
POSE-ID-on—A Novel Framework for Artwork Pose Clustering



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
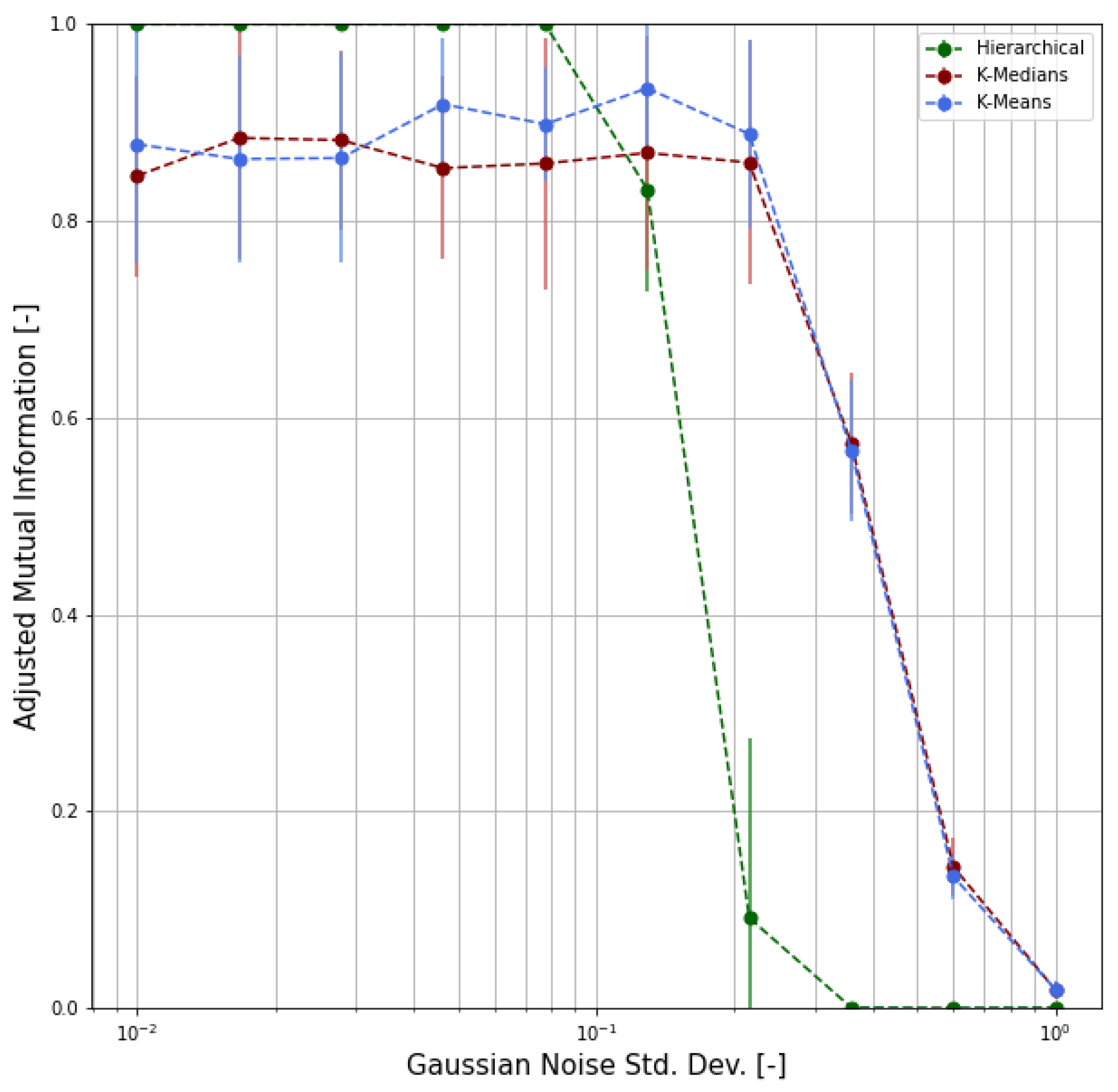
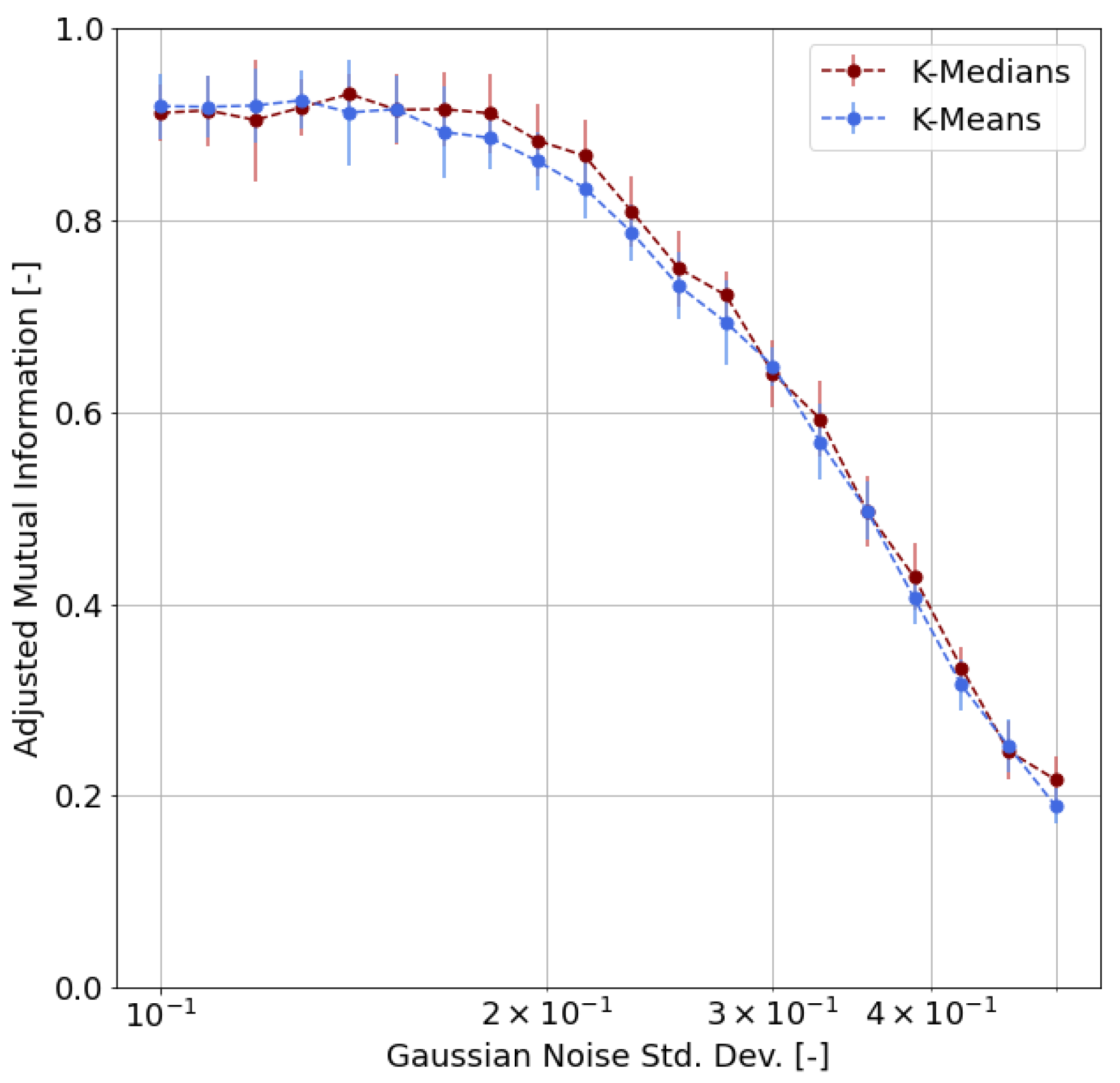
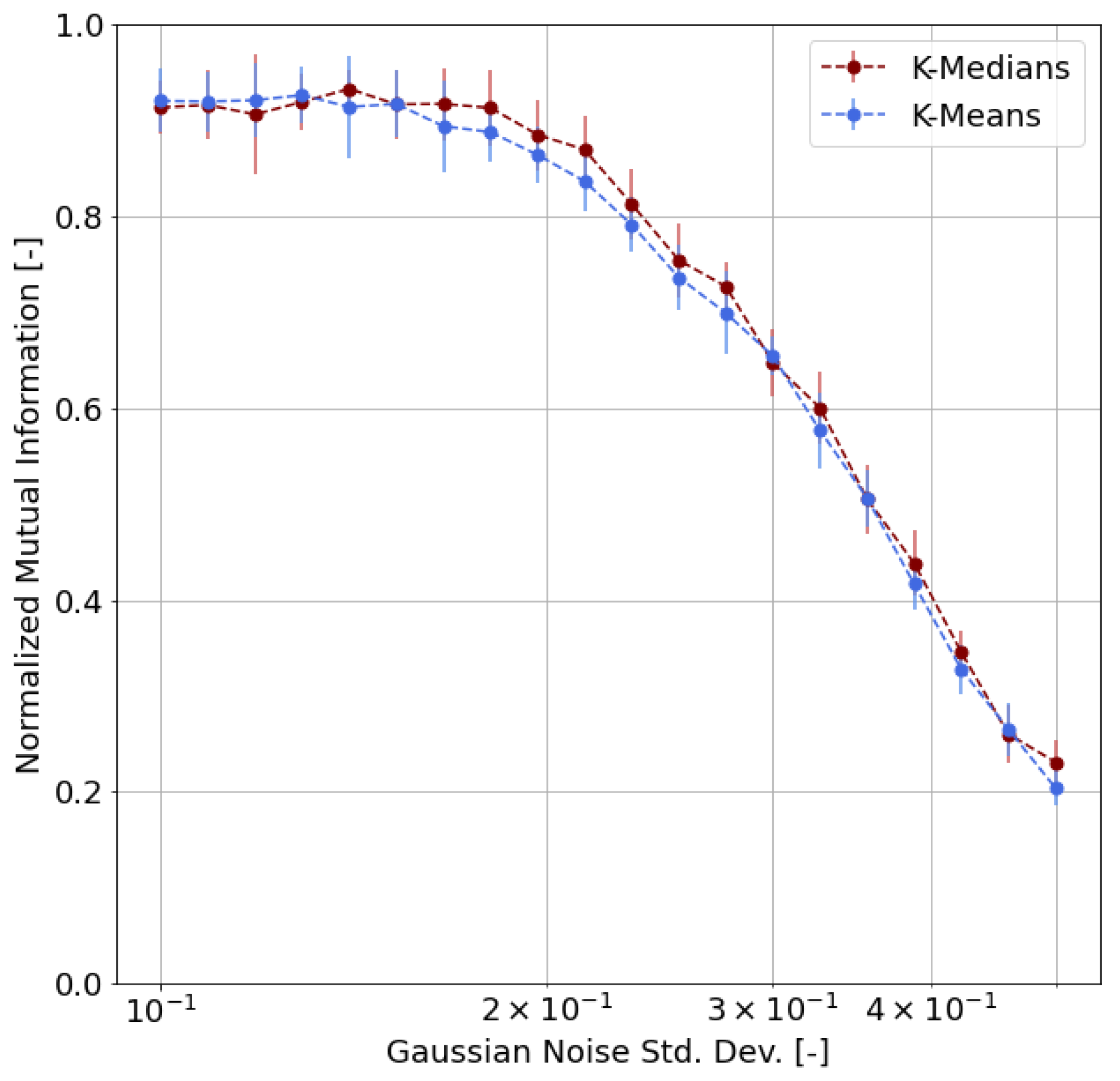
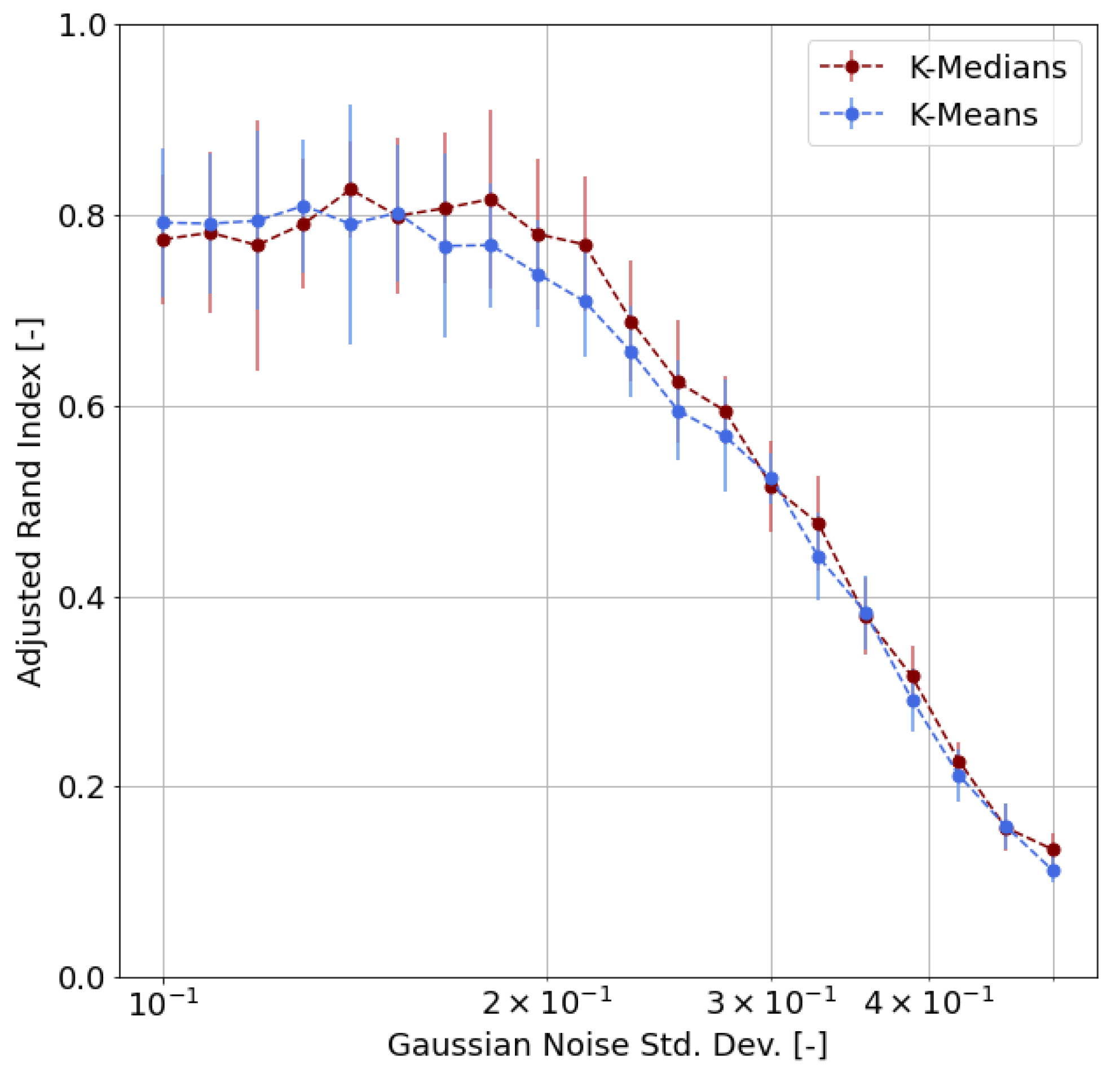
