
Heat Maps: Perfect Maps for Quick Reading? Comparing Usability of Heat Maps with Different Levels of Generalization


Abstract
:1. Introduction
- RQ1: How does heat map’s generalization, defined by the size of the kernel radius, influence its effectiveness?
- RQ2: What are the discrepancies between differently generalized heat maps in the context of efficiency and perceived efficiency?
- RQ3: How do users perceive heat map difficulty depending on a generalization level?
2. Background
2.1. Heat Maps and Generalization in Cartography
2.2. Objective and Subjective Metrics
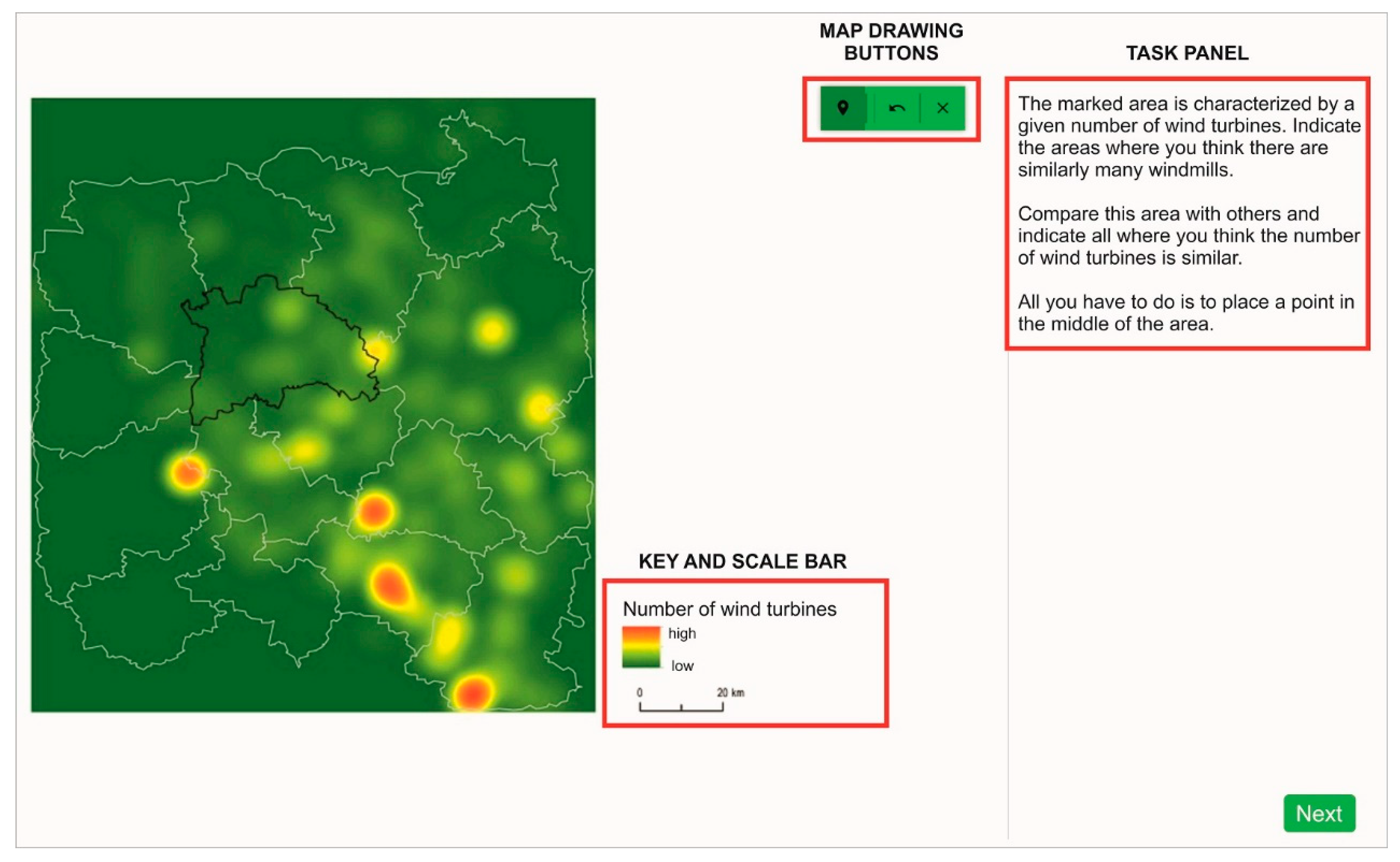
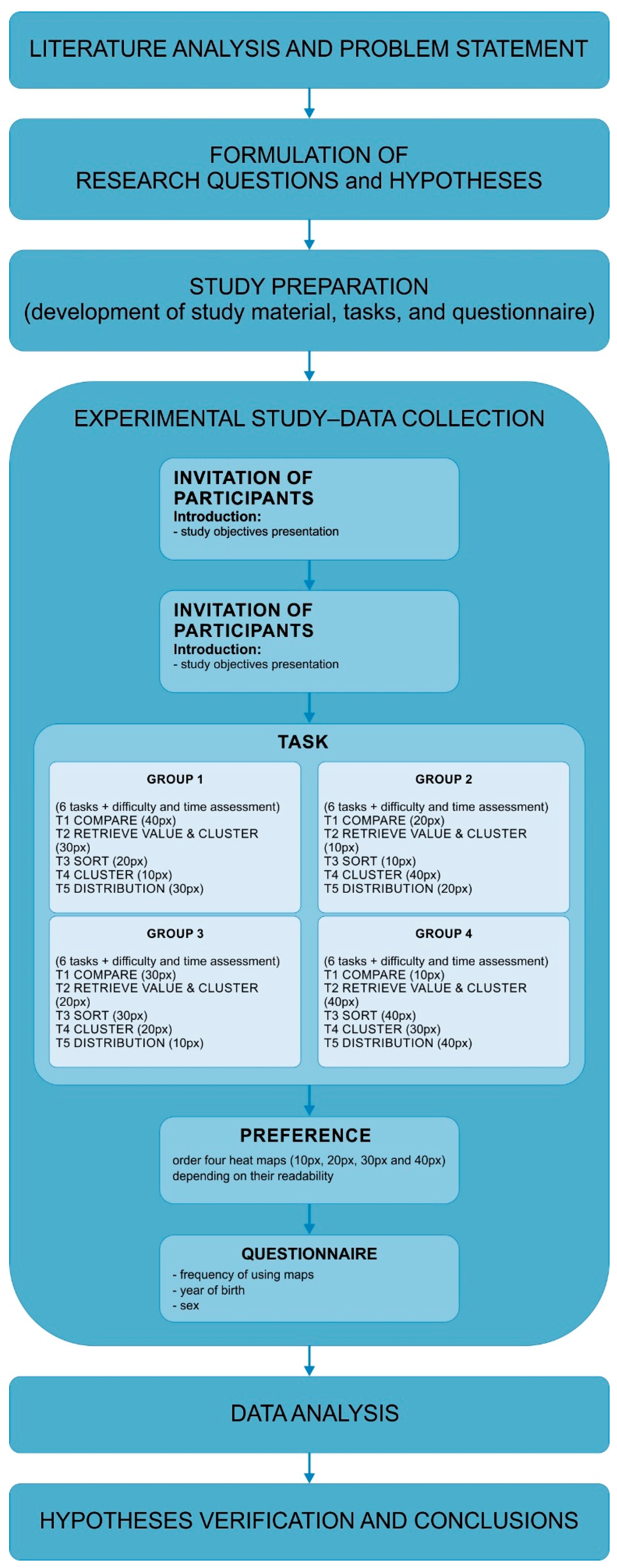
3. User Study
3.1. Study Material
3.2. Participants
3.3. Tasks and Procedures
