
Assessing the Generalization of Machine Learning-Based Slope Failure Prediction to New Geographic Extents

 ,
,
Abstract
:1. Introduction
2. Background
2.1. Model Generalization
2.2. Probabilistic Spatial Models with Random Forest
2.3. Digital Terrain Data for Landslide Mapping and Modeling
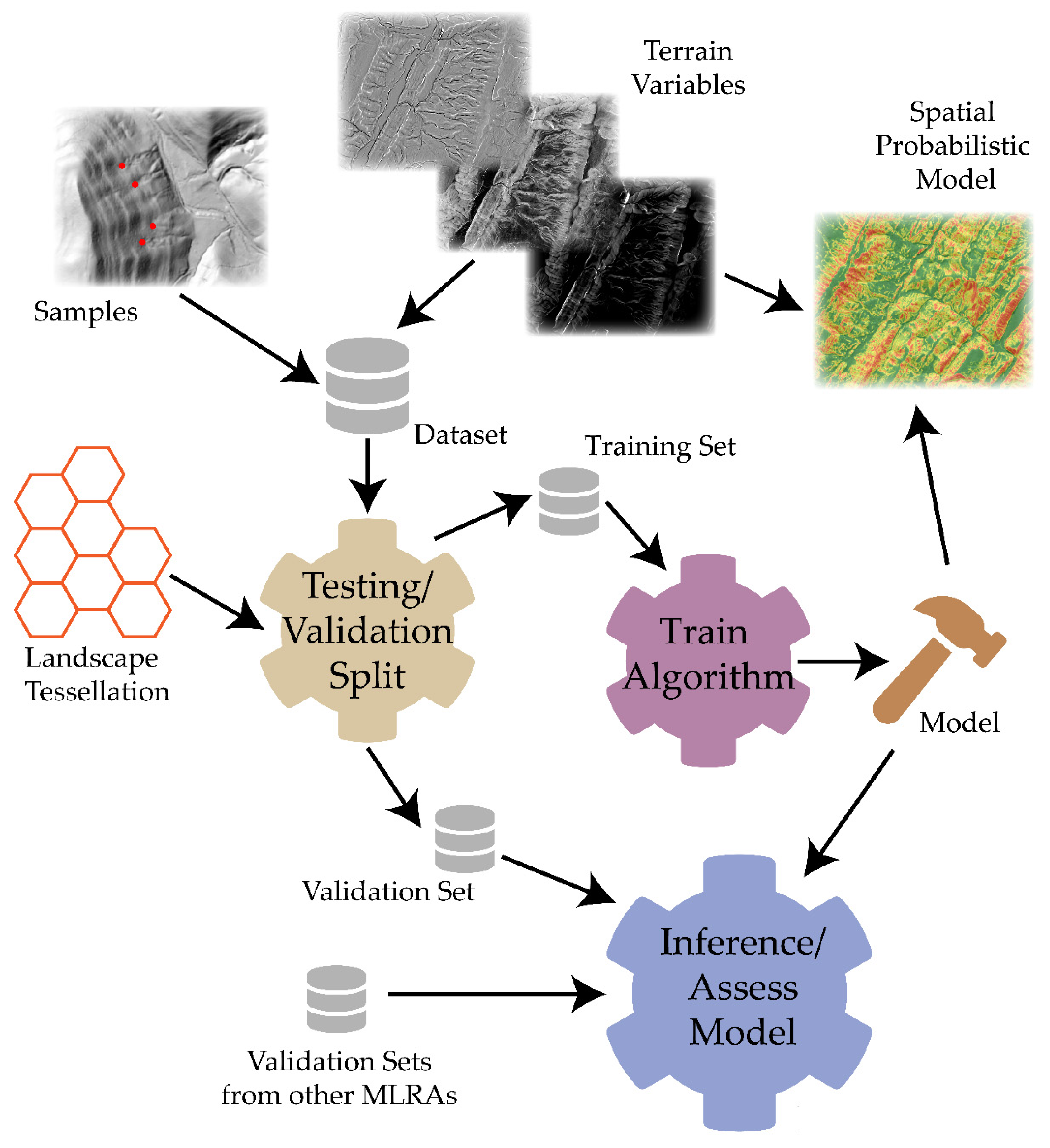
3. Methods
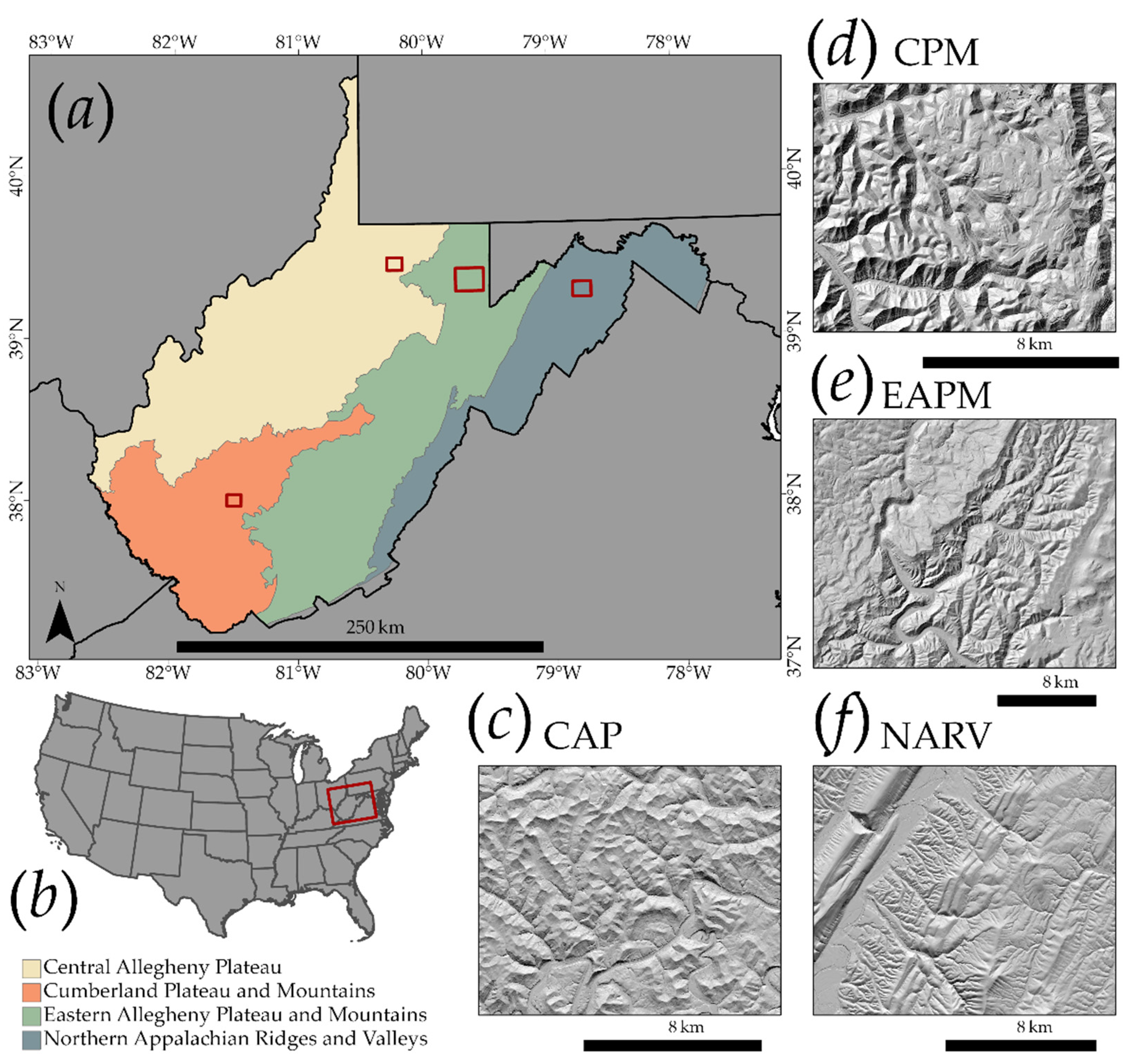
3.1. Study Area
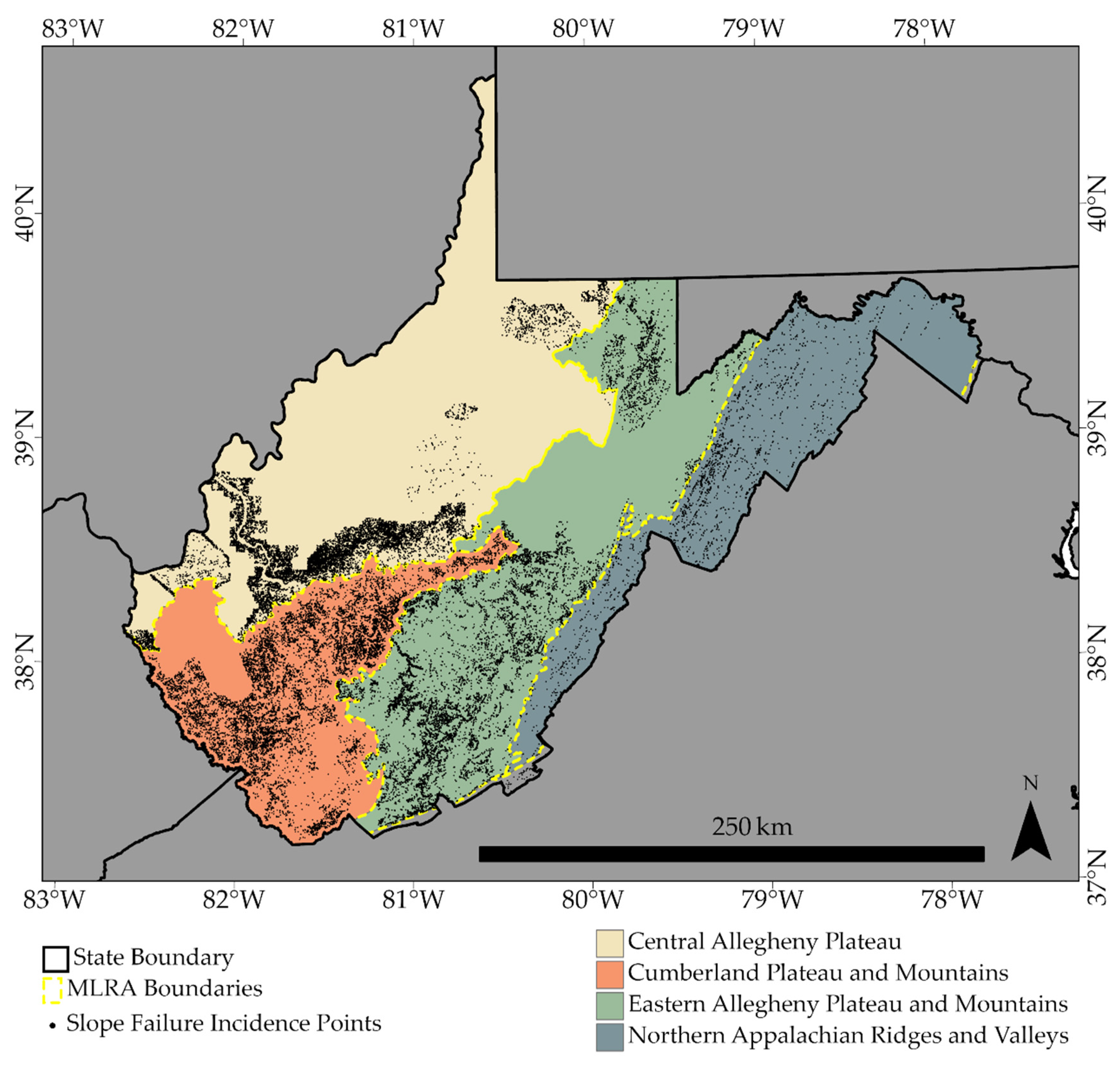
3.2. Landslide Inventory and Training Data Development
3.3. Topographic Predictor Variables
3.4. Model Training and Prediction
3.5. Model Validation and Variable Importance
4. Results
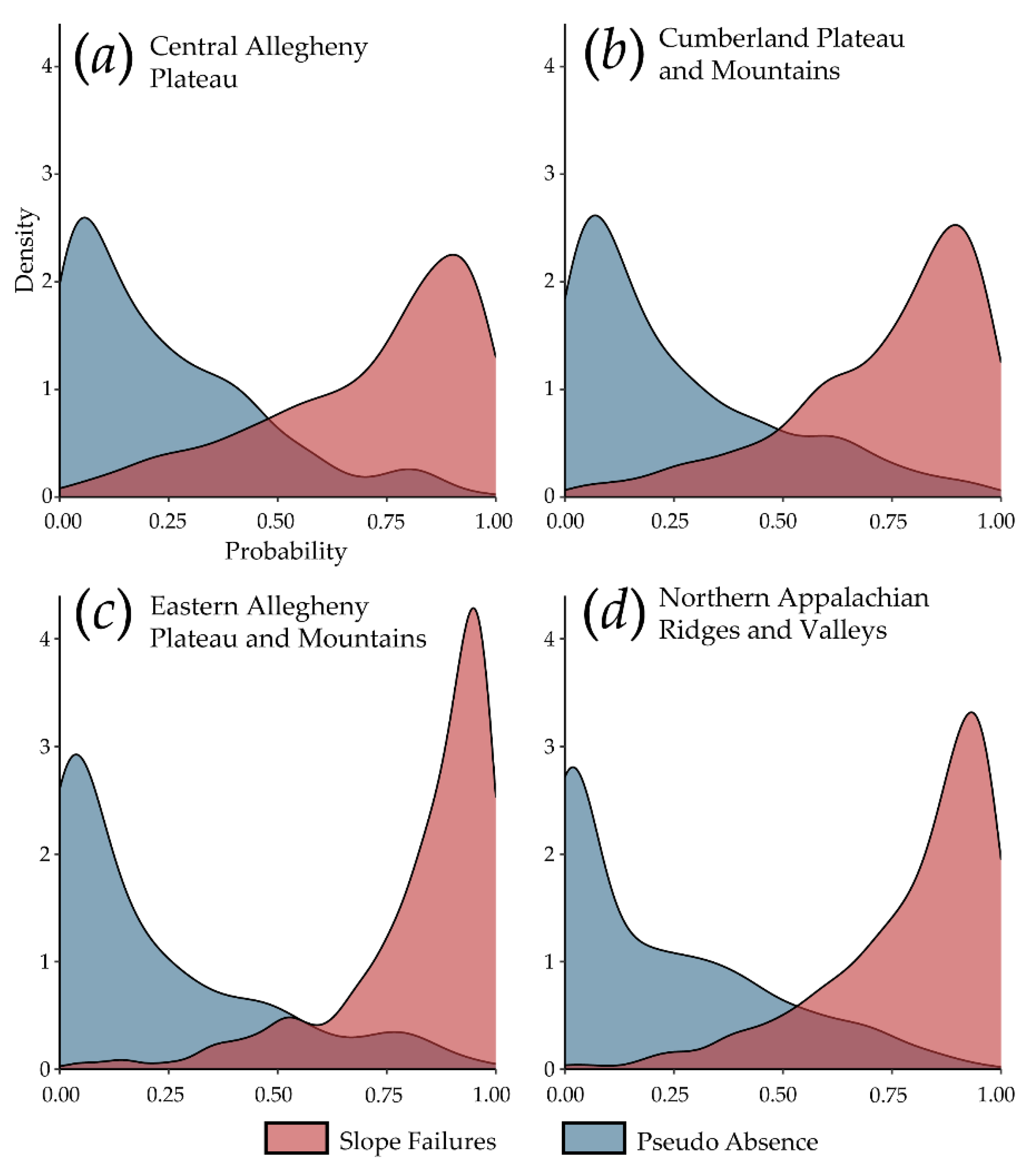
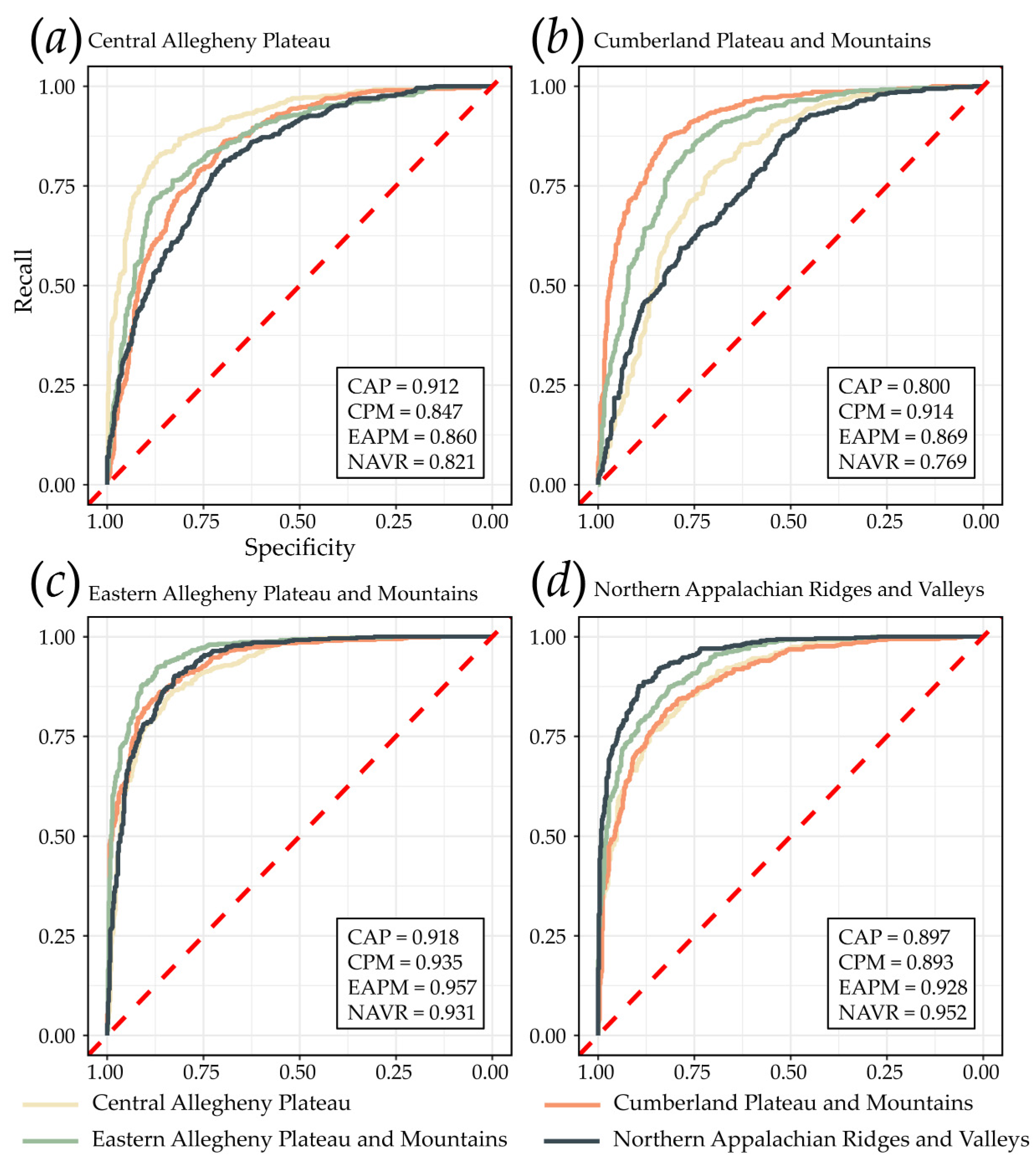
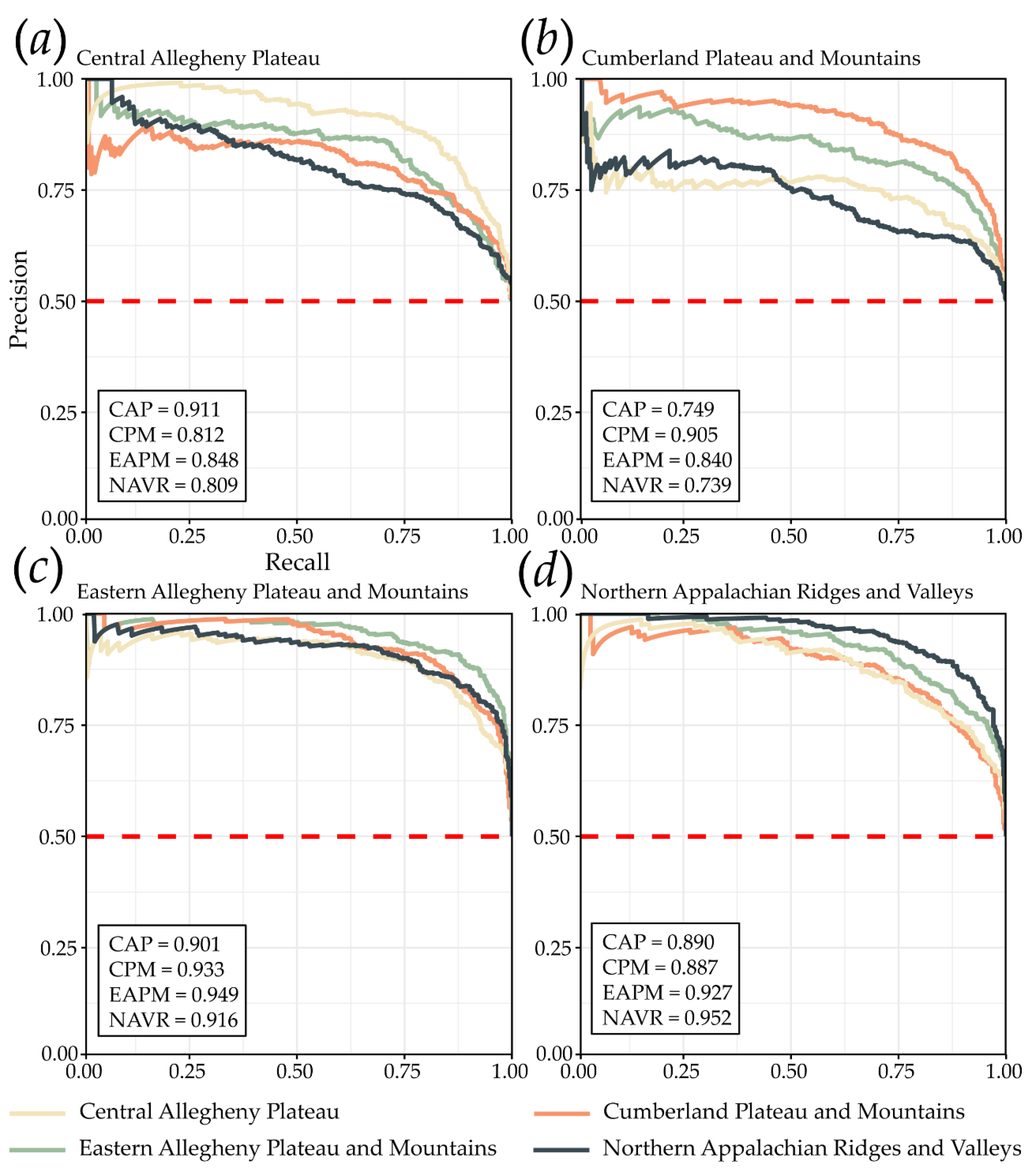
4.1. Model Performance within Same MLRA
4.2. Model Generalization to Different MLRAs
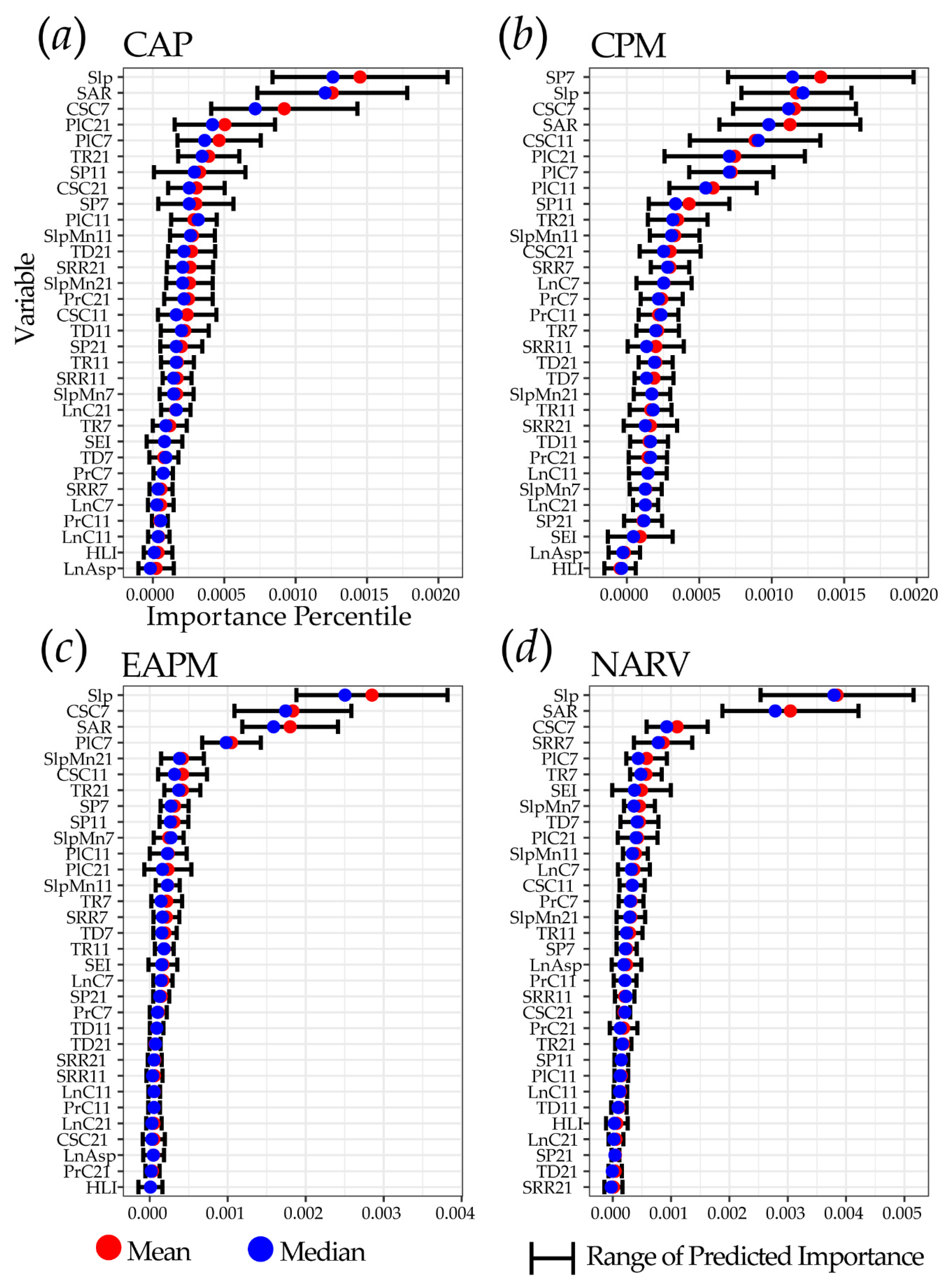
4.3. Comparison of Variable Importance Between MLRAs
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Petley, D. Global Patterns of Loss of Life from Landslides. Geology 2012, 40, 927–930. [Google Scholar] [CrossRef]
- Turner, A.K. Social and Environmental Impacts of Landslides. Innov. Infrastruct. Solut. 2018, 3, 70. [Google Scholar] [CrossRef]
- Highland, L.M.; Bobrowsky, P. The Landslide Handbook—A Guide to Understanding Landslides; Circular; U.S. Geological Survey: Reston, VA, USA, 2008; p. 147. [Google Scholar]
- Casagli, N.; Cigna, F.; Bianchini, S.; Hölbling, D.; Füreder, P.; Righini, G.; Del Conte, S.; Friedl, B.; Schneiderbauer, S.; Iasio, C.; et al. Landslide Mapping and Monitoring by Using Radar and Optical Remote Sensing: Examples from the EC-FP7 Project SAFER. Remote Sens. Appl. Soc. Environ. 2016, 4, 92–108. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Meena, S.R.; Blaschke, T.; Aryal, J. UAV-Based Slope Failure Detection Using Deep-Learning Convolutional Neural Networks. Remote Sens. 2019, 11, 2046. [Google Scholar] [CrossRef] [Green Version]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide Inventory Mapping From Bitemporal Images Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Lu, P.; Stumpf, A.; Kerle, N.; Casagli, N. Object-Oriented Change Detection for Landslide Rapid Mapping. IEEE Geosci. Remote Sens. Lett. 2011, 8, 701–705. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Combining Random Forests and Object-Oriented Analysis for Landslide Mapping from Very High Resolution Imagery. Procedia Environ. Sci. 2011, 3, 123–129. [Google Scholar] [CrossRef] [Green Version]