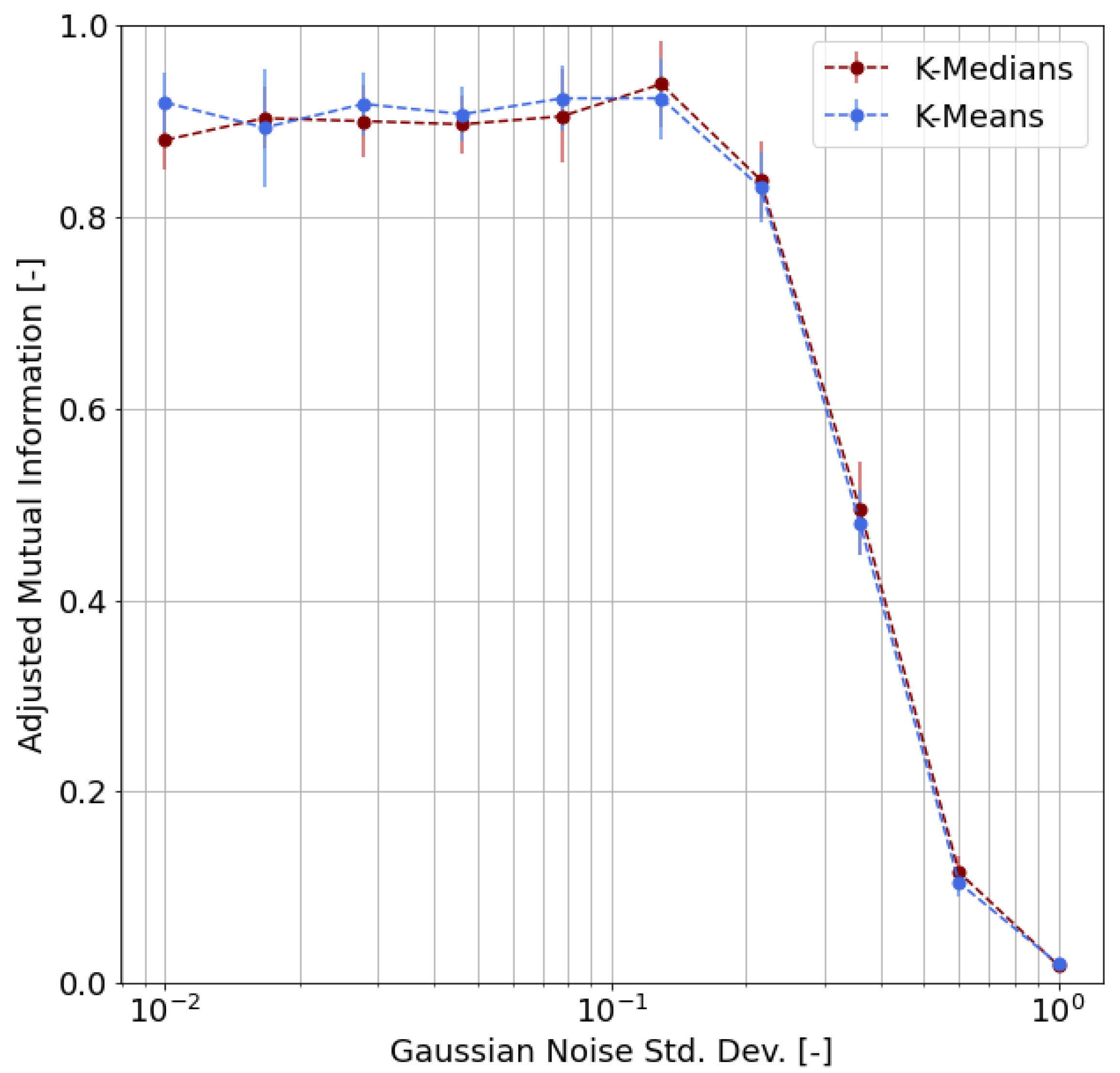
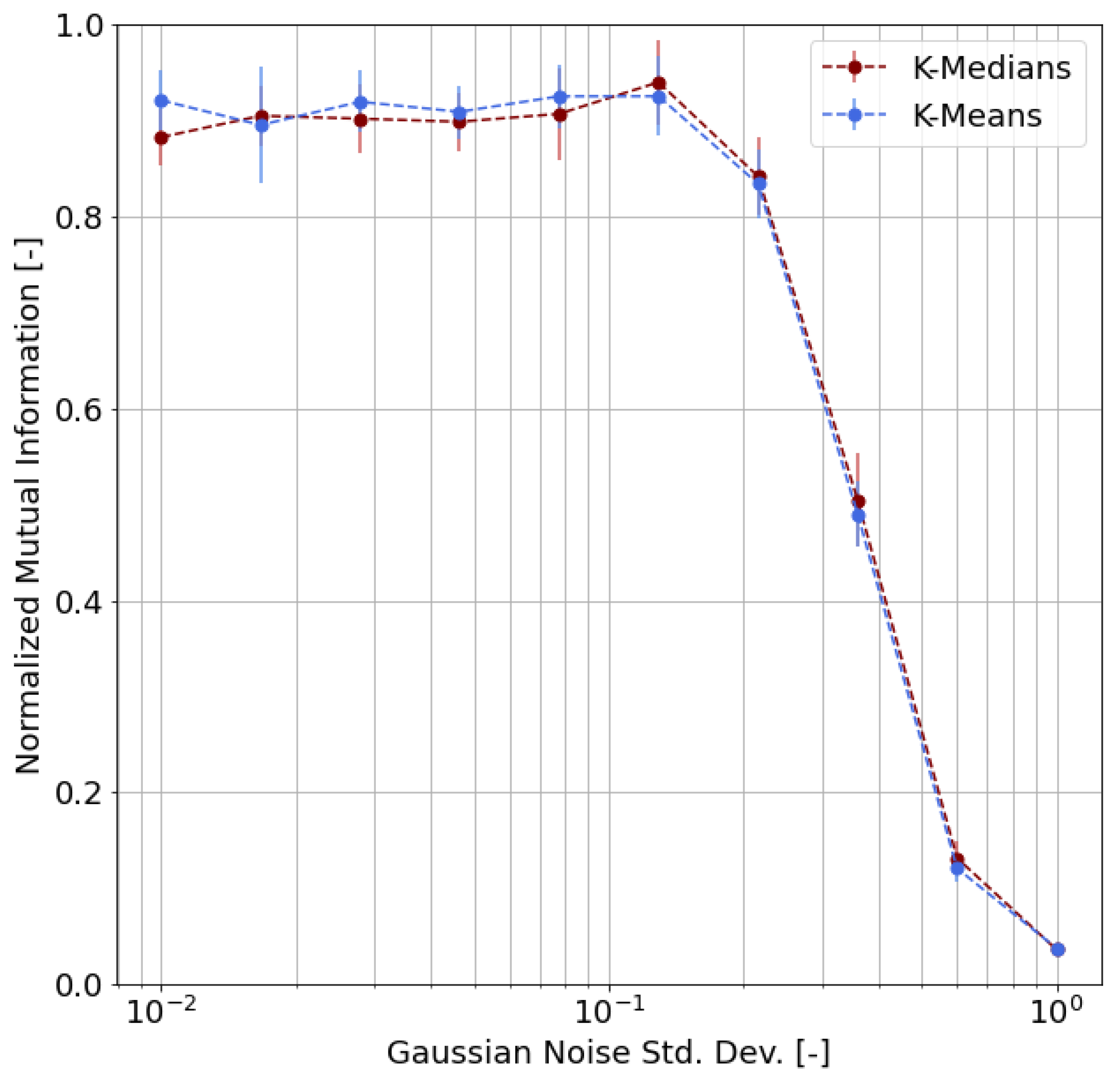
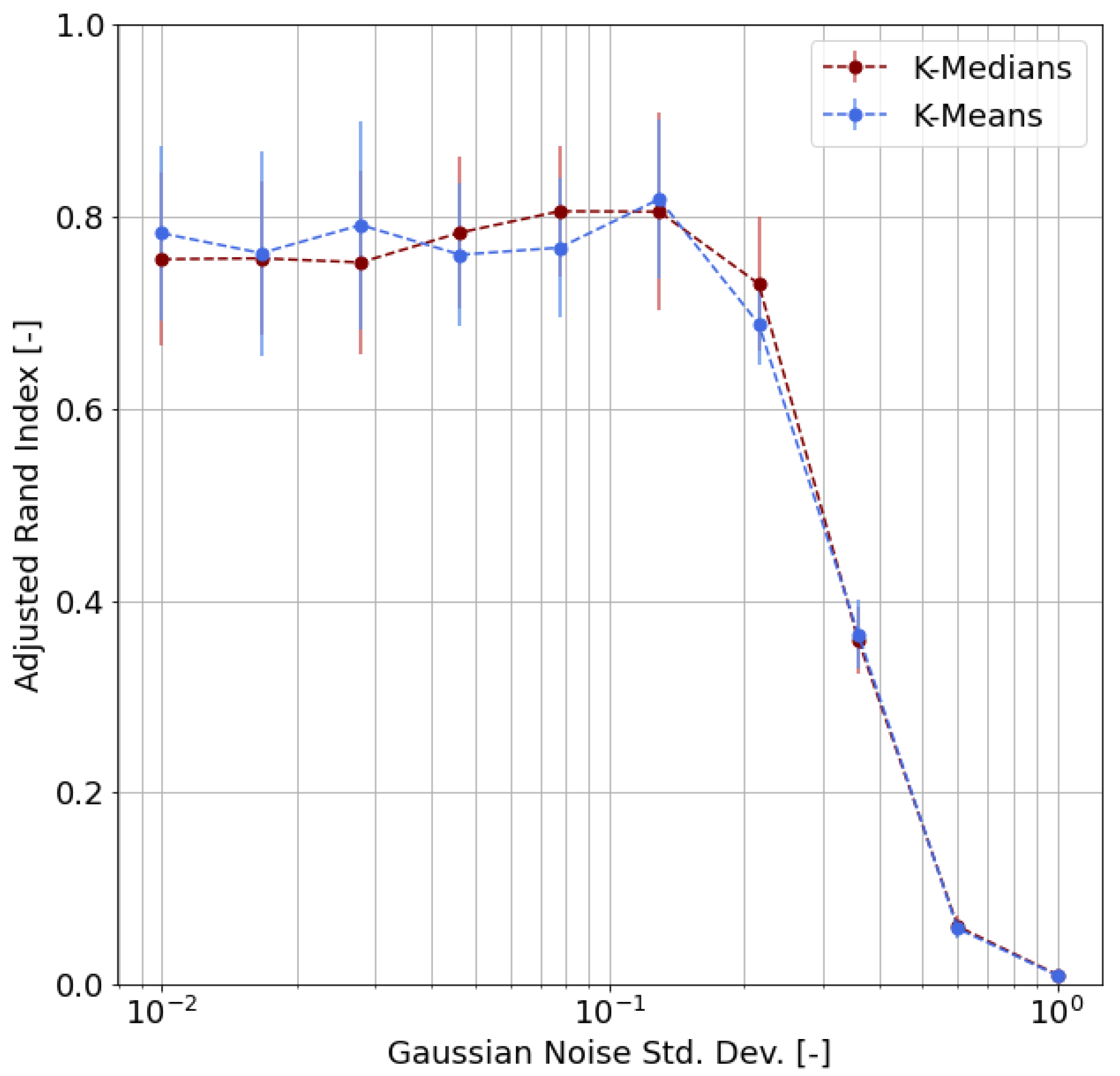
- First of all, we carried out a performance evaluation of the clustering approach based on simulated data according to suitable metrics, such as the Adjusted Rand Index (ARI), the Normalized Mutual Information (NMI), and the Adjusted Mutual Information (AMI);
- Secondly, the obtained clusters and the respective centroids were evaluated in a qualitative way to assess the coherence among the human poses with respect to the Warburgian concept of Pathosformel.