3.4. Data Analysis
4. Results
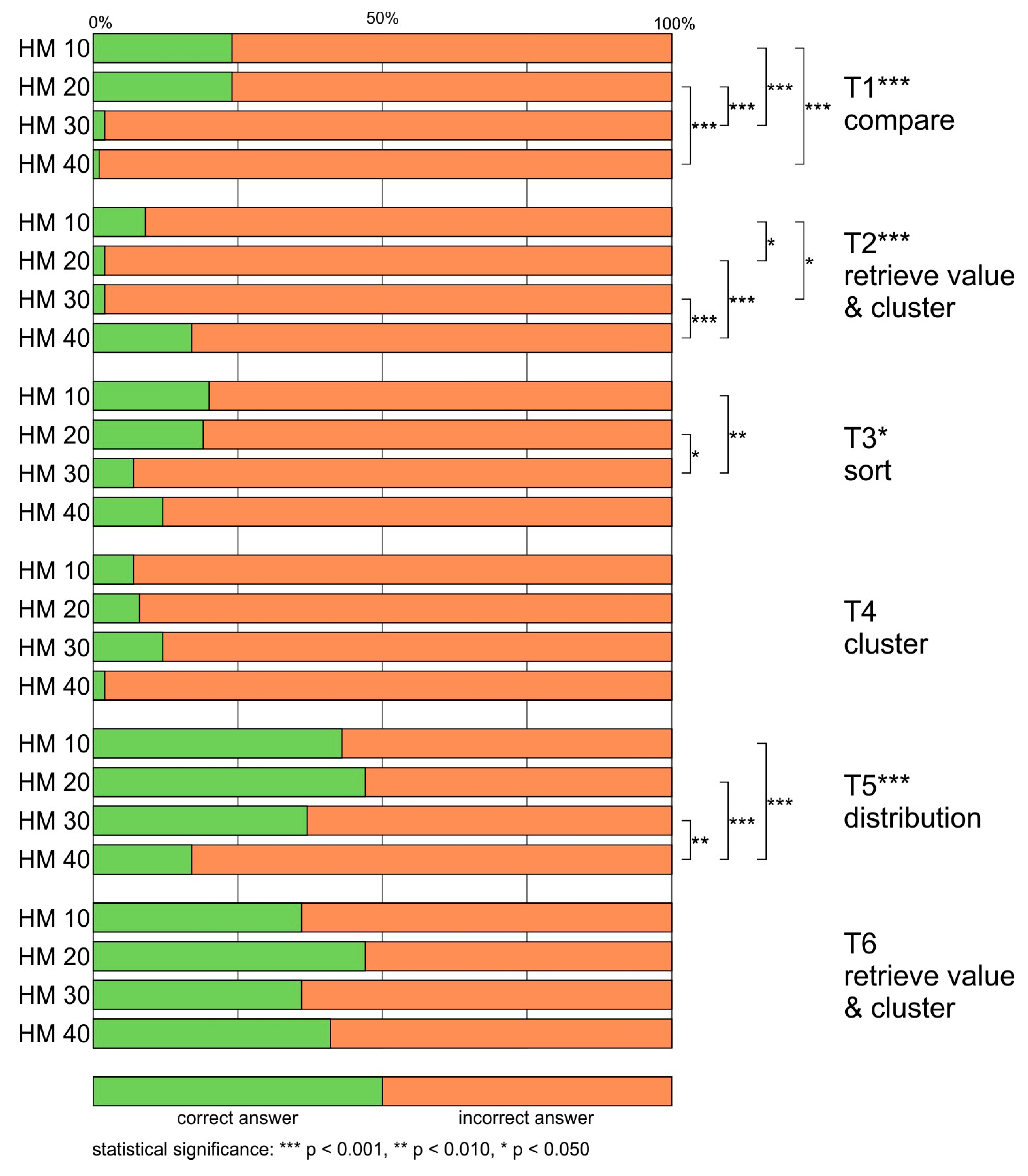
4.1. Answer Correctness
- HM10-HM20 X2 ns (the abbreviation ‘ns’ stands for ‘not statistically significant’);
- HM10-HM30 X2 (1, N = 1238) = 11.483, p < 0.001, Cramér’s V = 0.096, p < 0.001 (with better results for participants working with HM10);
- HM10-HM40 X2 (1, N = 1217) = 13.859, p < 0.001, Cramér’s V = 0.107, p < 0.001 (with better results for participants working with HM10);
- HM20-HM30 X2 (1, N = 1237) = 17.962, p < 0.001, Cramér’s V = 0.110, p < 0.001 (with better results for participants working with HM20);
- HM20-HM40 X2 (1, N = 1216) = 17.600, p < 0.001, Cramér’s V = 0.120, p < 0.001 (with better results for participants working with HM20);
- HM30-HM40 ns.