- Ballabio, C.; Sterlacchini, S. Support Vector Machines for Landslide Susceptibility Mapping: The Staffora River Basin Case Study, Italy. Math. Geosci. 2012, 44, 47–70. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, L. Review on Landslide Susceptibility Mapping Using Support Vector Machines. CATENA 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Kim, J.-C.; Lee, S.; Jung, H.-S.; Lee, S. Landslide Susceptibility Mapping Using Random Forest and Boosted Tree Models in Pyeong-Chang, Korea. Geocarto Int. 2018, 33, 1000–1015. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide Susceptibility Assessment Using SVM Machine Learning Algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Taalab, K.; Cheng, T.; Zhang, Y. Mapping Landslide Susceptibility and Types Using Random Forest. Big Earth Data 2018, 2, 159–178. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide Susceptibility Assessment in Vietnam Using Support Vector Machines, Decision Tree, and Naïve Bayes Models. Math. Probl. Eng. 2012, 2012, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Tham, L.G.; Dai, F.C. Landslide Susceptibility Mapping Based on Support Vector Machine: A Case Study on Natural Slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Sharma, M.; Kite, J.S.; Donaldson, K.A.; Thompson, J.A.; Bell, M.L.; Maynard, S.M. Slope Failure Prediction Using Random Forest Machine Learning and LiDAR in an Eroded Folded Mountain Belt. Remote Sens. 2020, 12, 486. [Google Scholar] [CrossRef] [Green Version]
- Mahalingam, R.; Olsen, M.J.; O’Banion, M.S. Evaluation of Landslide Susceptibility Mapping Techniques Using Lidar-Derived Conditioning Factors (Oregon Case Study). Geomat. Nat. Hazards Risk 2016, 7, 1884–1907. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Tien Bui, D.; Sahana, M.; Chen, C.-W.; Zhu, Z.; Wang, W.; Thai Pham, B. Evaluating GIS-Based Multiple Statistical Models and Data Mining for Earthquake and Rainfall-Induced Landslide Susceptibility Using the LiDAR DEM. Remote Sens. 2019, 11, 638. [Google Scholar] [CrossRef] [Green Version]