2. Related Works
2.1. Theoretical Background
2.2. Similar Approaches
3. Methodology
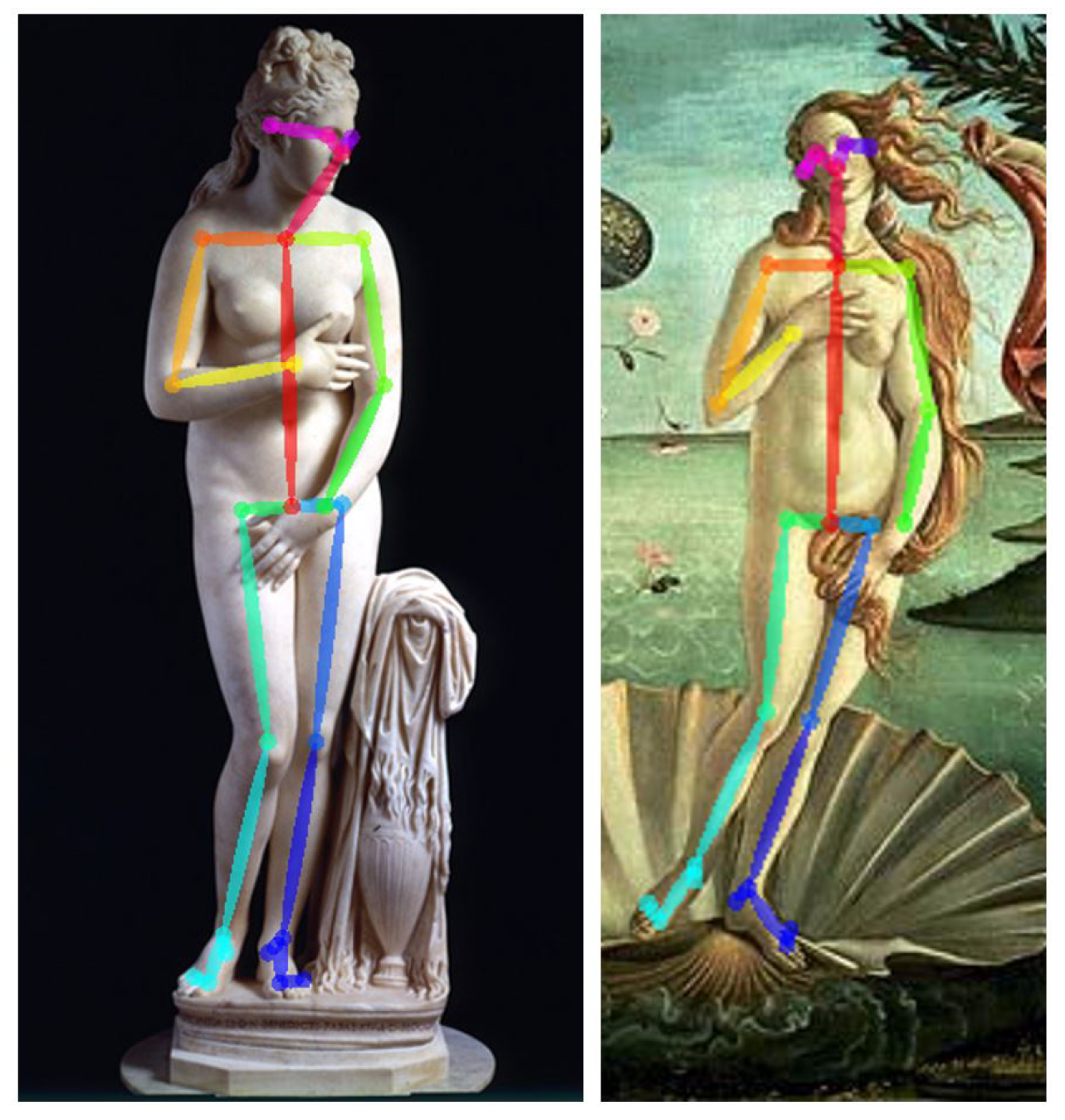
3.1. OpenPose
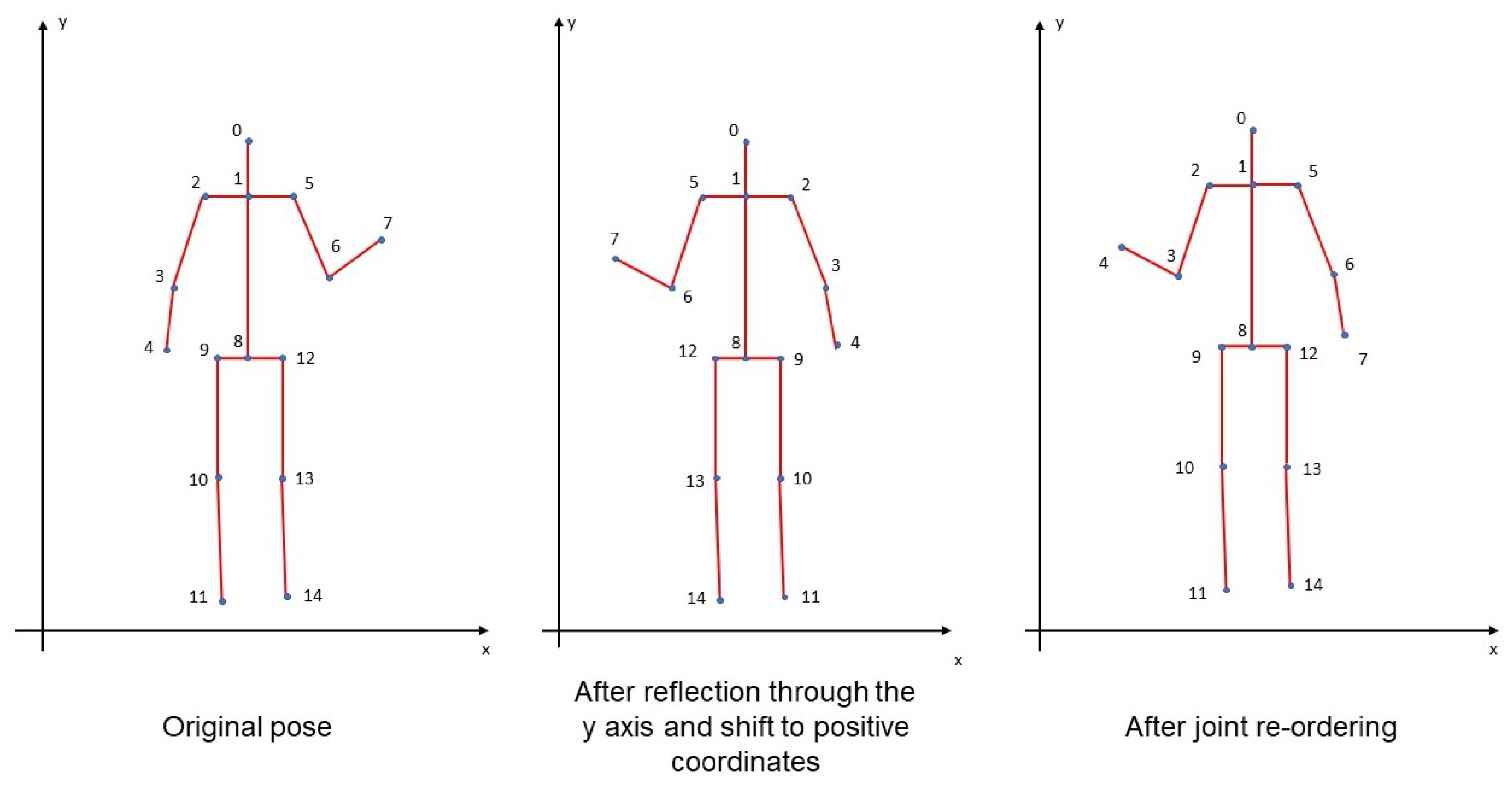
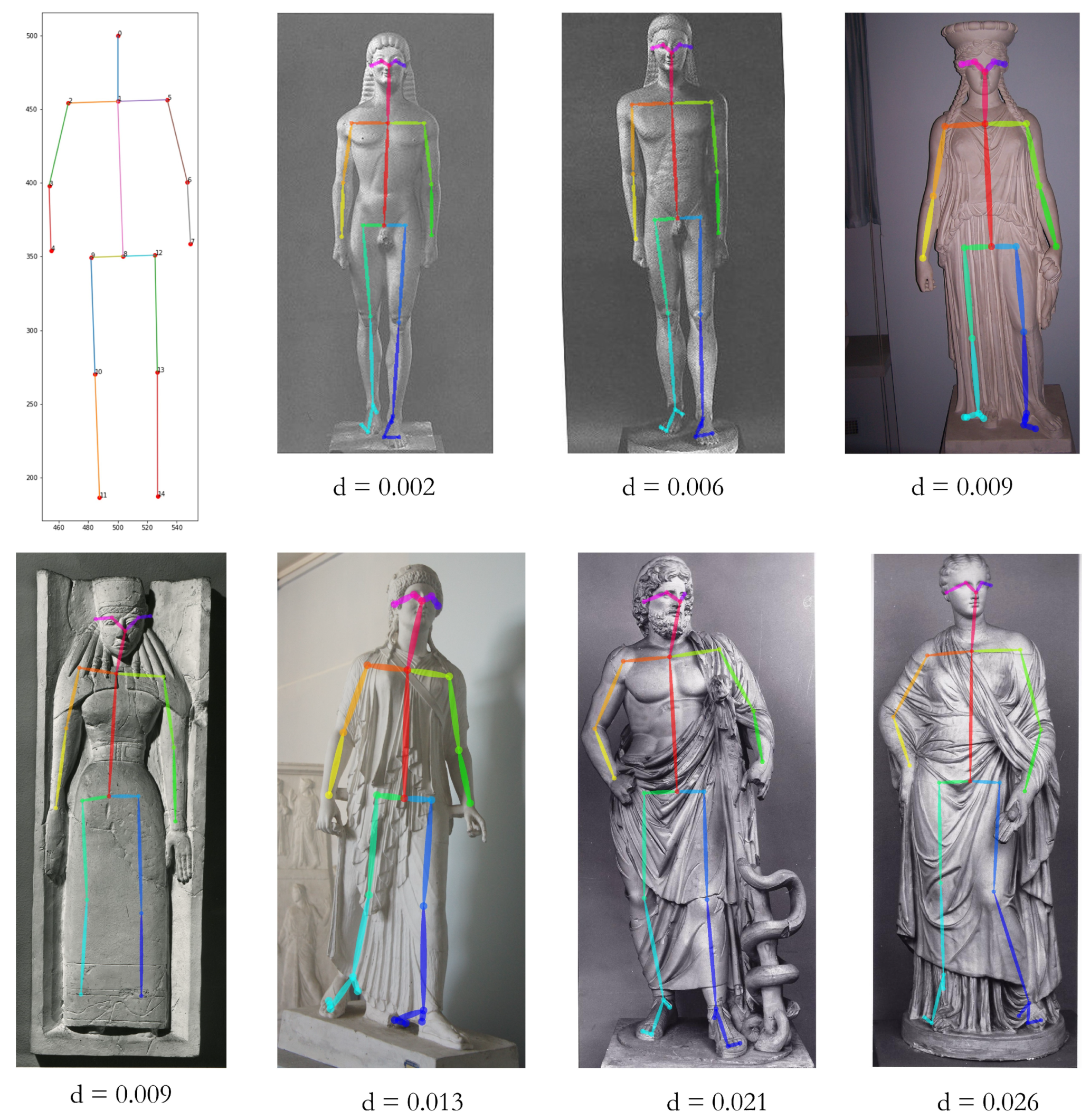
3.2. Pose Comparison
3.2.1. First Method
3.2.2. Second Method
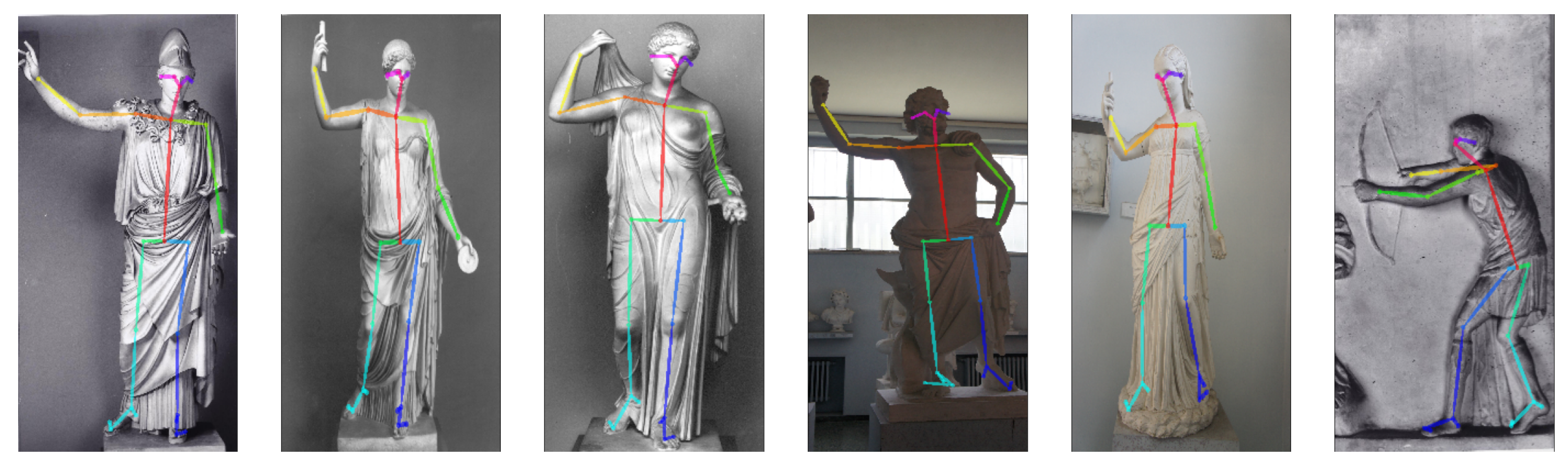
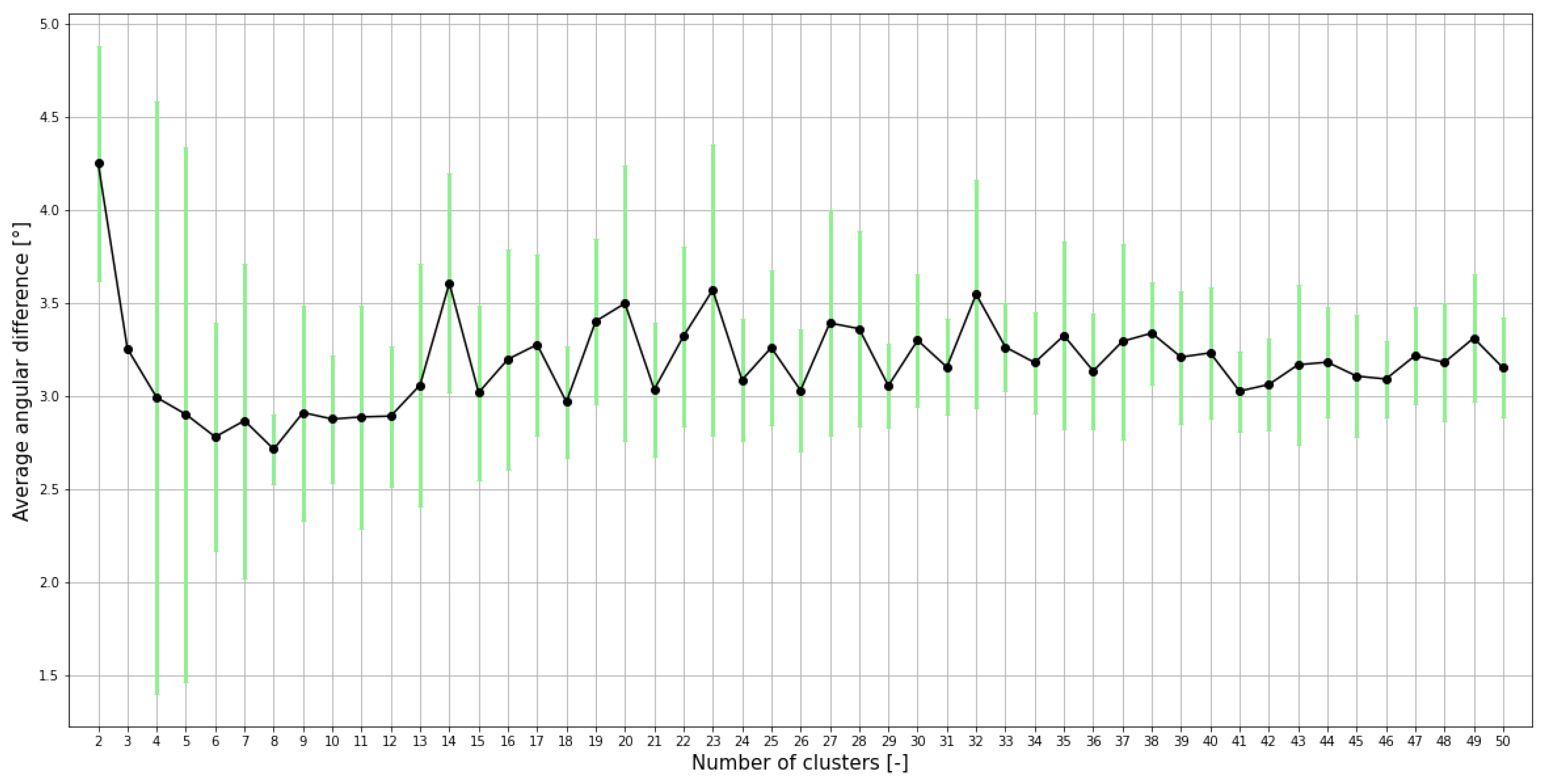
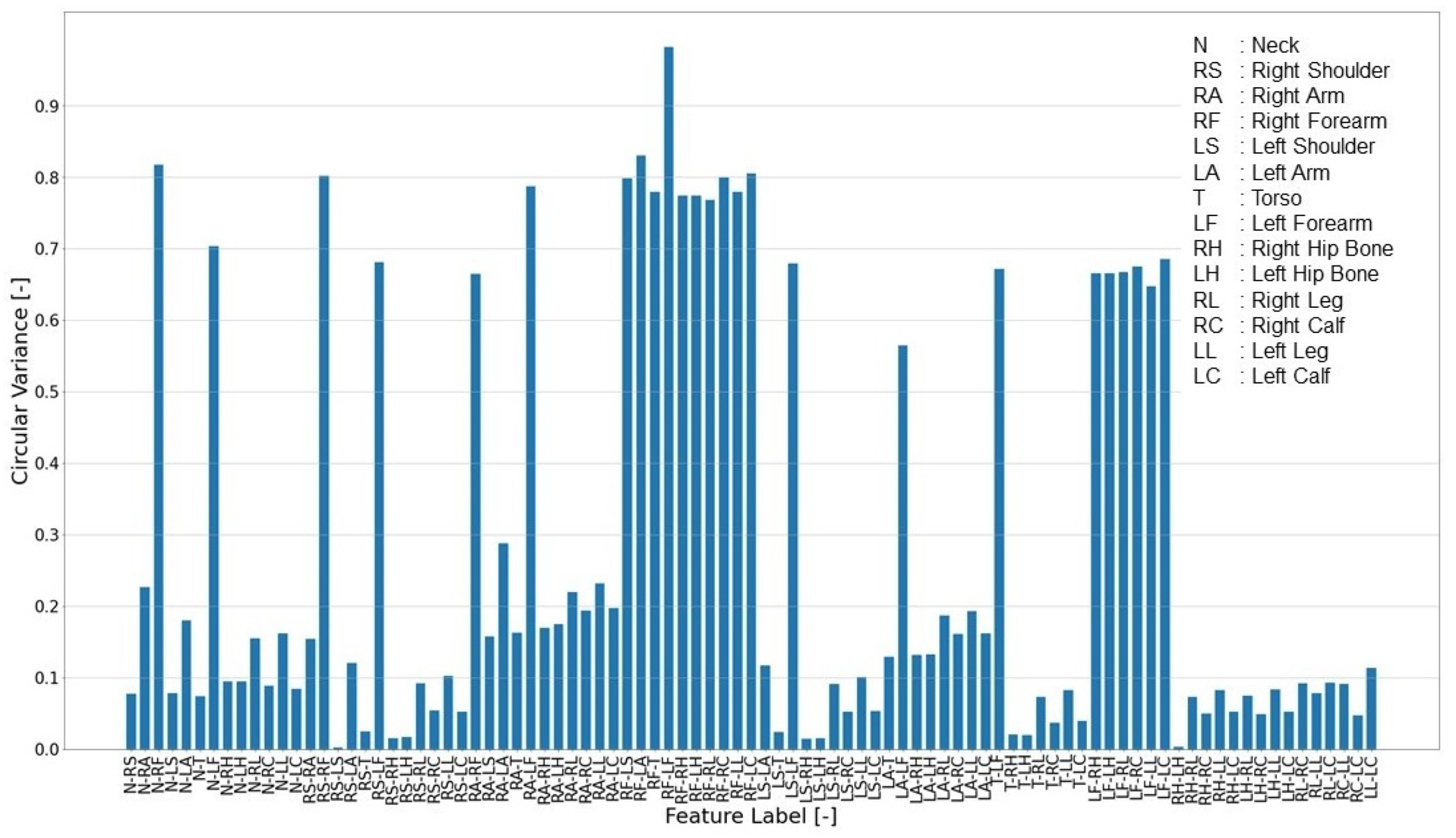
3.3. Pose Clustering
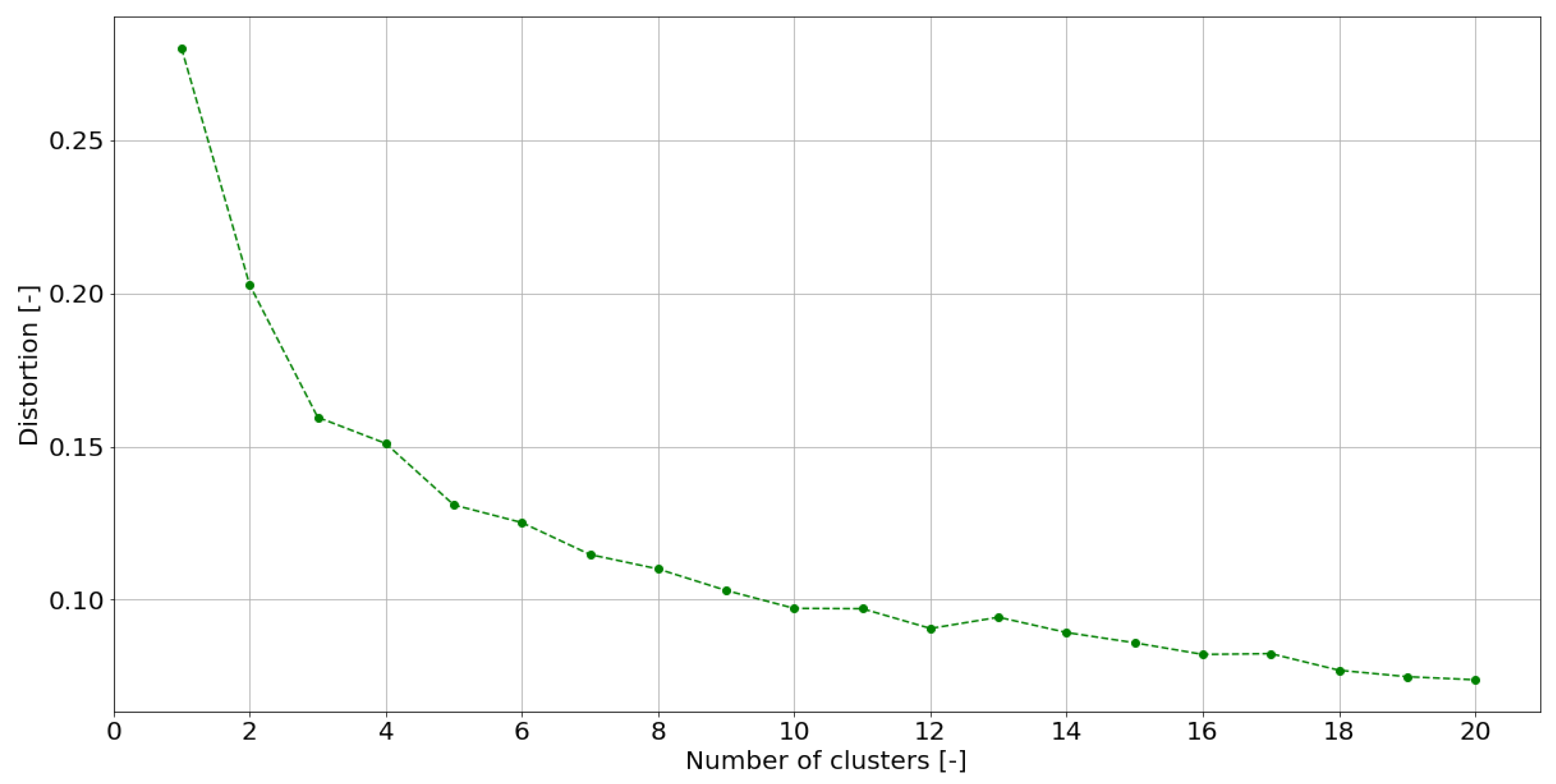
- Selection of the number of clusters m, which is a hyperparameter of the problem, with , where N is the number of poses in the dataset;
- Assignment of the instances to the closest centroid: the same Forgy approach assigns the rest of the instances to the cluster represented by the nearest seed according to the distance presented before in Equation (8);
- Update of the positions of the centroids: once all the instances have been assigned to a cluster, the new positions of the centroids are updated. The new centroid is the median of the instances assigned to the cluster that the centroid represents;
- Iteration of the process: the steps 3 and 4 are repeated until convergence—that is, until the distance between the j-th centroid at step t and the corresponding one at step is lower than a given threshold (fixed to 0.0001 in our tests) for all the centroids.
4. Experiments
4.1. Dataset
4.2. Tests Performed and Results
4.2.1. Pose Comparison
- 3.2 s per iteration for the first method without mirroring and turning options enabled;
- 10.0 s per iteration for the first method with mirroring and turning options enabled;
- 2.2 s per iteration for the second method, which we only ran with mirroring and turning options enabled.
4.2.2. Pose Clustering