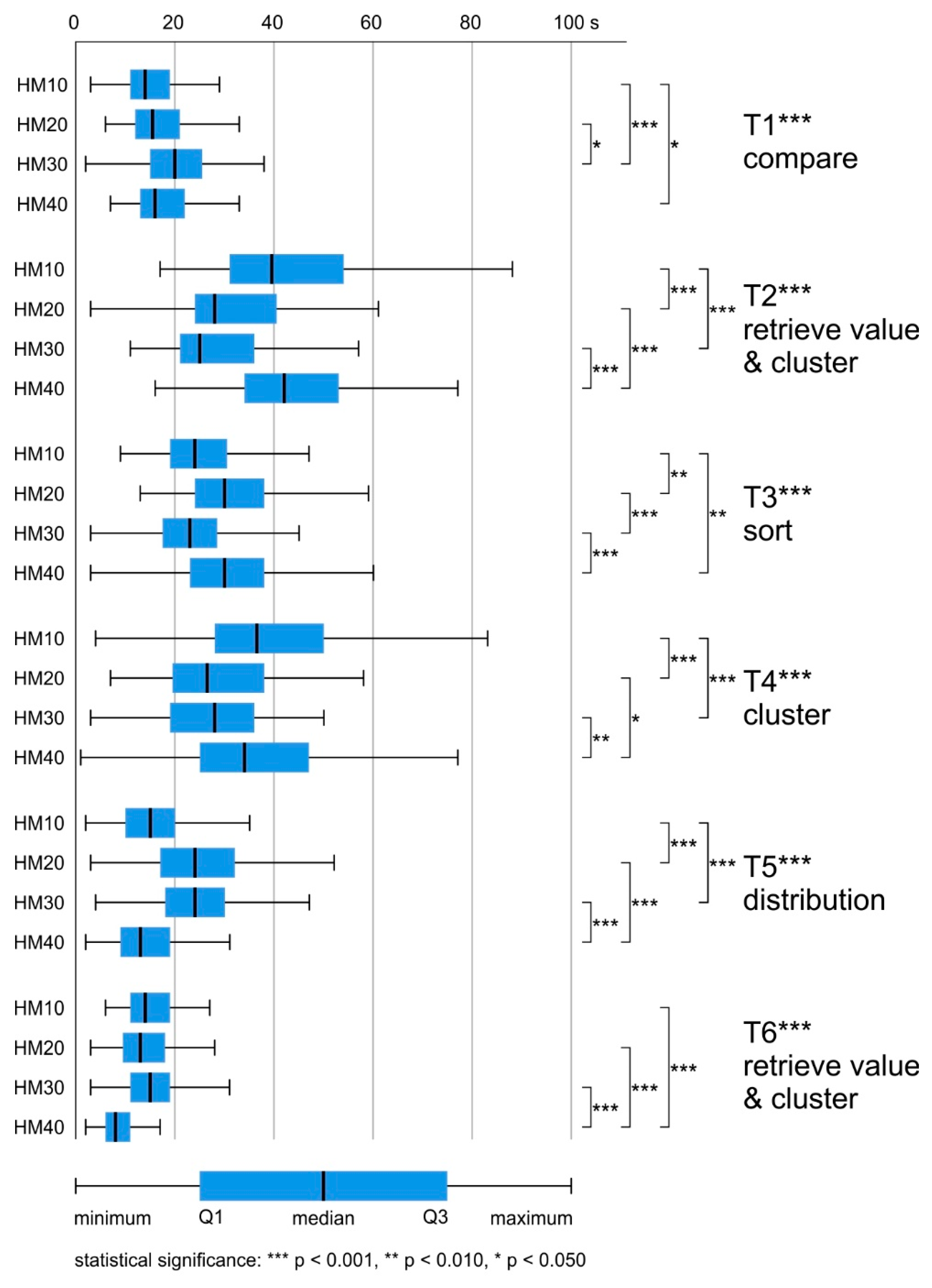
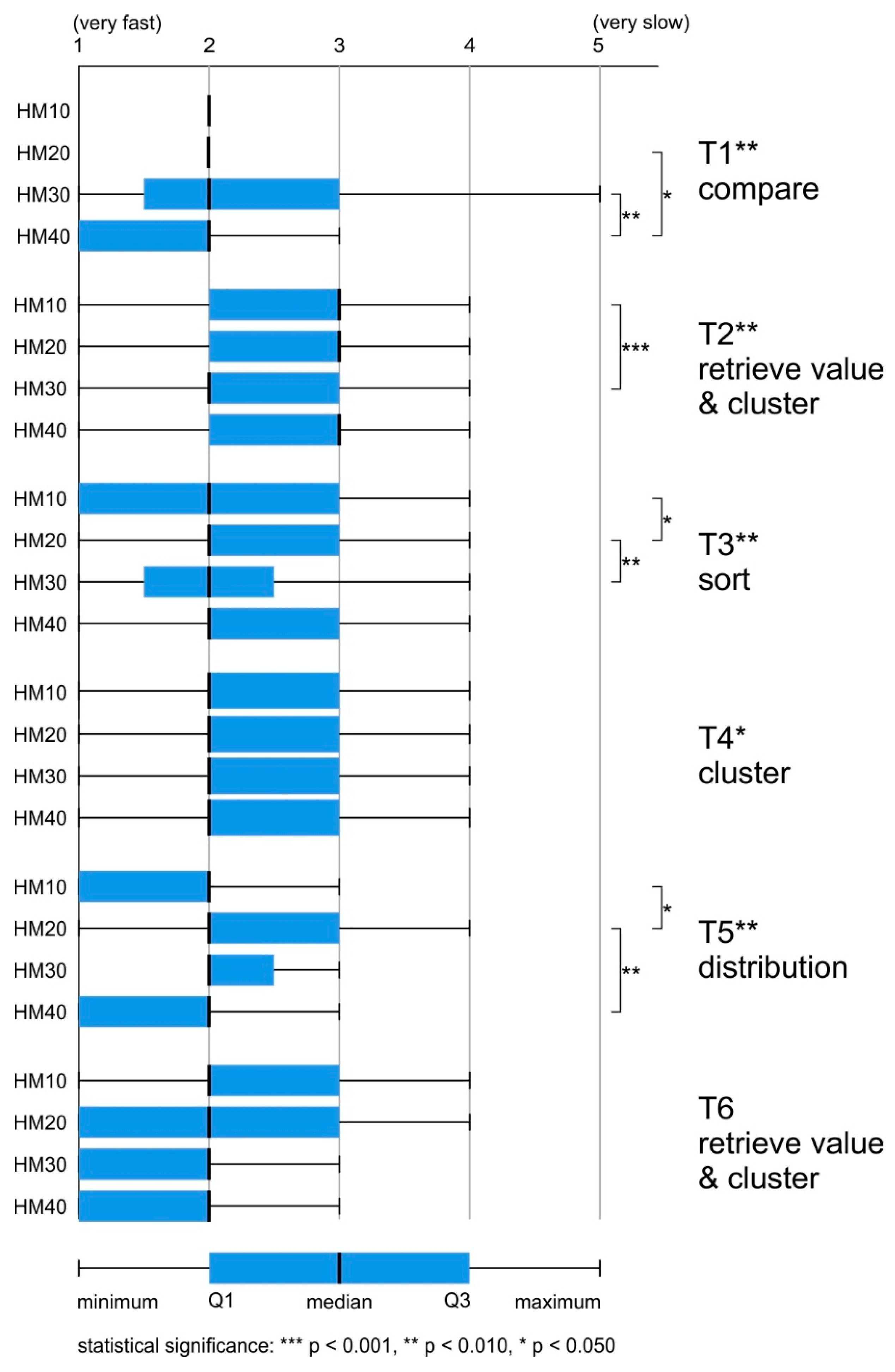
4.2. Response Time
4.3. Response Time Assessment
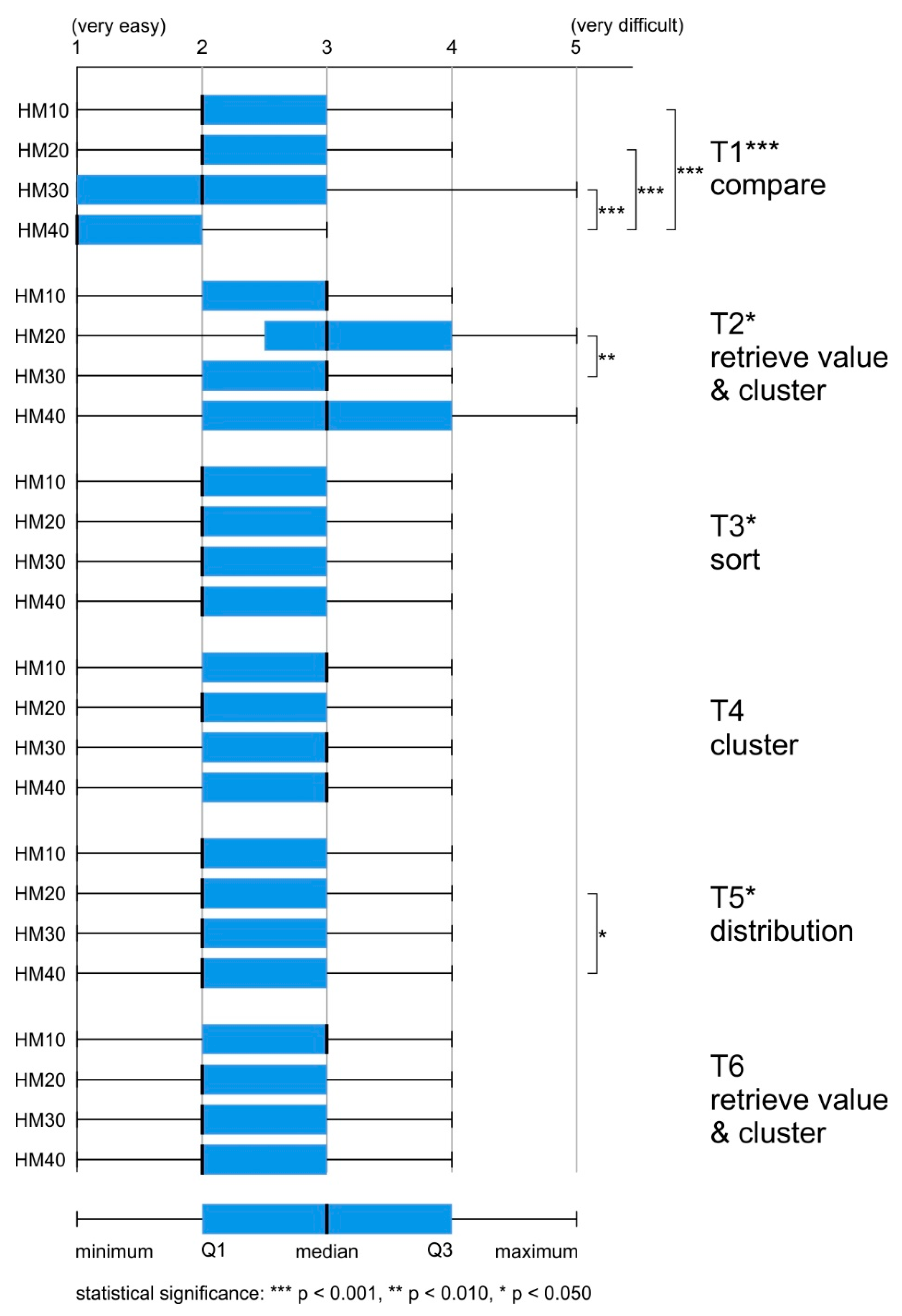
4.4. Difficulty of the Task
4.5. Preferences
5. Discussion
- RQ1. How does the heat map’s generalization, defined by the size of the kernel radius, influence its effectiveness?
- H1. Lower levels of generalization result in higher correctness of answers by heat map users.
- RQ2. What are the discrepancies between differently generalized heat maps in the context of efficiency and perceived efficiency?
- H2. Higher levels of generalization result in faster responses and a higher perceived efficiency by heat map users.
- RQ3. How do users perceive heat map difficulty depending on a generalization level?