- Höfle, B.; Rutzinger, M. Topographic Airborne LiDAR in Geomorphology: A Technological Perspective. Z. fur Geomorphol. Suppl. 2011, 55, 1–29. [Google Scholar] [CrossRef]
- Jaboyedoff, M.; Oppikofer, T.; Abellán, A.; Derron, M.-H.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in Landslide Investigations: A Review. Nat. Hazards 2012, 61, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital Terrain Modelling: A Review of Hydrological, Geomorphological, and Biological Applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Arundel, S.T.; Phillips, L.A.; Lowe, A.J.; Bobinmyer, J.; Mantey, K.S.; Dunn, C.A.; Constance, E.W.; Usery, E.L. Preparing The National Map for the 3D Elevation Program—Products, Process and Research. Cartogr. Geogr. Inf. Sci. 2015, 42, 40–53. [Google Scholar] [CrossRef]
- Stoker, J.M.; Abdullah, Q.A.; Nayegandhi, A.; Winehouse, J. Evaluation of Single Photon and Geiger Mode Lidar for the 3D Elevation Program. Remote Sens. 2016, 8, 767. [Google Scholar] [CrossRef] [Green Version]
- Bobrowsky, P.; Highland, L. The Landslide Handbook-a Guide to Understanding Landslides: A Landmark Publication for Landslide Education and Preparedness. In Landslides: Global Risk Preparedness; Sassa, K., Rouhban, B., Briceño, S., McSaveney, M., He, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 75–84. ISBN 978-3-642-22087-6. [Google Scholar]
- Kawaguchi, K.; Kaelbling, L.P.; Bengio, Y. Generalization in Deep Learning. arXiv 2020, arXiv:1710.05468. [Google Scholar]
- Maxwell, A.E.; Pourmohammadi, P.; Poyner, J.D. Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sens. 2020, 12, 547. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P. Predicting Palustrine Wetland Probability Using Random Forest Machine Learning and Digital Elevation Data-Derived Terrain Variables. Photogramm. Eng. Remote Sens. 2016, 82, 437–447. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sens. 2020, 12, 4145. [Google Scholar] [CrossRef]