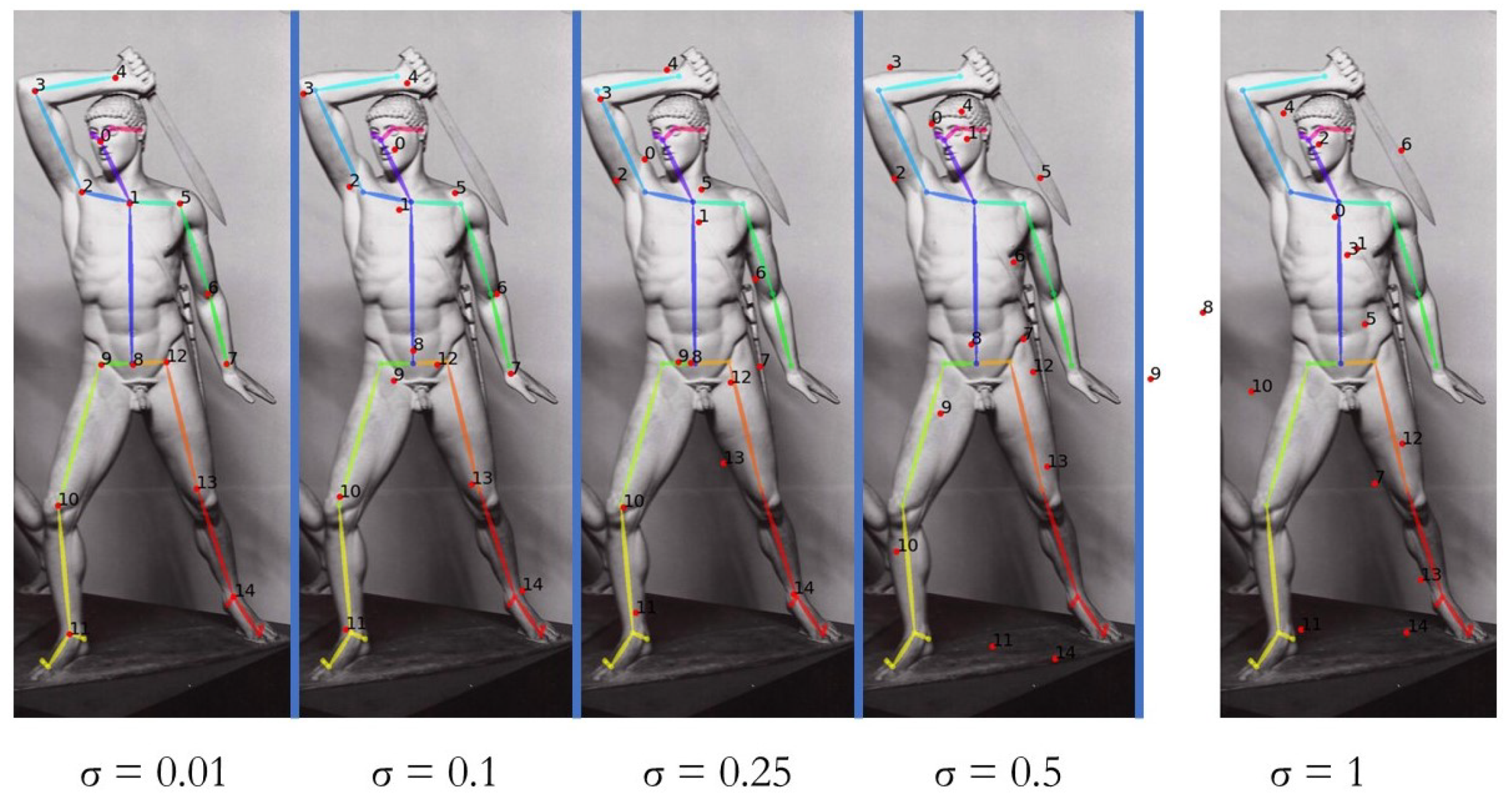
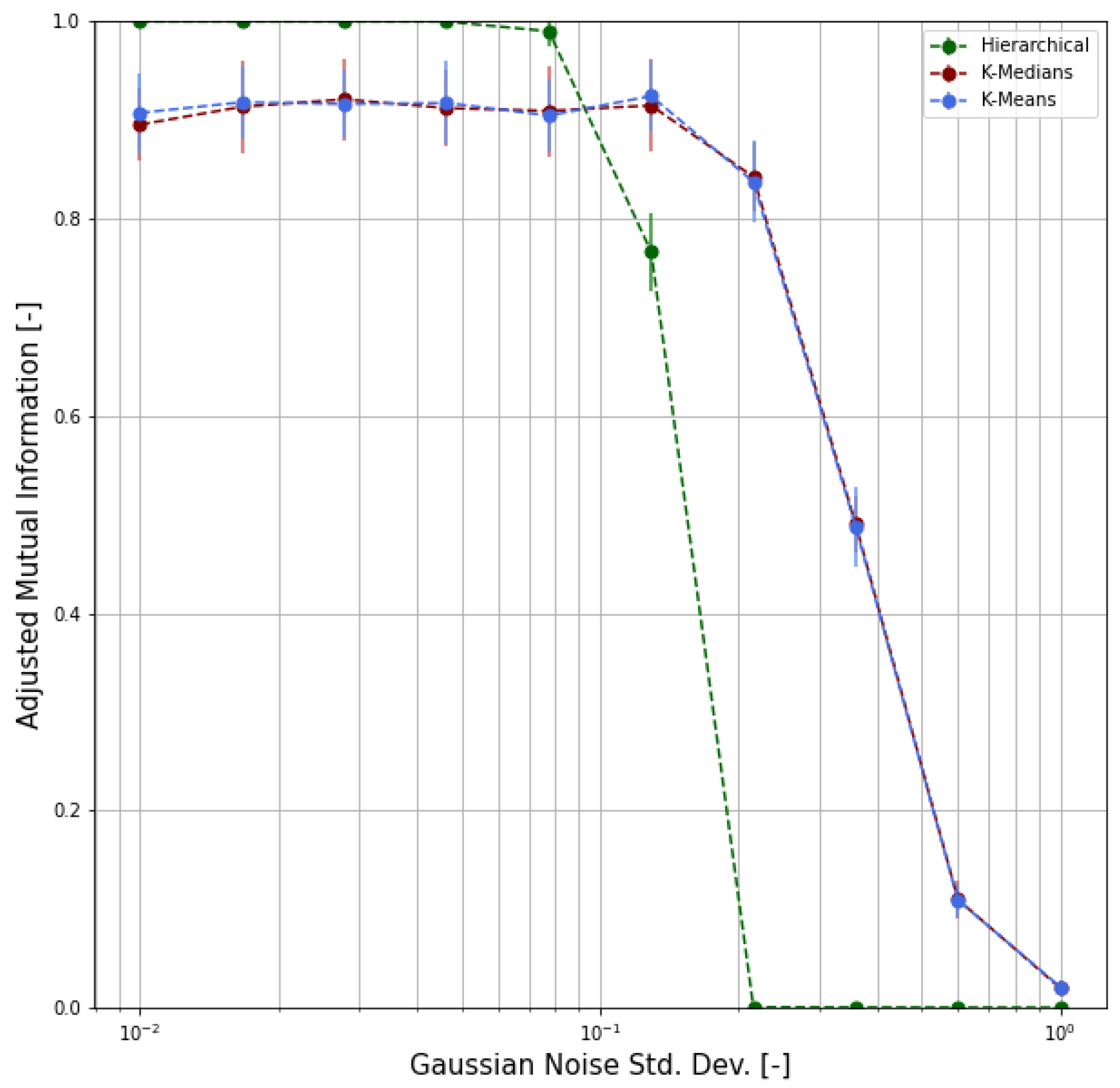
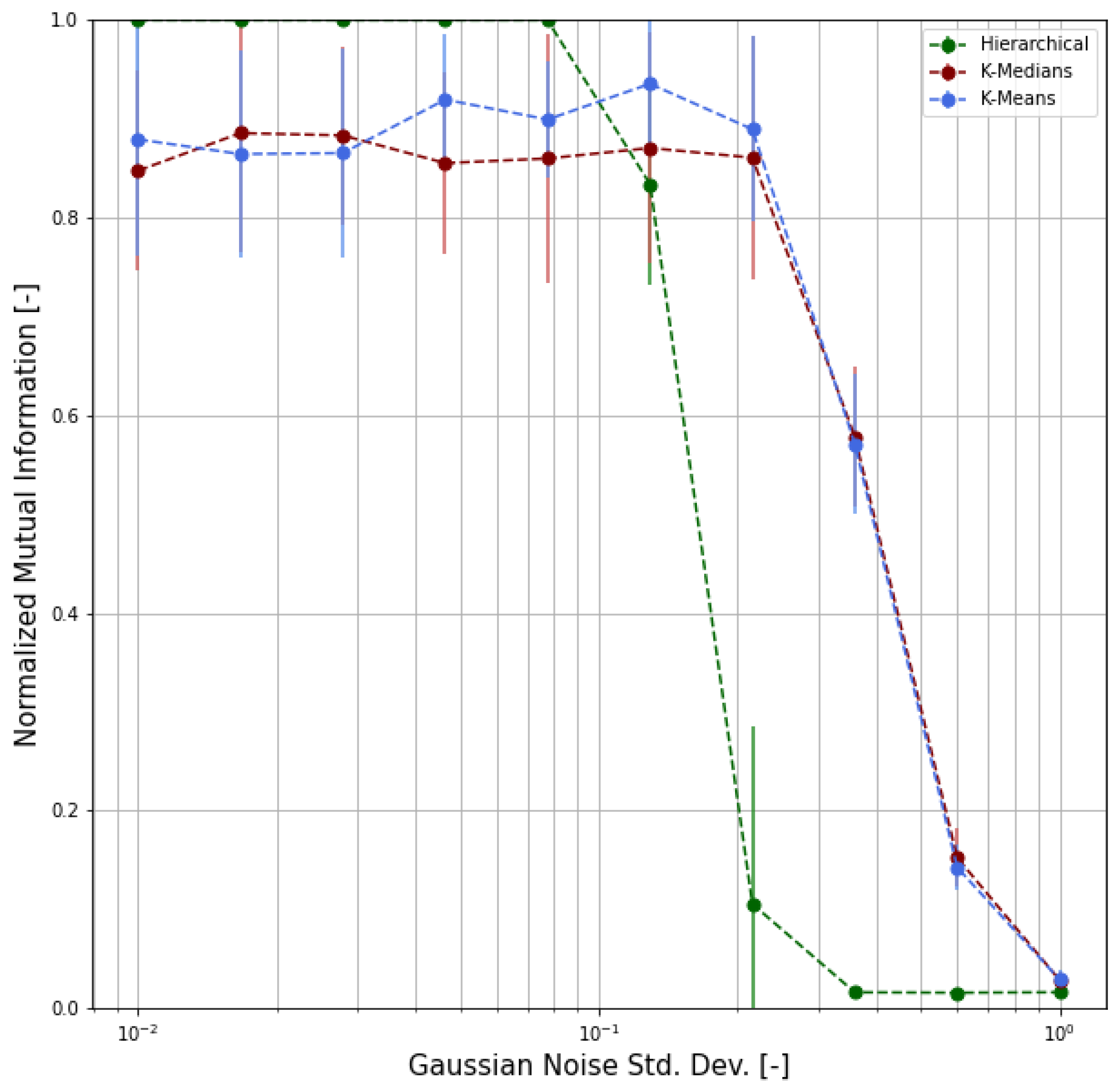
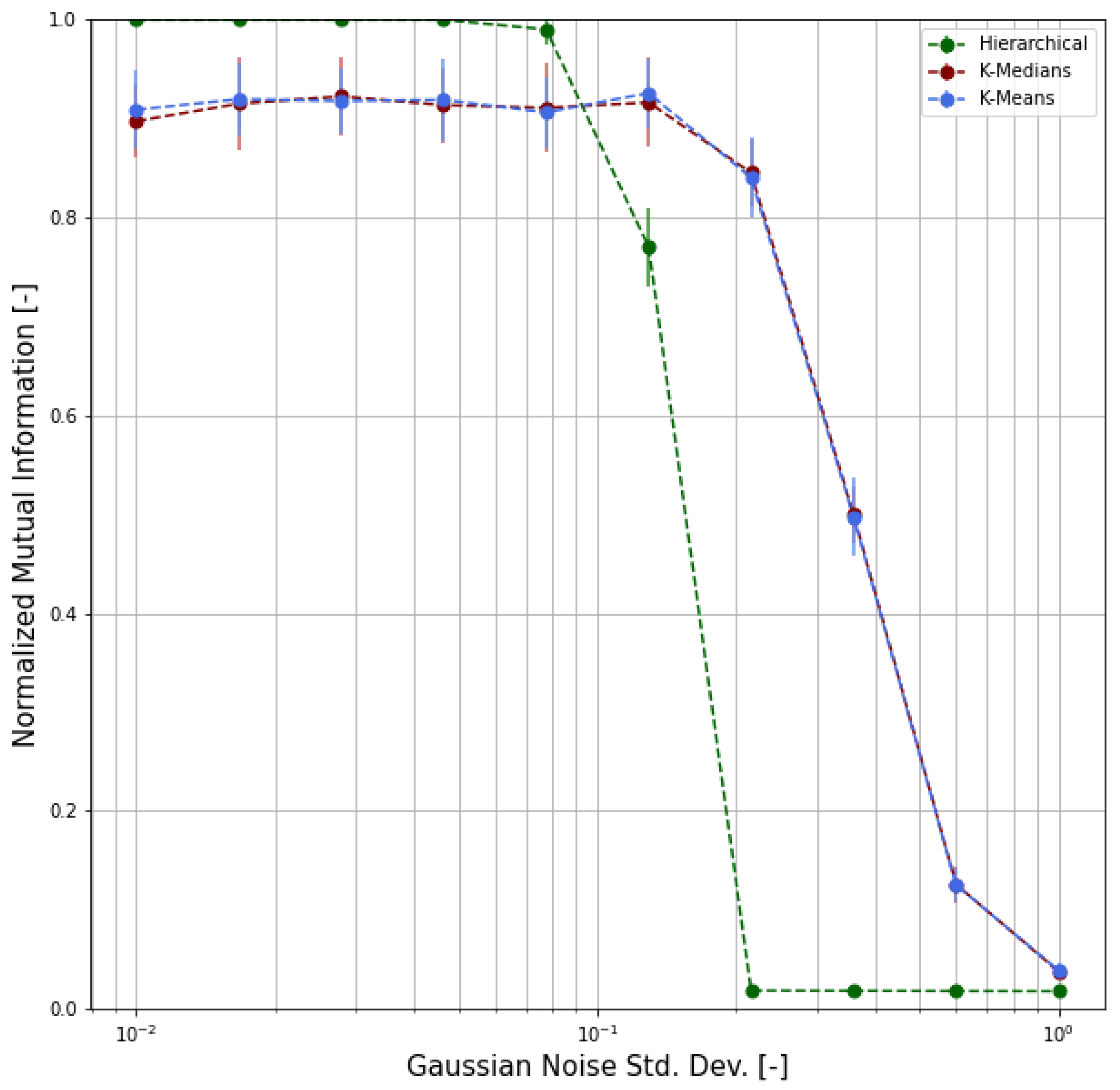
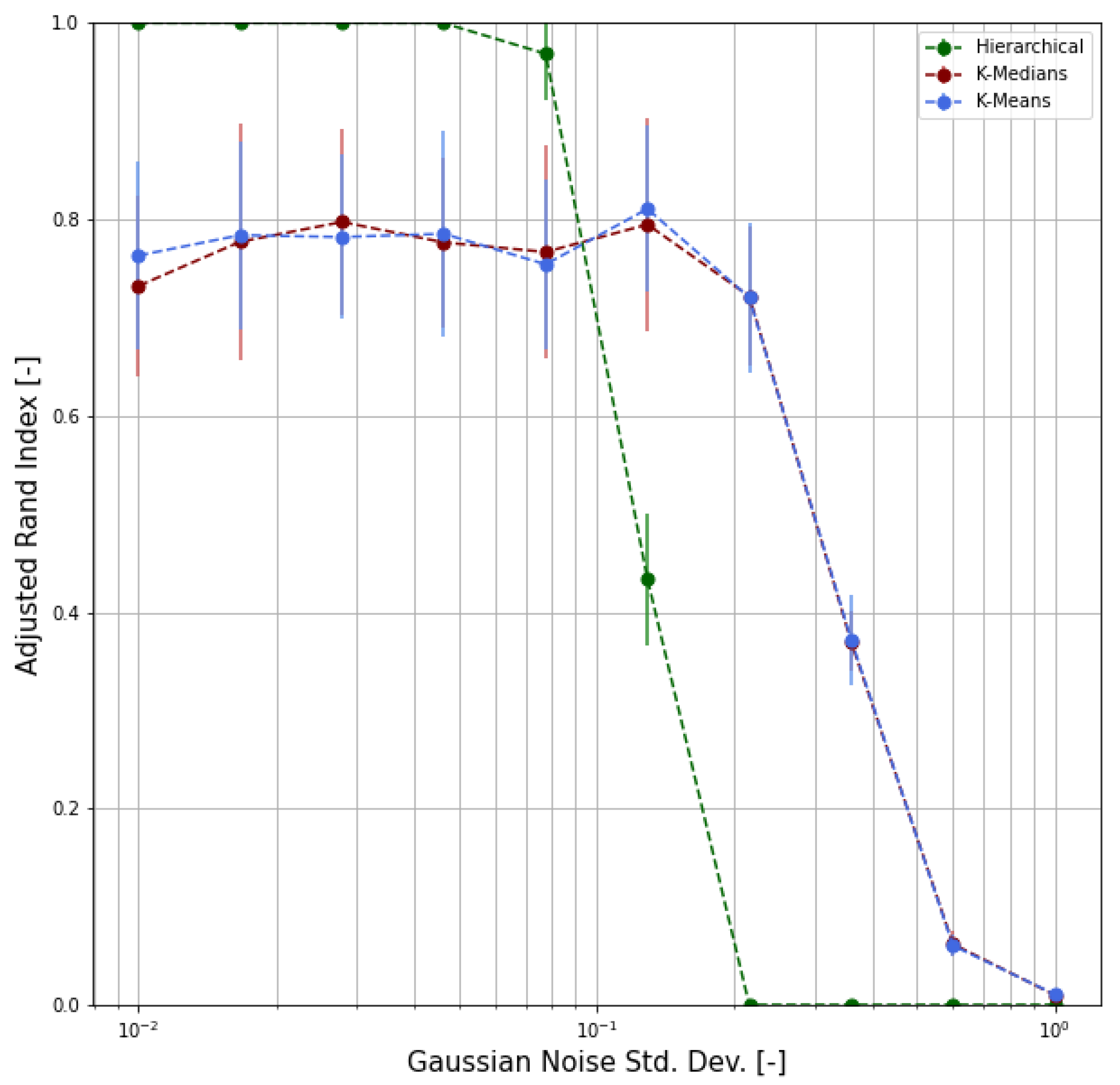
4.3. Validation
- We chose m representative or archetypal poses from our dataset;
- For each pose, we generated 100 samples by adding random noise to the archetypal pose keypoints, where is the radius of inertia of the archetypal pose and is the standard deviation of the Gaussian distribution;
- We obtained, as a result, a labeled dataset of samples;
- Based on this synthetic dataset, we were able to evaluate the clustering performance by means of proper functions and indicators.
- Adjusted Rand Index (ARI), which measures the similarity between the ground-truth assignment and the clustering, ignoring permutations and with chance normalization [31];
- Two different normalized versions of the Mutual Information function (which measures the agreement of the two assignments, ignoring permutations), namely the Normalized Mutual Information (NMI) and the Adjusted Mutual Information (AMI), where the latter is normalized against chance [32].
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Methodology
Appendix A.1. First Method
Appendix A.2. Second Method
Appendix A.3. Mirroring and Turning
Appendix B. Ablation Studies
Appendix B.1. Focus on the Standard Deviation Range




Appendix B.2. Number of Iterations






References
- Impett, L.; Süsstrunk, S. Pose and Pathosformel in Aby Warburg’s Bilderatlas. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 888–902. [Google Scholar]
- Aby Warburg Mnemosyne Atlas. Available online: http://www.engramma.it/eOS/core/frontend/eos_atlas_index.php (accessed on 3 February 2021).