- H3. Heat map users perceive less generalized maps as easier.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kraak, M.-J. Is There a Need for Neo-Cartography? Cartogr. Geogr. Inf. Sci. 2011, 38, 73–78. [Google Scholar] [CrossRef]
- Cartwright, W. Neocartography: Opportunities, Issues and Prospects. S. Afr. J. Geomat. 2012, 1, 14–31. [Google Scholar]
- DeBoer, M. Understanding the Heat Map. Cartogr. Perspect. 2015, 39–43. [Google Scholar] [CrossRef]
- Netek, R.; Pour, T.; Slezakova, R. Implementation of Heat Maps in Geographical Information System–Exploratory Study on Traffic Accident Data. Open Geosci. 2018, 10, 367–384. [Google Scholar] [CrossRef]
- Netek, R.; Tomecka, O.; Brus, J. Performance Testing on Marker Clustering and Heatmap Visualization Techniques: A Comparative Study on JavaScript Mapping Libraries. ISPRS Int. J. Geo-Inf. 2019, 8, 348. [Google Scholar] [CrossRef] [Green Version]
- MacEachren, A.M.; DiBiase, D. Animated Maps of Aggregate Data: Conceptual and Practical Problems. Cartogr. Geogr. Inf. Syst. 1991, 18, 221–229. [Google Scholar] [CrossRef]
- Bertin, J. Semiology of Graphics, 1st ed.; ESRI Press: Redlands, CA, USA, 2010; ISBN 978-1-58948-261-6. [Google Scholar]
- Pettit, C.; Widjaja, I.; Russo, P.; Sinnott, R.; Stimson, R.; Tomko, M. Visualisation Support for Exploring Urban Space and Place. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I-2, 153–158. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.-Y.; Jung, H.-J.; Moon, M.H.; Chung, B.C.; Choi, M.H. Heat-Map Visualization of Gas Chromatography-Mass Spectrometry Based Quantitative Signatures on Steroid Metabolism. J. Am. Soc. Mass Spectrom. 2009, 20, 1626–1637. [Google Scholar] [CrossRef] [Green Version]
- Rosenbaum, L.; Hinselmann, G.; Jahn, A.; Zell, A. Interpreting Linear Support Vector Machine Models with Heat Map Molecule Coloring. J. Cheminf. 2011, 3, 11. [Google Scholar] [CrossRef] [Green Version]
- Pleil, J.D.; Stiegel, M.A.; Madden, M.C.; Sobus, J.R. Heat Map Visualization of Complex Environmental and Biomarker Measurements. Chemosphere 2011, 84, 716–723. [Google Scholar] [CrossRef]
- Gove, R.; Gramsky, N.; Kirby, R.; Sefer, E.; Sopan, A.; Dunne, C.; Shneiderman, B.; Taieb-Maimon, M. NetVisia: Heat Map & Matrix Visualization of Dynamic Social Network Statistics & Content. In Proceedings of the 2011 IEEE Third Int’l Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third Int’l Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 19–26. [Google Scholar]
- Špakov, O.; Miniotas, D. Visualization of Eye Gaze Data Using Heat Maps. Elektron. Elektrotech. 2007, 74, 55–58. [Google Scholar]
- Borzuchowska, J. Poszukiwanie nowych metod kartograficznych dla mapowania prohlemów społecznych. In Główne Problemy Współczesnej Kartografii. Kartograficzne Programy Komputerowe. Konfrontacja Teorii z Praktyka̜; Żyszkowska, W., Spallek, W., Eds.; Uniwersytet Wrocławski: Wrocław, Poland, 2007; pp. 135–144. (In Polish) [Google Scholar]
- Silva, A.T.; Ribone, P.A.; Chan, R.L.; Ligterink, W.; Hilhorst, H.W.M. A Predictive Coexpression Network Identifies Novel Genes Controlling the Seed-to-Seedling Phase Transition in Arabidopsis Thaliana. Plant Physiol. 2016, 170, 2218–2231. [Google Scholar] [CrossRef] [Green Version]
- Cao, M.; Cai, B.; Ma, S.; Lü, G.; Chen, M. Analysis of the Cycling Flow Between Origin and Destination for Dockless Shared Bicycles Based on Singular Value Decomposition. ISPRS Int. J. Geo-Inf. 2019, 8, 573. [Google Scholar] [CrossRef] [Green Version]
- Sainio, J.; Westerholm, J.; Oksanen, J. Generating Heat Maps of Popular Routes Online from Massive Mobile Sports Tracking Application Data in Milliseconds While Respecting Privacy. IJGI 2015, 4, 1813–1826. [Google Scholar] [CrossRef] [Green Version]
- Pánek, J.; Benediktsson, K. Emotional Mapping and Its Participatory Potential: Opinions about Cycling Conditions in Reykjavík, Iceland. Cities 2017, 61, 65–73. [Google Scholar] [CrossRef]
- Anderson, T.K. Kernel Density Estimation and K-Means Clustering to Profile Road Accident Hotspots. Accid. Anal. Prev. 2009, 41, 359–364. [Google Scholar] [CrossRef]
- Plug, C.; Xia, J.; Caulfield, C. Spatial and Temporal Visualisation Techniques for Crash Analysis. Accid. Anal. Prev. 2011, 43, 1937–1946. [Google Scholar] [CrossRef]
- Location History Visualizer. Available online: https://locationhistoryvisualizer.com/heatmap/ (accessed on 17 August 2021).
- ArcGIS Online. Available online: https://www.arcgis.com/index.html (accessed on 17 August 2021).