- Neyshabur, B.; Bhojanapalli, S.; McAllester, D.; Srebro, N. Exploring Generalization in Deep Learning. arXiv 2017, arXiv:1706.08947. [Google Scholar]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forest Classification of Multisource Remote Sensing and Geographic Data. In Proceedings of the IGARSS 2004, 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; Volume 2, pp. 1049–1052. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Ramezan, C.A.; Morgan, A.N.; Pauley, C.E. Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations. Remote Sens. 2019, 11, 1409. [Google Scholar] [CrossRef] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for Land Cover Classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Evans, J.S.; Cushman, S.A. Gradient Modeling of Conifer Species Using Random Forests. Landsc. Ecol. 2009, 24, 673–683. [Google Scholar] [CrossRef]
- Strager, M.P.; Strager, J.M.; Evans, J.S.; Dunscomb, J.K.; Kreps, B.J.; Maxwell, A.E. Combining a Spatial Model and Demand Forecasts to Map Future Surface Coal Mining in Appalachia. PLoS ONE 2015, 10, e0128813. [Google Scholar] [CrossRef]
- Wright, C.; Gallant, A. Improved Wetland Remote Sensing in Yellowstone National Park Using Classification Trees to Combine TM Imagery and Ancillary Environmental Data. Remote Sens. Environ. 2007, 107, 582–605. [Google Scholar] [CrossRef]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide Susceptibility Estimation by Random Forests Technique: Sensitivity and Scaling Issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef] [Green Version]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating Machine Learning and Statistical Prediction Techniques for Landslide Susceptibility Modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.-X.; Chen, W.; Ahmad, B.B. Landslide Susceptibility Mapping Using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest Ensembles in the Guangchang Area (China). CATENA 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests Techniques for Shallow Landslide Susceptibility Assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide Susceptibility Mapping Using Random Forest, Boosted Regression Tree, Classification and Regression Tree, and General Linear Models and Comparison of Their Performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A.-X. GIS-Based Landslide Susceptibility Evaluation Using a Novel Hybrid Integration Approach of Bivariate Statistical Based Random Forest Method. CATENA 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Kerle, N. Random Forests and Evidential Belief Function-Based Landslide Susceptibility Assessment in Western Mazandaran Province, Iran. Environ. Earth Sci. 2016, 75, 185. [Google Scholar] [CrossRef]
