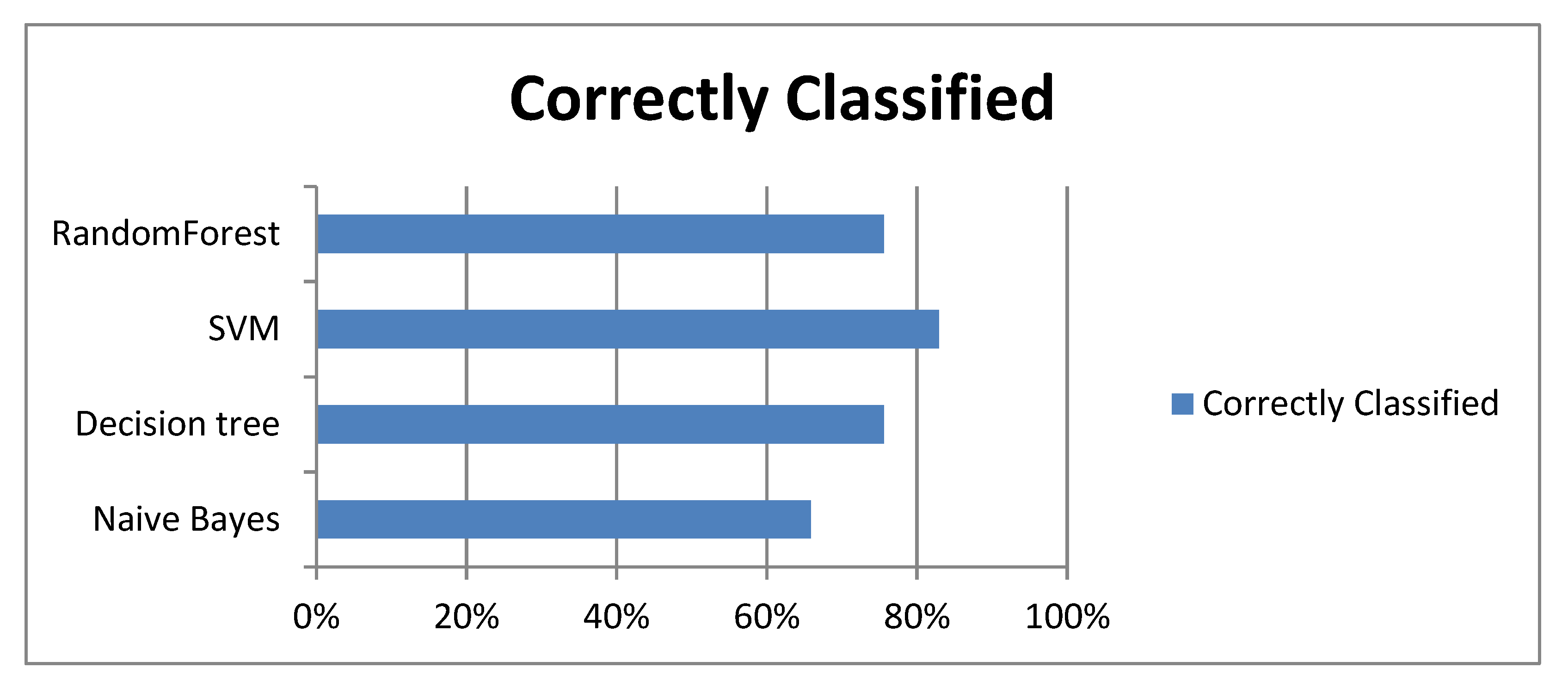
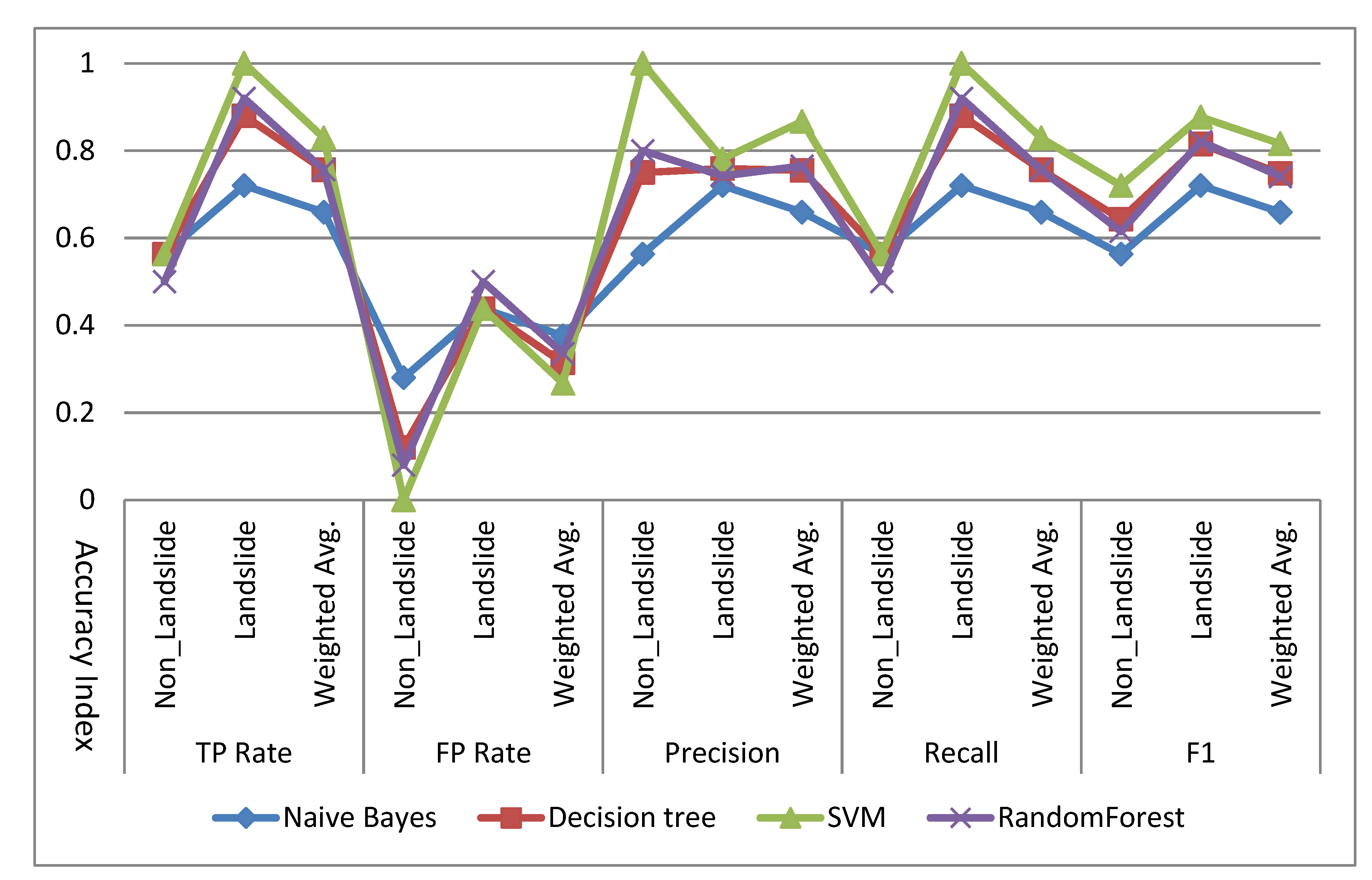
A number of test accuracy indexes of different algorithms were obtained, including Correctly Classified, true positive (TP) rate, false positive (FP) rate, false negative (FN) rate precision, recall, F1, and the AUC (Area Under the ROC curve). Correctly Classified represents the percentage of correct classification, which reflects the correct classification ratio of TP and true negative. TP Rate reflected the proportion of positive samples with correct classification.