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Monographs on Statistics and Applied Probability; Chapman and Hall: London, UK; New York, NY, USA, 1986; Volume 26. [Google Scholar]
- Yin, P. Kernels and Density Estimation. Geogr. Inf. Sci. Technol. Body Knowl. 2020. [Google Scholar] [CrossRef]
- Jenks, G.F. Generalization in Statistical Mapping. Ann. Assoc. Am. Geogr. 1963, 53, 15–26. [Google Scholar] [CrossRef]
- Raposo, P.; Touya, G.; Bereuter, P. A Change of Theme: The Role of Generalization in Thematic Mapping. ISPRS Int. J. Geo-Inf. 2020, 9, 371. [Google Scholar] [CrossRef]
- Roth, R.E.; Brewer, C.A.; Stryker, M.S. A Typology of Operators for Maintaining Legible Map Designs at Multiple Scales. Cartogr. Perspect. 2011, 29–64. [Google Scholar] [CrossRef] [Green Version]
- Bebortta, S.; Das, S.K.; Kandpal, M.; Barik, R.K.; Dubey, H. Geospatial Serverless Computing: Architectures, Tools and Future Directions. ISPRS Int. J. Geo-Inf. 2020, 9, 311. [Google Scholar] [CrossRef]
- Hwang; Lee; Kim Real-Time Pedestrian Flow Analysis Using Networked Sensors for a Smart Subway System. Sustainability 2019, 11, 6560. [CrossRef] [Green Version]
- Sun, H.; Li, Z. Effectiveness of Cartogram for the Representation of Spatial Data. Cartogr. J. 2010, 47, 12–21. [Google Scholar] [CrossRef]
- Dong, W.; Wang, S.; Chen, Y.; Meng, L. Using Eye Tracking to Evaluate the Usability of Flow Maps. ISPRS Int. J. Geo-Inf. 2018, 7, 281. [Google Scholar] [CrossRef] [Green Version]
- Korycka-Skorupa, J.; Gołębiowska, I. Numbers on Thematic Maps: Helpful Simplicity or Too Raw to Be Useful for Map Reading? IJGI 2020, 9, 415. [Google Scholar] [CrossRef]
- Schnürer, R.; Ritzi, M.; Çöltekin, A.; Sieber, R. An Empirical Evaluation of Three-Dimensional Pie Charts with Individually Extruded Sectors in a Geovisualization Context. Inf. Vis. 2020, 19, 183–206. [Google Scholar] [CrossRef]
- Ware, C. Color Sequences for Univariate Maps: Theory, Experiments and Principles. IEEE Comput. Graph. Appl. 1988, 8, 41–49. [Google Scholar] [CrossRef]
- Kumler, M.P.; Groop, R.E. Continuous-Tone Mapping of Smooth Surfaces. Cartogr. Geogr. Inf. Syst. 1990, 17, 279–289. [Google Scholar] [CrossRef]
- Reda, K.; Nalawade, P.; Ansah-Koi, K. Graphical Perception of Continuous Quantitative Maps. In Proceedings of the CHI 2018 Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 21–26 April 2018; ACM: New York, NY, USA, 2018; pp. 1–12. [Google Scholar]
- Gołebiowska, I.; Coltekin, A. Rainbow Dash: Intuitiveness, Interpretability and Memorability of the Rainbow Color Scheme in Visualization. IEEE Trans. Vis. Comput. Graph. 2020, 1. [Google Scholar] [CrossRef]
- Nelson, J.K.; MacEachren, A.M. User-Centered Design and Evaluation of a Geovisualization Application Leveraging Aggregated Quantified-Self Data. Cartogr. Perspect. 2020, 2020, 7–31. [Google Scholar] [CrossRef]
- Miller, O.M.; Voskuil, R.J. Thematic-Map Generalization. Geogr. Rev. 1964, 54, 13. [Google Scholar] [CrossRef]
- Steiniger, S.; Weibel, R. Relations among Map Objects in Cartographic Generalization. Cartogr. Geogr. Inf. Sci. 2007, 34, 175–197. [Google Scholar] [CrossRef]
- Roth, R.E.; Kelly, M.; Underwood, N.; Lally, N.; Vincent, K.; Sack, C. Interactive & Multiscale Thematic Maps: A Preliminary Study. Abstr. Int. Cartogr. Assoc. 2019, 1. [Google Scholar] [CrossRef] [Green Version]
- Roth, R.E.; Kelly, M.; Underwood, N.; Lally, N.; Liu, X.; Vincent, K.; Sack, C. Interactive & Multiscale Thematic Maps: Preliminary Results from an Empirical Study. In Proceedings of the AutoCarto 2020, Online, 18 November 2020. [Google Scholar]
- Tullis, T.; Albert, B. Measuring the User Experience: Collecting, Analyzing, and Presenting Usability Metrics; The Morgan Kaufmann series in interactive technologies; [5. pr.]; Elsevier/Morgan Kaufmann: Amsterdam, The Netherlands; Berlin/Heidelberg, Germany, 2011; ISBN 978-0-12-373558-4. [Google Scholar]
- Štěrba, Z.; Šašinka, Č.; Stachoň, Z.; Štampach, R.; Morong, K. Selected Issues of Experimental Testing in Cartography, 1st ed.; Masaryk University: Brno, Czech Republic, 2015; ISBN 80-210-7909-6. [Google Scholar]
- Mendonça, A.L.A.; Delazari, L.S. What do People prefer and What is more effective for Maps: A Decision making Test. In Advances in Cartography and GIScience, Volume 1; Lecture Notes in Geoinformation and Cartography; Ruas, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 29, pp. 163–181. ISBN 978-3-642-19142-8. [Google Scholar]
- Mendonça, A.; Delazari, L. Testing Subjective Preference and Map Use Performance: Use of Web Maps for Decision Making in the Public Health Sector. Cartogr. Int. J. Geogr. Inf. Geovis. 2014, 49, 114–126. [Google Scholar] [CrossRef]
- Andrienko, N.; Andrienko, G.; Voss, H.; Bernardo, F.; Hipolito, J.; Kretchmer, U. Testing the Usability of Interactive Maps in CommonGIS. Cartogr. Geogr. Inf. Sci. 2002, 29, 325–342. [Google Scholar] [CrossRef]
- Hegarty, M.; Smallman, H.S.; Stull, A.T. Decoupling of Intuitions and Performance in the Use of Complex Visual Displays. In Proceedings of the Proceedings of the 30th Annual Conference of the Cognitive Science Society; Cognitive Science Society, Washington, DC, USA, 23–26 July 2008; pp. 881–886. [Google Scholar]