- Goetz, J.N.; Guthrie, R.H.; Brenning, A. Integrating Physical and Empirical Landslide Susceptibility Models Using Generalized Additive Models. Geomorphology 2011, 129, 376–386. [Google Scholar] [CrossRef]
- Nichol, J.; Wong, M.S. Satellite Remote Sensing for Detailed Landslide Inventories Using Change Detection and Image Fusion. Int. J. Remote Sens. 2005, 26, 1913–1926. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-Oriented Mapping of Landslides Using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Lei, T.; Zhang, Q.; Xue, D.; Chen, T.; Meng, H.; Nandi, A.K. End-to-End Change Detection Using a Symmetric Fully Convolutional Network for Landslide Mapping. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3027–3031. [Google Scholar]
- Liu, Y.; Wu, L. Geological Disaster Recognition on Optical Remote Sensing Images Using Deep Learning. Procedia Comput. Sci. 2016, 91, 566–575. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, X.; Jian, J. Remote Sensing Landslide Recognition Based on Convolutional Neural Network. Available online: https://www.hindawi.com/journals/mpe/2019/8389368/ (accessed on 24 January 2020).
- Passalacqua, P.; Belmont, P.; Staley, D.M.; Simley, J.D.; Arrowsmith, J.R.; Bode, C.A.; Crosby, C.; DeLong, S.B.; Glenn, N.F.; Kelly, S.A.; et al. Analyzing High Resolution Topography for Advancing the Understanding of Mass and Energy Transfer through Landscapes: A Review. Earth Sci. Rev. 2015, 148, 174–193. [Google Scholar] [CrossRef] [Green Version]
- Warner, T.A.; Foody, G.M.; Nellis, M.D. The SAGE Handbook of Remote Sensing; SAGE Publications: Thousand Oaks, CA, USA, 2009; ISBN 978-1-4129-3616-3. [Google Scholar]
- Różycka, M.; Migoń, P.; Michniewicz, A. Topographic Wetness Index and Terrain Ruggedness Index in Geomorphic Characterisation of Landslide Terrains, on Examples from the Sudetes, SW Poland. Available online: https://www.ingentaconnect.com/content/schweiz/zfgs/2017/00000061/00000002/art00005 (accessed on 13 November 2019).