- The Warburg Institute. The Warburg Institute Archive. 2018. Available online: https://warburg.sas.ac.uk/library-collections/warburg-institute-archive (accessed on 26 August 2020).
- le Fevre Grundtmann, N. Digitising Aby Warburg’s Mnemosyne Atlas. Theory Cult. Soc. 2020, 37, 3–26. [Google Scholar] [CrossRef]
- Didi-Huberman, G. L’image Survivante Histoire de l’Art et Temps des Fantômes Selon aby Warburg; Les Éditions de Minuit: Paris, France, 2002. [Google Scholar]
- Becker, C. Aby Warburg’s Pathosformel as methodological paradigm. J. Art Historiogr. 2013, 9, CB1. [Google Scholar]
- imgs.ai. Available online: http://imgs.ai/ (accessed on 20 March 2021).
- Barmpoutis, A.; Bozia, E.; Fortuna, D. Interactive 3D Digitization, Retrieval, and Analysis of Ancient Sculptures, Using Infrared Depth Sensors for Mobile Devices. In International Conference on Universal Access in Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–11. [Google Scholar]
- Freedberg, D.; Gallese, V. Motion, emotion and empathy in esthetic experience. Trends Cogn. Sci. 2007, 11, 197–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, Z.; Hidalgo Martinez, G.; Simon, T.; Wei, S.; Sheikh, Y.A. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jenicek, T.; Chum, O. Linking Art through Human Poses. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1338–1345. [Google Scholar]
- Madhu, P.; Villar-Corrales, A.; Kosti, R.; Bendschus, T.; Reinhardt, C.; Bell, P.; Maier, A.; Christlein, V. Enhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning. arXiv 2020, arXiv:2012.05616. [Google Scholar]
- Madhu, P.; Marquart, T.; Kosti, R.; Bell, P.; Maier, A.; Christlein, V. Understanding Compositional Structures in Art Historical Images Using Pose and Gaze Priors. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 109–125. [Google Scholar]