- Hegarty, M.; Smallman, H.S.; Stull, A.T.; Canham, M.S. Naïve Cartography: How Intuitions about Display Configuration Can Hurt Performance. Cartogr. Int. J. Geogr. Inf. Geovis. 2009, 44, 171–186. [Google Scholar] [CrossRef]
- Panecki, T. Cyfrowe Edycje Map Dawnych: Perspektywy i Ograniczenia Na Przykładzie Mapy Gaula/Raczyńskiego (1807–1812). Stud. Źródłoznawcze Comment. 2020, 58, 185. (In Polish) [Google Scholar] [CrossRef]
- Główny Urząd Geodezji i Kartografii Geoportal Infrastruktury Informacji Przestrzennej. Available online: https://www.geoportal.gov.pl/ (accessed on 2 August 2021). (In Polish)
- Roth, R.E. Cartographic Interaction Primitives: Framework and Synthesis. Cartogr. J. 2012, 49, 376–395. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures, 3rd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2004; ISBN 1-58488-440-1. [Google Scholar]
- Lloyd, R.E.; Bunch, R.L. Technology and Map-Learning: Users, Methods, and Symbols. Ann. Assoc. Am. Geogr. 2003, 93, 828–850. [Google Scholar] [CrossRef]
- Wakabayashi, Y. Intergenerational Differences in the Use of Maps: Results from an Online Survey. In Proceedings of the ICC 2019 Proceedings, Shanghai, China, 20–24 May 2019. [Google Scholar]
- Beitlova, M.; Popelka, S.; Vozenilek, V. Differences in Thematic Map Reading by Students and Their Geography Teacher. IJGI 2020, 9, 492. [Google Scholar] [CrossRef]
- Wabiński, J.; Mościcka, A.; Kuźma, M. The Information Value of Tactile Maps: A Comparison of Maps Printed with the Use of Different Techniques. Cartogr. J. 2020, 1–12. [Google Scholar] [CrossRef]
- Li, Z.; Huang, P. Quantitative Measures for Spatial Information of Maps. Int. J. Geogr. Inf. Sci. 2002, 16, 699–709. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Search Radius (px) | The Search Radius (Meters) | Stimuli Code | Map Preview |
|---|---|---|---|
| 10 | 2640 | HM10 |  |
| 20 | 5290 | HM20 |  |
| 30 | 7930 | HM30 |  |
| 40 | 10,580 | HM40 |  |
| Task Number | Task | Answer Type |
|---|---|---|
| T1 compare | Identify the area where you see the highest number of wind turbine sites (among three marked). | A, B, C |
| T2 retrieve value and cluster | In the marked areas, there is a given number of wind turbines. Estimate how many turbines are in the highlighted area. | Open question |
| T3 sort | Order the areas, starting with the one where the number of wind turbines is the smallest. | Open question |
| T4 cluster | The marked area is characterized by a given number of wind turbines. Indicate the areas where you think there is a similar number of wind turbines. | Mark on map |
| T5 distribution | There are a different number of wind turbines in the area divided by the line. Estimate the proportions in which the whole area was divided in terms of their number. | A, B, C, D |
| T6 retrieve value & cluster | Estimate how many wind turbines are in the marked area. | A, B, C, D |
| Task | chi2 | p | Cramer’s V | P | Pairwise Comparison | chi-Square | p | Cramér’s V | p |
|---|---|---|---|---|---|---|---|---|---|
| T1 compare | X2 (3, N = 402) = 45.547 | p < 0.001 | V = 0.337 (MODERATE) | p < 0.001 | HM10-HM20 | X2 (1, N = 201) = 0.014 | ns | - | |
| HM10-HM30 | X2 (1, N = 198) = 21.429 | p < 0.001 | V = 0.329 | p < 0.001 | |||||
| HM10-HM40 | X2 (1, N = 201) = 24.962 | p < 0.001 | V = 0.352 | p < 0.001 | |||||
| HM20-HM30 | X2 (1, N = 201) = 20.638 | p < 0.001 | V = 0.320 | p < 0.001 | |||||
| HM20-HM40 | X2 (1, N = 204) = 24.115 | p < 0.001 | V = 0.344 | p < 0.001 | |||||
| HM30-HM40 | X2 (1, N = 201) = 0.369 | ns | - | ||||||
| T2 retrieve value and cluster | X2 (3, N = 403) = 22.213 | p < 0.001 | V = 0.235 (WEAK) | p < 0.001 | HM10-HM20 | X2 (1, N = 201) = 4.495 | p < 0.050 | V = 0.150 | p < 0.050 |
| HM10-HM30 | X2 (1, N = 204) = 4.708 | p < 0.050 | V = 0.152 | p < 0.050 | |||||
| HM10-HM40 | X2 (1, N = 202) = 3.010 | ns | - | ||||||
| HM20-HM30 | X2 (1, N = 201) = 0.001 | ns | - | ||||||
| HM20-HM40 | X2 (1, N = 199) = 12.926 | p < 0.001 | V = 0.255 | p < 0.001 | |||||
| HM30-HM40 | X2 (1, N = 202) = 13.403 | p < 0.001 | V = 0.258 | p < 0.001 | |||||
| T3 sort | X2 (3, N = 422) = 9.699 | p < 0.050 | V = 0.152 (WEAK) | p < 0.050 | HM10-HM20 | X2 (1, N = 200) = 0.062 | ns | - | |
| HM10-HM30 | X2 (1, N = 210) = 7.647 | p < 0.010 | V = 0.191 | p < 0.010 | |||||
| HM10-HM40 | X2 (1, N = 210) = 2.848 | ns | |||||||
| HM20-HM30 | X2 (1, N = 212) = 6.408 | p < 0.050 | V = 0.174 | p < 0.050 | |||||
| HM20-HM40 | X2 (1, N = 212) = 2.080 | ns | - | ||||||
| HM30-HM40 | X2 (1, N = 222) = 1.315 | ns | - | ||||||
| T4 cluster | X2 (3, N = 411) = 7.300 | ns | - | ||||||
| T5 distribution | X2 (3, N = 421) = 23.250 | p < 0.001 | V = 0.235 (WEAK) | p < 0.001 | HM10-HM20 | X2 (1, N = 222) = 0.291 | nsns | ||
| HM10-HM30 | X2 (1, N = 211) = 0.852 | nsns | |||||||
| HM10-HM40 | X2 (1, N = 210) = 16.643 | p < 0.001 | V = 0.282 | p < 0.001 | |||||
| HM20-HM30 | X2 (1, N = 211) = 2.091 | ns | - | ||||||
| HM20-HM40 | X2 (1, N = 210) = 20.888 | p < 0.001 | V = 0.315 | p < 0.001 | |||||
| HM30-HM40 | X2 (1, N = 199) = 9.892 | p < 0.010 | V = 0.223 | p < 0.010 | |||||
| T6 retrieve value and cluster | X2 (3, N = 400) = 3.063 | ns | - | ||||||