- Pike, R.J.; Wilson, S.E. Elevation-Relief Ratio, Hypsometric Integral, and Geomorphic Area-Altitude Analysis. GSA Bull. 1971, 82, 1079–1084. [Google Scholar] [CrossRef]
- Moreno, M.; Levachkine, S.; Torres, M.; Quintero, R. Geomorphometric Analysis of Raster Image Data to Detect Terrain Ruggedness and Drainage Density. In Proceedings of the Progress in Pattern Recognition, Speech and Image Analysis, Havana, Cuba, 26–29 November 2003; Sanfeliu, A., Ruiz-Shulcloper, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 643–650. [Google Scholar]
- Huisman, O. Principles of Geographic Information Systems—An Introductory Textbook. 540. Available online: https://webapps.itc.utwente.nl/librarywww/papers_2009/general/principlesgis.pdf (accessed on 2 May 2021).
- Gessler, P.E.; Moore (deceased), I.D.; McKenzie, N.J.; Ryan, P.J. Soil-Landscape Modelling and Spatial Prediction of Soil Attributes. Int. J. Geogr. Inf. Syst. 1995, 9, 421–432. [Google Scholar] [CrossRef]
- Zevenbergen, L.W.; Thorne, C.R. Quantitative Analysis of Land Surface Topography. Earth Surf. Process. Landf. 1987, 12, 47–56. [Google Scholar] [CrossRef]
- Albani*, M.; Klinkenberg, B.; Andison, D.W.; Kimmins, J.P. The Choice of Window Size in Approximating Topographic Surfaces from Digital Elevation Models. Int. J. Geogr. Inf. Sci. 2004, 18, 577–593. [Google Scholar] [CrossRef]
- Franklin, S.E. Interpretation and Use of Geomorphometry in Remote Sensing: A Guide and Review of Integrated Applications. Int. J. Remote Sens. 2020, 41, 7700–7733. [Google Scholar] [CrossRef]
- Major Land Resource Area (MLRA) | NRCS Soils. Available online: https://www.nrcs.usda.gov/wps/portal/nrcs/detail/soils/survey/geo/?cid=nrcs142p2_053624 (accessed on 28 February 2021).
- Strausbaugh, P.D.; Core, E.L. Flora of West Virginia; West Virginia University bulletin; West Virginia University: Morgantown, WV, USA, 1952. [Google Scholar]
- Hooke, R.L. Spatial Distribution of Human Geomorphic Activity in the United States: Comparison with Rivers. Earth Surf. Process. Landf. 1999, 24, 687–692. [Google Scholar] [CrossRef]
- Hooke, R.L. On the History of Humans as Geomorphic Agents. Geology 2000, 28, 843–846. [Google Scholar] [CrossRef]
- WVGES. WV Physiographic Provinces. Available online: https://www.wvgs.wvnet.edu/www/maps/pprovinces.htm (accessed on 14 November 2019).