- Hidalgo, G. Openpose. Available online: https://github.com/CMU-Perceptual-Computing-Lab/openpose/ (accessed on 1 May 2020).
- Scala Archives. Available online: http://www.scalarchives.com/ (accessed on 1 September 2020).
- Art Resource. Available online: https://www.artres.com/ (accessed on 1 September 2020).
- Impett, L. Analyzing Gesture in Digital Art History. In The Routledge Companion to Digital Humanities and Art History; Brown, K., Ed.; Routledge: Oxfordshire, UK, 2020. [Google Scholar]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Carneiro, G.; Da Silva, N.P.; Del Bue, A.; Costeira, J.P. Artistic Image Classification: An Analysis on the PRINTART Database. European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 143–157. [Google Scholar]
- Isekenmeier, G. Interpiktorialität: Theorie und Geschichte der Bild-Bild-Bezüge; Transcript Verlag: Bielefeld, Germany, 2014; Volume 42. [Google Scholar]
- Heydemann, N.; Dhabi, A. The Art of Quotation: Forms and Themes of the Art Quote, 1990–2010—An Essay. Vis. Past 2015, 2, 11–64. [Google Scholar]
- Impett, L.; Moretti, F. Totentanz. Operationalizing Aby Warburg’s Pathosformeln; Technical Report; Stanford Literary Lab: Stanford, CA, USA, 2017. [Google Scholar]
- Bell, P.; Impett, L. Ikonographie und Interaktion. Computergestützte Analyse von Posen in Bildern der Beilsgeschichte. Das Mittelalter 2019, 24, 31–53. [Google Scholar] [CrossRef]
- Ferrari, V.; Marin-Jimenez, M.; Zisserman, A. Pose search: Retrieving people using their pose. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1–8. [Google Scholar]