| Task | Kruskal–Wallis H | p | Method | M (s) | SD | Post Hoc Groups | p |
|---|---|---|---|---|---|---|---|
| T1 compare | X2 (3, N = 402) = 23.783 | p < 0.001 | HM10 | 15.7 | 0.741 | HM10-HM20 | ns |
| HM20 | 17.4 | 0.757 | HM10-HM30 | p < 0.001 | |||
| HM30 | 21.7 | 1.187 | HM10-HM40 | p < 0.050 | |||
| HM40 | 19.7 | 1.203 | HM20-HM30 | p < 0.050 | |||
| HM20-HM40 | ns | ||||||
| HM30-HM40 | ns | ||||||
| T2 retrieve value & cluster | X2 (3, N = 403) = 76.113 | p < 0.001 | HM10 | 45.4 | 2.301 | HM10-HM20 | p < 0.001 |
| HM20 | 33.7 | 1.346 | HM10-HM30 | p < 0.001 | |||
| HM30 | 31.0 | 1.699 | HM10-HM40 | ns | |||
| HM40 | 45.1 | 1.693 | HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.001 | ||||||
| HM30-HM40 | p < 0.001 | ||||||
| T3 sort | X2 (3, N = 422) = 37.750 | p < 0.001 | HM10 | 26.7 | 1.230 | HM10-HM20 | p < 0.010 |
| HM20 | 31.9 | 1.219 | HM10-HM30 | ns | |||
| HM30 | 24.4 | 1.004 | HM10-HM40 | p < 0.010 | |||
| HM40 | 32.3 | 1.434 | HM20-HM30 | p < 0.001 | |||
| HM20-HM40 | ns | ||||||
| HM30-HM40 | p < 0.001 | ||||||
| T4 cluster | X2 (3, N = 411) = 29.231 | p < 0.001 | HM10 | 39.8 | 2.071 | HM10-HM20 | p < 0.001 |
| HM20 | 30.1 | 1.619 | HM10-HM30 | p < 0.001 | |||
| HM30 | 28.0 | 1.181 | HM10-HM40 | ns | |||
| HM40 | 36.7 | 2.344 | HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.050 | ||||||
| HM30-HM40 | p < 0.010 | ||||||
| T5 distribution | X2 (3, N = 421) = 97.307 | p < 0.001 | HM10 | 16.5 | 0.843 | HM10-HM20 | p < 0.001 |
| HM20 | 25.4 | 1.165 | HM10-HM30 | p < 0.001 | |||
| HM30 | 25.6 | 1.412 | HM10-HM40 | ns | |||
| HM40 | 14.3 | 0.671 | HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.001 | ||||||
| HM30-HM40 | p < 0.001 | ||||||
| T6 retrieve value & cluster | X2 (3, N = 400) = 91.527 | p < 0.001 | HM10 | 15.1 | 0.562 | HM10-HM20 | ns |
| HM20 | 14.5 | 0.749 | HM10-HM30 | ns | |||
| HM30 | 16.9 | 0.989 | HM10-HM40 | p < 0.001 | |||
| HM40 | 8.7 | 0.364 | HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.001 | ||||||
| HM30-HM40 | p < 0.001 | ||||||
| Task | Kruskal–Wallis H | p | Post Hoc Groups | p |
|---|---|---|---|---|
| T1 compare | X2 (3, N = 402) = 12.871 | p < 0.010 | HM10-HM20 | ns |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.050 | |||
| HM30-HM40 | p < 0.010 | |||
| T2 retrieve value and cluster | X2 (3, N = 403) = 14.858 | p < 0.010 | HM10-HM20 | ns |
| HM10-HM30 | p < 0.001 | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | ns | |||
| HM30-HM40 | ns | |||
| T3 sort | X2 (3, N = 422) = 13.273 | p < 0.010 | HM10-HM20 | p < 0.050 |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | p < 0.010 | |||
| HM20-HM40 | ns | |||
| HM30-HM40 | ns | |||
| T4 cluster | X2 (3, N = 411) = 8.442 | p < 0.050 | HM10-HM20 | ns |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | ns | |||
| HM30-HM40 | ns | |||
| T5 distribution | X2 (3, N = 421) = 13.660 | p < 0.010 | HM10-HM20 | p < 0.050 |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.010 | |||
| HM30-HM40 | ns | |||
| T6 retrieve value and cluster | X2 (3, N = 400) = 5.853, ns | ns | - | |
| Task | Kruskal–Wallis H | P | Post Hoc Groups | p |
|---|---|---|---|---|
| T1 compare | X2 (3, N = 402) = 46.843 | p < 0.001 | HM10-HM20 | ns |
| HM10-HM30 | ns | |||
| HM10-HM40 | p < 0.001 | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.001 | |||
| HM30-HM40 | p < 0.001 | |||
| T2 retrieve value and cluster | X2 (3, N = 403) = 9.953 | p < 0.050 | HM10-HM20 | ns |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | p < 0.010 | |||
| HM20-HM40 | ns | |||
| HM30-HM40 | ns | |||
| T3 sort | X2 (3, N = 422) = 7.836 | p < 0.050 | HM10-HM20 | ns |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | ns | |||
| HM30-HM40 | ns | |||
| T4 cluster | X2 (3, N = 411) = 6.695, ns | ns | - | |
| T5 distribution | X2 (3, N = 421) = 10.614 | p < 0.050 | HM10-HM20 | ns |
| HM10-HM30 | ns | |||
| HM10-HM40 | ns | |||
| HM20-HM30 | ns | |||
| HM20-HM40 | p < 0.050 | |||
| HM30-HM40 | ns | |||
| T6 retrieve value and cluster | X2 (3, N = 400) = 5.210 | ns | - | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Słomska-Przech, K.; Panecki, T.; Pokojski, W. Heat Maps: Perfect Maps for Quick Reading? Comparing Usability of Heat Maps with Different Levels of Generalization. ISPRS Int. J. Geo-Inf. 2021, 10, 562. https://doi.org/10.3390/ijgi10080562
Słomska-Przech K, Panecki T, Pokojski W. Heat Maps: Perfect Maps for Quick Reading? Comparing Usability of Heat Maps with Different Levels of Generalization. ISPRS International Journal of Geo-Information. 2021; 10(8):562. https://doi.org/10.3390/ijgi10080562
Chicago/Turabian StyleSłomska-Przech, Katarzyna, Tomasz Panecki, and Wojciech Pokojski. 2021. "Heat Maps: Perfect Maps for Quick Reading? Comparing Usability of Heat Maps with Different Levels of Generalization" ISPRS International Journal of Geo-Information 10, no. 8: 562. https://doi.org/10.3390/ijgi10080562
APA StyleSłomska-Przech, K., Panecki, T., & Pokojski, W. (2021). Heat Maps: Perfect Maps for Quick Reading? Comparing Usability of Heat Maps with Different Levels of Generalization. ISPRS International Journal of Geo-Information, 10(8), 562. https://doi.org/10.3390/ijgi10080562