- Fox, J. Mountaintop Removal in West Virginia: An Environmental Sacrifice Zone. Organ. Environ. 1999, 12, 163–183. [Google Scholar] [CrossRef]
- Fritz, K.M.; Fulton, S.; Johnson, B.R.; Barton, C.D.; Jack, J.D.; Word, D.A.; Burke, R.A. Structural and Functional Characteristics of Natural and Constructed Channels Draining a Reclaimed Mountaintop Removal and Valley Fill Coal Mine. J. N. Am. Benthol. Soc. 2010, 29, 673–689. [Google Scholar] [CrossRef] [Green Version]
- Lindberg, T.T.; Bernhardt, E.S.; Bier, R.; Helton, A.M.; Merola, R.B.; Vengosh, A.; Giulio, R.T.D. Cumulative Impacts of Mountaintop Mining on an Appalachian Watershed. Proc. Natl. Acad. Sci. USA 2011, 108, 20929–20934. [Google Scholar] [CrossRef] [Green Version]
- Miller, A.J.; Zégre, N.P. Mountaintop Removal Mining and Catchment Hydrology. Water 2014, 6, 472–499. [Google Scholar] [CrossRef] [Green Version]
- Palmer, M.A.; Bernhardt, E.S.; Schlesinger, W.H.; Eshleman, K.N.; Foufoula-Georgiou, E.; Hendryx, M.S.; Lemly, A.D.; Likens, G.E.; Loucks, O.L.; Power, M.E.; et al. Mountaintop Mining Consequences. Science 2010, 327, 148–149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wickham, J.D.; Riitters, K.H.; Wade, T.G.; Coan, M.; Homer, C. The Effect of Appalachian Mountaintop Mining on Interior Forest. Landsc. Ecol. 2007, 22, 179–187. [Google Scholar] [CrossRef]
- Wickham, J.; Wood, P.B.; Nicholson, M.C.; Jenkins, W.; Druckenbrod, D.; Suter, G.W.; Strager, M.P.; Mazzarella, C.; Galloway, W.; Amos, J. The Overlooked Terrestrial Impacts of Mountaintop Mining. BioScience 2013, 63, 335–348. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P. Assessing Landform Alterations Induced by Mountaintop Mining. Nat. Sci. 2013, 5, 229–237. [Google Scholar] [CrossRef] [Green Version]
- Ross, M.R.V.; McGlynn, B.L.; Bernhardt, E.S. Deep Impact: Effects of Mountaintop Mining on Surface Topography, Bedrock Structure, and Downstream Waters. Environ. Sci. Technol. 2016, 50, 2064–2074. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.-T. Geographic Information System. In International Encyclopedia of Geography; American Cancer Society: Atlanta, GA, USA, 2017; pp. 1–9. ISBN 978-1-118-78635-2. [Google Scholar]
- Maxwell, A.E.; Warner, T.A. Is High Spatial Resolution DEM Data Necessary for Mapping Palustrine Wetlands? Int. J. Remote Sens. 2019, 40, 118–137. [Google Scholar] [CrossRef]
- ArcGIS Pro 2.2; ESRI: Redlands, CA, USA, 2018. Available online: https://www.esri.com/arcgis-blog/products/arcgis-pro/uncategorized/arcgis-pro-2-2-now-available/ (accessed on 2 May 2021).
- Evans, J.S. Jeffreyevans/GradientMetrics; 2020. Available online: https://evansmurphy.wixsite.com/evan (accessed on 2 May 2021).
- Stage, A.R. An Expression for the Effect of Aspect, Slope, and Habitat Type on Tree Growth. For. Sci. 1976, 22, 457–460. [Google Scholar] [CrossRef]
- Lopez, M.; Berry, J.K. Use Surface Area for Realistic Calculations. GeoWorld 2002, 15, 25. [Google Scholar]
- Reily, S.J.; DeGloria, S.D.; Elliot, R.A. Terrain Ruggedness Index That Quantifies Topographic Heterogeneity. Intermt. J. Sci. 1999, 5, 23. [Google Scholar]
- Jacek, S. Landform Characterization with Geographic Information Systems. Photogramm. Eng. Remote Sens. 1997, 63, 183–191. [Google Scholar]
- Evans, I.S. General Geomorphometry, Derivatives of Altitude, and Descriptive Statistics. In Spatial Analysis in Geomorphology; Methuen & Co.: London, UK, 1972; pp. 17–90. [Google Scholar]
- Pike, R.J.; Evans, I.S.; Hengl, T. Chapter 1 Geomorphometry: A Brief Guide. In Developments in Soil Science; Hengl, T., Reuter, H.I., Eds.; Geomorphometry; Elsevier: Amsterdam, The Netherlands, 2009; Volume 33, pp. 3–30. [Google Scholar]
- Ironside, K.E.; Mattson, D.J.; Arundel, T.; Theimer, T.; Holton, B.; Peters, M.; Edwards, T.C.; Hansen, J. Geomorphometry in Landscape Ecology: Issues of Scale, Physiography, and Application. Environ. Ecol. Res. 2018, 6, 397–412. [Google Scholar] [CrossRef]
- McCune, B.; Keon, D. Equations for Potential Annual Direct Incident Radiation and Heat Load. J. Veg. Sci. 2002, 13, 603–606. [Google Scholar] [CrossRef]
- Wood, J. Chapter 14 Geomorphometry in LandSerf. In Developments in Soil Science; Hengl, T., Reuter, H.I., Eds.; Geomorphometry; Elsevier: Amsterdam, The Netherlands, 2009; Volume 33, pp. 333–349. [Google Scholar]
- Wood, J. The Geomorphological Characterisation of Digital Elevation Models. Ph.D. Thesis, University of Leicester, Leicester, UK, 1996. [Google Scholar]
- Module Morphometric Features/SAGA-GIS Module Library Documentation (v2.2.5). Available online: http://www.saga-gis.org/saga_tool_doc/2.2.5/ta_morphometry_23.html (accessed on 14 November 2019).
- SAGA—System for Automated Geoscientific Analyses. Available online: http://www.saga-gis.org/en/index.html (accessed on 14 November 2019).
- Florinsky, I.V. An Illustrated Introduction to General Geomorphometry. Prog. Phys. Geogr. Earth Environ. 2017, 41, 723–752. [Google Scholar] [CrossRef]
- Spearman, C. The Proof and Measurement of Association between Two Things. Int. J. Epidemiol. 2010, 39, 1137–1150. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2020. [Google Scholar] [CrossRef]
- Clopper, C.J.; Pearson, E.S. The Use of Confidence OR Fiducial Limits Illustrated in the Case of the Binomial. Biometrika 1934, 26, 404–413. [Google Scholar] [CrossRef]
- Beck, J.R.; Shultz, E.K. The Use of Relative Operating Characteristic (ROC) Curves in Test Performance Evaluation. Arch. Pathol. Lab. Med. 1986, 110, 13–20. [Google Scholar]
- Bradley, A.P. The Use of the Area under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recogn. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Müller, M. PROC: An Open-Source Package for R and S+ to Analyze and Compare ROC Curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grau, J.; Grosse, I.; Keilwagen, J. PRROC: Computing and Visualizing Precision-Recall and Receiver Operating Characteristic Curves in R. Bioinformatics 2015, 31, 2595–2597. [Google Scholar] [CrossRef]
- Kuhn, M.; Vaughan, D.; RStudio. Yardstick: Tidy Characterizations of Model Performance. 2020. Available online: https://cran.r-project.org/web/packages/yardstick/index.html (accessed on 2 May 2021).