Precision is the Precision rate, which is used to measure the ability of the classification algorithm to reject irrelevant information, precision is calculated as:
Recall is the Recall ratio, which is used to measure the ability of classification algorithm to detect relevant information and is calculated as:
F-Measure (F1) is the harmonic mean of precision and recall, and is calculated as:
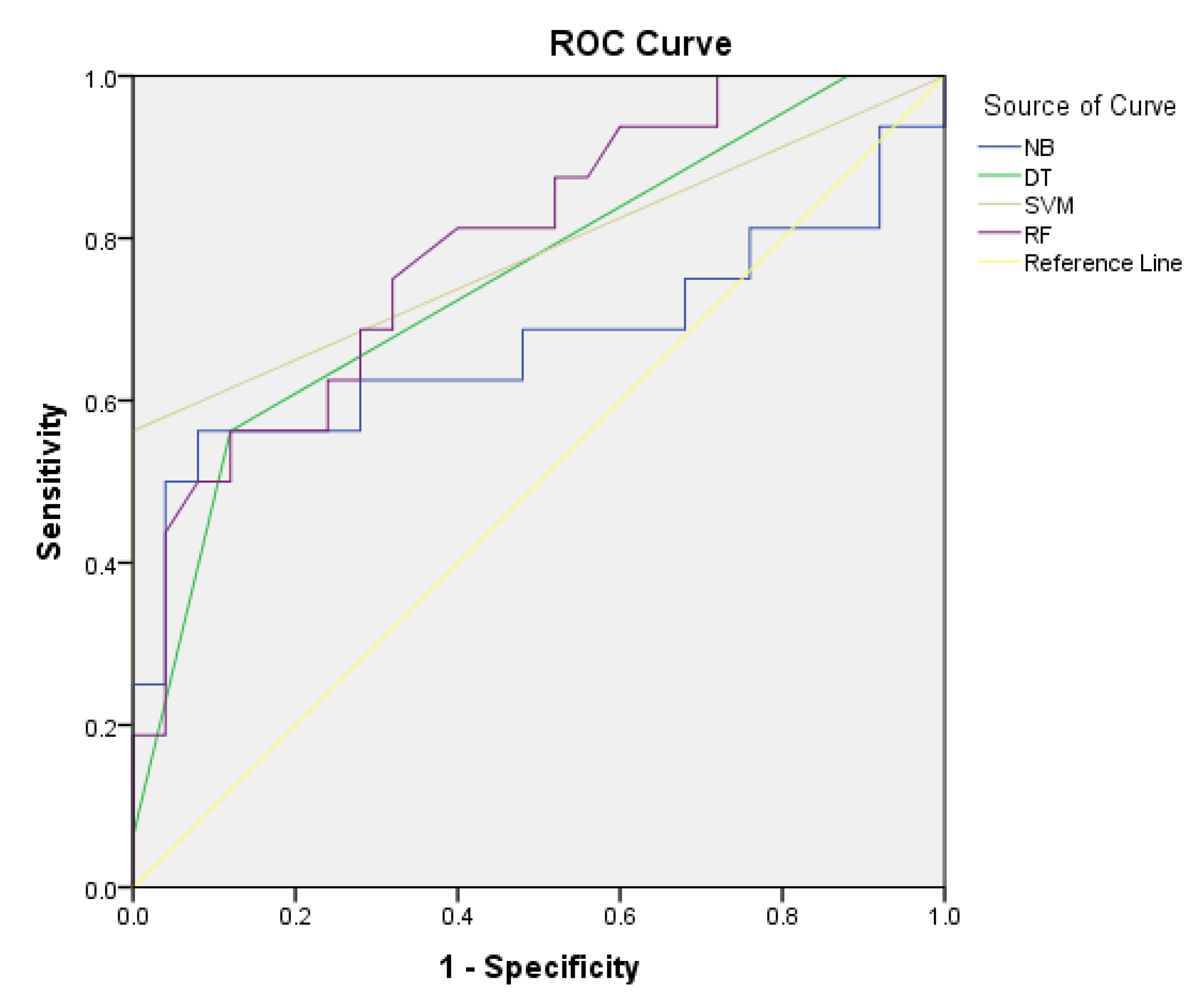
AUC is generally greater than 0.5. The closer this value is to 1, the better the classification effect of the model is.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}