- Eichner, M.; Marin-Jimenez, M.; Zisserman, A.; Ferrari, V. 2D Articulated Human Pose Estimation and Retrieval in (Almost) Unconstrained Still Images. Int. J. Comput. Vis. 2012, 99, 190–214. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Pena, J.M.; Lozano, J.A.; Larranaga, P. An empirical comparison of four initialization methods for the K-Means algorithm. Pattern Recogn. Lett. 1999, 20, 1027–1040. [Google Scholar] [CrossRef]
- Forgey, E. Cluster Analysis of Multivariate Data: Efficiency versus Interpretability of Classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing Partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Vinh, N.X.; Epps, J.; Bailey, J. Information Theoretic Measures for Clusterings Comparison: Variants, Properties, Normalization and Correction for Chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Fisher, N.I. Statistical Analysis of Circular Data; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]























Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marsocci, V.; Lastilla, L. POSE-ID-on—A Novel Framework for Artwork Pose Clustering. ISPRS Int. J. Geo-Inf. 2021, 10, 257. https://doi.org/10.3390/ijgi10040257
Marsocci V, Lastilla L. POSE-ID-on—A Novel Framework for Artwork Pose Clustering. ISPRS International Journal of Geo-Information. 2021; 10(4):257. https://doi.org/10.3390/ijgi10040257
Chicago/Turabian StyleMarsocci, Valerio, and Lorenzo Lastilla. 2021. "POSE-ID-on—A Novel Framework for Artwork Pose Clustering" ISPRS International Journal of Geo-Information 10, no. 4: 257. https://doi.org/10.3390/ijgi10040257
APA StyleMarsocci, V., & Lastilla, L. (2021). POSE-ID-on—A Novel Framework for Artwork Pose Clustering. ISPRS International Journal of Geo-Information, 10(4), 257. https://doi.org/10.3390/ijgi10040257