- Strobl, C.; Hothorn, T.; Zeileis, A. Party on! A New, Conditional Variable Importance Measure Available in the Party Package. R J. 2009, 1, 14–17. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional Variable Importance for Random Forests. BMC Bioinform. 2008, 9, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Landslide Hazards—Maps. Available online: https://www.usgs.gov/natural-hazards/landslide-hazards/maps (accessed on 4 March 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MLRA | Abbreviation | Land Area in WV | Number of Slope Failures Mapped |
|---|---|---|---|
| Central Allegheny Plateau | CAP | 22,281 km2 | 15,259 |
| Cumberland Plateau and Mountains | CPM | 11,644 km2 | 12,533 |
| Eastern Allegheny Plateau and Mountains | EAPM | 18,071 km2 | 12,438 |
| Northern Appalachian Ridges and Valleys | NARV | 10,320 km2 | 1799 |
| Variable | Abbreviation | Description | Window Radius (Cells) |
|---|---|---|---|
| Slope Gradient | Slp | Gradient or rate of maximum change in Z as degrees of rise | 1 |
| Mean Slope Gradient | SlpMn | Slope averaged over a local window | 7, 11, 21 |
| Linear Aspect | LnAsp | Transform of topographic aspect to linear variable | 1 |
| Profile Curvature | PrC | Curvature parallel to direction of maximum slope | 7, 11, 21 |
| Plan Curvature | Plc | Curvature perpendicular to direction of maximum slope | 7, 11, 21 |
| Longitudinal Curvature | LnC | Profile curvature intersecting with the plane defined by the surface normal and maximum gradient direction | 7, 11, 21 |
| Cross-Sectional Curvature | CSC | Tangential curvature intersecting with the plane defined by the surface normal and a tangent to the contour-perpendicular to maximum gradient direction | 7, 11, 21 |
| Slope Position | SP | Z—Mean Z | 7, 11, 21 |
| Topographic Roughness | TR | Square root of standard deviation of slope in local window | 7, 11, 21 |
| Topographic Dissection | TD | 7, 11, 21 | |
| Surface Area Ratio | SAR | 1 | |
| Surface Relief Ratio | SRR | 7, 11, 21 | |
| Site Exposure Index | SEI | Measure of exposure based on slope and aspect | 1 |
| Heat Load Index | HLI | Measure of solar insolation based on slope, aspect, and latitude | 1 |
| Reference Data | |||
|---|---|---|---|
| True | False | ||
| Classification Result | True | TP | FP |
| False | FN | TN | |
| MLRA | OA | Kappa | Precision | Recall | Specificity | F1 Score | AUC ROC | AUC PR |
|---|---|---|---|---|---|---|---|---|
| CAP | 0.843 | 0.686 | 0.870 | 0.806 | 0.880 | 0.837 | 0.912 | 0.911 |
| CPM | 0.843 | 0.686 | 0.836 | 0.854 | 0.832 | 0.845 | 0.914 | 0.905 |
| EAPM | 0.890 | 0.780 | 0.864 | 0.926 | 0.854 | 0.894 | 0.957 | 0.949 |
| NAVR | 0.879 | 0.758 | 0.858 | 0.908 | 0.850 | 0.882 | 0.952 | 0.952 |
| Validation Set | Model | OA | Kappa | Precision | Recall | Specificity | F1 Score | AUC ROC | AUC PR |
|---|---|---|---|---|---|---|---|---|---|
| CAP | CAP | 0.843 | 0.686 | 0.870 | 0.806 | 0.880 | 0.837 | 0.912 | 0.911 |
| CAP | CPM | 0.641 | 0.282 | 0.851 | 0.342 | 0.940 | 0.488 | 0.847 | 0.812 |
| CAP | EAPM | 0.795 | 0.590 | 0.814 | 0.764 | 0.826 | 0.788 | 0.860 | 0.848 |
| CAP | NAVR | 0.751 | 0.502 | 0.727 | 0.804 | 0.698 | 0.764 | 0.821 | 0.809 |
| CPM | CAP | 0.734 | 0.468 | 0.750 | 0.702 | 0.766 | 0.725 | 0.800 | 0.749 |
| CPM | CPM | 0.843 | 0.686 | 0.836 | 0.854 | 0.832 | 0.845 | 0.914 | 0.905 |
| CPM | EAPM | 0.734 | 0.468 | 0.662 | 0.958 | 0.510 | 0.783 | 0.869 | 0.840 |
| CPM | NAVR | 0.662 | 0.324 | 0.604 | 0.944 | 0.380 | 0.736 | 0.769 | 0.739 |
| EAPM | CAP | 0.836 | 0.672 | 0.891 | 0.766 | 0.906 | 0.824 | 0.918 | 0.901 |
| EAPM | CPM | 0.796 | 0.592 | 0.925 | 0.644 | 0.948 | 0.759 | 0.935 | 0.933 |
| EAPM | EAPM | 0.890 | 0.780 | 0.864 | 0.926 | 0.854 | 0.894 | 0.957 | 0.949 |
| EAPM | NAVR | 0.849 | 0.698 | 0.794 | 0.942 | 0.756 | 0.862 | 0.931 | 0.916 |
| NAVR | CAP | 0.758 | 0.516 | 0.919 | 0.566 | 0.950 | 0.700 | 0.897 | 0.890 |
| NAVR | CPM | 0.677 | 0.354 | 0.959 | 0.370 | 0.984 | 0.534 | 0.893 | 0.887 |
| NAVR | EAPM | 0.830 | 0.660 | 0.886 | 0.758 | 0.902 | 0.817 | 0.928 | 0.927 |
| NAVR | NAVR | 0.879 | 0.758 | 0.858 | 0.908 | 0.850 | 0.882 | 0.952 | 0.952 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maxwell, A.E.; Sharma, M.; Kite, J.S.; Donaldson, K.A.; Maynard, S.M.; Malay, C.M. Assessing the Generalization of Machine Learning-Based Slope Failure Prediction to New Geographic Extents. ISPRS Int. J. Geo-Inf. 2021, 10, 293. https://doi.org/10.3390/ijgi10050293
Maxwell AE, Sharma M, Kite JS, Donaldson KA, Maynard SM, Malay CM. Assessing the Generalization of Machine Learning-Based Slope Failure Prediction to New Geographic Extents. ISPRS International Journal of Geo-Information. 2021; 10(5):293. https://doi.org/10.3390/ijgi10050293
Chicago/Turabian StyleMaxwell, Aaron E., Maneesh Sharma, J. Steven Kite, Kurt A. Donaldson, Shannon M. Maynard, and Caleb M. Malay. 2021. "Assessing the Generalization of Machine Learning-Based Slope Failure Prediction to New Geographic Extents" ISPRS International Journal of Geo-Information 10, no. 5: 293. https://doi.org/10.3390/ijgi10050293
APA StyleMaxwell, A. E., Sharma, M., Kite, J. S., Donaldson, K. A., Maynard, S. M., & Malay, C. M. (2021). Assessing the Generalization of Machine Learning-Based Slope Failure Prediction to New Geographic Extents. ISPRS International Journal of Geo-Information, 10(5), 293. https://doi.org/10.3390/ijgi10050293